
Prediction of In-Hospital Cardiac Arrest Using Shallow and Deep Learning



Abstract
:1. Introduction
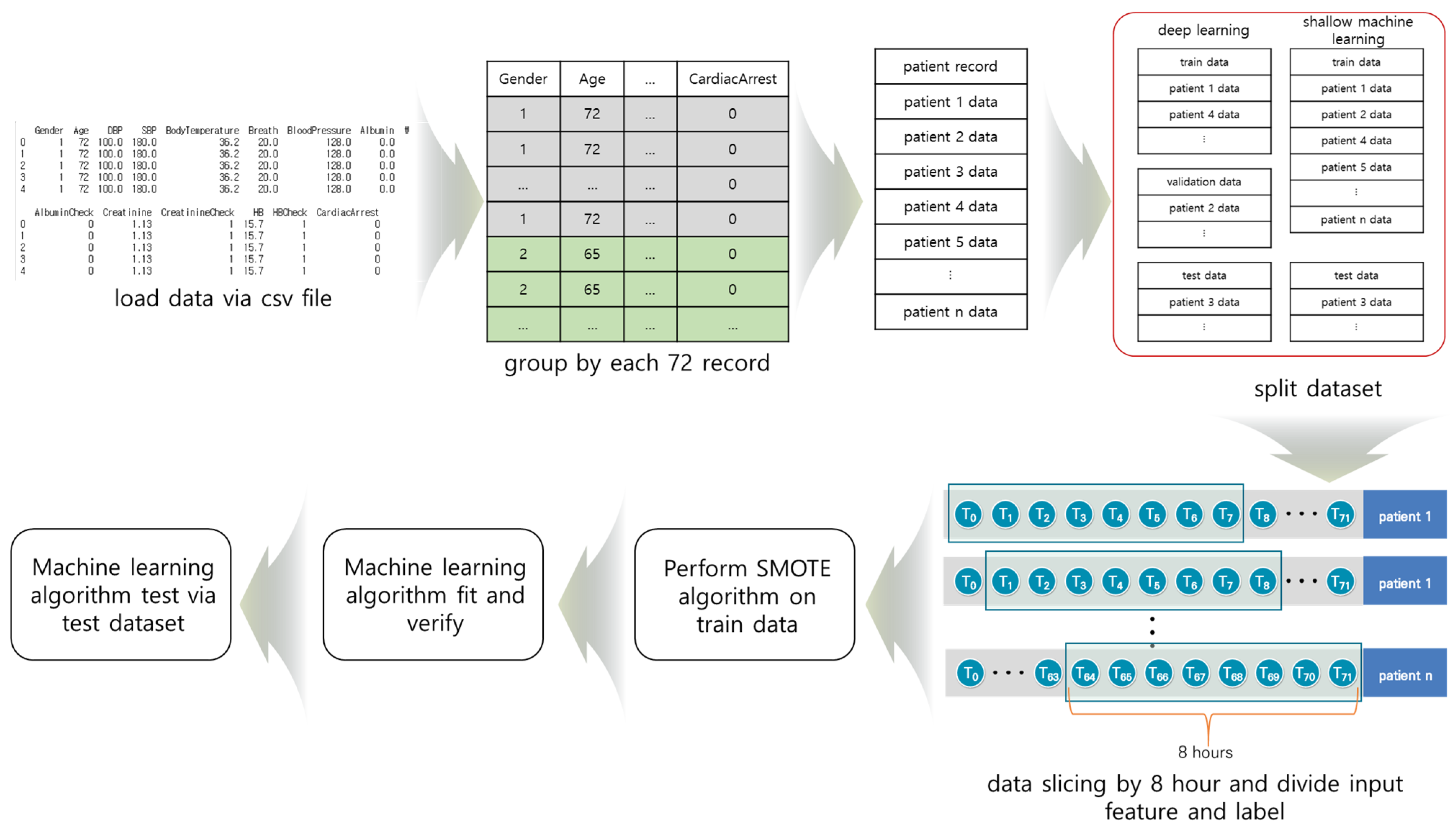
2. Materials
3. Methods
3.1. Shallow Machine Learning Model
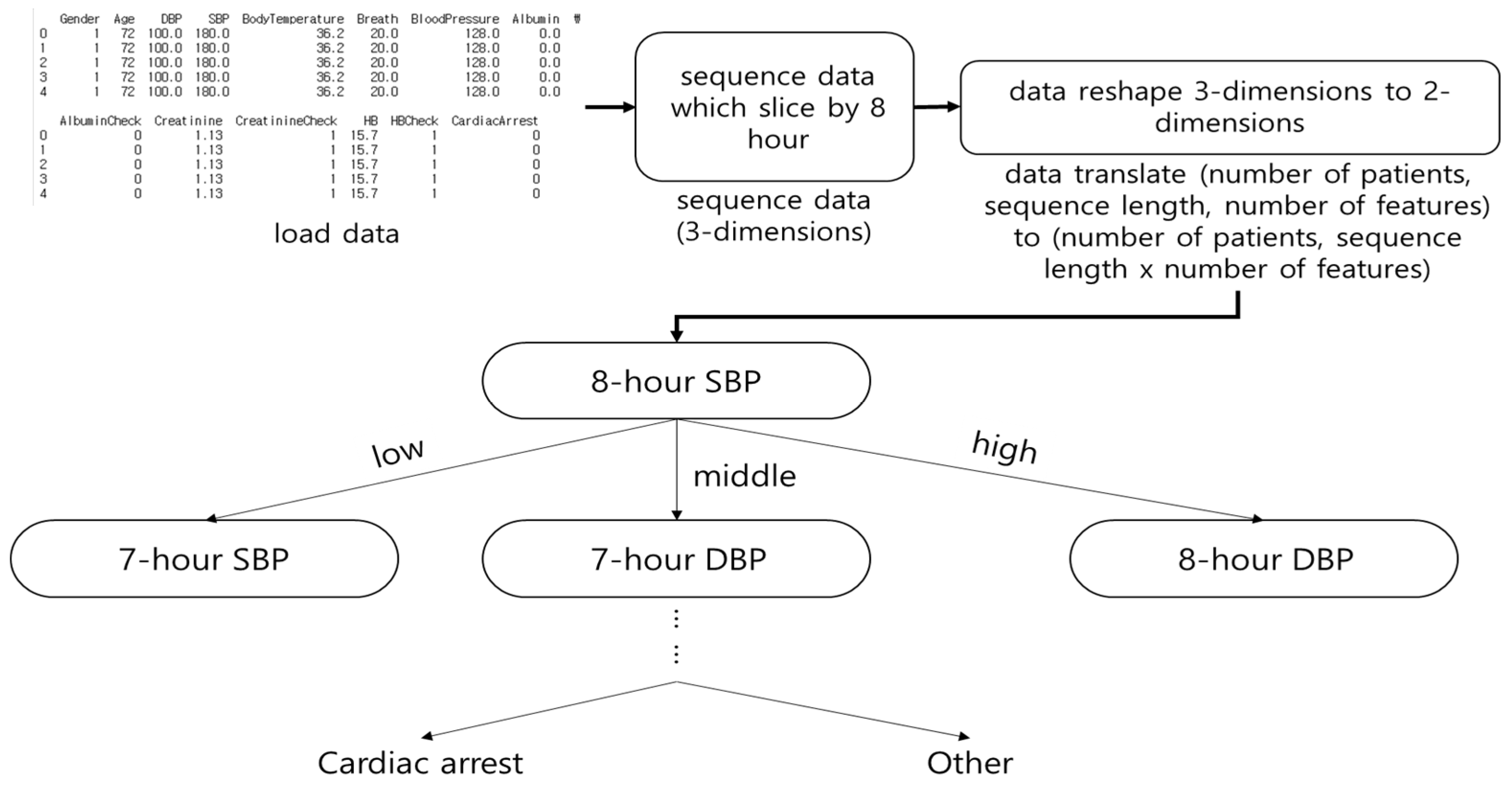
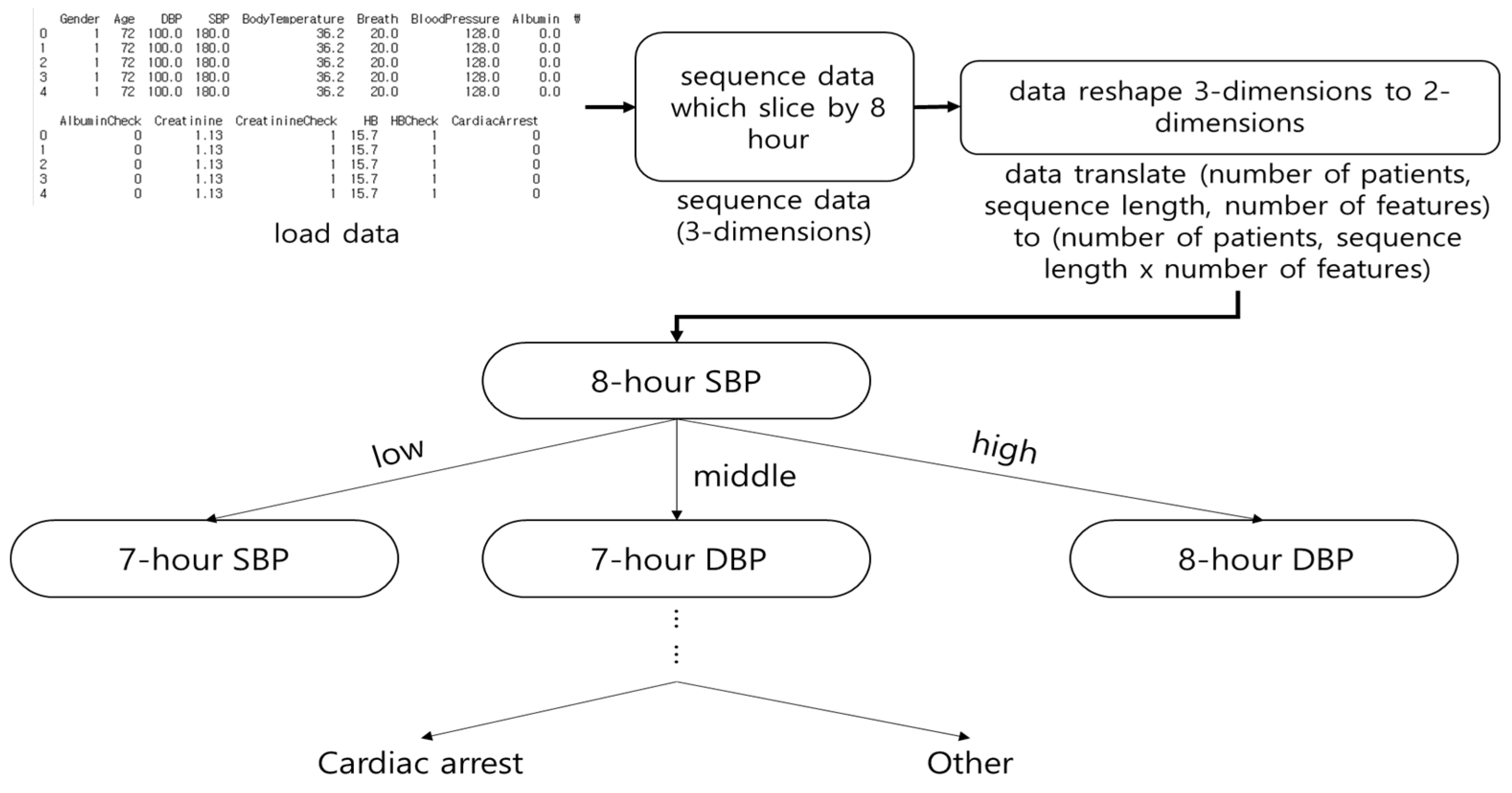
3.1.1. Decision Tree
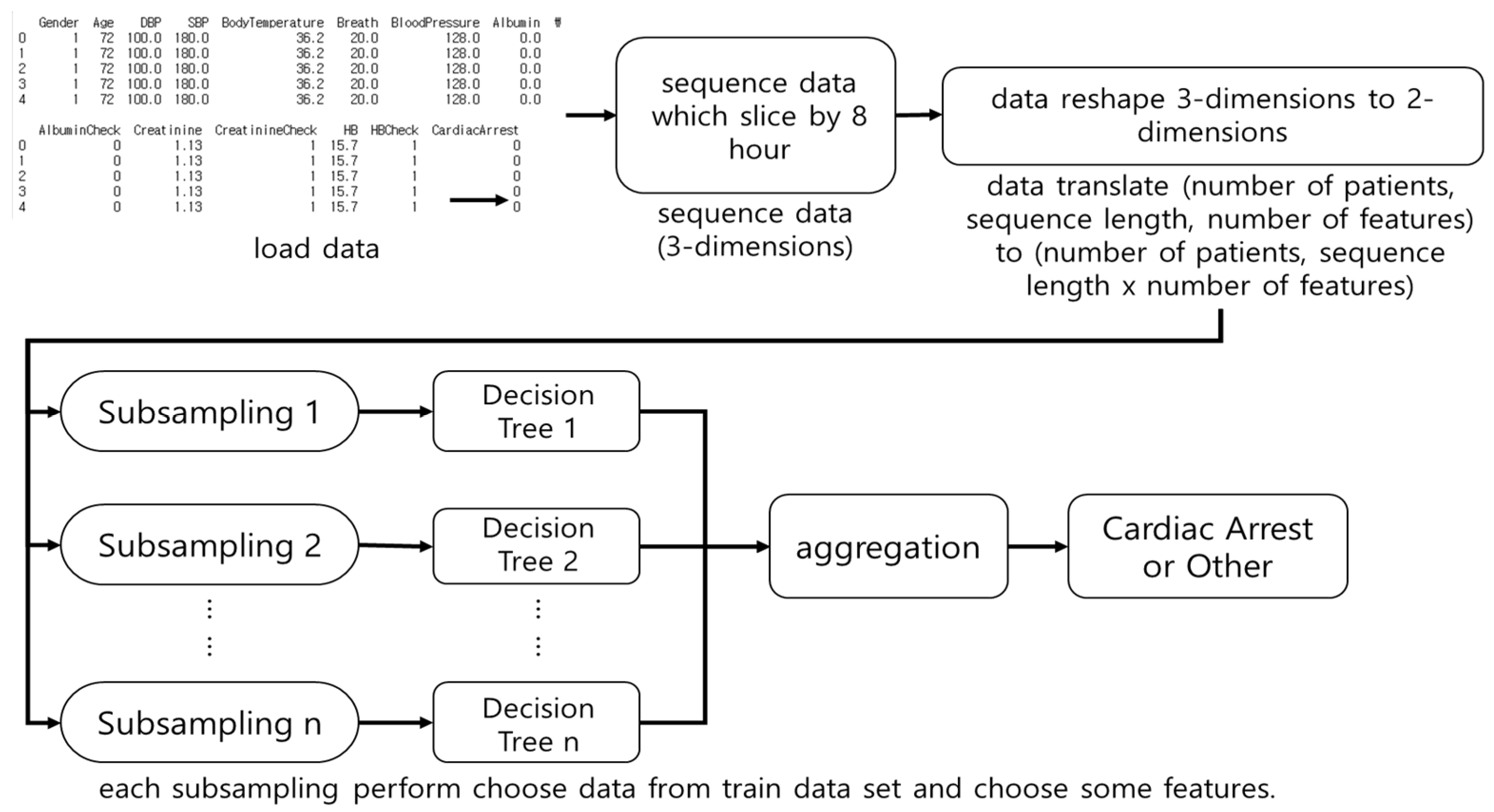
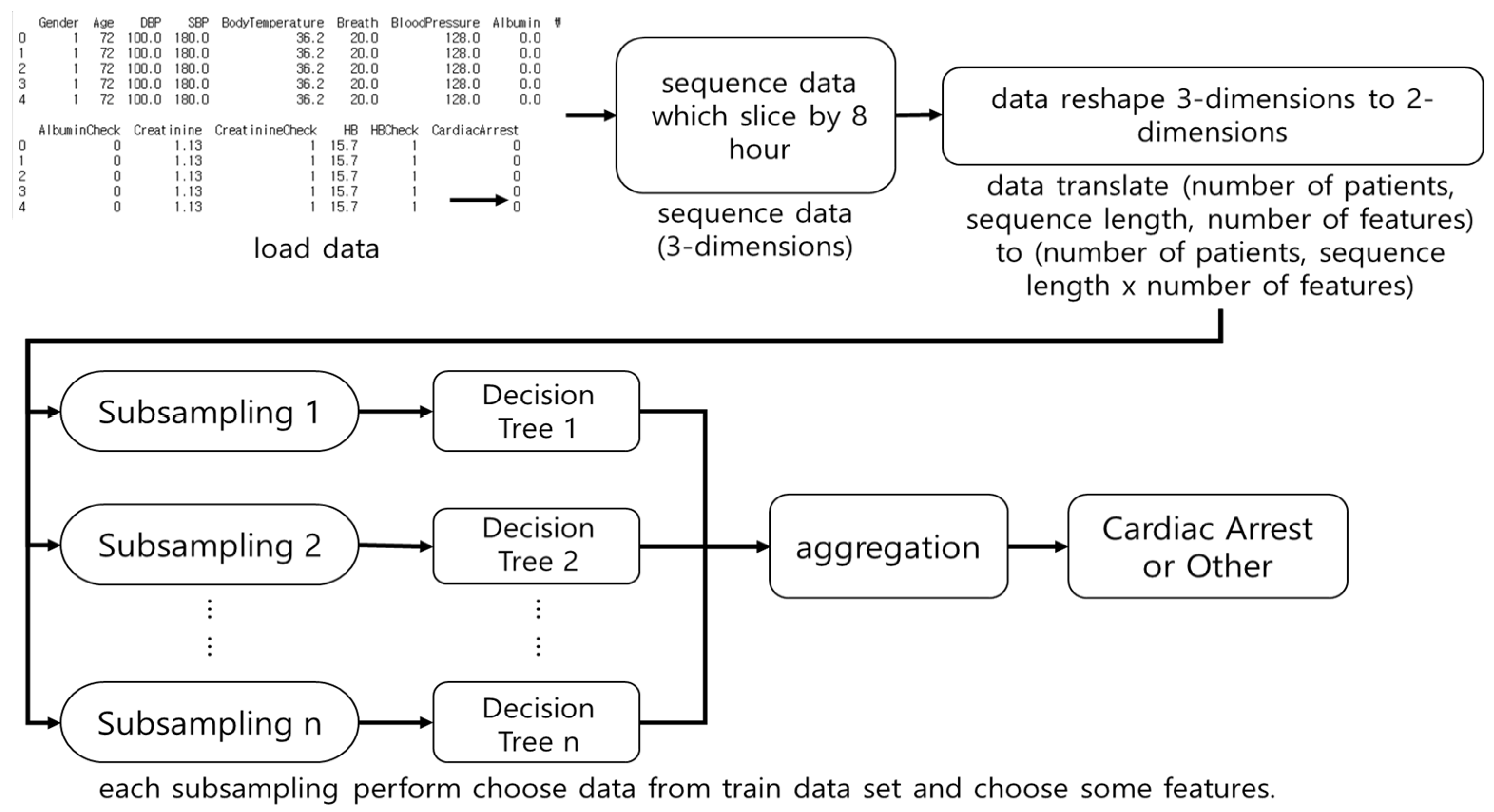
3.1.2. Random Forest
3.1.3. Logistic Regression
3.2. Deep Learning
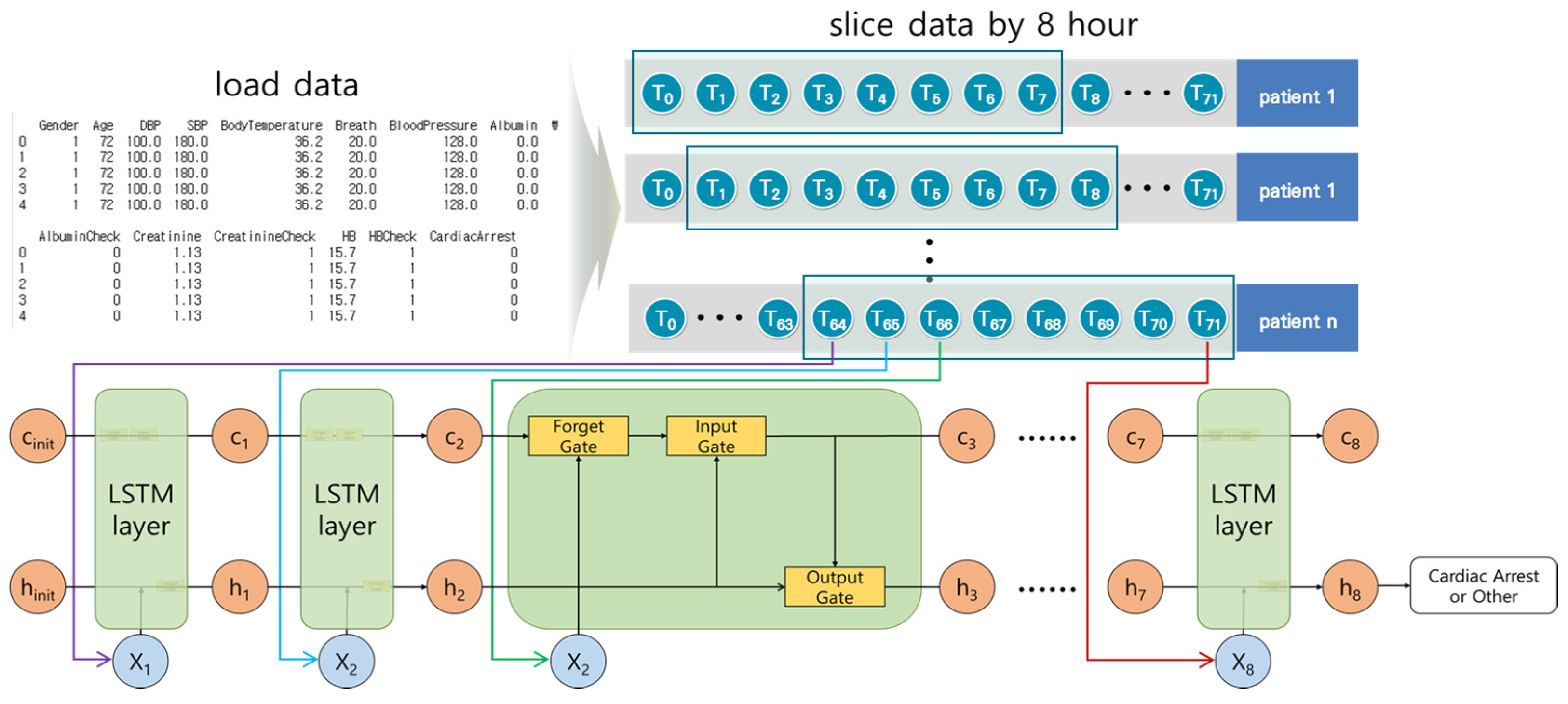
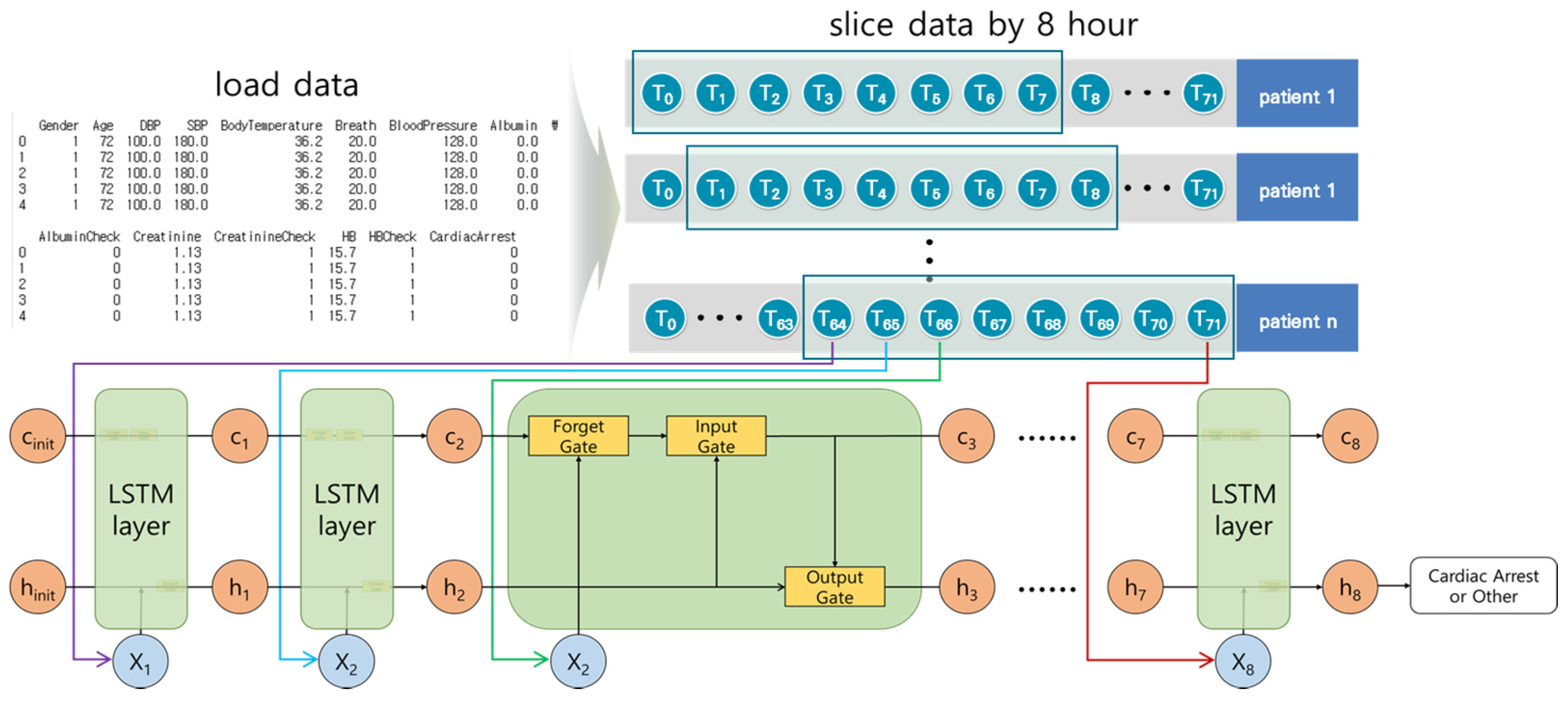
3.2.1. Long Short-Term Memory Model
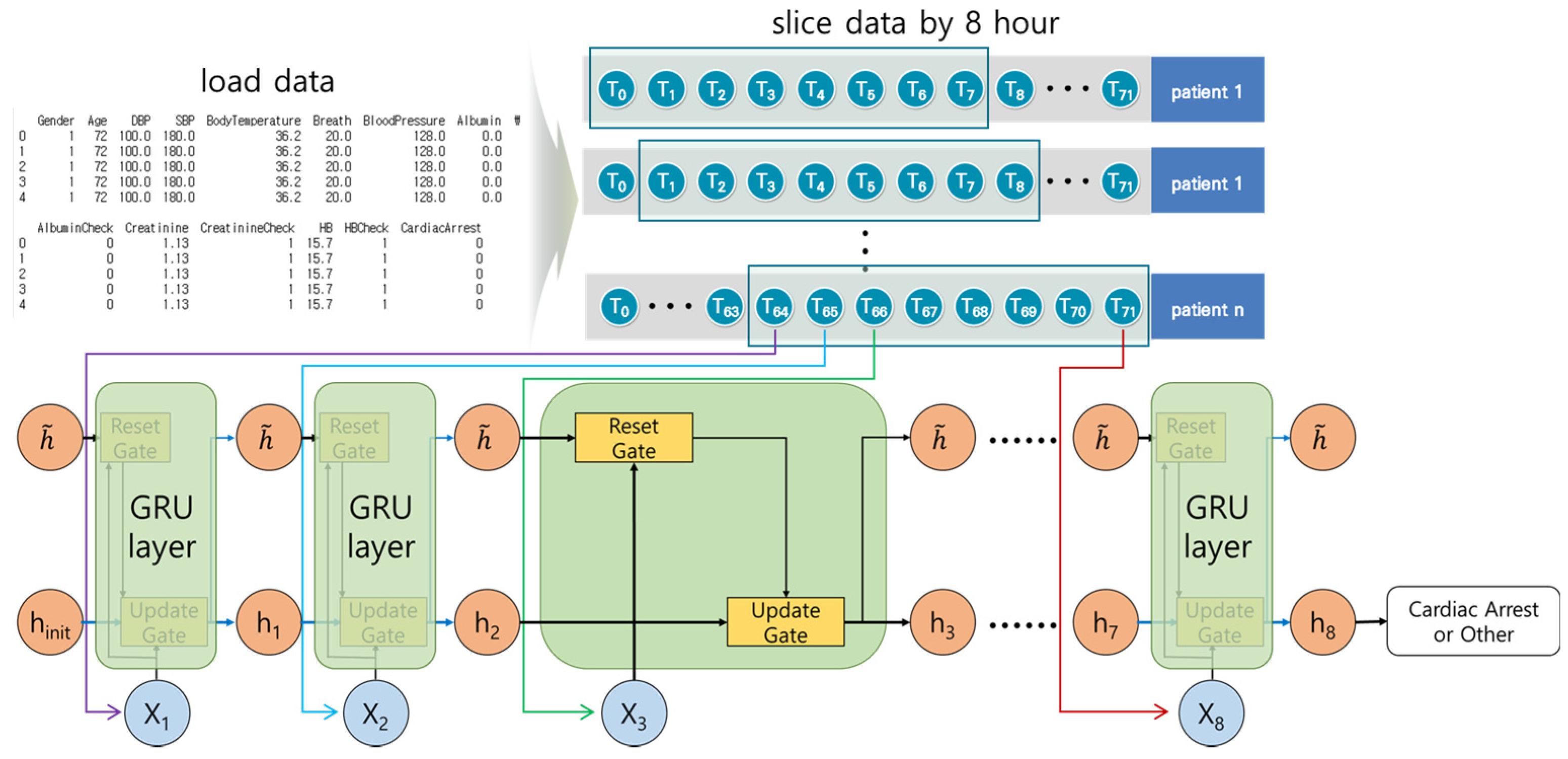
3.2.2. Gated Recurrent Unit Model
3.3. Synthetic Minority Oversampling Technique
3.4. K-Fold Cross-Validation
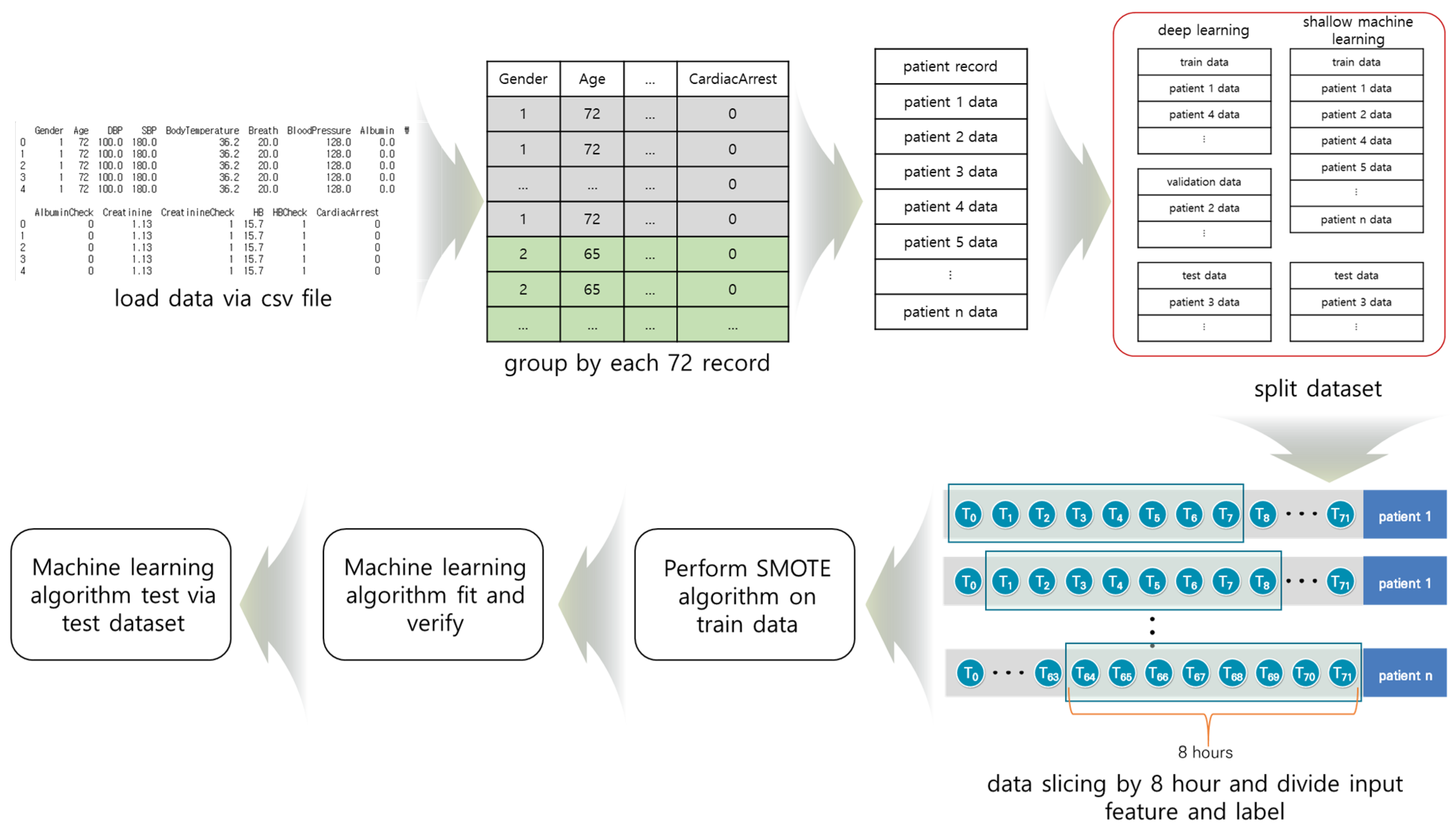
3.5. Material Preprocessing
4. Results
4.1. Performance Evaluation Method
4.2. Performance Evaluation According to SMOTE Ratio
4.3. Results of Shallow Machine Learning
4.4. Results of LSTM Model
4.5. Results of GRU Model
4.6. Results of LSTM–GRU Hybrid Model
4.7. Result of the Performance Evaluation of Shallow and Deep Learning
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Brennan, T.A.; Leape, L.L.; Laird, N.M.; Hebert, L.; Localio, A.R.; Lawthers, A.G.; Newhouse, J.P.; Weiler, P.C.; Hiatt, H.H. Incidence of Adverse Events and Negligence In Hospitalized Patients—Results of the Harvard Medical Practice Study I. N. Engl. J. Med. 1991, 324, 370–376. [Google Scholar] [CrossRef] [Green Version]
- Holmberg, M.J.; Ross, C.E.; Fitzmaurice, G.M.; Chan, P.S.; Duval-Arnould, J.; Grossestreuer, A.V.; Yankama, T.; Donnino, M.W.; Andersen, L.W. Annual incidence of adult and pediatric in-hospital cardiac arrest in the United States. Circ. Cardiovasc. Qual. Outcomes 2019, 12, e005580. [Google Scholar] [CrossRef] [PubMed]
- Juyeon, A.; Kweon, S.; Yoon, H. Incidences of Sudden Cardiac Arrest in Korea, 2019; Korea Disease Control and Prevention Agency: Seoul, Korea, 2021. [Google Scholar]
- Andersen, L.W.; Kim, W.; Chase, M.; Berg, K.M.; Mortensen, S.J.; Moskowitz, A.; Novack, V.; Cocchi, M.N.; Donnino, M.W. The prevalence and significance of abnormal vital signs prior to in-hospital cardiac arrest. Resuscitation 2016, 98, 112–117. [Google Scholar] [CrossRef] [Green Version]
- Schein, R.M.H.; Hazday, N.; Pena, M.; Ruben, B.H.; Sprung, C.L. Clinical Antecedents to In-Hospital Cardiopulmonary Arrest. Chest 1990, 98, 1388–1392. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Buist, M.; Bernard, S.; Nguyen, T.V.; Moore, G.; Anderson, J. Association between clinically abnormal observations and subsequent in-hospital mortality: A prospective study. Resuscitation 2004, 62, 137–141. [Google Scholar] [CrossRef]
- Hall, K.K.; Lim, A.; Gale, B. The Use of Rapid Response Teams to Reduce Failure to Rescue Events: A Systematic Review. J. Patient Saf. 2020, 16, S3–S7. [Google Scholar] [CrossRef]
- Churpek, M.M.; Yuen, T.C.; Edelson, D.P. Risk stratification of hospitalized patients on the wards. Chest 2013, 143, 1758–1765. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Prytherach, D.R.; Smith, G.B.; Schmidt, P.E.; Featherstone, P.I. ViEWS—towards a national early warning score for detecting adult inpatient deterioration. Resuscitation 2010, 81, 932–937. [Google Scholar] [CrossRef] [PubMed]
- Smith, G.B.; Prytherch, D.R.; Schmidt, P.E.; Featherstone, P.I.; Higginsc, B. A review, and performance evaluation, of single-parameter “track and trigger” systems. Resuscitation 2008, 79, 11–21. [Google Scholar] [CrossRef]
- Smith, G.B.; Prytherch, D.R.; Schmidt, P.E.; Featherstone, P.I. Review and performance evaluation of aggregate weighted ‘track and trigger’systems. Resuscitation 2008, 77, 170–179. [Google Scholar] [CrossRef]
- Romero-Brufau, S.; Huddleston, J.M.; Naessens, J.M.; Johnson, M.G.; Hickman, J.; Morlan, B.W.; Jensen, J.B.; Caples, S.M.; Elmer, J.L.; Schmidt, J.A.; et al. Widely used track and trigger scores: Are they ready for automation in practice? Resuscitation 2014, 85, 549–552. [Google Scholar] [CrossRef] [Green Version]
- Vähätalo, J.H.; Huikur, H.V.; Holmström, L.T.A.; Kenttä, T.V.; Haukilaht, M.A.E.; Pakanen, L.; Kaikkonen, K.S.; Tikkanen, J.; Perkiömäki, J.S.; Myerburg, R.J.; et al. Association of Silent Myocardial Infarction and Sudden Cardiac Death. JAMA Cardiol. 2019, 4, 796–802. [Google Scholar] [CrossRef]
- Miyazaki, A.; Sakaguchi, H.; Ohuchi, H.; Yasuda, K.; Tsujii, N.; Matsuoka, M.; Yamamoto, T.; Yazaki, S.; Tsuda, E.; Yamada, O. The clinical characteristics of sudden cardiac arrest in asymptomatic patients with congenital heart disease. Heart Vessel. 2015, 30, 70–80. [Google Scholar] [CrossRef]
- Kwon, J.; Lee, Y.; Lee, Y.; Lee, S.; Park, J. An algorithm based on deep learning for predicting in-hospital cardiac arrest. J. Am. Heart Assoc. 2018, 7, e008678. [Google Scholar] [CrossRef] [Green Version]
- Dumas, F.; Wulfran, B.; Alain, C. Cardiac arrest: Prediction models in the early phase of hospitalization. Curr. Opin. Crit. Care 2019, 25, 204–210. [Google Scholar] [CrossRef]
- Somanchi, S.; Adhikari, S.; Lin, A.; Eneva, E.; Ghani, R. Early prediction of cardiac arrest (code blue) using electronic medical records. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, Australia, 10–13 August 2015; pp. 2119–2126. [Google Scholar]
- Ong, M.E.H.; Ng, C.H.L.; Goh, K.; Liu, N.; Koh, Z.X.; Shahidah, N.; Xhang, T.T.; Chong, W.F.; Lin, Z. Prediction of cardiac arrest in critically ill patients presenting to the emergency department using a machine learning score incorporating heart rate variability compared with the modified early warning score. Crit. Care 2012, 16, R108. [Google Scholar] [CrossRef] [Green Version]
- Churpek, M.M.; Yuen, T.C.; Huber, M.T.; Park, S.; Hall, J.B.; Edelson, D.P. Predicting cardiac arrest on the wards: A nested case-control study. Chest 2012, 141, 1170–1176. [Google Scholar] [CrossRef] [Green Version]
- Churpek, M.M.; Yuen, T.C.; Park, S.; Meltzer, D.O.; Hall, J.B.; Edelson, D.P. Derivation of a cardiac arrest prediction model using ward vital signs. Crit. Care Med. 2012, 40, 2102–2108. [Google Scholar] [CrossRef] [Green Version]
- Liu, N.; Lin, Z.; Cao, J.; Koh, Z.; Zhang, T.; Huang, G.; Ser, W.; Ong, M.E.H. An intelligent scoring system and its application to cardiac arrest prediction. IEEE Trans. Inf. Technol. Biomed 2012, 16, 1324–1331. [Google Scholar] [CrossRef]
- Murukesan, L.; Murugappan, M.; Iqbal, M.; Saravanan, K. Machine learning approach for sudden cardiac arrest prediction based on optimal heart rate variability features. J. Med. Imaging Health Inform. 2014, 4, 521–532. [Google Scholar] [CrossRef]
- ElSaadany, Y.; Majumder, A.J.A.; Ucci, D.R. A wireless early prediction system of cardiac arrest through IoT. In Proceedings of the 2017 IEEE 41st Annual Computer Software and Applications Conference (COMPSAC), Turin, Italy, 4–8 July 2017; pp. 690–695. [Google Scholar]
- Ueno, R.; Xu, L.; Uegami, W.; Matsui, H.; Okui, J.; Hayashi, H.; Miyajima, T.; Hayashi, Y.; Pilcher, D.; Jones, D. Value of laboratory results in addition to vital signs in a machine learning algorithm to predict in-hospital cardiac arrest: A single-center retrospective cohort study. PLoS ONE 2020, 15, e0235835. [Google Scholar] [CrossRef]
- Hardt, M.; Rajkomar, A.; Flores, G.; Dai, A.; Howell, M.; Corrado, G.; Cui, C.; Hardt, M. Explaining an increase in predicted risk for clinical alerts. In Proceedings of the ACM CHIL ‘20: ACM Conference on Health, Inference, and Learning, Toronto, ON, Canada, 2–4 April 2020; pp. 80–89. [Google Scholar]
- Raghu, A.; Guttag, J.; Young, K.; Pomerantsev, E.; Dalca, A.V.; Stultz, C.M. Learning to predict with supporting evidence: Applications to clinical risk prediction. In Proceedings of the ACM CHIL ‘21: ACM Conference on Health, Inference, and Learning, Virtual Event, 8–10 April 2021; pp. 95–104. [Google Scholar]
- Viton, F.; Elbattah, M.; Guérin, J.; Dequen, G. Heatmaps for Visual Explainability of CNN-Based Predictions for Multivariate Time Series with Application to Healthcare. In Proceedings of the IEEE International Conference on Healthcare Informatics (ICHI), Oldenbug, Germany, 30 November–3 December 2020. [Google Scholar]
- Sbrollini, A.; Jongh, D.M.C.; Haar, C.C.T.; Treskes, R.W.; Man, S.; Burattini, L.; Swenne, C.A. Serial electrocardiography to detect newly emerging or aggravating cardiac pathology: A deep-learning approach. Biomed Eng. Online 2019, 18, 15. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, L.; Mesinovic, M.; Yang, K.; Eid, M.A. Explainable prediction of acute myocardial infarction using machine learning and shapley values. IEEE Access 2020, 8, 210410–210417. [Google Scholar] [CrossRef]
- Chollet, F. Keras. GitHub Repository. 2015. Available online: https://github.com/fchollet/keras (accessed on 2 March 2020).
- Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th (USENIX) Symposium on Operating Sys-tems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283.
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neurl Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014; pp. 1724–1734. [Google Scholar]
- Vuttipittayamongkol, P.; Elyan, E. Neighbourhood-based undersampling approach for handling imbalanced and overlapped data. Inf. Sci. 2020, 509, 47–70. [Google Scholar] [CrossRef]
- García, V.; Sánchez, J.S.; Mollineda, R.A. On the effectiveness of preprocessing methods when dealing with different levels of class imbalance. Knowl. Based Syst. 2012, 25, 13–21. [Google Scholar] [CrossRef]
- Douzas, G.; Fernando, B.; Felix, L. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- sklearn.tree.DecisionTreeClassifier—Scikit-Learn 0.24.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html (accessed on 1 November 2020).
- sklearn.ensemble.RandomForestClassifier—Scikit-Learn 0.24.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html (accessed on 1 November 2020).
- sklearn.linear_model.LogisticRegression—Scikit-Learn 0.24.1 Documentation. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html (accessed on 1 November 2020).
- Yoo, H.; Park, C.R.; Chung, K. IoT-Based Health Big-Data Process Technologies: A Survey. KSII Trans. Internet Inf. Syst. 2021, 15, 974–992. [Google Scholar]
- Mohemmed, S.M.; Rahamathulla, P.M. Cloud-based Healthcare data management Framework. KSII Trans. Internet Inf. Syst. 2020, 14, 1014–1025. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Characteristics | Data |
|---|---|
| Study period | January 2016–June 2019 |
| Total patients, n | 83,543 |
| Patients with in-hospital cardiac arrest, n | 1154 |
| Number of features, n | 13 |
| Number of data for each patient, n | 72 |
| Sequence data slice size | 8 |
| Age, years, (mean ± SD) | 57.5 ± 17.0 |
| Males, n (%) | 39,428 (47.2%) |
| Hospital | Soonchunhyang University Cheonan Hospital |
| Variable | Description |
|---|---|
| Age | Age at hospitalization |
| Sex | Man (1) or woman (2) |
| DBP | Diastolic blood pressure (30 ≤ DBP ≤ 300, mmHg) |
| SBP | Systolic blood pressure (30 ≤ SBP ≤ 300, mmHg) |
| Body temperature | Body temperature (30 ≤ BodyTemperature ≤ 45) |
| Respiratory rate | Breaths per minute (3 ≤ Breath ≤ 60) |
| Blood Pressure | Blood pressure (30 ≤ BloodPressure ≤ 300, mmHg) |
| Albumin | Albumin values (Laboratory data) |
| Albumin check | Presence of albumin (Present: 1, absent: 0) |
| Creatinine | Creatinine values (Laboratory data) |
| Creatinine check | Presence of creatinine (Present: 1, absent: 0) |
| Hb | Hemoglobin values (Laboratory data) |
| Hb check | Presence of HB (Present: 1, absent: 0) |
| Ratio | PPV | NPV | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|---|
| 1:1 | 20.78% | 99.12% | 37.46% | 98.01% | 26.73% |
| 1:0.08 | 38.14% | 99.10% | 35.17% | 99.20% | 36.59% |
| 1:0.07 | 41.47% | 99.20% | 42.43% | 99.16% | 41.95% |
| 1:0.06 | 41.49% | 99.14% | 38.57% | 99.24% | 39.98% |
| 1:0.055 | 39.83% | 99.14% | 38.16% | 99.20% | 38.98% |
| 1:0.05 | 43.28% | 99.11% | 35.86% | 99.34% | 39.22% |
| 1:0.045 | 36.13% | 99.08% | 33.74% | 99.17% | 34.89% |
| 1:0.025 | 36.82% | 99.06% | 32.80% | 99.21% | 34.69% |
| Algorithm | K | PPV | NPV | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|---|---|
| DT | 4 | 43.99% | 98.97% | 25.80% | 99.54% | 32.52% |
| 5 | 45.02% | 98.98% | 26.67% | 99.55% | 33.50% | |
| 10 | 46.80% | 99.01% | 28.99% | 99.54% | 35.80% | |
| RF | 4 | 97.20% | 98.94% | 23.48% | 99.99% | 37.82% |
| 5 | 98.22% | 98.95% | 24.25% | 100.00% | 38.94% | |
| 10 | 96.44% | 98.98% | 26.18% | 99.99% | 41.19% | |
| LR | 4 | 5.12% | 99.57% | 75.07% | 80.60% | 9.59% |
| 5 | 5.12% | 99.57% | 74.98% | 80.60% | 9.58% | |
| 10 | 5.14% | 99.57% | 76.33% | 80.35% | 9.64% |
| Unit Size | PPV | NPV | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|---|
| 16 | 27.77% | 99.05% | 31.98% | 98.84% | 29.73% |
| 32 | 33.80% | 99.08% | 32.56% | 99.11% | 33.17% |
| 64 | 32.71% | 99.06% | 34.01% | 99.02% | 33.35% |
| 96 | 38.37% | 99.06% | 32.66% | 99.27% | 35.28% |
| 128 | 35.45% | 99.06% | 32.46% | 99.18% | 33.91% |
| Unit Size | PPV | NPV | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|---|
| 16 | 26.28% | 99.07% | 33.62% | 98.68% | 29.50% |
| 32 | 28.75% | 99.19% | 42.61% | 98.53% | 34.33% |
| 64 | 32.05% | 99.11% | 36.33% | 98.93% | 34.06% |
| 96 | 32.05% | 99.11% | 36.33% | 98.93% | 32.50% |
| 128 | 34.59% | 99.09% | 34.59% | 99.09% | 34.69% |
| Unit Size | PPV | NPV | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|---|
| 16 | 31.79% | 98.62% | 22.51% | 99.33% | 26.36% |
| 32 | 23.34% | 99.06% | 33.33% | 98.47% | 27.46% |
| 64 | 27.39% | 99.06% | 32.66% | 98.79% | 29.79% |
| 96 | 30.53% | 99.14% | 38.65% | 98.77% | 34.12% |
| 128 | 35.30% | 99.06% | 32.37% | 99.17% | 33.77% |
| Algorithm | PPV | NPV | Sensitivity | Specificity | F1 Score |
|---|---|---|---|---|---|
| DT | 46.80% | 99.01% | 28.99% | 99.54% | 35.80% |
| RF | 98.22% | 98.95% | 24.25% | 100.00% | 38.94% |
| LR | 5.14% | 99.57% | 76.33% | 80.35% | 9.64% |
| LSTM model | 38.37% | 99.06% | 32.66% | 99.27% | 35.28% |
| GRU model | 34.59% | 99.09% | 34.59% | 99.09% | 34.69% |
| LSTM–GRU hybrid model | 30.53% | 99.14% | 38.65% | 98.77% | 34.12% |
| Algorithm | PPV | NPV | Sensitivity | Specificity | F1 Score | |
|---|---|---|---|---|---|---|
| Traditional EWS [15] | SPTTS | 0.4% | 99.9% | 60.7% | 77.0% | 0.8% |
| MEWS ≥ 3 | 0.5% | 99.9% | 63.0% | 79.9% | 1.0% | |
| MEWS ≥ 4 | 0.6% | 99.9% | 49.3% | 86.8% | 1.2% | |
| MEWS ≥ 5 | 0.6% | 99.9% | 37.3% | 90.6% | 1.3% | |
| Joon-myoung Kwon et al. [15] | RF | 0.4% | 99.9% | 75.3% | 69.9% | 0.8% |
| LR | 0.2% | 99.9% | 76.3% | 34.6% | 0.4% | |
| DEWS ≥ 2.9 | 0.5% | 99.9% | 75.7% | 76.5% | 1.0% | |
| DEWS ≥ 3 | 0.5% | 99.9% | 75.3% | 77.0% | 1.0% | |
| DEWS ≥ 7.1 | 0.8% | 99.9% | 63.0% | 87.0% | 1.5% | |
| DEWS ≥ 8.0 | 0.8% | 99.9% | 60.7% | 88.3% | 1.6% | |
| DEWS ≥ 18.2 | 1.4% | 99.9% | 49.3% | 94.6% | 2.8% | |
| DEWS ≥ 52.8 | 3.7% | 99.9% | 37.3% | 98.4% | 7.1% | |
| Ueno Ryo et al. [24] | RF (vital signs, medical patients) | 0.47% | 99.7% | 80.30% | 78.30% | 0.9% |
| RF (vital signs and lab data, medical patients) | 0.52% | 99.7% | 79.60% | 80.90% | 1.0% | |
| Ibrahim Lujain et al. [29] | CNN model | - | - | 88.1% | 93.2% | 89.9% |
| RNN model | - | - | 78.0% | 87.8% | 82.2%% | |
| XGBoost | - | - | 93.5% | 99.4% | 97.1% | |
| Our methods | DT | 46.80% | 99.01% | 28.99% | 99.54% | 35.80% |
| RF | 98.22% | 98.95% | 24.25% | 100.00% | 38.94% | |
| LR | 5.14% | 99.57% | 76.33% | 80.35% | 9.64% | |
| LSTM model | 38.37% | 99.06% | 32.66% | 99.27% | 35.28% | |
| GRU model | 34.59% | 99.09% | 34.59% | 99.09% | 34.69% | |
| LSTM–GRU hybrid model | 30.53% | 99.14% | 38.65% | 98.77% | 34.12% | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chae, M.; Han, S.; Gil, H.; Cho, N.; Lee, H. Prediction of In-Hospital Cardiac Arrest Using Shallow and Deep Learning. Diagnostics 2021, 11, 1255. https://doi.org/10.3390/diagnostics11071255
Chae M, Han S, Gil H, Cho N, Lee H. Prediction of In-Hospital Cardiac Arrest Using Shallow and Deep Learning. Diagnostics. 2021; 11(7):1255. https://doi.org/10.3390/diagnostics11071255
Chicago/Turabian StyleChae, Minsu, Sangwook Han, Hyowook Gil, Namjun Cho, and Hwamin Lee. 2021. "Prediction of In-Hospital Cardiac Arrest Using Shallow and Deep Learning" Diagnostics 11, no. 7: 1255. https://doi.org/10.3390/diagnostics11071255
APA StyleChae, M., Han, S., Gil, H., Cho, N., & Lee, H. (2021). Prediction of In-Hospital Cardiac Arrest Using Shallow and Deep Learning. Diagnostics, 11(7), 1255. https://doi.org/10.3390/diagnostics11071255