

Automated Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Deep Learning Methods and Sequential Data


 , , ,
, , ,
Abstract
1. Introduction
1.1. Background
1.2. Literature Review
1.3. Motivation and Research Gap
1.4. Main Contributions
2. Methods
2.1. Data Collection and Study Design
2.2. Identification of PSAMO
2.3. Data Preprocessing and Engineering
2.4. Model Developlemt
2.4.1. Categorical Embedding
2.4.2. Multi-Layer Perceptron
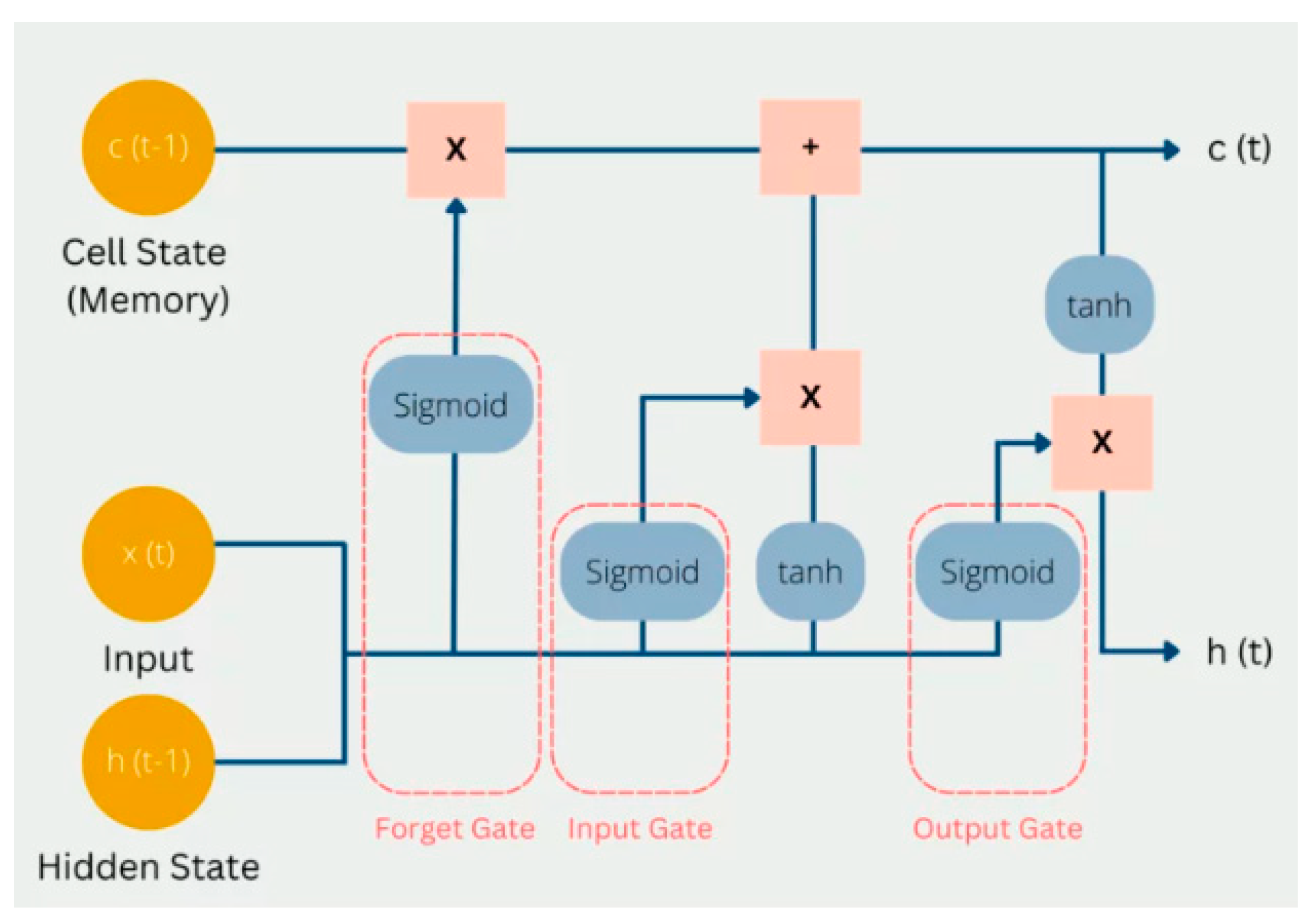
2.4.3. Long-Short Term Memory (LSTM)
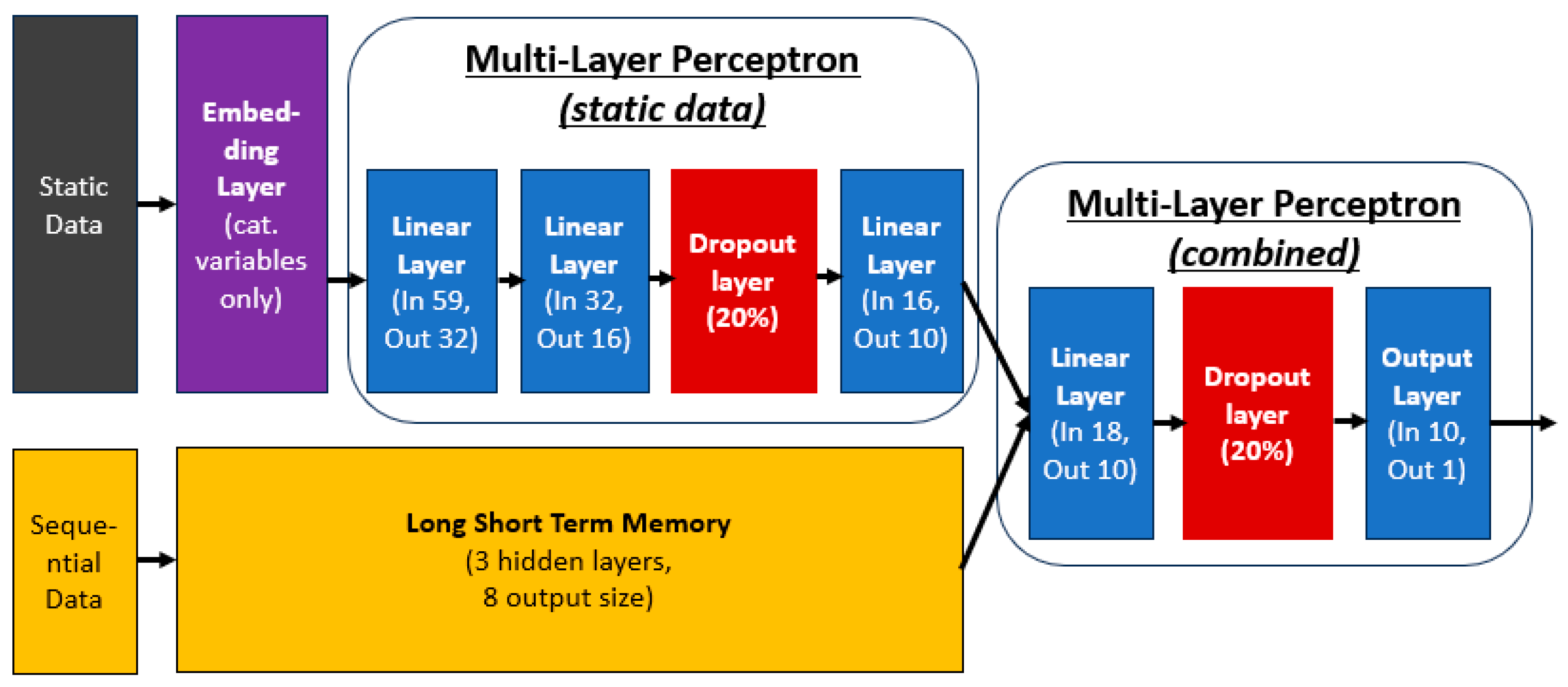
2.4.4. Model Architecture
2.4.5. Model Initialization
2.4.6. Model Training
2.5. Model Evaluation
2.6. Packages Used
3. Results
4. Discussion
4.1. Model Performance
4.2. Related Works
4.3. Advantages and Limitations
4.4. Potential Implementation
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| HADS | Hospital Anxiety and Depression Scale |
| PHQ | Patient Health Questionnaire |
| PSAMO | Post-Stroke Adverse Mental Outcomes |
| PSA | Post-Stroke Anxiety |
| PSD | Post-Stroke Depression |
Appendix A

{kind=link}
{kind=link}
{kind=link}
| No. | Package Name | Functions |
|---|---|---|
| 1 | Pandas | Data preprocessing and engineering |
| 2 | Numpy | |
| 3 | fancyimpute | Implementation of MICE imputation |
| 4 | scikit-learn | Implementation of 10-fold cross-validation and model diagnostic metrics |
| 5 | Matplotlib | Display of graphs and charts |
| 6 | Pytorch | Training of deep learning models |
References
- Feigin, V.L.; Brainin, M.; Norrving, B.; Martins, S.; Sacco, R.L.; Hacke, W.; Fisher, M.; Pandian, J.; Lindsay, P. World Stroke Organization (WSO): Global Stroke Fact Sheet 2022. Int. J. Stroke Off. J. Int. Stroke Soc. 2022, 17, 18–29. [Google Scholar] [CrossRef]
- Stroke—National Registry of Diseases Office. Available online: https://nrdo.gov.sg/publications/stroke (accessed on 29 February 2024).
- Miller, A.H.; Raison, C.L. The role of inflammation in depression: From evolutionary imperative to modern treatment target. Nat. Rev. Immunol. 2016, 16, 22–34. [Google Scholar] [CrossRef] [PubMed]
- American Heart Association; American Stroke Association. Diabetes and Stroke: A Scientific Statement for Healthcare Professionals From the American Heart Association/American Stroke Association. Stroke 2014, 45, 3035–3058. [Google Scholar]
- Schöttke, H.; Giabbiconi, C.-M. Post-stroke depression and post-stroke anxiety: Prevalence and predictors. Int. Psychogeriatr. 2015, 27, 1805–1812. [Google Scholar] [CrossRef] [PubMed]
- Burton, C.A.C.; Murray, J.; Holmes, J.; Astin, F.; Greenwood, D.; Knapp, P. Frequency of Anxiety after Stroke: A Systematic Review and Meta-Analysis of Observational Studies. Int. J. Stroke 2013, 8, 545–559. [Google Scholar] [CrossRef]
- Ellis, C.; Zhao, Y.; Egede, L.E. Depression and increased risk of death in adults with stroke. J. Psychosom. Res. 2010, 68, 545–551. [Google Scholar] [CrossRef]
- de Mello, R.F.; Santos, I.d.S.; Alencar, A.P.; Benseñor, I.M.; Lotufo, P.A.; Goulart, A.C. Major Depression as a Predictor of Poor Long-Term Survival in a Brazilian Stroke Cohort (Study of Stroke Mortality and Morbidity in Adults) EMMA study. J. Stroke Cerebrovasc. Dis. 2016, 25, 618–625. [Google Scholar] [CrossRef]
- Cai, W.; Mueller, C.; Li, Y.-J.; Shen, W.-D.; Stewart, R. Post stroke depression and risk of stroke recurrence and mortality: A systematic review and meta-analysis. Ageing Res. Rev. 2019, 50, 102–109. [Google Scholar] [CrossRef] [PubMed]
- Astuti, P.; Kusnanto, K.; Dwi Novitasari, F. Depression and functional disability in stroke patients. J. Public Health Res. 2020, 9, 1835. [Google Scholar] [CrossRef]
- Lee, E.-H.; Kim, J.-W.; Kang, H.-J.; Kim, S.-W.; Kim, J.-T.; Park, M.-S.; Cho, K.-H.; Kim, J.-M. Association between Anxiety and Functional Outcomes in Patients with Stroke: A 1-Year Longitudinal Study. Psychiatry Investig. 2019, 16, 919–925. [Google Scholar] [CrossRef]
- Starkstein, S.E.; Cohen, B.S.; Fedoroff, P.; Parikh, R.M.; Price, T.R.; Robinson, R.G. Relationship between anxiety disorders and depressive disorders in patients with cerebrovascular injury. Arch. Gen. Psychiatry 1990, 47, 246–251. [Google Scholar] [CrossRef] [PubMed]
- Fang, Y.; Mpofu, E.; Athanasou, J. Reducing depressive or anxiety symptoms in post-stroke patients: Pilot trial of a constructive integrative psychosocial intervention. Int. J. Health Sci. 2017, 11, 53–58. [Google Scholar]
- Woranush, W.; Moskopp, M.L.; Sedghi, A.; Stuckart, I.; Noll, T.; Barlinn, K.; Siepmann, T. Preventive Approaches for Post-Stroke Depression: Where Do We Stand? A Systematic Review. Neuropsychiatry Dis. Treat. 2021, 17, 3359–3377. [Google Scholar] [CrossRef]
- Mikami, K.; Jorge, R.E.; Moser, D.J.; Arndt, S.; Jang, M.; Solodkin, A.; Small, S.L.; Fonzetti, P.; Hegel, M.T.; Robinson, R.G. Prevention of Post-Stroke Generalized Anxiety Disorder, Using Escitalopram or Problem-Solving Therapy. J. Neuropsychiatry Clin. Neurosci. 2014, 26, 323–328. [Google Scholar] [CrossRef] [PubMed]
- Yu, Z.; Wang, K.; Wan, Z.; Xie, S.; Lv, Z. Popular deep learning algorithms for disease prediction: A review. Cluster Comput. 2023, 26, 1231–1251. [Google Scholar] [CrossRef]
- Byeon, H.; Gc, P.; Hannan, S.A.; Alghayadh, F.Y.; Soomar, A.M.; Soni, M.; Bhatt, M.W. Deep neural network model for enhancing disease prediction using auto encoder based broad learning Byeon. SLAS Technol. 2024, 29, 100145. [Google Scholar] [CrossRef]
- Khalifa, M.; Albadawy, M. Artificial Intelligence for Clinical Prediction: Exploring Key Domains and Essential Functions. Comput. Methods Programs Biomed. Update 2024, 5, 100148. [Google Scholar] [CrossRef]
- Çallı, E.; Sogancioglu, E.; van Ginneken, B.; van Leeuwen, K.G.; Murphy, K. Deep learning for chest X-ray analysis: A survey. Med. Image Anal. 2021, 72, 102125. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, D.; Lin, M.; Huang, X.; Shang, X. Post-Stroke Anxiety Analysis via Machine Learning Methods. Front. Aging Neurosci. 2021, 13, 657937. Available online: https://www.frontiersin.org/articles/10.3389/fnagi.2021.657937 (accessed on 13 July 2023). [CrossRef]
- Oei, C.W.; Ng, E.Y.K.; Ng, M.H.S.; Tan, R.-S.; Chan, Y.M.; Chan, L.G.; Acharya, U.R. Explainable Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Machine Learning Techniques in a Population of 1780 Patients. Sensors 2023, 23, 7946. [Google Scholar] [CrossRef]
- Ryu, Y.H.; Kim, S.Y.; Kim, T.U.; Lee, S.J.; Park, S.J.; Jung, H.-Y.; Hyun, J.K. Prediction of Poststroke Depression Based on the Outcomes of Machine Learning Algorithms. J. Clin. Med. 2022, 11, 2264. [Google Scholar] [CrossRef] [PubMed]
- Fast, L.; Temuulen, U.; Villringer, K.; Kufner, A.; Ali, H.F.; Siebert, E.; Huo, S.; Piper, S.K.; Sperber, P.S.; Liman, T.; et al. Machine Learning-Based Prediction of Clinical Outcomes After First-Ever Ischemic Stroke. Front. Neurol. 2023, 14, 1114360. Available online: https://www.frontiersin.org/articles/10.3389/fneur.2023.1114360 (accessed on 13 July 2023). [CrossRef] [PubMed]
- Gao, R.; Cheng, W.X.; Suganthan, P.N.; Yuen, K.F. Inpatient Discharges Forecasting for Singapore Hospitals by Machine Learning. IEEE J. Biomed. Health Inform. 2022, 26, 4966–4975. [Google Scholar] [CrossRef]
- Davis, S.; Zhang, J.; Lee, I.; Rezaei, M.; Greiner, R.; McAlister, F.A.; Padwal, R. Effective hospital readmission prediction models using machine-learned features. BMC Health Serv. Res. 2022, 22, 1415. [Google Scholar] [CrossRef]
- Nithya, B.; Ilango, V. Predictive analytics in health care using machine learning tools and techniques. In Proceedings of the 2017 International Conference on Intelligent Computing and Control Systems (ICICCS), Madurai, India, 15–16 June 2017; pp. 492–499. [Google Scholar]
- Vandana; Marriwala, N.; Chaudhary, D. A hybrid model for depression detection using deep learning. Meas. Sens. 2023, 25, 100587. [Google Scholar] [CrossRef]
- Uddin, M.Z.; Dysthe, K.K.; Følstad, A.; Brandtzaeg, P.B. Deep learning for prediction of depressive symptoms in a large textual dataset. Neural Comput. Appl. 2022, 34, 721–744. [Google Scholar] [CrossRef]
- Daza, A.; Saboya, N.; Necochea-Chamorro, J.I.; Zavaleta Ramos, K.; Vásquez Valencia, Y. del R. Systematic review of machine learning techniques to predict anxiety and stress in college students. Inform. Med. Unlocked 2023, 43, 101391. [Google Scholar] [CrossRef]
- Aström, M.; Adolfsson, R.; Asplund, K. Major depression in stroke patients. A 3-year longitudinal study. Stroke 1993, 24, 976–982. [Google Scholar] [CrossRef]
- Shafiee, M.; Tayefi, M.; Hassanian, S.M.; Ghaneifar, Z.; Arabzadeh, S.; Ferns, G.A. Depression and anxiety symptoms are associated with white blood cell count and red cell distribution width: A sex-stratified analysis in a population-based study. Brain Behav. Immun. 2017, 61, 198–203. [Google Scholar] [CrossRef]
- Sealock, J.M.; Lee, Y.H.; Moscati, A.; Smoller, J.W.; Davis, L.K. Use of the PsycheMERGE network to investigate the association between depression polygenic scores and white blood cell count. JAMA Psychiatry 2021, 78, 1365–1374. [Google Scholar] [CrossRef]
- Zhang, D.; Yin, C.; Zeng, J.; Yuan, X.; Zhang, P. Combining structured and unstructured data for predictive models: A deep learning approach. BMC Med. Inform. Decis. Mak. 2020, 20, 280. [Google Scholar] [CrossRef]
- Chen, Y.-M.; Chen, P.-C.; Lin, W.-C.; Hung, K.-C.; Chen, Y.-C.B.; Hung, C.-F.; Wang, L.-J.; Wu, C.-N.; Hsu, C.-W.; Kao, H.-Y. Predicting New-Onset Post-Stroke Depression from Real-World Data Using Machine Learning Algorithm. Front. Psychiatry 2023, 14, 1195586. Available online: https://www.frontiersin.org/articles/10.3389/fpsyt.2023.1195586 (accessed on 20 June 2023). [CrossRef] [PubMed]
- Zhanina, M.Y.; Druzhkova, T.A.; Yakovlev, A.A.; Vladimirova, E.E.; Freiman, S.V.; Eremina, N.N.; Guekht, A.B.; Gulyaeva, N.V. Development of Post-Stroke Cognitive and Depressive Disturbances: Associations with Neurohumoral Indices. Curr. Issues Mol. Biol. 2022, 44, 6290–6305. [Google Scholar] [CrossRef]
- Li, J.; Oakley, L.D.; Brown, R.L.; Li, Y.; Luo, Y. Properties of the Early Symptom Measurement of Post-Stroke Depression: Concurrent Criterion Validity and Cutoff Scores. J. Nurs. Res. JNR 2020, 28, e107. [Google Scholar] [CrossRef] [PubMed]
- Khazaal, W.; Taliani, M.; Boutros, C.; Abou-Abbas, L.; Hosseini, H.; Salameh, P.; Sadier, N.S. Psychological Complications at 3 Months Following Stroke: Prevalence and Correlates Among Stroke Survivors in Lebanon. Front. Psychol. 2021, 12, 663267. [Google Scholar] [CrossRef]
- Qiu, X.; Wang, H.; Lan, Y.; Miao, J.; Pan, C.; Sun, W.; Li, G.; Wang, Y.; Zhao, X.; Zhu, Z.; et al. Blood biomarkers of post-stroke depression after minor stroke at three months in males and females. BMC Psychiatry 2022, 22, 162. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Levis, B.; Sun, Y.; He, C.; Krishnan, A.; Neupane, D.; Bhandari, P.M.; Negeri, Z.; Benedetti, A.; Thombs, B.D. Accuracy of the Hospital Anxiety and Depression Scale Depression subscale (HADS-D) to screen for major depression: Systematic review and individual participant data meta-analysis. BMJ 2021, 373, n972. [Google Scholar] [CrossRef]
- Urtasun, M.; Daray, F.M.; Teti, G.L.; Coppolillo, F.; Herlax, G.; Saba, G.; Rubinstein, A.; Araya, R.; Irazola, V. Validation and calibration of the patient health questionnaire (PHQ-9) in Argentina. BMC Psychiatry 2019, 19, 291. [Google Scholar] [CrossRef]
- Kroenke, K.; Spitzer, R.L.; Williams, J.B.W. The Patient Health Questionnaire-2: Validity of a two-item depression screener. Med. Care 2003, 41, 1284–1292. [Google Scholar] [CrossRef]
- Jakobsen, J.C.; Gluud, C.; Wetterslev, J.; Winkel, P. When and how should multiple imputation be used for handling missing data in randomised clinical trials—A practical guide with flowcharts. BMC Med. Res. Methodol. 2017, 17, 162. [Google Scholar] [CrossRef]
- Guo, C.; Berkhahn, F. Entity Embeddings of Categorical Variables 2016. arXiv 2016, arXiv:1604.06737. [Google Scholar] [CrossRef]
- Popescu, M.-C.; Balas, V.; Perescu-Popescu, L.; Mastorakis, N. Multilayer perceptron and neural networks. WSEAS Trans. Circuits Syst. 2009, 8, 579–588. [Google Scholar]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Ghojogh, B.; Ghodsi, A. Recurrent Neural Networks and Long Short-Term Memory Networks: Tutorial and Survey. arXiv 2023, arXiv:2304.11461. Available online: http://arxiv.org/abs/2304.11461 (accessed on 4 March 2024).
- Long Short-Term Memory Networks (LSTM)- Simply Explained! | Data Basecamp. Available online: https://databasecamp.de/en/ml/lstms (accessed on 4 March 2024).
- Nath Saha, B.; Senapati, A. Long Short Term Memory (LSTM) based Deep Learning for Sentiment Analysis of English and Spanish Data. In Proceedings of the 2020 International Conference on Computational Performance Evaluation (ComPE), Shillong, India, 2–4 July 2020; pp. 442–446. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Staudemeyer, R.C.; Morris, E.R. Understanding LSTM—A tutorial into Long Short-Term Memory Recurrent Neural Networks. arXiv 2019, arXiv:1909.09586. [Google Scholar] [CrossRef]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 929–1958. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. arXiv 2015, arXiv:1502.01852. [Google Scholar] [CrossRef]
- Glorot, X.; Bengio, Y. Understanding the Difficulty of Training Deep Feedforward Neural Networks. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, Sardinia, Italy, 13–15 May 2010; JMLR Workshop and Conference Proceedings; pp. 249–256. Available online: https://proceedings.mlr.press/v9/glorot10a.html (accessed on 24 February 2024).
- Sutskever, I.; Martens, J.; Dahl, G.; Hinton, G. On the Importance of Initialization and Momentum in Deep Learning. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; PMLR; pp. 1139–1147. Available online: https://proceedings.mlr.press/v28/sutskever13.html (accessed on 4 March 2024).
- Kumar, S.K. On weight initialization in deep neural networks. arXiv 2017, arXiv:1704.08863. [Google Scholar] [CrossRef]
- Qian, X.; Klabjan, D. The Impact of the Mini-batch Size on the Variance of Gradients in Stochastic Gradient Descent. arXiv 2020, arXiv:2004.13146. [Google Scholar] [CrossRef]
- Khirirat, S.; Feyzmahdavian, H.R.; Johansson, M. Mini-batch gradient descent: Faster convergence under data sparsity. In Proceedings of the 2017 IEEE 56th Annual Conference on Decision and Control (CDC), Melbourne, Australia, 12–15 December 2017; pp. 2880–2887. [Google Scholar] [CrossRef]
- Li, M.; Zhang, T.; Chen, Y.; Smola, A.J. Efficient mini-batch training for stochastic optimization. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014; pp. 661–670. [Google Scholar]
- Wali, R. Xtreme Margin: A Tunable Loss Function for Binary Classification. Mach. Learn. 2022. [Google Scholar] [CrossRef]
- Zhang, Z.; Sabuncu, M.R. Generalized Cross Entropy Loss for Training Deep Neural Networks with Noisy Labels. arXiv 2018, arXiv:1805.07836. [Google Scholar] [CrossRef]
- Bradley, A.P. The use of the area under the ROC curve in the evaluation of machine learning algorithms. Pattern Recognit. 1997, 30, 1145–1159. [Google Scholar] [CrossRef]
- McKinney, W. Data structures for statistical computing in Python. In Proceedings of the 9th Python in Science Conference, Austin, TX, USA, 28 June–3 July 2010; pp. 51–56. [Google Scholar] [CrossRef]
- Array Programming with NumPy | Nature. Available online: https://www.nature.com/articles/s41586-020-2649-2 (accessed on 20 June 2023).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Droettboom, M.; Hunter, J.; Firing, E.; Caswell, T.A.; Dale, D.; Lee, J.-J.; Elson, P.; McDougall, D.; Straw, A.; Root, B.; et al. Matplotlib, version 1.4.0; Zenodo: Geneva, Switzerland, 2014. [Google Scholar] [CrossRef]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar] [CrossRef]
- Raudys, Š. How good are support vector machines? Neural Netw. 2000, 13, 17–19. [Google Scholar] [CrossRef]
- Dargan, S.; Kumar, M.; Ayyagari, M.R.; Kumar, G. A Survey of Deep Learning and Its Applications: A New Paradigm to Machine Learning. Arch. Comput. Methods Eng. 2020, 27, 1071–1092. [Google Scholar] [CrossRef]
- Lee, J.; Woo, J.; Kang, A.R.; Jeong, Y.-S.; Jung, W.; Lee, M.; Kim, S.H. Comparative Analysis on Machine Learning and Deep Learning to Predict Post-Induction Hypotension. Sensors 2020, 20, 4575. [Google Scholar] [CrossRef]
- Badawy, M.; Ramadan, N.; Hefny, H.A. Healthcare predictive analytics using machine learning and deep learning techniques: A survey. J. Electr. Syst. Inf. Technol. 2023, 10, 40. [Google Scholar] [CrossRef]
- Djerioui, M.; Brik, Y.; Ladjal, M.; Attallah, B. Heart Disease prediction using MLP and LSTM models. In Proceedings of the 2020 International Conference on Electrical Engineering (ICEE), Istanbul, Turkey, 25–27 September 2020; pp. 1–5. [Google Scholar]
- Brain Sciences | Free Full-Text | Predictive Biomarkers of Treatment Response in Major Depressive Disorder. Available online: https://www.mdpi.com/2076-3425/13/11/1570 (accessed on 7 March 2024).
- Nathan, R.; Monk, C.T.; Arlinghaus, R.; Adam, T.; Alós, J.; Assaf, M.; Baktoft, H.; Beardsworth, C.E.; Bertram, M.G.; Bijleveld, A.I.; et al. Big-data approaches lead to an increased understanding of the ecology of animal movement. Science 2022, 375, eabg1780. [Google Scholar] [CrossRef]
- Meyer, P.G.; Cherstvy, A.G.; Seckler, H.; Hering, R.; Blaum, N.; Jeltsch, F.; Metzler, R. Directedeness, correlations, and daily cycles in springbok motion: From data via stochastic models to movement prediction. Phys. Rev. Res. 2023, 5, 043129. [Google Scholar] [CrossRef]
- Cabalar, I.; Le, T.H.; Silber, A.; O’Hara, M.; Abdallah, B.; Parikh, M.; Busch, R. The Role of Blood Testing in Prevention, Diagnosis, and Management of Chronic Disease. Am. J. Med. Sci. 2024, 368, 274–286. [Google Scholar] [CrossRef] [PubMed]
- Glasziou, P.; Irwig, L.; Mant, D. Monitoring in Chronic Disease: A Rational Approach. BMJ 2005, 330, 901–904. [Google Scholar] [CrossRef]
- Sheng, J.Q.; Hu, P.J.-H.; Liu, X.; Huang, T.-S.; Chen, Y.H. Predictive Analytics for Care and Management of Patients with Acute Diseases: Deep Learning–Based Method to Predict Crucial Complication Phenotypes. J. Med. Internet Res. 2021, 23, e18372. [Google Scholar] [CrossRef]
- Dev, S.; Wang, H.; Nwosu, C.S.; Jain, N.; Veeravalli, B.; John, D. A predictive analytics approach for stroke prediction using machine learning and neural networks. Healthc. Anal. 2022, 2, 100032. [Google Scholar] [CrossRef]
- Eack, S.M.; Greeno, C.G.; Lee, B.-J. Limitations of the Patient Health Questionnaire in Identifying Anxiety and Depression: Many Cases Are Undetected. Res. Soc. Work Pract. 2006, 16, 625–631. [Google Scholar] [CrossRef]
- Maters, G.A.; Sanderman, R.; Kim, A.Y.; Coyne, J.C. Problems in Cross-Cultural Use of the Hospital Anxiety and Depression Scale: “No Butterflies in the Desert”. PLoS ONE 2013, 8, e70975. [Google Scholar] [CrossRef]
- Moulton, C.D.; Hopkins, C.W.P.; Mohamedali, Z.; Powell, N. Out of Sight, Out of Mind: The Limitations of the Hospital Anxiety and Depression Scale in Inflammatory Bowel Disease. Inflamm. Bowel Dis. 2019, 25, e100. [Google Scholar] [CrossRef]
- Pinto-Meza, A.; Serrano-Blanco, A.; Peñarrubia, M.T.; Blanco, E.; Haro, J.M. Assessing Depression in Primary Care with the PHQ-9: Can It Be Carried Out over the Telephone? J. Gen. Intern. Med. 2005, 20, 738–742. [Google Scholar] [CrossRef] [PubMed]
- Topol, E.J. High-performance medicine: The convergence of human and artificial intelligence. Nat. Med. 2019, 25, 44–56. [Google Scholar] [CrossRef] [PubMed]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under Concept Drift: A Review. IEEE Trans. Knowl. Data Eng. 2019, 31, 2346–2363. [Google Scholar] [CrossRef]

| Author | Dataset | Features | Outcome | Techniques | Best Performance |
|---|---|---|---|---|---|
| Wang et al., 2021 [20] | 395 cases | Demographics, lab results, vascular risk factors | PSA | RF, DT, SVM, stochastic gradient descent, multi-layer perceptron | Demographics, lab results, vascular risk factors |
| Oei at al., 2023 [21] | 285 PSAMO and 1495 no PSAMO cases | Demographics, stroke-related data, surgical and medical history, etc. | PSAMO 1 | Logistic regression, DT, GBT, RF, XGBoost, CatBoost, AdaBoost, LightGBM | GBT: AUC 0.620; Acc 0.747; F1 score 0.341 |
| Ryu et al., 2022 [22] | 31 PSD and 34 non-PSD cases | Medical history, demographics, neurological, cognitive, and functional test data | PSD | SVM, KNN, RF | SVM: AUC 0.711; Acc 0.70; Sens 0.742; Spec 0.517 |
| Fast et al., 2023 [23] | 49 PSD and 258 non-PSD cases | Demographics, clinical, serological, and MRI data | PSD 1 | GBT, SVM | GBT: Balanced Acc 0.63; AUC 0.70 |
| Developed Models | Train Set | Test Set | ||||
|---|---|---|---|---|---|---|
| Accuracy | AUROC | F1 Score | Accuracy | AUROC | F1 Score | |
| Gradient-Boosted Trees (Oei et al., 2023) [21] (Best Model using Classical ML Approach) | 0.973 (0.958–0.982) | 0.946 (0.932–0.957) | 0.950 (0.924–0.964) | 0.747 | 0.620 | 0.341 |
| MLP + LSTM (Using both static and sequential data) | 0.823 (0.721–0.852) | 0.752 (0.621–0.784) | 0.586 (0.328–0.622) | 0.796 | 0.789 | 0.353 |
| Predicted Label | |||
|---|---|---|---|
| Non-PSAMO | PSAMO | ||
| Actual label | Non-PSAMO | 40 cases | 0 cases |
| PSAMO | 11 cases | 3 cases | |
| Author | Data Type | Artificial Intelligence Methods | Outcome | Best Performance | ||
|---|---|---|---|---|---|---|
| Static | Sequential | Machine Learning | Deep Learning | |||
| Wang et al., 2021 [20] | √ | √ | PSA | 18.625 Euclidean distance between anxiety scores | ||
| Oei at al., 2023 [21] | √ | √ | PSAMO 1 | AUC 0.620; Acc 0.747; F1 score 0.341 | ||
| Ryu et al., 2022 [22] | √ | √ | PSD | AUC 0.711; Acc 0.70; Sens 0.742; Spec 0.517 | ||
| Fast et al., 2023 [23] | √ | √ | PSD 1 | Balanced Acc 0.63; AUC 0.70 | ||
| Current study | √ | √ | √ | PSAMO | AUC 0.789; Acc 0.796; F1-score 0.353 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Oei, C.W.; Ng, E.Y.K.; Ng, M.H.S.; Chan, Y.M.; Subbhuraam, V.; Chan, L.G.; Acharya, U.R. Automated Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Deep Learning Methods and Sequential Data. Bioengineering 2025, 12, 517. https://doi.org/10.3390/bioengineering12050517
Oei CW, Ng EYK, Ng MHS, Chan YM, Subbhuraam V, Chan LG, Acharya UR. Automated Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Deep Learning Methods and Sequential Data. Bioengineering. 2025; 12(5):517. https://doi.org/10.3390/bioengineering12050517
Chicago/Turabian StyleOei, Chien Wei, Eddie Yin Kwee Ng, Matthew Hok Shan Ng, Yam Meng Chan, Vinithasree Subbhuraam, Lai Gwen Chan, and U. Rajendra Acharya. 2025. "Automated Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Deep Learning Methods and Sequential Data" Bioengineering 12, no. 5: 517. https://doi.org/10.3390/bioengineering12050517
APA StyleOei, C. W., Ng, E. Y. K., Ng, M. H. S., Chan, Y. M., Subbhuraam, V., Chan, L. G., & Acharya, U. R. (2025). Automated Risk Prediction of Post-Stroke Adverse Mental Outcomes Using Deep Learning Methods and Sequential Data. Bioengineering, 12(5), 517. https://doi.org/10.3390/bioengineering12050517