
Generation of Time-Series Working Patterns for Manufacturing High-Quality Products through Auxiliary Classifier Generative Adversarial Network

 ,
, 

Abstract
:1. Introduction
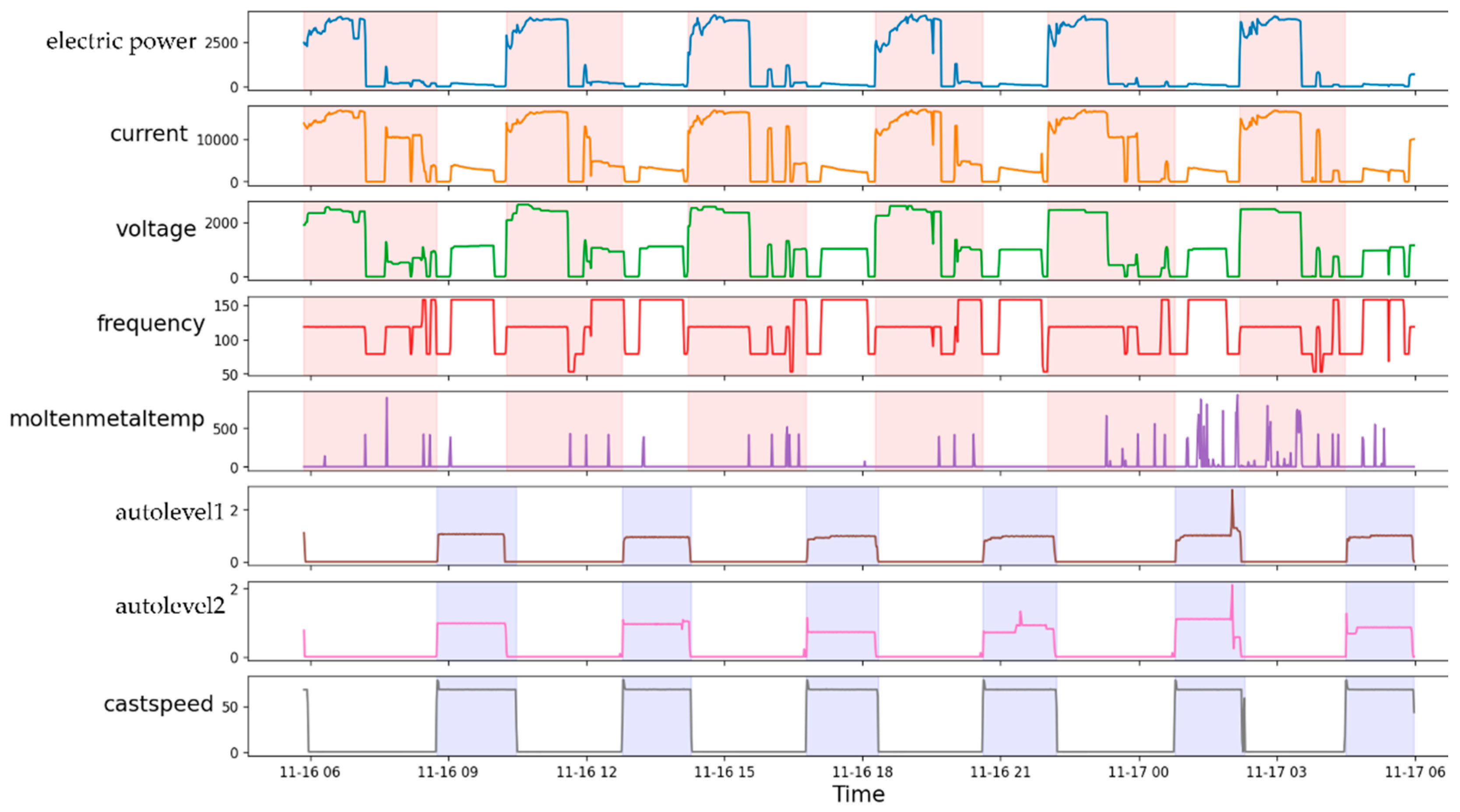
- We first defined a TSWP dataset. The TSWP dataset was generated by integrating various information related to the melting and casting processes, such as material weights, ingredient percentages, controllers (i.e., electric power, current, voltage, etc.), and time measures because each process consists of different steps.
- We then applied several data preprocessing techniques to prepare the dataset for the training and testing of the proposed model. The proposed TSWP dataset has different characteristics. First, the number of features in the TSWP dataset is different in each row because the duration of the process varies. To solve this problem, we expanded the data using the maximum number of features. Second, we applied the data normalization technique to solve the large variations in the TSWP dataset. Third, we transformed some categorical features into numerical features. Lastly, we filtered the data for high-quality products to generate TSWP only for such products.
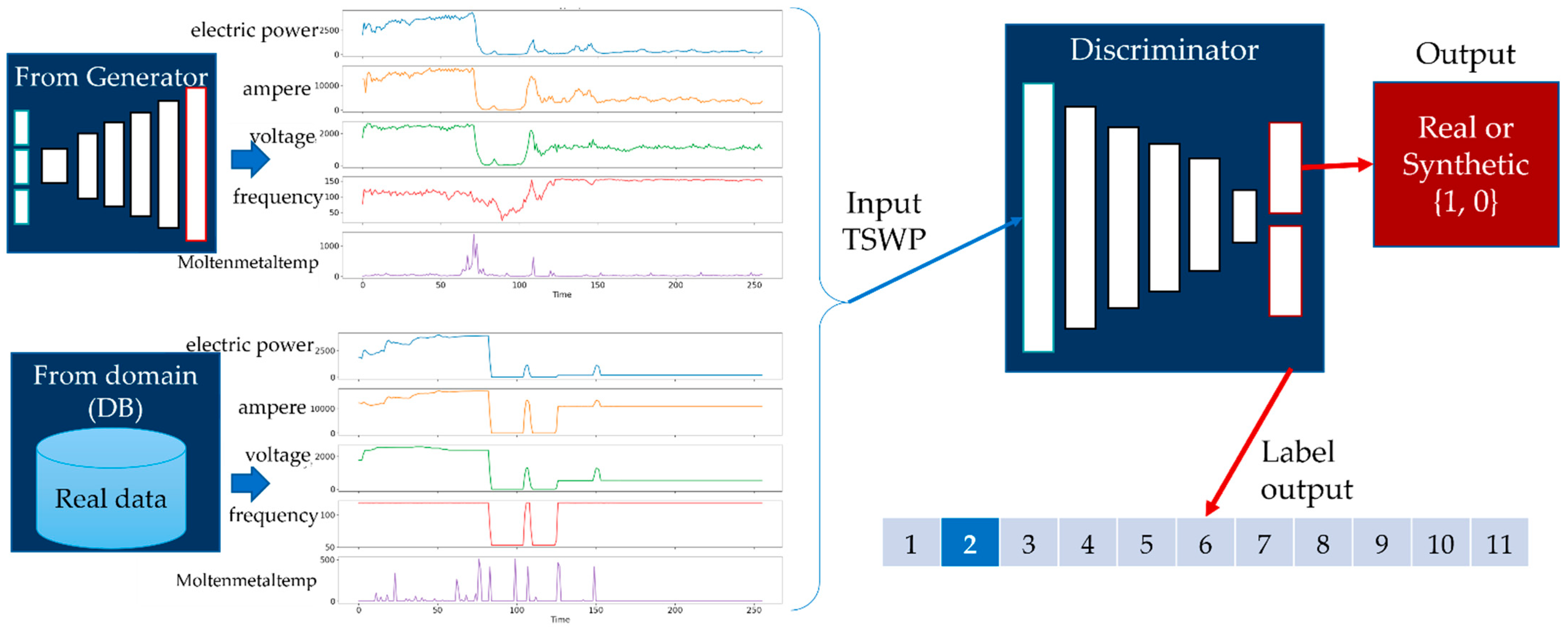
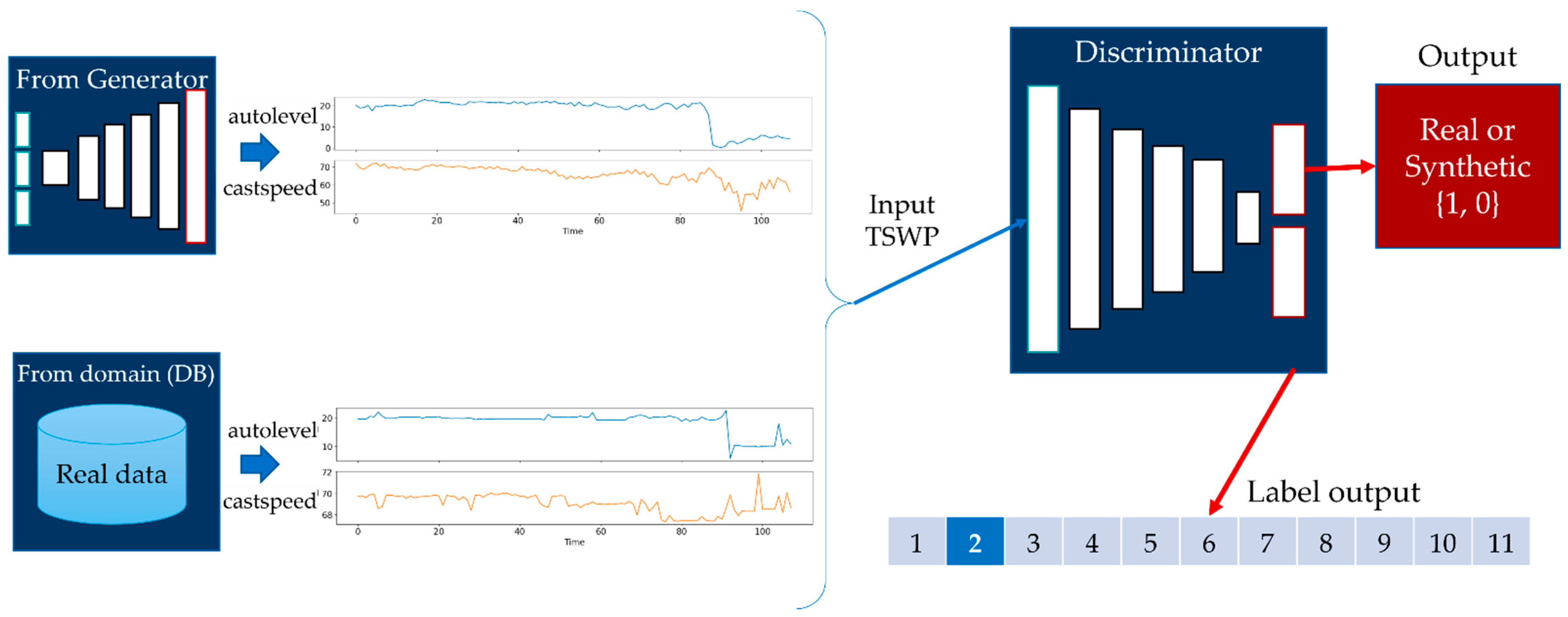
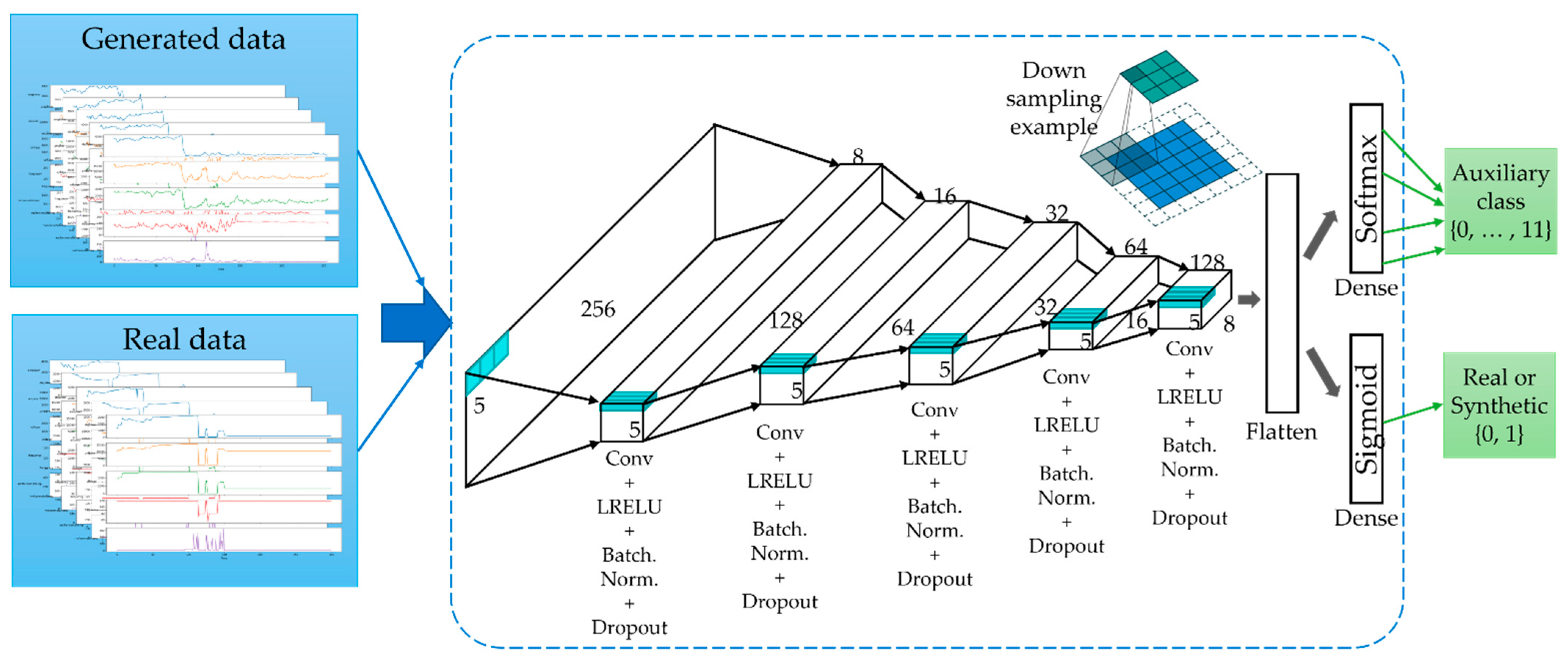
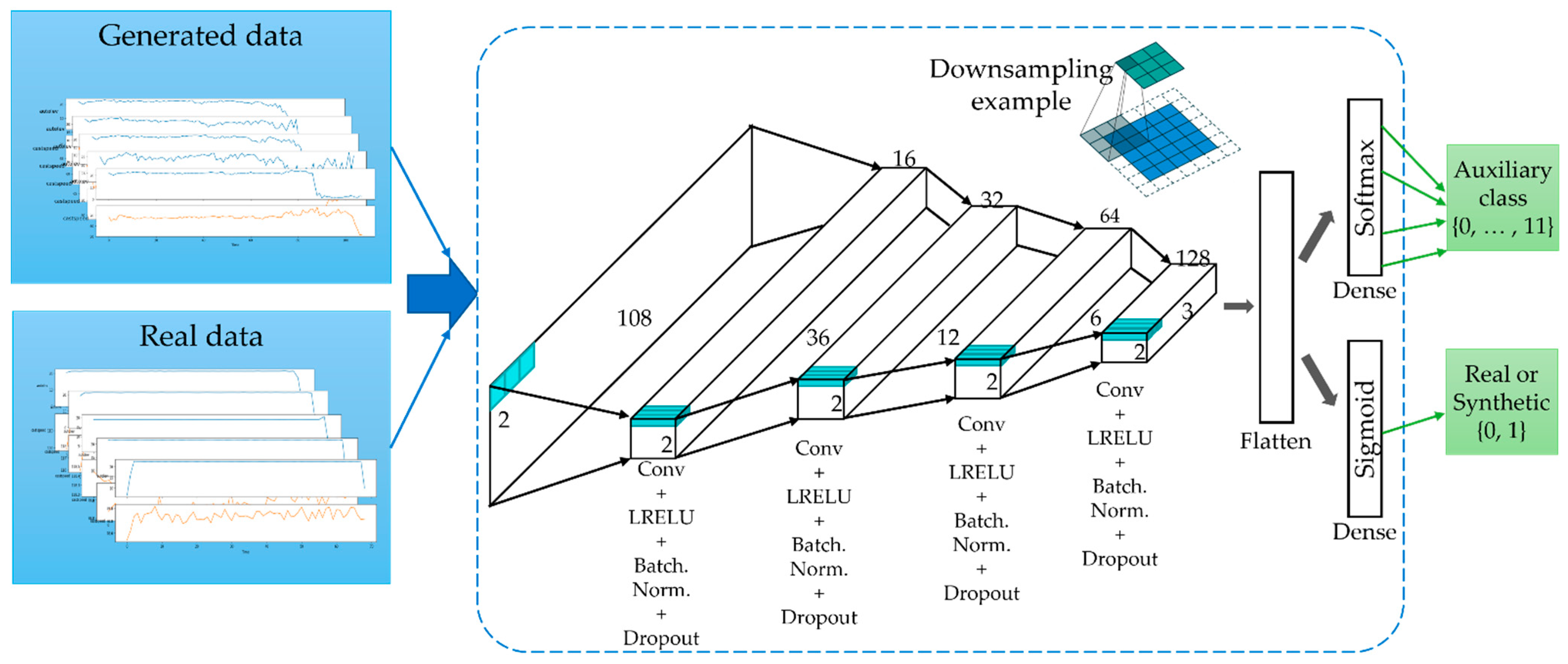
- We used the AC-GAN method to generate the TSWP based on the historical data from the melting and casting processes. This method consists of two models: a generator and a discriminator. First, the discriminator is trained by a batch of actual data from the training set and an equal number of synthetic data points from the generator. Then, the generator produces another batch of data, and the discriminator determines whether the data are actual or synthetic.
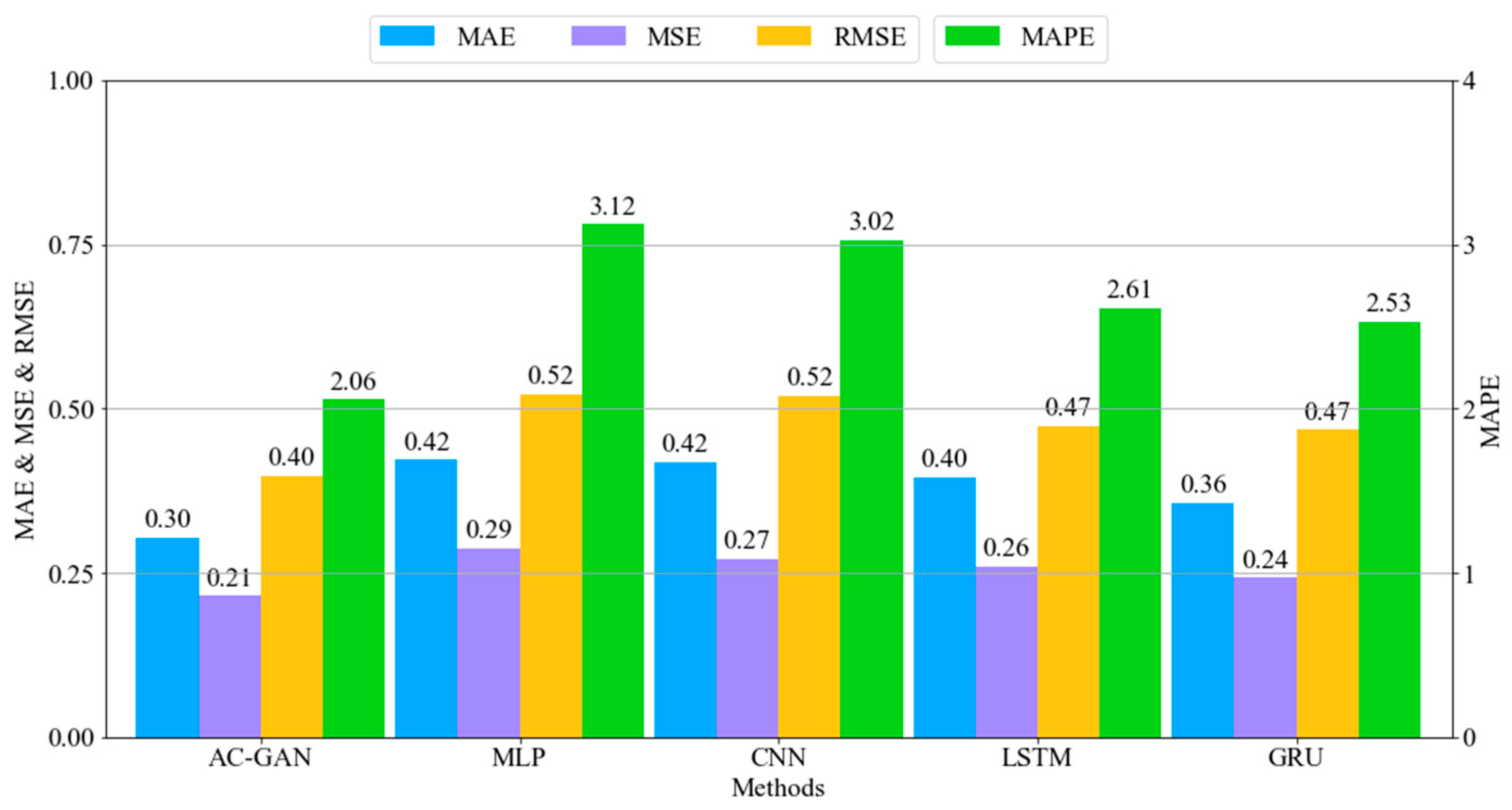
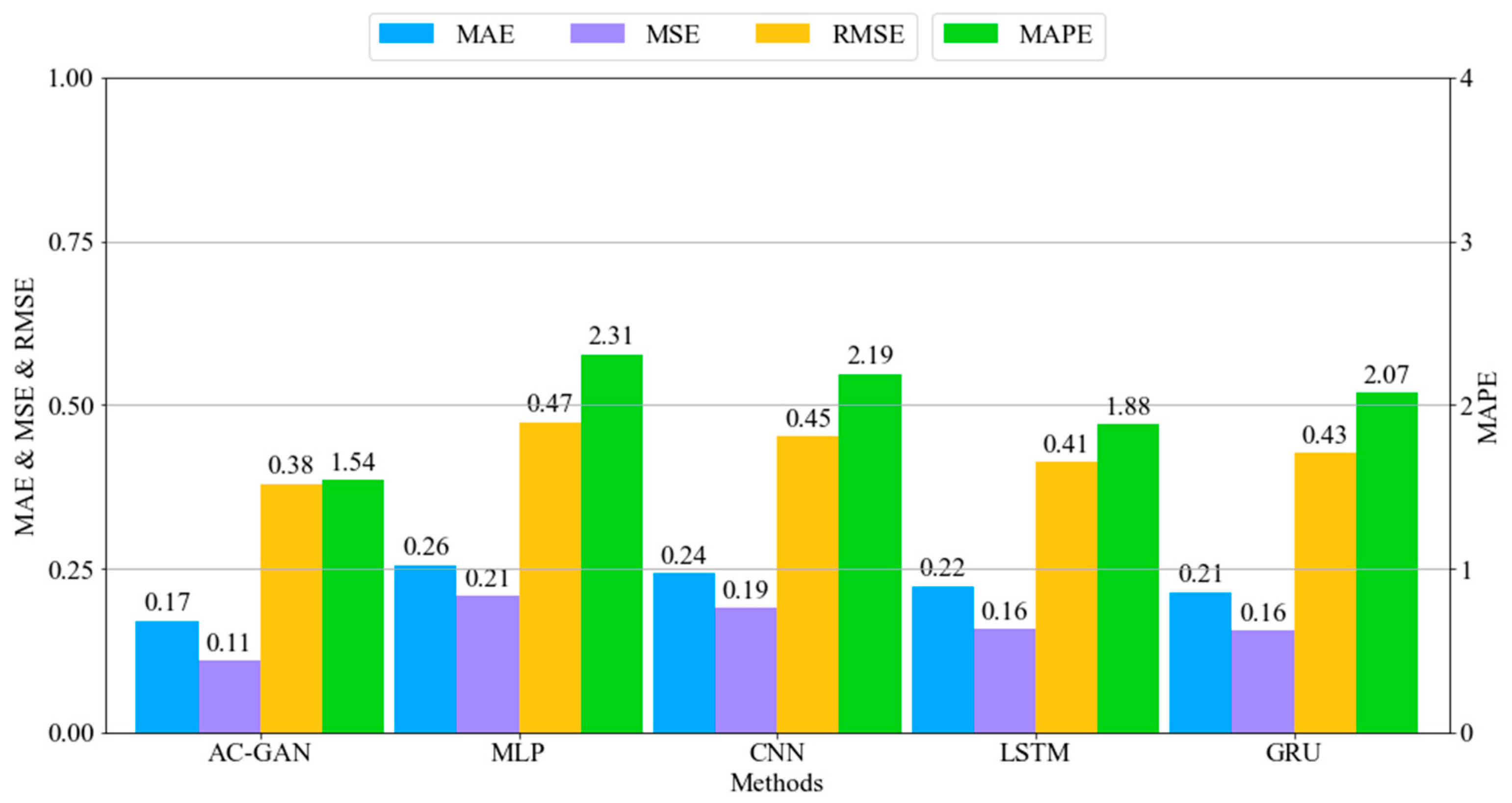
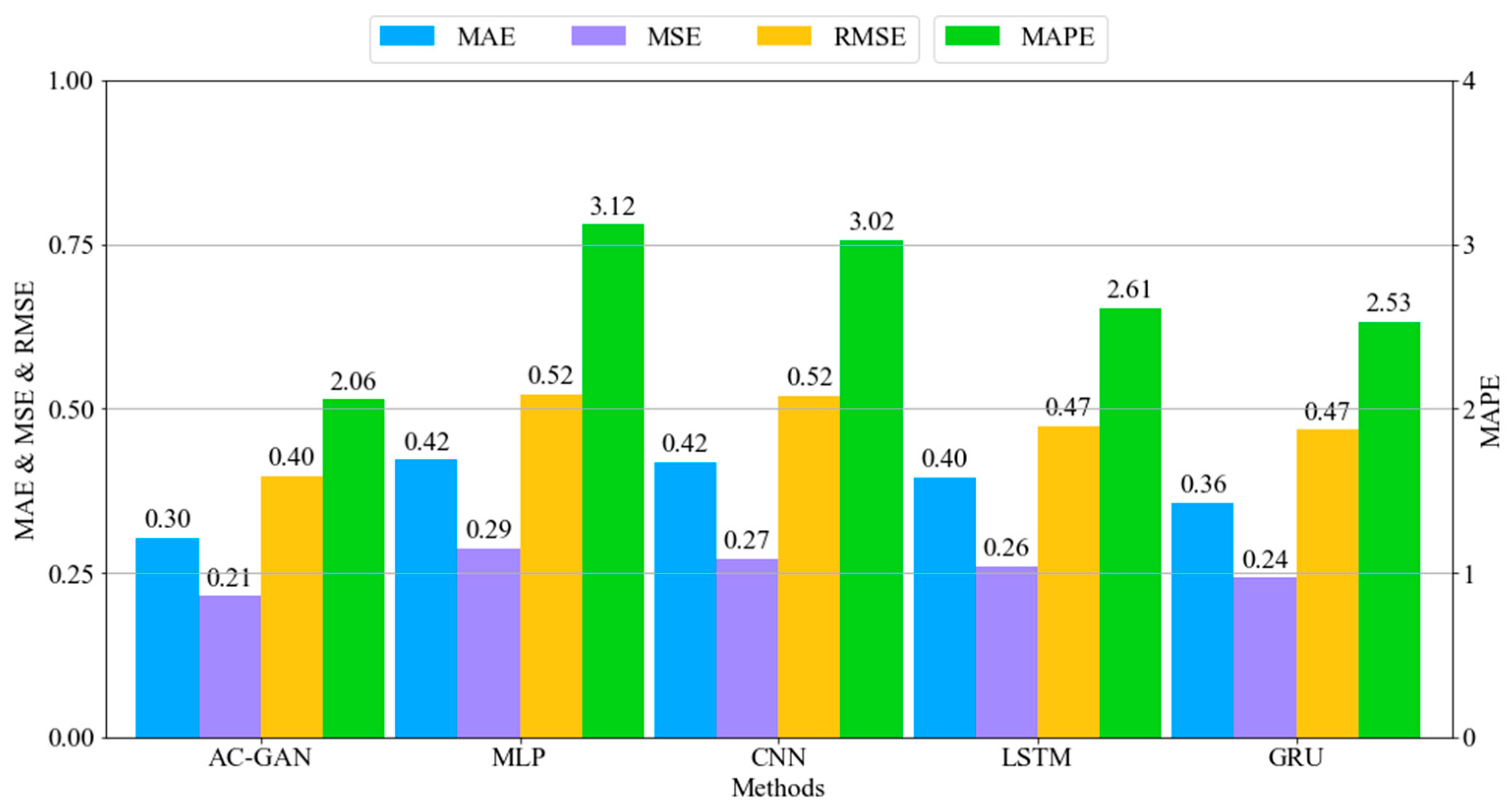
- Lastly, we trained and evaluated the AC-GAN method and other deep learning methods: MLP, CNN, LSTM, and GRU. The experiments demonstrated that the proposed method has two advantages over the other deep learning methods: (1) it dramatically reduces the error rate, and (2) it generates different outputs for different inputs.
2. Related Work
2.1. Statistical Methods
2.2. Machine Learning Methods
2.3. Deep Learning Methods
2.4. Discussions
3. Materials and Methods
3.1. Overview
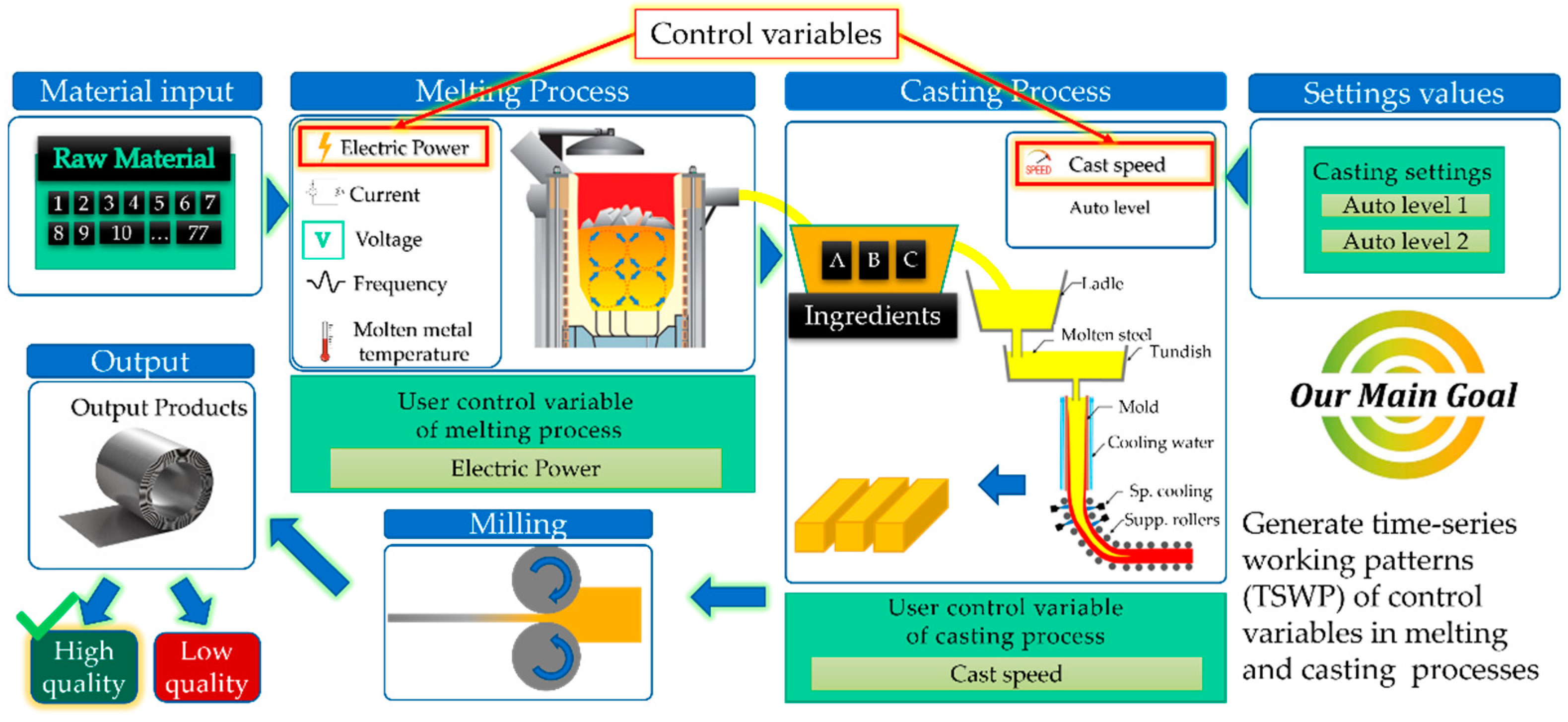
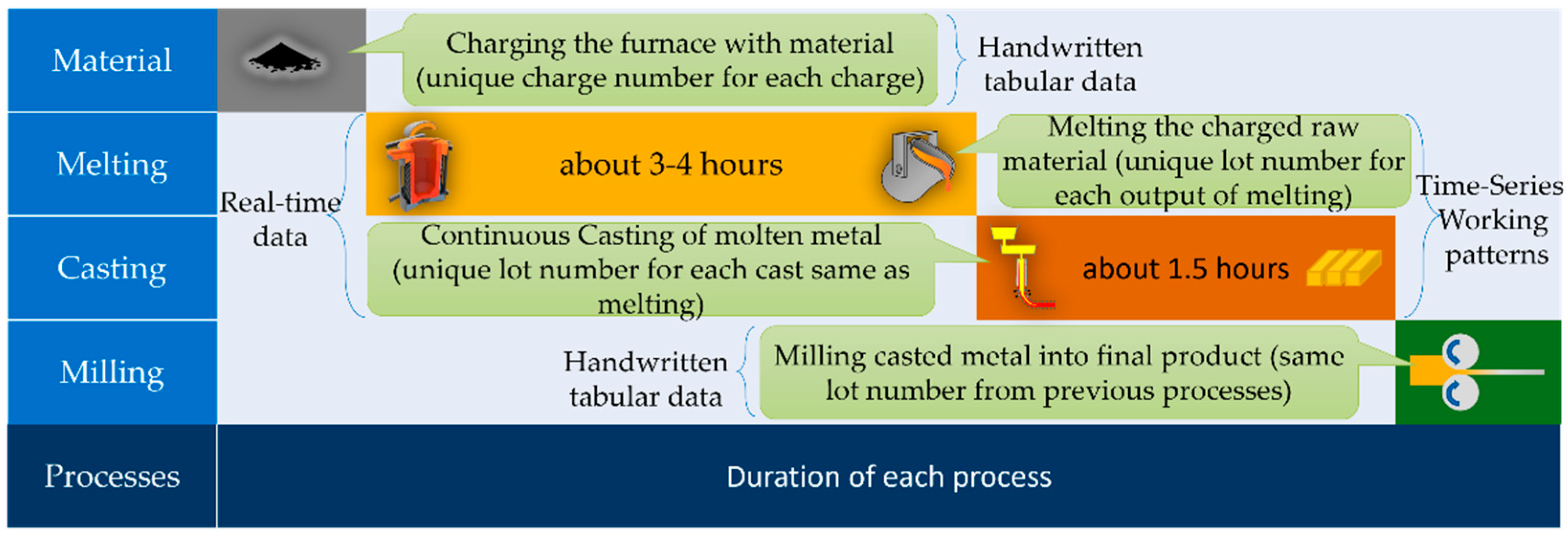
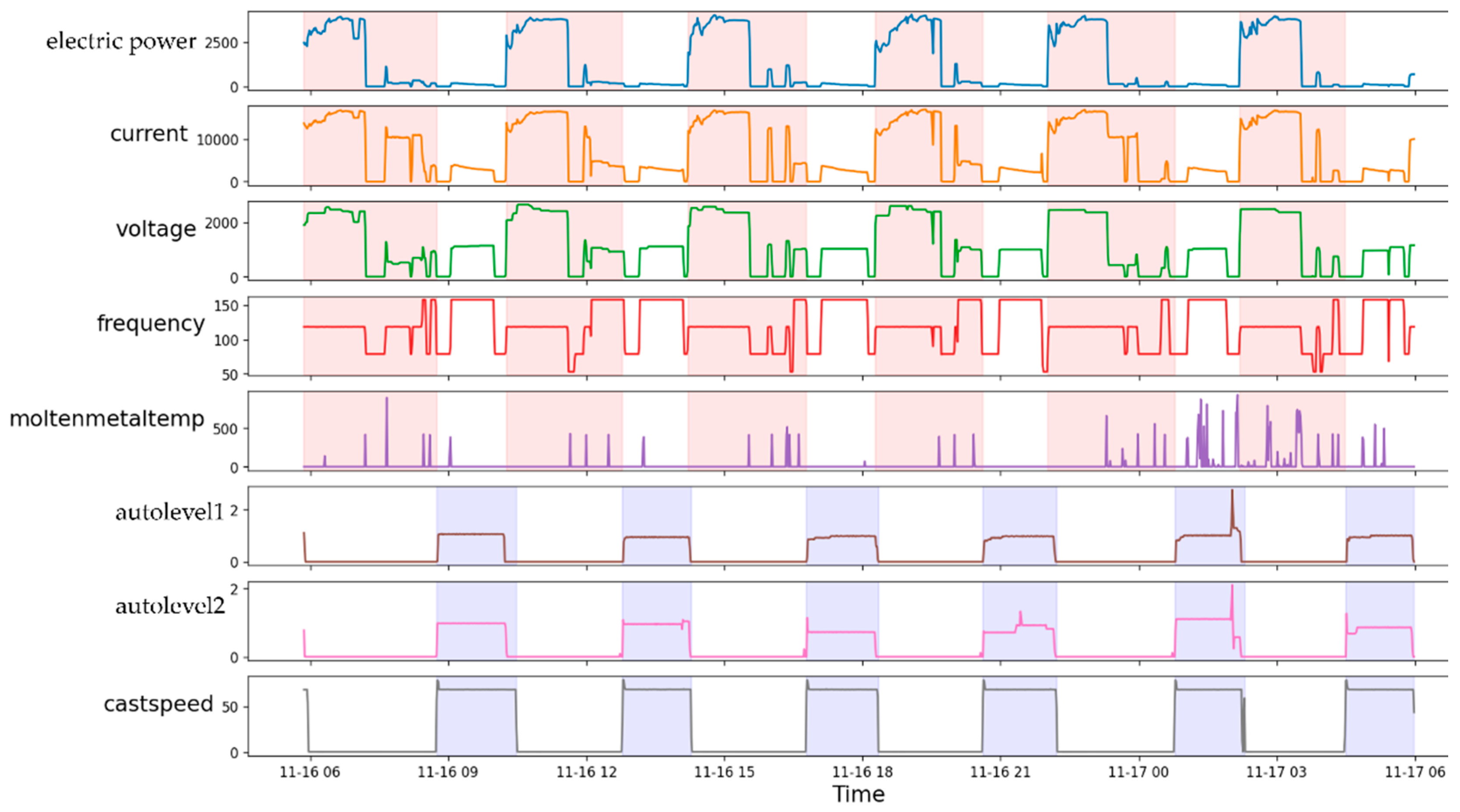
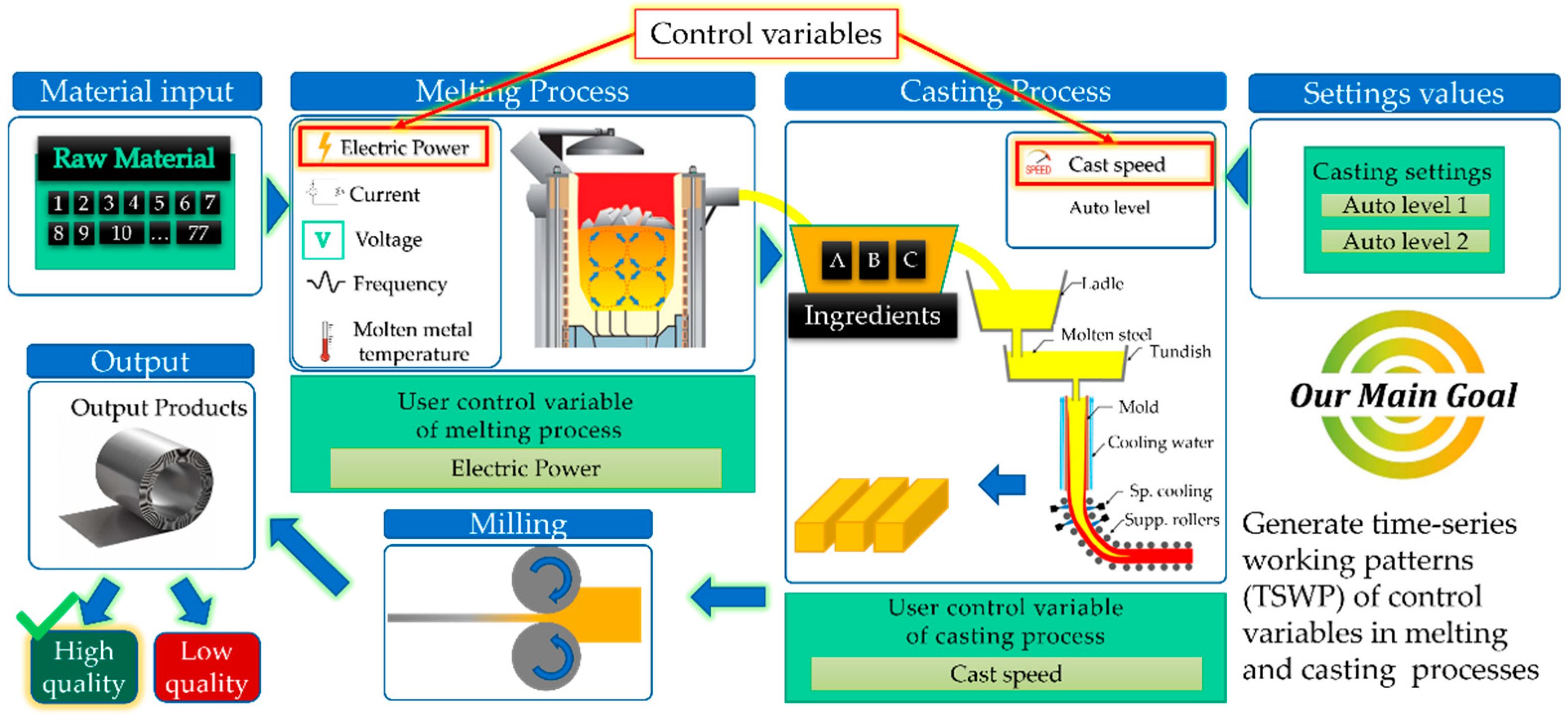
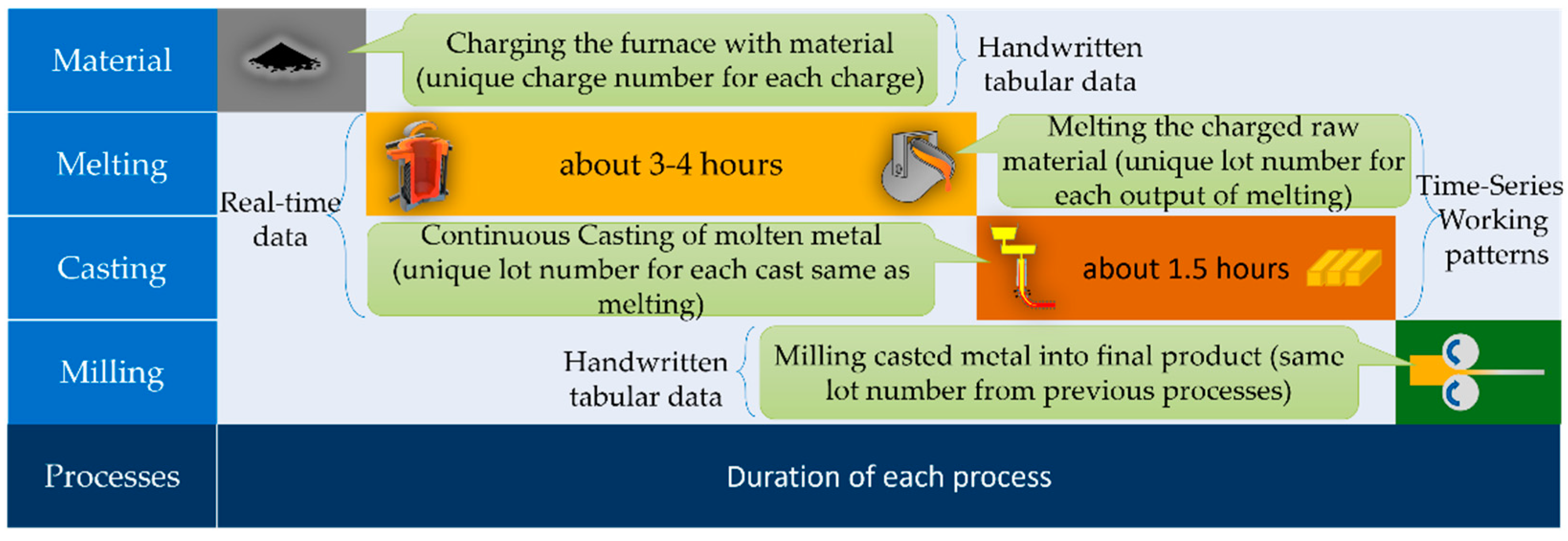
3.2. Production Process
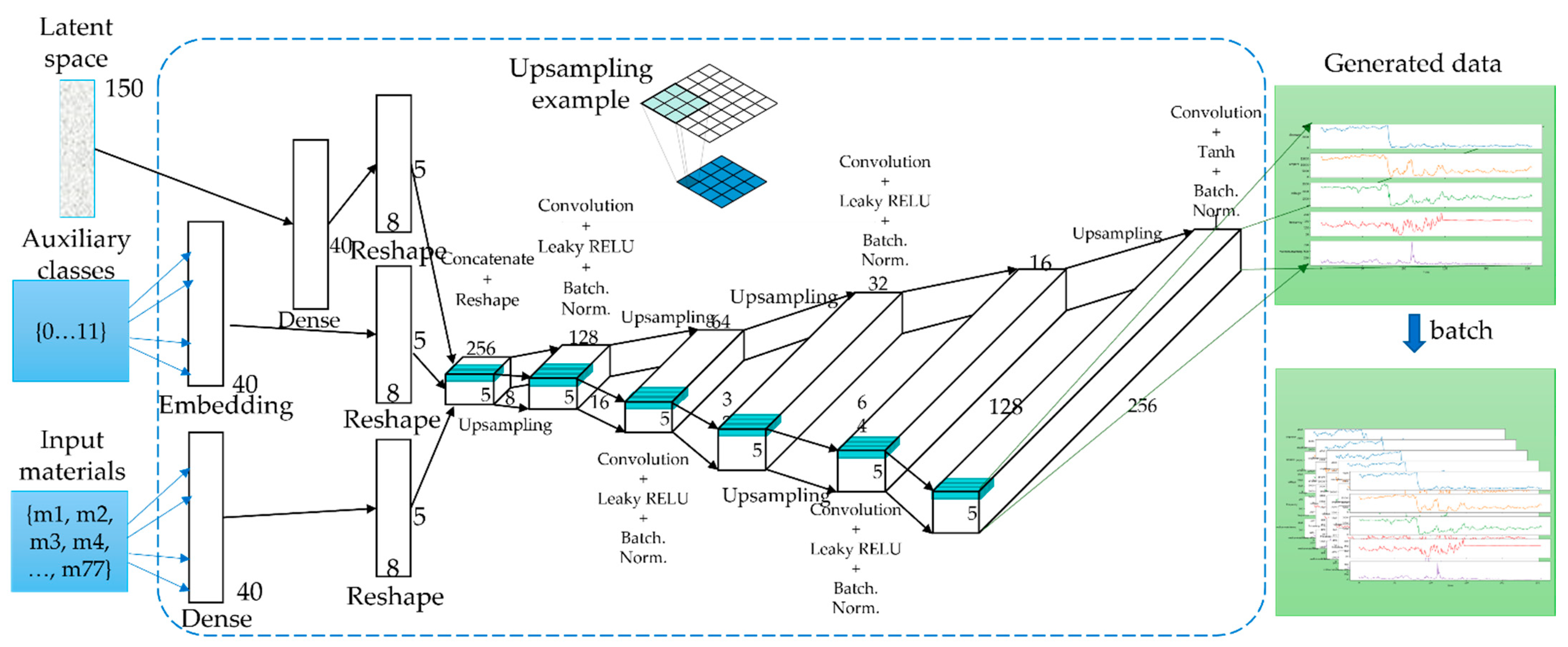
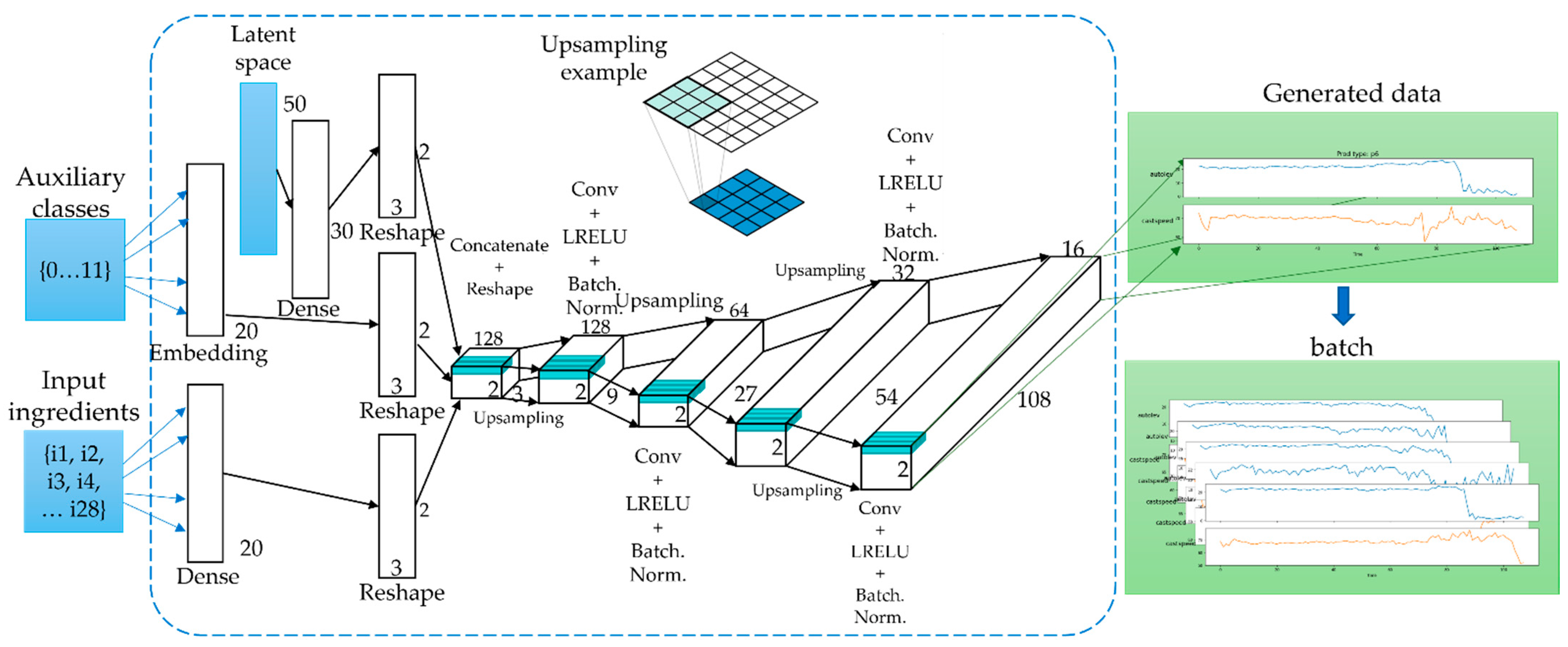
3.3. Problem Statement
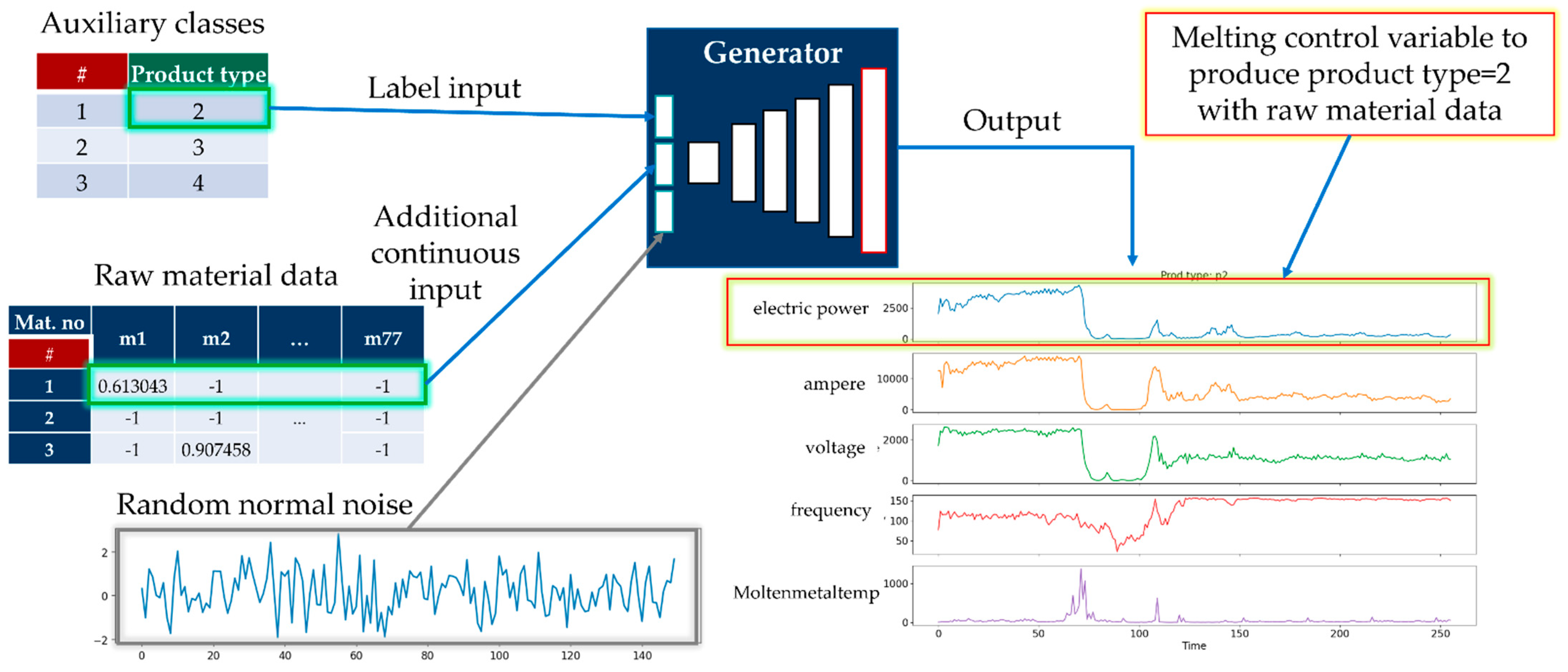
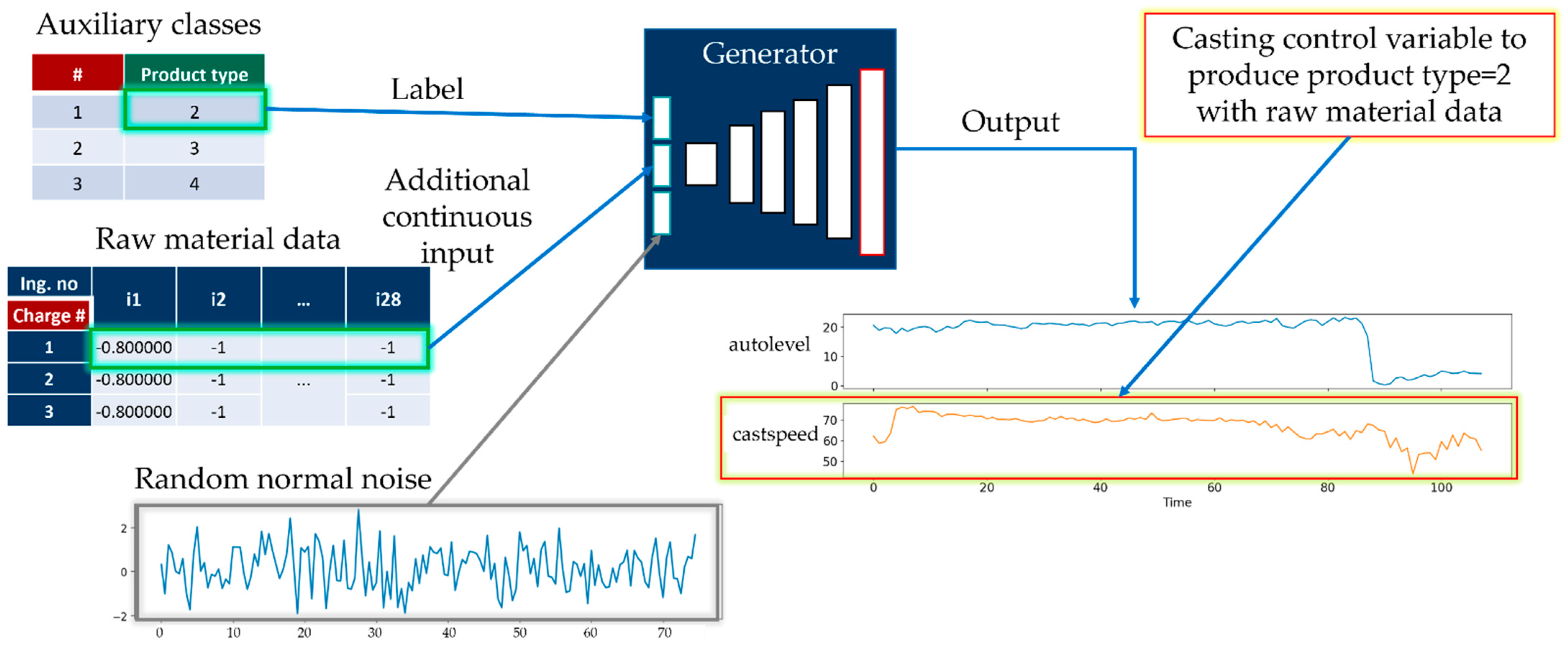
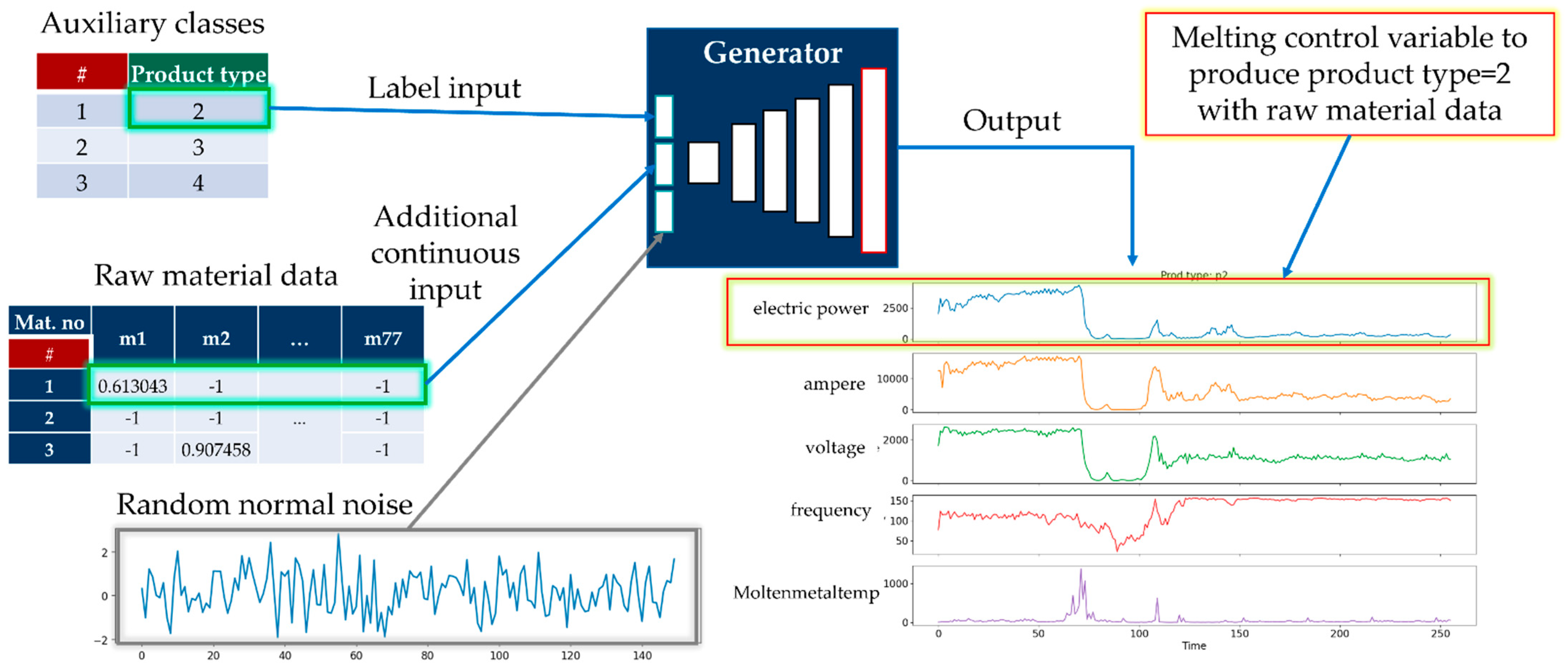
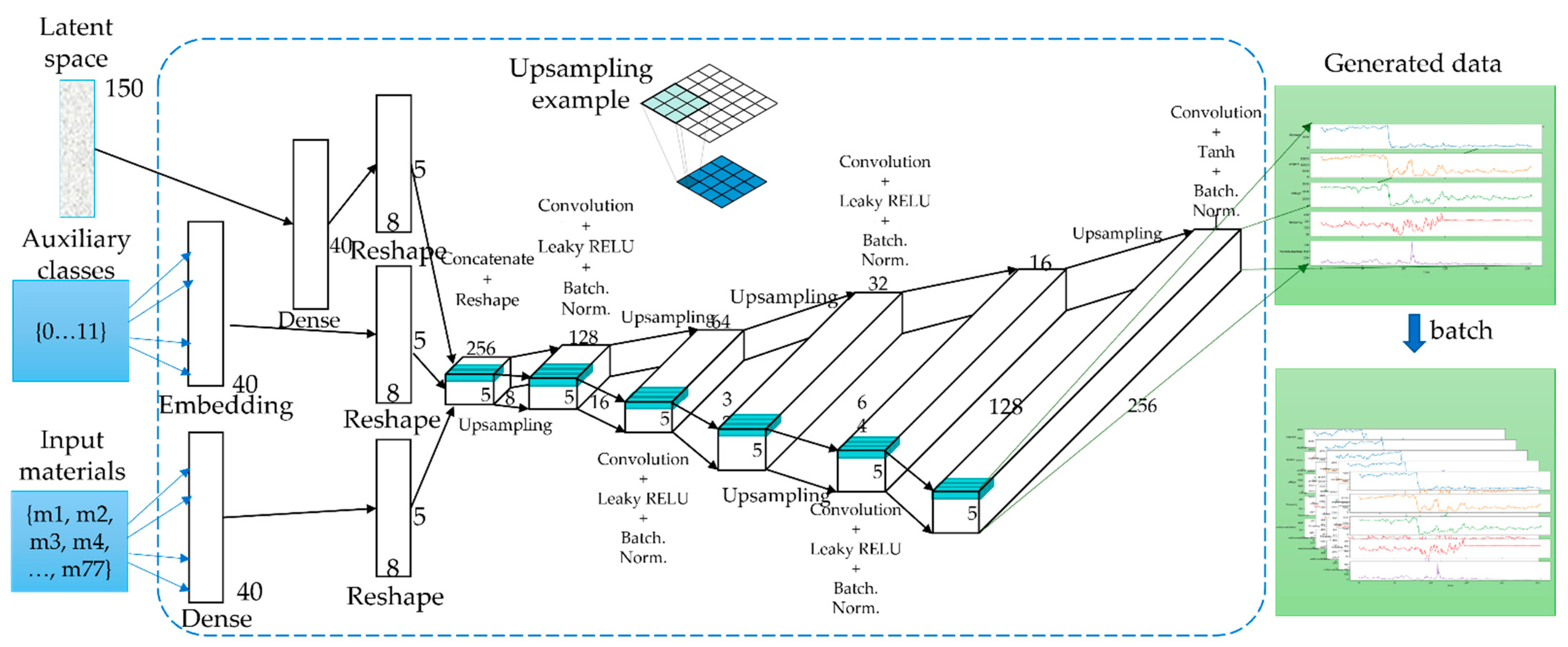
- Auxiliary class input, product type of working cycle data;
- Auxiliary continuous input from raw material data;
- Latent space data (random normal) of length 150.
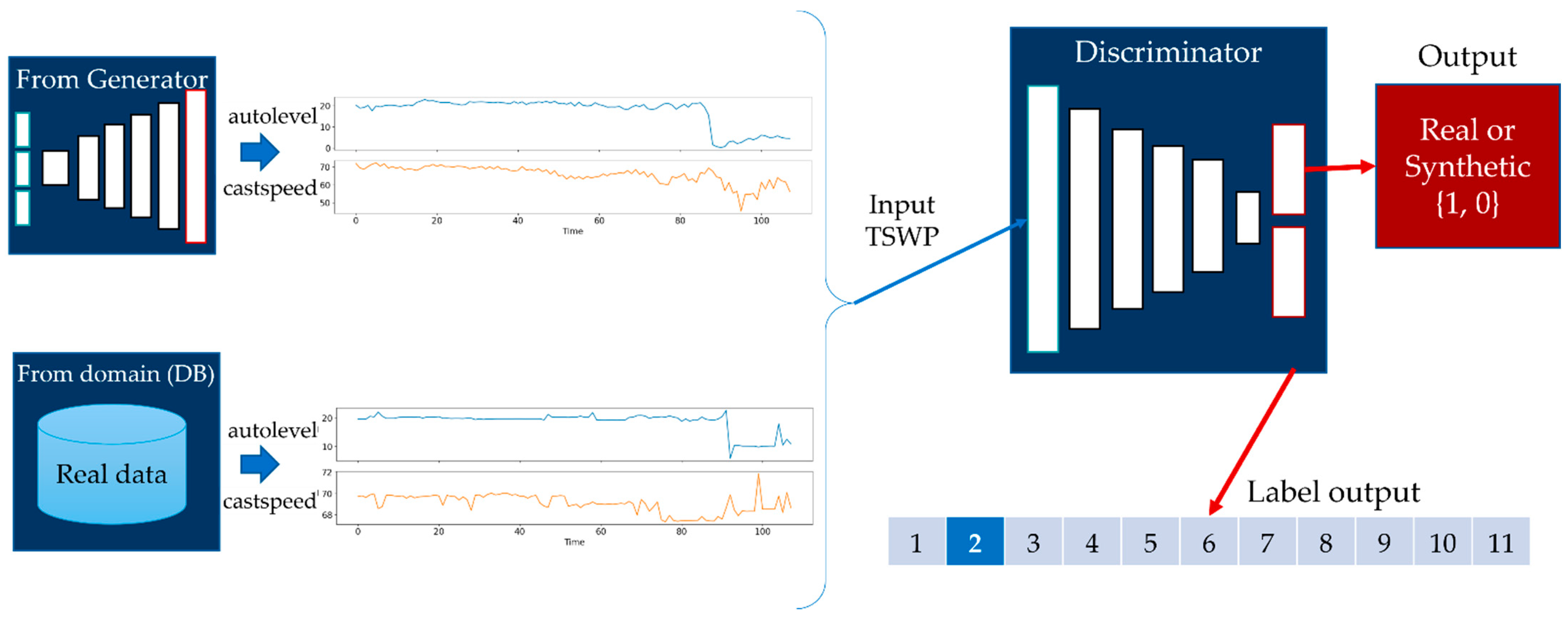
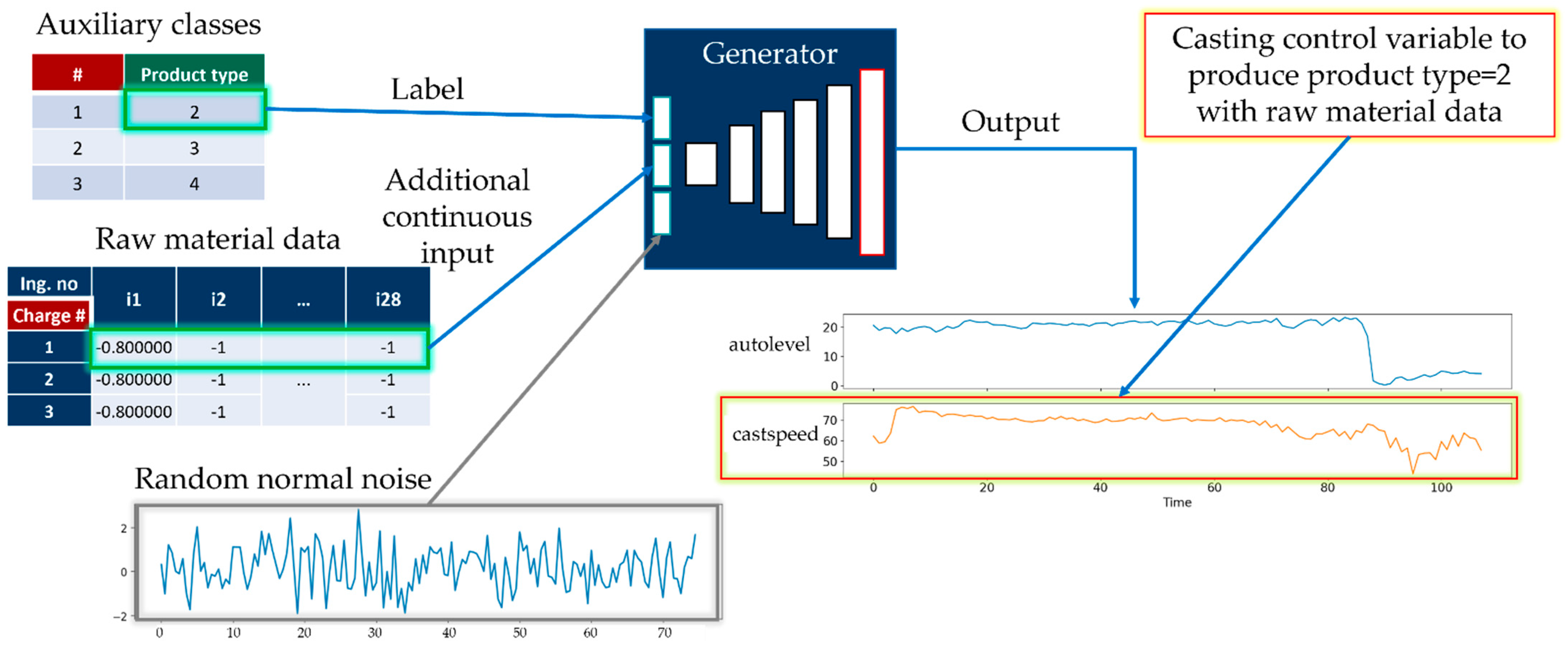
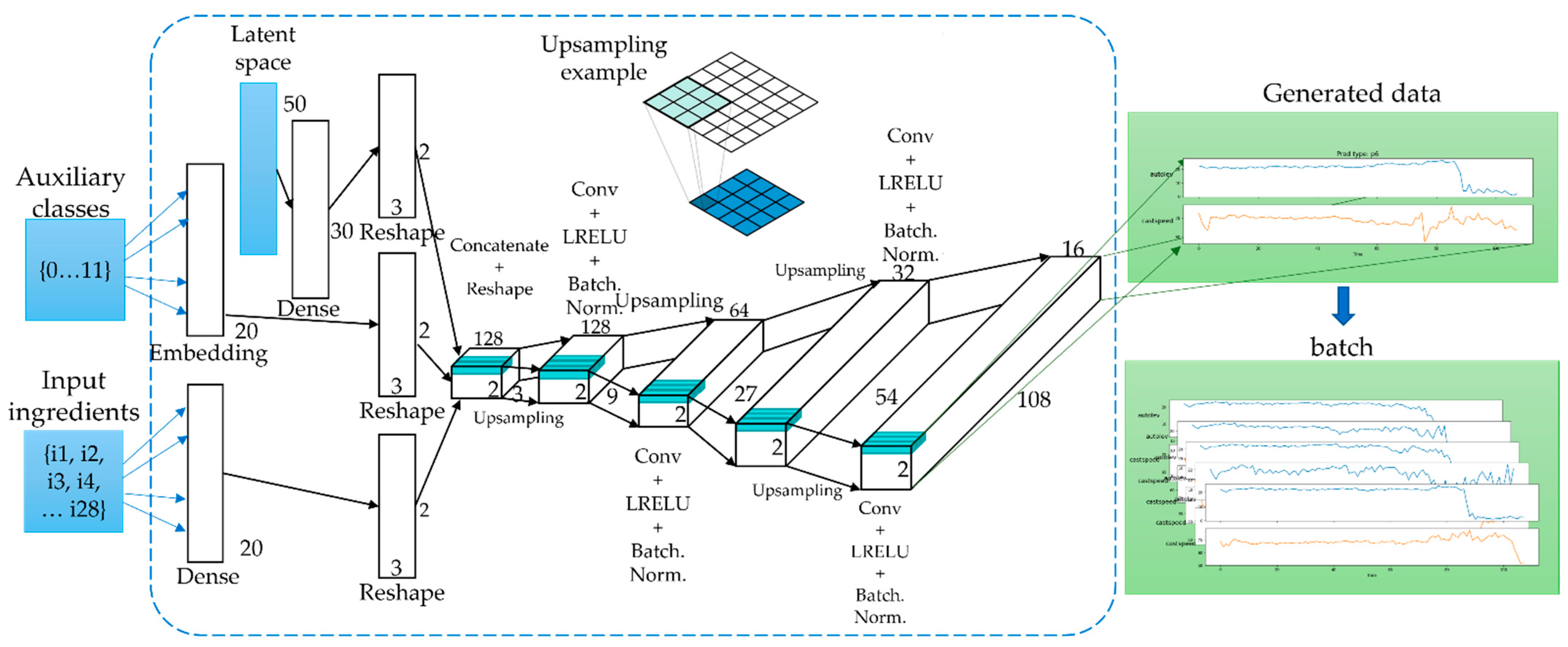
- Auxiliary class input, the product type of working cycle data;
- Auxiliary continuous input from ingredient data;
- Latent space data (random normal) of length 80.
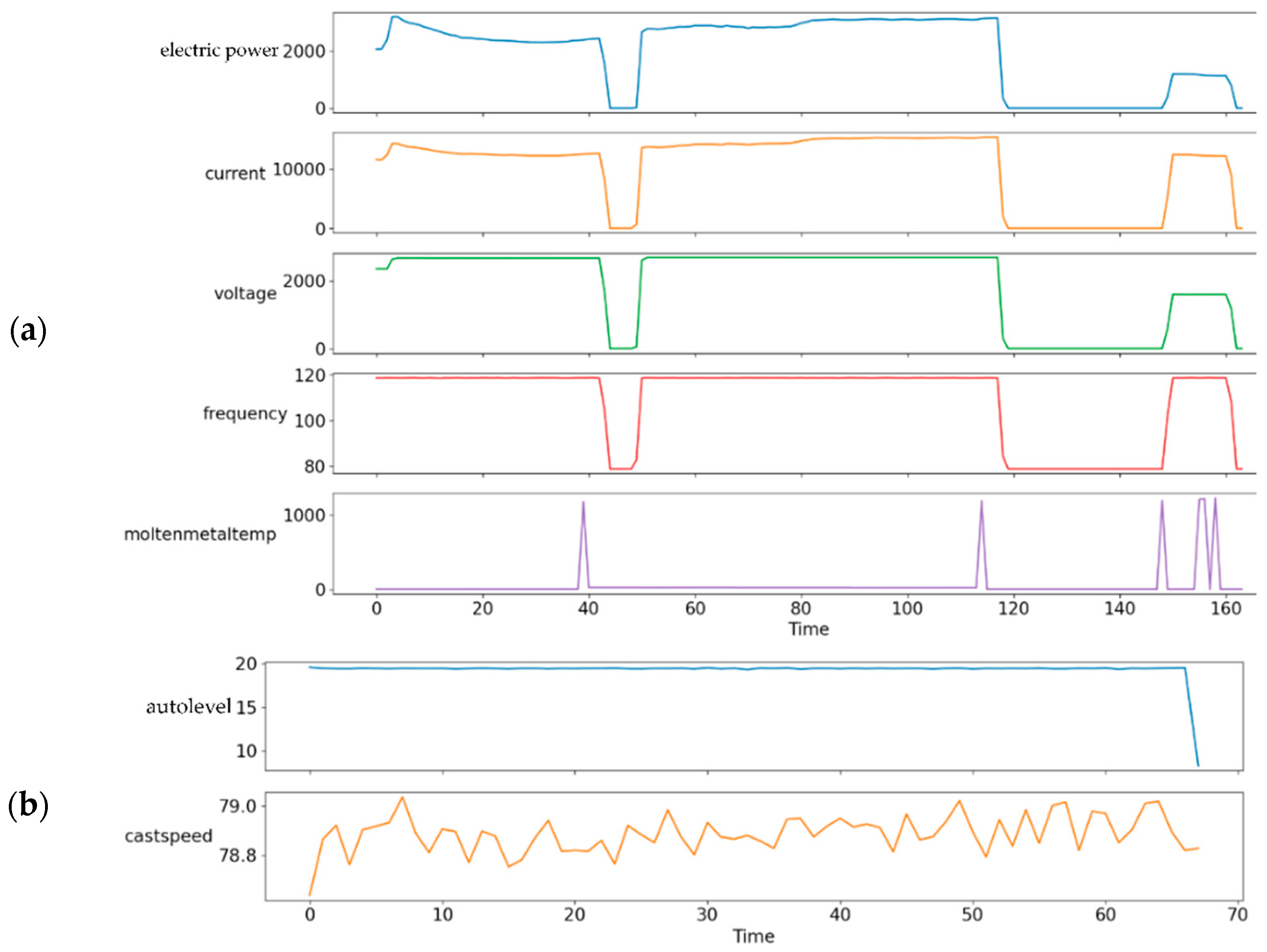
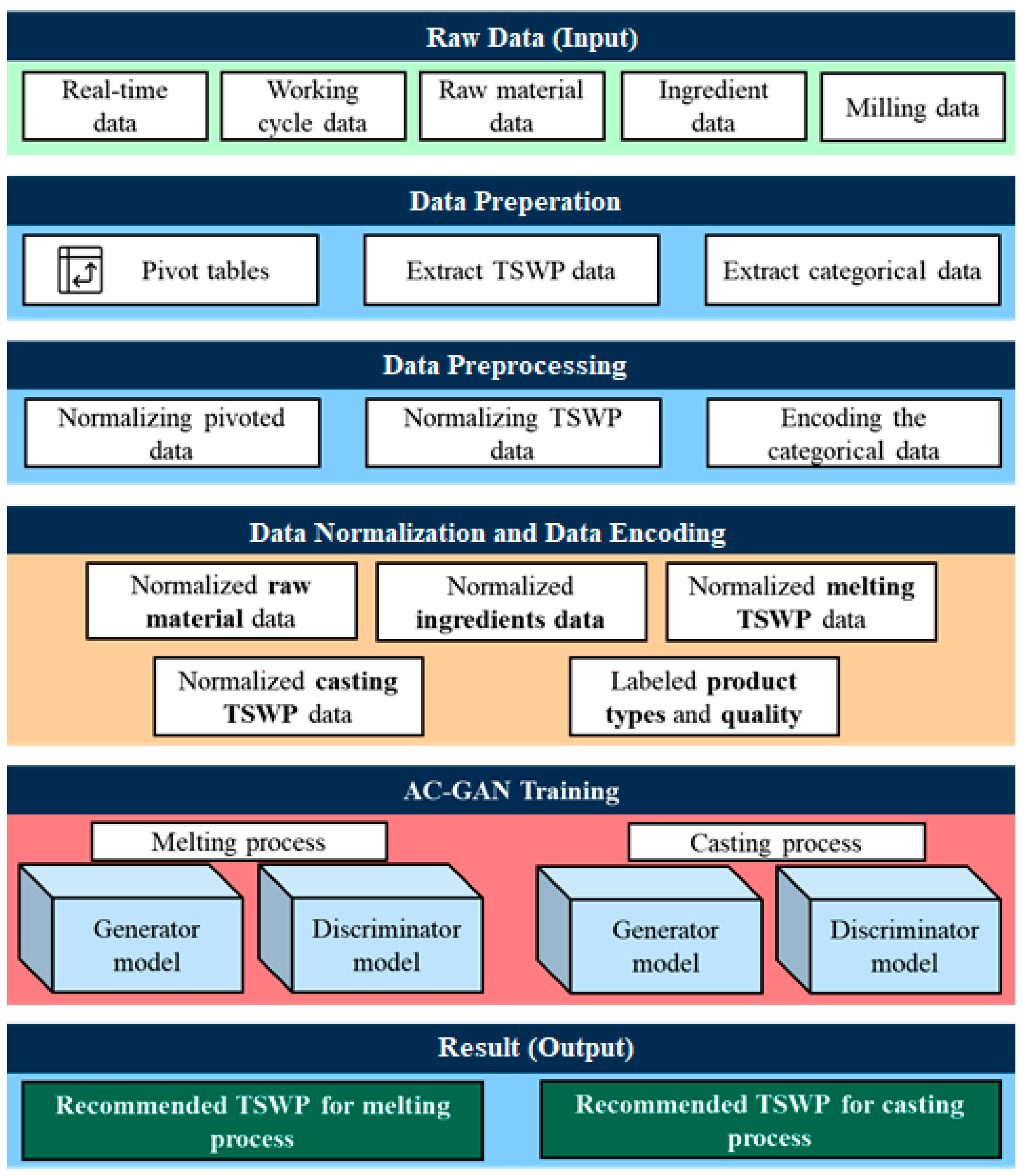
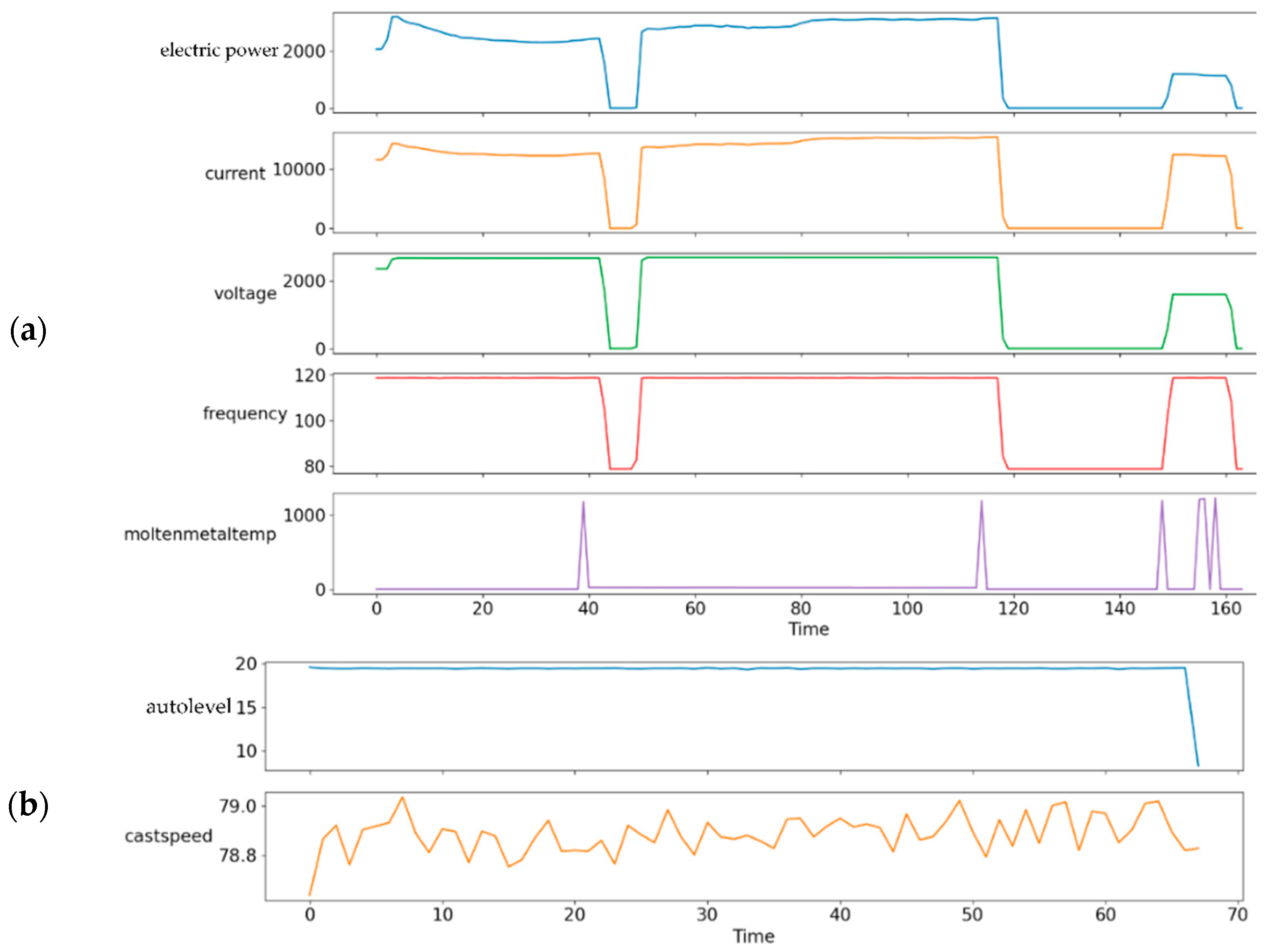
3.4. Dataset
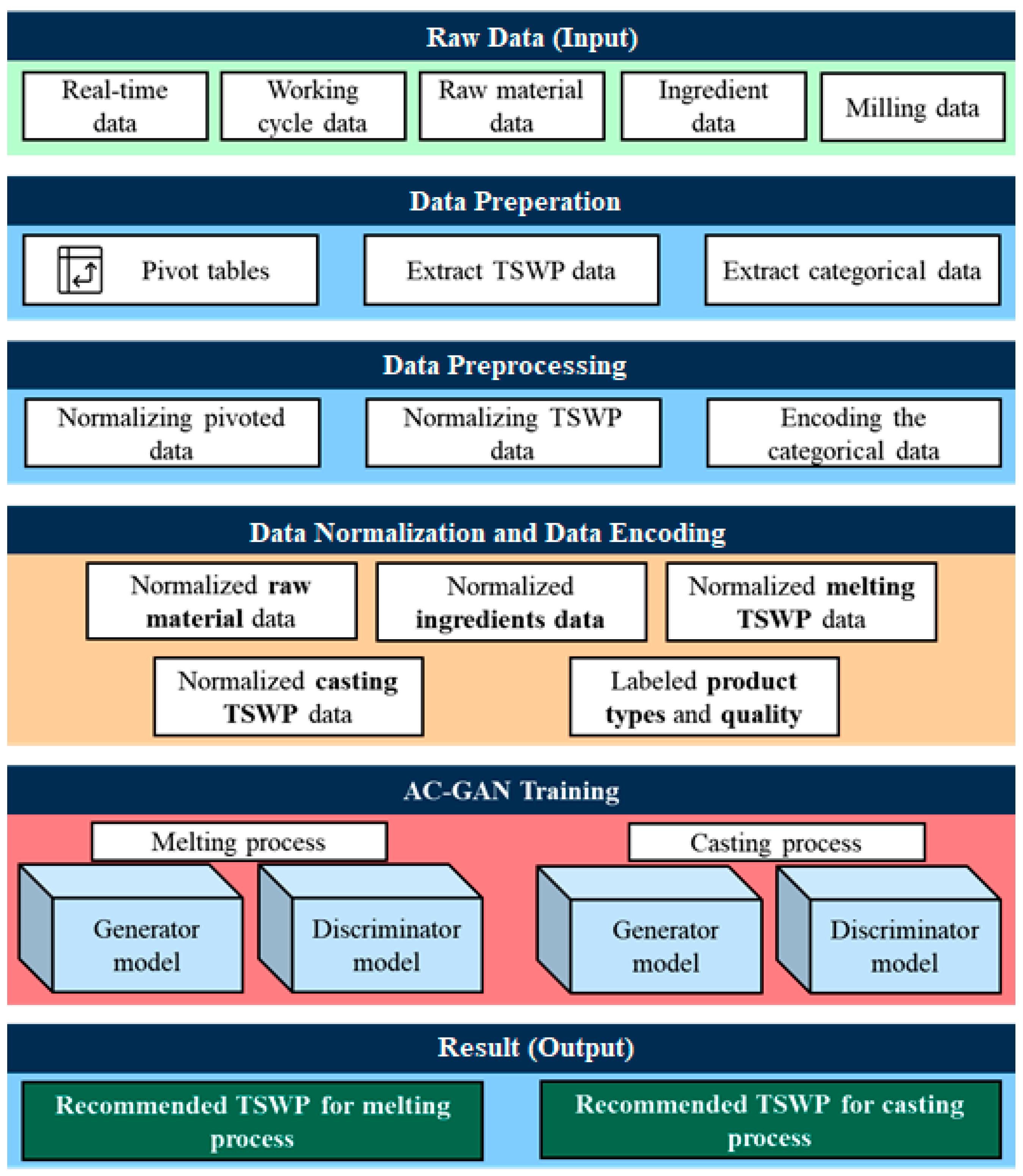
3.4.1. Data Preparation
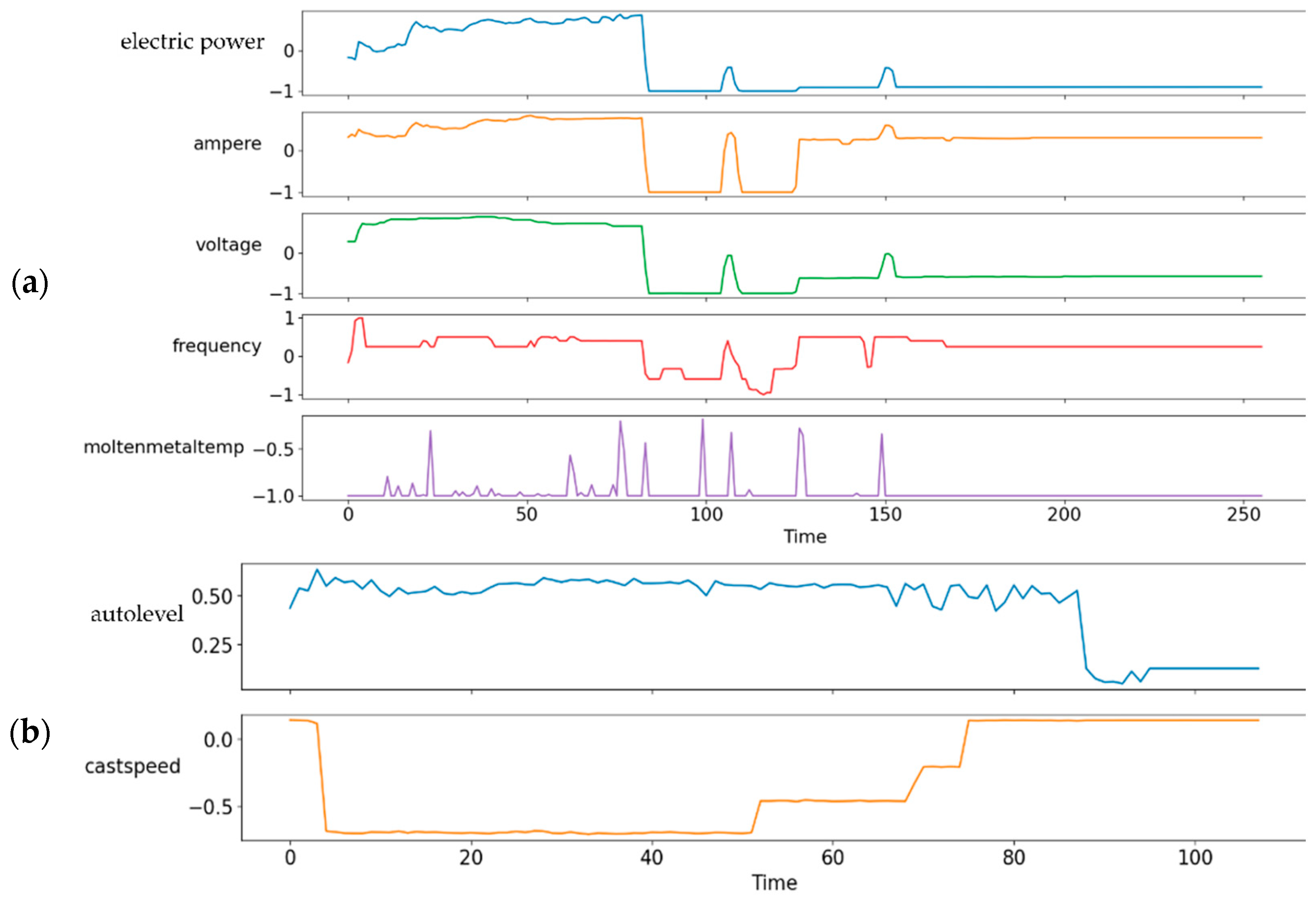
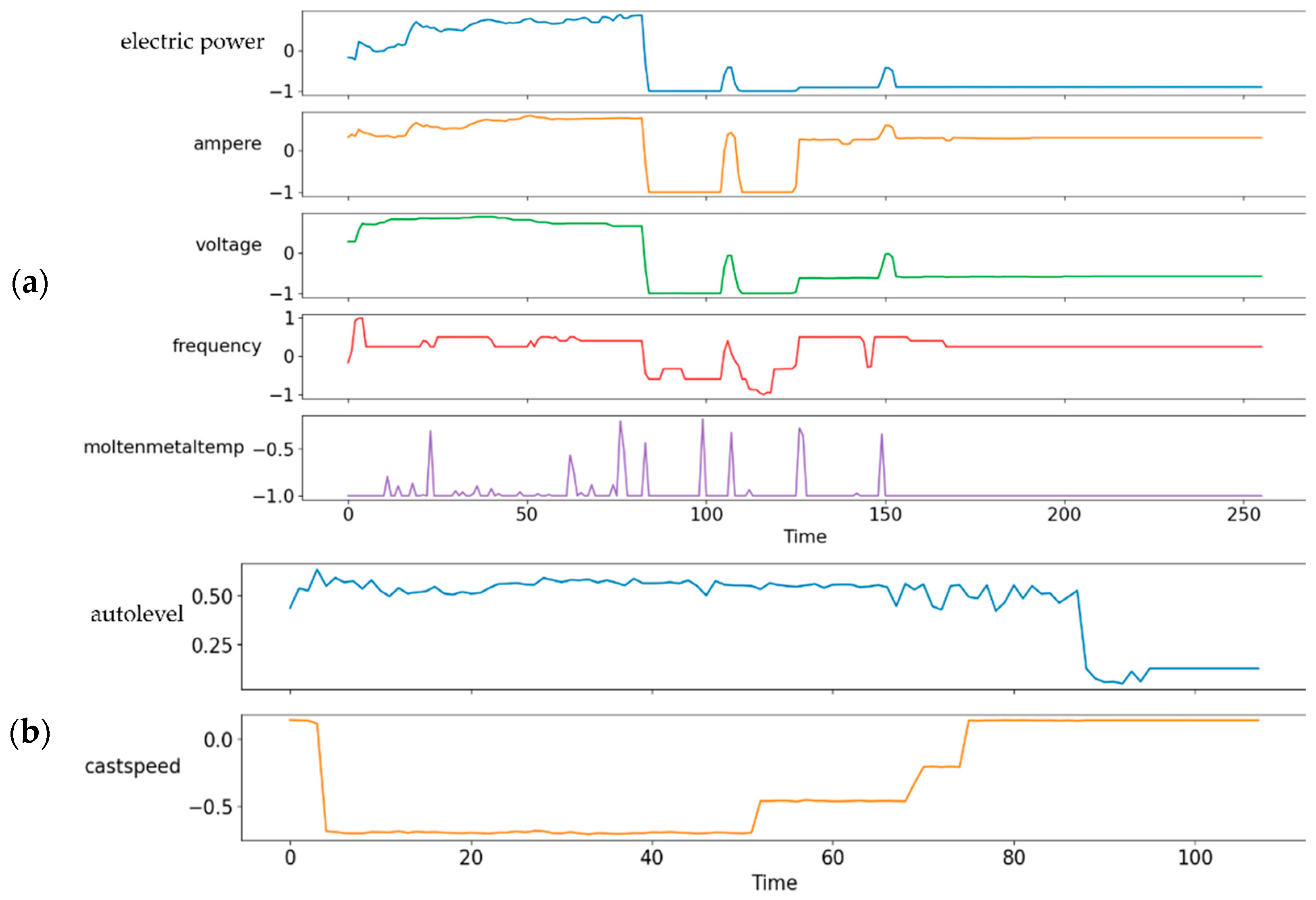
3.4.2. Data Preprocessing
| Algorithm 1. Expanding data into length n. | |
| 1 2 3 4 5 6 7 8 9 | INPUT: N ← desired length list D ← list to expand. last_value ← Last value of list D. OUTPUT: expanded_list_D for n-len(D) do Append last_value to D. end for |
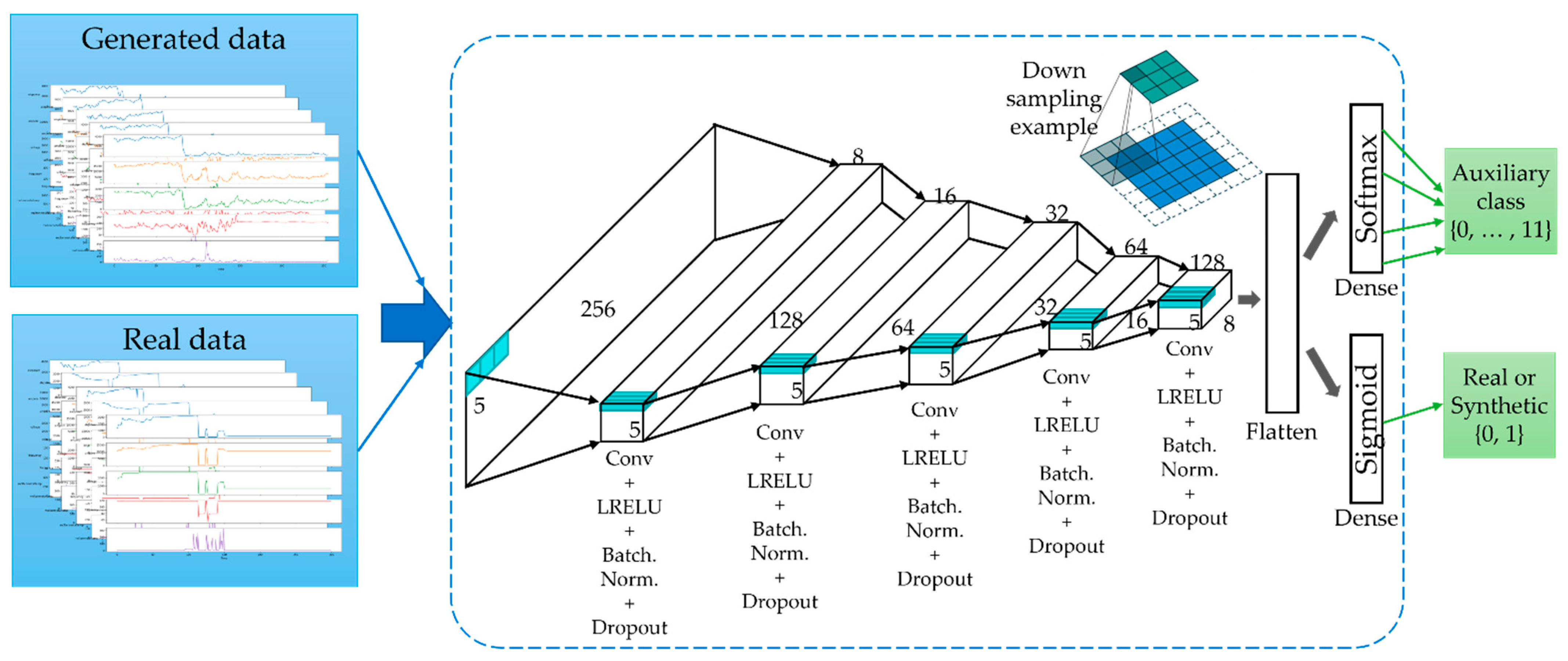
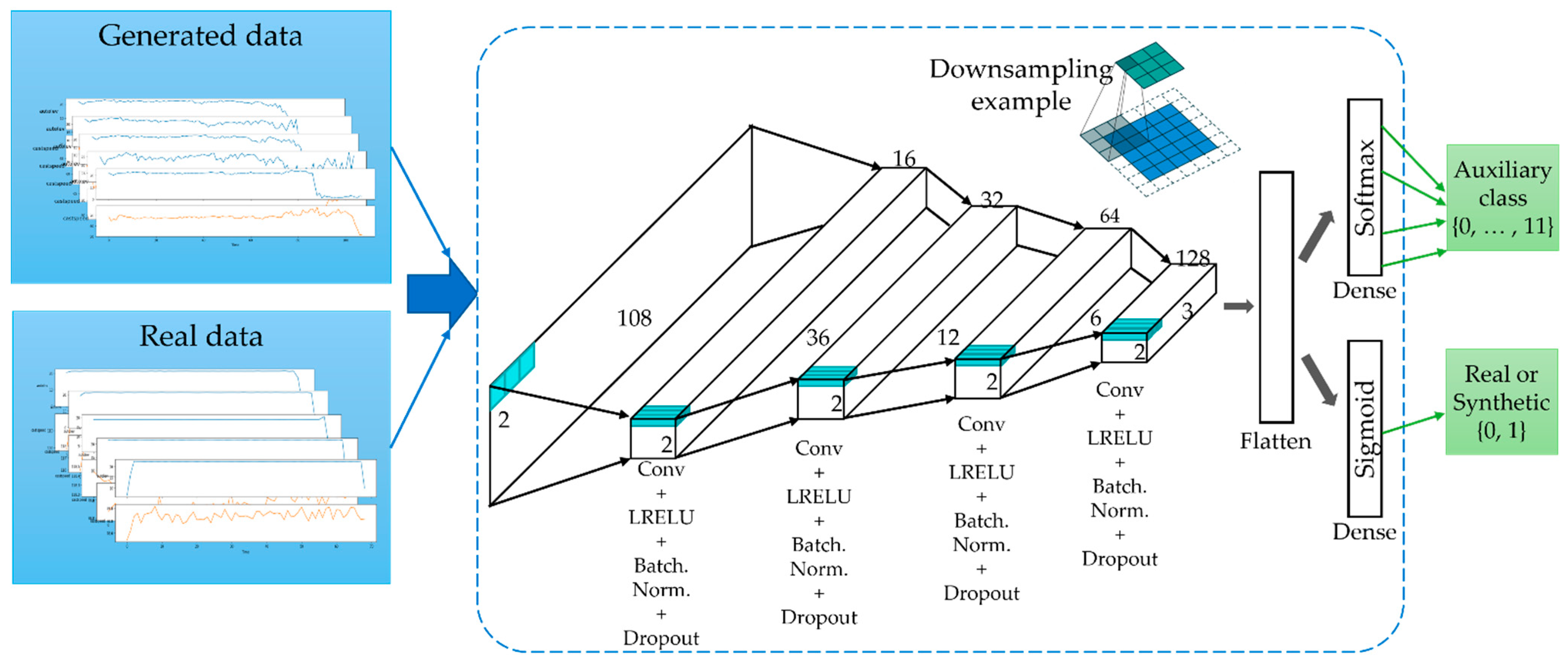
3.5. Generation of Time-Series Working Patterns Using AC-GAN
| Algorithm 2. AC-GAN | ||
| INPUT: | ||
| 1 | n ← number of training iterations | |
| 2 | k ← number of steps | |
| 3 | m ← minibatch size | |
| 4 | z(i)← noise data | |
| 5 | x(i)← real data | |
| 6 | c(i)← class data | |
| 7 | η← learning rate | |
| 8 | OUTPUT: | |
| 9 | generated_TWSP | |
| Initialize: discriminator D with parameter and generator G with parameter | ||
| 10 | for N do | |
| 11 | for k steps do | |
| 12 | Sample minibatch of m noise samples {z(1), …, z(m)} from noise prior pg(z) with class labels {c(1), …, c(m)} | |
| 13 | Sample minibatch of m examples {x(1), …, x(m)} from data generating distribution pdata(x). | |
| 14 | Update by maximizing : | |
| 15 | (4) | |
| 16 | end for | |
| 17 | Sample minibatch of m noise samples {z(1), …, z(m)} from noise prior pg(z). | |
| 18 | Update by maximizing : | |
| (5) | ||
| 19 | end for | |
3.6. Methods under Comparison
4. Results
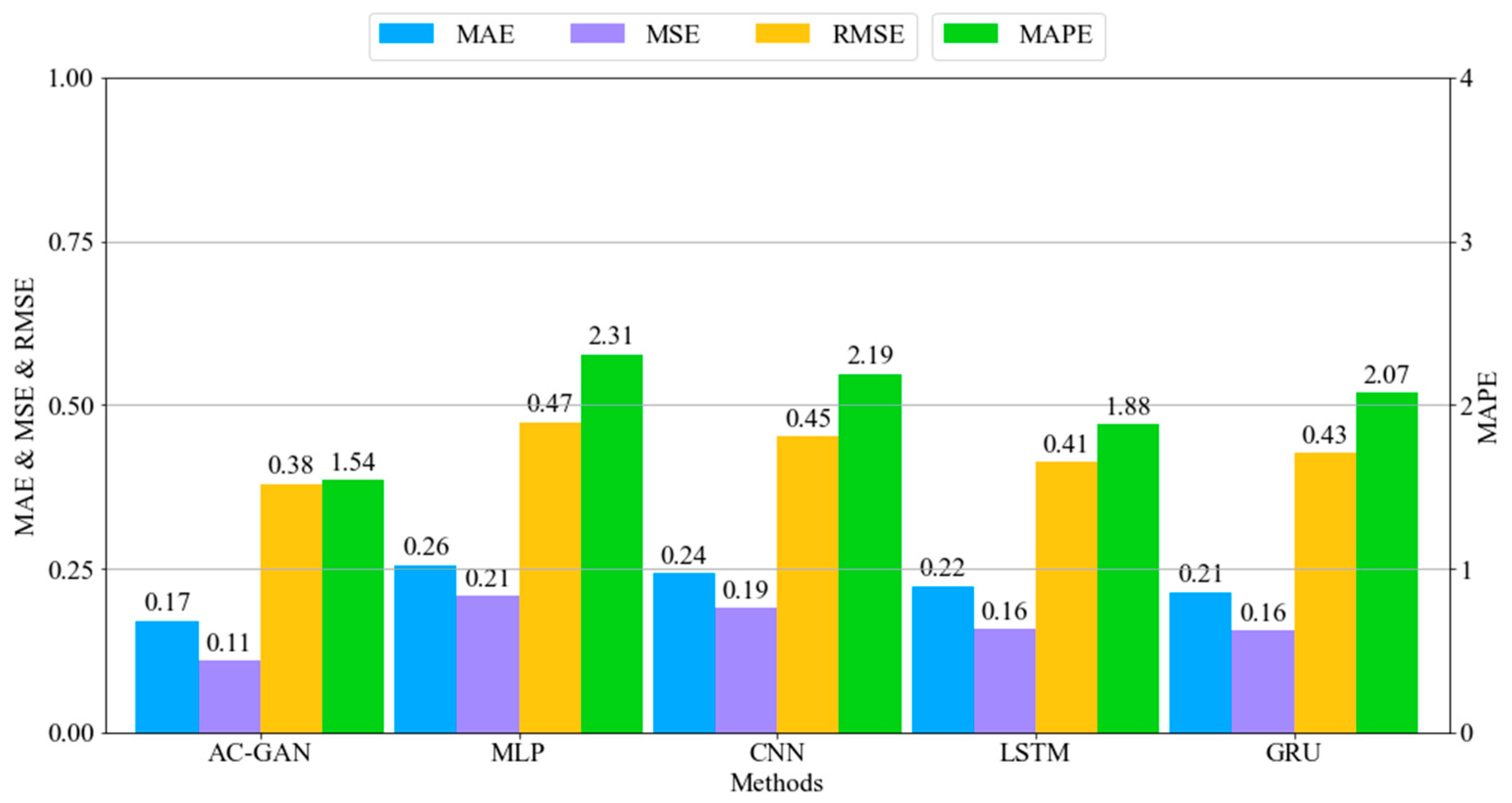
4.1. Evaluation
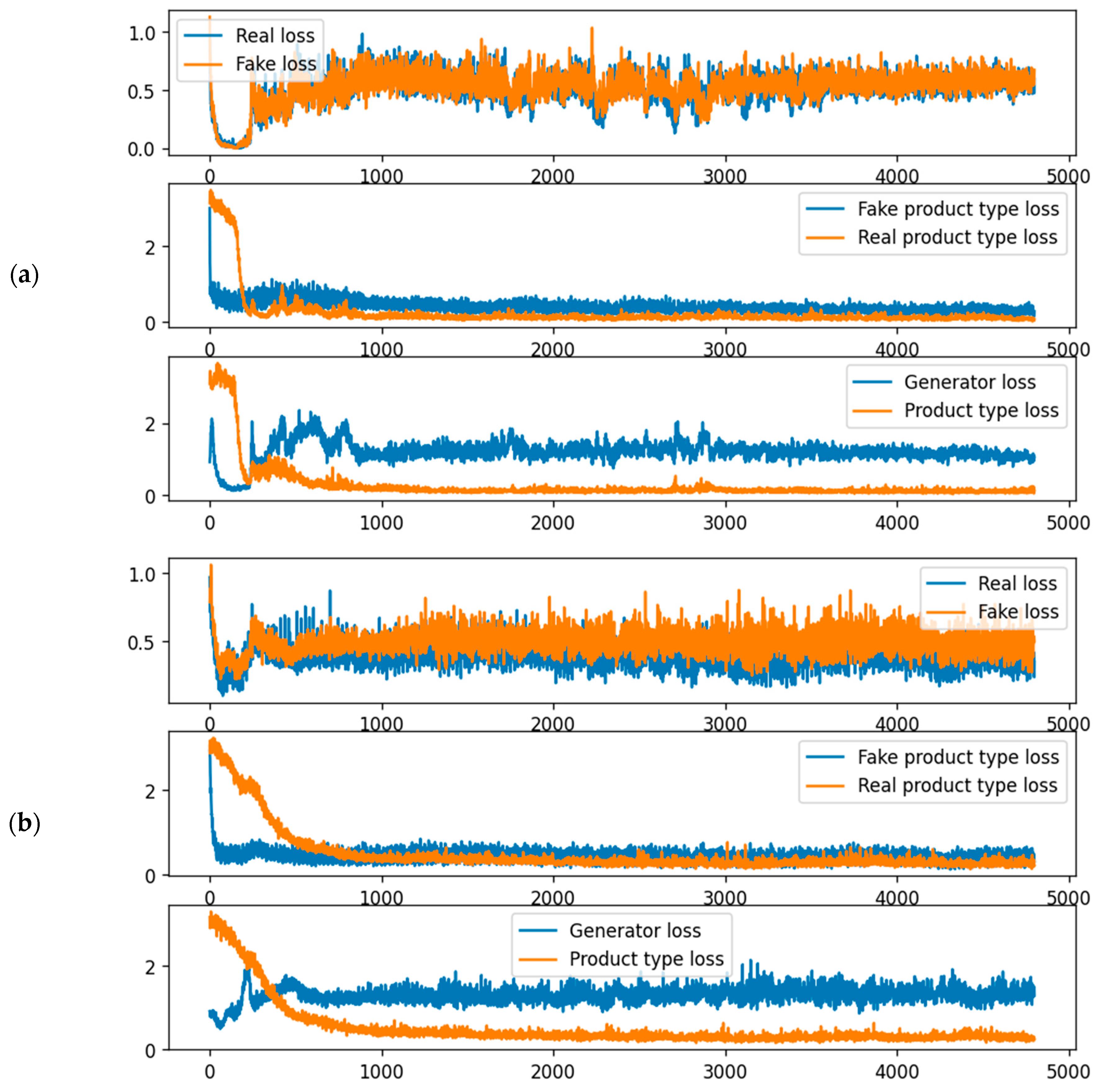
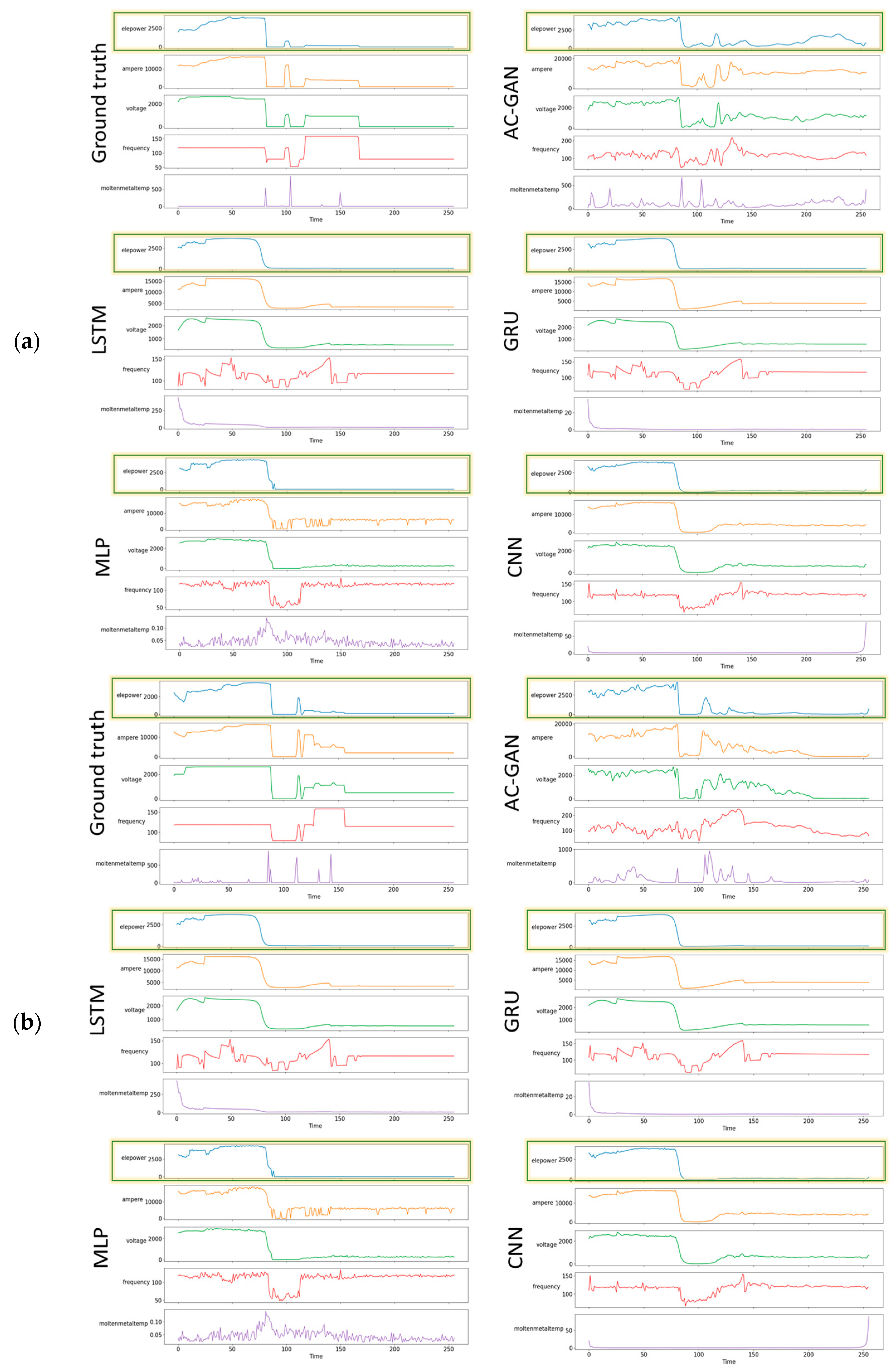
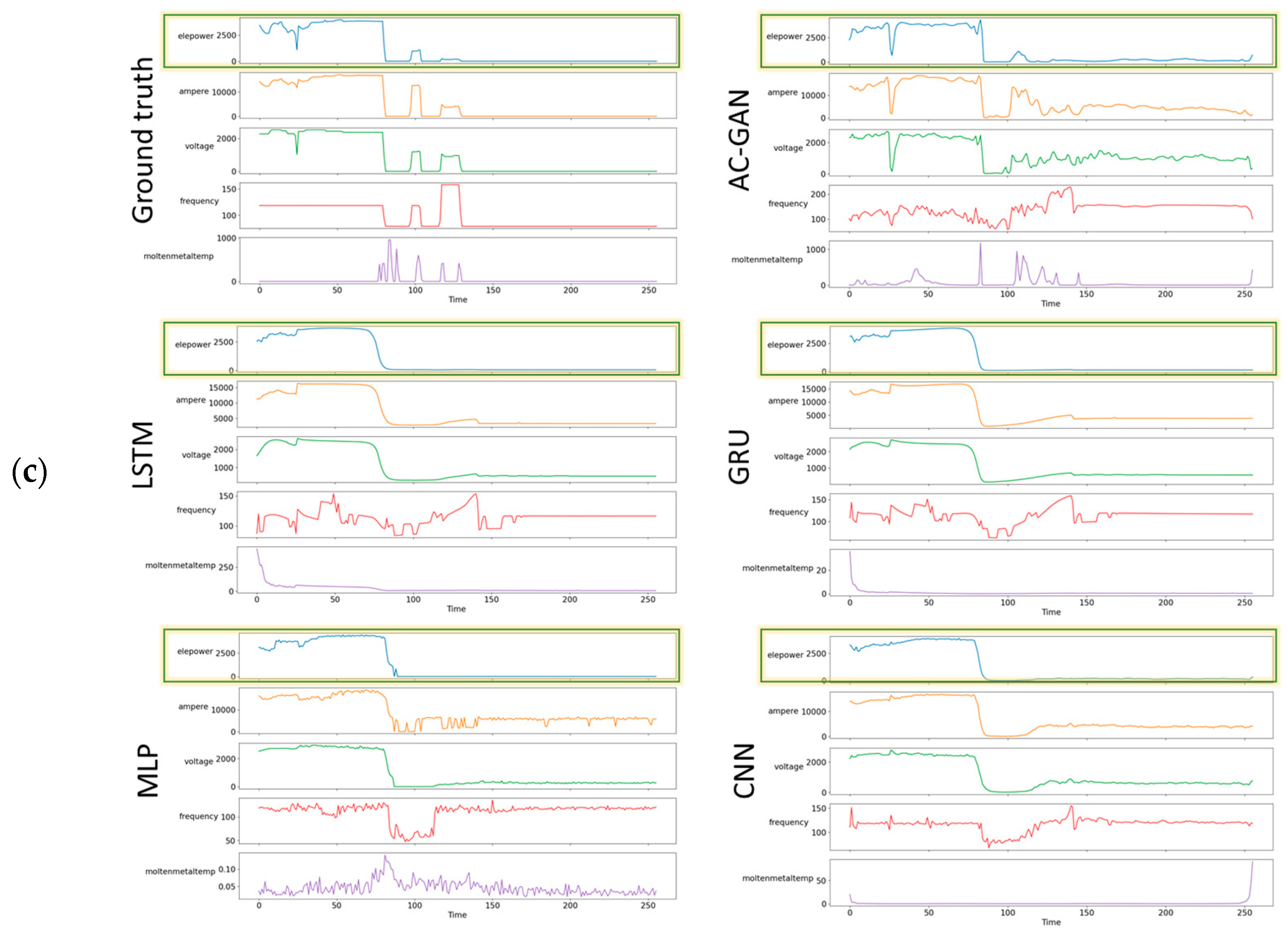
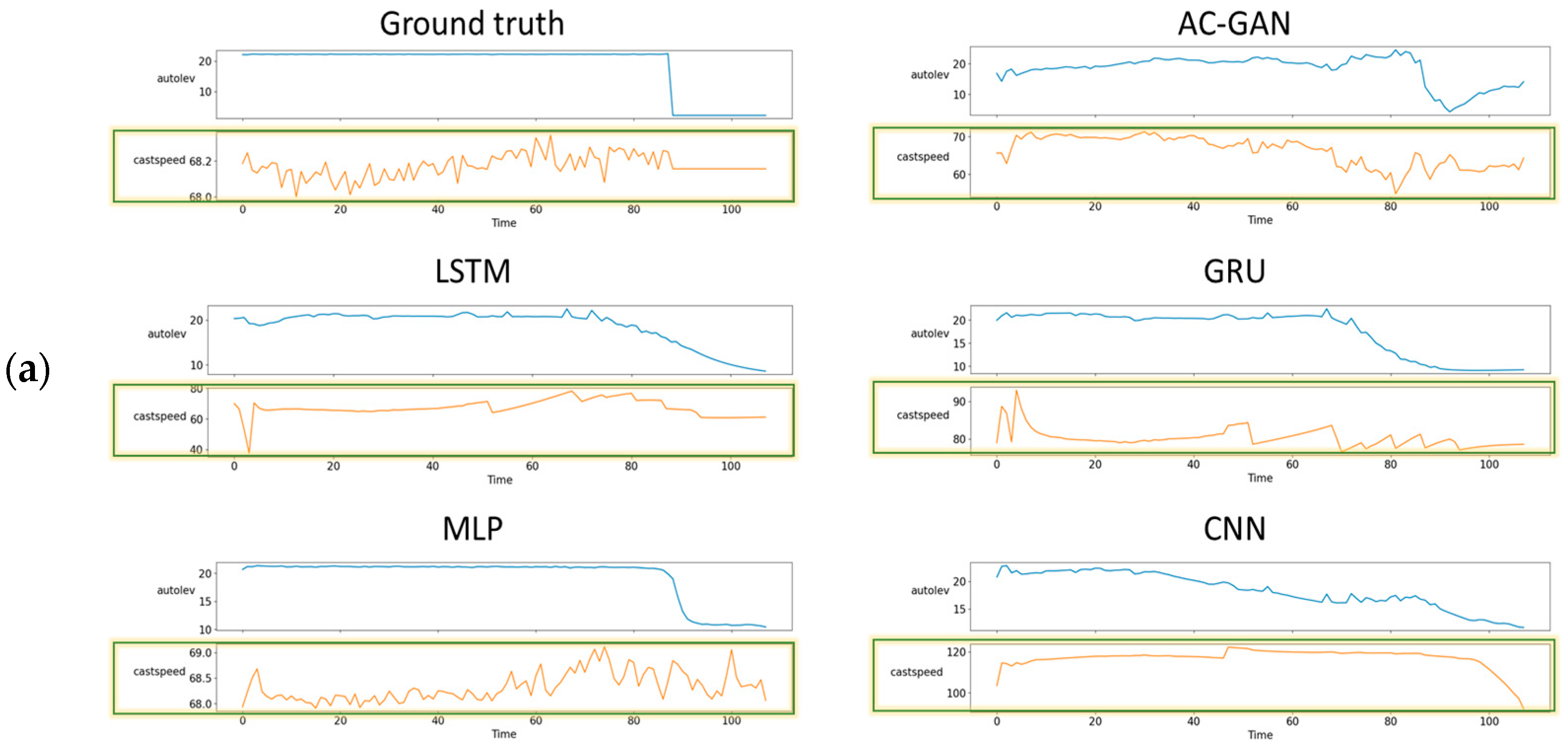
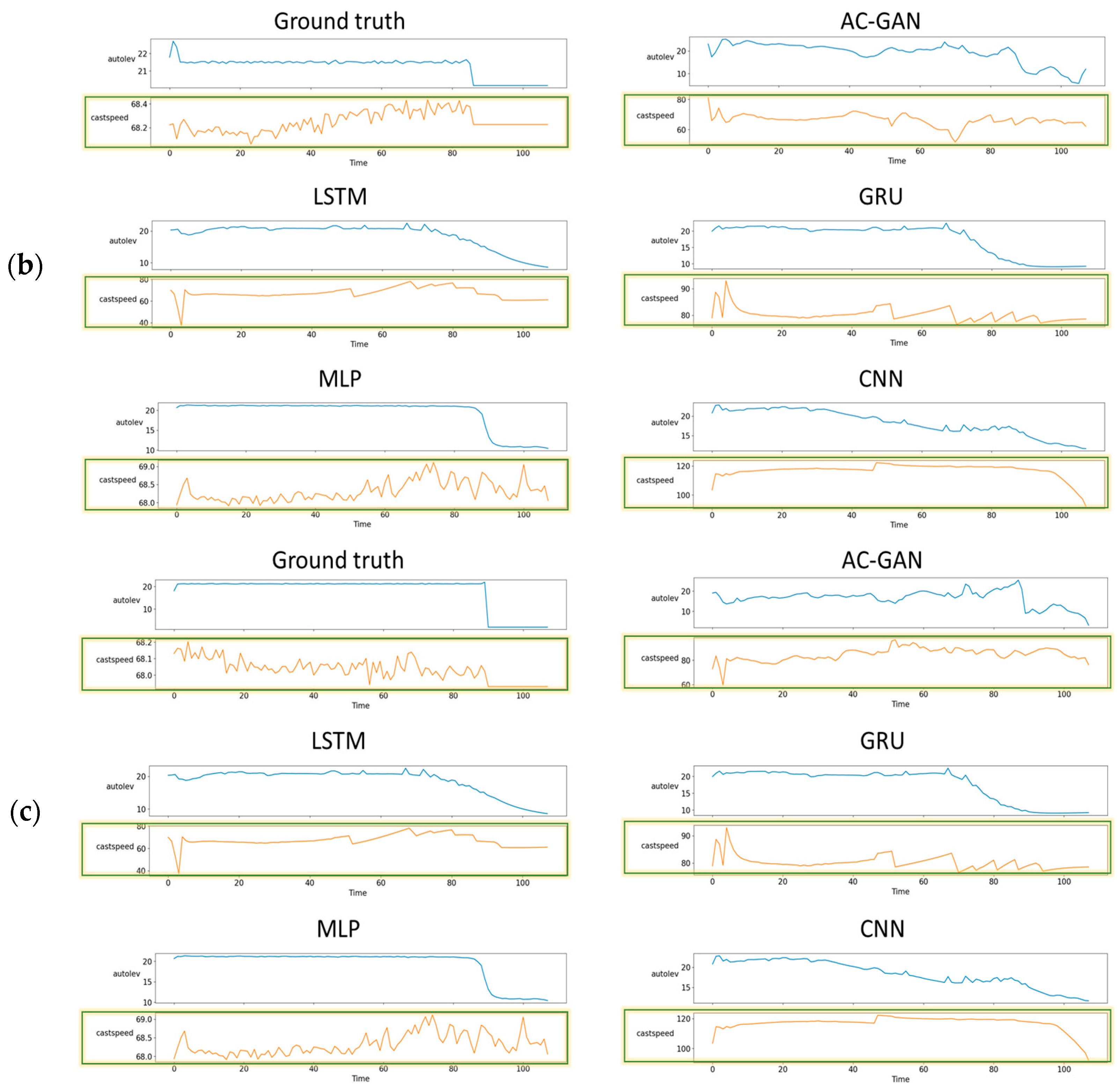
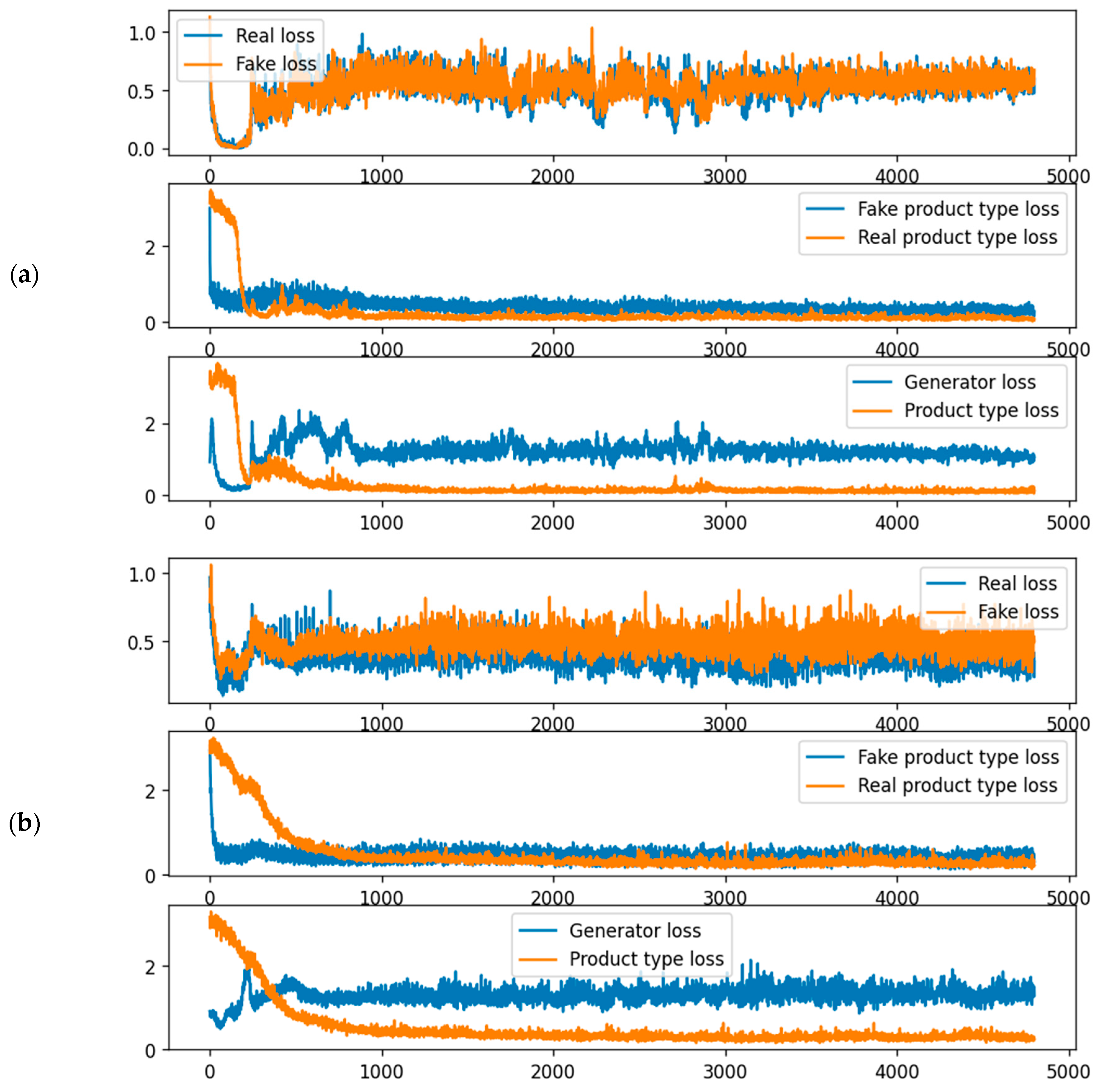
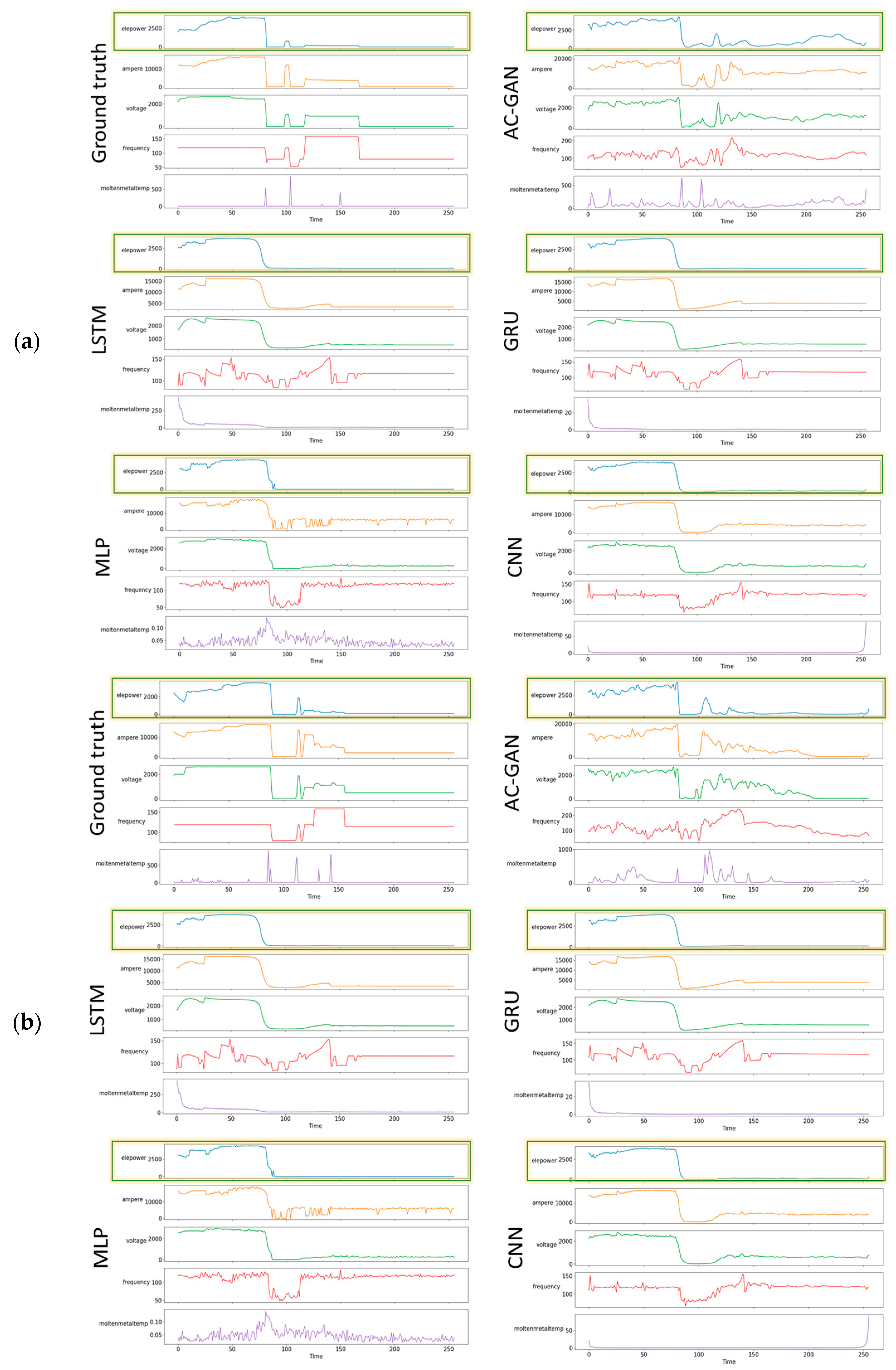
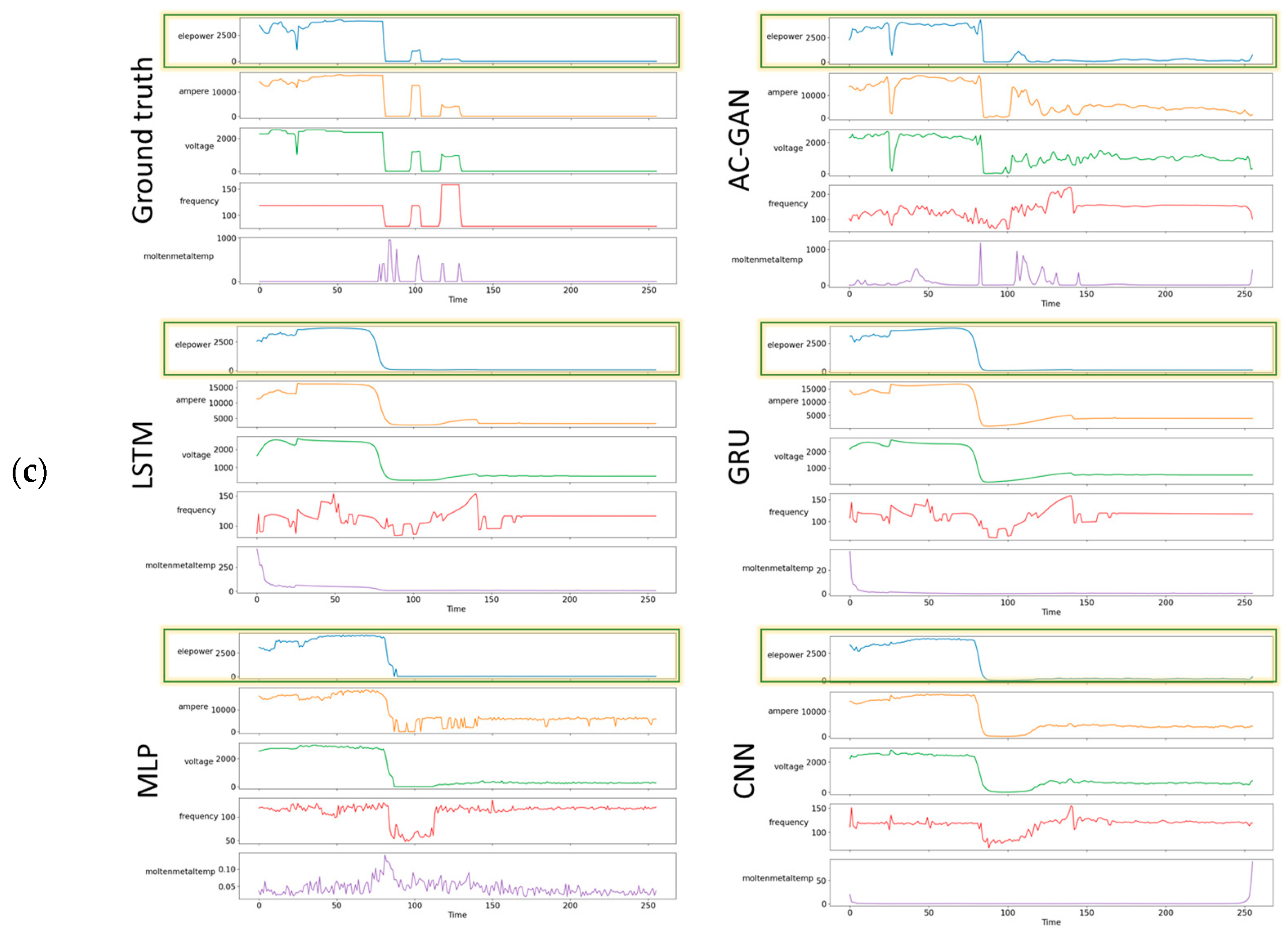
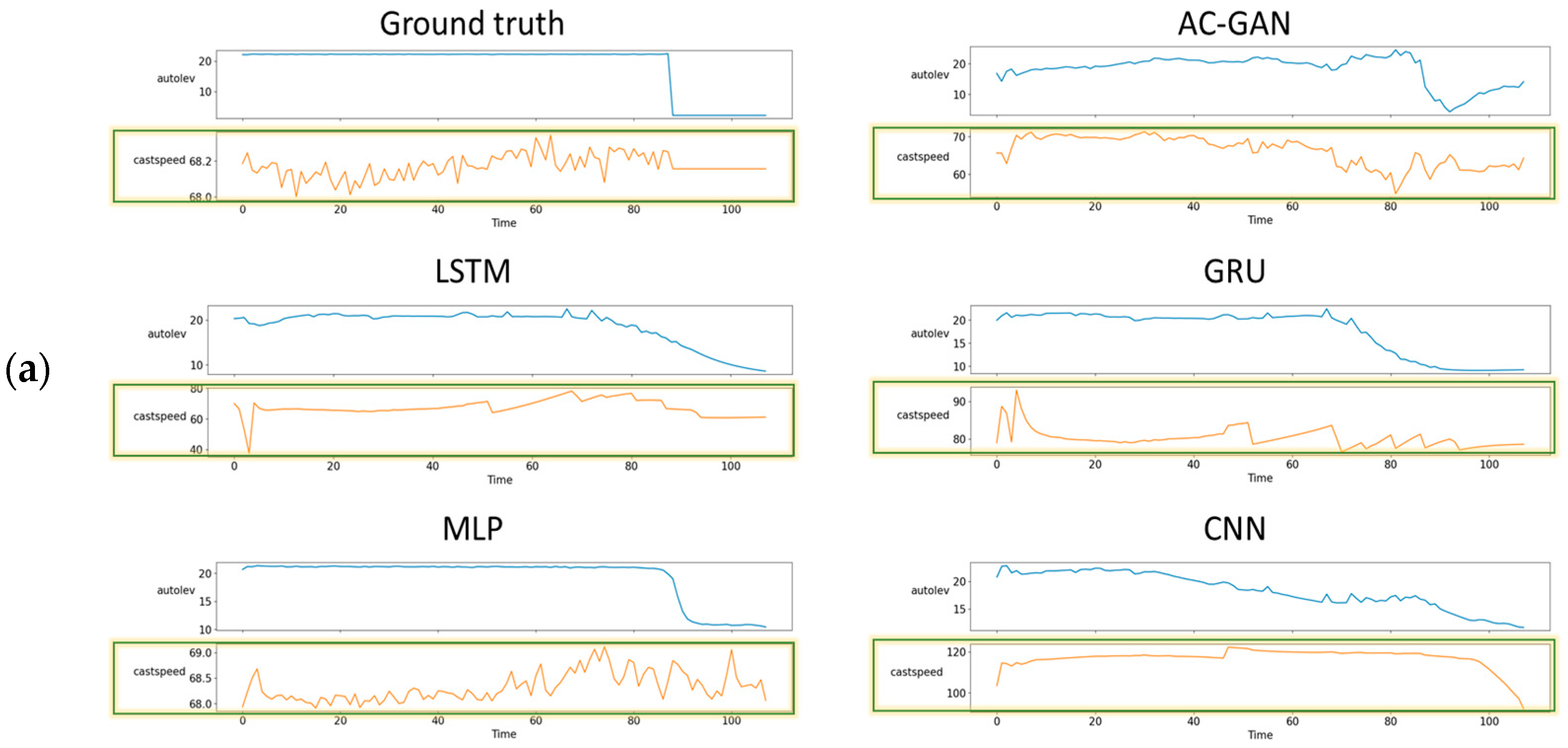
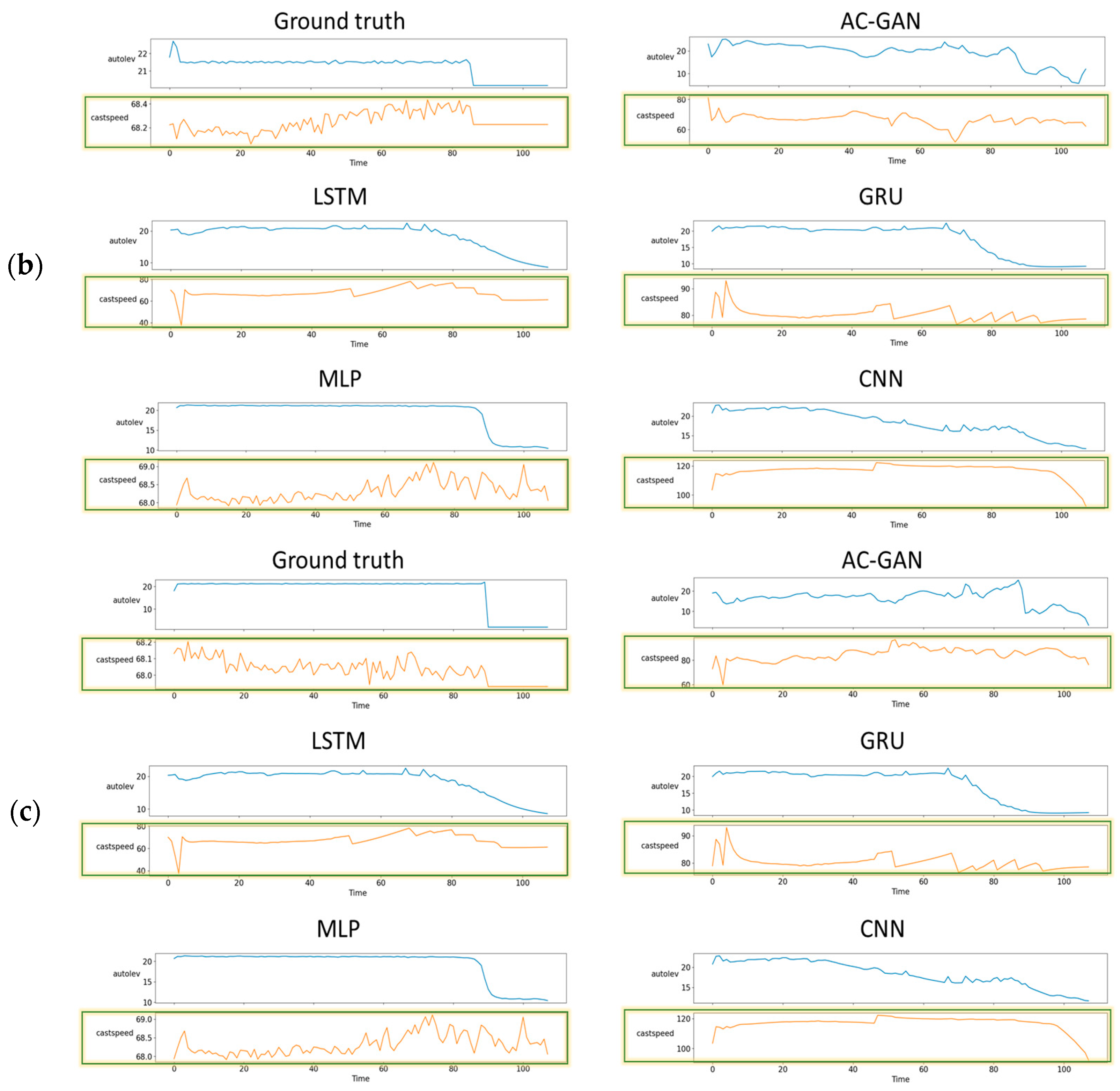
4.2. Visual Comparison of Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
References
- Jenkins, B.; Mullinger, P. Industrial and Process Furnaces: Principles, Design and Operation, 2nd ed.; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Choi, Y.; Kwun, H.; Kim, D.; Lee, E.; Bae, H. Residual Life Prediction for Induction Furnace by Sequential Encoder with s-Convolutional LSTM. Processes 2021, 9, 1121. [Google Scholar] [CrossRef]
- Melting and Pouring Metal. Available online: https://www.reliance-foundry.com/blog/melting-metal-pouring (accessed on 14 September 2021).
- Lee, M.K.; Han, C.S.; Jun, J.N.; Lee, J.H.; Lee, S.H. Batch-Free Event Sequence Pattern Mining for Communication Stream Data with Instant and Persistent Events. Wirel. Pers. Commun. 2019, 105, 673–689. [Google Scholar] [CrossRef]
- Li, D.; Chen, D.; Goh, J.; Ng, S.-K. Anomaly Detection with Generative Adversarial Networks for Multivariate Time Series. arXiv 2019, arXiv:1809.04758. [Google Scholar]
- Takahashi, S.; Chen, Y.; Tanaka-Ishii, K. Modeling financial time-series with generative adversarial networks. Phys. A Stat. Mech. Appl. 2019, 527, 121261. [Google Scholar] [CrossRef]
- Geiger, A.; Liu, D.; Alnegheimish, S.; Cuesta-Infante, A.; Veeramachaneni, K. TadGAN: Time Series Anomaly Detection Using Generative Adversarial Networks. In Proceedings of the International Conference on Big Data (Big Data), Atlanta, GA, USA, 10–13 December 2020. [Google Scholar]
- Bashar, M.A.; Nayak, R. TAnoGAN: Time Series Anomaly Detection with Generative Adversarial Networks. In Proceedings of the IEEE Symposium Series on Computational Intelligence (SSCI), Canberra, Australia, 1–4 December 2020. [Google Scholar]
- Saiz, F.A.; Alfaro, G.; Barandiaran, I.; Graña, M. Generative Adversarial Networks to Improve the Robustness of Visual Defect Segmentation by Semantic Networks in Manufacturing Components. Appl. Sci. 2021, 11, 6368. [Google Scholar] [CrossRef]
- Singh, R.; Garg, R.; Patel, N.S.; Braun, M.W. Generative Adversarial Networks for Synthetic Defect Generation in Assembly and Test Manufacturing. In Proceedings of the Annual SEMI Advanced Semiconductor Manufacturing Conference (ASMC), Saratoga Springs, NY, USA, 24–26 August 2020. [Google Scholar]
- Zirui, W.; Jun, W.; Youren, W. An intelligent diagnosis scheme based on generative adversarial learning deep neural networks and its application to planetary gearbox fault pattern recognition. Neurocomputing 2018, 310, 213–222. [Google Scholar]
- Liu, J.; Zhang, F.; Yang, B.; Zhang, F.; Gao, Y.; Wang, H. Focal Auxiliary Classifier Generative Adversarial Network for Defective Wafer Pattern Recognition with Imbalanced Data. In Proceedings of the IEEE Electron Devices Technology & Manufacturing Conference (EDTM), Chengdu, China, 8–11 April 2021. [Google Scholar]
- Luo, J.; Zhu, L.; Li, Q.; Liu, D.; Chen, M. Imbalanced Fault Diagnosis of Rotating Machinery Based on Deep Generative Adversarial Networks with Gradient Penalty. Processes 2021, 9, 1751. [Google Scholar] [CrossRef]
- Adetunji, O.; Ojo, S.S.; Oyetunji, A.; Itua, N. Melting Time Prediction Model for Induction Furnace Melting Using Specific Thermal Consumption from Material Charge Approach. J. Miner. Mater. Charact. Eng. 2021, 9, 61–74. [Google Scholar] [CrossRef]
- Ean, S.; Bazarbaev, M.; Lee, K.M.; Nasridinov, A.; Yoo, K.-H. Dynamic programming-based computation of an optimal tap working pattern in nonferrous arc furnace. J. Supercomput. 2021, 1–21. [Google Scholar] [CrossRef]
- Kovačič, M.; Stopar, K.; Vertnik, R.; Šarler, B. Comprehensive Electric Arc Furnace Electric Energy Consumption Modeling: A Pilot Study. Energies 2019, 12, 2142. [Google Scholar] [CrossRef] [Green Version]
- Karunakar, D.B.; Datta, G.L. Prevention of defects in castings using backpropagation neural networks. Int. J. Adv. Manuf. Technol. 2008, 39, 1111–1124. [Google Scholar] [CrossRef]
- Hore, S.; Das, S.K.; Humane, M.M.; Peethala, A.K. Neural Network Modelling to Characterize Steel Continuous Casting Process Parameters and Prediction of Casting Defects. Trans. Indian. Inst. Met. 2019, 72, 3015–3025. [Google Scholar] [CrossRef]
- Ye, X.; Wu, X.; Guo, Y. Real-time Quality Prediction of Casting Billet Based on Random Forest Algorithm. In Proceedings of the IEEE International Conference on Progress in Informatics and Computing (PIC), Suzhou, China, 14–16 December 2018; pp. 140–143. [Google Scholar]
- Lee, J.; Noh, S.D.; Kim, H.-J.; Kang, Y.-S. Implementation of Cyber-Physical Production Systems for Quality Prediction and Operation Control in Metal Casting. Sensors 2018, 18, 1428. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dučić, N.; Jovičić, A.; Manasijević, S.; Radiša, R.; Ćojbašić, Ž.; Savković, B. Application of Machine Learning in the Control of Metal Melting Production Process. Appl. Sci. 2020, 10, 6048. [Google Scholar] [CrossRef]
- Lee, S.Y.; Tama, B.A.; Choi, C.; Hwang, J.-Y.; Bang, J.; Lee, S. Spatial and Sequential Deep Learning Approach for Predicting Temperature Distribution in a Steel-Making Continuous Casting Process. IEEE Access 2020, 8, 21953–21965. [Google Scholar] [CrossRef]
- Lee, J.; Lee, Y.C.; Kim, J.T. Fault detection based on one-class deep learning for manufacturing applications limited to an imbalanced database. J. Manuf. Syst. 2020, 57, 357–366. [Google Scholar] [CrossRef]
- Song, G.W.; Tama, B.A.; Park, J.; Hwang, J.Y.; Bang, J.; Park, S.J.; Lee, S. Temperature Control Optimization in a Steel-Making Continuous Casting Process Using a Multimodal Deep Learning Approach. Steel Res. Int. 2019, 90, 1900321. [Google Scholar] [CrossRef]
- Habibpour, M.; Gharoun, H.; Tajally, A.; Shamsi, A.; Asgharnezhad, H.; Khosravi, A.; Nahavandi, S. An Uncertainty-Aware Deep Learning Framework for Defect Detection in Casting Products. arXiv 2021, arXiv:2107.11643. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis With Auxiliary Classifier GANs. arXiv 2016, arXiv:1610.09585. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar] [CrossRef]
- Wei, W.; Yan, J.; Wan, L.; Wang, C.; Zhang, G.; Wu, X. Enriching Indoor Localization Fingerprint using A Single AC-GAN. In Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC), Nanjing, China, 29 March–1 April 2021; pp. 1–6. [Google Scholar]
- McCullog, W.S.; Pitts, W. A logical calculus of the ideas immanent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClelland, J.L. Learning internal representations by error propagation. In Parallel Distributed Processing: Explorations in the Microstructure of Cognition: Foundations, 1st ed.; MIT Press: Cambridge, MA, USA, 1987; pp. 318–362. [Google Scholar]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An experimental review on deep learning architectures for time-series forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef] [PubMed]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Cho, K.; Merrienboer, B.V.; Gülçehre, Ç.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sagheer, A.; Kotb, M. Unsupervised Pre-training of a Deep LSTM-based Stacked Autoencoder for Multivariate Time-series Forecasting Problems. Sci. Rep. 2019, 9, 19038. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time | Electric Power (kW) | Current (A) | Voltage (V) | Frequency (Hz) | Molten Metal Temp. (°C) | Auto Level 1 | Auto Level 2 | Cast Speed (m/min) |
|---|---|---|---|---|---|---|---|---|
| 28 April 2019 03:29 | 1603.631 | 13,215.75 | 1728.342 | 118.5624 | 0 | 0 | 0 | 0.544504 |
| 28 April 2019 03:30 | 1654.445 | 13,283.57 | 1785.511 | 118.586 | 0 | 0 | 0 | 0.526617 |
| 28 April 2019 03:31 | 1654.862 | 13,277.32 | 1785.814 | 118.5019 | 0 | 0 | 0 | 0.515043 |
| 28 April 2019 03:32 | 1653.959 | 13,269.91 | 1784.986 | 118.6013 | 0 | 0 | 0 | 0.543978 |
| 28 April 2019 03:33 | 1653.589 | 13,309.26 | 1785.321 | 118.5899 | 1312.96 | 0 | 0 | 0.491895 |
| Time | Electric Power (kW) | Current (A) | Voltage (V) | Frequency (Hz) | Molten Metal Temp. (°C) | Charge# | Lot# |
|---|---|---|---|---|---|---|---|
| 28 April 2019 03:29 | 1603.631 | 13,215.75 | 1728.342 | 118.5624 | 0 | 1 | 1 |
| 28 April 2019 03:30 | 1654.445 | 13,283.57 | 1785.511 | 118.586 | 0 | ||
| 28 April 2019 03:31 | 1654.862 | 13,277.32 | 1785.814 | 118.5019 | 0 | ||
| 28 April 2019 03:32 | 1653.959 | 13,269.91 | 1784.986 | 118.6013 | 0 | ||
| 28 April 2019 03:33 | 1653.589 | 13,309.26 | 1785.321 | 118.5899 | 1312.96 |
| Time | Auto Level | Cast Speed (m/min) | Charge# | Lot# |
|---|---|---|---|---|
| 28 April 2019 03:29 | 0 | 0.544504 | 1 | 1 |
| 28 April 2019 03:30 | 0 | 0.526617 | ||
| 28 April 2019 03:31 | 0 | 0.515043 | ||
| 28 April 2019 03:32 | 0 | 0.543978 | ||
| 28 April 2019 03:33 | 0 | 0.491895 |
| Stats | Melting Process | Casting Process | |||||
|---|---|---|---|---|---|---|---|
| Electric Power | Current | Voltage | Frequency | Molten Metal Temp. | Auto Level | Cast Speed | |
| Count | 802,569 | 802,569 | 802,569 | 802,569 | 802,569 | 802,569 | 802,569 |
| Mean | 861.81932 | 5726.0772 | 848.32506 | 91.467603 | 47.89989 | 5.055849 | 18.09078 |
| Std | 1413.053 | 6412.5779 | 985.21228 | 45.932171 | 176.60719 | 9.030655 | 31.79986 |
| Min | 0 | 0 | 0 | 0.007639 | 0 | 0 | 0.34722 |
| 25% | 1.388889 | 13.888889 | 5.72917 | 53.022801 | 0 | 0 | 0.526617 |
| 50% | 97.316385 | 3082.8703 | 529.46239 | 118.48553 | 0 | 0 | 0.543982 |
| 75% | 988.3102 | 11,525.926 | 1321.9415 | 118.60775 | 0 | 1.181452 | 0.715042 |
| Max | 4800 | 24,000 | 3300 | 264 | 1600 | 802,569 | 802,569 |
| Parameters/Methods | AC-GAN | MLP | CNN | LSTM | GRU |
|---|---|---|---|---|---|
| Optimizer | ADAM | ADAM | ADAM | ADAM | ADAM |
| Loss | MAE | MAE | MAE | MAE | MAE |
| Learning_rate | 0.0002 | 0.0002 | 0.0002 | 0.0002 | 0.0002 |
| Beta_1 | 0.5 | 0.9 | 0.99 | 0.5 | 0.5 |
| AC-GAN | MLP | CNN | LSTM | GRU |
|---|---|---|---|---|
| Execution time for melting models | ||||
| 1 min 45 s | 1 min 33 s | 1 min 19 s | 1 min 15 s | 1 min 17 s |
| Execution time for casting models | ||||
| 1 min 24 s | 1 min 5 s | 58 s | 55 s | 57 s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bazarbaev, M.; Chuluunsaikhan, T.; Oh, H.; Ryu, G.-A.; Nasridinov, A.; Yoo, K.-H. Generation of Time-Series Working Patterns for Manufacturing High-Quality Products through Auxiliary Classifier Generative Adversarial Network. Sensors 2022, 22, 29. https://doi.org/10.3390/s22010029
Bazarbaev M, Chuluunsaikhan T, Oh H, Ryu G-A, Nasridinov A, Yoo K-H. Generation of Time-Series Working Patterns for Manufacturing High-Quality Products through Auxiliary Classifier Generative Adversarial Network. Sensors. 2022; 22(1):29. https://doi.org/10.3390/s22010029
Chicago/Turabian StyleBazarbaev, Manas, Tserenpurev Chuluunsaikhan, Hyoseok Oh, Ga-Ae Ryu, Aziz Nasridinov, and Kwan-Hee Yoo. 2022. "Generation of Time-Series Working Patterns for Manufacturing High-Quality Products through Auxiliary Classifier Generative Adversarial Network" Sensors 22, no. 1: 29. https://doi.org/10.3390/s22010029
APA StyleBazarbaev, M., Chuluunsaikhan, T., Oh, H., Ryu, G.-A., Nasridinov, A., & Yoo, K.-H. (2022). Generation of Time-Series Working Patterns for Manufacturing High-Quality Products through Auxiliary Classifier Generative Adversarial Network. Sensors, 22(1), 29. https://doi.org/10.3390/s22010029