
Data Augmentation for Deep Learning-Based Speech Reconstruction Using FOC-Based Methods


Abstract
:1. Introduction
2. Materials and Methods
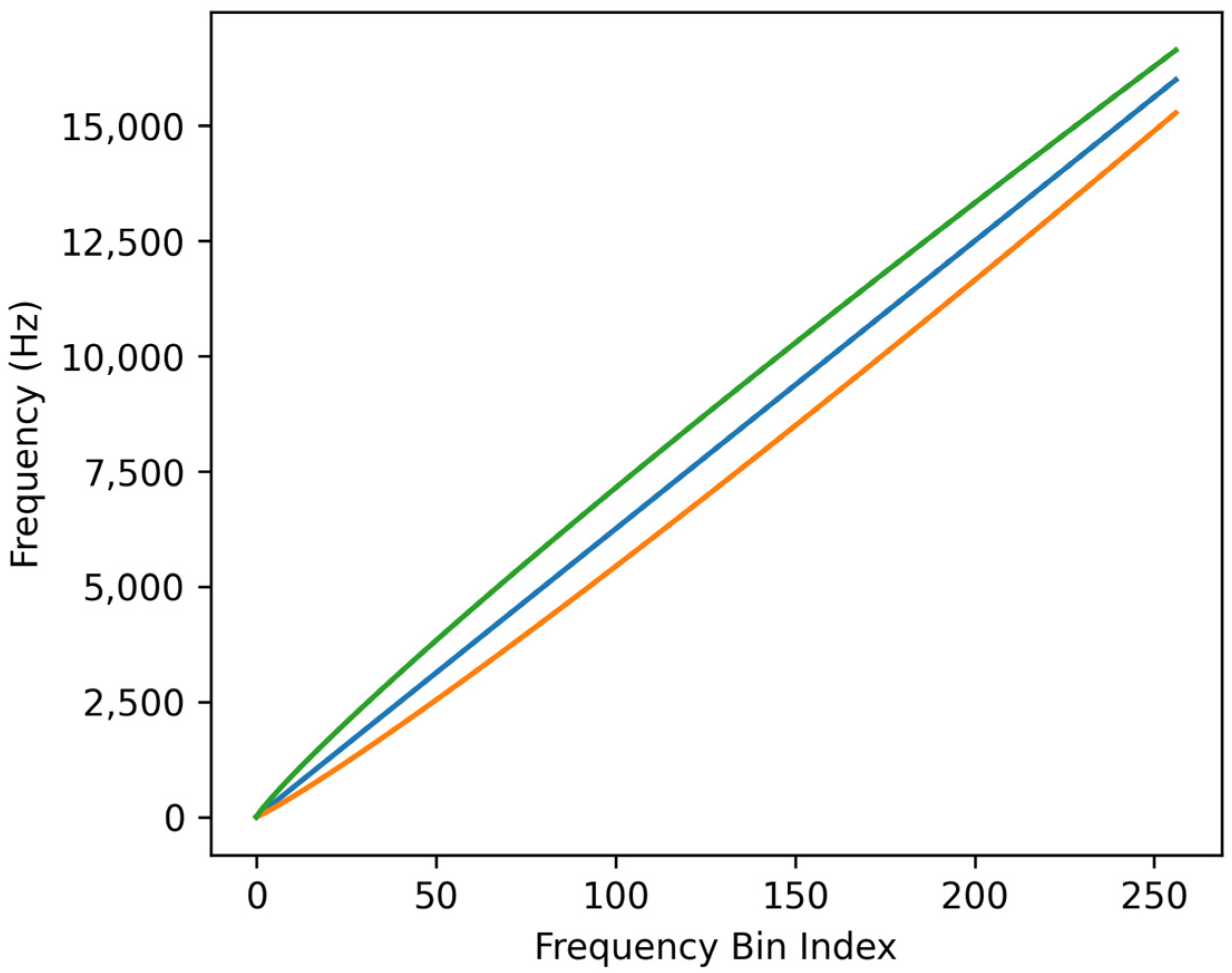
2.1. Fractional Order Scaling
2.2. Data Augmentation Strategies
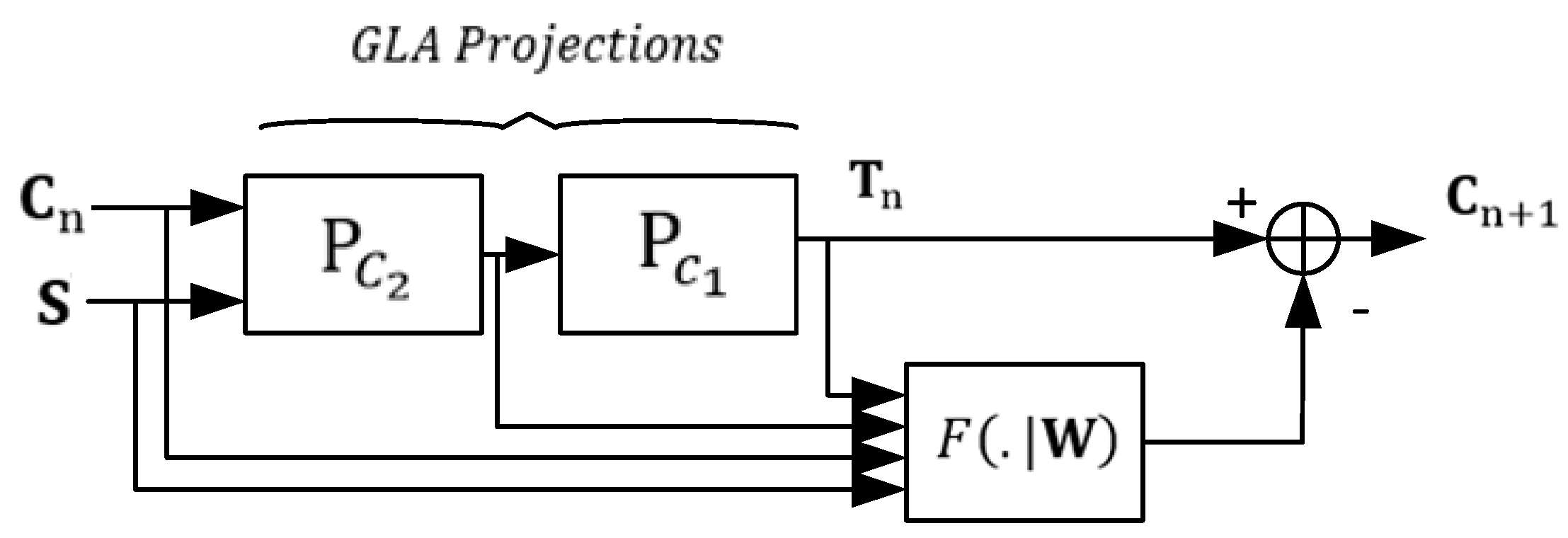
2.3. Deep Griffin-Lim Iteration
2.4. Dataset
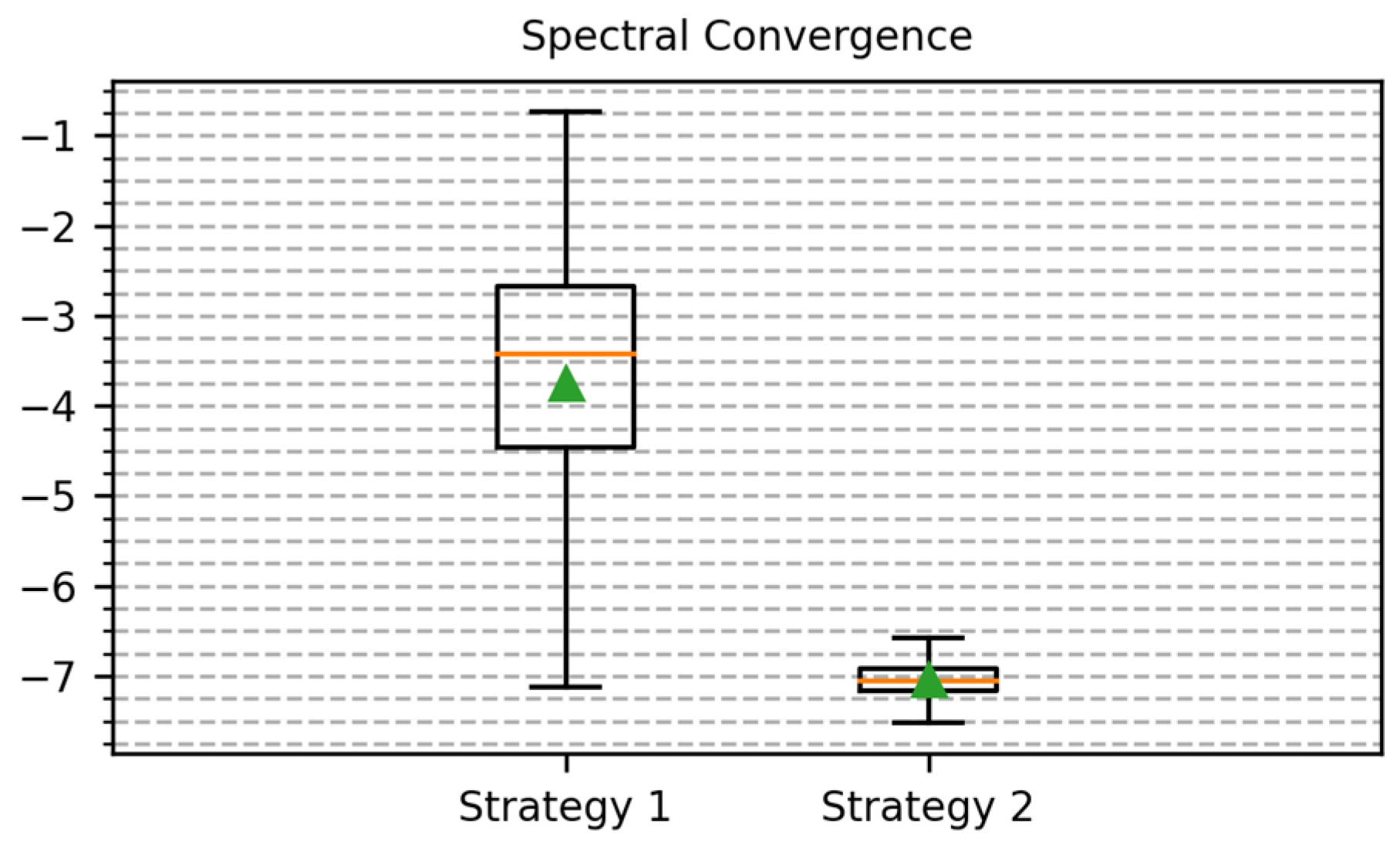
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A. Spectral Consistency
| Algorithm A1 Griffin–Lim Algorithm [41] |
| Fix the initial phase Initialize Iterate for n = 1, 2, … do Until convergence |
References
- Podlubny, I. Fractional Differential Equations: Introduction to Fractional Derivatives, Fractional Differential Equations, to Methods of Their Solution and Some of Their Applications; Academic Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Petráš, I. Fractional-Order Nonlinear Systems: Modeling, Analysis and Simulation; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Ortigueira, M.; Machado, J. Which Derivative? Fractal Fract. 2017, 1, 3. [Google Scholar] [CrossRef]
- Sabanal, S.; Nakagawa, M. The Fractal Properties of Vocal Sounds and Their Application in the Speech Recognition Model. Chaos Solitons Fractals 1996, 7, 1825–1843. [Google Scholar] [CrossRef]
- Al-Akaidi, M. Fractal Speech Processing; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar] [CrossRef]
- Lévy-Véhel, J. Fractal Approaches in Signal Processing. Fractals 1995, 3, 755–775. [Google Scholar] [CrossRef]
- Assaleh, K.; Ahmad, W.M. Modeling of Speech Signals Using Fractional Calculus. In Proceedings of the 2007 9th International Symposium on Signal Processing and Its Applications, Sharjah, United Arab Emirates, 12–15 February 2007; IEEE: Piscataway, NJ, USA, 2007; pp. 1–4. [Google Scholar] [CrossRef]
- Despotovic, V.; Skovranek, T.; Peric, Z. One-Parameter Fractional Linear Prediction. Comput. Electr. Eng. 2018, 69, 158–170. [Google Scholar] [CrossRef]
- Skovranek, T.; Despotovic, V.; Peric, Z. Optimal Fractional Linear Prediction with Restricted Memory. IEEE Signal Process. Lett. 2019, 26, 760–764. [Google Scholar] [CrossRef]
- Skovranek, T.; Despotovic, V. Audio Signal Processing Using Fractional Linear Prediction. Mathematics 2019, 7, 580. [Google Scholar] [CrossRef]
- Maragos, P.; Young, K.L. Fractal Excitation Signals for CELP Speech Coders. In Proceedings of the International Conference on Acoustics, Speech, and Signal Processing, Albuquerque, NM, USA, 3–6 April 1990; IEEE: Piscataway, NJ, USA, 1990; pp. 669–672. [Google Scholar] [CrossRef]
- Maragos, P.; Potamianos, A. Fractal Dimensions of Speech Sounds: Computation and Application to Automatic Speech Recognition. J. Acoust. Soc. Am. 1999, 105, 1925–1932. [Google Scholar] [CrossRef] [PubMed]
- Tamulevičius, G.; Karbauskaitė, R.; Dzemyda, G. Speech Emotion Classification Using Fractal Dimension-Based Features. Nonlinear Anal. Model. Control 2019, 24, 679–695. [Google Scholar] [CrossRef]
- Pitsikalis, V.; Maragos, P. Analysis and Classification of Speech Signals by Generalized Fractal Dimension Features. Speech Commun. 2009, 51, 1206–1223. [Google Scholar] [CrossRef]
- Mathieu, B.; Melchior, P.; Oustaloup, A.; Ceyral, C. Fractional Differentiation for Edge Detection. Signal Process. 2003, 83, 2421–2432. [Google Scholar] [CrossRef]
- Henriques, M.; Valério, D.; Gordo, P.; Melicio, R. Fractional-Order Colour Image Processing. Mathematics 2021, 9, 457. [Google Scholar] [CrossRef]
- Padlia, M.; Sharma, J. Brain Tumor Segmentation from MRI Using Fractional Sobel Mask and Watershed Transform. In Proceedings of the 2017 International Conference on Information, Communication, Instrumentation and Control (ICICIC), Indore, India, 17–19 August 2017; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Coelho, C.; Costa, M.F.P.; Ferrás, L.L. Fractional Calculus Meets Neural Networks for Computer Vision: A Survey. AI 2024, 5, 1391–1426. [Google Scholar] [CrossRef]
- Bai, Y.-C.; Zhang, S.; Chen, M.; Pu, Y.-F.; Zhou, J.-L. A Fractional Total Variational CNN Approach for SAR Image Despeckling. In Proceedings of the Intelligent Computing Methodologies: 14th International Conference, ICIC 2018, Wuhan, China, 15–18 August 2018; pp. 431–442. [Google Scholar] [CrossRef]
- Jia, X.; Liu, S.; Feng, X.; Zhang, L. Focnet: A Fractional Optimal Control Network for Image Denoising. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6047–6056. [Google Scholar] [CrossRef]
- Krouma, H.; Ferdi, Y.; Taleb-Ahmedx, A. Neural Adaptive Fractional Order Differential Based Algorithm for Medical Image Enhancement. In Proceedings of the 2018 International Conference on Signal, Image, Vision and their Applications (SIVA), Guelma, Algeria, 26–27 November 2018. [Google Scholar] [CrossRef]
- Arora, S.; Suman, H.K.; Mathur, T.; Pandey, H.M.; Tiwari, K. Fractional Derivative Based Weighted Skip Connections for Satellite Image Road Segmentation. Neural Netw. 2023, 161, 142–153. [Google Scholar] [CrossRef] [PubMed]
- Lakra, M.; Kumar, S. A Fractional-Order PDE-Based Contour Detection Model with CeNN Scheme for Medical Images. J. Real-Time Image Process. 2022, 19, 147–160. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, Z.; Lu, Y.; Chen, Y.; Wang, Y. Accelerated Gradient Descent Driven by Lévy Perturbations. Fractal Fract. 2024, 8, 170. [Google Scholar] [CrossRef]
- Wagner, P.; Beskow, J.; Betz, S.; Edlund, J.; Gustafson, J.; Eje Henter, G.; Le Maguer, S.; Malisz, Z.; Székely, É.; Tånnander, C.; et al. Speech Synthesis Evaluation—State-of-the-Art Assessment and Suggestion for a Novel Research Program. In Proceedings of the 10th ISCA Workshop on Speech Synthesis (SSW 10), Vienna, Austria, 20–22 September 2019; ISCA: Singapore, 2019; pp. 105–110. [Google Scholar] [CrossRef]
- Kaur, N.; Singh, P. Conventional and Contemporary Approaches Used in Text to Speech Synthesis: A Review. Artif. Intell. Rev. 2023, 56, 5837–5880. [Google Scholar] [CrossRef]
- Shi, Z. A Survey on Audio Synthesis and Audio-Visual Multimodal Processing. arXiv 2021, arXiv:2108.00443. [Google Scholar]
- Wang, Y.; Skerry-Ryan, R.J.; Stanton, D.; Wu, Y.; Weiss, R.J.; Jaitly, N.; Yang, Z.; Xiao, Y.; Chen, Z.; Bengio, S.; et al. Tacotron: Towards End-to-End Speech Synthesis. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; ISCA: Singapore, 2017; pp. 4006–4010. [Google Scholar] [CrossRef]
- AlBadawy, E.A.; Gibiansky, A.; He, Q.; Wu, J.; Chang, M.-C.; Lyu, S. Vocbench: A Neural Vocoder Benchmark for Speech Synthesis. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 23–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; Volume 2022-May, pp. 881–885. [Google Scholar] [CrossRef]
- van den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. WaveNet: A Generative Model for Raw Audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural TTS Synthesis by Conditioning Wavenet on MEL Spectrogram Predictions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 5–20 April 2018; IEEE: Piscataway, NJ, USA, 2018; Volume 2018-April, pp. 4779–4783. [Google Scholar] [CrossRef]
- Juvela, L.; Bollepalli, B.; Tsiaras, V.; Alku, P. GlotNet—A Raw Waveform Model for the Glottal Excitation in Statistical Parametric Speech Synthesis. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1019–1030. [Google Scholar] [CrossRef]
- Kalchbrenner, N.; Elsen, E.; Simonyan, K.; Noury, S.; Casagrande, N.; Lockhart, E.; Stimberg, F.; van den Oord, A.; Dieleman, S.; Kavukcuoglu, K. Efficient Neural Audio Synthesis. In Proceedings of the 35th International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Donahue, C.; McAuley, J.; Puckette, M. Adversarial Audio Synthesis. In Proceedings of the International Conference on Learning Representations (ICLR) 2019, New Orleans, LA, USA, 6–9 May 2019; pp. 1–16. [Google Scholar]
- Griffin, D.; Lim, J. Signal Estimation from Modified Short-Time Fourier Transform. In Proceedings of the ICASSP ’83. IEEE International Conference on Acoustics, Speech, and Signal Processing, Boston, MA, USA, 14–16 April 1983; IEEE: Piscataway, NJ, USA, 1983; Volume 8, pp. 804–807. [Google Scholar] [CrossRef]
- Krawczyk, M.; Gerkmann, T. STFT Phase Reconstruction in Voiced Speech for an Improved Single-Channel Speech Enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 1931–1940. [Google Scholar] [CrossRef]
- Stefanakis, N.; Abel, M.; Bergner, A. Sound Synthesis Based on Ordinary Differential Equations. Comput. Music J. 2015, 39, 46–58. [Google Scholar] [CrossRef]
- Laroche, J.; Dolson, M. Phase-Vocoder: About This Phasiness Business. In Proceedings of the 1997 Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 19–22 October 1997. [Google Scholar] [CrossRef]
- Prusa, Z.; Balazs, P.; Sondergaard, P.L. A Noniterative Method for Reconstruction of Phase from STFT Magnitude. IEEE/ACM Trans. Audio Speech Lang. Process. 2017, 25, 1154–1164. [Google Scholar] [CrossRef]
- Dolson, M. The Phase Vocoder: A Tutorial. Comput. Music J. 1986, 10, 14. [Google Scholar] [CrossRef]
- Perraudin, N.; Balazs, P.; Sondergaard, P.L. A Fast Griffin-Lim Algorithm. In Proceedings of the 2013 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 20–23 October 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 1–4. [Google Scholar] [CrossRef]
- Le Roux, J.; Kameoka, H.; Ono, N.; Sagayama, S. Fast Signal Reconstruction from Magnitude Stft Spectrogram Based on Spectrogram Consistency. In Proceedings of the 13th International Conference on Digital Audio Effects (DAFx-10), Graz, Austria, 6–10 September 2010; pp. 397–403. [Google Scholar]
- Masuyama, Y.; Yatabe, K.; Oikawa, Y. Griffin–Lim Like Phase Recovery via Alternating Direction Method of Multipliers. IEEE Signal Process. Lett. 2019, 26, 184–188. [Google Scholar] [CrossRef]
- Beauregard, G.T.; Harish, M.; Wyse, L. Single Pass Spectrogram Inversion. In Proceedings of the 2015 IEEE International Conference on Digital Signal Processing (DSP), Singapore, 21–24 July 2015; IEEE: Piscataway, NJ, USA, 2015; Volume 2015-September, pp. 427–431. [Google Scholar] [CrossRef]
- Prusa, Z.; Søndergaard, P.L. Real-Time Spectrogram Inversion Using Phase Gradient Heap Integration. In Proceedings of the 19th International Conference on Digital Audio Effects (DAFx-16), Brno, Czech Republic, 5–9 September 2016; pp. 17–21. [Google Scholar]
- Valin, J.M.; Skoglund, J. LPCNET: Improving Neural Speech Synthesis Through Linear Prediction. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; Volume 2019-May, pp. 5891–5895. [Google Scholar] [CrossRef]
- Govalkar, P.; Fischer, J.; Zalkow, F.; Dittmar, C. A Comparison of Recent Neural Vocoders for Speech Signal Reconstruction. In Proceedings of the 10th ISCA Workshop on Speech Synthesis (SSW 10), Vienna, Austria, 20–22 September 2019; ISCA: Singapore, 2019; pp. 7–12. [Google Scholar] [CrossRef]
- Masuyama, Y.; Yatabe, K.; Koizumi, Y.; Oikawa, Y.; Harada, N. Deep Griffin–Lim Iteration: Trainable Iterative Phase Reconstruction Using Neural Network. IEEE J. Sel. Top. Signal Process. 2021, 15, 37–50. [Google Scholar] [CrossRef]
- Halevy, A.; Norvig, P.; Pereira, F. The Unreasonable Effectiveness of Data. IEEE Intell. Syst. 2009, 24, 8–12. [Google Scholar] [CrossRef]
- Shorten, C.; Khoshgoftaar, T.M. A Survey on Image Data Augmentation for Deep Learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Perez, L.; Wang, J. The Effectiveness of Data Augmentation in Image Classification Using Deep Learning. arXiv 2017, arXiv:1712.04621. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving Deep Learning with Generic Data Augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar] [CrossRef]
- Ragni, A.; Knill, K.M.; Rath, S.P.; Gales, M.J.F. Data Augmentation for Low Resource Languages. In Interspeech 2014; ISCA: Singapore, 2014; Volume 2019-September, pp. 810–814. [Google Scholar] [CrossRef]
- Rebai, I.; Benayed, Y.; Mahdi, W.; Lorré, J.P. Improving Speech Recognition Using Data Augmentation and Acoustic Model Fusion. Procedia Comput. Sci. 2017, 112, 316–322. [Google Scholar] [CrossRef]
- Park, D.S.; Chan, W.; Zhang, Y.; Chiu, C.C.; Zoph, B.; Cubuk, E.D.; Le, Q.V. Specaugment: A Simple Data Augmentation Method for Automatic Speech Recognition. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; ISCA: Singapore, 2019; pp. 2613–2617. [Google Scholar] [CrossRef]
- Jaitly, N.; Hinton, G.E. Vocal Tract Length Perturbation (VTLP) Improves Speech Recognition. In Proceedings of the ICML Workshop on Deep Learning for Audio, Speech and Language, Marseille, France, 22–23 August 2013; Volume 90, pp. 42–51. [Google Scholar]
- Nanni, L.; Maguolo, G.; Paci, M. Data Augmentation Approaches for Improving Animal Audio Classification. Ecol. Inform. 2020, 57, 101084. [Google Scholar] [CrossRef]
- Nam, H.; Kim, S.-H.; Park, Y.-H. Filteraugment: An Acoustic Environmental Data Augmentation Method. In Proceedings of the ICASSP 2022—2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Singapore, 22–27 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4308–4312. [Google Scholar] [CrossRef]
- Adams, M. Differint: A Python Package for Numerical Fractional Calculus. arXiv 2019, arXiv:1912.05303. [Google Scholar]
- Diethelm, K. An Algorithm for the Numerical Solution of Differential Equations of Fractional Order. Electron. Trans. Numer. Anal. 1997, 5, 1–6. [Google Scholar]
- Yazgaç, B.G.; Kırcı, M. Fractional Differential Equation-Based Instantaneous Frequency Estimation for Signal Reconstruction. Fractal Fract. 2021, 5, 83. [Google Scholar] [CrossRef]
- Yazgaç, B.G.; Kırcı, M. Fractional-Order Calculus-Based Data Augmentation Methods for Environmental Sound Classification with Deep Learning. Fractal Fract. 2022, 6, 555. [Google Scholar] [CrossRef]
- Ping, W.; Peng, K.; Zhao, K.; Song, Z. WaveFlow: A Compact Flow-Based Model for Raw Audio. arXiv 2019, arXiv:1912.01219. [Google Scholar]
- Popov, V.; Kudinov, M.; Sadekova, T. Gaussian Lpcnet for Multisample Speech Synthesis. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; IEEE: Piscataway, NJ, USA, 2020; Volume 2020-May, pp. 6204–6208. [Google Scholar] [CrossRef]
- Hershey, J.R.; Roux, J.L.; Weninger, F. Deep Unfolding: Model-Based Inspiration of Novel Deep Architectures. arXiv 2014, arXiv:1409.2574. [Google Scholar]
- Venkatakrishnan, S.V.; Bouman, C.A.; Wohlberg, B. Plug-and-Play Priors for Model Based Reconstruction. In Proceedings of the 2013 IEEE Global Conference on Signal and Information Processing, Austin, TX, USA, 3–5 December 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 945–948. [Google Scholar] [CrossRef]
- Garofolo, J.S.; Lamel, L.F.; Fisher, W.M.; Pallett, D.S.; Dahlgren, N.L.; Zue, V.; Fiscus, J.G. TIMIT Acoustic-Phonetic Continuous Speech Corpus; NIST Speech Disc 1-1.1; Linguistic Data Consortium: Philadelphia, PA, USA, 1993. [Google Scholar]
- Loizou, P.C. Speech Enhancement: Theory and Practice, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2017. [Google Scholar]
- Le Roux, J.; Ono, N.; Sagayama, S. Explicit Consistency Constraints for STFT Spectrograms and Their Application to Phase Reconstruction. In Proceedings of the ITRW on Statistical and Perceptual Audio Processing, SAPA 2008, Brisbane, Australia, 21 September 2008; pp. 23–28. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Neural Audio Synthesis Architecture | Number of Trainable Parameters |
|---|---|
| Wavenet-30 [63] | 4.57 M |
| WaveRNN-896 [33] | 3 M |
| LPCNet [64] | 843 K–1.24 M |
| GlotNet [32] | 602 K–1.56 M |
| Architecture and Training Parameters | Original DeGLI [48] | Implemented DeGLI |
|---|---|---|
| # of Amplitude Informed Gated Convolutional (AI-GC) Layers | 3 | 3 |
| # of Complex Convolutional Layers | 1 | 1 |
| # of Channels | 64 | 32 |
| Filter size of AI-GC | 5 × 3 | 5 × 3 |
| Filter size of Last Complex Convolutional Layer | 1 × 1 | 1 × 1 |
| Stride for Convolutional Layers | 1 × 1 | 1 × 1 |
| # of Trainable Parameters | 380 k | 98 k |
| Optimizer | ADAM | ADAM |
| Initial Learning Rate Step Size | 0.0004 | 0.0004 |
| Batch Size | 32 | 16 |
| # of Epochs | 300 | 100 |
| Randomly selected SNR values for Denoiser Training | [−6, 12] dB | [−6, 12] dB |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yazgaç, B.G.; Kırcı, M. Data Augmentation for Deep Learning-Based Speech Reconstruction Using FOC-Based Methods. Fractal Fract. 2025, 9, 56. https://doi.org/10.3390/fractalfract9020056
Yazgaç BG, Kırcı M. Data Augmentation for Deep Learning-Based Speech Reconstruction Using FOC-Based Methods. Fractal and Fractional. 2025; 9(2):56. https://doi.org/10.3390/fractalfract9020056
Chicago/Turabian StyleYazgaç, Bilgi Görkem, and Mürvet Kırcı. 2025. "Data Augmentation for Deep Learning-Based Speech Reconstruction Using FOC-Based Methods" Fractal and Fractional 9, no. 2: 56. https://doi.org/10.3390/fractalfract9020056
APA StyleYazgaç, B. G., & Kırcı, M. (2025). Data Augmentation for Deep Learning-Based Speech Reconstruction Using FOC-Based Methods. Fractal and Fractional, 9(2), 56. https://doi.org/10.3390/fractalfract9020056