Improving Convergence in Therapy Scheduling Optimization: A Simulation Study


Abstract
1. Introduction
2. Gradient Descent Optimization Algorithms
2.1. Variants
2.1.1. Momentum
2.1.2. Nesterov
2.1.3. Adagrad
2.1.4. RMSprop
2.1.5. Adam and Adam-Bias
2.1.6. GD-Normalized
3. The Optimal Control Algorithm for Optimizing Therapy Schedules
3.1. The Optimal Control Problem Definition
- (P) Determine the schedule of n injectionsthat solves;
3.2. Optimization Algorithm
| Algorithm 1: Schedule Optimization with stochastic step |
|
4. Application to a Dendritic Vaccine Schedule for Tumor Cells Model
- T, the tumor cells.
- H, the T helper cells.
- C, the T or cytotoxic cells.
- D, the antigen loaded dendritic cells.
- I, the Interleukin-2 cytokine.
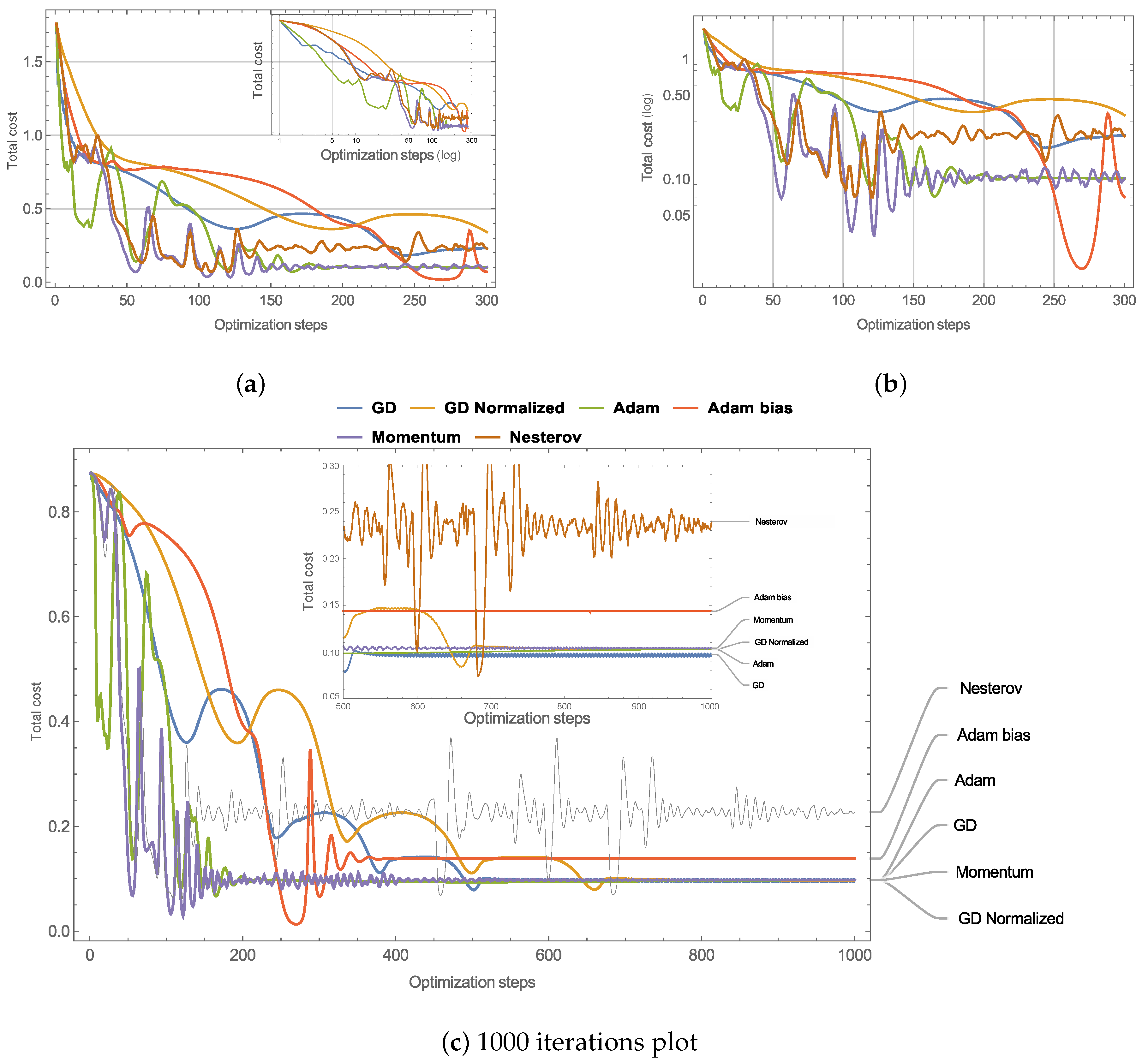
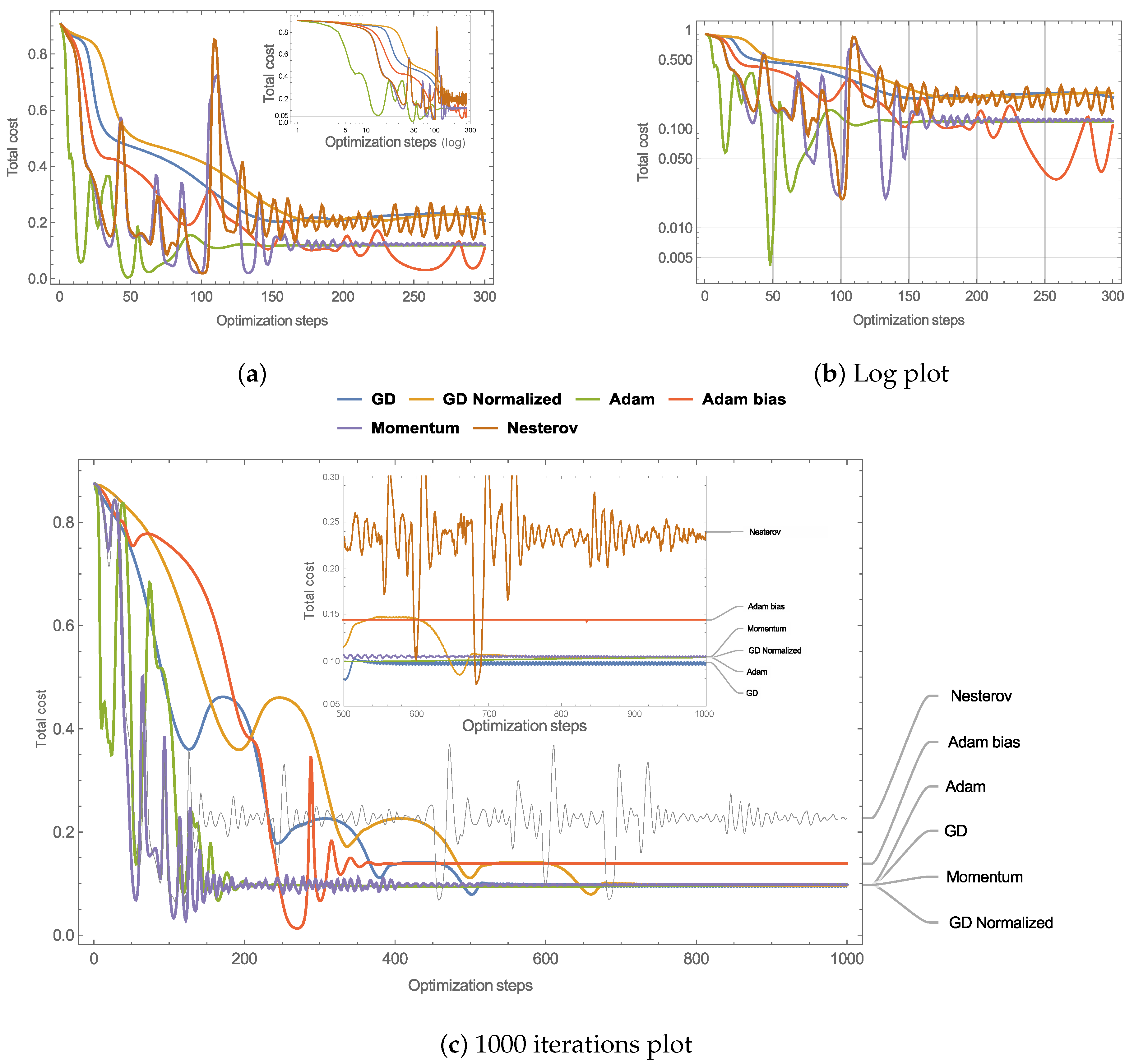
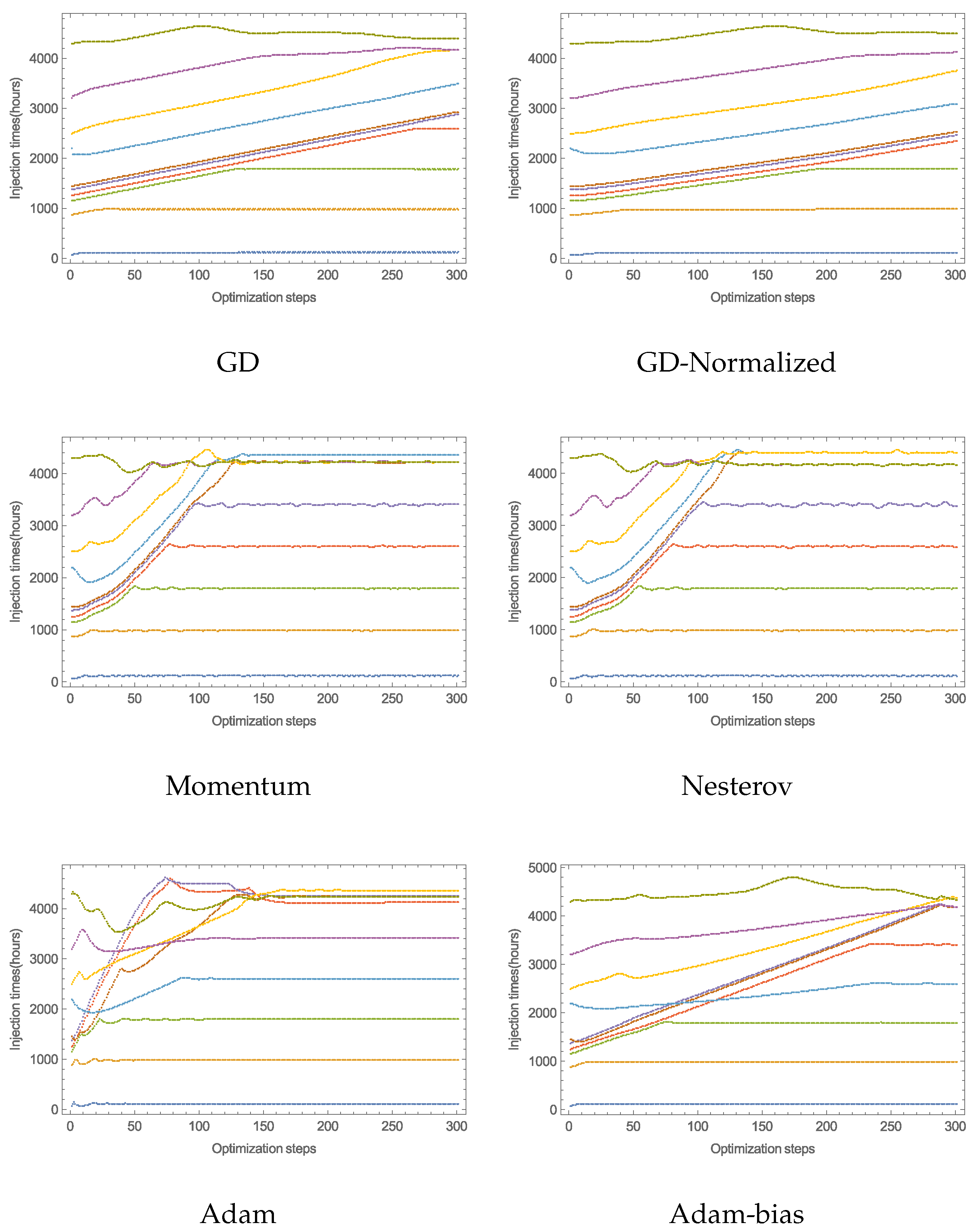
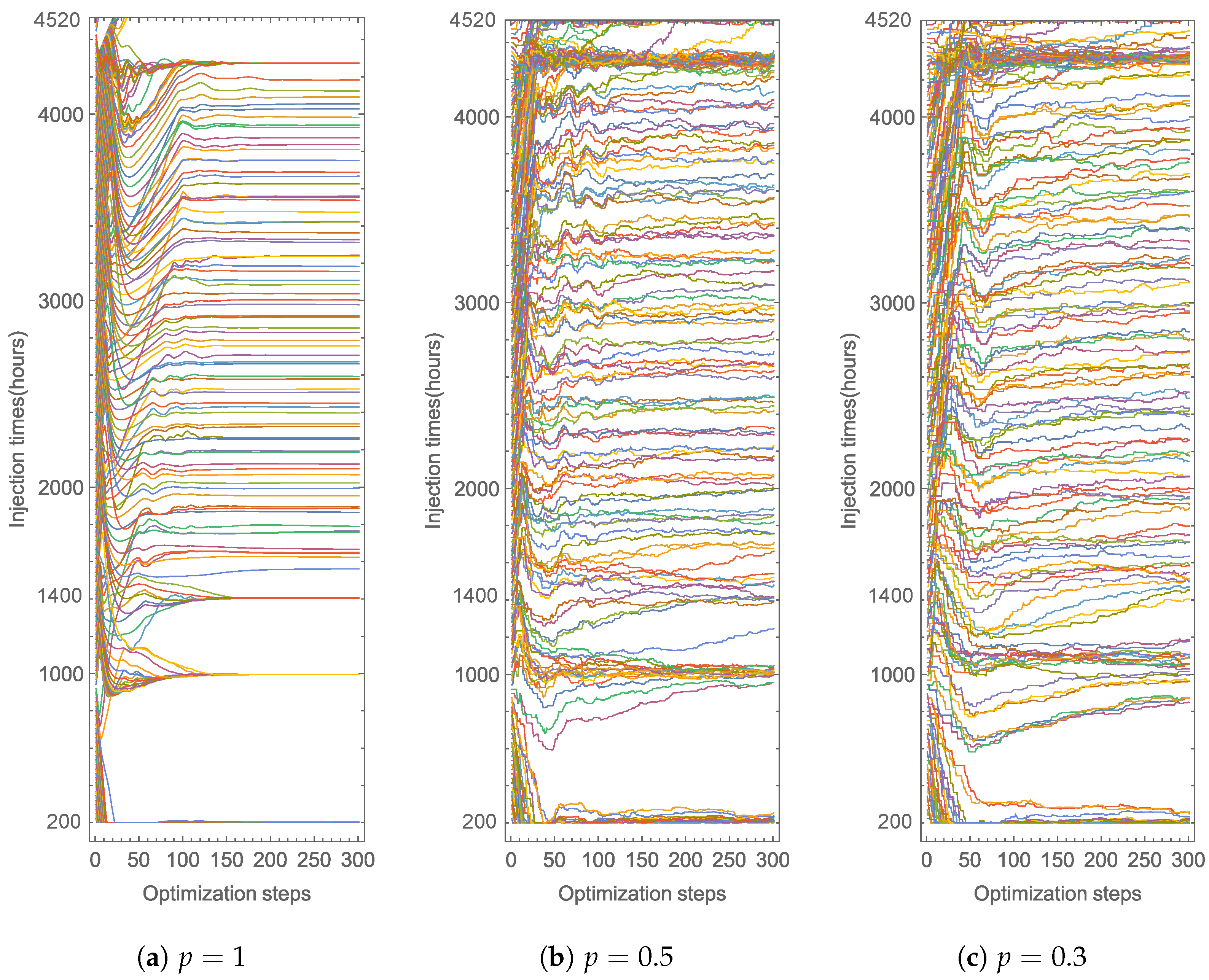
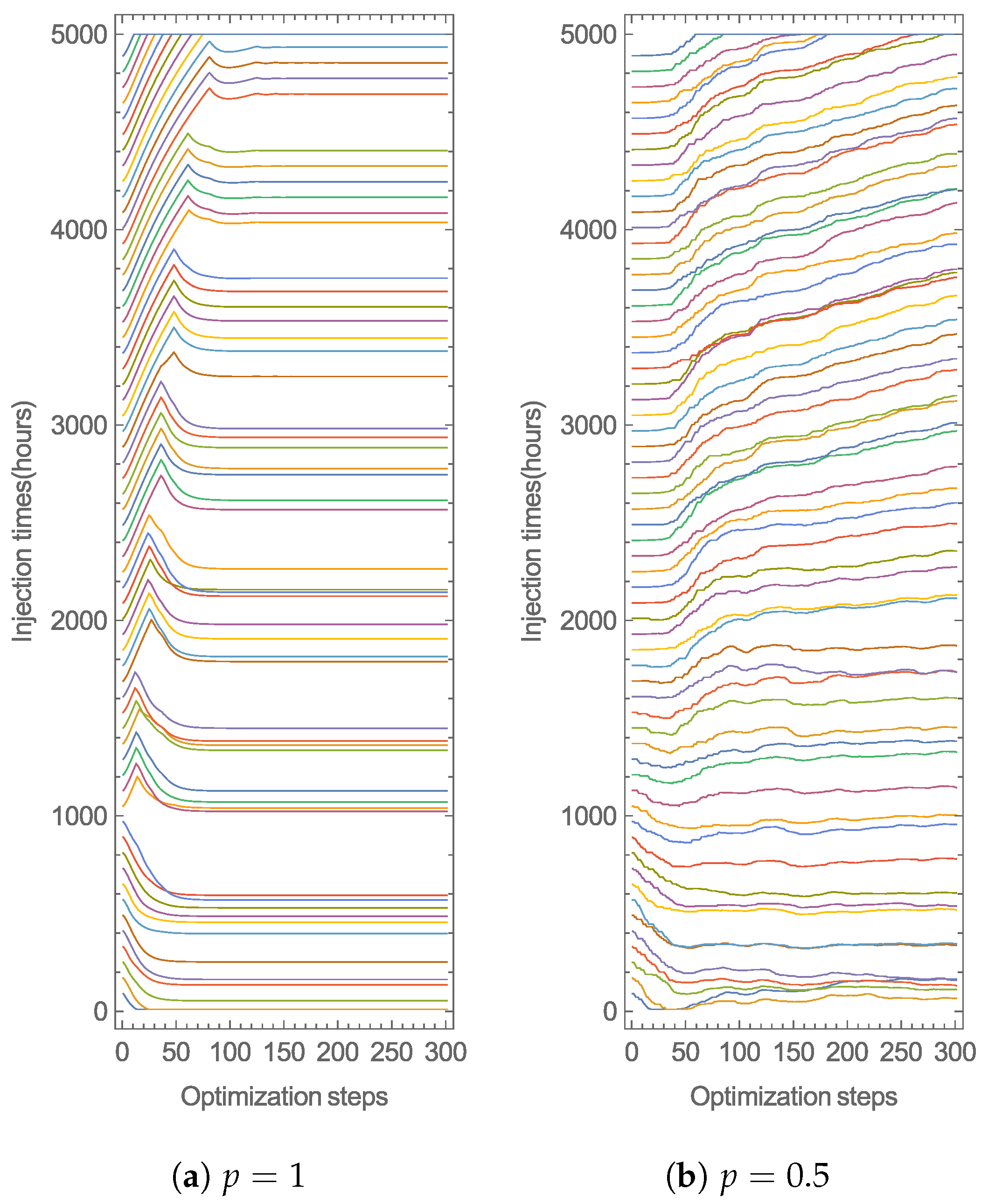
4.1. Optimization and Comparison of GD Variants
Daily Doses over Six Months
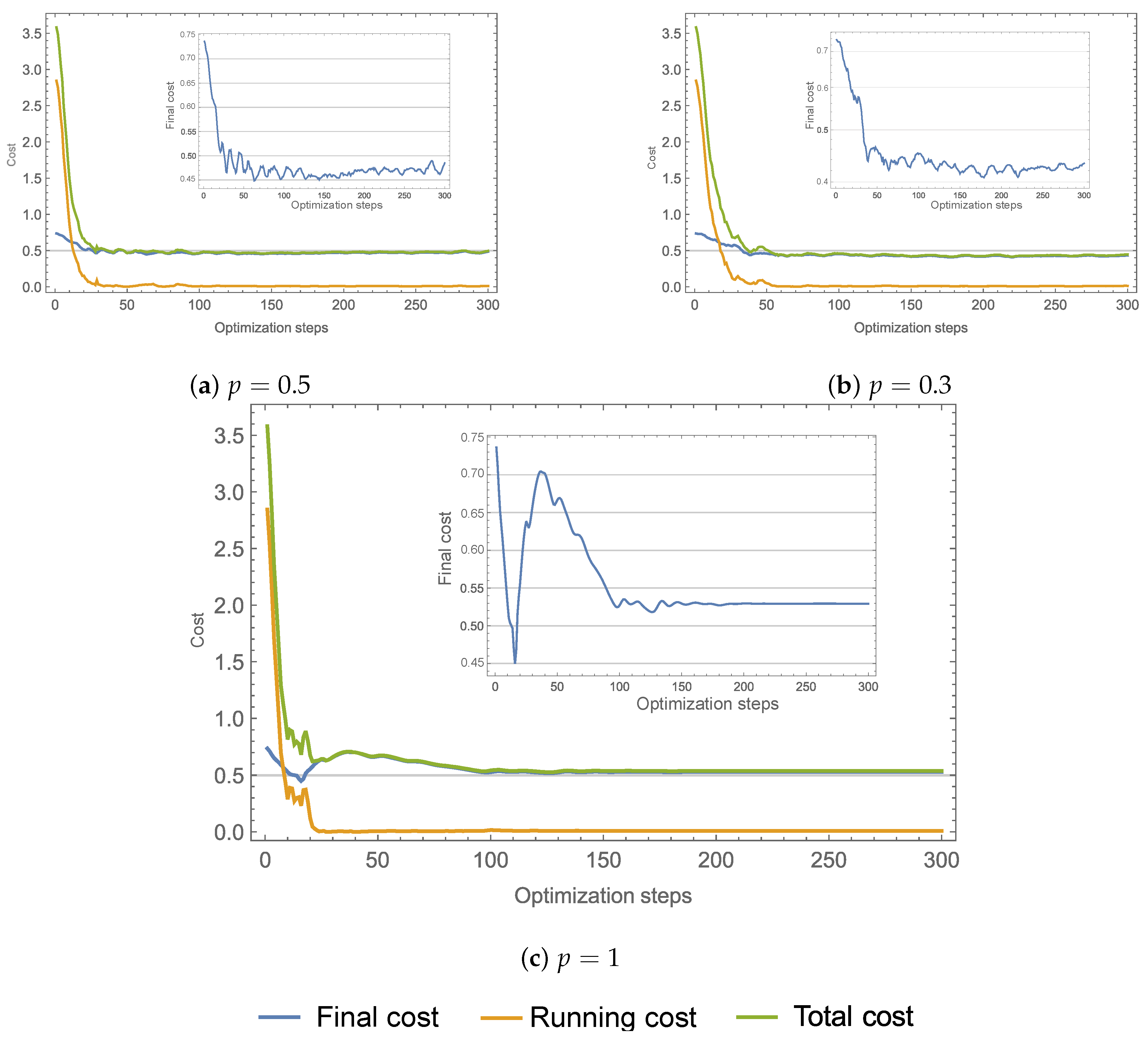
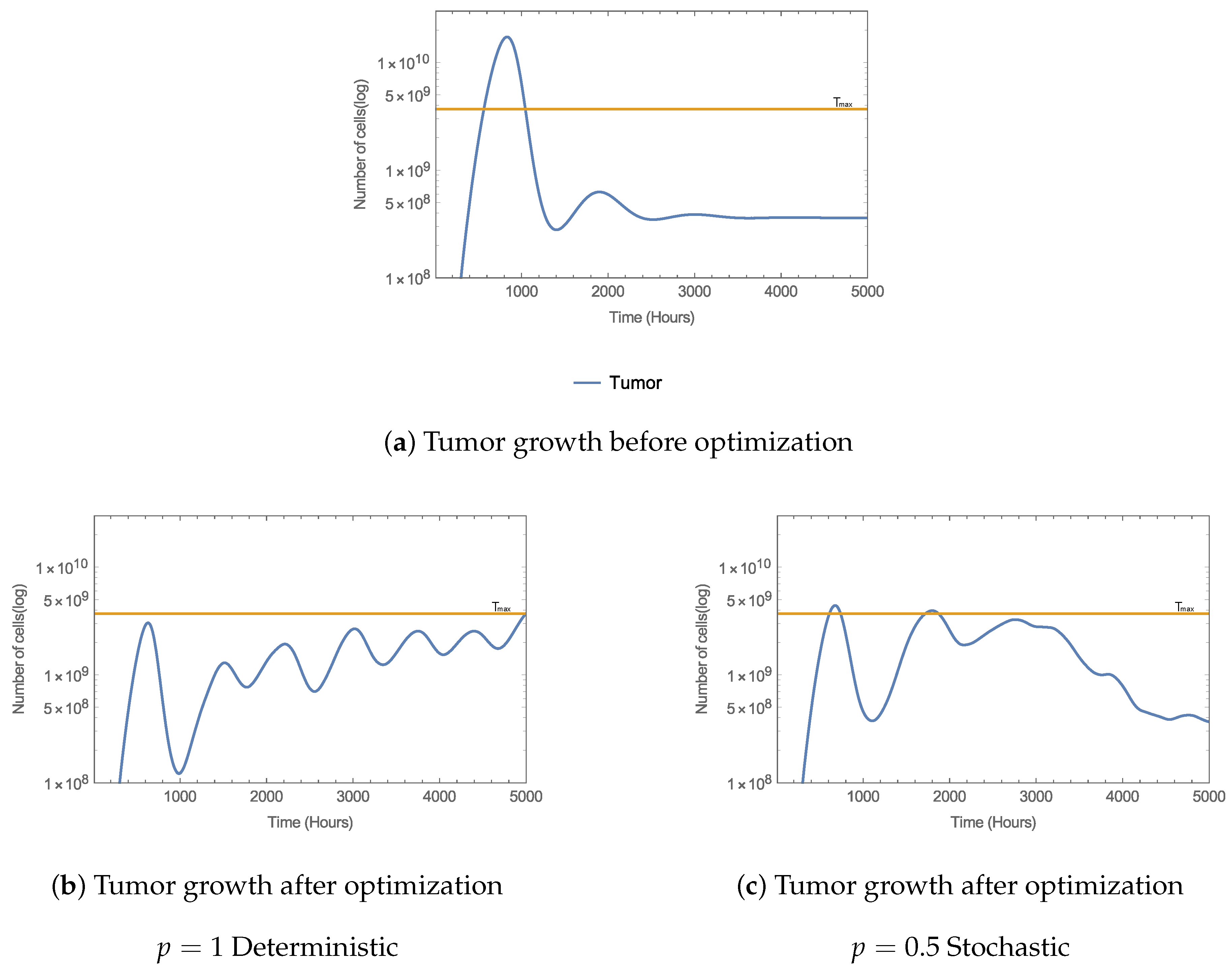
5. Application for Therapy Schedule Improvement in Murine Model
- T, the tumor cells.
- H, the T helper cells.
- C, the T or cytotoxic cells.
- D, the antigen loaded dendritic cells.
- I, the Interleukin-2 cytokine.
- , the T cell inhibitor.
- , the which up-regulates class 1.
- , is the number class 1 receptors per melanoma cell.
6. Concluding Remarks
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- De Pillis, L.G.; Fister, K.R.; Gu, W.; Head, T.; Maples, K.; Neal, T.; Murugan, A.; Kozai, K. Optimal control of mixed immunotherapy and chemotherapy of tumors. J. Biol. Syst. 2008, 16, 51–80. [Google Scholar] [CrossRef]
- Schättler, H.; Ledzewicz, U. Optimal control of cancer treatments: Mathematical models for the tumor microenvironment. In Analysis and Geometry in Control Theory and Its Applications; Springer: Cham, Switzerland, 2015; pp. 209–235. [Google Scholar] [CrossRef]
- Kronik, N.; Kogan, Y.; Schlegel, P.G.; Wölfl, M. Improving T-cell immunotherapy for melanoma through a mathematically motivated strategy: Efficacy in numbers? J. Immunother. 2012, 35, 116–124. [Google Scholar] [CrossRef]
- Castillo-Montiel, E.; Chimal-Eguía, J.C.; Tello, J.I.; Piñon-Zaráte, G.; Herrera-Enríquez, M.; Castell-Rodríguez, A.E. Enhancing dendritic cell immunotherapy for melanoma using a simple mathematical model. Theor. Biol. Med. Model. 2015, 12, 1–14. [Google Scholar] [CrossRef] [PubMed][Green Version]
- Onyejekwe, O.O.; Tigabie, A.; Ambachew, B.; Alemu, A. Application of Optimal Control to the Epidemiology of Dengue Fever Transmission. J. Appl. Math. Phys. 2019, 7, 148–165. [Google Scholar] [CrossRef]
- Gutiérrez-diez, P.J. The effects of time valuation in cancer optimal therapies: A study of chronic myeloid leukemia. Theor. Biol. Med. Model. 2019, 16, 10. [Google Scholar] [CrossRef] [PubMed]
- Cunningham, J.J.; Brown, J.S.; Gatenby, R.A.; Stankova, K. Optimal control to develop therapeutic strategies for metastatic castrate resistant prostate cancer. J. Theor. Biol. 2018, 459, 67–78. [Google Scholar] [CrossRef] [PubMed]
- Ghaffari, A.; Naserifar, N. Optimal therapeutic protocols in cancer immunotherapy. Comput. Biol. Med. 2010, 40, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Moore, H. How to mathematically optimize drug regimens using optimal control. J. Pharmacokinet. Pharmacodyn. 2018, 45, 127–137. [Google Scholar] [CrossRef]
- Head, T.; Maples, K.; Neal, T.; Murugan, A.; Kozai, K. Optimal Control of Mixed Immunotherapy. Optim. Control. Mix. Immunother. 2008, 16, 51–80. [Google Scholar]
- de Pillis, L.G.; Radunskaya, A. A Mathematical Tumor Model with Immune Resistance and Drug Therapy: An Optimal Control Approach. J. Theor. Med. 2001, 3, 79–100. [Google Scholar] [CrossRef]
- De Pillis, L.G.; Radunskaya, A. The dynamics of an optimally controlled tumor model: A case study. Math. Comput. Model. 2003, 37, 1221–1244. [Google Scholar] [CrossRef]
- Wei, H.C. A modified numerical method for bifurcations of fixed points of ODE systems with periodically pulsed inputs. Appl. Math. Comput. 2014, 236, 373–383. [Google Scholar] [CrossRef]
- Wei, H.C.; Yu, J.L.; Hsu, C.Y. Periodically Pulsed Immunotherapy in a Mathematical Model of Tumor, CD4 T Cells, and Antitumor Cytokine Interactions. Comput. Math. Methods Med. 2017, 2017, 2906282. [Google Scholar] [CrossRef] [PubMed]
- Castiglione, F.; Piccoli, B. Optimal control in a model of dendritic cell transfection cancer immunotherapy. Bull. Math. Biol. 2006, 68, 255–274. [Google Scholar] [CrossRef] [PubMed]
- Rangel-Reyes, J.C.; Chimal-Eguía, J.C.; Castillo-Montiel, E. Dendritic Immunotherapy Improvement for an Optimal Control Murine Model. Comput. Math. Methods Med. 2017, 2017. [Google Scholar] [CrossRef] [PubMed]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nat. Methods 2015, 13, 35. [Google Scholar] [CrossRef] [PubMed]
- Goh, G. Why Momentum Really Works. Distill 2017. [Google Scholar] [CrossRef]
- Hinton, G.E. Optimization: How to make the learning go faster. Coursera 2012, 4, 26–31. Available online: https://www.coursera.org/learn/neural-networks/lecture/YQHki/rmsprop-divide-the-gradient-by-a-running-average-of-its-recent-magnitude (accessed on 1 September 2018).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Eftimie, R.; Gillard, J.J.; Cantrell, D.A. Mathematical Models for Immunology: Current State of the Art and Future Research Directions. Bull. Math. Biol. 2016, 78, 2091–2134. [Google Scholar] [CrossRef]
- Piccoli, B.; Castiglione, F. Optimal vaccine scheduling in cancer immunotherapy. Phys. A Stat. Mech. Its Appl. 2006, 370, 672–680. [Google Scholar] [CrossRef]
- Scharovsky, O.G.; Mainetti, L.E.; Rozados, V.R. Metronomic chemotherapy: Changing the paradigm that more is better. Curr. Oncol. 2009, 16, 7–15. [Google Scholar] [CrossRef] [PubMed]
- Piñón-Zárate, G.; Herrera-Enríquez, M.Á.; Hernández-Téllez, B.; Jarquín-Yáñez, K.; Castell-Rodríguez, A.E. GK-1 improves the immune response induced by bone marrow dendritic Cells Loaded with MAGE-AX in Mice with Melanoma. J. Immunol. Res. 2015, 2015, 176840. [Google Scholar] [CrossRef] [PubMed]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Parameters |
|---|---|
| GD | |
| GD Normalized | |
| Adam | , , |
| Adam bias | , , |
| Momentum | , |
| Nesterov Normalized | , |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chimal-Eguia, J.C.; Rangel-Reyes, J.C.; Paez-Hernandez, R.T. Improving Convergence in Therapy Scheduling Optimization: A Simulation Study. Mathematics 2020, 8, 2114. https://doi.org/10.3390/math8122114
Chimal-Eguia JC, Rangel-Reyes JC, Paez-Hernandez RT. Improving Convergence in Therapy Scheduling Optimization: A Simulation Study. Mathematics. 2020; 8(12):2114. https://doi.org/10.3390/math8122114
Chicago/Turabian StyleChimal-Eguia, Juan C., Julio C. Rangel-Reyes, and Ricardo T. Paez-Hernandez. 2020. "Improving Convergence in Therapy Scheduling Optimization: A Simulation Study" Mathematics 8, no. 12: 2114. https://doi.org/10.3390/math8122114
APA StyleChimal-Eguia, J. C., Rangel-Reyes, J. C., & Paez-Hernandez, R. T. (2020). Improving Convergence in Therapy Scheduling Optimization: A Simulation Study. Mathematics, 8(12), 2114. https://doi.org/10.3390/math8122114