Passive Exercise Adaptation for Ankle Rehabilitation Based on Learning Control Framework

 , , ,
, , ,  ,
, 
Abstract
:1. Introduction
- -
- Exploitation of force sensing in an LfD framework for ankle rehabilitation using a PR that integrates ILC and DMPs to learn different passive exercises and adapt them autonomously;
- -
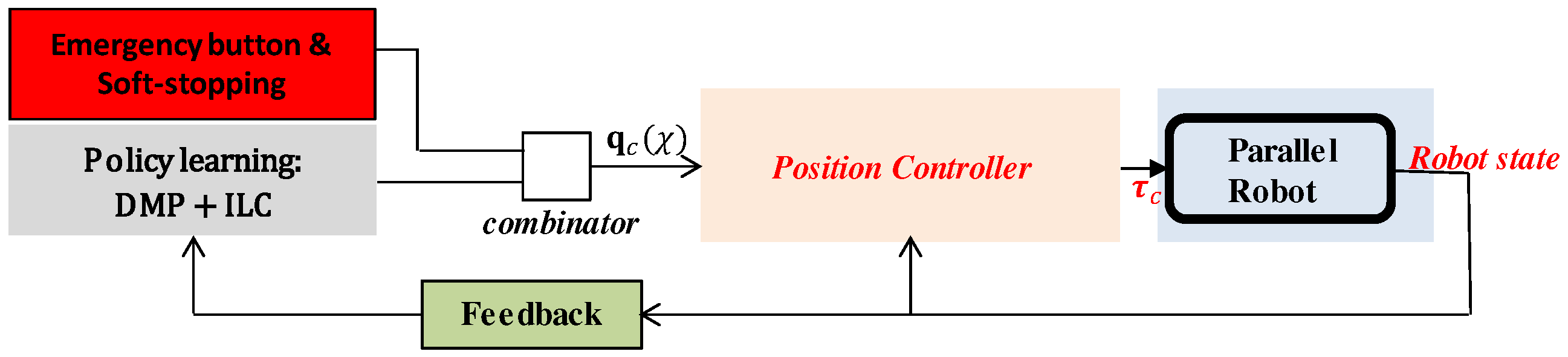
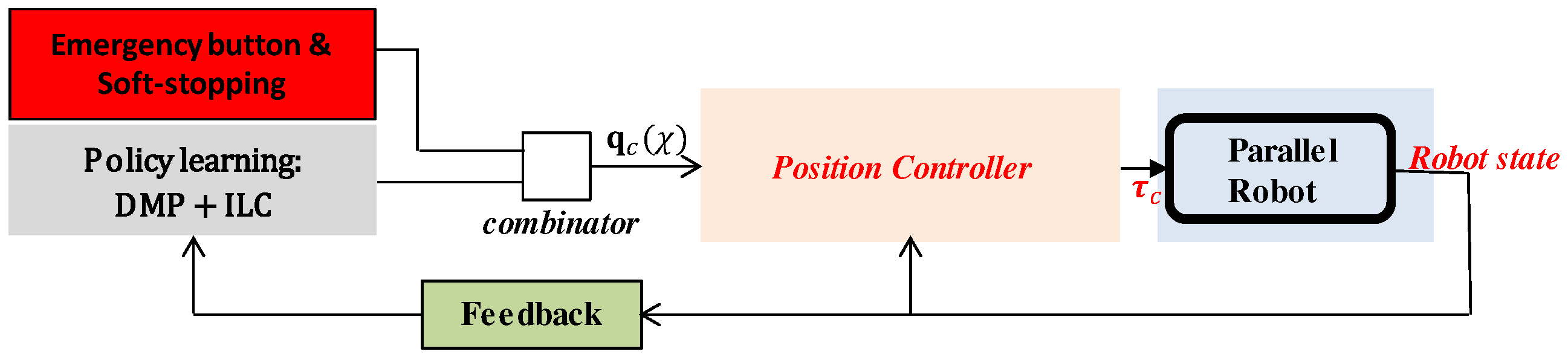
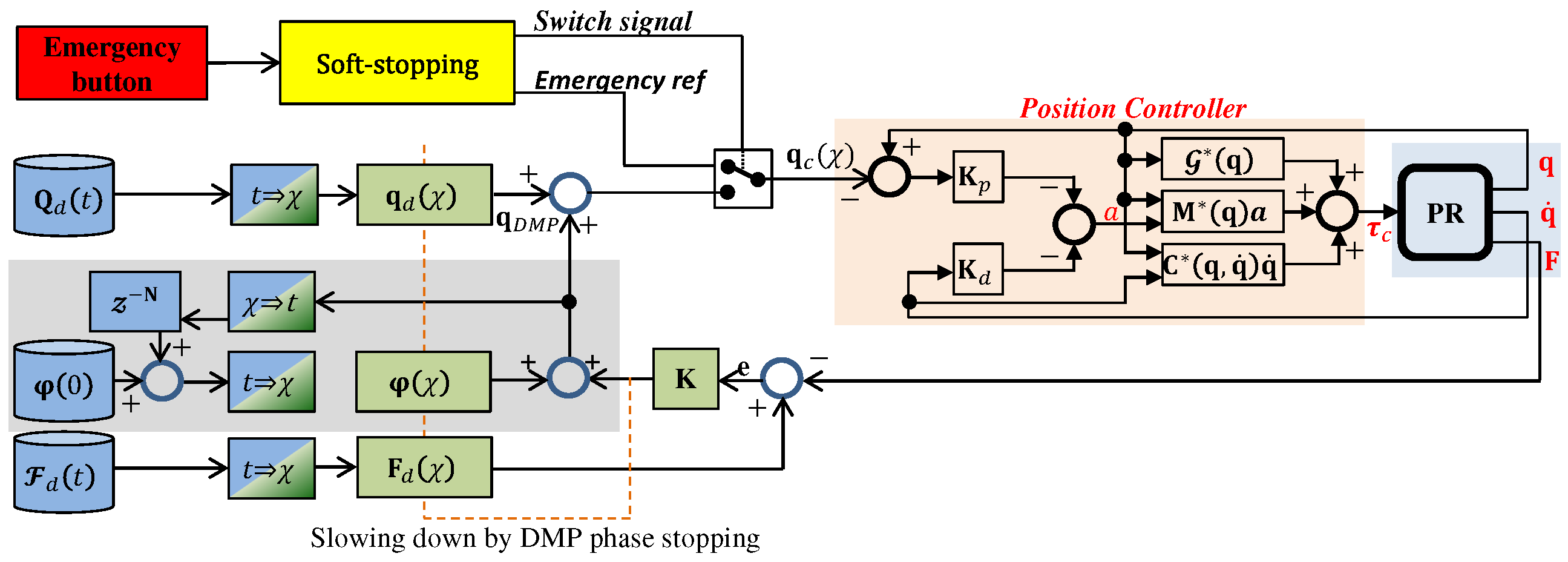
- Implementation of soft emergency stopping due to the integration of DMP phase-stopping in the emergency button control loop in order to provide soft and smooth stopping;
- -
- Provision of a stability analysis of our learning control;
- -
- Provision of a brief review of ankle rehabilitation devices, injuries, and exercises;
- -
- Implementation of different experiments in order to validate our control scheme.
2. Overview of the Ankle Joint: Anatomy, Physiology, and Injuries
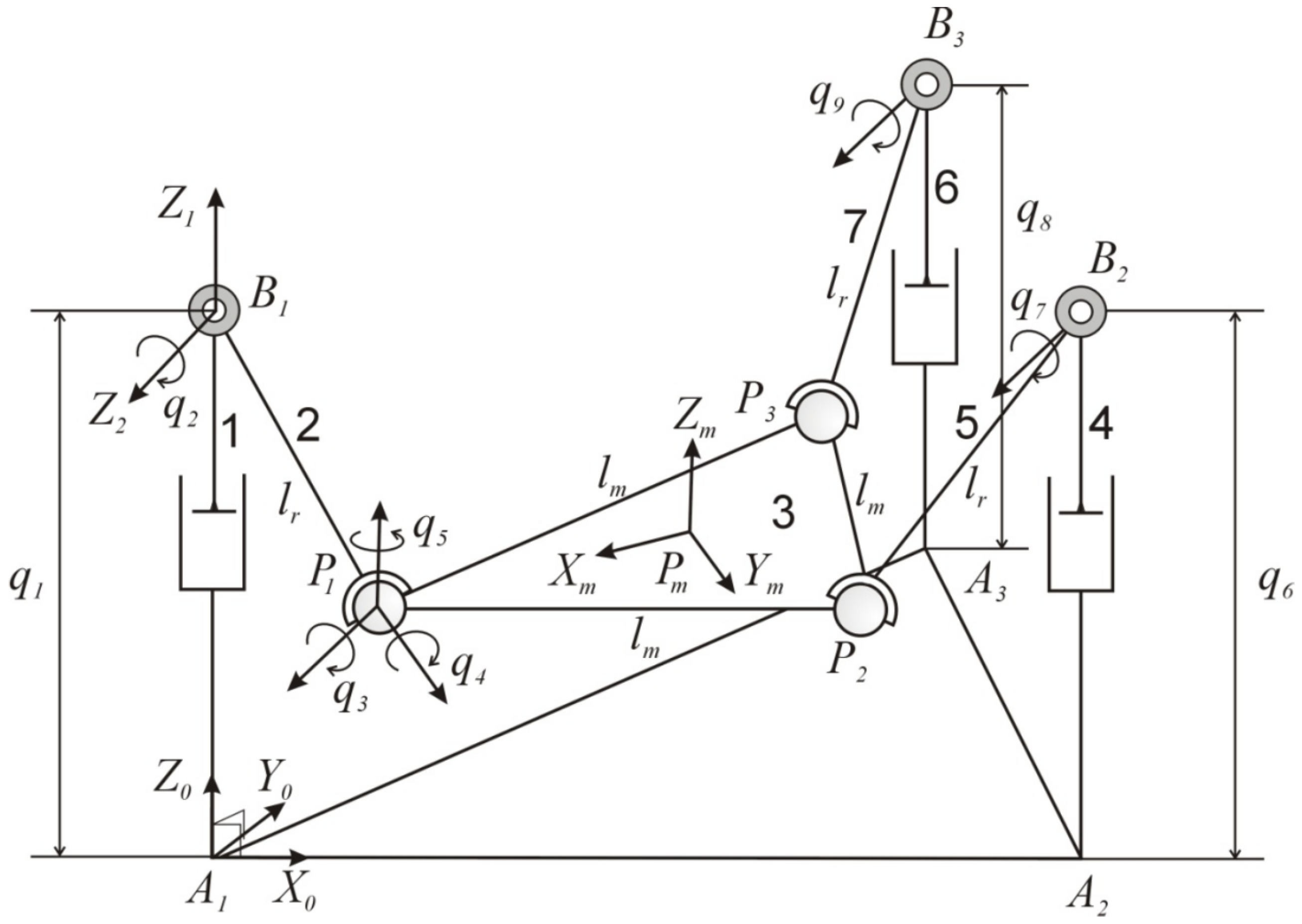
3. Parallel Robot: Kinematics And Dynamics
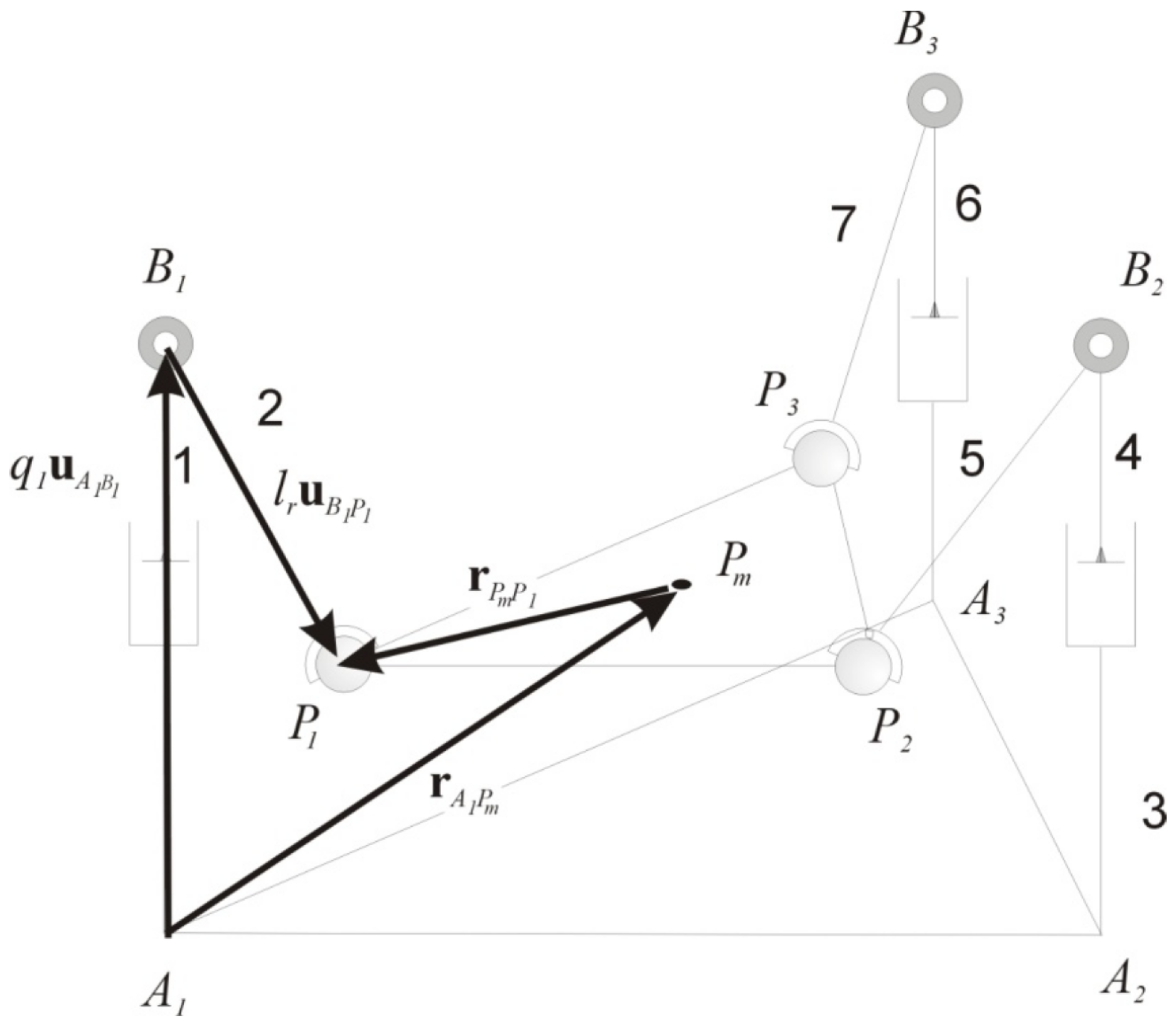
3.1. Three-PRS Kinematics
3.2. Three-PRS Dynamics
4. Policy Learning and Adaptation Algorithm
4.1. Learning from Demonstration for Rehabilitation Exercises
4.2. Overview of DMPs
4.3. Exercise Generation Using DMPs
4.4. Overview of ILC
4.5. Error Feedback and DMP Phase Stopping
4.6. Offset Learning
4.7. Ankle Rehabilitation Control Scheme
4.8. Stability Analysis
5. Results
5.1. Hardware Description
5.2. Experiments in Simulation
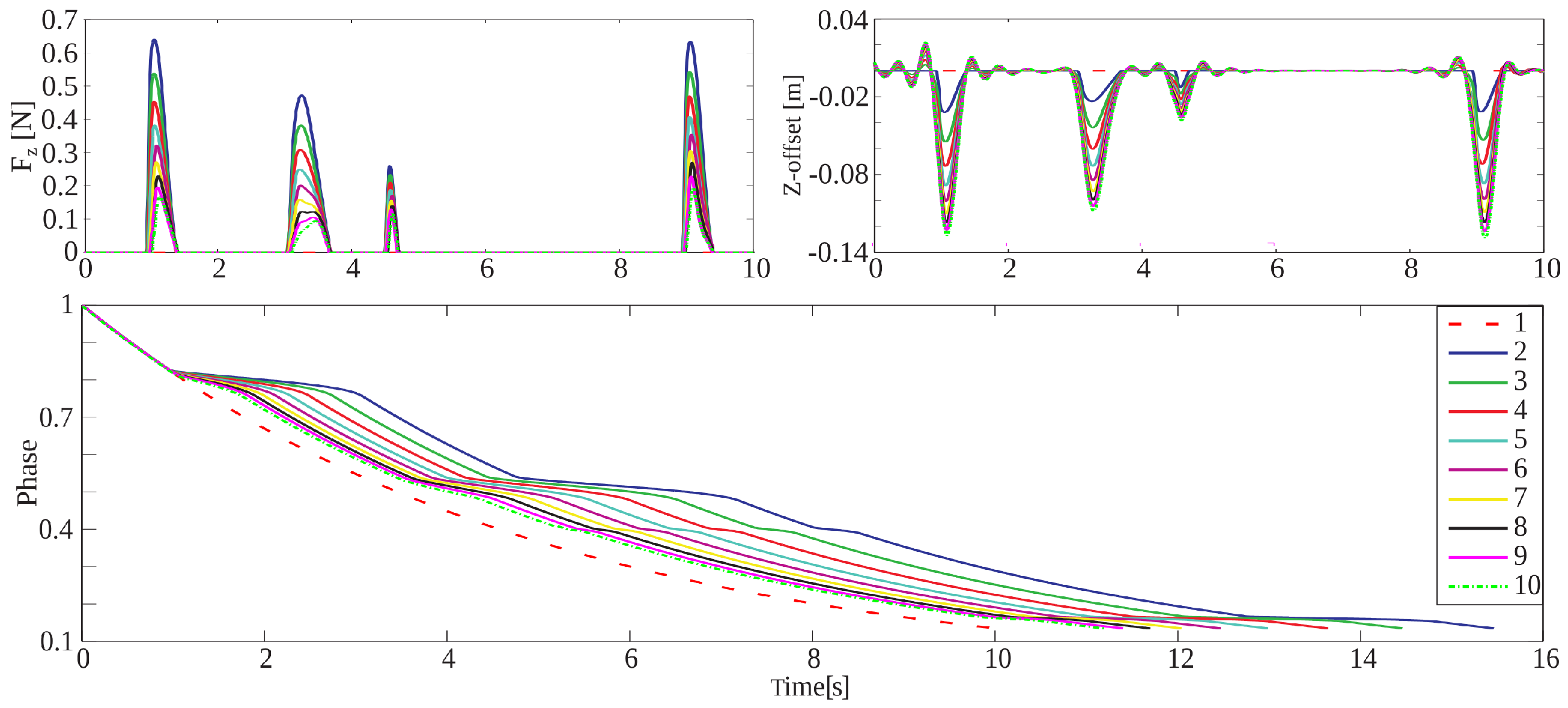
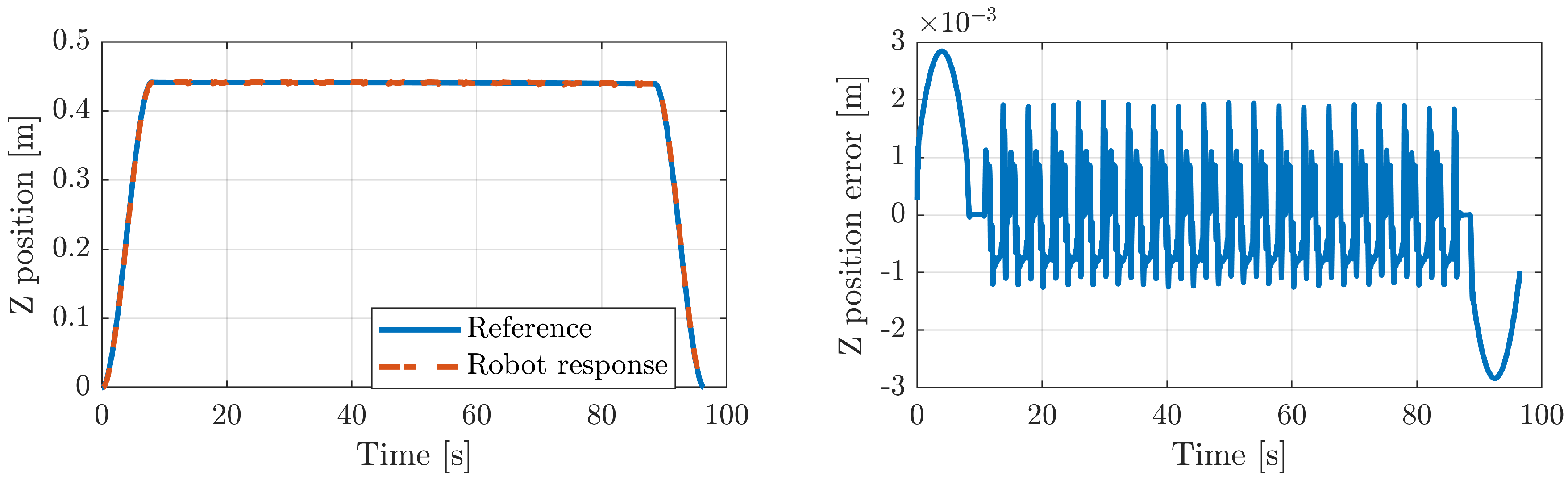
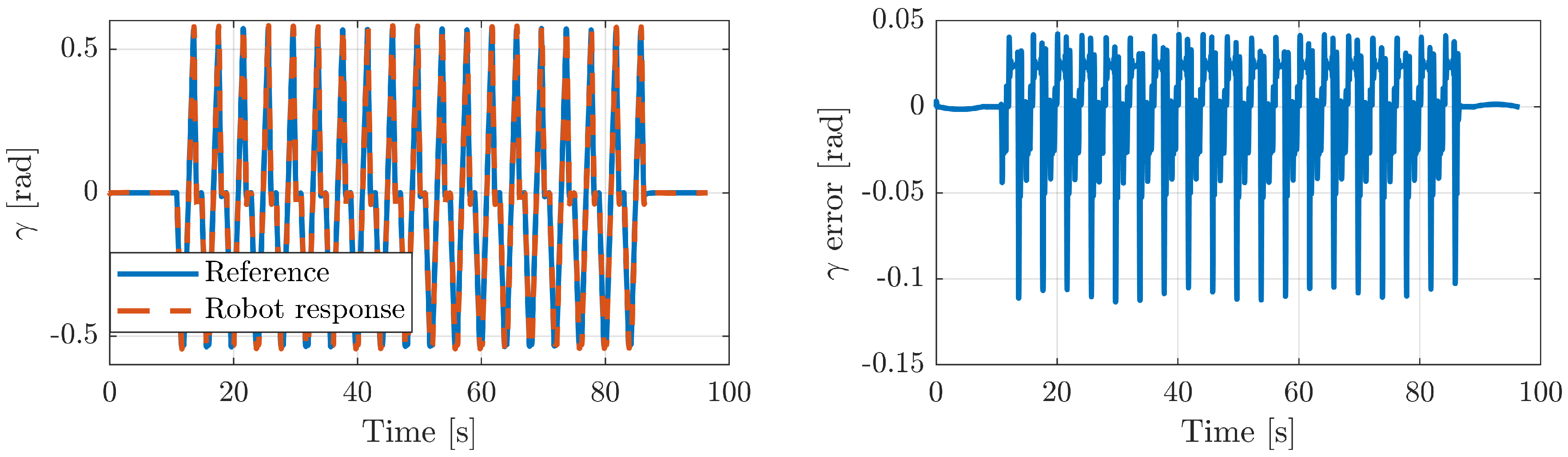
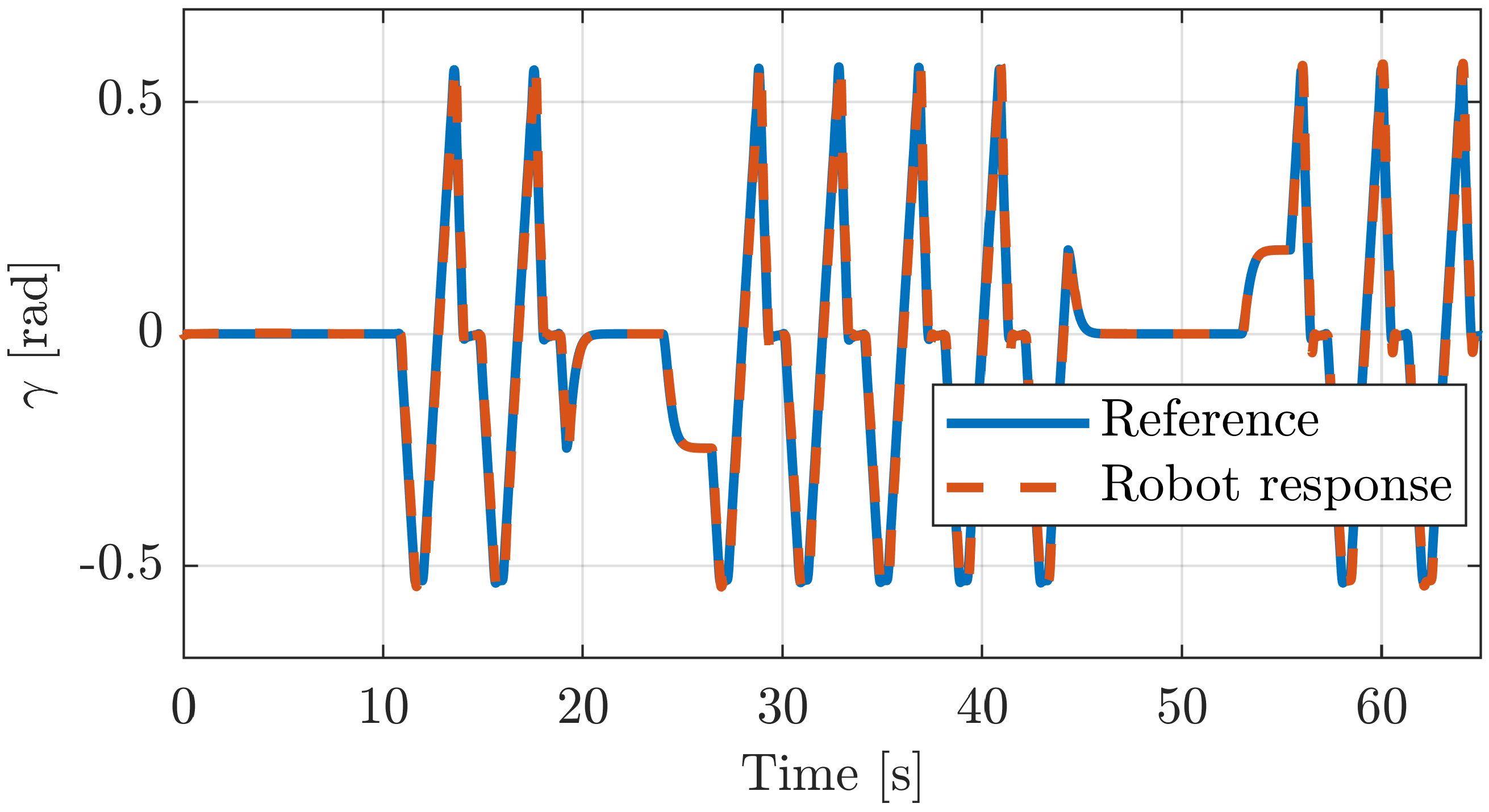
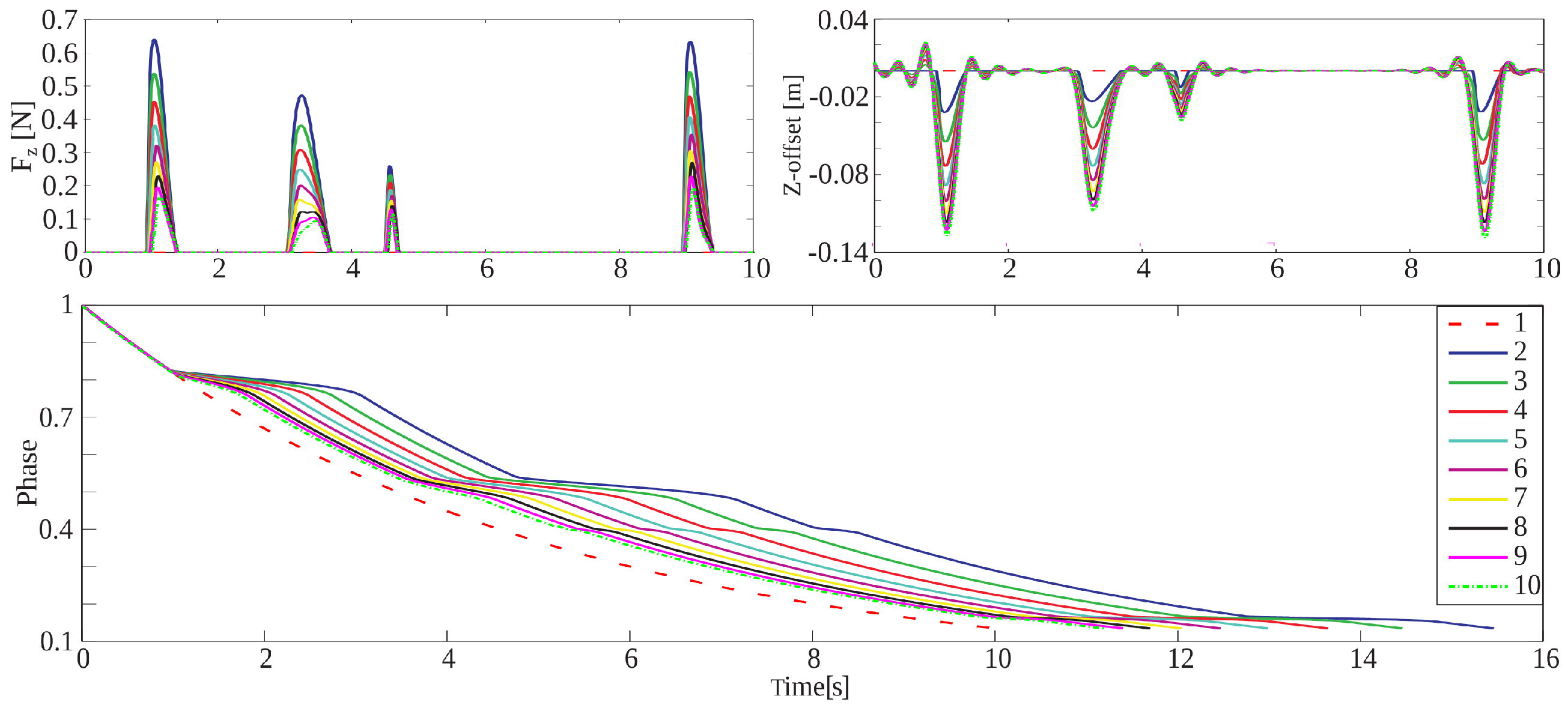
5.2.1. Execution of Different Exercises
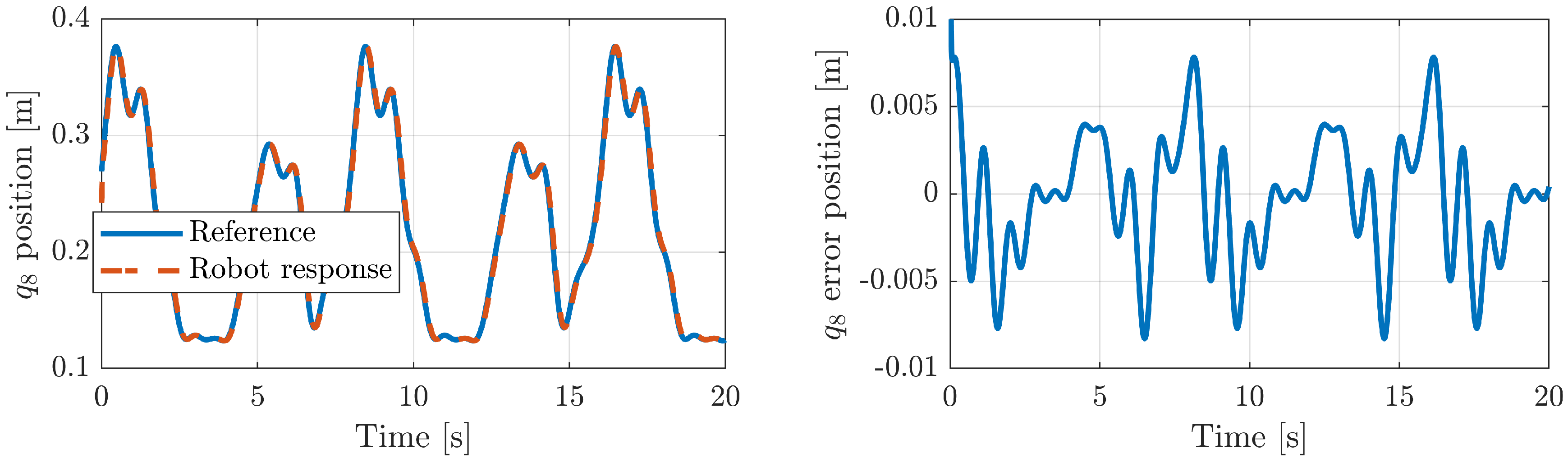
5.2.2. Position Tracking Error
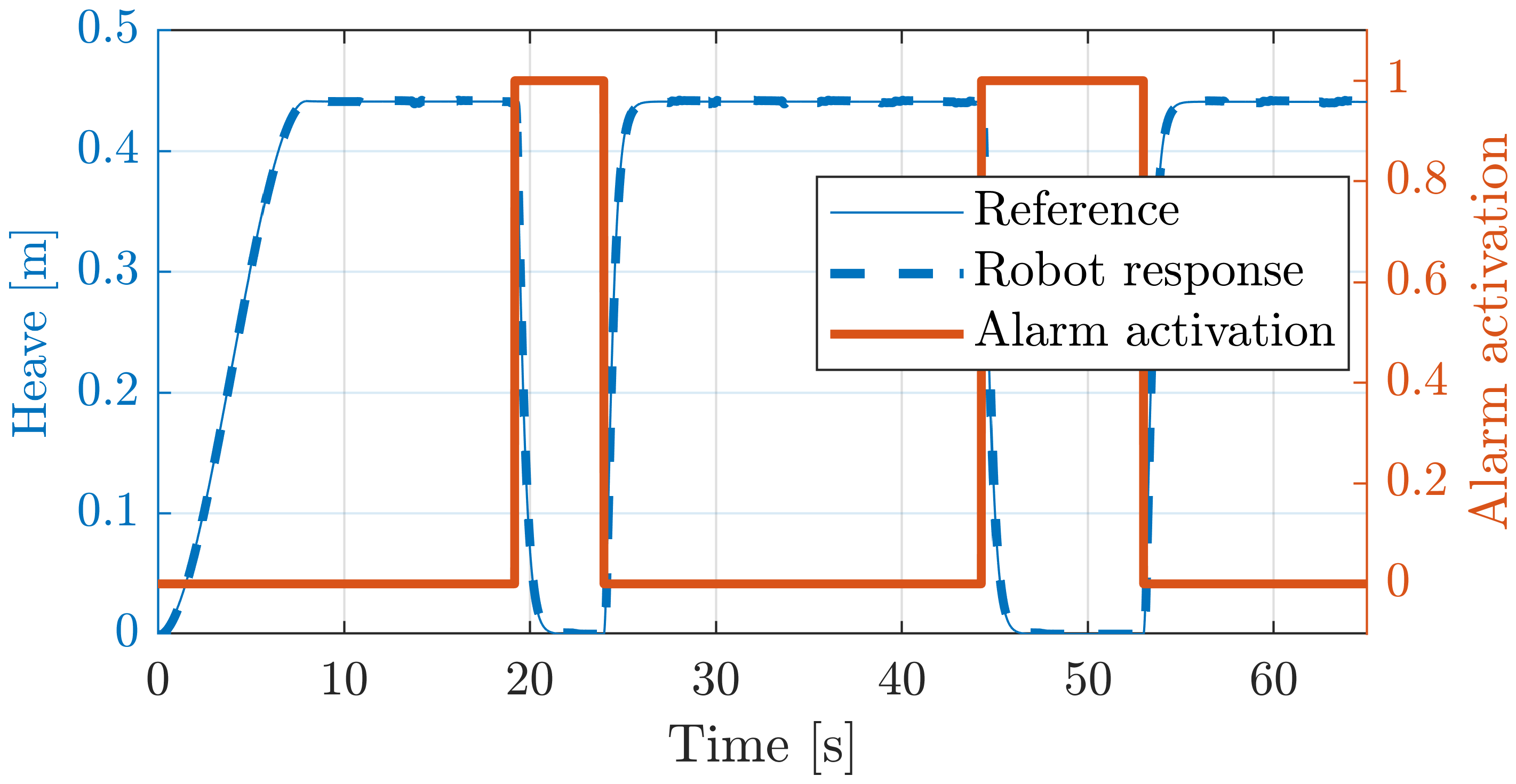
5.2.3. Emergency Button Testing
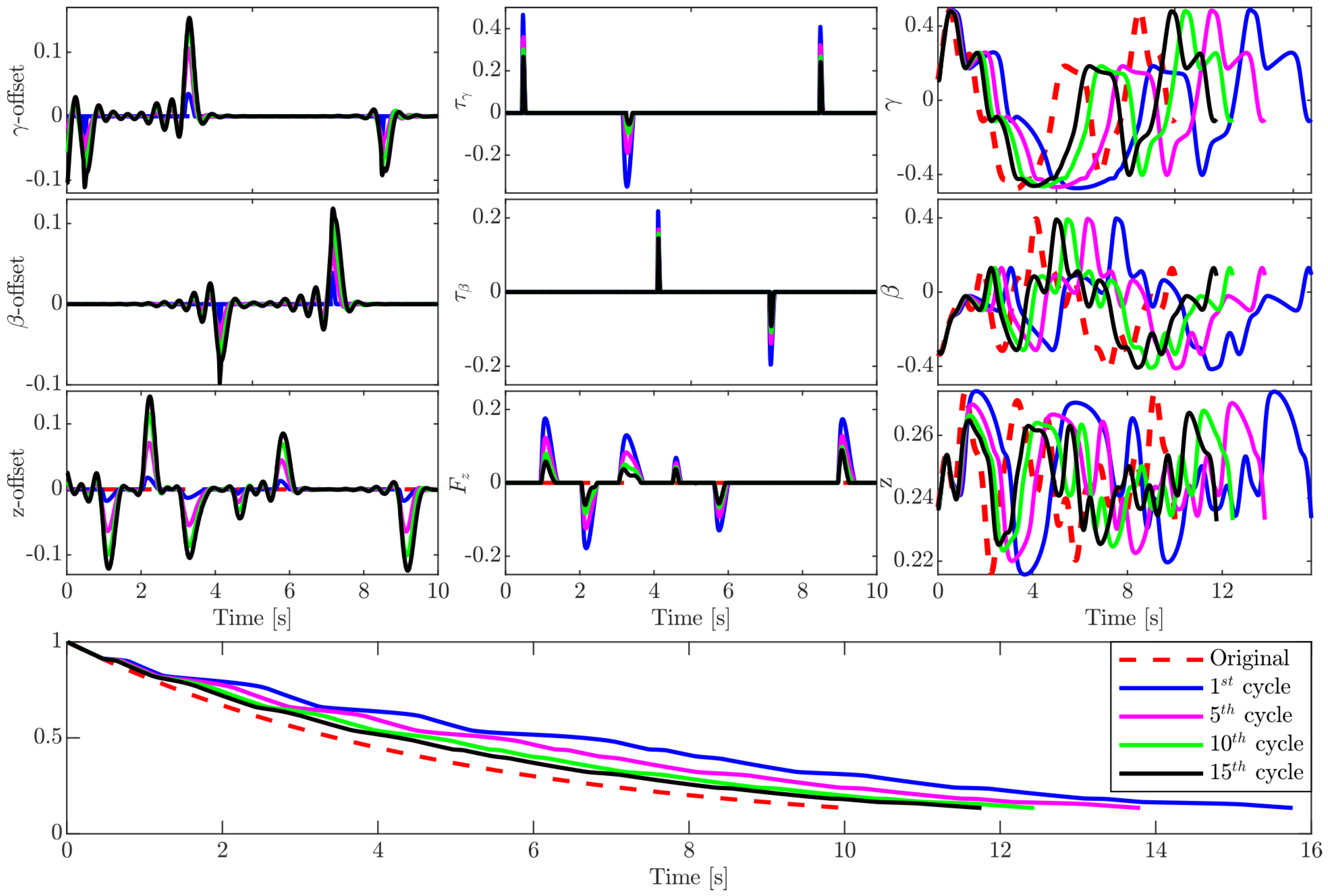
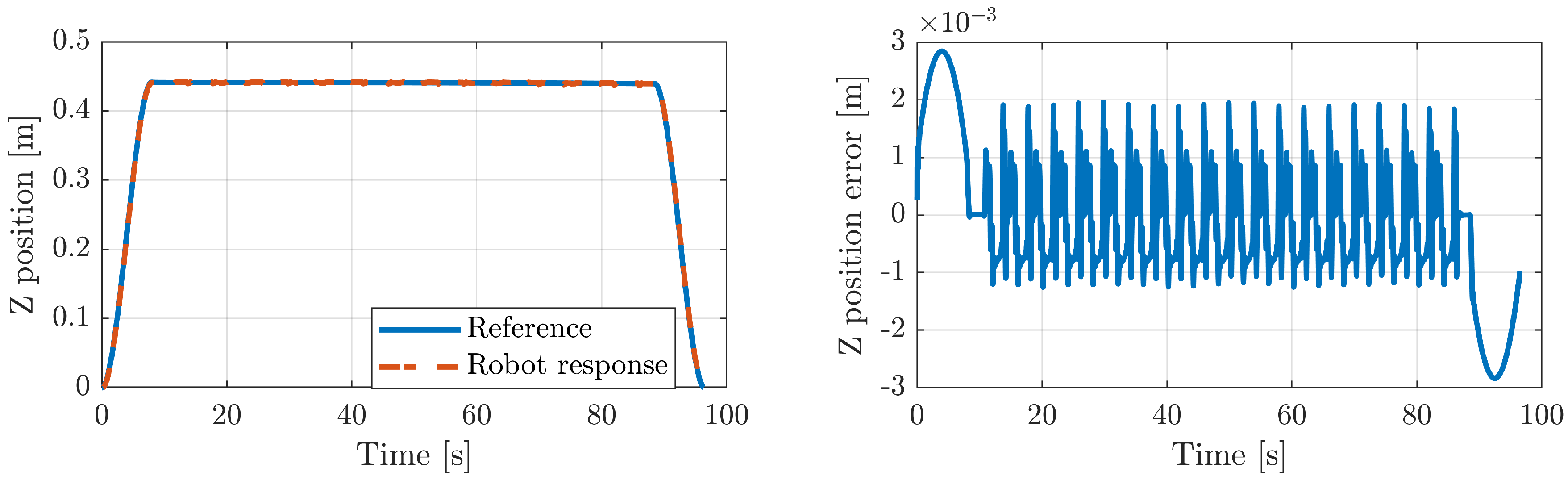
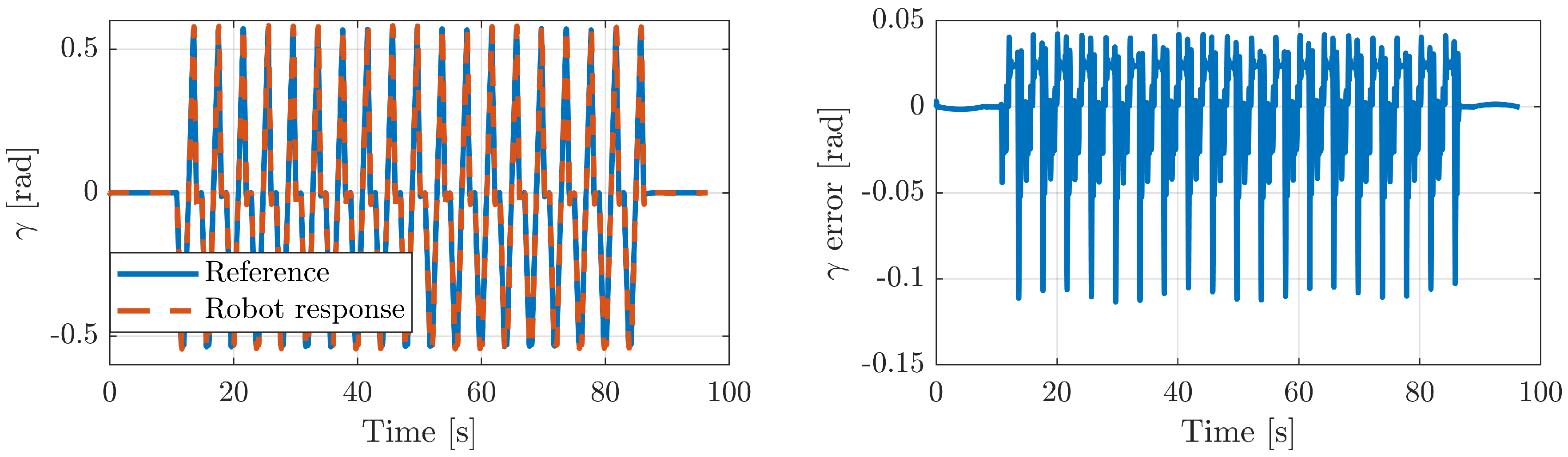
5.3. Experiments in Real Robot
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DMP | Dynamic Movement Primitive |
| ILC | Iterative learning control |
| PR | Parallel Robot |
| RICE | Rest, Ice, Compression, and Elevation |
| ROM | Range of Motion |
References
- Brewer, B.R.; McDowell, S.K.; Worthen-Chaudhari, L.C. Poststroke upper extremity rehabilitation: A review of robotic systems and clinical results. Top. Stroke Rehabil. 2007, 14, 22–44. [Google Scholar] [CrossRef]
- Michmizos, K.P.; Rossi, S.; Castelli, E.; Cappa, P.; Krebs, H.I. Robot-aided neurorehabilitation: A pediatric robot for ankle rehabilitation. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 23, 1056–1067. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Marchal-Crespo, L.; Reinkensmeyer, D.J. Review of control strategies for robotic movement training after neurologic injury. J. Neuroeng. Rehabil. 2009, 6, 20. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Balasubramanian, S.; Colombo, R.; Sterpi, I.; Sanguineti, V.; Burdet, E. Robotic assessment of upper limb motor function after stroke. Am. J. Phys. Med. Rehabil. 2012, 91, S255–S269. [Google Scholar] [CrossRef] [PubMed]
- Rea, P.; Ottaviano, E.; Castelli, G. A procedure for the design of novel assisting devices for the sit-to-stand. J. Bionic Eng. 2013, 10, 488–496. [Google Scholar] [CrossRef]
- Sale, P.; Franceschini, M.; Waldner, A.; Hesse, S. Use of the robot assisted gait therapy in rehabilitation of patients with stroke and spinal cord injury. Eur. J. Phys. Rehabil. Med. 2012, 48, 111–121. [Google Scholar]
- Rohrer, B.; Fasoli, S.; Krebs, H.I.; Hughes, R.; Volpe, B.; Frontera, W.R.; Stein, J.; Hogan, N. Movement smoothness changes during stroke recovery. J. Neurosci. 2002, 22, 8297–8304. [Google Scholar] [CrossRef] [PubMed]
- Martí Carrillo, F.; Butchart, J.; Knight, S.; Scheinberg, A.; Wise, L.; Sterling, L.; McCarthy, C. Adapting a General-Purpose Social Robot for Paediatric Rehabilitation through In Situ Design. ACM Trans. Hum. Robot. Interact. 2018, 7, 1–30. [Google Scholar] [CrossRef] [Green Version]
- Chisholm, K.; Klumper, K.; Mullins, A.; Ahmadi, M. A task oriented haptic gait rehabilitation robot. Mechatronics 2014, 24, 1083–1091. [Google Scholar] [CrossRef]
- Munih, M.; Bajd, T. Rehabilitation robotics. Technol. Health Care 2011, 19, 483–495. [Google Scholar] [CrossRef]
- Krebs, H.I.; Palazzolo, J.J.; Dipietro, L.; Ferraro, M.; Krol, J.; Rannekleiv, K.; Volpe, B.T.; Hogan, N. Rehabilitation robotics: Performance-based progressive robot-assisted therapy. Auton. Robot. 2003, 15, 7–20. [Google Scholar] [CrossRef]
- Hesse, S.; Schmidt, H.; Werner, C.; Bardeleben, A. Upper and lower extremity robotic devices for rehabilitation and for studying motor control. Curr. Opin. Neurol. 2003, 16, 705–710. [Google Scholar] [CrossRef]
- Dai, J.S.; Zhao, T.; Nester, C. Sprained ankle physiotherapy based mechanism synthesis and stiffness analysis of a robotic rehabilitation device. Auton. Robot. 2004, 16, 207–218. [Google Scholar] [CrossRef]
- Zhen, H.; Yongsheng, Z.; Tieshi, Z. Advanced Spatial Mechanism; Higher Education Press: Beijing, China, 2006; pp. 195–201. [Google Scholar]
- Díaz, I.; Gil, J.; Sánchez, E. Lower-limb robotic rehabilitation: Literature review and challenges. J. Robot. 2011, 2011, 1–11. [Google Scholar] [CrossRef]
- Del Ama, A.; Koutsou, A.; Moreno, J. Review of hybrid exoskeletons to restore gait following spinal cord injury. J. Rehabil. Res. Dev. 2012, 49, 497–514. [Google Scholar] [CrossRef] [PubMed]
- Zhang, M.; Davies, T.C.; Xie, S. Effectiveness of robot-assisted therapy on ankle rehabilitation—A systematic review. J. Neuroeng. Rehabil. 2013, 10, 30. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jamwal, P.K.; Hussain, S.; Xie, S.Q. Review on design and control aspects of ankle rehabilitation robots. Disabil. Rehabil. Assist. Technol. 2015, 10, 93–101. [Google Scholar] [CrossRef] [PubMed]
- Schmitt, C.; Métrailler, P.; Al-Khodairy, A. The Motion MakerTM: A Rehabilitation System Combining an Orthosis with Closed-Loop Electrical Muscle Stimulation. In Proceedings of the 8th Vienna International Workshop on Functional Electrical Stimulation, Vienna, Austria, 10–13 September 2004; pp. 117–120. [Google Scholar]
- Peshkin, M.; Brown, D.; Santos-Munné, J. KineAssist: A robotic overground gait and balance training device. In Proceedings of the 9th IEEE International Conference on Rehabilitation Robotics, (ICORR’05), Chicago, IL, USA, 28 June–1 July 2005; pp. 241–246. [Google Scholar]
- Abdullah, H.; Tarry, C.; Datta, R.; Mittal, G.; Abderrahim, M. Dynamic biomechanical model for assessing and monitoring robot-assisted upper-limb therapy. J. Rehabil. Res. Dev. 2007, 44, 43–62. [Google Scholar] [CrossRef]
- Van Delden, A.; Peper, C.; Kwakkel, G. A Systematic Review of Bilateral Upper Limb Training Devices for Poststroke Rehabilitation. Stroke Res. Treat. 2012, 2012, 1–17. [Google Scholar] [CrossRef]
- Wang, C.; Wang, L.; Qin, J.; Wu, Z.; Duan, L.; Li, Z.; Cao, M.; Li, W.; Lu, Z.; Li, M.; et al. Development of an ankle rehabilitation robot for ankle training. In Proceedings of the Information and Automation, 2015 IEEE International Conference on IEEE, Lijiang, China, 8–10 August 2015; pp. 94–99. [Google Scholar]
- Ayas, M.S.; Altas, I.H.; Sahin, E. Fractional order based trajectory tracking control of an ankle rehabilitation robot. Trans. Inst. Meas. Control 2018, 40, 550–564. [Google Scholar] [CrossRef]
- Ayas, M.S.; Altas, I.H. Fuzzy logic based adaptive admittance control of a redundantly actuated ankle rehabilitation robot. Control Eng. Pract. 2017, 59, 44–54. [Google Scholar] [CrossRef]
- Syrseloudis, C.E.; Emiris, I.Z. A parallel robot for ankle rehabilitation-evaluation and its design specifications. In Proceedings of the 8th IEEE International Conference on BioInformatics and BioEngineering, Athens, Greece, 8–10 October 2008. [Google Scholar]
- Saglia, J.; Tsagarakis, N.; Dai, J.; Caldwell, D. Control Strategies for Patient-Assisted Training Using the Ankle Rehabilitation Robot (ARBOT). IEEE/ASME Trans. Mechatron. 2012, 99, 1–10. [Google Scholar] [CrossRef]
- Patel, Y.D.; George, P.M. Parallel Manipulators Applications—A Survey. Mod. Mech. Eng. 2012, 2, 57–64. [Google Scholar] [CrossRef] [Green Version]
- Girone, M.; Burdea, G.; Bouzit, M. The Rutgers Ankle orthopedic rehabilitation interface. In Dynamic Systems and Control Division; ASME: New York, NY, USA, 1999; Volume 67, pp. 305–312. [Google Scholar]
- Girone, M.; Burdea, G.; Bouzit, M.; Popescu, V.; Deutsch, J. Orthopedic rehabilitation using the “Rutgers ankle” interface. Stud. Health Technol. Inform. 2000, 70, 89–95. [Google Scholar] [PubMed]
- Deutsch, J.E.; Lewis, J.A.; Burdea, G. Technical and patient performance using a virtual reality-integrated telerehabilitation system: Preliminary finding. IEEE Trans. Neural Syst. Rehabil. Eng. 2007, 15, 30–35. [Google Scholar] [CrossRef] [PubMed]
- Saglia, J.A.; Tsagarakis, N.G.; Dai, J.S.; Caldwell, D.G. Control strategies for ankle rehabilitation using a high performance ankle exerciser. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA2010), Anchorage, AK, USA, 3–7 May 2010; pp. 2221–2227. [Google Scholar]
- Yoon, J.; Ryu, J.; Lim, K. Reconfigurable ankle rehabilitation robot for various exercises. J. Robot. Syst. 2006, 11, 15–33. [Google Scholar] [CrossRef]
- Liu, G.; Gao, J.; Yue, H.; Zhang, X.; Lu, G. Design and kinematics simulation of parallel robots for ankle rehabilitation. In Proceedings of the International Conference on Mechatronics and Automation, Luoyang, China, 25–28 June 2006; pp. 1109–1113. [Google Scholar]
- Wang, C.; Fang, Y.; Guo, S.; Zhou, C. Design and kinematic analysis of redundantly actuated parallel mechanisms for ankle rehabilitation. Robotica 2015, 33, 366–384. [Google Scholar] [CrossRef]
- Fan, Y.; Yin, Y. Mechanism design and motion control of a parallel ankle joint for rehabilitation robotic exoskeleton. In Proceedings of the IEEE Robotics and Biomimetics, Guilin, China, 19–23 December 2009; pp. 2527–2532. [Google Scholar]
- Mao, Y.; Agrawal, S.K. Design of a cable-driven arm exoskeleton (CAREX) for neural rehabilitation. IEEE Trans. Robot. 2012, 28, 922–931. [Google Scholar] [CrossRef]
- Vallés, M.; Cazalilla, J.; Valera, Á.; Mata, V.; Page, Á.; Díaz-Rodríguez, M. A 3-PRS parallel manipulator for ankle rehabilitation: Towards a low-cost robotic rehabilitation. Robotica 2017, 35, 1939–1957. [Google Scholar] [CrossRef]
- Azcaray, H.; Blanco, A.; García, C.; Adam, M.; Reyes, J.; Guerrero, G.; Guzmán, C. Robust GPI Control of a New Parallel Rehabilitation Robot of Lower Extremities. Int. J. Control Autom. Syst. 2018, 16, 2384–2392. [Google Scholar] [CrossRef]
- Chang, T.C.; Zhang, X.D. Kinematics and reliable analysis of decoupled parallel mechanism for ankle rehabilitation. Microelectron. Reliab. 2019, 99, 203–212. [Google Scholar] [CrossRef]
- Zhang, M.; McDaid, A.; Veale, A.J.; Peng, Y.; Xie, S.Q. Adaptive trajectory tracking control of a parallel ankle rehabilitation robot with joint-space force distribution. IEEE Access 2019, 7, 85812–85820. [Google Scholar] [CrossRef]
- Li, J.; Fan, W.; Dong, M.; Rong, X. Implementation of passive compliance training on a parallel ankle rehabilitation robot to enhance safety. Ind. Robot. Int. J. Robot. Res. Appl. 2020. [Google Scholar] [CrossRef]
- Patanè, F.; Cappa, P. A 3-DOF Parallel Robot With Spherical Motion for the Rehabilitation and Evaluation of Balance Performance. IEEE Trans. Neural Syst. Rehabil. Eng. 2011, 19, 157–166. [Google Scholar] [CrossRef]
- Billard, A.; Calinon, S.; Dillmann, R.; Schaal, S. Robot Programming by Demonstration. In Springer Handbook of Robotics; Springer: Berlin/Heidelberg, Germany, 2008; Chapter 59; pp. 1371–1394. [Google Scholar]
- Ravichandar, H.; Polydoros, A.S.; Chernova, S.; Billard, A. Recent advances in robot learning from demonstration. Annu. Rev. Control Robot. Auton. Syst. 2020, 3, 297–330. [Google Scholar] [CrossRef] [Green Version]
- Fong, J.; Tavakoli, M. Kinesthetic teaching of a therapist’s behavior to a rehabilitation robot. In Proceedings of the 2018 International Symposium on Medical Robotics (ISMR), Atlanta, GA, USA, 1–3 March 2018; pp. 1–6. [Google Scholar]
- Ma, Z.; Ben-Tzvi, P.; Danoff, J. Hand rehabilitation learning system with an exoskeleton robotic glove. IEEE Trans. Neural Syst. Rehabil. Eng. 2015, 24, 1323–1332. [Google Scholar] [CrossRef] [PubMed]
- Lauretti, C.; Cordella, F.; Guglielmelli, E.; Zollo, L. Learning by demonstration for planning activities of daily living in rehabilitation and assistive robotics. IEEE Robot. Autom. Lett. 2017, 2, 1375–1382. [Google Scholar] [CrossRef]
- Wang, H.; Chen, J.; Lau, H.Y.; Ren, H. Motion planning based on learning from demonstration for multiple-segment flexible soft robots actuated by electroactive polymers. IEEE Robot. Autom. Lett. 2016, 1, 391–398. [Google Scholar] [CrossRef]
- Bhattacharjee, T.; Lee, G.; Song, H.; Srinivasa, S.S. Towards robotic feeding: Role of haptics in fork-based food manipulation. IEEE Robot. Autom. Lett. 2019, 4, 1485–1492. [Google Scholar] [CrossRef] [Green Version]
- Ijspeert, A.J.; Nakanishi, J.; Schaal, S. Nonlinear Dynamical Systems for Imitation with Humanoid Robots. In Proceedings of the IEEE International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 21–26 May 2001; pp. 219–226. [Google Scholar]
- Moore, K.; Chen, Y.; Ahn, H.S. Iterative Learning Control: A Tutorial and Big Picture View. In Proceedings of the 45th IEEE Conference on Decision and Control, San Diego, CA, USA, 13–15 December 2006; pp. 2352–2357. [Google Scholar]
- Ijspeert, A.; Nakanishi, J.; Hoffmann, H.; Pastor, P.; Schaal, S. Dynamical movement primitives: Learning attractor models for motor behaviors. Neural Comput. 2013, 25, 328–373. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Abu-Dakka, F.J.; Nemec, B.; Jørgensen, J.A.; Savarimuthu, T.R.; Krüger, N.; Ude, A. Adaptation of manipulation skills in physical contact with the environment to reference force profiles. Auton. Robot. 2015, 39, 199–217. [Google Scholar] [CrossRef]
- Abu-Dakka, F.J.; Kyrki, V. Geometry-aware dynamic movement primitives. In Proceedings of the IEEE International Conference on Robotics and Automation, Paris, France, 31 May–31 August 2020. [Google Scholar]
- Bristow, D.; Tharayil, M.; Alleyne, A. A survey of iterative learning control. IEEE Control Syst. Mag. 2006, 26, 96–114. [Google Scholar]
- Abu-Dakk, F.J.; Valera, A.; Escalera, J.A.; Vallés, M.; Mata, V.; Abderrahim, M. Trajectory adaptation and learning for ankle rehabilitation using a 3-PRS parallel robot. In Proceedings of the International Conference on Intelligent Robotics and Applications; Springer: Berlin/Heidelberg, Germany, 2015; pp. 483–494. [Google Scholar]
- Dul, J.; Johnson, G. A kinematic model of the human ankle. J. Biomed. Eng. 1985, 7, 137–143. [Google Scholar] [CrossRef]
- Alcocer, W.; Vela, L.; Blanco, A.; Gonzalez, J.; Oliver, M. Major Trends in the Development of Ankle Rehabilitation Devices. Dyna 2012, 79, 45–55. [Google Scholar]
- Siegler, S.; Chen, J.; Schneck, C. The three-dimensional kinematics and flexibility characteristics of the human ankle and subtalar joints–Part I: Kinematics. J. Biomech. Eng. 1988, 110, 364–373. [Google Scholar] [CrossRef]
- Parenteau, C.S.; Viano, D.C.; Petit, P. Biomechanical properties of human cadaveric ankle-subtalar joints in quasi-static loading. J. Biomech. Eng. 1998, 120, 105–111. [Google Scholar] [CrossRef] [PubMed]
- Kearney, R.; Weiss, P.; Morier, R. System identification of human ankle dynamics: Intersubject variability and intrasubject reliability. Clin. Biomech. 1990, 5, 205–217. [Google Scholar] [CrossRef]
- Kleipool, R.P.; Blankevoort, L. The relation between geometry and function of the ankle joint complex: A biomechanical review. Knee Surg. Sports Traumatol. Arthrosc. 2010, 18, 618–627. [Google Scholar] [CrossRef]
- Safran, M.; Benedetti, R.; Bartolozzi, A. Lateral ankle sprains: A comprehensive review: Part 1: Etiology, pathoanatomy, histopathogenesis, and diagnosis. Med. Sci. Sports Exerc. 1999, 31, 429–437. [Google Scholar] [CrossRef]
- DiStefano, L.J.; Padua, D.A.; Brown, C.N.; Guskiewicz, K.M. Lower extremity kinematics and ground reaction forces after prophylactic lace-up ankle bracing. J. Athl. Train. 2008, 43, 234–241. [Google Scholar] [CrossRef] [Green Version]
- Takao, M.; Uchio, Y.; Naito, K.; Fukazawa, I.; Ochi, M. Arthroscopic assessment for intra-articular disorders in residual ankle disability after sprain. Am. J. Sports Med. 2005, 33, 686–692. [Google Scholar] [CrossRef] [PubMed]
- Ren, Y.; Xu, T.; Wang, L.; Yang, C.; Guo, X.; Harvey, R.; Zhang, L.Q. Develop a Wearable Ankle Robot for in-Bed Acute Stroke Rehabilitation. In Proceedings of the 33rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Boston, MA, USA, 30 August–3 September 2011; pp. 7483–7486. [Google Scholar]
- Cioi, D.; Kale, A.; Burdea, G.; Engsberg, J.; Janes, W.; Ross, S. Ankle Control and Strength Training for Children with Cerebral Palsy Using the Rutgers Ankle CP: A Case Study. In Proceedings of the IEEE international conference on rehabilitation robotics, Zurich, Switzerland, 29 June–1 July 2011; pp. 654–659. [Google Scholar]
- Díaz-Rodríguez, M.; Mata, V.; Valera, A.; Page, A. A Methodology for Dynamic Parameters Identification of 3-DOF Parallel Robots in Terms of Relevant Parameters. Mech. Mach. Theory 2010, 45, 1337–1356. [Google Scholar] [CrossRef]
- Garcia de Jalon, J.; Bayo, E. Kinematic and Dynamic Simulation of Multibody Systems: The Real Time Challenge; Springer: New York, NY, USA, 1994. [Google Scholar]
- Nakanishi, J.; Morimoto, J.; Endo, G.; Cheng, G.; Schaal, S.; Kawato, M. Learning from demonstration and adaptation of biped locomotion. Robot. Auton. Syst. 2004, 47, 79–91. [Google Scholar] [CrossRef] [Green Version]
- Gams, A.; Ijspeert, A.J.; Schaal, S.; Lenarčič, J. On-line learning and modulation of periodic movements with nonlinear dynamical systems. Auton. Robot. 2009, 27, 3–23. [Google Scholar] [CrossRef]
- Peters, J.; Schaal, S. Reinforcement learning of motor skills with policy gradients. Neural Netw. 2008, 21, 682–697. [Google Scholar] [CrossRef] [Green Version]
- Nemec, B.; Abu-Dakka, F.J.; Ridge, B.; Ude, A.; Jorgensen, J.; Savarimuthu, T.R.; Jouffroy, J.; Petersen, H.G.; Kruger, N. Transfer of assembly operations to new workpiece poses by adaptation to the desired force profile. In Proceedings of the 16th International Conference on Advanced Robotics (ICAR13), Montevideo, Uruguay, 25–29 November 2013; pp. 1–7. [Google Scholar]
- Abu-Dakka, F.J.; Nemec, B.; Kramberger, A.; Buch, A.G.; Krüger, N.; Ude, A. Solving peg-in-hole tasks by human demonstration and exception strategies. Ind. Robot Int. J. 2014, 41, 575–584. [Google Scholar] [CrossRef]
- Ude, A.; Gams, A.; Asfour, T.; Morimoto, J. Tasks-specific generalization of discrete and periodic dynamic movement primitives. IEEE Trans. Robot. 2010, 26, 800–815. [Google Scholar] [CrossRef] [Green Version]
- Villani, L.; De Schutter, J. Force Control. In Springer Handbook of Robotics; Siciliano, B., Khatib, O., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Chapter 7; pp. 161–185. [Google Scholar]
- Cazalilla, J.; Vallés, M.; Mata, V.; Díaz-Rodríguez, M.; Valera, A. Adaptive control of a 3-DOF parallel manipulator considering payload handling and relevant parameter models. Robot. Comput. Integr. Manuf. 2014, 30, 468–477. [Google Scholar] [CrossRef]
- Vallés, M.; Díaz-Rodríguez, M.; Valera, A.; Mata, V.; Page, A. Mechatronic Development and Dynamic Control of a 3-DOF Parallel Manipulator. Mech. Des. Struct. Mach. 2012, 40, 434–452. [Google Scholar] [CrossRef] [Green Version]
- Nemec, B.; Petric, T.; Ude, A. Force adaptation with recursive regression Iterative Learning Controller. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Hamburg, Germany, 28 September–2 October 2015; pp. 2835–2841. [Google Scholar]
- Likar, N.; Nemec, B.; Zlajpah, L.; Ando, S.; Ude, A. Adaptation of bimanual assembly tasks using iterative learning framework. In Proceedings of the IEEE-RAS 15th International Conference on Humanoid Robots (Humanoids), Seoul, Korea, 3–5 November 2015; pp. 771–776. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ankle Motion | Range of Motion ROM [60] | Maximum Passive Moment (Nm) [61,62,63] | |
|---|---|---|---|
| Dorsiflexion | 20.3 to 29.8 | 34.1 ± 14.5 | |
| Plantarflexion | 37.6 to 45.75 | 48.1 ± 12.2 | |
| Inversion | 14.5 to 22 | 33.1 ± 16.5 | |
| Eversion | 10,0 to 17 | 40.1 ± 9.2 | |
| Adduction | 22.0 to 36 | - | |
| Abduction | 15.4 to 25.9 | - |
| Joint | Mean Errors | RMSE | Variance |
|---|---|---|---|
| 0.00343 | 0.00405 | 1.643 × 10 | |
| 0.00320 | 0.00396 | 1.567 × 10 | |
| 0.00265 | 0.00341 | 1.156 × 10 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Abu-Dakka, F.J.; Valera, A.; Escalera, J.A.; Abderrahim, M.; Page, A.; Mata, V. Passive Exercise Adaptation for Ankle Rehabilitation Based on Learning Control Framework. Sensors 2020, 20, 6215. https://doi.org/10.3390/s20216215
Abu-Dakka FJ, Valera A, Escalera JA, Abderrahim M, Page A, Mata V. Passive Exercise Adaptation for Ankle Rehabilitation Based on Learning Control Framework. Sensors. 2020; 20(21):6215. https://doi.org/10.3390/s20216215
Chicago/Turabian StyleAbu-Dakka, Fares J., Angel Valera, Juan A. Escalera, Mohamed Abderrahim, Alvaro Page, and Vicente Mata. 2020. "Passive Exercise Adaptation for Ankle Rehabilitation Based on Learning Control Framework" Sensors 20, no. 21: 6215. https://doi.org/10.3390/s20216215
APA StyleAbu-Dakka, F. J., Valera, A., Escalera, J. A., Abderrahim, M., Page, A., & Mata, V. (2020). Passive Exercise Adaptation for Ankle Rehabilitation Based on Learning Control Framework. Sensors, 20(21), 6215. https://doi.org/10.3390/s20216215