
Electricity GANs: Generative Adversarial Networks for Electricity Price Scenario Generation


Abstract
:1. Introduction
2. Literature Review
3. Basic Facts and Fundamental Concepts behind GANs
3.1. The Basic Structure of a GAN
3.2. The Original GAN Architecture and the Proposed GAN Types
- •
- WGAN, WGAN-GP, LSGAN, SAGAN, RAGAN, and RALSGAN, which use a modified objective function;
- •
- DCGAN, DRAGAN, and YLGAN, which use specialized neural network designs;
- •
- BigGAN and BigGAN-DEEP, which use both a modified objective function and specialized neural network structures.
4. Empirical Analysis: Electricity Price Scenario Generation with GANs
4.1. The Data and Hyperparameters
4.2. Implementation Details
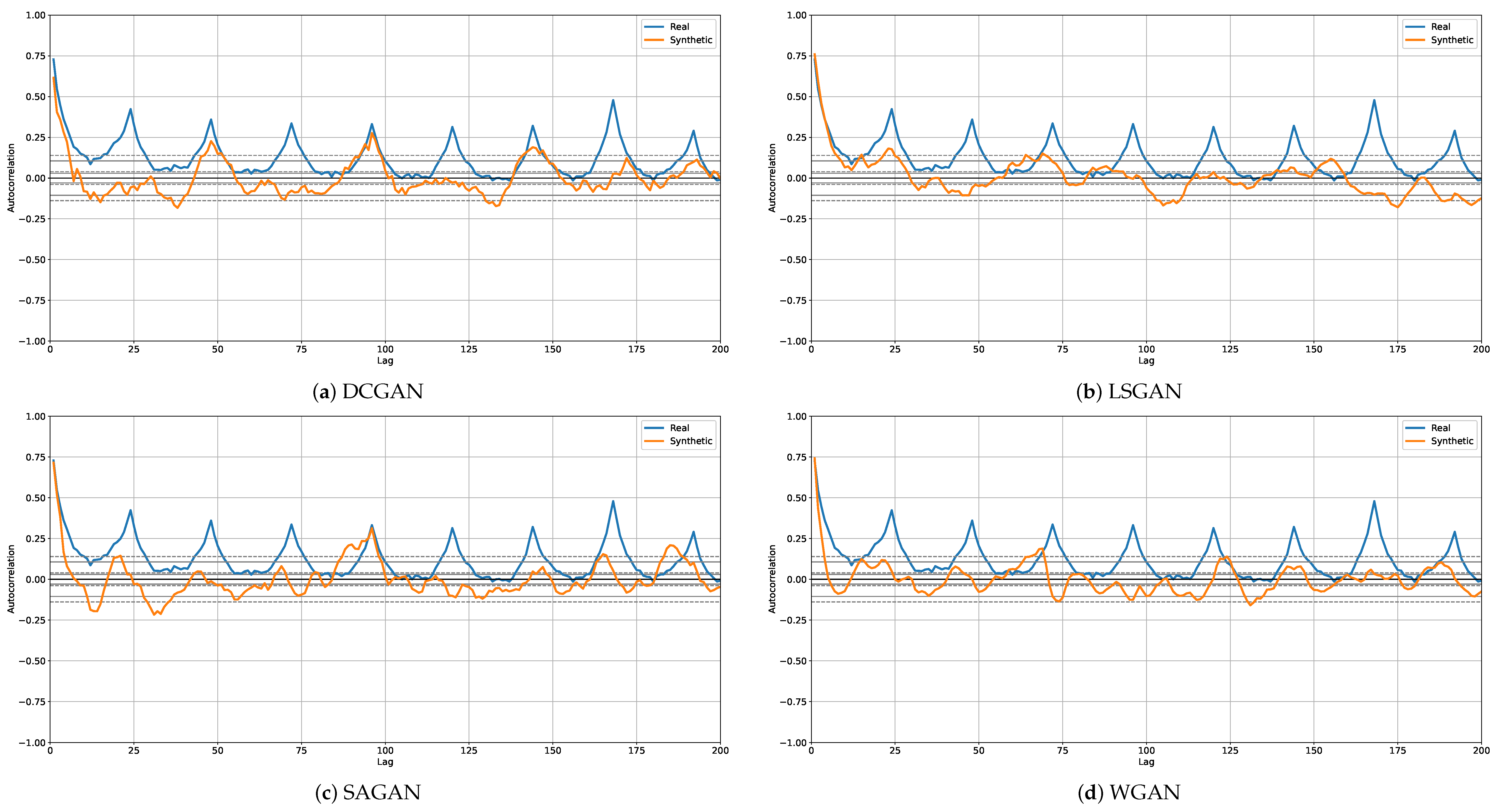
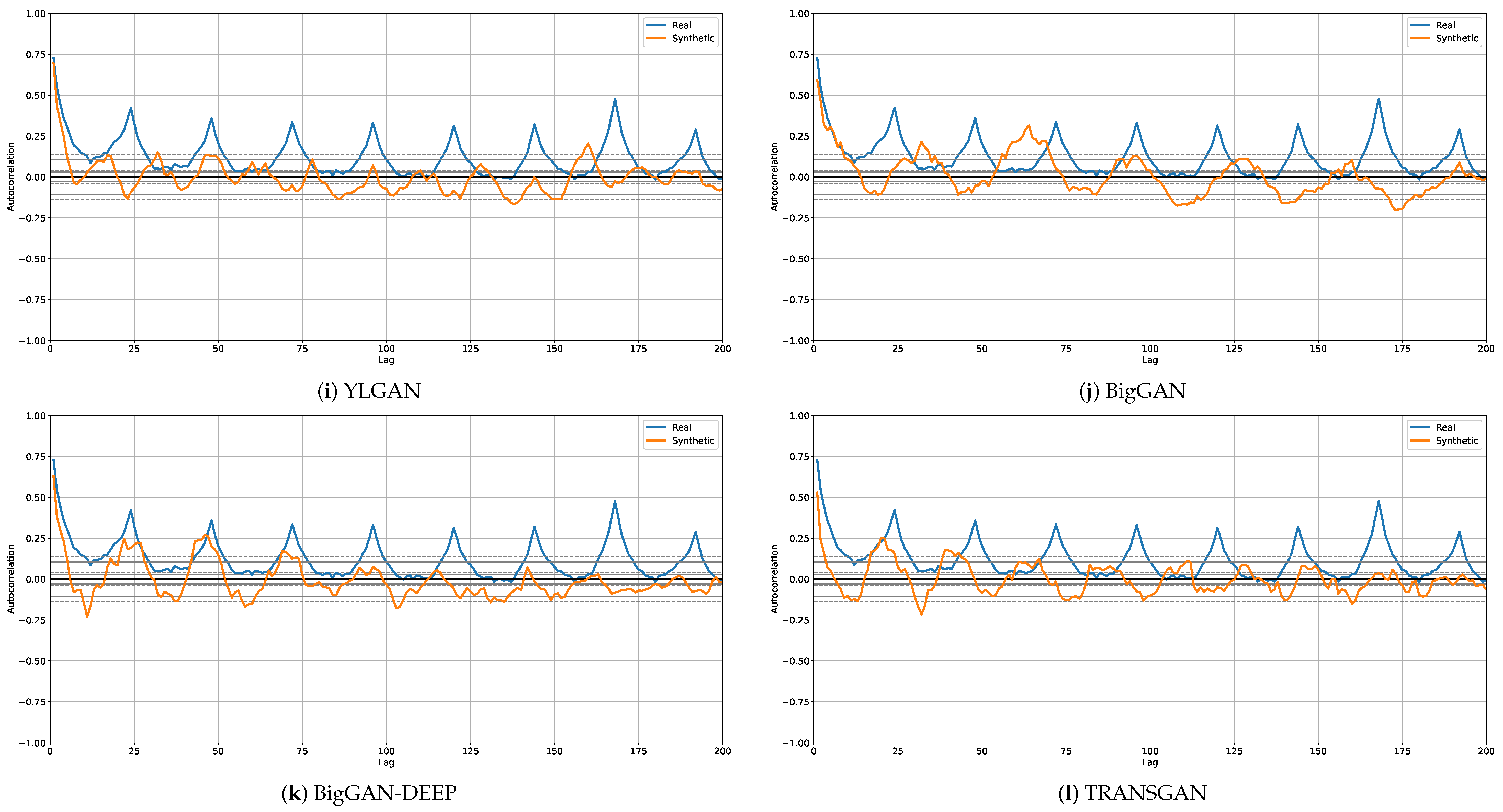
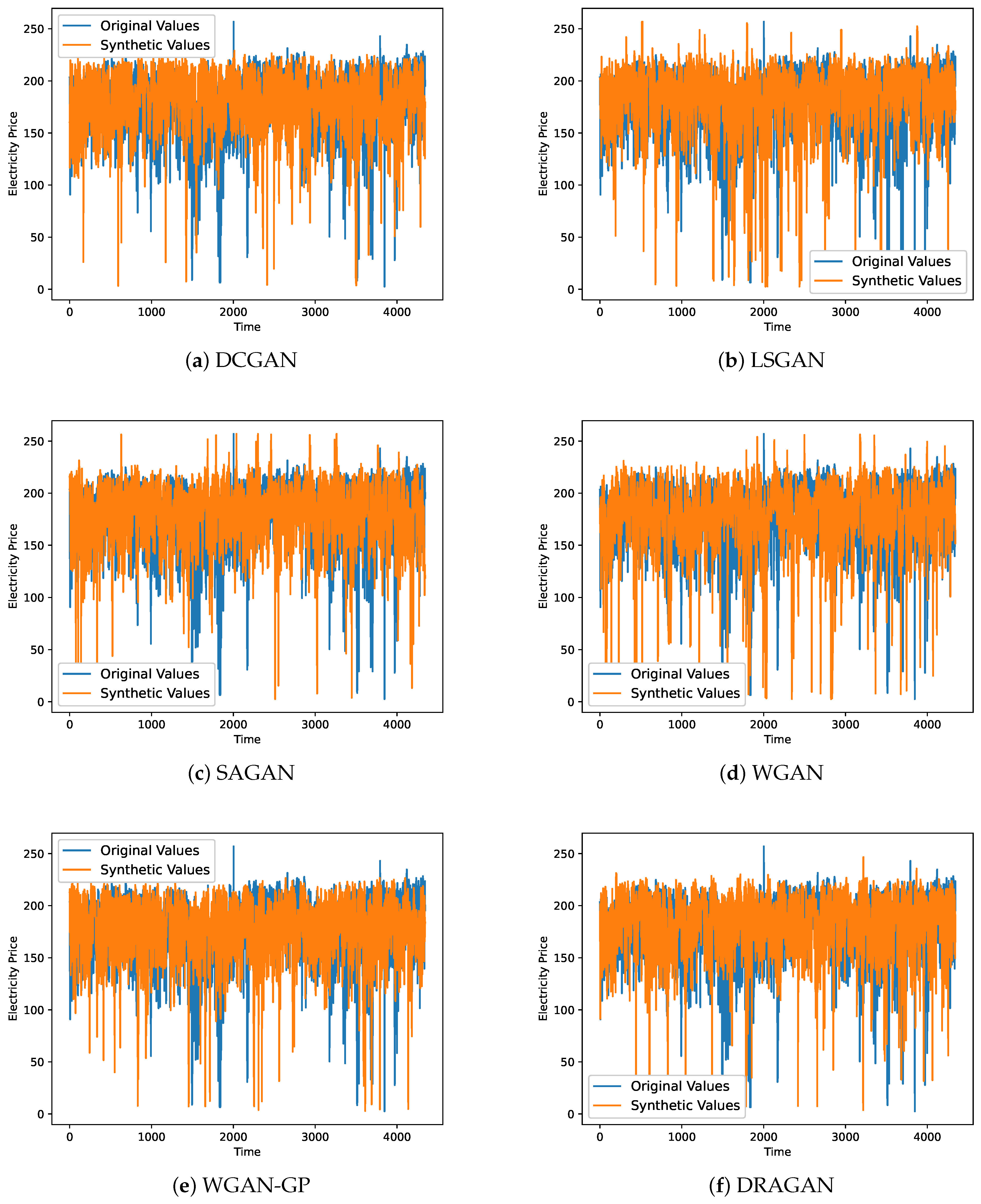
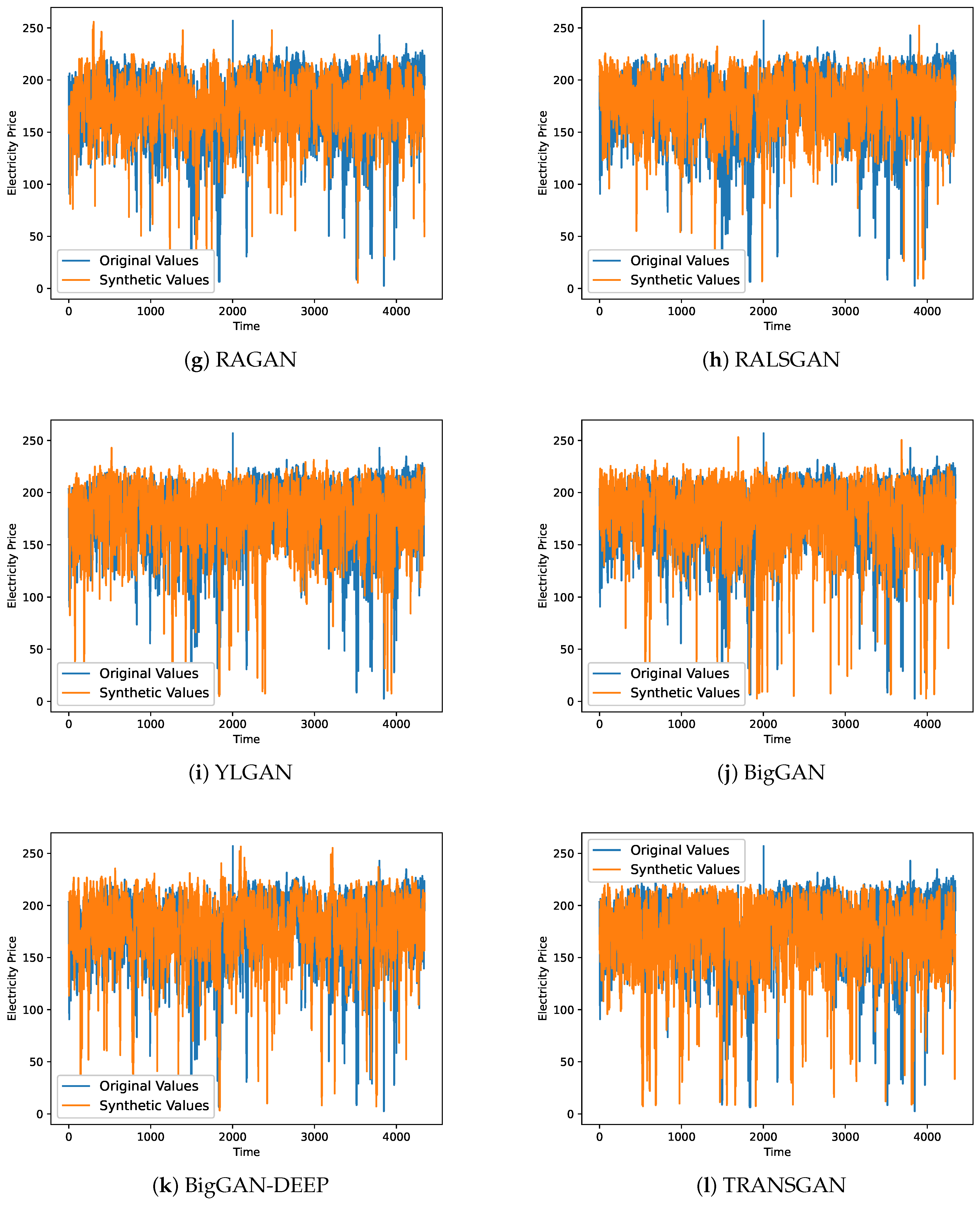
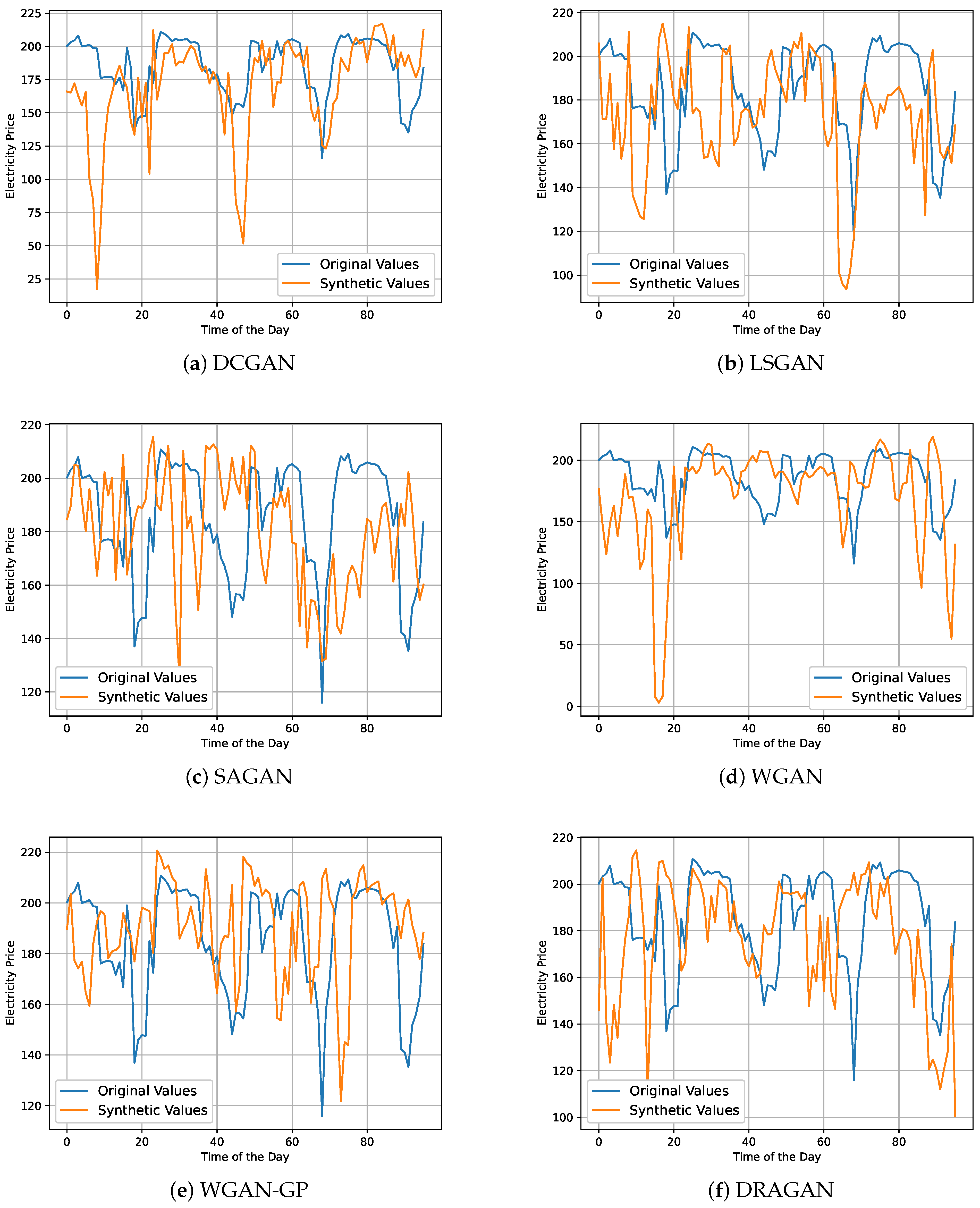
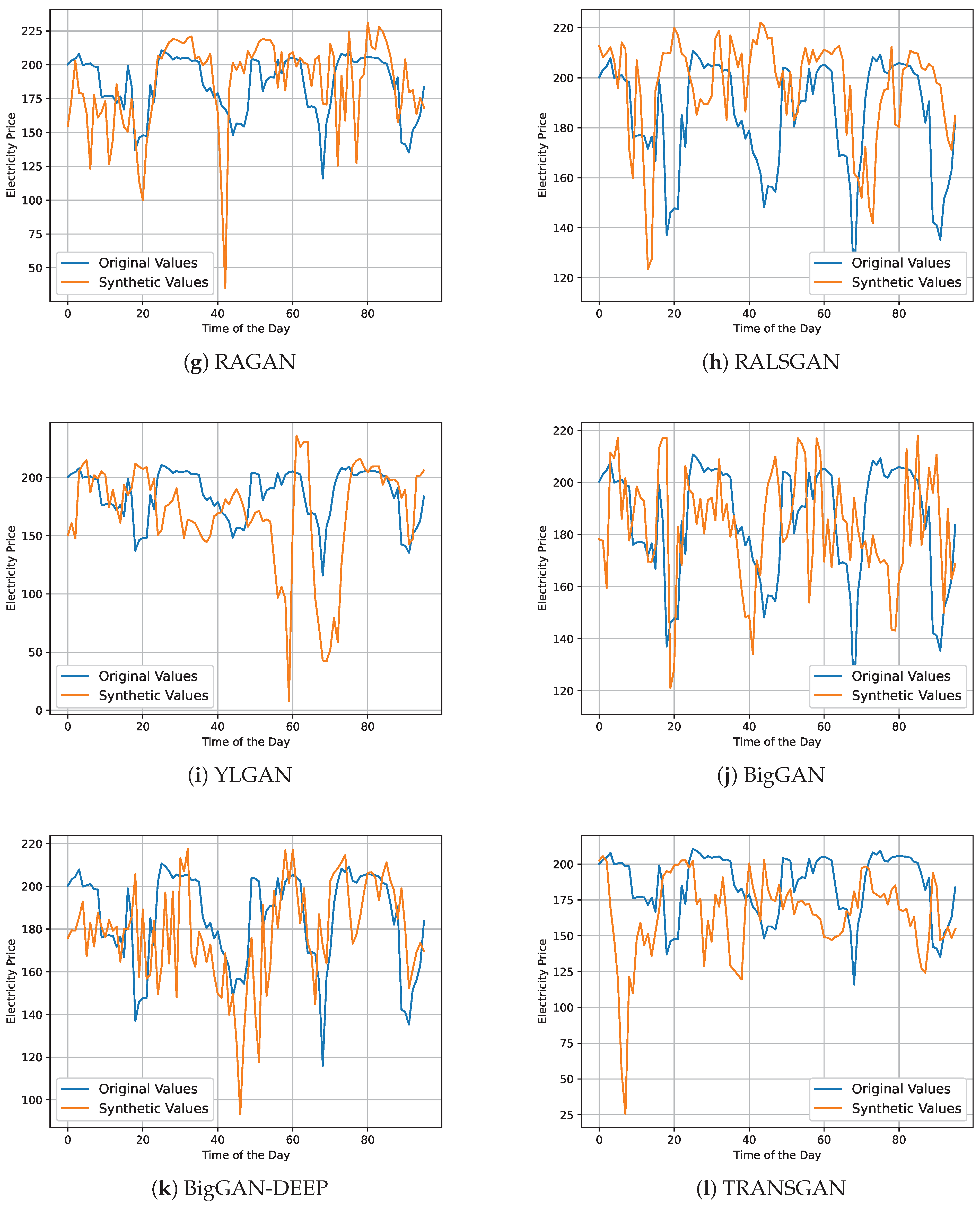
4.3. Qualitative Analysis
5. Conclusions
- Replication of complex dynamics: We conducted a comprehensive empirical analysis using diverse GAN architectures and demonstrated the ability of GANs to replicate the complex dynamics and statistical characteristics of electricity price data.
- Comprehensive performance evaluation: We leveraged a robust evaluation methodology comprising qualitative and quantitative techniques such as histograms, visual comparisons, ACF, KS statistics, and the ACE test. Further, we thoroughly assessed the performance and computational costs associated with various GAN architectures and provided valuable guidance to practitioners on utilizing synthetic data for strategy testing, risk model validation, and decision-making enhancement in the energy market, assessing the strengths and limitations of each GAN and offering practical guidance for their application in strategy testing, risk model validation, and decision-making in the energy market.
- Quality and utility of synthetic data: We generated high-quality synthetic electricity price data that can help address privacy concerns and data scarcity issues and enable market participants to overcome the limitations related to restricted access to real-world data, facilitating innovation and informed decision-making.
- Insights into computational efficiency: We highlighted significant variations in computational costs across the various GAN architectures; we showed that simpler GANs often offer a favorable balance between performance and computational efficiency compared to more complex models.
- Addressing privacy and data scarcity: We highlighted the potential of high-quality synthetic electricity price data to address privacy concerns and data scarcity issues, enabling market participants to overcome the limitations associated with restricted access to real-world data.
- Exploring novel GAN architectures, optimization techniques, and evaluation metrics to enhance the precision and robustness of synthetic data generation might increase the value of GANs;
- Investigating the applicability of synthetic data in other domains within the energy sector to broaden impact and stimulate interdisciplinary collaborations may increase modeling efficiency and decrease investment risk in energy markets.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. A Sample Code for GANs Training (BigGAN-DEEP)
| Listing A1. The Generator. |
 |
| Listing A2. The Discriminator. |
 |
| Listing A3. The Discriminator Loss. |
 |
| Listing A4. The Generator Loss. |
 |
| Listing A5. Optimizers. |
 |
| Listing A6. Training. |
 |
References
- Zhang, J.; Tan, Z.; Wei, Y. An adaptive hybrid model for short term electricity price forecasting. Appl. Energy 2020, 258, 114087. [Google Scholar] [CrossRef]
- Yang, Z.; Ce, L.; Lian, L. Electricity price forecasting by a hybrid model, combining wavelet transform, ARMA and kernel-based extreme learning machine methods. Appl. Energy 2017, 190, 291–305. [Google Scholar] [CrossRef]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2020, arXiv:1703.10593. [Google Scholar]
- Chen, Y.; Lai, Y.K.; Liu, Y.J. Cartoongan: Generative adversarial networks for photo cartoonization. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9465–9474. [Google Scholar]
- Jin, Y.; Zhang, J.; Li, M.; Tian, Y.; Zhu, H.; Fang, Z. Towards the automatic anime characters creation with generative adversarial networks. arXiv 2017, arXiv:1708.05509. [Google Scholar]
- Efimov, D.; Xu, D.; Kong, L.; Nefedov, A.; Anandakrishnan, A. Using generative adversarial networks to synthesize artificial financial datasets. arXiv 2020, arXiv:2002.02271. [Google Scholar]
- Yu, L.; Zhang, W.; Wang, J.; Yu, Y. SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient. arXiv 2017, arXiv:1609.05473. [Google Scholar]
- Li, J.; Chen, Z.; Cheng, L.; Liu, X. Energy data generation with Wasserstein deep convolutional generative adversarial networks. Energy 2022, 257, 124694. [Google Scholar] [CrossRef]
- Wang, Z.; Hong, T. Generating realistic building electrical load profiles through the Generative Adversarial Network (GAN). Energy Build. 2020, 224, 110299. [Google Scholar] [CrossRef]
- Yilmaz, B.; Korn, R. Synthetic demand data generation for individual electricity consumers: Generative Adversarial Networks (GANs). Energy AI 2022, 9, 100161. [Google Scholar] [CrossRef]
- Yilmaz, B. A scenario framework for electricity grid using Generative Adversarial Networks. Sustain. Energy Grids Netw. 2023, 36, 101157. [Google Scholar] [CrossRef]
- Yilmaz, B. Generative adversarial network for load data generation: Türkiye energy market case. Math. Model. Numer. Simul. Appl. 2023, 3, 141–158. [Google Scholar] [CrossRef]
- Wiese, M.; Knobloch, R.; Korn, R.; Kretschmer, P. Quant GANs: Deep generation of financial time series. Quant. Financ. 2020, 20, 1419–1440. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Lin, Y.; Sinha, A.; Wellman, M.P. Generating Realistic Stock Market Order Streams. arXiv 2020, arXiv:2006.04212. [Google Scholar] [CrossRef]
- Dwibedi, D.; Misra, I.; Hebert, M. Cut, paste and learn: Surprisingly easy synthesis for instance detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1301–1310. [Google Scholar] [CrossRef]
- Georgakis, G.; Mousavian, A.; Berg, A.C.; Kosecka, J. Synthesizing training data for object detection in indoor scenes. arXiv 2017, arXiv:1702.07836. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Networks. arXiv 2014, arXiv:1406.2661. [Google Scholar]
- de Souza, V.L.T.; Marques, B.A.D.; Batagelo, H.C.; Gois, J.P. A review on generative adversarial networks for image generation. Comput. Graph. 2023, 114, 13–25. [Google Scholar] [CrossRef]
- Wang, T. Research and Application Analysis of Correlative Optimization Algorithms for GAN. Highlights Sci. Eng. Technol. 2023, 57, 141–147. [Google Scholar] [CrossRef]
- Gui, J.; Sun, Z.; Wen, Y.; Tao, D.; Ye, J. A review on generative adversarial networks: Algorithms, theory, and applications. IEEE Trans. Knowl. Data Eng. 2021, 35, 3313–3332. [Google Scholar] [CrossRef]
- Tavse, S.; Varadarajan, V.; Bachute, M.; Gite, S.; Kotecha, K. A systematic literature review on applications of GAN-synthesized images for brain MRI. Future Internet 2022, 14, 351. [Google Scholar] [CrossRef]
- Yilmaz, B.; Korn, R. A Comprehensive guide to Generative Adversarial Networks (GANs) and application to individual electricity demand. Expert Syst. Appl. 2024, 250, 123851. [Google Scholar] [CrossRef]
- Uddin, K.; Jeong, T.H.; Oh, B.T. Counter-act against GAN-based attacks: A collaborative learning approach for anti-forensic detection. Appl. Soft Comput. 2024, 153, 111287. [Google Scholar] [CrossRef]
- Wiese, M.; Bai, L.; Wood, B.; Buehler, H. Deep Hedging: Learning to Simulate Equity Option Markets. arXiv 2019, arXiv:1911.01700. [Google Scholar]
- Yilmaz, B. Housing GANs: Deep Generation of Housing Market Data. Comput. Econ. 2023, 1–16. [Google Scholar] [CrossRef]
- van Rhijn, J.; Oosterlee, C.W.; Grzelak, L.A.; Liu, S. Monte carlo simulation of sdes using gans. Jpn. J. Ind. Appl. Math. 2023, 40, 1359–1390. [Google Scholar] [CrossRef]
- Wang, Z.; She, Q.; Ward, T.E. Generative adversarial networks in computer vision: A survey and taxonomy. ACM Comput. Surv. (CSUR) 2021, 54, 1–38. [Google Scholar] [CrossRef]
- Borji, A. Pros and cons of GAN evaluation measures: New developments. Comput. Vis. Image Underst. 2022, 215, 103329. [Google Scholar] [CrossRef]
- Borji, A. Pros and cons of gan evaluation measures. Comput. Vis. Image Underst. 2019, 179, 41–65. [Google Scholar] [CrossRef]
- Sutherland, D.J.; Tung, H.Y.; Strathmann, H.; De, S.; Ramdas, A.; Smola, A.; Gretton, A. Generative models and model criticism via optimized maximum mean discrepancy. arXiv 2016, arXiv:1611.04488. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training GANs. Adv. Neural Inf. Process. Syst. 2016, 29, 2234–2242. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. Adv. Neural Inf. Process. Syst. 2017, 30, 6629–6640. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Bryant, F.B.; Yarnold, P.R. Principal-components analysis and exploratory and confirmatory factor analysis. In Reading and Understanding Multivariate Statistics; American Psychological Association: Washington, DC, USA, 1995; pp. 99–136. [Google Scholar]
- Yoon, J.; Jarrett, D.; van der Schaar, M. Time-series Generative Adversarial Networks. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (Medical) Time Series Generation with Recurrent Conditional GANs. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Hanif, M.; Shahzad, M.K.; Mehmood, V.; Saleem, I. EPFG: Electricity price forecasting with enhanced Gans neural network. IETE J. Res. 2023, 69, 6473–6482. [Google Scholar] [CrossRef]
- Yuan, R.; Wang, B.; Mao, Z.; Watada, J. Multi-objective wind power scenario forecasting based on PG-GAN. Energy 2021, 226, 120379. [Google Scholar] [CrossRef]
- Demir, S.; Mincev, K.; Kok, K.; Paterakis, N.G. Data augmentation for time series regression: Applying transformations, autoencoders and adversarial networks to electricity price forecasting. Appl. Energy 2021, 304, 117695. [Google Scholar] [CrossRef]
- Cheng, T.; Li, X.; Li, Y. Hybrid deep learning techniques for providing incentive price in electricity market. Comput. Electr. Eng. 2022, 99, 107808. [Google Scholar] [CrossRef]
- Wang, X.; Li, F.; Zhao, J.; Olama, M.; Dong, J.; Shuai, H.; Kuruganti, T. Tri-level hybrid interval-stochastic optimal scheduling for flexible residential loads under GAN-assisted multiple uncertainties. Int. J. Electr. Power Energy Syst. 2023, 146, 108672. [Google Scholar] [CrossRef]
- Dimitriadis, C.N.; Tsimopoulos, E.G.; Georgiadis, M.C. A Review on the Complementarity Modelling in Competitive Electricity Markets. Energies 2021, 14, 7133. [Google Scholar] [CrossRef]
- Villani, C. Optimal Transport: Old and New; Springer: Berlin/Heidelberg, Germany, 2009; Volume 338. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. arXiv 2017, arXiv:1701.07875. [Google Scholar]
- Mao, X.; Li, Q.; Xie, H.; Lau, R.Y.K.; Wang, Z.; Smolley, S.P. Least Squares Generative Adversarial Networks. arXiv 2017, arXiv:1611.04076. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. arXiv 2018, arXiv:1805.08318. [Google Scholar]
- Jolicoeur-Martineau, A. The relativistic discriminator: A key element missing from standard GAN. arXiv 2018, arXiv:1807.00734. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Kodali, N.; Abernethy, J.; Hays, J.; Kira, Z. On convergence and stability of gans. arXiv 2017, arXiv:1705.07215. [Google Scholar]
- Brock, A.; Donahue, J.; Simonyan, K. Large Scale GAN Training for High Fidelity Natural Image Synthesis. arXiv 2018, arXiv:1809.11096. [Google Scholar]
- Daras, G.; Odena, A.; Zhang, H.; Dimakis, A.G. Your Local GAN: Designing Two Dimensional Local Attention Mechanisms for Generative Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zhang, Z.; Wu, M. Predicting real-time locational marginal prices: A gan-based approach. IEEE Trans. Power Syst. 2021, 37, 1286–1296. [Google Scholar] [CrossRef]
- Avkhimenia, V.; Weis, T.; Musilek, P. Generation of synthetic ampacity and electricity pool prices using generative adversarial networks. In Proceedings of the 2021 IEEE Electrical Power and Energy Conference (EPEC), Virtual, 22–31 October 2021; pp. 225–230. [Google Scholar]
- Dogariu, M.; Ştefan, L.D.; Boteanu, B.A.; Lamba, C.; Kim, B.; Ionescu, B. Generation of realistic synthetic financial time-series. Acm Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–27. [Google Scholar] [CrossRef]
- Meyer-Brandis, T.; Tankov, P. Multi-factor jump-diffusion models of electricity prices. Int. J. Theor. Appl. Financ. 2008, 11, 503–528. [Google Scholar] [CrossRef]
- Wunderlich, A.; Sklar, J. Data-driven modeling of noise time series with convolutional generative adversarial networks. Mach. Learn. Sci. Technol. 2023, 4, 035023. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017, arXiv:1412.6980. [Google Scholar]
- Chollet, F. Keras. GitHub. 2015. Available online: https://github.com/fchollet/keras (accessed on 13 May 2024).
- Hodges, J.L. The significance probability of the Smirnov two-sample test. Arkiv Mat. 1958, 3, 469–486. [Google Scholar] [CrossRef]

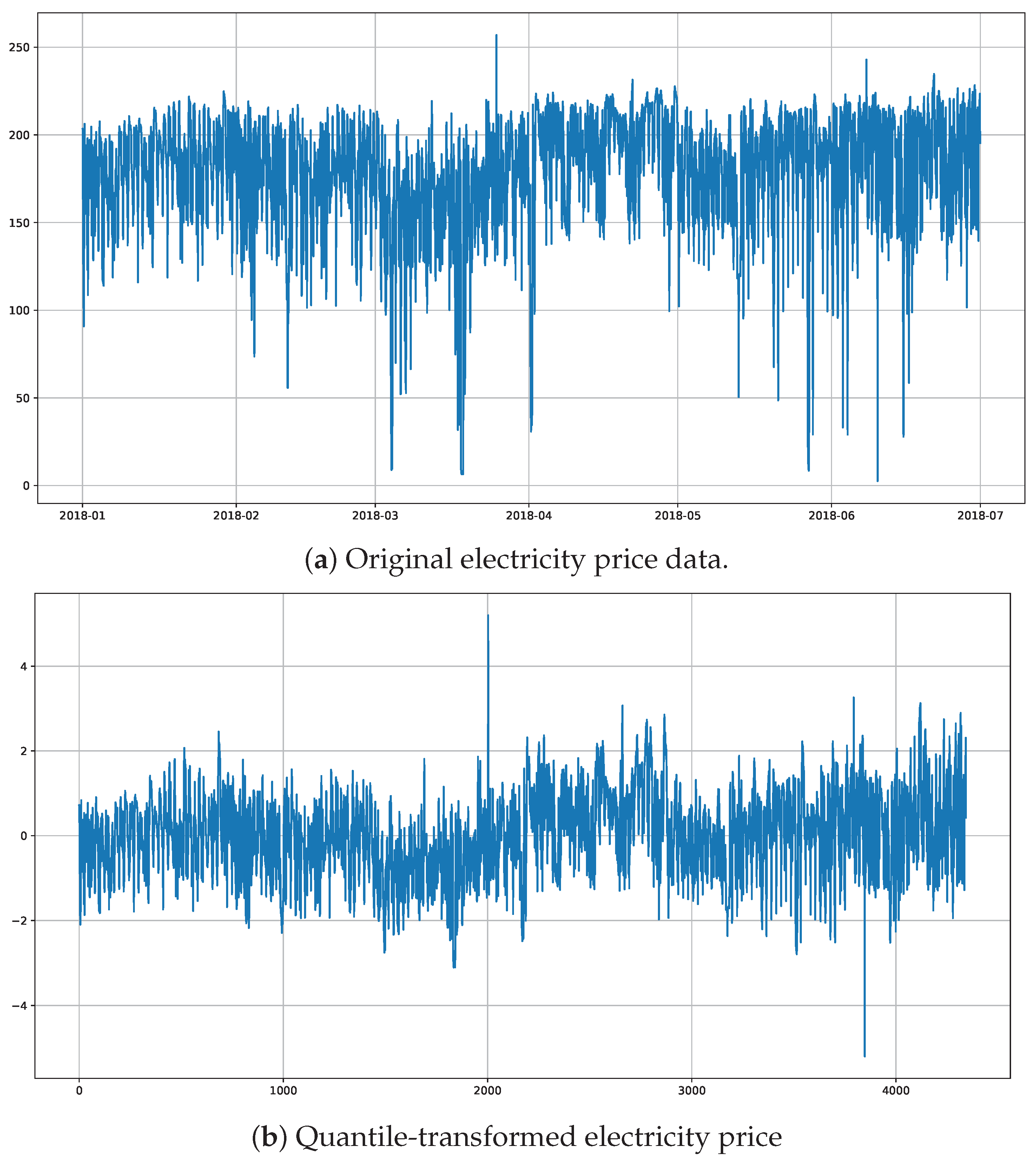
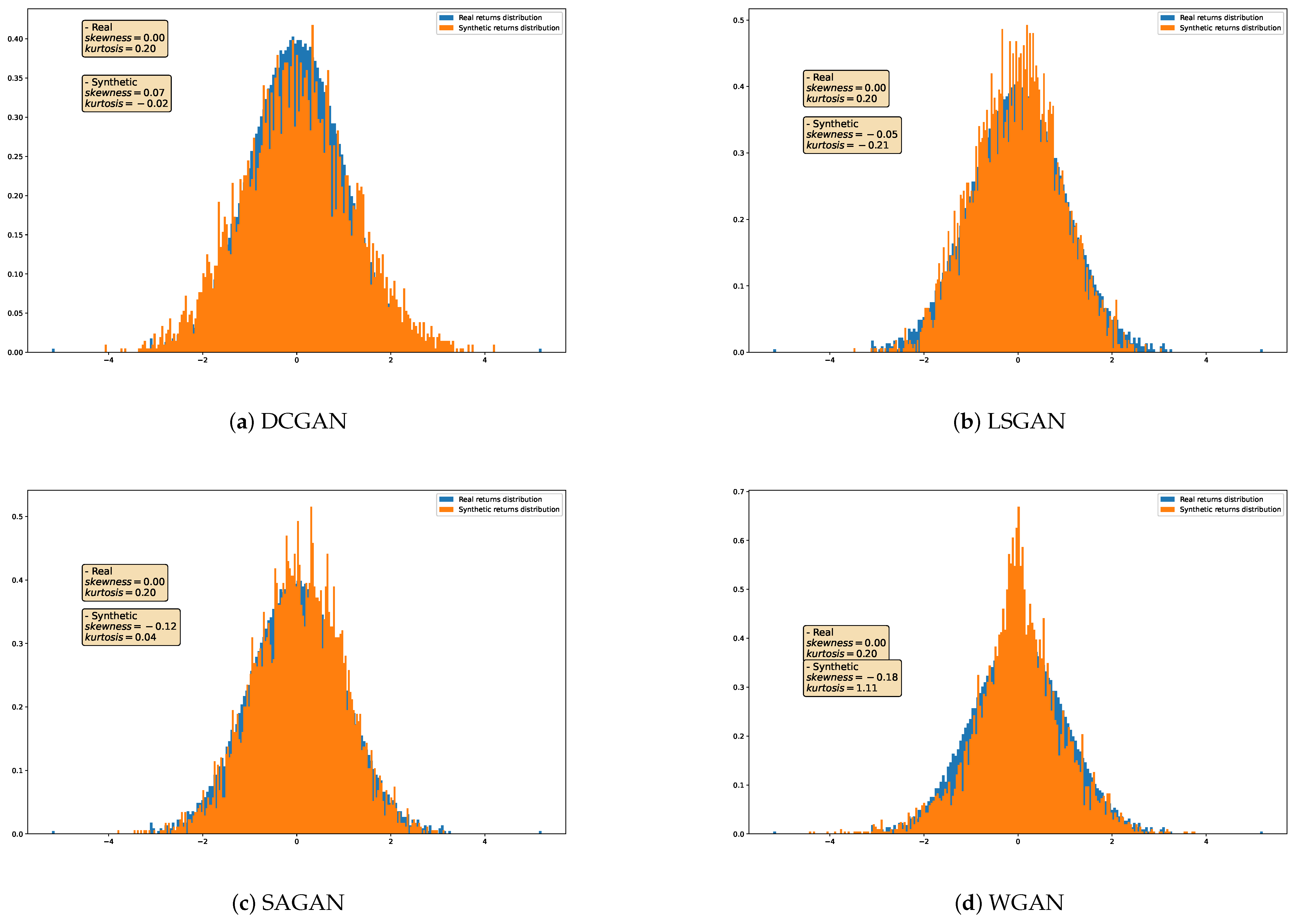
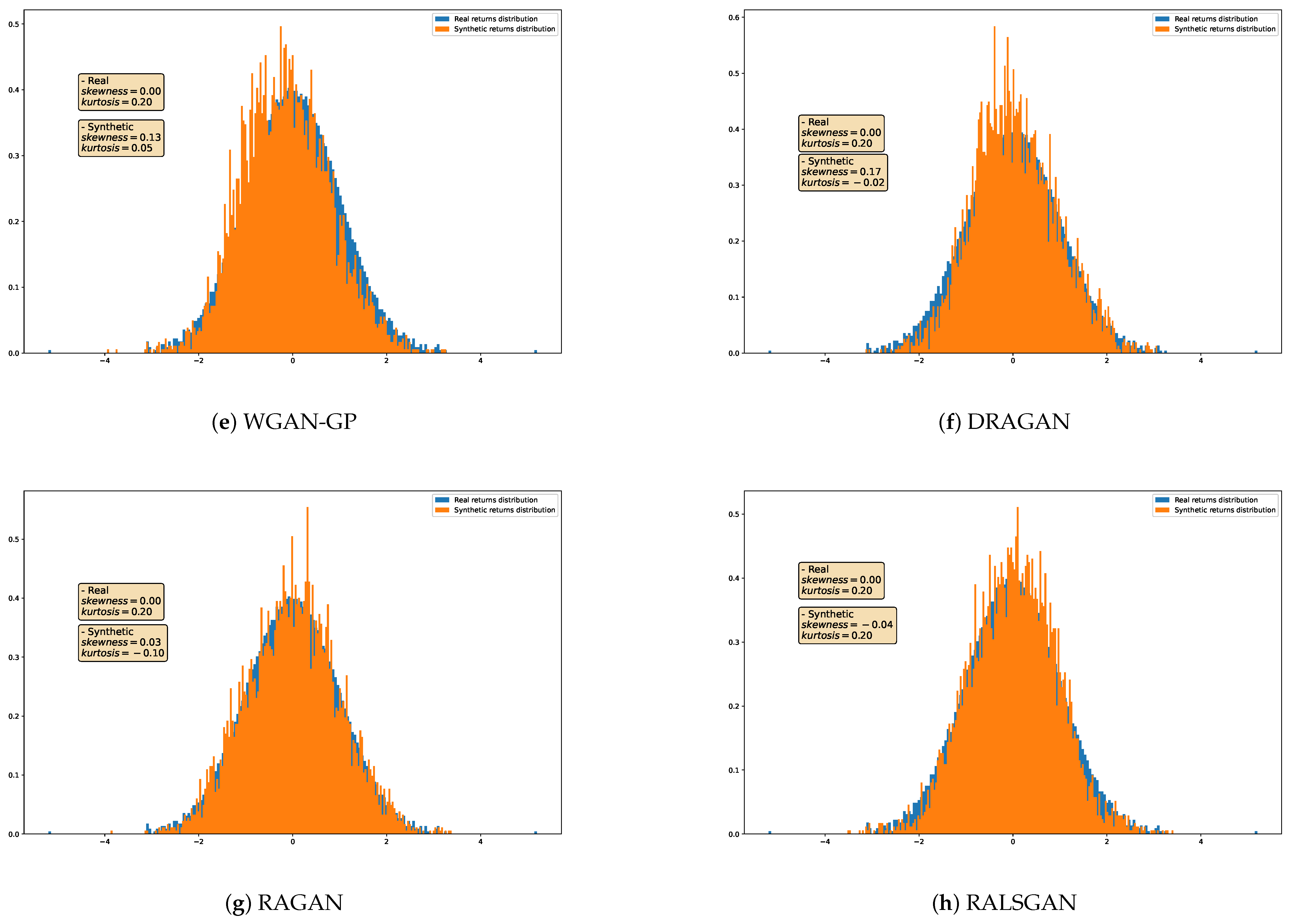
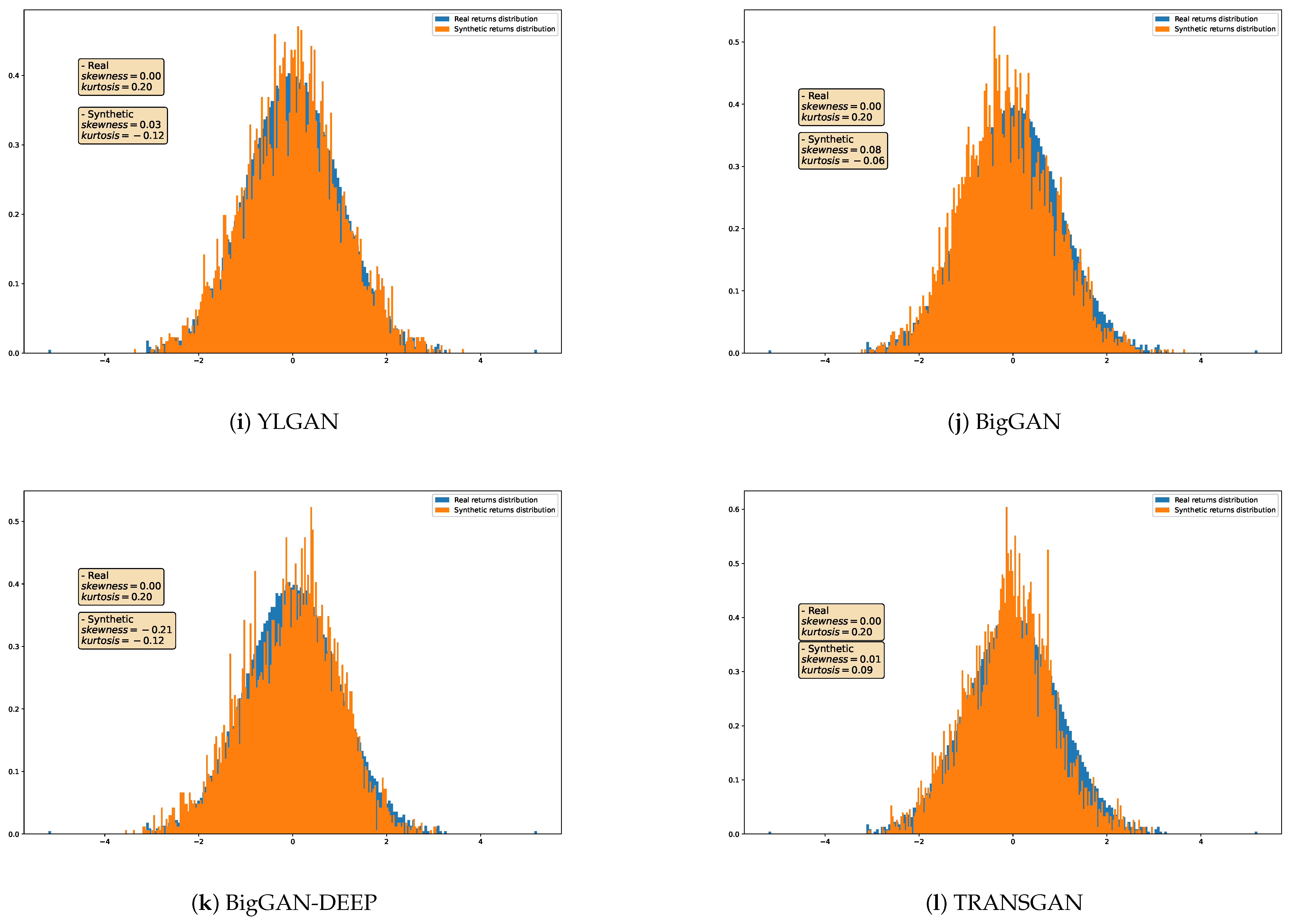


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GAN Type | Application Domain | Key Contributions | Main Outcomes |
|---|---|---|---|
| TimeGAN [36] | General time series | Introduces TimeGAN, a model that combines unsupervised adversarial training with supervised autoregression. | Demonstrates superior performance in generating realistic and diverse time series data. |
| QuantGAN [25] | Finance | Proposes a GAN model for financial time series, focusing on the generation of synthetic stock prices. | Shows that GAN-generated data can improve the performance of trading strategies. |
| RNN-GAN [37] | Healthcare | Develops RNN-GAN for generating realistic patient data to augment small medical datasets. | Generated data aids in enhancing the performance of predictive models in healthcare applications. |
| C-RNN-GAN [38] | Music | Introduces C-RNN-GAN for generating polyphonic music sequences. | Demonstrates the ability to generate coherent and diverse musical pieces. |
| RCGAN, TimeGAN, CWGAN, RCWGAN [11] | Energy | Use GANs to generate synthetic electricity consumption data. | Efficient electricity consumption data generation. |
| RCGAN, TimeGAN, CWGAN, RCWGAN [12] | Energy | Introduces new evaluation metrics. | An efficient evaluation metric for GANs in time series applications. |
| Original GAN [39] | Energy | Estimates electricity price prediction. | The classification for probabilistic electricity price. |
| PG-GAN [40] | Energy | Designed wind power and point forecast scenarios. | PG-GAN enriches the details of wind power scenarios. |
| WDCGAN [9] | Energy | Proposed an improved GAN. | Produce realistic data similar to the original data. |
| WGANGP [41] | Energy | Proposed a novel time series augmentation method, using generative models. | Reduces significantly a majority of forecast errors. |
| GAN-WT [42] | Energy | Introducing a swarm-based GAN deep learning. | High prediction accuracy. |
| Original GAN [43] | Energy | Generating uncertain PV solar scenarios. | Presents the power and effectiveness of GANs in PV scenario generation. |
| Min | Max | |||
|---|---|---|---|---|
| Original | 178.130 | 33.096 | 2.530 | 256.930 |
| Transformed | 0.000 | 1.004 | −5.199 | 5.199 |
| Max | Min | KS-stat | p-val | ACE | CC (min) | |||
|---|---|---|---|---|---|---|---|---|
| DCGAN | 182.30 | 28.39 | 253.18 | 16.99 | 0.023 | 0.19 | −0.004 | 24.95 |
| LSGAN | 184.09 | 34.09 | 256.92 | 2.60 | 0.030 | 0.38 | −0.012 | 23.64 |
| SAGAN | 182.25 | 29.36 | 255.26 | 4.73 | 0.041 | 0.49 | −0.021 | 40.04 |
| WGAN | 178.41 | 32.99 | 256.88 | 2.55 | 0.045 | 0.91 | 0.002 | 24.04 |
| WGAN-GP | 176.96 | 30.78 | 225.32 | 4.98 | 0.043 | 0.75 | −0.029 | 24.64 |
| DRAGAN | 181.86 | 28.22 | 254.25 | 8.64 | 0.038 | 0.27 | 0.001 | 48.84 |
| RAGAN | 177.24 | 30.37 | 256.90 | 7.16 | 0.011 | 0.58 | 0.011 | 25.84 |
| RALSGAN | 178.55 | 31.05 | 230.74 | 3.42 | 0.036 | 0.63 | 0.015 | 25.23 |
| YLGAN | 179.53 | 31.21 | 256.55 | 6.70 | 0.027 | 0.76 | −0.002 | 44.49 |
| BigGAN | 180.45 | 30.62 | 249.72 | 3.77 | 0.019 | 0.43 | 0.008 | 52.03 |
| BigGAN-DEEP | 178.04 | 32.15 | 256.93 | 3.11 | 0.043 | 0.63 | −0.042 | 90.69 |
| TRANSGAN | 175.65 | 34.71 | 226.39 | 6.96 | 0.048 | 0.15 | −0.039 | 159.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yilmaz, B.; Laudagé, C.; Korn, R.; Desmettre, S. Electricity GANs: Generative Adversarial Networks for Electricity Price Scenario Generation. Commodities 2024, 3, 254-280. https://doi.org/10.3390/commodities3030016
Yilmaz B, Laudagé C, Korn R, Desmettre S. Electricity GANs: Generative Adversarial Networks for Electricity Price Scenario Generation. Commodities. 2024; 3(3):254-280. https://doi.org/10.3390/commodities3030016
Chicago/Turabian StyleYilmaz, Bilgi, Christian Laudagé, Ralf Korn, and Sascha Desmettre. 2024. "Electricity GANs: Generative Adversarial Networks for Electricity Price Scenario Generation" Commodities 3, no. 3: 254-280. https://doi.org/10.3390/commodities3030016
APA StyleYilmaz, B., Laudagé, C., Korn, R., & Desmettre, S. (2024). Electricity GANs: Generative Adversarial Networks for Electricity Price Scenario Generation. Commodities, 3(3), 254-280. https://doi.org/10.3390/commodities3030016