Abstract
The ability to automate and personalize the recommendation of multimedia contents to consumers has been gaining significant attention recently. The burgeoning demand for digitization and automation of formerly analog communication processes has caught the attention of researchers and professionals alike. In light of the recent interest and anticipated transition to fully autonomous vehicles, this study proposes a text–image embedding method recommender system for the optimization of personalized multimedia content for in-vehicle infotainment. This study leverages existing pre-trained text embedding models and pre-trained image feature extraction methods. Previous research to date has focused mainly on textual-only or image-only analyses. By employing similarity measurements, this study demonstrates how recommendation of the most relevant multimedia content to consumers is enhanced through text–image embedding.
1. Introduction
In recent years, there has been rising interest and rapid developments in the digitization and algorithmic automation of processes formerly performed by humans [1]. Likewise, interest in recommender systems, which aims to make optimal predictions for its users based on pre-existing information, as well as artificial intelligence (AI) algorithms have been on the rise. Despite some resistance to giving full agency to machines, attention to and demand for technologically mediated communication and automating communication processes has been growing for their efficiency and accuracy [2]. To illustrate this, the challenges of personalizing promotional messages and targeting specific consumers and markets may be alleviated by a recommender system that automatically detects consumers’ interests using public social media data or cookies [2]. The ability to show personalized advertisements to targeted consumer groups has been known to enhance message relevance to consumers while helping brands to stand out from the cluttered online environment [2]. Whereas most research to date focuses on recommender systems using textual analysis or image analysis separately [3,4], this paper examines both textual data and images simultaneously and proposes the automation of optimal multimedia content recommendation in the context of in-vehicle infotainment for self-driving cars.
Lately, autonomous vehicles and their technological capacities have garnered much attention. Autonomous vehicles are defined as vehicles that recognize their environment and operate without driver intervention. Autonomous vehicles are also described as driverless, self-driving, unmanned, or robotic vehicles. With most autonomous vehicle technologies nearing commercialization [5,6], this study considers a recommender system for personalized in-vehicle infotainment for drivers who will no longer be preoccupied with the task of driving.
Autonomous vehicles are classified with Automated Driving Systems (ADS) to indicate the various levels of driving automation from no automation (Level 0) to full automation (Level 5). Level 0 to 3 require direct human driving while levels 4 and 5 do not require direct human driving [7,8,9]. While several automobile manufacturers predict that fully autonomous vehicles that do not require human intervention to drive will take more than a decade to be developed [10], there are vehicles on the road today at levels 2 and 3 with autopilot systems that are autonomous, requiring minimal human intervention [11]. However, in anticipation of the fully automated (level 5) autonomous vehicles, numerous automobile manufacturers have showcased designs with large displays, such as tablets and full dash screens, to enhance user experience of in-vehicle entertainment systems. Such interior designs of an autonomous vehicle with large displays were announced at the 2024 Consumer Electronics Show (CES) and are expected to be commercialized in the future [12]. Defined as “infotainment”, a compound word of information and entertainment, an infotainment system is an integrated multimedia system that most commonly provides features such as navigation, communication, vehicle information as well as entertainment (i.e., radio, streaming, and media systems) on a display or tablet that is designed to enhance the driving experience and provide convenience to the driver. With fully automated cars, the authors anticipate that significant focus will be placed on improving the infotainment system to elevate in-vehicle entertainment experiences. Therefore, in anticipation of autonomous vehicles nearing level 5 of ADS in the foreseeable future, this study aims to conduct research on the personalization of in-vehicle infotainment systems, specifically the optimization of multimedia content for drivers who are freed from the task of driving and navigating. This research is timely, as fully autonomous vehicles have not been commercialized yet and research on the recommendation of multimedia content in an autonomous vehicle environment is limited.
Existing research on recommending multimedia content has been conducted by embedding text and images individually, converting them into vectors, and comparing the vectors [13,14,15]. Rather than separating text and images, using texts and images together not only allows the utilization of all available information but improved recommendation results can also be expected. While current deep learning techniques are showing improved performances, they are growing increasingly complex with deeper architectures and larger computational demands, which requires not only significant computational resources but also time. Consequently, it is important to consider the purpose and expected outcomes when designing deep learning models.
Therefore, in this paper, we aim to achieve better results with simpler architectures and methods. This paper proposes a text–image embedding method where text and images are first vectorized using existing pre-trained text embedding models and image feature extraction models, and then combined and dimensionally reduced. By utilizing pre-trained models, in-vehicle systems with limited computational resources can achieve faster deployment, improved response times, and enhanced efficiency. This approach enables significant performance gains without the need to design new models or conduct extensive computations involving deep architectures. Additionally, we compare the performance of several pre-trained text embedding models and text–image embedding models. Then, the performance between the two models, cases where only text is used versus when texts and images are used together, are compared. The comparison demonstrates that performance is better when text and images are used together and the proposed model in this paper is most suitable when recommending personalized multimedia content.
In the following section, we outline previous methods that use texts and images to recommend multimedia as well as existing text embedding methods and image feature extraction methods. Section 3 describes the proposed text–image embedding method using several pre-trained models. Section 4 describes the proposed experiment and Section 5 provides a conclusion with a discussion of the findings and future research directions.
2. Related Works
2.1. Multimedia Recommendation Using Text and Image Embedding
The multimedia recommendation method leveraging text and image embedding involves vectorizing data to represent meaningful relationships and correlations between vectors [13,14,15]. In recommendation models based on text embedding, selecting an effective embedding method is critical for improving performance. Traditional heterogeneous embedding methods rely on higher-order Markov chains. However, Markov chains cannot utilize stationary distribution because of limitations in deep architecture due to their computational complexity, extensive resource demands, and time-consuming processes. To address these challenges, recent research has proposed a heterogeneous personalized spacey random walk strategy that bypasses the need for Markov chains, offering a more efficient alternative [13].
In research on methods for combining text and image vectors, one approach involves training text-conditional embedding with images [14]. This method expresses image characteristics as edges, enabling each characteristic to be effectively represented through text-conditional embedding. By aligning image characteristics with textual descriptions, this process allows the semantic characteristics of an image to be identified and interpreted within a textual context.
Additionally, research on combining text and image vectors includes creating a shared embedding space by processing both modalities through a nonlinear layer. This layer consists of an input-> ReLU -> Weight -> L2-Norm, applied separately to text and images [15]. This approach enhances the accuracy of image-to-text and text-to-image searches, improving cross-modal search performance.
Previous research has explored reducing the computational demands of embedding techniques, though most of these efforts focus solely on text-based information [14]. While there have been studies demonstrating performance improvements through the combined use of text and image embeddings, they often overlook the issue of computational complexity introduced by deeper models or new architectural layers [14,15]. Therefore, this paper proposes a text–image embedding method that leverages pre-trained models to mitigate the computation burden and complexity typically associated with deep learning architectures.
2.2. Text Embedding
Text embedding is a method for converting natural language into a format that computers can efficiently process and understand. Typically, words or sentences are represented as vectors, with various methods designed to capture the meaning or relationship between texts effectively.
Sent2Vec extends the principles of Word2Vec by embedding entire sentences rather than individual words [16]. In Sent2Vec, the window size, which in Word2Vec refers to the number of words in an entire sentence, is adjusted to cover the entire sentence, thus generating a vector representation for each sentence [17].
Universal Sentence Encoder addresses the issue of performance degradation in Natural Language Processing (NLP) caused by limited datasets. By utilizing transfer learning, Universal Sentence Encoder significantly enhances performance across various NLP tasks. Universal Sentence Encoder employs two core models: the Transformer and the Deep Averaging Network (DAN). While the Transformer model offers high accuracy, it requires substantial computational resources. In contrast, the DAN model is more resource-efficient, though with slightly lower accuracy. The Universal Sentence Encoder demonstrated that sentence-level embeddings outperform word-level embeddings, making it a valuable tool for NLP tasks. [18].
Bidirectional Encoder Representations from Transformers (BERT) shares a similar goal with the Universal Sentence Encoder: improving NLP performance when working with limited text datasets through transfer learning. Built on the Transformer architecture [19], BERT is known for its superior performance across a wide range of applications. Unlike earlier models that processed texts in a unidirectional manner, BERT uses a bidirectional approach, enabling it to understand sentence contexts more comprehensively. BERT’s architecture includes two main components. Masked Language Model (MLM) predicts masked words in a sentence to understand contextual relationships by converting parts of words in sentences into Mask tokens. Next Sentence Prediction (NSP) trains the model to determine the correct sequential relationship between sentences [20].
The Robustly Optimized BERT Approach (RoBERTa) further enhances BERT’s performance by optimizing the hyperparameters and increasing dataset size. Since BERT’s introduction, numerous various models have been developed, but RoBERTa has been proven to match or exceed the performance of many of these subsequent models, demonstrating its robustness and efficiency in NLP tasks [21].
2.3. Image Feature Extraction
Image feature extraction is a method that enables computers to efficiently process and interpret images, similar to how text embedding works for natural language. When image features are accurately extracted, they serve as representative values for the image, effectively encoding its essential characteristics.
EfficientNet focuses on Model Scaling, introducing a comprehensive approach that adjusts the model size through width, depth, and resolution scaling. Width scaling modifies the convolutional filters, depth scaling adjusts the number of layers, and resolution scaling alters the input image resolution.
While ResNet [22] primarily addresses depth scaling, and MobileNet [23] focuses on width scaling, EfficientNet optimizes all three dimensions of width, depth, and resolution simultaneously, resulting in superior performance [24].
Xception builds on the Inception v3 model [25] by refining the separation of channel-wise and spatial correlations, offering a more precise architecture for image feature extraction [26].
NASNetLarge is based on Neural Architecture Search (NAS) [27], which leverages reinforcement training to design optimal deep learning architectures. NAS employs 800 top-of-the-line GPUs, requiring nearly a month to train even on a relatively small dataset like CIFAR-10 (32 × 32 resolution). When dealing with larger and more diverse image classes, the computational time and resource demands increase exponentially. NASNet addresses this challenge by focusing on CNN architecture search for image classification, significantly reducing resource requirements and training time [28].
DenseNet introduces a densely connected CNN architecture via DenseBlock, where each layer is directly connected to every subsequent layer. Unlike ResNet [22] which adds feature maps, DensNet concatenates them, leading to enhanced performance and efficiency [29].
3. Text–Image Embedding Using Pre-Trained Models
This section outlines the text–image embedding and multimedia recommendation methods leveraging pre-trained models. The target for multimedia recommendations include content from video platforms such as YouTube, Netflix, Amazon Prime Video, etc. In this study, movie plots and movie posters are used as the textual and visual inputs, respectively. Text and image features are extracted using pre-trained sentence embedding models and image extraction models.
We compare the performance of various pre-trained text embedding and text–image embedding models to identify the most effective approach for multimedia recommendations. The proposed method demonstrates superior performance in recommending multimedia content.
The pre-trained models used for text embedding include Sent2Vec, Universal Sentence Encoder, BERT, and RoBERTa, while models for image feature extraction include Xception, DenseNet, NASNetLarge, and DenseNet. Since the output vector dimensions vary across pre-trained models, an additional layer is added at the end of each pre-trained image feature extraction model to standardize the output dimensions.
To combine text and image vectors, the output dimensions are aligned in the final layer of the pre-trained models, and a vector product operation is performed, resulting in a high-dimensional vector. This high-dimensional vector is then reduced to a two-dimensional space using T-Stochastic Nearest Neighbor Embedding (TSNE) to preserve the neighborhood structure [30]. The similarity between the image–text embedding vectors for each movie and the user’s query embedding is then measured to recommend the most relevant multimedia content.
In Section 3.1, this paper details the pre-trained models used for text embedding. In Section 3.2, we discuss the pre-trained models employed for image feature extraction.
3.1. Text Embedding
In this study, the pre-trained models used for text embedding are Sent2Vec, Universal Sentence Encoder, BERT, and RoBERTa. Each of these models is widely recognized for its effectiveness in sentence embedding.
Sent2Vec [17] builds Word2Vec [13], embedding entire sentences rather than individual words. While Word2Vec uses a configurable window size, Sent2Vec fixes the window size to encompass all words in a sentence, allowing for sentence-level vectorization.
Universal Sentence Encoder [18] introduces an Encoder designed to embed sentences across multiple natural languages. Given the limited availability of large datasets in NLP, transfer learning has become essential for performance improvements.
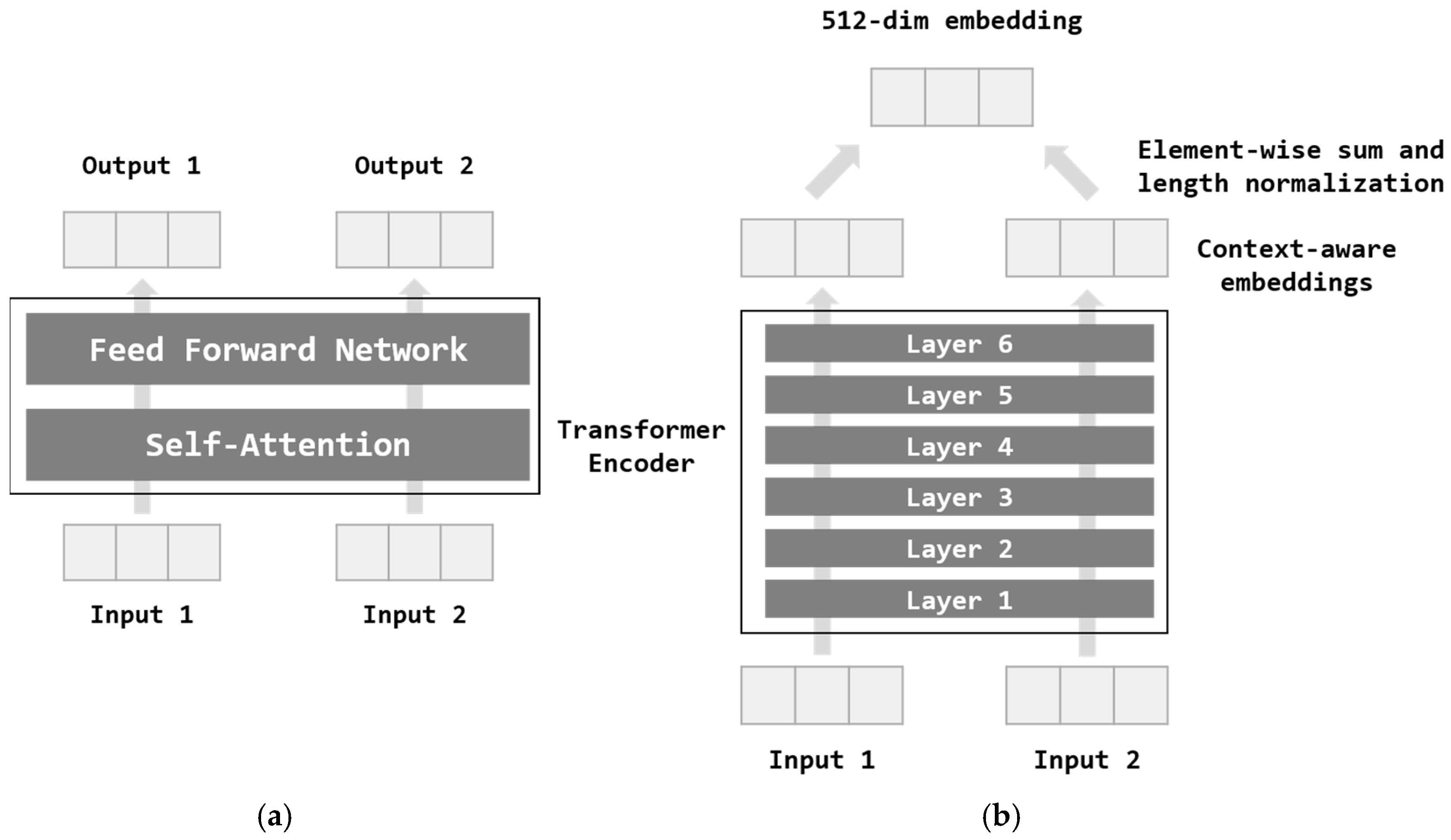
Figure 1 illustrates the architecture of the Transformer used in the Universal Sentence Encoder [18], which comprises six layers designed to capture contextual relationships within sentences. Each Transformer Encoder Layer, depicted in Figure 1a, integrates two key components: a self-attention mechanism and a feed-forward network. The self-attention mechanism processes each word by generating a context-aware representation, considering both word order and surrounding context. This allows the model to understand the relationships between words within the broader sentence structure. The output is then refined through the feed-forward network. The final output is a 512-dim sentence embedding, ensuring consistent vector length across different inputs. The complete Transformer Encoder architecture is shown in Figure 1b.
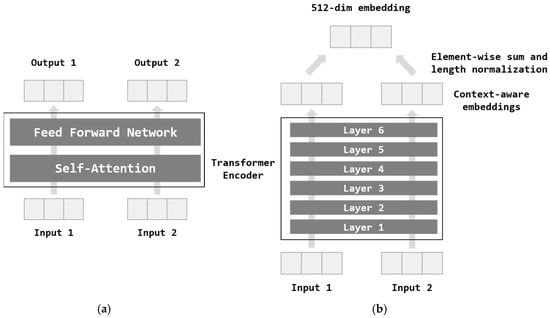
Figure 1.
Transformer architecture of the Universal Sentence Encoder. (a) Transformer encoder layer, and (b) Transformer encoder.
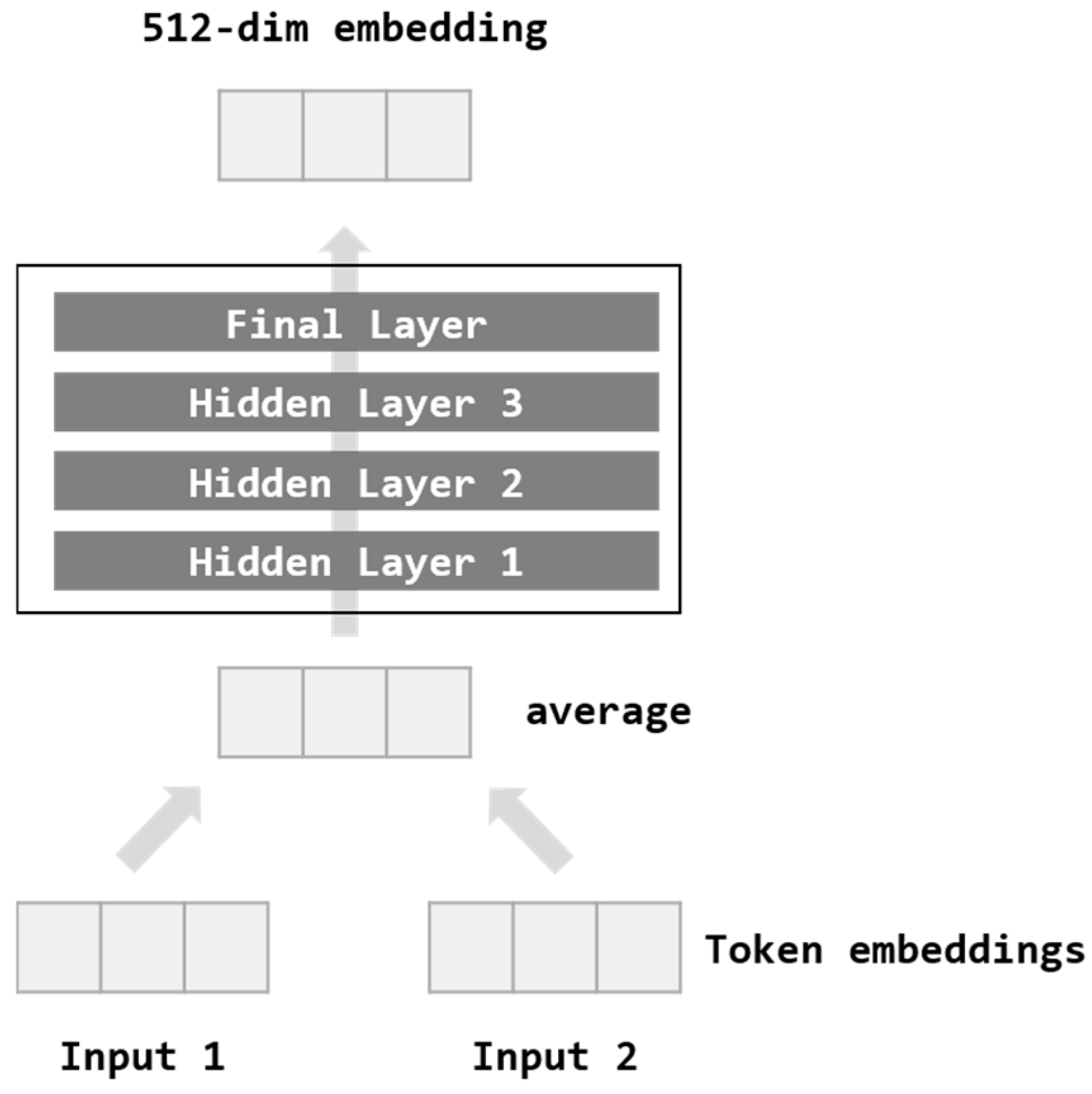
Figure 2 shows the Deep Averaging Network (DAN) model. The input tokenizes the words of the sentence into bi-grams. Each word is averaged to create a vector and passes through four feed-forward DNN structures. Then, 512-dim embedding is obtained as output.
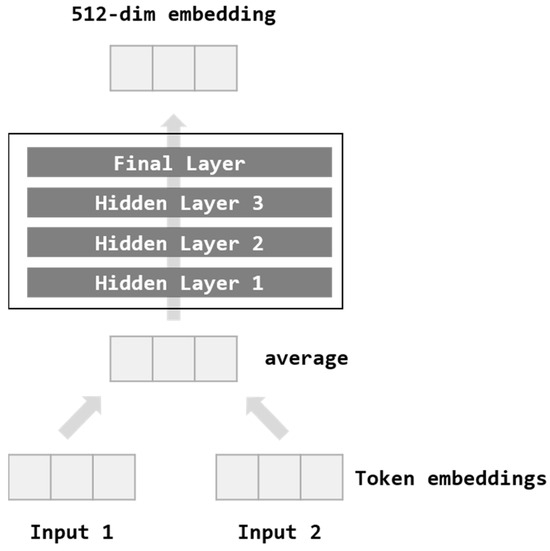
Figure 2.
Deep Averaging Network (DAN) architecture of the Universal Sentence Encoder.
Universal Sentence Encoder’s Transformer model and DAN model are different in time complexity and performance. While the Transformer model has excellent accuracy, it takes a significant amount of time and requires much more computing resources due to its complex architecture. On the other hand, since the DAN model has a relatively simple configuration, it takes less time and computational resources and has slightly lower accuracy.
In this paper, transfer learning was not performed, and only pre-trained models are used. Therefore, because utilized time and computational resources are considerably less, sentence embedding is performed using the Transformer model with excellent performance.
The goal of BERT [20] is similar to that of Universal Sentence Embedding [18]. BERT is a model used for pre-training and transfer learning to improve performance degradation due to the lack of textual data in NLP work. BERT embeds sentences through token embedding, segment embedding, and position embedding in the input step. Through token embedding, the beginning and the end of the sentence are distinguished through a special token. Segment embedding marks the number of sentences in each word. Position embedding marks the position of each token by the method used in the transformer [18]. BERT uses two unsupervised models for sentence embedding: Masked Language Model and Next Sentence Prediction.
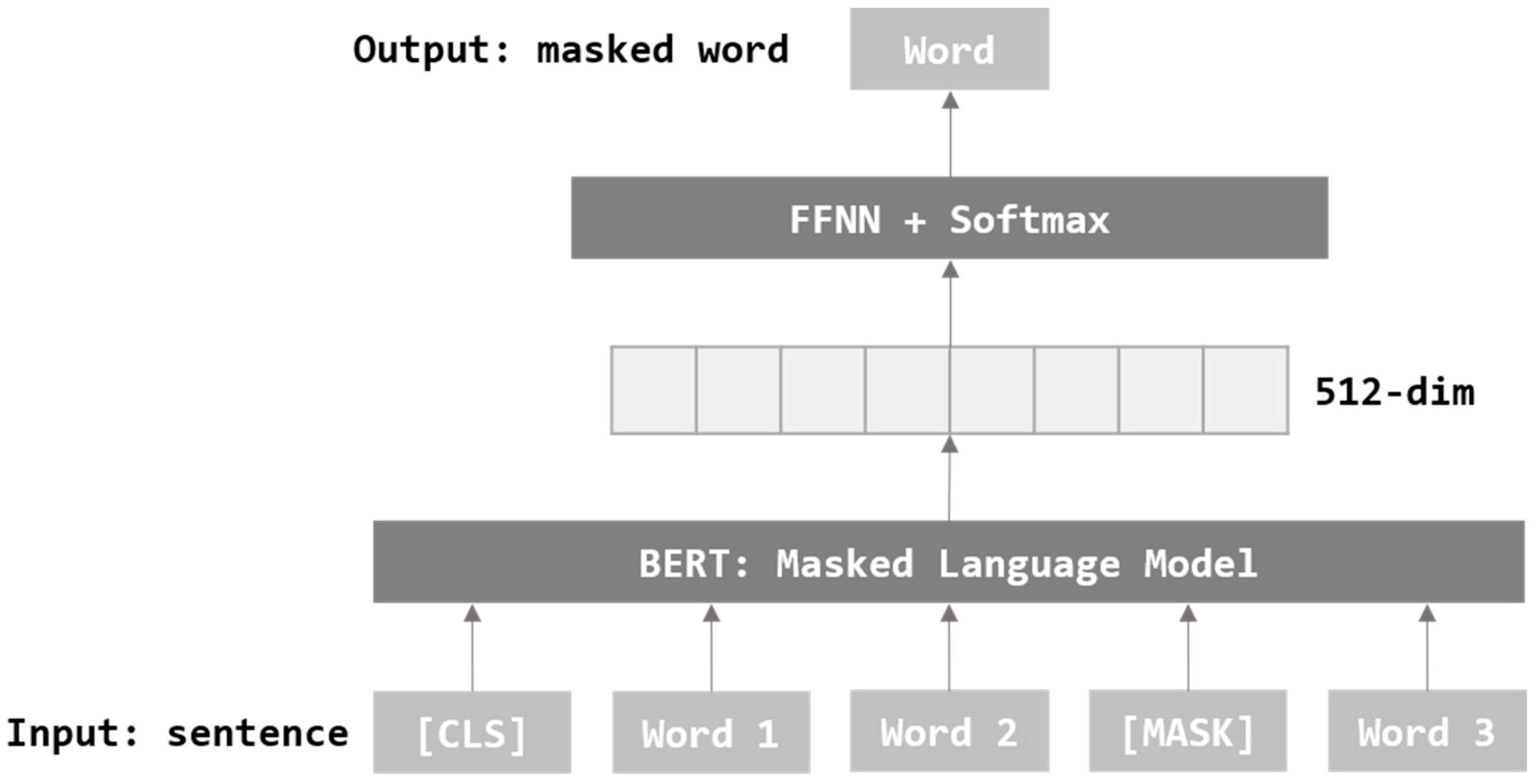
Figure 3 describes MLM where some words in a sentence are replaced with Mask tokens. It goes through the process of training to be able to predict the words covered by the mask. MLM grasps the context and applies the most appropriate words according to its context.
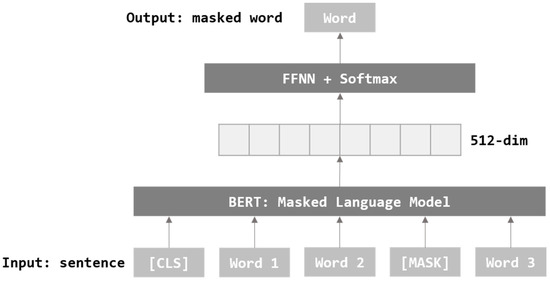
Figure 3.
Masked Language Model Architecture of BERT.
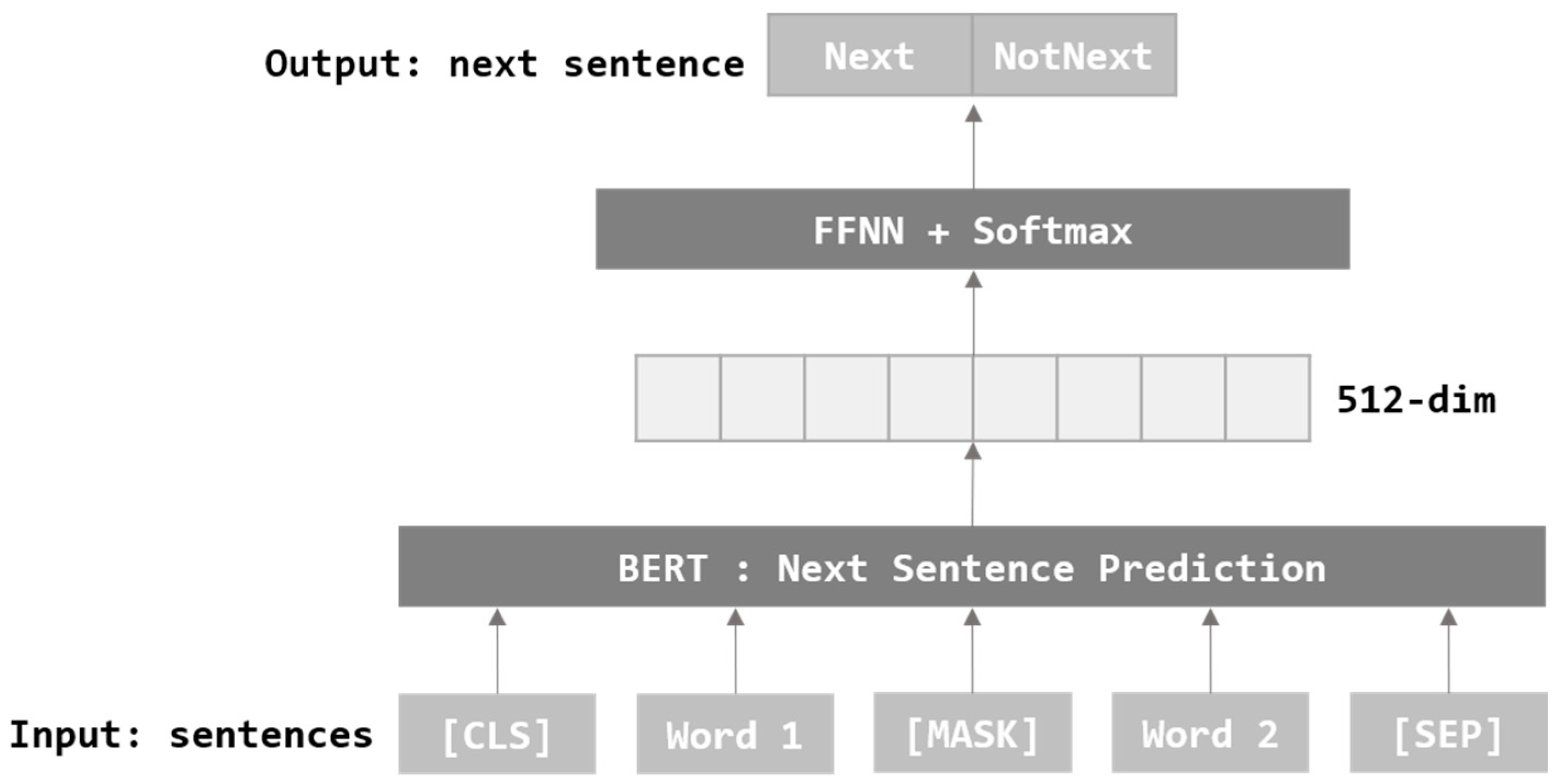
As shown above in Figure 4, NSP goes through the process of training an appropriate sentence following the target sentence. Through this, it trains the relationship and order between the two sentences. In this paper, sentence embedding is performed using BERT, which has been pre-trained with MLM.
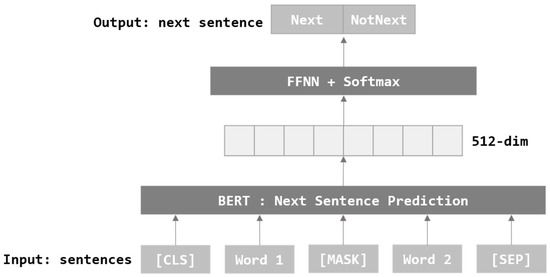
Figure 4.
Next Sentence Prediction Architecture of BERT.
RoBERTa [21] is used to fine-tune and to improve the performance of BERT [20]. BERT has a complex and large structure, so numerous hyperparameters and data are used. RoBERTa trains models by experimenting with multiple values of the hyperparameter used in BERT and exploring the most stable length for a sentence. Although RoBERTa uses the structure of BERT as it is, the main differences used in the hyperparameter and data are as follows: Dynamic Masking, Full-Sentence, Large Mini-Batches, Byte-level Byte-pair Encoding. In this paper, sentence embedding is performed using RoBERTa, which is pre-trained with MLM.
3.2. Image Feature Extraction
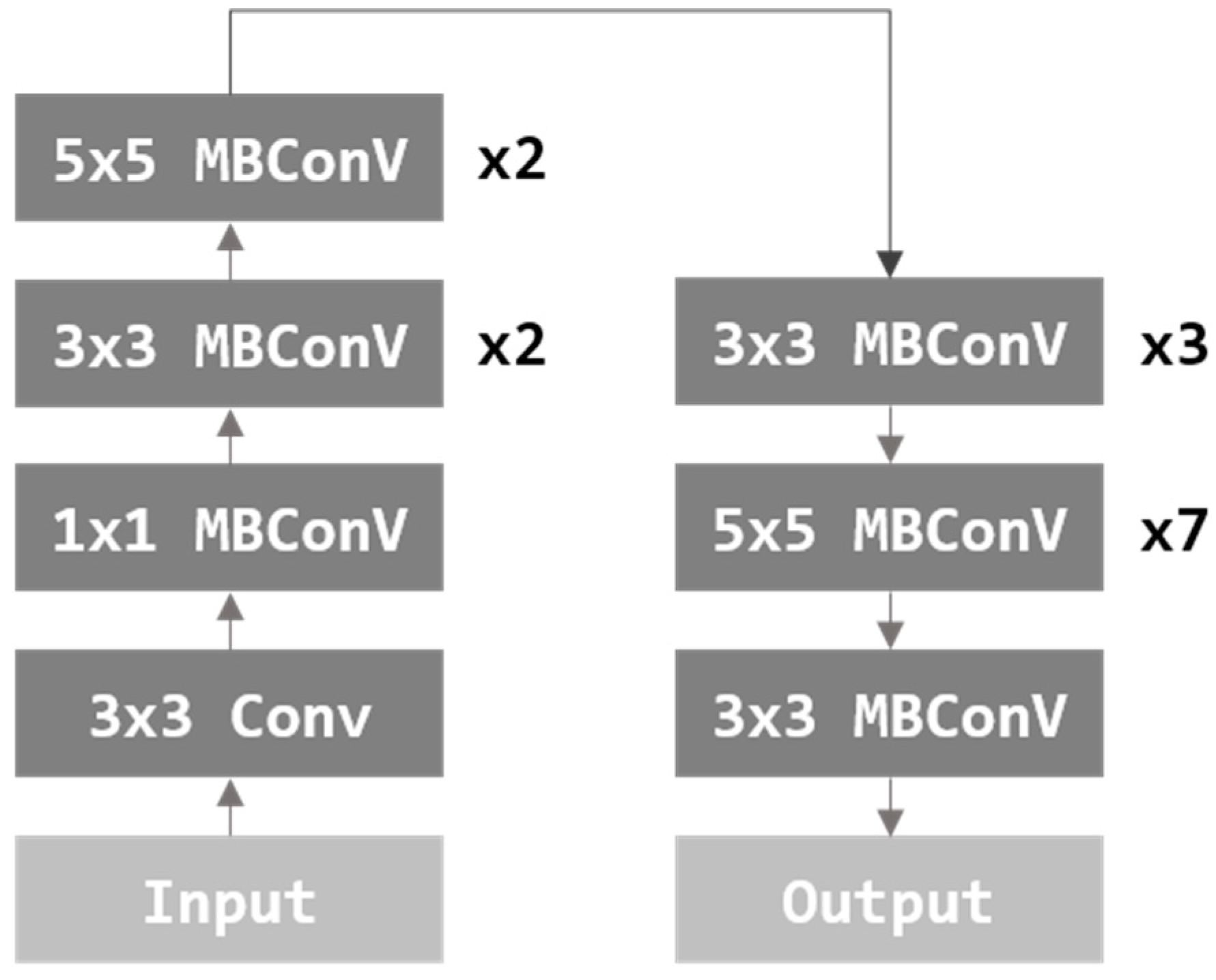
EfficientNet [24] proposed a method of adjusting the size of a model through width scaling, depth scaling, and resolution scaling, focusing on Model Scaling. Width scaling is a method of controlling convolutional filters. Depth scaling is a method of controlling the number of layers. Resolution scaling is a method of adjusting the resolution of an input image. Among the previously proposed image classification models, some models control depth scaling and width scaling [2,23]. However, EfficientNet proposed a model that simultaneously considers width, depth, and resolution scaling. Figure 5 is the architecture of the EfficientNet model. In this paper, image features are extracted using a pre-trained EfficientNet b7 model.
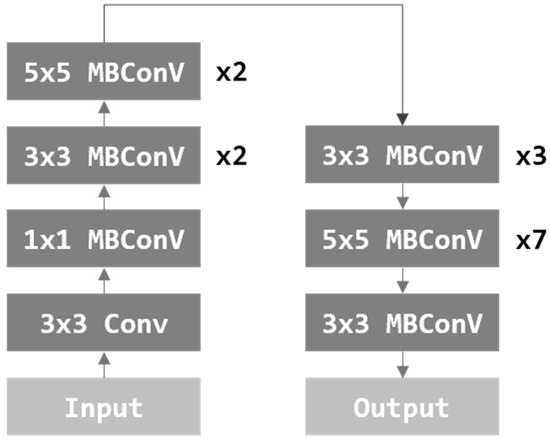
Figure 5.
Architecture of EfficientNet.
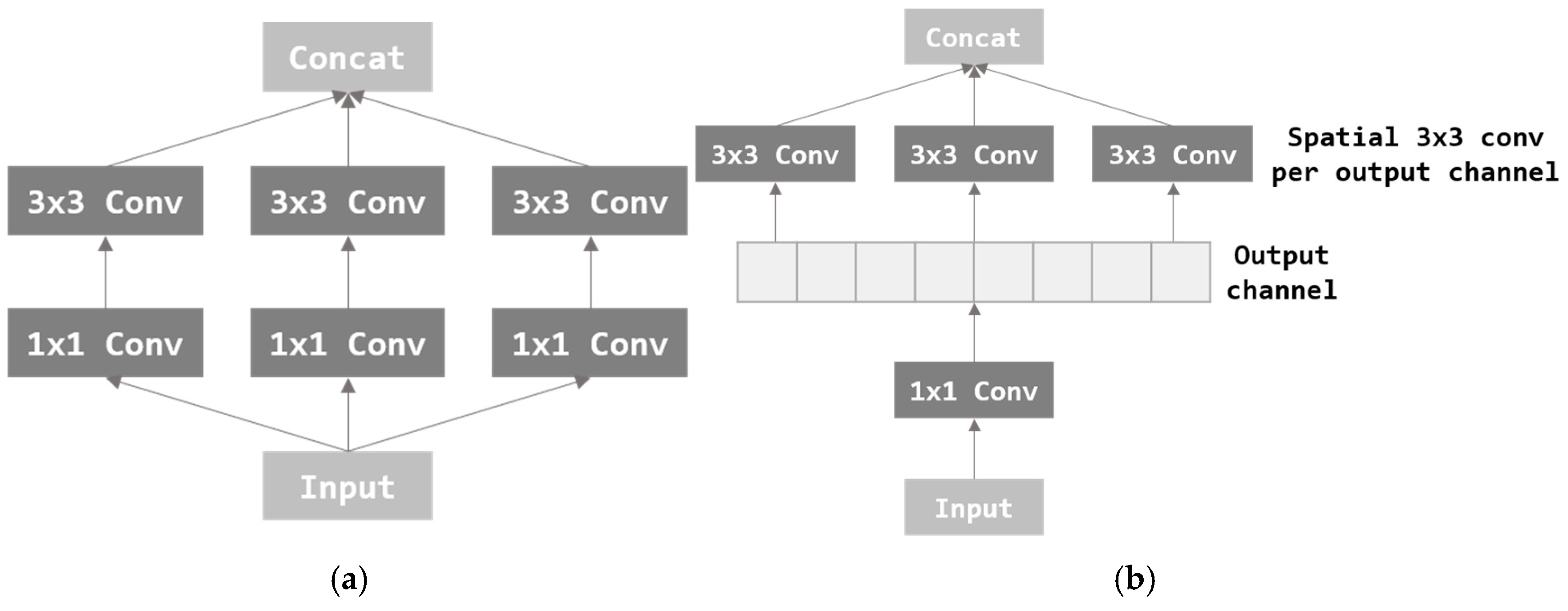
Xception [26] is a modified and improved version of the Inception [25] module. Inception performs 3 × 3 convolution after dimension reduction through 1 × 1 convolution. As a result, the amount of calculation was reduced, and thus, excellent performance was achieved through deep network implementation. The Inception module is shown in Figure 6a. Xception applies the channel-wise correlation and spatial correlation which is considered more strongly in inception. After separating all channels through 1 × 1 convolution, 3 × 3 convolution is applied per channel. Separating channels can completely separate mapping in two directions, channel-wise and spatial. In this paper, image features are extracted using a pre-trained Xception model composed of the Xception module.
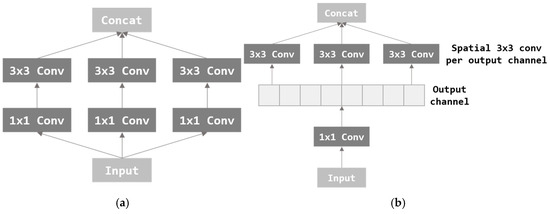
Figure 6.
Architectures of the Inception module and Xception module. (a) Inception module and (b) Xception module.
NASNetLarge [28] performs Architecture Search through AutoML. Auto ML is research that designs the optimal architecture through reinforcement learning for the network configuration of the model used in deep learning. The network of architecture is designed for the convolution layer, filter size, stride, etc., using reinforcement learning. NASNet is discovered through Neural Architecture Search (NAS) [27]. NAS took approximately a month when using 800 GPUs to find the best model for CIFAR-10. The neural architecture searched by NAS showed better performance than resnet [22] and was almost similar to that of DenseNet [29]. NASNetLarge limits its work to searching the Convolutional Neural Network (CNN) for image classification to improve NAS. When 500 GPUs were used, it took approximately four days. NASNetLarge demonstrated that the performance of the architecture search was improved compared to NASNet. Therefore, in this paper, image features are extracted using NASNetLarge, an architecture searched through reinforcement learning in AutoML.
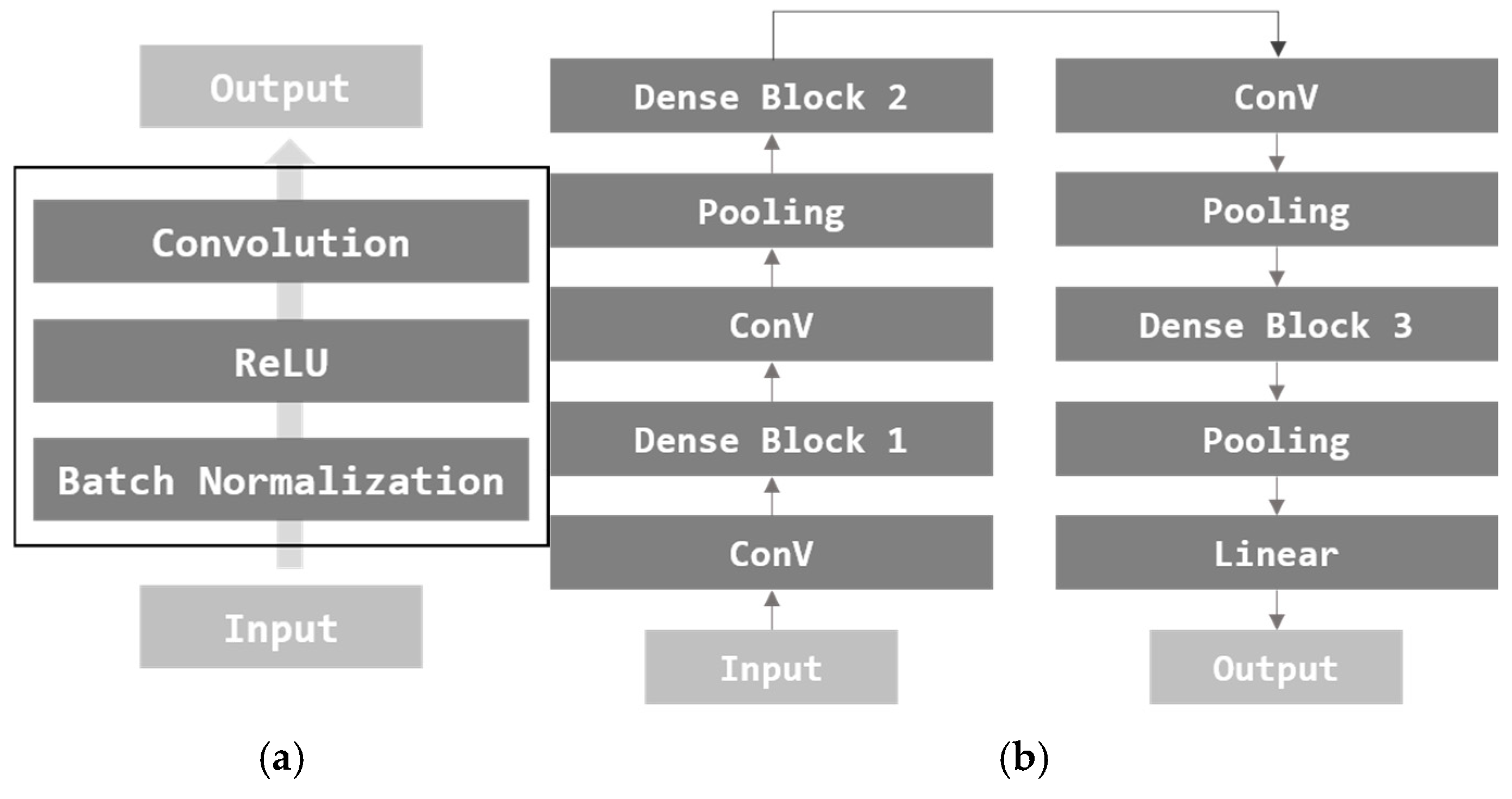
DenseNet [29] is an image classification model based on the CNN architecture. DenseNet proposes a structure that produces good performance with a simple model configuration. In order to extract features, each layer was configured based on convolution with ConV connecting each layer. Resnet also followed the same method as DenseNet [22]. Resnet performs additional operations between features, but DenseNet differs in that it does concatenation. DenseBlock is illustrated in Figure 7a, and DenseNet architecture is illustrated in Figure 7b.
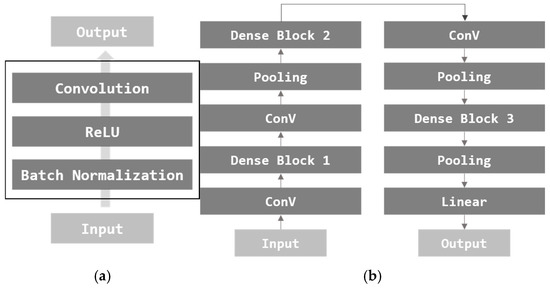
Figure 7.
Architecture of DenseBlock and DenseNet. (a) DenseBlock and (b) basic DenseNet.
DenseBlock has a simple structure of Batch Normalization (BN), ReLU, and Convolution. Basic DenseNet consists of three DenseBlocks, a convolution layer, and a pooling layer. In this paper, image features are extracted using DenseNet.
3.3. Text–Image Embedding
This section describes how text embedding and image features are combined. This paper uses pre-trained text embedding models and image feature extraction models. As the output size of each model is different, the output sizes are matched by adding a layer to the pre-trained image feature extraction model and performing the vector product. As a result, a text–image embedding vector in which text embedding of data size x data size and image features are combined is created. The text–image embedding vector has a large dimension equal to the data size. Therefore, the dimension is reduced by using TSNE considering the relationship between the neighbors of the vector. As a result, the similarity between text–image embedding movies can be confirmed through visualization.
4. Experiments
4.1. Text–Image Embedding
This section details the experimental results of the text–image embedding method for recommending multimedia content. In this study, the datasets utilized include movie plots and posters. The movie dataset is derived from movielens [31], which comprises 9536 movies. The experiments were conducted within a computational environment configured with Python 3.8, Tensorflow2, and an NVIDIA GeForce RTX 2080 Ti GPU. To evaluate the performance of the embedding results, three distinct similarity metrics were employed: Cosine Similarity, Euclidean Distance, and Arccos Distance. These metrics serve as quantitative measures for evaluating the proximity or similarity between vectors within the embedding space. Specifically, Cosine Similarity, Euclidean Distance, and Arccos Distance are defined in such a way that higher values (closer to 1) indicate greater similarity between the vectors. The mathematical formulations for these three similarity measures are presented in Equations (1), (2) and (3), respectively.
4.2. Performance Comparison of Text Embedding
This section evaluates the similarity of vector-based text embeddings derived from movie plot descriptions. The aim of this evaluation is to identify the model with the best performance among the various text embedding techniques employed in this study. Additionally, we compare the performance of text-only embeddings with that of text–image embeddings. The pre-trained models used for text embedding in this paper include Sent2Vec, Universal Sentence Encoder, BERT, and RoBERTa. The results of measuring the similarity of text embeddings for the movie plots are presented in Table 1.

Table 1.
Similarity measurement score of text embedding on movie plot.
From similarity measurement results shown in Table 1, it was demonstrated that BERT achieved the best performance for movie plot text embedding. While conventional expectations might suggest the following performance order: Sent2Vec < Universal Sentence Encoder < BERT < RoBERTa, the actual results deviated from this hierarchy. Specifically, BERT outperformed all other models, while Sent2Vec demonstrated better performance than Universal Sentence Encoder. This deviation indicates that the most suitable model can vary depending on the dataset and specific objectives of the task. Therefore, for this study, if only text embedding is utilized, BERT can achieve the best performance.
4.3. Performance Comparison of Text–Image Embedding
This section evaluates the similarity between movie plots and the text–image embedding vectors of corresponding movie posters. The pre-trained models used in this study were selected based on their similarity performance. Compared to using text embeddings alone, the results confirm that combining text and image embeddings yields superior performance. The pre-trained text embedding models used for text–image embeddings are the same as those described in Section 4.1. For image feature extraction, the pre-trained models include EfficientNet, Xception, NASNetLarge, and DenseNet.
The similarity measurement results are presented in the three tables above. Table 2 displays the Cosine Similarity results for text–image embeddings, Table 3 presents the Euclidean Distance results, and Table 4 provides the Arccos Distance results. Across all three tables, the combination of BERT and EfficientNet for image feature extraction consistently outperformed other model pairs. The BERT and EfficientNet combination achieved the highest scores in all three similarity metrics. Specifically, the Cosine Similarity score was 0.9152, the Euclidean Distance was 0.8867, and the Arccos Distance score was 0.8587. In contrast, when only text embeddings were used, BERT delivered the best performance with a Cosine Similarity score of 0.8934, a Euclidean Distance score of 0.8533, and an Arccos Distance score of 0.8252. These findings demonstrate that combining text and image embeddings provides a richer and more informative representation, resulting in improved similarity scores. The proposed text–image embedding method proves to be more effective than text-only embedding, showing that the integration of both text and visual data significantly enhances the performance of multimedia content recommendation.
Table 2.
Cosine Similarity measurement score of text–image embedding on movie plot and movie poster.
Table 3.
Euclidean distance measurement score of text–image embedding on movie plot and movie poster.
Table 4.
Arccos distance measurement score of text–image embedding on movie plot and movie poster.
4.4. Multimedia Recommendation Using Text–Image Embedding
Among the text–image embedding methods proposed in this study, the combination of pre-trained BERT for text embedding and EfficientNet for image feature extraction yielded the best performance in multimedia recommendations. The recommendation process, illustrated in the right box of Figure 1, begins with embedding the user’s query using pre-trained BERT. The system then measures the similarity between the query’s embedding vector and the text–image embedding vectors of movies, using Cosine Similarity to identify the most relevant matches. Table 5 presents an example of this recommendation process, showcasing the results of matching a user query with corresponding movie embeddings based on Cosine Similarity.
Table 5.
Example of multimedia content recommendation to users.
For example, a user may submit the query “An animated popular movie with a prince and princess. The characters have an adventure in a fantasy world”. The system generates embedding vectors for both the query and the movies in the database, compares them using Cosine Similarity, and ranks the results. The top five movies with the highest similarity scores are displayed in Table 5, identified by their MovieID from the MovieLens dataset. The recommended movies include Cinderella, Beauty and the Beast, The Swan Princess, Alice in Wonderland, and Snow White and the Seven Dwarfs. Each of these movies aligns with the thematic elements described in the query, demonstrating the system’s effectiveness in generating human-relevant recommendations. This result confirms that the proposed text–image embedding approach, combining text and visual features, enhances the accuracy and relevance of multimedia recommendations.
5. Conclusions
In this paper, a text–image embedding method was proposed to recommend personalized multimedia content to drivers and passengers in an autonomous vehicle environment. The challenges of deep learning with text–image embedding are addressed using pre-trained models, Sent2vec, Universal Sentence Encoder, BERT, and RoBERTa. The pre-trained image feature extraction models utilized in this study are EfficientNet, Xception, NASNetLarge, and DenseNet. The vectorized texts and images were combined into a vector product, and dimension reduction was performed through TSNE. Since the dimension of the vector product result was deemed to be too large, dimension reduction was performed by considering the relationship between neighbors through TSNE. Furthermore, the performance of text–image embedding was evaluated through similarity measurement methods, specifically Cosine Similarity, Euclidean Distance, and Arccos Distance.
Our proposed method showed that BERT is the best performing pre-training model for text embedding. Additionally, it was demonstrated that BERT and EfficientNet are the best performing pre-training models for text–image embedding. Furthermore, by comparing the results of the similarity measurements between text embedding and text–image embedding methods, this study found that the performance of text–image embedding is superior. Therefore, this demonstrated that the combined use of texts and images together can process more information and show better performance than using only text. Lastly, personalized multimedia content was recommended by receiving a query from the user, embedding sentences, and recommending the most similar multimedia content through text–image embedding and similarity measurements. For future research, the personalization of multimedia content and automated recommendation systems should be explored further through text–video embedding as text–video content is expected to contain even more information than text–image.
Author Contributions
Conceptualization, J.-A.C. and K.L.; Methodology, T.H.; Software, T.H.; Validation, T.H.; Data curation, T.H.; Writing—original draft, J.-A.C.; Writing—review & editing, J.-A.C. and K.L.; Supervision, J.-A.C. and K.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Data Availability Statement
The original contributions presented in the study are included in the article, further inquiries can be directed to the corresponding authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Rydenfelt, H. Transforming media agency? Approaches to automation in Finnish legacy media. New Media Soc. 2022, 24, 2598–2613. [Google Scholar] [CrossRef]
- Hong, T.; Lim, K.; Kim, P. Video-Text Embedding based Multimedia Recommendation for Intelligent Vehicular Environments. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Virtual Conference, 27 September–28 October 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Sterling, J.A.; Montemore, M.M. Combining citation network information and text similarity for research article recommender systems. IEEE Access 2021, 10, 16–23. [Google Scholar] [CrossRef]
- Kuanr, M.; Mohapatra, P.; Mittal, S.; Maindarkar, M.; Fouda, M.M.; Saba, L.; Saxena, S.; Suri, J.S. Recommender system for the efficient treatment of COVID-19 using a convolutional neural network model and image similarity. Diagnostics 2022, 12, 2700. [Google Scholar] [CrossRef] [PubMed]
- Lee, T. Waymo Finally Launches an Actual Public, Driverless Taxi Service. Ars Technica, Magazine Article. 2020. Available online: https://arstechnica.com/cars/2020/10/waymo-finally-launches-an-actual-public-driverless-taxi-service/ (accessed on 20 February 2021).
- Levin, T. Elon Musk Says Tesla Will Release Its ‘Full Self-Driving’ Feature as a Subscription in Early 2021. Business Insider Australia, Magazine Article. 2020. Available online: https://www.businessinsider.com/tesla-autopilot-full-self-driving-subscription-early-2021-elon-musk-2020-12 (accessed on 20 February 2021).
- Barabás, I.; Todoruţ, A.; Cordoş, N.; Molea, A. Current challenges in autonomous driving. In IOP Conference Series: Materials Science and Engineering; IOP Publishing: Bristol, UK, 2017; Volume 252, p. 012096. [Google Scholar]
- On-Road Automated Driving (ORAD) Committee. Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles: J3016. SAE International, Standard. 2021. Available online: https://www.sae.org/standards/content/j3016 (accessed on 20 February 2021).
- Moradloo, N.; Mahdinia, I.; Khattak, A.J. Safety in higher level automated vehicles: Investigating edge cases in crashes of vehicles equipped with automated driving systems. Accid. Anal. Prev. 2024, 203, 107607. [Google Scholar] [CrossRef]
- Stefanovic, M. Leveling Up AI: How Close Are We to Self-Driving Cars? Here 360 News. 2024. Available online: https://www.here.com/learn/blog/ai-how-close-are-we-to-self-driving-cars (accessed on 23 April 2024).
- When Will Self-Driving Cars Be Available? (n.d.) Imagination. Available online: https://www.imaginationtech.com/future-of-automotive/when-will-autonomous-cars-be-available/ (accessed on 23 April 2024).
- LG Display. LG Display Unveils the World’s Largest Automotive Display to Advance Future Mobility at CES 2024. PR Newswire. 2024. Available online: https://www.prnewswire.com/news-releases/lg-display-unveils-the-worlds-largest-automotive-display-to-advance-future-mobility-at-ces-2024-302029558.html (accessed on 30 March 2024).
- Ruan, Q.; Zhang, Y.; Zheng, Y.; Wang, Y.; Wu, Q.; Ma, T.; Liu, X. Recommendation Model Based on a Heterogeneous Personalized Spacey Embedding Method. Symmetry 2021, 13, 290. [Google Scholar] [CrossRef]
- Plummer, B.A.; Kordas, P.; Kiapour, M.H.; Zheng, S.; Piramuthu, R.; Lazebnik, S. Conditional image-text embedding networks. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 249–264. [Google Scholar]
- Wang, L.; Li, Y.; Lazebnik, S. Learning deep structure-preserving image-text embeddings. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 5005–5013. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pagliardini, M.; Gupta, P.; Jaggi, M. Unsupervised learning of sentence embeddings using compositional n-gram features. arXiv 2017, arXiv:1703.02507. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal sentence encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zoph, B.; Le, Q.V. Neural architecture search with reinforcement learning. arXiv 2016, arXiv:1611.01578. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2018), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8697–8710. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Van der Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- MovieLens Datasets. Available online: https://grouplens.org/datasets/movielens/ (accessed on 20 February 2021).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).