
Real-Time Diminished Reality Application Specifying Target Based on 3D Region
Abstract
1. Introduction
2. Methods
2.1. Overview
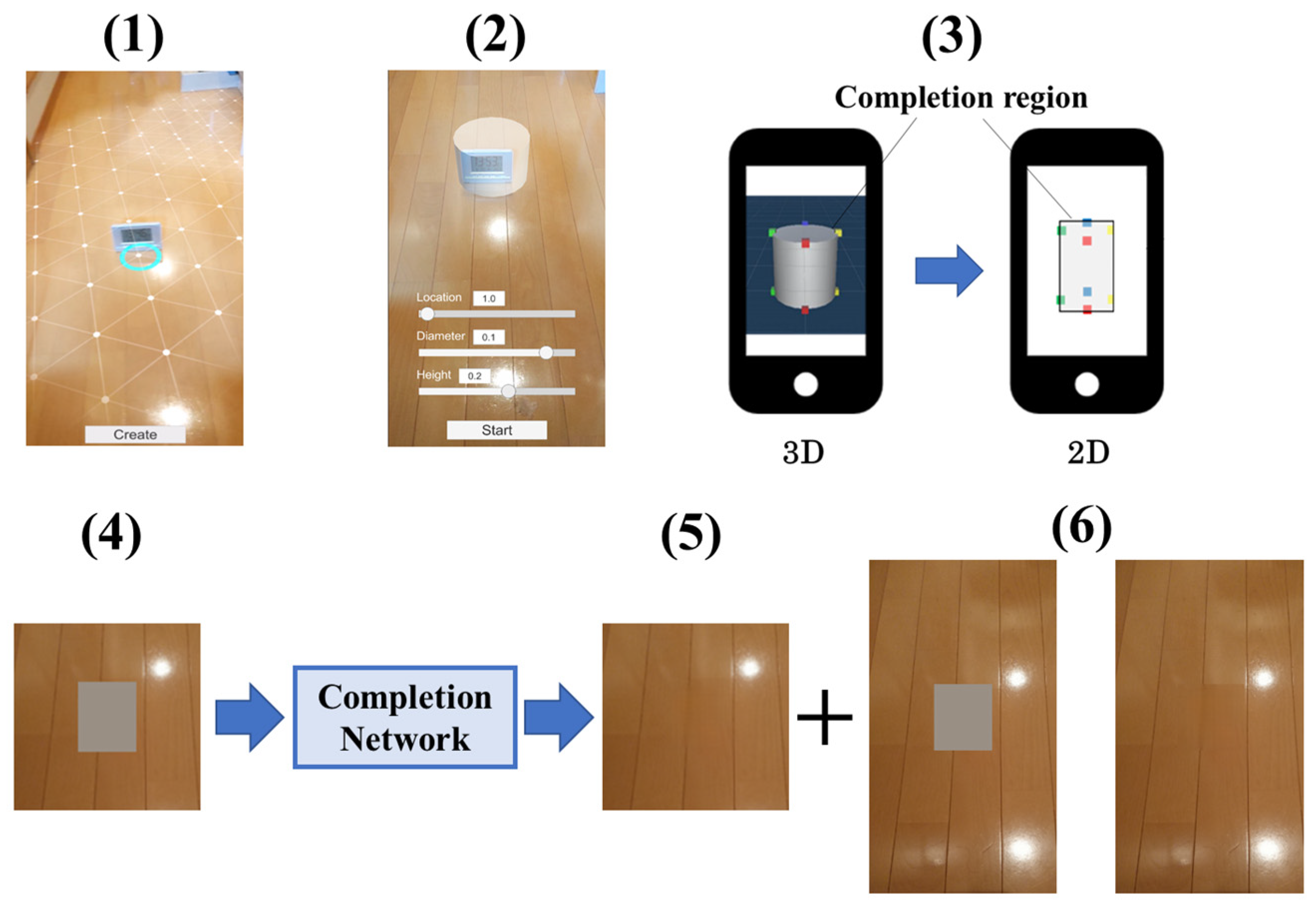
- (1)
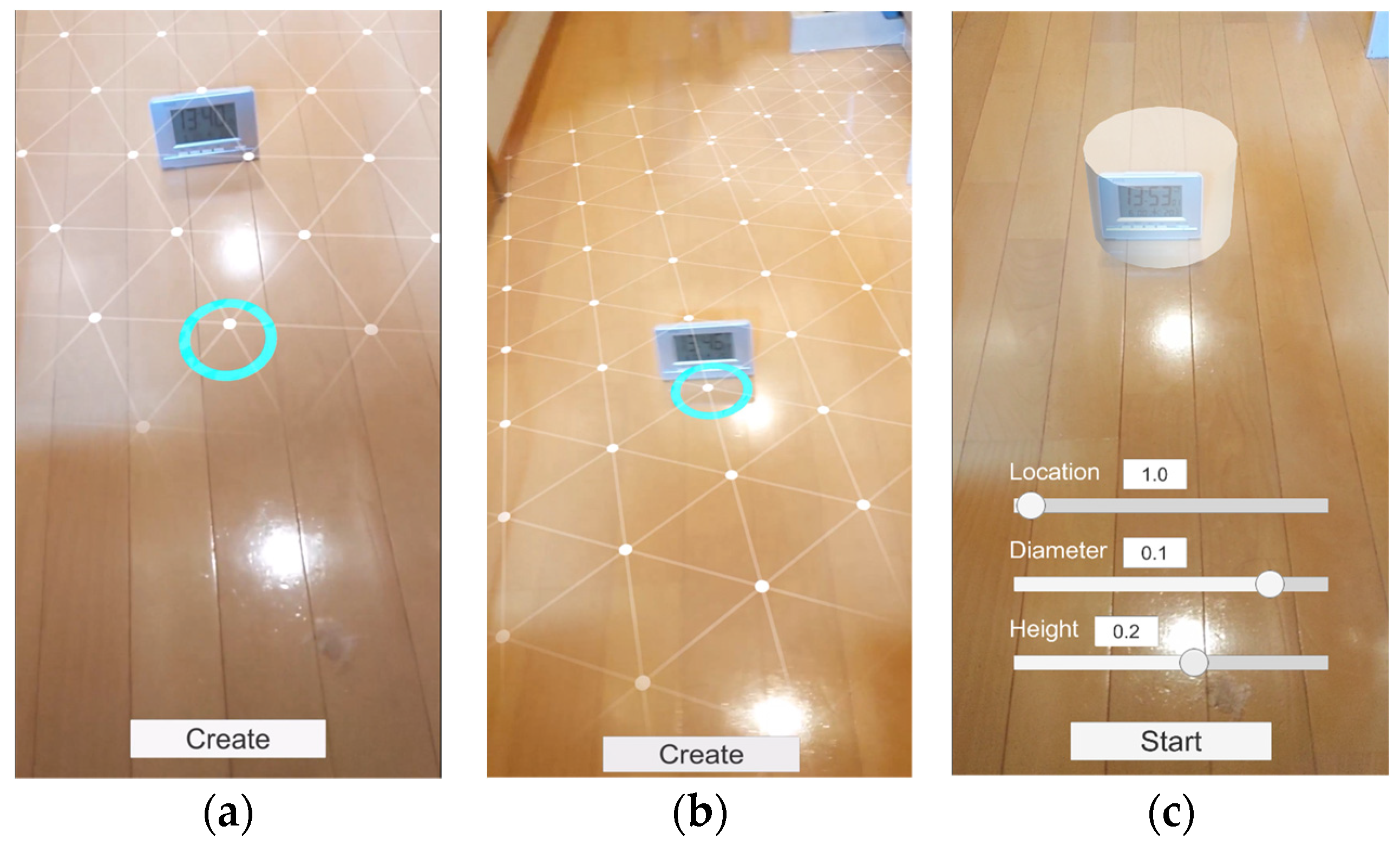
- The plane in which the deletion target exists in the image is detected and captured using the smartphone camera. A virtual plane is constructed in the virtual space so that it overlaps the detected plane.
- (2)
- The virtual cylinder is placed so that the target to be removed fits inside. The user specifies the placement position and the size of the virtual cylinder. The 3D completion region is inside the virtual cylinder.
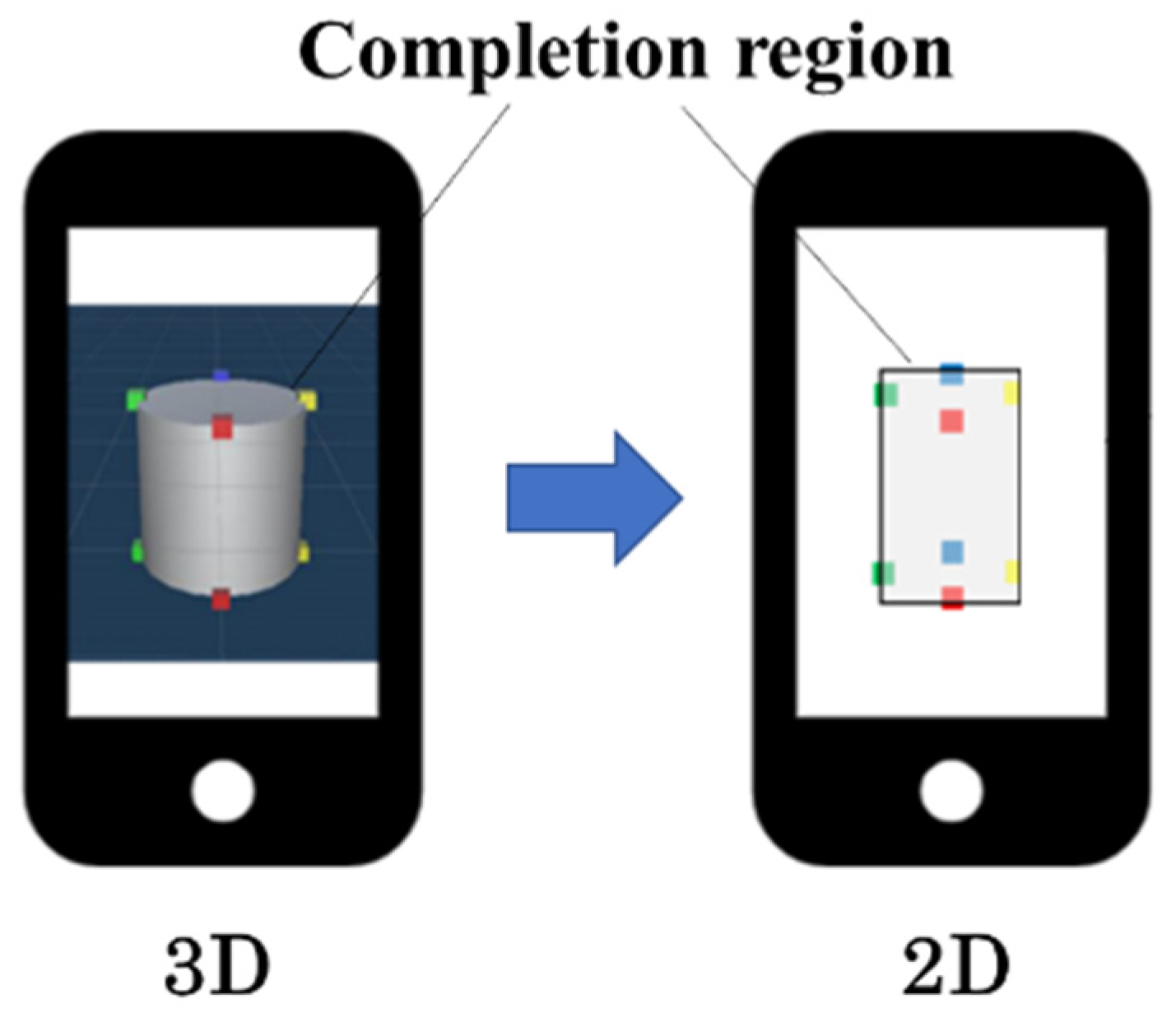
- (3)
- The 3D coordinates of eight points that could be the top, bottom, left, or right edge on the contour of the virtual cylinder are calculated. The coordinates of each point in the camera image are calculated from the camera parameters and the 3D coordinates, and their bounding rectangles are used as the 2D completion region.
- (4)
- The 2D completion region of the camera image is filled to create the input image for the completion network.
- (5)
- The completion network is used to generate the image in which the completion region is completed (completion images).
- (6)
- The camera image and the completion image are combined to create and display a camera image in which DR is performed.
- (7)
- Steps (3) to (6) are repeated per frame.
2.2. Self-Location Estimation of a Camera
2.3. Detection of the Real Plane and Construction of the Virtual Plane
2.4. Determination of 3D Completion Region
2.5. Calculation of 2D Completion Region
- The 3D coordinates of the eight points on the contours of the virtual cylinder are obtained, including the top, bottom, left, or right edges, as shown in Figure 4.
- The camera image coordinates for each point are calculated from their 3D coordinates and the camera parameters. The points on the contours of the virtual cylinder and the corresponding points in the camera image are marked with the same color in Figure 4.
- The bounding rectangle of the eight camera image coordinates are calculated to obtain the 2D completion region.
2.6. Creation of Input Images
2.7. Generation of Completion Images
2.8. Composition of the Camera Image and the Completion Image
3. Image Completion Function
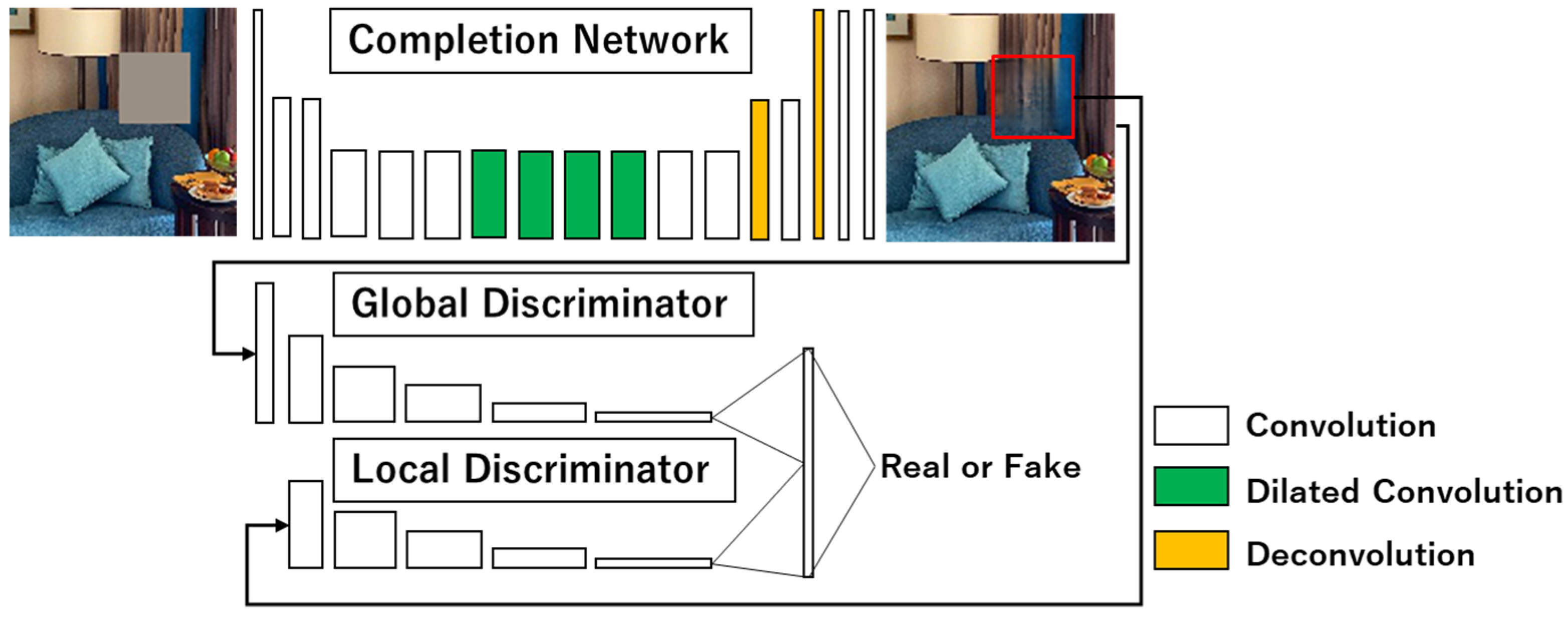
3.1. Image Completion Network
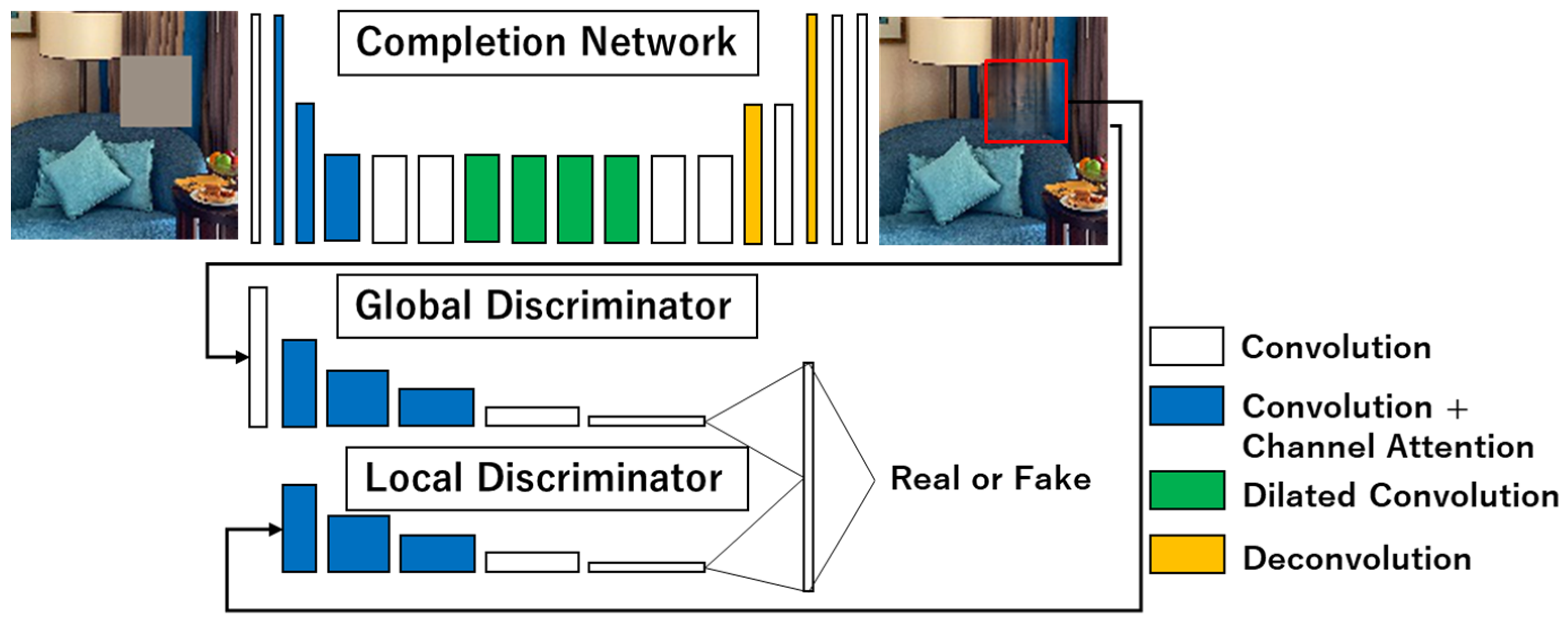
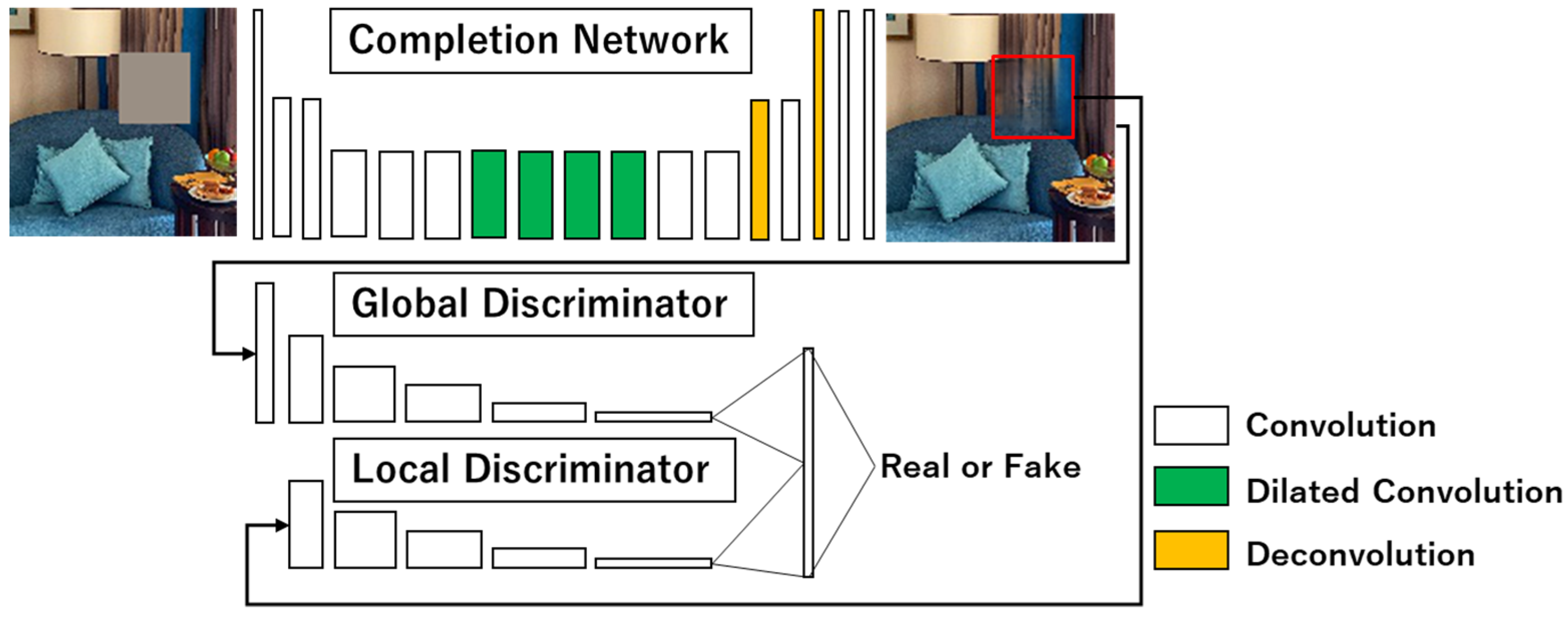
3.2. Globally and Locally Consistent Image Completion (GLCIC)
3.3. Channel Attention (Ch-GLCIC)
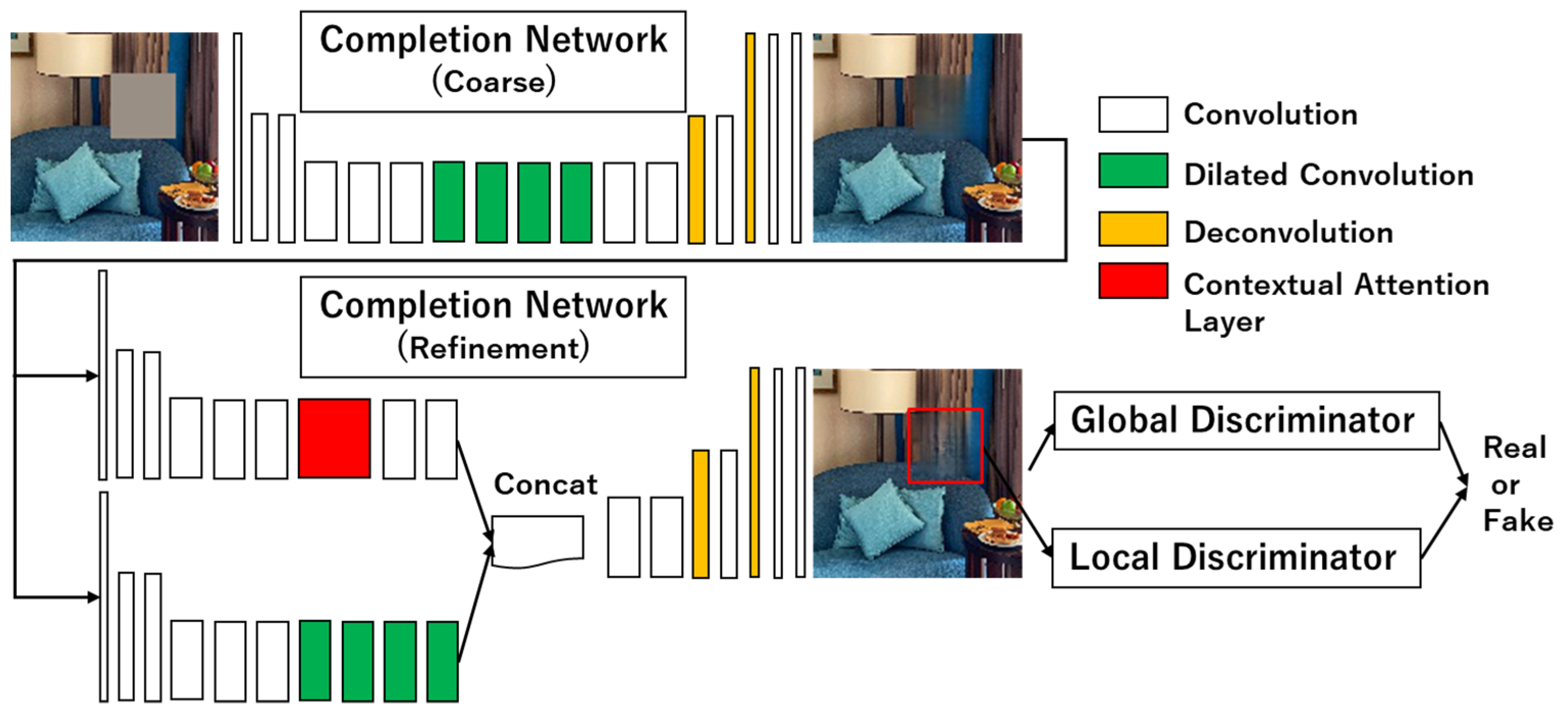
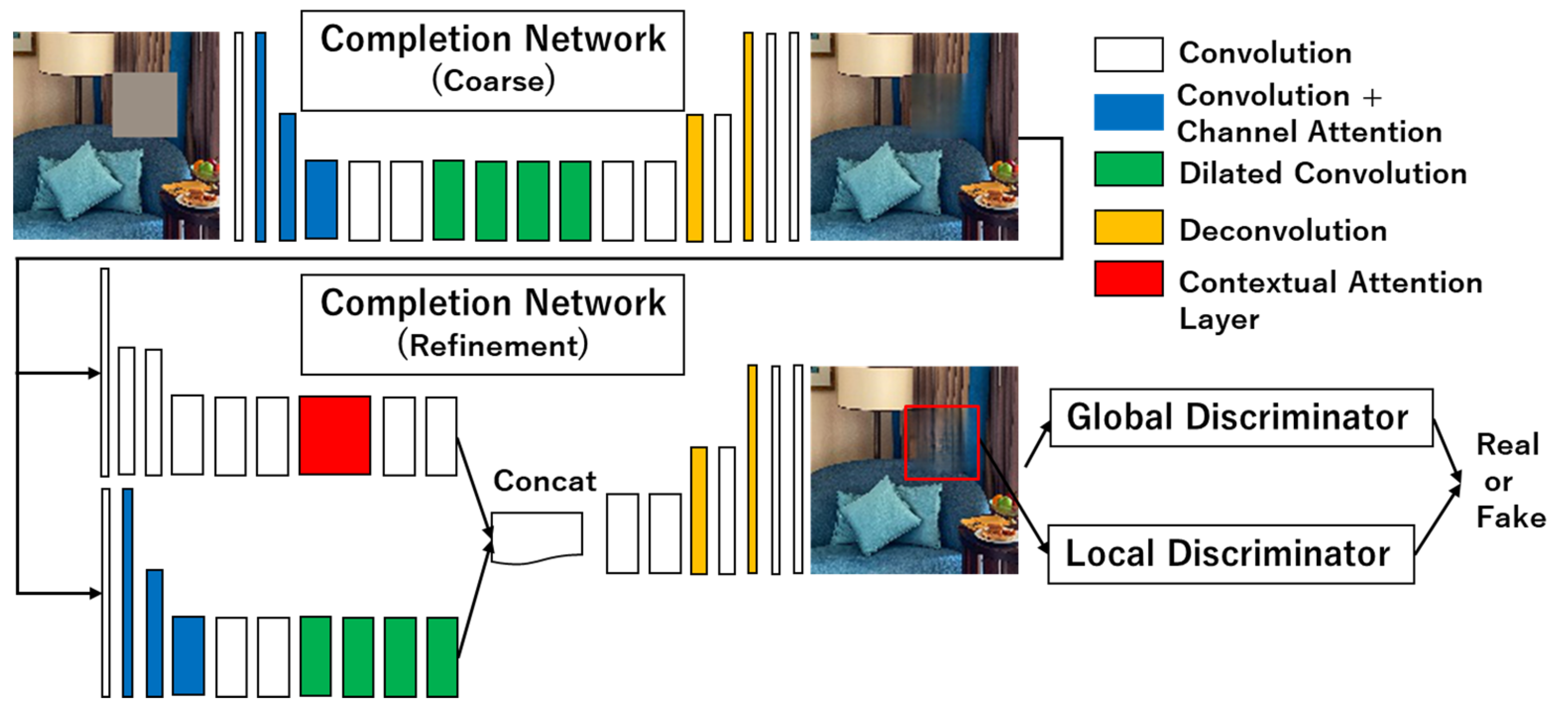
3.4. Contextual Attention (Co-GLCIC)
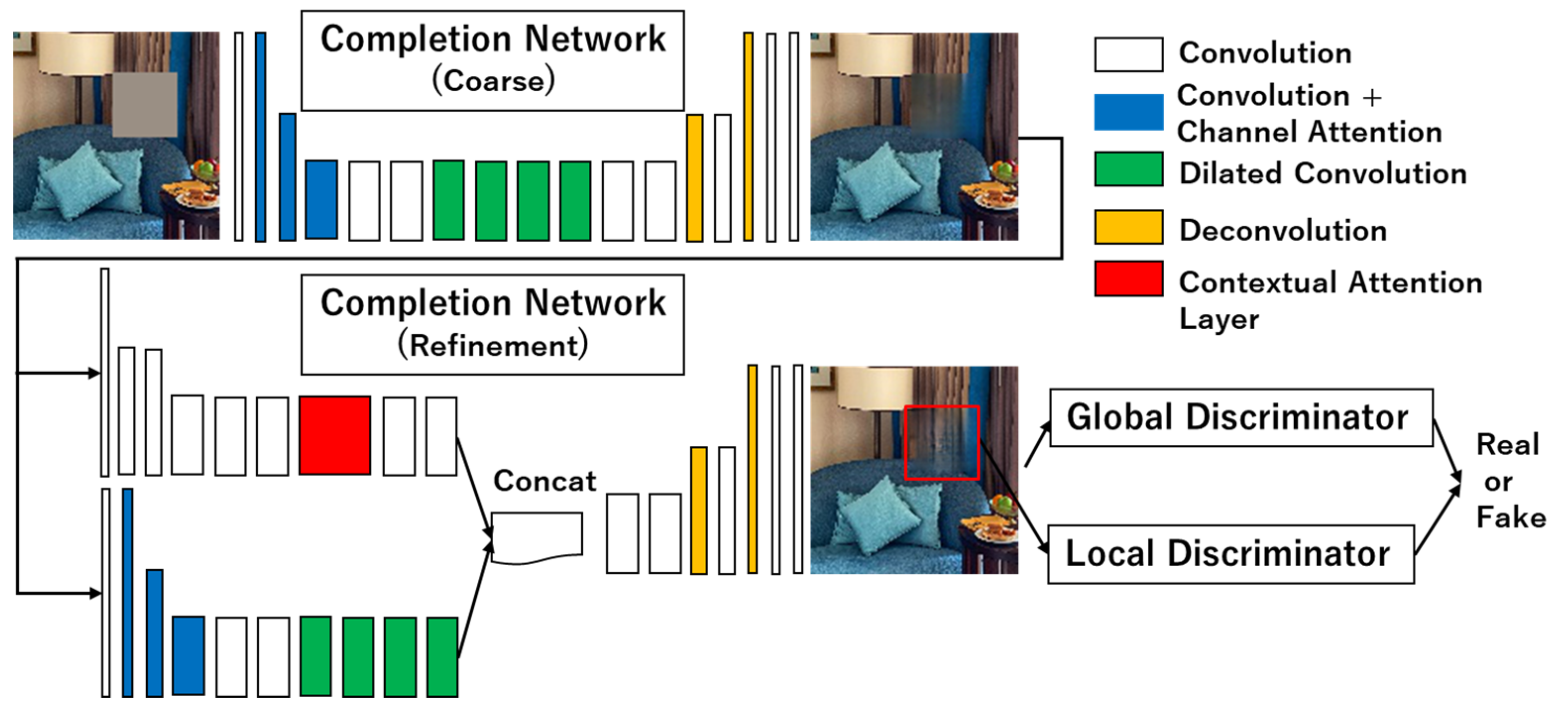
3.5. Channel Attention and Contextual Attention (CC-GLCIC)
4. Experiment
4.1. Training
- It requires a dataset of combinations of images with the target object to be removed and the same image without the object. Therefore, it is difficult to increase the number of variations in the dataset.
- The surrounding pixel values are altered by the light reflected by the object and shadows of the object. As a result, the pixel values of the generated completion images change from the background image without a target object. Therefore, it is difficult to evaluate the completion images accurately.
- It is difficult to evaluate completion images where objects in various positions and of various sizes are removed.
- This method can easily increase the number of variations in the dataset rather than having combinations of images with the target object to be removed and the same image without the object.
- The effect of the object’s placement on the surrounding pixel values can be suppressed. Therefore, the evaluation of the completion images can also be performed accurately.
- Completion images with various positions and various sizes of target objects can be evaluated.
- The data with variations may have a positive impact on the training of the network.
4.2. Evaluation Method
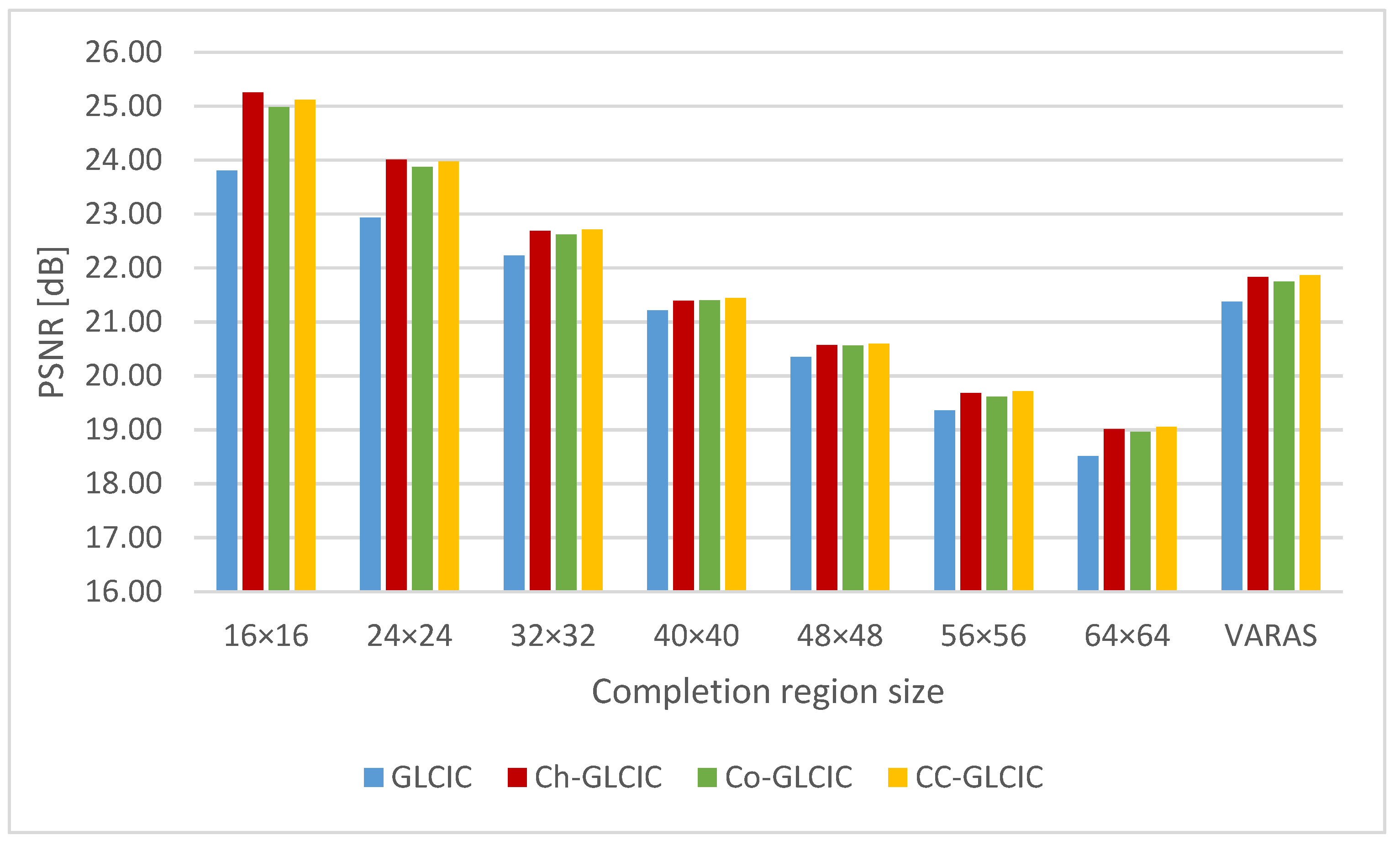
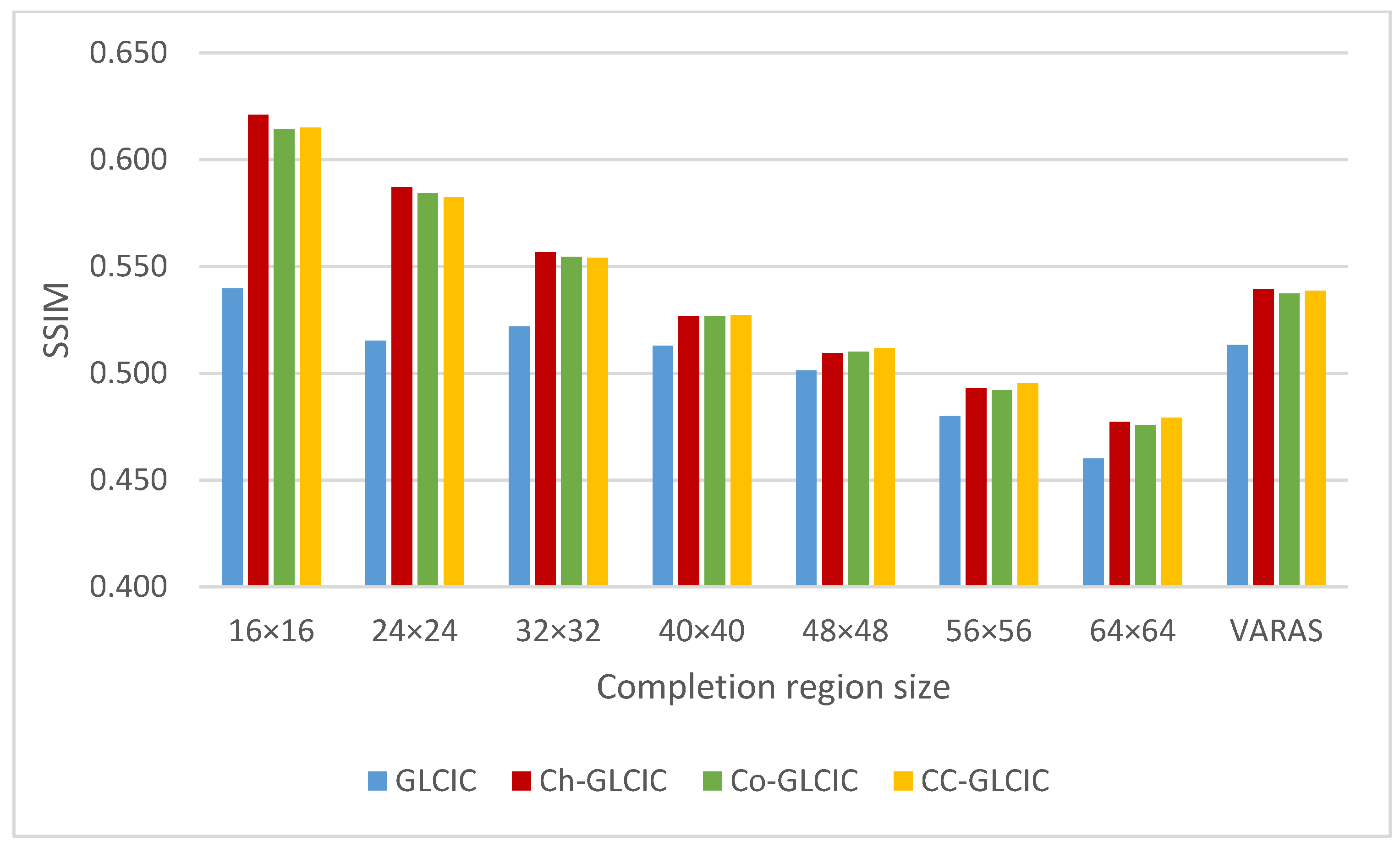
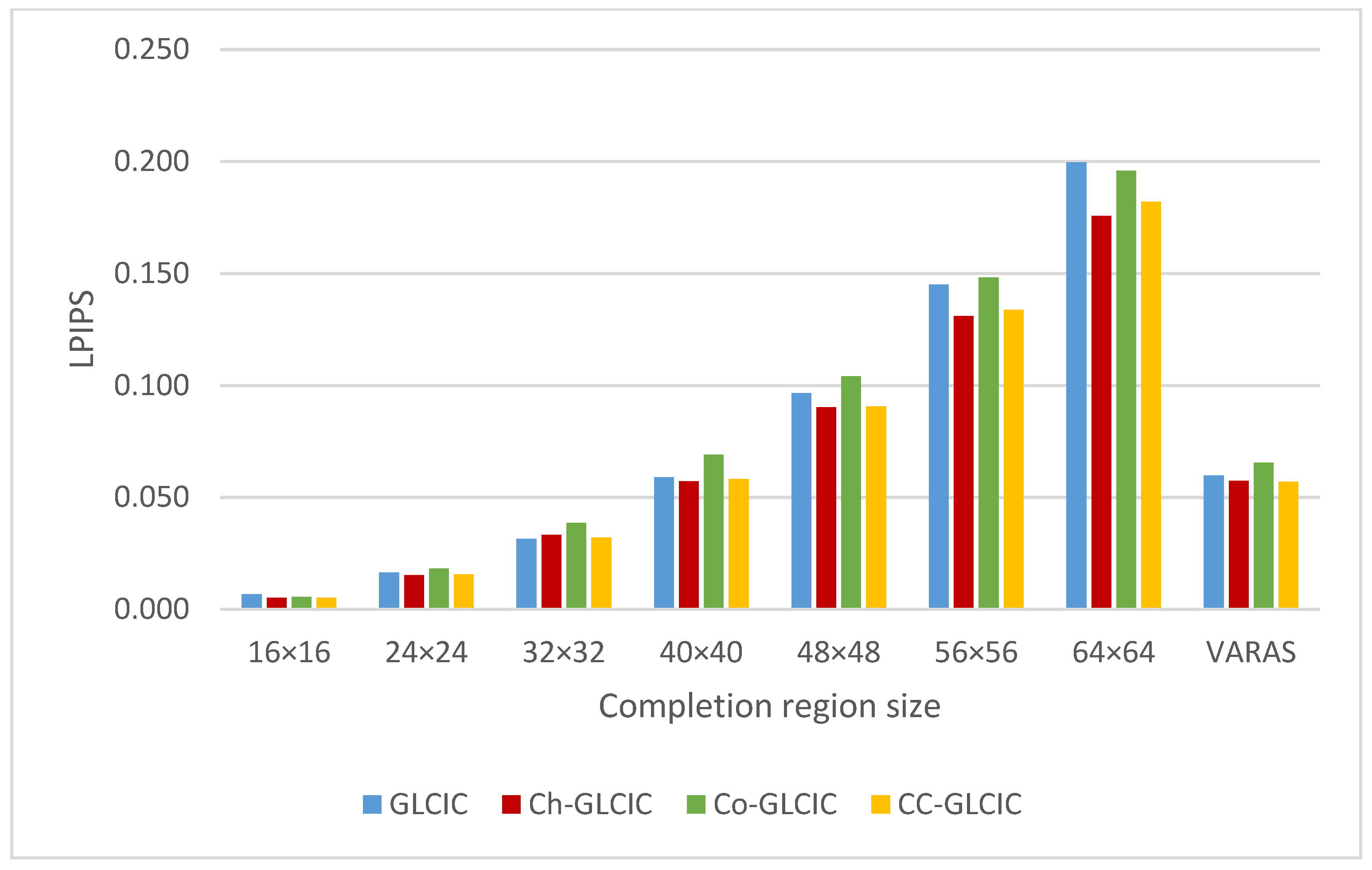
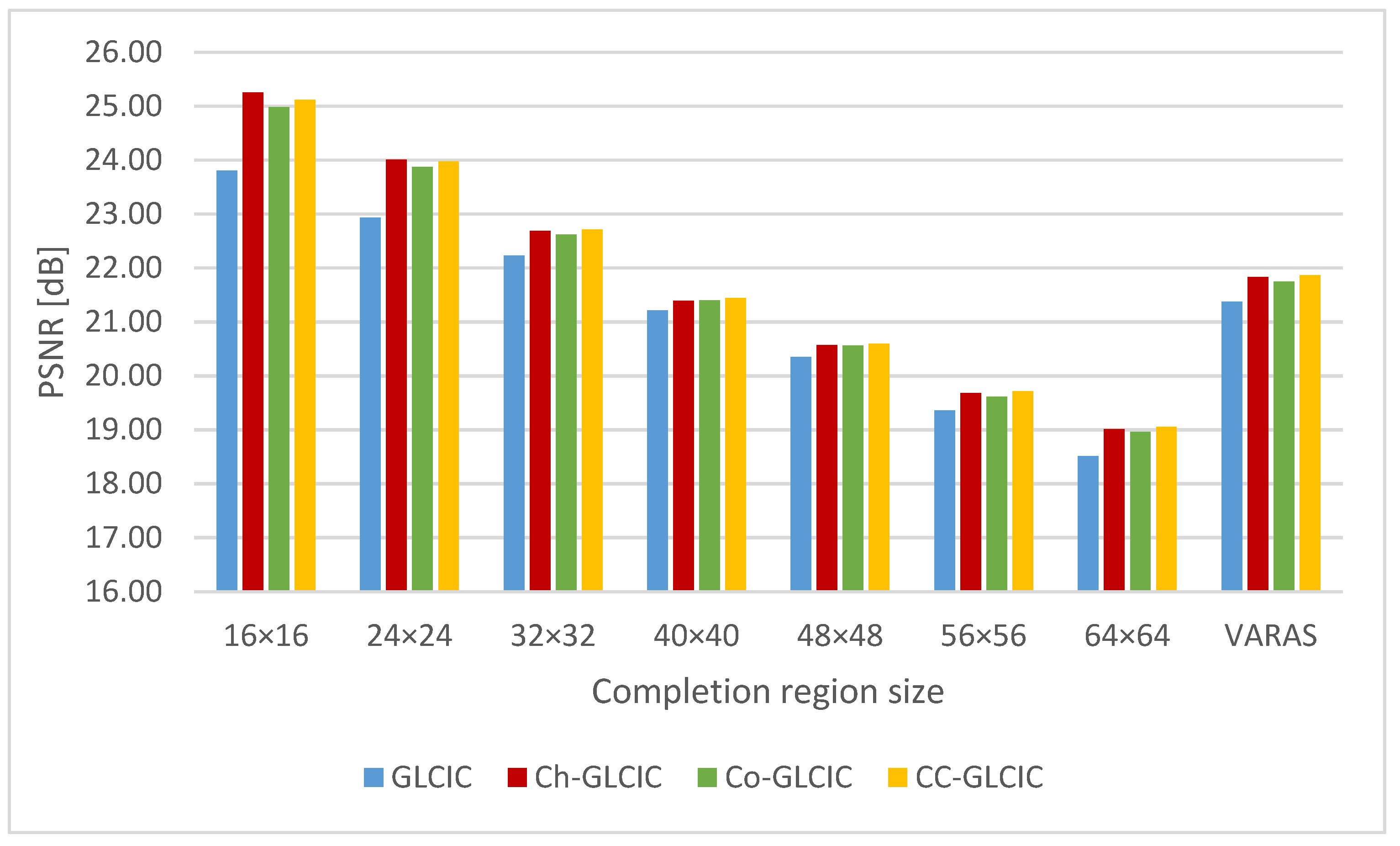
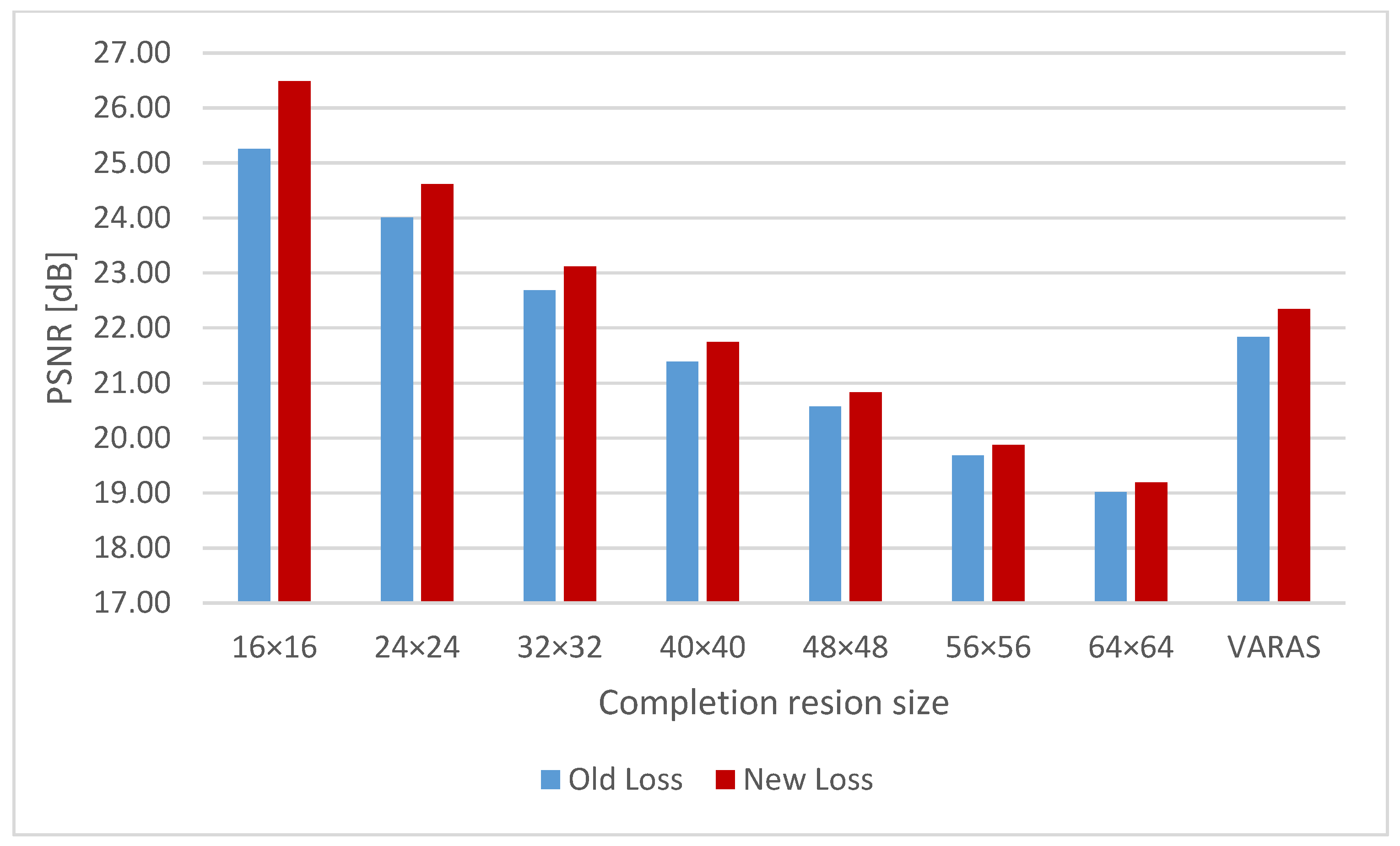
4.3. Comparison of Completion Networks
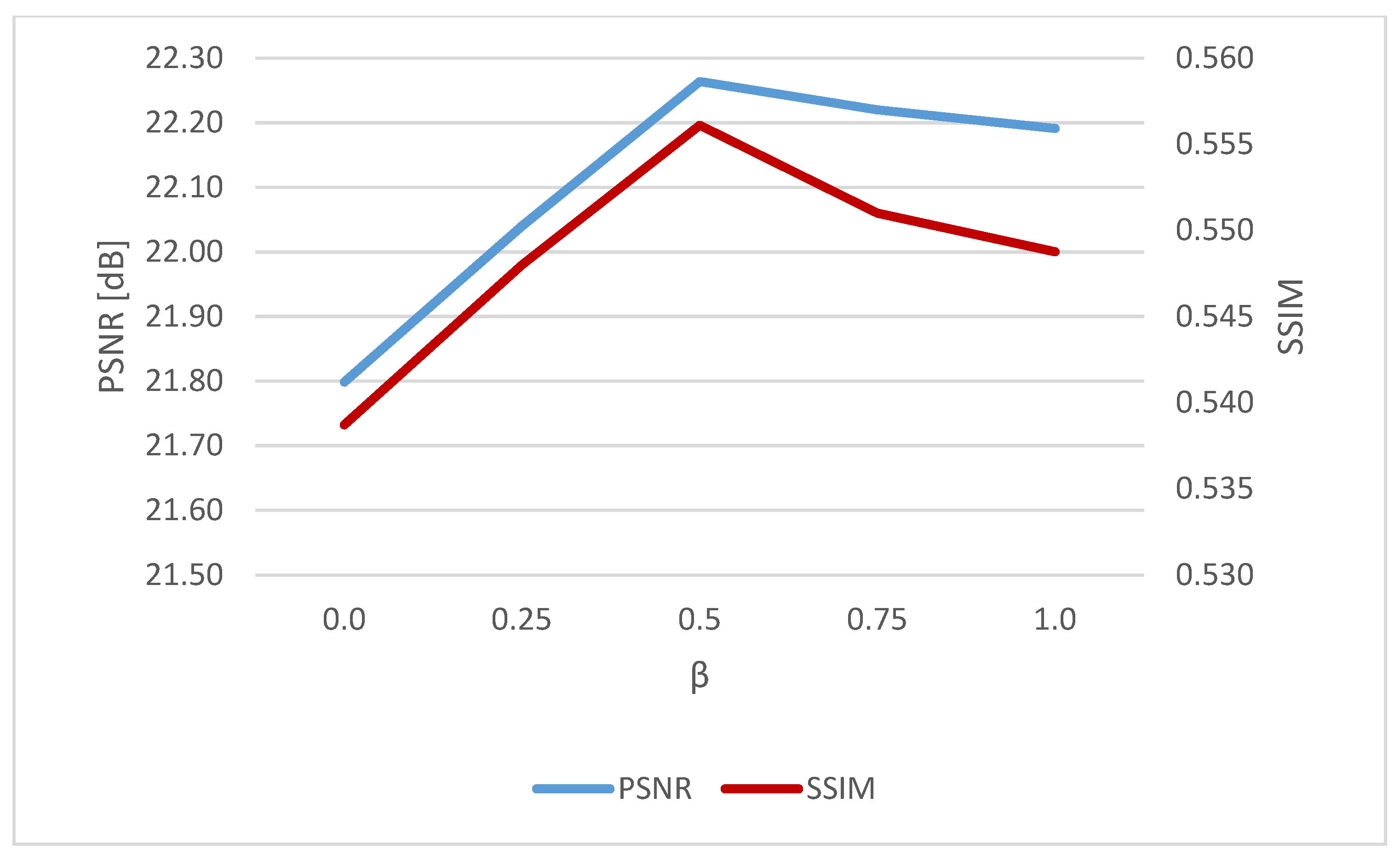
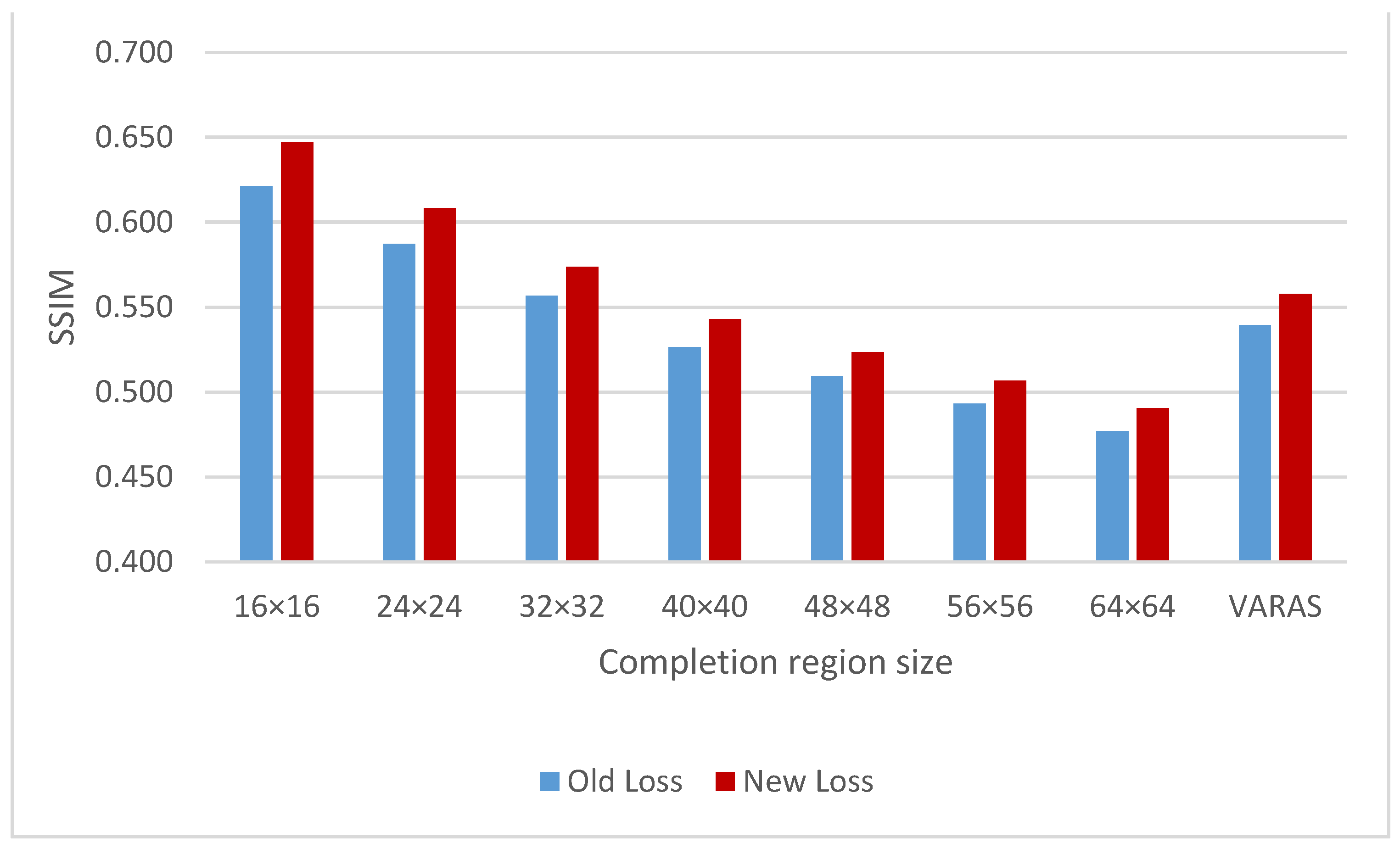
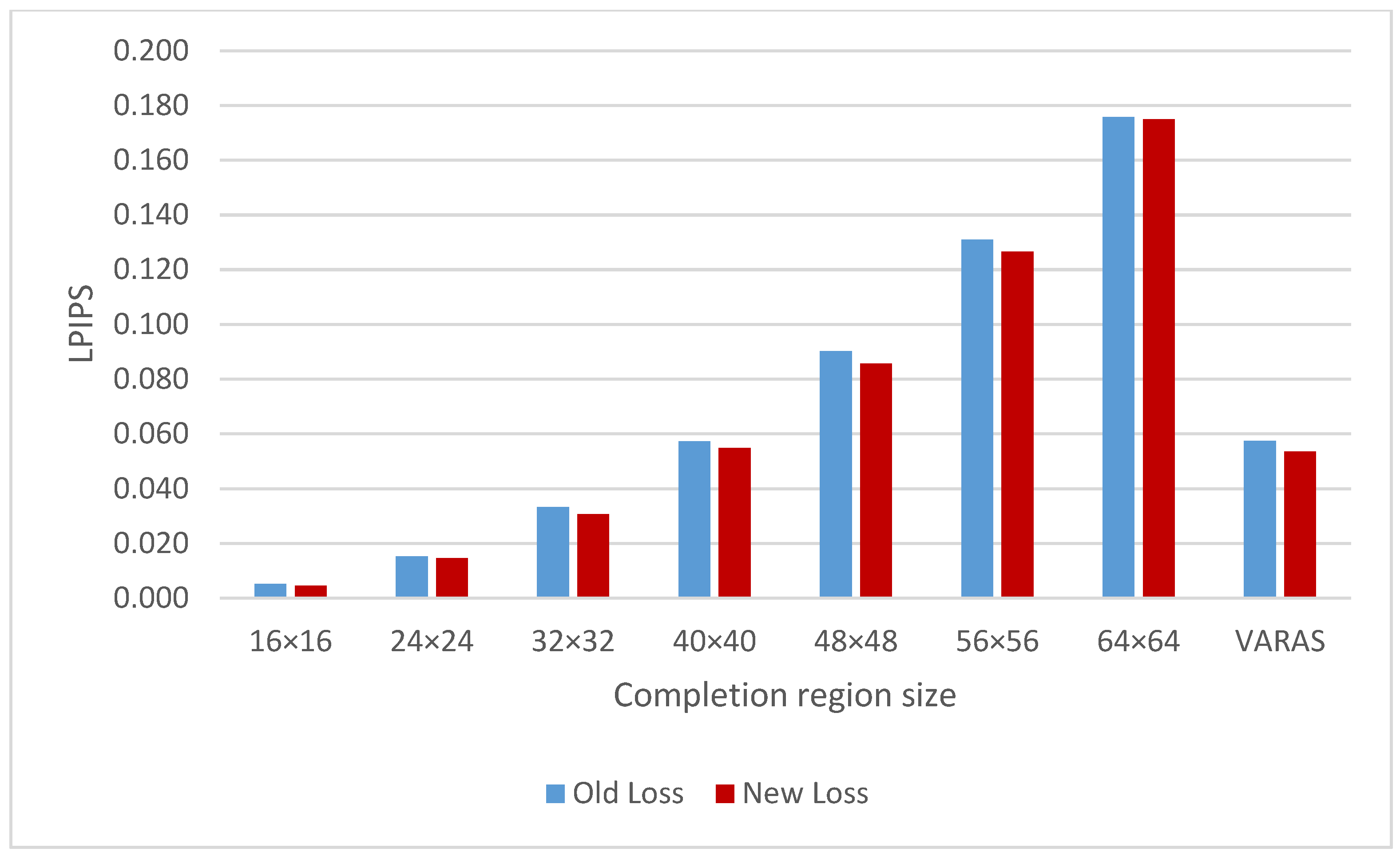
4.4. Improvement in Network Training
4.5. Operational Experiments of the DR Application
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mori, S.; Ikeda, S.; Saito, H. A survey of diminished reality: Techniques for visually concealing, eliminating, and seeing through real objects. IPSJ Trans. Comput. Vis. Appl. 2017, 9, 17. [Google Scholar] [CrossRef]
- Bamum, P.; Sheikh, B.; Datta, A.; Kanade, T. Dynamic Seethroughs: Synthesizing Hidden Views of Moving Objects. In Proceedings of the 2009 8th IEEE International Symposium on Mixed and Augmented Reality, Orlando, FL, USA, 19–22 October 2009; pp. 111–114. [Google Scholar] [CrossRef]
- Zokai, S.; Esteve, J.; Genc, Y.; Navab, N. Multiview paraperspective projection model for diminished reality. In Proceedings of the Second IEEE and ACM International Symposium on Mixed and Augmented Reality, Tokyo, Japan, 10 October 2003; pp. 217–226. [Google Scholar] [CrossRef]
- Kameda, Y.; Takemasa, T.; Ohta, Y. Outdoor see-through vision utilizing surveillance cameras. In Proceedings of the Third IEEE and ACM International Symposium on Mixed and Augmented Reality, Arlington, VA, USA, 5 November 2004; pp. 151–160. [Google Scholar] [CrossRef]
- Rameau, F.; Ha, H.; Joo, K.; Choi, J.; Park, K.; Kweon, I.S. A real-time augmented reality system to see-through car. IEEE Trans. Vis. Comput. Graph. 2016, 22, 2395–2404. [Google Scholar] [CrossRef] [PubMed]
- Queguiner, G.; Fradet, M.; Rouhani, M. Towards Mobile Diminished Reality. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality Adjunct, Munich, Germany, 16–20 October 2018; pp. 226–231. [Google Scholar] [CrossRef]
- Kunert, C.; Schwandt, T.; Broll, W. An efficient diminished reality approach using real-time surface reconstruction. In Proceedings of the 2019 International Conference on Cyberworlds, Kyoto, Japan, 2–4 October 2019; pp. 9–16. [Google Scholar] [CrossRef]
- Kato, T.; Isoyama, N.; Kawai, N.; Uchiyama, H.; Sakata, N.; Kiyokawa, K. Online Adaptive Integration of Observation and Inpainting for Diminished Reality with Online Surface Reconstruction. In Proceedings of the 2022 IEEE International Symposium on Mixed and Augmented Reality Adjunct, Singapore, 17–21 October 2022; pp. 308–314. [Google Scholar] [CrossRef]
- Nakajima, Y.; Mori, S.; Saito, H. Semantic object selection and detection for diminished reality based on slam with viewpoint class. In Proceedings of the 2017 IEEE International Symposium on Mixed and Augmented Reality, Nantes, France, 9–13 October 2017; pp. 338–343. [Google Scholar] [CrossRef]
- Herling, J.; Broll, W. PixMix: A Real-Time Approach to High-Quality Diminished Reality. In Proceedings of the 2012 IEEE International Symposium on Mixed and Augmented Reality, Atlanta, GA, USA, 5–8 November 2012; pp. 141–150. Available online: https://ieeexplore.ieee.org/abstract/document/6402551 (accessed on 27 August 2023).
- Mori, S.; Erat, O.; Saito, H.; Schmalstieg, D.; Kalkofen, D. InpaintFusion: Incremental RGB-D Inpainting for 3D Scenes. IEEE Trans. Vis. Comput. Graph. 2020, 26, 2994–3007. [Google Scholar] [CrossRef]
- Gkitsas, V.; Sterzentsenko, V.; Zioulis, N.; Albanis, G.; Zarpalas, D. Panodr: Spherical panorama diminished reality for indoor scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Montreal, QC, Canada, 11 October 2021. [Google Scholar] [CrossRef]
- Adobe. Available online: https://helpx.adobe.com/jp/photoshop/how-to/remove-person-from-photo.html (accessed on 27 August 2023).
- Google Photo. Available online: https://www.google.com/intl/ja/photos/about/ (accessed on 27 August 2023).
- Siltanen, S. Texture generation over the marker area. In Proceedings of the 2006 IEEE/ACM International Symposium on Mixed and Augmented Reality, Santa Barbara, CA, USA, 22–25 October 2006; pp. 253–254. [Google Scholar] [CrossRef]
- Kawai, N.; Sato, T.; Yokoya, N. Augmented reality marker hiding with texture deformation. IEEE Trans. Vis. Comput. Graph. 2017, 23, 2288–2300. [Google Scholar] [CrossRef] [PubMed]
- Mori, S.; Schmalstieg, D.; Kalkofen, D. Good Keyframes to Inpaint. IEEE Trans. Vis. Comput. Graph. 2023, 29, 3989–4000. [Google Scholar] [CrossRef]
- Kikuchi, T.; Kukuda, T.; Yabuki, N. Diminished reality using semantic segmentation and generative adversarial network for landscape assessment: Evaluation of image inpainting according to colour vision. J. Comput. Des. Eng. 2022, 9, 1633–1649. [Google Scholar] [CrossRef]
- Gsaxner, C.; Mori, S.; Schmalstieg, D.; Egger, J.; Paar, G.; Bailer, W.; Kalkofen, D. DeepDR: Deep Structure-Aware RGB-D Inpainting for Diminished Reality. In Proceedings of the International Conference on 3D Vision 2024, Davos, Switzerland, 18–21 March 2024. [Google Scholar]
- Kari, M.; Puppendahl, T.G.; Coelho, L.F.; Fender, A.R.; Bethge, D.; Schutte, R.; Holz, C. TransforMR: Pose-Aware Object Substitution for Composing Alternate Mixed Realities. In Proceedings of the 2021 IEEE International Symposium on Mixed and Augmented Reality, Bari, Italy, 4–8 October 2021; pp. 69–79. [Google Scholar] [CrossRef]
- Kawai, N.; Sato, T.; Yokoya, N. Diminished reality based on image inpainting considering background geometry. IEEE Trans. Vis. Comput. Graph. 2016, 22, 1236–1247. [Google Scholar] [CrossRef]
- Fundamental Concepts|ARCore|Google Developers. Available online: https://developers.google.com/ar/discover/concepts (accessed on 27 August 2023).
- Iizuka, S.; Simo-Serra, E.; Ishikawa, H. Globally and Locally Consistent Image Completion. ACM Trans. Graph. 2017, 36, 1–14. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018. [Google Scholar] [CrossRef]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18 June 2018. [Google Scholar] [CrossRef]
- Quattoni, A.; Torralba, A. Recognizing Indoor Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20 June 2009. [Google Scholar]
- Pixabay. Available online: https://pixabay.com/ja/ (accessed on 27 August 2023).
- Unsplash. Available online: https://unsplash.com/ (accessed on 27 August 2023).
- GAHAG. Available online: https://gahag.net (accessed on 27 August 2023).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| GLCIC | Ch-GLCIC | Co-GLCIC | CC-GLCIC |
|---|---|---|---|
| 80.4 | 79.3 | 37.7 | 36.6 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kobayashi, K.; Takahashi, M. Real-Time Diminished Reality Application Specifying Target Based on 3D Region. Virtual Worlds 2024, 3, 115-134. https://doi.org/10.3390/virtualworlds3010006
Kobayashi K, Takahashi M. Real-Time Diminished Reality Application Specifying Target Based on 3D Region. Virtual Worlds. 2024; 3(1):115-134. https://doi.org/10.3390/virtualworlds3010006
Chicago/Turabian StyleKobayashi, Kaito, and Masanobu Takahashi. 2024. "Real-Time Diminished Reality Application Specifying Target Based on 3D Region" Virtual Worlds 3, no. 1: 115-134. https://doi.org/10.3390/virtualworlds3010006
APA StyleKobayashi, K., & Takahashi, M. (2024). Real-Time Diminished Reality Application Specifying Target Based on 3D Region. Virtual Worlds, 3(1), 115-134. https://doi.org/10.3390/virtualworlds3010006