
A Systematic Approach for Assessing Large Language Models’ Test Case Generation Capability


Abstract
1. Introduction
2. Related Work
2.1. Test Cases Generation via LLMs
2.2. Benchmark for Evaluating LLMs
2.3. Summary
- Can we develop a flexible benchmark dataset?
- Can users use only a single prompt with source codes given to an LLM to generate test cases?
- How well can LLMs generate test cases while solely inputting source codes?
3. Method
3.1. Overall Process
3.2. Guiding Principles of Benchmark Creation
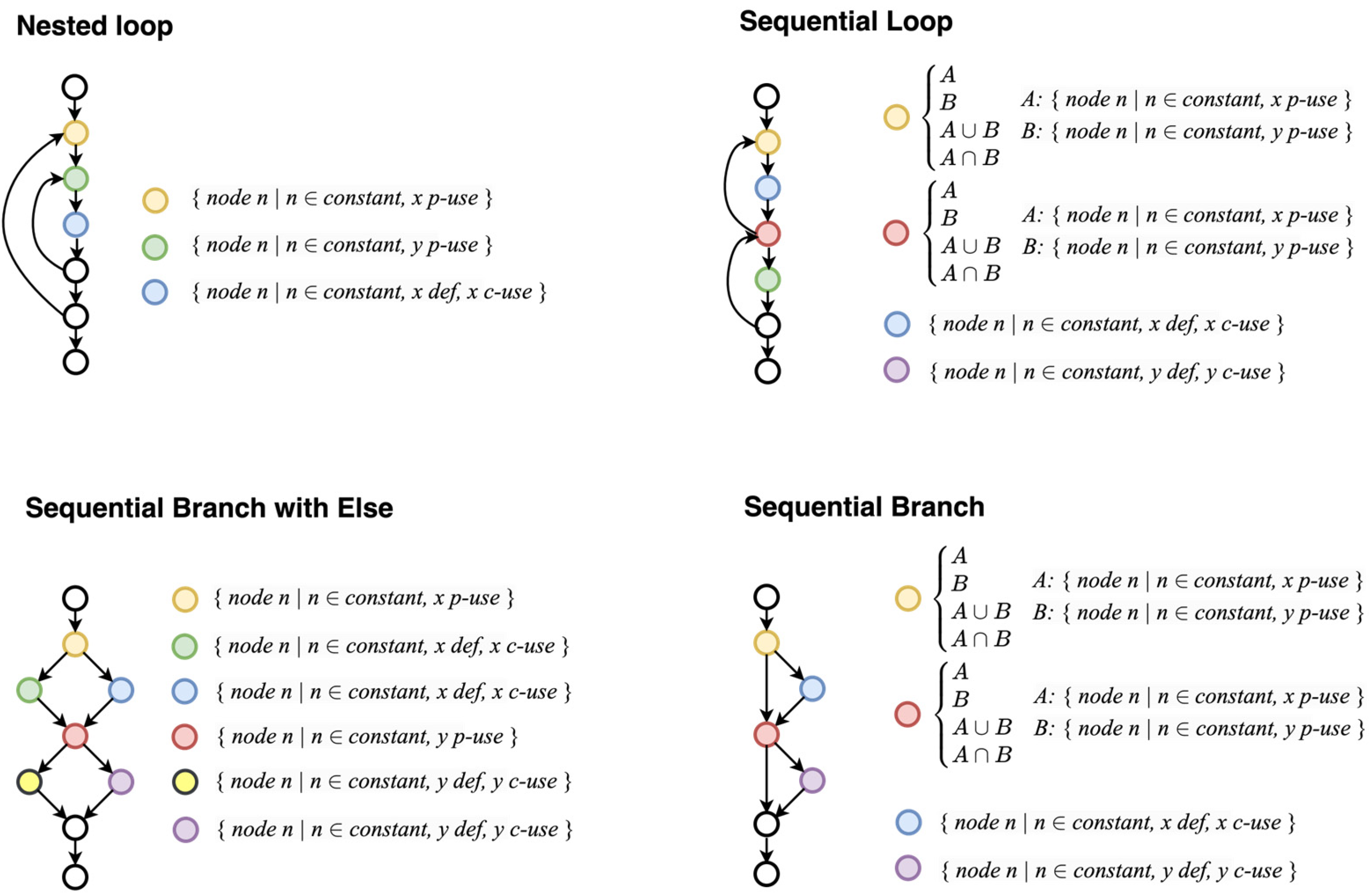
3.3. Dataset Creation
- Boundary and Comparison
- ▪
- Branch, sequential branch, sequential branch with else:
- ○
- x p-use set 1: x > 5, x < 5 …, x == 5.
- ○
- x p-use set 2: x > 15, x < 15 …, x == 15.
- ○
- y p-use: y > 10, y < 10 …, y == 10.
- ○
- Compound predicate for x and y: x > 5 and y > 10, … x == 5 or y == 10.
- 2.
- Computation
- ▪
- Sequence, loop, branch, sequential branch, sequential branch with else:
- ○
- x def with x c-use: x = x + 10, … x = x*7, x = x − 7.
- ○
- y def with y c-use: y = y + 7, …, y = y − 7.
- ○
- x def with x c-use and y c-use: x = x + y + 10, …, x = x + y − 7.
- 3.
- Iteration
- ▪
- Loop, sequential loop, nested loop:
- ○
- Constant value: 3.
- ○
- Dynamic value: y p-use.
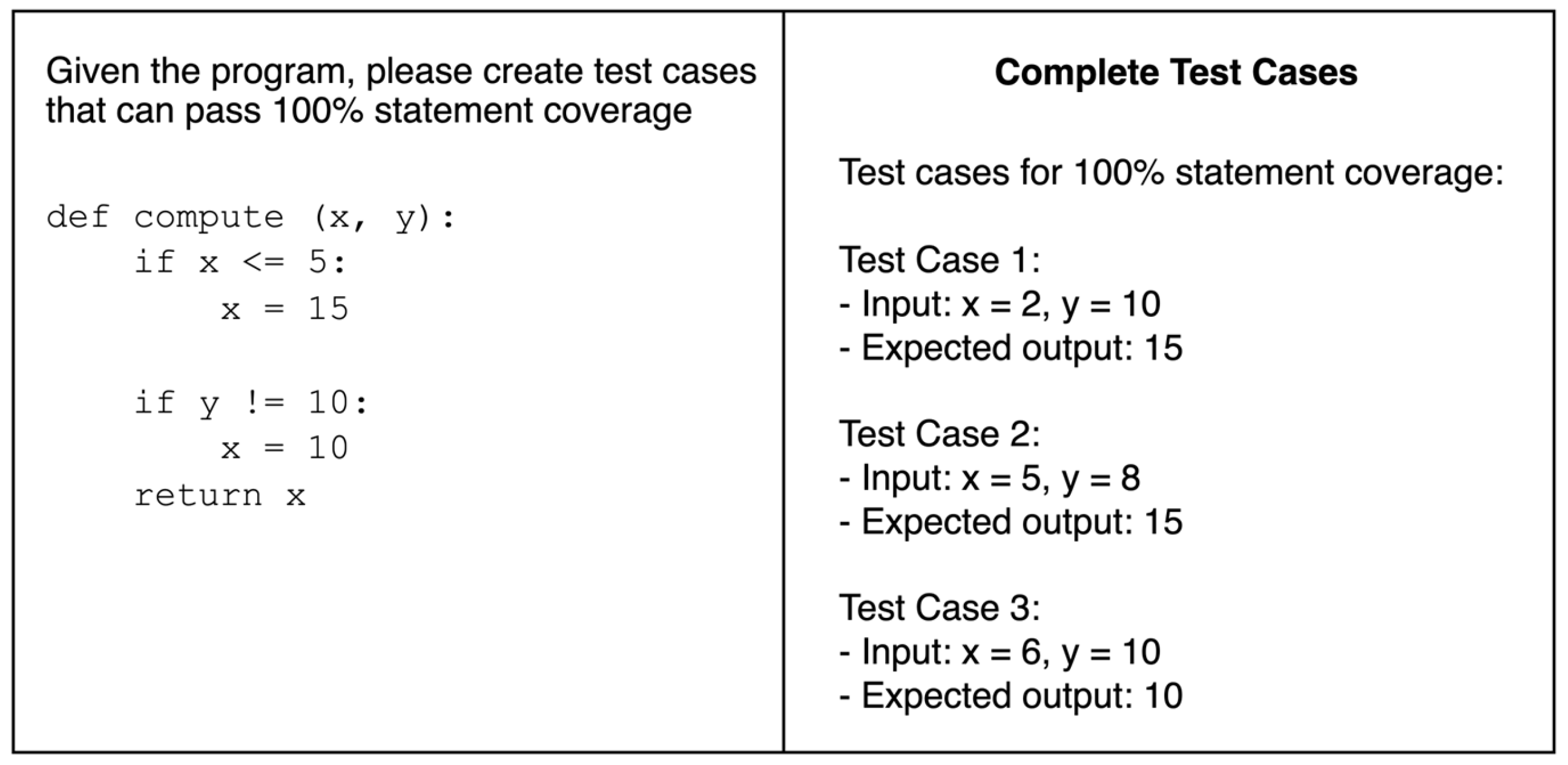
3.4. Metrics
- Complete (valid) and incomplete (invalid) test case.
- Complete (valid) test cases: (input values, output values).
- Incomplete (invalid) test cases: (input values).
- 2.
- Correct test case.
- 3.
- Untestable program (codes)
4. Results
5. Discussion
5.1. Simple vs. Composite Structure
- GPT-4o performs better with composite structures, whereas GPT-4o-mini excels with simpler ones (as seen in the average error rate in Table 4).
- Both the GPT-4o and GPT-4o-mini models produce more complete test cases than GPT-3.5-Turbo, particularly when dealing with composite program structures.
5.2. Computation
- Computation tasks continue to be a challenge in test case generation.
- Computations involving two c-use variables produce incorrect results more easily.
5.3. Boundary and Comparison
5.4. Iteration
- Adding a c-use variable leads to incorrect results in computations.
- The GPT-4o family shows partial success in handling iterations.
5.5. Limitations
6. Conclusions
7. Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Tassey, G. The Economic Impacts of Inadequate Infrastructure for Software Testing; National Institute of Standards and Technology: Gaithersburg, MD, USA, 2002. [Google Scholar]
- Grano, G.; Scalabrino, S.; Gall, H.C.; Oliveto, R. An Empirical Investigation on the Readability of Manual and Generated Test Cases. In Proceedings of the 26th International Conference on Program Comprehension, ICPC, Gothenburg, Sweden, 27 May–3 June 2018; Zurich Open Repository and Archive (University of Zurich): Zürich, Switzerland, 2018. [Google Scholar] [CrossRef]
- Tufano, M.; Drain, D.; Svyatkovskiy, A.; Deng, S.K.; Sundaresan, N. Unit Test Case Generation with Transformers and Focal Context. arXiv 2020, arXiv:2009.05617. Available online: http://arxiv.org/abs/2009.05617 (accessed on 17 November 2024).
- Winkler, D.; Urbanke, P.; Ramler, R. Investigating the Readability of Test Code. Empir. Softw. Eng. 2024, 29, 53. [Google Scholar] [CrossRef]
- Chen, Y.; Hu, Z.; Zhi, C.; Han, J.; Deng, S.; Yin, J. ChatUniTest: A Framework for LLM-Based Test Generation. arXiv 2023, arXiv:2305.04764. Available online: http://arxiv.org/abs/2305.04764 (accessed on 17 November 2024).
- Siddiq, M.L.; Da Silva Santos, J.C.; Tanvir, R.H.; Ulfat, N.; Al Rifat, F.; Carvalho Lopes, V. Using Large Language Models to Generate JUnit Tests: An Empirical Study. In Proceedings of the 28th International Conference on Evaluation and Assessment in Software Engineering, Salerno Italy, 18–21 June 2024; pp. 313–322. [Google Scholar] [CrossRef]
- Daka, E.; Fraser, G. A Survey on Unit Testing Practices and Problems. In Proceedings of the International Symposium on Software Reliability Engineering, Naples, Italy, 3–6 November 2014; pp. 201–211. [Google Scholar]
- Anand, S.; Burke, E.K.; Chen, T.Y.; Clark, J.; Cohen, M.B.; Grieskamp, W.; Harman, M.; Harrold, M.J.; McMinn, P.; Bertolino, A.; et al. An Orchestrated Survey of Methodologies for Automated Software Test Case Generation. J. Syst. Softw. 2013, 86, 1978–2001. [Google Scholar] [CrossRef]
- Kaur, A.; Vig, V. Systematic Review of Automatic Test Case Generation by UML Diagrams. Int. J. Eng. Res. Technol. 2012, 1, 6. [Google Scholar]
- Brunetto, M.; Denaro, G.; Mariani, L.; Pezzè, M. On Introducing Automatic Test Case Generation in Practice: A Success Story and Lessons Learned. J. Syst. Softw. 2021, 176, 110933. [Google Scholar] [CrossRef]
- Li, J.; Li, G.; Li, Y.; Jin, Z. Structured Chain-of-Thought Prompting for Code Generation. ACM Trans. Softw. Eng. Methodol. 2024, 34, 1–23. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Li, G.; Jin, Z.; Hao, Y.; Hu, X. SKCODER: A Sketch-Based Approach for Automatic Code Generation. In Proceedings of the 2023 IEEE/ACM 45th International Conference on Software Engineering (ICSE), Melbourne, VIC, Australia, 14–20 May 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 2124–2135. [Google Scholar]
- Li, J.; Zhao, Y.; Li, Y.; Li, G.; Jin, Z. AceCoder: Utilizing Existing Code to Enhance Code Generation. Available online: https://api.semanticscholar.org/CorpusID:257901190 (accessed on 17 November 2024).
- Dong, Y.; Jiang, X.; Jin, Z.; Li, G. Self-Collaboration Code Generation via ChatGPT. arXiv 2023, arXiv:2304.07590. [Google Scholar] [CrossRef]
- Chen, Y.; Zhang, R.; Yang, K.; Yasunaga, M.; Wang, D.; Li, Z.; Metcalfe, J.; Li, I.; Yao, Q.; Roman, S.; et al. Spider: A Large-Scale Human-Labeled Dataset for Complex and Cross-Domain Semantic Parsing and Text-To-SQL Task. arXiv 2018, arXiv:1809.08887. [Google Scholar] [CrossRef]
- Li, J.; Hui, B.; Qu, G.; Li, B.; Yang, J.; Li, B.; Wang, B.; Qin, B.; Cao, R.; Geng, R.; et al. Can LLM Already Serve as a Database Interface? A BIg Bench for Large-Scale Database Grounded Text-To-SQLs. arXiv 2023, arXiv:2305.03111. [Google Scholar] [CrossRef]
- Wang, W.; Yang, C.; Wang, Z.; Huang, Y.; Chu, Z.; Song, D.; Zhang, L.; Chen, A.R.; Ma, L. TESTEVAL: Benchmarking Large Language Models for Test Case Generation. arXiv 2024, arXiv:2406.04531. [Google Scholar] [CrossRef]
- Anand, S.; Harrold, M.J. Heap Cloning: Enabling Dynamic Symbolic Execution of Java Programs. In Proceedings of the 2011 26th IEEE/ACM International Conference on Automated Software Engineering (ASE 2011), Lawrence, KS, USA, 6–10 November 2011. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. Evolutionary Generation of Whole Test Suites. In Proceedings of the 2011 11th International Conference on Quality Software, Madrid, Spain, 13–14 July 2011. [Google Scholar] [CrossRef]
- Fraser, G.; Arcuri, A. EvoSuite. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering—SIGSOFT/FSE ’11, Szeged, Hungary, 5–9 September 2011. [Google Scholar] [CrossRef]
- Almasi, M.M.; Hemmati, H.; Fraser, G.; Arcuri, A.; Benefelds, J. An Industrial Evaluation of Unit Test Generation: Finding Real Faults in a Financial Application. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering: Software Engineering in Practice Track (ICSE-SEIP), Buenos Aires, Argentina, 20–28 May 2017. [Google Scholar] [CrossRef]
- Panichella, A.; Panichella, S.; Fraser, G.; Sawant, A.A.; Hellendoorn, V.J. Replication Package of “Revisiting Test Smells in Automatically Generated Tests: Limitations, Pitfalls, and Opportunities”; Zenodo (CERN European Organization for Nuclear Research): Geneva, Switzerland, 2020. [Google Scholar] [CrossRef]
- Schäfer, M.; Nadi, S.; Eghbali, A.; Tip, F. An Empirical Evaluation of Using Large Language Models for Automated Unit Test Generation. arXiv 2023, arXiv:2302.06527. Available online: https://arxiv.org/abs/2302.06527 (accessed on 10 December 2023). [CrossRef]
- Yuan, Z.; Lou, Y.; Liu, M.; Ding, S.; Wang, K.; Chen, Y.; Peng, X. No More Manual Tests? Evaluating and Improving ChatGPT for Unit Test Generation. arXiv 2023. [Google Scholar] [CrossRef]
- Xie, Z.; Chen, Y.; Chen, Z.; Deng, S.; Yin, J. ChatUniTest: A ChatGPT-Based Automated Unit Test Generation Tool. arXiv 2023, arXiv:2305.04764. [Google Scholar] [CrossRef]
- Vikram, V.; Lemieux, C.; Padhye, R. Can Large Language Models Write Good Property-Based Tests? arXiv 2023, arXiv:2307.04346. [Google Scholar] [CrossRef]
- Koziolek, H.; Ashiwal, V.; Bandyopadhyay, S.; Chandrika, K.R. Automated Control Logic Test Case Generation Using Large Language Models. arXiv 2024, arXiv:2405.01874. [Google Scholar] [CrossRef]
- Plein, L.; Ouédraogo, W.C.; Klein, J.; Bissyandé, T.F. Automatic Generation of Test Cases Based on Bug Reports: A Feasibility Study with Large Language Models. arXiv 2024, arXiv:2310.06320. [Google Scholar] [CrossRef]
- Wang, C.; Pastore, F.; Göknil, A.; Briand, L.C. Automatic Generation of Acceptance Test Cases from Use Case Specifications: An NLP-Based Approach. arXiv 2019, arXiv:1907.08490. [Google Scholar] [CrossRef]
- Lan, W.; Wang, Z.; Chauhan, A.; Zhu, H.; Li, A.; Guo, J.; Zhang, S.; Hang, C.-W.; Lilien, J.; Hu, Y.; et al. UNITE: A Unified Benchmark for Text-To-SQL Evaluation. arXiv 2023, arXiv:2305.16265. [Google Scholar] [CrossRef]
- Chen, M.I.-C.; Tworek, J.; Jun, H.; Yuan, Q.; Henrique; Kaplan, J.; Edwards, H.; Burda, Y.; Joseph, N.; Brockman, G.; et al. Evaluating Large Language Models Trained on Code. arXiv 2021, arXiv:2107.03374. [Google Scholar] [CrossRef]
- Liu, J.; Xia, C.S.; Wang, Y.; Zhang, L. Is Your Code Generated by ChatGPT Really Correct? Rigorous Evaluation of Large Language Models for Code Generation. Available online: https://openreview.net/forum?id=1qvx610Cu7 (accessed on 10 May 2024).
- Yan, W.; Liu, H.; Wang, Y.; Li, Y.; Chen, Q.; Wang, W.; Lin, T.; Zhao, W.; Zhu, L.; Deng, S.; et al. CodeScope: An Execution-Based Multilingual Multitask Multidimensional Benchmark for Evaluating LLMs on Code Understanding and Generation. arXiv 2023, arXiv:2311.08588. [Google Scholar] [CrossRef]
- Watson, A.H.; Wallace, D.R.; McCabe, T.J. Structured Testing: A Testing Methodology Using the Cyclomatic Complexity Metric; NIST Special Publication: Gaithersburg, MD, USA, 1996; p. 500. [Google Scholar]
- Shao, J.; Wang, Y. A New Measure of Software Complexity Based on Cognitive Weights. Can. J. Electr. Comput. Eng. 2003, 28, 69–74. [Google Scholar] [CrossRef]
- Misra, S. A Complexity Measure Based on Cognitive Weights. Int. J. Theor. Appl. Comput. Sci. 2006, 1, 1–10. [Google Scholar]
- Wei, J.S.; Wang, X.; Schuurmans, D.; Bosma, M.; Chi, E.H.; Le, Q.V.; Zhou, D. Chain-of-Thought Prompting Elicits Reasoning in Large Language Models. arXiv 2022, arXiv:2201.11903. [Google Scholar] [CrossRef]
- Winterer, D.; Zhang, C.; Su, Z. On the Unusual Effectiveness of Type-Aware Operator Mutations for Testing SMT Solvers. Proc. ACM Program. Lang. 2020, 4, 1–25. [Google Scholar] [CrossRef]
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Principles | Element Description | Complexity Level * | Examples |
|---|---|---|---|
| Types of predicates with number of predicates | Single comparison: equality | L | x == 18 |
| Single comparison: relational | L | x > 18 | |
| Single predicate with computation | M | is_positive(x) x%2 == 0 | |
| Compound predicates (two predicates) | M | x >= 18 and y < 5 x >= 18 && y < 5 | |
| Compound predicates (multiple predicates) | M-H | x >= 18 and y < 5 and z x >= 18 && y < 5 && z | |
| Compound predicates (two predicates) with computations | M-H | x+ y > 5 and x%2 == 0 x+ y > 5 && x%2 == 0 | |
| Compound predicates (multiple predicates) with computations | H | x+ y > 5 and x%2 == 0 and z x+ y > 5 && x%2 == 0 && z | |
| Number of computations | 1–3 | L | |
| >3 | M-H | ||
| Type of computations | Four basic arithmetic operations | L | x = x + 5+ 2*x/5 |
| Beyond four basic arithmetic operations | M-H | math.sqrt(5) 5**2 5^2 | |
| Variable datatypes or constant values or used values | Integer | L | 25 |
| Floating point | L-M | 1.22 | |
| String | L-M | “abc” | |
| Boolean | L | True/False | |
| Complex | M-H | Object Nested list | |
| Number of basic structures | 1 | L | |
| 2 | L-M | ||
| >2 | M-H | ||
| Formation of multiple basic structures | Sequential | L-M | |
| Nested | M-H | ||
| Recursive | H | ||
| Mixed | H |
| Category | Average Complexity (Average SLOC) | Coverage (% of Total Programs) |
|---|---|---|
| Branch | 6 | 9.16% |
| Loop | 5 | 3.94% |
| Nested loop | 6 | 3.81% |
| Sequence | 4.4 | 2.22% |
| Sequential branch | 8 | 37.1% |
| Sequential branch with else | 12 | 37.15% |
| Sequential loop | 7 | 6.62% |
| Model i | Total Test Cases TTi | Complete Test Cases CTi | Incomplete Test Case Rate TRi |
|---|---|---|---|
| GPT-3.5-Turbo | 2941 | 1978 | 32.74% |
| GPT-4o-mini | 3030 | 2845 | 6.1% |
| GPT-4o | 3032 | 2803 | 7.5% |
| Category | Models | Average Test Cases (AvgTNi) | Average Error Rate (AvgEi) |
|---|---|---|---|
| Branch | GPT-3.5-Turbo | 3.62 | 0.196 |
| GPT-4o-mini | 3.5 | 0.02 | |
| GPT-4o | 2.92 | 0.058 | |
| Loop | GPT-3.5-Turbo | 4 | 0.5 |
| GPT-4o-mini | 4.67 | 0.267 | |
| GPT-4o | 3.33 | 0.6 | |
| Nested loop | GPT-3.5-Turbo | 3 | 0.826 |
| GPT-4o-mini | 3.64 | 0.511 | |
| GPT-4o | 3.5 | 0.363 | |
| Sequence | GPT-3.5-Turbo | 3 | 0.2 |
| GPT-4o-mini | 3.75 | 0.1 | |
| GPT-4o | 4.67 | 0.167 | |
| Sequential branch | GPT-3.5-Turbo | 3.69 | 0.587 |
| GPT-4o-mini | 3.79 | 0.154 | |
| GPT-4o | 4.01 | 0.084 | |
| Sequential branch with else | GPT-3.5-Turbo | 3.89 | 0.882 |
| GPT-4o-mini | 4.08 | 0.224 | |
| GPT-4o | 3.98 | 0.196 | |
| Sequential loop | GPT-3.5-Turbo | 3.21 | 0.883 |
| GPT-4o-mini | 3.91 | 0.506 | |
| GPT-4o | 3.13 | 0.290 |
| Category | Models | % of Untestable Programs * |
|---|---|---|
| Branch | GPT-3.5-Turbo | 19.4% |
| GPT-4o-mini | 1.38% | |
| GPT-4o | 6.94% | |
| Loop | GPT-3.5-Turbo | 33.3% |
| GPT-4o-mini | 0% | |
| GPT-4o | 0% | |
| Nested loop | GPT-3.5-Turbo | 14.29% |
| GPT-4o-mini | 0% | |
| GPT-4o | 14.29% | |
| Sequence | GPT-3.5-Turbo | 0% |
| GPT-4o-mini | 0% | |
| GPT-4o | 20% | |
| Sequential branch | GPT-3.5-Turbo | 31.77% |
| GPT-4o-mini | 2.43% | |
| GPT-4o | 3.3% | |
| Sequential branch with else | GPT-3.5-Turbo | 42.19% |
| GPT-4o-mini | 23.44% | |
| GPT-4o | 17.19% | |
| Sequential loop | GPT-3.5-Turbo | 26.92% |
| GPT-4o-mini | 11.54% | |
| GPT-4o | 23.08% |
| Code | GPT-3.5-Turbo | GPT-4o | GPT-4o-mini |
|---|---|---|---|
| def compute (x, y): if x > 5: x = x + y + 10 if y == 10: x = x + y − 7 return x | Input 1: (x, y) = (6, 10) | Input 1: (x, y) = (6, 10) | Input 1: (x, y) = (6, 5) |
| Input 2: (x, y) = (7, 10) | Input 2: (x, y) = (5, 10) | Input 2: (x, y) = (5, 10) | |
| Input 3: (x, y) = (4, 10) | Input 3: (x, y) = (6, 5) | Input 3: (x, y) = (7, 10) | |
| Input 4: (x, y) = (6, 8) | Input 4: (x, y) = (5, 5) | Input 4: (x, y) = (4, 5) | |
| Input 5: (x, y) = (3, 11) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chang, H.-F.; Shokrolah Shirazi, M. A Systematic Approach for Assessing Large Language Models’ Test Case Generation Capability. Software 2025, 4, 5. https://doi.org/10.3390/software4010005
Chang H-F, Shokrolah Shirazi M. A Systematic Approach for Assessing Large Language Models’ Test Case Generation Capability. Software. 2025; 4(1):5. https://doi.org/10.3390/software4010005
Chicago/Turabian StyleChang, Hung-Fu, and Mohammad Shokrolah Shirazi. 2025. "A Systematic Approach for Assessing Large Language Models’ Test Case Generation Capability" Software 4, no. 1: 5. https://doi.org/10.3390/software4010005
APA StyleChang, H.-F., & Shokrolah Shirazi, M. (2025). A Systematic Approach for Assessing Large Language Models’ Test Case Generation Capability. Software, 4(1), 5. https://doi.org/10.3390/software4010005