
Implementing Mathematics of Arrays in Modern Fortran: Efficiency and Efficacy



Abstract
1. Introduction
1.1. Motivation
1.2. Background
2. Materals and Methods
2.1. Hardware and Software
- We chose the Linux system (64 bits) because it provides an easy-to-use system function, getrusage(), to measure a variety of resources used by the programs that were developed.
- The compilers were Intel Fortran 2021.2.0 and gfortran 10.1.0. We mostly used default options, but we also experimented with straightforward optimization options.
2.2. -Calculus
- B = A(n:1:−1,:)
2.3. Mechanization
2.4. MoA and Fortran Pointers and Arrays
integer :: array(2,3,5) write(*,’(a,3i5)’) ’Shape:˽’, shape(array)
- The entity (scalar or array) being pointed to has to be explicitly declared with the target attribute.
- The pointer is an array object and thus carries more information than simply the memory address. For example, pointers can be used to access a part of the array as if it were an array of its own or even access the elements in a reverse order or non-contiguously:
integer :: i integer, target :: value(20) integer, pointer :: pvalue(:) ! Fill the array value = [ (i, i = 1,20) ] ! Access in reverse order pvalue => value(5:1:−1) write(*,’(i5)’) pvalue(1) write(*,’(5i5))˽pvalue
5
5 4 3 2 1
integer, target :: value(20,30,50) integer, pointer :: pvalue(:,:,:) pvalue => value(1:5,1:10,:) ! Writes 5, 10 and 50 as the ! respective extents write(*,*) shape(pvalue)
integer :: lower_limit integer, target :: value(20) integer, pointer :: pvalue(:) ! Limit access to the last ! 3 elements − drop all others ! (Index starts at 1) ! lower_limit = size(value,1) − 3 + 1 pvalue => value(lower_limit:)
pvalue => 3 .drop. value
integer :: array(2,0,5) write(*,’(a,i5)’) ’Size:˽˽’, size(array) write(*,’(a,3i5)’) ’Shape:˽’, shape(array)
Size: 0 Shape: 2 0 5
integer, pointer :: p(:,:), q(:,:,:) integer, target :: array(200) p(1:10,1:20) => array q(1:8,1:5,1:5) => array write(*,’(a,i5)’) ’Array:˽˽˽˽˽’, shape(array) write(*,’(a,5i5)’) ’Pointer˽p:˽’, shape(p) write(*,’(a,5i5)’) ’Pointer˽q:˽’, shape(q)
-
prints
Array: 200 Pointer p: 10 20 Pointer q: 8 5 5
3. Results and Discussion
3.1. The Catenation Operation
integer, allocatable :: array(:), new_array(:)
allocate( array(10), new_array(10) )
…
array = [ array, new_array ]
! Prints 10 + 10 = 20
write(*,*) ’Size:’, size(array)
type(moa_view_type) :: view integer :: array1(10), array2(20), & array3(100) ! Initialise the arrays array1 = 0 array2 = 0 array3 = 0 ! Catenate two arrays to give a “view” ! on the result view = array1 //array2 ! Catenate the third array, so that a “view” ! results of three pieces view = view // array3 ! Writes 130 (the sum of the individual sizes) write(*,*) size(view) array2(1) = 1 ! Writes 0 and 1 (array1(10) and array2(1) write(*,*) ’Elements˽10˽and˽11:’, & view%elem(10), view%elem(11)
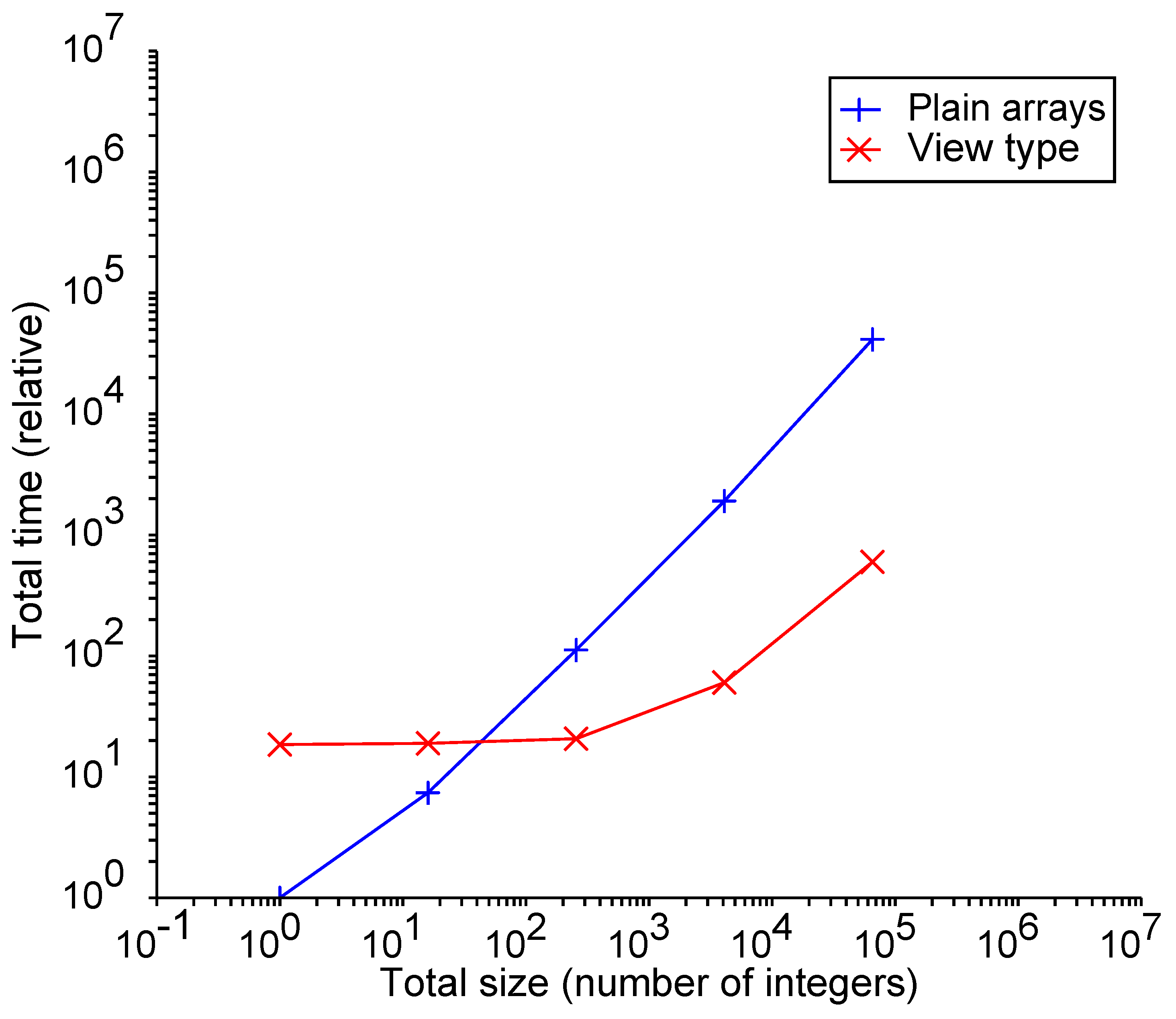
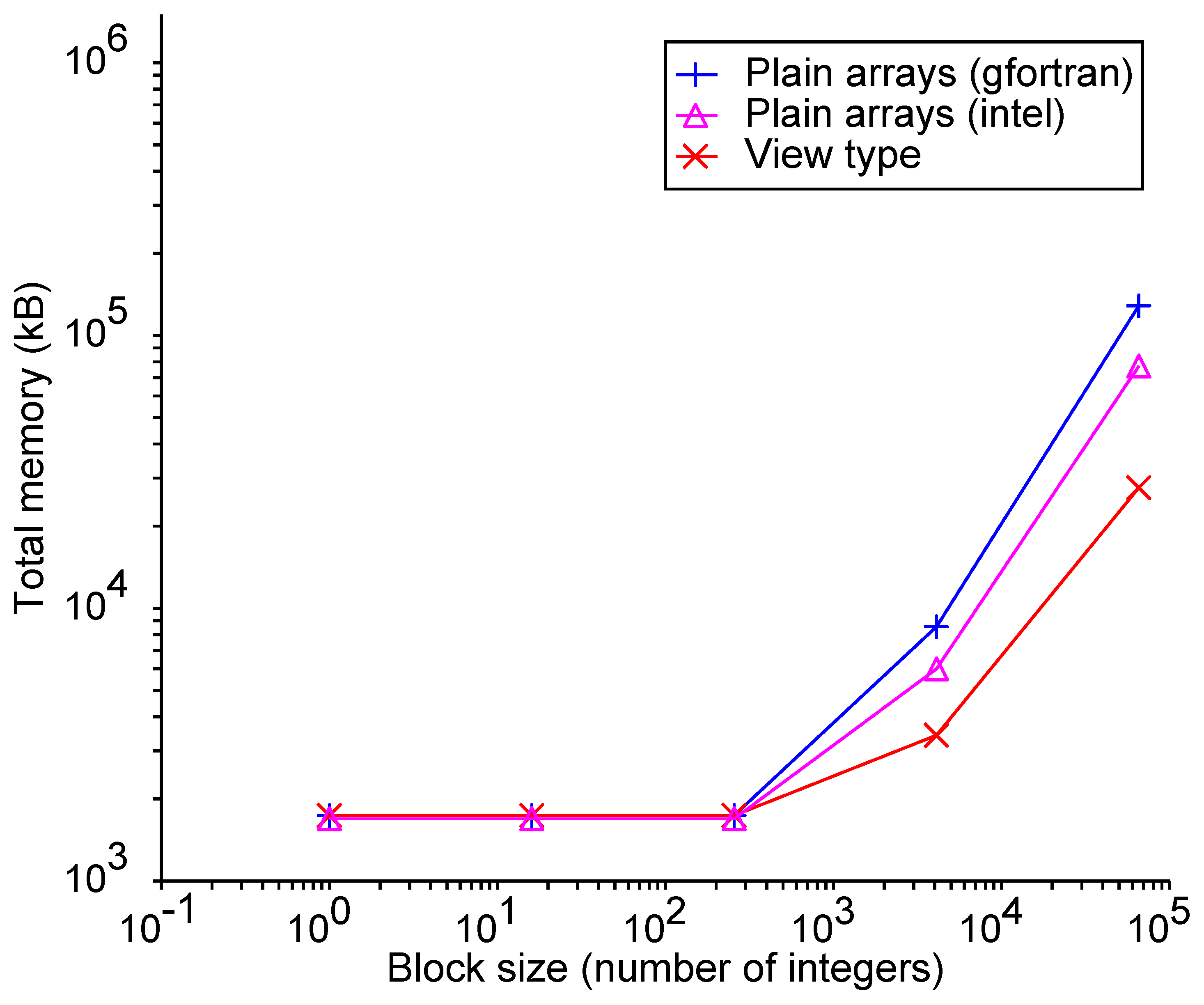
3.2. Experiment 1: Extending Arrays
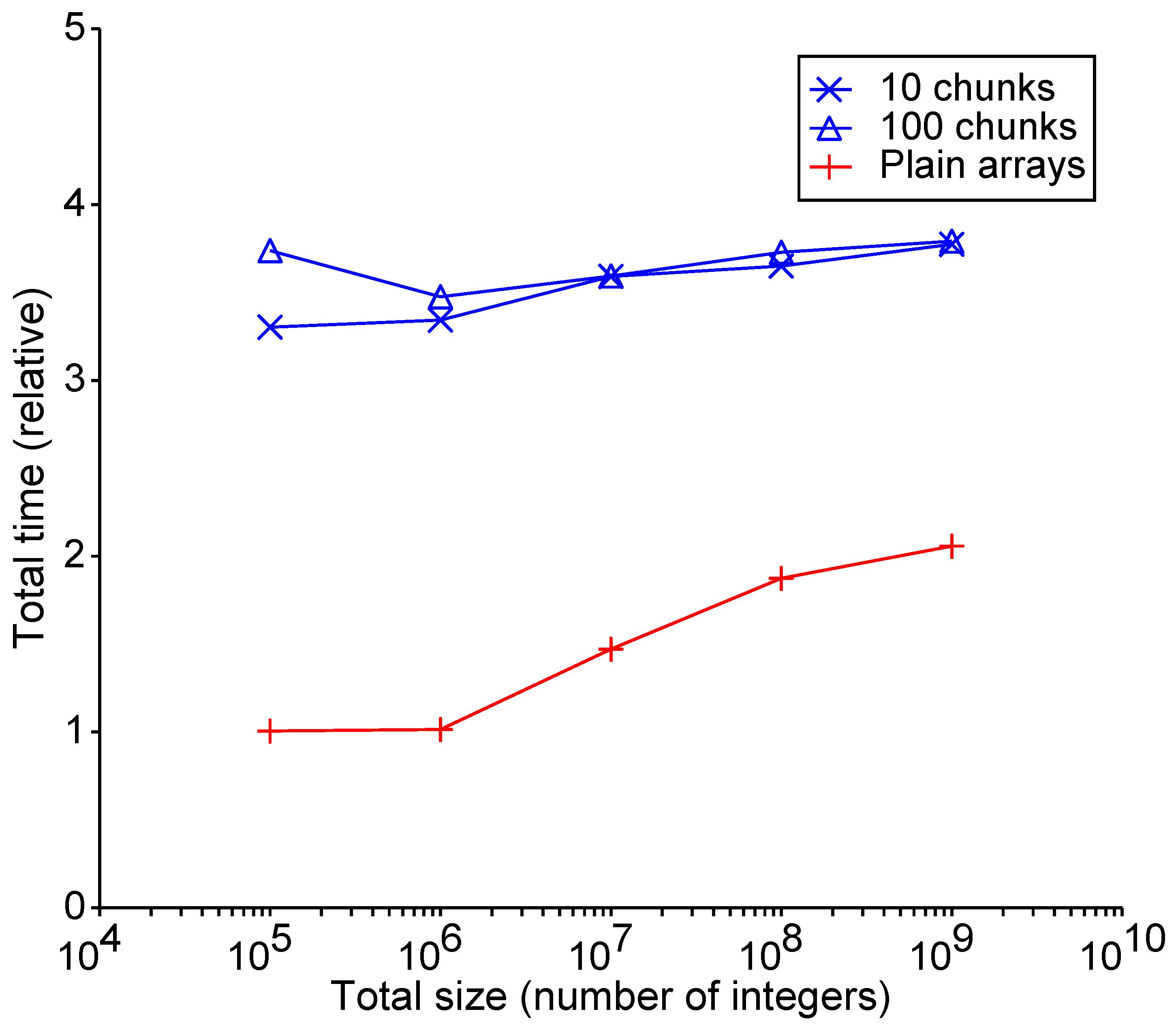
3.3. Experiment 2: Accessing Array Elements
do i = 1,number_seq j = 1 + mod((i − 1) ∗ step, sz ) subtotal = subtotal + x%elem(j) enddo total = total + mod(subtotal, 2)
- The work conducted in the loop must be large enough to let a measureable amount of time pass. Otherwise, noise will contaminate the results.
- The loops were repeated several thousands times to obtain a stable result, and even then, the measurements may have been influenced by whatever function the machine was performing at the time. So, the results presented here are the average of 30 individual runs.
- Optimizing compilers needed to be fooled; we were not interested in the result of the calculation, but the compiler may have noticed this and therefore “optimized away” the loop. For this reason, the result (total) was written to an external file.
- The “array” version and the “view” version should perform the same work for the timing results to be comparable. This is also applicable for compiler options (optimization and others).
4. Conclusions and Further Steps
- The programmer does not need to implement them themselves, something that may be quite non-trivial.
- The compiler knows the semantics exactly and can therefore decide on any number of optimizations and implementations. Typical libraries for linear algebra, like BLAS and LAPACK, have been highly optimized to take all possibilities into account with respect to memory layout and other machine-dependent characteristics. Such optimizations cannot be required from an individual programmer and are therefore limited to widely used libraries.
C = matmul( transpose(A), B )
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. N-Dimensional Transpose
Appendix B. Array Reduction and Inner Products
- There is an associative binary operation .
- The operation on the array works along the primary axis.
B = sum(A, dim = 1)
real :: A(imax,jmax,kmax), & B(kmax,lmax,mmax), & AB(imax,jmax,lmax,mmax) … do j = 1,jmax do i = 1,imax AB(i,j,:,:) = & sum( reshape( [(A(i,j,k)∗B(k,:,:), k = 1,kmax)], & [lmax,mmax,kmax]), dim=3) enddo enddowhere the order of the dimensions of the intermediate array is dictated by the implied do-loop, so the summation needs to be performed over the last dimension.
Appendix C. Matching MoA Operations with Fortran Features
- Arrays (and pointers to such arrays) in Fortran are usually indexed from 1 onwards but can be given any starting index. In MoA, the starting index is always 0. This fact means that negative indices should not be given a meaning like in a language like Python, where it indicates a array element “left” of the last one.
- Multidimensional arrays in Fortran are organized in a column-major order, that is, the left-most index of an array like runs faster so that is adjacent in memory to . The array element is adjacent to . In MoA, use is made of the principal axis, so, for Fortran, it corresponds to the left-most index, whereas in C/C++, it corresponds to the right-most index.
- A (or A) is a two-dimensional array.
- (or s) is a scalar. Also, m and n are scalars representing a (new) size.
- v and w (or v and w) are one-dimensional arrays.
- p is a pointer to a one-dimensional array, and p2 is a pointer to a two-dimensional array.
- sz is the size of the array A.

{kind=link}
{kind=link}
{kind=link}
| Meaning | MoA | Fortran |
|---|---|---|
| Size of an array (1) | size(A) | |
| Shape of an array (2) | shape(A) | |
| Taking part of an array | A(1:s,:) | |
| along the major axis | ||
| Dropping part of an array | A(L:,:) | |
| along the major axis (3) | ||
| Ravel (n-dim to 1-dim) | p(1:sz)=>A | |
| Dimension lifting | p2(1:m,1:n)=>v | |
| Reversing an array | p(sz:1:-1)=>A | |
| Rotating an array | cshift(A,s,1) | |
| Catenation (4) | vnew=[v,w] |
- For take, the indices range from 1 to .
- For drop, the indices ranging from 1 to are instead dropped, and the valid index runs from to the full extent.
Appendix D. User-Defined Operators: Drop
module~userOperators interface operator(.drop.) module procedure dropArray end interface … contains function dropArray( lower_limit, array ) integer, target, intent(in) :: array(:) integer, intent(in) :: lower_limit integer, pointer :: dropArray(:) dropArray => array(size(array,1)−lower_limit+1:) end function dropArray end module userOperators
References
- Berkling, K. Arrays and the Lambda Calculus; Technical Report 93, Electrical Engineering and Computer Science Technical Reports; Syracuse University: Syracuse, NY, USA, 1990. [Google Scholar]
- Leiserson, C.E.; Thompson, N.C.; Emer, J.S.; Kusmaul, B.C.; Lampson, B.W.; Sanchez, D.; Schardl, T.B. There’s Plenty of Room at the Top: What will drive computer performance after Moore’s Law? Science 2020, 368, eaam9744. [Google Scholar] [CrossRef]
- Backus, J.W. Can Programming Be Liberated From the von Neumann Style? A Functional Style and its Algebra of Programs. Commun. ACM 1978, 21, 613–641. [Google Scholar] [CrossRef]
- Abrams, P.S. An APL Machine; Technical Report TR SLAC-114 UC-32(MISC); Stanford Linear Accelerator Center: Menlo Park, CA, USA, 1970. [Google Scholar]
- Hassitt, A.; Lyon, L.E. Efficient Evaluation of Array Subscripts of Arrays. IBM J. Res. Dev. 1972, 16, 45–57. [Google Scholar] [CrossRef]
- Mullin, L.M.R. A Mathematics of Arrays. Ph.D. Thesis, Syracuse University, Syracuse, NY, USA, 1988. [Google Scholar]
- Mullin, L.R. Psi, the Indexing Function: A Basis for FFP with Arrays. In Arrays, Functional Languages, and Parallel Systems; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1991. [Google Scholar]
- Grout, I.A.; Mullin, L. Realizing Mathematics of Arrays Operations as Custom Architecture Hardware-Software Co-Design Solutions. Information 2022, 13, 528. [Google Scholar] [CrossRef]
- Mullin, L.R.; Raynolds, J.E. Conformal Computing: Algebraically connecting the hardware/software boundary using a uniform approach to high-performance computation for software and hardware applications. arXiv 2008, arXiv:0803.2386. [Google Scholar]
- ISO/IEC 1539-1:2023; Information Technology—Programming Languages—Fortran—Part 1: Base Language. ISO/IEC: Geneva, Switzerland, 2023. Available online: https://www.iso.org/standard/82170.html (accessed on 25 November 2024).
- Reid, J. The new features of Fortran 2018. ACM SIGPLAN Fortran Forum 2018, 37, 5–43. [Google Scholar] [CrossRef]
- Čertik, O. LFortran Compiler. 2022. Available online: https://lfortran.org/ (accessed on 25 November 2024).
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Markus, A.; Mullin, L. Implementing Mathematics of Arrays in Modern Fortran: Efficiency and Efficacy. Software 2024, 3, 534-548. https://doi.org/10.3390/software3040026
Markus A, Mullin L. Implementing Mathematics of Arrays in Modern Fortran: Efficiency and Efficacy. Software. 2024; 3(4):534-548. https://doi.org/10.3390/software3040026
Chicago/Turabian StyleMarkus, Arjen, and Lenore Mullin. 2024. "Implementing Mathematics of Arrays in Modern Fortran: Efficiency and Efficacy" Software 3, no. 4: 534-548. https://doi.org/10.3390/software3040026
APA StyleMarkus, A., & Mullin, L. (2024). Implementing Mathematics of Arrays in Modern Fortran: Efficiency and Efficacy. Software, 3(4), 534-548. https://doi.org/10.3390/software3040026