
A Systematic Mapping of the Proposition of Benchmarks in the Software Testing and Debugging Domain

 , ,
, ,
Abstract
:1. Introduction
2. Background
3. Systematic Mapping Study
3.1. Planning
- RQ1: What are the proposed benchmarks for STD and their target topics?
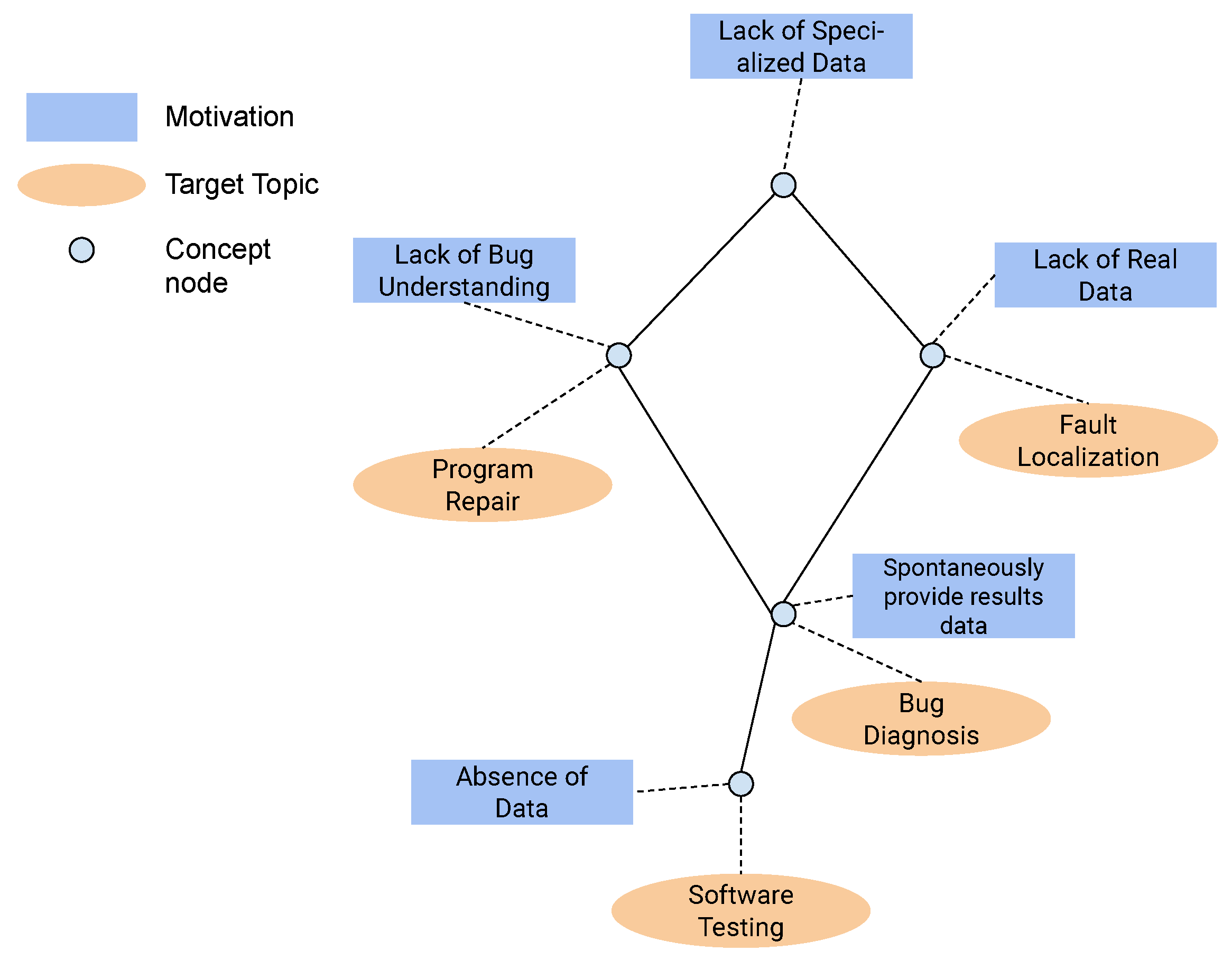
- Rationale: By answering this RQ, we aim to provide a list of benchmarks to support researchers in selecting the benchmarks that they could use to exercise their novel STD techniques empirically. Moreover, answering RQ1 also provides a classification of the reported benchmarks according to their target topics, i.e., the context for which it was proposed. The target topics include software testing, bug diagnosis, program repair, and fault localization.
- RQ2: What are the languages used to write the programs that compose the proposed benchmarks?
- Rationale: The program repair community website [32] points out existing benchmarks that are highly restricted to Java and C code. The answer to this RQ may provide a broader panorama about the benchmarks that are available and that are composed of programs written in other diverse programming languages.
- RQ3: Are the bugs that compose the proposed benchmarks real or artificial?
- Rationale: The program debugging community often discusses whether or not bugs artificially introduced in a real program could represent real bugs [31]. Hence, providing such information is an essential contribution to better support researchers when choosing benchmarks for their studies. The proposed benchmarks can be characterized by the nature (real or artificial) of the bugs.
- RQ4: What were the identified motivations for proposing the benchmarks?
- Rationale: Benchmarks are built to match a set of intentions. This RQ aims to reveal the main motivations and needs that lead the community to create the benchmarks reported in the included studies.
- RQ5: What was the identified scope of use for the proposed benchmarks?
- Rationale: The aim of answering this RQ is to map the scope of use that led researchers to create benchmarks, as discussed at the beginning of this section.
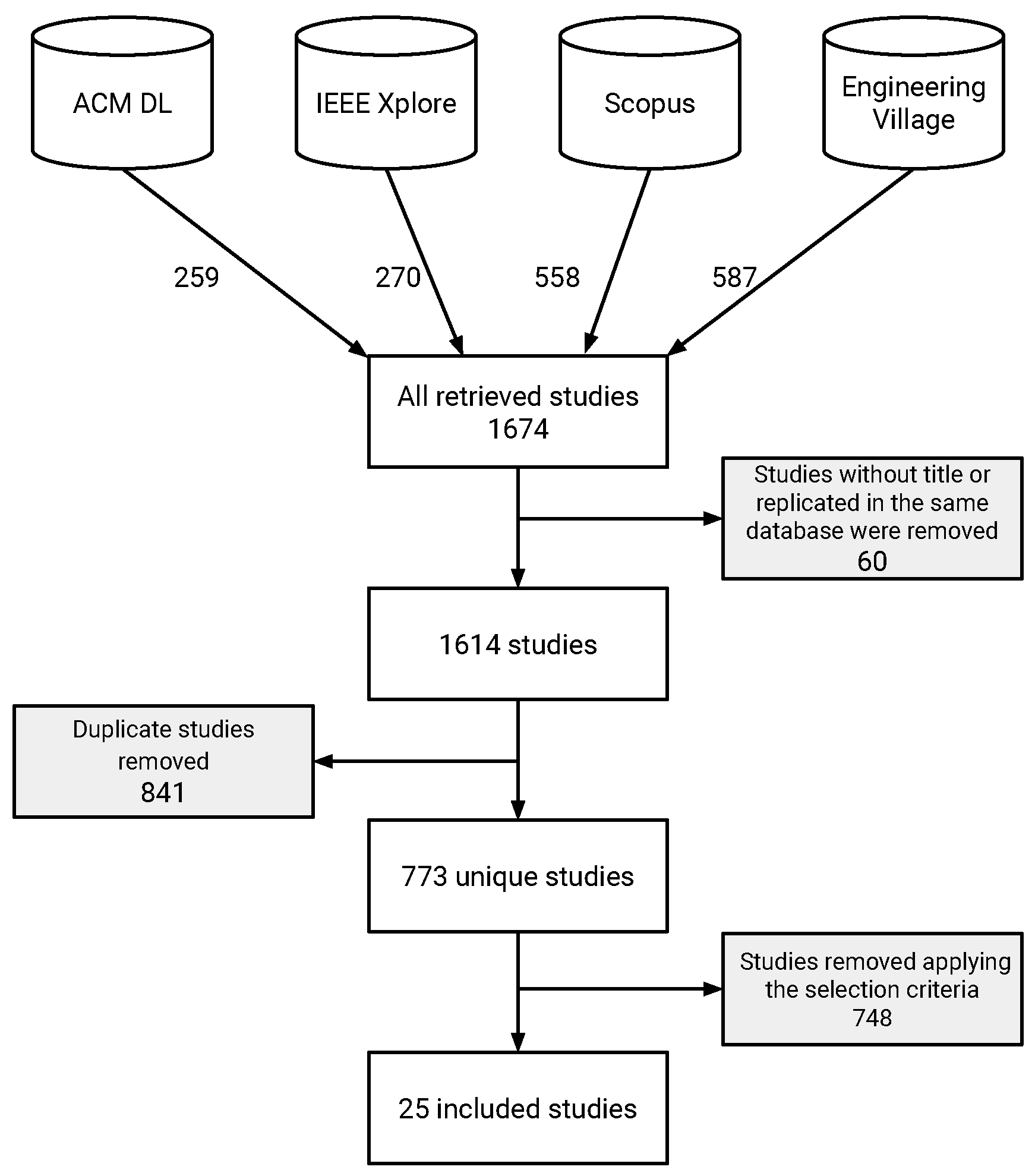
3.1.1. Search Strategy
- Search databases. We conducted searches in the following databases by applying filters on the titles, abstracts, and keywords. The databases were selected between the most common publication databases used to conduct systematic literature studies in software engineering [38,39]. The chosen databases comply with the recommendations made by Kitchenham and Charters [37] and Petersen et al. [40].
- IEEExplore (http://ieeexplore.ieee.org) (accessed on 9 Ocotober 2023);
- ACM Digital Library (http://dl.acm.org) (accessed on 9 Ocotober 2023);
- Scopus (http://www.scopus.com) (accessed on 9 Ocotober 2023);
- Engineering Village (http://www.engineeringvillage.com) (accessed on 9 Ocotober 2023).
- Control studies. The program repair community website provides a set of benchmarks considered relevant for the area [32]. Apart from benchmarks, the website also provides the corresponding study that reports each benchmark proposition. We used that set of studies as a control group, i.e., a set of studies that should be retrieved by the elaborated search string. The control group includes the following benchmarks.
“benchmark” AND “software” AND (“fault localization” OR “repair”)
“benchmark” AND “software” AND (“fault localization” OR “repair” OR “testing” OR “debugging”) AND “buggy”
(“benchmark” OR “benchmarking” OR “dataset” OR “dataset” OR “database” OR “datasets” OR “datasets” OR “benchmarks”) AND (“software” OR “program”) AND ((“fault localization” OR “error localization” OR “defect localization” OR “bug localization” OR “error localisation” OR “defect localisation” OR “bug localisation” OR “fault localisation”) OR (“software repair” OR “software fixing” OR “program repair” OR “program fixing” OR “bug fixing” OR “bug-fixing” OR “automatic repair”) OR (“software testing” OR “software test”) OR (“software debugging”)) AND (“bug” OR “defect” OR “buggy” OR “faulty” OR “failing” OR “failed” OR “bugs” OR “defects”)
3.1.2. Selection Criteria
- IC:
- The study proposes a benchmark and makes it available as a single project in a URL link.
- EC1:
- The study is not related to software testing or debugging.
- EC2:
- The study does not propose a new benchmark specific to software testing or debugging techniques.
- EC3:
- The study is not written in English.
- EC4:
- The study is not a full article or is not available for access.
- EC5:
- The study does not provide the proposed benchmark for access as a single project in a unique URL.
3.1.3. Data Extraction and Synthesis Method
3.2. Conduction and Data Extraction
3.3. Reporting
- QQ1:
- There is a rationale for the study to be undertaken.
- QQ2:
- The authors present an overview of the related works and background of the area in which the study is developed.
- QQ3:
- There is an adequate description of the context (industry, laboratory setting, products used, etc.) in which the work was carried out.
- QQ4:
- The study provides a clear justification of the methods used during the study.
- QQ5:
- There is a clear statement of contributions and sufficient data have been presented to support them.
- QQ6:
- The authors explicitly discuss the credibility and limitations of their findings.
- QQ7:
- The authors discuss perspectives of future works based on the contributions of the study.
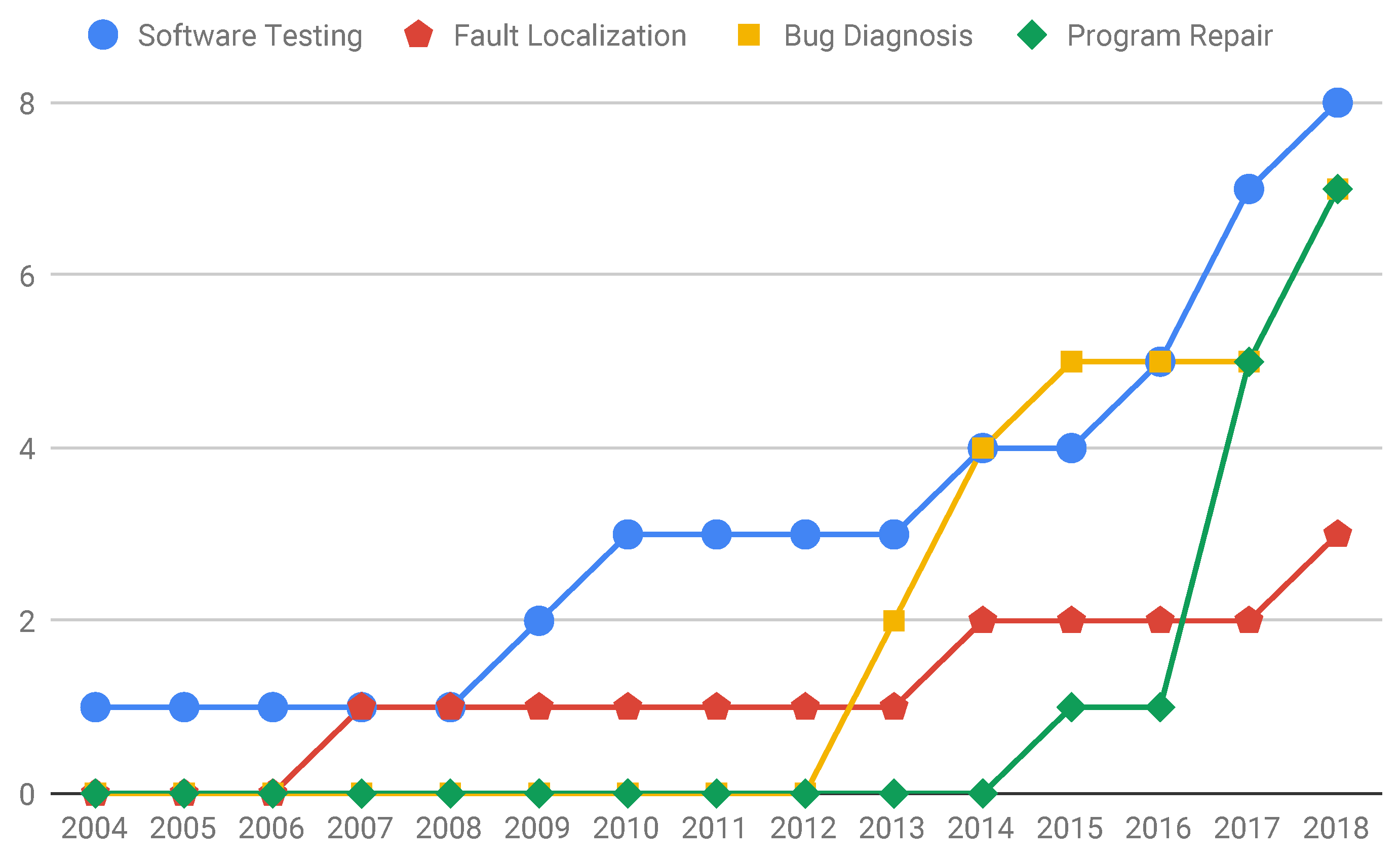
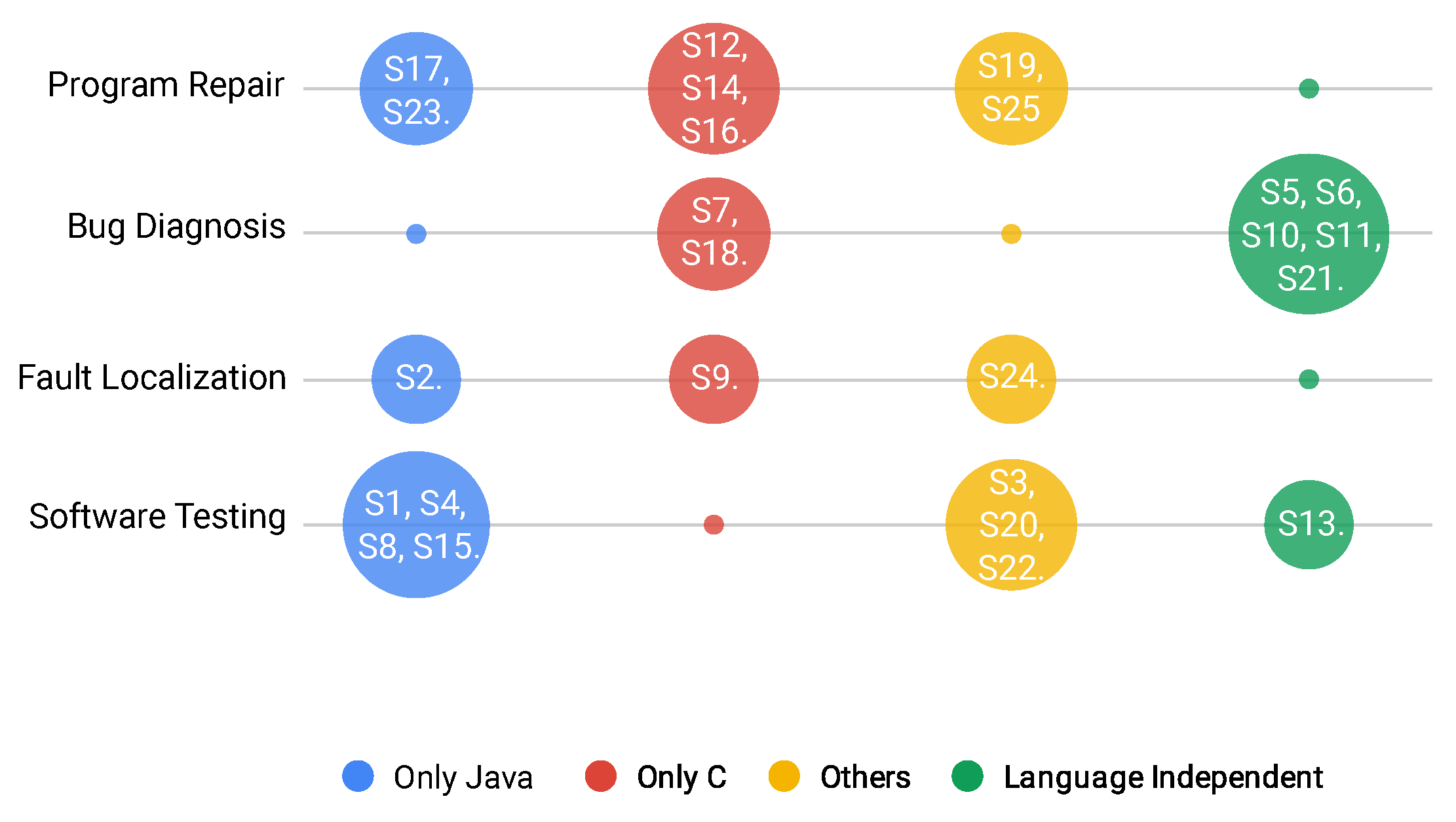
3.3.1. RQ1: What Are the Benchmarks Proposed in the Software Testing and Debugging Context and Their Target Topics?
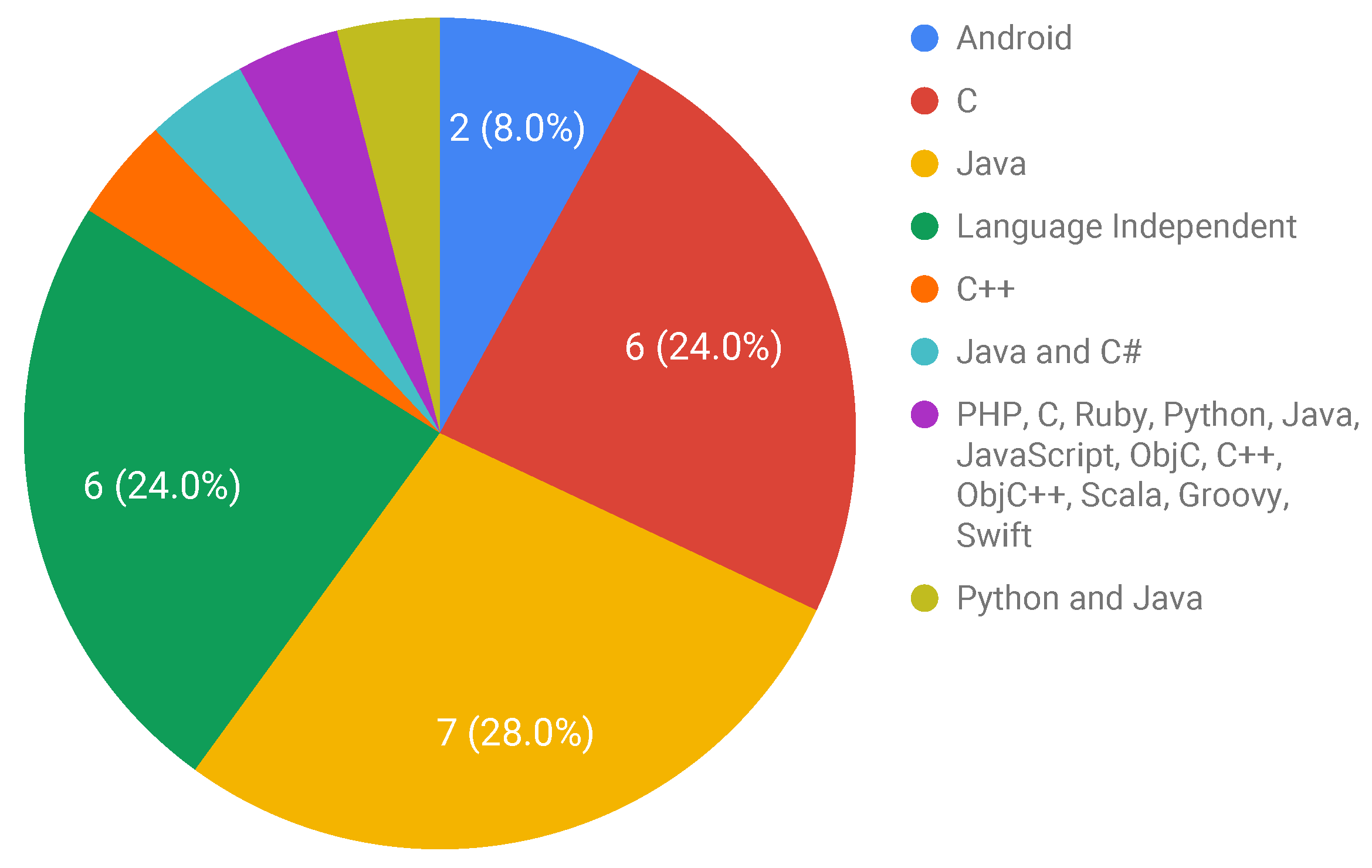
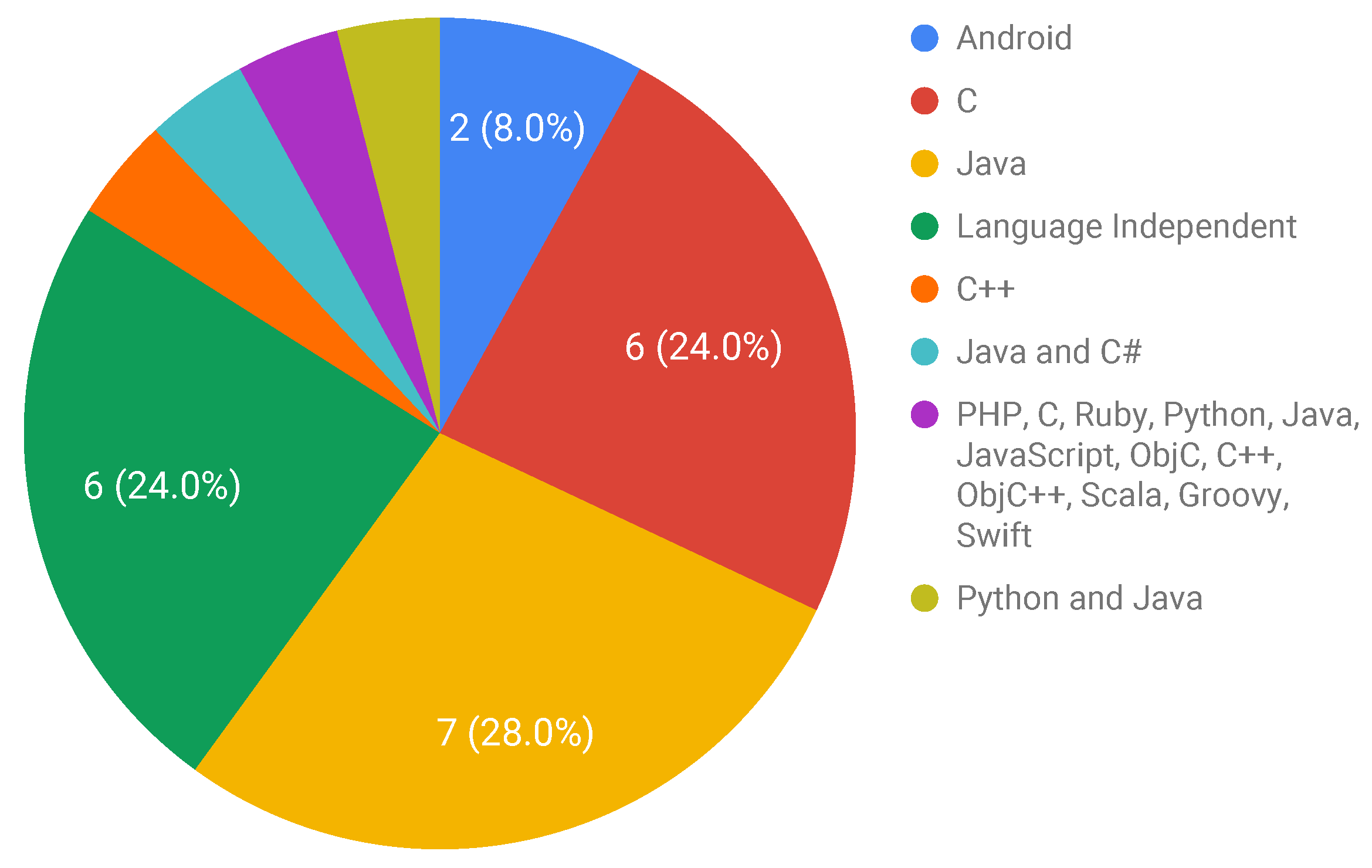
3.3.2. RQ2: What Are the Languages Used to Write the Programs That Compose the Proposed Benchmarks?
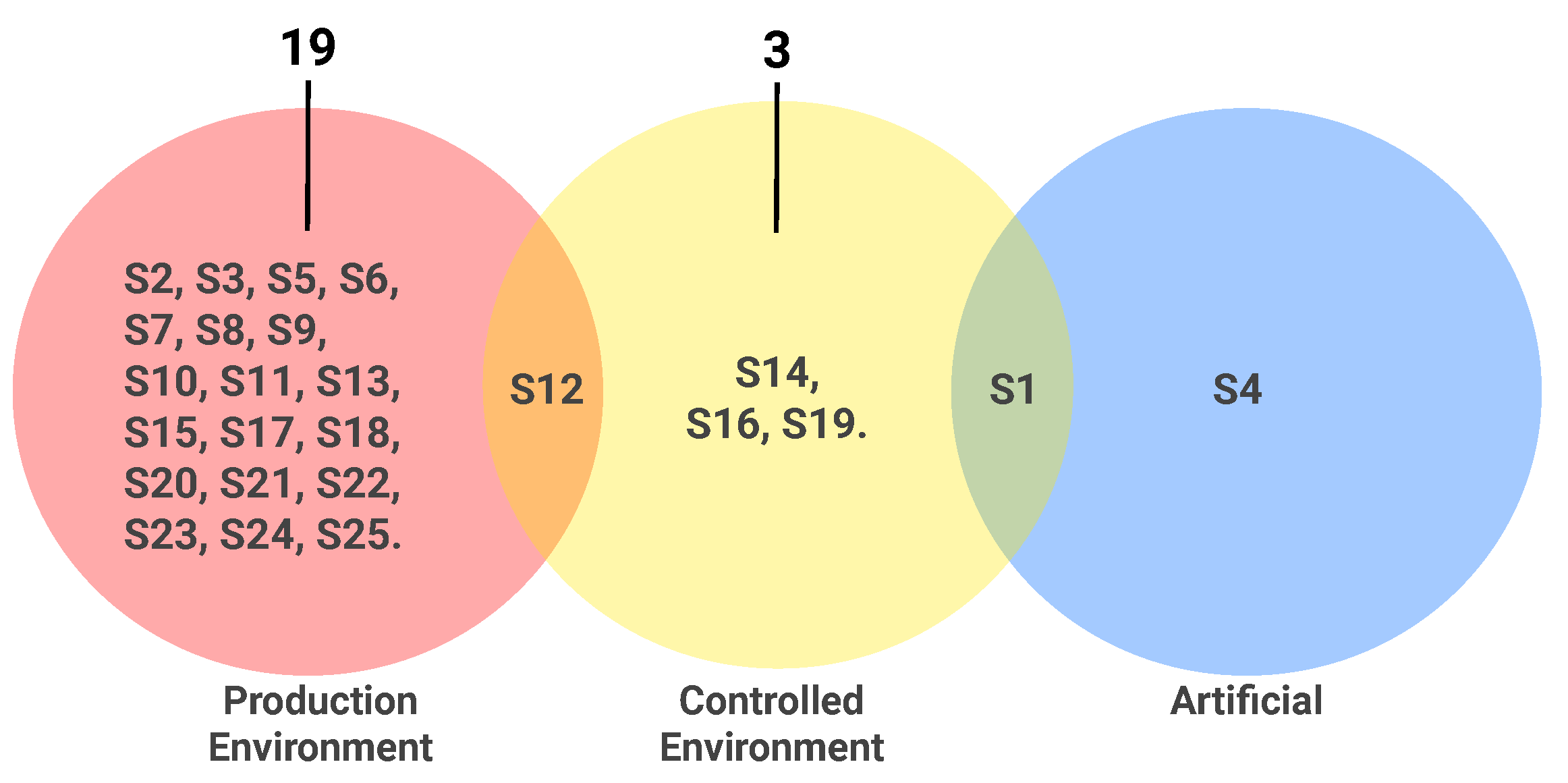
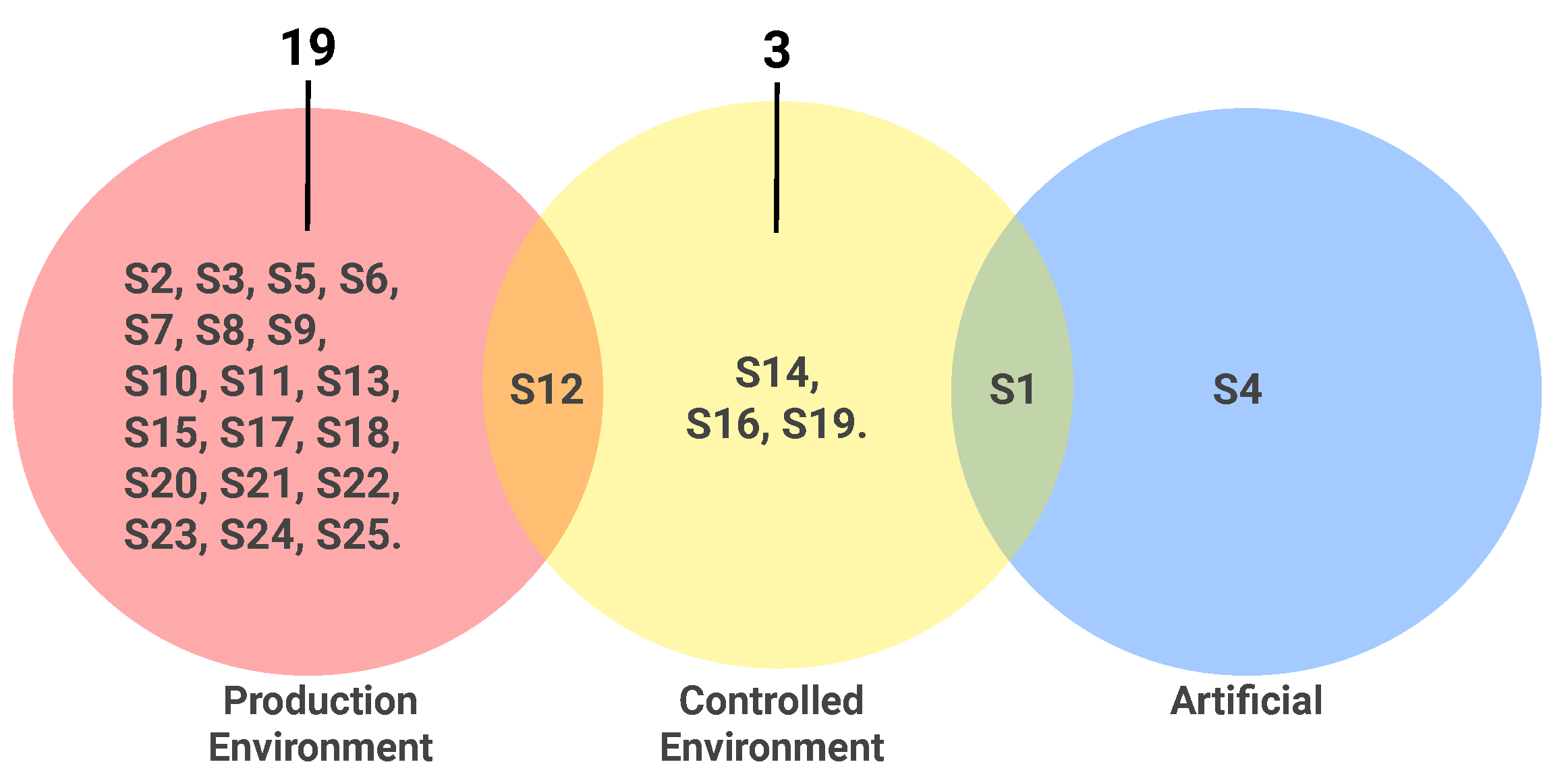
3.3.3. RQ3: Are the Bugs That Compose the Proposed Benchmarks Real or Artificial?
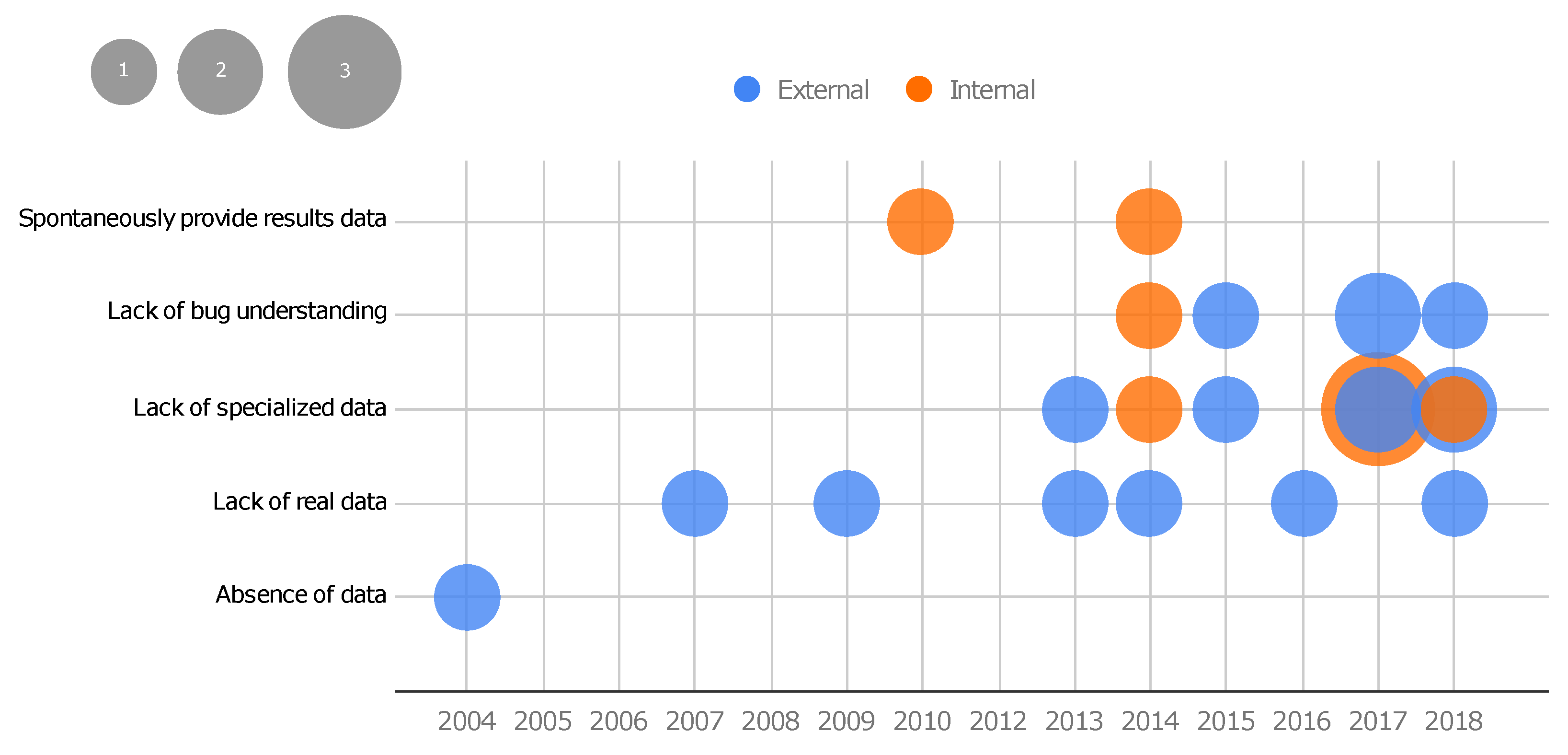
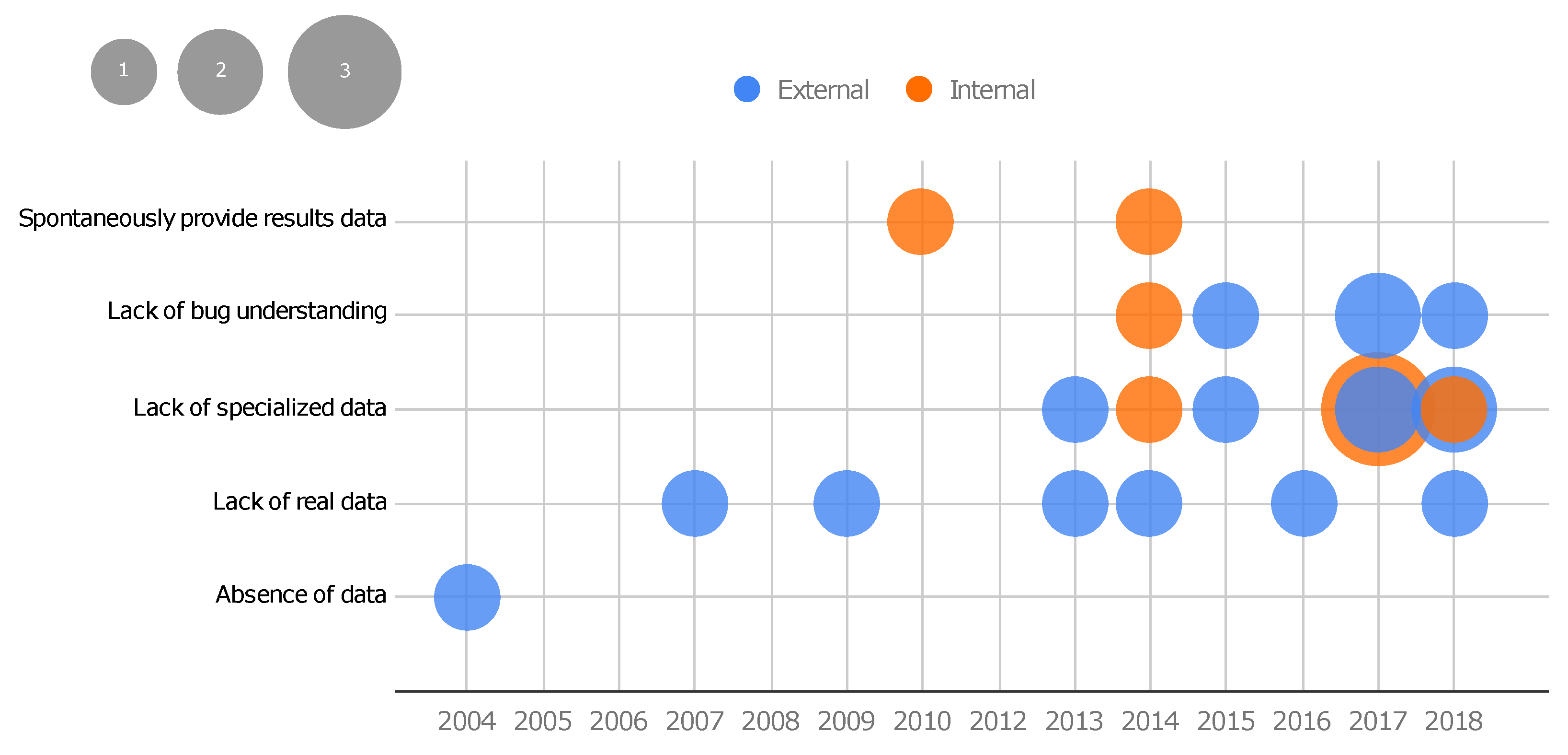
3.3.4. RQ4: What Were the Identified Motivations for Proposing the Benchmarks?
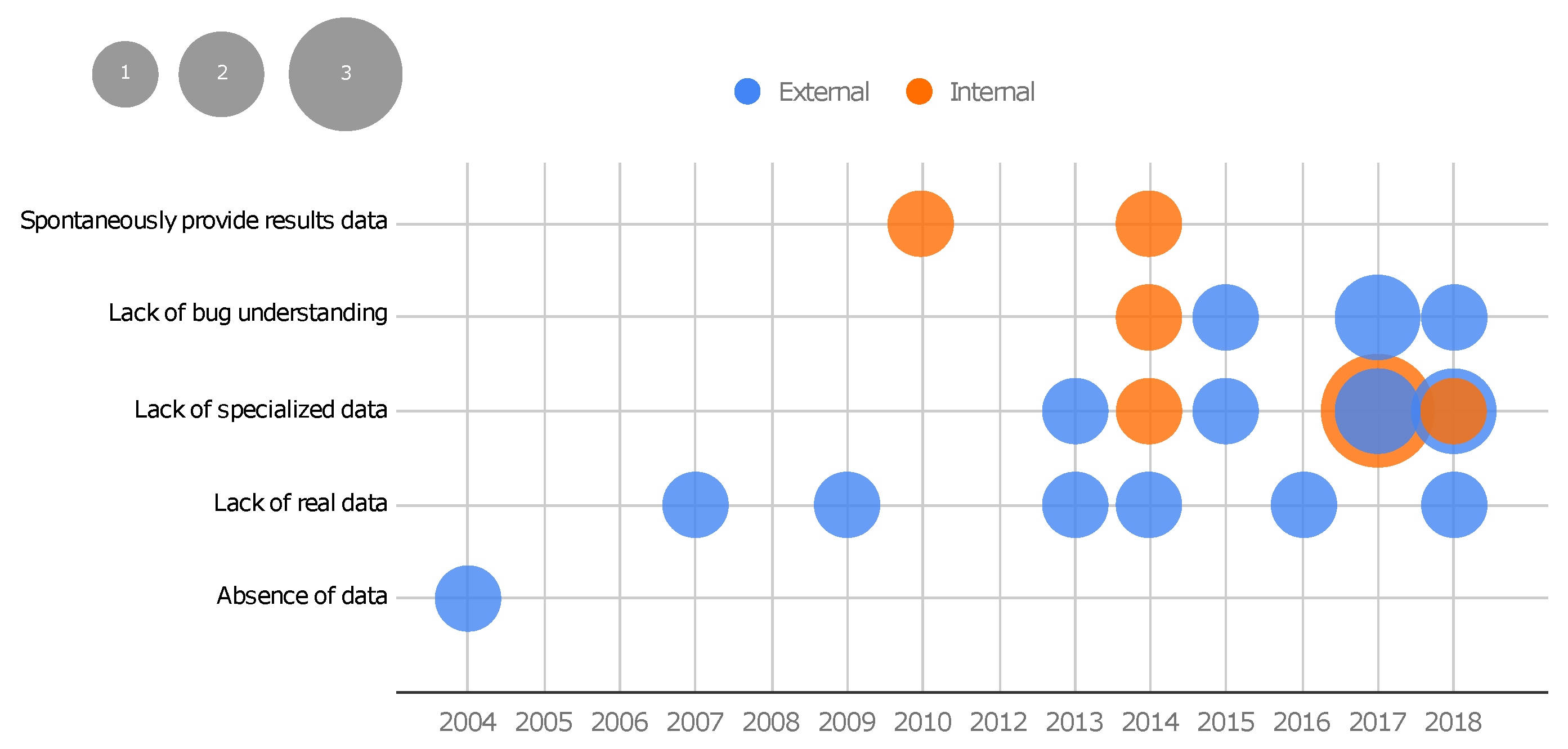
- Absence of data: This motivation comprises the situation where a testing or debugging technique exists, and an expert intends to assess the technique. Once the evaluation of those techniques requires a dataset, the absence of data motivates the creation of a new benchmark. In this scenario, even simple datasets with synthetic data are useful. For instance, Eytani et al. show that concurrency defects are difficult to cover and analyze without a standard dataset. To evaluate and compare techniques developed to deal with these types of defects, Eytani et al. proposed the first benchmark of multi-thread programs in 2004 [36]. Only study S1 falls into this class.
- Lack of real data: This motivation targets techniques whose evaluations overcome artificial data or are restricted to real data. With this motivation, iBugs was proposed in 2007 [42]. The authors highlight that until that moment, the benchmarks available for debugging only had artificially seeded defects. Due to the difficulty of validating whether artificial bugs represent reality, it was necessary to create a new benchmark with real defects in large programs. Studies S2, S3, S6, S8, S13, and S23 fit into this class.
- Lack of specialized data: Some methods need specific information to be evaluated. For instance, the evaluation of crashes in a mobile platform inherently requires code and data that are specific to that platform. Hence, highly specialized data are demanded in some categories of software, which motivates the creation of new benchmarks. This motivation is related to benchmarks that aim to fulfill this lack and to make the specialized data available. For instance, in 2013, Bissyandé et al. [45] proposed a benchmark that contains bug reports. Until that moment, techniques of bug localization that use such information could not be evaluated or straightforwardly compared to other techniques due to the lack of specialized data. Android crash automated repair techniques also match this category, since it exposed the need for specialized data available in benchmarks, as reported in S25 (Droixbench benchmark). Benchmarks that fall into this type of motivation often require much attention to avoid biased data, since a technique can be beneficial when the same people create both the benchmark and the technique under evaluation. This is actually a recurrent threat to the validity reported by the included studies themselves as they address the need to develop new benchmarks to evaluate a technique also created by the same authors (e.g., [48,52]). Studies S5, S9, S12, S14, S15, S16, S17, S19, S21, S24, and S26 belong to this class of motivation.
- Lack of bug understanding: This motivation refers to structuring data and providing additional data aiming to support the understanding of classes and origins of bugs. For instance, Reis and Abreu [55] propose a set of security bugs, created specifically to support the analysis of such a defect type. Apart from the previous types of motivation, this one comprises the lack of more in-depth information about bugs. Studies S7, S11, S18, S20, S23 belong to this class.
- Spontaneously providing results data: This motivation refers to a spontaneous contribution by creating a basis for the evaluation of further techniques; i.e., the authors made their results available as benchmark data. Studies S4 and S10 made their study results (respectively, mutated code and run-time log) available for community use to compare other techniques in the same context. Only studies S4 and S10 belong to this class.
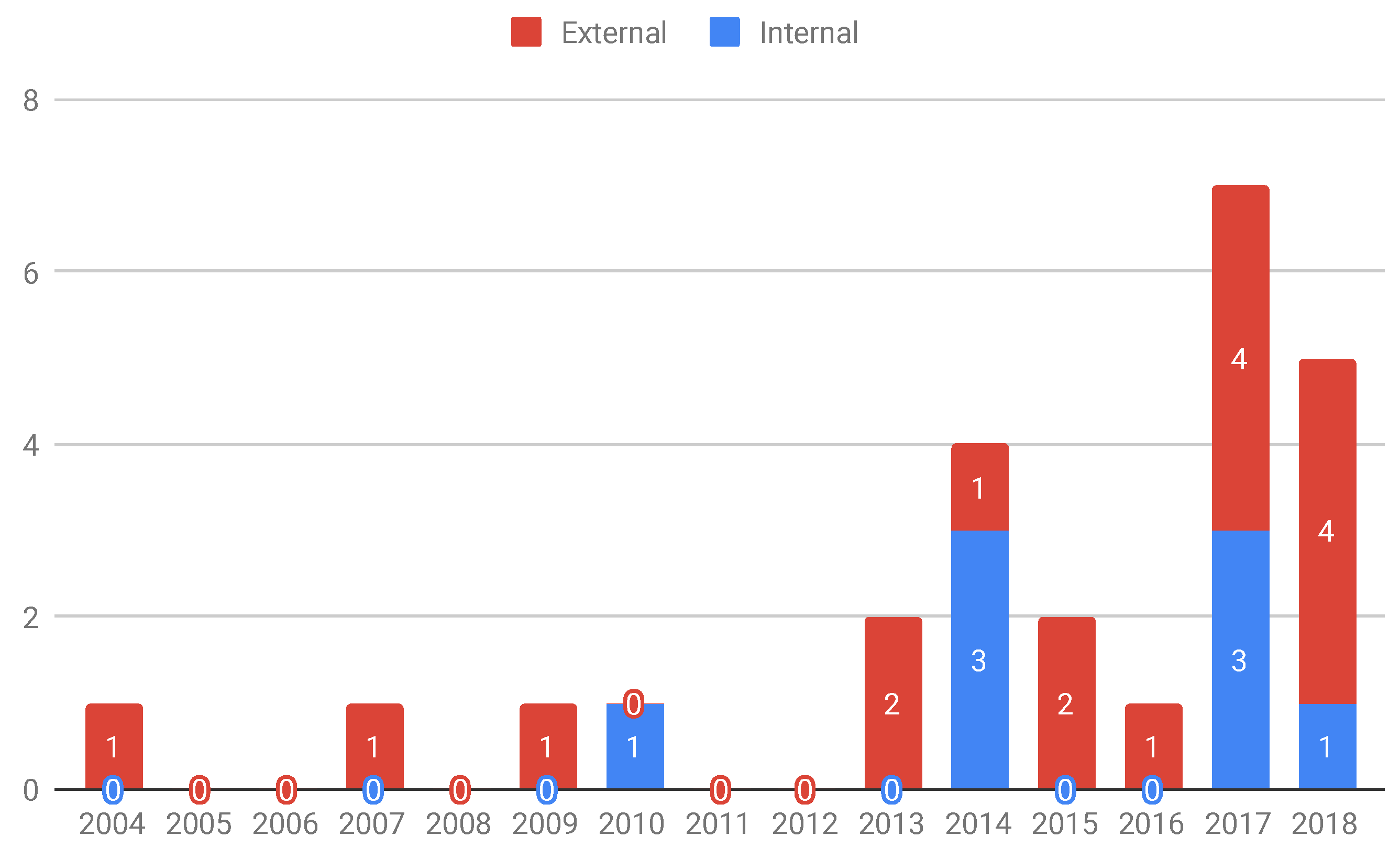
3.3.5. RQ5: What Were the Identified Scopes of Use for the Proposed Benchmarks?
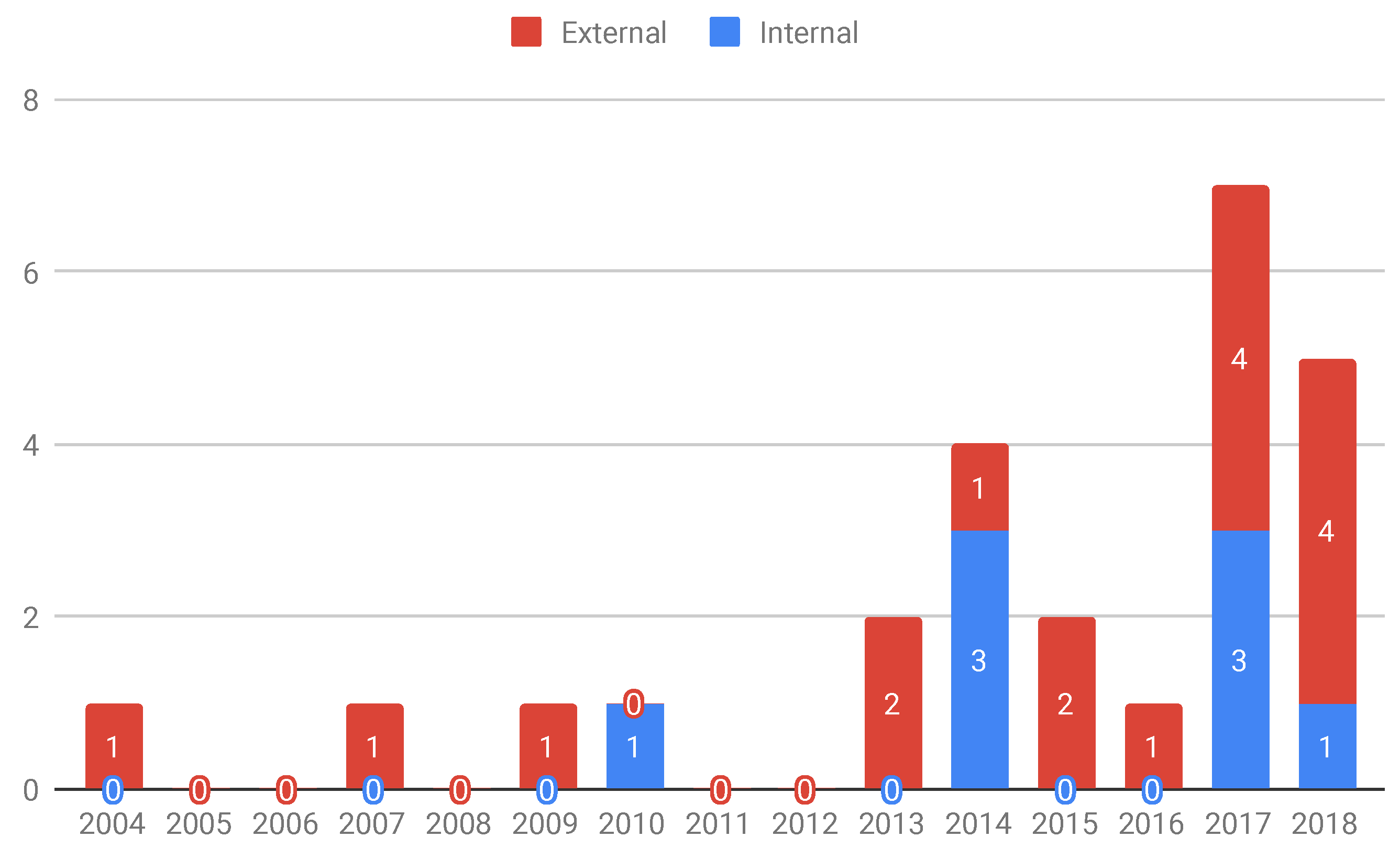
- External: This is the case where benchmarks are made available to supply the community needs. For instance, Pairika (S24) is a benchmark proposed for the bug diagnosis of C++ programs, i.e., it was not created for a specific technique, but an open-accessed use of an entire programming community. Several research studies can use the datasets provided by benchmarks of this category. We identified 17 studies that are addressed to this category: S1, S2, S3, S5, S6, S8, S11, S12, S13, S16, S18, S19, S20, S21, S22, S23, and S24.
- Internal: This class of objectives represents the benchmarks built to evaluate the technique of a particular research group. In general, they may be used in other related studies but the main objective was to provide a benchmark because no other existing one could be used in the study. In those cases, the included study actually presents testing or debugging techniques, and the benchmark is jointly proposed to introduce the technique being reported. Eight studies are addressed to this category, S4, S7, S9, S10, S14, S15, S17, and S25.
3.4. Synthesis
3.4.1. Additional Findings
- Create benchmarks regardless of software testing and debugging techniques. New techniques may have no data in the literature that support their assessment in regard to other techniques (for instance, study S9 proposes a dataset with bug reports and codes and uses it to validate a novel bug localization technique), which require the creation of new benchmarks. Then a recurrent threat reported in the included studies is the creation of benchmarks along with the creation and evaluation of techniques: a benchmark was created ‘for’ that technique, and the benchmark is suitable for the technique, not evaluating it at large. To avoid such excessive fit, benchmarks should be unbiased, i.e., when comparing different techniques on the same dataset, the dataset should not positively or negatively influence the results of the techniques. Thus, from the review of the included studies, a possible perception is that benchmarks should be proposed independently of the techniques they are used to evaluate.
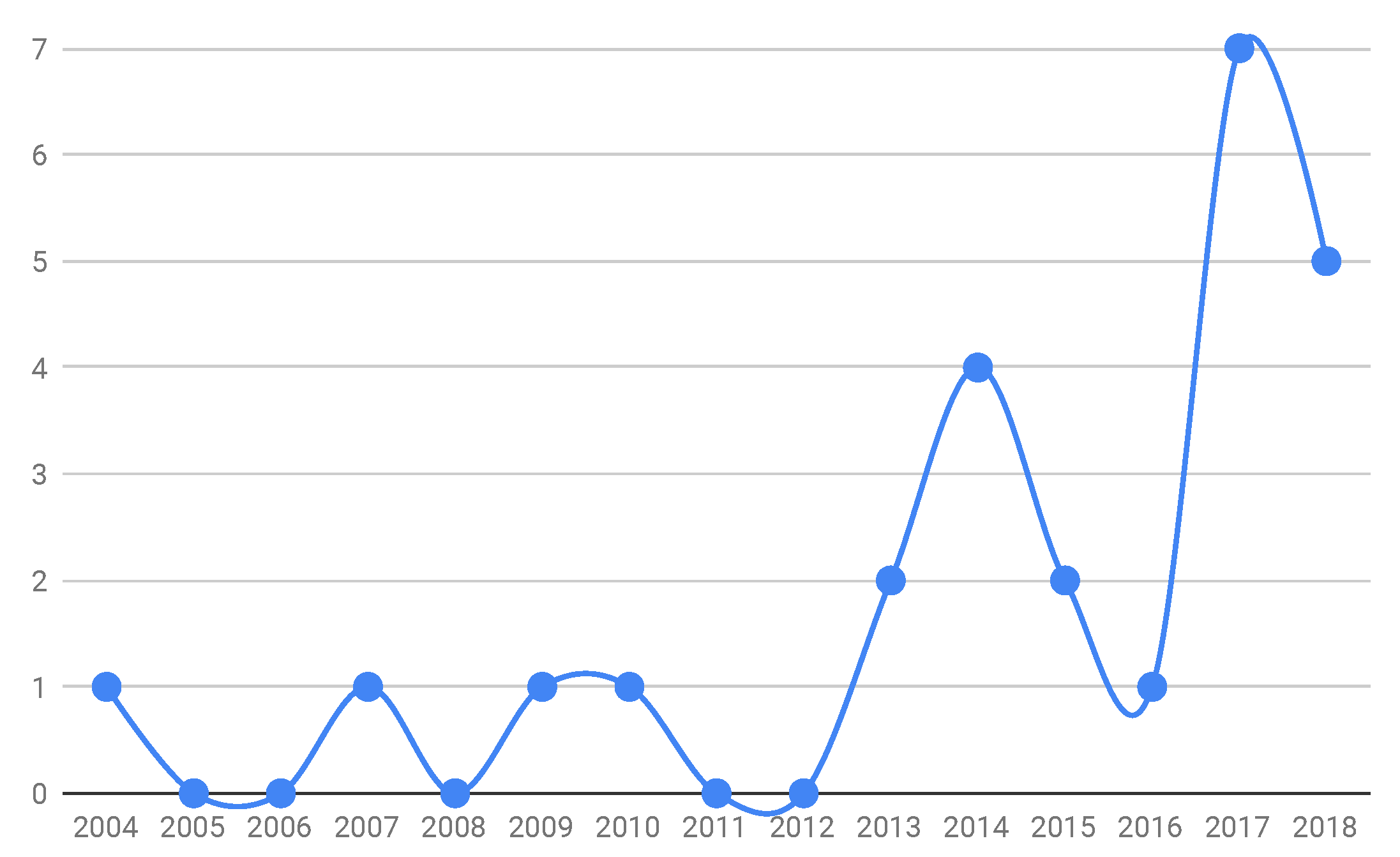
- Benchmarks are often surpassed. A motivational example comprises the use of benchmarks composed of programs with artificial bugs. The proposition of iBugs [42], for instance, was motivated by the lack of real data. Specifically, they report that the existent benchmarks, such as Siemens Suite [28], were wholly composed of programs with artificial bugs. Then, at some moment, the techniques were well-succeeded to deal with artificial bugs but not validated with real bugs. In turn, the iBugs was not exhaustive about real bugs since it was only one program with multiple versions of real bugs. This characteristic raised the need to create Defects4J (initially composed of five programs) [33], superseding iBugs since novel techniques demanded benchmarks with a larger number of programs with real bugs to deliver a better evaluation of testing techniques. In line with this perspective, in Section 3.3, we observed a tendency for benchmarks to be created in a wave pattern, i.e., in regular periods (about every two years, and increasing). We conjecture that this pattern will be repeated in forthcoming years, as novel techniques can be created in future years due to similar motivations: lack of data, novel techniques, and existing benchmarks being deprecated.
- Out-of-the-box use. Another interesting finding is the fact that benchmarks can be used in other areas—even if they are not explicitly created for that purpose. An instance is Defects4J, which is recurrently used in program repair [64] and fault localization [65], despite the fact that software testing was its original target topic. Other benchmarks exhibit this same phenomenon, reinforcing the out-of-the-box usage of them. For instance, ‘Codeflaws’, which was proposed for program repair, has also been utilized in fault localization [14].
3.4.2. Triangulation
4. Summary of Contributions and Research Opportunities
- Mapping of the area: This study provides an overview of the proposition of benchmarks for software testing and debugging, including several dimensions of the area, such as (i) research topics for which benchmarks were proposed, (ii) programming languages contained in the dataset associated with the benchmark, (iii) sources of defects in the programs contained in the benchmark, and (iv) information related to the intention of the proposition of a new benchmark, as motivation and scope of use.
- A list of proposed benchmarks for software testing and debugging: A significant contribution from this study is a list of 25 proposed benchmarks for testing and debugging software in the period 2004–2018. This set of benchmarks can be adopted and used by researchers and practitioners who create novel software testing and debugging techniques. Professionals can adopt or adapt an existing benchmark that matches the requirements (programming languages, research topics, or origin of bugs) of their novel techniques to support the evaluation of their techniques instead of creating new benchmarks. This contribution can increase the level of reusability of benchmarks and reduce the efforts frequently undertaken to elaborate new benchmarks. Moreover, the adoption of the same benchmark can also increase the level of reproducibility of the studies and assessments performed on testing and debugging techniques.
- Guidelines for proposing benchmarks: During the analysis of the included studies, we do not extract some characteristics due to the lack of uniformity of the provided data about the benchmarks and how they are structured. For instance, QuixBugs [41] has 40 Python and Java programs; the study that presented Defects4J [33] had five programs, but currently, Defects4J is composed of six programs. iBugs initially only had one program, but currently, it has three programs with different versions. S10 only has runtime data from program execution, and S11, in turn, only has bug reports that are manually classified. The material that composes a proposed benchmark is often presented in different sizes (the number of versions and lines of code), but some studies do not even have descriptions of these aspects. From these data, we observe that a lack of standard description and format exists among the benchmarks, potentially hindering a more in-depth analysis of other characteristics not covered herein. By defining guidelines on how to propose benchmarks, a list of requirements could be presented and should be considered for creating and reporting new datasets, which could foster standardization for the area, enabling an even more solid analysis, apart from the selection and use of benchmarks.
- Suitability of a benchmark according to the evaluation interests: Benchmarks are often used for the assessment of testing and debugging techniques, revealing the potential of benchmark characteristics to impact the evaluation results. Hence, it is best to be aware of how a benchmark could influence the evaluation results regarding some attributes, such as efficacy, type of faults, and efficiency, among others. In this sense, more development is required to create a framework to conduct a benchmark analysis in the context of testing and debugging target topics. For instance, the results of such a study could help one to evaluate whether a benchmark is suitable to be used in the evaluation procedures of different techniques in specific research fields. Such a framework could also contribute to comparing several benchmarks and evaluating whether one of them is more effective for a research topic.
- Benchmark usage by research field: Benchmark usage refers to the search for studies in order to analyze how a benchmark has been applied by addressing target topics, methods (or method categories) under evaluation, evaluation metrics, and research questions. More review studies about benchmarks are also needed, especially from the point of view of different research topics (for example, those used in Section 3.3.1) seeks to expose which benchmarks have been and are being used during the evaluation of new approaches in that particular research area, as well as map the evaluation metrics and methods that are commonly used as baselines. This type of mapping may be one more artifact-used to support researchers in selecting which benchmarks to use, but also in providing guidance on how to use them.
- Interchangeability/Customization of benchmarks between different domains: Some benchmarks have been used in topics other than their initial aim, as seen in Section 3.4.1. After analyzing the selected studies, we noticed that not all benchmarks suggested by the program repair community were proposed for this purpose; however, this did not prevent them from being used for a different context. Hence, a study about the interchangeability of benchmarks between areas such as fault localization and program repair may expand the suite of programs that researchers in both areas may use.
- Definition of guidelines for benchmark selection: In this mapping, we reported the potential bias that can emerge from the use of a benchmark jointly proposed with the technique that uses it to be evaluated. Another potentially biased context is the selection of benchmarks, i.e., when a researcher chooses a benchmark to use in his/her study. Studies often present evaluations obtained by using only some parts of a dataset offered by a benchmark. For instance, not all programs contained in Defects4J have been used during the analysis and evaluation of some techniques, which can bring about some imprecision to the obtained results. For reliability purposes, benchmark-based technique evaluations should be conducted according to guidelines. These guidelines could advise researchers on how to select benchmarks to reduce bias, and maximize the empirical value of the results since the most popular benchmark is not necessarily the most suitable for a context.
5. Threats to Validity
- The omission of important primary studies: Important studies can also be missed during the automated search in the selected databases. To alleviate this threat, we (i) adopted the set of bibliographic bases recommended by Dyba et al. [67], which could return a more significant number of relevant studies of the area, (ii) did not delimit a time period in order to obtain the maximum of relevant studies, (iii) considered keywords suggested by software testing and debugging experts, (iv) performed trial searches to calibrate the search string, and (v) used a set of studies as a control group to confirm that our search string retrieved the main studies of the area.
- Selection reliability: The inclusion and exclusion processes can also be critical since a misunderstanding could cause the exclusion of relevant studies or the inclusion of irrelevant studies. At least two researchers were involved in each step of the study, aiming to mitigate this problem and others related to the interpretation during the selection process. If a conflict emerged, a consensus meeting was used to reduce the possibility of misinterpretation in this step.
- Data extraction: A recurrent threat to this systematic mapping refers to how the data were extracted from the primary studies. To alleviate this threat, we performed the extraction and synthesis of data in a cooperative way with two reviewers working together to reach an agreement on possible conflicts caused by the extracted data and their classification. Furthermore, when disagreement occurred, consensus meetings were conducted to ensure a full agreement between the reviewers.
- Quality assessment: We elaborated a set of quality questions to assess the quality of each selected study. A possible threat that emerges is that the results of the quality questions can be influenced by the interpretation of the reviewers. However, quality questions were also performed in a double-check procedure so that both reviewers involved in the extraction answered the same quality questions for the same studies in order to obtain a reliable opinion about the quality of that study, which reduces the threat to the validity of the conclusions obtained about the quality of the included studies.
6. Final Remarks and Future Work
- Benchmarks are mainly proposed for software testing, bug diagnosis, and program repair, rather than fault localization (only three studies reported the proposition of benchmarks for this domain);
- The first decade of analysis produced nine different benchmarks, whilst the period 2013–2018 was responsible for 16 different benchmarks, showing a significant increase in the number of benchmarks being proposed. This result endorses the importance of benchmarks for supporting the evaluation of software testing and debugging techniques and an increase in the interest over the years;
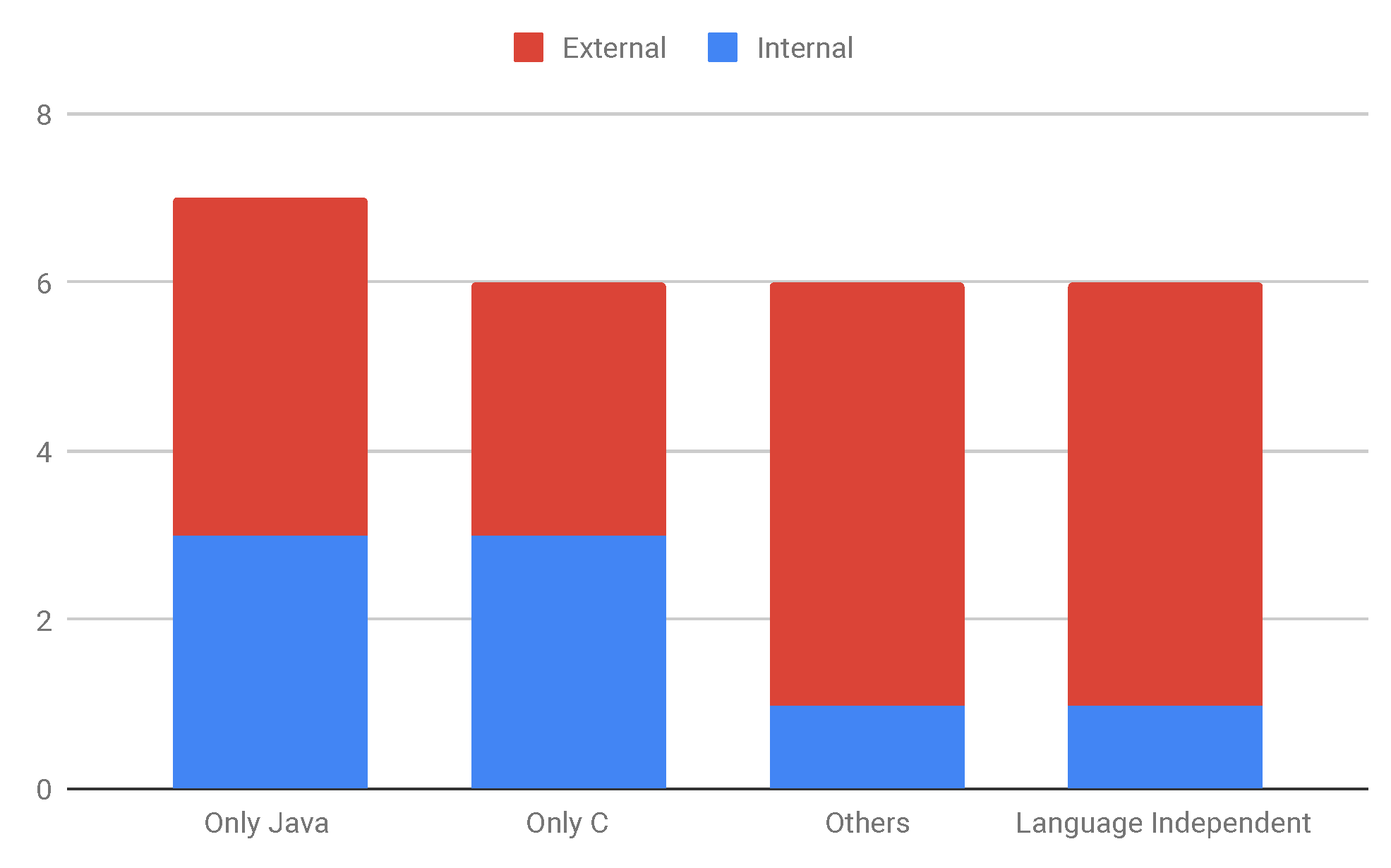
- Approximately 50% of the retrieved studies report benchmarks proposed for exclusively C or Java. The other half refers to language-independent benchmarks or benchmarks proposed for other languages;
- Most of the proposed benchmarks (92% of the studies, 23 out of 25) are composed of real bugs from a controlled environment (we understand a controlled environment as a non-commercial situation in which software testing activities are carried out, such as in academic environments and competitions) or a production environment (a production environment comprises the software testing environment for commercial software in production);
- The motivation for a proposition of benchmarks could be classified into five different categories: (i) absence of data, representing benchmarks proposed because there are no available data (such as a set of buggy programs or execution logs) until that moment to support the proper evaluation of a testing or debugging technique; (ii) lack of real data, revealing that several techniques demanded real data and the use of programs with real defects; (iii) Lack of specialized data, which indicates that while some benchmarks do exist, they may not be composed of programs in a specific programming language or contain descriptive data about bug fixes, revealing a lack of specialized data that motivates the proposition of novel benchmarks; (iv) lack of bug understanding, since some benchmarks exist, but their data are not structured or provided in a way that supports understanding the classes and origins of bugs, thereby motivating the proposition of new ones, and (v) spontaneously providing results data, as some benchmarks are obtained through the execution of techniques and are provided to the community as a public dataset.
- The scope of use for the creation of benchmarks can be split into two classes: internal and external. The former refers to an inner evaluation of particular testing or debugging techniques, which demand the creation of a benchmark. The latter refers to benchmarks created to be available for community needs.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A
- What is the study title?
- What is the publication vehicle name? Is it a conference or a journal?
- What are the authors’ affiliation?
- What is a benchmarks’ name?
- What is a benchmarks’ link?
- Does a programming language or platform apply to a benchmark? If so, which one?
- As for the origin of defects (or behaviors), are they real, artificial or both?
- What are the motivations described in the study? Why was the benchmark built?
- What are the objectives described in the study? What was the benchmark built for?
- What is the classification of the techniques to which the benchmark was intended to be used? If fault localization, automated program repair, bug analysis, etc.
- Other important notes.
Appendix B

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
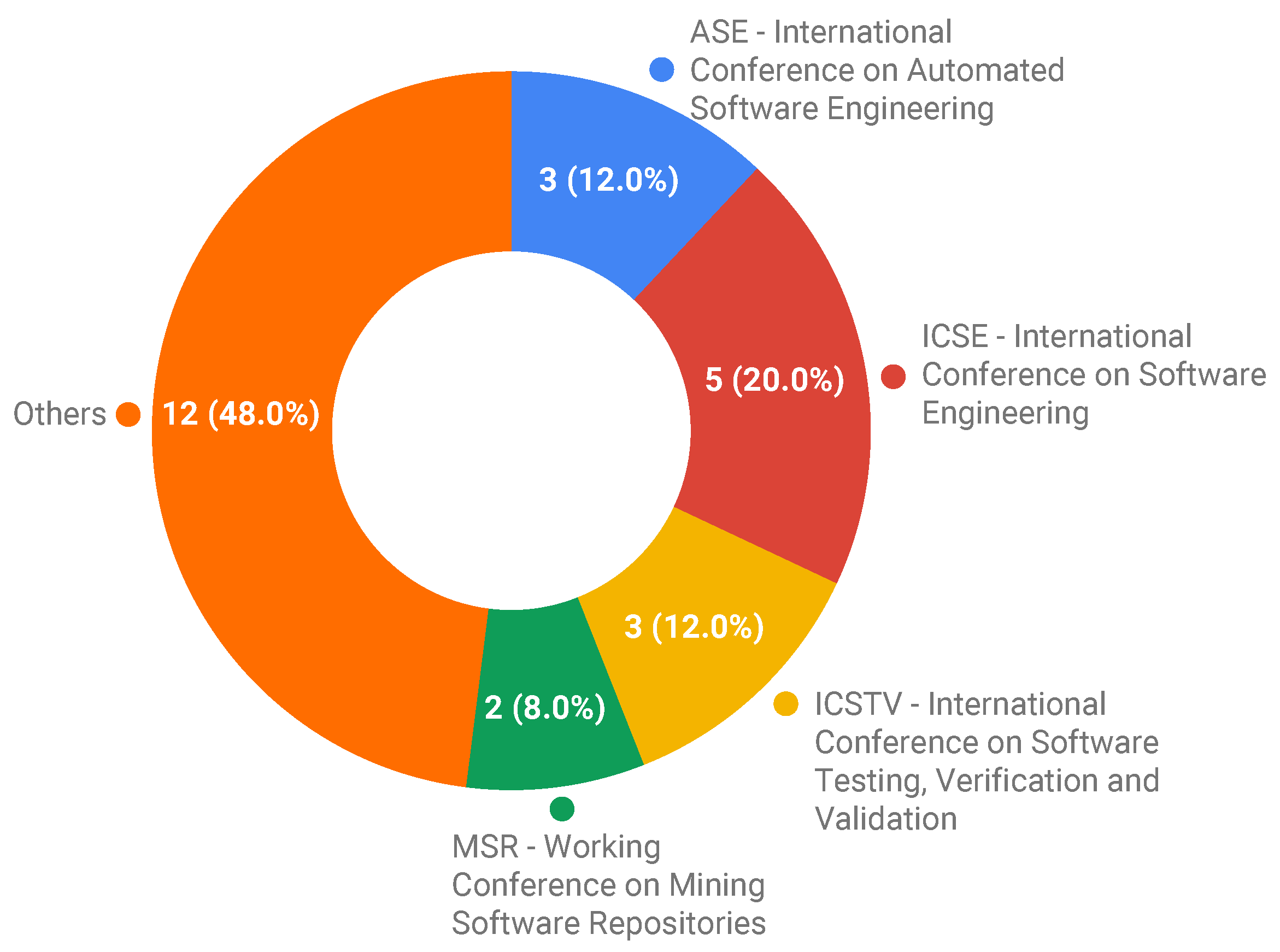
| Study | Title | Year | Bench. Name | Topic | PL or Technology | Bugs Origins | Motivation | Purpose | Vehicle |
|---|---|---|---|---|---|---|---|---|---|
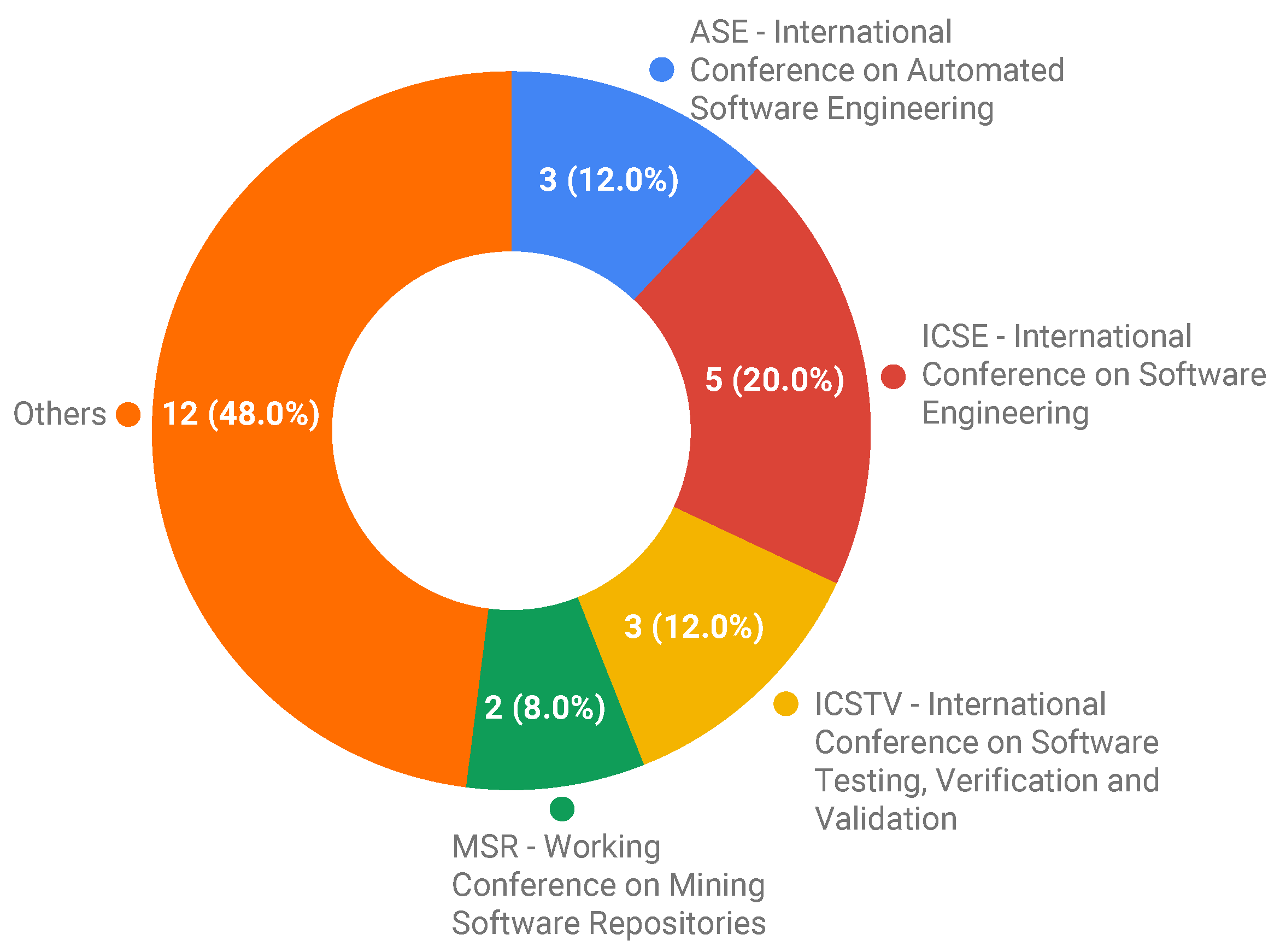
| S1 | Compiling a benchmark of documented multi-threaded bugs | 2004 | [Eytani et al.] | Software Testing | Java | Artificial and Controlled Environment | Absence of data | External | Conference |
| S2 | Extraction of Bug Localization Benchmarks from History | 2007 | iBugs | Fault Localization | Java | Production Environment | Lack of real data | External | Conference |
| S3 | Clash of the Titans: Tools and Techniques for Hunting Bugs in Concurrent Programs | 2009 | [Rungta et al.] | Software Testing | Java and C# | Production Environment | Lack of real data | External | Conference |
| S4 | (Un-)Covering Equivalent Mutants | 2010 | JAVALANCHE Subject Programs | Software Testing | Java | Artificial | Spontaneously-provided results data | Internal | Conference |
| S5 | Empirical Evaluation of Bug Linking | 2013 | [Bissyandé et al.] | Bug Diagnosis | Language Independent | Production Environment | Lack of specialized data | External | Conference |
| S6 | The Eclipse and Mozilla Defect Tracking Dataset: A Genuine Dataset for Mining Bug Information | 2013 | Eclipse and Mozilla Defect Tracking Dataset | Bug Diagnosis | Language Independent | Production Environment | Lack of real data | External | Conference |
| S7 | 42 Variability Bugs in the Linux Kernel: A Qualitative Analysis | 2014 | The Variability Bugs Database | Bug Diagnosis | C | Production Environment | Lack of bug understanding | Internal | Conference |
| S8 | Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs | 2014 | Defects4J | Software Testing | Java | Production Environment | Lack of real data | External | Conference |
| S9 | On the Effectiveness of Information Retrieval Based Bug Localization for C Programs | 2014 | [Saha et al.] | Fault Localization | C | Production Environment | Lack of specialized data | Internal | Conference |
| S10 | Automated Bug Finding in Video Games: A Case Study for Runtime Monitoring | 2014 | [Varvaressos et al.] | Bug Diagnosis | Language Independent | Production Environment | Spontaneously-provided results data | Internal | Conference |
| S11 | A Dataset of High Impact Bugs: Manually-Classified Issue Reports | 2015 | High Impact Bug Dataset | Bug Diagnosis | Language Independent | Production Environment | Lack of bug understanding | External | Conference |
| S12 | The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs | 2015 | ManyBugs and IntroClass | Program Repair | C | Production and Controlled Environment | Lack of specialized data | External | Journal |
| S13 | TaxDC: A Taxonomy of Non-Deterministic Concurrency Bugs in Data Center Distributed Systems | 2016 | TaxDC | Software Testing | Language Independent | Production Environment | Lack of real data | External | Conference |
| Study | Title | Year | Bench. Name | Topic | PL or Technology | Bugs Origins | Motivation | Purpose | Vehicle |
|---|---|---|---|---|---|---|---|---|---|
| S14 | A Feasibility Study of Using Automated Program Repair for Introductory Programming Assignments | 2017 | [Yi et al.] | Program Repair | C | Controlled Environment | Lack of specialized data | Internal | Conference |
| S15 | Automatic detection and demonstrator generation for information flow leaks in object-oriented programs | 2017 | KEG Experiments | Software Testing | Java | Production Environment | Lack of specialized data | Internal | Journal |
| S16 | Codeflaws: A Programming Competition Benchmark for Evaluating Automated Program Repair Tools | 2017 | Codeflaws | Program Repair | C | Controlled Environment | Lack of specialized data | External | Conference |
| S17 | ELIXIR: Effective Object-Oriented Program Repair | 2017 | Bugs.jar | Program Repair | Java | Production Environment | Lack of specialized data | Internal | Conference |
| S18 | How Developers Debug Software The DBGBENCH Dataset | 2017 | DBGBENCH | Bug Diagnosis | C | Production Environment | Lack of bug understanding | External | Conference |
| S19 | QuixBugs: a multi-lingual program repair benchmark set based on the Quixey challenge | 2017 | QuixBugs | Program Repair | Python and Java | Controlled Environment | Lack of specialized data | External | Conference |
| S20 | SECBENCH: A Database of Real Security Vulnerabilities | 2017 | Secbench | Software Testing | PHP, C, Ruby, Python, Java, JavaScript, ObjC, C++, ObjC++, Scala, Groovy, Swift | Production Environment | Lack of bug understanding | External | Conference |
| S21 | Crashing Simulated Planes is Cheap: Can Simulation Detect Robotics Bugs Early? | 2018 | ArduBugs | Bug Diagnosis | Language Independent | Production Environment | Lack of specialized data | External | Conference |
| S22 | Large-Scale Analysis of Framework-Specific Exceptions in Android Apps | 2018 | Dataset Crash Analysis | Software Testing | Android | Production Environment | Lack of real data | External | Conference |
| S23 | Mining repair model for exception-related bug | 2018 | Exception-related bugs | Program Repair | Java | Production Environment | Lack of bug understanding | External | Journal |
| S24 | Pairika-A Failure Diagnosis Benchmark for C++ Programs | 2018 | Pairika | Fault Localization | C++ | Production Environment | Lack of specialized data | External | Conference |
| S25 | Repairing Crashes in Android Apps | 2018 | Droixbench | Program Repair | Android | Production Environment | Lack of specialized data | Internal | Conference |
References
- Pelliccione, P.; Kobetski, A.; Larsson, T.; Aramrattana, M.; Aderum, T.; Agren, S.M.; Jonsson, G.; Heldal, R.; Bergenhem, C.; Thorsén, A. Architecting cars as constituents of a system of systems. In Proceedings of the International Colloquium on Software-Intensive Systems-of-Systems at 10th European Conference on Software Architecture (SiSoSECSA’16), Copenhagen, Denmark, 28 November–2 December 2016; pp. 5:1–5:7. [Google Scholar] [CrossRef]
- Wang, X.; Ning, Z.; Hu, X.; Ngai, E.C.H.; Wang, L.; Hu, B.; Kwok, R.Y. A city-wide real-time traffic management system: Enabling crowdsensing in social internet of vehicles. IEEE Commun. Mag. 2018, 56, 19–25. [Google Scholar] [CrossRef]
- Horita, F.E.A.; Rhodes, D.H.; Inocêncio, T.J.; Gonzales, G.R. Building a conceptual architecture and stakeholder map of a system-of-systems for disaster monitoring and early-warning: A case study in brazil. In Proceedings of the XV Brazilian Symposium on Information Systems (SBSI’19), Aracaju, Brazil, 20–24 May 2019; pp. 6:1–6:8. [Google Scholar] [CrossRef]
- Fraser, G.; Rojas, J.M. Software Testing; Cha, S., Taylor, R.N., Kang, K., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 123–192. [Google Scholar] [CrossRef]
- Zhivich, M.; Cunningham, R.K. The real cost of software errors. IEEE Secur. Priv. 2009, 7, 87–90. [Google Scholar] [CrossRef]
- IEEE Std 1059-1993; IEEE Guide for Software Verification and Validation Plans. IEEE: Piscataway, NJ, USA, 1994; pp. 1–87. [CrossRef]
- Lopes, V.C.; Norberto, M.; RS, D.W.; Kassab, M.; da Silva Soares, A.; Oliveira, R.; Neto, V.V.G. A systematic mapping study on software testing for systems-of-systems. In Proceedings of the 5th Brazilian Symposium on Systematic and Automated Software Testing, Natal, Brazil, 20–21 October 2020; pp. 88–97. [Google Scholar]
- Kassab, M.; Laplante, P.; Defranco, J.; Neto, V.V.G.; Destefanis, G. Exploring the profiles of software testing jobs in the United States. IEEE Access 2021, 9, 68905–68916. [Google Scholar] [CrossRef]
- Myers, G.J.; Sandler, C. The Art of Software Testing; John Wiley Sons, Inc.: Hoboken, NJ, USA, 2004. [Google Scholar]
- Hailpern, B.; Santhanam, P. Software debugging, testing, and verification. IBM Syst. J. 2002, 41, 4–12. [Google Scholar] [CrossRef]
- Kassab, M.; DeFranco, J.F.; Laplante, P.A. Software testing: The state of the practice. IEEE Softw. 2017, 34, 46–52. [Google Scholar] [CrossRef]
- Vessey, I. Expertise in debugging computer programs: An analysis of the content of verbal protocols. IEEE Trans. Syst. Man. Cybern. 1986, 16, 621–637. [Google Scholar] [CrossRef]
- Godefroid, P.; de Halleux, P.; Nori, A.V.; Rajamani, S.K.; Schulte, W.; Tillmann, N.; Levin, M.Y. Automating software testing using program analysis. IEEE Softw. 2008, 25, 30–37. [Google Scholar] [CrossRef]
- De-Freitas, D.M.; Leitao-Junior, P.S.; Camilo-Junior, C.G.; Harrison, R. Mutation-based evolutionary fault localisation. In Proceedings of the 2018 IEEE Congress on Evolutionary Computation (CEC), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Goues, C.L.; Dewey-Vogt, M.; Forrest, S.; Weimer, W. A systematic study of automated program repair: Fixing 55 out of 105 bugs for $8 each. In Proceedings of the 2012 34th International Conference on Software Engineering (ICSE), Zurich, Switzerland, 2–9 June 2012; pp. 3–13. [Google Scholar]
- Sim, S.E.; Easterbrook, S.; Holt, R.C. Using benchmarking to advance research: A challenge to software engineering. In Proceedings of the 25th International Conference on Software Engineering (ICSE’03), Portland, OR, USA, 3–10 May 2003; pp. 74–83. Available online: http://dl.acm.org/citation.cfm?id=776816.776826 (accessed on 9 October 2023).
- McDaniel, G. IBM Dictionary of Computing; McGraw-Hill, Inc.: New York, NY, USA, 1994. [Google Scholar]
- Wong, W.E.; Gao, R.; Li, Y.; Abreu, R.; Wotawa, F. A survey on software fault localization. IEEE Trans. Softw. Eng. 2016, 42, 707–740. [Google Scholar] [CrossRef]
- Gazzola, L.; Micucci, D.; Mariani, L. Automatic software repair: A survey. IEEE Trans. Softw. Eng. 2019, 45, 34–67. [Google Scholar] [CrossRef]
- Petersen, K.; Feldt, R.; Mujtaba, S.; Mattsson, M. Systematic mapping studies in software engineering. In Proceedings of the 12th International Conference on Evaluation and Assessment in Software Engineering (EASE’08), Bari, Italy, 26–27 June 2008; pp. 68–77. [Google Scholar]
- Ammann, P.; Offutt, J. Introduction to Software Testing, 2nd ed.; Cambridge University Press: Cambridge, UK; New York, NY, USA, 2017. [Google Scholar]
- Bertolino, A. Knowledge area description of software testing. In Guide to the Software Engineering Body of Knowledge SWEBOK (v 07); IEEE: Piscataway, NJ, USA, 2000. [Google Scholar]
- Burnstein, I. Practical Software Testing: A Process-Oriented Approach; Springer Professional Computing; Springer: New York, NY, USA, 2003. [Google Scholar]
- Parnin, C.; Orso, A. Are automated debugging techniques actually helping programmers? In Proceedings of the 2011 International Symposium on Software Testing and Analysis (ISSTA’11), Toronto, ON, Canada, 17–21 July 2011; pp. 199–209. [Google Scholar] [CrossRef]
- Böhme, M.; Soremekun, E.O.; Chattopadhyay, S.; Ugherughe, E.; Zeller, A. Where is the bug and how is it fixed? An experiment with practitioners. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering, ESEC/FSE 2017, Paderborn, Germany, 4–8 September 2017; pp. 117–128. [Google Scholar] [CrossRef]
- Böhme, M.; Soremekun, E.O.; Chattopadhyay, S.; Ugherughe, E.J.; Zeller, A. How Developers Debug Software—The DBGBENCH Dataset. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering Companion (ICSE-C), Buenos Aires, Argentina, 20–28 May 2017; pp. 244–246. [Google Scholar]
- Qi, Y.; Mao, X.; Lei, Y.; Dai, Z.; Wang, C. The strength of random search on automated program repair. In Proceedings of the 36th International Conference on Software Engineering (ICSE 2014), Hyderabad, India, May 31–June 7 2014; pp. 254–265. [Google Scholar] [CrossRef]
- Hutchins, M.; Foster, H.; Goradia, T.; Ostrand, T. Experiments on the effectiveness of dataflow- and control-flow-based test adequacy criteria. In Proceedings of the 16th International Conference on Software Engineering, Sorrento, Italy, 16–21 May 1994; pp. 191–200. [Google Scholar]
- Zakari, A.; Lee, S.P.; Alam, K.A.; Ahmad, R. Software fault localisation: A systematic mapping study. IET Softw. 2019, 13, 60–74. [Google Scholar] [CrossRef]
- Andrews, J.H.; Briand, L.C.; Labiche, Y. Is mutation an appropriate tool for testing experiments? [software testing]. In Proceedings of the 27th International Conference on Software Engineering (ICSE 2005), St. Louis, MO, USA, 15–21 May 2005; pp. 402–411. [Google Scholar]
- Jia, Y.; Harman, M. Higher order mutation testing. Inf. Softw. Technol. 2009, 51, 379–1393. [Google Scholar] [CrossRef]
- Program-Repair.org-Community-Driven Website on Automated Program Repair (Automatic Bug Fixing). Available online: http://program-repair.org/ (accessed on 15 January 2019).
- Just, R.; Jalali, D.; Ernst, M.D. Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs. In Proceedings of the 2014 International Symposium on Software Testing and Analysis (ISSTA 2014), San Jose, CA, USA, 21–25 July 2014; pp. 437–440. [Google Scholar] [CrossRef]
- Tan, S.H.; Yi, J.; Yulis; Mechtaev, S.; Roychoudhury, A. Codeflaws: A Programming Competition Benchmark for Evaluating Automated Program Repair Tools. In Proceedings of the 39th International Conference on Software Engineering Companion (ICSE-C’17), Buenos Aires, Argentina, 20–28 May 2017; pp. 180–182. [Google Scholar] [CrossRef]
- Goues, C.L.; Holtschulte, N.; Smith, E.K.; Brun, Y.; Devanbu, P.; Forrest, S.; Weimer, W. The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs. IEEE Trans. Softw. Eng. 2015, 41, 1236–1256. [Google Scholar] [CrossRef]
- Eytani, Y.; Ur, S. Compiling a benchmark of documented multi-threaded bugs. In Proceedings of the International Parallel and Distributed Processing Symposium, IPDPS 2004 (Abstracts and CD-ROM), Santa Fe, NM, USA, 26–30 April 2004; Volume 18, pp. 3641–3648. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-12444295463%7B&%7DpartnerID=40%7B&%7Dmd5=f7c2175aeb242de8e8c043cce33de7db (accessed on 15 January 2019).
- Kitchenham, B.; Charters, S. Guidelines for Performing Systematic Literature Reviews in Software Engineering; Technical Report EBSE, 2007-001; Keele University: Keele, UK; Durham University: Durham, UK, 2007. [Google Scholar]
- Guessi, M.; Graciano Neto, V.V.; Bianchi, T.; Felizardo, K.; Oquendo, F.; Nakagawa, E.Y. A systematic literature review on the description of software architectures for systems of systems. In Proceedings of the 30th Annual ACM Symposium on Applied Computing (SAC’15), Association for Computing Machinery. New York, NY, USA, 13–17 April 2015; pp. 1433–1440. [Google Scholar] [CrossRef]
- Dyba, T.; Kitchenham, B.; Jorgensen, M. Evidence-based software engineering for practitioners. IEEE Softw. 2005, 22, 58–65. [Google Scholar] [CrossRef]
- Petersen, K.; Vakkalanka, S.; Kuzniarz, L. Guidelines for conducting systematic mapping studies in software engineering: An update. Inf. Softw. Technol. 2015, 64, 1–18. [Google Scholar] [CrossRef]
- Lin, D.; Koppel, J.; Chen, A.; Solar-Lezama, A. QuixBugs: A Multi-lingual Program Repair Benchmark Set Based on the Quixey Challenge. In Proceedings of the 2017 ACM SIGPLAN International Conference on Systems, Programming, Languages, and Applications: Software for Humanity, SPLASH Companion 2017, Vancouver, BC, Canada, 22–27 October 2017; pp. 55–56. [Google Scholar] [CrossRef]
- Dallmeier, V.; Zimmermann, T. Extraction of Bug Localization Benchmarks from History. In Proceedings of the Twenty-Second IEEE/ACM International Conference on Automated Software Engineering (ASE’07), Atlanta, GA, USA, 5–9 November 2007; pp. 433–436. [Google Scholar] [CrossRef]
- Rungta, N.; Mercer, E.G. Clash of the Titans: Tools and Techniques for Hunting Bugs in Concurrent Programs. In Proceedings of the 7th Workshop on Parallel and Distributed Systems: Testing, Analysis, and Debugging (PADTAD’09), Chicago, IL, USA, 19–20 July 2009; pp. 9:1–9:10. [Google Scholar] [CrossRef]
- Schuler, D.; Zeller, A. (Un-)Covering Equivalent Mutants. In Proceedings of the 2010 Third International Conference on Software Testing, Verification and Validation (ICST’10), Paris, France, 6–10 April 2010; pp. 45–54. [Google Scholar] [CrossRef]
- Bissyande, T.F.; Thung, F.; Wang, S.; Lo, D.; Jiang, L.; Reveillere, L. Empirical Evaluation of Bug Linking. In Proceedings of the 2013 17th European Conference on Software Maintenance and Reengineering (CSMR’13), Genova, Italy, 5–8 March 2013; pp. 89–98. [Google Scholar] [CrossRef]
- Lamkanfi, A.; Pérez, J.; Demeyer, S. The Eclipse and Mozilla Defect Tracking Dataset: A Genuine Dataset for Mining Bug Information. In Proceedings of the 10th Working Conference on Mining Software Repositories (MSR’13), San Francisco, CA, USA, 18–19 May 2013; pp. 203–206. Available online: http://dl.acm.org/citation.cfm?id=2487085.2487125 (accessed on 9 October 2023).
- Abal, I.; Brabrand, C.; Wasowski, A. 42 Variability Bugs in the Linux Kernel: A Qualitative Analysis. In Proceedings of the 29th ACM/IEEE International Conference on Automated Software Engineering (ASE’14), Vsters, Sweden, 15–19 September 2014; pp. 421–432. [Google Scholar] [CrossRef]
- Saha, R.K.; Lawall, J.; Khurshid, S.; Perry, D.E. On the Effectiveness of Information Retrieval Based Bug Localization for C Programs. In Proceedings of the 2014 IEEE International Conference on Software Maintenance and Evolution, Victoria, BC, Canada, 29 September–3 October 2014; pp. 161–170. [Google Scholar]
- Varvaressos, S.; Lavoie, K.; Massé, A.B.; Gaboury, S.; Hallé, S. Automated bug finding in video games: A case study for runtime monitoring. In Proceedings of the 2014 IEEE Seventh International Conference on Software Testing, Verification and Validation, Cleveland, OH, USA, 31 March– 4 April 2014; pp. 143–152. [Google Scholar]
- Ohira, M.; Kashiwa, Y.; Yamatani, Y.; Yoshiyuki, H.; Maeda, Y.; Limsettho, N.; Fujino, K.; Hata, H.; Ihara, A.; Matsumoto, K. A Dataset of High Impact Bugs: Manually-Classified Issue Reports. In Proceedings of the 2015 IEEE/ACM 12th Working Conference on Mining Software Repositories, Florence, Italy, 16–17 May 2015; pp. 518–521. [Google Scholar]
- Leesatapornwongsa, T.; Lukman, J.F.; Lu, S.; Gunawi, H.S. TaxDC: A taxonomy of non-deterministic concurrency bugs in datacenter distributed systems. In Proceedings of the International Conference on Architectural Support for Programming Languages and Operating Systems-ASPLOS, Atlanta, GA, USA, 2–6 April 2016; pp. 517–530. [Google Scholar] [CrossRef]
- Yi, J.; Ahmed, U.Z.; Karkare, A.; Tan, S.H.; Roychoudhury, A. A Feasibility Study of Using Automated Program Repair for Introductory Programming Assignments. In Proceedings of the 2017 11th Joint Meeting on Foundations of Software Engineering (ESEC/FSE 2017), Paderborn, Germany, 4–8 September 2017; pp. 740–751. [Google Scholar] [CrossRef]
- Do, Q.H.; Bubel, R.; Hähnle, R. Automatic detection and demonstrator generation for information flow leaks in object-oriented programs. Comput. Secur. 2017, 67, 335–349. [Google Scholar] [CrossRef]
- Saha, R.K.; Lyu, Y.; Yoshida, H.; Prasad, M.R. ELIXIR: Effective Object Oriented Program Repair. In Proceedings of the 32Nd IEEE/ACM International Conference on Automated Software Engineering (ASE 2017), Urbana, IL, USA, 30 October–3 November 2017; pp. 648–659. Available online: http://dl.acm.org/citation.cfm?id=3155562.3155643 (accessed on 9 October 2023).
- Reis, S.; Abreu, R. Secbench: A Database of Real Security Vulnerabilities. In CEUR Workshop Proceedings; Volume 1977, pp. 69–85. Available online: https://www.scopus.com/inward/record.uri?eid=2-s2.0-85035242201%7B&%7DpartnerID=40%7B&%7Dmd5=2677afd851481f16b0d8c44668e1d16b (accessed on 9 October 2023).
- Timperley, C.S.; Afzal, A.; Katz, D.S.; Hernandez, J.M.; Goues, C.L. Crashing Simulated Planes is Cheap: Can Simulation Detect Robotics Bugs Early? In Proceedings of the 2018 IEEE 11th International Conference on Software Testing, Verification and Validation (ICST), Västerås, Sweden, 9–13 April 2018; pp. 331–342. [Google Scholar]
- Fan, L.; Su, T.; Chen, S.; Meng, G.; Liu, Y.; Xu, L.; Pu, G.; Su, Z. Large-scale Analysis of Framework-specific Exceptions in Android Apps. In Proceedings of the 40th International Conference on Software Engineering (ICSE’18), Gothenburg, Sweden, 27 May–3 June 2018; pp. 408–419. [Google Scholar] [CrossRef]
- Zhong, H.; Mei, H. Mining repair model for exception-related bug. J. Syst. Softw. 2018, 141, 16–31. [Google Scholar] [CrossRef]
- Rahman, M.R.; Golagha, M.; Pretschner, A. Pairika: A Failure Diagnosis Benchmark for C++ Programs. In Proceedings of the 40th International Conference on Software Engineering: Companion Proceeedings (ICSE’18), Gothenburg, Sweden, 27 May 2018–3 June 2018; pp. 204–205. [Google Scholar] [CrossRef]
- Tan, S.H.; Dong, Z.; Gao, X.; Roychoudhury, A. Repairing Crashes in Android Apps. In Proceedings of the 40th International Conference on Software Engineering (ICSE’18), Gothenburg, Sweden, 27 May–3 June 2018; pp. 187–198. [Google Scholar] [CrossRef]
- Dybå, T.; Dingsøyr, T. Empirical studies of agile software development: A systematic review. Inf. Softw. Technol. 2008, 50, 833–859. [Google Scholar] [CrossRef]
- Ali, M.S.; Ali-Babar, M.; Chen, L.; Stol, K.J. A systematic review of comparative evidence of aspect-oriented programming. Inf. Softw. Technol. 2010, 52, 871–887. [Google Scholar] [CrossRef]
- Yusifoğlu, V.G.; Amannejad, Y.; Can, A.B. Software test-code engineering: A systematic mapping. Inf. Softw. Technol. 2015, 58, 123–147. [Google Scholar] [CrossRef]
- Martinez, M.; Durieux, T.; Sommerard, R.; Xuan, J.; Monperrus, M. Automatic repair of real bugs in java: A large-scale experiment on the defects4j dataset. Empir. Softw. Eng. 2017, 22, 1936–1964. [Google Scholar] [CrossRef]
- Pearson, S.; Campos, J.; Just, R.; Fraser, G.; Abreu, R.; Ernst, M.D.; Pang, D.; Keller, B. Evaluating and improving fault localization. In Proceedings of the 2017 IEEE/ACM 39th International Conference on Software Engineering (ICSE), Buenos Aires, Argentina, 20–28 May 2017; pp. 609–620. [Google Scholar]
- Snelting, G. Concept analysis—A new framework for program understanding. In Proceedings of the 1998 ACM SIGPLAN-SIGSOFT Workshop on Program Analysis for Software Tools and Engineering (PASTE’98), Montreal, QC, Canada, 16 June 1998; pp. 1–10. [Google Scholar] [CrossRef]
- Dyba, T.; Dingsoyr, T.; Hanssen, G.K. Applying systematic reviews to diverse study types: An experience report. In Proceedings of the First International Symposium on Empirical Software Engineering and Measurement (ESEM 2007), Madrid, Spain, 20–21 September 2007; pp. 225–234. [Google Scholar]







| Study | Ref | Title | Year |
|---|---|---|---|
| S1 | [36] | Compiling a benchmark of documented multi-threaded bugs | 2004 |
| S2 | [42] | Extraction of Bug Localization Benchmarks from History | 2007 |
| S3 | [43] | Clash of the Titans: Tools and Techniques for Hunting Bugs in Concurrent Programs | 2009 |
| S4 | [44] | (Un-)Covering Equivalent Mutants | 2010 |
| S5 | [45] | Empirical Evaluation of Bug Linking | 2013 |
| S6 | [46] | The Eclipse and Mozilla Defect Tracking Dataset: A Genuine Dataset for Mining Bug Information | 2013 |
| S7 | [47] | 42 Variability Bugs in the Linux Kernel: A Qualitative Analysis | 2014 |
| S8 | [33] | Defects4J: A Database of Existing Faults to Enable Controlled Testing Studies for Java Programs | 2014 |
| S9 | [48] | On the Effectiveness of Information Retrieval Based Bug Localization for C Programs | 2014 |
| S10 | [49] | Automated Bug Finding in Video Games: A Case Study for Runtime Monitoring | 2014 |
| S11 | [50] | A Dataset of High Impact Bugs: Manually-Classified Issue Reports | 2015 |
| S12 | [35] | The ManyBugs and IntroClass Benchmarks for Automated Repair of C Programs | 2015 |
| S13 | [51] | TaxDC: A Taxonomy of Non-Deterministic Concurrency Bugs in Data Center Distributed Systems | 2016 |
| S14 | [52] | A Feasibility Study of Using Automated Program Repair for Introductory Programming Assignments | 2017 |
| S15 | [53] | Automatic detection and demonstrator generation for information flow leaks in object-oriented programs | 2017 |
| S16 | [34] | Codeflaws: A Programming Competition Benchmark for Evaluating Automated Program Repair Tools | 2017 |
| S17 | [54] | ELIXIR: Effective Object-Oriented Program Repair | 2017 |
| S18 | [26] | How Developers Debug Software The DBGBENCH Dataset | 2017 |
| S19 | [41] | QuixBugs: a multi-lingual program repair benchmark set based on the Quixey challenge | 2017 |
| S20 | [55] | Secbench: A Database of Real Security Vulnerabilities | 2017 |
| S21 | [56] | Crashing Simulated Planes is Cheap: Can Simulation Detect Robotics Bugs Early? | 2018 |
| S22 | [57] | Large-Scale Analysis of Framework-Specific Exceptions in Android Apps | 2018 |
| S23 | [58] | Mining repair model for exception-related bug | 2018 |
| S24 | [59] | Pairika-A Failure Diagnosis Benchmark for C++ Programs | 2018 |
| S25 | [60] | Repairing Crashes in Android Apps | 2018 |
| Quality Question | Yes | To Some Extent | No |
|---|---|---|---|
| QQ1 | 25 | 0 | 0 |
| QQ2 | 20 | 4 | 1 |
| QQ3 | 21 | 4 | 0 |
| QQ4 | 22 | 3 | 0 |
| QQ5 | 19 | 5 | 1 |
| QQ6 | 13 | 3 | 9 |
| QQ7 | 15 | 7 | 3 |
| Benchmark Name or Author | Study | Topic |
|---|---|---|
| [Eytani et al.] | S1 | Software Testing |
| [Rungta et al.] | S3 | |
| JAVALANCHE Subject Programs | S4 | |
| Defects4J | S8 | |
| TaxDC | S13 | |
| KEG Experiments | S15 | |
| Secbench | S20 | |
| Dataset Crash Analysis | S22 | |
| iBugs | S2 | Fault Localization |
| [Saha et al.] | S9 | |
| Pairika | S24 | |
| [Bissyandé et al.] | S5 | Bug Diagnosis |
| Eclipse and Mozilla Defect Tracking Dataset | S6 | |
| The Variability Bugs Database | S7 | |
| [Varvaressos et al.] | S10 | |
| High Impact Bug Dataset | S11 | |
| DBGBENCH | S18 | |
| ArduBugs | S21 | |
| ManyBugs and IntroClass | S12 | Program Repair |
| [Yi et al.] | S14 | |
| Codeflaws | S16 | |
| Bugs.jar | S17 | |
| QuixBugs | S19 | |
| Exception-related bugs | S23 | |
| Droixbench | S25 |
| Programming Language or OS | Studies |
|---|---|
| Android | S22, S25 |
| C | S7, S9, S12, S14, S16, S18 |
| C++ | S24 |
| Language Independent | S5, S6, S10, S11, S13, S21 |
| Java | S1, S2, S4, S8, S15, S17, S23 |
| Java and C# | S3 |
| PHP, C, Ruby, Python, Java, JavaScript, ObjC, C++, ObjC++, Scala, Groovy, Swift. | S20 |
| Python and Java | S19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Silva-Junior, D.d.; Graciano-Neto, V.V.; de-Freitas, D.M.; Leitão-Junior, P.d.S.; Kassab, M. A Systematic Mapping of the Proposition of Benchmarks in the Software Testing and Debugging Domain. Software 2023, 2, 447-475. https://doi.org/10.3390/software2040021
Silva-Junior Dd, Graciano-Neto VV, de-Freitas DM, Leitão-Junior PdS, Kassab M. A Systematic Mapping of the Proposition of Benchmarks in the Software Testing and Debugging Domain. Software. 2023; 2(4):447-475. https://doi.org/10.3390/software2040021
Chicago/Turabian StyleSilva-Junior, Deuslirio da, Valdemar V. Graciano-Neto, Diogo M. de-Freitas, Plinio de Sá Leitão-Junior, and Mohamad Kassab. 2023. "A Systematic Mapping of the Proposition of Benchmarks in the Software Testing and Debugging Domain" Software 2, no. 4: 447-475. https://doi.org/10.3390/software2040021
APA StyleSilva-Junior, D. d., Graciano-Neto, V. V., de-Freitas, D. M., Leitão-Junior, P. d. S., & Kassab, M. (2023). A Systematic Mapping of the Proposition of Benchmarks in the Software Testing and Debugging Domain. Software, 2(4), 447-475. https://doi.org/10.3390/software2040021