
Orbit Classification and Sensitivity Analysis in Dynamical Systems Using Surrogate Models †



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Methods
2.1. Hamiltonian Systems
2.2. Symplectic Gaussian Process Emulation
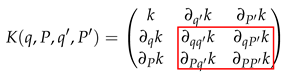
2.3. Sensitivity Analysis
2.4. Local Lyapunov Exponents
3. Results and Discussion
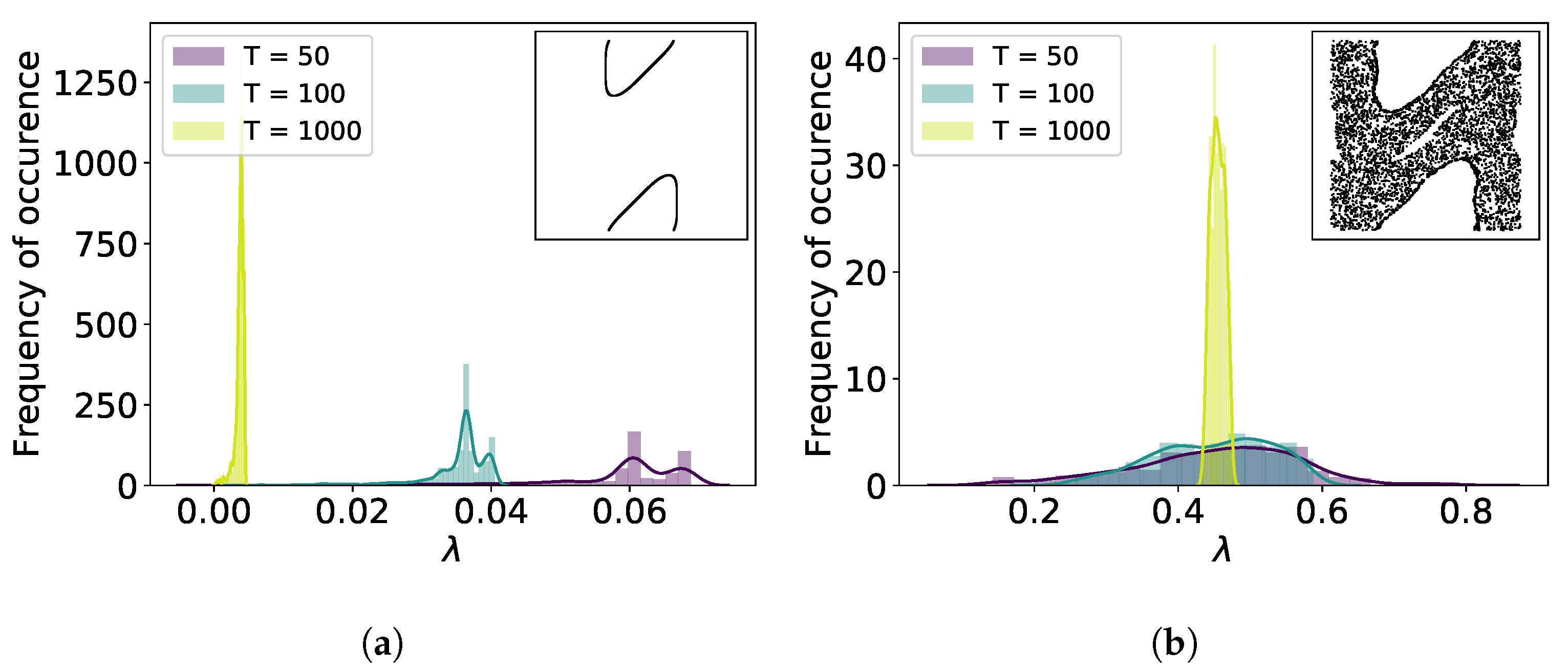
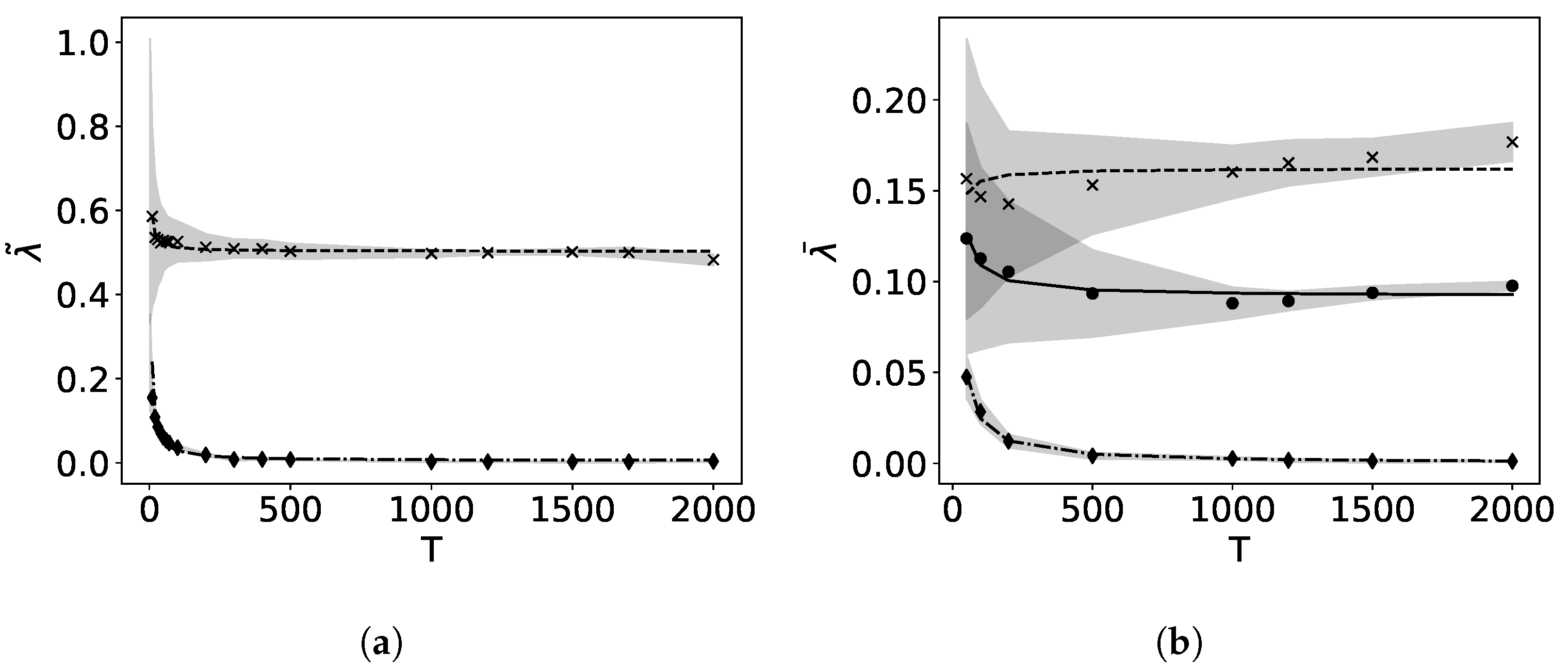
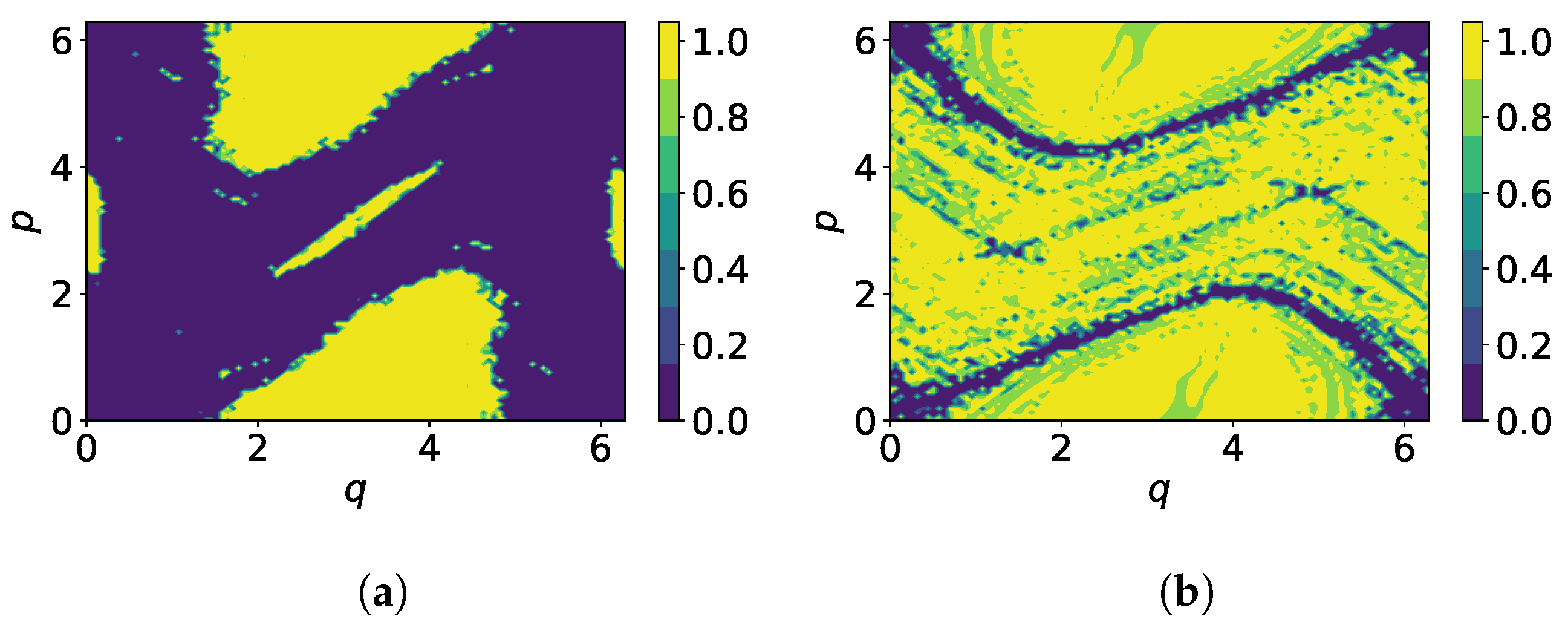
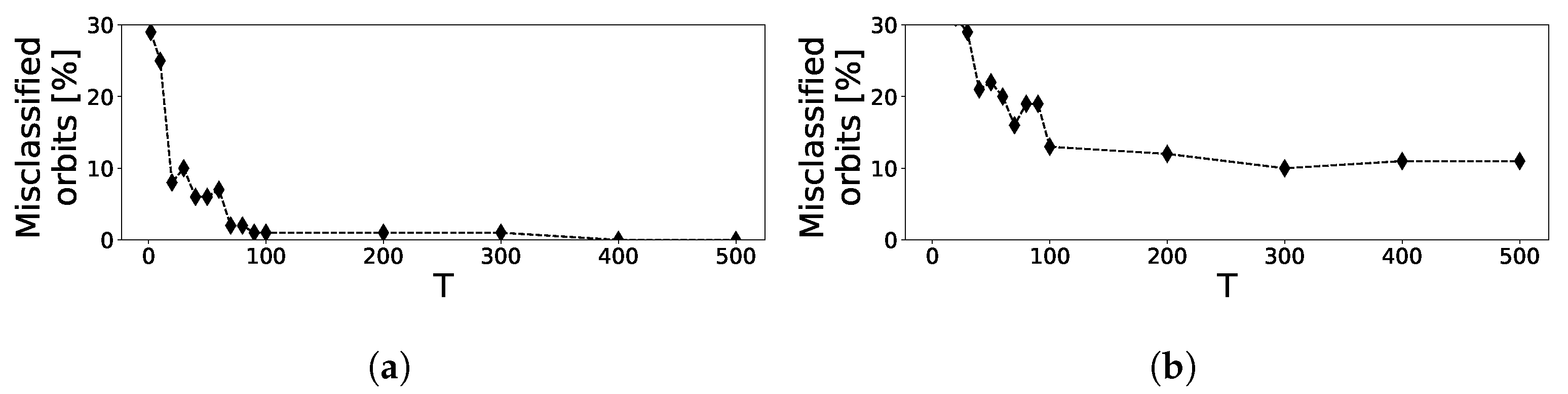
3.1. Local Lyapunov Exponents and Orbit Classification
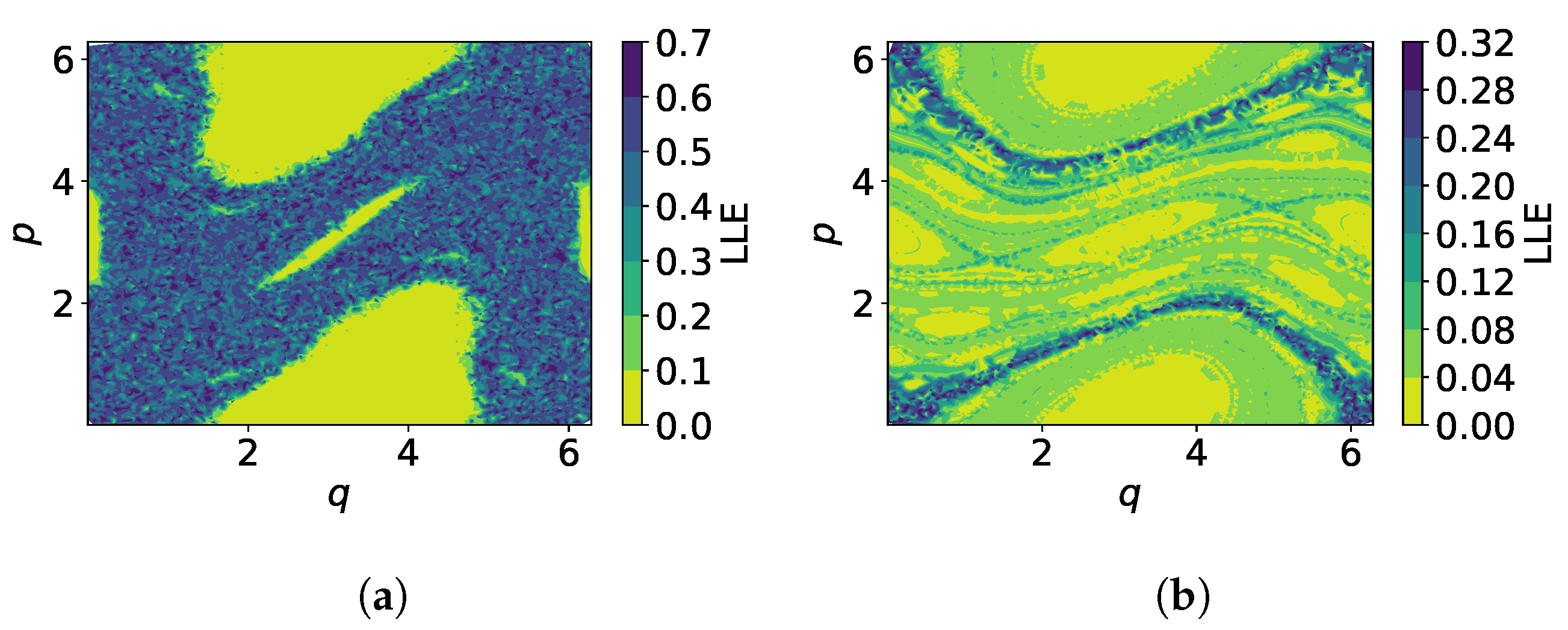
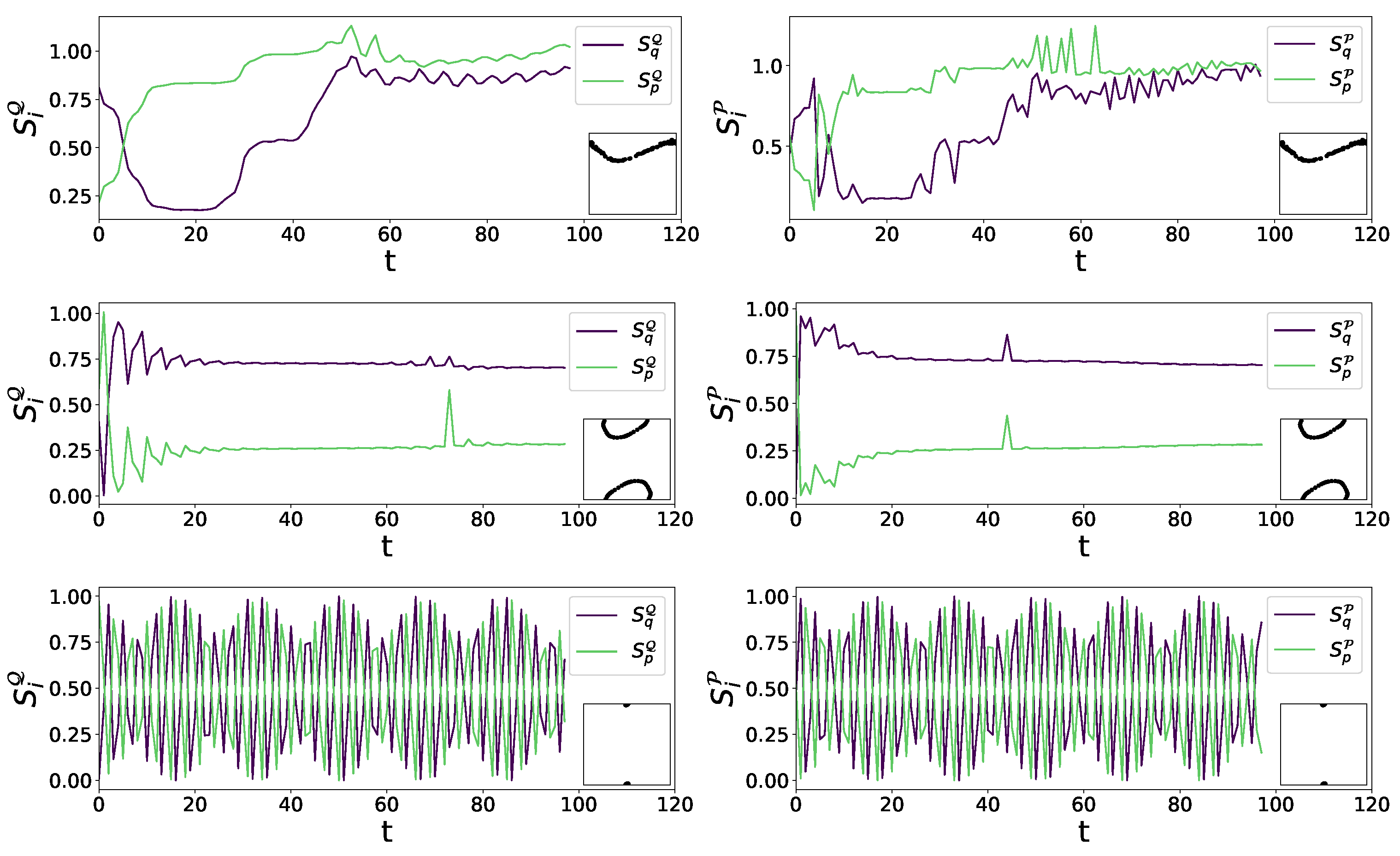
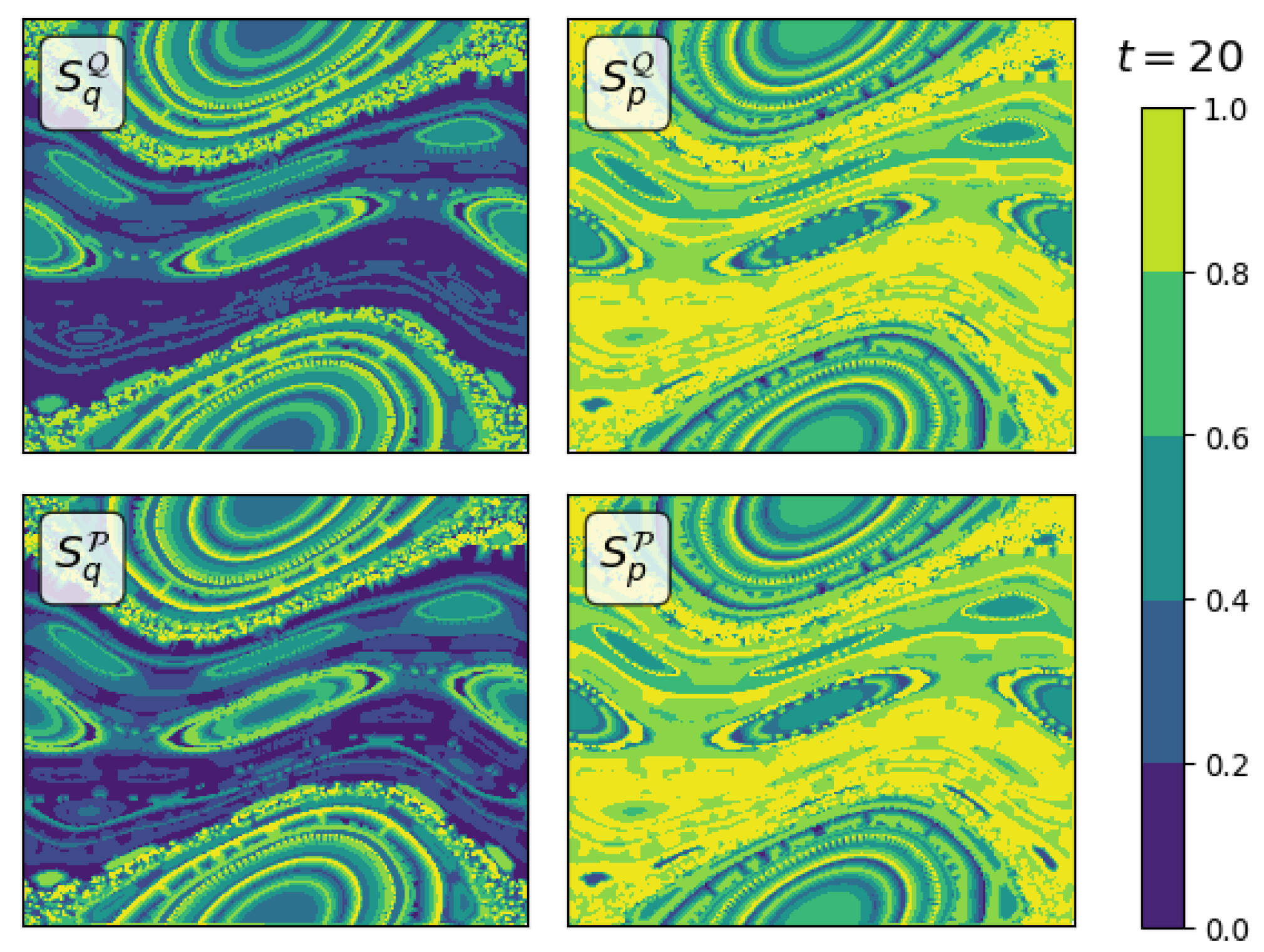
3.2. Sensitivity Analysis
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Ott, E. Chaos in Hamiltonian systems. In Chaos in Dynamical Systems, 2nd ed.; Cambridge University Press: Cambridge, UK, 2002; pp. 246–303. [Google Scholar] [CrossRef]
- Lichtenberg, A.; Lieberman, M. Regular and Chaotic Dynamics; Springer: New York, NY, USA, 1992. [Google Scholar]
- Albert, C.G.; Kasilov, S.V.; Kernbichler, W. Accelerated methods for direct computation of fusion alpha particle losses within, stellarator optimization. J. Plasma Phys. 2020, 86, 815860201. [Google Scholar] [CrossRef]
- Eckmann, J.P.; Ruelle, D. Ergodic theory of chaos and strange attractors. Rev. Mod. Phys. 1985, 57, 617–656. [Google Scholar] [CrossRef]
- Benettin, G.; Galgani, L.; Giorgilli, A.; Strelcyn, J. Lyapunov Characteristic Exponents for smooth dynamical systems and for Hamiltonian systems; A method for computing all of them. Part 1: Theory. Meccanica 1980, 15, 9–20. [Google Scholar] [CrossRef]
- Benettin, G.; Galgani, L.; Giorgilli, A.; Strelcyn, J. Lyapunov Characteristic Exponents for smooth dynamical systems and for Hamiltonian systems; A method for computing all of them. Part 2: Numerical application. Meccanica 1980, 15, 21–30. [Google Scholar] [CrossRef]
- Abarbanel, H.; Brown, R.; Kennel, M. Variation of Lyapunov exponents on a strange attractor. J. Nonlinear Sci. 1991, 1, 175–199. [Google Scholar] [CrossRef]
- Abarbanel, H.D.I. Local Lyapunov Exponents Computed From Observed Data. J. Nonlinear Sci. 1992, 2, 343–365. [Google Scholar] [CrossRef]
- Eckhardt, B.; Yao, D. Local Lyapunov exponents in chaotic systems. Phys. D Nonlinear Phenom. 1993, 65, 100–108. [Google Scholar] [CrossRef]
- Amitrano, C.; Berry, R.S. Probability distributions of local Liapunov exponents for small clusters. Phys. Rev. Lett. 1992, 68, 729–732. [Google Scholar] [CrossRef]
- Arnold, V. Mathematical Methods of Classical Mechanics; Springer: New York, NY, USA, 1989; Volume 60. [Google Scholar]
- Rath, K.; Albert, C.G.; Bischl, B.; von Toussaint, U. Symplectic Gaussian process regression of maps in Hamiltonian systems. Chaos 2021, 31, 053121. [Google Scholar] [CrossRef]
- Skokos, C. The Lyapunov Characteristic Exponents and Their Computation. In Dynamics of Small Solar System Bodies and Exoplanets; Springer: Berlin/Heidelberg, Germany, 2010; pp. 63–135. [Google Scholar] [CrossRef] [Green Version]
- Sobol, I. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Sobol, I. On sensitivity estimation for nonlinear math. models. Matem. Mod. 1990, 2, 112–118. [Google Scholar]
- Saltelli, A.; Annoni, P.; Azzini, I.; Campolongo, F.; Ratto, M.; Tarantola, S. Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput. Phys. Commun. 2010, 181, 259–270. [Google Scholar] [CrossRef]
- Chirikov, B.V. A universal instability of many-dimensional oscillator systems. Phys. Rep. 1979, 52, 263–379. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Álvarez, M.A.; Rosasco, L.; Lawrence, N.D. Kernels for Vector-Valued Functions: A Review. Found. Trends Mach. Learn. 2012, 4, 195–266. [Google Scholar] [CrossRef]
- Solak, E.; Murray-smith, R.; Leithead, W.E.; Leith, D.J.; Rasmussen, C.E. Derivative Observations in Gaussian Process Models of Dynamic Systems. In NIPS Proceedings 15; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2003; pp. 1057–1064. [Google Scholar]
- Eriksson, D.; Dong, K.; Lee, E.; Bindel, D.; Wilson, A. Scaling Gaussian process regression with derivatives. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6868–6878. [Google Scholar]
- Sudret, B. Global sensitivity analysis using polynomial chaos expansions. Reliab. Eng. Syst. Saf. 2008, 93, 964–979. [Google Scholar] [CrossRef]
- Marrel, A.; Iooss, B.; Laurent, B.; Roustant, O. Calculations of Sobol indices for the Gaussian process metamodel. Reliab. Eng. Syst. Saf. 2009, 94, 742–751. [Google Scholar] [CrossRef] [Green Version]
- Geist, K.; Parlitz, U.; Lauterborn, W. Comparison of Different Methods for Computing Lyapunov Exponents. Prog. Theor. Phys. 1990, 83, 875–893. [Google Scholar] [CrossRef]
- Ellner, S.; Gallant, A.; McCaffrey, D.; Nychka, D. Convergence rates and data requirements for Jacobian-based estimates of Lyapunov exponents from data. Phys. Lett. A 1991, 153, 357–363. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Skokos, C.; Bountis, T.; Antonopoulos, C. Geometrical properties of local dynamics in Hamiltonian systems: The Generalized Alignment Index (GALI) method. Phys. D Nonlinear Phenom. 2007, 231, 30–54. [Google Scholar] [CrossRef] [Green Version]
- Rath, K.; Albert, C.; Bischl, B.; von Toussaint, U. SympGPR v1.1: Symplectic Gaussian process regression. Zenodo 2021. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rath, K.; Albert, C.G.; Bischl, B.; von Toussaint, U. Orbit Classification and Sensitivity Analysis in Dynamical Systems Using Surrogate Models. Phys. Sci. Forum 2021, 3, 5. https://doi.org/10.3390/psf2021003005
Rath K, Albert CG, Bischl B, von Toussaint U. Orbit Classification and Sensitivity Analysis in Dynamical Systems Using Surrogate Models. Physical Sciences Forum. 2021; 3(1):5. https://doi.org/10.3390/psf2021003005
Chicago/Turabian StyleRath, Katharina, Christopher G. Albert, Bernd Bischl, and Udo von Toussaint. 2021. "Orbit Classification and Sensitivity Analysis in Dynamical Systems Using Surrogate Models" Physical Sciences Forum 3, no. 1: 5. https://doi.org/10.3390/psf2021003005
APA StyleRath, K., Albert, C. G., Bischl, B., & von Toussaint, U. (2021). Orbit Classification and Sensitivity Analysis in Dynamical Systems Using Surrogate Models. Physical Sciences Forum, 3(1), 5. https://doi.org/10.3390/psf2021003005