Abstract
Dynamics of many classical physics systems are described in terms of Hamilton’s equations. Commonly, initial conditions are only imperfectly known. The associated volume in phase space is preserved over time due to the symplecticity of the Hamiltonian flow. Here we study the propagation of uncertain initial conditions through dynamical systems using symplectic surrogate models of Hamiltonian flow maps. This allows fast sensitivity analysis with respect to the distribution of initial conditions and an estimation of local Lyapunov exponents (LLE) that give insight into local predictability of a dynamical system. In Hamiltonian systems, LLEs permit a distinction between regular and chaotic orbits. Combined with Bayesian methods we provide a statistical analysis of local stability and sensitivity in phase space for Hamiltonian systems. The intended application is the early classification of regular and chaotic orbits of fusion alpha particles in stellarator reactors. The degree of stochastization during a given time period is used as an estimate for the probability that orbits of a specific region in phase space are lost at the plasma boundary. Thus, the approach offers a promising way to accelerate the computation of fusion alpha particle losses.
1. Introduction
Hamilton’s equations describe the dynamics of many classical physics systems such as classical mechanics, plasma physics or electrodynamics. In most of these cases, chaos plays an important role []. One fundamental question in analyzing these chaotic Hamiltonian systems is the distinction between regular and chaotic regions in phase space. A commonly used tool are Poincaré maps, which connect subsequent intersections of orbits with a lower-dimensional subspace, called Poincaré section. For example, in a planetary system one could record a section each time the planet has made a turn around the Sun. The resulting pattern of intersection points on this subspace allow insight into the dynamics of the underlying system: regular orbits stay bound to a closed hyper-surface and do not leave the confinement volume, whereas chaotic orbits might spread over the whole phase space. This is related to the breaking of KAM (Kolmogorov-Arnold-Moser) surfaces that form barriers for motion in phase space []. The classification of regular versus chaotic orbits is performed, e.g., via box-counting [] or by calculating the spectrum of Lyapunov exponents [,,]. Lyapunov exponents measure the asymptotic average exponential rate of divergence of nearby orbits in phase space over infinite time and are therefore invariants of the dynamical system. When considering only finite time, the obtained local Lyapunov exponents (LLEs) for a specific starting position depend on the position in phase space and give insight into the local predictability of the dynamical system of interest [,,,]. Poincaré maps are in most cases inefficient to compute as their computation involves numerical integration of Hamilton’s equations even though only intersections with the surface of interest are recorded. When using a surrogate model to interpolate the Poincaré map, the symplectic structure of phase space arising from the description in terms of the Hamiltonian description has to be preserved to obtain long-term stability and conservation of invariants of motion, e.g., volume preservation. Additional information on Hamiltonian systems and symplecticity can be found in [,]. Here, we use a structure-preserving Gaussian process surrogate model (SympGPR) that interpolates directly between Poincaré sections and thus avoids unnecessary computation while achieving similar accuracy as standard numerical integration schemes [].
In the present work, we investigate how the symplectic surrogate model [] can be used for early classification of chaotic versus regular trajectories based on the calculation of LLEs. The latter are calculated using the Jacobian that is directly available from the surrogate model []. As LLEs also depend on time, we study their distribution on various time scales to estimate the needed number of mapping iterations. We combine the orbit classification with a sensitivity analysis based on variance decomposition [,,] to evaluate the influence of uncertain initial conditions in different regions of phase space. The analysis is carried out on the well-known standard map [] that is well suited for validation purposes as a closed form expression for the Poincaré maps is available. This, however, does not influence the performance of the surrogate model that is applicable also in cases where such a closed form doesn’t exist [].
The intended application is the early classification of regular and chaotic orbits of fusion alpha particles in stellarator reactors []. While regular particles can be expected to remain confined indefinitely, only chaotic orbits have to be traced to the end. This offers a promising way to accelerate loss computations for stellarator optimization.
2. Methods
2.1. Hamiltonian Systems
A dimensional system (with dimensional phase space) described by its Hamiltonian depending on f generalized coordinates and f generalized momenta satisfies Hamilton’s canonical equations of motion,
which represent the time evolution as integral curves of the Hamiltonian vector field.
Here, we consider the standard map [] that is a well-studied model to investigate chaos in Hamiltonian systems. Each mapping step corresponds to one Poincaré map of a periodically kicked rotator:
where K is the stochasticity parameter corresponding to the intensity of the perturbation. The standard map is an area-preserving map with , where J is its Jacobian:
2.2. Symplectic Gaussian Process Emulation
A Gaussian process (GP) [] is a collection of random variables, any finite number of which have a joint Gaussian distribution. A GP is fully specified by its mean and kernel or covariance function and is denoted as
for input data points . Here, we allow vector-valued functions []. The covariance function is a positive semidefinite matrix-valued function, whose entries express the covariance between the output dimensions i and j of .
For regression, we rely on observed function values with entries . These observations may contain local Gaussian noise , i.e., the noise is independent at different positions but may be correlated between components . The input variables are aggregated in the design matrix X, where N is the number of training data points. The posterior distribution, after taking training data points into account, is still a GP with updated mean and covariance function allowing to make predictions for test data :
where is the covariance matrix of the multivariate output noise for each training data point. Here we use the shorthand notation for the block matrix assembled over the output dimension D in addition to the number of input points as in a single-output GP with a scalar covariance function that expresses the covariance of different input data points and . The kernel parameters are estimated given the input data by minimizing the negative log-likelihood [].
To construct a GP emulator that interpolates symplectic maps for Hamiltonian systems, symplectic Gaussian process regression (SympGPR) was presented in [] where the generating function and its gradients are interpolated using a multi-output GP with derivative observations [,]. The generating function links old coordinates to new coordinates (e.g., after one iteration of the standard map Equation (2)) via a canonical transformation such that the symplectic property of phase space is preserved. Thus, input data points consist of pairs . Then, the covariance matrix contains the Hessian of an original scalar covariance function as the lower block matrix (denoted with the red box):
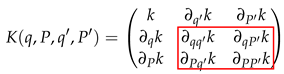
Using the algorithm for the (semi-)implicit symplectic GP map as presented in [], once the SympGPR model is trained and the covariance matrix calculated, the model is used to predict subsequent time steps or Poincaré maps for arbitrary initial conditions.
For the estimation of the Jacobian (Equation (3)) from the SympGPR, the Hessian of the generating function has to be inferred from the training data. Thus, the covariance matrix is extended with a block matrix C containing third derivatives of :
The mean of the posterior distribution of the desired Hessian of the generating function is inferred via
As we have a dependence on mixed coordinates and , where we used and to correctly carry out the inner derivatives, the needed elements for the Jacobian can be calculated employing the chain rule. The Jacobian is then given as the solution of the well-determined linear set of equations:
where we use the following correspondence to determine all factors of the SOEs:
2.3. Sensitivity Analysis
Variance-based sensitivity analysis decomposes the variance of the model output into portions associated with uncertainty in the model inputs or initial conditions [,]. Assuming independent input variables , , the functional analysis of variance (ANOVA) allows a decomposition of the scalar model output Y from which the decomposition of the variance can be deduced:
The first term describes the variation in variance only due to changes in single variables , whereas higher-order interactions are depicted in the contributions of the interaction terms. From this, first-order Sobol’ indices are defined as the corresponding fraction of the total variance, whereas total Sobol’ indices also take the influence of interacting with other input variables into account [,]:
Several methods for efficiently calculating Sobol’ indices have been presented, e.g., MC sampling [,] or direct estimation from surrogate models [,]. Here, we use the MC sampling strategy presented in [] using two sampling matrices and a combination of both , where all columns are from except the i-th column which is from :
where f denotes the model to be evaluated.
2.4. Local Lyapunov Exponents
For a dynamical system in , D Lyapunov characteristic exponents give the exponential separation of trajectories with initial conditions of a dynamical system with perturbation over time:
where is a time-ordered product of Jacobians []. The Lyapunov exponents are then given as the logarithm of the eigenvalues of the positive and symmetric matrix.
where ⊤ denotes the transpose of .
For a D-dimensional system, there exist D Lyapunov exponents giving the rate of growth of a D-volume element with corresponding to the rate of growth of the determinant of the Jacobian . From this follows that for a Hamiltonian system with a symplectic (e.g., volume-preserving) phase space structure, Lyapunov exponents exist in additive inverse pairs as the determinant of the Jacobian is constant, = 0. In the dynamical system of the standard map with considered here, the Lyapunov exponents allow a distinction between regular and chaotic motion. If the Lyapunov exponents , neighboring orbits separate exponentially which corresponds to a chaotic region. In contrast, when the motion is regular [].
As the product of Jacobians is ill-conditioned for large values of T, several algorithms have been proposed to calculate the spectrum of Lyapunov exponents []. Here, we determine local Lyapunov exponents (LLE) that determine the predictability of an orbit of the system at a specific phase point for finite time. In contrast to global Lyapunov exponents they depend on T and on the position in phase space . We use recurrent Gram-Schmidt orthonormalization procedure through QR decomposition [,,], where we follow the evolution of D initially orthonormal deviation vectors . The Jacobian is decomposed into , where is an orthogonal matrix and is an upper triangular matrix yielding a new set of orthonormal vectors . At the next mapping iteration, the matrix product is again decomposed. This procedure is repeated T times to arrive at . The Lyapunov exponents are then estimated from the diagonal elements of
3. Results and Discussion
In the following we apply an implicit SympGPR model with a product kernel []. Due to the periodic topology of the standard map we use a periodic kernel function to construct the covariance matrix in Equation (7) with periodicity in q, whereas a squared exponential kernel is used in P:
Here specifies the amplitude of the fit and is set in accordance with the observations to , where Y corresponds to the change in coordinates. The hyperparameters are set to their maximum likelihood value by minimizing the negative log-likelihood given the input data using the L-BFGS-B routine implemented in Python []. The noise in observations is set to . 30 initial data points are sampled from a Halton sequence to ensure good coverage of the training region in the range and Equation (2) is evaluated once to obtain the corresponding final data points. Each pair of initial and final conditions constitutes one sample of the training data set. Once the model is trained, it is used to predict subsequent mapping steps for arbitrary initial conditions and to infer the corresponding Jacobians for the calculation of the local Lyapunov exponents. Here, we consider two test cases of the standard map with different values of the stochasticity parameter and (Equation (2)). For each of the test cases, a surrogate model is trained. While in the first case the last KAM surface is not yet broken and therefore the region of stochasticity is still confined in phase space, in the latter case the chaotic region covers a much larger portion of phase space. However, there still exist islands of stability with regular orbits []. For the mean squared error (MSE) for the training data is , whereas the test MSE after one mapping application is found to be . A similar quality of the surrogate model is reached for , where the training MSE is and the test MSE .
3.1. Local Lyapunov Exponents and Orbit Classification
For the evaluation of the distribution of the local Lyapunov exponents with respect to the number of mapping iterations T and phase space position , 1000 points are sampled from each orbit under investigation. In the following, we only consider the maximum local Lyapunov exponent as it determines the predictability of the system. For each of the 1000 points, the LLEs are calculated using Equation (18), where the needed Jacobians are given by the surrogate model by evaluating Equation (9) and solving Equation (11).
Figure 1 shows the distributions for , , and for two different initial conditions resulting in a regular and a chaotic orbit. In the regular case the distribution exhibits a sharp peak and with increasing T moves closer to 0. This bias due to the finite number of mapping iterations decreases with as shown in Figure 2 []. For the chaotic orbit, the distribution looks smooth and its median is clearly >0 as expected. For a smaller value of the dynamics in phase space exhibit larger variety with regular, chaotic and also weakly chaotic orbits that remain confined in a small stochastic layer around hyperbolic points. Hence, the transition between regular, weakly chaotic and chaotic orbits is continuous due to the larger variety in phase space. For fewer mapping iterations, possible values of are overlapping, thus preventing a clear distinction between confined chaotic and chaotic orbits.
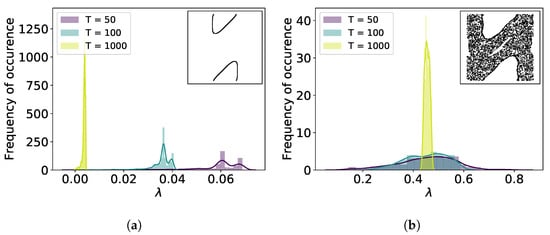
Figure 1.
Distribution of local Lyapunov exponents for a (a) regular orbit and (b) chaotic orbit in the standard map with .
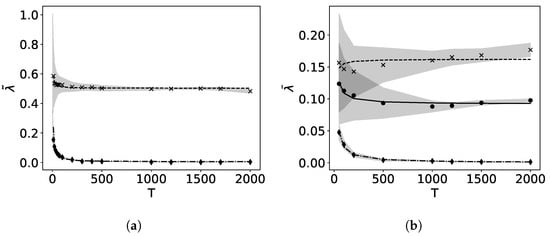
Figure 2.
Rate of convergence of the block bias due to finite number of mapping iterations for (a) with a regular orbit (diamond) and a chaotic orbit (x) and (b) with a regular orbit (diamond), a confined chaotic orbit (circle) and a chaotic orbit (x). The graphs show , the median of for each T, with fitted by linear regression of on T. The gray areas correspond to the standard deviation for 1000 test points.
When considering the whole phase space with 200 orbits with initial conditions sampled from a Halton sequence in the range , already mapping iterations provide insight in the predictability of the standard map (Figure 3). If for a region in phase space the obtained LLE is positive, the predictability in this region is restricted as the instability there is relatively large. If, however, the LLE is close to zero, we can conclude that this region in phase space is governed by regular motion and is therefore highly predictable. For the orbits constituting the chaotic sea have large positive LLEs, whereas islands of stability built by regular orbits show LLEs close to 0. A similar behavior can be observed for , where again regions around stable elliptic points feature while stochastic regions exhibit a varying range of LLEs in accordance to Figure 2.
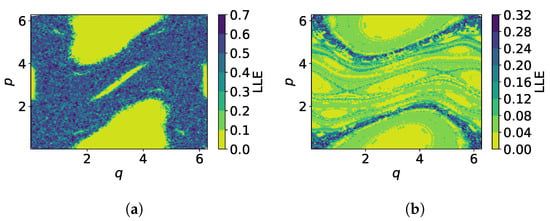
Figure 3.
Local Lyapunov exponents in phase space of the standard map calculated with mapping iterations for (a) , (b) .
Based on the estimation of the LLEs, a Gaussian Bayesian classifier [] is used to determine the probability of an orbit being regular, where we assume that LLEs are normally distributed in each class. First, the classifier is trained on LLEs resulting from 200 different initial conditions for T mapping iterations with the corresponding class labels resulting from the chosen reference being the generalized alignment index (GALI) []. Then, test orbits are sampled from a regular grid in the range with , their LLE is calculated for T mapping iterations and the orbits are then classified. The results for and with are shown in Figure 4, where the color map indicates the probability that the test orbit is regular. While for the classifier provides a very clear distinction between regular and chaotic regions, the distinction between confined chaotic and regular orbits for is less clear. With increasing number of mapping iterations, the number of misclassifications reduces as depicted in Figure 5. If the predicted probability that an orbit belongs to a certain class is lower than , the prediction is not accepted and the orbit is marked as misclassified. With , the percentage of misclassified orbits does not drop below approximately , because the transition between regular and chaotic motion is continuous.
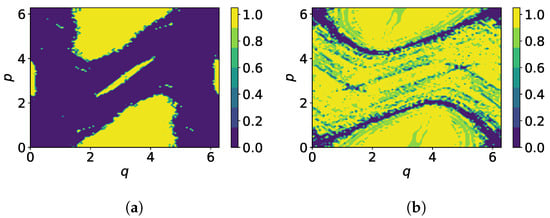
Figure 4.
Orbit classification in standard map, (a) , (b) for . The color map indicates the probability that the orbit is regular.
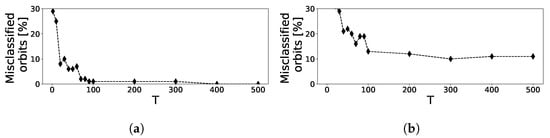
Figure 5.
Percentage of misclassified orbits using a Bayesian classifier trained with 200 orbits for (a) and (b) . 100 test orbits on an equally spaced grid in the range of are classified as regular or chaotic depending on their LLE.
3.2. Sensitivity Analysis
The total Sobol’ indices are calculated for the outputs from the symplectic surrogate model using Equation (15) with uniformly distributed random points within a box of size for each of the mapping iterations as we are interested in the temporal evolution of the indices. For the standard map at with input and output dimensions, 4 total Sobol’ indices are obtained: and denoting the influence of q and and marking the influence of p on the output. We obtain good agreement with an MSE in the order of between the indices obtained by the surrogate model and those using reference data.
As shown in Figure 6 for three different initial conditions for depending on the orbit type, either chaotic or regular, the sensitivity indices behave differently. In case of a regular orbit close to a fixed point, are oscillating, indicating that both input variables have similar influence on average. Getting further from the fixed point, closer to the border of stability, the influence of q gets bigger. This, however, is in contrast to the behavior in the chaotic case, where initially the variance in p has larger influence on the model output. However, when observing the indices over longer periods of time, both variables have similar influence. In Movie S01 in the supplemental material, the time evolution of all four total Sobol’ indices obtained for the standard map are shown in phase space. Each frame is averaged over 10 subsequent mapping iterations. One snapshot is shown in Figure 7. The observation of the whole phase space sustains the findings in Figure 6.
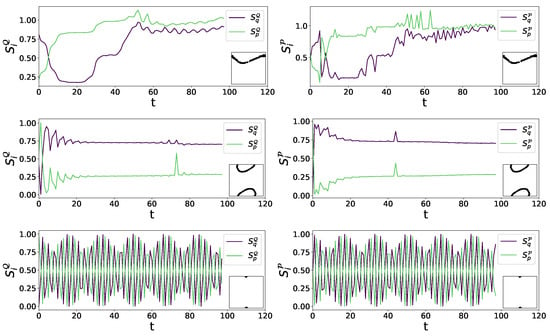
Figure 6.
Total Sobol’ indices as a function of time for three orbits of the standard map with —upper: chaotic orbit , middle: regular orbit , lower: regular orbit very close to fixed point .
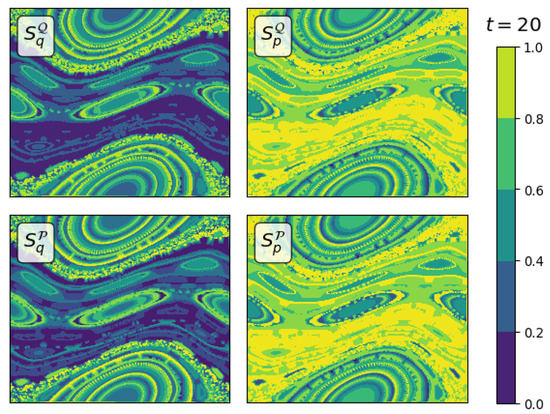
Figure 7.
Total Sobol’ indices (Equation (15)) for the standard map with averaged from to .
4. Conclusions
We presented an approach for orbit classification in Hamiltonian systems based on a structure preserving surrogate model combined with early classification based on local Lyapunov exponents directly available from the surrogate model. The approach was tested on two cases of the standard map. Depending on the perturbation strength, we either see a continuous transition from regular to chaotic orbits for or a sharp separation between those two classes for higher perturbation strengths. This also impacts the classification results obtained from a Bayesian classifier. The presented method is applicable to chaotic Hamiltonian systems and is especially useful when a closed form expression for Poincaré maps is not available. Also, the accompanying sensitivity analysis provides valuable insight: in transition regions between regular and chaotic motion the Sobol’ indices for time-series can be used to analyze the influence of input variables.
Author Contributions
Conceptualization, K.R., C.G.A., B.B. and U.v.T.; methodology, K.R., C.G.A., B.B. and U.v.T.; software, K.R.; validation, K.R., C.G.A., B.B. and U.v.T.; formal analysis, K.R., C.G.A., B.B. and U.v.T.; writing—original draft preparation, K.R.; visualization, K.R.; supervision, C.G.A., U.v.T. and B.B.; funding acquisition, C.G.A., B.B. and U.v.T. All authors have read and agreed to the published version of the manuscript.
Funding
The present contribution is supported by the Helmholtz Association of German Research Centers under the joint research school HIDSS-0006 “Munich School for Data Science-MUDS” and the Reduced Complexity grant No. ZT-I-0010.
Data Availability Statement
The data and source code that support the findings of this study are openly available [] and maintained on https://github.com/redmod-team/SympGPR.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Ott, E. Chaos in Hamiltonian systems. In Chaos in Dynamical Systems, 2nd ed.; Cambridge University Press: Cambridge, UK, 2002; pp. 246–303. [Google Scholar] [CrossRef]
- Lichtenberg, A.; Lieberman, M. Regular and Chaotic Dynamics; Springer: New York, NY, USA, 1992. [Google Scholar]
- Albert, C.G.; Kasilov, S.V.; Kernbichler, W. Accelerated methods for direct computation of fusion alpha particle losses within, stellarator optimization. J. Plasma Phys. 2020, 86, 815860201. [Google Scholar] [CrossRef]
- Eckmann, J.P.; Ruelle, D. Ergodic theory of chaos and strange attractors. Rev. Mod. Phys. 1985, 57, 617–656. [Google Scholar] [CrossRef]
- Benettin, G.; Galgani, L.; Giorgilli, A.; Strelcyn, J. Lyapunov Characteristic Exponents for smooth dynamical systems and for Hamiltonian systems; A method for computing all of them. Part 1: Theory. Meccanica 1980, 15, 9–20. [Google Scholar] [CrossRef]
- Benettin, G.; Galgani, L.; Giorgilli, A.; Strelcyn, J. Lyapunov Characteristic Exponents for smooth dynamical systems and for Hamiltonian systems; A method for computing all of them. Part 2: Numerical application. Meccanica 1980, 15, 21–30. [Google Scholar] [CrossRef]
- Abarbanel, H.; Brown, R.; Kennel, M. Variation of Lyapunov exponents on a strange attractor. J. Nonlinear Sci. 1991, 1, 175–199. [Google Scholar] [CrossRef]
- Abarbanel, H.D.I. Local Lyapunov Exponents Computed From Observed Data. J. Nonlinear Sci. 1992, 2, 343–365. [Google Scholar] [CrossRef]
- Eckhardt, B.; Yao, D. Local Lyapunov exponents in chaotic systems. Phys. D Nonlinear Phenom. 1993, 65, 100–108. [Google Scholar] [CrossRef]
- Amitrano, C.; Berry, R.S. Probability distributions of local Liapunov exponents for small clusters. Phys. Rev. Lett. 1992, 68, 729–732. [Google Scholar] [CrossRef]
- Arnold, V. Mathematical Methods of Classical Mechanics; Springer: New York, NY, USA, 1989; Volume 60. [Google Scholar]
- Rath, K.; Albert, C.G.; Bischl, B.; von Toussaint, U. Symplectic Gaussian process regression of maps in Hamiltonian systems. Chaos 2021, 31, 053121. [Google Scholar] [CrossRef]
- Skokos, C. The Lyapunov Characteristic Exponents and Their Computation. In Dynamics of Small Solar System Bodies and Exoplanets; Springer: Berlin/Heidelberg, Germany, 2010; pp. 63–135. [Google Scholar] [CrossRef] [Green Version]
- Sobol, I. Global sensitivity indices for nonlinear mathematical models and their Monte Carlo estimates. Math. Comput. Simul. 2001, 55, 271–280. [Google Scholar] [CrossRef]
- Sobol, I. On sensitivity estimation for nonlinear math. models. Matem. Mod. 1990, 2, 112–118. [Google Scholar]
- Saltelli, A.; Annoni, P.; Azzini, I.; Campolongo, F.; Ratto, M.; Tarantola, S. Variance based sensitivity analysis of model output. Design and estimator for the total sensitivity index. Comput. Phys. Commun. 2010, 181, 259–270. [Google Scholar] [CrossRef]
- Chirikov, B.V. A universal instability of many-dimensional oscillator systems. Phys. Rep. 1979, 52, 263–379. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2005. [Google Scholar]
- Álvarez, M.A.; Rosasco, L.; Lawrence, N.D. Kernels for Vector-Valued Functions: A Review. Found. Trends Mach. Learn. 2012, 4, 195–266. [Google Scholar] [CrossRef]
- Solak, E.; Murray-smith, R.; Leithead, W.E.; Leith, D.J.; Rasmussen, C.E. Derivative Observations in Gaussian Process Models of Dynamic Systems. In NIPS Proceedings 15; Becker, S., Thrun, S., Obermayer, K., Eds.; MIT Press: Cambridge, MA, USA, 2003; pp. 1057–1064. [Google Scholar]
- Eriksson, D.; Dong, K.; Lee, E.; Bindel, D.; Wilson, A. Scaling Gaussian process regression with derivatives. In Advances in Neural Information Processing Systems 31: Annual Conference on Neural Information Processing Systems 2018 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018; Curran Associates, Inc.: Red Hook, NY, USA, 2018; pp. 6868–6878. [Google Scholar]
- Sudret, B. Global sensitivity analysis using polynomial chaos expansions. Reliab. Eng. Syst. Saf. 2008, 93, 964–979. [Google Scholar] [CrossRef]
- Marrel, A.; Iooss, B.; Laurent, B.; Roustant, O. Calculations of Sobol indices for the Gaussian process metamodel. Reliab. Eng. Syst. Saf. 2009, 94, 742–751. [Google Scholar] [CrossRef] [Green Version]
- Geist, K.; Parlitz, U.; Lauterborn, W. Comparison of Different Methods for Computing Lyapunov Exponents. Prog. Theor. Phys. 1990, 83, 875–893. [Google Scholar] [CrossRef]
- Ellner, S.; Gallant, A.; McCaffrey, D.; Nychka, D. Convergence rates and data requirements for Jacobian-based estimates of Lyapunov exponents from data. Phys. Lett. A 1991, 153, 357–363. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Skokos, C.; Bountis, T.; Antonopoulos, C. Geometrical properties of local dynamics in Hamiltonian systems: The Generalized Alignment Index (GALI) method. Phys. D Nonlinear Phenom. 2007, 231, 30–54. [Google Scholar] [CrossRef] [Green Version]
- Rath, K.; Albert, C.; Bischl, B.; von Toussaint, U. SympGPR v1.1: Symplectic Gaussian process regression. Zenodo 2021. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).