Abstract
In Bayesian analysis, testing for linearity requires placing a prior to the entire space of potential regression functions. This poses a problem for many standard tests, as assigning positive prior probability to such a hypothesis is challenging. The Full Bayesian Significance Test (FBST) sidesteps this issue, standing out for also being logically coherent and offering a measure of evidence against , although its application to nonparametric settings is still limited. In this work, we use Gaussian process priors to derive FBST procedures that evaluate general linearity assumptions, such as testing the adherence of data and performing variable selection to linear models. We also make use of pragmatic hypotheses to verify if the data might be compatible with a linear model when factors such as measurement errors or utility judgments are accounted for. This contribution extends the theory of the FBST, allowing for its application in nonparametric settings and requiring, at most, simple optimization procedures to reach the desired conclusion.
1. Introduction
Although linear models are widespread in the scientific literature, their validity is rarely tested in its full complexity. Generally, linearity is tested as a particular case of a more general parametric model [1] or compared to a finite selection of models—each with their own prior specification—through measures such as the Deviance Information Criterion [2]. In actuality, testing the adherence of linear models to data requires (i) assigning a nonparametric prior to the set of regression functions and (ii) devising a procedure that highlights the evidence against the linear model hypothesis based on the data and the prior. Devising a test solely based on the posterior probability of the hypothesis in this case is seldom advised, as it imposes positive prior probability to the set of linear models when there are countless nonlinear functions arbitrarily close to any element of it.
The Full Bayesian Significance Test (FBST, [3]) is the testing framework used throughout this work. The FBST does not violate the likelihood principle, does not require setting positive prior probabilities to hypotheses, and provides a measure of evidence against , along with other desirable characteristics. With the exceptions of Corrêa Filho [4] and Liu et al. [5], the FBST has not been applied to nonparametrics, still requiring new theoretical developments to systematically embrace such settings.
Bridging the gaps above, this paper provides a nonparametric FBST formulation that tests the adherence of linear models to data. By using a Gaussian Process (GP, [6]) as a prior to model the regression function, we propose FBST procedures that depend on whether the covariates’ domain is finite or infinite. Furthermore, we lay out FBST procedures for hypotheses that include negligible deviations from , known as pragmatic hypotheses [7], useful to evaluate if is approximately instead of precisely compatible with the data.
In Figure 1, we illustrate how the FBST operates when applied to and its pragmatic version, . For , the posterior is used to obtain the Highest Posterior Density (HPD) region, the smallest credible region with probability of containing the quantity of interest. The hypothesis is rejected if it does not intersect with the HPD. This procedure is meaningful even when is precise, that is, when .
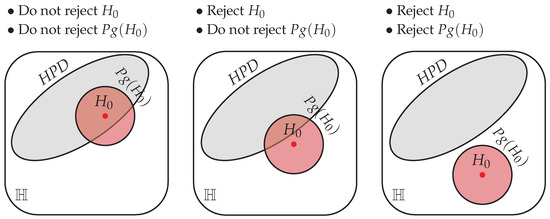
Figure 1.
Illustration of the FBST for a precise and its pragmatic version, , in the hypothesis space . Each panel presents a possible configuration of the hypotheses and the HPD, with the text above the panels indicating the conclusion.
Even though our contribution makes exclusive use of the FBST, this does not imply that it is the only valid framework for the problem. While no other testing procedure as general as ours has been proposed, Mulder [8] uses Bayes factors to test if a single covariate may be nonlinearly related to the response variable and Lassance et al. [9] (Section 3.1) test the pragmatic version of the linear model hypothesis through its posterior probability.
This work is organized as follows. In Section 2, the required background knowledge is provided. Our findings are presented in Section 3, leading in Section 4 to an application that puts all the FBST procedures to use. Lastly, Section 5 describes how to enhance the FBST further and establishes potential future research. All proofs can be found in Appendix A.
2. Materials and Methods
2.1. Full Bayesian Significance Test (FBST)
The FBST is composed of three steps [3]. For , where is the parameter space, these steps are as follows:
- Delimit the set of elements in that are more likely than those in . That is, if is the posterior density of given the data ,
- Obtain the Bayesian evidence value.
- Reject if for a previously specified significance level .
In this paper, we use a procedure equivalent to the FBST: reject if the Highest Posterior Density (HPD) region is such that . The HPD is the smallest region with posterior probability of , obtained by finding the value such that
When is normally distributed, the HPD region is equivalent to the credible interval symmetric around the posterior mean. For its multivariate counterpart, , we have that , and thus , where stands for the chi-squared distribution with k degrees of freedom. Therefore, if is the 100% quantile function, the HPD is given by the following ellipsoid ([10], Result 4.7):
2.2. Gaussian Processes (GPs)
A GP is a nonparametric family of priors used to model functions in regression settings. The random function behaves according to a GP if
where and , respectively, determine the mean and covariance of the process. When the response variable Y is such that for , that is,
then the GP is conjugate and its posterior is such that
The choice of m, K, and reflect positions on the mean, smoothness, and variation surrounding the GP. In Section 4, we use the specifics of the application to choose them. For more general settings, one may assume that the uncertainty of m and K is reducible to a finite number of parameters. Then, one can either set priors to such parameters directly [11] or plug point estimates for them based on the maximum partial likelihood [12].
Conditionally on , the HPD region of the GP can be analytically obtained for any finite set . Since the marginals of the posterior GP are also normally distributed, Equation (1) entails that the HPD region for is
It is also possible to obtain an HPD set for the GP without setting . Let and , respectively, be the prior and posterior probability measures of the GP defined on a measurable space . Hence,
Since , the Radon–Nikodym derivative of the GP for is such that
i.e., it suffices to evaluate h only on the values of in the sample. To account for repeated lines in , let be the matrix with all unique observations from and be the number of lines of . Defining as a diagonal matrix that counts how many times each appears in and as the vector of means of all elements of related to each ,
Thus, for a constant , a Weighted Residual Sum of Squares (WRSS) defines the HPD:
2.3. Pragmatic Hypotheses
The pragmatic hypothesis enlarges to a set deemed as practically equivalent. The implementation uses the notion of negligible deviations from . The degree to which the hypothesis is enlarged depends on the choice of a threshold , and factors such as the scale of measurement errors or expert’s utility judgments could help set it (see Section 4 for a practical example and (Lassance et al. [9], Section 4) for suggestions). Formally, for a hypothesis space , let be the dissimilarity function from which one can express how much of a departure from is reasonable. Then, the pragmatic hypothesis is given by
that is, the pragmatic hypothesis contains all elements such that, for some element , . In this work, we assume that is a space of functions of the type . Further specifications on are presented in Section 3. When and are implicit, we use to denote the pragmatic hypothesis.
3. Results
Throughout this work, we use the modeling assumptions in Section 2.2 for the data and the regression function , and assume that the hypothesis of interest is
where is a linearly independent set of linear functions and is the covariates’ domain. The choice of determines the test performed, such as evaluating linear models () or doing variable selection ().
Our findings are divided in two settings: those applicable to and those to . In both cases, we explore when is a finite or an infinite set. The finite case provides a closed-form solution for the FBST of and a solution for the pragmatic hypothesis that requires a univariate optimization procedure. When is infinite, testing or also requires determining in the HPD of Equation (5), which is achieved by noting that the can be expressed as a linear combination of noncentral chi-squared random variables; therefore, is the quantile of a generalized chi-squared distribution [13].
Theorem 1 (FBST of the linear model hypothesis).
Let be the hypothesis in Equation (7) and . Then,
- When is a finite set, the FBST does not reject if and only ifwhere and is the size of .
- When is an infinite set, the FBST does not reject if and only if
Before presenting the FBST for the pragmatic version of Equation (7), we specify and provide the infimum when the dissimilarity function in Equation (6) is the distance in the probability space of . The hypothesis space is such that
As for the infimum, it is described in the following Lemma:
Lemma 1 (Infimum of the dissimilarity on the linear model set).
Theorem 2 (FBST of the pragmatic version of ).
Let be given by Equation (8) and define . Assume that . Then,
- When is a finite set, the FBST does not reject if and only ifwhere and is a diagonal matrix formed by the vector .
- When is an infinite set, the FBST does not reject if and only ifwhere and is a diagonal matrix formed by the vector .
In the infinite case of in Theorem 2, an appealing choice for the distribution of is based on the posterior of a Dirichlet process [14]. For a concentration parameter and a centering distribution , set a Dirichlet process such that . Then,
where for . With this choice, one can ensure that positive probability will always be assigned to all . Moreover, can leverage the weight of the prior on the FBST, with higher values of leading to a higher chance of not rejecting .
4. Application: Water Droplet Experiment
The dataset from Duguid [15] provides a setting where small water droplets (ranging from 3 to 9 μm) are free falling through a tube that keeps factors such as temperature and humidity constant. As a droplet falls, a camera takes a picture at every 0.5 s, ceasing activity after 7 s. One of the objectives of the study was to evaluate Fick’s law, which in this setting implies that—when time is a covariate—the decrease in radius of the droplet can be described through a linear model. The two hypotheses of interest are
with the first hypothesis testing the validity of Fick’s law for this case and the second one verifying if time can be removed as a covariate.
We use the GP in Section 2.2 to model the data, with the following prior settings:
As shown in Figure 2a, this choice leads to functions that obey the 3–9 m restriction without becoming too restrictive as a consequence. In Figure 2b, we observe that the posterior draws resemble a linear model except on , due to the missing observation.
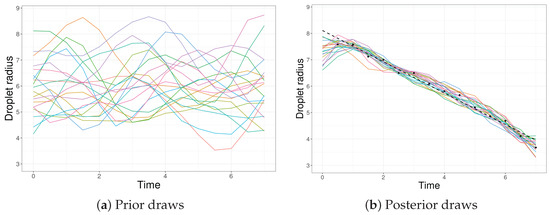
Figure 2.
GP draws of the (a) prior and (b) posterior for the water droplet data. The colored curves represent each draw, the black dots are the observed data and the dashed line is the least squares estimate of the linear model.
In Table 1, we present the e-value for both hypotheses of interest, assuming that is either finite or infinite. Since small e-values provide strong evidence against , with we conclude that both and should be rejected, i.e., Fick’s law would fail.

Table 1.
e-value of under finite and infinite for the water droplet experiment.
While this analysis shows that Fick’s law is not exactly valid, it might still provide an adequate approximation, motivating the use of pragmatic hypotheses. This requires setting the threshold , which is detailed below.
In the original experiment, the radius of the droplets was obtained indirectly through Stoke’s law, that is,
where is the terminal velocity and . Since the mean velocity () was used in (9) instead of , there are two sources of measurement error: the estimate of (maximum error of ) and switching for in (9) (maximum error of ([9], Example 1.3)). We conclude that the margin of error of the radius is
While relates to the distance, Lemma 1 uses the distance. To obtain an estimate of the latter from the former, we use Proposition 6.11 of Folland [16], which implies that
thus .
Table 2 presents the e-values for the pragmatic hypotheses , . We assume either that (original setting, discrete uniform) or that , with (continuous uniform as centering distribution). Contrary to Table 1, the first hypothesis is not rejected, demonstrating that Fick’s law provides a good approximation of the phenomenon.
Table 2.
e-value of under finite and infinite for the water droplet experiment.
5. Discussion
Regarding the results of the application (Section 4), we believe to have demonstrated the importance of using pragmatic hypotheses whenever reasonable. While choosing is not a simple task in nonparametric settings, there are strategies available for deriving it [9]. Furthermore, while the e-value is not a measure of evidence against [3], combining it with a pragmatic hypothesis allows one to perform the Generalized FBST (GFBST, [17]), which can discriminate “evidence of absence” from “absence of evidence”, along with many other desirable properties.
One of the main limitations of this work is in the strategy of performing variable selection. While the aforementioned GFBST allows for multiple testing without the necessity of correcting , variable selection is only possible through Equation (7) if the linear model hypothesis is not rejected. Therefore, one future research direction is developing tests that evaluate conditional independence without assuming a specific functional form for the relationship between variables.
Author Contributions
Conceptualization, all authors; methodology, R.F.L.L. and R.B.S.; software, R.F.L.L.; validation, R.F.L.L.; formal analysis, R.F.L.L.; investigation, J.M.S.; resources, R.F.L.L.; data curation, R.F.L.L.; writing—original draft preparation, R.F.L.L.; writing—review and editing, all authors; visualization, R.F.L.L.; supervision, R.B.S. and J.M.S.; project administration, R.B.S.; funding acquisition, Interinstitutional Graduate Program in Statistics UFSCar-USP. All authors have read and agreed to the published version of the manuscript.
Funding
This study was financed in part by the Coordenação de Aperfeiçoamento de Pessoal de Nível Superior—Brasil (CAPES)—Finance Code 001. This research was funded by FAPESP (grants 2019/11321-9 and CEPID CeMEAI 2013/07375-0) and CNPq (grants 309607/2020-5, 422705/2021-7 and PQ 303290/2021-8).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data and the functions used in this study are available in GitHub at https://github.com/rflassance/lmFBST (accessed on 24 June 2025). These data were derived from the following resource available in the public domain: https://scholarsmine.mst.edu/cgi/viewcontent.cgi?params=/context/masters_theses/article/6294 (page 42, accessed on 15 May 2024).
Conflicts of Interest
The authors declare no conflicts of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the manuscript; or in the decision to publish the results.
Abbreviations
The following abbreviations are used in this manuscript:
| FBST | Full Bayesian Significance Test |
| GFBST | Generalized Full Bayesian Significance Test |
| GP | Gaussian Process |
| HPD | Highest Posterior Density |
| WRSS | Weighted Residual Sum of Squares |
Appendix A. Proofs
Proof of Theorem 1.
The proof is done in parts:
Finite .
Infinite .
In this case, the FBST does not reject the hypothesis iff such that . If , this is equivalent to not rejecting iff
since is the weighted least squares estimate of . ■
□
Proof of Lemma 1.
The proof is found in (Lassance et al. [9], Theorem 2). □
Proof of Theorem 2.
The proof is done in parts:
Finite .
Lemma 1 implies that
and thus
Since the HPD is given by Equation (2), the FBST does not reject if and only if
are intersecting ellipsoids. From Proposition 2 of Gilitschenski and Hanebeck [18], the ellipsoids intersect if and only if
■
Infinite .
The FBST does not reject if
The ellipsoid is such that, for any function where , we can conclude that . Therefore, the contains functions that are linear outside of , and thus
where , thus . Therefore, the FBST does not reject if the ellipsoids G and intersect, which can be verified through Proposition 2 of Gilitschenski and Hanebeck [18]. □
■
References
- Kershaw, J.; Kashikura, K.; Zhang, X.; Abe, S.; Kanno, I. Bayesian technique for investigating linearity in event-related BOLD fMRI. Magn. Reson. Med. 2001, 45, 1081–1094. [Google Scholar] [CrossRef] [PubMed]
- Spiegelhalter, D.J.; Best, N.G.; Carlin, B.P.; Van Der Linde, A. Bayesian measures of model complexity and fit. J. R. Stat. Soc. Ser. B (Stat. Methodol.) 2002, 64, 583–639. [Google Scholar] [CrossRef]
- de Bragança Pereira, C.A.; Stern, J.M.; Wechsler, S. Can a significance test be genuinely Bayesian? Bayesian Anal. 2008, 3, 79–100. [Google Scholar] [CrossRef]
- Corrêa Filho, F.P.T. Nonparametric Tests for Pólya Trees: Non-Parametric Versions of the FBST. Master’s Thesis, Institute of Mathematics and Statistics, University of São Paulo, São Paulo, Brazil, 2024. [Google Scholar]
- Liu, Z.; Li, Z.; Wang, J.; He, Y. Full Bayesian Significance Testing for Neural Networks. arXiv 2024, arXiv:2401.13335. [Google Scholar] [CrossRef]
- Rasmussen, C.E.; Williams, C.K.I. Gaussian Processes for Machine Learning; The MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Esteves, L.G.; Izbicki, R.; Stern, J.M.; Stern, R.B. Pragmatic Hypotheses in the Evolution of Science. Entropy 2019, 21, 883. [Google Scholar] [CrossRef]
- Mulder, J. Bayesian Testing of Linear Versus Nonlinear Effects Using Gaussian Process Priors. Am. Stat. 2023, 77, 1–11. [Google Scholar] [CrossRef]
- Lassance, R.F.; Izbicki, R.; Stern, R.B. Adding imprecision to hypotheses: A Bayesian framework for testing practical significance in nonparametric settings. Int. J. Approx. Reason. 2025, 178, 109332. [Google Scholar] [CrossRef]
- Johnson, R.; Wichern, D. Applied Multivariate Statistical Analysis, 6th ed.; Prentice Hall India Learning Private Limited: Delhi, India, 2012; p. 163. [Google Scholar]
- Oakley, J. Eliciting Gaussian process priors for complex computer codes. J. R. Stat. Soc. Ser. D (Stat.) 2002, 51, 81–97. [Google Scholar] [CrossRef]
- Wang, X.; Berger, J.O. Estimating Shape Constrained Functions Using Gaussian Processes. SIAM/ASA J. Uncertain. Quantif. 2016, 4, 1–25. [Google Scholar] [CrossRef]
- Davies, R.B. Algorithm AS 155: The Distribution of a Linear Combination of χ2 Random Variables. Appl. Stat. 1980, 29, 323. [Google Scholar] [CrossRef]
- Ferguson, T.S. A Bayesian Analysis of Some Nonparametric Problems. Ann. Stat. 1973, 1, 209–230. [Google Scholar] [CrossRef]
- Duguid, H.A. A Study of the Evaporation Rates of Small Freely Falling Water Droplets. Master’s Thesis, Missouri University of Science and Technology, Rolla, MO, USA, 1969. [Google Scholar]
- Folland, G. Real Analysis: Modern Techniques and Their Applications, 2nd ed.; Pure and Applied Mathematics: A Wiley Series of Texts, Monographs and Tracts; Wiley: Hoboken, NJ, USA, 1999; p. 186. [Google Scholar]
- Esteves, L.G.; Izbicki, R.; Stern, J.M.; Stern, R.B. Logical coherence in Bayesian simultaneous three-way hypothesis tests. Int. J. Approx. Reason. 2023, 152, 297–309. [Google Scholar] [CrossRef]
- Gilitschenski, I.; Hanebeck, U.D. A robust computational test for overlap of two arbitrary-dimensional ellipsoids in fault-detection of Kalman filters. In Proceedings of the 2012 15th International Conference on Information Fusion, Singapore, 9–12 July 2012; pp. 396–401. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).