Abstract
We have studied how the readability of a text can change in translation by considering Matthew’s Gospel, written in Greek, translated into Latin and 35 modern languages. We have found that the deep-language parameters (characters per word), (words per sentence), (words per interpunctions), (interpunctions per sentence) and a universal readability index of each translation are so diverse from language to language, and even within a given language for which there are many versions of Matthew—such as in English and Spanish—that the resulting texts mathematically seem to be diverse. The several tens of versions of Matthew’s Gospel studied appear to address very diverse audiences. If a reader could understand all of them well, he/she would have the impression of reading texts written by diverse authors, although all of them tell the same story.
1. A Common Ground for Measuring Readability across Time and Languages
Readability formulae [1,2,3,4,5,6,7,8,9] are applicable to any alphabetical language. Based on the length of words and sentences, they allow for the comparison of diverse texts automatically and objectively to assess the difficulty that readers may find in reading them. From the point of view of the writer, a readability formula allows one to better match readers and texts. Many readability formulae have been proposed for English [5], but only a few have been proposed for a very small number of other languages [9].
In response to the need to provide a readability formula applicable to any alphabetical language and the interest to compare the readability of texts written in diverse languages, including translations, in Reference [10], we have proposed a universal readability index which includes, for the first time, an estimate of the short-term memory (STM) processing capacity of readers. This capacity seems to be linked to the response of readers’ STM to the partial stimuli contained in a sentence, singled out by interpunctions, a process described by the so-called word interval , i.e., the number of words between two following interpunctions [11,12]. In fact, all other readability formulae neglect the empirical connection found between readers’ STM processing capacity (described by Miller’s law [13]) and the word interval , which appears, at least empirically, justified and natural [10,11,12,14,15,16].
The possibility of comparing the readability of texts written in any alphabetical language, including ancient languages such as Greek and Latin, can be very useful in cognitive psychology, theory of communication, information theory, phonics and linguistics. Before Reference [10], however, scholars had never considered , but the scatterplots of versus any readability index show that texts sharing the same readability index can have very diverse values of [11]. Now, it is unlikely that has no impact on reading difficulty; therefore, by introducing in the mathematical definition of a readability index, the readability index is better “fine-tuned” to readers and reveals their STM processing capacity.
In Reference [10], the global readability index that was developed from Italian [12] was transformed into the universal readability index after showing that the popular Flesch’s Reading Ease Index [1] and the Automated Readability Index [2], largely used in assessing the readability of English texts, are connected to .
As the title of this article claims, our purpose is to assess whether the translation of an ancient text written in Greek—namely, in our exercise, the Gospel according to Matthew—into Latin and 35 modern languages may reveal similarities or differences in the reading ability required to readers for understanding it across time and translation. The mathematical parameters we use for this study are the deep-language parameters recalled in Section 2 and the universal readability index recalled in Section 3. We have studied Matthew’s Gospel because of its great heritage value and its multiple translations [14].
After this introductory section, Section 2 deals with Matthew’s Gospel translations in Latin and in 35 modern languages, together with their representation in a vector plane; Section 3 deals with a universal readability index in translated texts; Section 4 deals with many diverse translations of Matthew within the same language (English and Spanish); finally, Section 5 summarizes some final remarks and proposes further developments.
2. Matthew’s Gospel Translations and the Vector Plane of Deep-Language Parameters
The defined deep-language parameters (number of characters per word), (number of words per sentence), (word interval, number of words per interpunctions) and (number of interpunctions per sentence) [11] are listed in Table 1 alongside their average values in the original Greek Matthew and its translation into Latin and 35 modern languages [14].

Table 1.
Average values of (characters per word), (words per sentence), (words per interpunction), (interpunctions, or number of , per sentence), (universal readability index, recalled and calculated in Section 3) in Matthew in the indicated languages and listed according to their belonging to a language family. The source of these texts is reported in Reference [14].
Notice that verses 1.1 to 1.17 (genealogy) have been deleted every time for not biasing the statistics of , and [14,16,17], as with all titles, notes and other characters not belonging to the pure text. This work was done manually with WinWord.
Similar to in References [14,15,16,17], the 28 chapters of Matthew were statistically weighted with the fraction of total words. For example, the original Greek Matthew contains total words; therefore, each sample does not weigh but the number of its words divided by the total words: Chapter 5, for example, is made of words; therefore, its weight is . This choice is mandatory to avoid a short chapter (or, in general, a short text) affecting the statistical results as though it were a long one.
The averages of the four deep-language parameters can be used to represent each text graphically in the first Cartesian quadrant [11], thereby allowing a first assessment of whether texts are mathematically similar or “close” according to these parameters.
Let us consider the following six vectors of the indicated components, made of the average values of Table 1 ), ), ), ), ), ), and their resulting ending point:
Figure 1 shows the ending point of vector (1) of the original Greek text and its translations. We notice a very large spread, as discussed in Reference [14], because most translations are not verbatim, although they all maintain the conventional division in chapters and verses of the Greek text. The spread is so large to be almost identical to that shown by seven centuries of Italian literature [11]. In other words, the texts of Table 1, mathematically, could describe an entire culture’s literature, not a single text.
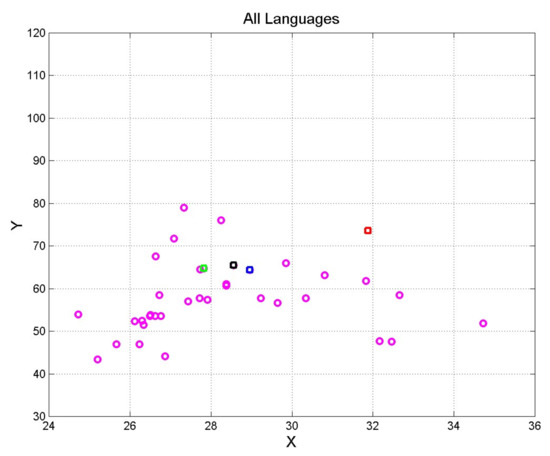
Figure 1.
Scatter plot of vector (1) coordinates concerning the translations in Table 1. The original Greek Matthew is indicated with the red square; Latin: blue square; Spanish: green square; English: black square.
For two texts to be mathematically similar, the vicinity in this plane is only a necessary condition. Because based on averages only, the “vicinity” of two texts should be further studied and assessed with Communication Theory involving the “sentences channel”, the “interpunctions channel” and the “likeness index”, as shown in [12,14,15,16].
After showing this large spread, let us recall and apply the concept of a universal readability index proposed in Reference [10] to Matthew’s translations.
3. Universal Readability Index in Translations
As shown in Reference [10], the universal readability index is given by the following formula:
with :
The symbol indicates average values, as with those reported in Table 1; refers to Italian. Notice that since, in the following, we calculate Equation (4) according to average values, hence .281 for all languages.
The rationale for this latter choice is that is a parameter typical of a language which, if not scaled before calculating Equation (2), would bias any readability index without really quantifying the change in reading difficulty experimented by readers used to reading, in their language, shorter or longer words than those found in Italian. This scaling, therefore, avoids changing and for the only reason that a language has, on average, words shorter or longer than their Italian counterparts. In any case, as shown in Reference [11], affects readability much less than .
Figure 2 shows the scatterplot of versus concerning the translations listed in Table 1. Since is mostly affected by , the rationale for introducing in Equation (2) becomes clear [10,11]. For example, if , can range from 4 to 8.5, practically by Miller’s range of .
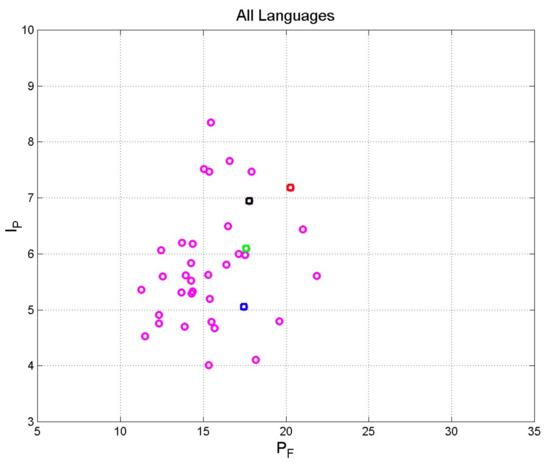
Figure 2.
Scatterplot of versus concerning the translations in Table 1. The original Greek Matthew is indicated with the red square; Latin: blue square; Spanish: green square; English: black square. Notice that for a fixed , extends in the full Miller’s range .
In conclusion, a readability formula that does not consider assumes, unrealistically, that a text with a given readability index is readable, with the same effort, both by readers who display powerful STM processing capacity (large ) and by readers who do not (small ).
Equation (2) sets for —a center value for texts according to the equivalence between and Miller’s law, see [18,19,20,21,22,23,24,25,26,27]— for and for . In other words, if a text has a small word interval (therefore matched to readers gifted with average-to-weak STM processing capacity), then it should be read more easily than a text with the same but larger (matched to readers gifted with an average-to-powerful STM processing capacity). These changes quantify and introduce important aspects of readers’ STM; therefore, should better “measure” relative reading difficulties, which are very likely linked to readers’ schooling.
In fact, can be related to the number of years of school attended in Italy’s school system [10,11]—assumed as a reference school system for any language if is adopted as a universal readability index—as shown in Figure 3. From it, we notice that the larger , the more readable the text for a given number of school years. The continuous lines divide the quadrant into areas of the same reading performance, such as “almost unintelligible”, “very difficult”, etc. For example, the area labelled “easy” indicates all combinations of values of and school years required to declare a text “easy” to read. In all cases, as readers’ schooling increases, they can read more difficult texts as far as readability is concerned.
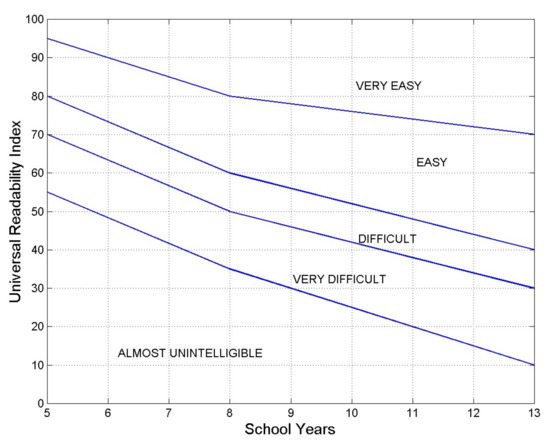
Figure 3.
Universal readability index , as a function of the number of school years attended in Italy (see References [10,11] and the further citations there reported), as reference for all languages. The continuous lines divide the quadrant into areas of the same performance of texts. Elementary school lasts 5 years; Junior High School lasts 3 years; High School lasts 5 years. Kids stay at school until they are 19 years old.
The rightmost column of Table 1 reports calculated with the average values of and listed there. Table 2 reports the overall average values and ranges of , and calculated from Table 1. We can notice a large range for each parameter. In other words, if there were a reader who could understand all languages equally well, he/she would experiment with quite diverse reading difficulties, not to mention he/she would read texts which would appear diverse, with diverse lengths of sentences and diverse distribution of interpunctions, although they all convey the same story.
Table 2.
Average values and range (minimum–maximum) of (words per sentence), (words per interpunction) and (universal readability index) found in the texts listed in Table 1.
For example, the Cebuano version (least readable) requires at least 10 years of schooling to be considered “easy” to read (Figure 3), while the Polish version (most readable) requires less than 5.
Figure 4 shows the scatterplot of versus and Figure 5 shows the scatterplot of versus . Figure 4 clearly shows, in agreement with Equation (2), that decreases as increases. Figure 5 enhances the linear decrease of as increases. In all cases, notice that translations show values that are quite diverse compared to that of the original Greek text.
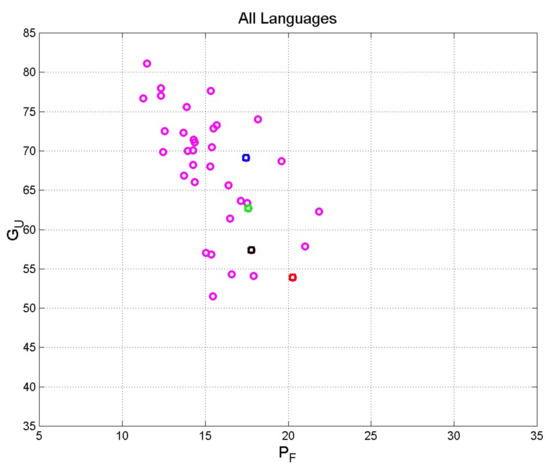
Figure 4.
Scatter plot of versus concerning the translations in Table 1. The original Greek Matthew is indicated with the red square; Latin: blue square; Spanish: green square; English: black square.
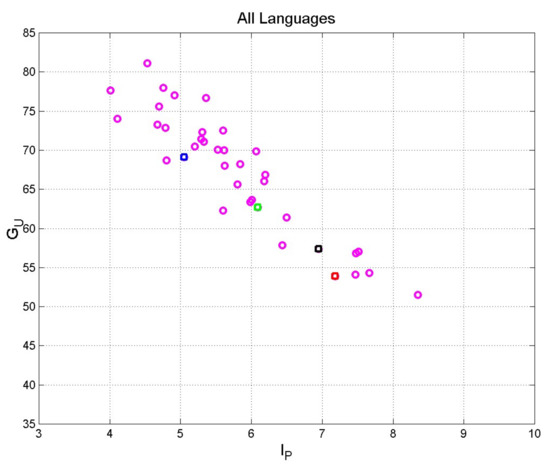
Figure 5.
Scatter plot of versus concerning the translations in Table 1. The original Greek Matthew is indicated with the red square; Latin: blue square; Spanish: green square; English: black
square.
The large spread found in translating Matthew’s Gospel into diverse languages is also found in translating it into the same language by diverse teams of translators—as is the case for the multiple versions in English and Spanish—discussed in the next section.
4. Many Diverse Translations within the Same Language
It may be curious to notice that within the same language, there are many diverse translations of the Bible. In most cases, the reason for this proliferation is not that the existing translation has become obsolete because of particularly convoluted sentences and/or old words no longer clearly understood. The reason, as it becomes clear in this section, is that each translation seems to be addressed to diverse contemporary readers. The most striking cases are English and Spanish, for which there are tens of translations, some of which we have studied.
Table 3 lists 40 English translations and their parameters, including the classical King James (1611), Table 4 lists 15 Spanish translations, including the classical Reina Valera Antigua. Both sets are freely available, along with other translations, on the website https://www.biblegateway.com/versions/ (accessed on 15 April 2023) The deep-language parameters and the universal readability indices calculated for each translation are extremely variable, especially in English.
Table 3.
Average values of (characters per word), (words per sentence), (words per interpunction), (interpunctions, or number of , per sentence) and (universal readability index) in Matthew in the indicated English translations, updated to the indicated year. Source: https://www.biblegateway.com/versions/ (last access, 15 April 2023).
Table 4.
Average values of (characters per word), (words per sentence), (words per interpunction), (interpunctions, or number of , per sentence), (universal readability index) in Matthew in the indicated English translations, updated to the indicated year. Source: https://www.biblegateway.com/versions/ (last access, 15 April 2023).
Figure 6 shows the scatterplot of versus concerning the English (black circles, Table 3) and Spanish (green circles, Table 4) translations. Again, we notice can vary in the full Miller’s range and the necessity and usefulness of introducing in readability formulae.
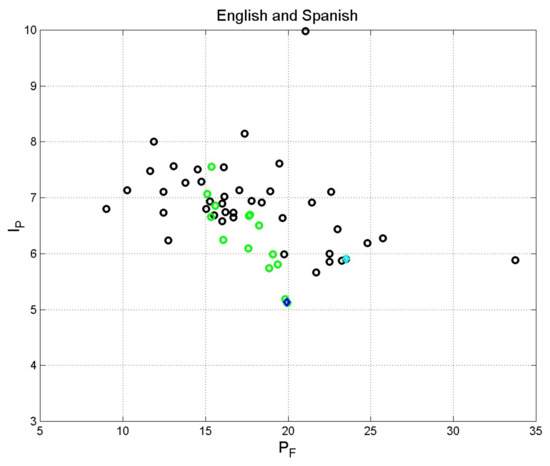
Figure 7 shows the ending point of vector (1) of the original Greek text compared with the English and Spanish translations. The spread is similar to that found in Figure 1 concerning diverse languages.
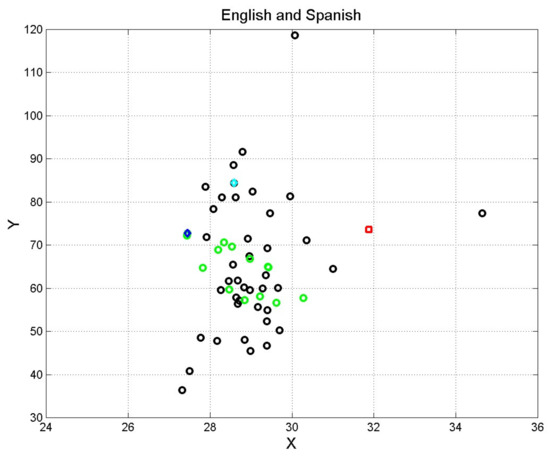
Figure 7.
Scatter plot of vector (1) coordinates concerning the English (black circles, Table 3) and Spanish translations (green circles, Table 5). The cyan diamond indicates King James (1611); the blue diamond indicates Reina Valera Antigua (1602). The red square indicates the original Greek Matthew.
Table 5 and Table 6 report the main statistics for these two sets. As noticed, the English translations are more varied than the Spanish ones, a find confirmed in Figure 8 and Figure 9 showing the scatterplot of versus and versus .
Table 5.
Average values and range (minimum–maximum) of (words per sentence), (words per interpunction) and (universal readability index) found in the English translations listed in Table 3.
Table 6.
Average values and range (minimum–maximum) of (words per sentence), (words per interpunction) and (universal readability index) found in the Spanish translations listed in Table 5.
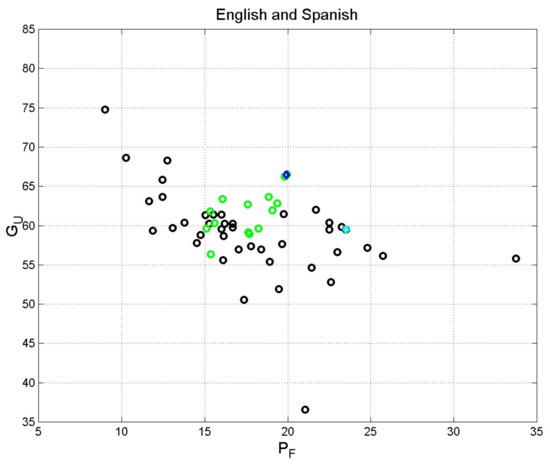
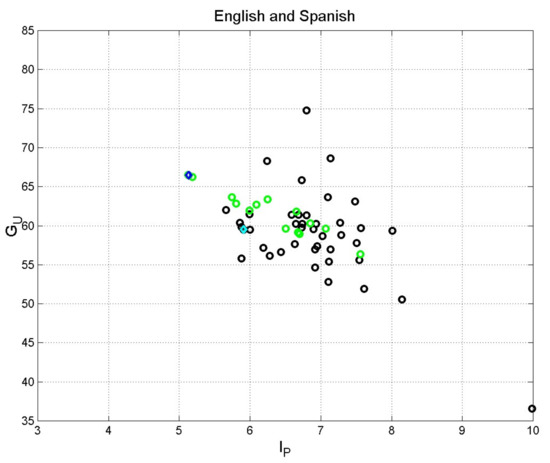
From Table 5 and Figure 3, in English, the least readable version (New American Standard Bible) requires more than 13 years of schooling for “easy” reading; the most readable version (New International Reader’s Version) only requires 6 years. The historical King James’ version (1611) requires 8 years.
Similarly, in Spanish (Table 6 and Figure 3), the least readable version (Palabra de Dios para todos) requires 9 years of schooling for “easy” reading, while the most readable version (Spanish Blue Red and Gold Letter Edition) requires about 7. The historical Reina Valera Antigua (1602) requires 7 years of schooling.
In conclusion, multiple translations within the same languages are likely addressed to readers with very different STM processing capacities and schooling.
5. Conclusions
We have studied how the readability of a text can change in translation. To arrive at a sound conclusion, we have considered the translation of an ancient text written in Greek—the Gospel according to Matthew (very important for its heritage value)—into Latin and 35 modern languages. We have found that the deep-language parameters , , , and a universal readability index of each translation are so diverse from language to language, and even within a given language for which there are many versions of Matthew—such as in English and in Spanish—that the resulting texts mathematically seem to be diverse texts. All the analyses performed confirm this extremely marked scattering, which does not depend on the year of translation.
What is really striking is the large range of the readability index, which does not depend on the year of translation. This index “measures” how difficult a text is to read and how many years of schooling it requires for “easy” reading. The several tens of versions of Matthew’s Gospel studied here appear to address very diverse audiences. If a reader could understand all the 37 languages considered well, he/she, on the one hand, would be surely guided by the traditional division in chapters and verses of Matthew common to all versions, but on the other hand, would also have the impression of reading texts written by diverse authors, although all of them tell the same story.
Future work should study how readability changes in translations of modern novels, which tend to be more verbatim than that of Matthew and, in general, of the New Testament.
Funding
This research received no external funding.
Data Availability Statement
Data are available from the author upon request.
Acknowledgments
The author warmly thanks all those scholars who, with continuous great care and dedication, keep the texts of the Bible in many languages online for the benefit of everyone, specifically Bible Gateway, Perseus Digital Library and the Vatican.
Conflicts of Interest
The author declares no conflict of interest.
References
- Flesch, R. A New Readability Yardstick. J. Appl. Psychol. 1948, 32, 222–233. [Google Scholar] [CrossRef] [PubMed]
- Kincaid, J.P.; Fishburne, R.P.; Rogers, R.L.; Chissom, B.S. Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted Personnel; Research Branch Report 8-75; Chief of Naval Technical Training; Naval Air Station: Memphis, TN, USA, 1975. [Google Scholar]
- DuBay, W.H. The Principles of Readability; Impact Information: Costa Mesa, CA, USA, 2004. [Google Scholar]
- Bailin, A.; Graftstein, A. The linguistic assumptions underlying readability formulae: A critique. Lang. Commun. 2001, 21, 285–301. [Google Scholar] [CrossRef]
- DuBay, W.H. The Classic Readability Studies; Impact Information: Costa Mesa, CA, USA, 2006. [Google Scholar]
- Zamanian, M.; Heydari, P. Readability of Texts: State of the Art. Theory Pract. Lang. Stud. 2012, 2, 43–53. [Google Scholar] [CrossRef]
- Benjamin, R.G. Reconstructing Readability: Recent Developments and Recommendations in the Analysis of Text Difficulty. Educ. Psycol. Rev. 2012, 24, 63–88. [Google Scholar] [CrossRef]
- Collins-Thompson, K. Computational Assessment of Text Readability: A Survey of Past, in Present and Future Research, Recent Advances in Automatic Readability Assessment and Text Simplification. ITL Int. J. Appl. Linguist. 2014, 165, 97–135. [Google Scholar] [CrossRef]
- Kandel, L.; Moles, A. Application de l’indice de Flesch à la langue française. Cah. Etudes De Radio-Télév. 1958, 19, 253–274. [Google Scholar]
- Matricciani, E. Readability Indices Do Not Say It All on a Text Readability. Analytics 2023, 2, 296–314. [Google Scholar] [CrossRef]
- Matricciani, E. Deep Language Statistics of Italian throughout Seven Centuries of Literature and Empirical Connections with Miller’s 7 ∓ 2 Law and Short-Term Memory. Open J. Stat. 2019, 9, 373–406. [Google Scholar] [CrossRef]
- Matricciani, E. A Statistical Theory of Language Translation Based on Communication Theory. Open J. Stat. 2020, 10, 936–997. [Google Scholar] [CrossRef]
- Miller, G.A. The Magical Number Seven, Plus or Minus Two. Some Limits on Our Capacity for Processing Information. Psychol. Rev. 1955, 63, 343–352. [Google Scholar]
- Matricciani, E. Linguistic Mathematical Relationships Saved or Lost in Translating Texts: Extension of the Statistical Theory of Translation and Its Application to the New Testament. Information 2022, 13, 20. [Google Scholar] [CrossRef]
- Matricciani, E. Multiple Communication Channels in Literary Texts. Open J. Stat. 2022, 12, 486–520. [Google Scholar] [CrossRef]
- Matricciani, E. Capacity of Linguistic Communication Channels in Literary Texts: Application to Charles Dickens’ Novels. Information 2023, 14, 68. [Google Scholar] [CrossRef]
- Matricciani, E.; Caro, L.D. A Deep-Language Mathematical Analysis of Gospels, Acts and Revelation. Religions 2019, 10, 257. [Google Scholar] [CrossRef]
- Baddeley, A.D.; Thomson, N.; Buchanan, M. Word Length and the Structure of Short-Term Memory. J. Verbal Learn. Verbal Behav. 1975, 14, 575–589. [Google Scholar] [CrossRef]
- Cowan, N. The magical number 4 in short-term memory: A reconsideration of mental storage capacity. Behav. Brain Sci. 2000, 24, 87–114. [Google Scholar] [CrossRef]
- Pothos, E.M.; Joula, P. Linguistic structure and short-term memory. Behav. Brain Sci. 2000, 24, 138–139. [Google Scholar] [CrossRef]
- Jones, G.; Macken, B. Questioning short-term memory and its measurements: Why digit span measures long-term associative learning. Cognition 2015, 144, 1–13. [Google Scholar] [CrossRef]
- Saaty, T.L.; Ozdemir, M.S. Why the Magic Number Seven Plus or Minus Two. Math. Comput. Model. 2003, 38, 233–244. [Google Scholar] [CrossRef]
- Mathy, F.; Feldman, J. What’s magic about magic numbers? Chunking and data compression in short-term memory. Cognition 2012, 122, 346–362. [Google Scholar] [CrossRef]
- Chen, Z.; Cowan, N. Chunk Limits and Length Limits in Immediate Recall: A. Reconciliation, J. Exp. Psychol. Mem. Cogn. 2005, 31, 1235–1249. [Google Scholar] [CrossRef]
- Chekaf, M.; Cowan, N.; Mathy, F. Chunk formation in immediate memory and how it relates to data compression. Cognition 2016, 155, 96–107. [Google Scholar] [CrossRef]
- Barrouillest, P.; Camos, V. As Time Goes By: Temporal Constraints in Working Memory. Curr. Dir. Psychol. Sci. 2012, 21, 413–419. [Google Scholar] [CrossRef]
- Conway, A.R.A.; Cowan, N.; Michael FBunting, M.F.; Therriaulta, D.J.; Minkoff, S.R.B. A latent variable analysis of working memory capacity, short-term memory capacity, processing speed, and general fluid intelligence. Intelligence 2002, 30, 163–183. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).