
A Rule-Based Approach for Mining Creative Thinking Patterns from Big Educational Data

 , , , , and
, , , , and
Abstract
1. Introduction
- We put the first step towards formalizing educational knowledge by constructing a domain-specific (Educational) KB to identify essential concepts, facts, and assumptions in identifying creativity patterns.
- We introduce a pipeline to turn raw educational data (e.g., assessments and reports) into contextualized data and knowledge.
- We present a rule-based approach to learning from the KB and facilitate mining creative thinking patterns from contextualized data and knowledge.
- We evaluate our approach with a real-world dataset and highlight how the proposed framework can help instructors understand creative thinking patterns from students’ activities and assessment tasks.
2. Background and Related Work
2.1. Educational Data
- Interaction between students, instructors, and also students and instructors (e.g., chat boxes, discussion forums, navigation behavior).
- Administrative data (e.g., institution, courses, instructors).
- Demographic data (e.g., age, nationality, gender).
- Students’ activities (e.g., assessments, questions, feedback).
- Students’ dispositions and affectivity (e.g., attitude and motivation).
2.2. Educational Knowledge
Creativity in Education
2.3. Educational Data Modeling
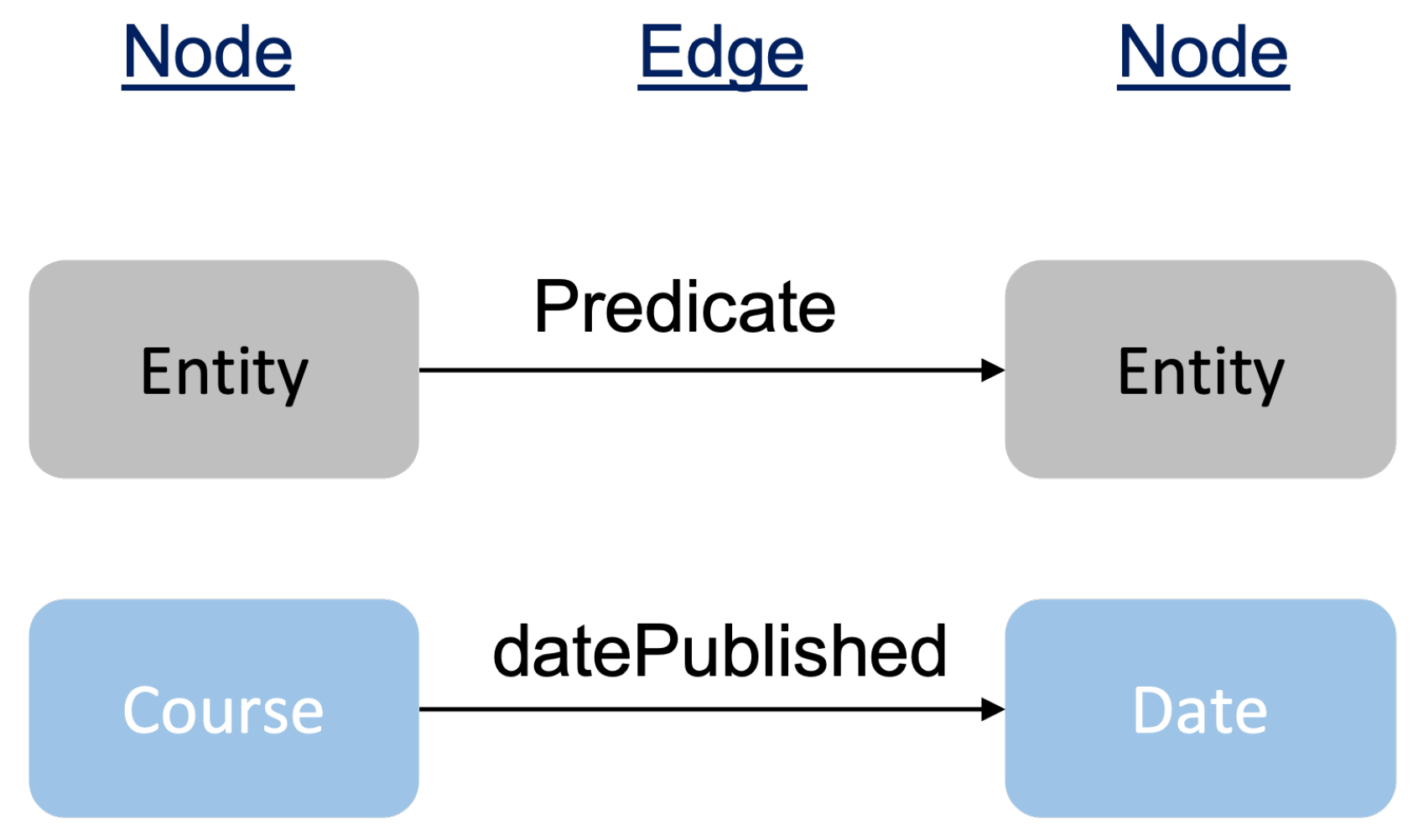
- Entity: An entity refers to a real-world object such as individuals, products, or organizations.
- Attribute: An attribute is a property of an entity such as age, color, or address.
- Relationship: A relationship is a connection between two entities.
2.3.1. Data Modeling Methods
- Hierarchical Data Model: This approach is well suited to situations when the information collection is based on an actual hierarchy in a tree shape or parent–child hierarchical structure. The hierarchical model has been used widely in education, e.g., to measure educational service quality [34], and to evaluate extrinsic and intrinsic motivation in students [35].
- Network Data Model: This approach enhances the hierarchical data model by enabling the existence of numerous parent records, which means allowing each child record to be linked to several parent records. In education, the network model has been used to, e.g., emphasize the importance of education in environmental protection [36] and develop a learning network model for higher education consortia formation and management [37]. Ref. [38] also presented a new framework called Hierarchical Network Models (HNM) for educational research and developed single-network statistical network models to multiple networks.
- Relational Data Model: A relational data model consists of a set of tables, recognized as relations, consisting of rows and columns. This method is the most used data model in education, e.g., Ref. [39] has introduced a tool that simplified and partially automated the process of designing relational educational data for students, and Ref. [40] examined employing relational model as a data analysis and management tool to study educational environments.
- NoSQL Data Model: Other non-relational or non-SQL models have been developed such as document model, multivalue model, and graph data model. These three are prominent examples of the NoSQL data model:
- -
- -
- The Multivalue Model allows the attributes to take a list of data instead of a single point, which makes it different from the relational data model. In education, this model proved to be useful to make the process of data analysis faster by using multidimensional arrays of student values [43].
- -
- The Graph Data Model allows any node connection with different structures coming from various sources of information [44]. This data model has recently gained popularity in the study of education. In the next subsection, we will explain the terms and concepts related to this model.
2.3.2. Graph Data Modeling
“A knowledge graph is a knowledge base that (1) replicates the model of information flow in an organization, (2) stores complex structured and unstructured knowledge, (3) is presented in the form of entities and relations between them, (4) covers a multitude of topical domains, (5) acquires and integrates knowledge, and (6) enables interrelation of arbitrary entities.”
2.4. Educational Data Mining and Learning Analytics
2.4.1. Common Methods in EDM and LA
2.4.2. Creativity Assessment Using EDM/LA
2.5. Summary and Added Value
3. Mining Creative Thinking Patterns from Contextualized Educational Data
3.1. Data Curation
3.2. Feature Selection
3.3. Domain-Specific KB
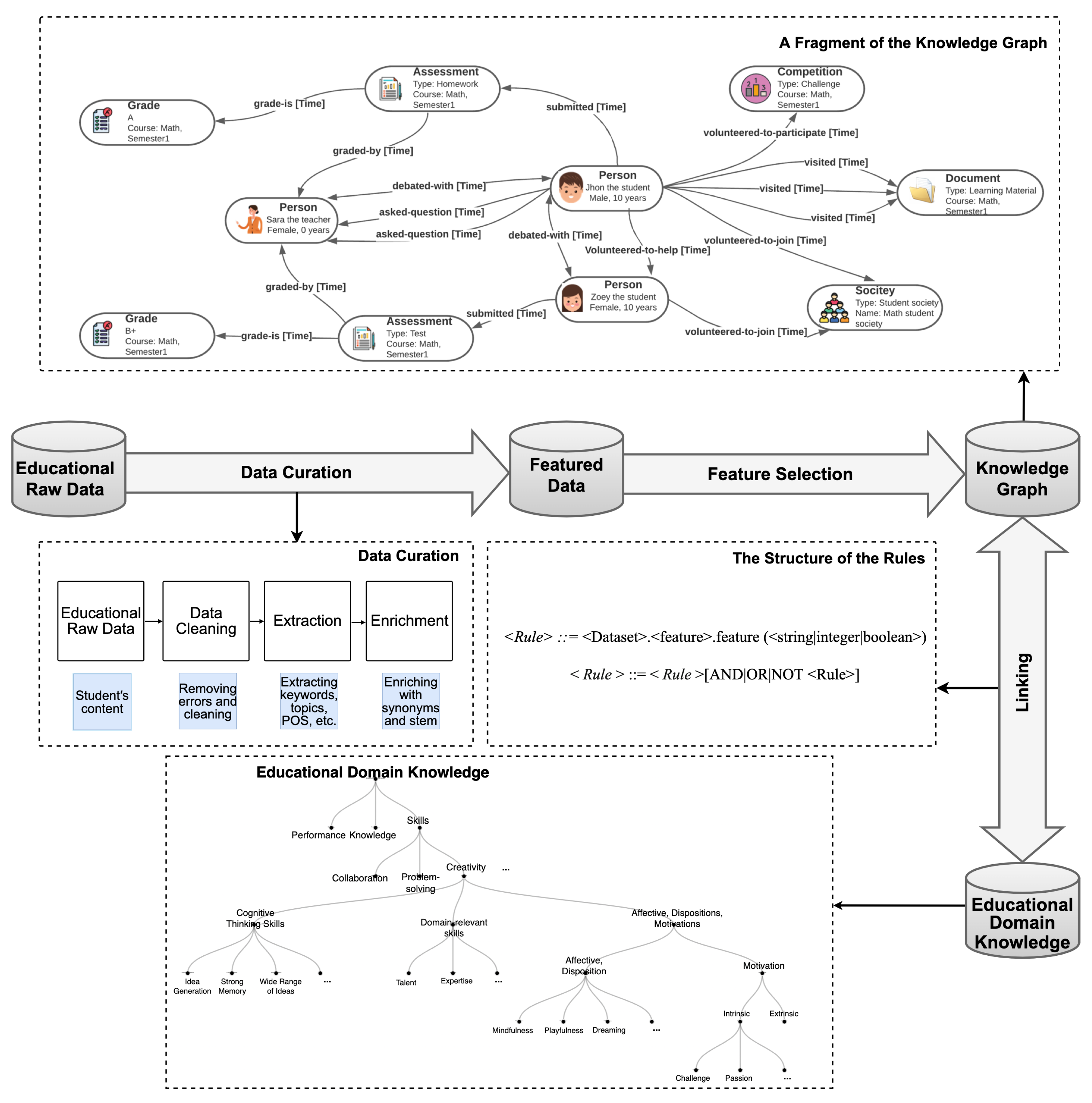
3.4. Educational Knowledge Graph
- Assessment Person: States that an assessment (e.g., homework) is graded by a person (e.g., a teacher).
- Person Person: States that two people debated over a topic (e.g., a teacher and a student debated with each other).
- Assessment Grade: States the grade of an assessment.
- Person Assessment: States that a person (e.g., a student) submitted an assessment.
- Person Society: States that a person (e.g., a student) is volunteered to join a society (e.g., a student society).
3.5. Rule-Based Insight Discovery
- select ?variable1 ?variable2 ...
- where { pattern1. pattern2. ... }
4. Experiment
4.1. Motivating Scenario
4.1.1. Use Case 1: Imitating the Knowledge of Experts in Education
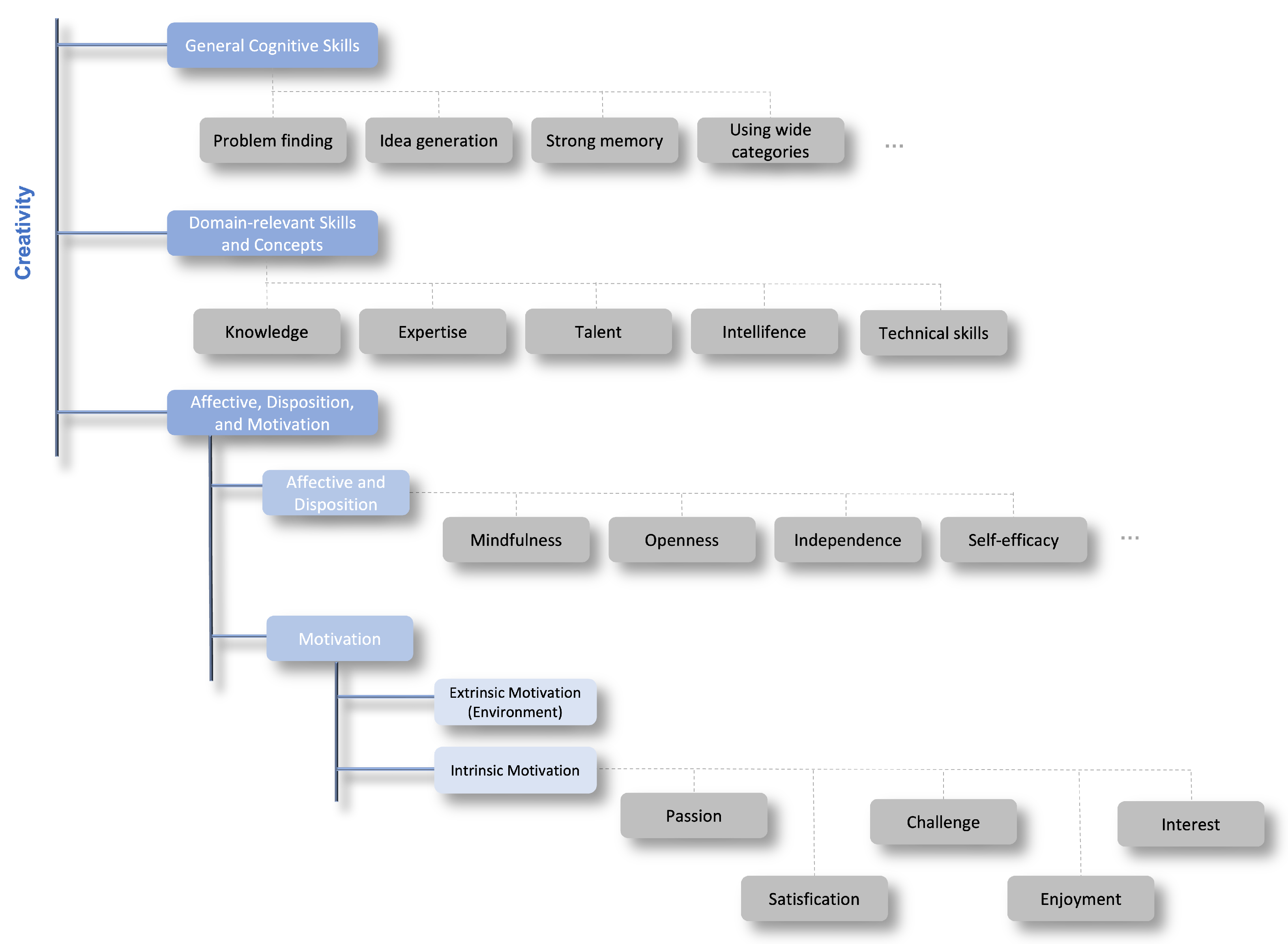
- (i)
- General Cognitive Thinking Skills: The mental processes involved in gaining knowledge and comprehension. These cognitive thinking processes include idea-generating, remembering, using wide categories, and problem-finding skills.
- (ii)
- Domain-relevant Skills and Concepts: The amount to which a person’s product or reaction will outperform past responses in the domain is determined by his or her usage of creativity-relevant abilities. It includes expertise, knowledge, technical skills, intelligence, and talent in the particular domain.
- (iii)
- Affective, Disposition, and Motivation: Affective and Disposition include the ways in which students deal with external and internal phenomena emotionally such as self-efficacy, independence, curiosity, and commitment. Furthermore, motivation encompasses both intrinsic and extrinsic factors such as passion, challenge, interest, enjoyment, and satisfaction.
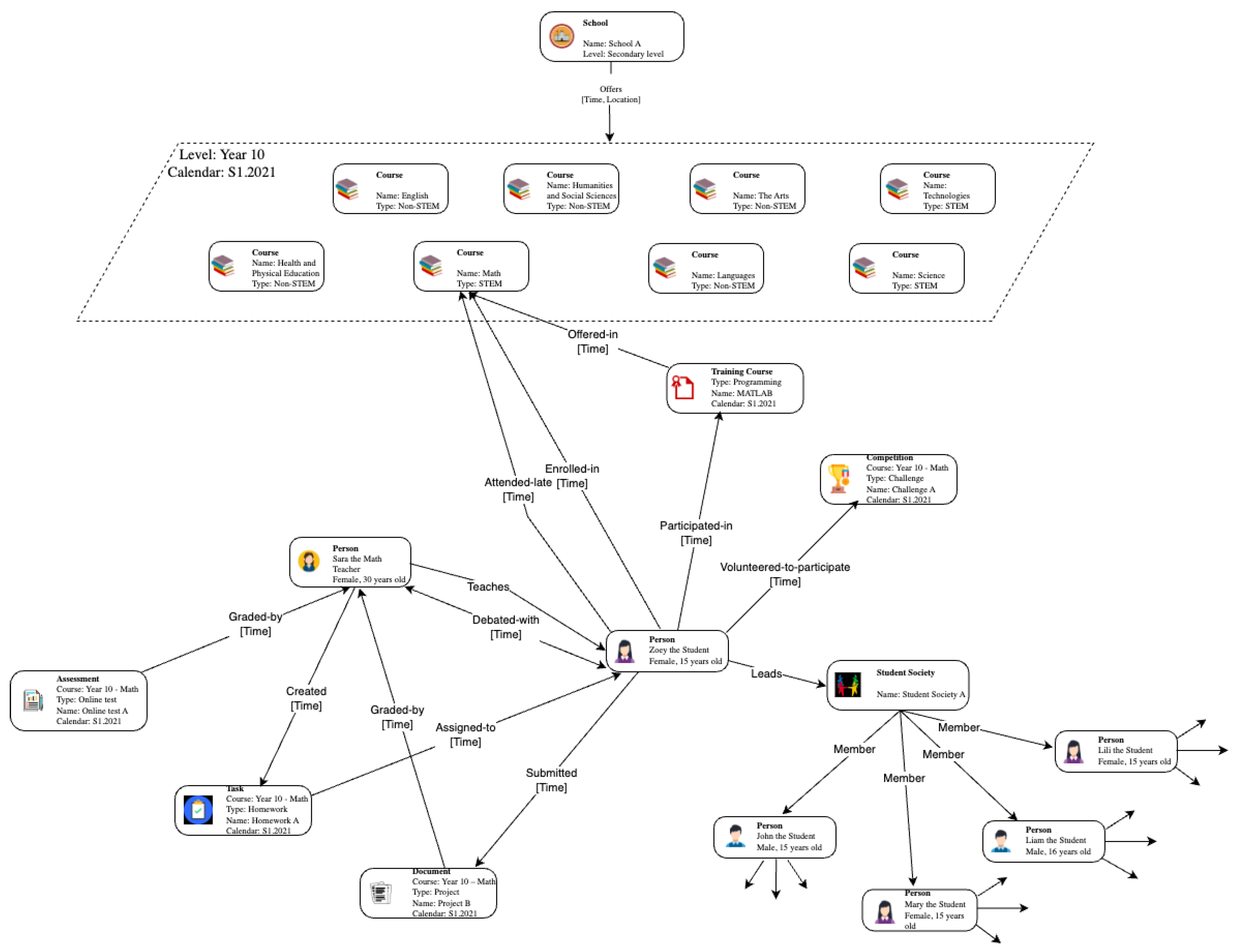
4.1.2. Use Case 2: Educational Knowledge Graph
- Course Person: States that a course (e.g., Math) is taught by a person (e.g., a teacher).
- Person Assignment: States that a person (e.g., a student) submitted his/her assignment (e.g., a homework).
- Person Person: States that two persons debated.
- Person Person: States that a person (e.g., a student) volunteered to help another person.
- Assessment QuestionBlock: States that an assessment (e.g., an online math test) contains a question block (e.g., fill-in question, multiple choice).
- Assessment person: States that an assessment (e.g., an online Math test) is graded by a person (e.g., a teacher).
- QuestionBlock Keyword: States that a question block of an assignment (e.g., a homework) contains desired keywords relevant to the context.
- Person StudentCommunity: States that a person (e.g., a student) volunteered to join a student community (e.g., Math community of students)
- QuestionBlock Time: States that a question block of an assessment is completed in a specific amount of time (e.g., 2 min or 120 s).
- Person TrainingCourse: States that a person (e.g., a student) volunteered to participate in a training course (e.g., MATLAB programming).
4.1.3. Use Case 3: Linking the Knowledge Base to the Knowledge Graph
4.2. Dataset
4.3. Experimental Setting
4.4. Experimental Results
Preprocessing and Feature Selection
4.5. Building the Knowledge Graph
- @prefix ns1: <http://www.example.org/>.
- ns1:Student1 ns1:AnnouncementsView 2;
- ns1:Student1 ns1:Discussion 20;
- ns1:Student1 ns1:EnrolledIn ns1:IT;
- ns1:Student1 ns1:Score ns1:Middle-Level;
- ns1:Student1 ns1:Semester ns1:Semester1;
- ns1:Student1 ns1:StudentAbsenceDays ns1:Under-7;
- ns1:Student1 ns1:VisITedResources 16;
- ns1:Student1 ns1:raisedhands 15.
4.6. Linking the Graph to the KB
5. Evaluation
- H1: The components of the KB are relevant to creativity.
- H2: The designed rules for pattern mining are useful and relevant to creativity patterns.
- H3: The query results are reasonable and show a successful link between the KB and educational data.
5.1. Experiment Setup
- Imitating the Knowledge of Educational Experts: We first underlined the importance of building the KB and how this helped us to link related information in the educational data and components of creativity in education.
- Data Contextualization: We explained how using existing data curation techniques helped us create enriched-contextualized data and knowledge.
- Linking Data and Finding Patterns: We presented a fragment of the data in a visualized graph-based format to be easily understood. We also demonstrated the results and implemented the defined rules for each creativity pattern.
5.2. Questionnaire
5.3. Experiment Results
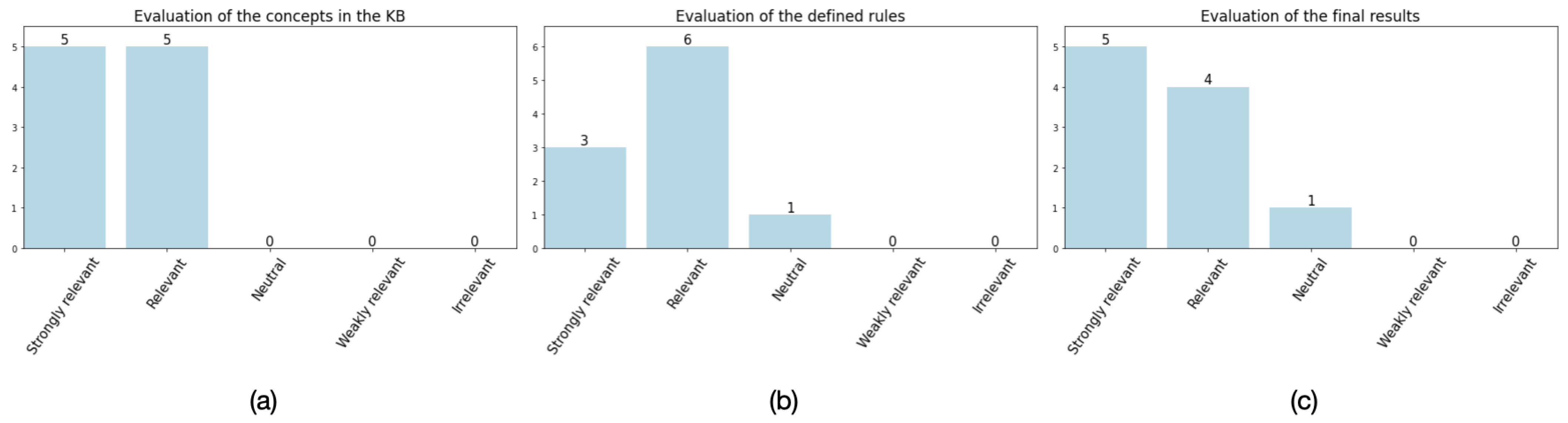
- Evaluation of H1: H1 assumes that the components of the KB are relevant to creativity. Figure 9a indicates that overall all the participants found that the linked concepts in the KB are relevant to creativity as a skill in education. Concepts such as “Using Wide Categories”, “Strong Memory”, and “Motivation” have been investigated and rated by participants. All the participants found the concepts either strongly relevant or relevant to creativity.
- Evaluation of H2: H2 states that the designed rules for pattern mining are useful and relevant to creativity patterns. Figure 9b indicates that overall all the participants except one found the rules relevant to “Using Wide Categories”, “Strong Memory”, and “Motivation” concepts in the taxonomy. Except for one, all the participants found the rules either strongly relevant or relevant to creativity.
- Evaluation of H3: H3 supposes the results of the query are reasonable and show a successful link between the KB and educational data. Figure 9c indicates that, overall, all the participants except one found that the model was successful in detecting those creativity patterns in the students. Except for one, all the participants found the results either strongly relevant or relevant to creativity.
5.4. Discussion
- The findings of the user study support hypotheses H1, H2, and H3. However, regarding H2, the rule-based pattern mining techniques require future improvement to gain a higher score in the evaluation.
- The assigned timeframe for training the most of participants seems to be adequate except for two with no background in computing and education. Eight out of ten participants successfully completed all four sections of the questionnaire in less than half an hour. Those participants with other backgrounds struggled to understand the related concepts and technical concepts. Hence, the training should be improved for future study cases.
- Based on our findings, mainly education experts with knowledge, expertise, and interest in education and computing found our approach valid and confirmed the hypotheses.
6. Conclusions and Future Work
6.1. Artificial Intelligence (AI)
6.2. Designing a Framework for Continuous Monitoring of Students’ Performance
6.3. Using Association Rule Mining to Discover Relationships among Educational Features
6.4. Exploring Key Patterns of Creativity
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hwang, Y. Adoption of Big Data in Higher Education for Better Institutional Effectiveness. Am. J. Creat. Educ. 2019, 2, 31–44. [Google Scholar] [CrossRef]
- Torrance, E.P. Predictive validity of the torrance tests of creative thinking. J. Creat. Behav. 1972, 6, 236–252. [Google Scholar] [CrossRef]
- Miller, A.L. A self-report measure of cognitive processes associated with creativity. Creat. Res. J. 2014, 26, 203–218. [Google Scholar] [CrossRef]
- Henriksen, D.; Mishra, P.; Mehta, R. Novel, effective, whole: Toward a NEW framework for evaluations of creative products. J. Technol. Teach. Educ. 2015, 23, 455–478. [Google Scholar]
- Beaty, R.E.; Johnson, D.R. Automating creativity assessment with SemDis: An open platform for computing semantic distance. Behav. Res. Methods 2021, 53, 757–780. [Google Scholar] [CrossRef]
- Diana, N.; Eagle, M.; Stamper, J.; Grover, S.; Bienkowski, M.; Basu, S. An instructor dashboard for real-time analytics in interactive programming assignments. In Proceedings of the Seventh International Learning Analytics & Knowledge Conference, Vancouver, BC, Canada, 13–17 March 2017; pp. 272–279. [Google Scholar]
- Baker, R. Data Mining. In International Encyclopedia of Education, 3rd ed.; Peterson, P., Baker, E., McGaw, B., Eds.; Elsevier: Oxford, UK, 2010; pp. 112–118. [Google Scholar] [CrossRef]
- Romero, C.; Ventura, S. Educational data mining and learning analytics: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar] [CrossRef]
- Laili, R.N.; Nashir, M. Higher education students’ perception on online learning during COVID-19 pandemic. Edukatif J. Ilmu Pendidik. 2021, 3, 689–697. [Google Scholar] [CrossRef]
- Syafnan, S.; Ritonga, M.; Lubis, F.S. Student Perception of the Online Lecture System during the COVID-19 Period. J. Innov. Educ. Cult. Res. 2022, 3, 80–85. [Google Scholar] [CrossRef]
- Shabani, N.; Beheshti, A.; Farhood, H.; Bower, M.; Garrett, M.; Rokny, H.A. iCreate: Mining Creative Thinking Patterns from Contextualized Educational Data. In Proceedings of the International Conference on Artificial Intelligence in Education; Springer: Berlin/Heidelberg, Germany, 2022; pp. 352–356. [Google Scholar]
- Baradwaj, B.K.; Pal, S. Mining educational data to analyze students’ performance. arXiv 2012, arXiv:1201.3417. [Google Scholar]
- Baig, M.I.; Shuib, L.; Yadegaridehkordi, E. Big data in education: A state of the art, limitations, and future research directions. Int. J. Educ. Technol. High. Educ. 2020, 17, 44. [Google Scholar] [CrossRef]
- Cantabella, M.; Martínez-España, R.; Ayuso, B.; Yáñez, J.A.; Muñoz, A. Analysis of student behavior in learning management systems through a Big Data framework. Future Gener. Comput. Syst. 2019, 90, 262–272. [Google Scholar] [CrossRef]
- Chaurasia, S.S.; Kodwani, D.; Lachhwani, H.; Ketkar, M.A. Big data academic and learning analytics: Connecting the dots for academic excellence in higher education. Int. J. Educ. Manag. 2018, 32, 1099–1117. [Google Scholar] [CrossRef]
- Petrova-Antonova, D.; Georgieva, O.; Ilieva, S. Modelling of Educational Data Following Big Data Value Chain. In Proceedings of the CompSysTech’17: 18th International Conference on Computer Systems and Technologies, Ruse, Bulgari, 23–24 June 2017; Association for Computing Machinery: New York, NY, USA, 2017; pp. 88–95. [Google Scholar] [CrossRef]
- Zhang, M. Internet use that reproduces educational inequalities: Evidence from big data. Comput. Educ. 2015, 86, 212–223. [Google Scholar] [CrossRef]
- Ong, V.K. Big data and its research implications for higher education: Cases from UK higher education institutions. In Proceedings of the IEEE 2015 IIAI 4th International Congress on Advanced Applied Informatics, Okayama, Japan, 12–16 July 2015; pp. 487–491. [Google Scholar]
- Martínez-Abad, F.; Gamazo, A.; Rodríguez-Conde, M.J. Big Data in Education: Detection of ICT Factors Associated with School Effectiveness with Data Mining Techniques. In Proceedings of the TEEM’18: Sixth International Conference on Technological Ecosystems for Enhancing Multiculturality, Salamanca, Spain, 24–26 October 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 145–150. [Google Scholar] [CrossRef]
- Dinter, B.; Jaekel, T.; Kollwitz, C.; Wache, H. Teaching big data management–an active learning approach for higher education. In Proceedings of the 2017 Pre-ICIS SIGDSA Symposium, Seoul, Republic of Korea, 10–13 December 2017; pp. 1–17. [Google Scholar]
- Buffum, P.S.; Martinez-Arocho, A.G.; Frankosky, M.H.; Rodriguez, F.J.; Wiebe, E.N.; Boyer, K.E. CS principles goes to middle school: Learning how to teach “Big Data”. In Proceedings of the 45th ACM Technical Symposium on Computer Science Education, Atlanta, GA, USA, 5–8 March 2014; pp. 151–156. [Google Scholar]
- Freitas, A.; Curry, E. Big Data Curation. In New Horizons for a Data-Driven Economy: A Roadmap for Usage and Exploitation of Big Data in Europe; Springer International Publishing: Cham, Switzerland, 2016; pp. 87–118. [Google Scholar] [CrossRef]
- Miller, R.J. Big Data Curation. In Proceedings of the COMAD, Hyderabad, India, 17–19 December 2014; p. 4. [Google Scholar]
- Beheshti, A.; Benatallah, B.; Tabebordbar, A.; Motahari-Nezhad, H.R.; Barukh, M.C.; Nouri, R. Datasynapse: A social data curation foundry. Distrib. Parallel Databases 2019, 37, 351–384. [Google Scholar] [CrossRef]
- Beheshti, A.; Benatallah, B.; Nouri, R.; Tabebordbar, A. CoreKG: A knowledge lake service. Proc. VLDB Endow. 2018, 11, 1942–1945. [Google Scholar] [CrossRef]
- Schleicher, A. Measuring Student Knowledge and Skills: A New Framework for Assessment; ERIC: Paris, France, 1999.
- Wang, M.C.; Haertel, G.D.; Walberg, H.J. Toward a knowledge base for school learning. Rev. Educ. Res. 1993, 63, 249–294. [Google Scholar] [CrossRef]
- Australian Bureau of Statistics (ABS). Australian Standard Classification of Education (ASCED). 2001. Available online: https://www.abs.gov.au/ (accessed on 15 March 2023).
- Bloom, B.S. Taxonomy of educational objectives. Vol. 1: Cognitive domain. N. Y. Mckay 1956, 20, 1. [Google Scholar]
- Bloom, B.S. Taxonomy of Educational Objectives: Affective Domain; Krathwohl, D.R., Bloom, B.S., Masia, B.B., Eds.; David McKay: New York, NY, USA, 1964; Volume 2. [Google Scholar]
- Amabile, T. Componential Theory of Creativity; Harvard Business School: Boston, MA, USA, 2011. [Google Scholar]
- Baer, J.; McKool, S.S. The gold standard for assessing creativity. Int. J. Qual. Assur. Eng. Technol. Educ. 2014, 3, 81–93. [Google Scholar] [CrossRef]
- Simsion, G.; Witt, G. Data Modeling Essentials; Elsevier: Amsterdam, The Netherlands, 2004. [Google Scholar]
- Teeroovengadum, V.; Kamalanabhan, T.; Seebaluck, A.K. Measuring service quality in higher education: Development of a hierarchical model (HESQUAL). In Quality Assurance in Education; Emerald Group Publishing Limited: London, UK, 2016. [Google Scholar]
- Vallerand, R.J.; Ratelle, C.F. Intrinsic and Extrinsic Motivation: A Hierarchical Model. In Handbook of Self-Determination Research; Deci, E.L., Ryan, R.M., Eds.; University of Rochester Press: Rochester, NY, USA, 2002; pp. 37–63. [Google Scholar]
- Yu, Y.; Tang, Y. The construction of hierarchical network model and wireless activation diffusion optimization model in English teaching. Eurasip J. Wirel. Commun. Netw. 2020, 2020, 1–14. [Google Scholar] [CrossRef]
- Sagan, E.L. A Network Model for Planning and Establishing Higher Education Consortiums; The Ohio State University: Columbus, OH, USA, 1969. [Google Scholar]
- Sweet, T.M.; Thomas, A.C.; Junker, B.W. Hierarchical network models for education research: Hierarchical latent space models. J. Educ. Behav. Stat. 2013, 38, 295–318. [Google Scholar] [CrossRef]
- Bogdanović, M.; Stanimirović, A.; Davidović, N.; Stoimenov, L. The development and usage of a relational database design tool for educational purposes. In Proceedings of the Informing Science & IT Education Conference (InSITE’08), Varna, Bulgaria, 22–25 June 2008; pp. 251–258. [Google Scholar]
- Winer, L.R.; Carrière, M. The use of a relational database in qualitative research on educational computing. In Computer Assisted Learning; Elsevier: Amsterdam, The Netherlands, 1990; pp. 213–220. [Google Scholar]
- Mason, R.T. NoSQL databases and data modeling techniques for a document-oriented NoSQL database. In Proceedings of the Proceedings of Informing Science & IT Education Conference (InSITE), Tampa, FL, USA, 29 June–5 July 2015; Volume 3, pp. 259–268. [Google Scholar]
- Franze, K.; Wehner, F. A Document Model for Generating Adaptable Courseware Using Background Data. In Proceedings of the WebNet World Conference on the WWW and Internet. Association for the Advancement of Computing in Education (AACE), Honolulu, HI, USA, 23–27 October 1999; pp. 1266–1267. [Google Scholar]
- Martin, A.J. Examining a multidimensional model of student motivation and engagement using a construct validation approach. Br. J. Educ. Psychol. 2007, 77, 413–440. [Google Scholar] [CrossRef] [PubMed]
- Frisendal, T. Graph Data Modeling for NoSQL and SQL: Visualize Structure and Meaning; Technics Publications: Denville, NJ, USA, 2016. [Google Scholar]
- Bondy, J.A.; Axler, S.; Ribet, K. Graduate Texts in Mathematics; Springer: London, UK, 2008; Volume 244. [Google Scholar]
- Velampalli, S.; Jonnalagedda, M.V. Graph based knowledge discovery using MapReduce and SUBDUE algorithm. Data Knowl. Eng. 2017, 111, 103–113. [Google Scholar] [CrossRef]
- Gomez-Perez, J.M.; Pan, J.Z.; Vetere, G.; Wu, H. Enterprise knowledge graph: An introduction. In Exploiting Linked Data and Knowledge Graphs in Large Organisations; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–14. [Google Scholar]
- Rizun, M. Knowledge graph application in education: A literature review. Acta Univ. Lodziensis. Folia Oeconomica 2019, 3, 7–19. [Google Scholar] [CrossRef]
- Wu, Y.; Pan, J.S.; Lu, P.; Lin, K.; Yu, X. Knowledge Graph Embedding Translation Based on Constraints. J. Inf. Hiding Multim. Signal Process. 2017, 8, 1119–1131. [Google Scholar]
- Chen, P.; Lu, Y.; Zheng, V.W.; Chen, X.; Yang, B. Knowedu: A system to construct knowledge graph for education. IEEE Access 2018, 6, 31553–31563. [Google Scholar] [CrossRef]
- Chi, Y.; Qin, Y.; Song, R.; Xu, H. Knowledge graph in smart education: A case study of entrepreneurship scientific publication management. Sustainability 2018, 10, 995. [Google Scholar] [CrossRef]
- Bienkowski, M.; Feng, M.; Means, B. Enhancing Teaching and Learning through Educational Data Mining and Learning Analytics: An Issue Brief; Office of Educational Technology, US Department of Education: Washington, DC, USA, 2012.
- Peña-Ayala, A. Educational data mining: A survey and a data mining-based analysis of recent works. Expert Syst. Appl. 2014, 41, 1432–1462. [Google Scholar] [CrossRef]
- Romero, C.; Romero, J.R.; Ventura, S. A survey on pre-processing educational data. In Educational Data Mining; Springer: Berlin/Heidelberg, Germany, 2014; pp. 29–64. [Google Scholar]
- Liñán, L.C.; Pérez, Á.A.J. Educational Data Mining and Learning Analytics: Differences, similarities, and time evolution. Int. J. Educ. Technol. High. Educ. 2015, 12, 98–112. [Google Scholar]
- Siemens, G. Learning analytics: The emergence of a discipline. Am. Behav. Sci. 2013, 57, 1380–1400. [Google Scholar] [CrossRef]
- Larusson, J.A.; White, B. Learning Analytics: From Research to Practice; Springer: Berlin/Heidelberg, Germany, 2014; Volume 13. [Google Scholar]
- Baker, R.S.; Inventado, P.S. Educational data mining and learning analytics. In Learning Analytics; Springer: Berlin/Heidelberg, Germany, 2014; pp. 61–75. [Google Scholar]
- Bakhshinategh, B.; Zaiane, O.R.; ElAtia, S.; Ipperciel, D. Educational data mining applications and tasks: A survey of the last 10 years. Educ. Inf. Technol. 2018, 23, 537–553. [Google Scholar] [CrossRef]
- Siemens, G.; Baker, R.S.d. Learning analytics and educational data mining: Towards communication and collaboration. In Proceedings of the 2nd International Conference on Learning Analytics and Knowledge, Vancouver, BC, Canada, 29 April–2 May 2012; pp. 252–254. [Google Scholar]
- Deng, D.; Leung, C.K.; Wodi, B.H.; Yu, J.; Zhang, H.; Cuzzocrea, A. An innovative framework for supporting cognitive-based big data analytics for frequent pattern mining. In Proceedings of the 2018 IEEE International Conference on Cognitive Computing (ICCC), San Francisco, CA, USA, 2–7 July 2018; pp. 49–56. [Google Scholar]
- Lu, Y.L.; Wu, Y.C.; Chen, W.M.; Lien, Y.C.; Lien, C.J. Using data mining to investigate cognitive processes by a creativity test-a preliminary study. In Proceedings of the 9th IEEE International Conference on Cognitive Informatics (ICCI’10), Beijing, China, 7–9 July 2010; pp. 454–457. [Google Scholar]
- Singelmann, L.; Alvarez, E.; Swartz, E.; Pearson, M.; Striker, R.; Ewert, D. Innovators, learners, and surveyors: Clustering students in an innovation-based learning course. In Proceedings of the 2020 IEEE Frontiers in Education Conference (FIE), Uppsala, Sweden, 21–24 October 2020; pp. 1–9. [Google Scholar]
- Yu, J. Rough set based creativity rule extracting for middle school students. In Proceedings of the IEEE Third International Workshop on Advanced Computational Intelligence, Suzhou, China, 25–27 August 2010; pp. 209–212. [Google Scholar]
- Amabile, T.M.; Collins, M.A.; Conti, R.; Phillips, E.; Picariello, M.; Ruscio, J.; Whitney, D. Creativity in Context: Update to the Social Psychology of Creativity; Routledge: New York, NY, US, 2018. [Google Scholar]
- Ekwonwune, E.N.; Oparah, C.C. A Multimedia Based Virtual Learning System: A Panacea for Nigerian Tertiary Institutions. Circuits Syst. 2020, 11, 1–9. [Google Scholar] [CrossRef]
- Beheshti, A. Knowledge base 4.0: Using crowdsourcing services for mimicking the knowledge of domain experts. In Proceedings of the 2022 IEEE International Conference on Web Services (ICWS), Barcelona, Spain, 11–15 July 2022; pp. 425–427. [Google Scholar]
- Hammoud, M.; Rabbou, D.A.; Nouri, R.; Beheshti, S.M.R.; Sakr, S. DREAM: Distributed RDF engine with adaptive query planner and minimal communication. Proc. VLDB Endow. 2015, 8, 654–665. [Google Scholar] [CrossRef]
- Beheshti, S.; Benatallah, B.; Nezhad, H.R.M.; Sakr, S. A Query Language for Analyzing Business Processes Execution. In Proceedings of the Business Process Management—9th International Conference, BPM 2011, Clermont-Ferrand, France, 30 August–2 September 2011; Lecture Notes in Computer Science. Springer: Berlin/Heidelberg, Germany, 2011; Volume 6896, pp. 281–297. [Google Scholar]
- Farouk, M.; Ishizuka, M. A Rule-based SPARQL Endpoint Wrapper. In Proceedings of the WEBIST, Porto, Portugal, 18–21 April 2012; pp. 729–732. [Google Scholar]
- Huang, J.; Abadi, D.J.; Ren, K. Scalable SPARQL querying of large RDF graphs. Proc. VLDB Endow. 2011, 4, 1123–1134. [Google Scholar] [CrossRef]
- Amabile, T.M. How to Kill Creativity; Harvard Business School Publishing: Boston, MA, USA, 1998; Volume 87. [Google Scholar]
- Guilford, J.P. Characteristics of Creativity. Am. Psychol. 1973, 5, 444–454. [Google Scholar] [CrossRef]
- James, K.; Asmus, C. Personality, cognitive skills, and creativity in different life domains. Creat. Res. J. 2001, 13, 149–159. [Google Scholar] [CrossRef]
- Sternberg, R.J.; O’Hara, L.A. Creativity and intelligence. In Handbook of Creativity; Springer: Berlin/Heidelberg, Germany, 1999. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Domain | Description | Publications |
|---|---|---|
| Educational Knowledge | Using traditional tools and techniques for measuring and detecting creativity. | The Torrance Tests of Creativity (TTCT) [2], gold standard of creativity assessment [32], self-report measures of creativity [3], and judgment of products [65]. |
| Educational Data Modeling | Organizing the educational data in a way that is suitable for a specific data structure. | Hierarchical Data Model [34], Network Data Model [36], Object-oriented Data Model [66], Relational Data Model [39], and NoSQL Data Models [41,42,43,44,50,51]. |
| EDM/LA | A cycle of data mining and knowledge discovery which is involved with students, instructors or academic authorities, and educational environments to produce educational data and ultimately new knowledge. | Frequent pattern mining using cognitive-based big data analytics [61], rule extraction using a data mining tool [64], clustering students for problem-solving skill [63], and associate rule mining to investigate on cognitive processes [62]. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shabani, N.; Beheshti, A.; Farhood, H.; Bower, M.; Garrett, M.; Alinejad-Rokny, H. A Rule-Based Approach for Mining Creative Thinking Patterns from Big Educational Data. AppliedMath 2023, 3, 243-267. https://doi.org/10.3390/appliedmath3010014
Shabani N, Beheshti A, Farhood H, Bower M, Garrett M, Alinejad-Rokny H. A Rule-Based Approach for Mining Creative Thinking Patterns from Big Educational Data. AppliedMath. 2023; 3(1):243-267. https://doi.org/10.3390/appliedmath3010014
Chicago/Turabian StyleShabani, Nasrin, Amin Beheshti, Helia Farhood, Matt Bower, Michael Garrett, and Hamid Alinejad-Rokny. 2023. "A Rule-Based Approach for Mining Creative Thinking Patterns from Big Educational Data" AppliedMath 3, no. 1: 243-267. https://doi.org/10.3390/appliedmath3010014
APA StyleShabani, N., Beheshti, A., Farhood, H., Bower, M., Garrett, M., & Alinejad-Rokny, H. (2023). A Rule-Based Approach for Mining Creative Thinking Patterns from Big Educational Data. AppliedMath, 3(1), 243-267. https://doi.org/10.3390/appliedmath3010014