Dynamic Decision Trees

 , , , and
, , , and
Abstract
1. Introduction
- Support for a simple-to-author text description of the expert system for domain experts who are non-programmers. The text source code is also easy to maintain because authors can use standard text editors.
- The text description is highly functional, allowing for callouts to other dynamic decision trees, to websites, and to databases.
- The reader interface guides the reader through questions starting at the root of the decision tree. The interface makes visible to the reader only those nodes that are still possible based on the answers to those questions, thus limiting the cognitive load to the reader.
Plan of the Paper
2. Dynamic Decision Trees in Action
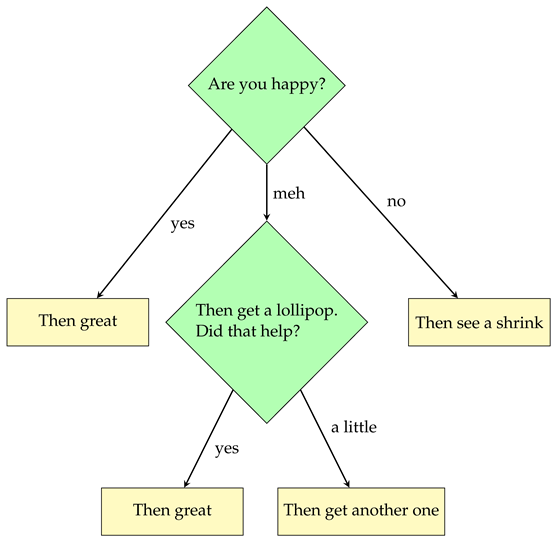
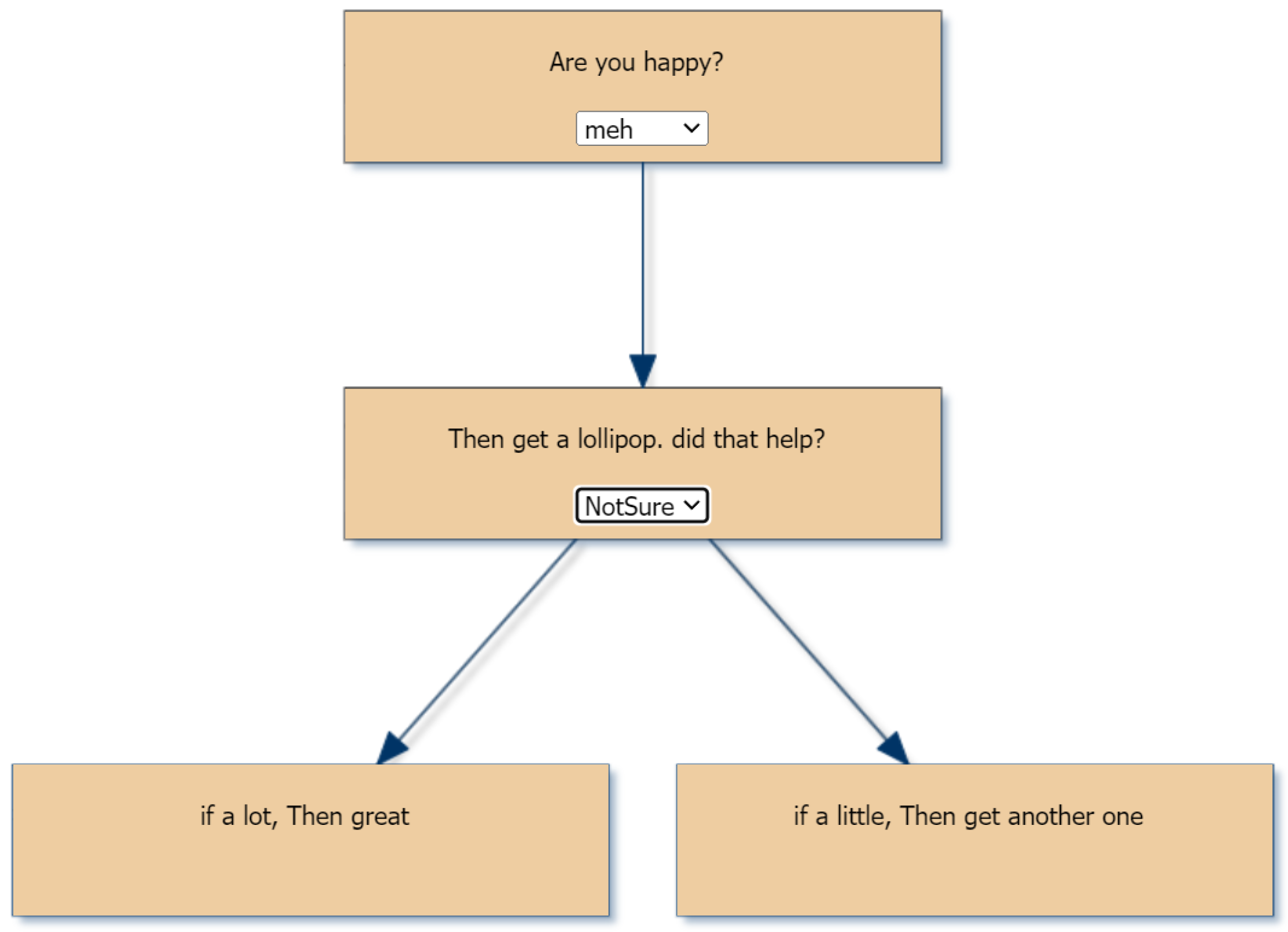
- Are you happy?
- --if yes, Then great
- --if meh, Then get a lollipop. Did that help?
- ----if a lot, Then great
- ----if a little, Then get another one
- --if no, Then see a shrink
2.1. Searching
- (i)
- Boxes in the tree so far (already visited nodes).
- (ii)
- Boxes reachable from the current tree (nodes reachable from visited nodes).
- (iii)
- Other boxes (neither reachable nor visited nodes).
2.2. User Interface Guidelines Followed
- Consistency and standards: The decision tree adheres to the principle of consistency, using similar colors, shapes, and layouts across all nodes. This helps readers navigate through the interface without surprises.
- Visibility of system status: The decision tree clearly indicates the current step in the process and offers alternative paths forward in the form of possible answers to the current question, thus asking readers to make local decisions in modifying the current state of their search. Readers can navigate non-locally by using the "Search" function.
- User control and freedom: The UI allows readers to select their choices through drop-downs, checkboxes, text input, and radio buttons. So, readers control their navigation through the decision tree.
- Labeling and instruction clarity: The question boxes pose questions and offer pull-downs that are entirely standard. The zoom capability and the instructions within the search box are self-contained. Our philosophy has been to eliminate the need for instructions by making the choices clear.
- Color coding: Using a color-coding scheme to differentiate between decision points and outcomes could help users better understand the flow through the tree.
- Visual cues: Implementing visual cues such as highlighting the current step and allowing selective zooming are among the enhancements we are considering.
- Dynamic box layouts: Resizing and repositioning boxes based on the number of boxes displayed and the amount of text in each box could minimize the need for users to scroll both within the page and within each box.
- Eliminate dependency on the mouse: It should be possible to manipulate the system entirely from the keyboard.
- Screen reader compatibility: To enable a screen reader to help a visually impaired person navigate through a dynamic decision tree, it would be essential to ensure that all elements, such as drop-downs and buttons, are labeled with descriptive text that screen readers can interpret. This includes ensuring that the order of elements in the DOM (Document Object Model) matches the logical flow of the decision tree.
- An alternative enhancement for the visually impaired is to support a purely voice-controlled interface.
3. Authoring a Dynamic Decision Tree
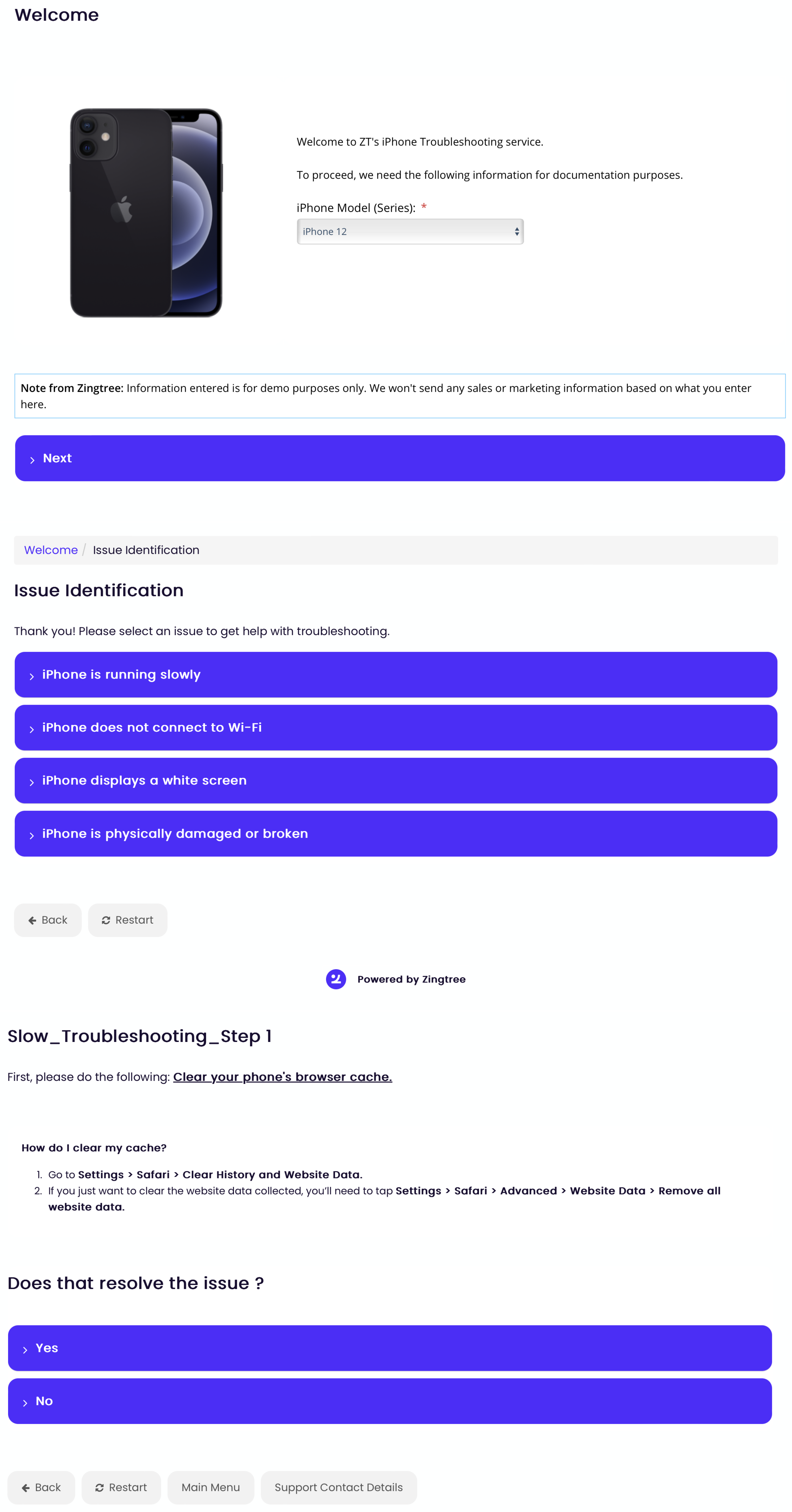
- Hyperlinks: If the authored text contains the keyword DOCUMENT, the system converts everything after “DOCUMENT:” into a clickable hyperlink. For the command to work as intended, all text after “DOCUMENT:” must be a valid URL. For example, if the author wrote “If Yes, Check out this link: DOCUMENT: https://apple.com, the current node would contain “Check out this link: DOCUMENT: https://apple.com”, where “https://apple.com” is a hyperlink to the URL “https://apple.com”.
- Reducing repetition in authoring: When constructing decision trees, authors may find that they have to repeat subtrees. For example, if two sequences of answers lead to the same diagnosis, the treatment options to present to a patient may be the same. Repeating text is both time-consuming and may result in inconsistencies if that text is changed in one place but not in another. The DECISIONTREE command solves this by allowing authors to repeat subtrees without rewriting them multiple times. The subtree is first stored in a text file in the text format of a complete dynamic decision tree. To insert a subtree into the larger decision tree, authors can use the DECISIONTREE command in the line followed by the URL of the subtree’s text file. The system then extracts the subtree text file from the link in the node and combines the decision tree from the link with the current one, forming a larger decision tree. When the reader clicks “show next”, they can continue interacting with the linked subtree as if it was a part of the original decision tree. See the box at the beginning of Section 4, as well as Figure 7 and Figure 8 for an example.
- Collecting data from the reader: If the author’s line contains the keyword INPUT, the system displays a message to input a number to the reader. The prompt message is the substring after the first colon following the INPUT keyword and before the next special keyword. The system waits until something is input. Pressing “cancel” or the escape key prompts the reader to input a value again. Only by pressing the “OK” button can the reader avoid recording an input value. That in turn may cause an error later if a query that should include the reader’s input is executed. The author can set up several inputs, each having a distinct name. Names can be individualized by adding any characters after an INPUT keyword and before a following semicolon. For example, if the author’s line is “INPUT123: Enter a number:”, the reader is prompted to “Enter a number:” and the value the reader enters is stored in a dictionary of inputs with the key-value pair “INPUT123” and the reader-entered value. See the box at the beginning of Section 4 and Figure 9 for an example.
- Accessing a database: Suppose the author’s line contains the keyword QUERY. In that case, the system passes the substring between “QUERY:” and the following RETURN keyword into the back end, along with the dictionary of inputs mentioned above. The system then replaces all instances of dictionary keys (e.g., INPUT123) in the query with their corresponding values. Finally, the system executes a SQLite query, which can include any inputs previously received from the reader. For example, if the author’s line is “QUERY: SELECT (INPUT1 * INPUT2)", the system passes the string “SELECT (INPUT1 * INPUT2)” into the back end. Then, “INPUT1” and “INPUT2” in the query are replaced with their corresponding values, and the query is executed. See the box at the beginning of Section 4 and Figure 10 for an example.
- If the author’s line contains the keyword RETURN, the system displays a message with “RETURN:”. Note that this command applies only when using the QUERY command. If a return message includes the keyword RESULT, the RESULT keyword is replaced by the query results. The system then displays the author’s return message, including the query results. For example, the line “QUERY: SELECT (1 + 1) RETURN: The answer is RESULT” shows the reader “The answer is 2” in the current node.
- User Input Handling: If the line contains the keyword “INPUT”, the user is prompted to input a string, and the user input is stored. Note that one line can contain multiple “INPUT” keywords, in which case the system prompts the user for an input multiple times and stores each input.
- Query Extraction: If the line contains the keywords “QUERY” and “RETURN”, The substring between “QUERY:” and “RETURN:”, along with any previous user inputs, is passed into the back end.
- Query Processing: If the query contains an “INPUT” keyword, the system replaces each input keyword with the user’s corresponding input.
- Query Execution: The back end executes the query substring as an SQLite query and stores the result as a string.
- Return Message Processing: The return message is defined as the substring after “RETURN”. If the return message contains the keyword “RESULT”, the query result replaces the keyword “RESULT”.
- Final Output: The user sees the updated return message in the current node.
4. Fully Functional Dynamic Decision Tree: Case Study
- Are you happy?
- --if yes, Then great
- --if meh, Then get a lollipop. did that help?
- ----if a lot, Then great
- ----if a little, Then get another one
- --if no, Would any of these topics cheer you up: NYU, myeloma, Apple?
- ----if interested in NYU, DOCUMENT: https://www.nyu.edu
- ----if interested in myeloma, DECISIONTREE: https://elliot2878.github.io/decision_tree.github.io/myeloma.txt
- ----if interested in Apple, Which category of Apple products are you interested in?
- ------if interested in iPhone, QUERY: SELECT product_name FROM apple_products WHERE category = ‘iPhone’ RETURN: Which of the following iPhones are you interested in: RESULT?
- --------If iPhone 15 Pro, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPhone 15 Pro’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------If iPhone 15, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPhone 15’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------If iPhone 14, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPhone 14’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------If iPhone 13, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPhone 13’ RETURN: You can find this product here: DOCUMENT: RESULT
- ------if interested in iPad, QUERY: SELECT product_name FROM apple_products WHERE category = ‘iPad’ RETURN: Which of the following iPads are you interested in: RESULT?
- --------if iPad Pro, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPad Pro’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if iPad Air, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPad Air’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if iPad (10th Generation), QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPad (10th Generation)’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if iPad (9th Generation), QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPad (9th Generation)’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if iPad Mini, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPad Mini’ RETURN: You can find this product here: DOCUMENT: RESULT
- ------if interested in Mac, QUERY: SELECT product_name FROM apple_products WHERE category = ‘Mac’ RETURN: Which of the following Macs are you interested in: RESULT?
- --------if Mac Pro, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘Mac Pro’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if Mac Studio, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘Mac Studio’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if Mac Mini, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘Mac Mini’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if iMac, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iMac’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if Mac MacBook Pro 16, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘MacBook Pro 16’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if Mac MacBook Pro 14, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘MacBook Pro 14’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if Mac MacBook Air M1, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘MacBook Air M1’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if MacBook Air 13-inch M2, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘MacBook Air 13-inch M2’ RETURN: You can find this product here: DOCUMENT: RESULT
- --------if MacBook Air 15-inch M2, QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘MacBook Air 15-inch M2’ RETURN: You can find this product here: DOCUMENT: RESULT
- ------if interested in Apple Watch, INPUT1: Enter the name of the Apple Watch you are interested in. Your options are ‘‘Apple Watch Series 9’’, ‘‘Apple Watch Ultra 2’’, or ‘‘Apple Watch SE’’ QUERY: SELECT product_link FROM apple_products WHERE lower(product_name) = lower(INPUT1) RETURN: You can find this product here: DOCUMENT: RESULT
- DECISIONTREE: https://elliot2878.github.io/decision_tree.github.io/myeloma.txt
- QUERY: SELECT product_name FROM apple_products WHERE category = ‘iPhone’ RETURN: Which of the following iPhones are you interested in: RESULT?
- 1.
- QUERY: SELECT product_name FROM apple_products WHERE category = ‘iPhone’
- 2.
- RETURN: Which of the following iPhones are you interested in: RESULT?
- QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPhone 15’ RETURN: You can find this product here: DOCUMENT: RESULT
- 1. QUERY: SELECT product_link FROM apple_products WHERE product_name = ‘iPhone 15’
- 2. RETURN: You can find this product here: DOCUMENT: RESULT
- INPUT1: Enter the name of the Apple Watch you are interested in. Your options are ‘‘Apple Watch Series 9’’, ‘‘Apple Watch Ultra 2’’, or ‘‘Apple Watch SE’’ QUERY: SELECT product_link FROM apple_products WHERE product_name = INPUT1 RETURN: You can find this product here: DOCUMENT: RESULT
- 1. INPUT1: Enter the name of the Apple Watch you are interested in. Your options are ‘‘Apple Watch Series 9’’, ‘‘Apple Watch Ultra 2’’, or ‘‘Apple Watch SE’’
- 2. QUERY: SELECT product_link FROM apple_products WHERE product_name = INPUT1
- 3. ‘‘RETURN: You can find this product here: DOCUMENT: RESULT’’
5. Related Work
5.1. Uses of Decision Trees
5.2. Interactive Decision Tree Tools
5.3. Analytical Hierarchy Process
5.4. Decision Tree Drawing Tools
6. Functionality Comparison with State of the Art Systems
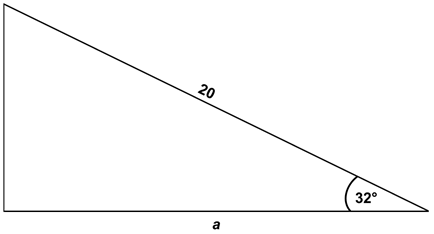
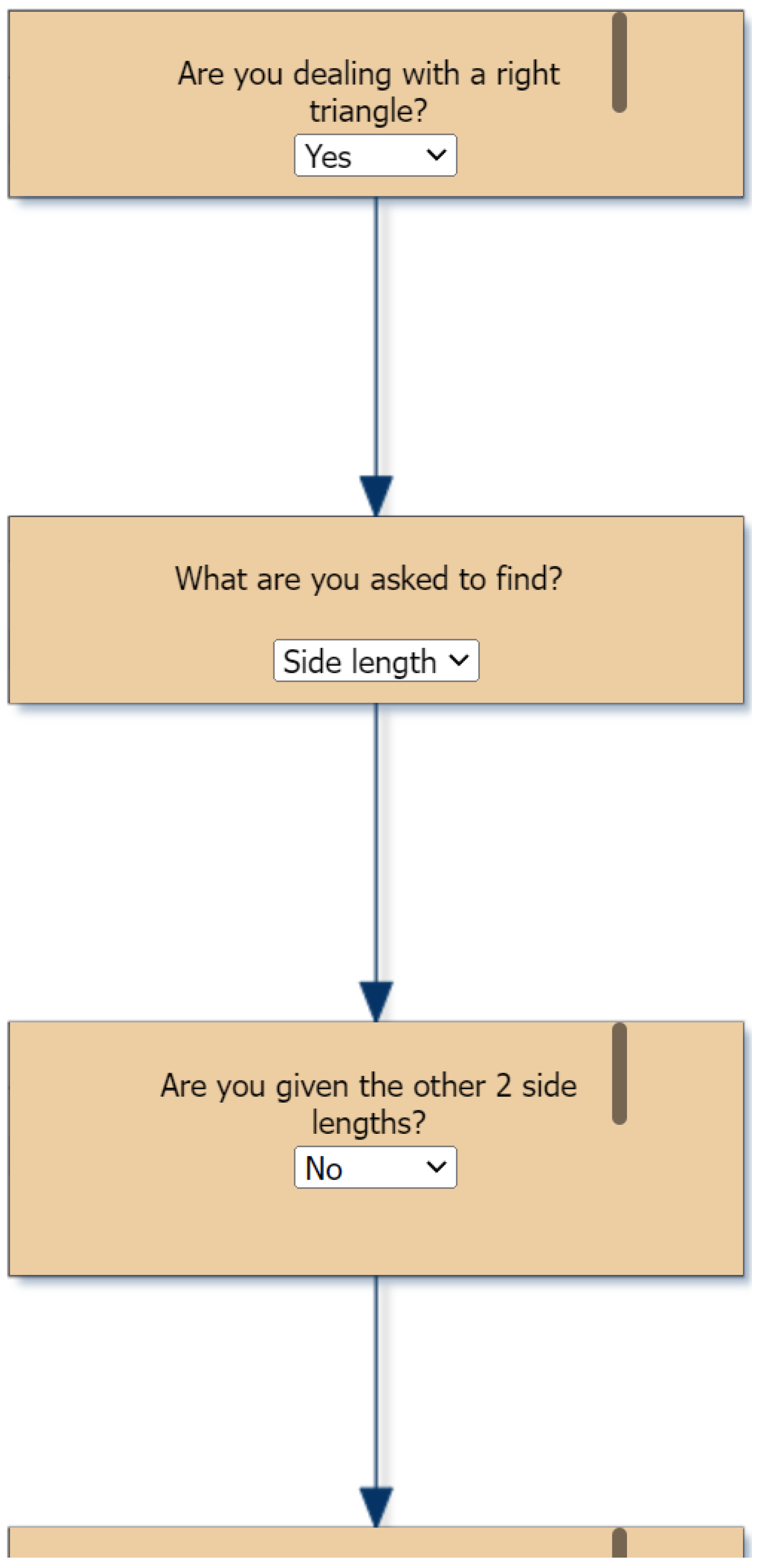
- Calculate the length of the leg by multiplying the hypotenuse length by the cosine of the given angle (Ex: If Hypotenuse = 5, angle = 60, find Adjacent side: Adjacent = 5 ∗ cos(60) = 2.5).
- Social media is also a place where people with similar struggles can interact and support each other. Many digital groups are dedicated towards mental health and support. However, doesn’t this seem like social media is trying to solve the insecurities it creates?
7. Conclusions
Future Work
- Support for advanced text formatting using TeX typesetting. This would allow for more versatile authoring capabilities, such as including complex mathematical formulas.
- Interfaces for mobile devices.
- Deeper improvements include support for the visually impaired as outlined in Section 2.2.
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
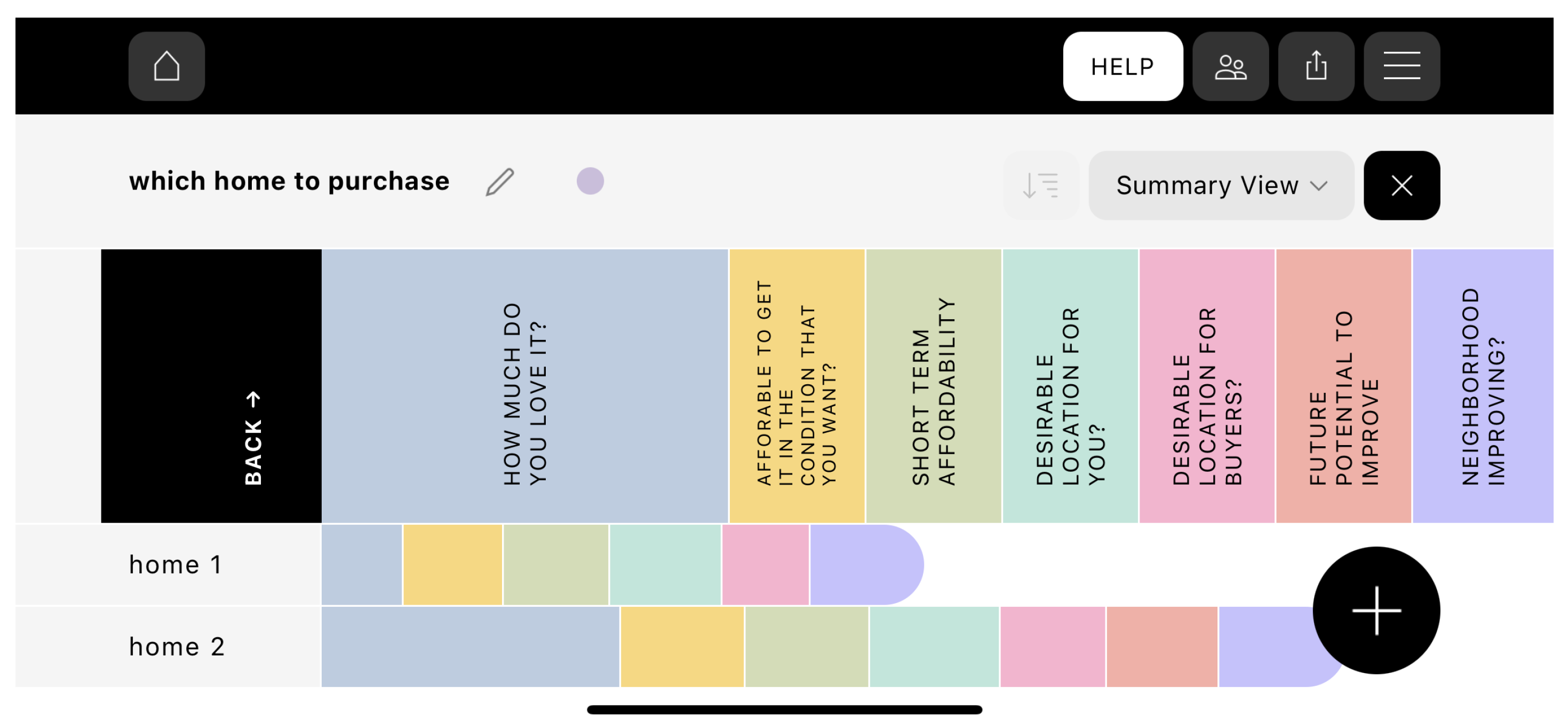
Appendix A. Home Appraisal Case Study
Appendix A.1. Full Decision Tree Source Text for Appraisal
- Do you have a valid legal description that is sufficient to identify the exact residential property?
- --If Yes, Have you inspected the interior and exterior of the residential property in person and documented its results (ex: condition, age, construction type)?
- ----If Yes, Have you documented the home’s structural elements (e.g., foundation, roof, walls) and its key systems (like plumbing, electrical, heating)?
- ------If Yes, Have you documented the value of the actual land (based on prices of similar empty lots nearby)?
- --------If Yes, Have you documented local amenities (like distance to schools, parks, malls) and distinctive elements (like a garden, unique design)?
- ----------If Yes, Have you documented any zoning or usage restrictions (e.g., limits on extensions or business activities)?
- ------------If Yes, Have you documented all upcoming projects (like new highways or shopping districts) that might affect the residential property’s value?
- --------------If Yes, Is your property in the state of Washington?
- ----------------If Yes, INPUT1: Enter the zip code of your residential property: INPUT2: Enter the number of bedrooms in your residential property: QUERY: SELECT COUNT(price) FROM comps WHERE zipcode = INPUT1 AND bedrooms = INPUT2 RETURN: There were RESULT comparable properties found with this criteria. If the number of properties found is 0, please answer ‘‘No’’. Otherwise, will you please respond ‘‘Yes’’?
- ------------------If Yes, QUERY: SELECT(ROUND(AVG(price), 2)) AS avg_price FROM comps WHERE zipcode = INPUT1 AND bedrooms = INPUT2 RETURN: Based on comparable properties in the area, your property is worth approximately RESULT. Use this number to determine your property’s value. Draft the appraisal report, including the property’s value as calculated. Include the other information in your appraisal report, but do not use it to calculate the value of the property directly.
- ------------------If No, Can you determine your property’s purchase price and its total depreciation since being purchased?
- --------------------If Yes, INPUT3: Enter your property’s purchase price: INPUT4: Enter the total depreciation amount since the property was purchased: QUERY: SELECT(ROUND(INPUT3 - INPUT4, 2)) RETURN: Your property’s salvage value is RESULT. Draft the appraisal report, including the property’s value as calculated. Include the other information in your appraisal report, but do not use it to calculate the value of the property directly.
- --------------------If No, Can you calculate your property’s capitalization rate (based on the rate of return for similar properties in the area) and its potential yearly net operating income (by subtracting all costs, such as property taxes, mortgage payments, and capital expenditures, from all sources of revenue, such as rental income and any fees collected from the tenant)?
- ----------------------If Yes, INPUT5: Enter the potential yearly net operating income from renting your property: INPUT6: Enter your property’s capitalization rate: QUERY: SELECT(ROUND(INPUT5/INPUT6, 2)) RETURN: Your property’s value can be determined by dividing the net operating income by the capitalization rate. Based on this formula your property is worth approximately RESULT. Draft the appraisal report, including the property’s value as calculated. Include the other information in your appraisal report, but do not use it to calculate the value of the property directly.
- ----------------------If No, You are missing key information required to get the value of the property. Gather more information, such as the estimated cost to build the house, the depreciation rate, and the potential net income from renting the property. Once done, revisit the decision tree.
- ----------------If No, Can you determine your property’s purchase price and its total depreciation since being purchased?
- ------------------If Yes, INPUT3: Enter your property’s purchase price: INPUT4: Enter the total depreciation amount since the property was purchased: QUERY: SELECT(ROUND(INPUT3 - INPUT4, 2)) RETURN: Your property’s salvage value is RESULT. Draft the appraisal report, including the property’s value as calculated. Include the other information in your appraisal report, but do not use it to calculate the value of the property directly.
- ------------------If No, Can you calculate your property’s capitalization rate (based on the rate of return for similar properties in the area) and its potential yearly net operating income (by subtracting all costs, such as property taxes, mortgage payments, and capital expenditures, from all sources of revenue, such as rental income and any fees collected from the tenant)?
- --------------------If Yes, INPUT5: Enter the potential yearly net operating income from renting your property: INPUT6: Enter your property’s capitalization rate: QUERY: SELECT(ROUND(INPUT5/INPUT6, 2)) RETURN: Your property’s value can be determined by dividing the net operating income by the capitalization rate. Based on this formula your property is worth approximately RESULT. Draft the appraisal report, including the property’s value as calculated. Include the other information in your appraisal report, but do not use it to calculate the value of the property directly.
- --------------------If No, You are missing key information required to get the value of the property. Gather more information, such as the estimated cost to build the house, the depreciation rate, and the potential net income from renting the property. Once done, revisit the decision tree.
- --------------If No, Research upcoming developments that may affect the property’s value and restart the decision tree once finished. (e.g., a nearby gym being built may boost the property’s value.)
- ------------If No, Research and document any zoning or usage rules affecting the property and revisit the decision tree once done. (e.g., if the house is in a heritage zone, the value of the property might be diminished due to limited extension options)
- ----------If No, Research and document local amenities, unique elements, and any environmental factors that could affect value. Then, refer back to the decision tree. (e.g., Proximity to a lake or special architectural facets may boost the property’s value, so this information should be included in the appraisal report).
- --------If No, Document the value of the land. The value can be calculated based on similar empty lots nearby. Resume the decision tree once done. (e.g., if comparable vacant lots are priced at 80 per square foot, and your property is 1000 square feet, your land is worth 800,000. Consider using multiple other vacant lots and averaging the price per square foot to get a more accurate value)
- ------If No, Document the home’s structure and essential systems. Then, come back to this decision tree. (e.g., check the basement for moisture issues, check the HVAC system, and review wiring. Any major issues must be included in the final appraisal report.)
- ----If No, Inspect the property thoroughly, document its results, then redo the decision tree.
- --If No, First obtain a legal description for the residential property. A legal description can usually be found in the most recent deed to the property. Consult local authorities or check legal documentation for the correct legal description. Once obtained, redo the decision tree.
Appendix A.2. Comparables Approach
- --If Yes, INPUT1: What is your zip code? INPUT2: How many bedrooms does your property contain? QUERY: SELECT COUNT(∗) FROM comps WHERE zipcode = INPUT1 AND bedrooms = INPUT2 RETURN: There were RESULT comparable properties found with this criteria. If the number of properties found is 0, please answer ‘‘No’’. Otherwise, will you please respond ‘‘Yes’’?
- QUERY: SELECT(ROUND(AVG(price), 2)) AS avg_price FROM comps WHERE zipcode = INPUT1 AND bedrooms = INPUT2 RETURN: Based on comparable properties in the area, your property is worth approximately RESULT. Use this number to determine your property’s value. Draft the appraisal report, including the property’s value as calculated. Include the other information in your appraisal report, but do not use it to calculate the value of the property directly.
Appendix A.3. The Cost Approach
Appendix A.4. Income Approach
Appendix B. Software Architecture
- datasets
- −
- federal_tax_brackets.csv
- −
- kentucky_comps.csv
- input
- −
- ESG.txt
- −
- collect_social.txt
- −
- commercialPropertyAppraisal.txt
- −
- derivatives.txt
- −
- dynamicAntibiotic.txt
- −
- federal_tax_rates.txt
- −
- housing.txt
- −
- immigration.txt
- −
- laptopRepair.txt
- −
- macbookrepair.txt
- −
- myeloma.txt
- −
- residentialPropertyAppraisal.txt
- −
- seriesConvergence.txt
- −
- social_helper.txt
- −
- tax_free_exchange.txt
- −
- test_input.txt
- −
- trigonometry.txt
- −
- visa.txt
- static
- −
- MindFusion.Common.js
- −
- MindFusion.Diagramming.js
- −
- homepage.css
- −
- homepage.js
- −
- tree.css
- −
- tree.js
- templates
- −
- index.html
- −
- sql.html
- −
- tree.html
- app.py
- dt.db
- requirements.txt
- root_to_curr.txt
- The datasets folder includes, in the appraisal example, kentucky_comps.csv and federal_tax_brackets.csv, two datasets that are used in the Python back end to create SQL tables.
- The input folder includes the decision tree text files, many of which are accessible by clicking the corresponding radio buttons on the website.
- The static folder includes all of the JavaScript and CSS files used, namely homepage.css, homepage.js, MindFusion.Common.js, MindFusion.Diagramming.js, tree.css, and tree.js.
- The templates folder includes all of the HTML files, namely index.html, tree.html, and sql.html. The back-end Python file named app.py and the database named dt.db are not stored in an additional folder.
- The MindFusion libraries are in two JavaScript files, MindFusion.Common.js and MindFusion.Diagramming.js. Both HTML and JavaScript files refer to these library files.
- The system imports Mindfusion.Diagramming, MindFusion.Drawing, and MindFusion.Animations.
- Each box in a dynamic decision tree (e.g., the “Are you happy?” box) is a node.
- For each box that needs to be created:
- (i)
- Mindfusion.Diagramming creates the node objects.
- (ii)
- Mindfusion.Drawing draws a rectangle for each node.
- (iii)
- Mindfusion.Animations draws arrows between nodes.
- The code for error detection is in a function called input, which converts the text input to a general tree structure in homepage.js. input is called when authors click “Submit” in the index.html page. It can detect the following types of errors: incorrect number of hyphens, having a question but no answer, having an answer but no question, and a question having duplicated answers.
- The jump function in homepage.js moves the input text to the line containing errors so authors can correct the error conveniently.
- The keywordSearch, findPath, and inputSearch functions are called when readers click the “search” button in the tree.html. They are responsible for searching for phrases in nodes.
- keywordSearch in tree.js searches the nodes by phrase.
- findPath in tree.js finds the path from the root to the node containing that phrase.
- inputSearch in tree.js renders the search results.After a search is completed, the reader has the option to see the text of the subtree of the node that has been searched thanks to the subtree function. The subtree’s text format is in the same form as the input: text with hyphens.
- The dragElement function is called in tree.js when readers click “Click here to move this box” in the search box. It allows the reader to drag the search box. In this way, readers can move the search box when the tree and the search box overlap.
- The rootNode function is called in tree.js whenever the page is loaded. rootNode displays the root.
- The nextOption is called in tree.js when a single answer in the drop-down menu is selected. The function creates and shows a single next node.
- The notSure function is called in tree.js where the reader clicks “notSure” in the drop-down menu. This function creates and shows all possible children of the current node.
- The showCheckbox function is called in tree.js when readers click the “Submit” button in a node containing a checkbox. A node will contain a checkbox when there are more than five child nodes, potential answers. This function thus gives finer control of the branching than “notSure” does because it allows the reader to choose among possible outcomes, rejecting those that the reader deems impossible. After the reader selects their desired answers and clicks “Submit”, the system will display all of the children nodes that have been checked.
Appendix C. Trigonometry Decision Tree Text File
- Are you dealing with a right triangle?
- --If Yes, What are you asked to find?
- ----If Side length, Are you given the other 2 side lengths?
- ------If Yes, Solve for a^2 + b^2 = c^2 where a and b are the respective leg lengths and c is the hypotenuse length (Ex: If a = 3, b = 4, find c: c = sqrt(32 + 42) = 5).
- ------If No, Are you given a side length and an angle?
- --------If Yes, Are you given the hypotenuse or a leg??
- ----------If Hypotenuse, Are you asked to find the leg length adjacent or opposite to the given angle?
- ------------If Adjacent, Calculate the length of the leg by multiplying the hypotenuse length by the cosine of the given angle (Ex: If Hypotenuse = 5, angle = 60°, find Adjacent side: Adjacent = 5 ∗ cos(60°) = 2.5).
- ------------If Opposite, Calculate the length of the leg by multiplying the hypotenuse length by the sine of the given angle (Ex: If Hypotenuse = 5, angle = 60°, find Opposite side: Opposite = 5 ∗ sin(60°) ≈ 4.33).
- ----------If Leg, Is the given angle adjacent or opposite to the leg whose length you are asked to find?
- ------------If Adjacent, Calculate the length of the missing side by dividing the length of the given leg by the cosine of the given angle (Ex: If Adjacent side = 3, angle = 60°, find Hypotenuse: Hypotenuse = 3/cos(60°) = 6).
- ------------If Opposite, Calculate the length of the missing side by dividing the length of the given leg by the sine of the given angle (Ex: If Opposite side = 3, angle = 60°, find Hypotenuse: Hypotenuse = 3/sin(60°) ≈ 3.46).
- --------If No, Try to use other methods to gain more information and help you find the side length.
- ----If Angle, Are you given the length of the 2 sides of the triangle?
- ------If Yes, Which 2 side lengths were you given?
- --------If 2 legs, Calculate the angle by taking the arctangent of the leg length opposite the angle divided by the leg length adjacent to the angle (Ex: If Opposite side = 4, Adjacent side = 3, find angle: Angle = arctan(4/3) ≈ 53.13°).
- --------If 1 leg and 1 hypotenuse, Is the given leg length adjacent or opposite to the angle you are trying to find?
- ----------If Adjacent, Calculate the angle by taking the arccosine of the leg length adjacent to the angle divided by the length of the hypotenuse (Ex: If Adjacent side = 3, Hypotenuse = 5, find angle: Angle = arccos(3/5) ≈ 53.13°).
- ----------If Opposite, Calculate the angle by taking the arcsine of the leg length opposite the angle divided by the length of the hypotenuse (Ex: If Opposite side = 4, Hypotenuse = 5, find angle: Angle = arcsin(4/5) ≈ 53.13°).
- ------If No, Are you given the other acute angle?
- --------If Yes, Calculate the the angle by subtracting the given acute angle from 90 (Ex: If one acute angle is 30°, find other acute angle: Other Angle = 90 − 30 = 60°)
- --------If No, Try to use other methods to gain more information and help you find the angle.
- ----If Area, Are you given the lengths of two sides that form the right angle?
- ------If Yes, Calculate the area as 1/2 ∗ first leg length ∗ second leg length (Ex: If leg one = 4 and leg 2 = 3, Area = 1/2 ∗ 4 ∗ 3 = 6).
- ------If No, Try to use other methods to gain more information and help you find the area.
- ----If Height, Are you given the length of the hypotenuse and an angle?
- ------If Yes, Calculate the height as hypotenuse ∗ sin(angle) (Ex: If hypotenuse = 5 and angle = 60°, height = 5 ∗ sin(60°) ≈ 4.33).
- ------If No, Try to use other methods to gain more information and help you find the height.
- --If No, What are you asked to find?
- ----If Side length, Are you given all three angles and one side or two sides and one included angle?
- ------If All three angles and one side, Use the Law of Sines to find the unknown side: a/sin(A) = b/sin(B) = c/sin(C) (Ex: If angle A = 30°, side a = 2, angle B = 60°, find side b: b = sin(60°) ∗ (2/sin(30°)) = 4)
- ------If Two sides and one included angle, Use the Law of Cosines to find the unknown side: c2 = a2 + b2 − 2abcos(C) (Ex: If a = 3, b = 4, angle C = 60°, find c: c = sqrt(32 + 42 − 2 ∗ 3 ∗ 4cos(60°)) = 1).
- ----If Angle, Are you given all three sides or two angles?
- ------If All three sides, Use the Law of Cosines to find the unknown angle: Take the arccosine of [a2 + b2 − c2]/2ab to find the unknown angle (Ex: If a = 3, b = 4, c = 5, find angle A: A = arccos((32 + 42 − 52)/(2 ∗ 3 ∗ 4)) ≈ 36.87°)
- ------If Two angles, Subtract the sum of the two known angles from 180° to find the unknown angle (Ex: If angle A = 60° and angle B = 50°, find angle C: C = 180 − 60 − 50 = 70°).
- ----If Area, Are you given two sides and the included angle?
- ------If Yes, Use the formula 1/2 ∗ a ∗ b ∗ sin(C) to find the area (Ex: If a = 3, b = 4, and C = 60°, Area = 1/2 ∗ 3 ∗ 4 ∗ sin(60°) = 3.46).
- ------If No, Are you given all three sides?
- --------If Yes, Use Heron’s formula to find the area: sqrt[s(s − a)(s − b)(s − c)] where s is half the perimeter of the triangle given by (a + b + c)/2 (Ex: If a = 2, b = 3, and c = 4, s = (2 + 3 + 4)/2 = 4.5, then Area = sqrt[4.5(4.5 − 2)(4.5 − 3)(4.5 − 4)] = 2.9).
- --------If No, Try to use other methods to gain more information and help you find the area.
- ----If Height, Are you given the longest side and its opposite angle?
- ------If Yes, Use the relationship h = a ∗ sin(B) where h is the height, a is the side length, and B is the opposite angle (Ex: If a = 3 and B = 60°, height = 3 ∗ sin(60°) ≈ 2.6).
- ------If No, Try to use other methods to gain more information and help you find the height.
- ----If Solution To Trigonometric Equation/Expression, Which identity or formula category does it belong to?
- ------If Pythagorean (Ex: cos^2(θ) + sin^2(θ) = ?), Do you know sin(θ) or cos(θ)?
- --------If sin(θ) (Ex: sin(θ) = 0.6), Use the identity: cos(θ) = sqrt(1 − sin^2(θ)) (Ex: If sin(θ) = 0.6, cos(θ) = sqrt(1 − 0.6^2) = 0.8).
- --------If cos(θ) (Ex: cos(θ) = 0.5), Use the identity: sin(θ) = sqrt(1 − cos^2(θ)) (Ex: If cos(θ) = 0.5, sin(θ) = sqrt(1 − 0.5^2) = 0.87).
- ------If Angle Sum or Difference (Ex: sin(45° + 30°) = ?), Are you working with sine, cosine, or tangent?
- --------If Sine (Ex: sin(45° + 30°) = ?), Use the identity: sin(A ± B) = sin(A)cos(B) ± cos(A)sin(B) (Ex: If A = 30° and B = 60°, sin(A + B) = sin(30°)cos(60°) + cos(30°)sin(60°)).
- --------If Cosine (Ex: cos(45° − 30°) = ?), Use the identity: cos(A ± B) = cos(A)cos(B) ± sin(A)sin(B) (Ex: If A = 30° and B = 60°, cos(A − B) = cos(30°)cos(60°) + sin(30°)sin(60°)).
- --------If Tangent (Ex: tan(45° + 30°) = ?), Use the identity: tan(A ± B) = (tan(A) ± tan(B))/(1 ± tan(A)tan(B)) (Ex: If A = 45° and B = 30°, tan(A + B) = (tan(45°) + tan(30°))/(1 − tan(45°)tan(30°))).
- ------If Double Angle (Ex: sin(230°) = ?), Are you working with sine, cosine, or tangent?
- --------If Sine (Ex: sin(230°) = ?), Use the identity: sin(2θ) = 2sin(θ)cos(θ) (Ex: If θ = 30°, sin(2θ) = 2sin(30°)cos(30°)).
- --------If Cosine (Ex: cos(230°) = ?), Use the identity: cos(2θ) = cos^2(θ) − sin^2(θ) or 2cos^2(θ) − 1 or 1 − 2sin^2(θ) (Ex: If θ = 30°, cos(2θ) = 2cos^2(30°) − 1).
- --------If Tangent (Ex: tan(230°) = ?), Use the identity: tan(2θ) = (2tan(θ))/(1 − tan^2(θ)) (Ex: If θ = 30°, tan(2θ) = 2tan(30°)/(1 − tan^2(30°))).
- ------If Product-to-Sum (Ex: 2sin(30°)sin(45°) = ?), Are you working with sine, cosine, or a mix of both?
- --------If Sine (Ex: 2sin(30°)sin(45°) = ?), Use the identity: 2sin(A)sin(B) = cos(A − B) − cos(A + B) (Ex: If A = 45° and B = 30°, 2sin(45°)sin(30°) = cos(15°) − cos(75°)).
- --------If Cosine (Ex: 2cos(30°)cos(45°) = ?), Use the identity: 2cos(A)cos(B) = cos(A + B) + cos(A − B) (Ex: If A = 45° and B = 30°, 2cos(45°)cos(30°) = cos(75°) + cos(15°)).
- --------If Mix of both (Ex: 2sin(30°)cos(45°) = ?), Use the identity: 2sin(A)cos(B) = sin(A + B) + sin(A − B) or 2cos(A)sin(B) = sin(A + B) − sin(A − B) (Ex: If A = 45° and B = 30°, 2sin(45°)cos(30°) = sin(75°) + sin(15°)).
Appendix D. Technology Debate Decision Tree Text File
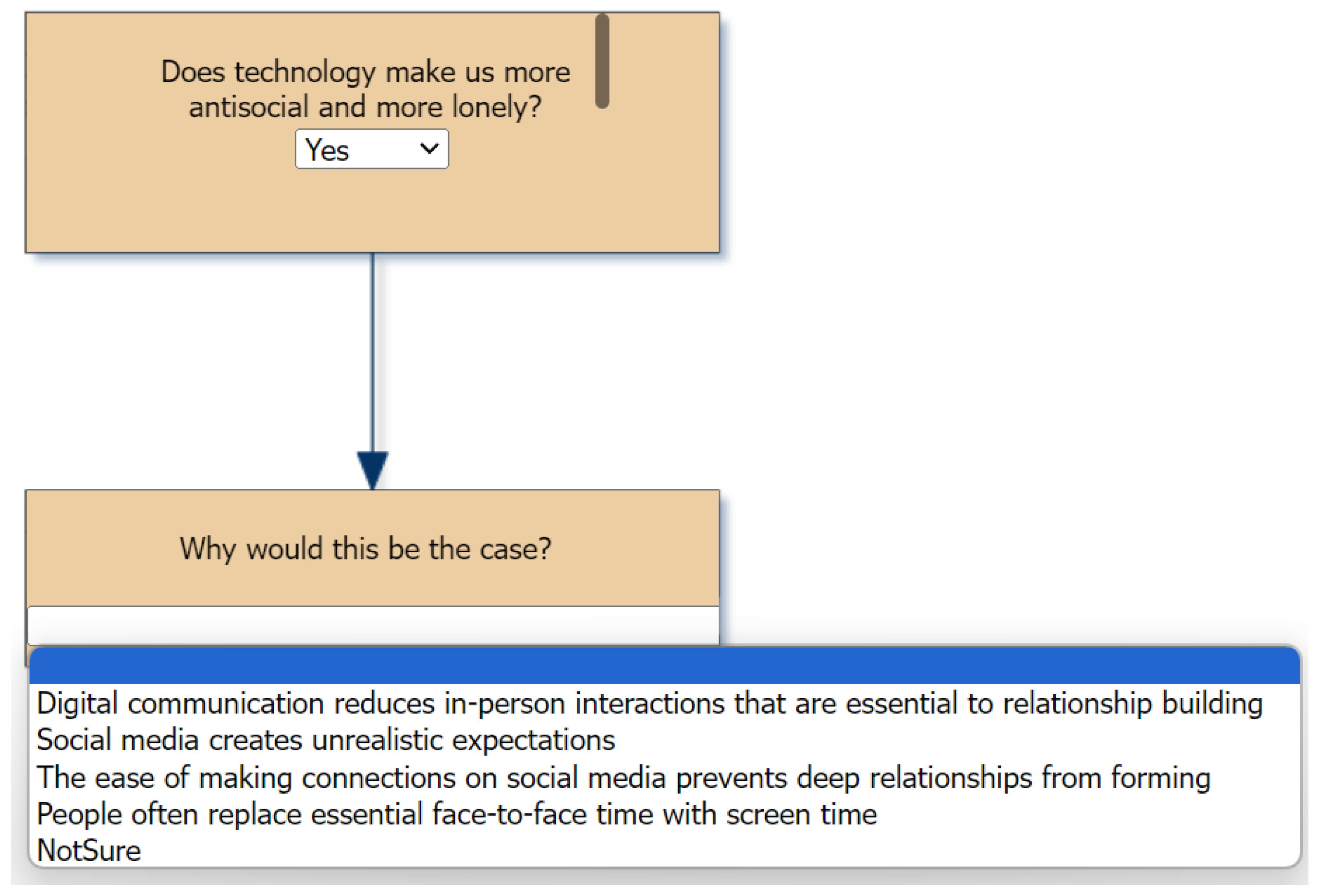
- Does technology make us more antisocial and more lonely?
- --If Yes, Why would this be the case?
- ----If Digital communication reduces in-person interactions that are essential to relationship building, Technology also allows people to maintain relationships over long distances through video calls and virtual meetings. It is about how people decide to use technology. According to Business Insider, 35% of Gen Zers agree social media has made them less lonely, whereas only 29% claimed social media made them more lonely. However, Isn’t it true that most relationships could not rely solely on digital interactions due to their inferior depth and satisfaction?
- ------If Yes, Digital communication allows long-distance friends or romantic partners to remain connected until they eventually meet in person.
- ------If No, A recent study shows nearly 1/3 of newlyweds met online! This simply shows the success of technology in sparking social bonds.
- ----If Social media creates unrealistic expectations, Social media is also a place where people with similar struggles can interact and support each other. Many digital groups are dedicated towards mental health and support. However, doesn’t this seem like social media is trying to solve the insecurities it creates?
- ------If No, A study by Common Sense Media found that one in five teens said social media makes them feel more confident, compared with 4% who said it makes them feel less so. Social media is overall beneficial in boosting the self-esteem of its users.
- ----If The ease of making connections on social media prevents deep relationships from forming, The ease of connecting with others on social media is a benefit, because it acts as a foundation for building deeper relationships in person. According to Business Insider, 35% of Gen Zers agree social media has made them less lonely, whereas only 29% claimed social media made them more lonely.
- ----If People often replace essential face-to-face time with screen time, Frank Herbert, an American author, once said, ‘‘Technology is both a tool for helping humans and for destroying them. This is the paradox of our times which we’re compelled to face.’’ Technology is a tool, and it is our choice whether to use it for good or bad. Unhealthy screen time habits are not the fault of technology, but of the user.
- --If No, We are in agreement. There is no debate here.
References
- DeTore, A.W. An Introduction to Expert Systems. J. Insur. Med. 1989, 21, 233–236. [Google Scholar]
- Ferrara, J.M.; Parry, J.D.; Lubke, M.M. Expert Systems Authoring Tools for the Microcomputer: Two Examples. Educ. Technol. 1985, 25, 39–41. [Google Scholar]
- Aleksandrovich, K.D. Research of the methods of creating content aggregation systems. Softw. Syst. Comput. Methods 2022, 9–31. [Google Scholar] [CrossRef]
- MangoApps. Issaquah, WA, USA. Available online: https://mangoapps.com/ (accessed on 11 August 2024).
- HelpJuice. Washington DC, USA. Available online: https://helpjuice.com/ (accessed on 11 August 2024).
- Freshworks. San Mateo, CA, USA. Available online: https://freshworks.com/ (accessed on 11 August 2024).
- Mirkowicz, M.; Grodner, G. Jakob Nielsen’s Heuristics in Selected Elements of Interface Design of Selected Blogs. Soc. Commun. 2018, 4, 30–51. [Google Scholar] [CrossRef]
- Apple Inc. 2024. Available online: https://www.apple.com/ (accessed on 6 January 2024).
- Yang, B.S.; Lim, D.S.; Tan, A.C.C. VIBEX: An expert system for vibration fault diagnosis of rotating machinery using decision tree and decision table. Expert Syst. Appl. 2005, 28, 735–742. [Google Scholar] [CrossRef]
- Dugerdil, P.; Sennhauser, D. Dynamic decision tree for legacy use-case recovery. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, New York, NY, USA, 18–22 March 2013; pp. 1284–1291. [Google Scholar] [CrossRef]
- Ciumasu, I.M. Dynamic decision trees for building resilience into future eco-cities. Technol. Forecast. Soc. Chang. 2013, 80, 1804–1814. [Google Scholar] [CrossRef]
- Son, C.S.; Kim, Y.N.; Kim, H.S.; Park, H.S.; Kim, M.S. Decision-making model for early diagnosis of congestive heart failure using rough set and decision tree approaches. J. Biomed. Inform. 2012, 45, 999–1008. [Google Scholar] [CrossRef] [PubMed]
- Gomes, C.M.A.; Almeida, L.S. Advocating the Broad Use of the Decision Tree Method in Education. Pract. Assessment Res. Eval. 2017, 22, 10. [Google Scholar] [CrossRef]
- Schrepel, T. The Making of an Antitrust API: Proof of Concept; Stanford University CodeX Research Paper; Stanford University: Stanford, CA, USA, 2022. [Google Scholar]
- Thakur, N.; Han, C.Y. A Study of Fall Detection in Assisted Living: Identifying and Improving the Optimal Machine Learning Method. J. Sens. Actuator Netw. 2021, 10, 39. [Google Scholar] [CrossRef]
- Le, T.M.; Tran, L.V.; Dao, S.V.T. A Feature Selection Approach for Fall Detection Using Various Machine Learning Classifiers. IEEE Access 2021, 9, 115895–115908. [Google Scholar] [CrossRef]
- Symbolic Frameworks, L. Protagonist: Decision Making. Available online: https://apps.apple.com/us/app/protagonist-decision-making/id1562381604 (accessed on 11 August 2024).
- Kowalski, L. Best Decision—Decision Maker. Available online: https://apps.apple.com/us/app/best-decision-decision-maker/id792954009 (accessed on 11 August 2024).
- Zingtree Inc. Zingtree. Available online: https://zingtree.com/en/resources/example-trees (accessed on 11 August 2024).
- Yonyx Inc. Yonyx. Available online: https://corp.yonyx.com (accessed on 11 August 2024).
- Ernest, H.; Forman, S.I.G. The Analytic Hierarchy Process—An Exposition. Oper. Res. 2001, 49, 469–486. [Google Scholar] [CrossRef]
- Dey, P. Project risk management: A combined analytic hierarchy process and decision tree approach. Cost Eng. 2002, 44, 13–26. [Google Scholar]
- Miro. Available online: https://miro.com (accessed on 11 August 2024).
- Structured Path GmbH. Diagrams. Available online: https://diagrams.app (accessed on 11 August 2024).
- Cinergix Pty Ltd. (Australia). Creately. Available online: https://creately.com (accessed on 11 August 2024).
- OpenEvidence. Cambridge, Massachusets. Available online: https://www.openevidence.com/ (accessed on 3 August 2024).
- KC House Data. 2022. Available online: https://www.kaggle.com/datasets/astronautelvis/kc-house-data (accessed on 11 August 2024).















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Product Name | Product Choice Application | Problem-Solving e.g., Trigonometry | Complex Rules e.g., Debate | External Data Integration | Search Functionality |
|---|---|---|---|---|---|
| Protagonist | Yes | No | No | No | No |
| Best Decision | Yes | No | No | No | No |
| ZingTree | Yes | Yes | Yes | Yes, using Google Sheets webhook integration | No |
| Yonyx | Yes | Yes | Yes | Yes, through API calls | Yes, but for authors only |
| Dynamic decision tree | Yes | Yes | Yes | Yes, using an SQL database | Yes |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vidal, J.; Jha, S.; Liang, Z.; Delgado, E.; Deneke, B.S.; Shasha, D. Dynamic Decision Trees. Knowledge 2024, 4, 506-542. https://doi.org/10.3390/knowledge4040027
Vidal J, Jha S, Liang Z, Delgado E, Deneke BS, Shasha D. Dynamic Decision Trees. Knowledge. 2024; 4(4):506-542. https://doi.org/10.3390/knowledge4040027
Chicago/Turabian StyleVidal, Joseph, Spriha Jha, Zhenyuan Liang, Ethan Delgado, Bereket Siraw Deneke, and Dennis Shasha. 2024. "Dynamic Decision Trees" Knowledge 4, no. 4: 506-542. https://doi.org/10.3390/knowledge4040027
APA StyleVidal, J., Jha, S., Liang, Z., Delgado, E., Deneke, B. S., & Shasha, D. (2024). Dynamic Decision Trees. Knowledge, 4(4), 506-542. https://doi.org/10.3390/knowledge4040027