
A Search Methodology Based on Industrial Ontology and Machine Learning to Analyze Georeferenced Italian Districts



Abstract
:1. Introduction
- A description of the searching approach by means of a Unified Modeling Language (UML) Activity Diagram (AD), defining the two-level searching approach useful to gain the knowledge base of the supply chain and providing the ontology construction mechanism;
- The results of the preliminary Smart District 4.0 project [18] from a prototypal search engine, highlighting the main functions of refinement research, such as hierarchical clustering and web scraping;
- A discussion focused on web scraping logic, a full list of possible technologies usable to implement the whole supply chain searching engine;
- A case study of a pilot industry based on the two-level searching process and constructing a sub-ontology.
2. Methodology
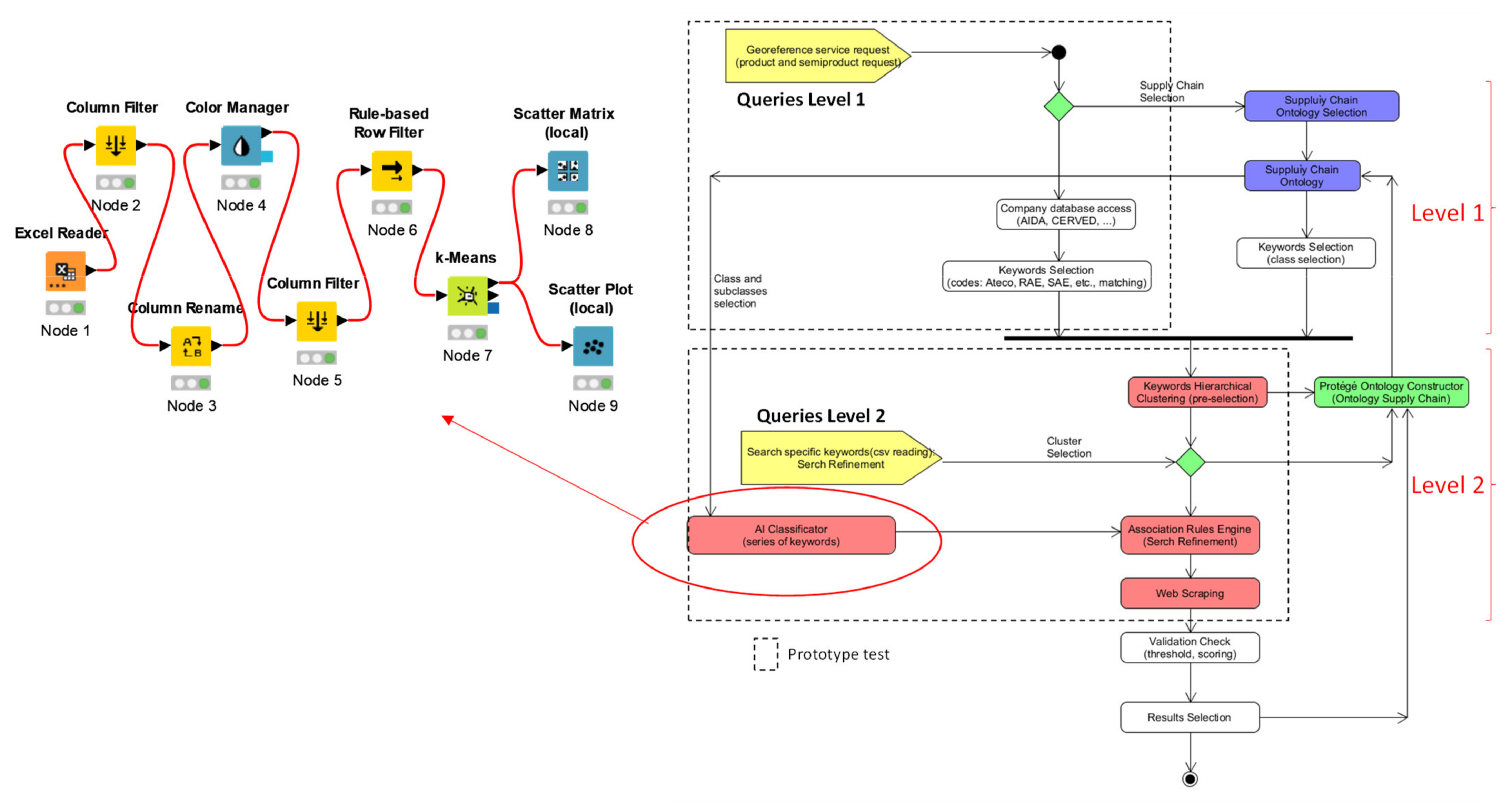
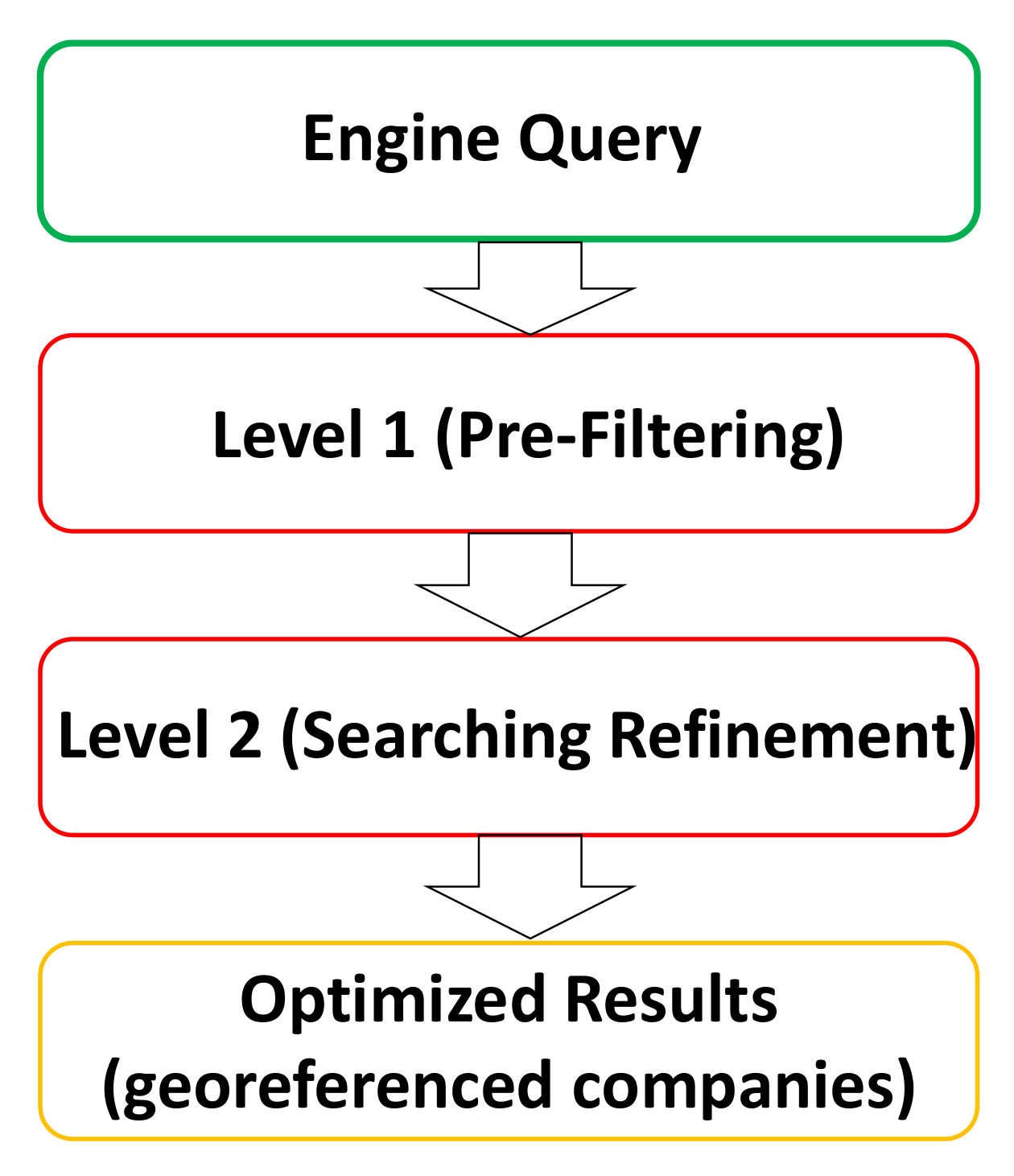
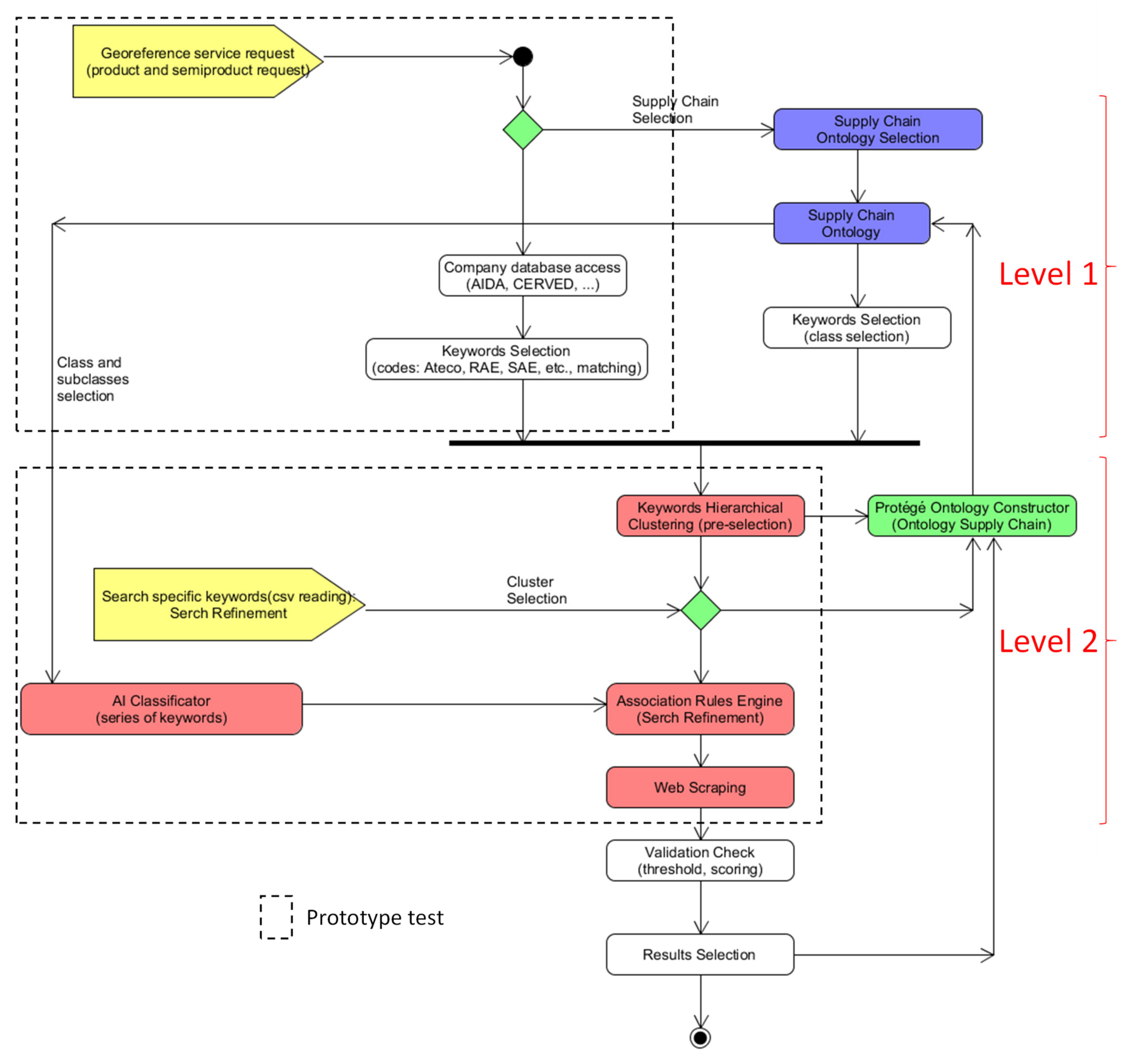
2.1. Architecture of the Innovative Supply Chain Two-Level Searching Method
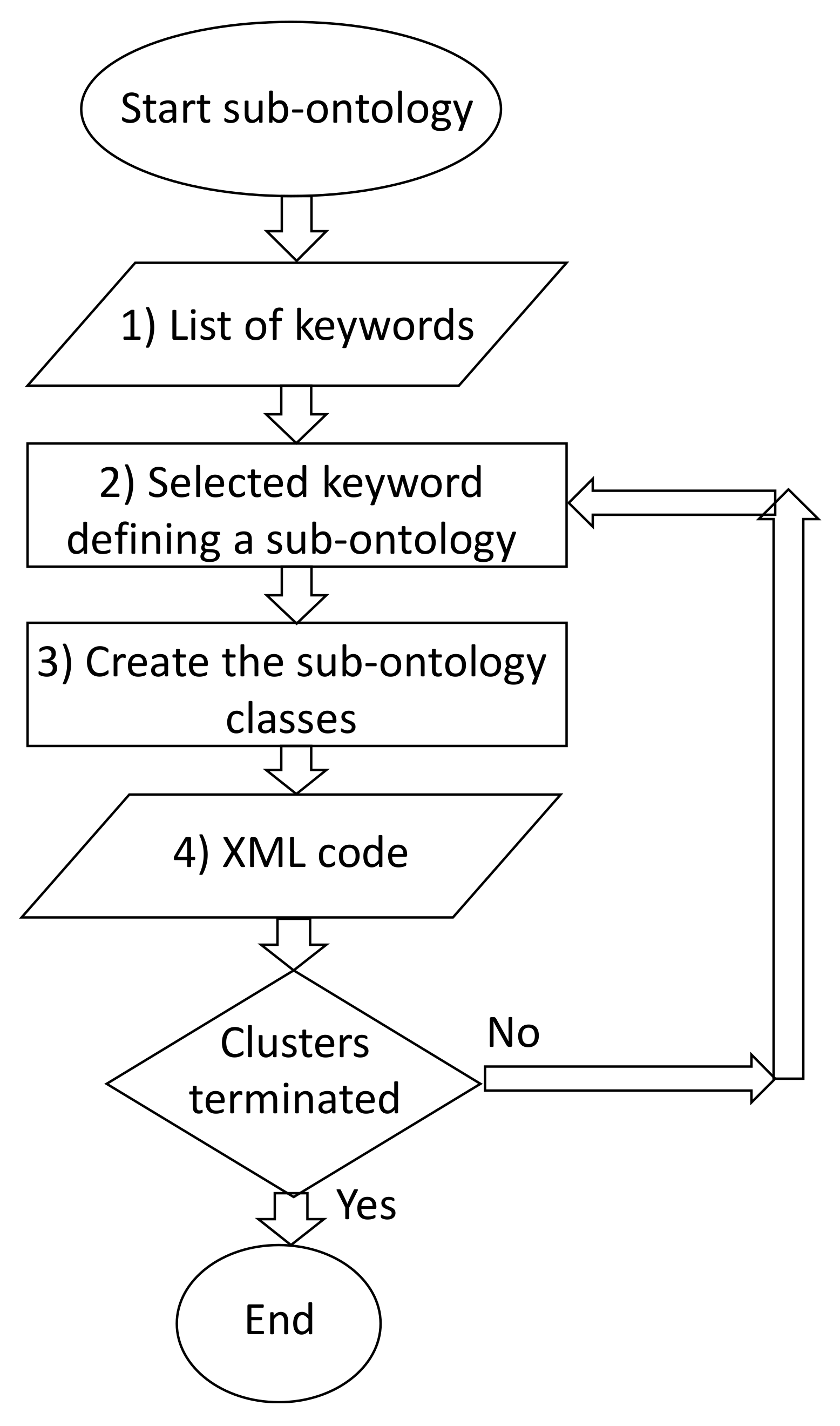
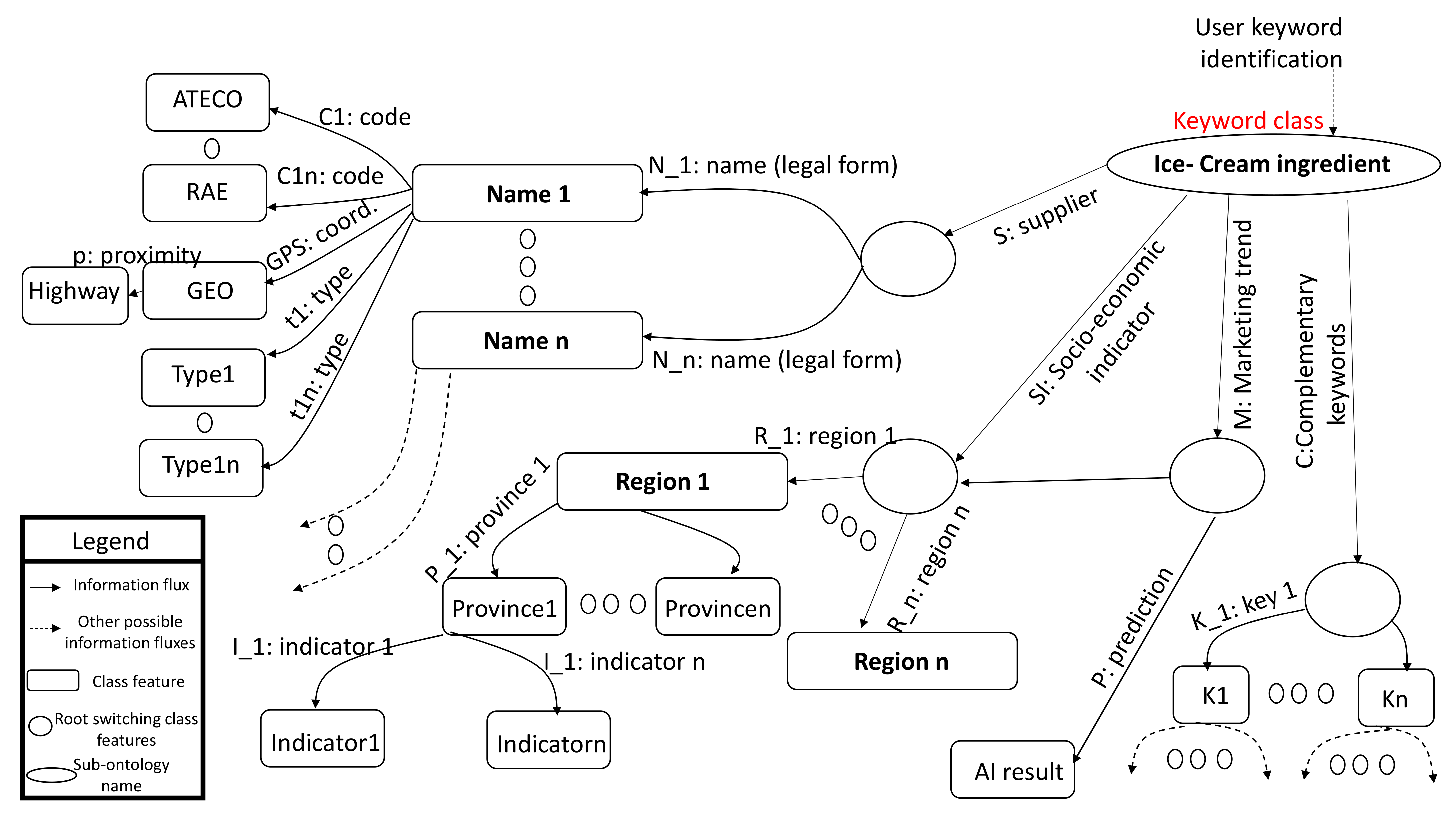
2.2. Automatisms Constructing SCO
- (1)
- Hierarchical clustering output: list of keywords (marketing, logistics, raw materials, etc.);
- (2)
- Create the sub-ontology referring to a specific selected keyword;
- (3)
- Create sub-ontology classes characterized by different features;
- (4)
- Translate the cluster’s information into an XML structured code;
- (5)
- Repeat for each sub-ontology (repeat from Step 2 until the clusters have ended);
- (6)
- End of the procedure (clusters are terminated).
2.3. Examples of Preliminary Interfaces and Possible Technologies
- -
- Node 1 (Excel reader): object collecting local data to process (results of Level 1);
- -
- Node 2 (Row Filter): object selecting the specific row of the dataset to process;
- -
- Node 3 (Column Filter): object deleting some columns of the dataset to process by cleaning the dataset of unnecessary information (columns with useless data or information to process);
- -
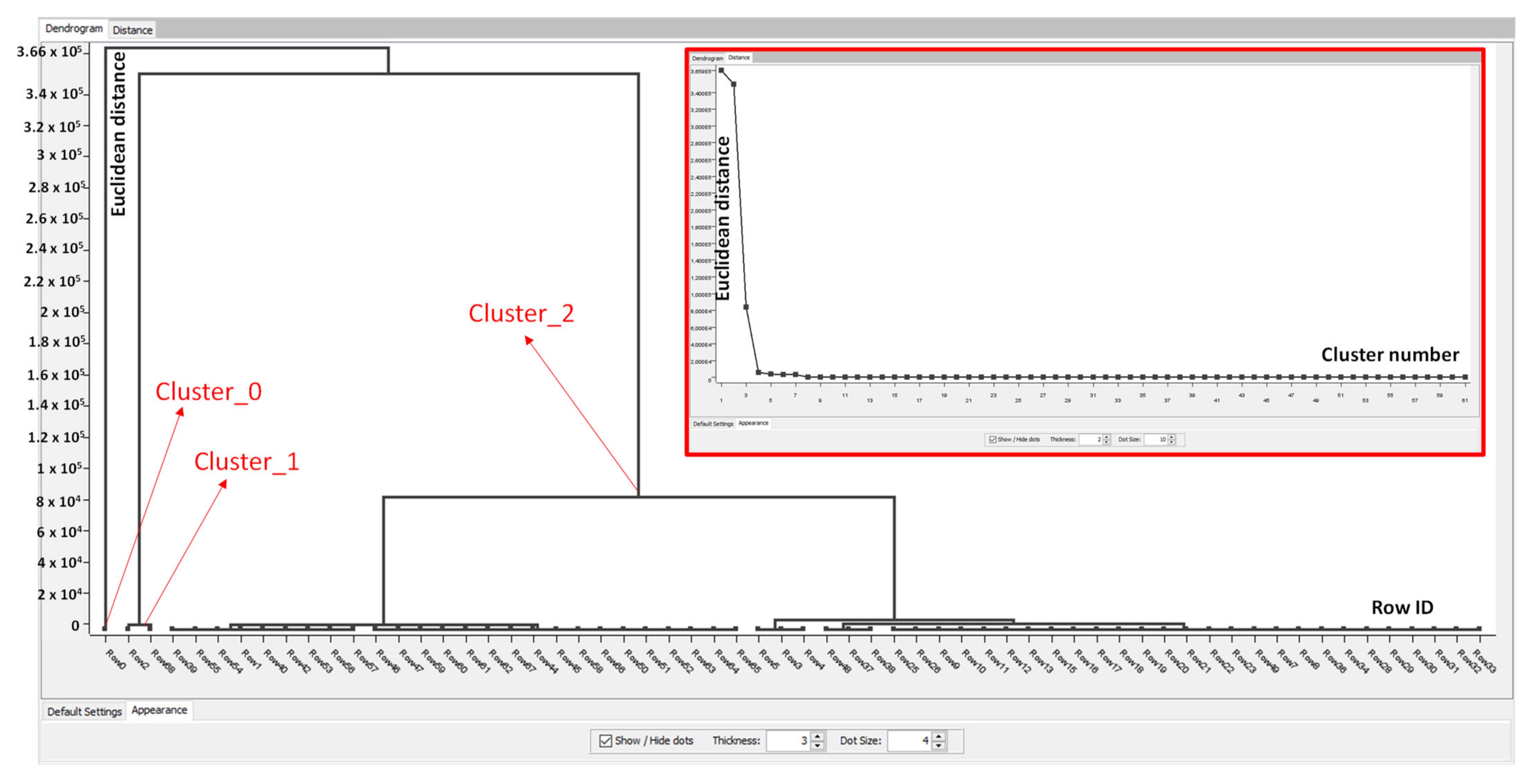
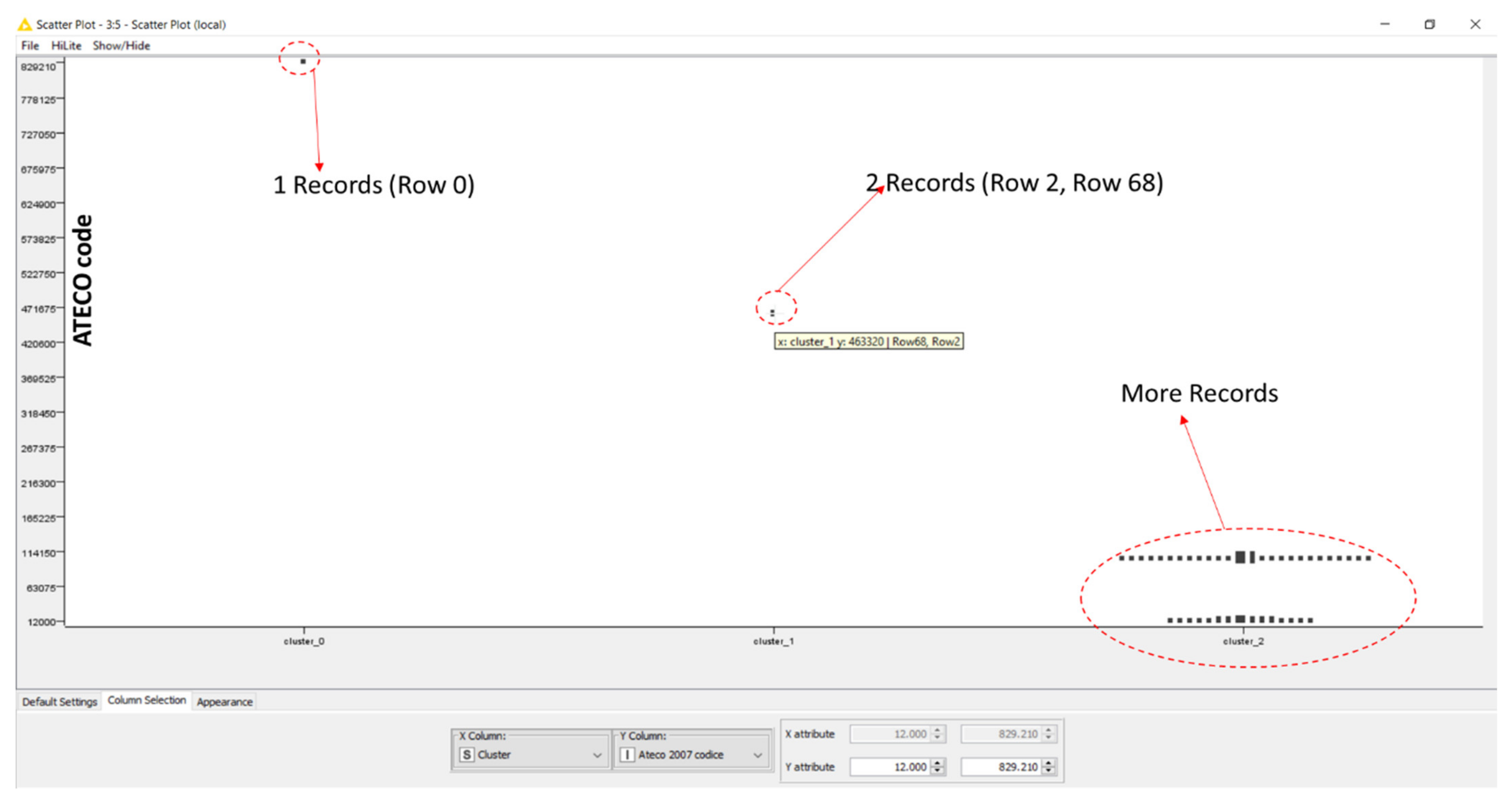
- Node 4 (Hierarchical Clustering): object implementing the clustering algorithm;
- -
- Node 5 (Scatter Plot): object providing graphical dashboards of the obtained results.
- -
- Name;
- -
- Website;
- -
- VAT (number);
- -
- RAE (description);
- -
- NACE (description);
- -
- Legal form;
- -
- Address;
- -
- Province.
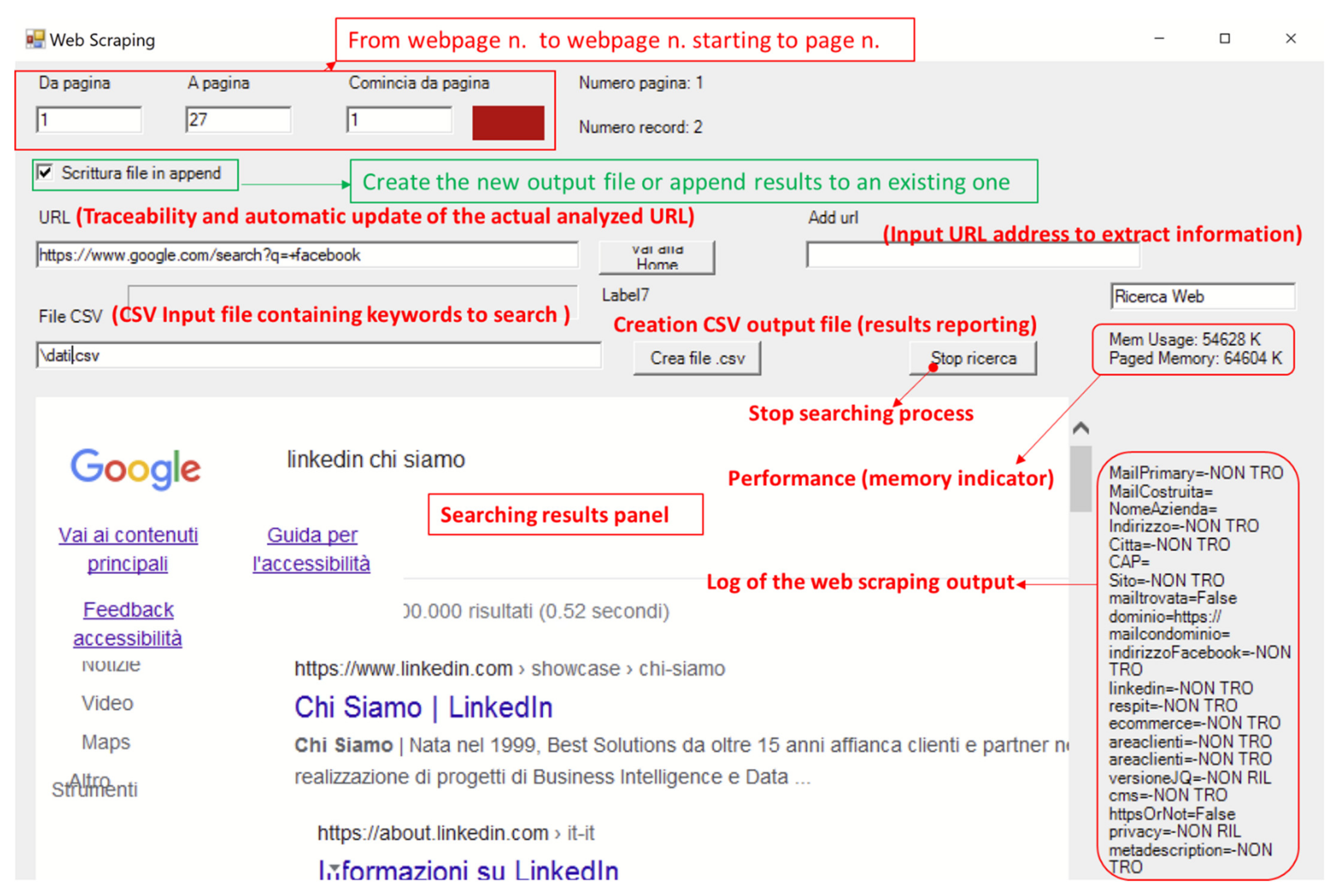
2.4. Web Scraping Approach
2.5. Possible Technologies to Implement
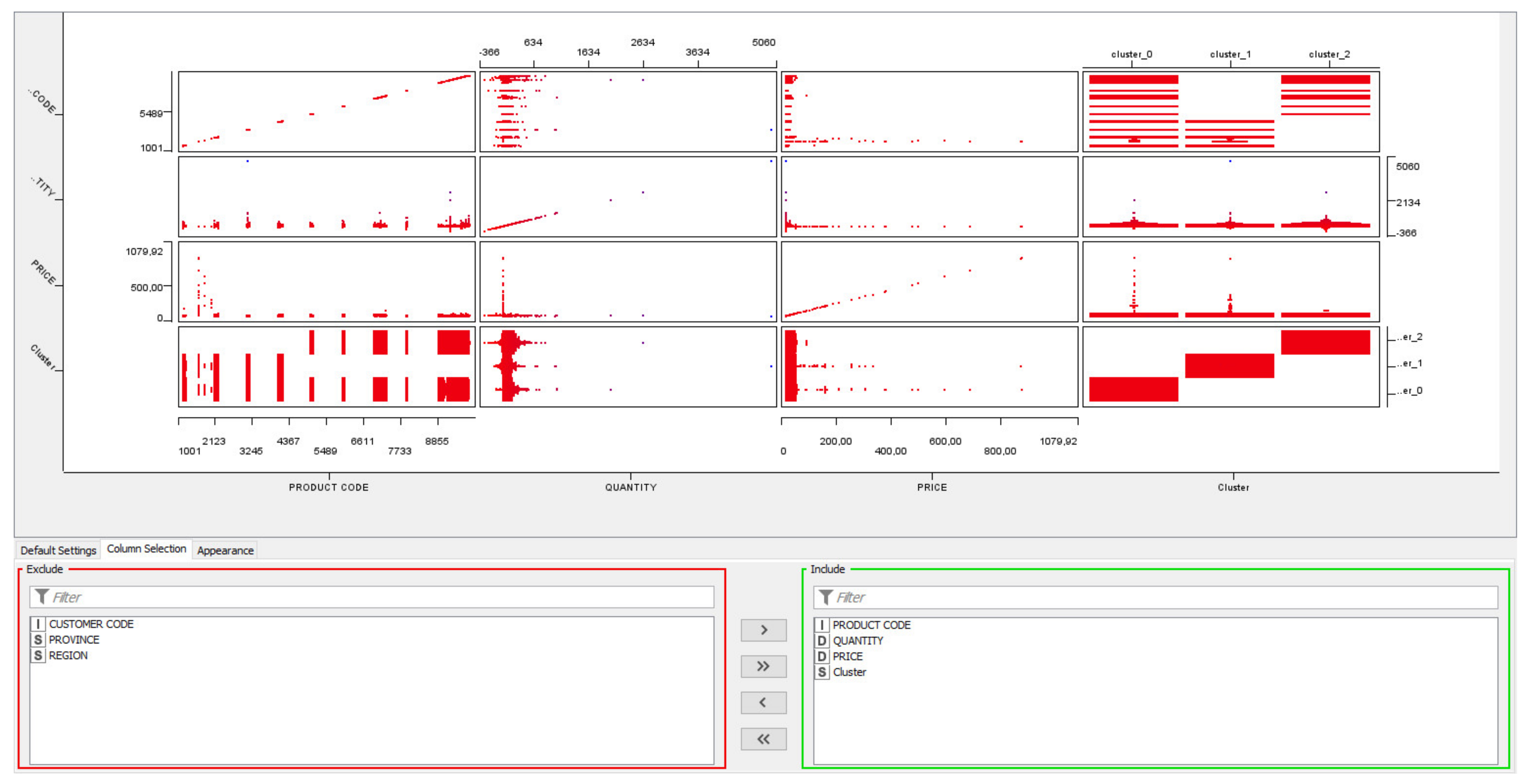
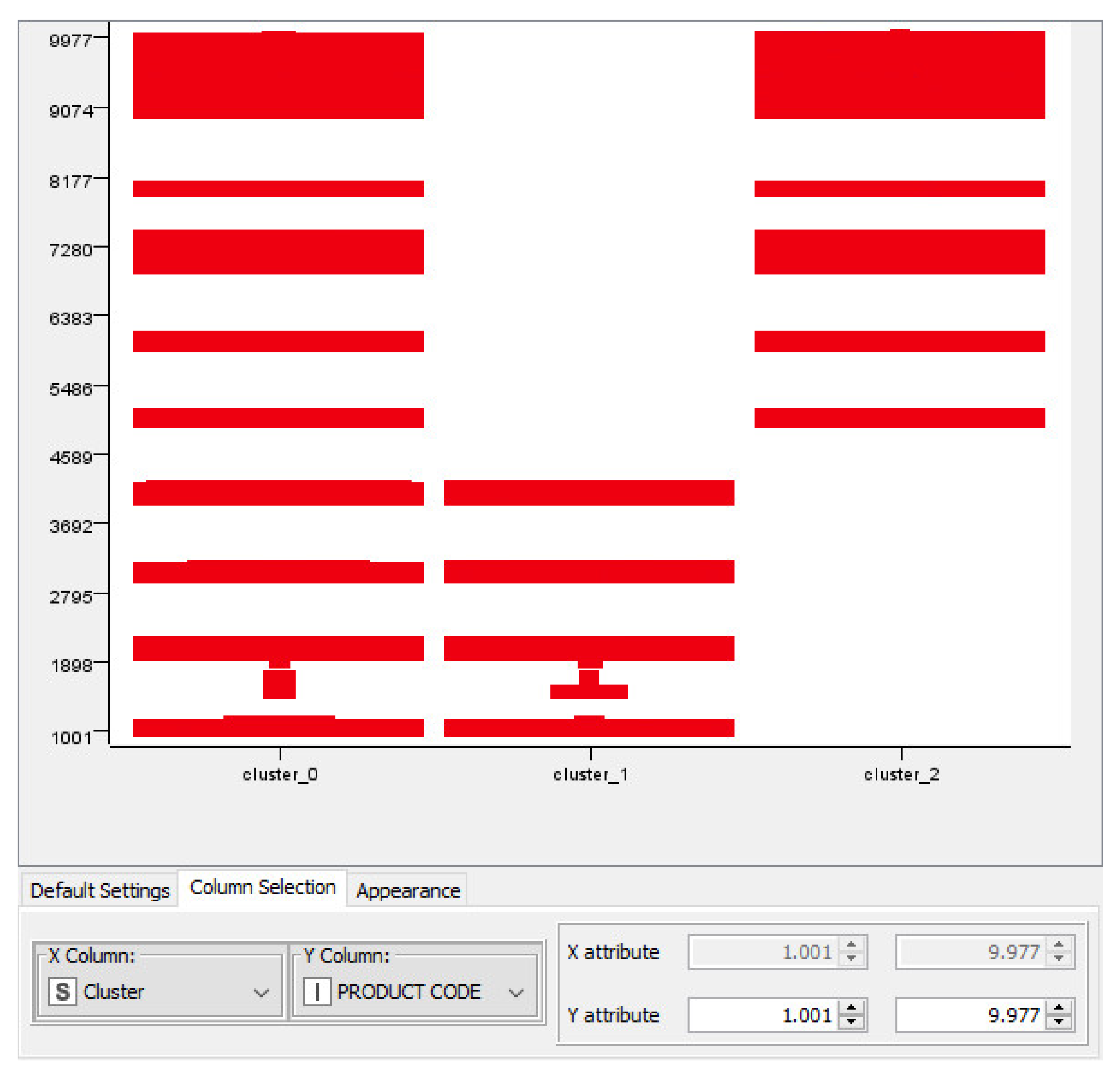
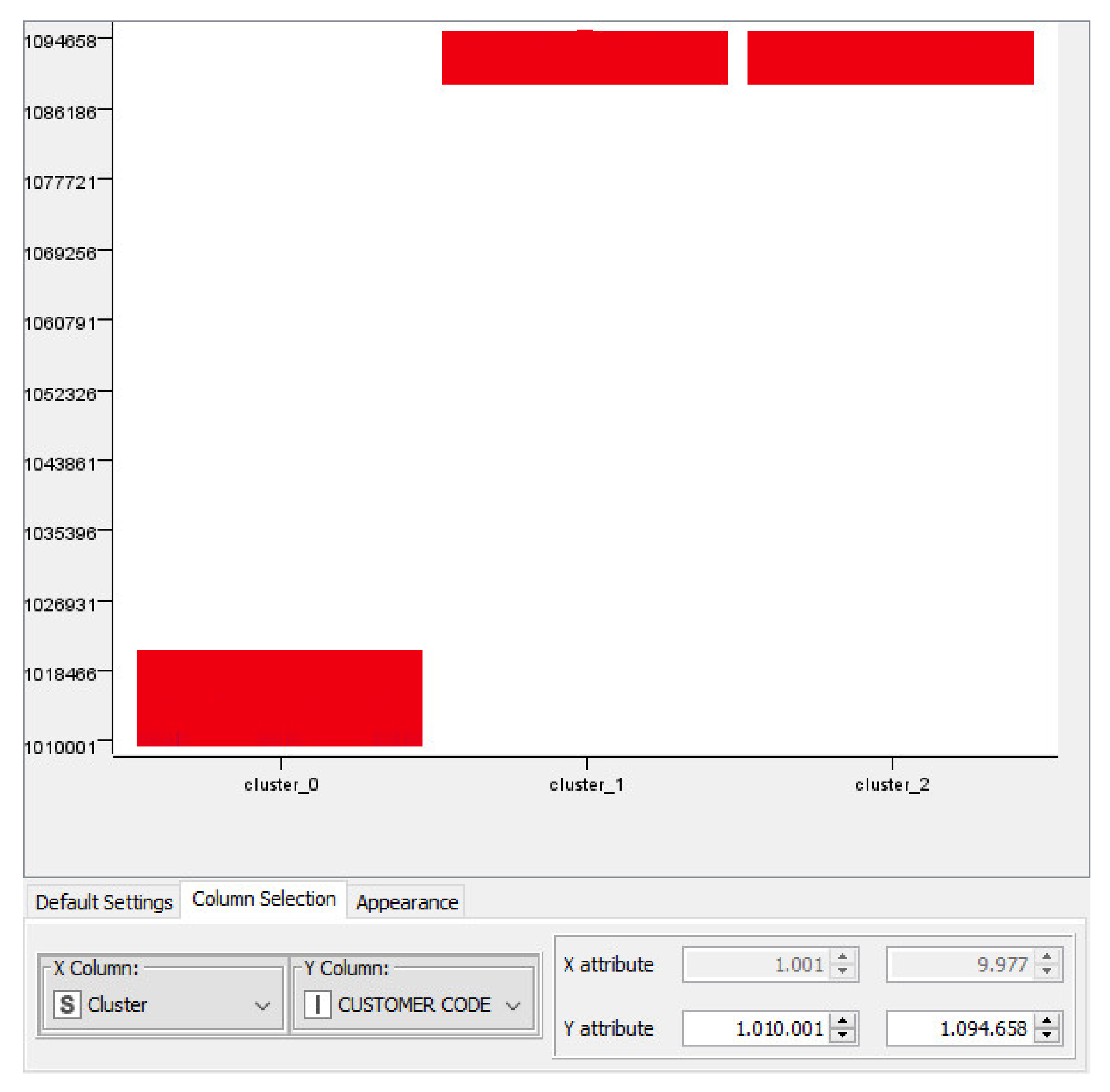
3. Partial Results of a Case Study and Discussion
3.1. Example of Procedures to Apply to Construct an Ontology: The Case of the Ice Cream Supply Chain
3.2. Originality, Performance and Advantages of the Proposed Solution
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. ML K-Means Data Processing: Classification of Ice Cream Ingredients Matching with Regions and Provinces of Supply Chain District
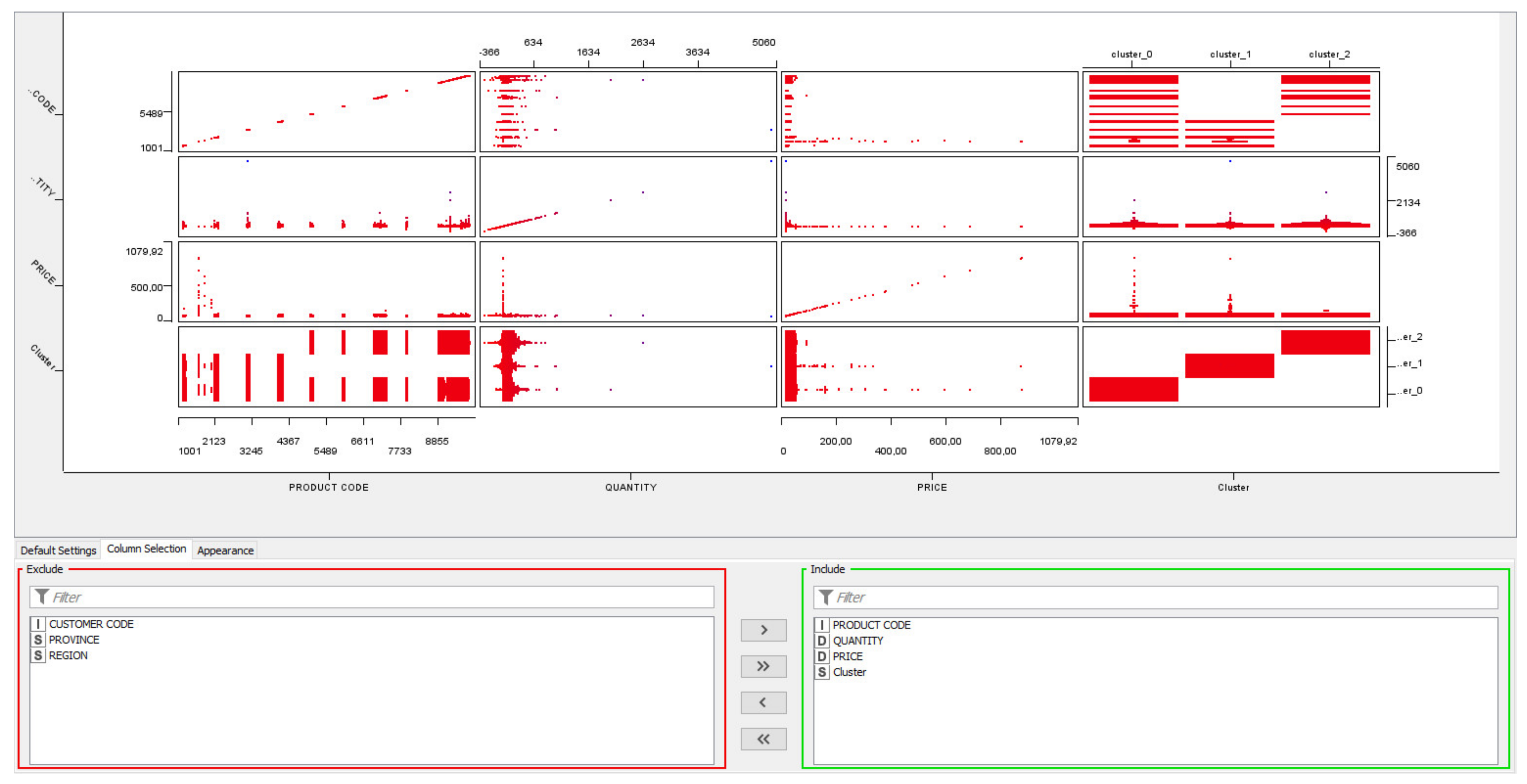
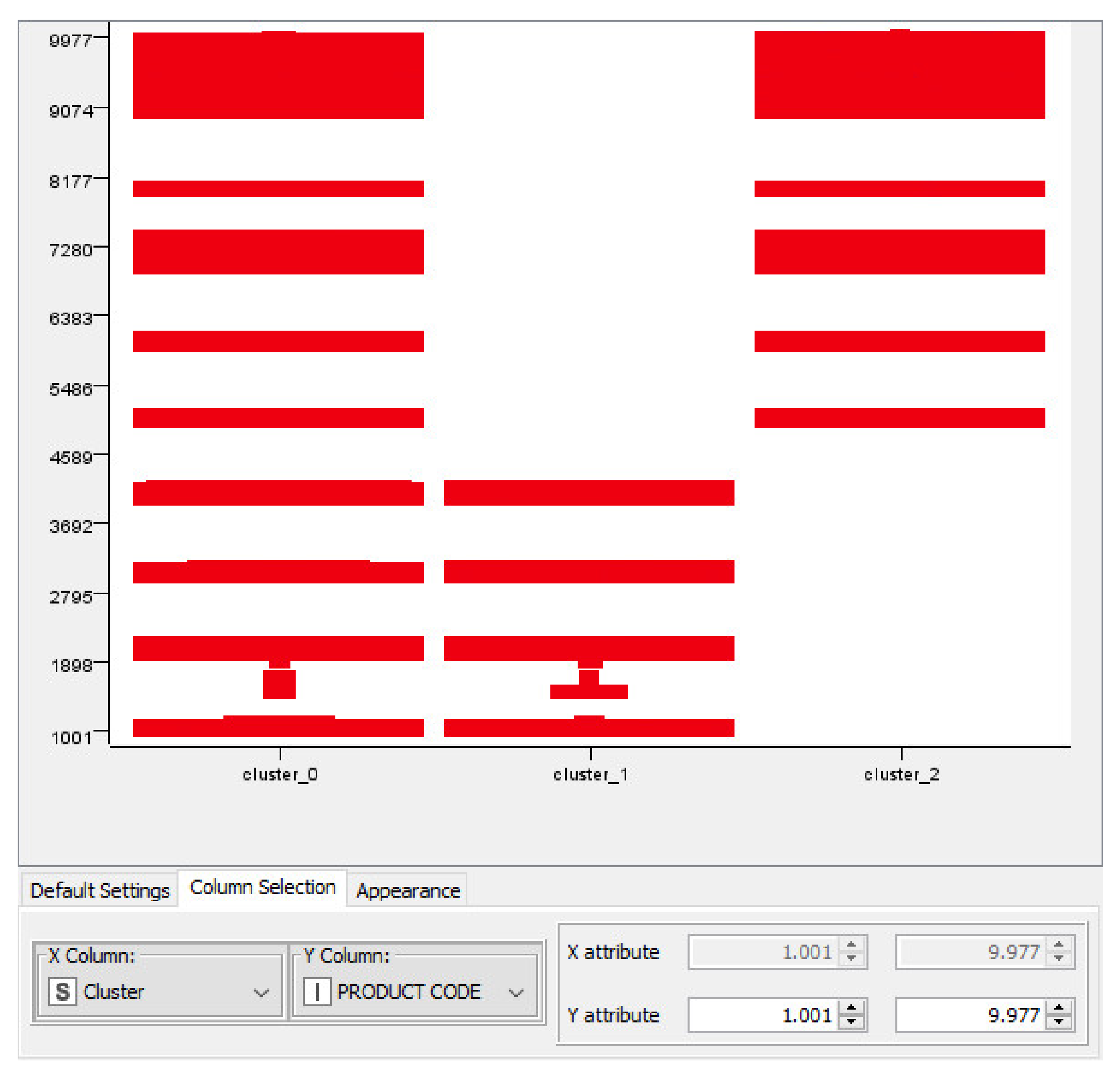
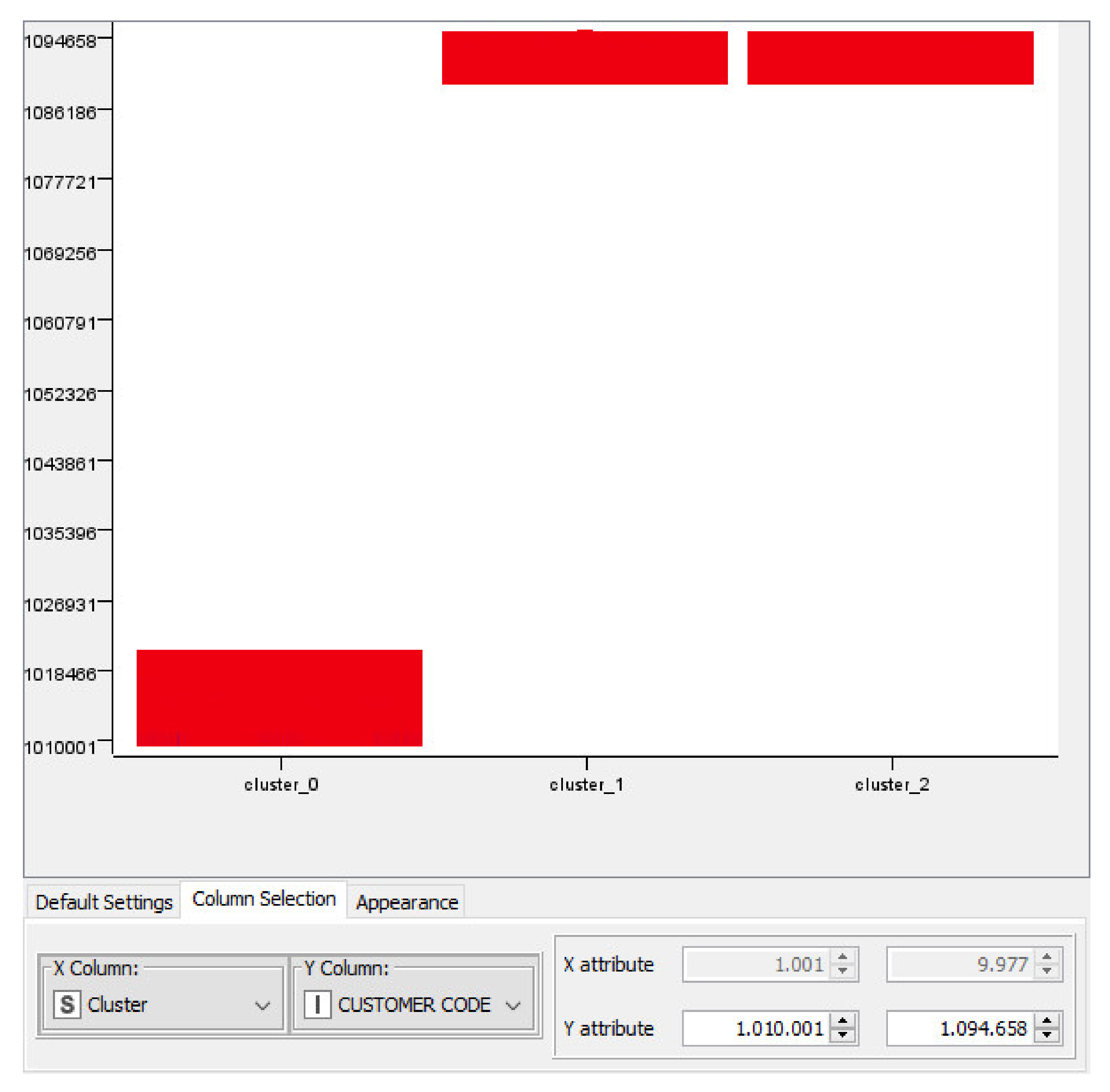
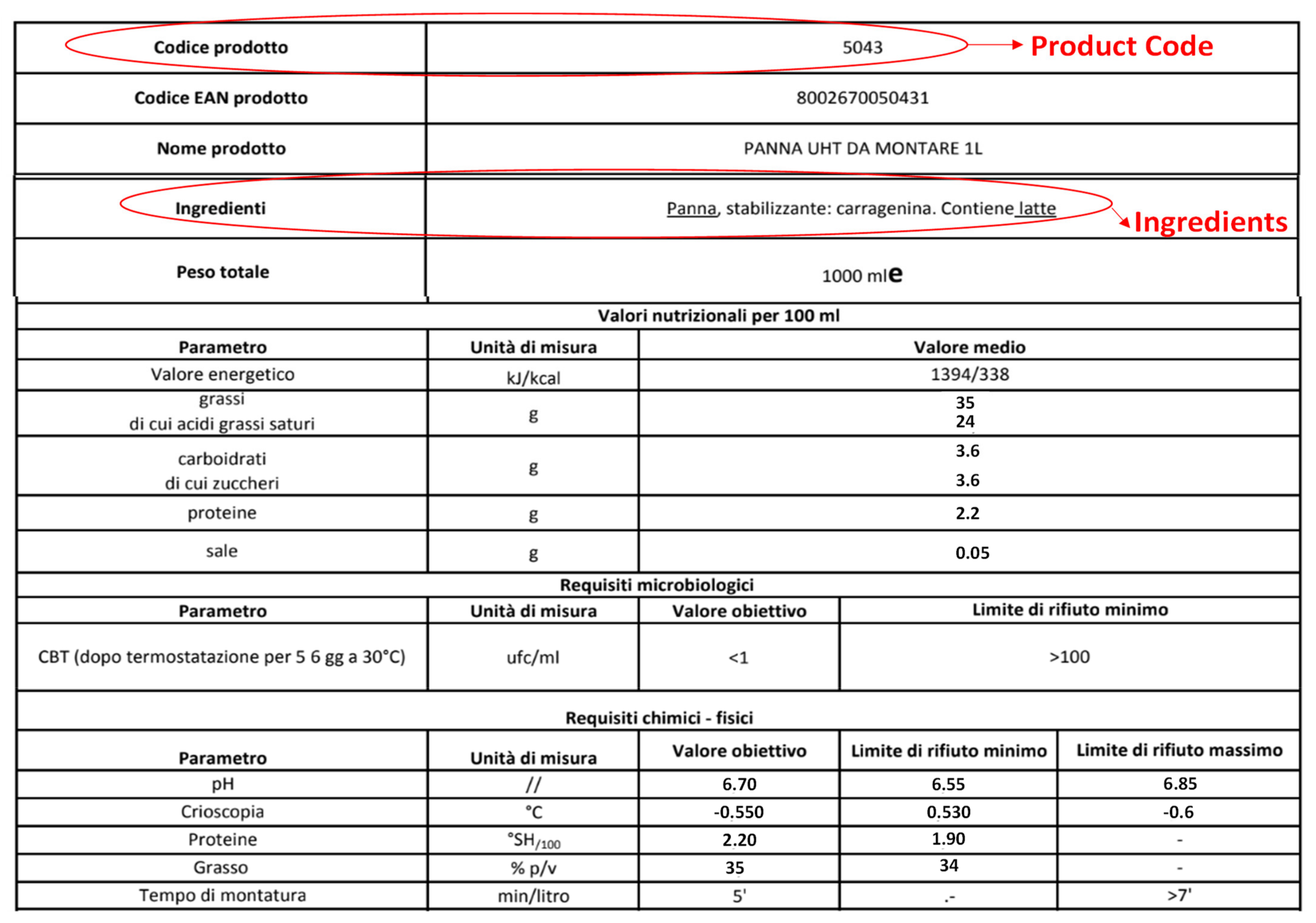
Appendix B. Example of Web Scraping Outputs
- Semi-finished products for ice cream
- Wholesale fruit
| Ateco 2007 | Ateco 2002 | RAE |
| 463100 463110 | 513100 | 617 |
- Milk suppliers

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N. | Company Category | Ateco 2007 | Ateco 2002 | RAE | Websites | Web Search | Web Keywords |
|---|---|---|---|---|---|---|---|
| 1 | Semi-finished products for ice cream | YES | YES | Region A ice cream preparations | |||
| 2 | Wholesale fruit in Region A | 463100 463110 | 513100 | 617 | YES | YES | wholesale fruit in Region A |
| 3 | Region A milk producers | YES | YES | Region A milk producers |
Appendix C. Artificial Neural Network (ANN) Visual Basic Code Integrated in the Web Scraping Tool
| Class Dendrite |
| Public Class Dndr |
| Dim _weight As Double |
| Property Weight As Double |
| Get |
| Return _weight |
| End Get |
| Set(value As Double) |
| _weight = value |
| End Set |
| End Property |
| Public Sub New() |
| Me.Weight = r.NextDouble() |
| End Sub |
| End Class |
| Class Neuron |
| Public Class Nrn |
| Dim _Dndrs As New List(Of Dndr) |
| Dim _DndrCount As Integer |
| Dim _bias As Double |
| Dim _value As Double |
| Dim _delta As Double |
| Public Property Dndrs As List(Of Dndr) |
| Get |
| Return _Dndrs |
| End Get |
| Set(value As List(Of Dndr)) |
| _Dndrs = value |
| End Set |
| End Property |
| Public Property Bias As Double |
| Get |
| Return _bias |
| End Get |
| Set(value As Double) |
| _bias = value |
| End Set |
| End Property |
| Public Property Value As Double |
| Get |
| Return _value |
| End Get |
| Set(value As Double) |
| _value = value |
| End Set |
| End Property |
| Public Property Delta As Double |
| Get |
| Return _delta |
| End Get |
| Set(value As Double) |
| _delta = value |
| End Set |
| End Property |
| Public ReadOnly Property DndrCount As Integer |
| Get |
| Return _Dndrs.Count |
| End Get |
| End Property |
| Public Sub New() |
| Me.Bias = r.NextDouble() |
| End Sub |
| End Class |
| Class Layer |
| Public Class Lyr |
| Dim _Nrns As New List(Of Nrn) |
| Dim _NrnCount As Integer |
| Public Property Nrns As List(Of Nrn) |
| Get |
| Return _Nrns |
| End Get |
| Set(value As List(Of Nrn)) |
| _Nrns = value |
| End Set |
| End Property |
| Public ReadOnly Property NrnCount As Integer |
| Get |
| Return _Nrns.Count |
| End Get |
| End Property |
| Public Sub New(NrnNum As Integer) |
| _NrnCount = NrnNum |
| End Sub |
| End Class |
| Class NeuralNetwork |
| Public Class NrnNtw |
| Dim _Lyrs As New List(Of Lyr) |
| Dim _learningRate As Double |
| Public Property Lyrs As List(Of Lyr) |
| Get |
| Return _Lyrs |
| End Get |
| Set(value As List(Of Lyr)) |
| _Lyrs = value |
| End Set |
| End Property |
| Public Property LearningRate As Double |
| Get |
| Return _learningRate |
| End Get |
| Set(value As Double) |
| _learningRate = value |
| End Set |
| End Property |
| Public ReadOnly Property LyrCount As Integer |
| Get |
| Return _Lyrs.Count |
| End Get |
| End Property |
| Sub New(LearningRate As Double, nLyrs As List(Of Integer)) |
| If nLyrs.Count < 2 Then Exit Sub |
| Me.LearningRate = LearningRate |
| For ii As Integer = 0 To nLyrs.Count − 1 |
| Dim l As Lyr = New Lyr(nLyrs(ii) − 1) |
| Me.Lyrs.Add(l) |
| For jj As Integer = 0 To nLyrs(ii) − 1 |
| l.Nrns.Add(New Nrn()) |
| Next |
| For Each n As Nrn In l.Nrns |
| If ii = 0 Then n.Bias = 0 |
| If ii > 0 Then |
| For k As Integer = 0 To nLyrs(ii − 1) − 1 |
| n.Dndrs.Add(New Dndr) |
| Next |
| End If |
| Next |
| Next |
| End Sub |
| Function Execute(inputs As List(Of Double)) As List(Of Double) |
| If inputs.Count <> Me.Lyrs(0).NrnCount Then |
| Return Nothing |
| End If |
| For ii As Integer = 0 To Me.LyrCount − 1 |
| Dim curLyr As Lyr = Me.Lyrs(ii) |
| For jj As Integer = 0 To curLyr.NrnCount − 1 |
| Dim curNrn As Nrn = curLyr.Nrns(jj) |
| If ii = 0 Then |
| curNrn.Value = inputs(jj) |
| Else |
| curNrn.Value = 0 |
| For k = 0 To Me.Lyrs(ii − 1).NrnCount − 1 |
| curNrn.Value = curNrn.Value + Me.Lyrs(ii − 1).Nrns(k).Value * curNrn.Dndrs(k).Weight |
| Next k |
| curNrn.Value = Sigmoid(curNrn.Value + curNrn.Bias) |
| End If |
| Next |
| Next |
| Dim outputs As New List(Of Double) |
| Dim la As Lyr = Me.Lyrs(Me.LyrCount − 1) |
| For ii As Integer = 0 To la.NrnCount − 1 |
| outputs.Add(la.Nrns(ii).Value) |
| Next |
| Return outputs |
| End Function |
| Public Function Train(inputs As List(Of Double), outputs As List(Of Double)) As Boolean |
| If inputs.Count <> Me.Lyrs(0).NrnCount Or outputs.Count <> Me.Lyrs(Me.LyrCount − 1).NrnCount Then |
| Return False |
| End If |
| Execute(inputs) |
| For ii = 0 To Me.Lyrs(Me.LyrCount − 1).NrnCount − 1 |
| Dim curNrn As Nrn = Me.Lyrs(Me.LyrCount − 1).Nrns(ii) |
| curNrn.Delta = curNrn.Value * (1 − curNrn.Value) * (outputs(ii) − curNrn.Value) |
| For jj = Me.LyrCount − 2 To 1 Step − 1 |
| For kk = 0 To Me.Lyrs(jj).NrnCount − 1 |
| Dim iNrn As Nrn = Me.Lyrs(jj).Nrns(kk) |
| iNrn.Delta = iNrn.Value * |
| (1 − iNrn.Value) * Me.Lyrs(jj + 1).Nrns(ii).Dndrs(kk).Weight * |
| Me.Lyrs(jj + 1).Nrns(ii).Delta |
| Next kk |
| Next jj |
| Next ii |
| For ii = Me.LyrCount − 1 To 0 Step − 1 |
| For jj = 0 To Me.Lyrs(ii).NrnCount − 1 |
| Dim iNrn As Nrn = Me.Lyrs(ii).Nrns(jj) |
| iNrn.Bias = iNrn.Bias + (Me.LearningRate * iNrn.Delta) |
| For kk = 0 To iNrn.DndrCount − 1 |
| iNrn.Dndrs(kk).Weight = iNrn.Dndrs(kk).Weight + (Me.LearningRate * Me.Lyrs(ii − 1).Nrns(kk).Value * iNrn.Delta) |
| Next kk |
| Next jj |
| Next ii |
| Return True |
| End Function |
| End Class |
| Method New() Sub New(LearningRate As Double, nLyrs As List(Of Integer)) |
| If nLyrs.Count < 2 Then Exit Sub |
| Me.LearningRate = LearningRate |
| For ii As Integer = 0 To nLyrs.Count − 1 |
| Dim l As Lyr = New Lyr(nLyrs(ii) − 1) |
| Me.Lyrs.Add(l) |
| For jj As Integer = 0 To nLyrs(ii) − 1 |
| l.Nrns.Add(New Nrn()) |
| Next |
| For Each n As Nrn In l.Nrns |
| If ii = 0 Then n.Bias = 0 |
| If ii > 0 Then |
| For k As Integer = 0 To nLyrs(ii − 1) − 1 |
| n.Dndrs.Add(New Dndr) |
| Next |
| End If |
| Next |
| Next |
| End Sub |
| Function Execute() Function Execute(inputs As List(Of Double)) As List(Of Double) |
| If inputs.Count <> Me.Lyrs(0).NrnCount Then |
| Return Nothing |
| End If |
| For ii As Integer = 0 To Me.LyrCount − 1 |
| Dim curLyr As Lyr = Me.Lyrs(ii) |
| For jj As Integer = 0 To curLyr.NrnCount − 1 |
| Dim curNrn As Nrn = curLyr.Nrns(jj) |
| If ii = 0 Then |
| curNrn.Value = inputs(jj) |
| Else |
| curNrn.Value = 0 |
| For k = 0 To Me.Lyrs(ii − 1).NrnCount − 1 |
| curNrn.Value = curNrn.Value + Me.Lyrs(ii − 1).Nrns(k).Value * curNrn.Dndrs(k).Weight |
| Next k |
| curNrn.Value = Sigmoid(curNrn.Value + curNrn.Bias) |
| End If |
| Next |
| Next |
| Dim outputs As New List(Of Double) |
| Dim la As Lyr = Me.Lyrs(Me.LyrCount − 1) |
| For ii As Integer = 0 To la.NrnCount − 1 |
| outputs.Add(la.Nrns(ii).Value) |
| Next |
| Return outputs |
| End Function |
| Function Train() Public Function Train(inputs As List(Of Double), outputs As List(Of Double)) As Boolean |
| If inputs.Count <> Me.Lyrs(0).NrnCount Or outputs.Count <> Me.Lyrs(Me.LyrCount − 1).NrnCount Then |
| Return False |
| End If |
| Execute(inputs) |
| For ii = 0 To Me.Lyrs(Me.LyrCount − 1).NrnCount − 1 |
| Dim curNrn As Nrn = Me.Lyrs(Me.LyrCount − 1).Nrns(ii) |
| curNrn.Delta = curNrn.Value * (1 − curNrn.Value) * (outputs(ii) − curNrn.Value) |
| For jj = Me.LyrCount − 2 To 1 Step − 1 |
| For kk = 0 To Me.Lyrs(jj).NrnCount − 1 |
| Dim iNrn As Nrn = Me.Lyrs(jj).Nrns(kk) |
| iNrn.Delta = iNrn.Value * |
| (1 − iNrn.Value) * Me.Lyrs(jj + 1).Nrns(ii).Dndrs(kk).Weight * |
| Me.Lyrs(jj + 1).Nrns(ii).Delta |
| Next kk |
| Next jj |
| Next ii |
| For ii = Me.LyrCount − 1 To 0 Step − 1 |
| For jj = 0 To Me.Lyrs(ii).NrnCount − 1 |
| Dim iNrn As Nrn = Me.Lyrs(ii).Nrns(jj) |
| iNrn.Bias = iNrn.Bias + (Me.LearningRate * iNrn.Delta) |
| For kk = 0 To iNrn.DndrCount − 1 |
| iNrn.Dndrs(kk).Weight = iNrn.Dndrs(kk).Weight + (Me.LearningRate * Me.Lyrs(ii − 1).Nrns(kk).Value * iNrn.Delta) |
| Next kk |
| Next jj |
| Next ii |
| Return True |
| End Function |
| Init NN |
| Dim network As NrnNtw |
| Private Sub Form1_Load(sender As Object, e As EventArgs) Handles MyBase.Load |
| Dim LyrList As New List(Of Integer) |
| With LyrList |
| .Add(2) |
| .Add(4) |
| .Add(2) |
| End With |
| network = New NrnNtw(21.5, LyrList) |
| End Sub |
| Execute NN |
| Dim inputs As New List(Of Double) |
| inputs.Add(txtIn01.Text) |
| inputs.Add(txtIn02.Text) |
| Dim ots As List(Of Double) = network.Execute(inputs) |
| txtOt01.Text = ots(0) |
| txtOt02.Text = ots(1) |
References
- Grubic, T.; Fan, I.-S. Supply chain ontology: Review, analysis and synthesis. Comput. Ind. 2010, 61, 776–786. [Google Scholar] [CrossRef]
- Kulvatunyou, B.; Ameri, F. Modeling a supply chain reference ontology based on a top-level ontology. In Proceedings of the ASME 2019 International Design Engineering Technical Conferences & Computers and Information in Engineering Conference IDETC/CIE, Anaheim, CA, USA, 18–21 August 2019; pp. 1–13. [Google Scholar]
- Üreten, S.; Đlter, H.K. Supply chain management ontology: Towards an ontology-based SCM model. In Proceedings of the Fourth International Logistics and Supply Chain Congress, Izmir, Turkey, 29 November–1 December 2006; pp. 741–749. [Google Scholar]
- Madhu, G.; Govardhan, A.; Rajinikanth, T.V. Intelligent semantic web search engines: A brief survey. Int. J. Web Semant. Technol. 2011, 2, 34–42. [Google Scholar] [CrossRef]
- Massaro, A.; Giannone, D.; Birardi, V.; Galiano, A.M. An innovative approach for the evaluation of the web page impact combining user experience and neural network score. Future Internet 2021, 13, 145. [Google Scholar] [CrossRef]
- Hillen, J. Web scraping for food price research. Br. Food J. 2019, 121, 3350–3361. [Google Scholar] [CrossRef]
- Uzun, E. A novel web scraping approach using the additional information obtained from web pages. IEEE Access 2020, 8, 61726–61740. [Google Scholar] [CrossRef]
- Al-Azmi, A.R. Data, text, and web mining for business intelligence: A survey. Int. J. Data Min. Knowl. Manag. Process 2013, 3, 1–21. [Google Scholar] [CrossRef]
- Massaro, A.; Vitti, V.; Galiano, A.; Morelli, A. Business intelligence improved by data mining algorithms and big data systems: An overview of different tools applied in industrial research. Comp. Sci. Inf. Technol. 2019, 7, 1–21. [Google Scholar] [CrossRef]
- Khan, A.; Baharudin, B.; Lee, L.H.; Khan, K. A review of machine learning algorithms for text-documents classification. J. Adv. Inf. Technol. 2010, 1, 4–20. [Google Scholar]
- Liu, F.; Huang, X.; Huang, W.; Duan, S.X. Performance evaluation of keyword extraction methods and visualization for student online comments. Symmetry 2020, 12, 1923. [Google Scholar] [CrossRef]
- Sharma, N.; Yalla, P. Keyphrase extraction and source code similarity detection-a survey. Conf. Ser. Mater. Sci. Eng. 2021, 1074, 012027. [Google Scholar] [CrossRef]
- Massaro, A.A.; Maritati, V.; Galiano, A. Automated self-learning chatbot initially built as a FAQs database information retrieval system: Multi-level and intelligent universal virtual front-office implementing neural network. Inform. J. 2018, 42, 515–526. [Google Scholar] [CrossRef] [Green Version]
- Massaro, A.; Lisco, P.; Lombardi, A.; Galiano, A.; Savino, N. A case study of research improvements in an service industry upgrading the knowledge base of the information system and the process management: Data flow automation, association rules and data mining. Int. J. Art. Intell. Appl. 2019, 10, 25–46. [Google Scholar] [CrossRef]
- Leogrande, A.; Saponaro, A.; Massaro, A.; Galiano, A. A GISbased estimation of quality of life in Italian regions. Am. J. Human. Soc. Sci. Res. 2020, 4, 196–210. [Google Scholar]
- Frascati Manual 2015: The Measurement of Scientific, Technological and Innovation Activities Guidelines for Collecting and Reporting Data on Research and Experimental Development; OECD: Paris, France, 2015; ISBN 978-926423901-2. [CrossRef]
- Garzoni, A.; De Turi, I.; Secundo, G.; Del Vecchio, P. Fostering digital transformation of SMEs: A four levels approach. Manag. Decis. 2020, 8, 1543–1562. [Google Scholar] [CrossRef]
- Smart District 4.0. Available online: http://sd40.io/ (accessed on 2 December 2021).
- Aida. Italian Company Information and Business Intelligence. Available online: https://aida.bvdinfo.com/version-202199/Login.serv?product=aidaneo&SetLanguage=en (accessed on 2 December 2021).
- Cerved. Available online: https://www.cerved.com/en/ (accessed on 2 December 2021).
- Istat. Istituto Nazionale di Statistica. Available online: https://www.istat.it/en/ (accessed on 2 December 2021).
- Massaro, A.; Galiano, A.; Fanelli, G.; Bousshael, B.; Vitti, V. Web app for dynamic pricing modeling in automotive applications and data mining analytics. Int. J. Comp. Sci. Inf. Technol. 2018, 9, 4–9. Available online: http://ijcsit.com/docs/Volume%209/vol9issue1/ijcsit2018090102.pdf (accessed on 22 March 2022).
- Simple Python OCR. Available online: https://github.com/goncalopp/simple-ocr-opencv (accessed on 2 December 2021).
- Protégé. A Free, Open-Source Ontology Editor and Framework for Building Intelligent System. Available online: https://protege.stanford.edu/ (accessed on 2 December 2021).
- Uba, U.H.; Abubakar, B.S.; Ibrahim, M.Y. Developing model for library ontology using Protégé tool: Process, reasoning and visualization. Int. J. Adv. Sci. Technol. Res. 2019, 6, 7–14. [Google Scholar] [CrossRef]
- Resource Description Framework (RDF). Available online: https://www.w3.org/RDF/ (accessed on 2 December 2021).
- Rdflib 6.1.1. Available online: https://rdflib.readthedocs.io/en/stable/ (accessed on 11 February 2022).
- Visual Studio Community. Available online: https://visualstudio.microsoft.com/it/vs/community/ (accessed on 2 December 2021).
- Zhao, B. Web Scraping. In Encyclopedia of Big Data; Schintler, L.A., McNeely, C.L., Eds.; Springer: Berlin/Heidelberg, Germany, 2017; pp. 1–3. [Google Scholar] [CrossRef]
- Google Maps Platform. Available online: https://developers.google.com/maps (accessed on 2 December 2021).
- Agglomerative Clustering. Available online: https://docs.rapidminer.com/latest/studio/operators/modeling/segmentation/agglomerative_clustering.html (accessed on 2 December 2021).
- Hierarchical Clustering. Available online: https://hub.knime.com/knime/extensions/org.knime.features.base/latest/org.knime.base.node.mine.cluster.hierarchical.HierarchicalClusterNodeFactory (accessed on 2 December 2021).
- Hierarchical Clustering. Available online: https://orange3.readthedocs.io/projects/orange-visual-programming/en/latest/widgets/unsupervised/hierarchicalclustering.html (accessed on 2 December 2021).
- Rapidminer. Available online: https://rapidminer.com/ (accessed on 2 December 2021).
- Orange. Available online: https://orangedatamining.com/ (accessed on 2 December 2021).
- Knime. Available online: https://www.knime.com/ (accessed on 2 December 2021).
- Massaro, A. Electronic in Advanced Research Industry: From Industry 4.0 to Industry 5.0 Advances, 1st ed.; Wiley: Hoboken, NJ, USA, 2021; ISBN 9781119716877. [Google Scholar] [CrossRef]
- Tensor Flow. Available online: https://www.tensorflow.org/ (accessed on 2 December 2021).
- Keras. Available online: https://keras.io/ (accessed on 2 December 2021).
- KNIME Textprocessing. Available online: https://hub.knime.com/knime/extensions/org.knime.features.ext.textprocessing/latest (accessed on 2 December 2021).
- Anaconda. Available online: https://www.anaconda.com/ (accessed on 2 December 2021).
- Docker. The Industry-Leading Container Runtime. Available online: https://www.docker.com/products/container-runtime (accessed on 2 December 2021).
- Rad, B.B.; Bhatti, H.J.; Ahmadi, M. An introduction to Docker and analysis of its performance. Int. J. Comp. Sci. Netw. Secur. 2017, 17, 228–235. [Google Scholar]
- Kubernetes. Available online: https://kubernetes.io/it/docs/concepts/overview/what-is-kubernetes/ (accessed on 2 December 2021).
- Red Hat. Virtualizzazione. La Tecnologia KVM. Available online: https://www.redhat.com/it/topics/virtualization/what-is-KVM (accessed on 2 December 2021).
- Vegetti, M.M.; Böhm, A.; Leone, H.L.; Henning, G.P. SCONTO: A modular ontology for supply chain representation. In Proceedings of the ESWC 2021 Workshop DORIC-MM, Online, 7 June 2021; pp. 40–55. [Google Scholar]
- Formica, A.; Pourabbas, E.; Taglino, F. Semantic Search Enhanced with Rating Scores. Future Internet 2020, 12, 67. [Google Scholar] [CrossRef] [Green Version]
- Koutsomitropoulos, D.; Likothanassis, S.; Kalnis, P. Semantics in the Deep: Semantic Analytics for Big Data. Data 2019, 4, 63. [Google Scholar] [CrossRef] [Green Version]
- Yahya, M.; Breslin, J.G.; Ali, M.I. Semantic Web and Knowledge Graphs for Industry 4.0. Appl. Sci. 2021, 11, 5110. [Google Scholar] [CrossRef]
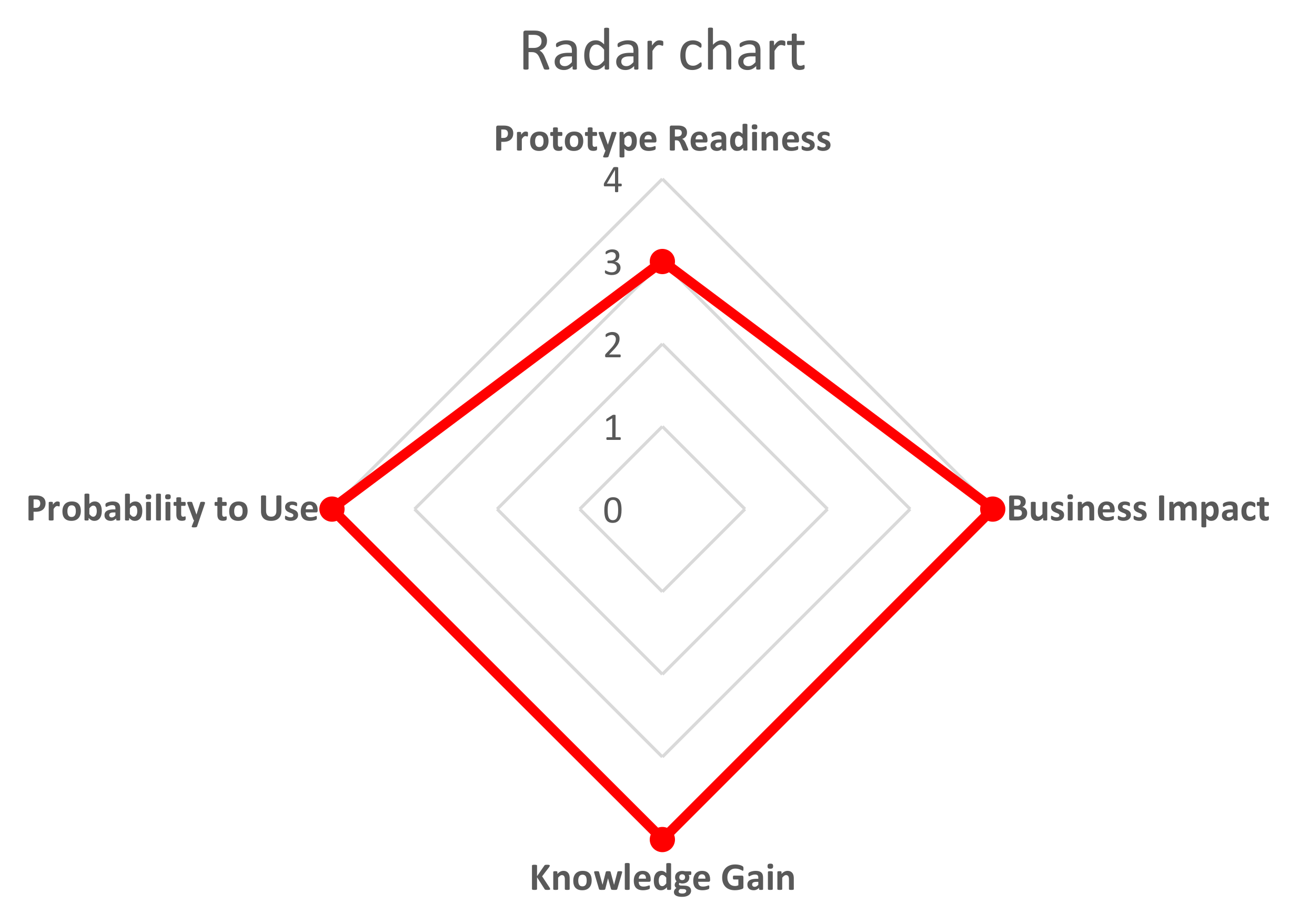
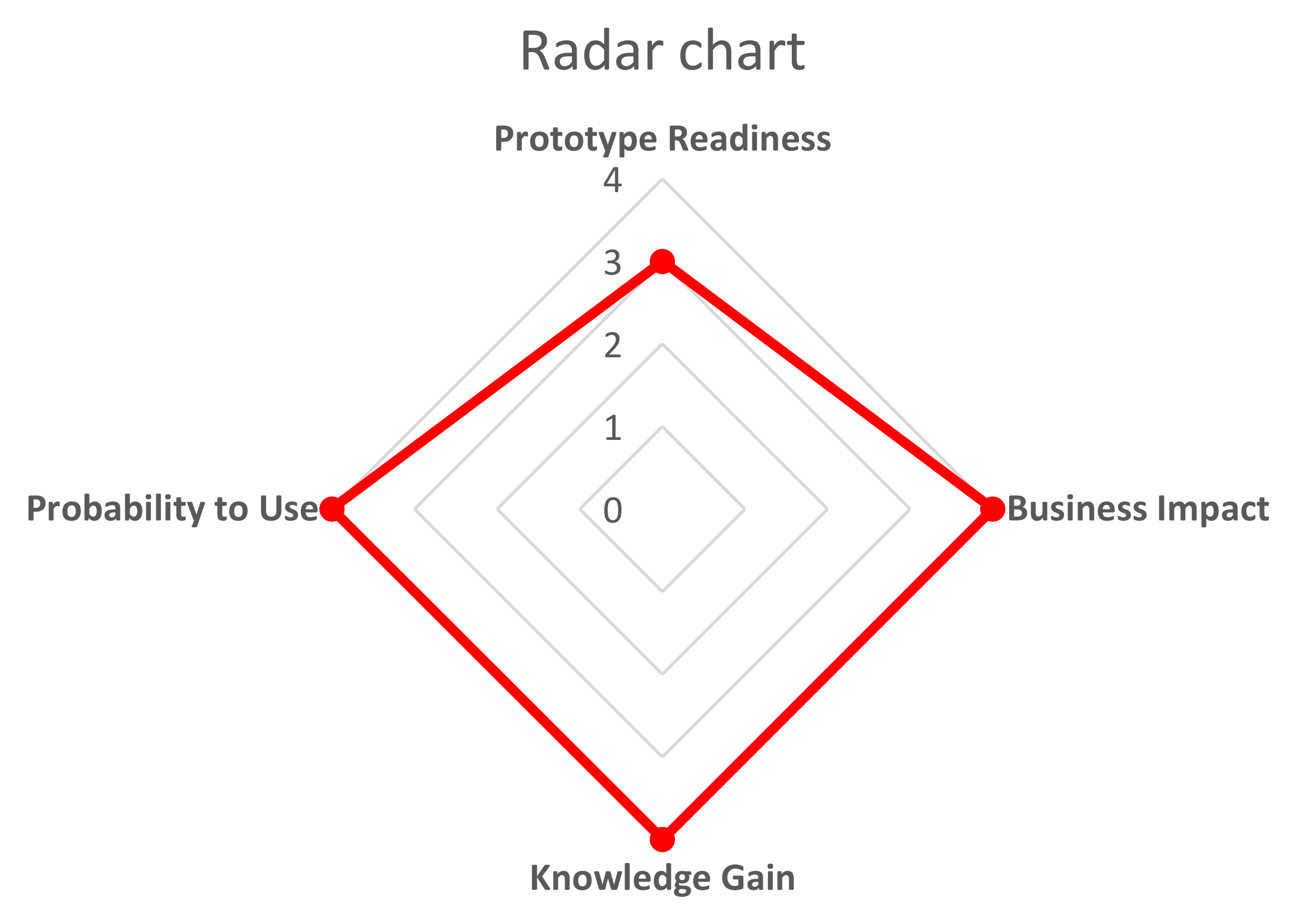
- Massaro, A.; Magaletti, N.; Cosoli, G. Project management: Radargram plot to validate stakeholder technology implemented in a research project. Zenodo 2022. [Google Scholar] [CrossRef]
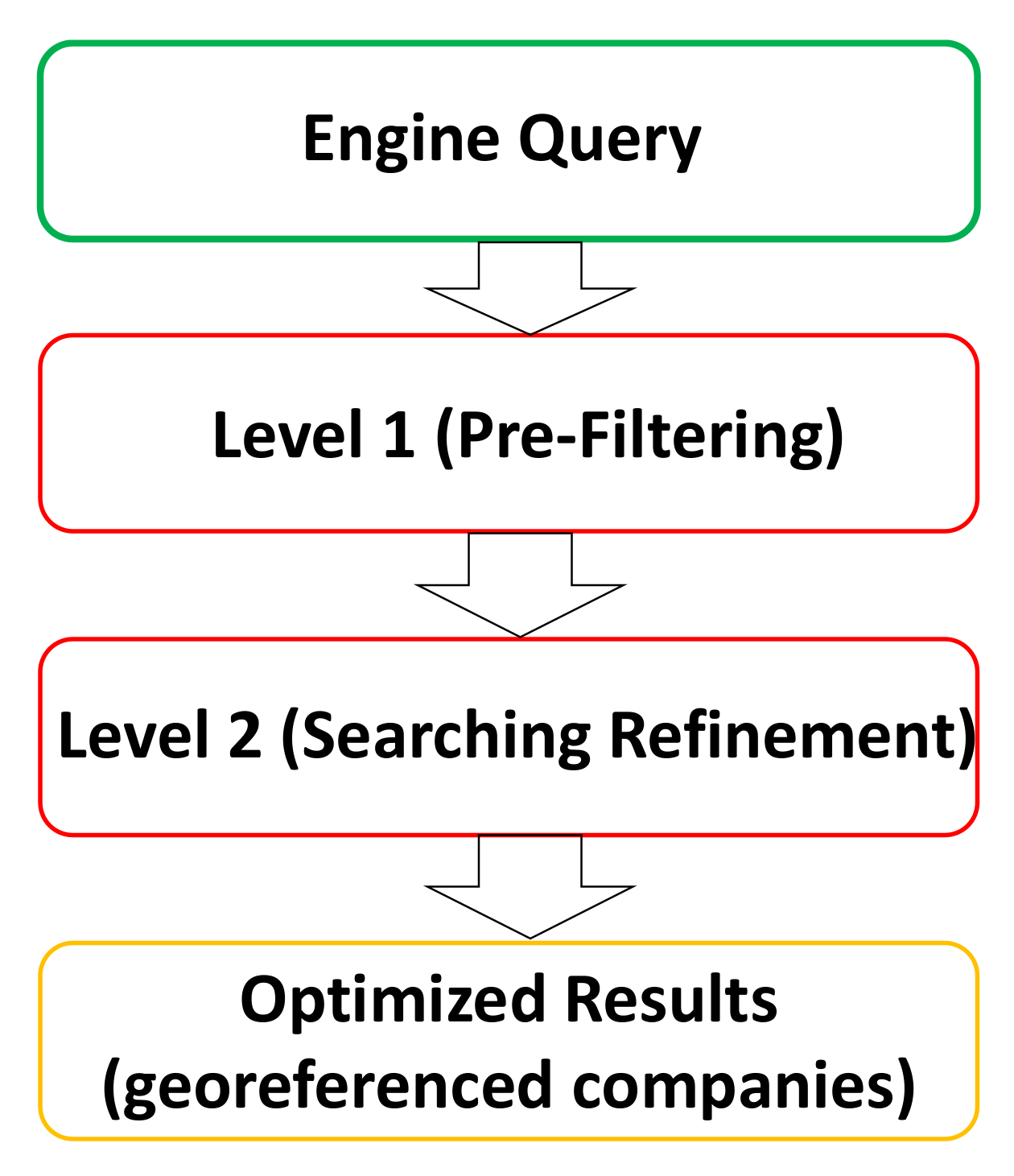
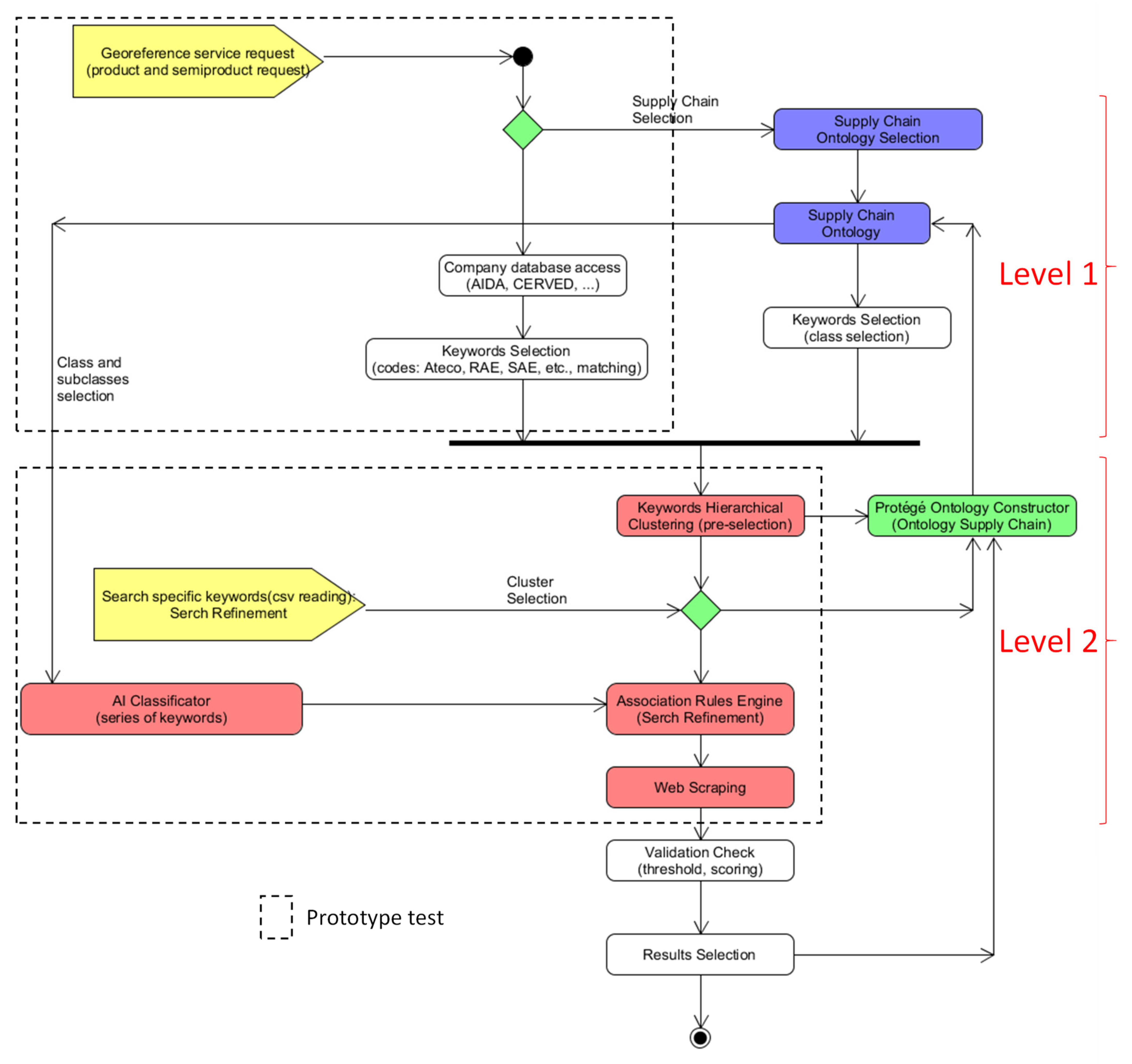
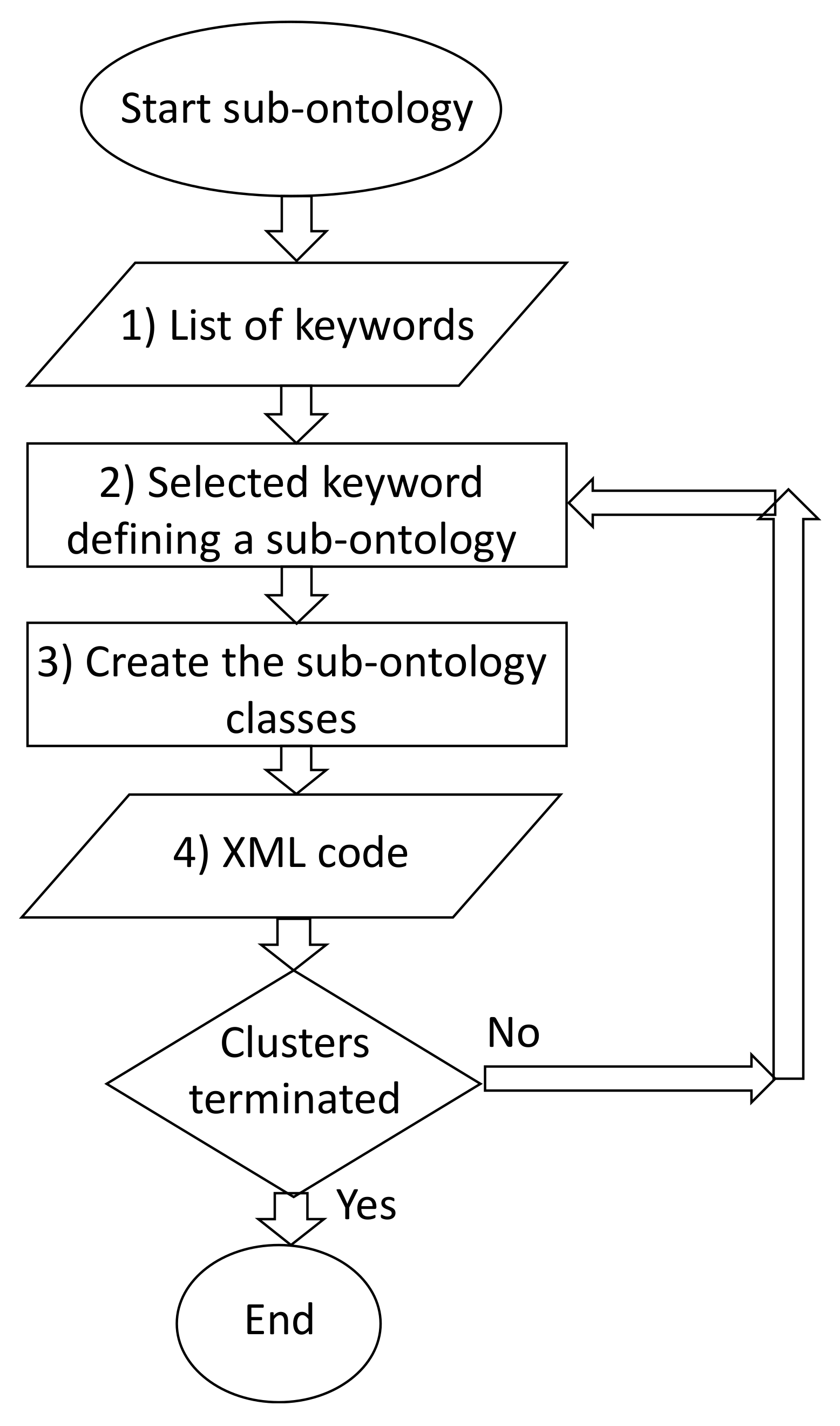
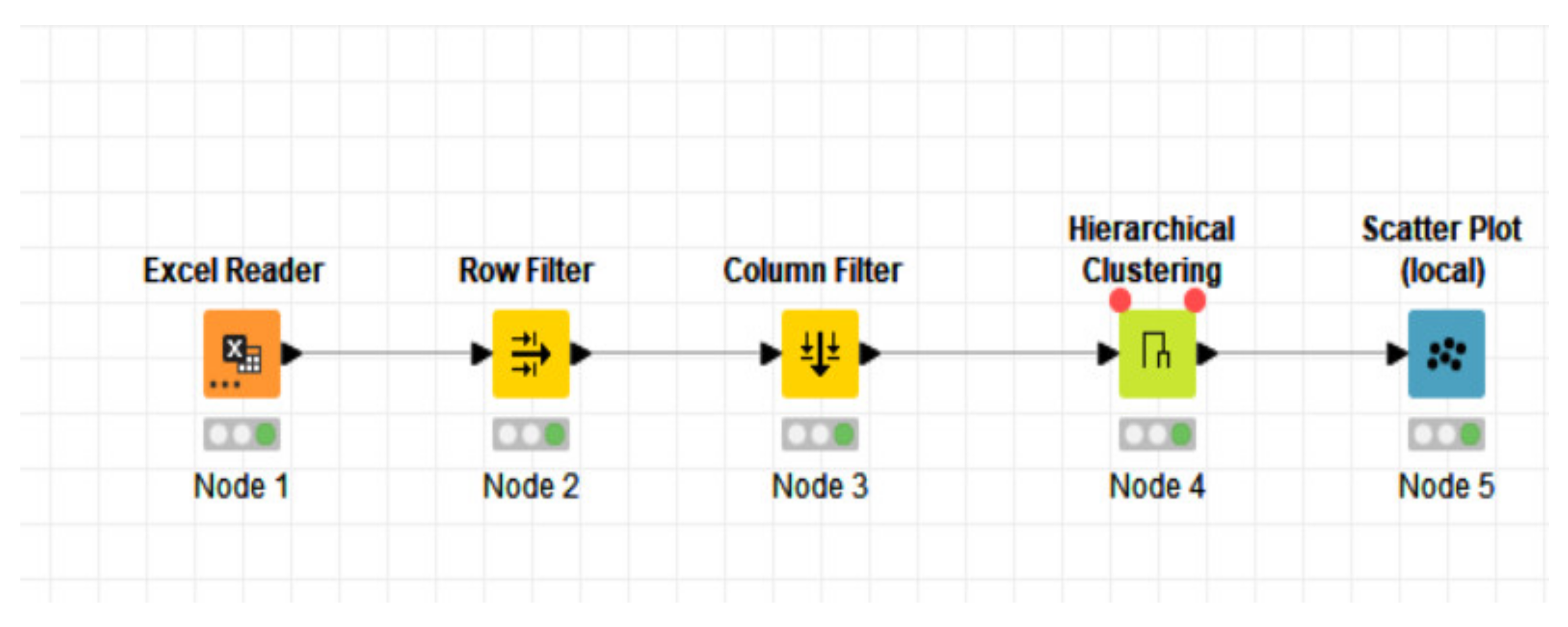
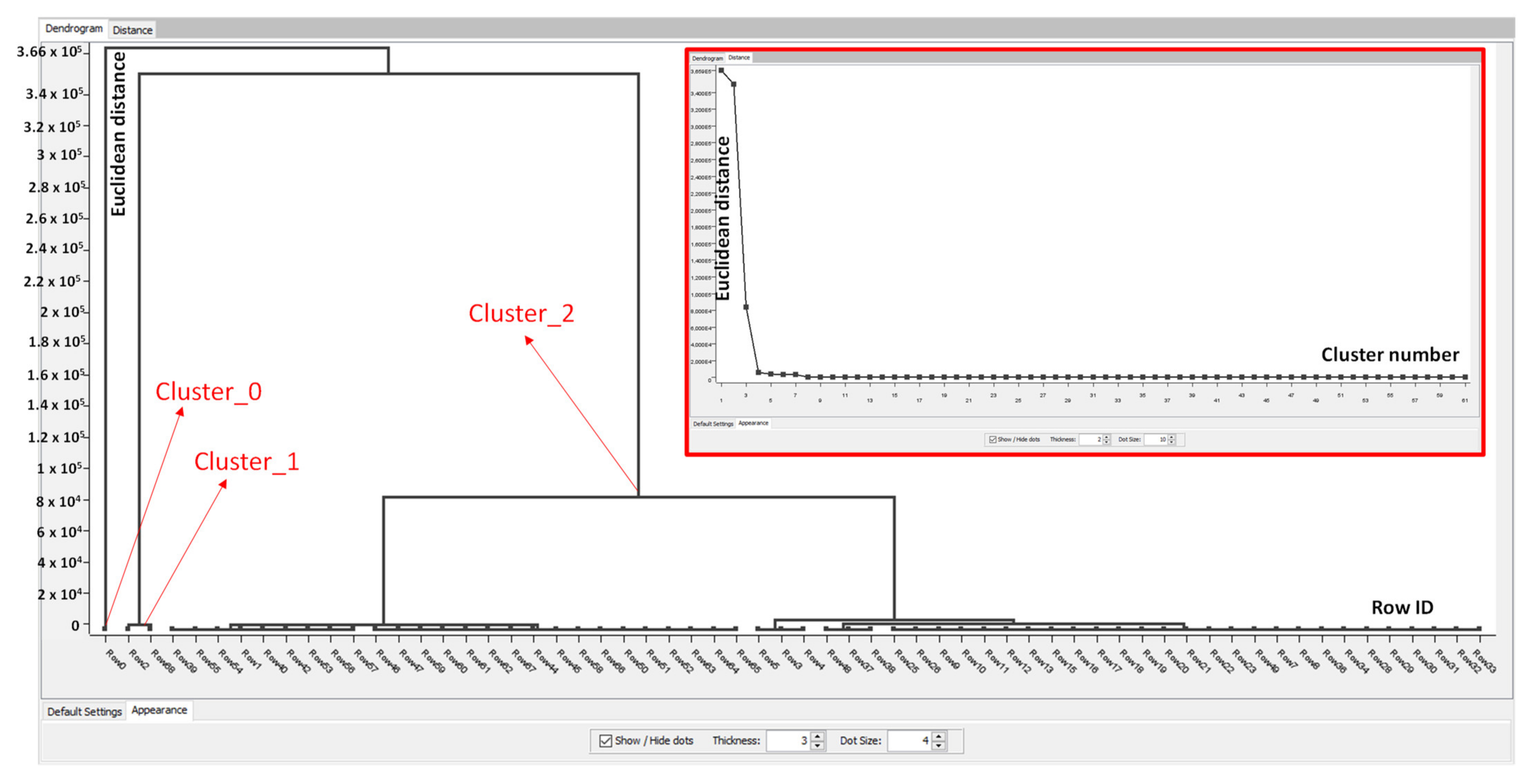
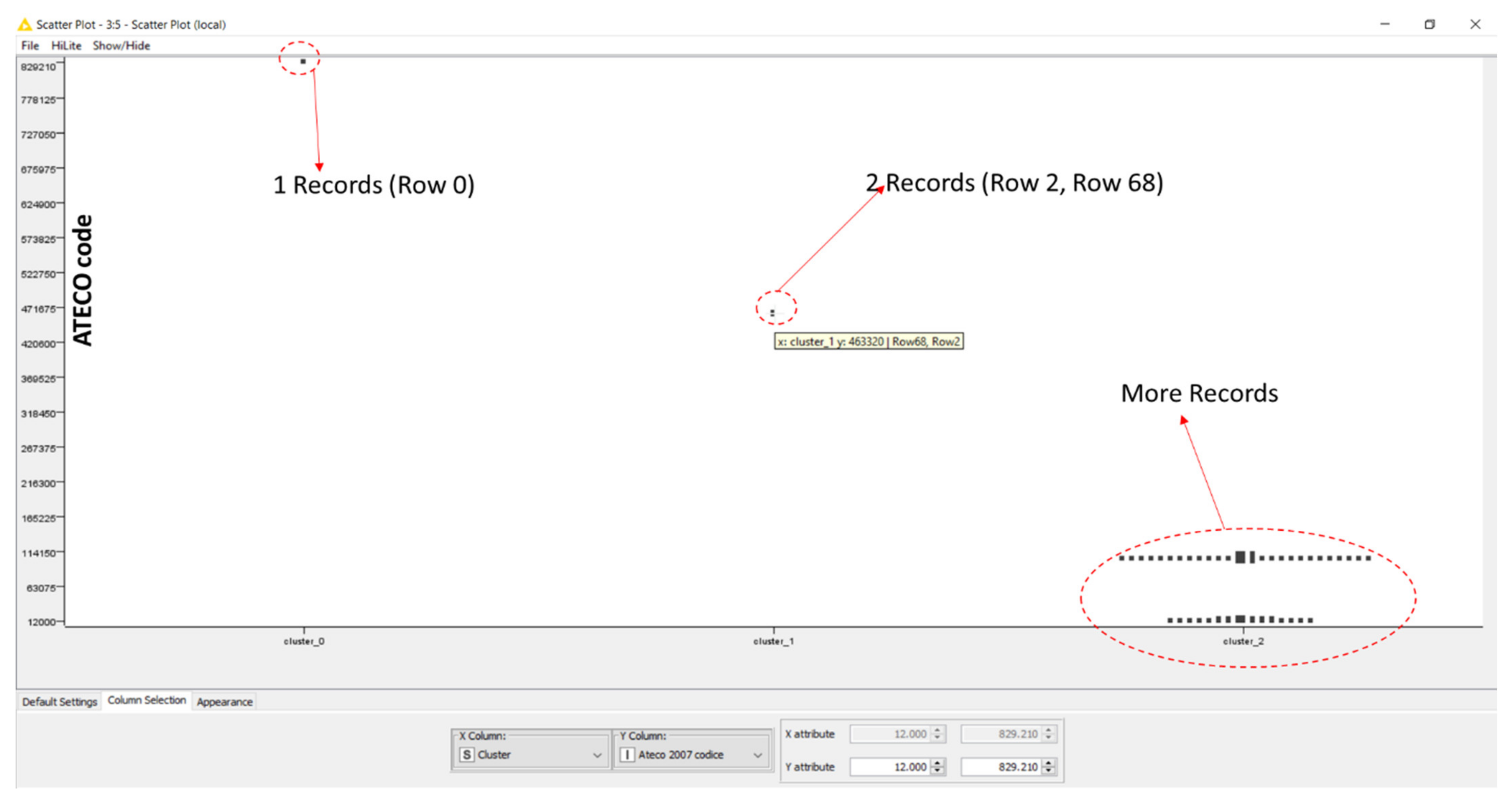
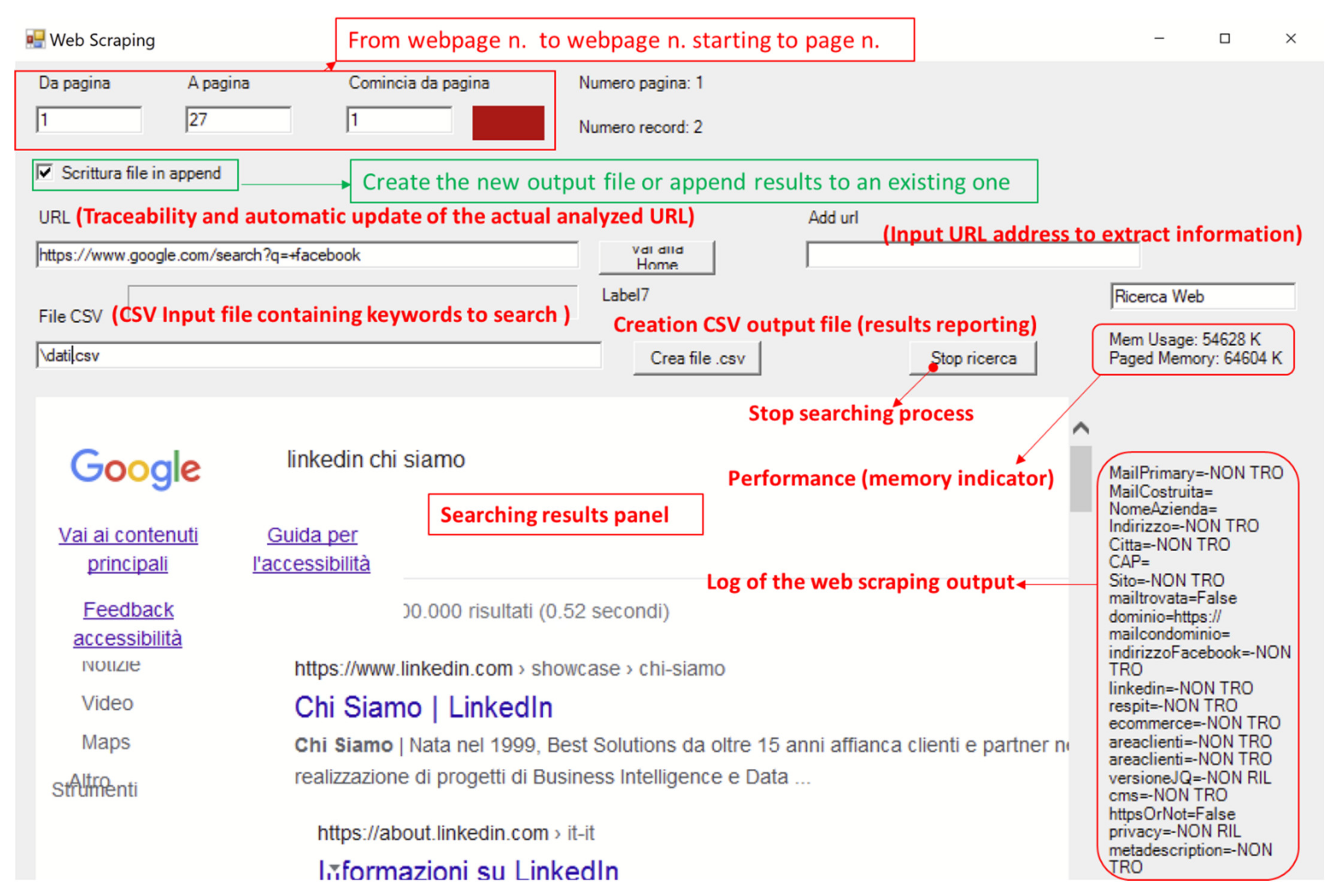
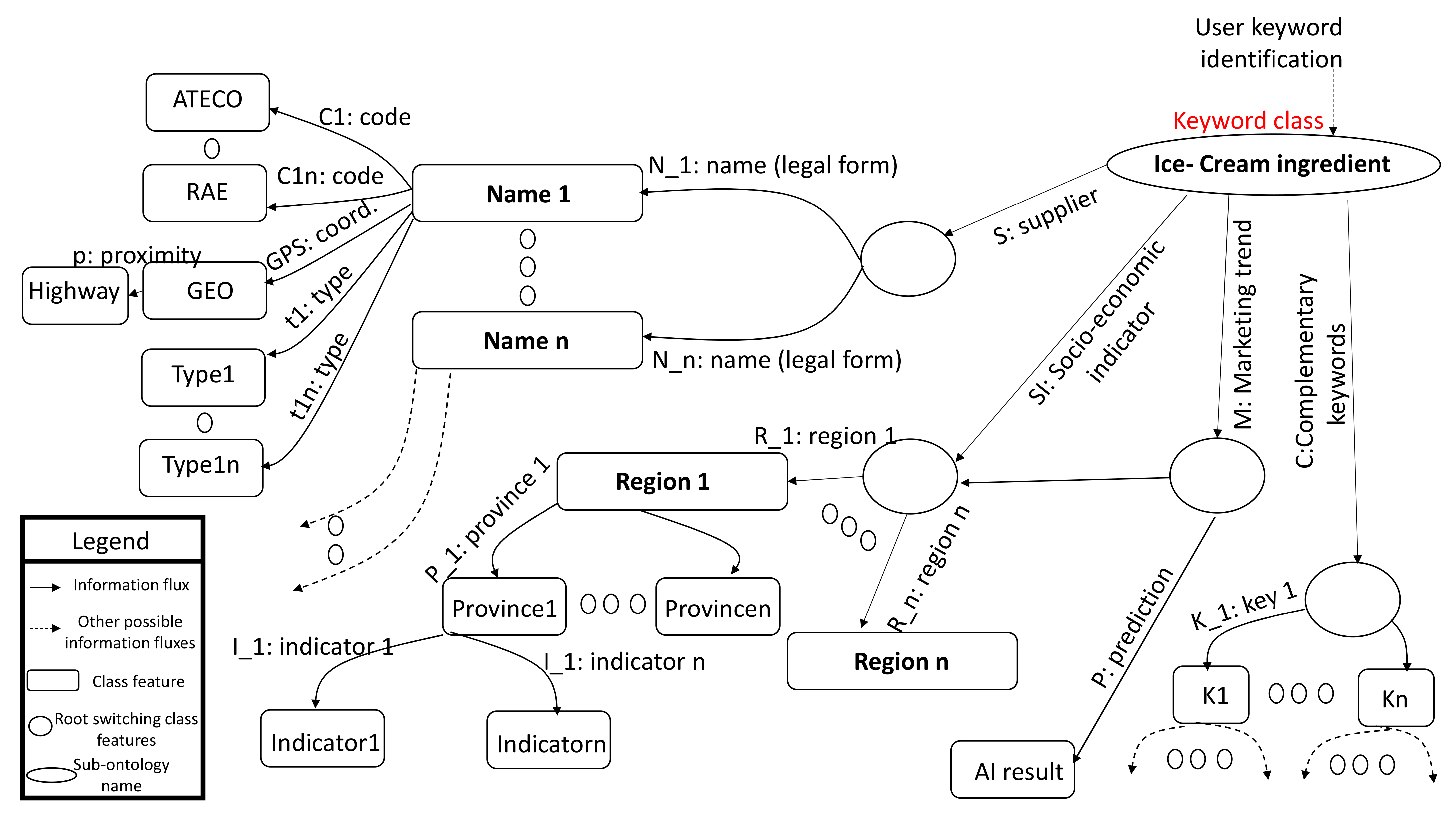
| Index/Code Type | Description |
|---|---|
| ATtività ECOnomiche (ATECO) | A type of classification adopted by the Italian National Statistical Institute (ISTAT) for national economic statistical surveys. |
| Ramo di Attività Economica (RAE) | It provides a representation of every economic activity active in Italy. |
| Settori o Sottogruppi di Attività Economica (SAE) | It specifies the business activity according to the European System of Economic Accounts (SEC 2010) classification. |
| Nomenclatura delle Attività economiche nella Comunità Europea (NACE) | Code with the aim of standardizing the classification of all economic activities in Europe. |
| Technology | Data Flow Phase of Figure 2 and Main Function Description | References |
|---|---|---|
| PDF documents | Keyword selection: ATECO, RAE, SAE, NACE indexes, etc. | AIDA [19], CERVED [20], ISTAT * [21] (socio-economic indicators) |
| Optical Character Recognition (OCR) | Keyword selection: keyword extraction from the analyzed pdf documents | OpenCV * [22,23] |
| Ontology | Supply Chain Ontology (SCO); ontology constructor; graphical interface to construct ontology graph models | PROTÉGÉ * (ontology constructor platform) [24,25] |
| RDF protocol (XML-based protocol) | Ontology constructor: extraction of the classes (keywords) from the ontology and ontology update. The ontology construction can be performed by programming subroutines using RDF Python packages, such as RDFLib | [26,27] |
| Languages: VB.NET, C++, C# | Web scraping graphical user interface | Visual Studio Community Edition 2019 * [28] |
| HTML source code (HTTP protocol) | Web scraping: extracting tags (keywords) from the analyzed webpage | [29] |
| Google maps API * (GPS geolocalization) | Search refinement (supplier and company information about their geolocalization) | [30] |
| ML unsupervised algorithm | Pre-selection: hierarchical clustering and graphical dashboards | RapidMiner * agglomerative clustering [31], KNIME * hierarchical clustering [32], Orange Canvas * hierarchical clustering [33] |
| AI classifiers (platforms): supervised algorithms as classifiers (ANN, LSTM, CNN, Decision Tree, XG Boost, etc.) | Association rules suggestion and graphical dashboards. Extraction of complementary keywords for the construction of new keyword series | RapidMiner * platform [34], Orange Canvas * platform [35], KNIME * platform [36,37], TensorFlow * [38], Keras * [39] |
| Text mining | Improvement of the web scraping process (classification of complementary keywords after the word extraction process by OCR) | KNIME * text processing [40] |
| Python platform framework | AI classifier and hierarchical clustering algorithms integration (use of Pandas, Keras, and TensorFlow libraries) | Anaconda * platform [41] |
| Container and virtualization engine | Each data processing phase: tool integration | Docker * [42,43] Kubernetes * [44], KVM (Red Hat operating system useful for customization) [45] |
| Query Example | Searching Level | Response |
|---|---|---|
| What kind of product or sub-product do you want to search for? | Level 1 | Ice cream, dessert, milk, raw material (semi-product/ice cream ingredients) |
| Would you like to consider suppliers (pre-screening by consulting the company database) | Level 1 | ATECO 2007 (463890108909, 107000, 105200, 108200 (ice cream semi-product); 105110 463310 (milk supplier); 16300, 12100, 463110, 463100, 463100, 103900 (fruit ingredients)) |
| Which specific keywords would you associate with the product or sub-product? | Level 2 | Italian ice cream, ice cream dessert, high quality |
| Are there consumers, such as bars, restaurants and ice cream shops, capable of processing specific ingredients or groups of ingredients? | Level 2 | Hierarchical clustering provides possible supply chain district areas located in a region, province and city. By processing Enterprise Resource planning (ERP) data, it is possible to associate the high quantity of ingredients sold within a district area. |
| Would you like to refine the suppliers list? (search refinement based on the response of the previous query) | Level 2 | Product certification and quality certification (Hazard Analysis and Critical Control Point (HACCP), biological, gluten free, lactose free, presence of allergens), chemical composition and ingredient combination, nutritional values |
| Is there a geolocalization request? | Level 2 | Near district useful for logistics, kilometer 0 (supplier in the same area), proximity of highway |
| Is there a socio-economic indicator to consider? | Level 2 | Tourism, tourist attractiveness rate, cultural attractivity (gastronomics), logistics/transportation, analysis of the demand associated with ice cream taste, analysis of consumer ice cream taste, income level of citizens, price of subsequent goods |
| Are the results are matching with the initial queries? | Level 2 (results validation) | If yes, the research is concluded and the training model is optimized (ontology classification optimization). If no, the keyword research restarts at Level 1 |
| Level of Knowledge | Research Method | Advantages | Disadvantages |
|---|---|---|---|
| Level 1 * | Initial query | Starts the sub-ontology construction | Only a query is insufficient to construct the supply chain ontology |
| Level 1 * | Indices and codes identifying an Italian company (Table 1) | High number of outputs | Not all the companies carry out the activities for which the research is carried out |
| Level 2 ** | Precise keywords | The outputs are correctly representative of companies operating in the indicated sector | Nothing |
| Level 2 ** | Adding queries and information classification by ML | Optimizes the useful information by eliminating redundant information | Nothing |
| Level 2 ** | ML application | Creation of new smart district area indicators | Nothing |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Massaro, A.; Cosoli, G.; Magaletti, N.; Costantiello, A. A Search Methodology Based on Industrial Ontology and Machine Learning to Analyze Georeferenced Italian Districts. Knowledge 2022, 2, 243-265. https://doi.org/10.3390/knowledge2020015
Massaro A, Cosoli G, Magaletti N, Costantiello A. A Search Methodology Based on Industrial Ontology and Machine Learning to Analyze Georeferenced Italian Districts. Knowledge. 2022; 2(2):243-265. https://doi.org/10.3390/knowledge2020015
Chicago/Turabian StyleMassaro, Alessandro, Gabriele Cosoli, Nicola Magaletti, and Alberto Costantiello. 2022. "A Search Methodology Based on Industrial Ontology and Machine Learning to Analyze Georeferenced Italian Districts" Knowledge 2, no. 2: 243-265. https://doi.org/10.3390/knowledge2020015
APA StyleMassaro, A., Cosoli, G., Magaletti, N., & Costantiello, A. (2022). A Search Methodology Based on Industrial Ontology and Machine Learning to Analyze Georeferenced Italian Districts. Knowledge, 2(2), 243-265. https://doi.org/10.3390/knowledge2020015