
Linking Entities from Text to Hundreds of RDF Datasets for Enabling Large Scale Entity Enrichment



Abstract
:1. Introduction
2. Background and Related Work
2.1. Background Resource Description Framework (RDF)
2.2. Related Work
2.2.1. Entity Recognition, Linking and Annotation over Knowledge Bases
2.2.2. Entity Enrichment over Multiple RDF Datasets
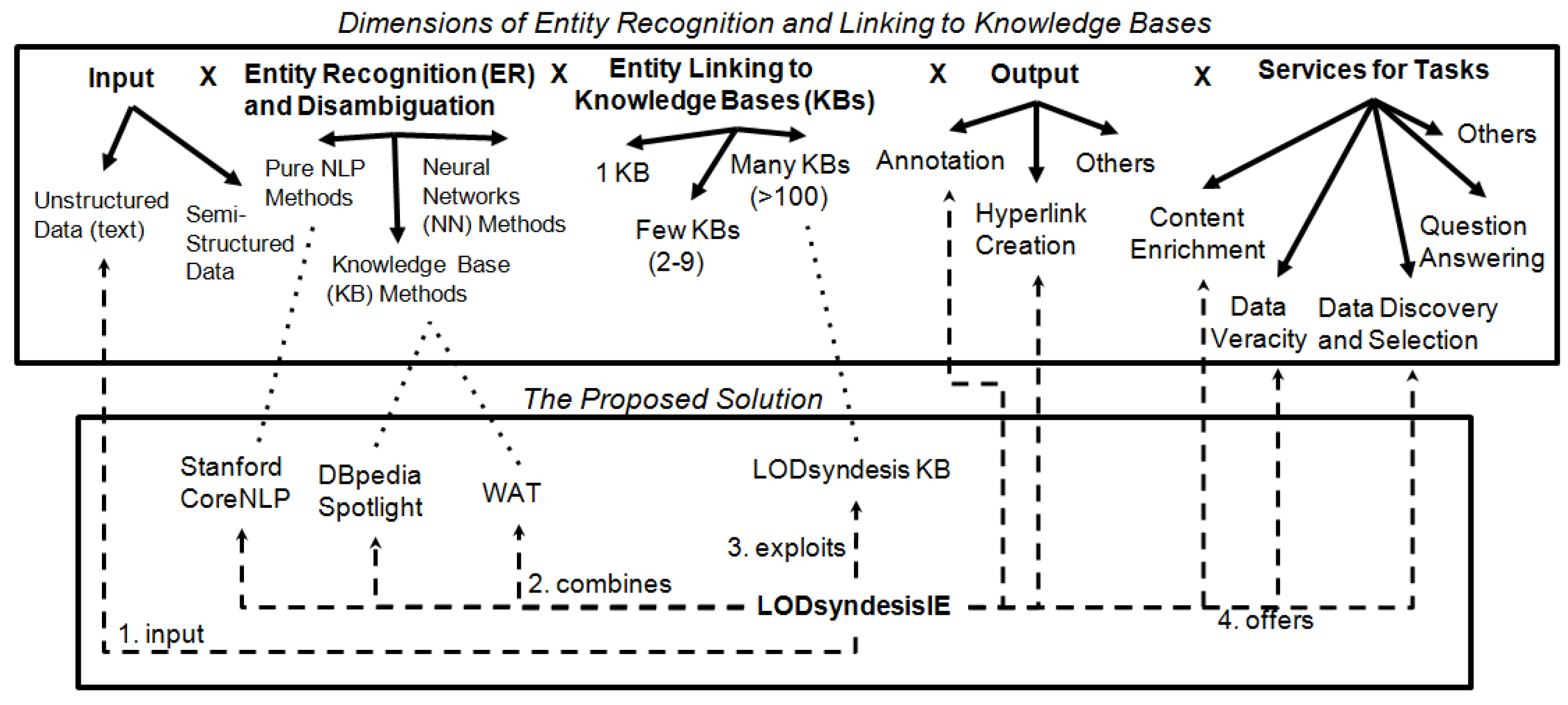
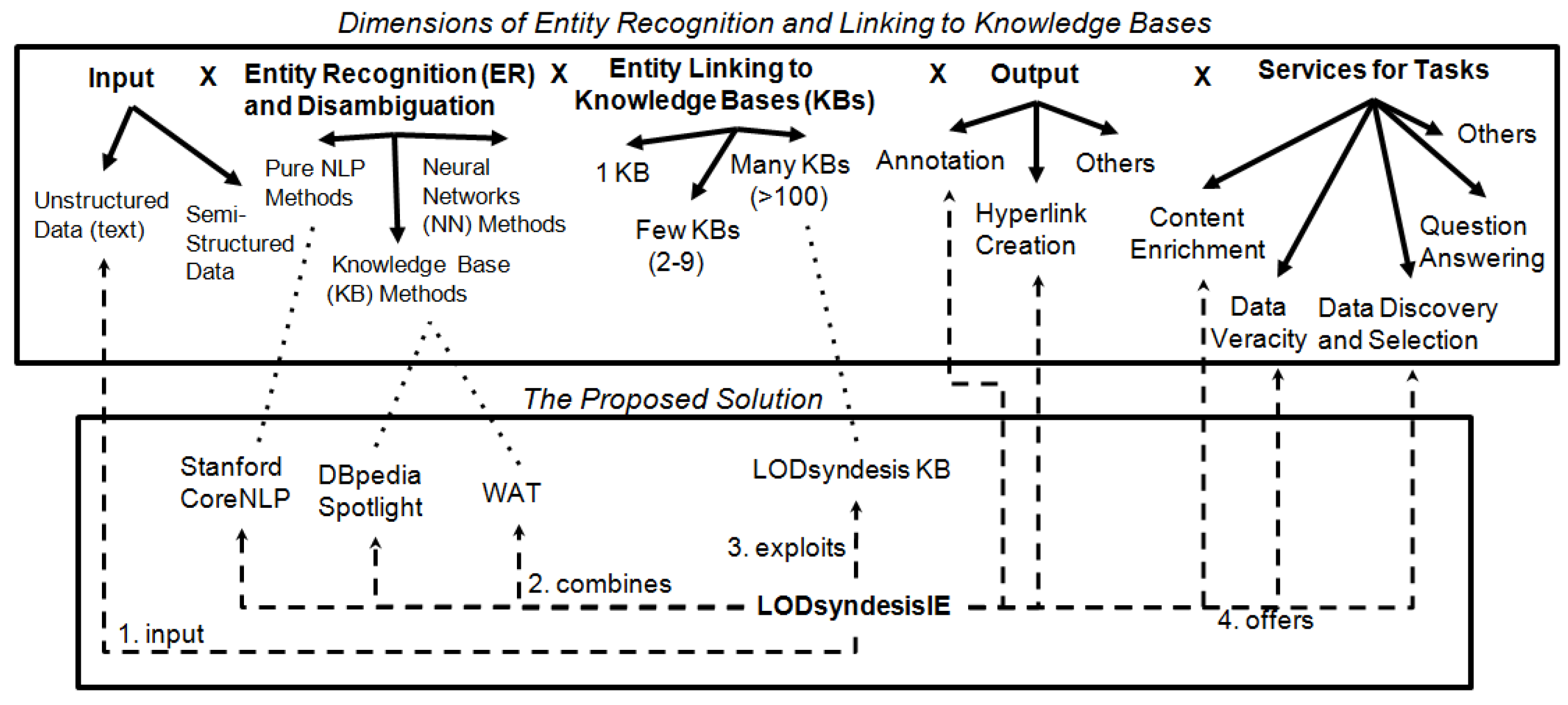
2.2.3. Placement and Novelty of LODsyndesis
3. The Proposed Approach of LODsyndesis
3.1. Input and the Entity Recognition Process
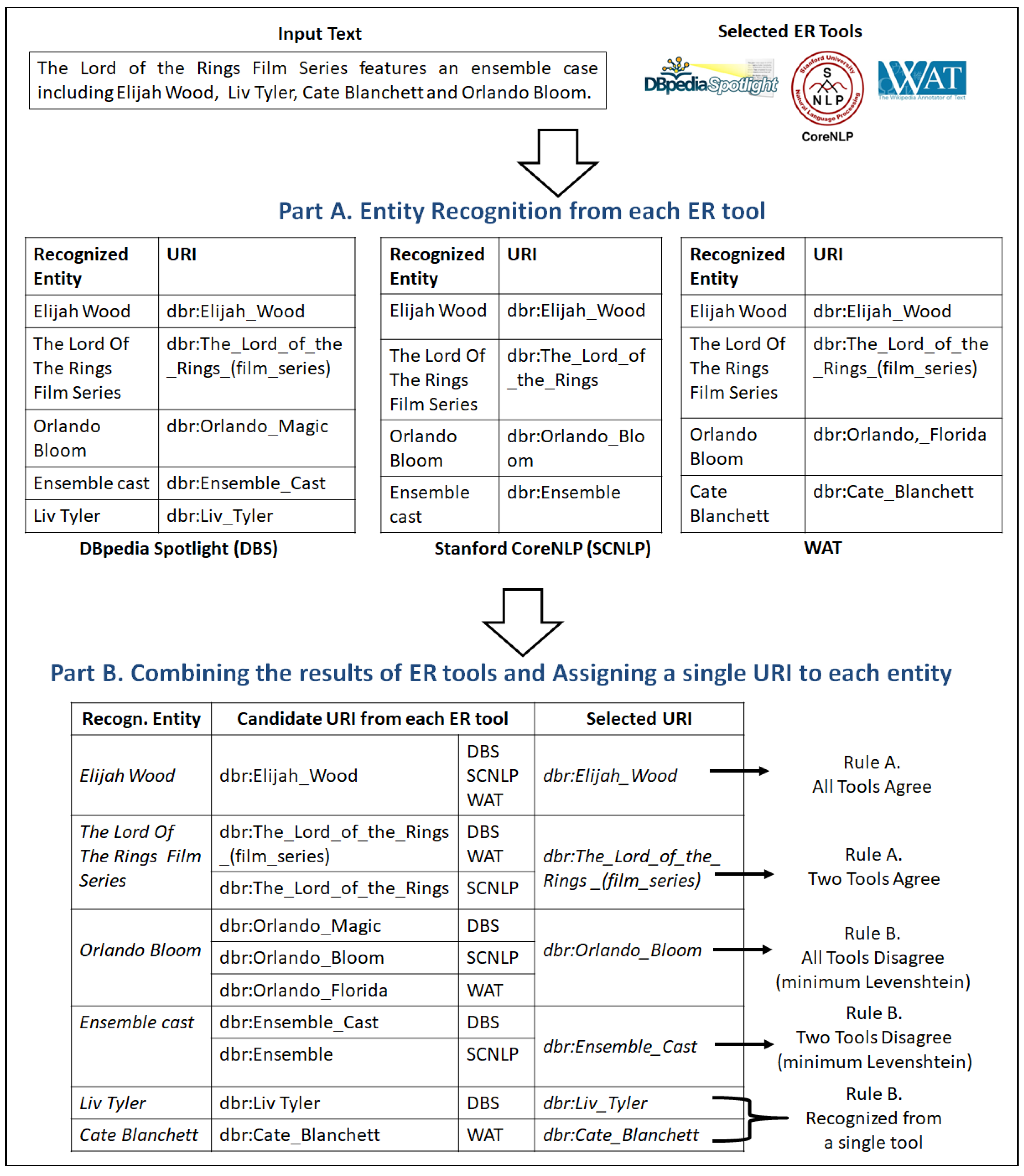
3.1.1. Part A. Entity Recognition from Each ER Tool Separately
3.1.2. Part B. Combining the Results of ER Tools and Assigning a Single URI to Each Entity
| Algorithm 1: The process of Entities Recognition by combining three ER tools |
| Input: A text t given by the user |
| Output: A set of entity-URI pairs denoted by , containing the recognized entities of text t and their corresponding link. |
|
- Rule A (The Majority Rule): If at least two ER tools recognized the entity e and assigned to e the same URI, then we select this URI for the entity e (see lines 16–19). The lines 16–17 include the cases where either (a) the tools SCNLP and WAT, (b) the tools SCNLP and DBS or (c) all the ER tools, managed to recognize the entity e and assigned to it the same URI. On the contrary, the lines 18–19 are executed when both WAT and DBS recognized e and provided the same URI.
- Examples of Rule A. As we can see in the lower part of Figure 3, for the entity “Elijah Wood” all the tools assigned the same URI. On the contrary, for the entity “The Lord of the Rings Film Series”, two tools (i.e., DBS and SCNLP) assigned the same URI, whereas WAT assigned a different URI. However, due to the majority rule, we selected the URI returned by DBS and SCNLP.
- Rule B (The Closest Name Rule): The lines 20–21 are executed in the following cases: (i) the entity e was recognized only from a single tool, and (ii) the entity e was recognized from two or three tools, however, each of them was assigned a different URI for entity e. In case (i), we have only a single candidate URI, therefore, we select that URI. In case (ii), we have more than one candidate URIs for e, and we select the URI u whose suffix, i.e., the last part of the URI, has the minimum Levenhstein distance with e.
- Examples of Rule B. In Figure 3, for the entity “Orlando Bloom”, each tool assigned a different URI. However, since the suffixes of the candidate URIs are “Orlando Magic”, “Orlando Bloom" and “Orlando, Florida”, the algorithm will select the second URI, since its Levenhstein distance with the desired entity is the minimum (i.e., zero). The same case holds also for the entity “Ensemble cast”. On the contrary, the entities “Liv Tyler” and “Cate Blanchett” recognized only from a single ER tool, so we selected the URI retrieved from the corresponding tool.
3.1.3. Time Complexity
3.2. Linking the Recognizing Entities to LODsyndesis
3.3. The Offered Services of LODsyndesis and Its REST API
3.3.1. Services for Data Annotation and Hyperlink Creation
3.3.2. Services for Content Enrichment
3.3.3. Services for Data Veracity
3.3.4. Services for Dataset Discovery and Selection and for Data Integration
3.3.5. Online Material of LODsyndesis
4. Evaluation
4.1. Evaluation Collections
4.2. Evaluation Metrics and Hardware Setup
- true positives (tp): The entities that are recognized from the ER tool(s) and their selected DBpedia URIs are exactly the same as in the gold standard. For instance, suppose that in our running example we use only DBS (i.e., see the table in the upper left part of Figure 3) for recognizing the entities. In that case, “Elijah Wood” is a true positive, i.e., the entity recognized and its URI is correct.
- false positives (fp): The entities are recognized from the ER tool(s), but their selected DBpedia URIs are different from the DBpedia URIs in gold standard. For example, suppose again that we use only DBS in Figure 3. In that case, the entity “Orlando Bloom” is a false positive, i.e., the tool recognized the entity, but the link was erroneous (i.e., “dbr:Orlando Magic”). Moreover, we treat as false positives the cases that are entities found by the ER tools, however, they are not in the gold standard, e.g., suppose in our running example a hypothetical case, where a tool identified the word “Wood” as an entity (and not “Elijah Wood”, which is the desired entity).
- false negatives (fn): The entities that are part of the gold standard but failed to be recognized from the ER tool(s). For instance, by using only “DBS” in Figure 3, the entity “Cate Blanchett” is a false negative, since it was not recognized from DBS.
4.3. Effectiveness of Combining Different Entity Recognition Tools for ER and Linking (Hypothesis H1)
4.4. The Benefits of Linking the Entities to Multiple RDF Datasets (Hypothesis H2)
4.4.1. Measurements for Content Enrichment and Data Veracity
4.4.2. Measurements for Dataset Discovery and Selection and Integration
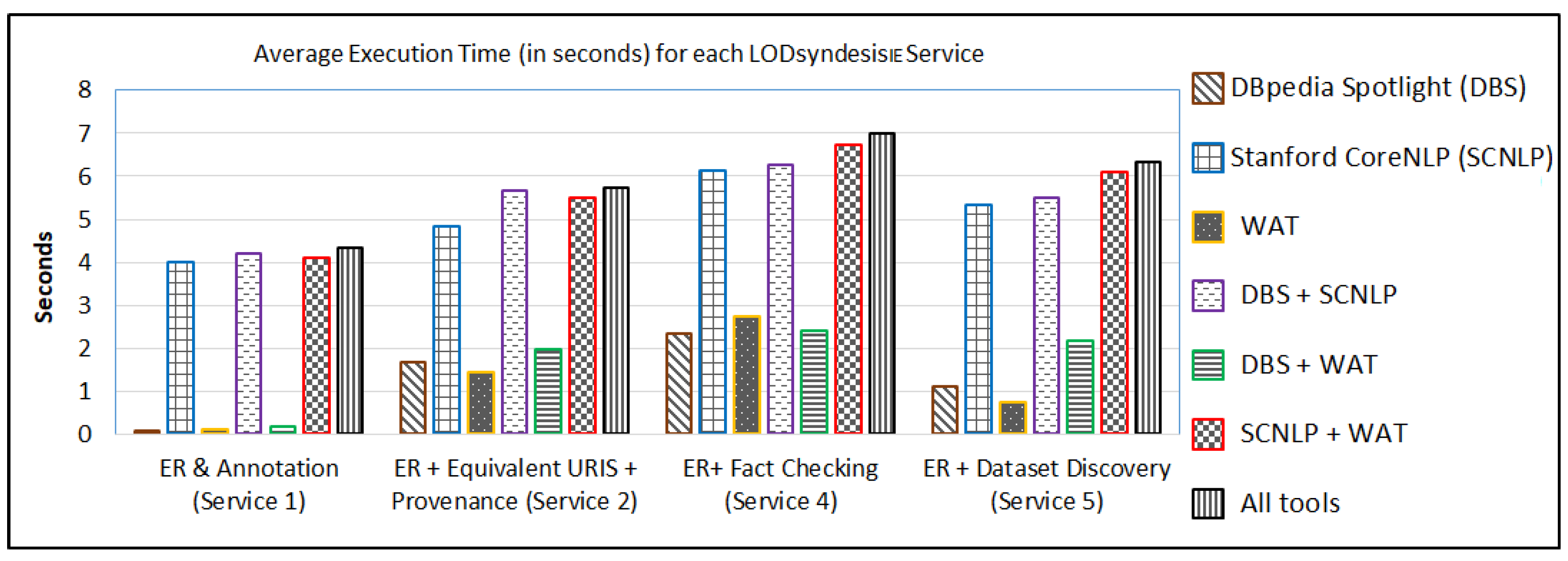
4.5. Efficiency of LODsyndesis
4.6. Discussion of Experimental Results
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
Appendix A. More Experiments for Entity Recognition Process
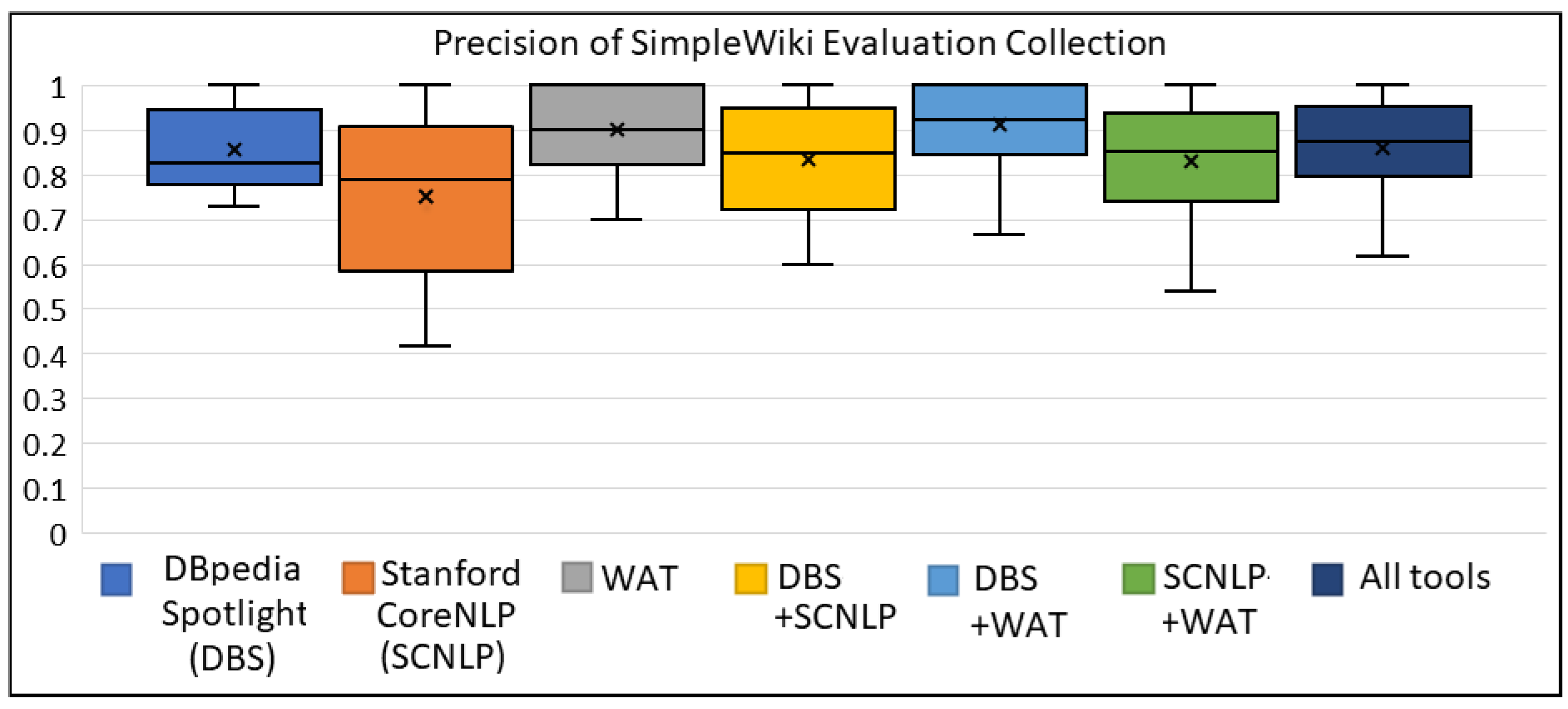
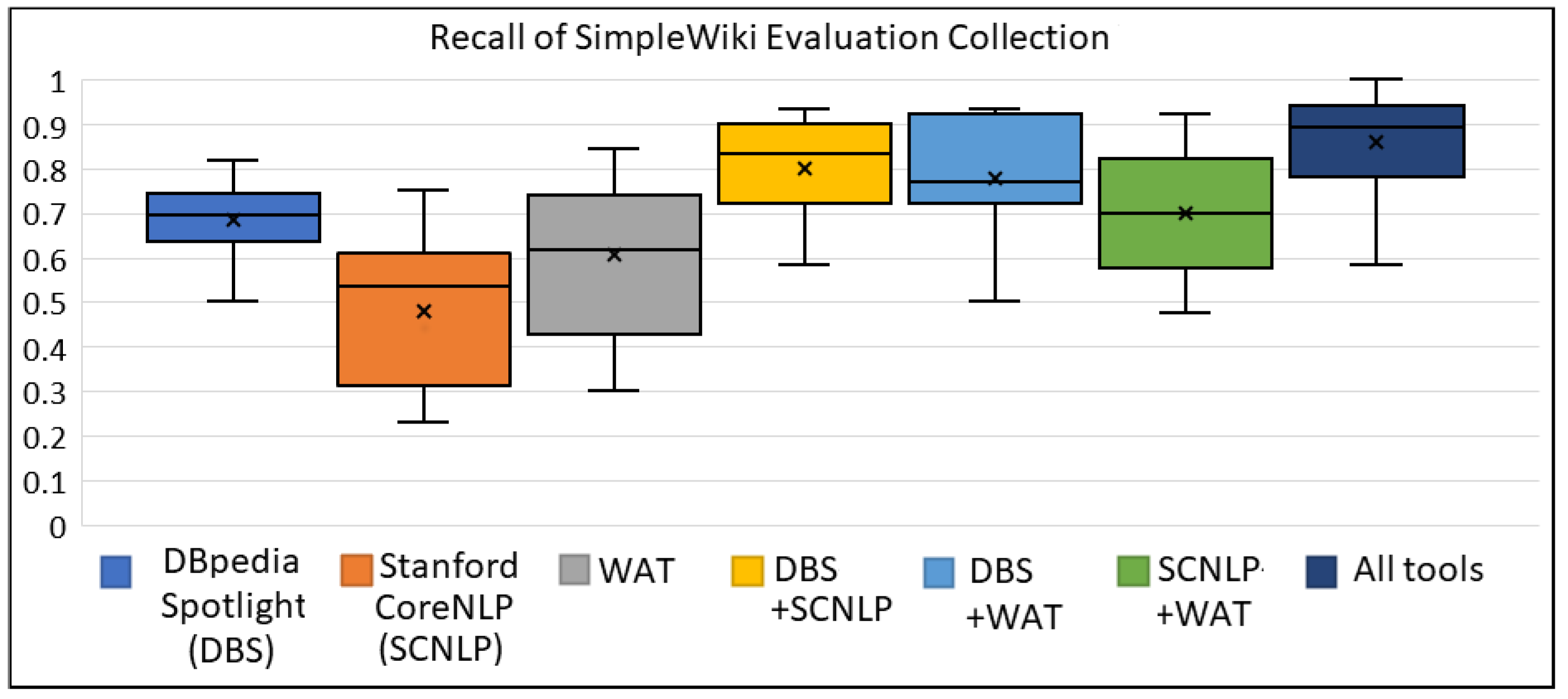
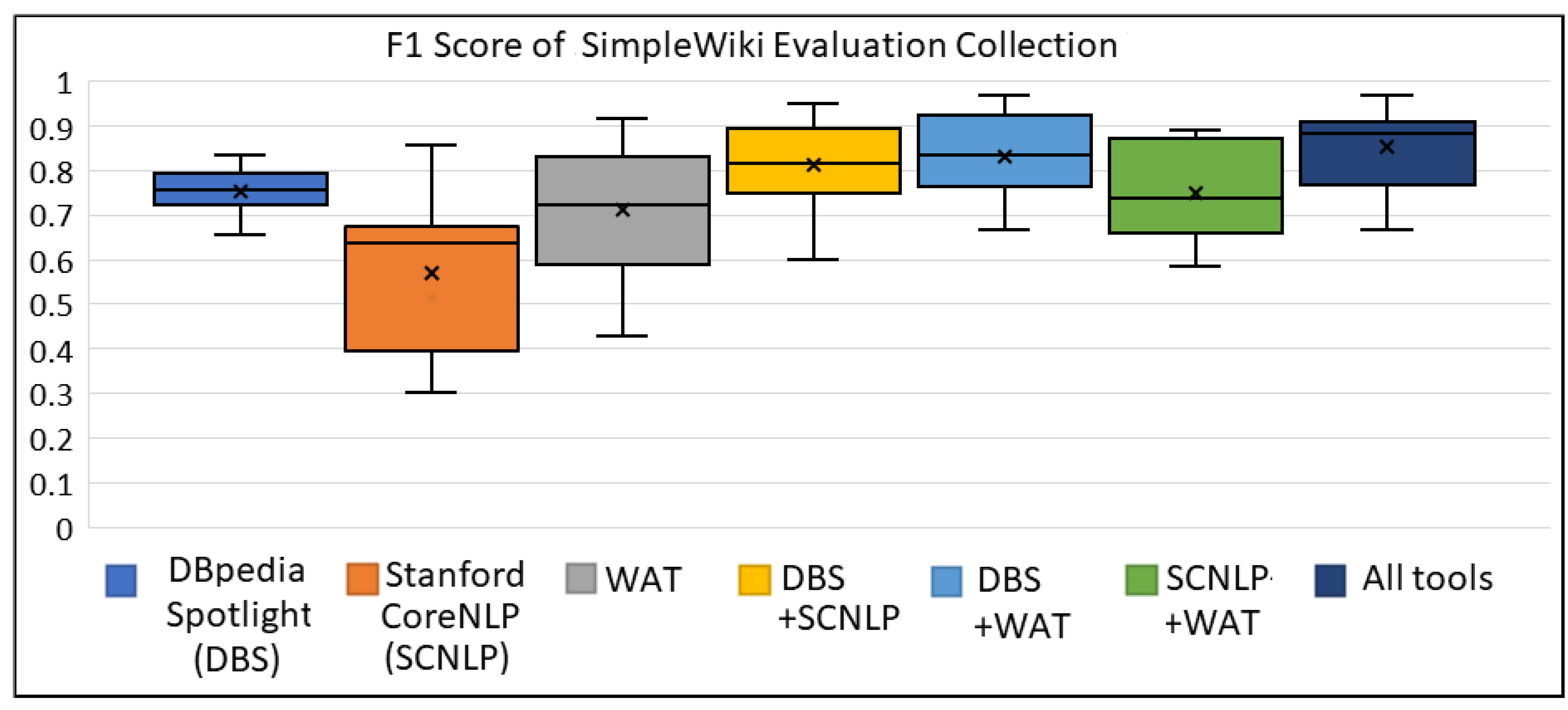
Appendix A.1. The Box Plots for SimpleWiki Evaluation Collection
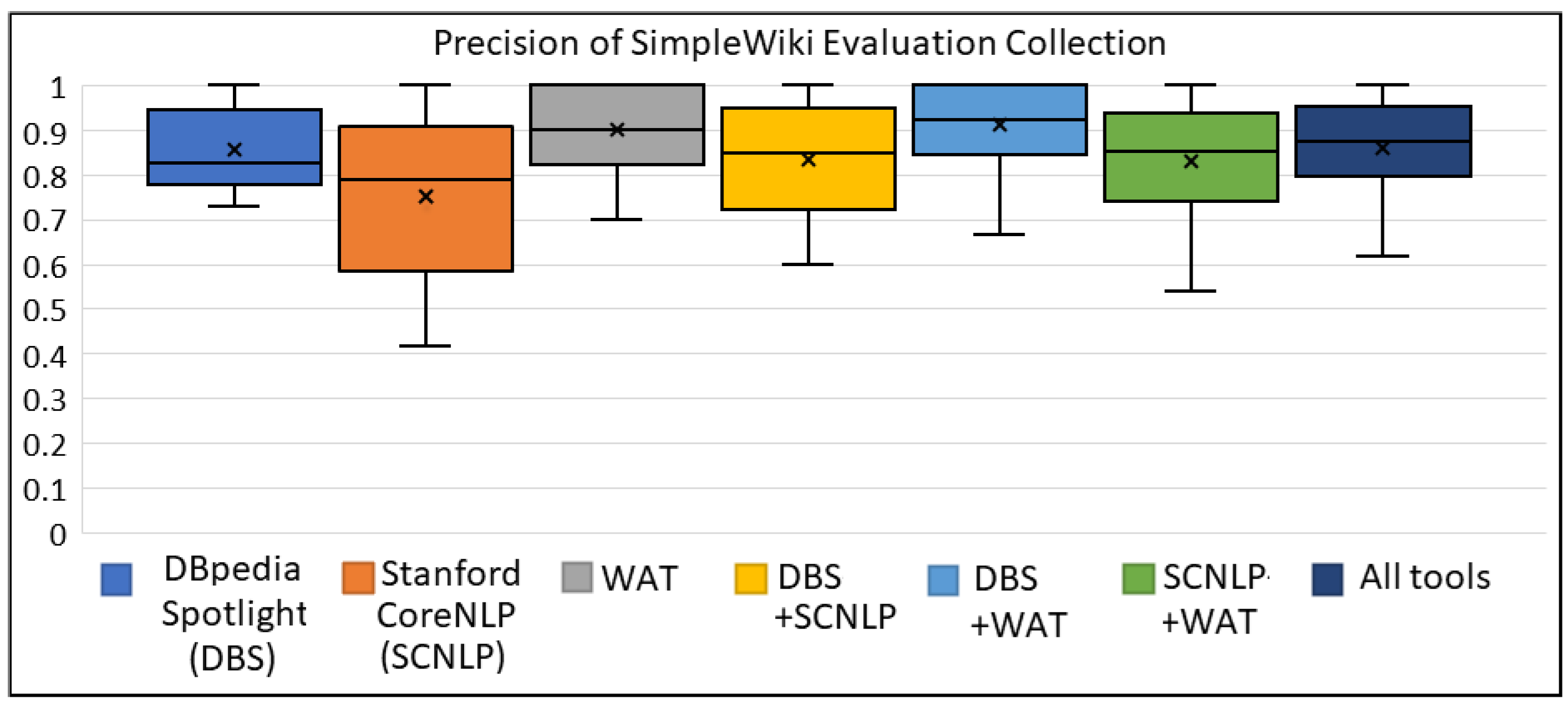


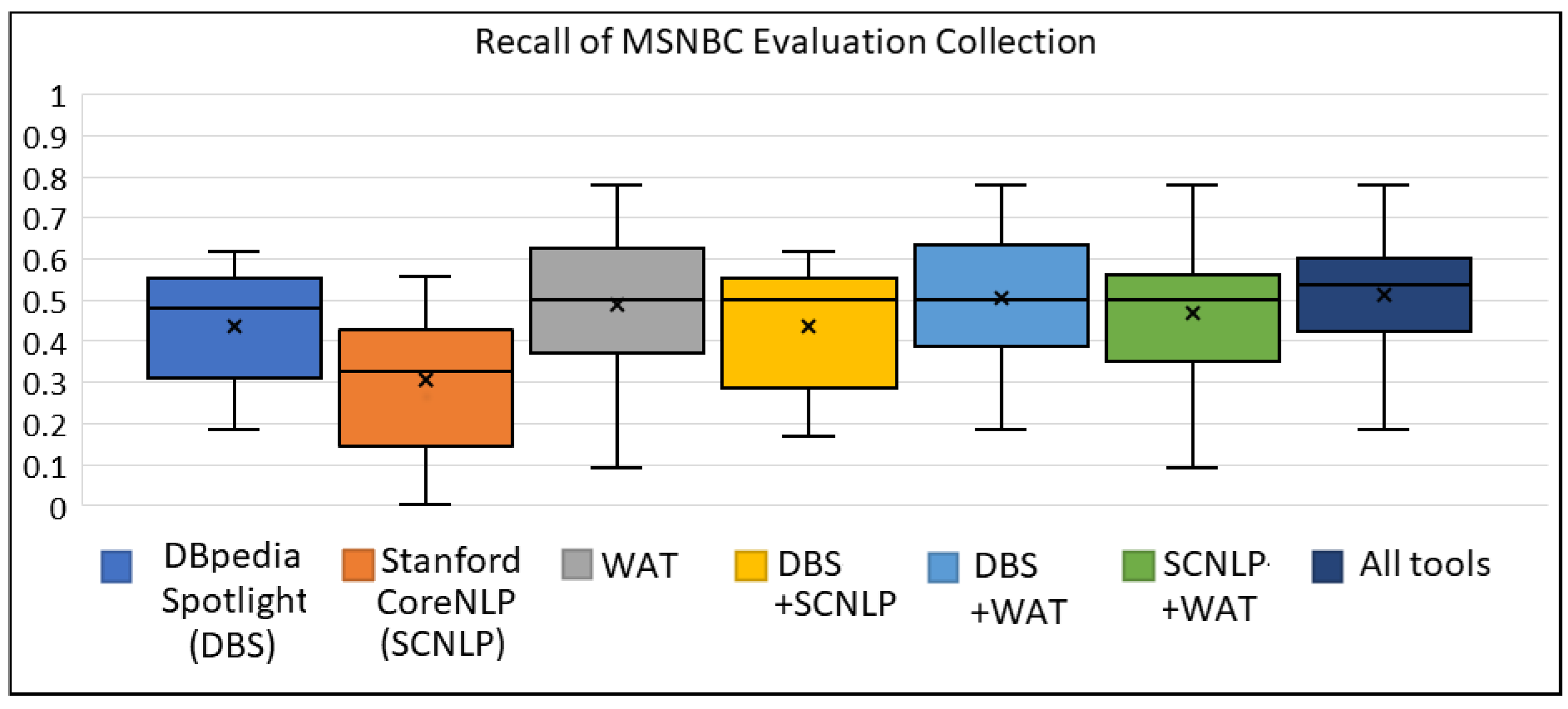
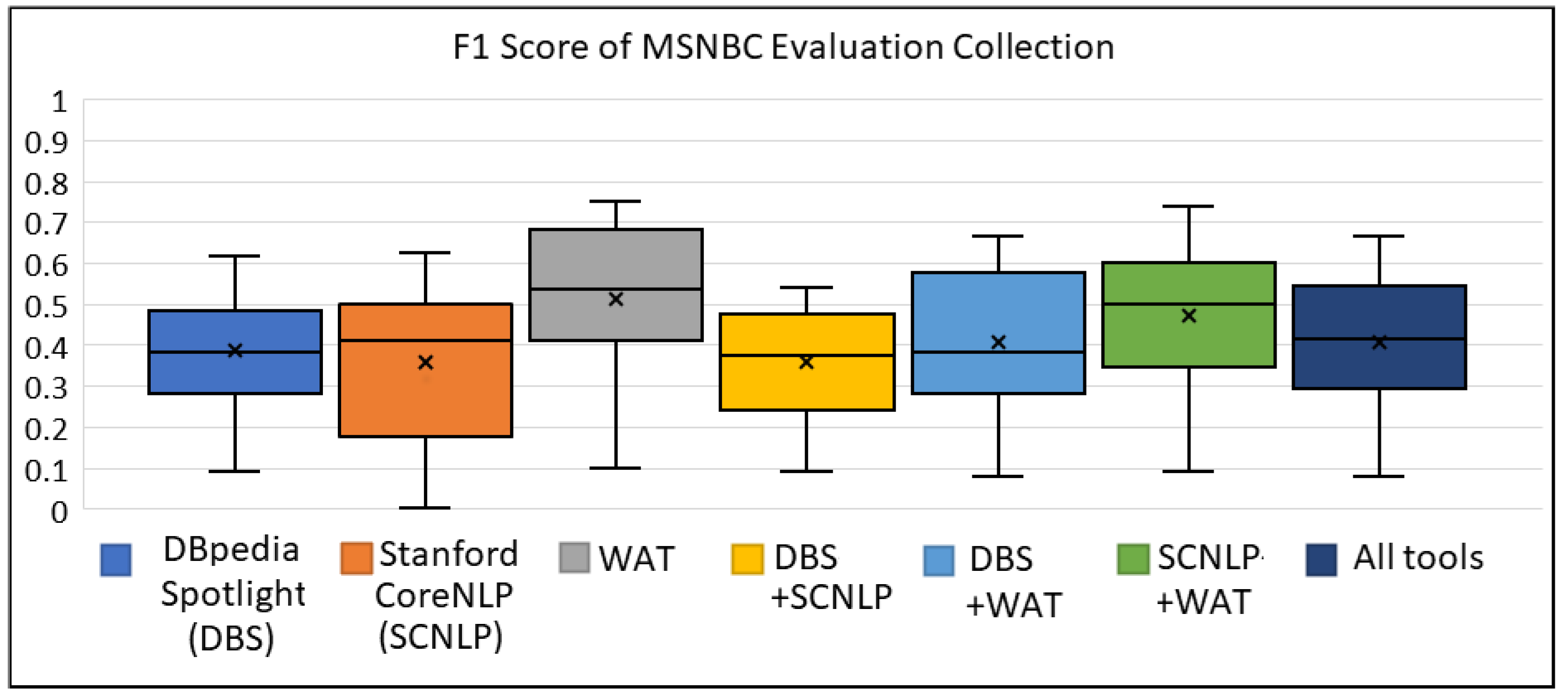
Appendix A.2. The Box Plots for MSNBC Evaluation Collection



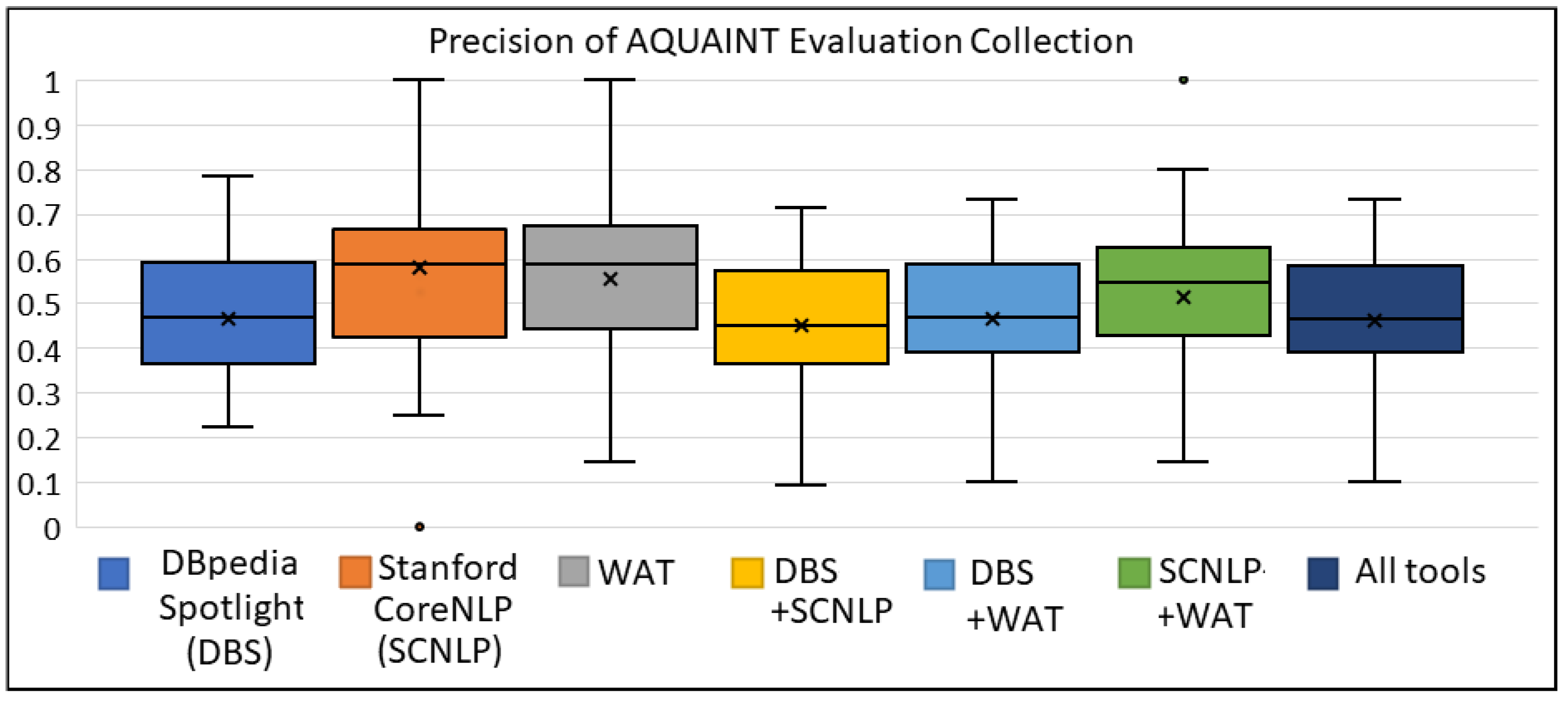
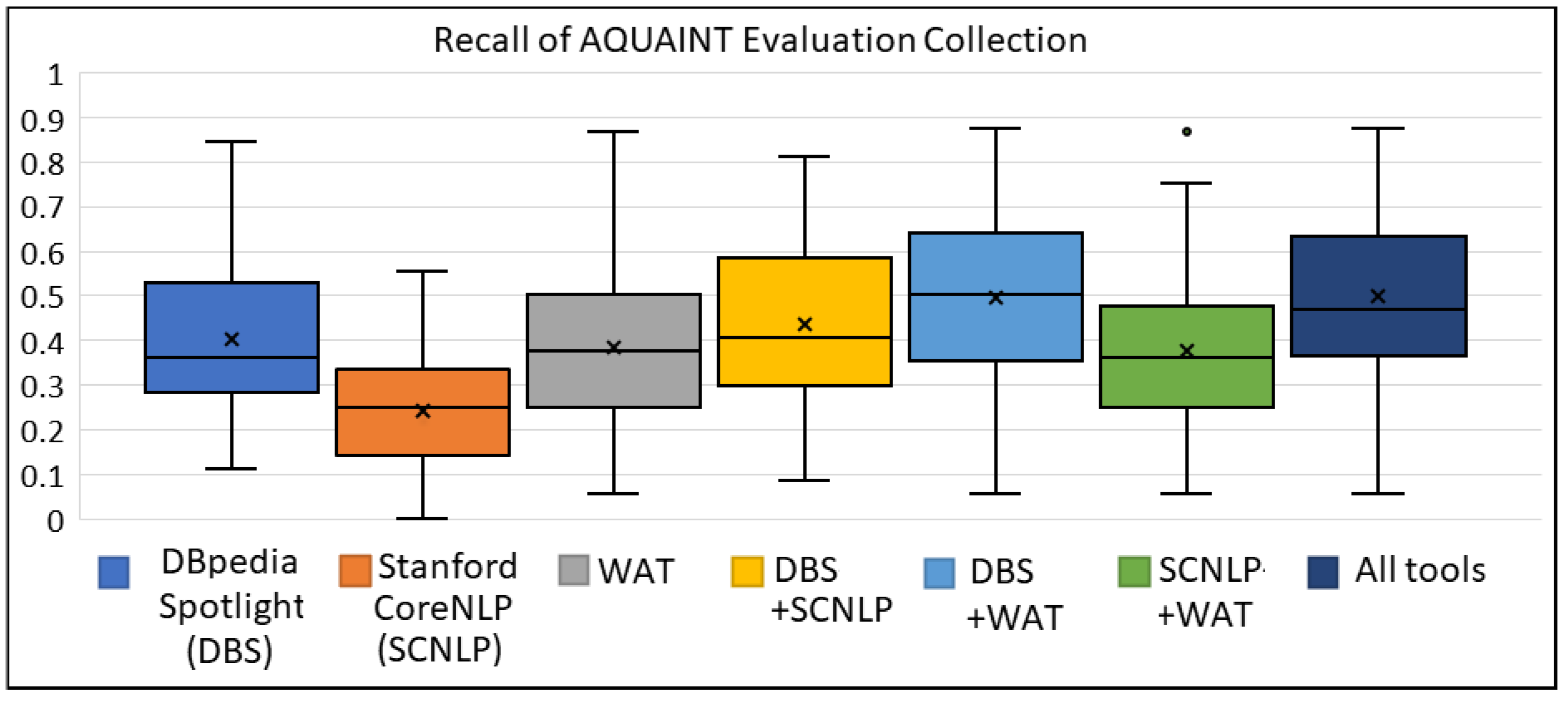
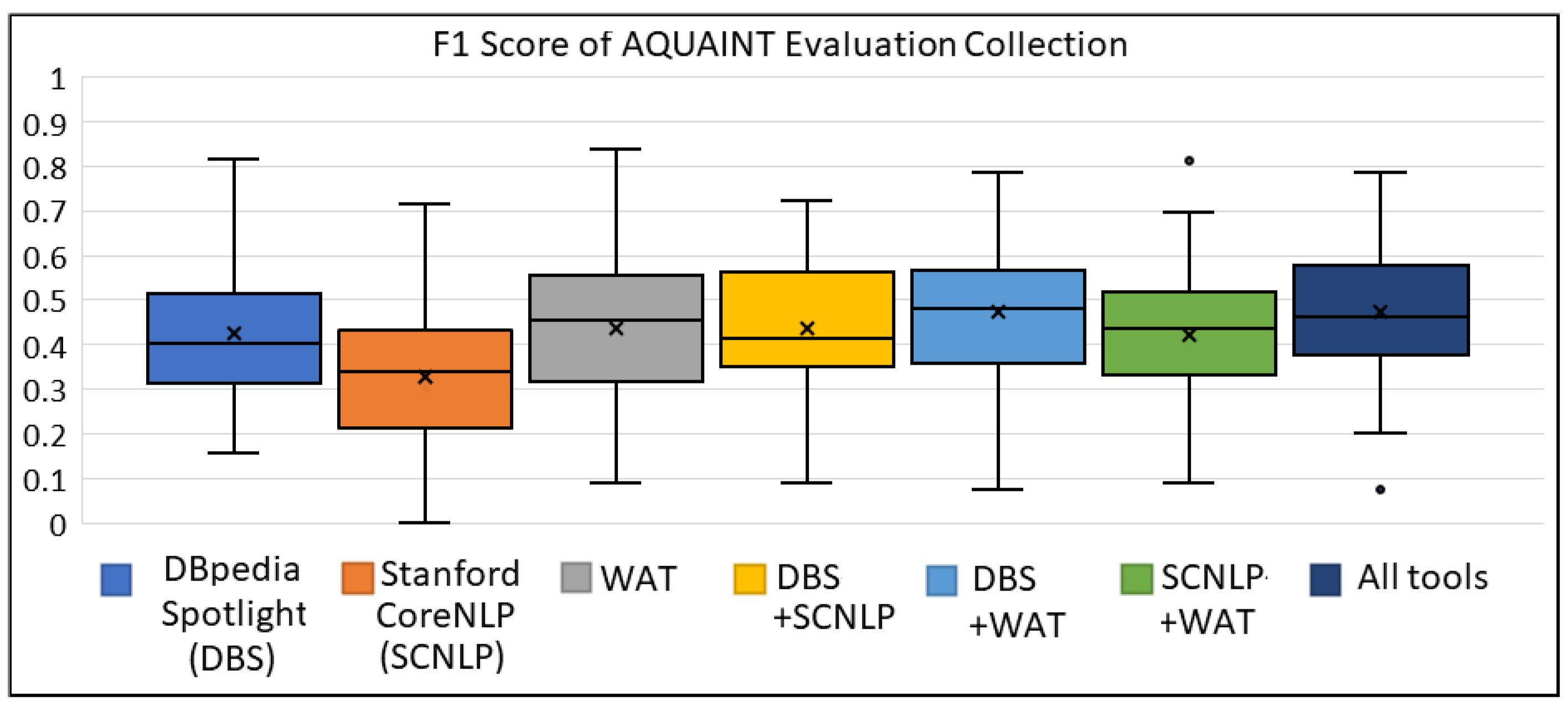
Appendix A.3. The Box Plots for AQUAINT Evaluation Collection



References
- Grishman, R. Information extraction: Techniques and challenges. In International Summer School on Information Extraction; Springer: Cham, Switzerland, 1997; pp. 10–27. [Google Scholar]
- Sarawagi, S. Information Extraction; Now Publishers Inc.: Delft, The Netherland, 2008. [Google Scholar]
- Ermilov, I.; Lehmann, J.; Martin, M.; Auer, S. LODStats: The data web census dataset. In International Semantic Web Conference; Springer: Cham, Switzerland, 2016; pp. 38–46. [Google Scholar]
- Mountantonakis, M. Services for Connecting and Integrating Big Numbers of Linked Datasets; IOS Press: Amsterdam, The Netherland, 2021. [Google Scholar]
- Röder, M.; Usbeck, R.; Ngonga Ngomo, A.C. Gerbil–benchmarking named entity recognition and linking consistently. Semant. Web 2018, 9, 605–625. [Google Scholar] [CrossRef]
- Mendes, P.N.; Jakob, M.; García-Silva, A.; Bizer, C. DBpedia spotlight: Shedding light on the web of documents. In SEMANTiCS; ACM: New York, NY, USA, 2011; pp. 1–8. [Google Scholar]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Cham, Switzerland, 2007; pp. 722–735. [Google Scholar]
- Piccinno, F.; Ferragina, P. From TagME to WAT: A new entity annotator. In Proceedings of the Workshop on Entity Recognition & Disambiguation, Gold Coast, QLD, Australia, 11 July 2014; pp. 55–62. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. LODsyndesis: Global scale knowledge services. Heritage 2018, 1, 335–348. [Google Scholar] [CrossRef] [Green Version]
- Beek, W.; Raad, J.; Wielemaker, J.; van Harmelen, F. sameAs.cc: The Closure of 500M owl: Same As Statements. In European Semantic Web Conference; Springer: Cham, Switzerland, 2018; pp. 65–80. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. LODsyndesisIE: Entity Extraction from Text and Enrichment Using Hundreds of Linked Datasets. In European Semantic Web Conference; Springer: Cham, Switzerland, 2020; pp. 168–174. [Google Scholar]
- Bizer, C.; Heath, T.; Berners-Lee, T. Linked data: The story so far. In Semantic Services, Interoperability and Web Applications: Emerging Concepts; IGI Global: Pennsylvania, PA, USA, 2011; pp. 205–227. [Google Scholar]
- Bechhofer, S.; Van Harmelen, F.; Hendler, J.; Horrocks, I.; McGuinness, D.L.; Patel-Schneider, P.F.; Stein, L.A. OWL web ontology language reference. W3C Recomm. 2004, 10, 1–53. [Google Scholar]
- Rebele, T.; Suchanek, F.; Hoffart, J.; Biega, J.; Kuzey, E.; Weikum, G. YAGO: A multilingual knowledge base from wikipedia, wordnet, and geonames. In International Semantic Web Conference; Springer: Cham, Switzerland, 2016; pp. 177–185. [Google Scholar]
- Moro, A.; Cecconi, F.; Navigli, R. Multilingual Word Sense Disambiguation and Entity Linking for Everybody. In International Semantic Web Conference (Posters & Demos); CEUR-WS.org: Aachen, Germany, 2014; pp. 25–28. [Google Scholar]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust disambiguation of named entities in text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- van Hulst, J.M.; Hasibi, F.; Dercksen, K.; Balog, K.; de Vries, A.P. Rel: An entity linker standing on the shoulders of giants. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Xi’an, China, 25–30 July 2020; pp. 2197–2200. [Google Scholar]
- Kolitsas, N.; Ganea, O.E.; Hofmann, T. End-to-End Neural Entity Linking. In Proceedings of the 22nd Conference on Computational Natural Language Learning, Brussels, Belgium, 31 October–1 November 2018; pp. 519–529. [Google Scholar]
- Martinez-Rodriguez, J.L.; Hogan, A.; Lopez-Arevalo, I. Information extraction meets the semantic web: A survey. Semant. Web 2020, 11, 255–335. [Google Scholar] [CrossRef]
- Al-Moslmi, T.; Ocaña, M.G.; Opdahl, A.L.; Veres, C. Named Entity Extraction for Knowledge Graphs: A Literature Overview. IEEE Access 2020, 8, 32862–32881. [Google Scholar] [CrossRef]
- Singh, K.; Lytra, I.; Radhakrishna, A.S.; Shekarpour, S.; Vidal, M.E.; Lehmann, J. No one is perfect: Analysing the performance of question answering components over the dbpedia knowledge graph. J. Web Semant. 2020, 65, 100594. [Google Scholar] [CrossRef]
- Diefenbach, D.; Singh, K.; Maret, P. WDAqua-core1: A Question Answering service for RDF Knowledge Bases. In Proceedings of the Companion Web Conference 2018, Lyon, France, 23–27 April 2018; pp. 1087–1091. [Google Scholar]
- Bast, H.; Haussmann, E. More accurate question answering on freebase. In Proceedings of the 24th ACM International on Conference on Information and Knowledge Management, Melbourne, VIC, Australia, 18–23 October 2015; pp. 1431–1440. [Google Scholar]
- Shekarpour, S.; Marx, E.; Ngomo, A.C.N.; Auer, S. Sina: Semantic interpretation of user queries for question answering on interlinked data. J. Web Semant. 2015, 30, 39–51. [Google Scholar] [CrossRef]
- Dimitrakis, E.; Sgontzos, K.; Mountantonakis, M.; Tzitzikas, Y. Enabling Efficient Question Answering over Hundreds of Linked Datasets. In International Workshop on Information Search, Integration, and Personalization; Springer: Cham, Switzerland, 2019; pp. 3–17. [Google Scholar]
- Dimitrakis, E.; Sgontzos, K.; Tzitzikas, Y. A survey on question answering systems over linked data and documents. J. Intell. Inf. Syst. 2019, 55, 233–259. [Google Scholar] [CrossRef]
- Maliaroudakis, E.; Boland, K.; Dietze, S.; Todorov, K.; Tzitzikas, Y.; Fafalios, P. ClaimLinker: Linking Text to a Knowledge Graph of Fact-checked Claims. In Proceedings of the Companion Proceedings of the Web Conference 2021, Ljubljana, Slovenia, 19–23 April 2021; pp. 669–672. [Google Scholar]
- Chabchoub, M.; Gagnon, M.; Zouaq, A. Collective disambiguation and semantic annotation for entity linking and typing. In Semantic Web Evaluation Challenge; Springer: Cham, Switzerland, 2016; pp. 33–47. [Google Scholar]
- Beno, M.; Filtz, E.; Kirrane, S.; Polleres, A. Doc2RDFa: Semantic Annotation for Web Documents. In Proceedings of the Posters and Demo Track of the 15th International Conference on Semantic Systems, Karlsruhe, Germany, 9–12 September 2019; CEUR-WS.org: Aachen, Germany, 2019. [Google Scholar]
- Xiong, C.; Callan, J.; Liu, T.Y. Word-entity duet representations for document ranking. In Proceedings of the 40th International ACM SIGIR Conference on Research and Development in Information Retrieval, Tokyo, Japan, 7–11 August 2017; pp. 763–772. [Google Scholar]
- Geiß, J.; Spitz, A.; Gertz, M. Neckar: A named entity classifier for wikidata. In International Conference of the German Society for Computational Linguistics and Language Technology; Springer: Cham, Switzerland, 2017; pp. 115–129. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledge base. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef]
- Sakor, A.; Singh, K.; Patel, A.; Vidal, M.E. Falcon 2.0: An entity and relation linking tool over Wikidata. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Xi’an, China, 19–23 October 2020; pp. 3141–3148. [Google Scholar]
- Noullet, K.; Mix, R.; Färber, M. KORE 50DYWC: An Evaluation Data Set for Entity Linking Based on DBpedia, YAGO, Wikidata, and Crunchbase. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 2389–2395. [Google Scholar]
- Valdestilhas, A.; Soru, T.; Nentwig, M.; Marx, E.; Saleem, M.; Ngomo, A.C.N. Where is my URI? In European Semantic Web Conference; Springer: Cham, Switzerland, 2018; pp. 671–681. [Google Scholar]
- Mountantonakis, M.; Tzitzikas, Y. Content-Based Union and Complement Metrics for Dataset Search over RDF Knowledge Graphs. J. Data Inf. Qual. (JDIQ) 2020, 12, 1–31. [Google Scholar] [CrossRef]
- Beek, W.; Rietveld, L.; Bazoobandi, H.R.; Wielemaker, J.; Schlobach, S. LOD laundromat: A uniform way of publishing other people’s dirty data. In International Semantic Web Conference; Springer: Cham, Switzerland, 2014; pp. 213–228. [Google Scholar]
- Fernández, J.D.; Beek, W.; Martínez-Prieto, M.A.; Arias, M. LOD-a-lot. In International Semantic Web Conference; Springer: Cham, Switzerland, 2017; pp. 75–83. [Google Scholar]
- Acosta, M.; Hartig, O.; Sequeda, J. Federated RDF query processing. In Encyclopedia of Big Data Technologies; Sakr, S., Zomaya, A., Eds.; Springer: Cham, Switzerland, 2018; pp. 1–8. [Google Scholar]
- Guha, R.V.; Brickley, D.; Macbeth, S. Schema. org: Evolution of structured data on the web. Commun. ACM 2016, 59, 44–51. [Google Scholar] [CrossRef]
- Mountantonakis, M.; Tzitzikas, Y. Large Scale Semantic Integration of Linked Data: A survey. ACM Comput. Surv. (CSUR) 2019, 52, 103. [Google Scholar] [CrossRef]
- Cucerzan, S. Large-scale named entity disambiguation based on Wikipedia data. In Proceedings of the 2007 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL), Prague, Czech Republic, 28–30 June 2007; pp. 708–716. [Google Scholar]
- Milne, D.; Witten, I.H. Learning to link with wikipedia. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 509–518. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Tool | Input | ER Method | Linking to KBs | Main Output |
|---|---|---|---|---|
| Stanford CoreNLP [11] | Text | pure NLP | 1 KB (Wikipedia, by using a dictionary) | Part-of-Speech Tagging, Annotation, Hyperlink Creation, others |
| DBpedia Spotlight [6] | Text | KB | 1 KB (DBpedia) | Annotation, Hyperlink Creation |
| WAT [8] | Text | KB | 1 KB (Wikipedia) | Annotation, Hyperlink Creation, Entity Relatedness |
| Babelfy [16] | Text | KB | 1 KB (DBpedia) | Annotation, Hyperlink Creation |
| AIDA [17] | Text, Tables | KB | 1 KB (YAGO) | Annotation, Hyperlink Creation |
| REL [18] | Text | NN | 1 KB (Wikipedia) | Annotation, Hyperlink Creation |
| SOTA NLP [19] | Text | NN | 1 KB (Wikipedia) | Annotation, Hyperlink Creation |
| ID | Service Name | Description | Parameters | Response Types |
|---|---|---|---|---|
| 1 | exportAsRDFa | Recognizing all the entities of a text and annotating the entities by using HTML+RDFa format. | text: A text of any length. ERtools: one of the following: [WAT, SCNLP, DBS, DBSWAT, SCNLPWAT, DBSCNLP, ALL]. | text/html |
| 2 | getEntities | Recognizing all the entities of a text and returns for each entity its DBpedia URI, its LODsyndesis URI, and optionally all its available URIs and its provenance. | text: A text of any length. ERtools: one of the following: [WAT, SCNLP, DBS, DBSWAT, SCNLPWAT, DBSCNLP, ALL] equivalentURIs: True for returning all the available URIs for each recognized entity (optional). provenance: True for returning all the available datasets for each recognized entity (optional). | text/tsv, application/ n-triples |
| 3 | getTriples OfEntities | Recognizing all the entities of a text and producing all the triples of each recognized entity from 400 RDF datasets. | text: A text of any length. ERtools: one of the following: [WAT, SCNLP, DBS, DBSWAT, SCNLPWAT, DBSCNLP, ALL] | application/ n-quads |
| 4 | findRelated Facts | Recognizing all the entities of a text and produces all the facts between the key entity of the text and any other entity. The key entity is by default the first entity of the text, but the user can optionally give an other entity. | text: A text of any length. ERtools: one of the following: [WAT, SCNLP, DBS, DBSWAT, SCNLPWAT, DBSCNLP, ALL]. keyEntity: Put a URI of an entity (optional). | application/ n-quads |
| 5 | textEntities DatasetDiscovery | Recognizing all the entities of a text. For the recognized entities, it returns the K datasets a) whose union contains the most triples for these entities (coverage) or b) that contains the most common triples for these entities (commonalities). | text: A text of any length. ERtools: one of the following: [WAT, SCNLP, DBS, DBSWAT, SCNLPWAT, DBSCNLP, ALL] resultsNumber: Number of Results. It can be any integer greater than 0, default is 10 (optional). subsetK: Number of Datasets: [1,2,3,4,5], default is 3 (optional). measurementType: It can be one of the following: [coverage, commonalities], default is coverage (optional). | text/csv |
| Evaluation Collection | Topic | Number of Texts | Entities per Text | Words per Text | Evaluation Task |
|---|---|---|---|---|---|
| SimpleWiki | Wikipedia texts | 10 | 15.80 | 83.2 | Effectiveness of ER tools, Data Enrichment, Efficiency. |
| MSNBC [43] | news | 20 | 37.35 | 543.9 | Effectiveness of ER tools |
| AQUAINT [44] | news | 50 | 14.54 | 220.5 | Effectiveness of ER tools |
| TextID | Text Description | # of Total Words | # of Entities |
|---|---|---|---|
| T1 | Lord of the Rings Film Series | 97 | 27 |
| T2 | Nikos Kazantzakis (greek writer) | 86 | 13 |
| T3 | Scorpions (band) | 81 | 21 |
| T4 | The Godfather (Movie) | 84 | 20 |
| T5 | 2011 NBA Finals | 70 | 12 |
| T6 | Argonauts (greek mythology) | 80 | 13 |
| T7 | Taj Mahal Mausoleum | 67 | 10 |
| T8 | Semantic Web and Tim Berners Lee | 92 | 15 |
| T9 | Phaistos Disc (minoan civilization) | 75 | 12 |
| T10 | Aristotle (Philosopher) | 100 | 15 |
| Selected Tool (s) | Avg Precision | Avg Recall | Avg F1 Score |
|---|---|---|---|
| DBpedia Spotlight (DBS) | 0.854 | 0.683 | 0.752 |
| Stanford CoreNLP (SCNLP) | 0.752 | 0.479 | 0.568 |
| WAT | 0.899 | 0.607 | 0.711 |
| DBS+SCNLP | 0.833 | 0.800 | 0.809 |
| DBS+WAT | 0.911 | 0.777 | 0.831 |
| SCNLP+WAT | 0.831 | 0.699 | 0.747 |
| All tools (DBS+SCNLP+WAT) | 0.857 | 0.857 | 0.850 |
| Text | Tool & Max Prec. | Tool & Max Rec. | Tool & Max F1 Sc. |
|---|---|---|---|
| (T1) Lord of the Rings | (WAT) 1.000 | (All tools) 0.888 | (All tools) 0.888 |
| (T2) N. Kazantzakis | (DBS + WAT) 0.923 | ( + WAT) 0.923 | (DBS + WAT) 0.923 |
| (T3) Scorpions Band | (All tools) 0.900 | (All tools) 0.857 | (All tools) 0.878 |
| (T4) Godfather | (All tools) 1.000 | (All tools) 0.900 | (All tools) 0.947 |
| (T5) 2011 NBA Finals | (DBS) 0.750 | (DBS) 0.818 | (DBS) 0.782 |
| (T6) Argonauts | (WAT) 1.000 | (All tools) 1.000 | (DBS + WAT) 0.923 |
| (T7) Taj Mahal | (DBS + WAT) 1.000 | (All tools) 0.900 | (All tools) 0.857 |
| (T8) Semantic Web | (DBS + WAT) 1.000 | (All tools) 1.000 | (All tools) 0.967 |
| (T9) Phaistos Disc | (All tools) 1.000 | (All tools) 0.583 | (All tools) 0.736 |
| (T10) Aristotle | (WAT) 0.900 | (All tools) 0.800 | (DBS + WAT) 0.785 |
| Selected Tool(s) | Avg Precision | Avg Recall | Avg F1 Score |
|---|---|---|---|
| DBpedia Spotlight (DBS) | 0.378 | 0.434 | 0.387 |
| Stanford CoreNLP (SCNLP) | 0.449 | 0.304 | 0.376 |
| WAT | 0.544 | 0.487 | 0.512 |
| DBS + SCNLP | 0.314 | 0.433 | 0.356 |
| DBS + WAT | 0.350 | 0.504 | 0.407 |
| SCNLP + WAT | 0.477 | 0.465 | 0.469 |
| All tools (DBS + SCNLP + WAT) | 0.346 | 0.509 | 0.405 |
| Selected Tool (s) | Avg Precision | Avg Recall | Avg F1 Score |
|---|---|---|---|
| DBpedia Spotlight (DBS) | 0.463 | 0.401 | 0.421 |
| Stanford CoreNLP (SCNLP) | 0.579 | 0.242 | 0.326 |
| WAT | 0.555 | 0.381 | 0.435 |
| DBS + SCNLP | 0.450 | 0.434 | 0.434 |
| DBS + WAT | 0.465 | 0.493 | 0.472 |
| SCNLP + WAT | 0.514 | 0.375 | 0.419 |
| All tools (DBS + SCNLP + WAT) | 0.461 | 0.496 | 0.470 |
| Selected Tool (s) | Avg Precision | Avg Recall | Avg F1 Score |
|---|---|---|---|
| DBpedia Spotlight (DBS) | 0.491 | 0.444 | 0.454 |
| Stanford CoreNLP (SCNLP) | 0.568 | 0.287 | 0.369 |
| WAT | 0.595 | 0.436 | 0.489 |
| DBS + SCNLP | 0.464 | 0.479 | 0.462 |
| DBS + WAT | 0.492 | 0.532 | 0.500 |
| SCNLP + WAT | 0.544 | 0.438 | 0.472 |
| All tools (DBS + SCNLP + WAT) | 0.482 | 0.544 | 0.501 |
| Measurements for Entities and Facts | Value |
|---|---|
| # of Entities in ≥2 Datasets | 25,289,605 |
| # of Entities in ≥3 Datasets | 6,979,109 |
| # of Entities in ≥5 Datasets | 1,673,697 |
| # of Entities in ≥10 Datasets | 119,231 |
| Pairs of Datasets having at least 1 common entity | 9075 |
| # of verifiable facts from ≥2 Datasets | 14,648,066 |
| # of verifiable facts from ≥3 Datasets | 4,348,019 |
| # of verifiable facts from ≥5 Datasets | 53,791 |
| # of verifiable facts from ≥10 Datasets | 965 |
| Pairs of Datasets having at least 1 common fact | 4468 |
| Measurement/Datasets | Linking Only to DBpedia | Linking only to Wikidata | Linking to DBpedia, Wikidata | Linking to LODsyndesis |
|---|---|---|---|---|
| avg URIs per recognized entity | 1.0 | 1.0 | 2.0 | 13.2 |
| avg Datasets per recogn. entity | 1.0 | 1.0 | 2.0 | 8.5 |
| avg Triples per recogn. entity | 406.7 | 326.8 | 733.5 | 1255.5 |
| avg Verified Facts per recognized entity from ≥2 Datasets | − | − | 1.8 | 9.2 |
| Text | # of Total Data Sets | # of Total Triples | Top 3 Datasets than Enriches at Most the Content of the Text Entities | # of Triples (Top 3 Datasets) |
|---|---|---|---|---|
| (T1) Lord of the Rings | 22 | 21,852 | DBpedia, Wikidata, Freebase | 17,393 |
| (T2) N. Kazantzakis | 18 | 7035 | DBpedia, Wikidata, Freebase | 4292 |
| (T3) Scorpions Band | 27 | 66,782 | DBpedia, Wikidata, Freebase | 64,003 |
| (T4) Godfather Movie | 20 | 16,514 | DBpedia, Wikidata, Freebase | 12,723 |
| (T5) 2011 NBA Finals | 13 | 7540 | DBpedia, YAGO, Freebase | 6,186 |
| (T6) Argonauts | 18 | 3607 | YAGO, Wikidata, Freebase | 2471 |
| (T7) Taj Mahal | 15 | 5350 | BNF, Wikidata, Freebase | 4284 |
| (T8) Semantic Web | 48 | 35,004 | DBpedia, Wikidata, BNF | 23,635 |
| (T9) Phaistos Disc | 20 | 6484 | DBpedia, Wikidata, BNF | 4788 |
| (T10) Aristotle | 34 | 22,837 | DBpedia, Wikidata, Freebase | 13,421 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mountantonakis, M.; Tzitzikas, Y. Linking Entities from Text to Hundreds of RDF Datasets for Enabling Large Scale Entity Enrichment. Knowledge 2022, 2, 1-25. https://doi.org/10.3390/knowledge2010001
Mountantonakis M, Tzitzikas Y. Linking Entities from Text to Hundreds of RDF Datasets for Enabling Large Scale Entity Enrichment. Knowledge. 2022; 2(1):1-25. https://doi.org/10.3390/knowledge2010001
Chicago/Turabian StyleMountantonakis, Michalis, and Yannis Tzitzikas. 2022. "Linking Entities from Text to Hundreds of RDF Datasets for Enabling Large Scale Entity Enrichment" Knowledge 2, no. 1: 1-25. https://doi.org/10.3390/knowledge2010001
APA StyleMountantonakis, M., & Tzitzikas, Y. (2022). Linking Entities from Text to Hundreds of RDF Datasets for Enabling Large Scale Entity Enrichment. Knowledge, 2(1), 1-25. https://doi.org/10.3390/knowledge2010001