4.1. Core Bounce Blockchain Protocol
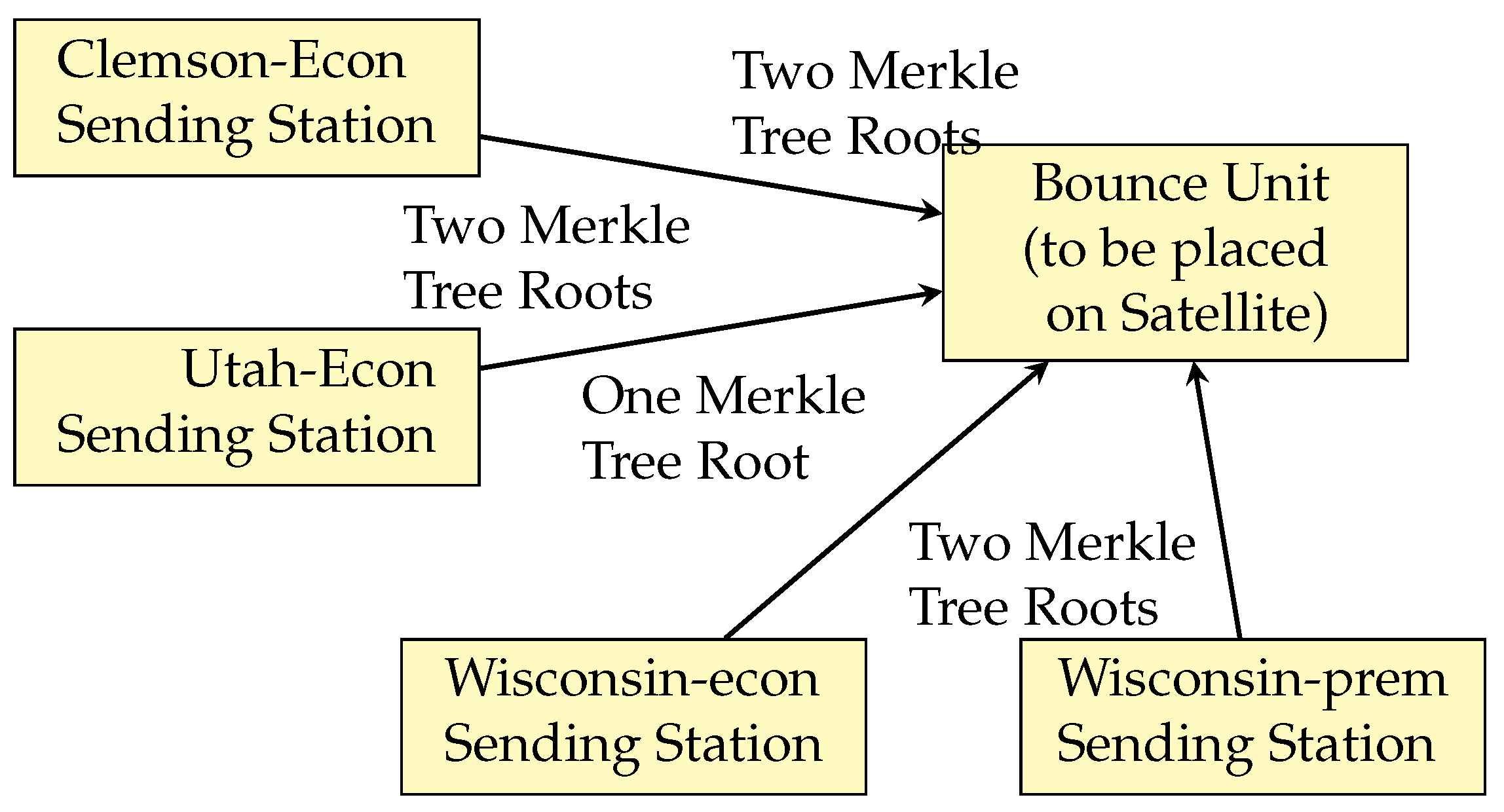
Step 1 (Before slot i begins) Each Sending Station that wishes to participate in the slot assembles one or more Merkle trees for slot i: A Sending Station adds each submitted transaction to some list
L. If the clock time is at
d seconds before the beginning of slot
i, the Sending Station for that slot builds a Merkle tree
T using the transactions in
L. The Merkle tree
T is then sent to at least
Broadcast Ground Stations (step 1 in
Figure 2 and detailed in Algorithm 1). Each Broadcast Ground Station computes the Merkle root from the Merkle tree and sends the signed root back to the Sending Station as well as to user nodes. User nodes will store that Merkle Tree but will process the contained transactions only after receiving a Commit Record containing the corresponding Merkle Tree root. (step 1’ in
Figure 2). The Sending Station then aggregates the
signatures to a single multisignature as described in Algorithm 2. In our experiments, we set
d to one second and
to be 80% of the Broadcast Ground Stations as you can see in
Section 6.
After the end of slot , Broadcast Ground Stations multisign the Commit Record for slot : Separately and possibly concurrently with Merkle Tree construction,
Broadcast Ground Stations form a multisignature of the Commit Record of slot
. That happens as follows: when a Satellite sends the Commit Record for slot
to a set of Broadcast Ground Stations (step 2 in
Figure 2), each receiving Broadcast Ground Station
G broadcasts the Commit Record to at least
f other Broadcast Ground Stations. Each receiving Broadcast Ground Station signs the Commit Record and sends it back to
G. The Broadcast Ground Station
G then aggregates at least
f other signatures and its own signature for the Commit Record for slot
into a single multisignature. Then, the Broadcast Ground Station
G sends the multisignature to all possible Sending Stations for slot
i (step 2’ in
Figure 2) as well as to User nodes. Several Broadcast Ground Stations may duplicate this effort for fault tolerance reasons.
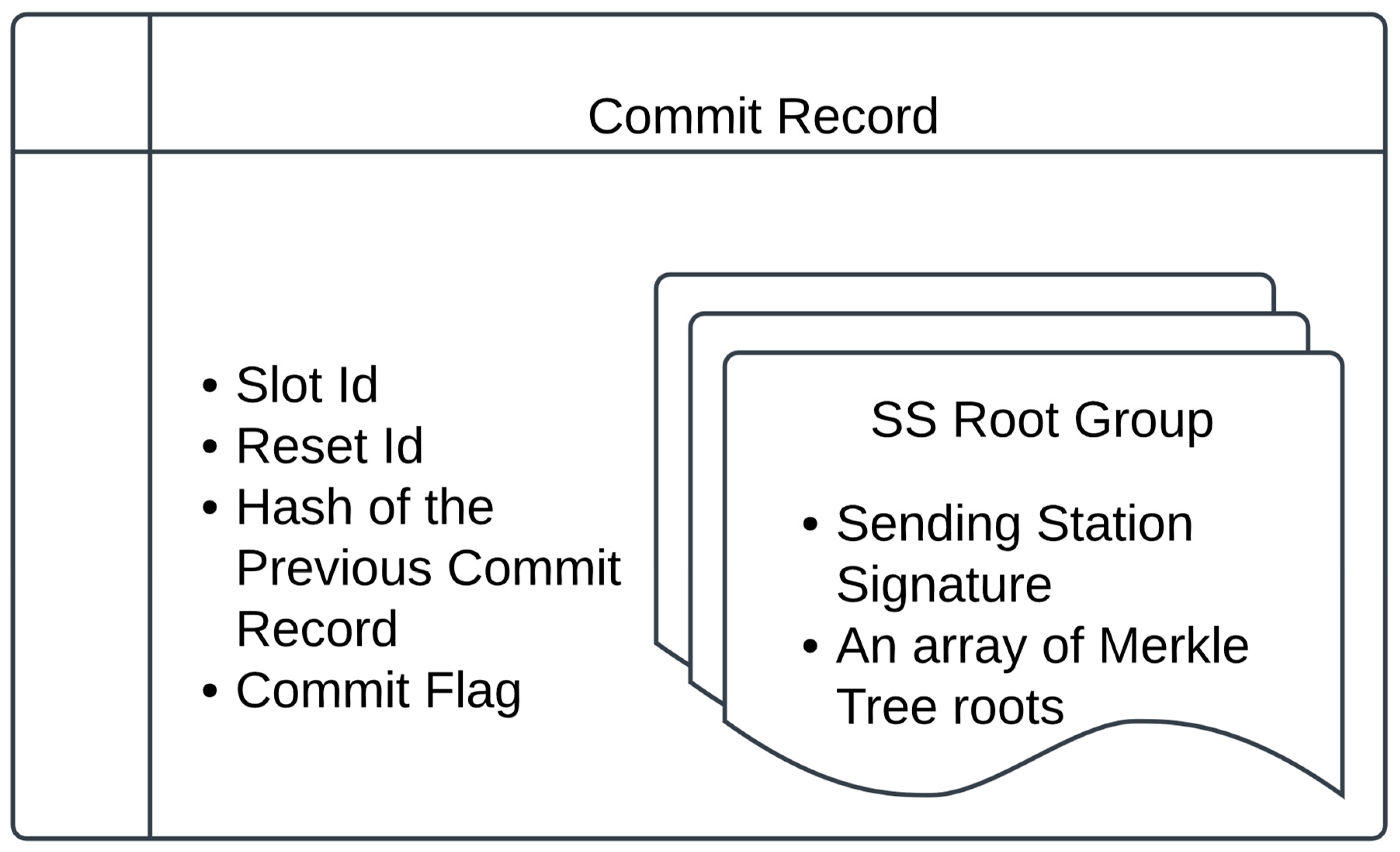
Sending Station sends Sending Station message (step 3 in Figure 2): At the beginning of slot
i, each Sending Station that wants to participate in slot
i creates a Sending Station message including both a multisigned Commit Record for slot
and the multisigned Merkle tree root (as described in Algorithm 3). It sends the Sending Station message to the Satellite that is responsible for slot
i. There could be multiple Sending Stations creating and sending the Sending Station messages to the same satellite for each slot
i.
Satellite creates Commit Record and broadcasts (step 4 in Figure 2): When a Satellite for slot
i receives a Sending Station message for that slot, it (a) tests that the signature is indeed signed by the Sending Station, (b) checks the identifier in the Sending Station message is
i, (c) validates the multisignature on the Commit Record for slot
, (d) the Commit Record is for slot
and Commit flag set to True, (e) validates the multisignature on the Merkle root (by checking the public keys of the Broadcast Ground Stations).
If all the tests succeed, the Satellite keeps the Sending Station message in a buffer holding the set of valid Sending Station messages. At the beginning of the slot i, the Satellite selects all of the valid Sending Station messages and creates a positive Commit Record with the Merkle Tree root in those Sending Station messages. Even if none of the sending station messages contains a Merkle Tree root, the satellite can still create a positive Commit Record if any valid Sending Station message contains the previous Commit Record.
If the satellite does not receive a previous Commit Record, however, it creates a negative Commit Record saying effectively that the Commit Record for slot
is unavailable. The satellite sends that negative Commit Record to Broadcast Ground Stations which will relay it to Mission Control to do a reset [
3]. In the case of a positive Commit Record, the satellite will give a total order of the Merkle Tree roots. If the same Merkle Tree root is contained in multiple Sending Station messages, the satellite keeps only the first.
| Algorithm 1 The Sending Stations constructs the Merkle Tree and sends the transactions to Broadcast Ground Stations |
- 1:
Create a SignMerkleTreeRequest object with: - 2:
Send the sign_merkle_tree_request to Broadcast Ground Stations in parallel. - 3:
Construct a Merkle Tree mt from txs. - 4:
Set self.root to the root of mt.
|
| Algorithm 2 Given the Signature of the Merkle Tree Root from a Broadcast Ground Station, the Sending Station checks its validity and if there are enough (viz. ) valid root signatures, the Sending Station assembles the multisignature on the Merkle Tree root, using the BLS algorithm of [49,50] |
- 1:
Verify the signature for the given root. - 2:
if signature verification fails or root doesn’t match the one created by the Sending Station then - 3:
exit - 4:
end if - 5:
if the root from this Broadcast Ground Station has already been processed then - 6:
exit - 7:
end if - 8:
Add the signature to root_to_sigs map. - 9:
Retrieve the list of signatures for the root. - 10:
if number of signatures then - 11:
Initialize a bit vector signers_bitvec. - 12:
for each ground station public key pk do - 13:
for each signature in sigs do - 14:
if signature is valid for pk and root then - 15:
Set corresponding bit in signers_bitvec. - 16:
break inner loop. - 17:
end if - 18:
end for - 19:
end for - 20:
if at least distinct signers then - 21:
Create multi_signed based on the signatures. - 22:
Cache multi_signed. - 23:
Mark root as processed and remove from root_to_sigs. - 24:
else - 25:
exit (f+1 check failed). - 26:
end if - 27:
end if
|
(4) Satellite then broadcasts the Commit Record back to Broadcast Ground Stations. This in turn triggers Broadcast Ground Stations to create a multisignature for the Commit Record of slot i.
Broadcast Ground Station broadcasts Satellite Commit Record: The Broadcast Ground Stations make this message (positive or negative Commit Record) widespread by sending it (step 5 in
Figure 2) (e.g., on a peer-to-peer network). They also send the Commit Record to the Sending Station (or, in general, Sending Stations) for the next slot, which handles it as described in Algorithm 4.
Users check validity of block: Any user of block
i can check the block’s validity by confirming that the Commit Record for slot
i: (a) is signed by the satellite for slot
i, (b) the Commit Record is positive, (c) the signed Sending Station message has slot
i and the Merkle root for slot
i in the Commit Record corresponds to the Merkle tree of slot
i. Assuming the Commit Record is positive, it now remains for users to check transactions for double-spending and other such abuses. We discuss this in
Section 4.3.
| Algorithm 3 The Sending Station constructs the Sending Station Message and sends it to the satellite |
- 1:
if no multisigned previous commit record is received then - 2:
exit - 3:
end if - 4:
Constructs the sending_station_message with: - 5:
Sends sending_station_message to the satellite.
|
| Algorithm 4 The Sending Station Handles a multisigned Commit Record |
- 1:
if CommitRecord signature verification fails then - 2:
exit. - 3:
end if - 4:
if Received cr.reset_id does not match expected self.reset_id then - 5:
exit. - 6:
end if - 7:
if Received cr.slot_id does not match expected self.slot_id then - 8:
exit. - 9:
end if - 10:
if Previous CommitRecord exists AND Previous CommitRecord hash does not match the received one then - 11:
exit. - 12:
end if - 13:
Set self.prev_cr to multi_signed_cr.
|
Negative Commit Record and Resets
If the user sees that some slot has no Commit Record or the Commit Record is negative, that user should alert Mission Control and show proof of the negative Commit Record. Mission Control then performs a reset [
3], which will reassign roles to terrestrial components and create a new slot assignment for satellites.
Briefly, a reset entails identifying the Commit Record of the last committed slot by polling Broadcast Ground Stations and users and re-starting the blockchain at the next slot value, possibly with new slot assignments for satellites and new Broadcast Ground Stations and Sending Stations. For technical reasons, to prevent certain race conditions, there is also a reset number, so the slot identifier is a pair of reset number and slot number. The book [
3] shows that the reset protocol is safe given the exposure-aversion trust assumptions.
Moreover, the reset message is simple to interpret because all it’s doing is assigning roles to satellites, Sending stations, and Broadcast Ground Station, so will be simple to monitor. We note that similar reputational mechanisms are used in many applications, including in vehicle-to-vehicle applications [
51]. Moreover, users of popular blockchains like Ethereum, must trust the administrators of the system, when they perform software updates.
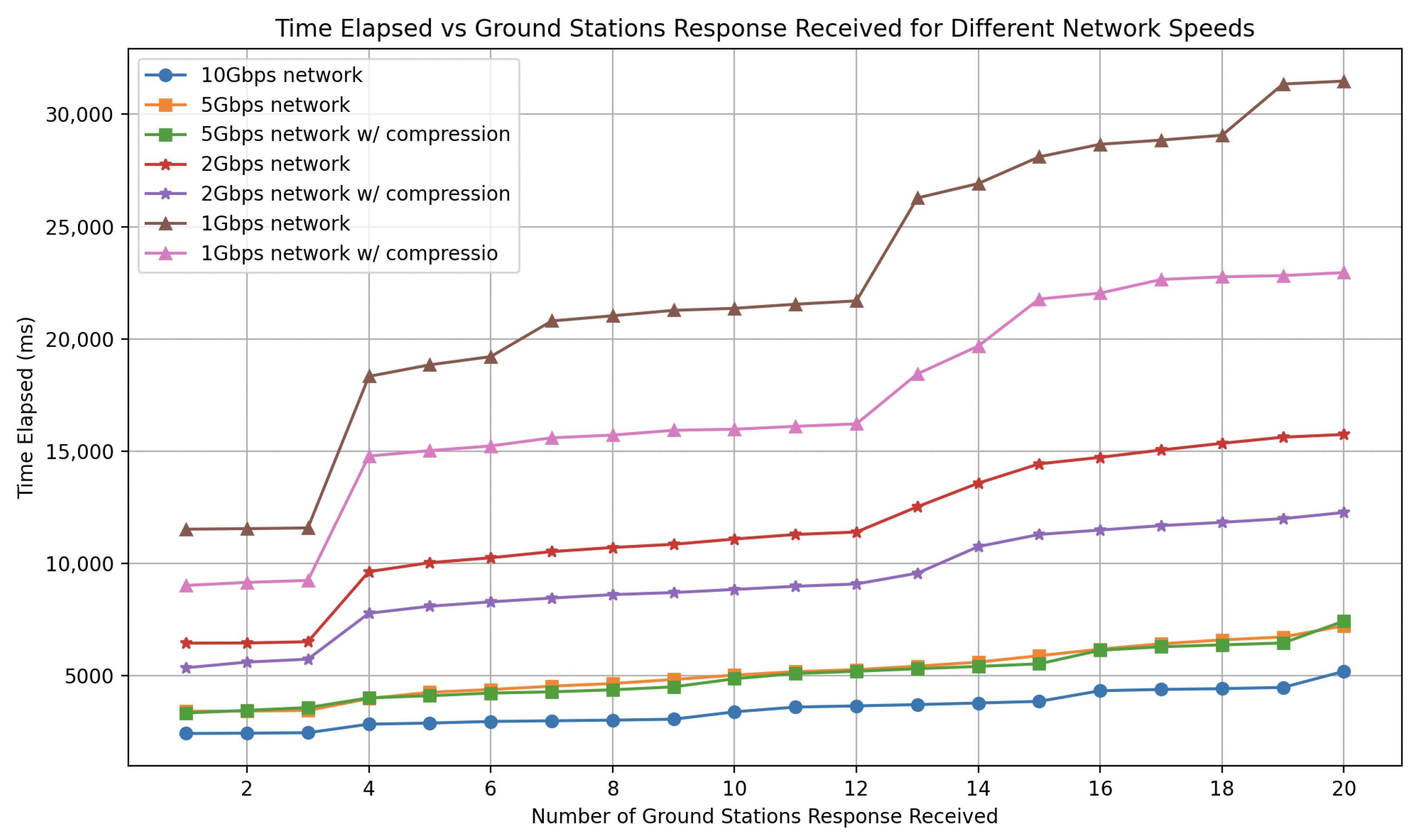
4.2. Failure/Response Summary
We summarize the possible failure cases, their consequences, and how we handle those in
Figure 3. Sending Stations might fail both cleanly (e.g., fail-stop) and traitorously. Neither failure type requires any specific action, because a failing Sending Station cannot forge user transactions nor the signatures of other agent. Sending Station failures do increase the response time of transactions that were sent to the failing Sending Stations. Such transactions will have to be sent to other Sending Stations.
Regarding the assumption of at most
f failing (clean and traitorous) Broadcast Ground Stations, with
f a number in the high teens, we believe this is reasonable given that the failure of any Broadcast Ground Station will be evident given that it signs a Merkle Tree (or Commit Record), but fails to send that to User Nodes. The only damage
f or fewer traitorous Broadcast Ground Stations can do is to cause denial of service. Malicious Ground Stations cannot forge user messages because messages are signed. Moreover, even if only 1 out of
properly makes information (Merkle trees and Commit Records) widespread, that is sufficient. This is in contrast to consensus algorithms such as Byzantine Fault Tolerance [
52] for which a supermajority of agents need to work correctly. Spreading information is simpler than consensus. Denial of service causes a slower response time for some transactions, but does not slow down the whole system.
Recall the assumption that the Bounce Units in the satellites don’t suffer from traitorous failures. We believe that this is reasonable because the Bounce Unit protocol is quite simple (check the signatures of one or more Sending Station messages, sign and send) and therefore can be verified and burned into Read-Only memory. Such an architecture makes Bounce Units secure against remote software modification.
Note however that satellites can fail cleanly, so may fail to send messages either intermittently or permanently. We believe satellite failures will be very infrequent though, on the order of once every few months or years. When such failures do occur, we invoke the reset protocol in which the human participants of Mission Control (over several minutes possibly) decide on a new slot assignment and send a reset message.
4.3. Accumulator Node Algorithms: Account Balances
As mentioned above, to support payments, one or more user nodes, called
Accumulators, can maintain the account balances of all account holder based on the ordered sequence of blocks in the blockchain. This is an application concern, so is not our primary focus. Nevertheless, because payments are a core use case of many blockchain systems, we describe the algorithms here and the implementation in
Section 7.
There are two main issues, the first having to do with the Bounce protocol itself and the second is generic to payment systems.
Because user transactions may be sent to several Sending Stations, the same transaction may appear in several Merkle trees. We would want to avoid processing the same transaction more than once.
In a payment setting, we want to guarantee that accounts can’t fall below zero coins.
The overall pseudo-code of an accumulator node is shown in Algorithm 5.
| Algorithm 5 The Accumulators Processing Commit Records |
- 1:
Input: Commit record containing root r and corresponding Merkle Tree . - 2:
Procedure: - 3:
if r has already been seen (possibly from a different Sending Station) then - 4:
Ignore - 5:
else - 6:
for each transaction T in do - 7:
if T has already appeared in the current or a previously committed Merkle tree then - 8:
Ignore T - 9:
else - 10:
Process T
|
Algorithm 5 ensures that an accumulator does not process the same transaction twice. The “Process T” step requires a data structure. We propose constructing transaction identifiers as the concatenation of the wallet identifier of the payor and a sequence number. The account record for a wallet W consists of W’s wallet id, a balance, and some representation of the sequence numbers of all committed transactions in which W is the payer. In the case where each wallet issues a payment transaction only when all of its previous transactions have already appeared in committed Merkle trees, this representation consists simply of the highest sequence number of any committed transaction.
We now elaborate on what process(T) does in Algorithm 6.
| Algorithm 6 The Accumulators Processing a Transaction T for the payer wallet Walletid |
- 1:
Extract transaction identifier of the payer from T - 2:
ifseqnum is not already in the set of committed transactions of Walletid then - 3:
Add seqnum to the set of committed transactions of Walletid - 4:
Execute T which will cause payment if there are sufficient funds in this wallet - 5:
end if
|
If the funds are insufficient, then the execution of T may be modified, either to do nothing or to perform a partial payment. In our algorithms, we assume for simplicity that insufficient funds result in no payment. When there are sufficient funds, an Accumulator node will update both Wallets.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}