
A User Location Reset Method through Object Recognition in Indoor Navigation System Using Unity and a Smartphone (INSUS)

 ,
,  ,
,  ,
,  ,
,  and
and 
Abstract
1. Introduction
2. Literature Review
2.1. YOLO Model-Based Detection Methods
2.2. Optical Character Recognition Methods
2.3. Indoor Positioning Methods of AR-Based Indoor Navigation Systems
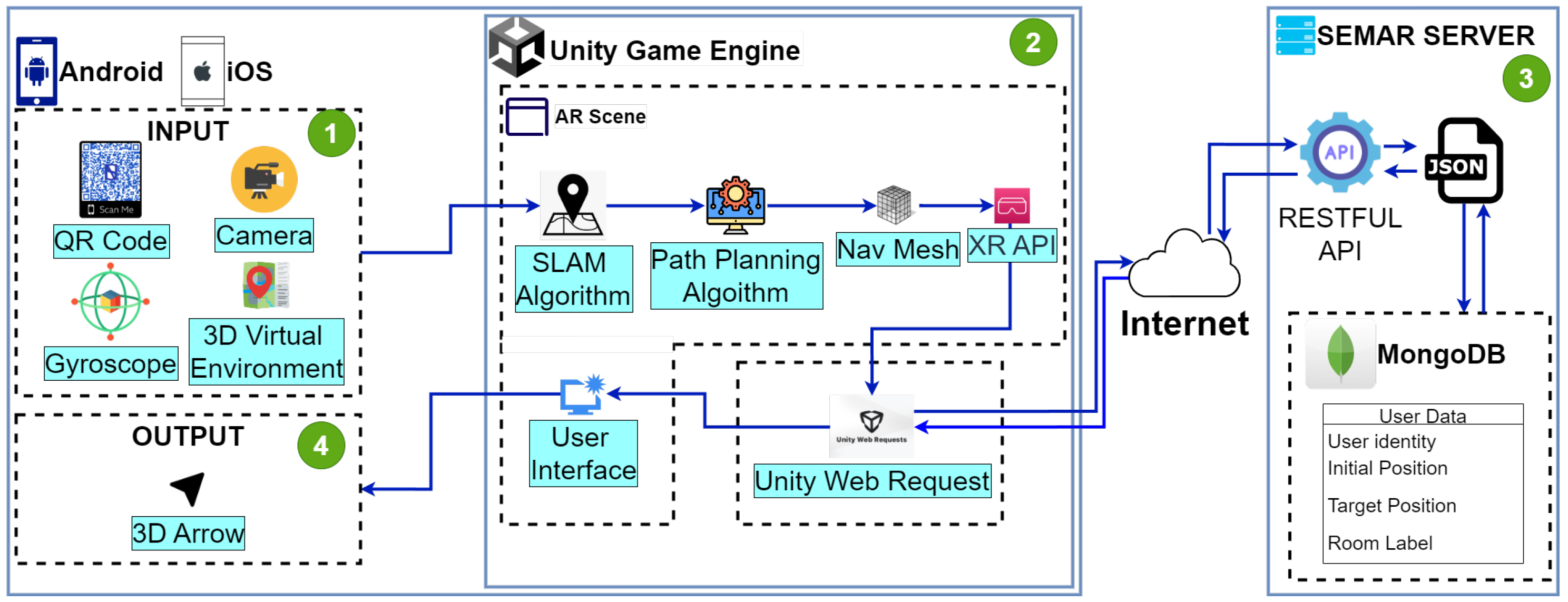
3. Review of Indoor Navigation System Using Unity and a Smartphone (INSUS)
3.1. INSUS Overview
3.2. Input
3.3. Unity Game Engine
3.4. Output
3.5. SEMAR Server
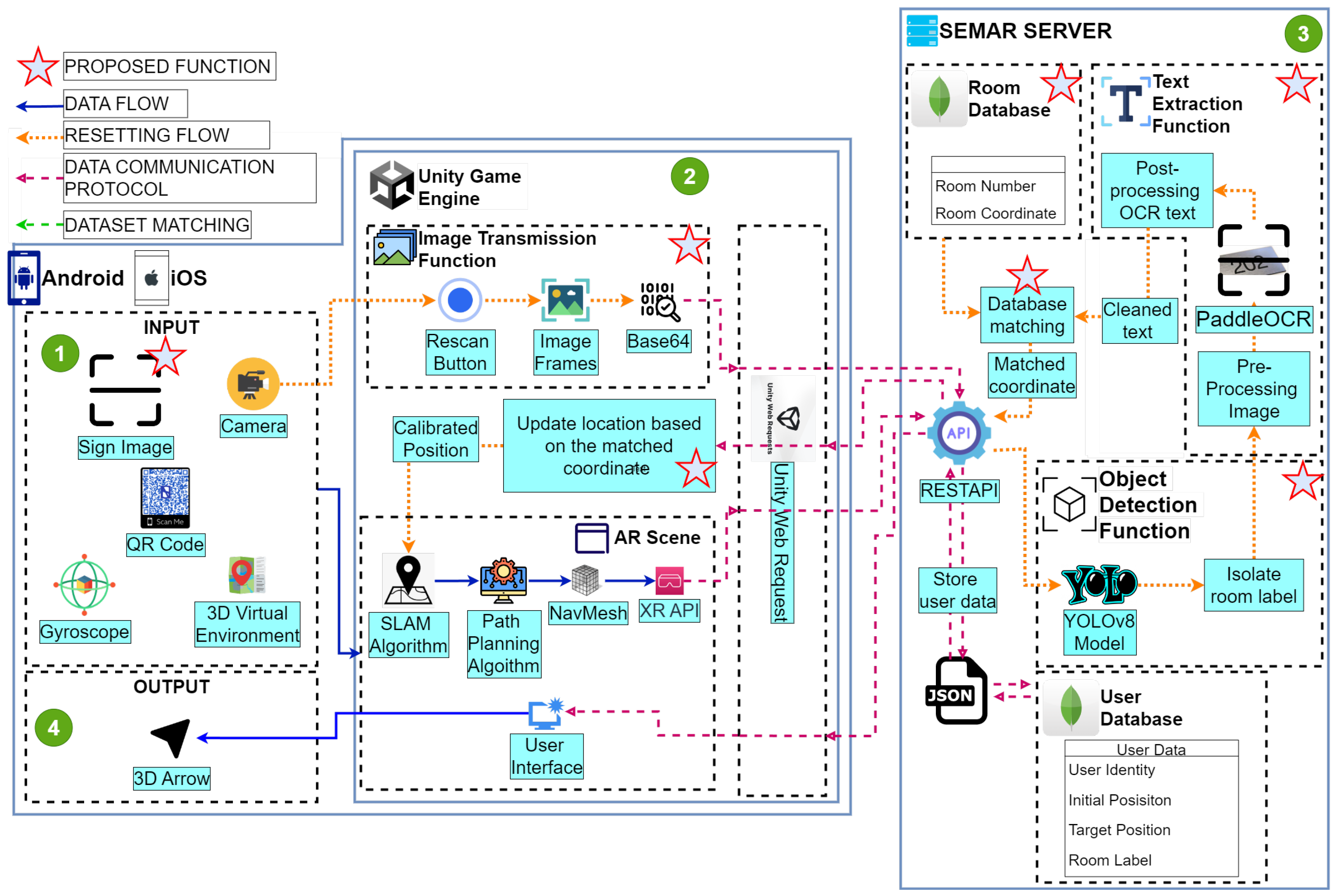
4. Proposal
4.1. System Overview
4.2. Sign Image
4.3. Image Transmission Function
4.4. Object Detection Function
4.5. Text Extraction Function
4.6. Database Matching Function
5. Evaluations
5.1. Training Preparation and Dataset Augmentation
5.2. Performance Analysis of the Object Detection Function
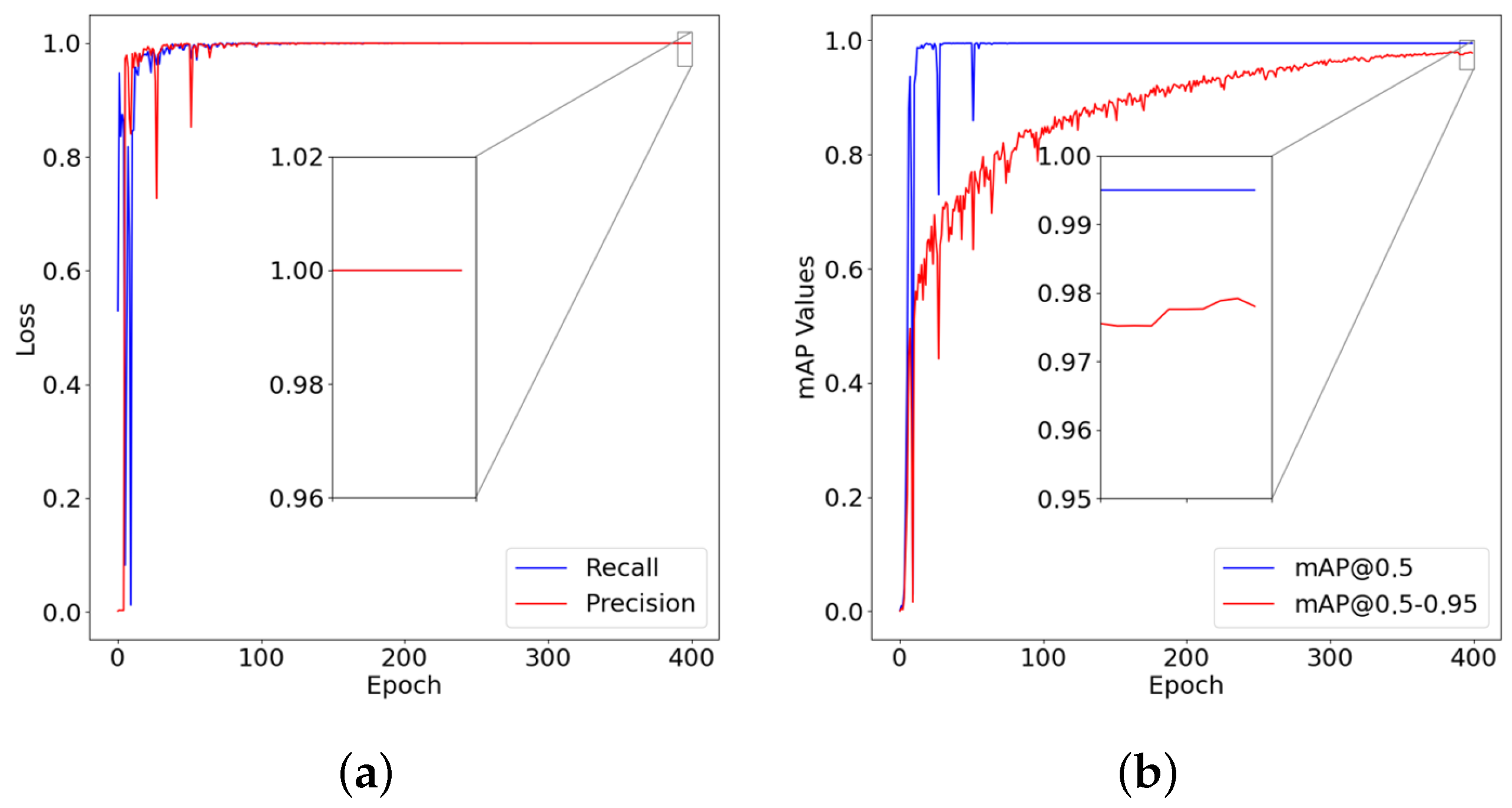
5.2.1. Box and Class Loss Validation of the Object Detection Function
5.2.2. Precision, Recall, and mAP Validation of the Object Detection Function
5.3. Performance Analysis of Text Extraction and Database Matching Function
5.3.1. Experimental Scenarios
5.3.2. Accuracy of Text Extraction and Database Matching Function
5.4. Comparison of the Execution Time of the User Location Reset Method
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Franco, J.T. Navigating Complexity and Change in Architecture with Data-Driven Technologies. 2023. Available online: https://www.archdaily.com/1001585/navigating-complexity-and-change-in-architecture-with-data-driven-technologies (accessed on 5 June 2024).
- Engel, C.; Mueller, K.; Constantinescu, A.; Loitsch, C.; Petrausch, V.; Weber, G.; Stiefelhagen, R. Travelling more independently: A Requirements Analysis for Accessible Journeys to Unknown Buildings for People with Visual Impairments. In Proceedings of the 22nd International ACM SIGACCESS Conference on Computers and Accessibility, Virtual Event, Greece, 26–28 October 2020; Volume 11. [Google Scholar] [CrossRef]
- Mansour, A.; Chen, W. SUNS: A user-friendly scheme for seamless and ubiquitous navigation based on an enhanced indoor-outdoor environmental awareness approach. Remote Sens. 2022, 14, 5263. [Google Scholar] [CrossRef]
- Fajrianti, E.D.; Funabiki, N.; Sukaridhoto, S.; Panduman, Y.Y.F.; Dezheng, K.; Shihao, F.; Surya Pradhana, A.A. Insus: Indoor navigation system using unity and smartphone for user ambulation assistance. Information 2023, 14, 359. [Google Scholar] [CrossRef]
- Simon, J. Augmented Reality Application Development using Unity and Vuforia. Interdiscip. Descr. Complex Syst. INDECS 2023, 21, 69–77. [Google Scholar] [CrossRef]
- Haas, J.K. A History of the Unity Game Engine. 2014. Available online: https://www.semanticscholar.org/paper/A-History-of-the-Unity-Game-Engine-Haas/5e6b2255d5b7565d11e71e980b1ca141aeb3391d (accessed on 7 July 2024).
- Unity. Unity Real-Time Development Platform: 3D, 2D, VR & AR Engine. Available online: https://unity.com/cn (accessed on 7 July 2024).
- Linowes, J. Augmented Reality with Unity AR Foundation: A Practical Guide to Cross-Platform AR Development with Unity 2020 and Later Versions; Packt Publishing Ltd.: Birmingham, UK, 2021. [Google Scholar]
- Afif, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation. Neural Process. Lett. 2020, 51, 2265–2279. [Google Scholar] [CrossRef]
- Pivavaruk, I.; Cacho, J.R.F. OCR Enhanced Augmented Reality Indoor Navigation. In Proceedings of the 2022 IEEE International Conference on Artificial Intelligence and Virtual Reality (AIVR), Virtual, 12–14 December 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 186–192. [Google Scholar]
- Farooq, J.; Muaz, M.; Khan Jadoon, K.; Aafaq, N.; Khan, M.K.A. An improved YOLOv8 for foreign object debris detection with optimized architecture for small objects. Multimed. Tools Appl. 2023, 83, 60921–60947. [Google Scholar] [CrossRef]
- Chidsin, W.; Gu, Y.; Goncharenko, I. Smartphone-Based Positioning Using Graph Map for Indoor Environment. In Proceedings of the 2023 IEEE 12th Global Conference on Consumer Electronics (GCCE), Kokura, Japan, 29 October–1 November 2024; IEEE: Piscataway, NJ, USA, 2023; pp. 895–897. [Google Scholar]
- Bueno, J. Development of Unity 3D Module For REST API Integration: Unity 3D and REST API Technology. 2017. Available online: https://www.academia.edu/83722981/Development_of_Unity_3D_Module_For_REST_API_Integration_Unity_3D_and_REST_API_Technology (accessed on 8 July 2024).
- Ward, T.; Bolt, A.; Hemmings, N.; Carter, S.; Sanchez, M.; Barreira, R.; Noury, S.; Anderson, K.; Lemmon, J.; Coe, J.; et al. Using unity to help solve intelligence. arXiv 2020, arXiv:2011.09294. [Google Scholar]
- Wang, Z.; Han, K.; Tiwari, P. Digital twin simulation of connected and automated vehicles with the unity game engine. In Proceedings of the 2021 IEEE 1st International Conference on Digital Twins and Parallel Intelligence (DTPI), Beijing, China, 15 July–15 August 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–4. [Google Scholar]
- Lubanovic, B. FASTAPI Modern Python Web Development; O’Reilly Media: Sebastopol, CA, USA, 2023. [Google Scholar]
- Dwarampudi, V.S.S.R.; Mandhala, V.N. Social Media Login Authentication with Unity and Web Sockets. In Proceedings of the 2023 International Conference on Computer Science and Emerging Technologies (CSET), Bangalore, India, 10–12 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–5. [Google Scholar]
- Kwon, H. Visualization Methods of Information Regarding Academic Publications, Research Topics, and Authors. Proceedings 2022, 81, 154. [Google Scholar] [CrossRef]
- Sun, W.; Dai, L.; Zhang, X.; Chang, P.; He, X. RSOD: Real-time small object detection algorithm in UAV-based traffic monitoring. Appl. Intell. 2022, 52, 8448–8463. [Google Scholar] [CrossRef]
- Schaefer, R.; Neudecker, C. A two-step approach for automatic OCR post-correction. In Proceedings of the 4th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature, Dubrovnik, Barcelona, Spain, 12 December 2020; pp. 52–57. [Google Scholar]
- Ahmad, T.; Ma, Y.; Yahya, M.; Ahmad, B.; Nazir, S.; Haq, A.u. Object detection through modified YOLO neural network. Sci. Program. 2020, 2020, 8403262. [Google Scholar] [CrossRef]
- Sang, J.; Wu, Z.; Guo, P.; Hu, H.; Xiang, H.; Zhang, Q.; Cai, B. An improved YOLOv2 for vehicle detection. Sensors 2018, 18, 4272. [Google Scholar] [CrossRef]
- Zhao, L.; Li, S. Object detection algorithm based on improved YOLOv3. Electronics 2020, 9, 537. [Google Scholar] [CrossRef]
- Wang, Y.; Bu, H.; Zhang, X.; Cheng, J. YPD-SLAM: A real-time VSLAM system for handling dynamic indoor environments. Sensors 2022, 22, 8561. [Google Scholar] [CrossRef]
- Cong, P.; Liu, J.; Li, J.; Xiao, Y.; Chen, X.; Feng, X.; Zhang, X. YDD-SLAM: Indoor Dynamic Visual SLAM Fusing YOLOv5 with Depth Information. Sensors 2023, 23, 9592. [Google Scholar] [CrossRef]
- Gupta, C.; Gill, N.S.; Gulia, P.; Chatterjee, J.M. A novel finetuned YOLOv6 transfer learning model for real-time object detection. J. Real-Time Image Process. 2023, 20, 42. [Google Scholar] [CrossRef]
- Kucukayan, G.; Karacan, H. YOLO-IHD: Improved Real-Time Human Detection System for Indoor Drones. Sensors 2024, 24, 922. [Google Scholar] [CrossRef] [PubMed]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-size object detection algorithm based on camera sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Wang, J.; Tang, J.; Yang, M.; Bai, X.; Luo, J. Improving OCR-based image captioning by incorporating geometrical relationship. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 1306–1315. [Google Scholar]
- Kamisetty, V.N.S.R.; Chidvilas, B.S.; Revathy, S.; Jeyanthi, P.; Anu, V.M.; Gladence, L.M. Digitization of Data from Invoice using OCR. In Proceedings of the 2022 6th International Conference on Computing Methodologies and Communication (ICCMC), Erode, India, 29–31 March 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–10. [Google Scholar]
- Salehudin, M.; Basah, S.; Yazid, H.; Basaruddin, K.; Safar, M.; Som, M.M.; Sidek, K. Analysis of Optical Character Recognition using EasyOCR under Image Degradation. J. Phys. Conf. Ser. 2023, 2641, 012001. [Google Scholar] [CrossRef]
- Peng, Q.; Tu, L. Paddle-OCR-Based Real-Time Online Recognition System for Steel Plate Slab Spray Marking Characters. J. Control. Autom. Electr. Syst. 2023, 35, 221–233. [Google Scholar] [CrossRef]
- Huang, B.C.; Hsu, J.; Chu, E.T.H.; Wu, H.M. Arbin: Augmented reality based indoor navigation system. Sensors 2020, 20, 5890. [Google Scholar] [CrossRef]
- Yang, G.; Saniie, J. Indoor navigation for visually impaired using AR markers. In Proceedings of the 2017 IEEE International Conference on Electro Information Technology (EIT), Lincoln, NE, USA, 14–17 May 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–5. [Google Scholar]
- Ng, X.H.; Lim, W.N. Design of a mobile augmented reality-based indoor navigation system. In Proceedings of the 2020 4th International Symposium on Multidisciplinary Studies and Innovative Technologies (ISMSIT), Istanbul, Turkey, 22–24 October 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–6. [Google Scholar]
- Fajrianti, E.D.; Haz, A.L.; Funabiki, N.; Sukaridhoto, S. A Cross-Platform Implementation of Indoor Navigation System Using Unity and Smartphone INSUS. In Proceedings of the 2023 Sixth International Conference on Vocational Education and Electrical Engineering (ICVEE), Surabaya, Indonesia, 14–15 October 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 249–254. [Google Scholar]
- Foxlin, E. Motion tracking requirements and technologies. In Handbook of Virtual Environment Technology; CRC Press: Boca Raton, FL, USA, 2002. [Google Scholar]
- Yan, J.; Zlatanova, S.; Diakité, A. A unified 3D space-based navigation model for seamless navigation in indoor and outdoor. Int. J. Digit. Earth 2021, 14, 985–1003. [Google Scholar] [CrossRef]
- Hussain, A.; Shakeel, H.; Hussain, F.; Uddin, N.; Ghouri, T.L. Unity game development engine: A technical survey. Univ. Sindh J. Inf. Commun. Technol 2020, 4, 73–81. [Google Scholar]
- Sukaridhoto, S.; Fajrianti, E.D.; Haz, A.L.; Budiarti, R.P.N.; Agustien, L. Implementation of virtual Fiber Optic module using Virtual Reality for vocational telecommunications students. JOIV Int. J. Inform. Vis. 2023, 7, 356–362. [Google Scholar] [CrossRef]
- Sukaridhoto, S.; Haz, A.L.; Fajrianti, E.D.; Budiarti, R.P.N. Comparative Study of 3D Assets Optimization of Virtual Reality Application on VR Standalone Device. Int. J. Adv. Sci. Eng. Inf. Technol. 2023, 13. [Google Scholar] [CrossRef]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 2564–2571. [Google Scholar]
- Brata, K.C.; Funabiki, N.; Panduman, Y.Y.F.; Fajrianti, E.D. An Enhancement of Outdoor Location-Based Augmented Reality Anchor Precision through VSLAM and Google Street View. Sensors 2024, 24, 1161. [Google Scholar] [CrossRef] [PubMed]
- Candra, A.; Budiman, M.A.; Hartanto, K. Dijkstra’s and a-star in finding the shortest path: A tutorial. In Proceedings of the 2020 International Conference on Data Science, Artificial Intelligence, and Business Analytics (DATABIA), Medan, Indonesia, 16–17 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 28–32. [Google Scholar]
- Panduman, Y.Y.F.; Funabiki, N.; Puspitaningayu, P.; Kuribayashi, M.; Sukaridhoto, S.; Kao, W.C. Design and implementation of SEMAR IoT server platform with applications. Sensors 2022, 22, 6436. [Google Scholar] [CrossRef]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Itseez. Open Source Computer Vision Library. 2015. Available online: https://github.com/itseez/opencv (accessed on 6 June 2024).
- Van Rossum, G. The Python Library Reference, Release 3.8.2; Python Software Foundation: Wilmington, DE, USA, 2020. [Google Scholar]
- Fajrianti, E.D.; Funabiki, N.; Haz, A.L.; Sukaridhoto, S. A Proposal of OCR-based User Positioning Method in Indoor Navigation System Using Unity and Smartphone (INSUS). In Proceedings of the 2023 12th International Conference on Networks, Communication and Computing, Osaka Japan, 15–17 December 2023; pp. 99–105. [Google Scholar]
- Po, D.K. Similarity based information retrieval using Levenshtein distance algorithm. Int. J. Adv. Sci. Res. Eng 2020, 6, 6–10. [Google Scholar] [CrossRef]
- Bachmann, M. Rapidfuzz/RapidFuzz: Release 3.8.1. 2024. Available online: https://github.com/rapidfuzz/RapidFuzz/releases (accessed on 23 May 2024).
- Yu, F.; Seff, A.; Zhang, Y.; Song, S.; Funkhouser, T.; Xiao, J. Lsun: Construction of a large-scale image dataset using deep learning with humans in the loop. arXiv 2015, arXiv:1506.03365. [Google Scholar]
- Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and flexible image augmentations. Information 2020, 11, 125. [Google Scholar] [CrossRef]
- Zhang, L.; Zhao, C.; Feng, Y.; Li, D. Pests identification of ip102 by yolov5 embedded with the novel lightweight module. Agronomy 2023, 13, 1583. [Google Scholar] [CrossRef]
- Beger, A. Precision-recall curves 2016.
- Zhu, H.; Wei, H.; Li, B.; Yuan, X.; Kehtarnavaz, N. A review of video object detection: Datasets, metrics and methods. Appl. Sci. 2020, 10, 7834. [Google Scholar] [CrossRef]
- Padilla, R.; Netto, S.L.; Da Silva, E.A. A survey on performance metrics for object-detection algorithms. In Proceedings of the 2020 International Conference on Systems, Signals and Image Processing (IWSSIP), Niteroi, Brazil, 1–3 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 237–242. [Google Scholar]
- Vochozka, V. Using a Mobile Phone as a Measurement Tool for Illuminance in Physics Education. J. Phys. Conf. Ser. 2024, 2693, 012016. [Google Scholar] [CrossRef]
- Bhandary, S.K.; Dhakal, R.; Sanghavi, V.; Verkicharla, P.K. Ambient light level varies with different locations and environmental conditions: Potential to impact myopia. PLoS ONE 2021, 16, e0254027. [Google Scholar] [CrossRef] [PubMed]
- da Silva, L.V.; Junior, P.L.J.D.; da Costa Botelho, S.S. An Optical Character Recognition Post-processing Method for technical documents. In Proceedings of the Anais Estendidos do XXXVI Conference on Graphics, Patterns and Images, Rio Grande, Brazil, 6–9 November 2023; SBC: Porto Alegre, Brazil, 2023; pp. 126–131. [Google Scholar]
- Randika, A.; Ray, N.; Xiao, X.; Latimer, A. Unknown-box approximation to improve optical character recognition performance. In Proceedings of the Document Analysis and Recognition–ICDAR 2021: 16th International Conference, Lausanne, Switzerland, 5–10 September 2021; Proceedings, Part I 16. Springer: Berlin/Heidelberg, Germany, 2021; pp. 481–496. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source | Object Detection Function | Text Extraction Function | Database Matching Function | |||
|---|---|---|---|---|---|---|
| YOLOv8 Output | Isolated Sign Image | PaddleOCR Output | Cleaned Text | Room Number | Room Coordinates | |
 |  |  | D-1D2 | d1d2 | d102 | x: 63.909 y: −0.473 z: 3.763 |
 |  |  | D-L01 | dl01 | d101 | x: 73.360 y: −0.473 z: 5.563 |
| Component | CPU | RAM | GPU | OS | Python Version | CUDA Version | PyTorch Version |
|---|---|---|---|---|---|---|---|
| Specification | Intel® Xeon® Gold 5218 | 24 GB | NVIDIA QUADRO RTX 6000 VRAM 24 GB | Ubuntu 20.04 | 3.9 | 11.3 | 1.12.1 |
| Hyperparameter Name | Hyperparameter Value |
|---|---|
| Optimizer | SGD |
| Initial Learning Rate () | 0.01 |
| Final Learning Rate () | 0.01 |
| Momentum | 0.937 |
| Weight Decay Coefficient | |
| Random set | 42 |
| Name | Floor Level | Number of Rooms | Average Illuminance (LUX) |
|---|---|---|---|
| #2 Engineering Building | 1 | 8 | 106.18 |
| 2 | 8 | 116.91 | |
| 3 | 8 | 91.67 | |
| 4 | 6 | 121.22 | |
| #3 Engineering Building | 1 | 18 | 112.11 |
| 2 | 16 | 123.68 | |
| 3 | 17 | 115.62 | |
| 4 | 18 | 97.21 |
| Samsung Galaxy S22 Ultra | iPhone X | |
|---|---|---|
| OS | Android | iOS |
| GPU | Adreno730 | Apple GPU |
| CPU | Octa-core ( GHz, GHz, GHz) | Hexa-core (2.39 GHz) |
| Memory | 8 GB | 3 GB |
| Camera | 108 MP | 12 MP |
| #2 Building | #3 Building | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Floor Level | 1F | 2F | 3F | 4F | 1F | 2F | 3F | 4F | |
| Android | PaddleOCR | 42% | 39% | 36% | 35% | 36% | 36% | 39% | 43% |
| YOLOv8 model + PaddleOCR | 2% | 2% | 5% | 8% | 3% | 5% | 3% | 2% | |
| iOS | PaddleOCR | 51% | 38% | 32% | 37% | 34% | 40% | 34% | 36% |
| YOLOv8 model + PaddleOCR | 2% | 2% | 3% | 4% | 4% | 3% | 3% | 2% | |
| Implementation Building | Cleaned text | Levenshtein Distance | Room Number | |
|---|---|---|---|---|
| #2 Engineering Building | 1F | d1d2 | 1 | d102 |
| 2F | d205 | 0 | d205 | |
| 3F | db01 | 1 | d301 | |
| 4F | d4o1 | 1 | d401 | |
| #3 Engineering Building | 1F | el13 | 1 | e113 |
| 2F | e2l2 | 1 | e212 | |
| 3F | 3303 | 1 | e303 | |
| 4F | e401 | 0 | e401 | |
| #2 Engineering Building | #3 Engineering Building | |||||||
|---|---|---|---|---|---|---|---|---|
| Floor Level | 1F | 2F | 3F | 4F | 1F | 2F | 3F | 4F |
| PaddleOCR | 11.7 | 11.2 | 10.57 | 10.8 | 11.16 | 11.05 | 10.72 | 10.47 |
| YOLOv8 model + PaddleOCR | 4.22 | 4.17 | 3.93 | 4.34 | 3.49 | 4.46 | 4.81 | 4.56 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fajrianti, E.D.; Panduman, Y.Y.F.; Funabiki, N.; Haz, A.L.; Brata, K.C.; Sukaridhoto, S. A User Location Reset Method through Object Recognition in Indoor Navigation System Using Unity and a Smartphone (INSUS). Network 2024, 4, 295-312. https://doi.org/10.3390/network4030014
Fajrianti ED, Panduman YYF, Funabiki N, Haz AL, Brata KC, Sukaridhoto S. A User Location Reset Method through Object Recognition in Indoor Navigation System Using Unity and a Smartphone (INSUS). Network. 2024; 4(3):295-312. https://doi.org/10.3390/network4030014
Chicago/Turabian StyleFajrianti, Evianita Dewi, Yohanes Yohanie Fridelin Panduman, Nobuo Funabiki, Amma Liesvarastranta Haz, Komang Candra Brata, and Sritrusta Sukaridhoto. 2024. "A User Location Reset Method through Object Recognition in Indoor Navigation System Using Unity and a Smartphone (INSUS)" Network 4, no. 3: 295-312. https://doi.org/10.3390/network4030014
APA StyleFajrianti, E. D., Panduman, Y. Y. F., Funabiki, N., Haz, A. L., Brata, K. C., & Sukaridhoto, S. (2024). A User Location Reset Method through Object Recognition in Indoor Navigation System Using Unity and a Smartphone (INSUS). Network, 4(3), 295-312. https://doi.org/10.3390/network4030014