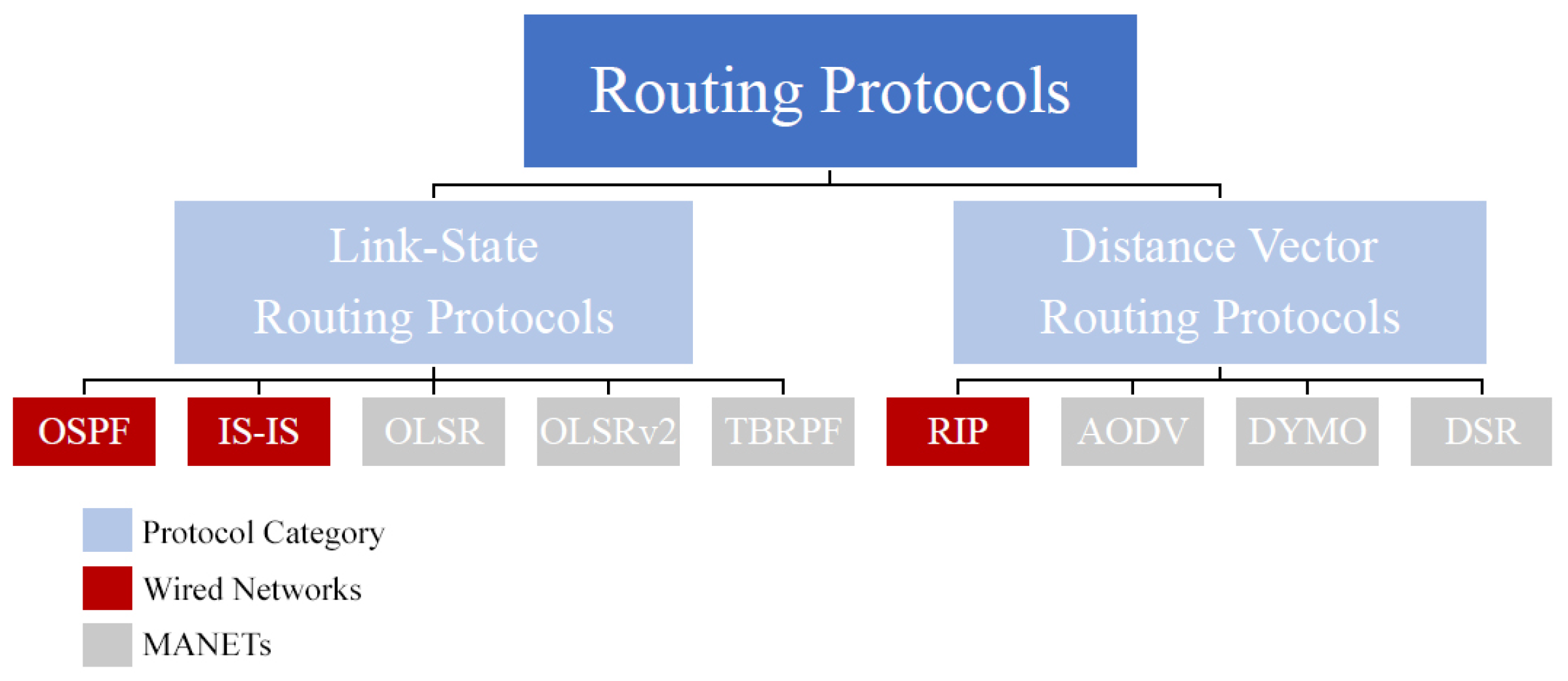
3.1. Link-State Routing Protocols (LSRPs)
The LSRP concept was introduced in 1979 by McQuillan [
32] to find the best path between a pair of nodes under network topology changes and create stable routing. In LSRP, nodes create a complete network topology map by collecting information from other nodes in the network. Thus, every node maintains routing information to every other node in the network. The first step for the nodes is to send “Hello” messages, also known as keep-alive messages, for neighbour discovery. Then, each node establishes a relationship with its direct neighbours, the first hop, to exchange routing information. This relationship between neighbour nodes is called adjacency, and it can be formed by periodically sending advertisement packets. Advertisement packets are divided into three different types: (i) Link-State Request (LSR), (ii) Link-State Update (LSU), and (iii) Link-State Acknowledgement (LSAck). These advertisement packets contain local topology information about the node itself, directly connected links and the state of those links [
33]. The information is then propagated through the entire network using a flooding technique. The collected information is used to (i) produce a Link-State Database (LSDB) for the network topology and (ii) select the best available path, usually the shortest path, between the source and the destination node.
The collected information about the direct neighbours is stored in a table known as the neighbour table. In contrast, the collected information about the entire network topology is stored in the topology table. A third table, namely the routing table, is then created by each node using its own LSDB. The routing table contains information about the shortest available paths to all the advertised neighbours based on some routing metrics. Each entry in the routing table represents a destination node pointing to the next hop, allowing the LSRP to immediately find alternative paths in the case of link failure. To update these tables, LSRP uses the concept of triggered updates, which means that “Hello” messages and advertisements, i.e., control packets, are only resent when topology changes occur in the network. LSRP typically uses the Dijkstra algorithm, i.e., Shortest Path First (SPF), to find the best path between a pair of nodes. The Dijkstra algorithm was created by E. Dijkstra and was published in 1959 to solve the shortest path problem in a directed graph [
34]. The algorithm starts at a start node and then searches through the topology map to find the shortest distance between this particular node, the start node, and its direct neighbours in the network. This search process then continues to find the shortest path for all the nodes in the network [
35]. In this way, LSRP has the required information to calculate the best available path connecting the source node to any destination node in the network.
The most common LSRPs designed for wired networks are Open Shortest Path First (OSPF) [
36,
37,
38] and Intermediate System–Intermediate System routing exchange protocol (IS-IS) [
39,
40]. OSPF allows the network to be divided into small areas, thereby creating a routing hierarchy. This hierarchy implies that a top-level routing area, i.e., the backbone area, connects other network areas. Routing information is exchanged through a group of nodes known as an Autonomous System (AS). The routing in AS takes place on two levels, intra-area and inter-area, depending on the position of the source and destination nodes. If the source and destination are in the same area, then intra-area routing is used, and if they are positioned in different areas, then inter-area routing is used.
Moreover, each node periodically sends “Hello” messages to establish a neighbour relationship. The shortest path to the destination is then calculated using the Dijkstra algorithm based on different link metrics such as link bandwidth and propagation delay. The information regarding the shortest distance to direct neighbours is stored in the neighbour table. In contrast, the routing information is stored in routing tables and updated when required. To store all of this information, i.e., neighbours and routing information, OSPF requires high CPU processing and consumes much memory. Moreover, the topology information of each area is hidden from the other areas in the network, and each area has its own LSDB [
41]. Nodes belonging to the same area have an identical area LSDB, and nodes connected to multiple areas have separate LSDBs for each area. This isolation of routing information decreases control overhead and routing traffic caused by propagating the topology changes.
IS-IS was developed in 1987 by the International Organisation Standardisation (ISO) to provide routing for Open System Interconnect (OSI) environments [
42,
43]. In particular, IS-IS was designed explicitly to work with two ISO protocols: (i) Connection-Less Network Protocol (CLNP) [
44] and (ii) End System to Intermediate System protocol (ES-IS) [
45]. In IS-IS, the network is divided into routing domains that are divided into small areas. Each routing domain defines boundaries by setting some links as external links. Thus, routing messages in IS-IS are not transmitted through external links or exceed the domain boundaries. This division creates two-level routing hierarchies, Level 1 (L1) and Level 2 (L2), which are equivalent to the intra-area and inter-area in OSPF, respectively. L1 nodes, known as L1-ISs, have the topology map of their own area, and can only exchange routing information with other nodes in the same area. On the other hand, L2 nodes, i.e., L2-ISs, have the L2 topology and can exchange routing information and data packets directly with nodes from other routing domains. In some cases, a node can act as an L1-IS and L2-IS simultaneously, thus having the topology maps for both L1 and L2 domains. Separating the topology maps between levels decreases control overhead and routing traffic, which may be caused by propagating the topology changes through the network.
IS-IS periodically sends “Hello” messages for neighbour discovery to establish a neighbour adjacency. Topology information is then exchanged in the form of a Link-State Packet (LSP) within the area using the flooding technique. Each IS builds an LSDB based on the information received from the LSPs. A routing table is then created containing routing information regarding the best available paths between a source node and the neighbour nodes in the same area. Similar to OSPF, the best routing path is calculated using the Dijkstra algorithm based on different routing metrics, such as bandwidth and delay. Later, in 1990, the existing IS-IS was extended to support routing over the Transmission Control Protocol/Internet Protocol (TCP/IP) in addition to OSI [
46]. The integrated IS-IS provides a single routing protocol that can efficiently perform over OSI, TCP/IP, and dual environments.
The most common LSRPs designed for MANETs are Optimised Link-State Routing (OLSR) [
47,
48], Optimised Link-State Routing version 2 (OLSRv2) [
49,
50], and Topology Dissemination Based on Reverse Path Forwarding (TBRPF) [
51,
52]. In OLSR, each node selects a set of direct neighbours known as Multi-Point Relays (MPR). In return, each MPR maintains a set of nodes that have chosen it to be an MPR called MPR selectors. These two sets are used to apply three optimisations: (i) only MPRs generate link-state information, (ii) only MPRs forward LSPs, and (iii) only MPRs advertise links connecting to its MPR selectors. In addition, OLSR establishes a new approach to minimise the number of flooding packets. This approach (i) imposes a time interval after each successful transmission of control packets and (ii) makes the triggered updates optional in case of topology changes. Compared with the traditional flooding technique, this new technique significantly reduces the number of control packets flooding through the network, thus reducing control overhead and bandwidth consumption [
53]. OLSR calculates the best available path mainly based on hop counts. Hence, the shortest path between a source and destination node, with the minimum number of hops, is selected. Routing based on hop counts results in less changes in the formed routing paths, thus less updates and a more stable network.
However, shortest links in terms of minimum hop counts may not always be considered reliable paths. Minimum hop count links may lead to heavy use of long links in terms of the physical distance of these links [
54]. For example, a source node may choose a long physical distance path with two hops to the destination over a shorter physical distance path with three hops. As a result, the long physical distance links may experience high (i) traffic load, (ii) bandwidth consumption, and (iii) packet loss; thus, lower PDRs occur. Therefore, in some situations, considering shorter physical distance links with extra hops may result in selecting more reliable paths with higher PDRs.
OLSRv2 is the successor of OLSR. It has the same functionality as OLSR with an enhanced ability to overcome the limitation in OLSR caused by using the hop count metric. OLSRv2 provides the ability to select the best path between source and destination nodes based on link metric rather than hop count. Another new feature of OLSRv2 is the use of MANET Neighborhood Discovery Protocol (NHDP) [
55] for neighbour discovery. OLSRV2 exchanges “Hello” messages locally using the NHDP. By using NHDP, each node determines the presence of, and connectivity to, its 1-hop and 2-hop neighbours. The 1-hop information provides connectivity to direct neighbours, while the 2-hop information employs the flooding reduction technique.
TBRPF is another LSPR designed for MANETs. TBRPF consists of two main modules: (i) neighbour discovery module and (ii) routing module. The neighbour discovery model performs neighbour discovery using differential “Hello” messages that advertise only the changes in the neighbour status. Thus, the created “Hello” messages are smaller and sent more frequently. This allows TBRPF to detect topology changes and link failures faster than other LSRPs. In the routing module, each node maintains a source tree that provides the shortest paths to all reachable nodes in the network. The source tree is calculated using a modified version of Dijkstra’s algorithm based on partial topology information stored in the topology table. In addition, each node periodically advertises only a subset of its source tree to the neighbouring nodes. These partial advertisements help reduce the overall control overhead in TBRPF compared to other LSRPs. To ensure that all neighbours are updated with the advertised part of the source tree, i.e., subtree, TBRPF uses a combination of periodic and differential updates. Periodic updates advertise new neighbours of the subtree and ensure that each neighbour has information regarding the subtree, even if it does not receive all the updates. Differential updates ensure the fast propagation of each topology change to all nodes affected by the updates. Hence, each node advertises (i) periodic topology updates, e.g., every five seconds, and (ii) changes, such as adding or deleting to the subtree in more frequent differential updates, e.g., every two seconds.
Furthermore, TBRPF uses Reverse-Path Forwarding (RPF) [
56] technique to flood LSU. RPF aims to establish loop-free forwarding of packets by forwarding packets in the reverse direction along the source tree. The received topology information is then used to compute the minimum hop count path between a pair of nodes in the source tree. Using RPF and minimum hop count in TBRPF instead of SPF results in more stable routing and less changes in the formed paths. Thus, less exchange of LSUs in comparison with other flooding techniques used in other LSRPs. In contrast, routing based on hop count only, without considering the link quality, may result in choosing unreliable paths with low bandwidth and PDRs. Therefore, TBRPF provides the option of selecting paths based on link metrics, e.g., signal strength, and selecting along paths with higher quality over minimum hop paths.
In general, the main advantage of LSRPs is the complete knowledge of the network topology, which allows nodes to find the shortest path to the destination quickly and efficiently. As well as recalculate the paths immediately in case of topology changes or link failures. In contrast, the two main disadvantages of LSRPs are (i) lack of scalability and (ii) excessive consumption of resources. The lack of scalability means that the routing protocol performance decreases with the increase in network size. This lack of scalability appears mainly as the number of nodes in the network increases, leading to an increase in advertisements and topology updates. Even though most LSRPs use triggered updates or partial updates, they often have high traffic loads as topology changes must propagate globally, which floods the network periodically with unnecessary packets. This flood tends to create excessive control overhead during path establishment. The more topology changes occur, the more advertisements are resent; thus, the higher control overhead and bandwidth consumption. Consequently, this type of routing is deemed unsuitable for (i) large networks or (ii) unstable networks with rapid topology changes.
Moreover, using an LSRP may impose high costs on the nodes. Each node has to (i) process packets, (ii) generate advertisement responses, and (iii) store massive amounts of topology and routing information. This results in excessive consumption of resources in terms of memory size, CPU processing, and power usage. Therefore, using an LSRP in a constrained network, such as LLN, that (i) often has nodes with very limited resources and (ii) suffers from rapid topology changes due to its Lossy channels, which may result in unstable performance with low PDR and high power consumption.
3.2. Distance Vector Routing Protocols (DVRPs)
The DVRP is a combination of the work proposed by Ford and Fulkerson [
57] and Bellman [
58]; it is referred to as the Ford–Fulkerson algorithm or the Bellman–Ford algorithm. In DVRP, the routing paths are advertised as vectors of distance and direction. Distance refers to the routing metric, whereas direction refers to the next hop. Each node maintains a routing table, i.e., Distance Vector Table (DVT), which contains the distance between the node itself and all its direct neighbours. In addition, nodes periodically advertise their entire routing table to all direct neighbours and rely on them to pass routing information to their neighbours as well. In this way, nodes learn about remote nodes in the network through second-hand information passed along by their direct neighbours. This is known as routing by rumour, whereby a node obtains information from a direct neighbour regarding remote nodes and accepts it without verifying its accuracy. This method is based on the assumption that the neighbour is trustworthy and has reliable information.
Furthermore, the received routing table entries are then combined with the existing entries. As a result, each node maintains and stores a complete routing table for the entire network. These routing tables are updated periodically. The best available path is calculated using the Bellman–Ford algorithm based on minimising the cost of each destination. The cost is mainly determined using the hop count metric. Thus, a source node selects the shortest path with minimum hop counts to a destination node. DVRP sends regular updates at a specified time interval, even if there are no changes in the network topology. This periodic update is a major source of routing information inconsistency and thus leads to a routing loop. Routing loops usually occur due to (i) link failure between a pair of nodes or (ii) two nodes sending routing updates simultaneously. Some DVRPs use the split horizon technique to overcome this problem by (i) preventing reverse route updates between two nodes and (ii) setting the maximum number of hops to 15.
The most common DVRP designed for wired networks is the Routing Information Protocol (RIP) [
59,
60,
61,
62]. The RIP is based on the Bellman–Ford algorithm that uses hop count as a routing metric to find the shortest path between a pair of nodes in terms of hops. Each node creates its own routing table that contains the routing information to all its direct neighbours. Then, it periodically advertises the entire content of the routing table to all direct neighbours. When a node receives an advertisement packet, it adds all entries to its routing table. This process ensures that every node has complete knowledge of all the paths in the network. A node can discover a link failure if it does not receive any advertisement packets from a direct neighbour for a long time. A directly connected neighbour has a hop count of 0, further nodes can be reached up to 15 hops, and any node after that, i.e., the 16th hop, is considered an unreachable node [
63]. Hence, RIP is limited to networks whose longest path between a source node and a destination is 15 hops, which makes it unsuitable for large networks that require more than 15 hops to reach further destinations. Moreover, since RIP uses a fixed routing metric, i.e., hop counts, to select the best paths, it is often considered an appropriate metric in situations where paths need to be chosen based on real-time metrics, such as link quality metrics.
The most common DVRPs for MANETs are Ad-hoc On-Demand Vector (AODV) [
64,
65,
66], Dynamic MANET On-Demand (DYMO) [
67,
68], and Dynamic Source Routing (DSR) [
69,
70]. AODV is an on-demand routing protocol in which a node searches for a path to another node only when the two nodes need to communicate. AODV uses the hop count metric; thus, the path with minimum hop counts between the source and destination is selected as the best available path. Other real-time metrics, such as link quality, are not considered, which may lead AODV to transmit packets over short but unreliable links. A source node initiates path discovery by flooding the network with route requests (RREQs) with an originator sequence number. The originator sequence number is used in path entry to point towards the source node that created the RREQ. When an RREQ reaches an intermediate node with a path leading to the destination, it sends route replies (RREPs) along the reverse path; otherwise, it retransmits the RREQ to its neighbours [
71]. In the case of link failure, mainly owing to topology changes, AODV floods the network with (i) route errors (RERRs) to notify the affected nodes and (ii) new RREQs to find an alternative path. This technique allows nodes to find new paths to destinations immediately and efficiently during path discovery or link failure. Another feature of AODV is the use of the destination sequence number for each path entry. A destination node creates a destination sequence number to overcome Bellman–Ford limitation and ensure loop-free routing.
AODV uses bandwidth efficiently by minimising data traffic and control overhead compared to other DVRPs. It also reduces memory requirements by storing only the needed paths for active communications [
72]. However, heavy traffic and control overhead may occur in two scenarios: (i) multiple RREPs may respond to a single RREQ and (ii) link failure where a large number of control packets are required to inform the affected nodes and find new paths. Moreover, AODV experiences a packet drop problem during link failure within active paths between a pair of nodes. This problem reduces efficiency in AODV as well as PDRs.
DYMO has been proposed as an evolution of AODV [
64] and can be referred to as AODVv2. It has the same functionality as AODV, with simpler operations, different packet formats, and support for path accumulation. The DYMO operations are (i) path discovery and (ii) path maintenance. Path discovery operates at the source node to find a path to a new destination. In contrast, path maintenance operates to (i) avoid broken links in the routing table and (ii) reduce packet dropping in case of link failure in an active path. During these operations, DYMO uses the same routing messages as AODV, i.e., RREQs, RREPs, and RERRs. The path accumulation allows a single RREQ to create a path to all intermediate nodes forming this path without initiating RREQ themselves. As a result, path accumulation reduces traffic and control overhead in DYMO and packet loss owing to link failure compared to AODV. Although DYMO overcomes the limitation of packet drops in AODV, it still selects paths based on hop counts. Depending on hop count alone may lead to choosing the worst possible paths in many situations where real-time metrics should be considered.
DSR protocol is very similar to AODV as it searches for paths on-demand when a pair of nodes need to communicate with each other. The main difference is that DSR uses source routing instead of routing tables. Source routing allows the source node to select and control the path of its own packets. Each data packet carries the complete list of nodes forming a path to the destination in the header. By adding the source path to the packets header, intermediate nodes forwarding the packets can easily learn and use this routing information in the future. Source routing is a loop-free technique where source nodes determine each path, avoiding any inconsistency caused by using routing tables. As a result, DSR does not require sequence numbers or other techniques to prevent routing loops. DSR comprises two primary operations: (i) path discovery and (ii) path maintenance. Path discovery is used only when a source node attempts to send a packet to a new destination and does not have a path to reach it. Path maintenance is performed by a source node while using a source path to a destination to detect changes in the network topology, such as link failure. Both operations, path discovery and path maintenance, operate entirely on demand [
73]. Therefore, unlike other protocols, DSR does not use any periodic routing advertisements, thus reducing traffic and control overheads. Path selection is based on hop counts, similar to other DVRPs, which repeat the possibility of routing over unreliable paths in terms of link quality.
The main advantage of DVRPs is routing based on local information received from direct neighbours rather than global knowledge of the entire network topology, such as LSRP. Hence, it significantly reduces overhead packets and bandwidth consumption compared to LSRP. In contrast, the main disadvantage of DVRPs is the disregard for link quality. Routing in DVRPs is mainly based on the minimum cost of distance, i.e., hop counts. It does not consider the link quality, an essential factor for Lossy channels as in LLNs, but not wired networks or hop-by-hop networks as MANETs for which these protocols are mainly designed. Therefore, using a DVRP in LLNs with a hop count metric only without taking into consideration the link quality may result in routing over unreliable paths with low PDRs.
3.3. Generic Routing Solutions vs. LLN Requirements
As generic routing protocols mentioned in
Section 3 were not mainly designed for LLNs, there is a trade-off as these protocols may or may not meet the requirements of LLNs. Therefore, the IETF decided to evaluate these protocols against LLN requirements [
74]. If an existing protocol meets these requirements, it can be used as a routing protocol for LLN, which would be very promising. Otherwise, a new protocol needs to be designed with all the requirements of LLN. The IETF has specified five criteria for a desirable routing protocol for LLN to compare the costs and benefits of the existing protocols in terms of these criteria. These criteria are (i) routing state, (ii) loss response, (iii) control cost, (iv) link cost, and (v) node cost.
The routing state reflects the ability to scale reasonably within the memory resources of LLN. Nodes often have very limited memory sizes for storing routing information, such as routing tables. Hence, routing protocols should take into consideration that nodes may be unable to store complete neighbour information. Therefore, it is important to ensure that the routing state scales with the size of the underlying network and within the memory constraints of a battery-powered node. As a result, a routing protocol that scales linearly with the network size fails to satisfy the routing state criterion. Loss response mainly illustrates how a routing protocol responds to link failures owing to loss of channel signal. A routing protocol that only propagates changes in an active path or to local neighbours passes this criterion. In contrast, a routing protocol that requires changes along any path to be propagated across the entire network fails in the loss response criterion.
Moreover, routing protocols require sending control packets for different tasks, such as detecting neighbours, discovering a topology, finding paths, or transmitting routing tables. The process of transmitting and receiving control packets, as well as data packets, costs nodes energy. In LLN, nodes often have limited power with low data rates. Routing protocols need to limit the transmission of control packets while conserving energy to minimise the network’s control overhead and energy consumption. By reducing these factors, routing protocols can significantly enhance network efficiency and longevity. Therefore, it is crucial to optimise routing protocols in terms of control packet transmission and energy consumption to ensure a highly efficient and long-lasting network. A routing protocol fails the control cost criterion if the transmission and receiving rates are not within the data rate limit. Link cost indicates the cost of finding a quality link. The quality of a link is measured using link quality metrics, and for each link, there is a cost associated with finding it. A routing protocol should be able to find the best available link with the minimum cost to pass this criterion. Node cost takes into account the node’s constraints, such as memory and power. A routing protocol that (i) considers these constraints when choosing the best path and (ii) can perform within the constraints of low memory and battery-powered nodes pass the node cost criterion. The IETF used these criteria to assess the routing protocols mentioned in
Section 3.1 and
Section 3.2, summarising the assessment results in
Table 2 [
74] along with the symbols description.
As shown in
Table 2, the first four protocols, LSRPs, passed the link cost criterion but failed or needed improvement to pass other criteria. LSRPs passed the link cost because these protocols take into consideration the link quality during path selection. In LSRPs, each node must learn the complete network topology map, which leads to large-size routing tables that scale linearly with the growth of network size. Therefore, LSPRs failed to satisfy the routing state criterion. The presence of routing information and topology changes in LSRPs can cause them to fail the control cost criterion. This is because this information needs to be propagated throughout the network, leading to an increase in control overheads. OLSRv2 [
49] may have the potential to reduce control overhead to an acceptable level by using the Fisheye routing technique. However, there is no specification of how to accomplish the Fisheye technique; thus, OLSRv2 needs improvement in the control cost criterion.
OSPF and IS-IS require advertising and responding to any loss or changes in the link, i.e., link failure, even if the link is not actively used. As a result, OSPF and IS-IS failed to pass the loss response criterion. In contrast, OLSRv2 makes the triggered updates optional; thus, only some links’ changes are advertised. This raises a problem in topology consistency, as some links may fail but are not advertised through the network. Therefore, OLSRv2 received a “*” in the loss response criterion as it needs improvement. The TBRPF only advertises and responds to link failure in the active paths, so it passed the loss response criterion. OSPF does not consider other routing metrics related to the node itself, such as remaining energy or memory size, during path selection, and so fails the node cost criterion. On the other hand, IS-IS and OLSRv2 provide the option of using other node metrics besides the link metric and, therefore, pass the node cost criterion. TBRPF provides a way to use additional metrics, such as node metrics, but without a specification policy on how to use these additional metrics. Therefore, TBRPF received “*” on the node cost criterion as TBRPF needs improvement to pass this requirement.
The remaining protocols, DVRPs, satisfied the control cost criterion but failed most of the other criteria. RIP passed the control cost criterion because it uses triggered updates for advertising topology changes in active links. The remaining DVRPs are on-demand protocols where nodes generate control traffic only when they need to send data packets and pass the control cost criterion. A routing table of AODV and DYMO contains only the paths for communicating nodes in the network and thus passes the routing state criterion. RIP also passes the routing state criterion because, for each node, the routing table size can be scaled to the number of destinations instead of the number of nodes in the network. In contrast, even though DSR uses source routing, each node stores the source paths for all the destinations in addition to a blacklist of all unidirectional neighbour links; thus failing the routing state criterion. RIP and AODV propagate changes in the links even if they are not actively used and fail the loss response criterion. DYMO assessment shows some potential to meet the loss response criterion but requires precise specifications on how to meet the criterion while maintaining broken links. In contrast, DSR advertises unreachable destinations to the source node and passes the loss response criterion.
Moreover, AODV and DSR fail both link cost and node cost criteria because they only use the hop count metric for path-finding. RIP mainly uses the hop count metric but also provides the option of using other routing metrics. However, using real-time metrics such as link quality in RIP may lead to network instability; therefore, RIP needs additional implementations to pass the link cost criterion. In DYMO, the distance of a link can vary from 1 to 65535; thus, some improvements are required to use the link metric efficiently and pass the link cost criterion. Furthermore, DYMO may have the mechanisms to use node properties but also require additional implementations in order to use them properly and pass the node cost criterion. The remaining DVRPs do not support any node properties as a routing metric and thus fail the node cost criterion. It should be emphasised that none of the protocols, LSRPs or DVRPs, satisfy all the five criteria.
Table 3 summarises the general differences between LSRPs and DVRPs.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}






