
Data Quality—Concepts and Problems


{kind=link}
{kind=link}
{kind=link}
Definition
:1. Introduction—History, Disambiguation and Scope
2. Data Quality: Context and Measurement
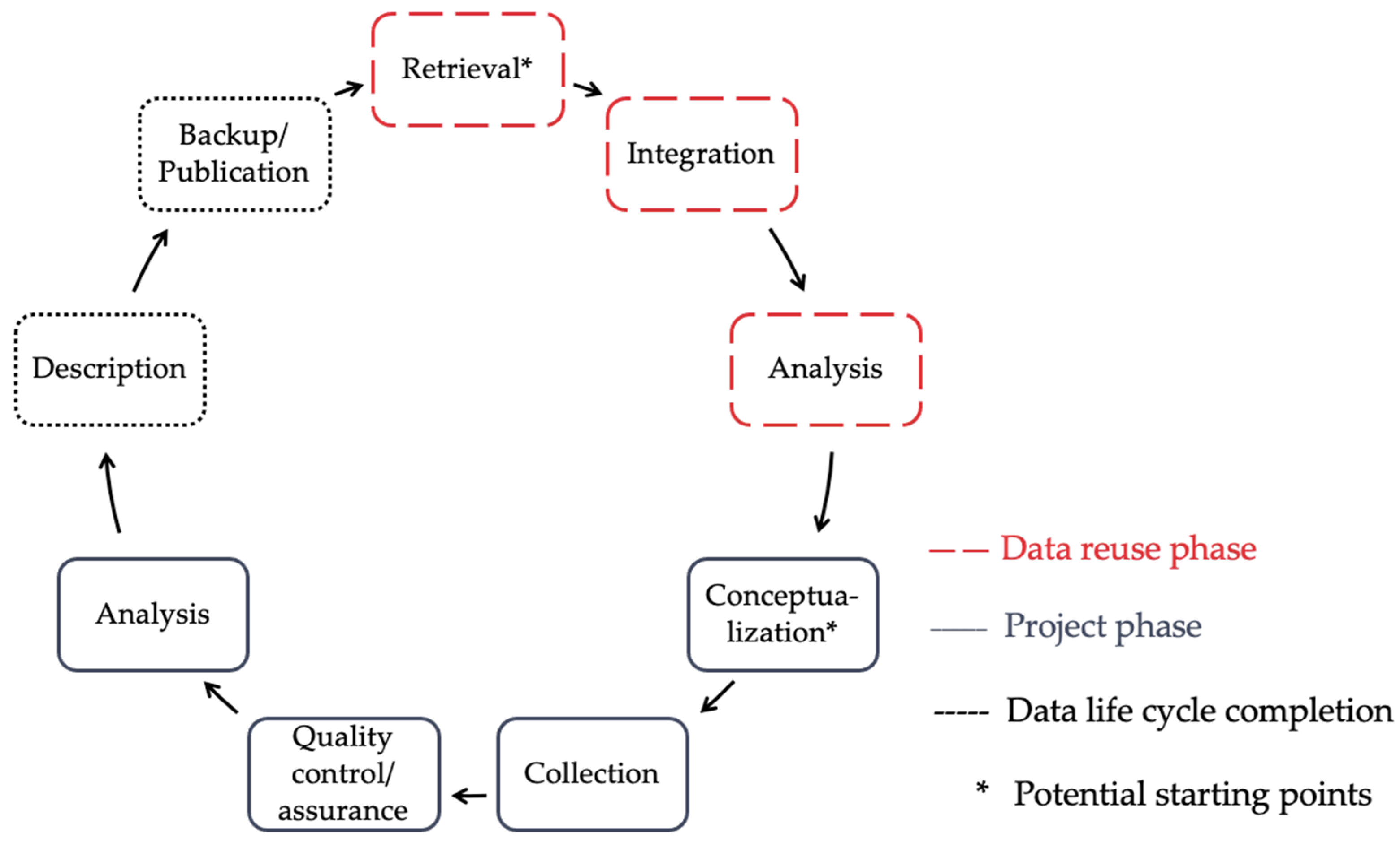
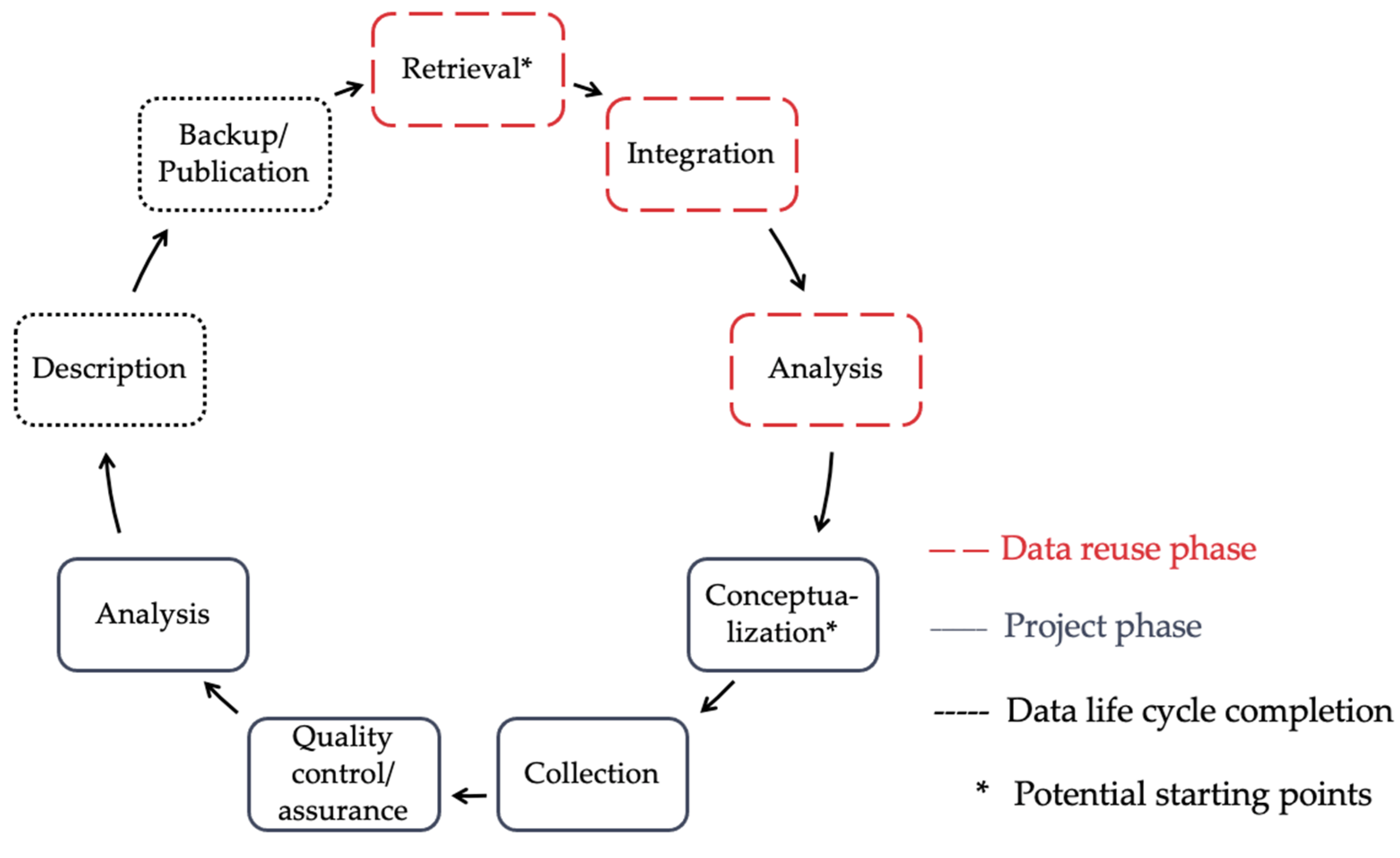
2.1. Data Life Cycle
2.2. Demands, Dimensions and Approach
2.2.1. The FAIR Principles and Good Scientific Practice
- Data are findable when they have a unique identifier, comprehensive metadata are provided, and if both the data and the metadata are indexed or registered to provide discoverability.
- Data are accessible when both the data and the metadata are retrievable, using a unique identifier and a free and open standardized communication protocol (while being generally implementable and providing features for authentication or authorization). Furthermore, the metadata availability should exceed that of the original data.
- For interoperability, the data and metadata must adhere to a standard form and be provided in a universal language. Both the data and the metadata should refer to other existing data.
- Regarding reusability, both the data and the metadata must be depicted in detail, including the statement of usage licenses along with their publication and the exact explanations of the data origin, and should generally be shared following standards used in the particular domains.
- a control mode of juridical nature introducing norms and standards (for example, professional or ISO-norms),
- the organizational nature relying on incentives and enhancements using data validation and organizational or procedure-based operationalizations of data quality (certificates, quality seals),
- contractual and communication-oriented approach-setting policies and guidelines for the handling of research data and its data management plans,
- the procedural ideal for the assurance of data quality following (for example) data life cycles (idealistic and schematic descriptions of processes to be improved, see Section 2.1), and
- the pragmatic and procedural control of quality developments specifying generalistic formula as fit-for-use, or the FAIR principles.
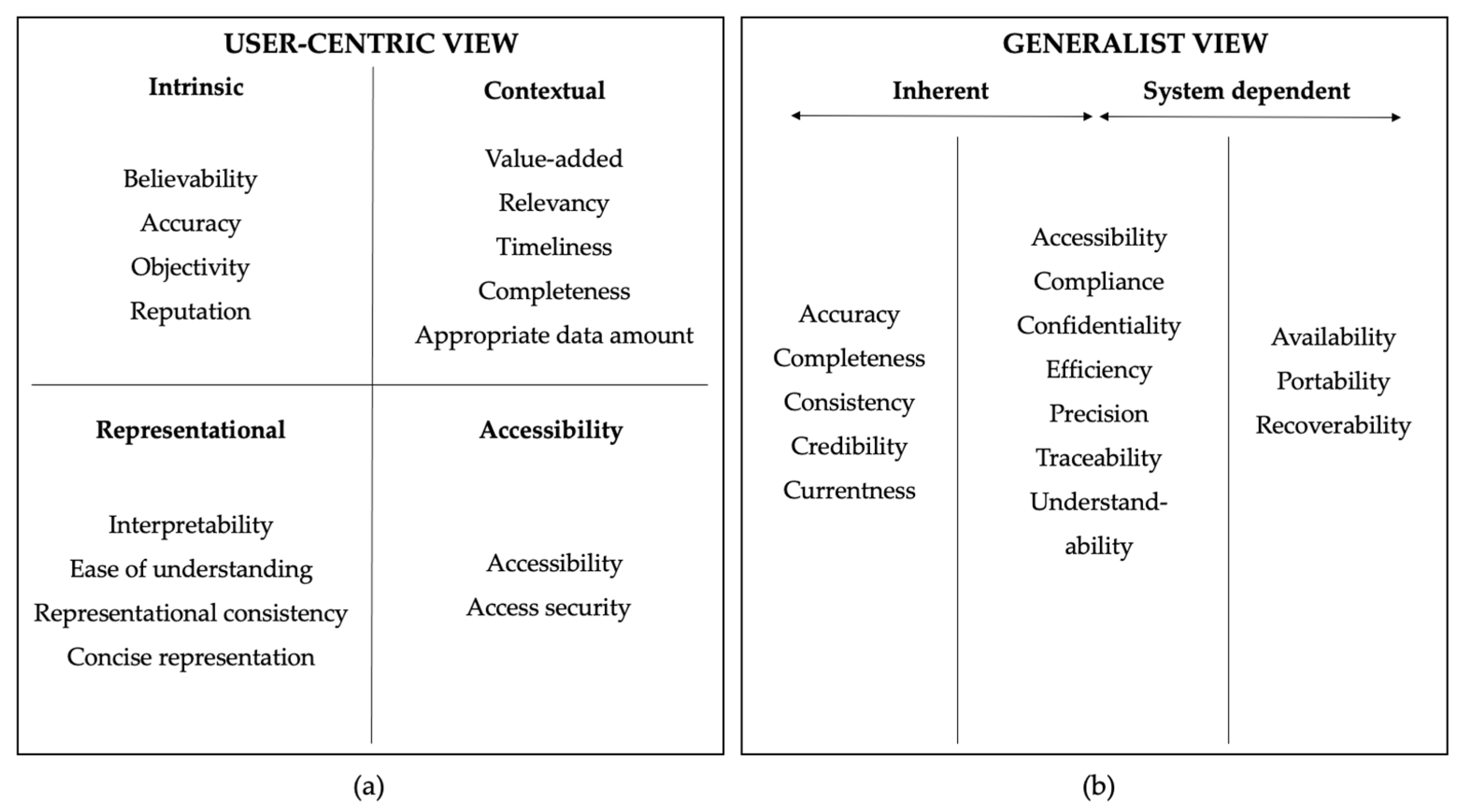
2.2.2. Data Quality Dimensions
- Accessibility generally refers to data availability. In detail, the dimension depicts the extent to which the data are available and with which ease the user can access them [12,41,43]. The ISO standard ISO/IEC 25012:2008(E) [33] in particular measures accessibility considering the targeted use of the data and considers the absence of barriers, promoting the data accessibility for people with disabilities. No quantitative measure is suggested for measuring accessibility; instead, this dimension should be assessed qualitatively or by a grade [44]. For example, we suggest utilizing a checklist that addresses documentation and machine readability issues.
- Accuracy is used to measure the degree of agreement between data and real-life object; it represents the extent to which the data are free of error and reliable [12] as well as the degree to which the data map (or are close to) the true values of the items [33,43], also understood as the correct value [45]. Accuracy may be calculated by dividing the accurate items or records by the total count of items or records [46]. As example, a local population register contains 932,904 phone numbers, and 813,942 have been confirmed, resulting in 87.25% (813,942/932,904 * 100) accuracy.
- Completeness is one of the most commonly applied data quality dimensions and generally provides a measure for the presence of data. The dimension maps the extent to which all expected and required data (records, attributes) are present or not missing, respectively [33]. Furthermore, it depicts the degree of sufficient resolution for the intended use [12,41]. Completeness may be computed by dividing the available items or records by the expected total number [46], resulting in a percentage if multiplied by 100. For example, a local population register contains all 932,904 inhabitants, but the date of birth is only available for 930,611 persons. This results in 99.75% (930,611/932,904 * 100) completeness.
- Consistency is also known as consistent representation and is the degree to which data are free of contradiction with themselves [33] or follow an established rule [43], and are provided in the same format [41], compatible with previous data [12]. Consistency may be represented as the proportion of items or records found to be consistent [46]. For instance, we presume the date of birth within a population register should be stored in the “YYYY-MM-DD” (year-month-day) format. In 61,196 of 930,611 total instances, date of birth was stored inverted as “DD-MM-YYYY”, resulting in 93.42% ((930,611 − 61,196)/930,611 * 100) consistency.
- Currency or Currentness refers to the extent to which the data are sufficiently or reasonably up to date for the intended task [33,43]. The currency of data may be assessed qualitatively [44]. For example, a dataset of bird observations from the summer of 1969 is not suited for estimating bird populations in 2022. Otherwise, the share of current records within a population register may be determined by dividing the count of recently validated entries (764,111) by the total population count (932,904), which results in 81.91% (764,111/932,904 * 100) currency.
- Timeliness is also frequently applied and may depict the extent to which the age of the data is suitable for the intended use [12,41], or the time difference between a real-time event and the time the corresponding data capture or verification take [43,45]. Timeliness may be measured as duration [46], explicitly the time difference between data collection and entry. For example, if employees of a population register enter addresses into the database collected nine days before, the timeliness of this data is nine days.
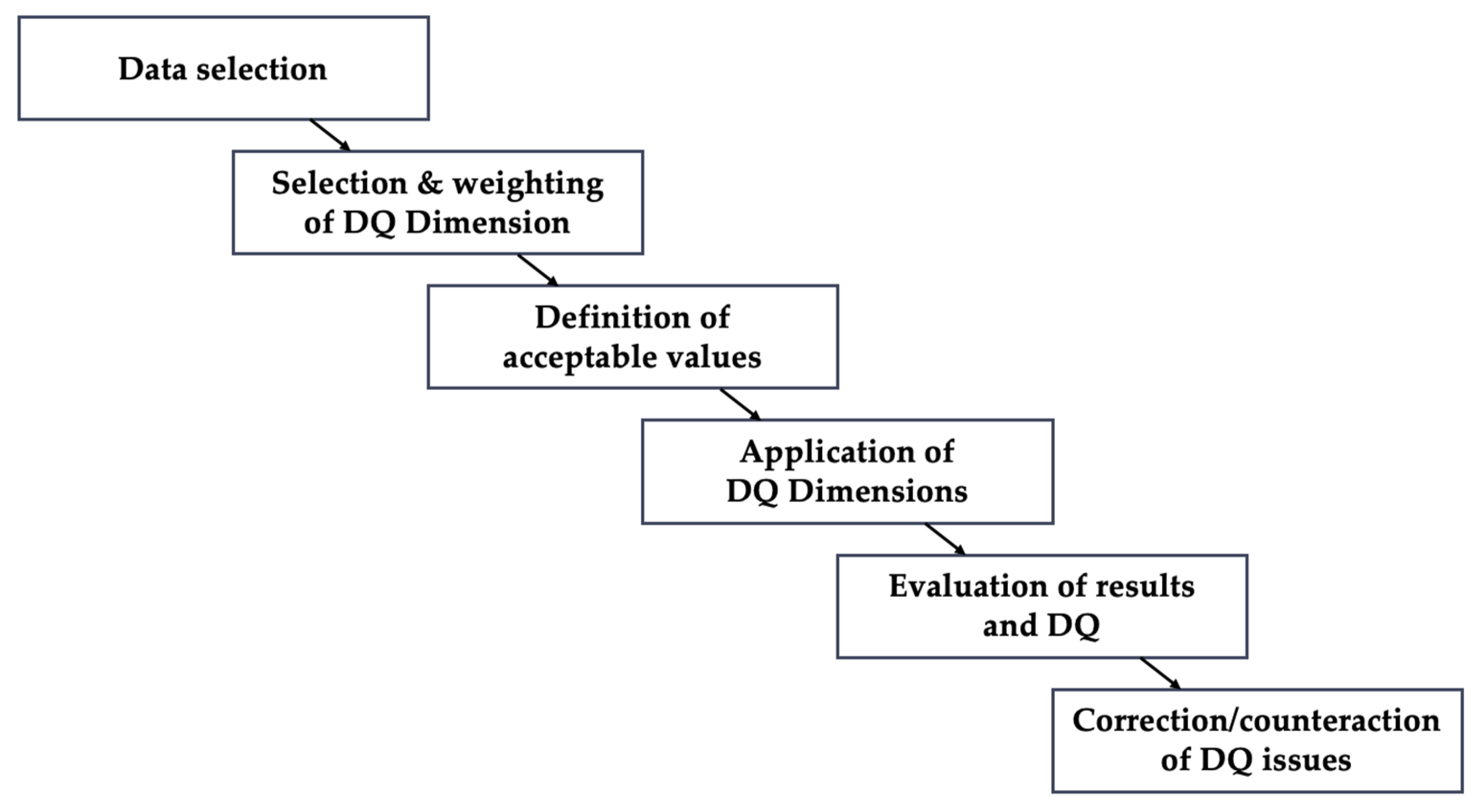
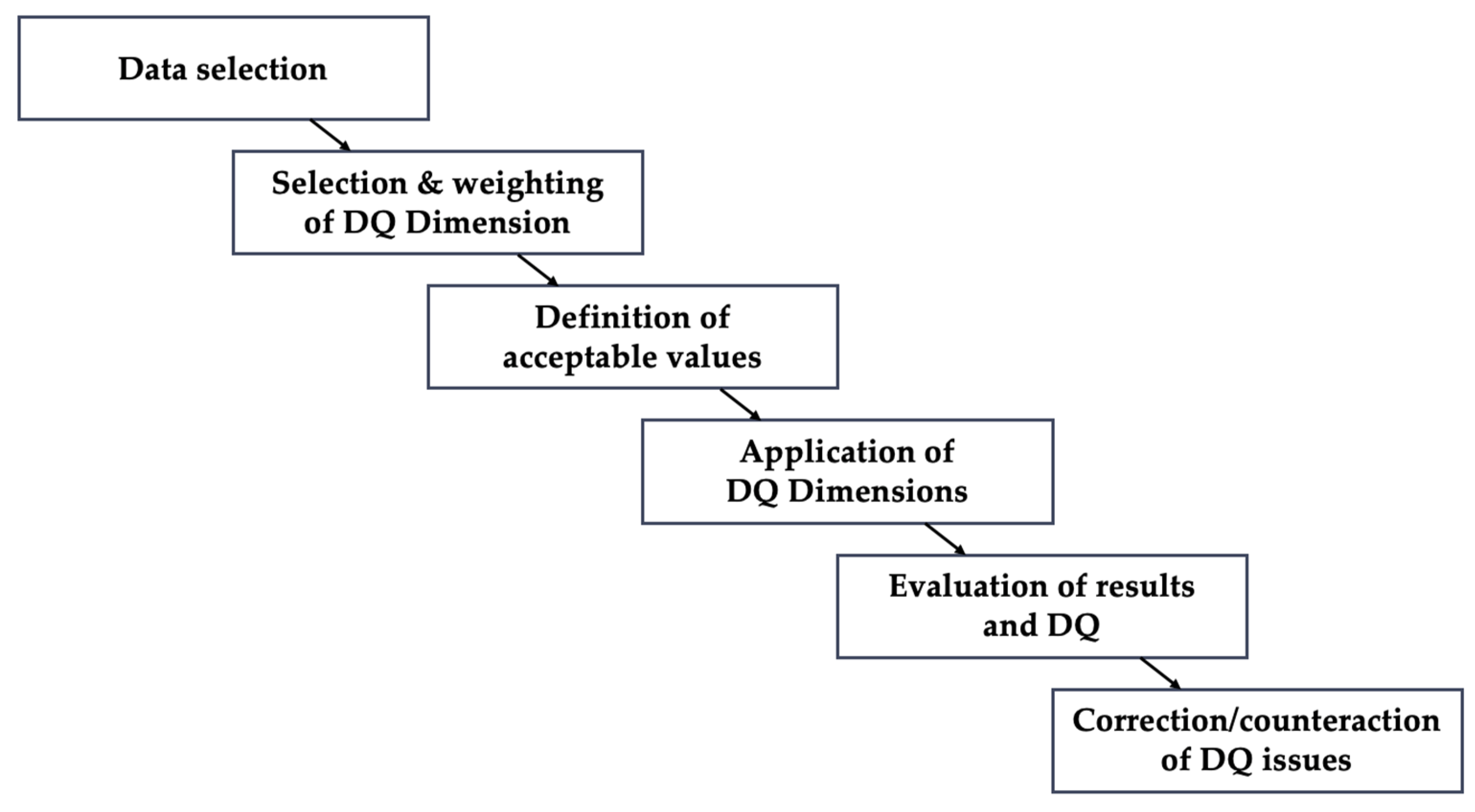
2.2.3. Data Quality Assessment
3. Data Quality in Context and Practice
3.1. Potential Consequences of Data Quality Issues
3.2. What Affects Data Quality: The Case of Data Collection in Health Sciences
- Impersonality: On the one hand, self-administered questionnaires may be preferred to inquire sensitive information, potentially triggering a sense of shame and leading to deviations from the true answer in interview situations (accuracy, consistency). On the other hand, the participant might be encouraged to respond and provide answers in all conscience (completeness, accuracy).
- Cognitive burden: The different methods require different efforts from the participant, such as listening, reading, comprehending, and classifying the answer. For example, during an interview, the participant usually has to listen, comprehend the question, and answer in natural language, while self-administered questionnaires require reading and writing or selecting pre-defined answers (completeness, accuracy).
- Study legitimacy: For phone interview participants, it may be difficult to judge the reputability of the study, leading to cautious answers or even non-response (accuracy, completeness, relevancy). In more official environments like a university’s web page or on-site, increasing trust and confidence in participation may be expected.
- Questionnaire control: In interviews, the interviewer can guide the participant through the questions (accuracy, relevancy, completeness). In contrast, paper-based questionnaires offer little to no control of the question sequence at the participant’s discretion; if applicable, written guidance is provided.
- Rapport: In face-to-face interviews, visual contact may simplify rapport establishment between interviewer and respondent compared to telephone interviews or even self-administered questionnaires, potentially increasing the motivation to participate (completeness) and mitigating the social desirability bias (accuracy).
- Communication: An interviewer can potentially elicit more information from the respondent than technically possible in self-administered questionnaires, for example, by further questioning or clarifying given answers (relevancy, accuracy, validity). Yet, social desirability bias may increase depending on the communication style (accuracy).
3.3. Challenges to Data Quality
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Acknowledgments
Conflicts of Interest
Entry Link on the Encyclopedia Platform
References
- Lexico English Dictionary (Online). Data. Oxford University Press, 2021. Available online: https://www.lexico.com/definition/data (accessed on 20 January 2022).
- Cambridge Dictionary. Data. Available online: https://dictionary.cambridge.org/dictionary/english/data (accessed on 20 January 2022).
- Tallet, P. Les Papyrus de la Mer Rouge I: Le Journal de Merer (PAPYRUS JARF A ET B); Institut Français D’archéologie Orientale: Kairo, Egypt, 2017. [Google Scholar]
- Unruh, F. “... Dass alle Welt geschätzt würde”: Volkszählung im Römischen Reich; Gesellschaft für Vor- und Frühgeschichte in Württemberg und Hohenzollern e.V.; Thiess: Stuttgart, Germany, 2001; Volume 54. [Google Scholar]
- Reinsel, D.; Gantz, J.; Rydning, J. Data Age 2025: The Evolution of Data to Life-Critical. An IDC White Paper; International Data Corporation (IDC): Framingham, MA, USA, 2017. [Google Scholar]
- Shannon, C.E. A Mathematical Theory of Communication. Repr. Correct. Bell Syst. Tech. J. 1948, 27, 379–423. [Google Scholar] [CrossRef]
- Logan, R.K. What Is Information?: Why Is It Relativistic and What Is Its Relationship to Materiality, Meaning and Organization. Information 2012, 3, 68–91. [Google Scholar] [CrossRef]
- Hewitt, S.M. Data, Information, and Knowledge. J. Histochem. Cytochem. 2019, 67, 227–228. [Google Scholar] [CrossRef]
- International Organization for Standardization. ISO 9000:2015, Quality Management Systems—Fundamentals and Vocabulary, 5th ed.; International Organization for Standardization: Geneva, Switzerland, 2015. [Google Scholar]
- Olson, J.E. Data Quality: The Accuracy Dimension; Morgan Kaufmann: San Francisco, CA, USA, 2003. [Google Scholar]
- Redman, T.C. Data Quality: The Field Guide; Digital Press: Boston, MA, USA, 2001. [Google Scholar]
- Wang, R.Y.; Strong, D.M. Beyond Accuracy: What Data Quality Means to Data Consumers. J. Manag. Inf. Syst. 1996, 12, 5–33. [Google Scholar] [CrossRef]
- Kahn, B.K.; Strong, D.M.; Wang, R.Y. Information quality benchmarks: Product and service performance. Commun. ACM 2002, 45, 184–192. [Google Scholar] [CrossRef]
- Fürber, C. Data Quality Management with Semantic Technologies, 1st ed.; Springer Gabler: Wiesbaden, Germany, 2015. [Google Scholar] [CrossRef]
- Piwek, L.; Ellis, D.A.; Andrews, S.; Joinson, A. The Rise of Consumer Health Wearables: Promises and Barriers. PLoS Med. 2016, 13, e1001953. [Google Scholar] [CrossRef] [PubMed]
- Jones, S. Health & Fitness Wearables: Market Size, Trends & Vendor Strategies 2020–2025; Juniper Research Ltd.: Basingstoke, Hampshire, UK, 2020. [Google Scholar]
- Rothman, K.J. Epidemiology: An Introduction, 2nd ed.; Oxford University Press: New York, NY, USA, 2012. [Google Scholar]
- Loh, W.-Y.; Zhang, Q.; Zhang, W.; Zhou, P. Missing data, imputation and regression trees. Stat. Sin. 2020, 30, 1697–1722. [Google Scholar]
- McCausland, T. The Bad Data Problem. Res.-Technol. Manag. 2021, 64, 68–71. [Google Scholar] [CrossRef]
- Arias, V.B.; Garrido, L.E.; Jenaro, C.; Martinez-Molina, A.; Arias, B. A little garbage in, lots of garbage out: Assessing the impact of careless responding in personality survey data. Behav. Res. Methods 2020, 52, 2489–2505. [Google Scholar] [CrossRef]
- Kilkenny, M.F.; Robinson, K.M. Data quality: “Garbage in-garbage out”. Health Inf. Manag. J. 2018, 47, 103–105. [Google Scholar] [CrossRef]
- Naroll, F.; Naroll, R.; Howard, F.H. Position of women in childbirth. A study in data quality control. Am. J. Obstet. Gynecol. 1961, 82, 943–954. [Google Scholar] [CrossRef]
- Vidich, A.J.; Shapiro, G. A Comparison of Participant Observation and Survey Data. Am. Sociol. Rev. 1955, 20, 28–33. [Google Scholar] [CrossRef]
- Jensen, D.L.; Wilson, T.F.; United States Bureau of Justice Statistics; Search Group. Data Quality Policies and Procedures: Proceedings of a BJS/SEARCH Conference: Papers; U.S. Department. of Justice, Bureau of Justice Statistics: Washington, DC, USA, 1986. [Google Scholar]
- Gray, A.; Richardson, K.; Rooke, K.; Thornburn, T. Systems Engineering and Project Management (SEPM) Joint Working Group: Guide to Life Cycles and Life Cycle Models; International Council for Systems Engineering (INCOSE UK Ltd.): Ilminster, Somerset, 2017. [Google Scholar]
- Charalabidis, Y.; Alexopoulos, C.; Ferro, E.; Janssen, M.; Lampoltshammer, T.; Zuiderwijk, A. The World of Open Data: Concepts, Methods, Tools and Experiences. In Public Administration and Information Technology, 1st ed.; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar] [CrossRef]
- Rüegg, J.; Gries, C.; Bond-Lamberty, B.; Bowen, G.J.; Felzer, B.S.; McIntyre, N.E.; Soranno, P.A.; Vanderbilt, K.L.; Weathers, K.C. Completing the data life cycle: Using information management in macrosystems ecology research. Front. Ecol. Environ. 2014, 12, 24–30. [Google Scholar] [CrossRef]
- Michener, W.K. Ten Simple Rules for Creating a Good Data Management Plan. PLOS Comput. Biol. 2015, 11, e1004525. [Google Scholar] [CrossRef]
- Wilkinson, M.D.; Dumontier, M.; Aalbersberg, I.J.; Appleton, G.; Axton, M.; Baak, A.; Blomberg, N.; Boiten, J.W.; da Silva Santos, L.B.; Bourne, P.E.; et al. The FAIR Guiding Principles for scientific data management and stewardship. Sci. Data 2016, 3, 1–9. [Google Scholar] [CrossRef]
- Partescano, E.; Jack, M.E.M.; Vinci, M.; Cociancich, A.; Altenburger, A.; Giorgetti, A.; Galgani, F. Data quality and FAIR principles applied to marine litter data in Europe. Mar. Pollut. Bull. 2021, 173, 112965. [Google Scholar] [CrossRef]
- Deutsche Forschungsgemeinschaft (DFG). Guidelines for Safeguarding Good Research Practice. In Code of Conduct; German Research Foundation: Bonn, Germany, 2019. [Google Scholar] [CrossRef]
- Rat für Informationsinfrastrukturen (RfII). Herausforderung Datenqualität. In Empfehlungen zur Zukunftsfähigkeit von Forschung im Digitalen Wandel; Rat für Informationsinfrastrukturen (RfII): Göttingen, Germany, 2019; Available online: https://rfii.de/download/herausforderung-datenqualitaet-november-2019/ (accessed on 20 January 2022).
- International Organization for Standardization. ISO/IEC 25012:2008(E), Software Engineering—Software Product Quality Requirements and Evaluation (SQuaRE)—Data Quality Model; International Organization for Standardization: Geneva, Switzerland, 2008. [Google Scholar]
- Haug, A. Understanding the differences across data quality classifications: A literature review and guidelines for future research. Ind. Manag. Data Syst. 2021, 121, 2651–2671. [Google Scholar] [CrossRef]
- Chen, H.; Hailey, D.; Wang, N.; Yu, P. A review of data quality assessment methods for public health information systems. Int. J. Environ. Res. Public Health 2014, 11, 5170–5207. [Google Scholar] [CrossRef]
- Juddoo, S.; George, C. Discovering Most Important Data Quality Dimensions Using Latent Semantic Analysis. In Proceedings of the 2018 International Conference on Advances in Big Data, Computing and Data Communication Systems (icABCD), Durban, South Africa, 6–7 August 2018; pp. 1–6. [Google Scholar]
- Stausberg, J.; Nasseh, D.; Nonnemacher, M. Measuring Data Quality: A Review of the Literature between 2005 and 2013. Stud. Health Technol. Inform. 2015, 210, 712–716. [Google Scholar]
- Bian, J.; Lyu, T.; Loiacono, A.; Viramontes, T.M.; Lipori, G.; Guo, Y.; Wu, Y.; Prosperi, M.; George, T.J.; Harle, C.A.; et al. Assessing the practice of data quality evaluation in a national clinical data research network through a systematic scoping review in the era of real-world data. J. Am. Med. Inform. Assoc. 2020, 27, 1999–2010. [Google Scholar] [CrossRef]
- Even, A.; Shankaranarayanan, G. Value-Driven Data Quality Assessment (Research Paper-IQ Concepts, Tools, Metrics, Measures, Models, and Methodologies). In Proceedings of the International Conference on Information Quality, Cambridge, MA, USA, 4–6 November 2005. [Google Scholar]
- Gürdür, D.; El-khoury, J.; Nyberg, M. Methodology for linked enterprise data quality assessment through information visualizations. J. Ind. Inf. Integr. 2019, 15, 191–200. [Google Scholar] [CrossRef]
- Pipino, L.L.; Lee, Y.W.; Wang, R.Y. Data quality assessment. Commun. ACM 2002, 45, 211–218. [Google Scholar] [CrossRef]
- Zaveri, A.; Rula, A.; Maurino, A.; Pietrobon, R.; Lehmann, J.; Auer, S. Quality assessment for Linked Data: A Survey. Semant. Web 2016, 7, 63–93. [Google Scholar] [CrossRef]
- Black, A.; van Nederpelt, P. Dictionary of Dimensions of Data Quality (3DQ), Dictionary of 60 Standardized Definitions; DAMA NL Foundation: Den Haag, The Netherlands, 2020; Available online: http://www.dama-nl.org/wp-content/uploads/2020/11/3DQ-Dictionary-of-Dimensions-of-Data-Quality-version-1.2-d.d.-14-Nov-2020.pdf (accessed on 20 January 2022).
- Black, A.; van Nederpelt, P. How to Select the Right Dimensions of Data Quality. In Includes 60 Dimensions of Data Quality and Their Standardized Definitions; DAMA NL Foundation: Den Haag, The Netherlands, 2020; Volume Version 1.1, Available online: http://www.dama-nl.org/wp-content/uploads/2020/11/How-to-Select-the-Right-Dimensions-of-Data-Quality-v1.1-d.d.-14-Nov-2020.pdf (accessed on 20 January 2022).
- Naumann, F. Quality-Driven Query Answering for Integrated Information Systems. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2002. [Google Scholar] [CrossRef]
- DAMA UK Working Group on “Data Quality Dimensions”. The Six Primary Dimensions For Data Quality Assessment. In Defining Data Quality Dimensions; DAMA UK: Bristol, UK, 2013. [Google Scholar]
- Nonnemacher, M.; Nasseh, D.; Stausberg, J. Datenqualität in der Medizinischen Forschung: Leitlinie zum Adaptiven Management von Datenqualität in Kohortenstudien und Registern, 2nd ed.; Medizinisch Wissenschaftliche Verlagsgesellschaft: Berlin, Germany, 2014; Volume 4. [Google Scholar]
- Zwirner, M. Datenbereinigung zielgerichtet eingesetzt zur permanenten Datenqualitätssteigerung. In Daten-und Informationsqualität-Die Grundlage der Digitalisierung, 5th ed.; Knut Hildebrand, M.G., Holger, H., Michael, M., Eds.; Springer Vieweg: Wiesbaden, Germany, 2021. [Google Scholar] [CrossRef]
- Cichy, C.; Rass, S. An Overview of Data Quality Frameworks. IEEE Access 2019, 7, 24634–24648. [Google Scholar] [CrossRef]
- Zhang, R.; Indulska, M.; Sadiq, S. Discovering Data Quality Problems. Bus. Inf. Syst. Eng. 2019, 61, 575–593. [Google Scholar] [CrossRef]
- Schmidt, C.O.; Struckmann, S.; Enzenbach, C.; Reineke, A.; Stausberg, J.; Damerow, S.; Huebner, M.; Schmidt, B.; Sauerbrei, W.; Richter, A. Facilitating harmonized data quality assessments. A Data Quality Framework for Observational Health Research Data Collections with Software Implementations in R. BMC Med. Res. Methodol. 2021, 21, 63. [Google Scholar] [CrossRef]
- Redman, T.C. The impact of poor data quality on the typical enterprise. Commun. ACM 1998, 41, 79–82. [Google Scholar] [CrossRef]
- Redman, T.C. Bad Data Costs the US $3 Trillion Per Year. Havard Bus. Rev. 2016, 22, 11–18. Available online: https://hbr.org/2016/09/bad-data-costs-the-u-s-3-trillion-per-year (accessed on 20 January 2022).
- Vanella, P.; Deschermeier, P.; Wilke, C.B. An Overview of Population Projections—Methodological Concepts, International Data Availability, and Use Cases. Forecasting 2020, 2, 19. [Google Scholar] [CrossRef]
- An der Heiden, M.; Buchholz, U. Modellierung von Beispielszenarien der SARS-CoV-2-Epidemie 2020 in Deutschland; Robert-Koch-Institut: Berlin, Germany, 2020. [Google Scholar] [CrossRef]
- Khailaie, S.; Mitra, T.; Bandyopadhyay, A.; Schips, M.; Mascheroni, P.; Vanella, P.; Lange, B.; Binder, S.C.; Meyer-Hermann, M. Development of the reproduction number from coronavirus SARS-CoV-2 case data in Germany and implications for political measures. BMC Med. 2021, 19, 1–16. [Google Scholar] [CrossRef]
- Kuhbandner, C.; Homburg, S.; Walach, H.; Hockertz, S. Was Germany’s Lockdown in Spring 2020 Necessary? How Bad Data Quality Can Turn a Simulation Into a Delusion that Shapes the Future. Futures 2022, 135, 102879. [Google Scholar] [CrossRef]
- Fadnes, L.T.; Taube, A.; Tylleskär, T. How to identify information bias due to self-reporting in epidemiological research. Internet J. Epidemiol. 2006, 7, 28–38. [Google Scholar]
- Andreadis, I.; Kartsounidou, E. The Impact of Splitting a Long Online Questionnaire on Data Quality. Surv. Res. Methods 2020, 14, 31–42. [Google Scholar]
- Bowling, A. Mode of questionnaire administration can have serious effects on data quality. J. Public Health 2005, 27, 281–291. [Google Scholar] [CrossRef] [PubMed]
- Ekerljung, L.; Ronmark, E.; Lotvall, J.; Wennergren, G.; Toren, K.; Lundback, B. Questionnaire layout and wording influence prevalence and risk estimates of respiratory symptoms in a population cohort. Clin. Respir. J. 2013, 7, 53–63. [Google Scholar] [CrossRef]
- Cocco, M.; Tuzzi, A. New data collection modes for surveys: A comparative analysis of the influence of survey mode on question-wording effects. Qual. Quant. 2013, 47, 3135–3152. [Google Scholar] [CrossRef]
- Sadiq, S.; Indulska, M. Open data: Quality over quantity. Int. J. Inf. Manag. 2017, 37, 150–154. [Google Scholar] [CrossRef]
- Zeeberg, B.R.; Riss, J.; Kane, D.W.; Bussey, K.J.; Uchio, E.; Linehan, W.M.; Barrett, J.C.; Weinstein, J.N. Mistaken identifiers: Gene name errors can be introduced inadvertently when using Excel in bioinformatics. BMC Bioinform. 2004, 5, 80. [Google Scholar] [CrossRef]
- Welsh, E.A.; Stewart, P.A.; Kuenzi, B.M.; Eschrich, J.A. Escape Excel: A tool for preventing gene symbol and accession conversion errors. PLoS ONE 2017, 12, e0185207. [Google Scholar] [CrossRef]
- Vanella, P.; Wiessner, C.; Holz, A.; Krause, G.; Möhl, A.; Wiegel, S.; Lange, B.; Becher, H. Pitfalls and solutions in case fatality risk estimation–A multi-country analysis on the effects of demographics, surveillance, time lags between case reports and deaths and healthcare system capacity on COVID-19 CFR estimates. Vienna Yearb. Popul. Res. 2022. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, B.; Zhao, Y.; Cheng, X.; Hu, F. Data Security and Privacy-Preserving in Edge Computing Paradigm: Survey and Open Issues. IEEE Access 2018, 6, 18209–18237. [Google Scholar] [CrossRef]
- Tahmasebian, F.; Xiong, L.; Sotoodeh, M.; Sunderam, V. Crowdsourcing Under Data Poisoning Attacks: A Comparative Study. In Data and Applications Security and Privacy XXXIV. DBSec 2020; Singhal, A., Vaidya, J., Eds.; Springer: Cham, Switzerland, 2020; pp. 310–332. [Google Scholar] [CrossRef]
- Yoon, A. Red flags in data: Learning from failed data reuse experiences. Proc. Assoc. Inf. Sci. Technol. 2016, 53, 1–6. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hassenstein, M.J.; Vanella, P. Data Quality—Concepts and Problems. Encyclopedia 2022, 2, 498-510. https://doi.org/10.3390/encyclopedia2010032
Hassenstein MJ, Vanella P. Data Quality—Concepts and Problems. Encyclopedia. 2022; 2(1):498-510. https://doi.org/10.3390/encyclopedia2010032
Chicago/Turabian StyleHassenstein, Max J., and Patrizio Vanella. 2022. "Data Quality—Concepts and Problems" Encyclopedia 2, no. 1: 498-510. https://doi.org/10.3390/encyclopedia2010032
APA StyleHassenstein, M. J., & Vanella, P. (2022). Data Quality—Concepts and Problems. Encyclopedia, 2(1), 498-510. https://doi.org/10.3390/encyclopedia2010032