Abstract
Artificial intelligence (AI) has become commonplace in our everyday lives and in healthcare. Peritoneal dialysis (PD) is a cost-effective method of treatment for kidney failure that is preferred by many patients, but its uptake is limited by several barriers. With the rapid advancements in AI, researchers are developing new tools that could mitigate some of these barriers to promote uptake and improve patient outcomes. AI has the capacity to assist with patient selection and management, predict patient technique failure, predict patient outcomes, and improve accessibility of patient education. Patients already have access to some open-source AI tools, and others are being rapidly developed for implementation in the dialysis space. For ethical implementation, it is essential for providers to understand the advantages and limitations of AI-based approaches and be able to interpret the common metrics used to evaluate their performance. In this review, we provide a general overview of AI with information necessary for clinicians to critically evaluate AI models and tools. We then review existing AI models and tools for PD.
1. Background
Artificial intelligence (AI), once only accessible to computer scientists and researchers, has become increasingly integrated into the medical field. Patients and clinicians alike now have access to AI-based risk models, chatbots, and recommendation toolkits. These tools provide an opportunity to facilitate high-quality patient care and optimize clinic workflows. Peritoneal dialysis (PD) is an efficacious and cost-effective treatment for kidney failure that has many benefits, including better quality of life and increased independence for many patients, but remains underutilized in the United States [1]. In 2019, the White House signed the Advancing Kidney Health initiative, which encouraged new patients with kidney failure to choose kidney replacement therapy options of transplantation or home dialysis options, such as PD. Already, researchers have started implementing AI approaches in treating patients using PD to treat kidney failure. As AI tools like ChatGPT become mainstream, both providers and patients wonder whether they can accurately answer basic and essential questions about medical care; for example, what to do when the catheter disconnects or stops draining, what it means when the outflow fluid is cloudy, and when to empty the belly of fluid in advance of a medical procedure. With the rapid proliferation of AI in the medical space, there is an opportunity for the development of tools to address these barriers and promote optimal outcomes among patients on PD. It is essential that providers have a basic understanding of these tools and evaluation approaches to implement them correctly and best advise their patients.
There remain many barriers to increasing the utilization of PD in the United States, one of which is the technique failure rate. PD outcomes have improved dramatically in recent decades, but rates of technique failure remain high [2,3]. Technique failure can arise from technical problems with catheter placement, inadequate filtration, and infection [2,3]. Some patients have an outsized risk for technique failure due to physiologic characteristics that are difficult to discern prior to therapy initiation [4]. Others could benefit from improved patient education about PD care and maintenance [5,6]. Considering these challenges and the risk of mortality with technique failure, patient selection is high stakes and challenging. Appropriate training and provider comfort with PD management are necessary to optimize outcomes and increase the number of patients treated with PD [7,8]. Through development of educational aids, outcome prediction algorithms, and other supportive tools, AI can potentially be used to address some of these barriers in the general field of dialysis, particularly for patients treated with peritoneal dialysis. In this review, we provide an overview of AI, how AI has been used in peritoneal dialysis, and limitations to current AI systems.
2. What Is AI
AI refers to computer systems designed to perform tasks that typically require human intelligence. Different types of AI serve different purposes. Machine learning (ML) allows computers to learn from data and make predictions or decisions. Deep learning, a more advanced type of ML, uses layers of processing to recognize complex patterns. Natural language processing helps computers understand and work with human language, while large language models use large amounts of text data to recognize patterns and generate language. These tools are commonly used in everyday technology, such as facial recognition, autocorrect, and language translation (Figure 1). In research and healthcare, AI can find patterns in data that people may not notice. There are two main types of learning: supervised, where the data have labels to guide the computer, and unsupervised, where the computer looks for patterns on its own. Supervised learning includes classification (grouping data) and regression (predicting outcomes). For example, doctors can use classification to sort patients by how they respond to a treatment or use regression to predict how well a patient might respond based on past data. Here, we describe common AI approaches and evaluation methods used in research and clinical tool development. To skip to an overview of clinical integration of these tools, please refer to the next section, AI in PD.
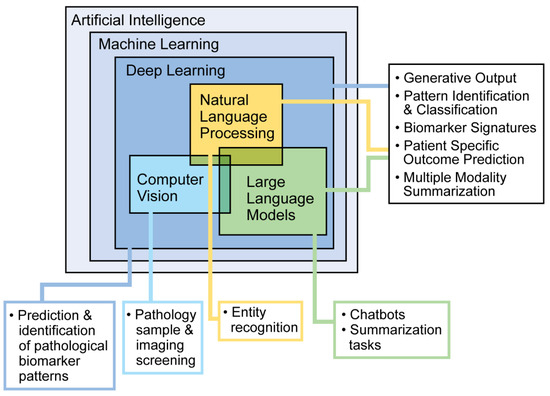
Figure 1.
Machine learning approaches and potential use cases.
3. Language Processing
An immense advantage of AI and the various word processing features is the possibility to make conclusions about large quantities of free-text data. While manual review remains the gold standard for accuracy, ML techniques can quickly identify patterns in large unstructured datasets—patients’ medical records or medical notes, for example—and identify patterns that would previously have taken multiple coders completing hypothesis-driven investigation to capture, identify, and quantify. Approaches incorporating free-text-based ML are useful for sentiment analysis, summarizing tasks, and prediction based on pattern identification. Researchers are currently evaluating the efficacy and accuracy of ambient AI scribes that can transcribe and format relevant facts from an ongoing conversation into a medical note [9]. Tools like dictation scribes, translation software, and note-writing assistants are based on large language models and natural language processing and have already been implemented to vastly reduce the amount of time providers spend writing notes and simultaneously increase standardization of the electronic health record.
4. Performance Evaluation
An advantage of AI is the capacity of machines to hold large quantities of data and identify patterns that might take hours of analysis for a human researcher to find. It is, therefore, difficult to intuitively assess output, and it is essential to utilize stringent assessment techniques to evaluate model performance before implementation in the clinical setting.
Several fundamental metrics help quantify model performance after comparison of output to ground truth. Recall is the model’s performance in correctly classifying positive examples: how many positives were identified correctly compared to the total number of positives in the ground truth sample. Recall is the same as the true positive rate: how many of the positives in the sample were correctly labeled as true. Precision refers to the model’s accuracy on positive examples: how many of the model’s classifications of “positive” were correct when compared to ground truth. Precision is the same as the positive predictive value that is generally used for diagnostic test accuracy. Finally, the general metric of negative predictive value (NPV), or the likelihood that a negative result is true, can also be used.
Once a machine learning model makes predictions for a classification task, there are several common methods used to measure how accurate those predictions are. One such method is the Receiver Operating Characteristic (ROC) curve, which compares how often the model correctly identifies positive cases versus how often it incorrectly identifies negatives as positives. The area under this curve, commonly referenced as AUROC, helps summarize the model’s overall performance—a value of 1 means perfect accuracy, while 0.5 means the model is no better than random guessing. Another method is the Precision–Recall (PR) curve, which focuses on how well the model performs when the outcome is rare, and its area under the curve (AUPRC) reflects how well the model balances correct results with missed ones. A higher AUROC or AUPRC generally means better model performance.
Some models also provide a probability for each prediction. To evaluate these, a measure called log loss is used, which compares the predicted probability with the actual result. The closer the model is to the truth, the lower the log loss. This measure is often used during training to help the model improve by penalizing confident but incorrect predictions.
When the dataset is imbalanced (meaning one outcome is much rarer than the other), standard metrics can be misleading. In such cases, tools like the Brier score or F1-score are more helpful. The Brier score looks at how close the predicted probabilities are to the actual outcomes; a lower score is better. The F1-score combines precision and recall, giving a single number that shows how well the model is at correctly identifying the less common cases. A score of 1 indicates perfect recall and precision, while a score of 0 indicates complete failure to correctly classify positive examples.
For models that predict numbers instead of categories (called regression tasks), the goal is to measure how close the predicted numbers are to the actual ones. The Mean Absolute Error shows the average amount that the model’s predictions are off, while the Mean Squared Error gives more weight to larger errors. The R2 score tells how well the model explains the variation in the data—a score of 1 means a perfect fit.
Evaluating the output of generative models, like large language models, is more difficult because they generate long text instead of simple answers. Some methods use statistics, like Levenshtein distance (which counts how many characters differ between the model’s output and a reference), or BLEU and METEOR scores (which compare how closely the generated text matches a reference). However, these can miss the meaning of the text if the wording is different but still correct.
To improve on this, more advanced tools use AI models to judge the output. These tools consider meaning and structure, not just wording. For example, the natural language inference scorer uses natural language processing to check whether the output makes logical sense, and BLEURT uses advanced language models to assess relevance and correctness. A newer method called “LLM-as-a-judge” asks a language model to evaluate another model’s output—either by giving it a score, grading it with a rubric, or choosing the better of two options. These approaches currently perform better than the previous statistical or model-based scorers, but they are limited by the probabilistic nature of large language models. Scoring is inconsistent and sometimes arbitrary, often influenced by extraneous factors, like the order in which the outputs were presented or the verbosity of the outputs. One such tool, G-Eval, uses GPT-based models to assess qualities of large language model output like relevance, coherence, and correctness [10]. While promising, these new tools can still be inconsistent.
5. AI in PD
Since the 2000s, researchers have been investigating ways to implement ML approaches to improve outcomes for patients on PD [1,11]. Many of these approaches are still in development but provide a glimpse into what the future might hold for PD care (Figure 2).
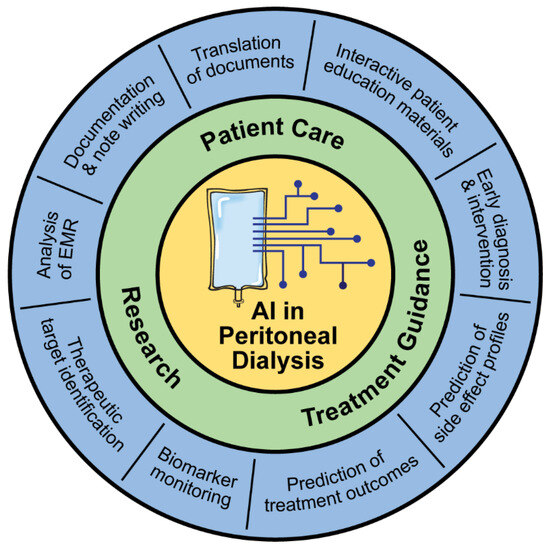
Figure 2.
Applications of AI in peritoneal dialysis.
5.1. Patient Selection and Management:
It is increasingly recognized that a personalized approach is needed in the care of patients. This is particularly true for patients on PD, as it utilizes a patient’s native peritoneal membrane for clearance and ultrafiltration. While PD offers many benefits, patients may develop peritonitis, which necessitates the early administration of appropriate antibiotics. The use of ML can assist in mitigating these challenges.
The fast transport rate of the peritoneal membrane, or the rate at which water and solutes move across the peritoneal membrane, can be associated with suboptimal outcomes in patients using PD, including higher mortality, higher technique failure, peritonitis, and protein energy malnutrition [4,12]. Discussion with patients about ways to optimize their treatment or even early transition to hemodialysis may lead to better outcomes for patients who have a fast transport rate [12,13]. These conversations can be difficult, particularly for patients who prefer PD for lifestyle reasons. It would, therefore, be helpful to approximate the patient transport rate prior to dialysis therapy initiation, but the transport rate is difficult to predict prior to initiating peritoneal dialysis therapy [12,14]. Chen et al. used an artificial neural network (ANN), a deep learning approach, to stratify patients’ transporter status using pre-dialysis information. The algorithm used pre-dialysis demographics, comorbidities, and blood and urine chemistries to predict transport status. The group compared the model output against the ground truth transport status from peritoneal equilibration test results within 1 month of dialysis initiation. The model performed well, with an AUC of 0.812 ± 0.041 [14]. While this study is promising and could potentially be used to help identify patients’ transport rate and help with initial prescription formulation, the overall small sample size (n = 111) and lack of external validation are key limitations of the study. Stratification tools used to predict outcomes and subsequently suggest treatment modalities have vast potential but must only be used with shared decision making and in the context of appropriate patient factors. For example, PD may be preferable for patients who live in rural areas with less access to dialysis units where monthly visits are preferred over thrice weekly in-center hemodialysis treatments, regardless of transport membrane status.
Peritonitis is a potential complication for people using PD that can contribute to patient dropout. Upon presentation, appropriate antibiotic treatment can be delayed by the time it takes to process and identify the culprit pathogens. Providers typically utilize empiric antibiotic treatment until the lab returns the pathology report from fluid samples. Early pathogen identification could expedite targeted antibiotic treatment and, therefore, improve patient outcomes. Delayed and inappropriate treatment can lead to chronic or recurrent infections. The use of broad-spectrum antibiotics for empiric therapy is a major contributor to multidrug resistance. Recognizing that the immune system responds to different pathogens in different ways, Zhang et al. aimed to identify and differentiate unique immune fingerprints that correlated with infection by Gram-negative and Gram-positive bacteria in patients on peritoneal dialysis. To select the most important features to train their models, they used recursive feature elimination to identify biomarkers that are associated with Gram-negative infections. The feature elimination approach tested one of the three ML approaches—support vector machine, which attempts to categorize data in a hyperplane such that the space between each group is maximized, ANN, and random forest, which is an ensemble decision tree analysis that utilizes the output of multiple decision trees to come to a conclusion [15]. The random forest model performed best and was used to identify five biomarkers that predicted pathogen species. Within Gram-positive bacteria, a random forest model could also identify biomarkers that differentiated immune responses to some Streptococcal and Staphylococcus subspecies. Zhang et al. also identified combinations of biomarkers that could be used to identify clinically meaningful subgroups. For example, the biomarkers matrix metalloproteinase 8, soluble IL-6 receptor, calprotectin, CD4:CD8, and transforming growth factor-β were associated with technique failure.
Early pathogen and outcome prediction using ML shows great promise for expediting and improving antibiotic treatment in patients treated with PD. However, further studies are necessary before broad implementation is appropriate. Each algorithm used had strong prediction performance, with an AUC of more than 0.9, but unique combinations of biomarkers were required for each task to achieve the best predictive capacity. Models that are able to differentiate pathogens and outcomes using a consistent and limited set of biomarkers would reduce computing power requirements and, therefore, be the most cost efficient, allowing for adoption across different healthcare settings. Zhang et al. trained their algorithm with a relatively small dataset of Welsh patients on PD: 83 patients with acute infection and 17 patients without infection. The results will need to be replicated in larger and more diverse cohorts to demonstrate generalizability. Immunogenicity can change with pathogen mutation, and it is further affected by many variables, many of which are influenced by patient-specific characteristics and geographic location. Future algorithm construction will either require a specific focus on individual locations and pathogens or extensive training with large datasets of geographically diverse patients. For this task, the model could be improved through the inclusion of basic demographic and electronic health record data. Analysis in other patient populations has shown that while application of ML with unimodal data is impressive, it can be further leveraged by including multimodal data, including patient demographics, longitudinal biomarker data, imaging, and notes from the electronic health record [16,17]. Researchers have utilized the ability of models to interpret multimodal data to predict the progression of kidney disease with high accuracy [18,19].
5.2. Predicting Technique Failure
Though PD is cost effective and preferred among some patients, high rates of technique failure can discourage the adoption of the approach. Tangri et al. assessed the feasibility of using an ANN approach to predict technique failure, defined as a change to hemodialysis for at least one month. In 2008, they used data from the United Kingdom Renal Registry and found that an ANN approach could predict technique failure with moderate accuracy (AUC 0.760) and with greater precision than logistic regression [20]. The approach was limited by sample selection bias, as all participants were currently treated with PD, and incomplete data collection. Etiology of technique failure was not documented, and two-thirds of the included participants lacked comorbidity data. In 2011, the group implemented an ANN approach again using the United Kingdom Renal Registry and compared it to logistic regression, but they included more complete data [21]. They found that the model could predict technique failure with an AUC of 0.765 and that the inclusion of PD center and time on dialysis had the largest impact on the fit of the model. The regression model performed almost as well, with an AUC of 0.762, but the variables with the largest impact on model fit differed; they were observation time, age, race, weight, laboratory data, and dialysis center [21]. These studies are still limited by external validation, sample size, and data completeness, but they provide evidence that an ANN approach could be useful in predicting technique failure. Larger datasets and advanced deep learning approaches that are capable of leveraging longitudinal and multimodal data have become available since the time of this paper, which could improve prediction accuracy and consistency in future iterations.
5.3. Predicting Outcomes of PD
ML is well suited to prediction tasks as machines can hold immense quantities of data and identify hidden patterns that might not be discernible through prediction-driven analysis by human researchers. The prediction of patient outcomes could help quantify expectations for patients and allow providers to make decisions about treatment course. Much research has focused on developing ML models for clinical outcomes, such as mortality and hospital length of stay.
Patients on PD are frequently admitted to the hospital [22]. The prediction of anticipated hospital length of stay can identify patients who are at risk for prolonged hospitalizations and promote the allocation of resources to support those individuals. One study by Kong et al. used a stacking model, or a model comprising multiple ML approaches, to predict patients at risk of a prolonged length of hospital stay, defined as more than 16 days [23]. The input data included hospitalization admissions data from 23,992 patients treated with PD in the Hospital Quality Monitoring System (HQMS), a mandatory national database in China, where the study took place. Prediction accuracy was compared to a traditional logistic regression model, output from each of the base models that comprise the stacking model, and the actual length of stay from the database. Each approach yielded varying degrees of specificity and sensitivity, and the stacking model outperformed the baseline logistic regression in terms of accuracy (0.695) and specificity (0.701). The stacking model and the random forest base model performed (Brier score 0.174 for both, with a lower score indicating better model performance) and discriminated (AUROC of 0.757 for the stacking model and 0.756 for the random forest model) equally well [23]. In a follow-up study, this group used ML to identify ten variables that were most predictive of risk of a prolonged hospital stay to develop a scoring tool to predict prolonged length of stay in patients on PD [24]. The random forest approach had the best metrics (Brier score 0.158 and AUROC 0.756) and was, therefore, used to identify the ten predictive variables [24]. The logistic regression using these variables performed well (AUROC of 0.721) and was used to construct a scoring tool to stratify patients into three groups: low, median, and high risk for prolonged length of stay [24].
While the authors used large datasets with extensive variables, they noted that some potentially significant variables were not accessible at the time of analysis and could have had more predictive power than those selected. The study is limited by a lack of external validity. All patients included resided in China, and some of the variables included in the models are not generalizable. For example, in the Wu study, three of the ten predictive variables were patients’ place of residence in regions in China. While patients’ residence and housing status are important proxies that are likely indicative of the patient’s social determinants of health, this information is not collected uniformly across countries. This highlights the need for standardized data collection that will allow for the development of generalizable models.
Despite overall improvements in the care of patients on PD, mortality remains high at 150.4 per 1000 person-years [22]. Substantial research efforts have been dedicated to improving the prediction of mortality in patients on PD. Zhou et al. used data from one hospital in China to develop deep learning ML models to predict mortality [25]. They compared the performance of a logistic regression model with two deep learning models: a classic ANN and a mixed model. In their classic ANN model, they integrated numerical and classical models, while in their mixed model, they built two separate neural networks for numerical variables and categorical variables and combined them. Among 859 patients included in the study, 77 met the primary endpoint within the study timeframe. In the test dataset, the logistic regression model had a higher AUROC than either of the ANN models, demonstrating that a more complex architecture is not always superior to standard statistical approaches. However, the ANN mixed model performed better in the follow-up datasets. This study has several notable limitations: it is an imbalanced dataset, as the primary outcome of mortality occurred infrequently; it has a small sample size; and it lacks geographical and operational diversity, as it took place at a single center.
In another study, Noh et al. used data from 1730 patients treated with PD from a nationwide Korean ESKD database to evaluate several ML models’ predictive ability of time to death and 5-year odds of death [26]. They compared the performance of Cox regression, a standard statistical model, to tree-based methods, including survival trees and more complex deep learning models. For analysis without imputation of missing variables, the survival tree method had better performance compared to the traditional Cox model, with an AUC of 0.769 vs. 0.746, respectively. For their 5-year prediction models, logistic regression performed well, with an AUC of 0.804. With the incorporation of a Long Short-Term Memory network approach, which allowed the algorithm to use an individual patient’s longitudinal data by “remembering” past data points and iteratively identifying patterns through inclusion of each additional data point, the AUC improved to 0.840. With addition of an auto-encoder, which allowed the algorithm to infer missing data points based on the patterns it assessed, the AUC was improved to 0.858 [26]. While only the AUC for model performance was reported, other informative metrics would be useful to externally assess performance. The study is again limited by its lack of external validation and imbalanced dataset, but it demonstrates that the integration of methods may be the most effective approach in predicting patient outcomes.
While several ML models for clinical outcomes in patients on PD have been developed, none, to our knowledge, have yet seen widespread use or acceptance. ML models require substantial computing power that is currently infeasible when considered on the scale of hundreds of thousands of medical records. Current models are developed in small samples and have not been externally validated; therefore, it is unclear if they are generalizable to different or more diverse patient samples. Small sample size also predisposes models to future error. Deep learning approaches, including neural networks, are susceptible to overfitting such that the algorithm is overly specific to the training data and cannot perform on new unseen data. Overfitting can occur as a result of a variety of common implementation pitfalls: small sample size, disproportionate noise, inclusion of irrelevant data, and continuous iteration or over-training on a single dataset. In these cases, the algorithm could strain to identify a pattern that explains the inclusion of all data points and subsequently misrepresent the pattern as it exists outside the training data in broader examples. Deep learning approaches, like Long Short-Term Memory, are often considered a “black box”, as it is difficult to understand the components that contributed to the conclusion. In the context of making decisions about patient care, provider comprehension and the capacity for validation are essential. Further work and provider education are needed before models can be implemented.
5.4. Patient Education for PD
Home kidney replacement therapies, such as PD, require high levels of patient health education, engagement, and self-care capacity. As the patient is mostly independent, questions regarding their treatments or about their PD catheter can arise at any time of the day or night. It can be difficult to expeditiously provide answers and instructions to patients when they arise. AI-based educational tools designed for patient use could effectively fill this gap. At this time, open-source AI tools are not yet reliable enough to accurately answer medical questions from patients. It is recommended that patients continue to obtain information directly from their healthcare providers. To improve this, researchers are studying how current AI tools perform and looking for ways to make them better. Some are also working on creating accurate AI-based educational tools specifically for patients with kidney disease and those treated with PD using trusted information and built-in safety checks.
Cheng et al. developed a LINE application-based AI chatbot to provide patients with educational material, including instructional videos, clinical reminders, home care, and dietary guidance [27]. Overall satisfaction with the chatbot was high, with an average patient satisfaction score of 4.5/5.0. The group tracked clicks and found that patients most frequently utilized sections on home PD care and PD dietary guidance. There was no significant difference in infection rates based on analysis of three months before and after the implementation, but there was an associated reduction in technique-related peritonitis one month before and after implementation (relative risk = 0.8) [27].
The results indicate that the implementation of the chatbot improved patient self-care efficacy and health knowledge. Chatbots and intentionally designed patient education delivery systems are useful in disseminating reliable knowledge quickly and appropriately. We suspect the use of chatbots to increase with increased accessibility to large language models, such as ChatGPT. However, the illusion of communicating with a trained healthcare provider can lead to overreliance on the output of the chatbot, which could discourage patients from talking to their providers about concerns [28]. Every patient is different, and providers must balance patient interaction and implementation of automated tools to enhance the patient experience. Chatbots must have accurate information to maintain patient trust. Accessibility of applications and language is important, though it can be difficult to anticipate an individual’s specific needs during application development. Cheng et al. noted that their chatbot could only be accessed on a smartphone or pad and that it was not yet accessible for patients with poor eyesight [27]. Not all patients have access to technology or are technologically literate; it will be important to provide detailed instructions or adequate alternatives for patients who cannot access these resources.
Patient privacy and bias mitigation are concerns for all modalities of AI tool implementation, especially chatbots and patient-facing interactive tools. Part of the strength of large language models’ performance is that they continue to learn from inputs, even after implementation. This allows the algorithm to obtain feedback from users to inform future behavior. Large language models, like ChatGPT and others, can be downloaded and run locally, meaning the trained algorithm is used, but the input data are not saved. Clear informed consent when implementing these tools is key, particularly in cases where the large language model stores and learns from input data and where patients might be inclined to enter personal information. Further, natural language processing and large language models are tools created from preexisting data, subject to human error and bias. Patterns recognized by these tools, therefore, can replicate systemic issues in the data, including disparate responses to certain language.
Given concerns about the appropriateness of large language model responses for chronic kidney disease (CKD) education, Acharya et al. tested the quality and accuracy of AI responses to standardized questions about nephrology care. The models tested included Bard AI, Bing AI, and two versions of ChatGPT, all of which were trained on large sets of publicly available data on the internet [29]. Two nephrologists reviewed the AI-generated answers to identify erroneous or misleading answers. They found that responses were generally correct but frequently provided incorrect references and sometimes provided misleading information. Any ML model is susceptible to hallucinations or incorrect or nonsensical outputs that do not appear to arise from patterns that exist in the data. This error can arise from many reasons: incomplete or inadequate training data, overfitting, or high algorithm complexity are just a few. As the authors indicate, a drawback to training large language models on large amounts of public data is that the algorithm can retrieve medical information from sources that are not necessarily peer reviewed and trustworthy [29]. To maintain trust in and reliability of ML tools, every effort must be made to ensure accurate information is disseminated.
Another area of research is focused on the ability of large language models to answer medical knowledge questions. Wu et al. tested the performance of several open-source and proprietary large language models on the Nephrology Self-Assessment Program (nephSAP), a multiple-choice exam that nephrologists can use for self-assessment, to evaluate their ability to answer complex medical questions. In a world in which patients increasingly ask open-source large language models medical questions, it is useful to understand their capabilities to advise patients in advance about their accuracy. The group found that the proprietary models GPT-4 and Claude-2 performed better than the open-source models, but no model achieved the human-passing score of 75% [30]. GPT-4 received a score of 73.3%, Claude-2 received a score of 54.4%, and the open-source models received scores ranging from 17.1% to 30.6%. GPT-4 performed worst on electrolyte questions, likely because large language models tend to have poor “reasoning” abilities [30]. The authors also used BLEU and Word Error Rates (WERs), a word-level metric derived from the character-level Levenshtein distance, to assess the quality of the output. All models had WER scores between 0 and 22%. When assessed with BLEU, all models scored below approximately 0.1, indicating suboptimal matching to reference output text. The difference in performance is surprising, but the authors hypothesized that the difference in performance lies in the proprietary models’ access to peer-reviewed third-party medical data as part of training [30]. A vast quantity of peer-reviewed data are not open source and are, therefore, omitted from the training of the open-source models. Access to proprietary large language models is limited by the high cost of obtaining a license. In future medical large language models and informational chatbots, it will be essential to ensure appropriate access to trustworthy data to improve performance. This access will be especially important for patients with complex medical treatment, like those treated with PD. Along with the advent of proprietary models, there is potential for discrepant access to the highest quality tools due to socioeconomic status. Ethical deployment of these tools needs to ensure access to everyone equally.
To address large language model hallucinations and the potential for misleading output, researchers have aimed to find ways to guide the models’ output to include data from appropriate sources. One method is retrieval-augmented generation, in which the large language model enhances its response to prompts using fresh data it retrieves from relevant and trusted sources. Particularly when large language models are trained on historical data, this method helps ensure that the output is updated and appropriately related to the scenario in question. For patients treated with PD requesting information about their symptoms or medical treatment, updated and accurate information is particularly crucial. Such a tool does not yet exist for patients treated with PD, but Miao et al. implemented the retrieval-augmented generation approach to improve GPT-4’s responses to inquiries about chronic kidney disease [31]. The team created a chronic kidney disease knowledge retrieval model that could quickly source information from a curated database with information based on the KDIGO 2023 chronic kidney disease guidelines. When prompted, the general GPT-4 tended to provide broad recommendations, while the GPT with integrated retrieval-augmented generation approach tended to output more specific recommendations that aligned with the KDIGO 2023 chronic kidney disease guidelines. As the authors outline, the implementation of a nephrology-specific large language model would require extensive curation of trusted source material that is constantly updated with updates in care guidelines. As large language models are not as adept at reasoning tasks, Miao et al. included instructions that the large language model should state when it is unable to answer a question or if the user should seek additional external medical advice. In an era of reliance on internet resources for care information, it will be important to implement such guards to protect patients from false or dangerous information. This type of maintenance and regulation will require extensive external validation, upkeep, and rigorous testing, which will be a barrier to rapid implementation.
6. Limitations
While AI approaches have the opportunity to improve patient education and accessibility to care, it is important to understand their limitations. Bugs in the input data or other unforeseen architecture problems can lead to hallucinatory outputs, or outputs that are incorrect or nonsensical. In the research arena, some of these issues can be addressed through cleaning input data and prompt engineering, the iterative practice of drafting instructions that will garner the intended output. As models become publicly available but are still improving, it is important to address the overarching concern of automation bias or outsized trust and reliance on computer algorithms [28].
It can be difficult for human researchers to follow how deep learning models arrived at their output given the input. For any clinical decision making, a comprehensive understanding of how algorithms use input to arrive at conclusions is necessary before implementation. It is important for physicians to understand evaluation metrics and the limitations of these tools to avoid overreliance on their output. Increased education will help providers avoid generalizing outputs from ML tools but rather identify errors, understand the context in which a given tool is meant to be implemented, and contextualize its limitations in other use cases [28].
The output of AI algorithms is based on human-constructed rules or training on human-entered data [32]. Thus, any systemic bias or errors could be reflected in the output. When writing notes using editors, consider the potential for the model to have been trained on data that includes disparate language and conclusions that could stigmatize or stereotype patients from minoritized groups. When using prediction tools, think about ways that social determinants of health might impact the presentation or outcomes for certain groups of patients and consider the possibility for certain groups to have inappropriate or delayed diagnosis times. AI treatment recommendations or outcome predictions must be contextualized within the patient’s history, and the provider should make the final decision until further testing and validation are completed.
Large data approaches, like ML, require immense quantities of data and large computing power to operate. Obtaining the datasets through data-sharing or data collection can be difficult and laborious; the datasets must be large enough, comprehensive, and inclusive of the patient population that the algorithm is intended to subsequently serve. Data maintenance and protection can be expensive and time consuming; the storage alone requires institutional investment in large computers and staff to maintain them. The ML tools themselves may improve treatment quality and reduce the cost of care, but the cost of computing is immense and can be a barrier to equitable use and implementation of these tools.
7. Future Use and Conclusions
As AI tools advance quickly and innovations emerge almost daily, they are becoming increasingly integrated into clinical care. Dictation software and ambient AI scribes already assist providers with documentation, and patients use existing AI chatbots to answer their questions. Even more advanced tools could predict patient outcomes and make treatment recommendations that could optimize patient care. These rapid advancements could provide the opportunity to revolutionize personalized patient care and streamline workflows for physicians, but many of these tools lack external validation across diverse patient samples and, therefore, do not make it to clinical implementation. Bridging the gap from bench to bedside will require real-world testing and collaboration among all stakeholders: patients, clinicians, regulatory bodies, and engineers. With these partnerships, AI tools can be ethically implemented to benefit both patients and providers.
AI has a place in the care of patients using any form of dialysis—especially home dialysis therapies, like PD—whether through improvement of patient education, stratification of patient symptomology, or even outcome prediction that can aid in the selection of treatment methodology. While ML approaches are extremely useful in certain settings, it is important for providers to understand their limitations. In the future, providers can expect the integration of AI-based tools to help monitor patient status and recommend treatment choices based on their unique biomarker data. In this era, physicians must be equipped to interpret and utilize AI tools while educating their patients to do the same.
Author Contributions
Conceptualization, L.C.; writing—original draft preparation, H.E.Y.; writing—review and editing, L.C.; supervision, L.C.; funding acquisition, L.C. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by NIH/NIDDK grant number K23DK124645, and NIDDK grant number U01DK137259.
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
Lili Chan is supported in part by a grant from the NIH/NIDDK/NIMHD (K23DK124645 and U01DK137259). Lili Chan is a consultant for Vifor Pharma INC.
References
- Bai, Q.; Tang, W. Artificial intelligence in peritoneal dialysis: General overview. Ren. Fail. 2022, 44, 682–687. [Google Scholar] [CrossRef] [PubMed]
- Chen, J.H.C.; Johnson, D.W.; Hawley, C.; Boudville, N.; Lim, W.H. Association between causes of peritoneal dialysis technique failure and all-cause mortality. Sci. Rep. 2018, 8, 3980. [Google Scholar] [CrossRef]
- Bonenkamp, A.A.; van Eck van der Sluijs, A.; Dekker, F.W.; Struijk, D.G.; de Fijter, C.W.; Vermeeren, Y.M.; van Ittersum, F.J.; Verhaar, M.C.; van Jaarsveld, B.C.; Abrahams, A.C. Technique failure in peritoneal dialysis: Modifiable causes and patient-specific risk factors. Perit. Dial. Int. 2023, 43, 73–83. [Google Scholar] [CrossRef] [PubMed]
- Brimble, K.S.; Walker, M.; Margetts, P.J.; Kundhal, K.K.; Rabbat, C.G. Meta-analysis: Peritoneal membrane transport, mortality, and technique failure in peritoneal dialysis. J. Am. Soc. Nephrol. 2006, 17, 2591–2598. [Google Scholar] [CrossRef]
- Wasse, H. Factors related to patient selection and initiation of peritoneal dialysis. J. Vasc. Access 2017, 18, 39–40. [Google Scholar] [CrossRef] [PubMed]
- Nessim, S.J. Prevention of peritoneal dialysis-related infections. Semin. Nephrol. 2011, 31, 199–212. [Google Scholar] [CrossRef]
- Teitelbaum, I.; Finkelstein, F.O. Why are we Not Getting More Patients onto Peritoneal Dialysis? Observations From the United States with Global Implications. Kidney Int. Rep. 2023, 8, 1917–1923. [Google Scholar] [CrossRef]
- Gupta, N.; Taber-Hight, E.B.; Miller, B.W. Perceptions of Home Dialysis Training and Experience Among US Nephrology Fellows. Am. J. Kidney Dis. 2021, 77, 713–718 e1. [Google Scholar] [CrossRef]
- Tierney, A.A.; Gayre, G.; Hoberman, B.; Mattern, B.; Ballesca, M.; Kipnis, P.; Liu, V.; Lee, K. Ambient Artificial Intelligence Scribes to Alleviate the Burden of Clinical Documentation. NEJM Catalyst 2024, 5, CAT.23.0404. [Google Scholar] [CrossRef]
- Liu, Y.; Iter, D.; Xu, Y.; Wang, S.; Xu, R.; Zhu, C. G-Eval: NLG Evaluation using GPT-4 with Better Human Alignment. arXiv 2023, arXiv:2303.16634. [Google Scholar] [CrossRef]
- Mushtaq, M.M.; Mushtaq, M.; Ali, H.; Sarwar, M.A.; Bokhari, S.F.H. Artificial intelligence and machine learning in peritoneal dialysis: A systematic review of clinical outcomes and predictive modeling. Int. Urol. Nephrol. 2024, 56, 3857–3867. [Google Scholar] [CrossRef] [PubMed]
- Kunin, M.; Beckerman, P. The Peritoneal Membrane-A Potential Mediator of Fibrosis and Inflammation among Heart Failure Patients on Peritoneal Dialysis. Membranes 2022, 12, 318. [Google Scholar] [CrossRef]
- Wiggins, K.J.; McDonald, S.P.; Brown, F.G.; Rosman, J.B.; Johnson, D.W. High membrane transport status on peritoneal dialysis is not associated with reduced survival following transfer to haemodialysis. Nephrol. Dial. Transplant. 2007, 22, 3005–3012. [Google Scholar] [CrossRef][Green Version]
- Chen, C.A.; Lin, S.H.; Hsu, Y.J.; Li, Y.C.; Wang, Y.F.; Chiu, J.S. Neural network modeling to stratify peritoneal membrane transporter in predialytic patients. Intern. Med. 2006, 45, 663–664. [Google Scholar] [CrossRef][Green Version]
- Zhang, J.; Friberg, I.M.; Kift-Morgan, A.; Parekh, G.; Morgan, M.P.; Liuzzi, A.R.; Lin, C.Y.; Donovan, K.L.; Colmont, C.S.; Morgan, P.H.; et al. Machine-learning algorithms define pathogen-specific local immune fingerprints in peritoneal dialysis patients with bacterial infections. Kidney Int. 2017, 92, 179–191. [Google Scholar] [CrossRef] [PubMed]
- Judge, C.S.; Krewer, F.; O'Donnell, M.J.; Kiely, L.; Sexton, D.; Taylor, G.W.; Skorburg, J.A.; Tripp, B. Multimodal Artificial Intelligence in Medicine. Kidney360 2024, 5, 1771–1779. [Google Scholar] [CrossRef] [PubMed]
- Lipkova, J.; Chen, R.J.; Chen, B.; Lu, M.Y.; Barbieri, M.; Shao, D.; Vaidya, A.J.; Chen, C.; Zhuang, L.; Williamson, D.F.K.; et al. Artificial intelligence for multimodal data integration in oncology. Cancer Cell 2022, 40, 1095–1110. [Google Scholar] [CrossRef]
- Ventrella, P.; Delgrossi, G.; Ferrario, G.; Righetti, M.; Masseroli, M. Supervised machine learning for the assessment of Chronic Kidney Disease advancement. Comput. Methods Programs Biomed. 2021, 209, 106329. [Google Scholar] [CrossRef]
- Makino, M.; Yoshimoto, R.; Ono, M.; Itoko, T.; Katsuki, T.; Koseki, A.; Kudo, M.; Haida, K.; Kuroda, J.; Yanagiya, R.; et al. Artificial intelligence predicts the progression of diabetic kidney disease using big data machine learning. Sci. Rep. 2019, 9, 11862. [Google Scholar] [CrossRef]
- Tangri, N.; Ansell, D.; Naimark, D. Predicting technique survival in peritoneal dialysis patients: Comparing artificial neural networks and logistic regression. Nephrol. Dial. Transplant. 2008, 23, 2972–2981. [Google Scholar] [CrossRef]
- Tangri, N.; Ansell, D.; Naimark, D. Determining factors that predict technique survival on peritoneal dialysis: Application of regression and artificial neural network methods. Nephron Clin. Pract. 2011, 118, c93–c100. [Google Scholar] [CrossRef] [PubMed]
- United States Renal Data System. 2024 USRDS Annual Data Report: Epidemiology of Kidney Disease in the United States; National Institutes of Health, National Institute of Diabetes and Digestive and Kidney Diseases: Bethesda, MD, USA, 2024. [Google Scholar]
- Kong, G.; Wu, J.; Chu, H.; Yang, C.; Lin, Y.; Lin, K.; Shi, Y.; Wang, H.; Zhang, L. Predicting Prolonged Length of Hospital Stay for Peritoneal Dialysis-Treated Patients Using Stacked Generalization: Model Development and Validation Study. JMIR Med. Inform. 2021, 9, e17886. [Google Scholar] [CrossRef] [PubMed]
- Wu, J.; Kong, G.; Lin, Y.; Chu, H.; Yang, C.; Shi, Y.; Wang, H.; Zhang, L. Development of a scoring tool for predicting prolonged length of hospital stay in peritoneal dialysis patients through data mining. Ann. Transl. Med. 2020, 8, 1437. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Q.; You, X.; Dong, H.; Lin, Z.; Shi, Y.; Su, Z.; Shao, R.; Chen, C.; Zhang, J. Prediction of premature all-cause mortality in patients receiving peritoneal dialysis using modified artificial neural networks. Aging 2021, 13, 14170–14184. [Google Scholar] [CrossRef]
- Noh, J.; Yoo, K.D.; Bae, W.; Lee, J.S.; Kim, K.; Cho, J.H.; Lee, H.; Kim, D.K.; Lim, C.S.; Kang, S.W.; et al. Prediction of the Mortality Risk in Peritoneal Dialysis Patients using Machine Learning Models: A Nation-wide Prospective Cohort in Korea. Sci. Rep. 2020, 10, 7470. [Google Scholar] [CrossRef]
- Cheng, C.I.; Lin, W.J.; Liu, H.T.; Chen, Y.T.; Chiang, C.K.; Hung, K.Y. Implementation of artificial intelligence Chatbot in peritoneal dialysis nursing care: Experience from a Taiwan medical center. Nephrology 2023, 28, 655–662. [Google Scholar] [CrossRef]
- Rajkomar, A.; Dean, J.; Kohane, I. Machine Learning in Medicine. N. Engl. J. Med. 2019, 380, 1347–1358. [Google Scholar] [CrossRef] [PubMed]
- Acharya, P.C.; Alba, R.; Krisanapan, P.; Acharya, C.M.; Suppadungsuk, S.; Csongradi, E.; Mao, M.A.; Craici, I.M.; Miao, J.; Thongprayoon, C.; et al. AI-Driven Patient Education in Chronic Kidney Disease: Evaluating Chatbot Responses against Clinical Guidelines. Diseases 2024, 12, 185. [Google Scholar] [CrossRef]
- Wu, S.; Koo, M.; Blum, L.; Black, A.; Kao, L.; Fei, Z.; Scalzo, F.; Kurtz, I. Benchmarking Open-Source Large Language Models, GPT-4 and Claude 2 on Multiple-Choice Questions in Nephrology. NEJM AI 2024, 1, AIdbp2300092. [Google Scholar] [CrossRef]
- Miao, J.; Thongprayoon, C.; Suppadungsuk, S.; Garcia Valencia, O.A.; Cheungpasitporn, W. Integrating Retrieval-Augmented Generation with Large Language Models in Nephrology: Advancing Practical Applications. Medicina 2024, 60, 445. [Google Scholar] [CrossRef]
- Garcia Valencia, O.A.; Suppadungsuk, S.; Thongprayoon, C.; Miao, J.; Tangpanithandee, S.; Craici, I.M.; Cheungpasitporn, W. Ethical Implications of Chatbot Utilization in Nephrology. J. Pers. Med. 2023, 13, 1363. [Google Scholar] [CrossRef] [PubMed]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).