1. Introduction
The dual pandemics of HIV and COVID-19 have placed substantial strain on vulnerable populations, deepening existing disparities in health outcomes, service access, and social stability. People living with HIV (PLWH) have faced heightened risks, including increased susceptibility to severe COVID-19, interruptions in routine care, and intensified economic hardship [
1]. These overlapping challenges point to the need for analytic frameworks capable of capturing the complex, intersecting determinants of risk and resilience among PLWH during times of crisis.
Network science and graph theory provide a useful approach to this challenge, offering tools to represent individuals as nodes linked by shared attributes or experiences. This allows for the detection of latent subgroups that may exhibit common patterns of vulnerability or resilience [
2]. In contrast to traditional statistical models, graph-based methods can capture nonlinear and multidimensional relationships that emerge from the social fabric of health determinants.
Our earlier work [
3], based on a local survey of HIV-positive individuals and their partners in semi-urban and rural Illinois, demonstrated that graph-based clustering could reveal meaningful subgroups with differing experiences of discrimination, healthcare access, and pandemic-related hardship. That study used a small local sample and identified distinct clusters of PLWH facing varying levels of structural vulnerability and community support.
Building on this approach, the current study expands the analysis to a national level, leveraging data from NIH’s
All of Us dataset, which involved a large, diverse cohort of participants across the United States. Our focus is on the subset of HIV-positive individuals who completed both the Social Determinants of Health (SDoH) and COVID-19 Participant Experience (COPE) [
4] surveys. Although the
All of Us dataset is large, the number of HIV-positive respondents with completed COPE surveys during the relevant time window was modest (
n = 242), reflecting persistent challenges in capturing timely data on this population.
A key strength of this work is its ability to identify both vulnerability and resilience within the population of PLWH. While some clusters were marked by housing instability, social disconnection, or emotional distress, others reflected relative stability and protective factors, such as emotionally resilient retirees or individuals with strong institutional ties. The recurrence of similar cluster types across three distinct graph configurations lends confidence to the robustness of these findings and demonstrates the capacity of graph-based methods to reveal complex, emergent social structures.
By extending graph-based clustering to a national cohort, this study contributes to the growing literature on syndemic interactions between HIV and COVID-19. It provides a flexible methodological framework for detecting meaningful subgroups among PLWH, with direct implications for targeted interventions and pandemic preparedness efforts. In particular, the results highlight the value of network-based methods in uncovering population heterogeneity that may not be readily captured by conventional analytic approaches.
2. Related Work
Research on the intersection of HIV and COVID-19 has largely emphasized clinical and public health outcomes, with relatively limited application of network science methods. Papers by Grubb et al. [
5] and Lopez et al. [
6] examined network characteristics in analyzing the spread of HIV. Brown et al. [
7] investigated the impact of the COVID-19 pandemic on HIV prevention and treatment services, highlighting disruptions in testing, access to antiretroviral therapy, and declines in viral suppression, disruptions that were particularly pronounced in underserved communities. The present study builds on this work by further examining the social and economic consequences of COVID-19 for PLWH.
Several papers document the compounded vulnerabilities experienced by PLWH during the COVID-19 pandemic. Elevated vaccine hesitancy among PLWH has been noted [
8], often linked to concerns about side effects and the lack of tailored information. Resilience-focused care models have been proposed to help mitigate the psychological impacts of the pandemic [
9], which include increased anxiety, depression, and social isolation [
10]. Mental health concerns are particularly pressing given the preexisting stigma and barriers to care faced by PLWH, now exacerbated by pandemic-related disruptions.
The socioeconomic impact of COVID-19 has also disproportionately affected PLWH, who have experienced higher rates of job loss [
11], economic instability, and interruptions in health insurance coverage [
12]. Social determinants of health as they relate to PLWH are examined in [
2,
13]. These trends motivated our decision to analyze COVID-related economic hardship as a central variable in our graph-theoretic approach.
Although the present study is grounded in graph-based methods, relatively few studies have applied network analysis to HIV-related data in the context of COVID-19. Most network science applications in HIV research have historically focused on transmission dynamics, contact tracing, or intervention design [
14,
15,
16]. Social and sexual network analyses have been used to identify high-risk clusters and inform targeted outreach strategies, particularly among MSM and substance-using populations. Graph-based molecular epidemiology, in which transmission clusters are inferred from HIV genetic sequence data, has also become a critical tool for public health surveillance [
17].
More recent work has begun to integrate network science with machine learning to uncover the latent community structure and improve intervention targeting. Xiang et al. [
18] review the use of artificial intelligence and machine learning in HIV care, highlighting predictive models for diagnosis, adherence, and behavioral risk. However, few of these approaches explicitly use graph-theoretic methods to model inter-individual similarity across multiple dimensions of socioeconomic and health experience, as is performed in the present study.
3. Methods
3.1. Network Science and Its Use in This Study
This study applies network science and graph-theoretic methods to identify patterns among HIV-positive individuals during the COVID-19 pandemic. In this framework, individuals are represented as nodes (also called vertices), and connections between individuals, based on their similarity across multiple features, are represented as edges. Each edge is assigned a weight that reflects the degree of similarity between two participants.
We follow the approach used in previous work [
3], in which networks are constructed from one-hot encoded survey responses, and community detection algorithms are applied to uncover clusters of individuals with shared characteristics or experiences. This allows us to examine whether certain traits, such as social isolation, economic hardship, or resilience, tend to co-occur and define meaningful subgroups within the population. For an illustrative example of how we convert survey answers into a graph, see
Appendix A.
Unlike traditional statistical approaches that rely on large sample sizes to achieve significance, network science enables the detection of structure and community patterns, even in modestly sized datasets. This is particularly valuable in studying subpopulations, such as PLWH, where granular insights are often needed but large targeted samples may be difficult to obtain.
Graph-based methods offer a complementary perspective to traditional regression or latent class modeling by allowing the population structure to emerge organically from the data without prespecifying groupings. The overall analytic workflow, from data preparation to clustering and interpretation, is summarized in
Figure 1.
3.2. Dataset: All of Us
To investigate the impact of COVID-19 on individuals living with HIV, we used data from the NIH’s
All of Us Research Program [
19]. Using the Cohort Builder tool [
20], we identified a cohort of HIV-positive participants who had completed the Basics, Social Determinants of Health (SDoH), and COVID-19 Participant Experience (COPE) surveys [
4]. These instruments were selected to capture multidimensional aspects of participants’ health, socioeconomic context, and pandemic-related experiences.
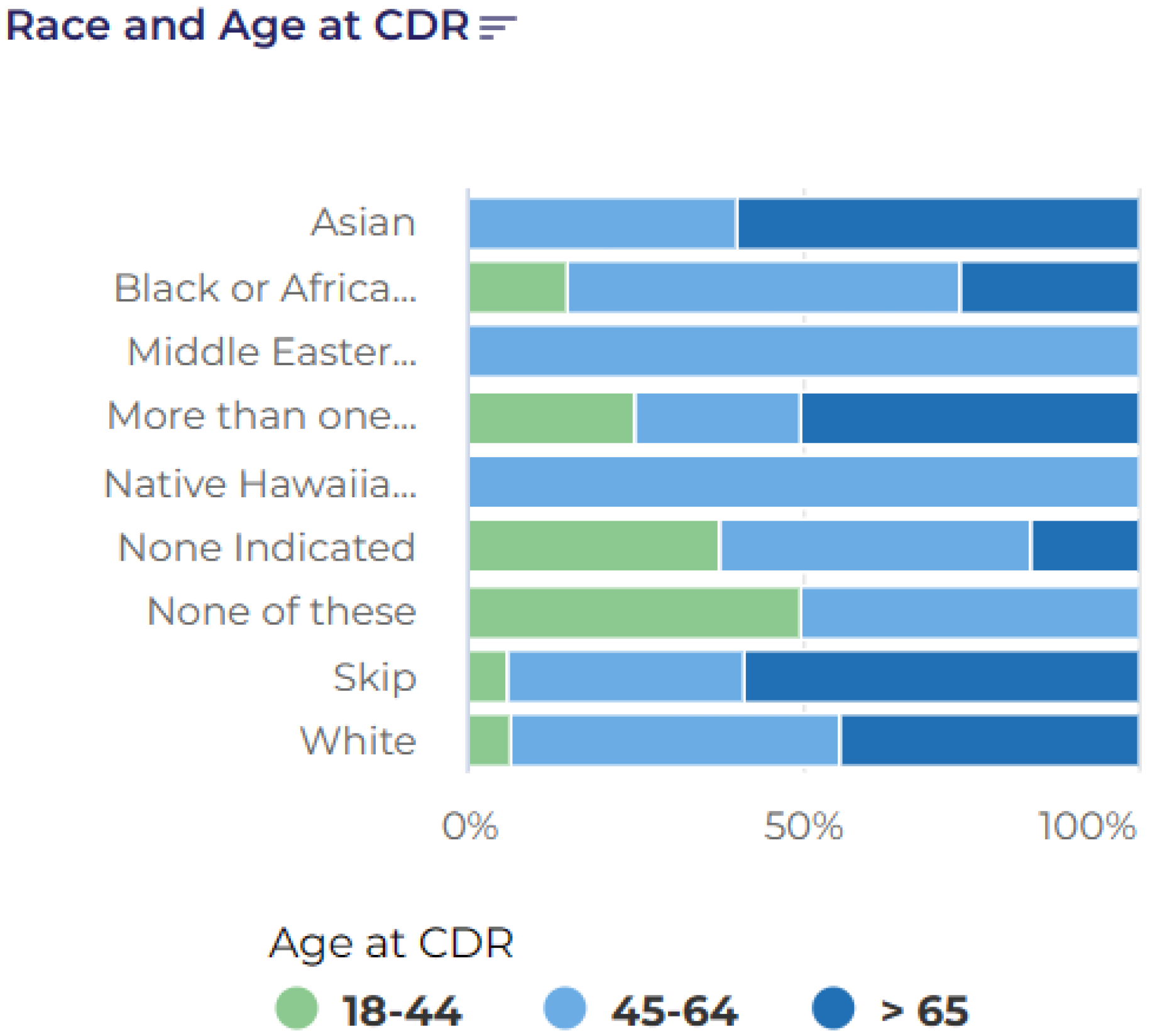
A total of 360 participants met these inclusion criteria. The cohort was demographically diverse, with a broad age range (18–65+) and approximately one-third identifying as Black or African American (
Figure 2 and
Figure 3). To temporally align the data with the Burden of HIV survey [
3], we restricted the responses to those from the February 2021 COPE survey release. This final filtering yielded a sample of 242 individuals, whose survey responses were used for the downstream analysis.
3.3. Dataset: The Burden of HIV Survey
The Burden of HIV survey [
3,
21], conducted in 2021 and 2022, was modeled on established surveys of HIV and HIV-adjacent populations, including the Sexual Acquisition and Transmission of HIV Cooperative Agreement Program (SATHCAP) survey [
22], conducted in 2006–2008, and the Latino MSM Community Involvement: HIV Protective Effects Survey (LMSM) [
23], conducted in 2005. Owing to its extensive list of questions and the diversity of the 22 survey participants, the Burden of HIV survey functions more as an ethnographic instrument, documenting changes in social determinants of health, economic outcomes, and social and medical environments since those earlier surveys.
3.4. Data Preprocessing and Feature Selection
All question–answer pairs from the three selected surveys were one-hot encoded, yielding a binary matrix with 958 features representing individual responses. For example, a feature might represent the answer to a question such as “Were you laid off work due to COVID,” where the values are 1 for yes and 0 for no. In this context, features may also be referred to as variables.
To focus the analysis on COVID-19-related economic hardship, we selected a multi-response question (Athena Code: 1333291) that asked participants to indicate whether they had experienced various pandemic-related disruptions, including job loss, income reduction, or difficulties affording childcare [
24]. Responses to this question were treated as the binary outcome variable in a logistic regression model, with the remaining one-hot encoded features serving as predictors.
We retained the top 15, 30, 45, 100, and 250 features most positively associated with economic hardship, providing flexibility for later graph construction while reducing the risk of overfitting.
3.5. Graph Construction
We constructed k-nearest neighbor (KNN) graphs based on participant similarity in the reduced feature spaces. For each feature subset (15, 30, 45, 100, and 250 features), the corresponding response matrix was used to compute KNN graphs using scikit-learn’s NearestNeighbors model [
25]. Each participant was a node, and edges were formed by connecting each node to its
k nearest neighbors, with
k values of 2, 3, 5, 7, and 10. The reciprocal of the Euclidean distance between feature vectors was used as the edge weight such that more similar individuals were connected by stronger (higher weight) edges.
All graphs were constructed using NetworkX [
26], resulting in 25 undirected, weighted graphs with 242 nodes each. Each graph was fully connected.
3.6. Clustering Methods
To identify subgroups of participants with shared characteristics, we applied three graph-based clustering methods: (1) the Louvain algorithm; (2) the NBR-Clust framework using vertex attack tolerance (VAT) as the resilience metric; and (3) the NBR-Clust framework using integrity as the resilience metric. Each of these methods reflects a distinct strategy for identifying meaningful structure within the graph, helping reveal hidden subgroups, and increasing robustness to methodological biases.
The first method was the widely used Louvain algorithm [
27], which detects communities by optimizing the modularity, a measure of how well a network is divided into clusters. Modularity compares the actual density of edges within a cluster to the density that would be expected if edges were distributed randomly, given each node’s degree. Clusters with a high modularity contain more intra-cluster connections than would be expected by chance. The Louvain algorithm operates in a greedy, hierarchical manner, repeatedly grouping nodes into communities and then refining the clustering.
The second and third methods were based on the NBR-Clust framework [
28], which uses resilience-based metrics to uncover meaningful subgroups in a network. Specifically, we applied NBR-Clust with two different resilience measures: vertex attack tolerance (VAT) [
29,
30] and integrity [
31]. This approach identifies individuals who act as structural “bridges” in the network, specifically nodes whose removal would fragment the graph into smaller components. By conceptually removing these key individuals, NBR-Clust reveals latent subgroups that are tightly connected, often reflecting distinct patterns of vulnerability, resilience, or social experience.
In a public health context, this approach helps uncover subgroups linked by shared lived experiences, such as housing insecurity, barriers to care, or pandemic-related hardship. For example, NBR-Clust may identify one cluster of participants primarily affected by job loss, another experiencing severe social isolation, and another facing disruptions in healthcare access. These clusters can guide more tailored intervention strategies.
For completeness, the mathematical definitions of the VAT and integrity metrics are provided below. Readers are not expected to follow the formulas in detail; they serve to formalize how these methods detect structurally meaningful subgroups in the network.
where
S is the set of nodes to be removed, and
is the size of the largest connected component after removing
S.
Each clustering method produced a different number of clusters, reflecting its sensitivity to different aspects of network structure. The combined use of modularity- and resilience-based methods provided a richer view of the population’s heterogeneity.
3.7. Cluster Evaluation Metrics
To evaluate the quality of the resulting clusterings, we computed four complementary metrics using scikit-learn [
25]:
Together, these metrics guided the selection of the most informative graph and clustering configurations for further analysis.
3.8. Cluster Over-Representation Calculation
To interpret the content of each cluster, we analyzed the frequency of each one-hot encoded feature within the cluster, relative to its frequency in the full sample. The percentages shown in
Figure 4,
Figure 5 and
Figure 6, as well as in
Table A1,
Table A2 and
Table A3, reflect this relative over-representation.
For each feature
f, we computed the difference in proportions as follows:
Positive values indicate that a feature is over-represented in the cluster compared with the overall sample, while negative values indicate under-representation. This calculation allowed us to characterize each cluster in terms of demographics, social determinants, emotional well-being, and pandemic-era hardships.
3.9. Cluster Frequency Analysis
Each graph was clustered using all three community detection methods. For each resulting set of clusters, the performance was evaluated using the four metrics described above. Full results for all graphs and clustering configurations are shown in
Appendix B.
To select representative graphs for further analysis, we applied a “Rank Sum” approach: for each graph, the ranks across the four metrics (Davies–Bouldin, Silhouette, Calinski–Harabasz, and Modularity) were summed, with lower totals indicating better overall performance. Ties were resolved by the number of first-place rankings. This process allowed us to identify the most informative clustering configurations from each method.
Based on this selection procedure, the following graphs were chosen for deeper analysis and visualization: the 250-feature, , Louvain-clustered graph (Louvain F250K7); the 250-feature, , NBR-Clust with VAT (VAT F250K10); and the 15-feature, , NBR-Clust with integrity (INT F15K10). Cluster frequency analysis was performed on each of these graphs to identify the over- and under-represented features within each cluster.
The resulting clustered graphs are presented in
Figure 4,
Figure 5 and
Figure 6. In accordance with the
All of Us data dissemination policy, clusters with fewer than 20 members are not shown.
In summary, this study used graph-based methods to analyze the patterns of social, economic, and pandemic-related experiences among people living with HIV. The highest-ranked configurations were selected for further analysis, providing a basis for identifying latent communities of vulnerability and resilience, as presented in the following section.
4. Results
Figure 4,
Figure 5 and
Figure 6 present the clustering results for the three graph configurations analyzed in this study. In each case, we observed distinct subgroups of HIV-positive individuals with varying profiles of housing stability, emotional well-being, pandemic-related behaviors, and social connectedness. As described in
Section 3.8, the percentages shown in each figure represent the relative over-representation of traits within a cluster, that is, the degree to which a given trait is more (or less) common in the cluster than in the full sample. Positive percentages indicate over-representation.
4.1. F250K7 Graph: Clustering with Full Feature Set and Louvain
Figure 4 shows the clustering results from the F250K7 graph constructed from the full feature set using Louvain community detection. This analysis produced five well-defined subgroups.
One cluster reflected housing instability and the inability to work. Participants unable to work were +26% over-represented, housing instability concerns were +25%, and inability to pay rent due to COVID-19 impacts was +15%. This subgroup illustrates the intersection of employment disruption and housing stress among PLWH during the pandemic.
Two clusters reflected contrasting patterns of neighborhood context and social connectedness. The “Safe Neighborhood” cluster was enriched for perceptions of neighborhood safety (+41%), although participants in this group who stayed home 3–4 days per week were over-represented by 40%. The “Community Disconnection and Isolation” cluster was enriched for social isolation (+20%), living alone (+21%), and not testing for COVID-19 (+34%), despite reporting a relatively safe environment. This suggests that objective neighborhood safety does not always translate into social well-being.
A fourth cluster reflected “COVID-cautious” behavior in higher-crime areas. Participants were +39% more likely to perceive crime in their neighborhood and were enriched for recent COVID-19 testing (+39%) and COVID-cautious behaviors.
Finally, one cluster represented individuals that received strong social support. Participants were enriched for receiving meals (+63%), bedside care (+57%), and companionship (+37%). This likely reflects individuals in assisted living settings or those with consistent caregiving support.
4.2. F250K10 Graph: Clustering Based on All Features Clustered with VAT
Figure 5 presents clustering results from the F250K10 graph constructed using NBR-Clust with VAT. This clustering yielded four subgroups larger than 20 participants.
Two clusters reflected isolation and economic hardship, though in different social contexts. The “Poor and Socially Isolated” cluster was enriched for never married (+22%), low income (+15%), and isolation (+11%), though some reported having help when confined in bed (+17%). The “Poor, Diverse, and Isolated” cluster had more women and black participants than average, and showed higher rates of disability (+36%), severe poverty (+31%), and limited mobility (+35%).
Another cluster reflected “Strong Social Support.” The participants consistently reported high levels of perceived and received support across multiple domains: always feeling loved (+47%), having meals prepared (+40%), and having companions for enjoyable activities (+38%).
The fourth cluster reflected “Household and Relationship Stability.” The participants were enriched for partnered living (+41%), long-term residence (+28%), and employment-based insurance (+34%), alongside positive emotional indicators.
4.3. F15K10 Graph: Clustering Based on Integrity
Figure 6 shows the results from the F15K10 graph clustered using NBR-Clust with integrity. Two clusters reflected emotional resilience and low pandemic distress. In the “Low-Anxiety Retirees” cluster, participants not bothered by anxiety were +42% over-represented, with similar enrichment for retirement status (+34%) and reports of being unaffected by COVID-19 (+25%). The “Neighborhood-Satisfied Retirees” cluster was enriched for positive neighborhood perceptions (+79%) and emotional well-being (+43%).
A second pair of clusters reflected institutional connection and proactive engagement. The “Employed and Insured” cluster was enriched for wage employment (+77%) and workplace-based COVID-19 testing (+21%). The “Outgoing and Vaccinated” cluster was marked by active social engagement (+54%) and elevated healthcare access.
Finally, one cluster reflected moderate anxiety with adaptive coping. Participants reported elevated anxiety (+55%) but also higher rates of positive coping indicators.
5. Discussion
This study used graph-based clustering methods to explore patterns of vulnerability and resilience among PLWH during the COVID-19 pandemic using national data from the All of Us Research Program. Across three varying graph configurations, we identified consistent subgroups shaped by housing stability, social connectedness, emotional well-being, and access to institutional resources.
A recurring theme was the importance of social and institutional connectedness as a protective factor. Subgroups characterized by strong relationships, whether through family, household partnerships, community networks, or stable employment, were consistently associated with higher emotional well-being and greater engagement with preventive behaviors, such as COVID-19 testing and vaccination. This is consistent with prior literature showing that relational stability and trust in institutions can mitigate pandemic-related stress and barriers to care.
In contrast, other subgroups faced overlapping challenges of housing instability, isolation, and emotional distress. These patterns reinforce a syndemic perspective [
35], in which structural and psychosocial disadvantages compound one another to shape health risks.
5.1. Comparisonwith Prior Regional Study
It is informative to compare these results with our earlier work that analyzed a local survey of PLWH in semi-urban and rural Illinois [
3]. That study used a similar network science framework, but was based on a small, locally recruited sample (n = 22), whereas the present analysis draws on a larger, nationally representative dataset (n = 242) from the
All of Us research program.
Table 1 summarizes the key similarities and differences between the two studies.
Despite the differences in scale and sampling, both studies revealed consistent clustering patterns involving social support, isolation, and hardship. For instance, in both datasets, we observed clusters of PLWH with strong family or community connections who also showed higher emotional well-being and greater engagement in COVID-related care behaviors. Conversely, clusters marked by housing instability or weak social networks were more likely to report emotional distress and reduced access to services. These parallels reinforce the conclusion that relational and structural factors shape both resilience and vulnerability during health crises.
There were also important differences between the studies, due in part to variations in the survey design and sampling context. The Illinois survey included more detailed questions about stigma, healthcare discrimination, and LGBT+ community belonging—factors that were not explicitly captured in the All of Us instruments. As a result, certain themes that emerged in the regional study, such as race-based healthcare discrimination or identity-based community engagement, were less prominent or absent in the national analysis. Conversely, the larger and more diverse national sample revealed new patterns, including clusters of emotionally resilient retirees and subgroups characterized by institutional trust and proactive health behaviors.
These differences underscore both the value and the limitations of comparing regional and national datasets. While the Illinois study offered rich, context-specific insights, the present study complements it by capturing population-level patterns and demonstrating the scalability of graph-based clustering approaches in large-scale public health research.
5.2. Limitations
This study has several limitations. First, although All of Us is a large and diverse national dataset, our analysis focused on a subset of 242 HIV-positive participants. This relatively modest sample size limits generalizability to the broader population of PLWH, particularly given the heterogeneity of experiences during the COVID-19 pandemic. However, the analytic approach employed, based on network science and graph-based clustering, was exploratory rather than inferential, and aimed to detect latent structure and uncover subgroups with shared patterns of vulnerability and resilience. Unlike traditional statistical methods that require large sample sizes to support significance testing, network analysis can reveal meaningful insights, even in smaller, well-characterized samples.
We also acknowledge that our reliance on self-reported data introduced the possibility of response bias, including underreporting or overreporting of health experiences. However, because our clustering approach focused on patterns across multiple dimensions rather than on individual variables, it may be more robust to isolated inaccuracies than methods that rely on precise measurement of single constructs. Additionally, by applying multiple clustering methods across a broad range of graph configurations, we increased the robustness of our findings and were better able to see hidden and hard-to-find populations.
The selection of COVID-related economic hardship as the primary target variable may have overlooked other crucial dimensions of the pandemic’s impact, including healthcare quality, stigma experiences, and more nuanced aspects of social support. These important factors were either not included or not sufficiently detailed in the available survey instruments. Future research should integrate richer measures to better capture the lived experiences of PLWH during public health crises, while also seeking to replicate these findings in larger, more targeted cohorts and explore the broader application of graph-based methods across other public health domains.
5.3. Strategic Opportunities
Taken together, these findings highlight opportunities for precision public health strategies that target support to the most vulnerable subgroups while leveraging existing sources of resilience.
Based on these results, several policy implications emerge:
Pandemic preparedness and HIV care programs should prioritize strengthening social support networks. Interventions that build connections, whether through peer groups, family-based support, or community programs, may help buffer isolation and emotional distress among PLWH during future public health emergencies [
36].
Housing stability should be addressed as a core component of both HIV care and pandemic planning. Stable housing is known to support health outcomes among PLWH and may reduce compounding risks during crises [
37,
38].
Public health systems should leverage institutional touchpoints, including employment settings, healthcare providers, and schools, to deliver pandemic-related services, such as testing, vaccination, and mental health resources [
39].
Public health agencies should adopt analytic methods that account for heterogeneity. Graph-based clustering techniques can help identify subgroups with complex, intersecting vulnerabilities and inform targeted, equity-focused interventions [
40].
For subgroups marked by housing instability, evidence-based approaches, such as Housing First programs and integrated case management services, may be especially effective at reducing both the health risk and social vulnerability. For clusters characterized by social isolation, interventions should prioritize community re-engagement through peer navigation, virtual support groups, or culturally tailored outreach. Meanwhile, subgroups with strong institutional trust and care engagement represent opportunities to reinforce and scale up protective behaviors, such as testing and vaccination, through trusted settings. By aligning intervention strategies with the unique characteristics of each cluster, public health agencies can move toward a more precise, equity-driven response.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}