
How Humans Evaluate AI Systems for Person Detection in Automatic Train Operation: Not All Misses Are Alike


Abstract
1. Introduction
1.1. What Factors Shape Human Evaluations of AI Performance?
1.1.1. AI Accuracy and Detection Difficulty
1.1.2. Types of AI Mistakes
1.1.3. Danger of the Situation
1.1.4. Method of Eliciting Human Evaluations
1.2. Contributions of the Present Study
- Investigating how a variety of influencing factors affect human evaluations of AI performance: type of AI mistake, detection difficulty, number of affected images, number of people, position relative to the danger zone, and elicitation method
- Investigating why these factors affect quantitative ratings by performing qualitative analyses of participants’ verbal explanations
- Showing that the results are highly robust and can be replicated across three experiments
- Making all study materials (i.e., stimuli, instructions, rating data, syntax files, and explanation coding tables) available via the Open Science Framework: https://osf.io/gyxbk/ (last accessed on 1 June 2025)
2. Experiment 1
2.1. Methods
2.1.1. Participants
2.1.2. Apparatus and Stimuli
2.1.3. Procedure
2.1.4. Data Analysis
2.2. Results and Discussion
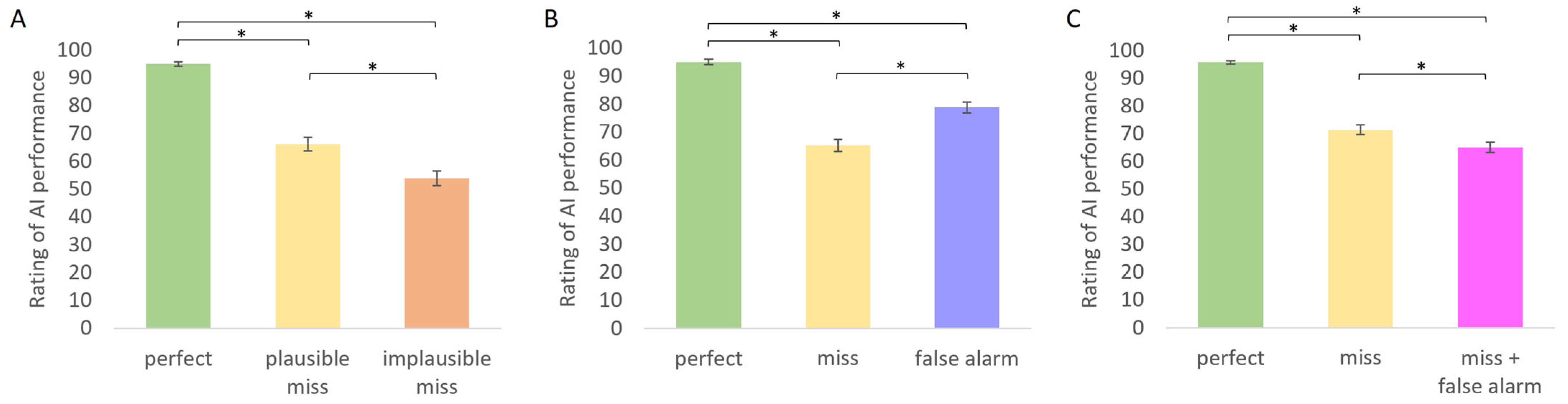
2.2.1. Ratings of AI Performance
2.2.2. Explanation of Ratings
2.2.3. Interim Summary
3. Experiment 2
3.1. Methods
3.1.1. Participants
3.1.2. Apparatus and Stimuli
3.1.3. Procedure
3.1.4. Data Analysis
3.2. Results and Discussion
3.2.1. Ratings of AI Performance
3.2.2. Explanations of Ratings
3.2.3. Interim Summary
4. Experiment 3
4.1. Methods
4.1.1. Participants
4.1.2. Apparatus and Stimuli
4.1.3. Procedure
4.1.4. Data Analysis
4.2. Results and Discussion
4.2.1. Ratings of AI Performance
4.2.2. Explanations of Ratings
4.2.3. Interim Summary
5. General Discussion
5.1. AI Accuracy, Mistake Plausibility, and Detection Difficulty
5.2. Type of AI Mistakes
5.3. Danger of the Situation
5.4. Methods of Eliciting Human Evaluations
5.5. Limitations and Outlook
5.6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Müller, R.; Schmidt, J. Beyond object identification: How train drivers evaluate the risk of collision. arXiv 2024, arXiv:2411.10475. [Google Scholar] [CrossRef]
- Cao, Z.; Qin, Y.; Jia, L.; Xie, Z.; Gao, Y.; Wang, Y.; Li, P.; Yu, Z. Railway Intrusion Detection Based on Machine Vision: A Survey, Challenges, and Perspectives. IEEE Trans. Intell. Transp. Syst. 2024, 25, 6427–6448. [Google Scholar] [CrossRef]
- Ristić-Durrant, D.; Franke, M.; Michels, K. A review of vision-based on-board obstacle detection and distance estimation in railways. Sensors 2021, 21, 3452. [Google Scholar] [CrossRef] [PubMed]
- Gesmann-Nuissl, D.; Kunitz, S. Auditing of AI in railway technology–A European legal approach. Digit. Soc. 2022, 1, 17. [Google Scholar] [CrossRef]
- Roßbach, J.; De Candido, O.; Hammam, A.; Leuschel, M. Evaluating AI-based components in autonomous railway systems: A methodology. In Proceedings of the German Conference on Artificial Intelligence (Künstliche Intelligenz), Würzburg, Germany, 25–27 September 2024; Springer Nature: Cham, Switzerland, 2024. [Google Scholar]
- Beery, S.; van Horn, G.; Perona, P. Recognition in terra incognita. In Proceedings of the European Conference on Computer Vision, Milan, Italy, 29 September–4 October 2018; pp. 456–473. [Google Scholar]
- Nartker, M.; Zhou, Z.; Firestone, C. When will AI misclassify? Intuiting failures on natural images. J. Vis. 2023, 23, 4. [Google Scholar] [CrossRef]
- Bos, N.; Glasgow, K.; Gersh, J.; Harbison, I.; Lyn Paul, C. Mental models of AI-based systems: User predictions and explanations of image classification results. In Proceedings of the Human Factors and Ergonomics Society Annual Meeting, Los Angeles, CA, USA, 28 October–1 November 2019; SAGE Publications: Thousand Oaks, CA, USA, 2019; pp. 184–188. [Google Scholar]
- Geirhos, R.; Jacobsen, J.H.; Michaelis, C.; Zemel, R.; Brendel, W.; Bethge, M.; Wichmann, F.A. Shortcut learning in deep neural networks. Nat. Mach. Intell. 2020, 2, 665–673. [Google Scholar] [CrossRef]
- Mueller, S.T. Cognitive anthropomorphism of AI: How humans and computers classify images. Ergon. Des. 2020, 28, 12–19. [Google Scholar] [CrossRef]
- Madhavan, P.; Wiegmann, D.A.; Lacson, F.C. Automation failures on tasks easily performed by operators undermine trust in automated aids. Hum. Factors 2006, 48, 241–256. [Google Scholar] [CrossRef]
- Heuer, H.; Breiter, A. More than accuracy: Towards trustworthy machine learning interfaces for object recognition. In Proceedings of the 28th ACM Conference on User Modeling, Adaptation and Personalization, Genoa, Italy, 12–18 July 2020. [Google Scholar]
- Rice, S.; McCarley, J.S. Effects of response bias and judgment framing on operator use of an automated aid in a target detection task. J. Exp. Psychol. Appl. 2011, 17, 320–331. [Google Scholar] [CrossRef]
- Wickens, C.D.; Dixon, S.; Goh, J.; Hammer, B. Pilot dependence on imperfect diagnostic automation in simulated UAV flights: An attentional visual scanning analysis. In 2005 International Symposium on Aviation Psychology; Wright State University: Fairborn, OH, USA, 2005. [Google Scholar]
- Dixon, S.R.; Wickens, C.D.; McCarley, J.S. On the independence of compliance and reliance: Are automation false alarms worse than misses? Hum. Factors 2007, 49, 564–572. [Google Scholar] [CrossRef]
- Hampel, F.; Leibner, P.; Manjunatheswaran, H.; Schotten, A.; Schindler, C. Obstacle detection on rail-tracks: Study on situations for requirement specification. Transp. Res. Procedia 2023, 72, 884–891. [Google Scholar] [CrossRef]
- Müller, R.; Reindel, D.F.; Stadtfeldt, Y.D. The benefits and costs of explainable artificial intelligence in visual quality control: Evidence from fault detection performance and eye movements. Hum. Factors Ergon. Manuf. Serv. Ind. 2024, 34, 396–416. [Google Scholar] [CrossRef]
- Huegli, D.; Chavaillaz, A.; Sauer, J.; Schwaninger, A. Effects of false alarms and miscues of decision support systems on human–machine system performance: A study with airport security screeners. Ergonomics 2025, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Kocielnik, R.; Amershi, S.; Bennett, P.N. Will you accept an imperfect ai? exploring designs for adjusting end-user expectations of ai systems. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019. [Google Scholar]
- Bach, T.A.; Kristiansen, J.K.; Babic, A.; Jacovi, A. Unpacking human-AI interaction in safety-critical industries: A systematic literature review. IEEE Access 2024, 12, 106385–106414. [Google Scholar] [CrossRef]
- Rosić, S.; Stamenković, D.; Banić, M.; Simonović, M.; Ristić-Durrant, D.; Ulianov, C. Analysis of the safety level of obstacle detection in autonomous railway vehicles. CTA Polytech. Hung. 2022, 19, 187–205. [Google Scholar] [CrossRef]
- Tagiew, R.; Köppel, M.; Schwalbe, K.; Denzler, P.; Neumaier, P.; Klockau, T.; Boekhoff, M.; Klasek, P.; Tilly, R. OSDaR23: Open Sensor Data for Rail 2023. In Proceedings of the 8th International Conference on Robotics and Automation Engineering, Singapore, 17–19 November 2023. [Google Scholar]
- Tagiew, R.; Wunderlich, I.; Sastuba, M.; Seitz, S. RailGoerl24: Görlitz rail test center CV dataset 2024. arXiv 2025, arXiv:2504.00204. [Google Scholar] [CrossRef]
- Baillargeon, R.; Spelke, E.S.; Wasserman, S. Object permanence in five-month-old infants. Cognition 1985, 20, 191–208. [Google Scholar] [CrossRef]
- D’Amico, G.; Marinoni, M.; Nesti, F.; Rossolini, G.; Buttazzo, G.; Sabina, S.; Lauro, G. TrainSim: A railway simulation framework for LiDAR and camera dataset generation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 15006–15017. [Google Scholar] [CrossRef]
- Müller, R. How explainable AI affects human performance: A systematic review of the behavioural consequences of saliency maps. Int. J. Hum.-Comput. Interact. 2024, 41, 2020–2051. [Google Scholar] [CrossRef]
- Poeta, E.; Ciravegna, G.; Pastor, E.; Cerquitelli, T.; Baralis, E. Concept-based explainable artificial intelligence: A survey. arXiv 2023, arXiv:2312.12936. [Google Scholar] [CrossRef]
- Cau, F.M.; Hauptmann, H.; Spano, L.D.; Tintarev, N. Effects of AI and logic-style explanations on users’ decisions under different levels of uncertainty. ACM Trans. Interact. Intell. Syst. 2023, 13, 1–42. [Google Scholar] [CrossRef]
- Jungmann, F.; Ziegelmayer, S.; Lohoefer, F.K.; Metz, S.; Müller-Leisse, C.; Englmaier, M.; Makowski, M.R.; Kaissis, G.A.; Braren, R.F. Algorithmic transparency and interpretability measures improve radiologists’ performance in BI-RADS 4 classification. Eur. Radiol. 2023, 33, 1844–1851. [Google Scholar] [CrossRef] [PubMed]
- Meyers, S.; Capiola, A.; Alarcon, G.M.; Bennette, W. Transparency and trustworthiness: Exploring human-machine interaction in an image classification task. In Proceedings of the 4th International Conference on Human-Machine Systems, Toronto, ON, Canada, 15–17 May 2024; IEEE: New York, NY, USA, 2024. [Google Scholar]
- Famiglini, L.; Campagner, A.; Barandas, M.; La Maida, G.A.; Gallazzi, E.; Cabitza, F. Evidence-based XAI: An empirical approach to design more effective and explainable decision support systems. Comput. Biol. Med. 2024, 170, 108042. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topics | Subtopics | Categories |
|---|---|---|
| AI performance | Detection | Correct detection, miss, correct rejection, false alarm |
| Number of people | All people, number of people | |
| Frequency and time | Always, never, number of images, image ID, point in time, loss and fluctuation | |
| AI capabilities | Interdependence, comparison, inference | |
| Image context | Consequences | Danger, relevance |
| Difficulty | Own perception, perceivability, confusability, light and weather, occlusion, parts visible | |
| People | Type | Identity |
| Location | On tracks, distance to tracks, distance to train, position in image, relation to objects, relation to people | |
| Behaviour | Movement, action, approach or leave tracks, approach or leave train, potential action | |
| Features | Size and shape, posture, clothing and colour, gadgets | |
| Objects | Detection | Object should be detected as person, attached to person, dangerous, correctly rejected, falsely detected |
| Perfect | Plausible Miss | Implausible Miss | ||
|---|---|---|---|---|
| AI accuracy | 95.0 (4.4) | 66.2 (13.6) | 53.9 (15.5) | |
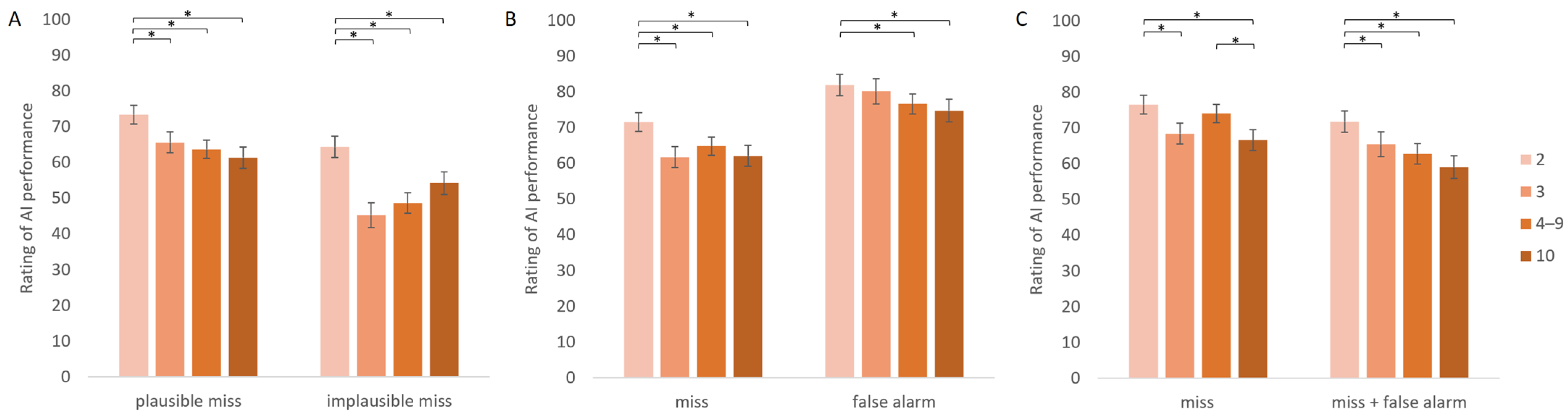
| Detection difficulty | Low | - | 56.4 (17.5) | - |
| Intermediate | - | 73.2 (15.0) | - | |
| High | - | 69.9 (16.0) | - | |
| Number of affected images | 2 | - | 73.4 (15.0) | 64.3 (17.1) |
| 3 | - | 65.6 (16.8) | 45.3 (20.0) | |
| 4–9 | - | 63.6 (14.7) | 48.6 (16.4) | |
| 10 | - | 61.3 (16.8) | 54.3 (18.2) | |
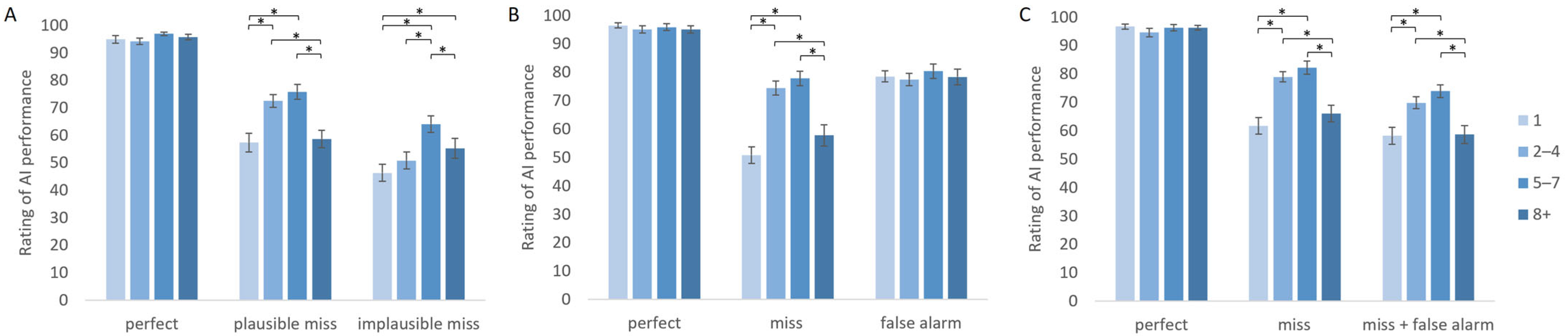
| Number of people | 1 | 95.0 (8.2) | 57.4 (19.5) | 46.4 (17.8) |
| 2–4 | 94.3 (6.9) | 72.6 (13.5) | 50.8 (17.9) | |
| 5–7 | 97.0 (3.3) | 75.9 (15.5) | 64.1 (17.6) | |
| 8+ | 95.7 (5.8) | 58.7 (18.2) | 55.3 (20.8) | |
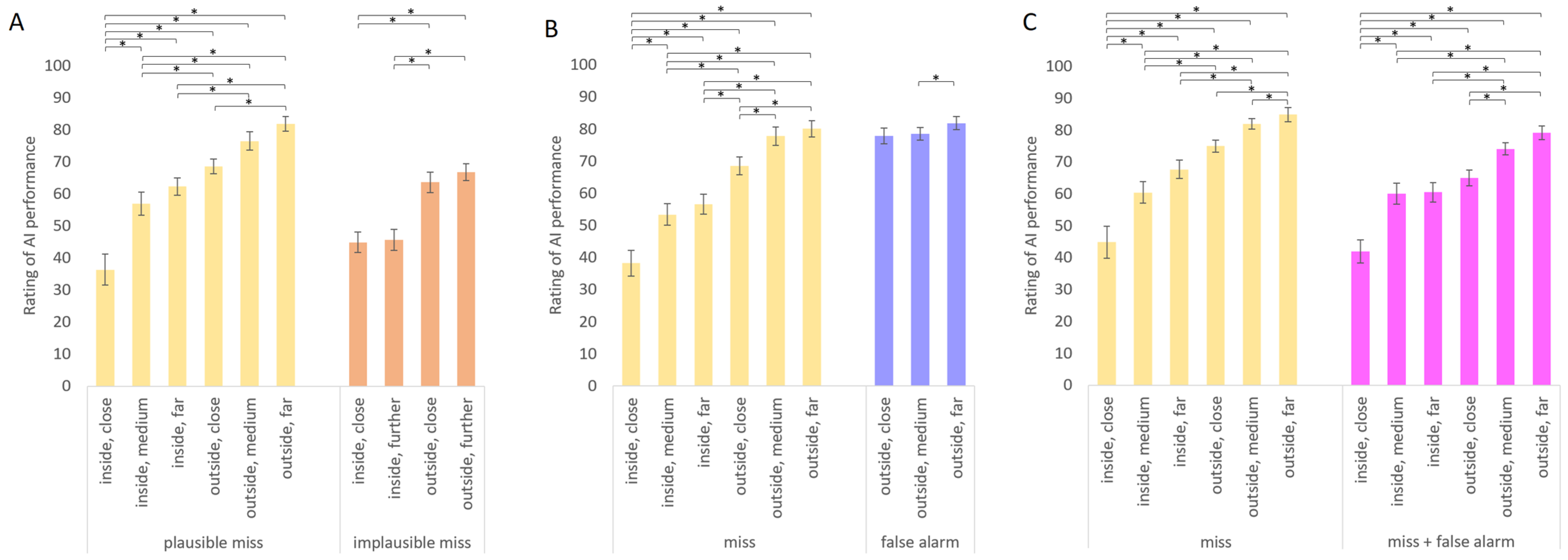
| Position relative to danger zone | Inside, close | - | 36.3 (27.9) | 44.9 (18.2) |
| Inside, medium | - | 56.9 (20.9) | 45.7 (19.0) | |
| Inside, far | - | 62.3 (15.6) | ||
| Outside, close | - | 68.6 (13.3) | 63.7 (18.4) | |
| Outside, medium | - | 76.5 (16.4) | 66.9 (15.0) | |
| Outside, far | - | 81.9 (13.1) | ||
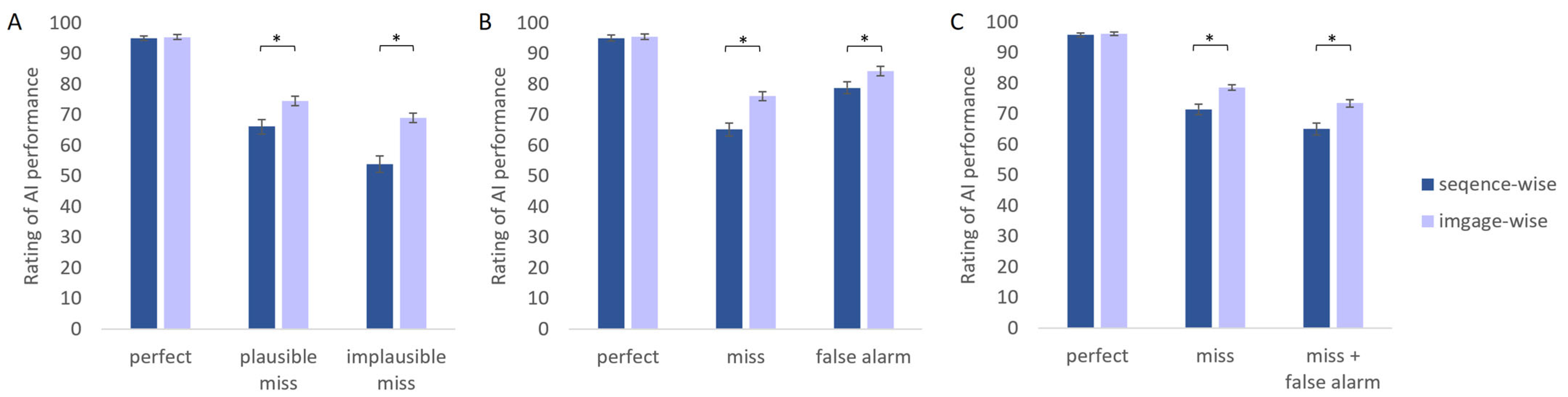
| Elicitation method | Sequence-wise | 95.0 (4.4) | 66.2 (13.6) | 53.9 (15.5) |
| Image-wise | 95.4 (4.5) | 74.5 (8.9) | 69.0 (8.9) |
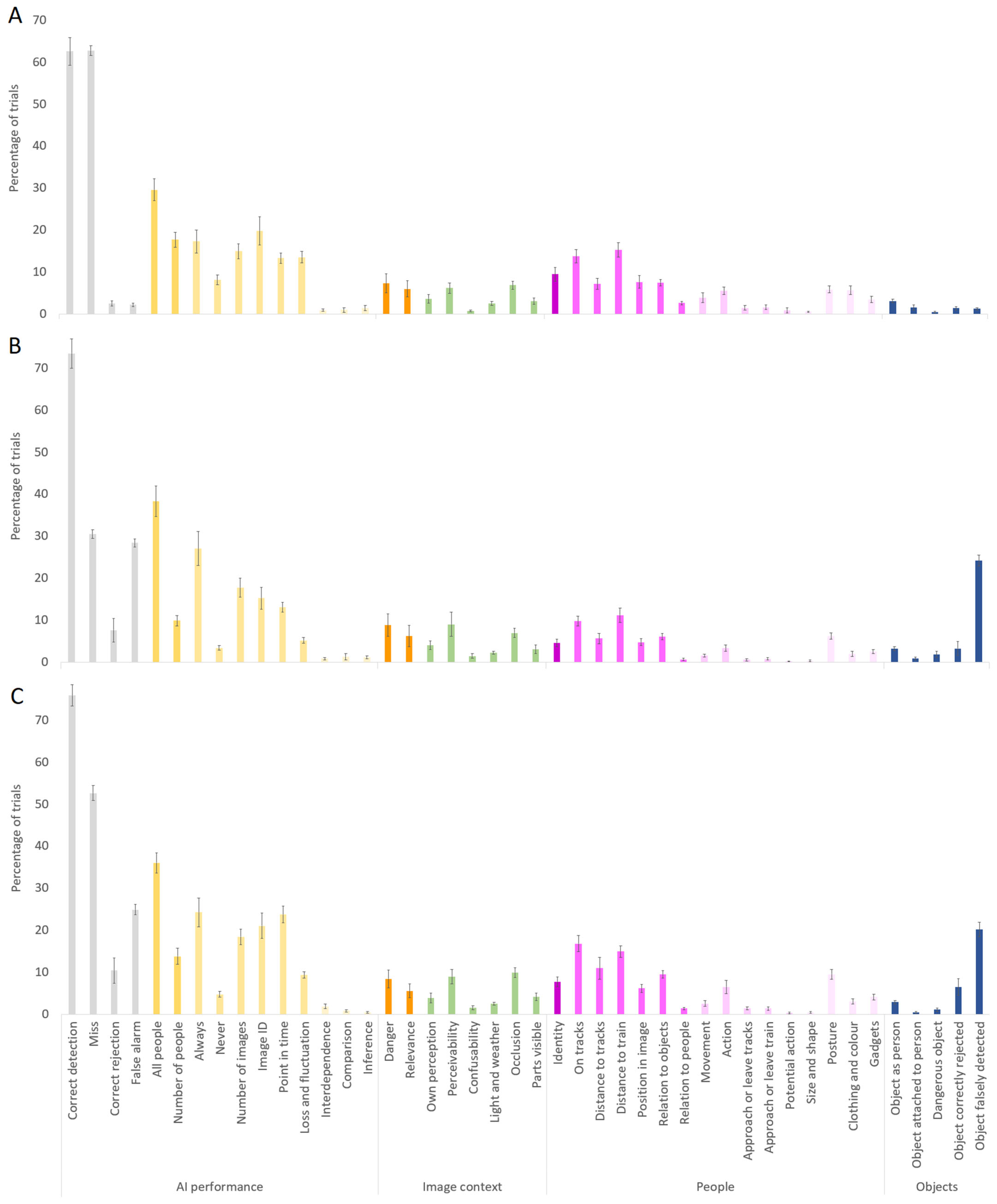
| Topic | Category | Experiment 1 | Experiment 2 | Experiment 3 |
|---|---|---|---|---|
| AI performance | Correct detection | 62.5 (19.1) | 73.4 (20.1) | 75.8 (14.5) |
| Miss | 62.7 (7.0) | 30.4 (6.0) | 52.6 (10.0) | |
| Correct rejection | 2.5 (3.5) | 7.6 (15.9) | 10.4 (17.4) | |
| False alarm | 2.1 (2.3) | 28.3 (5.3) | 24.9 (7.0) | |
| All people | 29.5 (15.1) | 38.3 (21.0) | 36.0 (13.9) | |
| Number of people | 17.7 (10.4) | 9.8 (7.3) | 13.8 (11.1) | |
| Always | 17.2 (15.9) | 27.0 (23.5) | 24.2 (19.9) | |
| Never | 8.1 (6.5) | 3.3 (3.0) | 4.7 (3.8) | |
| Number of images | 14.9 (10.5) | 17.7 (13.0) | 18.4 (10.8) | |
| Image ID | 19.8 (19.3) | 15.2 (15.0) | 21.0 (17.4) | |
| Point in time | 13.3 (7.2) | 13.0 (6.7) | 23.7 (11.7) | |
| Loss and fluctuation | 13.5 (7.9) | 5.1 (3.9) | 9.3 (4.2) | |
| Interdependence | 0.9 (1.8) | 0.8 (1.6) | 1.8 (3.0) | |
| Comparison | 0.9 (3.1) | 1.3 (4.1) | 0.8 (1.6) | |
| Inference | 1.4 (3.5) | 1.1 (2.0) | 0.4 (1.4) | |
| Image context | Danger | 7.3 (13.1) | 8.8 (15.5) | 8.4 (12.3) |
| Relevance | 5.9 (11.0) | 6.2 (14.4) | 5.6 (9.3) | |
| Own perception | 3.6 (5.8) | 4.0 (5.7) | 3.9 (6.4) | |
| Perceivability | 6.1 (7.2) | 9.0 (16.4) | 9.0 (9.9) | |
| Confusability | 0.7 (1.4) | 1.5 (2.9) | 1.5 (3.0) | |
| Light and weather | 2.5 (2.6) | 2.2 (2.2) | 2.5 (2.0) | |
| Occlusion | 6.8 (5.7) | 6.9 (6.2) | 9.9 (6.5) | |
| Parts visible | 3.0 (4.1) | 3.1 (6.0) | 4.1 (5.0) | |
| People | Identity | 9.5 (9.4) | 4.5 (4.8) | 7.7 (6.6) |
| On tracks | 13.7 (8.9) | 9.7 (6.7) | 16.8 (11.0) | |
| Distance to tracks | 7.1 (7.5) | 5.6 (7.0) | 10.9 (14.8) | |
| Distance to train | 15.2 (10.0) | 11.2 (10.0) | 14.9 (8.1) | |
| Position in image | 7.6 (8.6) | 4.7 (4.6) | 6.1 (5.8) | |
| Relation to objects | 7.4 (4.5) | 6.0 (4.4) | 9.5 (5.4) | |
| Relation to people | 2.6 (2.5) | 0.6 (1.2) | 1.3 (1.9) | |
| Movement | 3.9 (6.6) | 1.5 (2.2) | 2.5 (4.1) | |
| Action | 5.5 (4.9) | 3.3 (4.3) | 6.5 (9.0) | |
| Approach or leave tracks | 1.5 (3.2) | 0.5 (1.3) | 1.4 (2.1) | |
| Approach or leave train | 1.6 (3.1) | 0.8 (1.8) | 1.3 (2.0) | |
| Potential action | 0.9 (3.6) | 0.1 (0.5) | 0.3 (0.9) | |
| Size and shape | 0.5 (1.0) | 0.3 (1.1) | 0.4 (1.1) | |
| Posture | 5.8 (4.8) | 6.2 (4.4) | 9.5 (6.7) | |
| Clothing and colour | 5.6 (6.0) | 1.9 (3.6) | 3.0 (3.4) | |
| Gadgets | 3.5 (4.3) | 2.5 (2.6) | 4.1 (4.0) | |
| Objects | Object as person | 3.1 (2.4) | 3.2 (2.6) | 2.8 (2.7) |
| Object attached to person | 1.5 (3.8) | 0.8 (2.1) | 0.4 (0.9) | |
| Dangerous object | 0.4 (1.1) | 1.8 (4.1) | 1.1 (2.4) | |
| Object correctly rejected | 1.3 (2.3) | 3.2 (9.4) | 6.4 (11.4) | |
| Object falsely detected | 1.2 (1.7) | 24.1 (7.5) | 20.1 (10.0) |
| Perfect | Miss | False Alarm | ||
|---|---|---|---|---|
| AI accuracy | 95.0 (4.4) | 66.2 (13.6) | 53.9 (15.5) | |
| Number of affected images | 2 | - | 73.4 (15.0) | 64.3 (17.1) |
| 3 | - | 65.6 (16.8) | 45.3 (20.0) | |
| 4–9 | - | 63.6 (14.7) | 48.6 (16.4) | |
| 10 | - | 61.3 (16.8) | 54.3 (18.2) | |
| Number of people | 1 | 95.0 (8.2) | 57.4 (19.5) | 46.4 (17.8) |
| 2–4 | 94.3 (6.9) | 72.6 (13.5) | 50.8 (17.9) | |
| 5–7 | 97.0 (3.3) | 75.9 (15.5) | 64.1 (17.6) | |
| 8+ | 95.7 (5.8) | 58.7 (18.2) | 55.3 (20.8) | |
| Position relative to danger zone | Inside, close | - | 38.3 (23.1) | - |
| Inside, medium | - | 53.4 (19.2) | - | |
| Inside, far | - | 56.6 (17.7) | - | |
| Outside, close | - | 68.5 (15.8) | 77.8 (14.2) | |
| Outside, medium | - | 77.8 (16.1) | 78.6 (11.3) | |
| Outside, far | - | 80.1 (14.7) | 81.8 (11.8) | |
| Elicitation method | Sequence-wise | 95.0 (4.4) | 66.2 (13.6) | 53.9 (15.5) |
| Image-wise | 95.4 (4.5) | 74.5 (8.9) | 69.0 (8.9) |
| Perfect | Miss | Miss + False Alarm | ||
|---|---|---|---|---|
| AI accuracy | 95.8 (3.8) | 71.5 (9.8) | 65.1 (11.1) | |
| Number of affected images | 2 | - | 76.5 (11.7) | 71.8 (10.2) |
| 3 | - | 68.4 (14.1) | 65.4 (16.7) | |
| 4–9 | - | 74.1 (13.7) | 62.8 (13.7) | |
| 10 | - | 66.6 (11.4) | 59.0 (13.2) | |
| Number of people | 1 | 96.7 (5.2) | 61.7 (16.8) | 58.3 (17.1) |
| 2–4 | 94.6 (8.6) | 79.0 (10.0) | 69.9 (12.1) | |
| 5–7 | 96.3 (6.6) | 82.2 (13.2) | 74.0 (12.9) | |
| 8+ | 96.3 (4.6) | 66.1 (16.7) | 58.7 (18.0) | |
| Position relative to the danger zone | Inside, close | - | 44.8 (29.2) | 42.0 (21.1) |
| Inside, medium | - | 60.4 (19.4) | 60.1 (19.2) | |
| Inside, far | - | 67.7 (16.3) | 60.5 (17.4) | |
| Outside, close | - | 75.0 (10.9) | 65.0 (14.5) | |
| Outside, medium | - | 82.0 (9.5) | 74.1 (11.1) | |
| Outside, far | - | 84.9 (12.6) | 79.2 (12.5) | |
| Elicitation method | Sequence-wise | 95.8 (3.8) | 71.5 (9.8) | 65.1 (11.1) |
| Image-wise | 96.1 (3.3) | 78.7 (5.2) | 73.5 (7.0) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Müller, R. How Humans Evaluate AI Systems for Person Detection in Automatic Train Operation: Not All Misses Are Alike. Future Transp. 2025, 5, 78. https://doi.org/10.3390/futuretransp5030078
Müller R. How Humans Evaluate AI Systems for Person Detection in Automatic Train Operation: Not All Misses Are Alike. Future Transportation. 2025; 5(3):78. https://doi.org/10.3390/futuretransp5030078
Chicago/Turabian StyleMüller, Romy. 2025. "How Humans Evaluate AI Systems for Person Detection in Automatic Train Operation: Not All Misses Are Alike" Future Transportation 5, no. 3: 78. https://doi.org/10.3390/futuretransp5030078
APA StyleMüller, R. (2025). How Humans Evaluate AI Systems for Person Detection in Automatic Train Operation: Not All Misses Are Alike. Future Transportation, 5(3), 78. https://doi.org/10.3390/futuretransp5030078