1. Introduction
There is a rising global demand for energy, influenced by population growth, technological advancements and globalization. The U.S. Energy Information Administration [
1] projects that the annual energy demand will increase at a rate of 0.5% to 1.6%, leading to an estimated overall growth of up to 57% by 2050 compared to 2020 levels. Considering the pace at which renewable energy is growing, it necessitates considerable enhancements in oil and natural gas production to meet the growing demand, serving as an essential commodity towards the transition of cleaner energy. It is, therefore, imperative to employ techniques and mechanisms in the production of oil and gas resources that maximize the production potential of any oil and gas field. Production optimization is a practice that seeks to ensure the recovery of oil and gas from a field while maximizing the returns. Reservoir production optimization faces several key challenges, including the complexity of subsurface data, reservoir heterogeneity, high data acquisition costs, and uncertainties in predicting the performance of various recovery techniques. Traditional methods often fall short in handling the dynamic nature of reservoirs, particularly in terms of pressure, fluid composition, and permeability variations, which are critical to developing effective production strategies.
Machine learning techniques have been successfully applied in various aspects of oil recovery prediction, such as enhanced oil recovery (EOR) screening, critical parameter predictions for declining oil wells, and the identification of oil spill impacts using satellite imagery [
2,
3,
4]. By leveraging machine learning algorithms, reservoir and production data can be analyzed to improve oil recovery [
5]. These applications demonstrate the versatility and effectiveness of machine learning in optimizing oil recovery processes.
Recent studies have demonstrated the effectiveness of machine learning in various aspects of oil recovery prediction and optimization. For example, Huang et al. (2021) utilized support vector regression (SVR) based on the particle swarm optimization (PSO) algorithm for a precise tight oil recovery prediction [
5]. Similarly, ref. [
2] implemented regression algorithms to enhance the oil recovery prediction, highlighting the efficacy of machine learning in optimizing the recovery rates. Furthermore, ref. [
3] employed a data-driven approach to predict the critical parameters of declining oil wells, showcasing the potential of machine learning in optimizing oil production processes. Machine learning has been used for reservoir characterization [
6,
7,
8,
9,
10], for seismic data analysis [
11,
12,
13,
14], well log analysis [
15,
16] and for pipeline integrity evaluations [
17,
18]. Moreover, machine learning models have been instrumental in simulating production performances across different reservoir types, including gas condensate, shale gas and coalbed methane reservoirs.
Sun et al. [
19] exemplified the successful development of machine learning models for practical carbon dioxide—water alternating gas (CO
2-WAG) field operational designs—demonstrating the versatility of machine learning in optimizing production processes. Additionally, ref. [
20] proposed a data-driven approach for estimating oil recovery factors in hydrocarbon reservoirs, emphasizing the reliability and objectivity of machine learning-based predictions. Ref. [
21] used K-means clustering to define the relationship between magnetometric and radiometric data and further utilized the General Regression Neural Network (GRNN) and Back Propagation Neural Network (BPNN) to improve the accuracy of mineralization zone identification, highlighting ANN’s ability to model complex subsurface data. Similarly, ref. [
22] employed the Fuzzy Analytic Hierarchy Process (FAHP) and K-means clustering for multi-dimensional data fusion, showing how integrated approaches can handle multiple parameters, a key challenge in both mineral exploration and reservoir management.
Optimization through the machine learning approach is now possible and gaining attention due to technological advancement and an increase in computation performance [
23]. Numerous studies have applied machine learning techniques like ANN, PSO and genetic algorithms (GA), among others, to optimize oil and gas production across a range of scenarios [
24,
25,
26]. Wang et al. [
27] implemented a machine learning technique by combining cluster analysis and kernel principal component analysis (PCA) to reduce the dimensionality of the input variables and ANN techniques to both evaluate and predict the performance of hydraulically fractured wells in the Montney formation, located in the Western Canadian Sedimentary basin, and concluded, among other things, that differential evolution can be incorporated into the ANN model to improve the prediction accuracy. The study presented ways of implementing a machine learning workflow in the optimization of field cumulative oil production. Constructing an accurate reservoir model requires as much core data as possible. This, however, is very costly, especially for thicker net pay intervals. Koray et al. [
28] provides a comparative analysis on calculating field reservoir permeability using parametric, non-parametric and machine learning techniques from well logs using the limited core data available.
Reservoir simulation models are constructed to evaluate and optimize oil and gas production while mimicking real-world field performances. The models require input parameters which are adjusted to mimic observed field data with the least error through a history matching process. This is aided by conducting a sensitivity analysis to assess the impact of the input variables on the simulation model output. Obtaining an accurate simulation model is important in predicting the field performance for different field development scenarios and evaluating the economics involved in their implementation. When an optimum field development strategy is realized, further field optimization processes can be carried out.
Complex numerical simulations can be substituted by using proxy models to reduce the time spent on running simulation models. Using a proxy model, various machine learning algorithms can be implemented to improve the field production efficiency. Ref. [
29] presented an optimization methodology on the field production yield and CO
2 storage. A proxy was first generated and trained until it had reached their validation criteria. They were able to optimize their objective function of the oil recovery factor, CO
2 storage and net present value (NPV) by utilizing hybrid evolution and machine learning algorithms. Ref. [
30] provided a proxy model using both the least-squares SVR and the Gaussian process regression (GPR). After the proxy model had gone through a series of training and calibration, the sequential quadratic programming (SQP) algorithm was used to optimize the design variables for their NPV objective function in a CO
2 Huff and Puff Process.
In this study, we propose an approach to reservoir production optimization which utilizes a machine learning workflow. This was performed by constructing a proxy model after it had gone through a series of training and calibration. The calibrated proxy model was optimized using the ANN, PSO and GA. A comprehensive workflow employing machine learning across all phases of reservoir characterization, sensitivity analysis, history matching, and forecasting optimization is presented. Machine learning is utilized to estimate reservoir permeability by leveraging well logs and core data during reservoir characterization. Subsequently, a 3D geological model is created based on these permeability estimates. The history matching process is facilitated by conducting a sensitivity analysis to identify the most influential geological parameters in the simulation model. An evolutionary strategy optimizer adjusts uncertain parameters automatically to minimize disparities between reservoir simulation and actual production data. Forecasts for reservoir production over a 15-year period are generated, comparing the effectiveness of a normal depletion plan versus a secondary recovery plan using water flooding. Before generating a machine learning proxy model to forecast cumulative oil production and save computational resources, a sensitivity analysis is conducted on the field operating constraints.
The novelty of this work lies in the integration of advanced optimization algorithms within a comprehensive ML workflow designed for reservoir production optimization. By utilizing a proxy model to reduce the computational time and combining it with robust optimization techniques, this study significantly enhances the field production efficiency and delivers more accurate forecasts of the reservoir performance. This approach offers a practical, scalable solution that addresses the inherent uncertainties and heterogeneity of reservoirs, providing improvements over existing methods in real-world applications.
2. Methodology
2.1. Data Preprocessing
The initial step in data processing involves cleaning to eliminate outliers and ensure data integrity.
Table 1 presents the statistics of the core and well log data utilized in this study.
This is achieved by normalizing the data to remove any bias toward higher magnitude values. Subsequently, a similar data processing procedure is conducted for the bulk density and resistivity well log data, along with the porosity and permeability data. This comprehensive approach ensures that the dataset is accurately prepared for further analysis and modeling. A data normalization approach was utilized in this study due to the ability of this approach to preserve feature relationships and scale values and eliminate the effects of a variation in the scale of the dataset allowing data of higher magnitudes to be compared to data of relatively lower magnitudes. This is particularly important when utilizing models like the neural networks, which our study implements in both the permeability prediction steps and field production optimization phase of the proposed workflow [
30]. Depending on the dataset and applications, other approaches might be more appropriate.
Data normalization is a critical step in data preprocessing, particularly in domains like machine learning and statistical analysis, where the data quality directly impacts the model performance. This process involves scaling all values within a dataset to a standardized range, typically between 0 and 1. The primary goal of data normalization is to mitigate biases that may arise from variations in the magnitudes of features within the dataset. Machine learning models can exhibit bias when dealing with features of differing scales. This is because normalization ensures that features with larger scales do not overshadow others, allowing each feature to contribute meaningfully to the model’s predictions. Equation (1) represents the standard normalization procedure used to transform the dataset into a consistent format suitable for analysis. By applying this equation to each feature, data normalization guarantees that no bias is introduced due to differences in magnitude, thus enhancing the fairness and accuracy of the subsequent analysis.
where x is any given value of a variable to be normalized, x
minimum is the minimum value from the variable to be normalized, x
maximum is the maximum value from the variable to be normalized and x
normalized is the normalized value for the variable.
2.2. Reservoir Model Construction
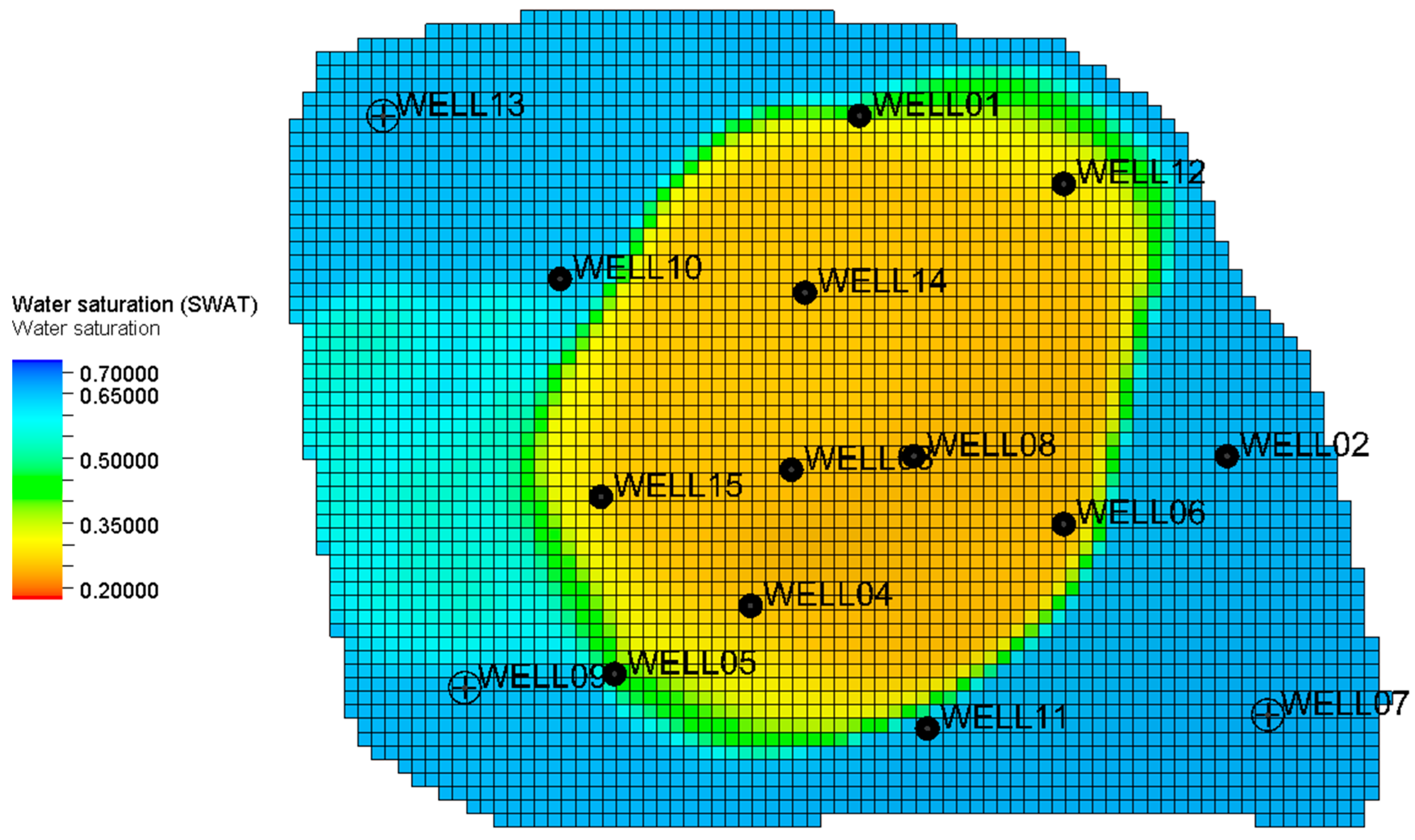
The studied reservoir comprises two distinct productive oil zones that are separated by an impermeable shale layer. Geological investigations have revealed that the reservoir predominantly consists of alternating sandstone and shale sequences. Moreover, the oil zones are partially surrounded by an aquifer. Within this reservoir setting, there are a total of 15 vertical wells, including 12 producers and 3 monitor wells. These wells have been actively producing from both the upper and lower zones since 1997, providing valuable data for reservoir characterization and analysis. The geological model delineates two productive zones separated by an impermeable shale layer, as presented in
Figure 1. The formation’s depth ranges from 7500 ft (2286 m) at the center to 8700 ft (2651 m) at the boundary, with an approximate thickness of 1720 ft (524 m). For numerical simulation purposes, the model is discretized into 81 × 60 × 11 grid blocks, with grid dimensions of 200 ft in both the x and y directions. This detailed discretization enables the precise representation and analysis of the fluid flow and reservoir behavior within the geological formation. Core and well log data from 12 production wells were analyzed to populate the reservoir porosity, as shown in
Figure 1. The reservoir porosity ranges from 5% (tight rock) to 33% (highly porous medium), with an arithmetic mean of 21%, indicating significant heterogeneity. In this context, a conventional linear correlation between porosity and permeability would not sufficiently characterize the fluid flow in the reservoir. Consequently, more rigorous algorithms are required for an accurate reservoir permeability prediction.
2.3. K-Means Clustering
The K-means clustering algorithm is utilized to extract meaningful clusters from large datasets. This algorithm aims to minimize the objective function of squared distances between clusters [
31]. This optimization process enables the algorithm to identify natural groupings or patterns within the data based on the underlying relationships among the variables. By applying the K-means clustering algorithm, it becomes possible to group complex datasets based on underlying relationships among variables within the dataset. This clustering process is particularly valuable in uncovering hidden structures and patterns that may not be immediately apparent through a manual inspection. Clustering analysis often involves using an elbow plot, which aids in determining the optimal number of clusters.
2.4. Hierarchical Clustering
Hierarchical clustering is a data analysis technique that arranges objects into tree-like structures based on their similarities. This method operates using two primary approaches: agglomerative and divisive clustering. In agglomerative clustering, individual data points are initially considered separate clusters and are progressively merged into larger clusters based on their similarities [
32]. Conversely, divisive clustering starts with all points in a single cluster and recursively divides them into smaller clusters. The clustering process involves iteratively combining or splitting clusters based on a chosen linkage criterion. Common linkage criteria include single linkage (minimum distance), complete linkage (maximum distance) and average linkage (average distance). These criteria dictate how clusters are merged or split during the hierarchical clustering process. The resulting hierarchical structure is visually represented by a dendrogram, providing valuable insights into the sequence of merging or splitting clusters. However, it is important to note that the computational complexity of hierarchical clustering increases with larger datasets. Additionally, the choice of the linkage method significantly influences the clustering outcome and must be carefully considered. In this study, the “Ward” linkage method was utilized due to its ability to minimize variance within clusters, its sensitivity to different cluster shapes, and its compatibility with the Euclidean distance. This choice of linkage method reflects a strategic decision to optimize the clustering performance and achieve a meaningful cluster formation.
2.5. Supervised Machine Learning Framework in Permeability Determination
After obtaining various clusters using both K-means and hierarchical clustering techniques, a supervised machine learning framework is applied to identify the most suitable machine learning algorithm for each cluster within the dataset. This framework aims to establish relationships between independent variables (including a gamma ray (GR) log, bulk density and porosity) and the dependent variable, which is the logarithm to base 10 of permeability. To evaluate the performance of different machine learning algorithms, a 5-fold cross-validation method is employed. This technique helps prevent overfitting by dividing the dataset into five subsets (folds) and assessing the accuracy of the models on each fold independently. Among the tested machine learning algorithms, those yielding the lowest root mean squared error (RMSE) are selected as the best fit for the dataset.
These algorithms are then utilized to determine correlations and calculate reservoir permeability for all other wells based on the available GR log, bulk density (RHOB) and porosity data. Following the implementation of K-means and hierarchical clustering techniques, the calculated permeability values are upscaled using an arithmetic average technique. Subsequently, these values are incorporated into the structural model using a Gaussian random function simulation, as depicted in
Figure 2 and
Figure 3. For a more comprehensive understanding of the geological model construction process, detailed discussions were presented by [
33,
34].
At first glance, both machine learning techniques exhibit a similar permeability range from 25 to 300 mD, corresponding to tight and highly porous rocks, as analyzed in the porosity range. However, permeability propagated by the hierarchical approach clearly delineates three distinct hydraulic flow units in the reservoir: high-permeability regions in dark red, medium-permeability zones in yellow–green and low-permeability areas in blue. The permeability distribution obtained through the K-means technique appears sparse and non-uniform compared to the more coherent and consistent permeability pattern produced by the hierarchical clustering method. By comparing RMSE values and incorporating hydraulic flow unit classification, reservoir characterization using the hierarchical clustering method demonstrates substantial advantages over other methods such as linear porosity–permeability correlations and K-means in capturing reservoir heterogeneity. This highlights the hierarchical method’s ability to provide a more accurate and detailed understanding of reservoir properties; hence, further analyses will be based on permeability predictions generated by a hierarchical method.
In addition to permeability calculations, the reservoir fluid model and rock physics saturation model have been constructed using available PVT data and relative permeability curves from one well within the area. These models contribute to a more comprehensive understanding of the fluid behavior and reservoir properties. To further refine the reservoir model, historical production and pressure data have been carefully analyzed. These data sets were utilized to develop an objective function for conducting a sensitivity analysis and optimization-based history matching. The resulting matched model is instrumental in forecasting optimization, allowing for the evaluation of different development scenarios and strategies to maximize the reservoir performance and recovery.
Figure 4 illustrates a schematic representation of the workflow, beginning with data cleaning and progressing until the data are prepared for optimization.
2.6. Proxy Development and Optimization
Achieving a successful history match model is crucial as it forms the foundation for a reliable forecasting tool within an optimization workflow. The process of field optimization begins by implementing the optimal field development strategy derived from the history match model. To expedite forecasting and reduce the computational time, a proxy model is constructed to approximate the behavior of the detailed geological model. This proxy model captures the relationship between the control variables and the cumulative oil production through a mathematical expression.
The advantage of using a proxy model is evident in its ability to significantly reduce the computational burden associated with running numerous forecasting scenarios. Instead of spending hours on hundreds of simulations to identify optimal control variables for maximum oil production, the proxy model streamlines this process.
Furthermore, the proxy model can be subjected to various solvers to determine the most effective optimization algorithm. This flexibility allows for the iterative refinement of the optimization strategy, ensuring robust and efficient decision making in field development.
Figure 5 provides a visual representation of the optimization framework, outlining the steps involved in leveraging the proxy model for efficient and effective field optimization [
29].
The proxy model undergoes training with 80 samples using the Monte Carlo sampling method and is subsequently validated with 20 validation points. For a comprehensive understanding of the process of constructing and validating the proxy model, a detailed methodology is outlined in [
35].
Upon successfully establishing the proxy model, the optimization process is further refined using advanced techniques such as artificial ANN, PSO, and GA optimizers. These optimization algorithms are employed to enhance the field’s cumulative oil production. These algorithms were chosen because they work very well and are suited for solving complex non-linear problems that come with having to optimize field production. In [
36], the ANN algorithm was used together with the GA and PSO algorithms to maximize the NPV by optimizing well spacing in a tight and fractured reservoir in Saskatchewan, Canada. The results for this study showed that the ANN-based model resulted in a faster exploration of well spacing and fracture designs as compared to a traditional simulation approach, which required longer simulation runtimes. The PSO algorithm was also found to outperform the GA in convergence speed and convergence at a higher objective function value. The next section provides more detail into the operation of the selected field optimization algorithms.
2.7. Artificial Neural Network (ANN) Optimizer
An ANN is a computational model composed of interconnected layers, including input, hidden and output layers, with nodes or neurons that imitate the functioning of the human brain. These neural networks excel at identifying intricate patterns and solving non-linear problems with exceptional accuracy. The development of a robust neural network model relies on generating a substantial dataset comprising known input–output pairs.
The ANN model learns from past patterns by storing information in the connections between neurons, represented as connection weights [
37]. These weights signify the strength of signals between interconnected neurons and the weighted inputs are summed to produce an output. The weight vectors control connections between hidden layers and from the hidden layers to the output layers [
29].
Activation functions, mathematical functions applied to neurons, determine their activation levels and a separate function calculates the network’s output. The ANN’s ability to tackle diverse non-linear problems hinges on the number of neurons in the hidden layer and the presence of multiple hidden layers [
38].
Figure 6 illustrates a three-layer ANN structure comprising input, hidden and output layers. In this study, an ANN optimizer is utilized to maximize the cumulative oil production in the field using a proxy model, capitalizing on the ANN’s capacity to process complex patterns and optimize outcomes efficiently.
2.8. Genetic Algorithm (GA) Optimizer
A GA is a methodology for solving optimization problems inspired by the principles of natural selection, which drive biological evolution. The GA algorithm operates by selecting individuals from a population as parents and then employing these parents to generate offspring for subsequent generations. This iterative process is iterated multiple times to produce a diverse set of individual solutions. To select members from the population, the fitness of each potential solution is evaluated, determining their suitability for reproduction.
Figure 7 provides a visual representation of the GA algorithm’s workflow, illustrating how it progresses through the selection, crossover, mutation and evaluation stages to iteratively refine and improve solutions [
39]. This algorithmic approach mimics the evolutionary process observed in nature, allowing for the exploration of a wide range of potential solutions and the identification of optimal outcomes for complex optimization problems.
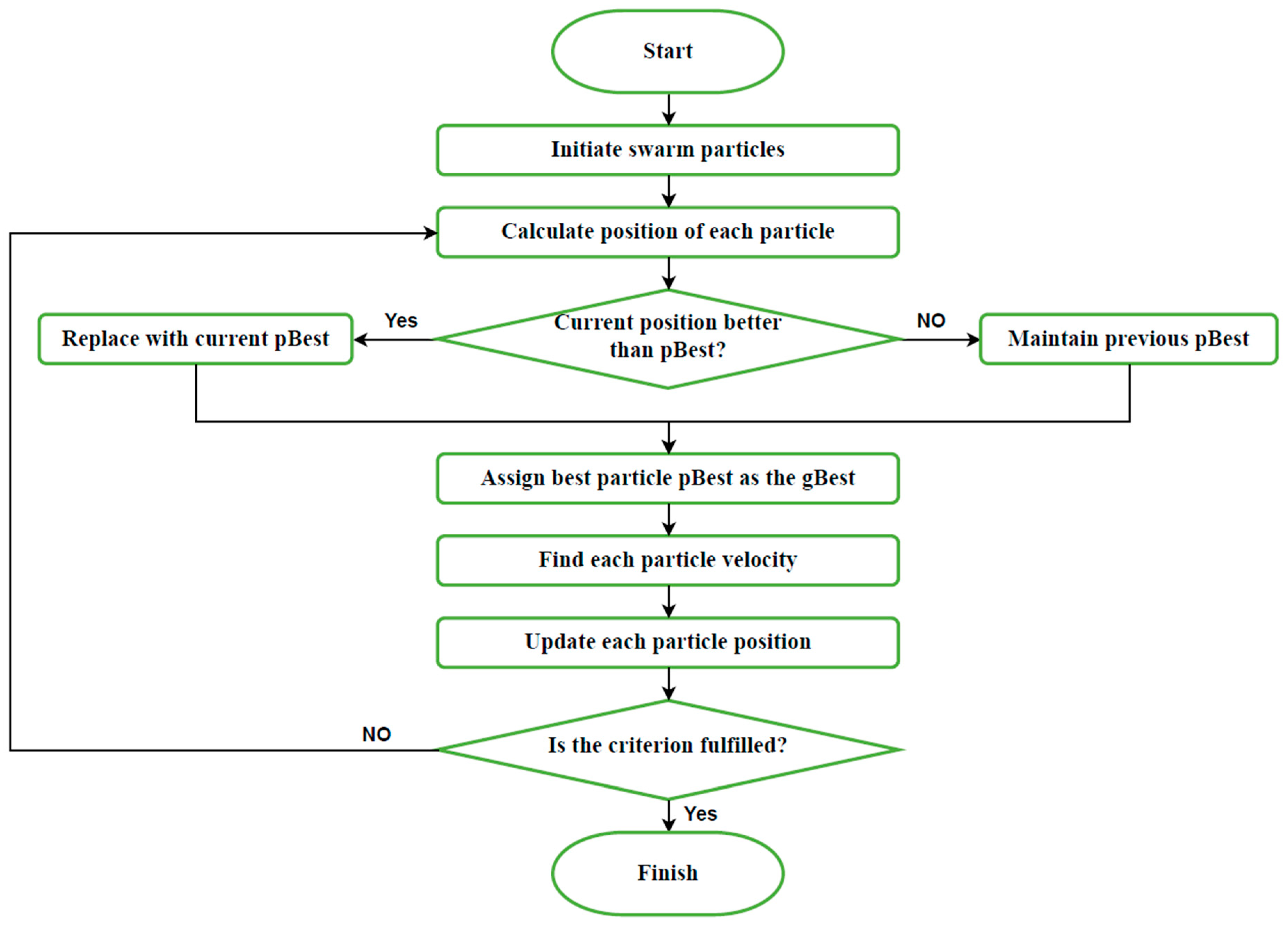
2.9. Particle Swarm Optimization (PSO)
PSO, introduced by [
40], operates by repeatedly seeking a solution among potential options guided by a quality-measuring objective function, applicable to numerous optimization tasks. This method is notably cost-effective and offers relatively swift computation times. PSO generates heuristic solutions and employs Swarm Intelligence (SI) principles [
41]. The algorithm emulates the collective and decentralized behaviors observed in natural swarms like those of birds and fish. The technique integrates both stochastic and deterministic elements to fine-tune the parameters or candidate solutions, referred to as particles, towards the target objective function [
42]. These particles adapt based on personal experience while also considering the movements of their neighbors and the entire group by updating their positions and velocity to reach a global optimum [
43].
The process operates by initially updating a particle’s position after assessing the most optimal position it has achieved to date, termed the pBest. Consequently, the position is refined to represent the best outcome since the iteration commenced. Following this, the method evaluates the most advantageous global position or the overall best position within the population, known as the gBest. Subsequently, the velocity is recalculated utilizing both the pBest and gBest values. The particle’s position is then adjusted according to the newly updated velocity. This cycle repeats until a specified termination criterion is met [
44].
Figure 8 illustrates the workflow of the PSO algorithm.
Table 2 shows a comparison of the field optimization algorithms.
3. Results
The reservoir permeability, determined through the hierarchical clustering technique, serves as the foundation for a case study focusing on optimizing cumulative oil production in both reservoir regions. This case study integrates a machine learning workflow to enhance production outcomes. The ANN optimizer was found to provide the best results for the field cumulative oil production. Before delving into history matching, a sensitivity analysis is conducted to assess the impact of selected input variables on the simulation results. This analysis generates a tornado chart, providing insights into each variable’s contribution to cumulative oil production [
45]. Control variables identified for the sensitivity analysis include permeability heterogeneity in different directions, the reservoir pore volume (PV), water–oil contacts in the upper and lower reservoirs, and various aquifer properties such as the initial pressure, depth, permeability, porosity, and external radius.
Figure 9 displays the results of the sensitivity analysis in a tornado plot, offering a visual representation of how changes in each control variable influence oil production. This analysis aids in understanding the key factors driving production variability and guides decision making in optimizing the reservoir performance.
Based on the insights gained from the sensitivity analysis, it is evident that the aquifer properties and PV exert the most significant influence on the simulation model’s outcomes. History matching, an optimization task, aims to minimize the disparity between the simulation results (such as oil and water production) and the actual field data.
Table 3 lists the uncertain parameters identified through the sensitivity analysis, which are crucial for optimization-based history matching. This table includes the ranges representing the maximum and minimum values for each parameter, providing a comprehensive overview of the optimization process. By addressing these uncertain parameters within their specified ranges, the history matching process aims to align simulated results closely with observed field data.
During the optimization-based history matching procedure, the evolution strategy optimizer systematically adjusts individual parameters to minimize the discrepancy between the simulated and observed production data. This iterative process aims to identify the optimal combination of parameters listed in
Table 1, which results in the least error when compared to the observed data. The model undergoes 500 iterations to converge towards the best solution by minimizing the objective function. Once the model is calibrated to closely match observed production data with minimal error, adjustments are made to geological properties to enhance the simulation model’s accuracy for future field development processes.
Figure 10 and
Figure 11 depict the optimal solutions achieved through the history matching process for the oil and water production rate of the twelve production wells and the cumulative production of the entire field. The daily rate and cumulative field production profiles for oil and gas production are indicated with the same color. The distinction in these two profiles can be seen in the shape of the curves. The curves for cumulative production for oil and water can be seen to start from the origin and show a steady increase in production. However, the production rate profiles for oil and water can be seen to vary as the production time increases. Regarding field cumulative production, the calibrated model shows a less than 1% deviation from the historical production data. These figures showcase excellent outcomes after implementing the hierarchical clustering technique. As a result, this permeability estimation was selected for utilization in subsequent field optimization processes. The field permeability calculated after implementing the hierarchical clustering technique proves to be more accurate and reliable in capturing the true reservoir behavior and dynamics, ultimately contributing to an enhanced reservoir performance and productivity.
Table 4 shows the final values implemented after history matching for the hierarchical clustering method to calculate the field permeability. These values are automatically applied to the matched model for subsequent field development processes.
5. Conclusions
This research provides a comprehensive machine learning workflow facilitating reservoir characterization, primary production history matching, field development, and optimizing oil recovery. Two distinct clustering methods were investigated, showing more accurate results in computing reservoir permeability in complex and highly heterogeneous sand-shale sequences compared with linear regression. Among them, the hierarchical method introduced a better prediction of formation property distribution and has been used to improve history matching and optimize oil production.
The use of machine learning-assisted history matching and sensitivity analysis facilitated an understanding of the most sensitive parameters that impact history matching outcomes. This study then assessed various strategies for field development to boost cumulative oil production. The conversion of the field pressure monitoring wells and the three highest water-producing wells resulted in the highest cumulative oil recovery by successfully reducing water production and maintaining the average reservoir pressure prior to optimization. The field production was improved further by leveraging the GA, ANN, and PSO optimizers across different software platforms, with the ANN algorithm outperforming other methods, resulting in higher cumulative oil recovery over a 15-year forecast.
This research provides a comprehensive and complete workflow for utilizing machine learning techniques across all stages, from reservoir characterization and building 3D models to history matching production data, and using machine learning to optimize the operating conditions for maximizing oil recovery. Future studies can build on the findings of this research to propose more field development plans and apply additional machine learning methods beyond GA, PSO, and ANN to achieve higher oil recovery. Based on the foundations of the proposed machine learning-assisted workflow, one can quickly apply it to field development and optimize oil recovery in their formations of interest.


 ,
, 















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}