
In Situ Skin Friction Capacity Modeling with Advanced Neuro-Fuzzy Optimized by Metaheuristic Algorithms


Abstract
1. Introduction
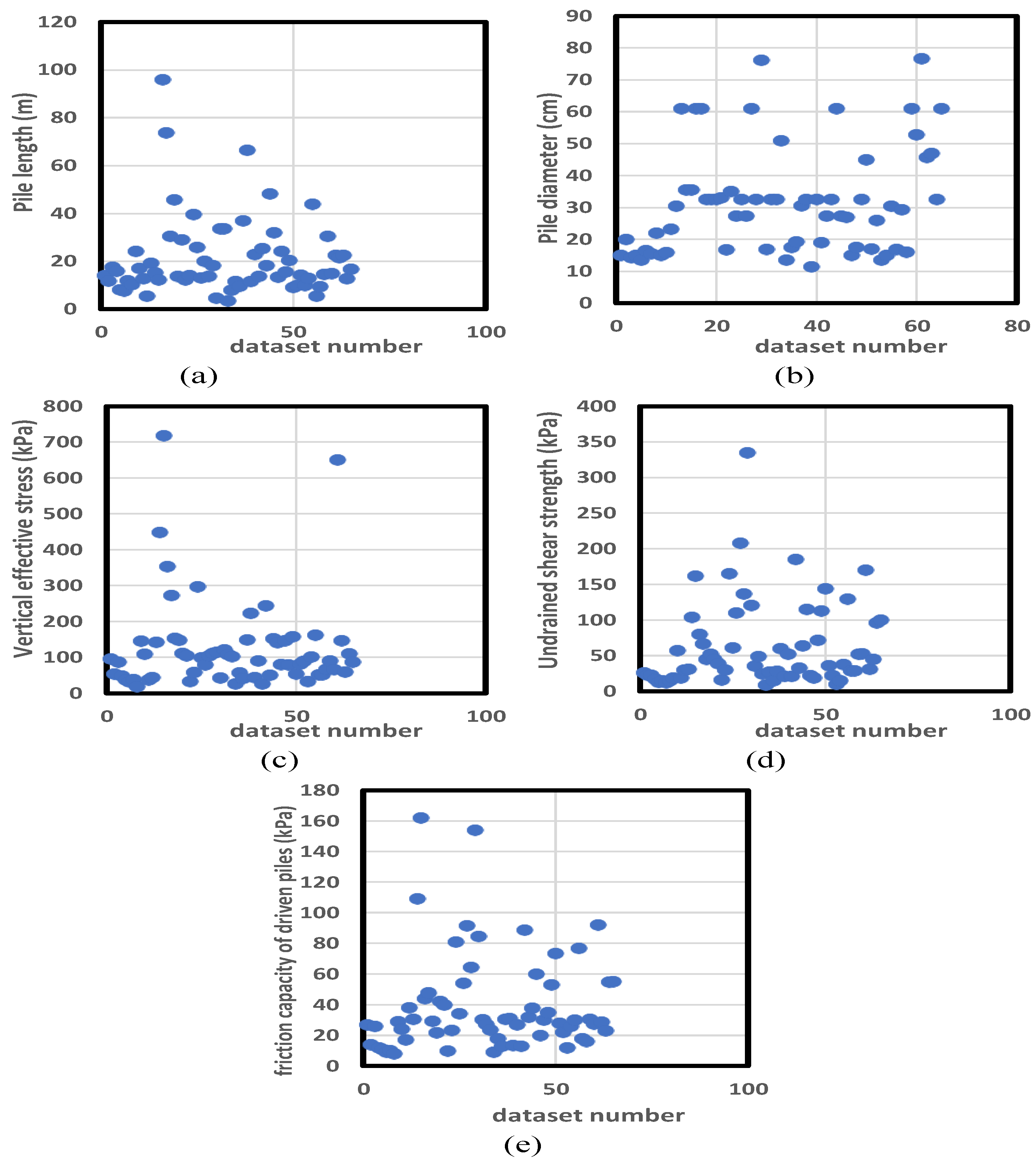
2. Established Database
3. Methodology
3.1. Adaptive Neuro-Fuzzy Inference Hybrid (ANFIS)
3.2. Hybrid Optimization Techniques
3.2.1. Harris Hawk Optimization (HHO)
3.2.2. Salp Swarm Inspired Algorithm (SSA)
3.2.3. Teaching-Learning-Based Optimization (TLBO)
3.2.4. Water-Cycle Algorithm (WCA)
3.3. Data Provision
4. Results and Discussion
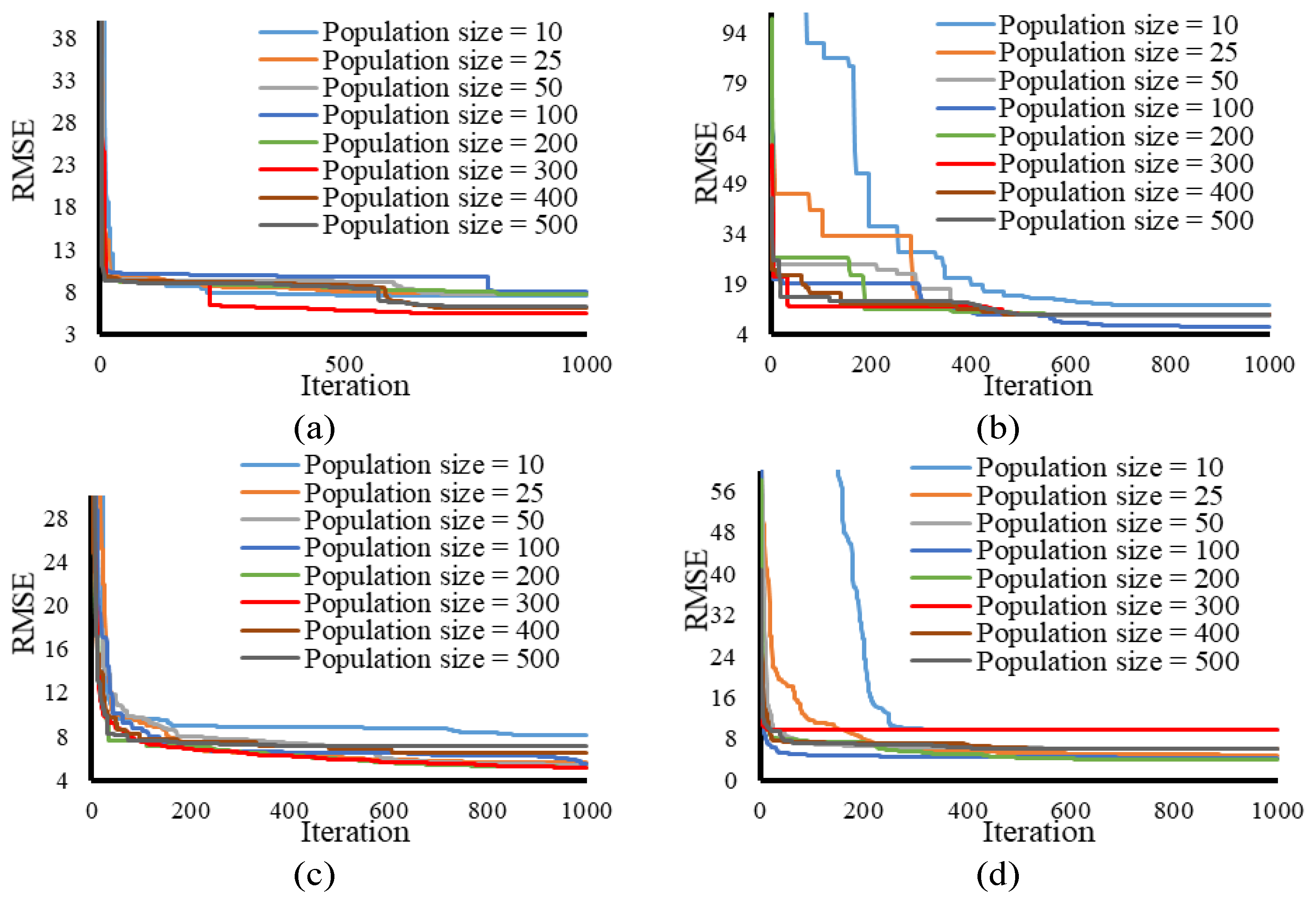
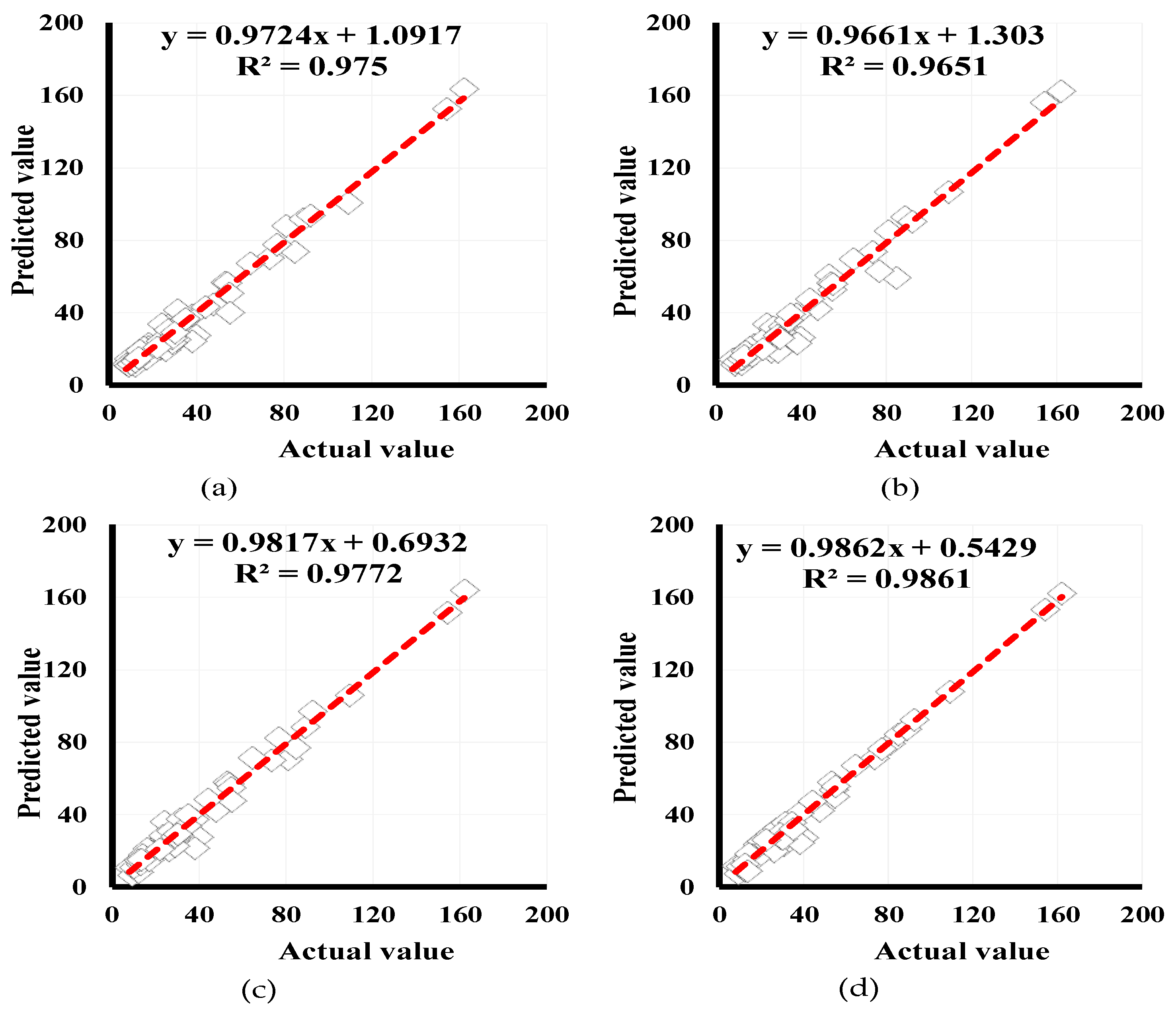
4.1. Developing Hybridized Fuzzy Tools
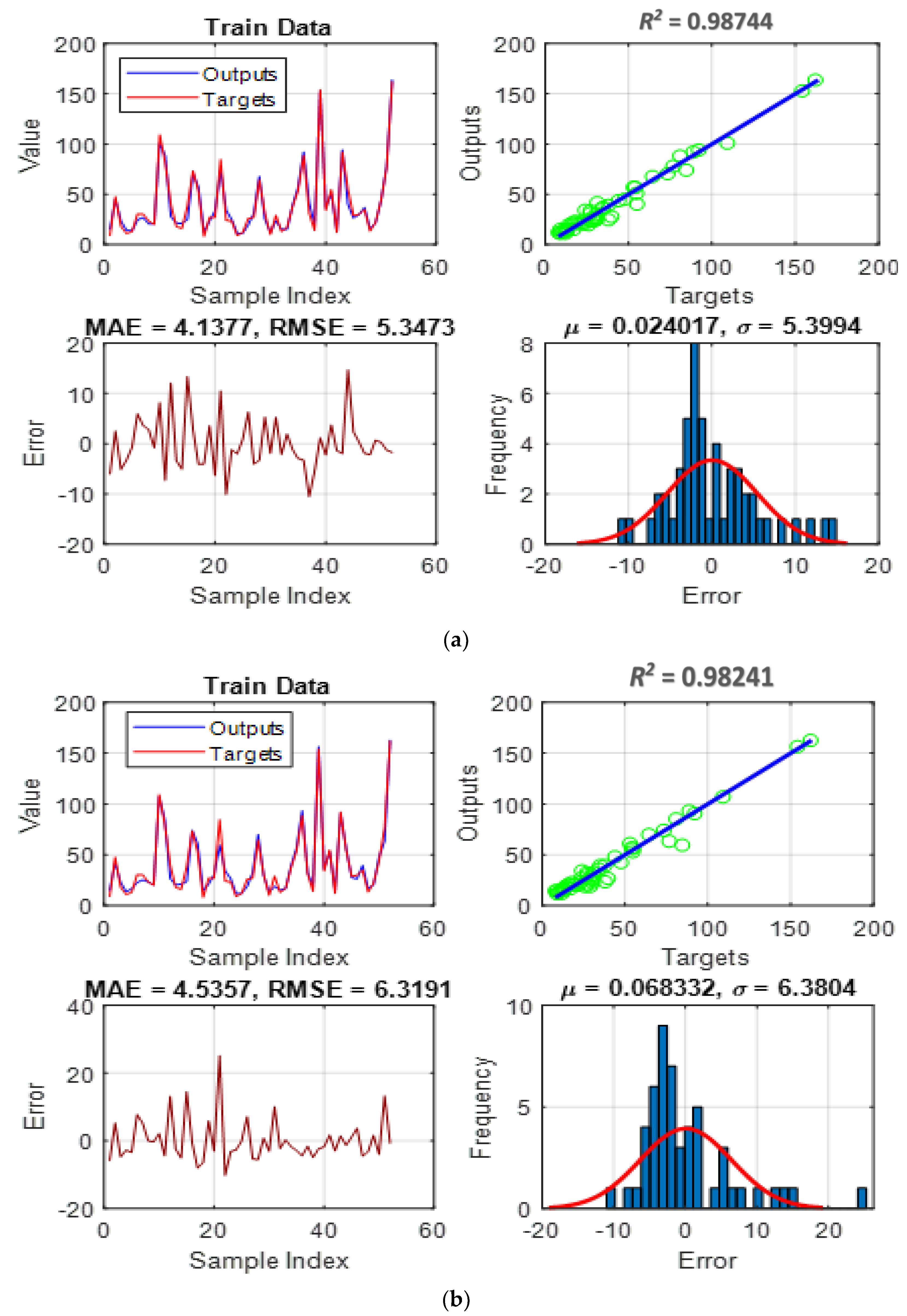
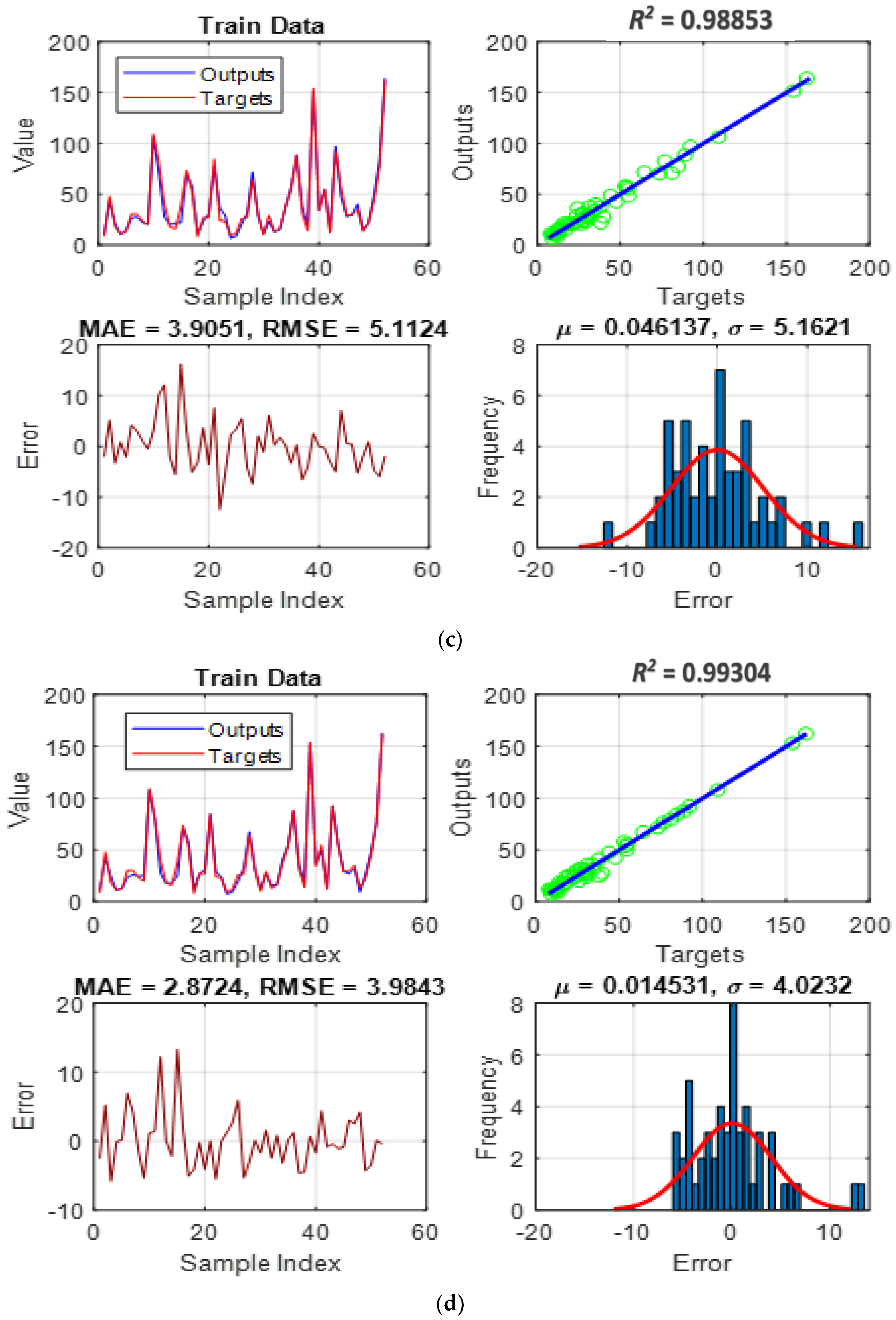
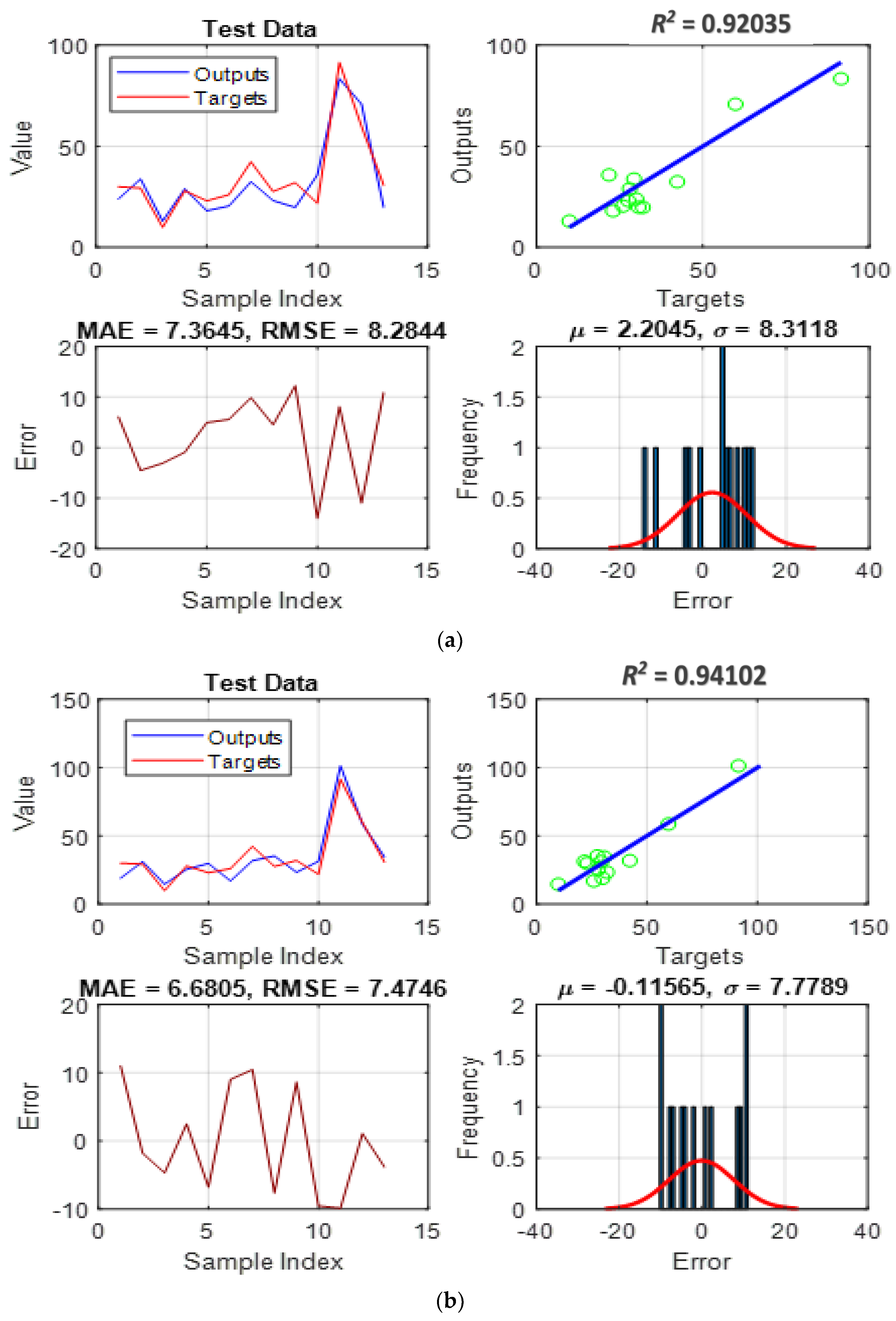
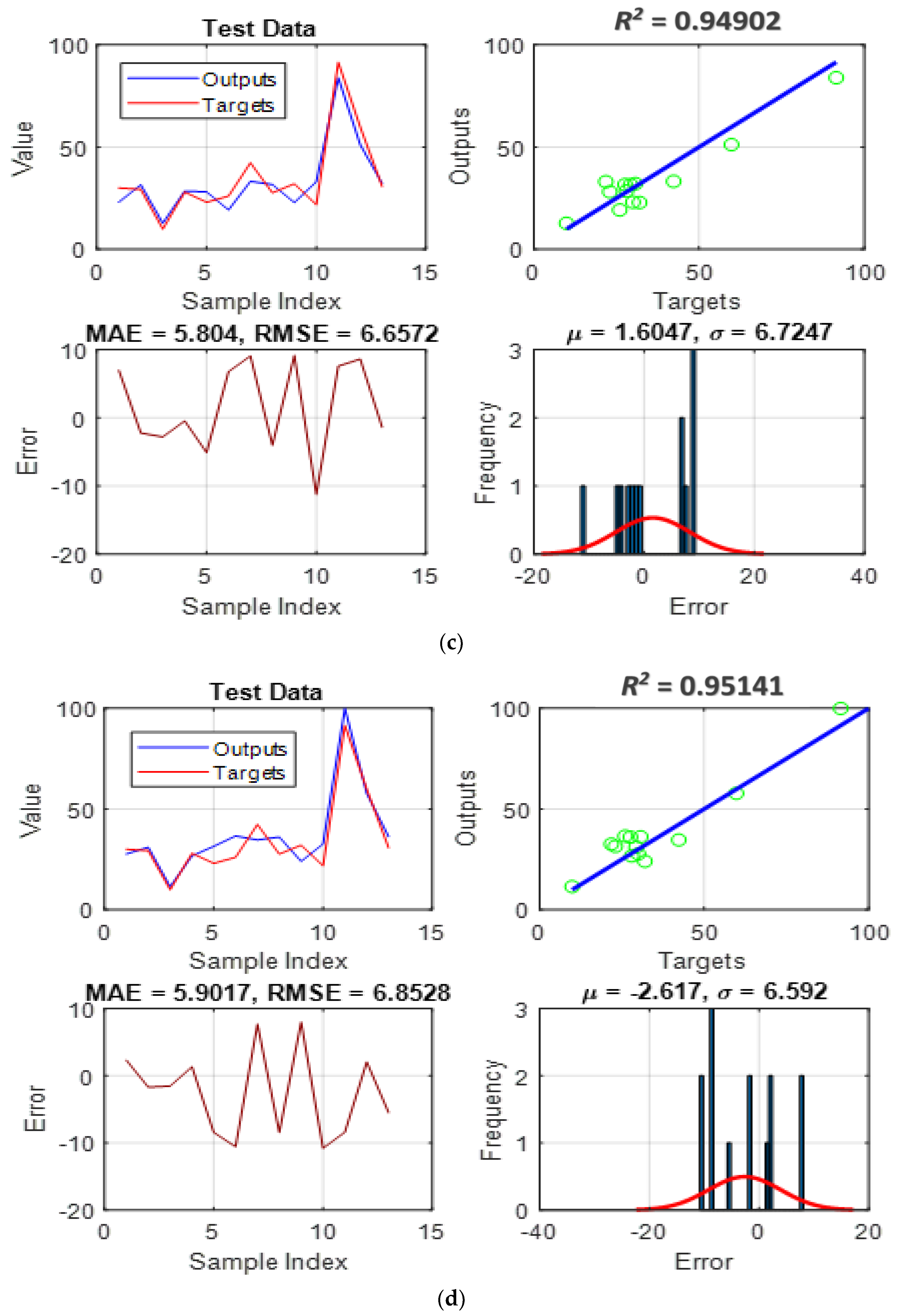
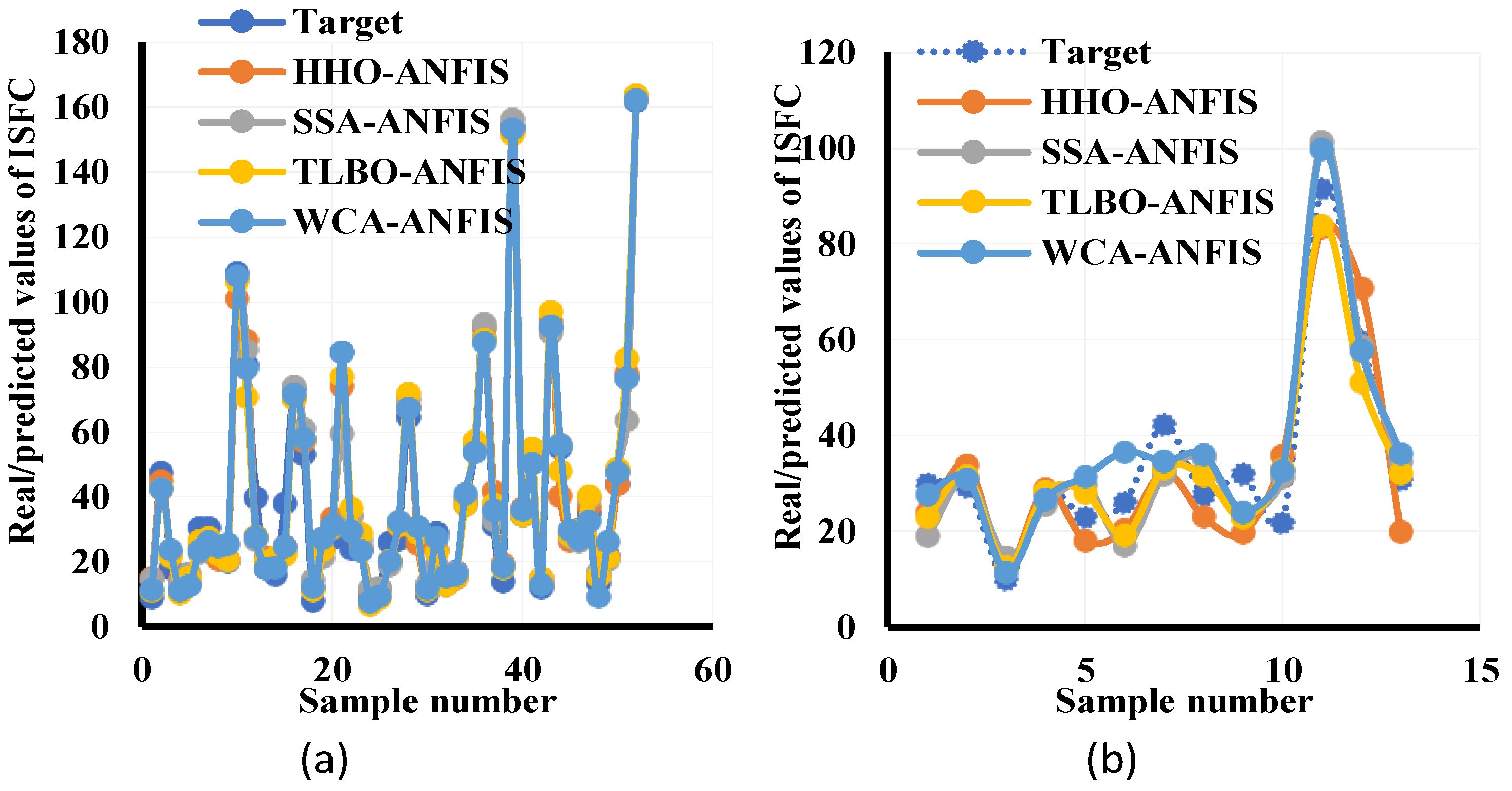
4.2. Simulation and Assessment
- Pattern recognition: It provides insight into the question, “How accurately could each model understand the link between pile length, pile diameter, effective vertical stress, and undrained shear strength using the ISFC?” As stated earlier, this task is realized through adjusting the parameters of membership functions that are variables of the ANFIS’s function.
- Pattern generalization: It responds to the question, “How well can each trained model predict the ISFC under unexpected circumstances?”, the purpose for which testing data is not similar to those utilized in the training phase.
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhao, Y.; Zhong, X.; Foong, L.K. Predicting the splitting tensile strength of concrete using an equilibrium optimization model. Steel and Composite Structures. Int. J. 2021, 39, 81–93. [Google Scholar]
- Zhang, Z.; Wang, L.; Zheng, W.; Yin, L.; Hu, R.; Yang, B. Endoscope image mosaic based on pyramid ORB. Biomed. Signal Process. Control. 2022, 71, 103261. [Google Scholar] [CrossRef]
- Liu, Y.; Tian, J.; Hu, R.; Yang, B.; Liu, S.; Yin, L.; Zheng, W. Improved Feature Point Pair Purification Algorithm Based on SIFT During Endoscope Image Stitching. Front. Neurorobot. 2022, 16, 840594. [Google Scholar] [CrossRef]
- Houssein, E.H.; Mahdy, M.A.; Shebl, D.; Manzoor, A.; Sarkar, R.; Mohamed, W.M. An efficient slime mould algorithm for solving multi-objective optimization problems. Expert Syst. Appl. 2021, 187, 115870. [Google Scholar] [CrossRef]
- Petersen, N.C.; Rodrigues, F.; Pereira, F.C. Multi-output bus travel time prediction with convolutional LSTM neural network. Expert Syst. Appl. 2019, 120, 426–435. [Google Scholar] [CrossRef]
- JianNai, X.; Shen, B. A novel swarm intelligence optimization approach: Sparrow serach algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar]
- Seghier, M.E.A.B.; Kechtegar, B.; Amar, M.N.; Correia, J.A.; Trung, N.-T. Simulation of the ultimate conditions of fibre-reinforced polymer confined concrete using hybrid intelligence models. Eng. Fail. Anal. 2021, 128, 105605. [Google Scholar] [CrossRef]
- Boussaïd, I.; Lepagnot, J.; Siarry, P. A survey on optimization metaheuristics. Inf. Sci. 2013, 237, 82–117. [Google Scholar] [CrossRef]
- Hussain, K.; Salleh, M.N.M.; Cheng, S.; Shi, Y. Metaheuristic research: A comprehensive survey. Artif. Intell. Rev. 2018, 52, 2191–2233. [Google Scholar] [CrossRef]
- Abualigah, L.; Diabat, A. Advances in Sine Cosine Algorithm: A comprehensive survey. Artif. Intell. Rev. 2021, 54, 2567–2608. [Google Scholar] [CrossRef]
- Sun, G.; Li, C.; Deng, L. An adaptive regeneration framework based on search space adjustment for differential evolution. Neural Comput. Appl. 2021, 33, 9503–9519. [Google Scholar] [CrossRef]
- Cabalar, A.F.; Cevik, A.; Gokceoglu, C. Some applications of Adaptive Neuro-Fuzzy Inference System (ANFIS) in geotechnical engineering. Comput. Geotech. 2012, 40, 14–33. [Google Scholar] [CrossRef]
- Moayedi, H.; Raftari, M.; Sharifi, A.; Jusoh, W.A.W.; Rashid, A.S.A. Optimization of ANFIS with GA and PSO estimating α ratio in driven piles. Eng. Comput. 2019, 36, 227–238. [Google Scholar] [CrossRef]
- Cai, T.; Yu, D.; Liu, H.; Gao, F. Computational Analysis of Variational Inequalities Using Mean Extra-Gradient Approach. Mathematics 2022, 10, 2318. [Google Scholar] [CrossRef]
- Shariati, M.; Mafipour, M.S.; Haido, J.H.; Yousif, S.T.; Toghroli, A.; Trung, N.T.; Shariati, A. Identification of the most influencing parameters on the properties of corroded concrete beams using an Adaptive Neuro-Fuzzy Inference System (ANFIS). Steel. Compos. Struct. 2020, 34, 155. [Google Scholar]
- Cao, Y.; Babanezhad, M.; Rezakazemi, M.; Shirazian, S. Prediction of fluid pattern in a shear flow on intelligent neural nodes using ANFIS and LBM. Neural Comput. Appl. 2019, 32, 13313–13321. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Asteris, P.G. A comparative study of ANN and ANFIS models for the prediction of cement-based mortar materials compressive strength. Neural Comput. Appl. 2020, 33, 4501–4532. [Google Scholar] [CrossRef]
- Hussein, A.M. Adaptive Neuro-Fuzzy Inference System of friction factor and heat transfer nanofluid turbulent flow in a heated tube. Case Stud. Therm. Eng. 2016, 8, 94–104. [Google Scholar] [CrossRef]
- Esmaeili Falak, M.; Sarkhani Benemaran, R.; Seifi, R. Improvement of the mechanical and durability parameters of construction concrete of the Qotursuyi Spa. Concr. Res. 2020, 13, 119–134. [Google Scholar]
- Bayat, S.; Pishkenari, H.N.; Salarieh, H. Observer design for a nano-positioning system using neural, fuzzy and ANFIS networks. Mechatronics 2019, 59, 10–24. [Google Scholar] [CrossRef]
- Fathy, A.; Kassem, A.M. Antlion optimizer-ANFIS load frequency control for multi-interconnected plants comprising photovoltaic and wind turbine. ISA Trans. 2018, 87, 282–296. [Google Scholar] [CrossRef] [PubMed]
- Fattahi, H.; Hasanipanah, M. An integrated approach of ANFIS-grasshopper optimization algorithm to approximate flyrock distance in mine blasting. Eng. Comput. 2021, 38, 2619–2631. [Google Scholar] [CrossRef]
- Sun, G.; Hasanipanah, M.; Amnieh, H.B.; Foong, L.K. Feasibility of indirect measurement of bearing capacity of driven piles based on a computational intelligence technique. Measurement 2020, 156, 107577. [Google Scholar] [CrossRef]
- Yu, D. Estimation of pile settlement socketed to rock applying hybrid ALO-ANFIS and GOA-ANFIS approaches. J. Appl. Sci. Eng. 2022, 25, 979–992. [Google Scholar]
- Shirazi, A.; Hezarkhani, A.; Pour, A.B.; Shirazy, A.; Hashim, M. Neuro-Fuzzy-AHP (NFAHP) Technique for Copper Exploration Using Advanced Spaceborne Thermal Emission and Reflection Radiometer (ASTER) and Geological Datasets in the Sahlabad Mining Area, East Iran. Remote Sens. 2022, 14, 5562. [Google Scholar] [CrossRef]
- Moayedi, H.; Hayati, S. Artificial intelligence design charts for predicting friction capacity of driven pile in clay. Neural Comput. Appl. 2018, 31, 7429–7445. [Google Scholar] [CrossRef]
- Mountrakis, G.; Im, J.; Ogole, C. Support vector machines in remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2011, 66, 247–259. [Google Scholar] [CrossRef]
- Yu, J.; Lu, L.; Chen, Y.; Zhu, Y.; Kong, L. An Indirect Eavesdropping Attack of Keystrokes on Touch Screen through Acoustic Sensing. IEEE Trans. Mob. Comput. 2019, 20, 337–351. [Google Scholar] [CrossRef]
- Li, P.; Li, Y.; Gao, R.; Xu, C.; Shang, Y. New exploration on bifurcation in fractional-order genetic regulatory networks incorporating both type delays. Eur. Phys. J. Plus 2022, 137, 598. [Google Scholar] [CrossRef]
- Prayogo, D.; Susanto, Y.T.T. Optimizing the Prediction Accuracy of Friction Capacity of Driven Piles in Cohesive Soil Using a Novel Self-Tuning Least Squares Support Vector Machine. Adv. Civ. Eng. 2018, 2018, 6490169. [Google Scholar] [CrossRef]
- Dehghanbanadaki, A.; Khari, M.; Amiri, S.T.; Armaghani, D.J. Estimation of ultimate bearing capacity of driven piles in c-φ soil using MLP-GWO and ANFIS-GWO models: A comparative study. Soft Comput. 2020, 25, 4103–4119. [Google Scholar] [CrossRef]
- Armaghani, D.J.; Harandizadeh, H.; Momeni, E.; Maizir, H.; Zhou, J. An optimized system of GMDH-ANFIS predictive model by ICA for estimating pile bearing capacity. Artif. Intell. Rev. 2021, 55, 2313–2350. [Google Scholar] [CrossRef]
- Kumar, M.; Bardhan, A.; Samui, P.; Hu, J.; Kaloop, M. Reliability Analysis of Pile Foundation Using Soft Computing Techniques: A Comparative Study. Processes 2021, 9, 486. [Google Scholar] [CrossRef]
- Wang, B.; Moayedi, H.; Nguyen, H.; Foong, L.K.; Rashid, A.S.A. Feasibility of a novel predictive technique based on artificial neural network optimized with particle swarm optimization estimating pullout bearing capacity of helical piles. Eng. Comput. 2019, 36, 1315–1324. [Google Scholar] [CrossRef]
- Liang, S.; Foong, L.K.; Lyu, Z. Determination of the friction capacity of driven piles using three sophisticated search schemes. Eng. Comput. 2020, 38, 1515–1527. [Google Scholar] [CrossRef]
- Goh, A.T.C. Empirical design in geotechnics using neural networks. Geotechnique 1995, 45, 709–714. [Google Scholar] [CrossRef]
- Heidari, A.A.; Mirjalili, S.; Faris, H.; Aljarah, I.; Mafarja, M.; Chen, H. Harris hawks optimization: Algorithm and applications. Futur. Gener. Comput. Syst. 2019, 97, 849–872. [Google Scholar] [CrossRef]
- Zhao, Y.; Hu, H.; Song, C.; Wang, Z. Predicting compressive strength of manufactured-sand concrete using conventional and metaheuristic-tuned artificial neural network. Measurement 2022, 194, 110993. [Google Scholar] [CrossRef]
- Moayedi, H.; Osouli, A.; Nguyen, H.; Rashid, A.S.A. A novel Harris hawks’ optimization and k-fold cross-validation predicting slope stability. Eng. Comput. 2019, 37, 369–379. [Google Scholar] [CrossRef]
- Rodríguez-Esparza, E.; Zanella-Calzada, L.A.; Oliva, D.; Heidari, A.A.; Zaldivar, D.; Pérez-Cisneros, M.; Foong, L.K. An efficient Harris hawks-inspired image segmentation method. Expert Syst. Appl. 2020, 155, 113428. [Google Scholar] [CrossRef]
- Qais, M.H.; Hasanien, H.M.; Alghuwainem, S. Parameters extraction of three-diode photovoltaic model using computation and Harris Hawks optimization. Energy 2020, 195, 117040. [Google Scholar] [CrossRef]
- Moayedi, H.; Abdullahi, M.M.; Nguyen, H.; Rashid, A.S.A. Comparison of dragonfly algorithm and Harris hawks optimization evolutionary data mining techniques for the assessment of bearing capacity of footings over two-layer foundation soils. Eng. Comput. 2019, 37, 437–447. [Google Scholar] [CrossRef]
- Wang, S.; Jia, H.; Liu, Q.; Zheng, R. An improved hybrid Aquila Optimizer and Harris Hawks Optimization for global optimization. Math. Biosci. Eng. 2021, 18, 7076–7109. [Google Scholar] [CrossRef] [PubMed]
- Alabool, H.M.; Alarabiat, D.; Abualigah, L.; Heidari, A.A. Harris hawks optimization: A comprehensive review of recent variants and applications. Neural Comput. Appl. 2021, 33, 8939–8980. [Google Scholar] [CrossRef]
- Yu, D.; Ma, Z.; Wang, R. Efficient Smart Grid Load Balancing via Fog and Cloud Computing. Math. Probl. Eng. 2022, 2022, 3151249. [Google Scholar] [CrossRef]
- Chantar, H.; Thaher, T.; Turabieh, H.; Mafarja, M.; Sheta, A. BHHO-TVS: A Binary Harris Hawks Optimizer with Time-Varying Scheme for Solving Data Classification Problems. Appl. Sci. 2021, 11, 6516. [Google Scholar] [CrossRef]
- Zhou, G.; Yang, F.; Xiao, J. Study on Pixel Entanglement Theory for Imagery Classification. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5409518. [Google Scholar] [CrossRef]
- Kamboj, V.K.; Nandi, A.; Bhadoria, A.; Sehgal, S. An intensify Harris Hawks optimizer for numerical and engineering optimization problems. Appl. Soft Comput. 2019, 89, 106018. [Google Scholar] [CrossRef]
- Kong, H.; Lu, L.; Yu, J.; Chen, Y.; Tang, F. Continuous Authentication Through Finger Gesture Interaction for Smart Homes Using WiFi. IEEE Trans. Mob. Comput. 2020, 20, 3148–3162. [Google Scholar] [CrossRef]
- Yin, Q.; Cao, B.; Li, X.; Wang, B.; Zhang, Q.; Wei, X. An Intelligent Optimization Algorithm for Constructing a DNA Storage Code: NOL-HHO. Int. J. Mol. Sci. 2020, 21, 2191. [Google Scholar] [CrossRef]
- Qu, C.; He, W.; Peng, X.; Peng, X. Harris Hawks optimization with information exchange. Appl. Math. Model. 2020, 84, 52–75. [Google Scholar] [CrossRef]
- Zhang, Y.; Liu, R.; Wang, X.; Chen, H.; Li, C. Boosted binary Harris hawks optimizer and feature selection. Eng. Comput. 2020, 37, 3741–3770. [Google Scholar] [CrossRef]
- Menesy, A.S.; Sultan, H.M.; Selim, A.; Ashmawy, M.G.; Kamel, S. Developing and Applying Chaotic Harris Hawks Optimization Technique for Extracting Parameters of Several Proton Exchange Membrane Fuel Cell Stacks. IEEE Access 2019, 8, 1146–1159. [Google Scholar] [CrossRef]
- Chen, H.; Jiao, S.; Wang, M.; Heidari, A.A.; Zhao, X. Parameters identification of photovoltaic cells and modules using diversification-enriched Harris hawks optimization with chaotic drifts. J. Clean. Prod. 2019, 244, 118778. [Google Scholar] [CrossRef]
- Moayedi, H.; Gör, M.; Lyu, Z.; Bui, D.T. Herding Behaviors of grasshopper and Harris hawk for hybridizing the neural network in predicting the soil compression coefficient. Measurement 2019, 152, 107389. [Google Scholar] [CrossRef]
- Wei, Y.; Lv, H.; Chen, M.; Wang, M.; Heidari, A.A.; Chen, H.; Li, C. Predicting Entrepreneurial Intention of Students: An Extreme Learning Machine with Gaussian Barebone Harris Hawks Optimizer. IEEE Access 2020, 8, 76841–76855. [Google Scholar] [CrossRef]
- Mirjalili, S.; Gandomi, A.H.; Mirjalili, S.Z.; Saremi, S.; Faris, H.; Mirjalili, S.M. Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Adv. Eng. Softw. 2017, 114, 163–191. [Google Scholar] [CrossRef]
- Abualigah, L.; Shehab, M.; Alshinwan, M.; Alabool, H. Salp swarm algorithm: A comprehensive survey. Neural Comput. Appl. 2020, 32, 11195–11215. [Google Scholar] [CrossRef]
- Liu, L.; Xiang, H.; Li, X. A novel perturbation method to reduce the dynamical degradation of digital chaotic maps. Nonlinear Dyn. 2021, 103, 1099–1115. [Google Scholar] [CrossRef]
- Rao, R.V.; Savsani, V.J.; Vakharia, D.P. Teaching–learning-based optimization: A novel method for constrained mechanical design optimization problems. Comput. Aided Des. 2011, 43, 303–315. [Google Scholar] [CrossRef]
- Rao, R.; Savsani, V.; Vakharia, D. Teaching–Learning-Based Optimization: An optimization method for continuous non-linear large scale problems. Inf. Sci. 2012, 183, 1–15. [Google Scholar] [CrossRef]
- Niknam, T.; Azizipanah-Abarghooee, R.; Narimani, M.R. A new multi objective optimization approach based on TLBO for location of automatic voltage regulators in distribution systems. Eng. Appl. Artif. Intell. 2012, 25, 1577–1588. [Google Scholar] [CrossRef]
- Tang, Y.; Liu, S.; Deng, Y.; Zhang, Y.; Yin, L.; Zheng, W. An improved method for soft tissue modeling. Biomed. Signal Process. Control. 2021, 65, 102367. [Google Scholar] [CrossRef]
- Chen, X.; Mei, C.; Xu, B.; Yu, K.; Huang, X. Quadratic interpolation based teaching-learning-based optimization for chemical dynamic system optimization. Knowl. Based Syst. 2018, 145, 250–263. [Google Scholar] [CrossRef]
- Chen, X.; Xu, B.; Yu, K.; Du, W. Teaching-Learning-Based Optimization with Learning Enthusiasm Mechanism and Its Application in Chemical Engineering. J. Appl. Math. 2018, 2018, 1806947. [Google Scholar] [CrossRef]
- Zhao, Y.; Moayedi, H.; Bahiraei, M.; Foong, L.K. Employing TLBO and SCE for optimal prediction of the compressive strength of concrete. Smart Struct. Syst. 2020, 26, 753–763. [Google Scholar]
- Eskandar, H.; Sadollah, A.; Bahreininejad, A.; Hamdi, M. Water cycle algorithm–A novel metaheuristic optimization method for solving constrained engineering optimization problems. Comput. Struct. 2012, 110, 151–166. [Google Scholar] [CrossRef]
- Mafarja, M.; Abdullah, S. Fuzzy Modified Great Deluge Algorithm for Attribute Reduction. In Recent Advances on Soft Computing and Data Mining; Springer Nature: Cham, Switzerland AG, 2014; pp. 195–203. [Google Scholar] [CrossRef]
- Mafarja, M.; Abdullah, S. A fuzzy record-to-record travel algorithm for solving rough set attribute reduction. Int. J. Syst. Sci. 2013, 46, 503–512. [Google Scholar] [CrossRef]
- Foong, L.K.; Zhao, Y.; Bai, C.; Xu, C. Efficient metaheuristic-retrofitted techniques for concrete slump simulation. Smart Struct. Syst. Int. J. 2021, 27, 745–759. [Google Scholar]
- Mosallanezhad, M.; Moayedi, H. Developing hybrid artificial neural network model for predicting uplift resistance of screw piles. Arab. J. Geosci. 2017, 10, 479. [Google Scholar] [CrossRef]
- Yu, D.; Wu, J.; Wang, W.; Gu, B. Optimal performance of hybrid energy system in the presence of electrical and heat storage systems under uncertainties using stochastic p-robust optimization technique. Sustain. Cities Soc. 2022, 83, 103935. [Google Scholar] [CrossRef]
- Mou, J.; Duan, P.; Gao, L.; Liu, X.; Li, J. An effective hybrid collaborative algorithm for energy-efficient distributed permutation flow-shop inverse scheduling. Futur. Gener. Comput. Syst. 2021, 128, 521–537. [Google Scholar] [CrossRef]
- Lu, C.; Liu, Q.; Zhang, B.; Yin, L. A Pareto-based hybrid iterated greedy algorithm for energy-efficient scheduling of distributed hybrid flowshop. Expert Syst. Appl. 2022, 204, 117555. [Google Scholar] [CrossRef]
- Seghier, M.E.A.B.; Ouaer, H.; Ghriga, M.A.; Menad, N.A.; Thai, D.-K. Hybrid soft computational approaches for modeling the maximum ultimate bond strength between the corroded steel reinforcement and surrounding concrete. Neural Comput. Appl. 2020, 33, 6905–6920. [Google Scholar] [CrossRef]
- Moayedi, H.; Mosavi, A. A water cycle-based error minimization technique in predicting the bearing capacity of shallow foundation. Eng. Comput. 2021, 1–14. [Google Scholar] [CrossRef]
- Yan, L.; Yin-He, S.; Qian, Y.; Zhi-Yu, S.; Chun-Zi, W.; Zi-Yun, L. Method of Reaching Consensus on Probability of Food Safety Based on the Integration of Finite Credible Data on Block Chain. IEEE Access 2021, 9, 123764–123776. [Google Scholar] [CrossRef]
- Foong, L.K.; Moayedi, H.; Lyu, Z. Computational modification of neural systems using a novel stochastic search scheme, namely evaporation rate-based water cycle algorithm: An application in geotechnical issues. Eng. Comput. 2020, 37, 3347–3358. [Google Scholar] [CrossRef]
- Nasir, M.; Sadollah, A.; Choi, Y.H.; Kim, J.H. A comprehensive review on water cycle algorithm and its applications. Neural Comput. Appl. 2020, 32, 17433–17488. [Google Scholar] [CrossRef]
- Eskandar, H.; Sadollah, A.; Bahreininejad, A. Weight optimization of truss structures using water cycle algorithm. Iran Univ. Sci. Technol. 2013, 3, 115–129. [Google Scholar]
- Haddad, O.B.; Moravej, M.; Loáiciga, H.A. Application of the Water Cycle Algorithm to the Optimal Operation of Reservoir Systems. J. Irrig. Drain. Eng. 2015, 141, 04014064. [Google Scholar] [CrossRef]
- Jabbar, A.; Zainudin, S. Water cycle algorithm for attribute reduction problems in rough set theory. J. Theor. Appl. Inf. Technol. 2014, 61, 107–117. [Google Scholar]
- Roeva, O.; Angelova, M.; Zoteva, D.; Pencheva, T. Water Cycle Algorithm for Modelling of Fermentation Processes. Processes 2020, 8, 920. [Google Scholar] [CrossRef]
- Sadollah, A.; Yoo, D.G.; Yazdi, J.; Kim, J.H.; Choi, Y. Application of water cycle algorithm for optimal cost design of water distribution systems. In Proceedings of the 11th International Conference on Hydroinformatics, New York, NY, USA, 16–20 August 2014. [Google Scholar]
- Sadollah, A.; Eskandar, H.; Bahreininejad, A.; Kim, J.H. Water cycle, mine blast and improved mine blast algorithms for discrete sizing optimization of truss structures. Comput. Struct. 2014, 149, 1–16. [Google Scholar] [CrossRef]
- Zhong, L.; Fang, Z.; Liu, F.; Yuan, B.; Zhang, G.; Lu, J. Bridging the Theoretical Bound and Deep Algorithms for Open Set Domain Adaptation. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Liu, F.; Fang, Z.; Yuan, B.; Zhang, G.; Lu, J. Learning from a Complementary-Label Source Domain: Theory and Algorithms. IEEE Trans. Neural Networks Learn. Syst. 2021, 32, 7667–7681. [Google Scholar] [CrossRef] [PubMed]
- Liu, K.; Ke, F.; Huang, X.; Yu, R.; Lin, F.; Wu, Y.; Ng, D.W.K. DeepBAN: A Temporal Convolution-Based Communication Framework for Dynamic WBANs. IEEE Trans. Commun. 2021, 69, 6675–6690. [Google Scholar] [CrossRef]
- Xie, Y.; Sheng, Y.; Qiu, M.; Gui, F. An adaptive decoding biased random key genetic algorithm for cloud workflow scheduling. Eng. Appl. Artif. Intell. 2022, 112, 104879. [Google Scholar] [CrossRef]
- Goh, A.T.C. Pile Driving Records Reanalyzed Using Neural Networks. J. Geotech. Eng. 1996, 122, 492–495. [Google Scholar] [CrossRef]
- Jang, J.-S.R. ANFIS: Adaptive-Network-Based Fuzzy Inference System. IEEE Trans. Syst. Man Cybern. 1993, 23, 665–685. [Google Scholar] [CrossRef]
- Zhao, L.; Wang, L. A new lightweight network based on MobileNetV3. KSII Trans. Internet Inf. Syst. 2022, 16, 1–15. [Google Scholar]
- Meng, Q.; Lai, X.; Yan, Z.; Su, C.-Y.; Wu, M. Motion Planning and Adaptive Neural Tracking Control of an Uncertain Two-Link Rigid–Flexible Manipulator with Vibration Amplitude Constraint. IEEE Trans. Neural Networks Learn. Syst. 2021, 33, 3814–3828. [Google Scholar] [CrossRef] [PubMed]
- Liang, X.; Luo, L.; Hu, S.; Li, Y. Mapping the knowledge frontiers and evolution of decision making based on agent-based modeling. Knowledge-Based Syst. 2022, 250, 108982. [Google Scholar] [CrossRef]
- Zhao, Y.; Wang, Z. Subset simulation with adaptable intermediate failure probability for robust reliability analysis: An unsupervised learning-based approach. Struct. Multidiscip. Optim. 2022, 65, 172. [Google Scholar] [CrossRef]
- Seghier, M.E.A.B.; Gao, X.-Z.; Jafari-Asl, J.; Thai, D.-K.; Ohadi, S.; Trung, N.-T. Modeling the nonlinear behavior of ACC for SCFST columns using experimental-data and a novel evolutionary-algorithm. Structures 2021, 30, 692–709. [Google Scholar] [CrossRef]
- Zhu, H.; Xue, M.; Wang, Y.; Yuan, G.; Li, X. Fast Visual Tracking with Siamese Oriented Region Proposal Network. IEEE Signal Process. Lett. 2022, 29, 1437–1441. [Google Scholar] [CrossRef]
- Razavi-Termeh, S.V.; Shirani, K.; Pasandi, M. Mapping of landslide susceptibility using the combination of neuro-fuzzy inference system (ANFIS), ant colony (ANFIS-ACOR), and differential evolution (ANFIS-DE) models. Bull. Eng. Geol. Environ. 2021, 80, 2045–2067. [Google Scholar] [CrossRef]
- Chen, Y.K.; Weng, S.X.; Liu, T.P. Teaching–learning based optimization (TLBO) with variable neighborhood search to retail shelf-space allocation. Mathematics 2020, 8, 1296. [Google Scholar] [CrossRef]
- Gill, H.S.; Khehra, B.S.; Singh, A.; Kaur, L. Teaching-learning-based optimization algorithm to minimize cross entropy for selecting multilevel threshold values. Egypt. Inform. J. 2019, 20, 11–25. [Google Scholar] [CrossRef]
- Moayedi, H.; Armaghani, D.J. Optimizing an ANN model with ICA for estimating bearing capacity of driven pile in cohesionless soil. Eng. Comput. 2017, 34, 347–356. [Google Scholar] [CrossRef]
- Moayedi, H.; Hayati, S. Applicability of a CPT-based neural network solution in predicting load-settlement responses of bored pile. Int. J. Geomech. 2018, 18, 06018009. [Google Scholar] [CrossRef]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Statistics | ||||
|---|---|---|---|---|---|
| Average | Standard Deviation | Sample Variance | Minimum | Maximum | |
| pile length (m) | 21.1 | 16.5 | 271.6 | 3.5 | 96.0 |
| pile diameter (cm) | 31.5 | 16.6 | 275.3 | 11.4 | 76.7 |
| vertical effective stress (kPa) | 124.6 | 127.7 | 16,309.9 | 19.0 | 718.0 |
| undrained shear strength (kPa) | 62.2 | 60.0 | 3603.6 | 9.0 | 335.0 |
| in situ friction capacity (ISFC) (kPa) | 39.3 | 31.9 | 1014.8 | 8.0 | 162.0 |
| HHO-ANFIS | SSA-ANFIS | TLBO-ANFIS | WCA-ANFIS |
|---|---|---|---|
| Npops = 300 | Npops =100 | Npops = 300 | Npops = 200 |
| Iteration = 1000 | Iteration = 1000 | Iteration = 1000 | Iteration = 1000 |
| Nsr = 4 | |||
| dmax = 1.0 × 10−6 |
| Population Sizes | HHO-ANFIS | SSA-ANFIS | TLBO-ANFIS | WCA-ANFIS |
|---|---|---|---|---|
| 10 | 7.472 | 12.483 | 8.077 | 9.656 |
| 25 | 7.795 | 9.715 | 5.645 | 4.808 |
| 50 | 7.747 | 9.186 | 5.341 | 6.042 |
| 100 | 8.021 | 6.319 | 5.545 | 4.292 |
| 200 | 7.679 | 9.705 | 5.140 | 3.984 |
| 300 | 5.347 | 9.705 | 5.112 | 9.705 |
| 400 | 6.093 | 9.705 | 6.552 | 6.129 |
| 500 | 6.198 | 9.705 | 7.054 | 5.987 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mu’azu, M.A. In Situ Skin Friction Capacity Modeling with Advanced Neuro-Fuzzy Optimized by Metaheuristic Algorithms. Geotechnics 2022, 2, 1035-1058. https://doi.org/10.3390/geotechnics2040049
Mu’azu MA. In Situ Skin Friction Capacity Modeling with Advanced Neuro-Fuzzy Optimized by Metaheuristic Algorithms. Geotechnics. 2022; 2(4):1035-1058. https://doi.org/10.3390/geotechnics2040049
Chicago/Turabian StyleMu’azu, Mohammed A. 2022. "In Situ Skin Friction Capacity Modeling with Advanced Neuro-Fuzzy Optimized by Metaheuristic Algorithms" Geotechnics 2, no. 4: 1035-1058. https://doi.org/10.3390/geotechnics2040049
APA StyleMu’azu, M. A. (2022). In Situ Skin Friction Capacity Modeling with Advanced Neuro-Fuzzy Optimized by Metaheuristic Algorithms. Geotechnics, 2(4), 1035-1058. https://doi.org/10.3390/geotechnics2040049