
Algorithm Literacy as a Subset of Media and Information Literacy: Competences and Design Considerations


Abstract
1. Introduction
Algorithm Literacy: A Dimension of MIL Still in Its Infancy
2. Methodology
2.1. Crossover: An Innovative Research–Action Design
2.2. Data Collection
- (1)
- The initial inquest: the online “trending” information of the moment;
- (2)
- The Apache.be investigation and news story;
- (3)
- A zoom on a search scenario of use with the Dashboard;
- (4)
- An explanation of a key algorithmic notion;
- (5)
- The resolution: the disinformation risk avoided/dealt with;
- (6)
- The MIL solutions and competences called for.
2.3. MIL Principles
- A modular approach (stories, podcasts, quizzes) to allow for a variety of entries for practitioners and educators;
- Authentic documents and examples to remain as close as possible to users’ experiences and societal issues;
- A competence-based framework with verbalised notions and actions to stimulate critical thinking and foster civic actions;
- A multi-stakeholder strategy that shows the perspectives of the different actors involved in understanding algorithms and in the co-design of MIL interventions (developers, journalists, experts).
3. Results
3.1. The MIL Algorithm-Literacy Matrix of Scenarios of Use
- Scenario 1, “the keyboard fighters”, showed the mismatch between the online calls for action and real-life mobilisations as the “liberty convoy” threats, which seemed threatening online, turned out to be insubstantial in real life. The role of algorithmic ranking was thus debunked in relation to user search. The MIL lesson drawn was that online disinformation did not always work and could be disproved by facts (see podcast 1).
- Scenario 2, “algorithms and propaganda: dangerous liaisons”, revealed how algorithms tended to promote state propaganda: as Russia Today was banned by the European decision (due to the war in Ukraine), algorithms recommended a new state-controlled media, CGTN, the state channel of the Chinese Communist Party, that relayed Russian propaganda. The role of algorithmic recommendation was thus exposed in relation to user engagement. The MIL lesson drawn was that disinformation was amplified along polarised lines and across borders (see podcast 2).
- Scenario 3, “how algorithms changed my life”, unveiled how conspiracy theories circulated on influential accounts, in “censorship free” and unmoderated networks like Odysee. It followed an influencer, the extreme-right political personality Dries Van Langenhove, who called for racism, violence and anti-COVID stances. The role of algorithmic recommendation was thus unveiled in relation to user echo chambers. The MIL lesson drawn was that information diversity was key to avoid being caught in the rabbit holes of the attention economy (see Podcast 3).
- Scenario 4, “the algorithm watchers”, demonstrated how Google auto-complete systematically offered users the Donbass Insider recommendation when they typed Donbass in their search bar, across all people user-meters. Donbass Insider relayed Russian false messages about the war in Ukraine and was linked to Christelle Néant, a Franco-Russian pro-Kremlin blogger and self-styled journalist. The role of algorithmic prediction was revealed in relation to user interactions with the tool affordances. The MIL lesson drawn was that queries and prompts can lead to automated bias and human manipulation (see podcast 4).
3.2. MIL Algo-Literacy Meta-Competence Framework
- Know the new context of news production and amplification via algorithms;
- Pay attention to emotions and how they are stirred by sensationalist contents and take a step back from “hot” news;
- Be suspicious and aware of “weak signals” for disinformation (lack of traffic on some accounts, except for some divisive topics; very little activity among and across followers on a so-called popular website or community, etc.);
- Fight confirmation biases and other cognitive biases.
- Vary sources of information;
- Be vigilant about divisive issues where opinions prevail and facts and sources are not presented;
- Modify social media uses to avoid filter bubbles and (unsolicited) echo chambers;
- Set limits to tracking so as to reduce targeting (as fewer data are collected from your devices);
- Deactivate some functionalities regularly and set the parameters of your accounts;
- Browse anonymously (use VPNs).
- Decipher algorithms, their biases and platform responsibility;
- “Ride” algorithms for specific purposes;
- Pay attention to RGPD and platform loyalty to data protection;
- Mobilise for more transparency and accountability about their impact;
- Require social networks to delete fake news accounts, to ban toxic personalities and to moderate content;
- Encourage the creation of information verification sites and use them;
- Use technical fact-checking tools like the Dashboard or InVID-Weverify;
- Signal or report to platforms or web managers if misuses are detected;
- Comment and/or rectify “fake news”, whenever possible;
- Alert fact-checkers, journalists or the community of affinity.
3.3. The Knowledge Base with Pedagogical Pathways and Design Considerations
4. Discussion
4.1. By-Passing the “Black Box” of Algorithms
4.2. Confirming the Definition of Algorithm Literacy
4.3. Fine-Tuning the Competence Framework with MIL Design
5. Conclusions
Funding
Data Availability Statement
Conflicts of Interest
References
- European Commission, DG-Connect. A Multi-Dimensional Approach to Disinformation—Report of the Independent High Level Group on Fake News and Online Disinformation; Publications Office of the European Union: Brussels, Belgium, 2018; Available online: https://digital-strategy.ec.europa.eu/en/library/final-report-high-level-expert-group-fake-news-and-online-disinformation (accessed on 1 February 2024).
- Seaver, N. Captivating Algorithms: Recommender Systems as Traps. J. Mater. Cult. 2019, 24, 421–436. [Google Scholar] [CrossRef]
- Dogruel, L.; Facciorusso, D.; Stark, B. ‘I’m still the master of the machine. ‘Internet users’ awareness of algorithmic decision-making and their perception of its effect on their autonomy. Inf. Commun. Soc. 2020, 25, 1311–1332. [Google Scholar] [CrossRef]
- Boyd, D.; Crawford, K. Critical questions for big data: Provocations for a cultural, technological, and scholarly phenomenon. Inf. Commun. Soc. 2012, 15, 662–679. [Google Scholar] [CrossRef]
- Hill, J. Policy Responses to False and Misleading Digital Content: A Snapshot of Children’s Media Literacy; Documents de Travail de l’OCDE sur l’éducation; OCDE: Paris, France, 2022; p. 275. [Google Scholar] [CrossRef]
- Crossover Project (2021–2022). Available online: https://crossover.social (accessed on 1 March 2024).
- Beer, D. The social power of algorithms. Inf. Commun. Soc. 2017, 20, 1–13. [Google Scholar] [CrossRef]
- Dogruel, L.; Masur, P.; Joeckel, S. Development and Validation of an Algorithm Literacy Scale for Internet Users. Commun. Methods Meas. 2022, 16, 115–133. [Google Scholar] [CrossRef]
- Cotter, K.M. Critical Algorithmic Literacy: Power, Epistemology, and Platforms. Ph.D. Dissertation, Michigan State University, East Lansing, MI, USA, 2020. Available online: https://search.proquest.com/openview/3d5766d511ea8a1ffe54c53011acf4f2/1?pq-origsite=gscholar&cbl=18750&diss=y (accessed on 1 March 2024).
- Nguyen, D.; Beijnon, B. The data subject and the myth of the ‘black box’ data communication and critical data literacy as a resistant practice to platform exploitation. Inf. Commun. Soc. 2023, 27, 333–349. [Google Scholar] [CrossRef]
- Matthews, P. Data literacy conceptions, community capabilities. J. Community Inform. 2016, 12, 47–56. [Google Scholar] [CrossRef]
- Shin, D.; Rasul, A.; Fotiadis, A. Why am I seeing this? Deconstructing algorithm literacy through the lens of users. Internet Res. 2022, 32, 1214–1234. [Google Scholar] [CrossRef]
- Head, A.; Fister, B.; MacMillan, M. Information Literacy in the Age of Algorithms. 2020. Available online: https://projectinfolit.org/pubs/algorithm-study/pil_algorithm-study_2020-01-15.pdf (accessed on 1 March 2024).
- Swart, J. Experiencing Algorithms: How Young People Understand, Feel About, and Engage with Algorithmic News Selection on Social Media. Soc. Media Soc. 2021, 7, 20563051211008828. [Google Scholar] [CrossRef]
- Bucher, T. The algorithmic imaginary: Exploring the ordinary affects of Facebook algorithms. Inf. Commun. Soc. 2017, 20, 30–44. [Google Scholar] [CrossRef]
- Brisson-Boivin, K.; McAleese, S. Algorithmic Awareness: Conversations with Young Canadians about Artificial Intelligence and Privacy; MediaSmarts: Ottawa, ON, Canada, 2021; Available online: https://mediasmarts.ca/sites/default/files/publication-report/full/report_algorithmic_awareness.pdf (accessed on 1 March 2024).
- Nygren, T.; Frau-Meigs, D.; Corbu, N.; Santoval, S. Teachers’ views on disinformation and media literacy supported by a tool designed for professional fact-checkers: Perspectives from France, Romania, Spain and Sweden. SN Soc. Sci. 2022, 2, 40. [Google Scholar] [CrossRef] [PubMed]
- Moylan, R.; Code, J. Algorithmic futures: An analysis of teacher professional digital competence frameworks through an algorithm literacy lens. Teach. Teach. Theory Pract. 2023. [Google Scholar] [CrossRef]
- Cotter, K.; Reisdorf, B.C. Algorithmic Knowledge Gaps: A New Horizon of (Digital) Inequality. Int. J. Commun. 2020, 14, 745–765. Available online: https://ijoc.org/index.php/ijoc/article/view/12450 (accessed on 1 May 2024).
- Frau-Meigs, D. User Empowerment through Media and Information Literacy Responses to the Evolution of Generative Artificial Intelligence (GAI); UNESCO: Paris, France, 2024; Available online: https://unesdoc.unesco.org/ark:/48223/pf0000388547 (accessed on 1 March 2024).
- Frau-Meigs, D. Transliteracy as the new research horizon for media and information literacy. Media Stud. 2012, 3, 14–27. Available online: https://hrcak.srce.hr/ojs/index.php/medijske-studije/article/view/6064 (accessed on 1 March 2024).
- Frau-Meigs, D. Transliteracy and the digital media: Theorizing Media and Information Literacy. In International Encyclopedia of Education, 4th ed.; Tierney, R., Rizvi, F., Ercikan, K., Eds.; Elsevier: Amsterdam, The Netherlands, 2022. [Google Scholar]
- Carroll, J.M. Making Use: Scenario-Based Design of Human-Computer Interactions; The MIT Press: Cambridge, MA, USA, 2000. [Google Scholar]
- Alexander, I.F.; Maiden, N. (Eds.) Scenarios, Stories, Use Cases through the Systems Development Life Cycle; Wiley: Hoboken, NJ, USA, 2004. [Google Scholar]
- Hargittai, E.; Gruber, J.; Djukaric, T.; Fuchs, J.; Brombach, L. Black box measures? How to study people’s algorithm skills. Inf. Commun. Soc. 2020, 23, 764–775. [Google Scholar] [CrossRef]
- Lloyd, A. Chasing Frankenstein’s Monster: Information literacy in the black box society. J. Doc. 2019, 75, 1475–1485. [Google Scholar] [CrossRef]
- Frau-Meigs, D.; Corbu, N. (Eds.) Disinformation Debunked: MIL to Build Online Resilience; Routledge: London, UK, 2024. [Google Scholar]
- Potter, W.J.; Thai, C.L. Reviewing media literacy intervention studies for validity. Rev. Commun. Res. 2019, 7, 38–66. [Google Scholar] [CrossRef]
- Savoir Devenir. Algo-Literacy Prebunking Kit. 2022. Available online: https://savoirdevenir.net/wp-content/uploads/2023/03/PREBUNKING-KIT-ENG.pdf (accessed on 1 March 2024).
- Kahne, J.; Hodgin, E.; Eidman-Aadahl, E. Redesigning civic education for the digital age: Participatory politics and the pursuit of democratic engagement. Theory Res. Soc. Educ. 2016, 44, 1–35. [Google Scholar] [CrossRef]
- McGrew, S.; Breakstone, J.; Ortega, T.; Smith, M.; Wineburg, S. Can Students Evaluate Online Sources? Learning From Assessments of Civic Online Reasoning. Theory Res. Soc. Educ. 2018, 46, 165–193. [Google Scholar] [CrossRef]
- Frau-Meigs, D. How Disinformation Reshaped the Relationship between Journalism and Media and Information Literacy (MIL): Old and New Perspectives Revisited. Digit. J. 2022, 10, 912–922. [Google Scholar] [CrossRef]
- Pasquale, F. The Black Box Society: The Secret Algorithms That Control Money and Information; Harvard UP: Cambridge, MA, USA, 2015. [Google Scholar]
- Burrell, J. How the machine ‘thinks’: Understanding opacity in machine learning algorithms. Big Data Soc. 2016, 3, 2053951715622512. [Google Scholar] [CrossRef]
- Le Deuff, O.; Roumanos, R. Enjeux définitionnels et scientifiques de la littératie algorithmique: Entre mécanologie et rétro-ingénierie documentaire. tic&société 2021, 15, 325–360. [Google Scholar]
- Masterman, L. Teaching the Media; Routledge: London, UK, 1985. [Google Scholar] [CrossRef]
- Wineburg, S.; McGrew, S. Lateral Reading and the Nature of Expertise: Reading Less and Learning More When Evaluating Digital Information. Teach. Coll. Rec. 2019, 121, 1–40. [Google Scholar] [CrossRef]
- Rieder, B. Engines of Order: A Mechanology of Algorithmic Techniques; Amsterdam University Press: Amsterdam, The Netherlands, 2020. [Google Scholar]
- European Commission, DG-EAC. Guidelines for Teachers and Educators on Tackling Disinformation and Promoting Digital Literacy through Education and Training; Publications Office of the European Union: Brussels, Belgium, 2022; Available online: https://data.europa.eu/doi/10.2766/28248 (accessed on 1 March 2024).
- Kemper, J.; Kolkman, D. Transparent to whom? No algorithmic accountability without a critical audience. Inf. Commun. Soc. 2019, 22, 2081–2096. [Google Scholar] [CrossRef]
- Kitchin, R. Thinking critically about and researching algorithms. Inf. Commun. Soc. 2017, 20, 14–29. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| MIL algo-literacy matrix. (that can be transferred to classroom interventions) | ||||
| Scenario of use | Real life event | Algorithmic focus | MIL competences | Larger societal issues |
| 1 https://crossover.social/podcast/crossover-podcast-episode-1-the-keyboard-fighters/ (accessed on 1 May 2024) | ||||
| Searching by keywords on search engines like Google keyword: Liberty convoy | Article 1 15 February 2022 Podcast 1 13 July 2022 The keyboard fighters Based on investigation looking at ‘Freedom Convoy’ threats to invade Brussels | FOCUS ON RANKING ALGORITHMS and SEARCH What is a keyword, its use in information, difference between a keyword and a hashtag…  | Analysis of mechanisms of disinformation and debunking process | Contrast between URL (virtual) and IRL (real) mobilizations |
| 2 https://crossover.social/podcast/crossover-podcast-episode-2-dangerous-liaisons/ (accessed on 1 May 2024) | ||||
| Searching for affinity communities, groups, influencers, actors via # on social networks like Youtube Hashtag: RT Russia | Article 2 podcast 2 3 November 2022 Algorithms and propaganda: dangerous liaisons Based on investigation looking at ban on RT during war in Ukraine and subsequent replacement by CGTN Français | FOCUS ON THE ROLE OF PARTICIPATION on social networks TRENDS What is engagement, how it affects ranking and dissemination, how communities influence trends…what is an echo chamber  | - Understand the economy of attention - Analysis of mechanisms of cyber-propaganda - Basic functioning of engagement and amplification via algorithms - State propaganda and algorithmic recommendation | Algorithmic “addiction” to state media that propagate disinformation |
| 3 https://crossover.social/podcast/crossover-podcast-episode-3-how-algorithms-changed-my-job/ (accessed on 1 May 2024) | ||||
| Searching for trends and influential accounts on forums such as Odysee Looking for personalities and influencers such as Dries Van Langenhove | Article 3 8 June 2022 Podcast 17 January 2023 How algorithms changed my work Based on reflexive discussions about using algorithms to do algo-journalism And dealing with conspiracy theories | FOCUS ON RECOMMANDATION ALGORITHMS and ATTENTION How prediction differs from recommendation, how it informs behaviour of algos (and users?)  | - Understand the role of communities and influencers on information/disinformation - Develop know-how to get more diversified information… | Economics of attention /recommendation |
| 4 https://crossover.social/podcast/crossover-podcast-episode-4-algorithm-watchers-digital-fact-checking-prediction-algorithms-disinformation/ (accessed on 1 May 2024) | ||||
| Searching for disinformation with a smart tool like Dashboard Google auto-complete Keyword: Donbass | Article 4 29 September 2022 Podcast 4 22 February 2023 The Algorithm watchers Based on reflexive discussions on experience of developers using the Dashboard and interacting with other stakeholders | FOCUS ON ALGORITHMIC PREDICTION And BIAS and PROPAGANDA What about Neutrality of algorithms? How does the dashboard prove that algorithms change the information game and help understand the way they work? 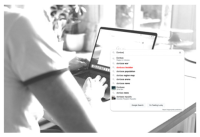 | - Understand how algorithms can bias the information and push disinformation - Identify manipulations - Objectify the work of journalists - Using technical tools to fight disinformation - Uncovering the functioning of algorithms across platforms - dealing with digital fact-checking, prediction algorithms and disinformation | Bias, manipulation |
| Goals | Solutions |
|---|---|
| Limiting the number of data collected from your devices to reduce targeting | Setting your cookies to limit tracking |
| Browsing anonymously | Using a VPN |
| Not falling for sensationalist news | Watching out for information that arouses a lot of emotion and verifying it |
| Going beyond the beaten path, varying your sources of information | Opening your community to people with different profiles and snooping elsewhere than in the first page of Google or searching on other sites |
| Making sure that informing yourself is a voluntary act that respects clear rules | Mobilising for an increased regulation of algorithms, for more transparency about their impact |
| Fake accounts and bots are created by the millions every day and are often the basis of raging debates. What are the signs that should make you suspicious? |
|
| Answer: the correct answers (in bold) are only clues. The more of them that converge, the higher the probability that you are dealing with a bot. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Frau-Meigs, D. Algorithm Literacy as a Subset of Media and Information Literacy: Competences and Design Considerations. Digital 2024, 4, 512-528. https://doi.org/10.3390/digital4020026
Frau-Meigs D. Algorithm Literacy as a Subset of Media and Information Literacy: Competences and Design Considerations. Digital. 2024; 4(2):512-528. https://doi.org/10.3390/digital4020026
Chicago/Turabian StyleFrau-Meigs, Divina. 2024. "Algorithm Literacy as a Subset of Media and Information Literacy: Competences and Design Considerations" Digital 4, no. 2: 512-528. https://doi.org/10.3390/digital4020026
APA StyleFrau-Meigs, D. (2024). Algorithm Literacy as a Subset of Media and Information Literacy: Competences and Design Considerations. Digital, 4(2), 512-528. https://doi.org/10.3390/digital4020026