1. Introduction
Many of the online activities place the cost of privacy on the users by requiring them to disclose their personal data in exchange for services. Due to the near permanent nature of the Internet, it results in a loss of privacy and can have a long-lasting effect on the user. A Pew Research Centre survey in 2015 found that a large percentage (91) of American adults had indicated that they feel they have lost control of the use of their private information [
1]. The collection of personal data by online service providers is often justified with claims of creating a more user-centric web experience. However, personal data are sold and shared frequently with third parties that use it to profile users and track them across domains. Many surveys and studies suggested that users are increasingly concerned about their privacy online [
2]. To help with users’ concerns and enhance trust, companies have implemented privacy enhancing technologies (PET). These technology solutions include reducing personal information collection in terms of volume; anonymization and de-identification of personal data; opt-out mechanisms; and ‘layered’ policies [
3,
4]. Privacy policies have continued to be opaque and verbose legal documents.
Privacy policies are intended to inform users about the collection, use, and dissemination of their private data. They are also aimed to reduce the concern of users [
5]. Regulations recommend that privacy policies should disclose extent and nature of information collection [
6,
7,
8,
9]. Unfortunately, most policies are often lengthy, difficult and time-consuming to read, and as a result are infrequently read [
2,
10,
11,
12]. The demotivating nature and the difficulty of reading privacy policies amounts to a lack of transparency. Failing to provide usable privacy policies prevents users from making informed decisions and can lead them to accept terms of use jeopardizing their privacy and personal data.
This paper proposes an approach to reduce the amount of text a user has to read using a domain ontology to identify key areas that address their concerns and allow them to take appropriate action. The approach consists of constructing a domain ontology for online privacy (DOOP), an ontology for online privacy policies, validated against Carnegie Mellon University’s (CMU) OPP-115 data set [
13] of annotated policies by domain experts. DOOP resulted in 69–99% reductions in reading for the three sample queries that were tested. Reducing the reading time will encourage users to read privacy policies and make informed decisions online.
It is important to note that DOOP is the first ontology to capture the vocabulary of online privacy policies. It also provides a method to describe the vocabulary in terms of the privacy categories that are widely used by the Federal Trade Commission (USA) and directives proposed by other commissions in Europe and Canada.
2. Background
To aid users, several attempts have been made to simplify policies. Platform for Privacy Preferences (P3P) was one of the early efforts [
14,
15] to propose the format and use of machine-readable privacy policies. The intent was that the standardized format would make it easier to extract relevant information with the help of logic systems, e.g., reasoners. P3P had limited industry and developer participation which resulted in limited adoption of this solution. This approach also had some shortcomings including its inability to validate policies which limited developers to create effective policies [
16].
Automation and crowdsourcing can reduce the cost of creating and maintaining such a data set, and still maintain reasonable quality. Terms of Service; Did not Read (ToS;DR) [
17] is a project that uses crowdsourced annotations to answer key questions about the policies. The crowdsourcing approach requires large scale participation rate to ensure success of the project. This requirement can delay the effort. To address this, researchers [
18,
19] have made an attempt to combine machine learning and ToS;DR natural language processing (NLP) techniques to automatically evaluate the content of privacy policies and find problematic content. These methods are only effective if there is access to high quality, reliable, annotated, and up-to-date crowdsourced data which is presently lacking due to the inherent de-motivating nature of reading privacy policies [
18].
In the research conducted by Ramnath et al., the researchers proposed combining machine learning and crowdsourcing (for validation) to semi-automate the extraction of key privacy practices [
20]. Through their preliminary study they were able to show that non-domain experts were able to find an answer to their privacy concerns relatively quickly (∼45 s per question) when they were only shown relevant paragraphs that were most likely to contain an answer to the question. They also found that answers to privacy concerns were usually concentrated rather than scattered all over the policy. This is an important finding because it means that if users are directed to relevant sections in the policy they should be able to address their privacy concerns relatively quickly.
In a user study conducted by Wilson et al., (2016) [
13], the quality of crowdsourced answering of privacy concerns was tested against domain experts with particular emphasis on highlighted text. The researchers found that highlighting relevant text had no negative impact on accuracy of answers. They also found out that users tend not to be biased by the highlights and are still likely to read the surrounding text to gain context and answer privacy concerning questions. They also found an
agreement rate between the crowdsourced workers and the domain experts for the same questions [
21]. These findings suggest that highlighting relevant text with appropriate keywords can provide some feedback to users inclined to read shorter policies. One way to automatically highlight relevant text in privacy policies, in a manner that can be easily scaled, is using semantic technologies (ST) such as an ontology.
There have been recent attempts to address some of the challenges related to privacy policy readability, analysis, and summarization. For instance, deep learning methods were used for automated analysis and presentation of privacy policies (e.g., Polisis tool [
22]). This method was also used to build chatbots, a free form question and answering system [
23]. Privacy policy evaluation and summarization methods such as natural language processing and machine learning were proposed in a few existing studies [
24,
25,
26]. Despite the effort, the use of ontology to highlight or summarize the content of privacy policies has not been fully explored. This paper evaluates the use of ontologies to enhance the readability of these legal documents.
3. Motivation
As established in the introduction, online privacy policies remain unusable to average users due to their length and elusive language. This contributes to a lack of transparency which in turn leads to uninformed decisions and risk-averse behaviour. Policies that are usable tend to be read more often and give the users more confidence in sharing their personal information. This suggests that a usable privacy policy benefits all parties. Research shows that policies which highlight sections that directly address the user’s concerns tend to be read more often, as it reduces the reading cost. Hence, a solution is required which considers concerns of all stakeholders, i.e., the online service providers that create privacy policies, as well as the users that do not necessarily like reading them. To avoid push-back, the solution must not require the online service providers to change their policies drastically, but must reduce the amount of text users have to read, and direct users to the text pertaining directly to their concerns.
In order to direct users to the relevant text within the policies, there needs to be a way to evaluate the text and highlight all relevant sections. Since the language being used within the policies differs so greatly [
11,
19] among privacy policies, there needed to be a system that is able to capture all the variations of a topic. Semantic technologies such as ontologies are a well-known way of mining text and reasoning. Since domain ontologies can capture the vocabulary of a domain and specify rules about each term, it is possible to capture the diversity of concepts within the online privacy domain and reason over them to find equivalent terms for analysis. Through NLP, it is possible to logically break apart the text in a policy, and working in conjunction with the ontology, be able to recognize relevant sections within policies. This paper proposes building an ontology that is easy to build, maintain, and relatively inexpensive to scale.
4. Ontology Engineering
It is generally accepted that ontologies have two basic features [
27]:
A taxonomy of terms used to name and describe the objects (concepts) being described by the ontology.
A specification, grounded in logic, used to add meaning between terms.
Ontologies may describe a wide variety of things in a domain, but they all share a common set of attributes [
28]:
Classes capture the core vocabulary that is used to describe a domain. They are also referred to as concepts, and are generally arranged in a hierarchical or taxonomical form as classes and sub-classes.
Relations are definitions of how concepts inter-relate to one another.
Attributes are the properties associated with classes that describe the features of that class.
Formal axioms are logical statements that always evaluate to true.
Functions are a special case of relations.
Instances are elements of a class; and are also called individuals. Not all ontologies must have these; but if they do then that ontology constitutes a knowledge base.
There are many different types of ontologies that differ based on not only their purpose but also their content. The purpose of the ontology is determined by how widely it is meant to be used and the content is determined by the richness of the term definitions.
Since the invention of ontologies in the early 1990s, ontology engineering has remained more of an art form rather than an engineering process with rigid rules [
29]. Which is to say, there is no one correct way of creating an ontology, rather the development differs depending on the ontology engineer and its purpose. However, several methodologies have been proposed to standardize the process of creating ontologies. Among those, Ontology 101 [
30] and NeOn [
31] are two of the commonly used ontology engineering methods. Ontology 101 provides a step-by-step methodology for creating simple ontologies iteratively using the Protégé-2000 [
32] ontology engineering tool, developed by Mark Musen’s research group at Stanford Medical Informatics. Since this methodology is geared towards the Protégé tool, it focuses more on declarative frame-based systems used to describe objects in a domain along with their properties rather than more complex and domain specific ontologies that can be constructed with the other methodologies. The NeOn methodology promotes reusing and combining ontologies to create new and networked ontologies drawing on multiple ontologies for their knowledge. NeOn provides a scenario-based framework to create ontologies and develop and expand ontology networks. Rather than a rigid work flow like Ontology 101, NeOn prescribes a set of guidelines for multiple alternative processes for various stages of ontology development that may change with the design decisions.
There are a few ways of evaluating an ontology, each depending on the type and purpose of the ontology constructed. One of the practical ways of evaluating ontologies is a data driven approach. In this approach, ontologies are simply compared with the sources of data from the domain that the ontology is meant to cover. This involves statistically extracting key terms and concepts from the corpus the ontology is meant to cover and evaluating if they exist in the ontology itself. This is done via calculation of the
precision and
recall scores [
33,
34,
35,
36].
Precision (P) is the ratio of the number of relevant terms returned from a term extraction algorithm ({manually selected}∩{machine-selected}) to the total numbers of retrieved terms by the algorithm ({machine-selected}). The precision is calculated using Equation (
1).
The
recall (R) of an information system is defined as the ratio of the number of relevant terms returned to the total number of relevant terms in the collection. The recall is computed using Equation (
2).
Formal competency questions (CQs), an evaluation strategy proposed by [
37,
38], is another ontology validation method. In this method, informal competency questions (queries) are first expressed formally. These questions are requirements that are in the form of questions that an ontology must be able to answer. The formal questions are then evaluated using completeness theorems with respect to first (axioms) and second order (situational calculus) logic representation of concepts, attributes, and relations.
5. Methodology
The end goal of DOOP is the creation of a tool, e.g., a browser extension, that uses the ontology as a knowledge base to parse online privacy policies and highlight sections in the policy that would addresses a user’s privacy-related queries. To that end, a hybrid construction approach was used, a combination of Ontology 101 and NeOn methodologies in conjunction with iterative development. Ontology 101 was proposed with the intent of using Protégé for the construction of ontology. Since the latest version of Protégé [
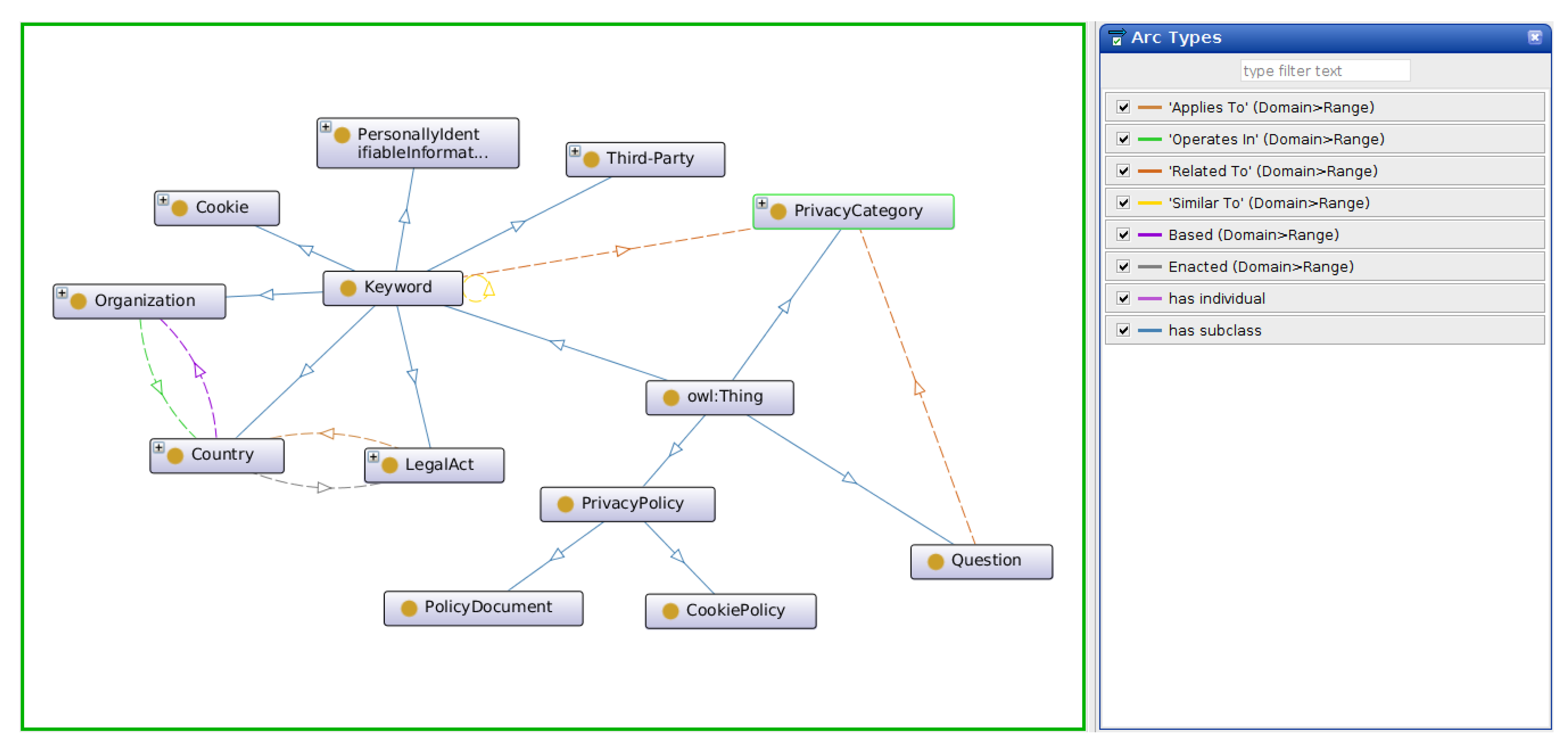
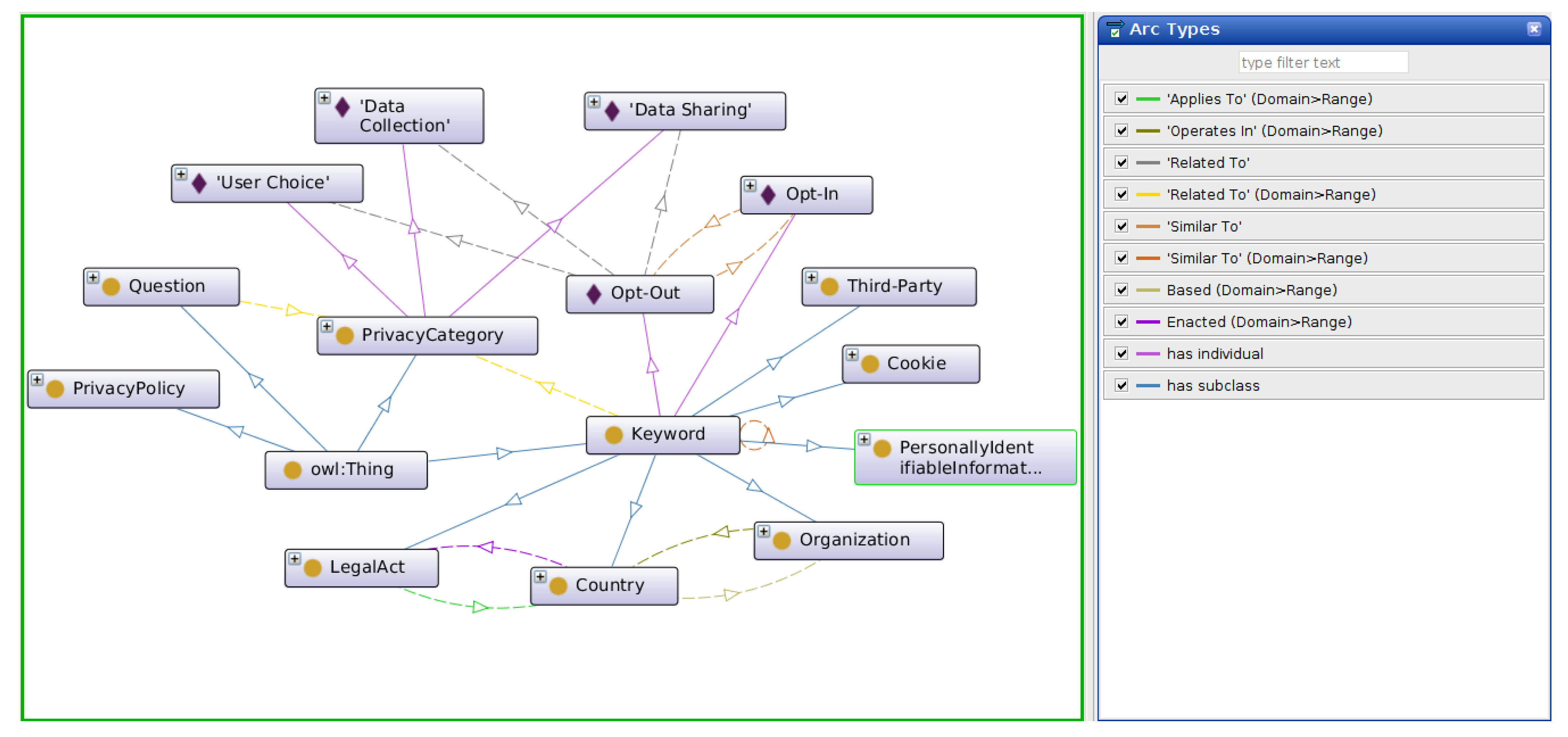
39] was used in the construction of DOOP, Ontology 101 was used as the prime methodology. Furthermore, ontology engineering guidelines provided under NeOn’s Scenario 1 (From Specification to Implementation), which includes steps from other methodologies, were used as the foundation to specify and build DOOP. Instead of building a complete ontology that exhaustively considers every possible case, DOOP was iteratively built in iterations as described by RapidOWL. By expanding the vocabulary one query at a time the ontology remains open and malleable enough such that future developments require relatively less effort to alter the structure of the ontology as needed. The ontology was implemented in OWL-DL using the Protégé tool (version 5.2.0) for ontology engineering.
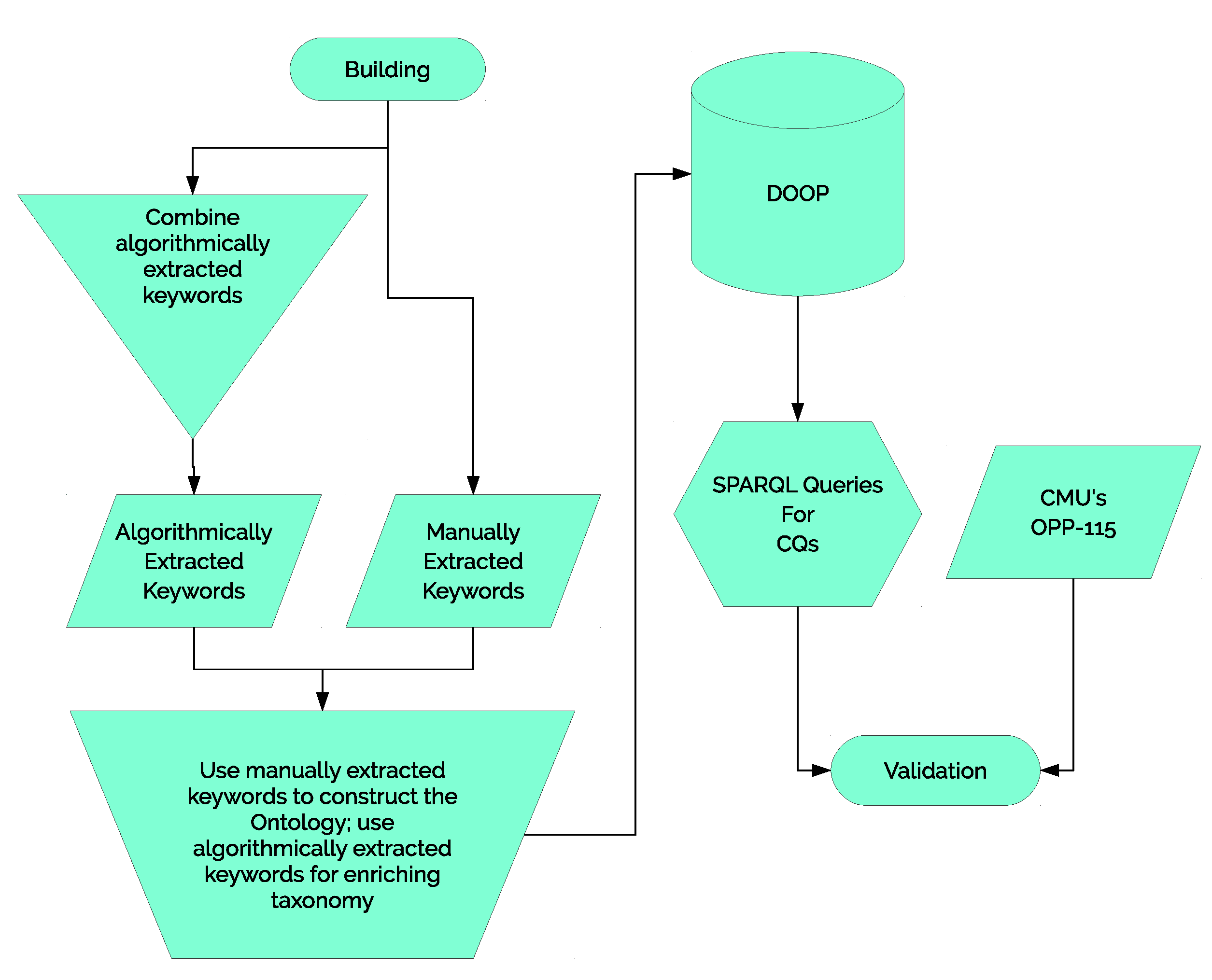
The language between privacy policies is inconsistent. These inconsistencies meant that the corpus of privacy policies used for ontology development had to be large and diverse to capture as many terms as possible, and from different economic zones. For this reason, we took a two-step approach to extract keywords and validate the ontology. First, the key terms extracted from a corpus of 631 privacy policies were gathered [
40]. Seven classes were identified: data collection, data retention, data security, data sharing, target audience, user access, and user choice. These were identified in the work done by [
41]; and were based on the logical division of policies described under the FIPPs (Fair Information Practice Principles), and principles identified under OECD’s guidelines for (Organization for Economic Co-operation and Development) protection of privacy and data flows [
42]. These classes are commonly found in both cookie and privacy policies. The hierarchy of the ontology was developed as needed to satisfy the CQs. Subsequently, CMU’s OPP-115 corpus, a corpus of 115 manually annotated privacy policies with 23,000 data practices was used to validate DOOP. Lastly, the goal of building DOOP was to support the following end-users: privacy researchers, NLP experts who are interested in doing work in the online privacy domain, and software developers who would like to use an ontology to create tools for the online privacy domain. An overview of DOOP construction and validation is shown in
Figure 1.
Competency Questions
Competency questions are a set of queries that the ontology should be able to answer based on its axioms. This is why they are used for not only defining ontology requirements but also ontology evaluation; the result from a CQ can be used to determine the correctness of an ontology. CQs can be used for evaluation either manually or automatically through the use of SPARQL queries. DOOP was constructed and evaluated through the use of CQs. After defining a CQ, the ontology was constructed iteratively by defining as many axioms needed to answer the CQ. The following 3 CQs were used for constructing the ontology:
Does this website share my personal information with third-parties?
Does this website use tracking cookies?
Can I opt-in/opt-out of information gathering?
The first query was selected based on the most common concern users report, a worry/ concern about their personal information being shared with unauthorized and unintended parties. It is also a question that every privacy policy is designed to address. The other two queries are more specific and hence were chosen to capture narrower results.
7. Discussion
In Experiment 1 (
Table 4), a mean of
match for privacy categories with a standard deviation of
was achieved. Since the OPP-115 data set was manually curated by domain experts, a high degree of match indicates a high degree of accuracy achieved by the ontology for identifying sentences in context based on the vocabulary. Now, the users need not read the entire policy, but can be directed to appropriate sentences in the policy that deal directly with their concerns with a reasonable amount of accuracy. Additionally, there is a negligible increase in the accuracy of the automatic categorization when the convergence threshold is
. This could be as consolidation reduces redundancy, without overdoing it at
convergence threshold.
One of the prime reasons that users do not read privacy policies and are left uninformed, is that they tend to be overly long. Any tool trying to fix this issue must not only find correct information but also require less reading. In Experiment 1, algorithmic assignment of privacy categories to sentences performed favorably against the manual annotations performed by domain experts. Thus, in Experiment 2, policy coverage was investigated to identify how much of a policy is the user asked to read for the three identified concerns. This experiment demonstrated (
Table 5) that the user has to read on average
sentences with a standard deviation of
, or about
of a policy with a standard deviation of
to know if all of their concerns are met. Assuming that a paragraph is roughly 10 sentences, then based on research done by [
20], we know that it would take roughly 45 s to read it. This reduced time makes the privacy policies more inviting and should encourage more users to read policies even if partially.
To further investigate these results, additional analysis of the individual results from experiments for all of the thresholds and queries was conducted.
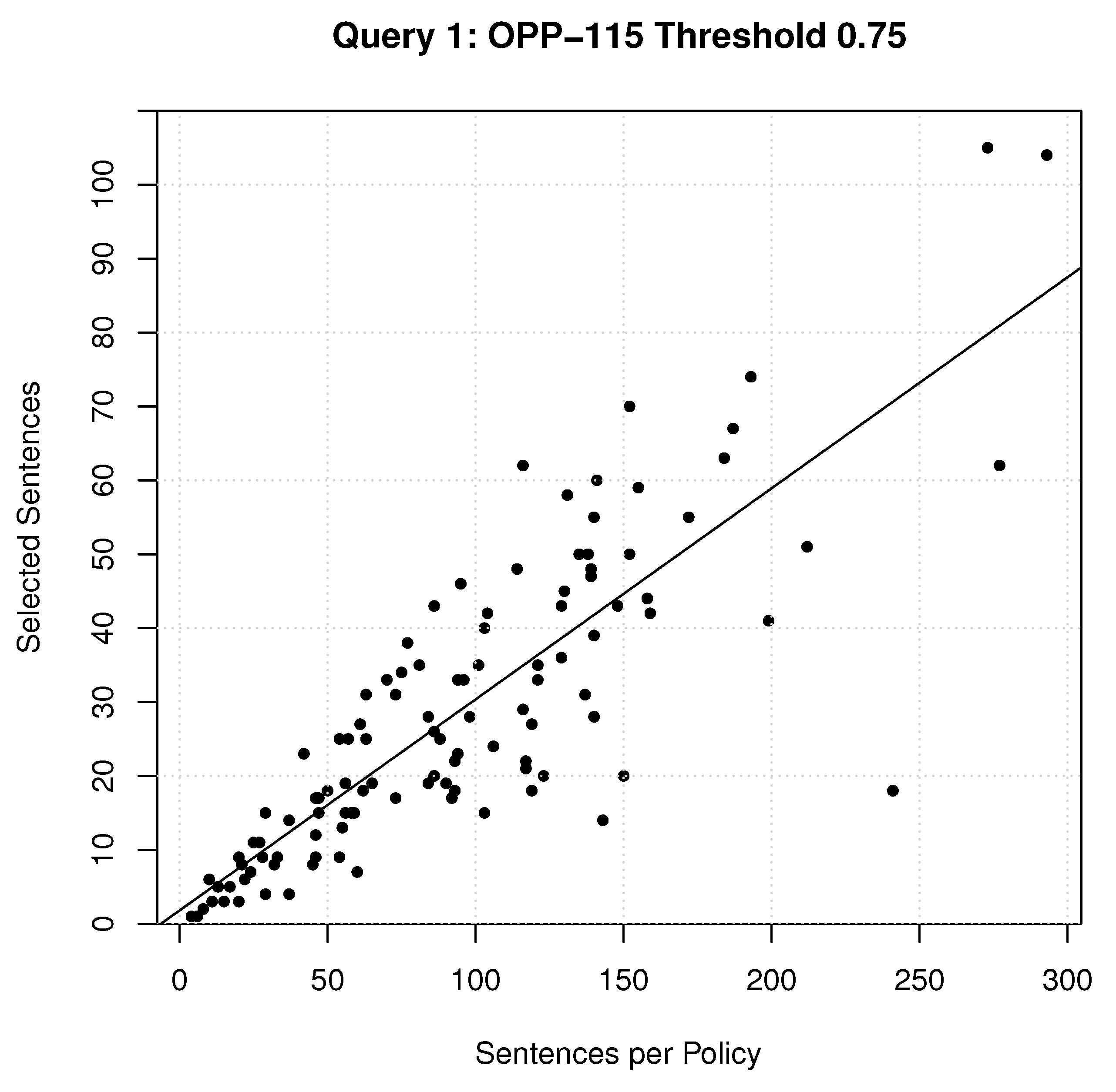
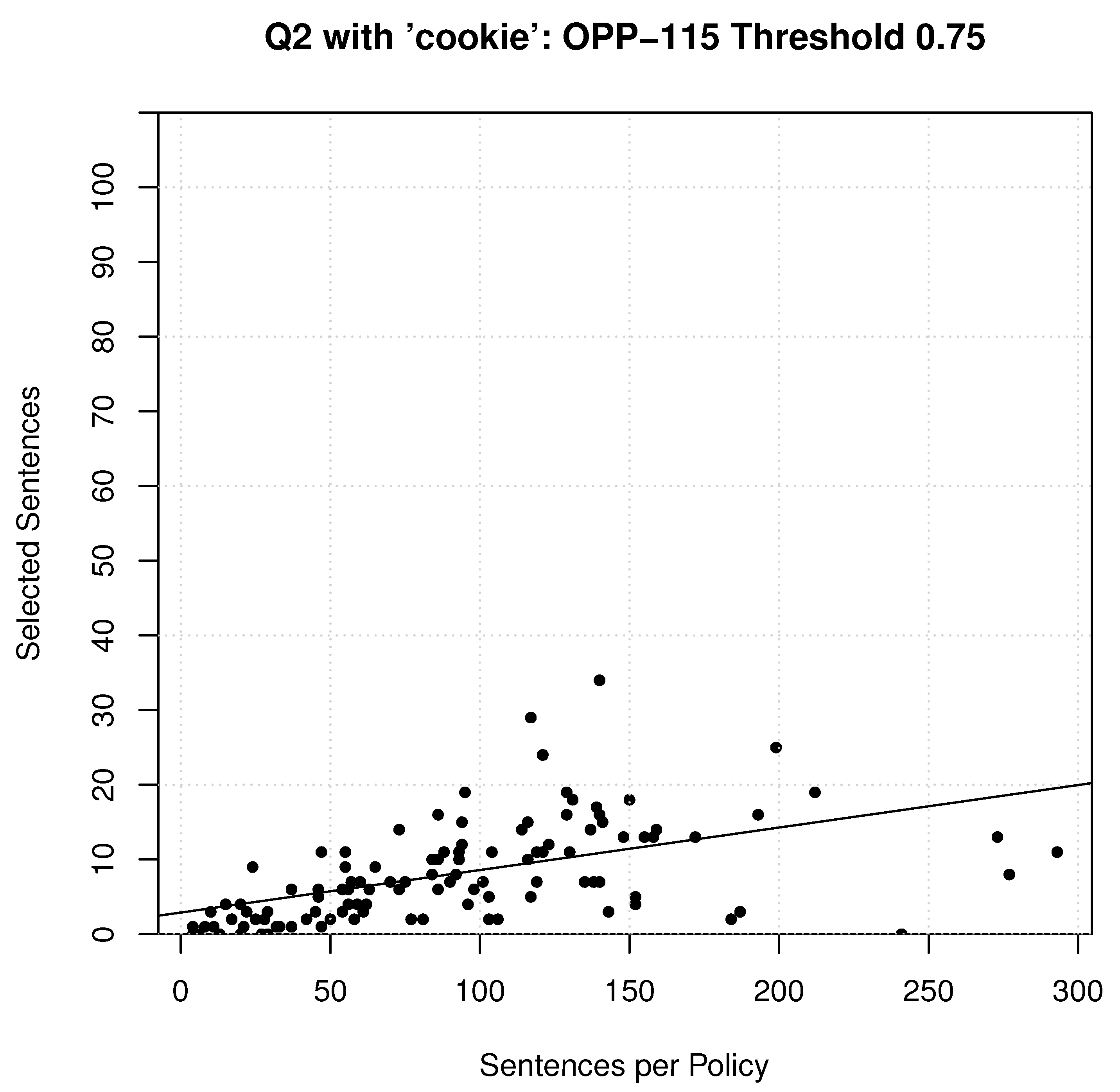
Figure 5,
Figure 6 and
Figure 7 show the results of the queries for the
threshold. A radical relationship between the number of sentences selected and the length of the policies was expected, where the reading proportionally increases as the length of the policies increase, but then stabilize at some horizontal asymptote. However, this did not occur. A strong positive linear relationship was observed for the first experiment (
Figure 5), no correlation for the second experiment (
Figure 6), and weak positive for the third experiment (
Figure 7). A qualitative analysis provided several clues for these behaviours:
The vocabulary in the first query, was trying to capture more than one concern. Since the ontology only returned a vocabulary of terms, it was hard to determine the correct context sometimes as one set of keywords could be used in multiple instances under different contexts. One possible solution to this problem is having the ontology also capture POS tags that determine the structure of the sentences and identifies the associated verb (e.g., sharing) and thus provide a context under which the sentence occurs. This would help distinguish one context from another where the most of the vocabulary is shared. This idea is explored in
Section 7.2.
Policies were repeated throughout the document. This accounted for the linear relationship for the first experiment. Redundancies in the policies drove up the number of sentences to read.
Keywords returned by the ontology were narrowly defined. This was an important distinction with the second query regarding tracking cookies. The keyword ‘cookie’ was not being used because not all cookies are tracking, this meant that several cases where that term was being used to establish context were not captured. For example, “We do not use tracking cookies”. would be selected, but, ‘Cookies may be used to track you’, would be ignored. Similar to the first problem, POS tags for some terms could be captured by the ontology to identify context as a remedy to this problem. In the OPP-115 data set, only of the policies had a ‘tracking cookie’ policy that was part of the privacy policy that was extracted.
Some policies were missing entirely. Sometimes, a supplementary document was used to state policies, e.g., ‘Cookie Policy’. This supplementary document was not stored on the same page as the privacy policy; hence, it was not picked up by the scraper scripts. This is a difficult challenge to solve as there is no consensus as to what the URL must be for the cookie policy. However, a reasonable attempt can be made to collect this page as well and amend it to the privacy policy.
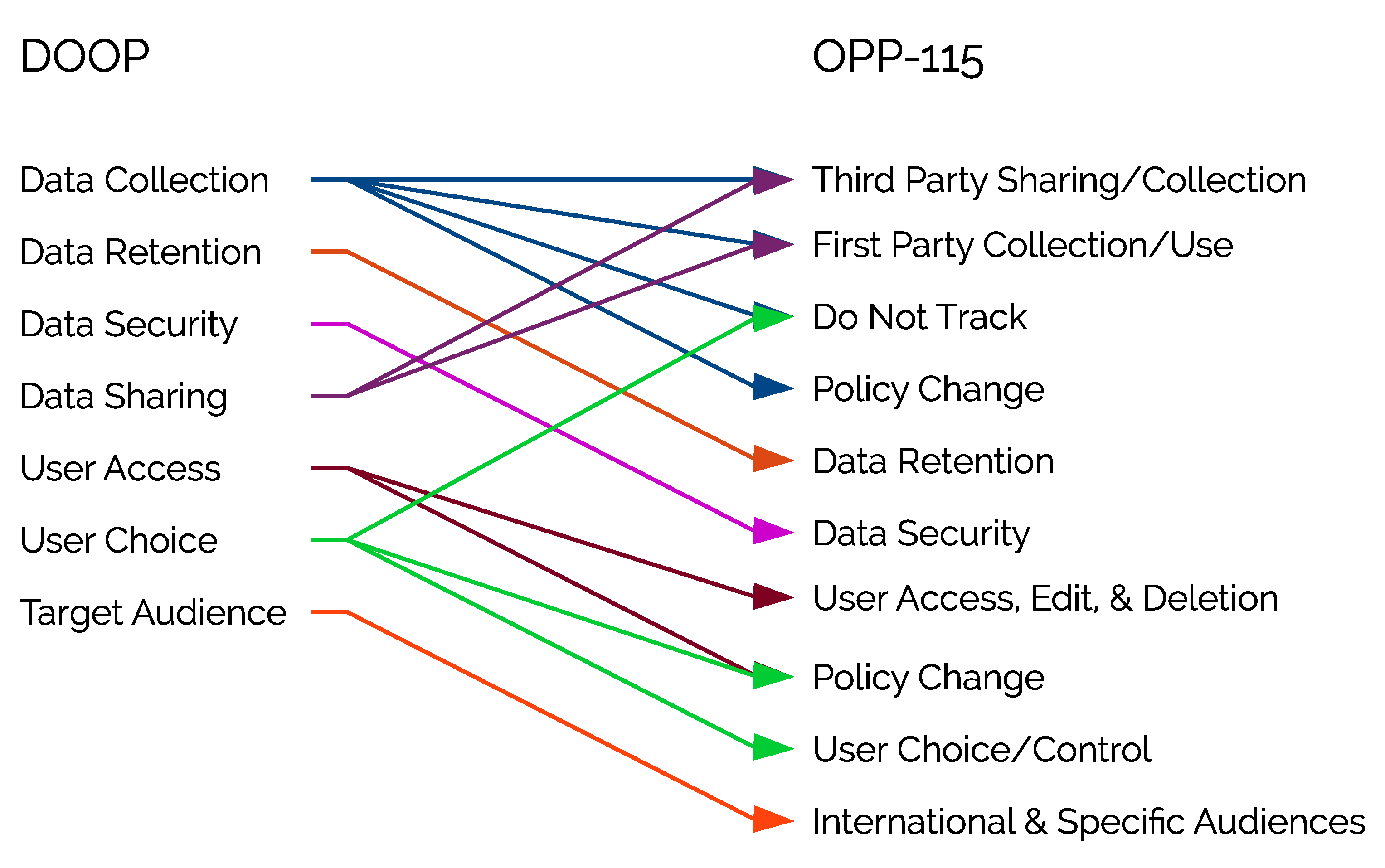
In the creation of the taxonomy for DOOP, the vocabulary was not restricted to a particular geographically intended audience (in order to make the ontology as general purpose as possible). OPP-115’s dataset contained only American privacy policies. Hence, there were terms in DOOP that did not exist in OPP-115. Experiment 3 was conducted to investigate the uniqueness of DOOP in comparison to OPP-115.
Table 6 shows that on average
of terms are unique to DOOP with a standard deviation of
. This was expected as not just American policies were considered when extracting keywords from privacy policies, but also Canadian and European ones. The
terms also include localization of the American spelling along with synonyms, hypernyms, and E.U. and Canada specific terms, which made the ontology more unique here, e.g., advertiser/advertizer, and name/full name.
Finally, Experiment 4 investigated how much the labels of keywords agreed between DOOP and OPP-115. The mean disagreement between the data sets was with a standard deviation of . The most disagreement being with query 3. One of the reasons for this discrepancy could be due to the mapping of categories from OPP-115 to DOOP. Since the mapping of the privacy categories between the data sets was not one-to-one, approximations had to be made. This meant that one category in one data set was mapped onto multiple categories in the other introducing a large amount of variance in the topics captured by each category. Another explanation has to do with the limited vocabulary DOOP currently captures. In its present state it was created to be a proof-of-concept system. As the vocabulary increases, it is expected that the results for all four experiments will also improve.
7.1. Generalizing Keyword Searches
An investigation was conducted to see what happens when more generic keywords are added to queries for focused and narrowly defined queries, such as query 2. The term ‘cookie’ was added to the list of keywords for the second query, and all of the experiments re-run. The results are shown in
Table 8,
Table 9,
Table 10 and
Table 11 and
Figure 8.
7.2. Contextualising Keyword Searches
In general, the total number of sentences dramatically increased from 364 to 1503 (
Table 8), and the accuracy went from
to
. This was expected as ‘cookies’ was mentioned more often because they are used for more than just tracking. They are also widely used for the storage of temporary data. This can be also observed in
Table 10, which shows there is at least one word common to the vocabulary in the ontology and is consistently being found in the policies. Furthermore, this resulted in an increase in the estimated number of sentences to read per policy (on average going from
to
Table 9). The addition of non-specific keywords also increased the variability of the sentences to read, as can be observed in
Figure 8. This also led to fewer policies being flagged as having 0 sentences to read. Once again, the number of sentences in a policy and the amount of reading a user has to do is linearly correlated. One of the most important measure is the increased disagreement between the recommended and the annotated sentences (
Table 11). This indicates that adding generic terms deteriorates the overall quality of the recommendations. The indicators in this short study demonstrates that in order for the recommended reading to be useful to the user, it must have fewer generic terms and more targeted ones.
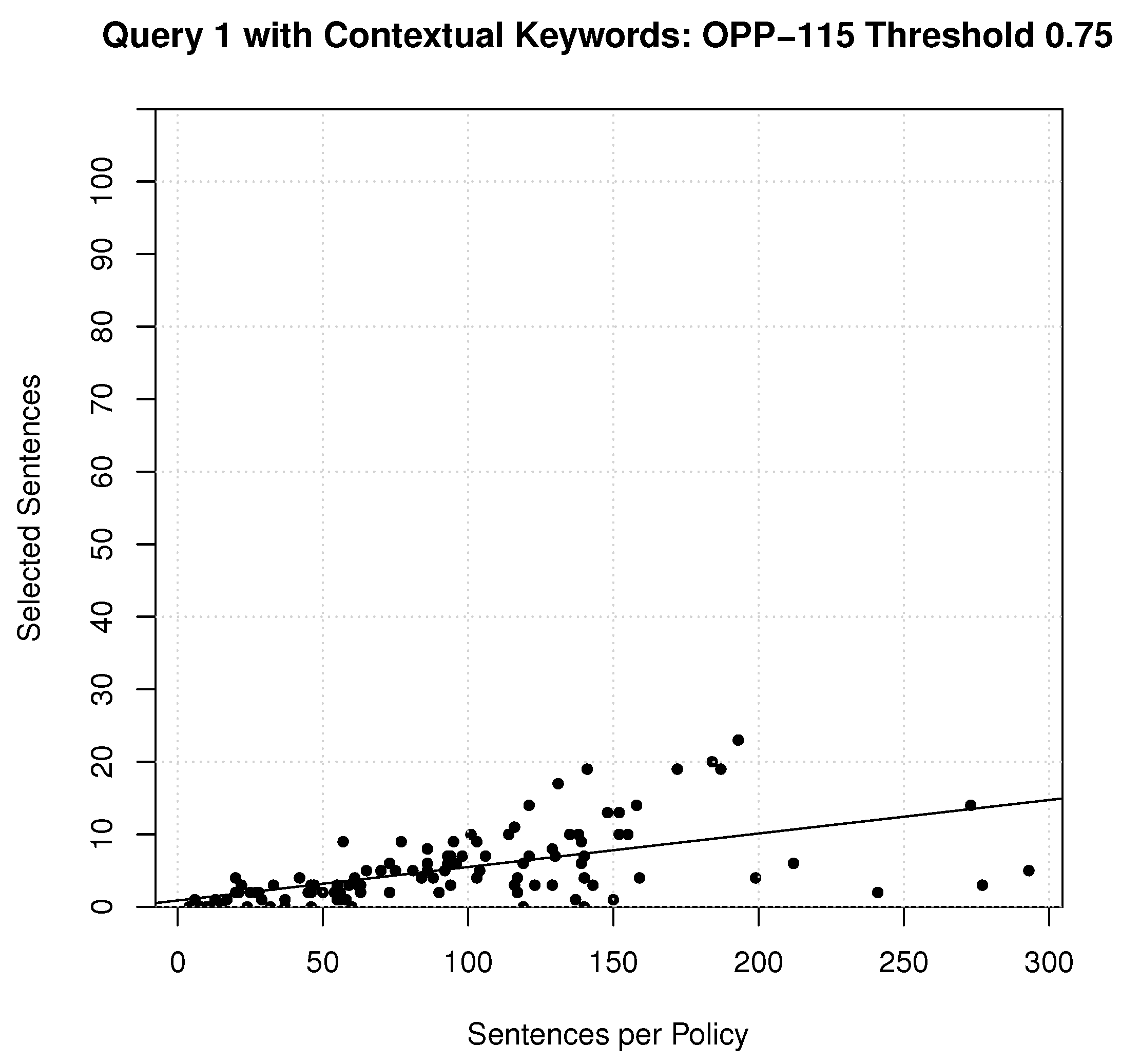
After a qualitative review of the sentences that were selected for Query 1 in Experiment 2, it was found that sentences were broadly selected to capture any mention of attributes associated with personal information and not necessarily-third-party sharing. To reduce the number of sentences selected for reading in Experiment 1, a simple experiment was conducted where contextual keywords were used to further limit the types of sentences that were only associated with ‘third-party’, ‘disclose’ and ‘sharing’. Only sentences with at least one of those keywords mentioned were chosen. The results of this The experiments are reported in
Table 12 and
Figure 9.
8. Conclusions and Future Work
Privacy policies play an important part in informing users about their privacy concerns. As the world becomes more interconnected and online, security threats prompt users to become more privacy aware, making online privacy policies the primary documents for users making informed decisions. These policies are long and difficult for most users to understand and are infrequently read, presenting a challenge for users. Previous attempts at creating machine readable policies have had limited success as they placed the onerous task of crafting these policies on businesses. This paper proposed a novel approach to reducing the amount of text a user has to read using a domain ontology and NLP to identify key areas of the policies that the user should read to address their concerns and take appropriate action. The approach consisted of constructing DOOP, a domain ontology for online privacy policies, validated against CMU’s OPP-115 data set of annotated policies by domain experts. DOOP resulted in
,
, and
reductions in reading for the 3 sample questions, and on average it would take about 45 s to read the relevant sentences (11 on average). By comparison, the average time to read privacy policies is estimated to be 29–32 min [
10]. Furthermore, the vocabulary was mapped to the queries stored in the ontology. This allows ontology developers to propose additional insight into related queries and their associated vocabulary. The development of DOOP showed the usefulness of domain ontologies when applied to privacy policies, and also demonstrated a cost-effective way of maintaining and expanding it in the future.
In some of the recent studies performed by the authors, we found that the length of privacy policies that have been generated after the enforcement of regulations such as the General Data Protection Regulation has increased. These new regulations include the traditional recommended sections, such as the ones used in this paper, in addition to new sections such as contact information. Therefore, the proof-of-concept tool proposed in this study is applicable to the new and old versions of privacy policies. Furthermore, the competency questions we used in this study are relevant in the context of new regulations and best practices. The proposed tool can be improved by adding more competency questions to the ontology, using new and larger privacy policy corpus, and considering more recent privacy policies that were generated after the enforcement of regulations such as the General Data Protection Regulation.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}