
Investigating Topic Modeling Techniques to Extract Meaningful Insights in Italian Long COVID Narration

 ,
,  , , and
, , and 
Abstract
:1. Introduction
2. Background
2.1. Text Mining
2.2. Topic Extraction on COVID-19 Related Texts
3. Materials and Methods
3.1. The Italian COVID-19 Narrative Medicine Dataset
- Collects all the URL of the testimonies per page,
- connects to the page and, by parsing the HTML document:
- -
- extracts only the textual narration,
- -
- performs a basic text cleaning,
- -
- tags it as “PASC”,
- the extracted information is stored in a CSV file format.
3.2. Topic Modeling Using LDA
- , be a mixture of k topics, having a Dirichlet probability distribution where is the per-document topic distribution;
- a topic , where n represents the number of words that define a topic;
3.3. Topic Modeling Using BERT
3.4. Data Analysis Pipeline
- Text preprocessing: includes standard NLP (Natural Language Processing) techniques. A key importance is played by text cleaning techniques that encompasses lowercasing, punctuation, separator, special characters and stop words removal. The preprocessing step has been executed by using regular expression, and the popular nltk (https://www.nltk.org/, accessed on 30 August 2022) and SpaCy (https://spacy.io/, accessed on 30 August 2022) libraries for Natural Language Processing in Python, which provide a set of preprocessing algorithms also for the Italian language. However, the set of stopwords provided by the aforementioned libraries has been massively expanded to improve the perfomance of preprocessing.
- Feature extraction: for each document, lemmatization has been carried out to reduce the inflected form of a word in its canonical form called “lemma”. After lemmatization, a word dictionary was built through the implemented function provided by the gensim (https://radimrehurek.com/gensim/, accessed on 30 August 2022) Python library [50]. The construction of the dictionary is essential to generate the bag-of-words model, which contains a numeric representation of the input sentences and, as said before, it constitute the starting point textual representation for an LDA approach. Therefore the present step of the pipeline has not been considered when performing topic modeling through a BERTopic-based approach.
- Topic modeling: In a first test battery Latent Dirichlet Allocation (LDA) model [49] has been exploited to extract relevant topic. For each document in the dataset, we considered the associated topic as the topic reaching higher probability. To select the LDA models that better fits the data and to assess the model’s clarity, perplexity and coherence score (Perplexity is an intrinsic evaluation method that statistically measures of how well a probability model predicts a sample while topic coherence scores a single topic by measuring the degree of semantic similarity between high scoring words in the topic.) have been considered as evaluation metrics. Both topic coherence and perplexity were calculated through the gensimlibrary. In a second test battery topics were modeled with a BERTopic-based approach, using the BERTopic Python library available at https://github.com/MaartenGr/BERTopic, accessed on 30 August 2022. Working with the Italian language, as language model we choose a multilingual sentence-transformers model. Sentence-transformers are a class of language models tuned to be used for sentence embedding generation [56]. In particular, the tested multilingual sentence embedding model was the distiluse-base-multilingual-cased-v1 model (https://www.sbert.net/docs/pretrained_models.html, accessed on 30 August 2022).
4. Results and Discussion
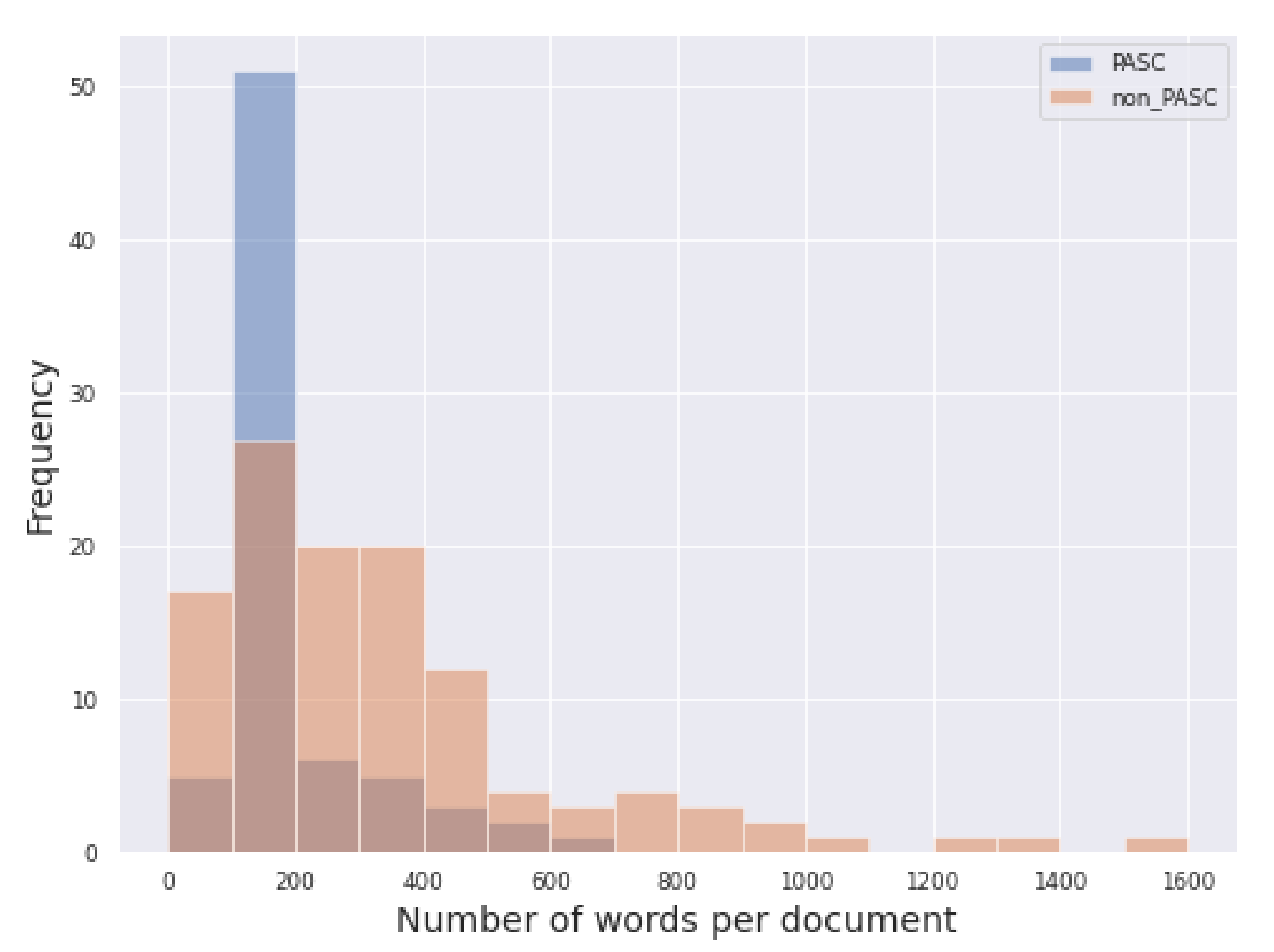
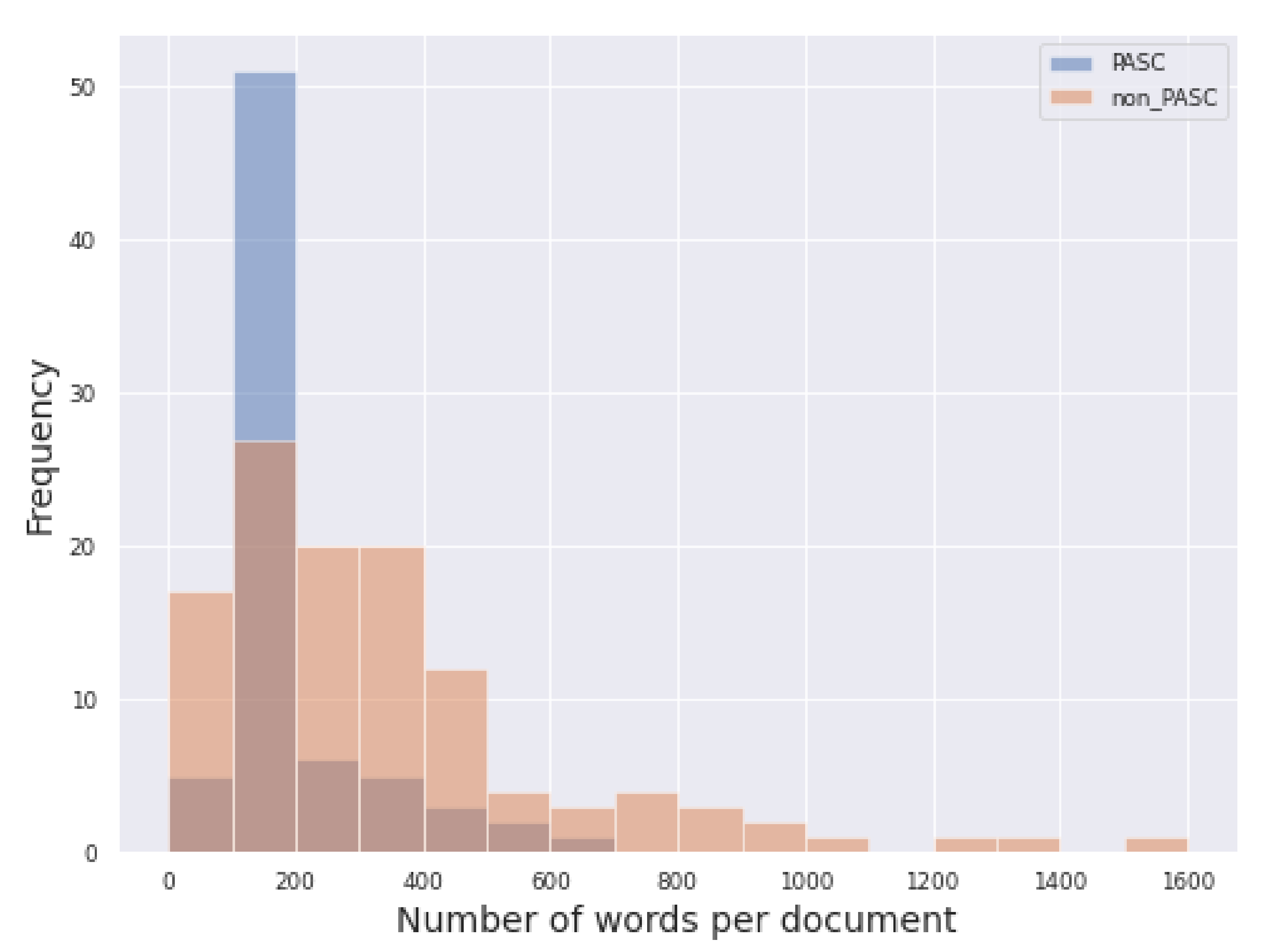
4.1. Exploratory Data Analysis
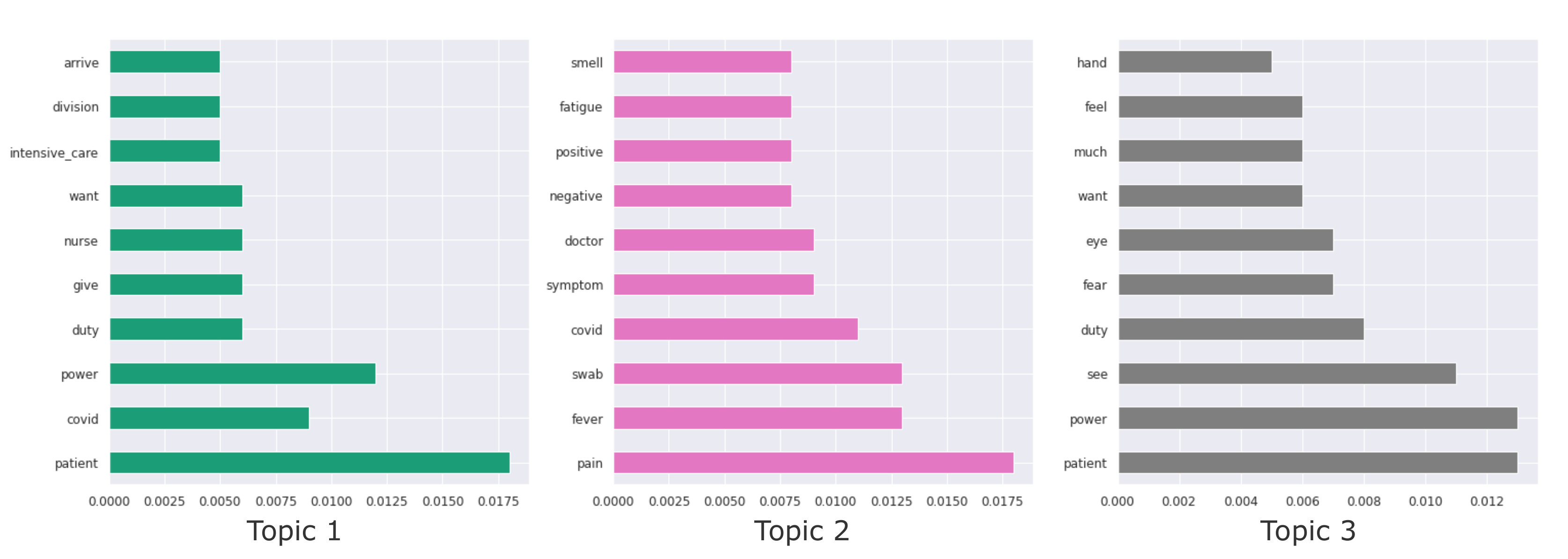
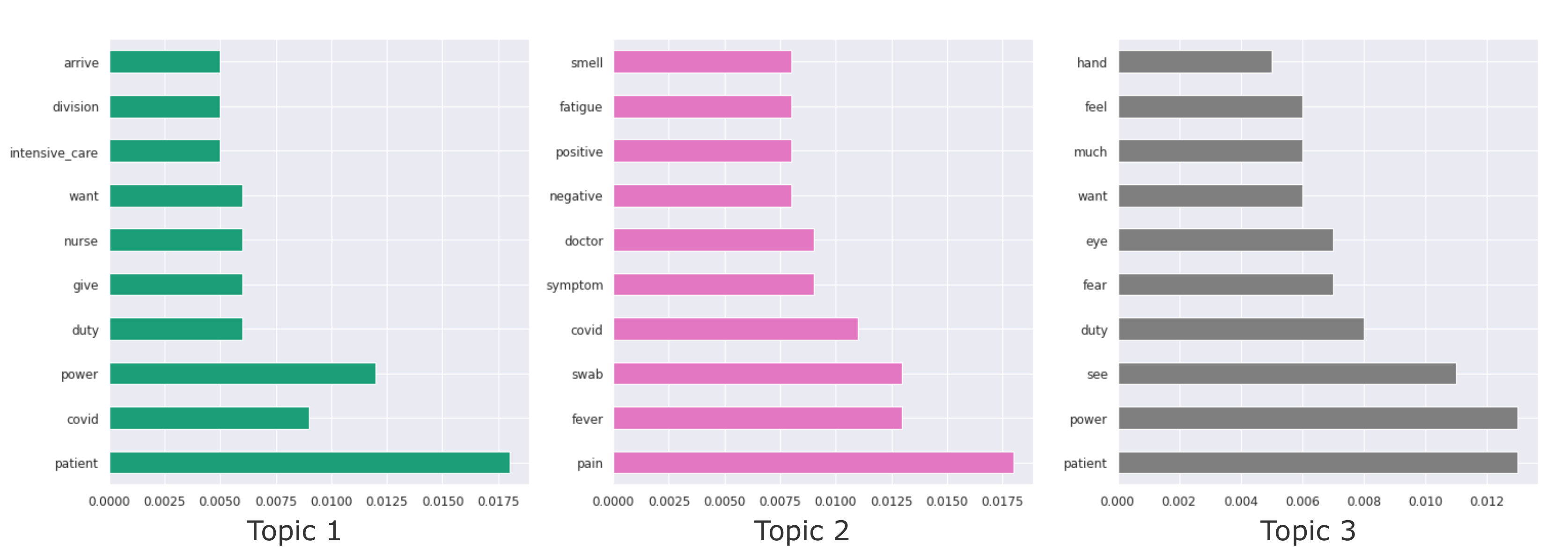
4.2. Lda Topic Modeling
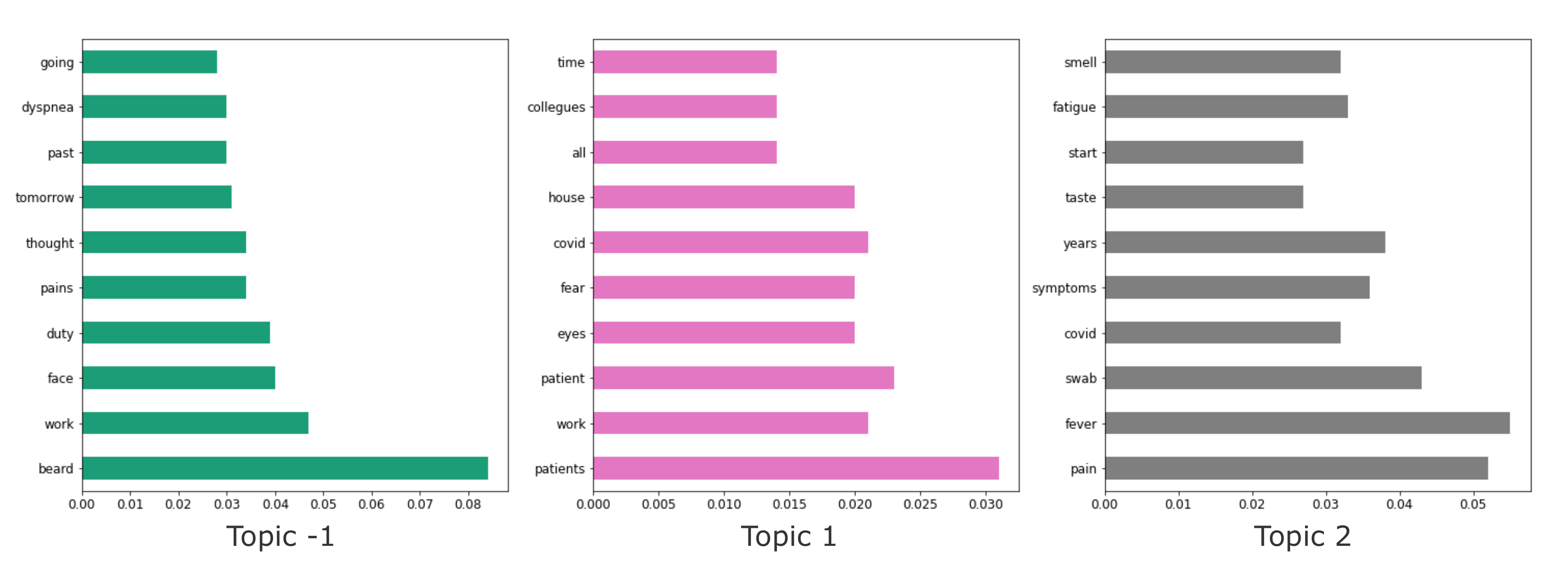
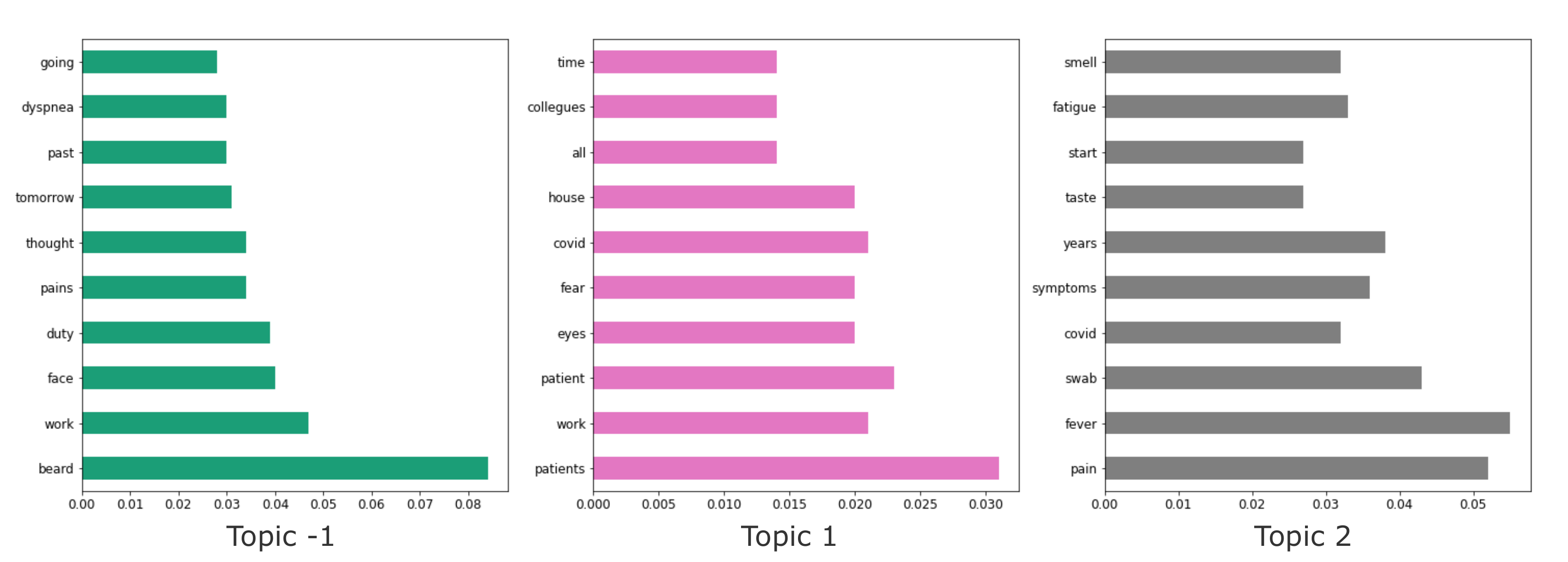
4.3. Bertopic-Based Topic Modeling
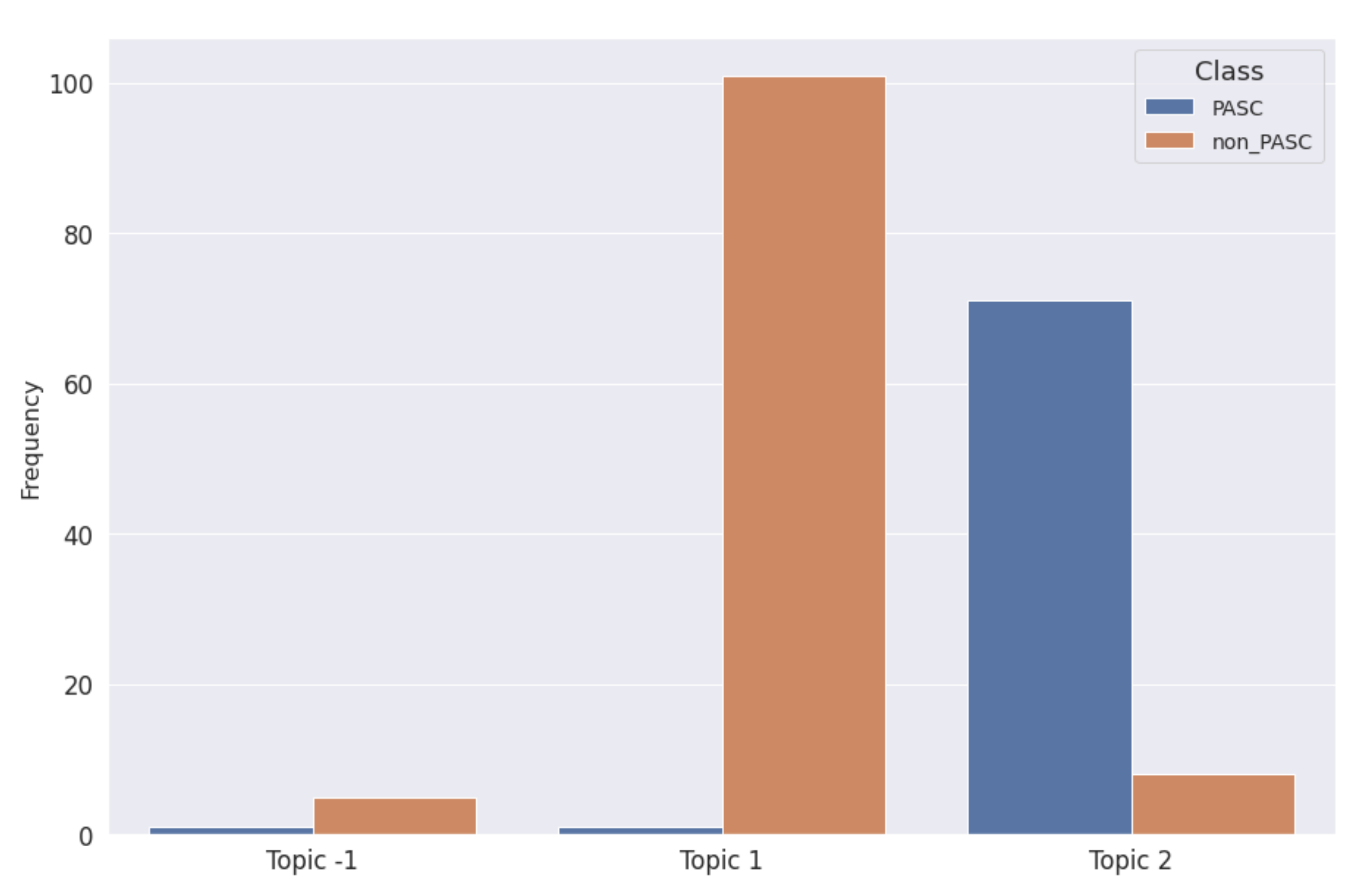
4.4. Comparing BERTopic with LDA for the Characterizazion of PASC Narrative
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Hossain, M.M.; Tasnim, S.; Sultana, A.; Faizah, F.; Mazumder, H.; Zou, L.; McKyer, E.L.J.; Ahmed, H.U.; Ma, P. Epidemiology of mental health problems in COVID-19: A review. F1000Research 2020, 9, 636. [Google Scholar] [CrossRef]
- Rossi, R.; Socci, V.; Talevi, D.; Mensi, S.; Niolu, C.; Pacitti, F.; Di Marco, A.; Rossi, A.; Siracusano, A.; Di Lorenzo, G. COVID-19 pandemic and lockdown measures impact on mental health among the general population in Italy. Front. Psychiatry 2020, 11, 790. [Google Scholar] [CrossRef] [PubMed]
- Maison, D.; Jaworska, D.; Adamczyk, D.; Affeltowicz, D. The challenges arising from the COVID-19 pandemic and the way people deal with them. A qualitative longitudinal study. PLoS ONE 2021, 16, e0258133. [Google Scholar] [CrossRef] [PubMed]
- Wicke, P.; Bolognesi, M.M. Covid-19 Discourse on Twitter: How the Topics, Sentiments, Subjectivity, and Figurative Frames Changed Over Time. Front. Commun. 2021, 6, 45. [Google Scholar] [CrossRef]
- Chandrasekaran, R.; Mehta, V.; Valkunde, T.; Moustakas, E. Topics, trends, and sentiments of tweets about the COVID-19 pandemic: Temporal infoveillance study. J. Med. Internet Res. 2020, 22, e22624. [Google Scholar] [CrossRef] [PubMed]
- Boon-Itt, S.; Skunkan, Y. Public perception of the COVID-19 pandemic on Twitter: Sentiment analysis and topic modeling study. JMIR Public Health Surveill. 2020, 6, e21978. [Google Scholar] [CrossRef]
- Medford, R.J.; Saleh, S.N.; Sumarsono, A.; Perl, T.M.; Lehmann, C.U. An “Infodemic”: Leveraging High-Volume Twitter Data to Understand Early Public Sentiment for the Coronavirus Disease 2019 Outbreak; Open Forum Infectious Diseases; Oxford University Press US: Oxford, UK, 2020; Volume 7. [Google Scholar]
- Valdez, D.; Ten Thij, M.; Bathina, K.; Rutter, L.A.; Bollen, J. Social media insights into US mental health during the COVID-19 pandemic: Longitudinal analysis of twitter data. J. Med. Internet Res. 2020, 22, e21418. [Google Scholar] [CrossRef]
- Zucco, C.; Calabrese, B.; Agapito, G.; Guzzi, P.H.; Cannataro, M. Sentiment analysis for mining texts and social networks data: Methods and tools. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1333. [Google Scholar] [CrossRef]
- Rosenberg, H.; Syed, S.; Rezaie, S. The Twitter pandemic: The critical role of Twitter in the dissemination of medical information and misinformation during the COVID-19 pandemic. Can. J. Emerg. Med. 2020, 22, 418–421. [Google Scholar] [CrossRef]
- Jelodar, H.; Wang, Y.; Orji, R.; Huang, S. Deep sentiment classification and topic discovery on novel coronavirus or COVID-19 online discussions: NLP using LSTM recurrent neural network approach. IEEE J. Biomed. Health Inform. 2020, 24, 2733–2742. [Google Scholar] [CrossRef]
- Leung, Y.T.; Khalvati, F. Exploring COVID-19 Related Stressors Using Topic Modeling. arXiv 2022, arXiv:2202.00476. [Google Scholar]
- Agrusta, M.; Cenci, C. Telemedicine and digital narrative medicine for the customization of the diagnostic-therapeutic path at the time of COVID 19. JAMD 2021, 24, 39–45. [Google Scholar] [CrossRef]
- Hurwitz, B.; Cushing, A.; Chisnall, B. Narrative medicine. BMJ 2012, 344, e2743. [Google Scholar] [CrossRef]
- Mehandru, S.; Merad, M. Pathological sequelae of long-haul COVID. Nat. Immunol. 2022, 23, 194–202. [Google Scholar] [CrossRef]
- Taquet, M.; Luciano, S.; Geddes, J.R.; Harrison, P.J. Bidirectional associations between COVID-19 and psychiatric disorder: Retrospective cohort studies of 62 354 COVID-19 cases in the USA. Lancet Psychiatry 2021, 8, 130–140. [Google Scholar] [CrossRef]
- Pye, A.; Roberts, S.R.; Blennerhassett, A.; Iqbal, H.; Beenstock, J.; Iqbal, Z. A public health approach to estimating the need for long COVID services. J. Public Health 2021, 2021, fdab365. [Google Scholar] [CrossRef]
- Baum, L.E.; Eagon, J.A. An inequality with applications to statistical estimation for probabilistic functions of Markov processes and to a model for ecology. Bull. Am. Math. Soc. 1967, 73, 360–363. [Google Scholar] [CrossRef]
- Baum, L.E.; Petrie, T. Statistical inference for probabilistic functions of finite state Markov chains. Ann. Math. Stat. 1966, 37, 1554–1563. [Google Scholar] [CrossRef]
- Blunsom, P. Hidden markov models. Lect. Notes 2004, 15, 48. [Google Scholar]
- Scarpino, I.; Zucco, C.; Cannataro, M. Characterization of Long COVID using text mining on narrative medicine texts. In Proceedings of the 2021 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Houston, TX, USA, 9–12 December 2021; pp. 2022–2027. [Google Scholar]
- Scarpino, I.; Zucco, C.; Cannataro, M. A Software Pipeline Based on Sentiment Analysis to Analyze Narrative Medicine Texts. In Proceedings of the International Conference on Computational Science, Krakow, Poland, 16–18 June 2021; Springer: Berlin/Heidelberg, Germany, 2021; pp. 587–593. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Lin, T.; Wang, Y.; Liu, X.; Qiu, X. A survey of transformers. arXiv 2021, arXiv:2106.04554. [Google Scholar]
- Evans, M. Reflections on the humanities in medical education. Med Educ. 2002, 36, 508–513. [Google Scholar] [CrossRef] [PubMed]
- Charon, R. Narrative Medicine: Honoring the Stories of Illness; Oxford University Press: Oxford, UK, 2008. [Google Scholar]
- Zannini, L. Medical Humanities and Narrative Medicine: New Perspectives in Healthcare Professionals’ Training; Raffaello Cortina: Milano, Italy, 2008. [Google Scholar]
- Bernegger, G.; Castiglioni, M.; Garrino, L. A doctor among clearings, tigers and jazz. A dialog with Rita Charon. J. Med Humanit. 2014, 28, 49–59. [Google Scholar]
- Owen, W.F. Interpretive themes in relational communication. Q. J. Speech 1984, 70, 274–287. [Google Scholar] [CrossRef]
- Bakhtin, M.; Ghāsemipour, G. The problem of speech genres. Lit. Crit. 2011, 4, 114–136. [Google Scholar]
- Weber, R.P. Basic Content Analysis; Sage: London, UK, 1990; Number 49. [Google Scholar]
- Rushforth, A.; Ladds, E.; Wieringa, S.; Taylor, S.; Husain, L.; Greenhalgh, T. Long Covid–The illness narratives. Soc. Sci. Med. 2021, 286, 114326. [Google Scholar] [CrossRef]
- Chyon, F.A.; Suman, M.N.H.; Fahim, M.R.I.; Ahmmed, M.S. Time series analysis and predicting COVID-19 affected patients by ARIMA model using machine learning. J. Virol. Methods 2022, 301, 114433. [Google Scholar] [CrossRef] [PubMed]
- Zhou, S.; Braca, P.; Marano, S.; Willett, P.; Millefiori, L.M.; Gaglione, D.; Pattipati, K.R. Application of Hidden Markov Models to Analyze, Group and Visualize Spatio-Temporal COVID-19 Data. IEEE Access 2021, 9, 134384–134401. [Google Scholar] [CrossRef]
- Prabhu, S.M.; Subramaniam, N. Surveillance of COVID-19 Pandemic using Hidden Markov Model. arXiv 2020, arXiv:2008.07609. [Google Scholar]
- Hearst, M. What Is Text Mining; SIMS, UC Berkeley: Berkeley, CA, USA, 2003; Volume 5. [Google Scholar]
- Sengupta, S.; Mugde, S.; Sharma, G. An Exploration of Impact of COVID 19 on mental health-Analysis of tweets using Natural Language Processing techniques. medRxiv 2020. [Google Scholar] [CrossRef]
- Le Bras, P.; Gharavi, A.; Robb, D.A.; Vidal, A.F.; Padilla, S.; Chantler, M.J. Visualising covid-19 research. arXiv 2020, arXiv:2005.06380. [Google Scholar]
- Älgå, A.; Eriksson, O.; Nordberg, M. Analysis of scientific publications during the early phase of the COVID-19 pandemic: Topic modeling study. J. Med. Internet Res. 2020, 22, e21559. [Google Scholar] [CrossRef] [PubMed]
- Zengul, F.D.; Zengul, A.G.; Mugavero, M.; Oner, N.; Ozaydin, B.; Delen, D.; Willig, J.H.; Kennedy, K.C.; Cimino, J. A critical analysis of COVID-19 research literature: Text mining approach. Intelligence-Based Med. 2021, 5, 100036. [Google Scholar] [CrossRef] [PubMed]
- Ghasiya, P.; Okamura, K. Investigating COVID-19 News Across Four Nations: A Topic Modeling and Sentiment Analysis Approach. IEEE Access 2021, 9, 36645–36656. [Google Scholar] [CrossRef]
- Bai, Y.; Jia, S.; Chen, L. Topic evolution analysis of COVID-19 news articles. J. Phys. Conf. Ser. 2020, 1601, 052009. [Google Scholar] [CrossRef]
- Liu, Q.; Zheng, Z.; Zheng, J.; Chen, Q.; Liu, G.; Chen, S.; Chu, B.; Zhu, H.; Akinwunmi, B.; Huang, J.; et al. Health communication through news media during the early stage of the COVID-19 outbreak in China: Digital topic modeling approach. J. Med. Internet Res. 2020, 22, e19118. [Google Scholar] [CrossRef]
- De Santis, E.; Martino, A.; Rizzi, A. An infoveillance system for detecting and tracking relevant topics from Italian tweets during the COVID-19 event. IEEE Access 2020, 8, 132527–132538. [Google Scholar] [CrossRef]
- Noor, S.; Guo, Y.; Shah, S.H.H.; Fournier-Viger, P.; Nawaz, M.S. Analysis of public reactions to the novel Coronavirus (COVID-19) outbreak on Twitter. Kybernetes 2020, 50, 1633–1653. [Google Scholar] [CrossRef]
- Han, X.; Wang, J.; Zhang, M.; Wang, X. Using social media to mine and analyze public opinion related to COVID-19 in China. Int. J. Environ. Res. Public Health 2020, 17, 2788. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Nguyen, Q.V.H.; Nguyen, D.T.; Hsu, E.B.; Yang, S.; Eklund, P. Artificial intelligence in the battle against coronavirus (COVID-19): A survey and future research directions. arXiv 2020, arXiv:2008.07343. [Google Scholar]
- Anderson, B.S. Using text mining to glean insights from COVID-19 literature. J. Inf. Sci. 2021. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent dirichlet allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Rehurek, R.; Sojka, P. Software framework for topic modelling with large corpora. In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, Valletta, Malta, 17–23 May 2010. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, 6000–6010. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. Umap: Uniform manifold approximation and projection for dimension reduction. arXiv 2018, arXiv:1802.03426. [Google Scholar]
- McInnes, L.; Healy, J.; Astels, S. hdbscan: Hierarchical density based clustering. J. Open Source Softw. 2017, 2, 205. [Google Scholar] [CrossRef]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing, Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Stroudsburg, PA, USA, 2019. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Topics | Coherence Score | Perplexity |
|---|---|---|
| 3 | 0.407 | −7.248 |
| 5 | 0.332 | −7.337 |
| 7 | 0.299 | −7.398 |
| 10 | 0.346 | −7.5239 |
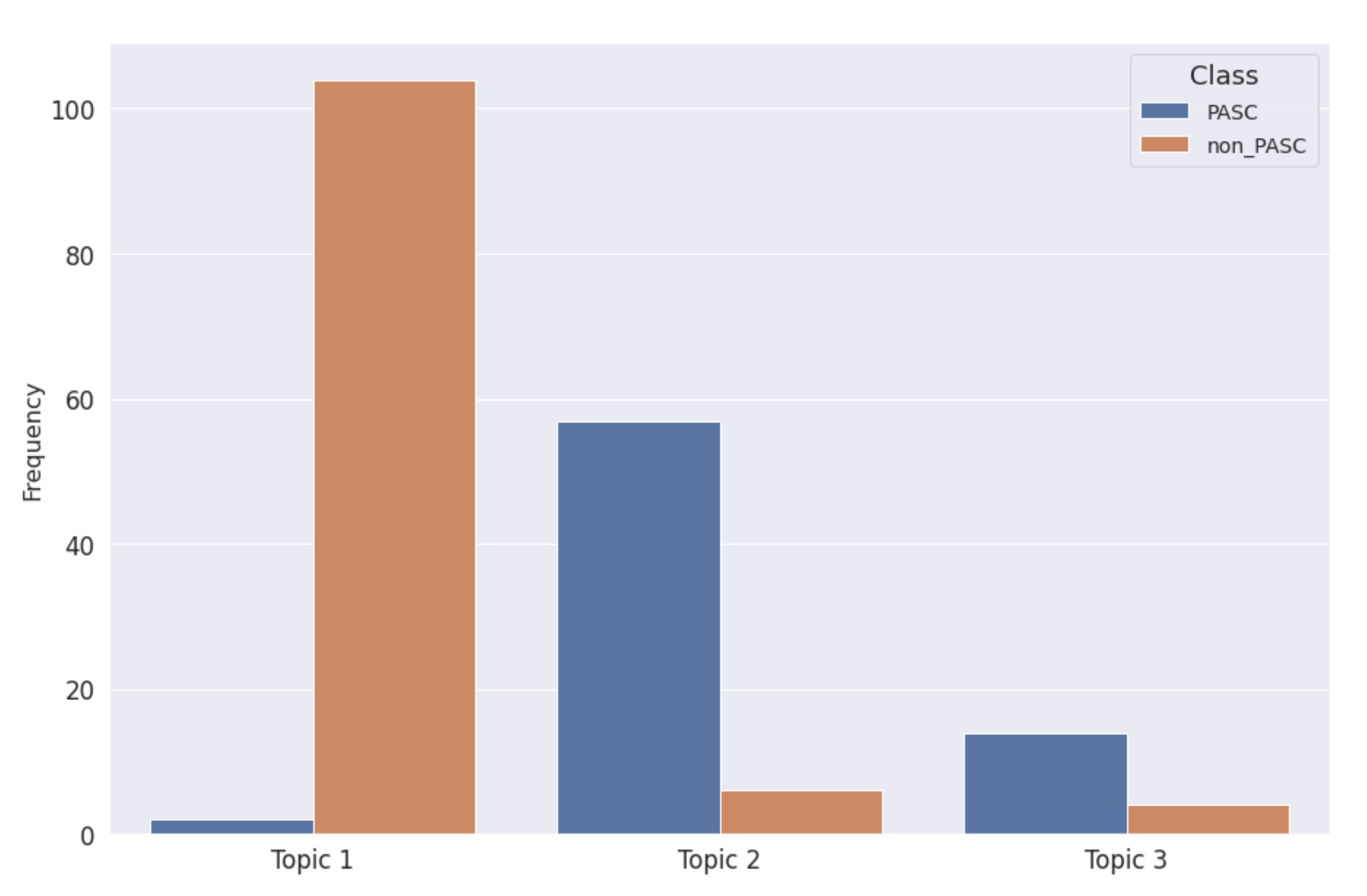
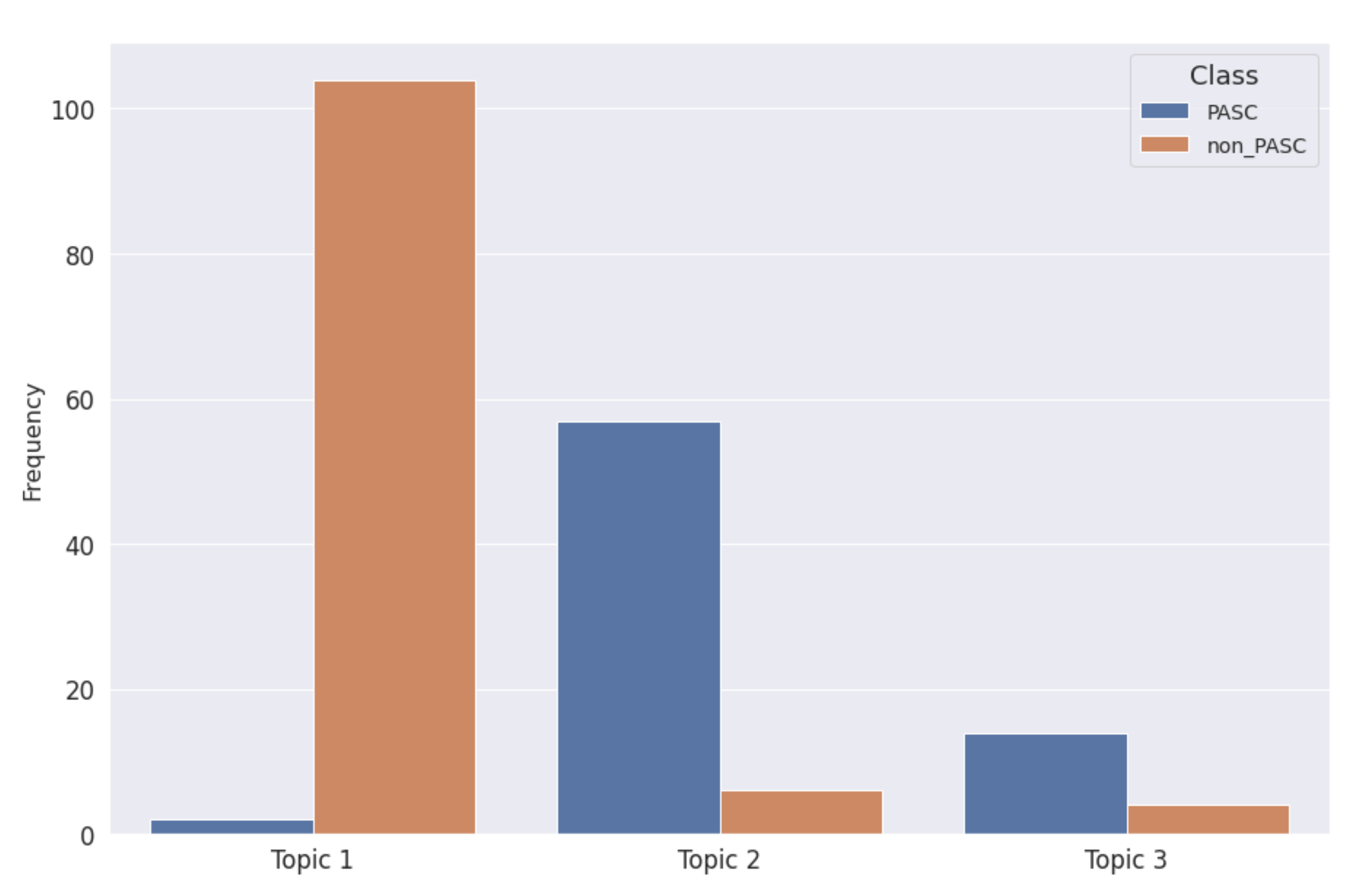
| Assigned LDA Topic | Class | Document Count |
|---|---|---|
| 1 | non-PASC | 104 |
| PASC | 2 | |
| 2 | non-PASC | 6 |
| PASC | 57 | |
| 3 | non-PASC | 4 |
| PASC | 14 |
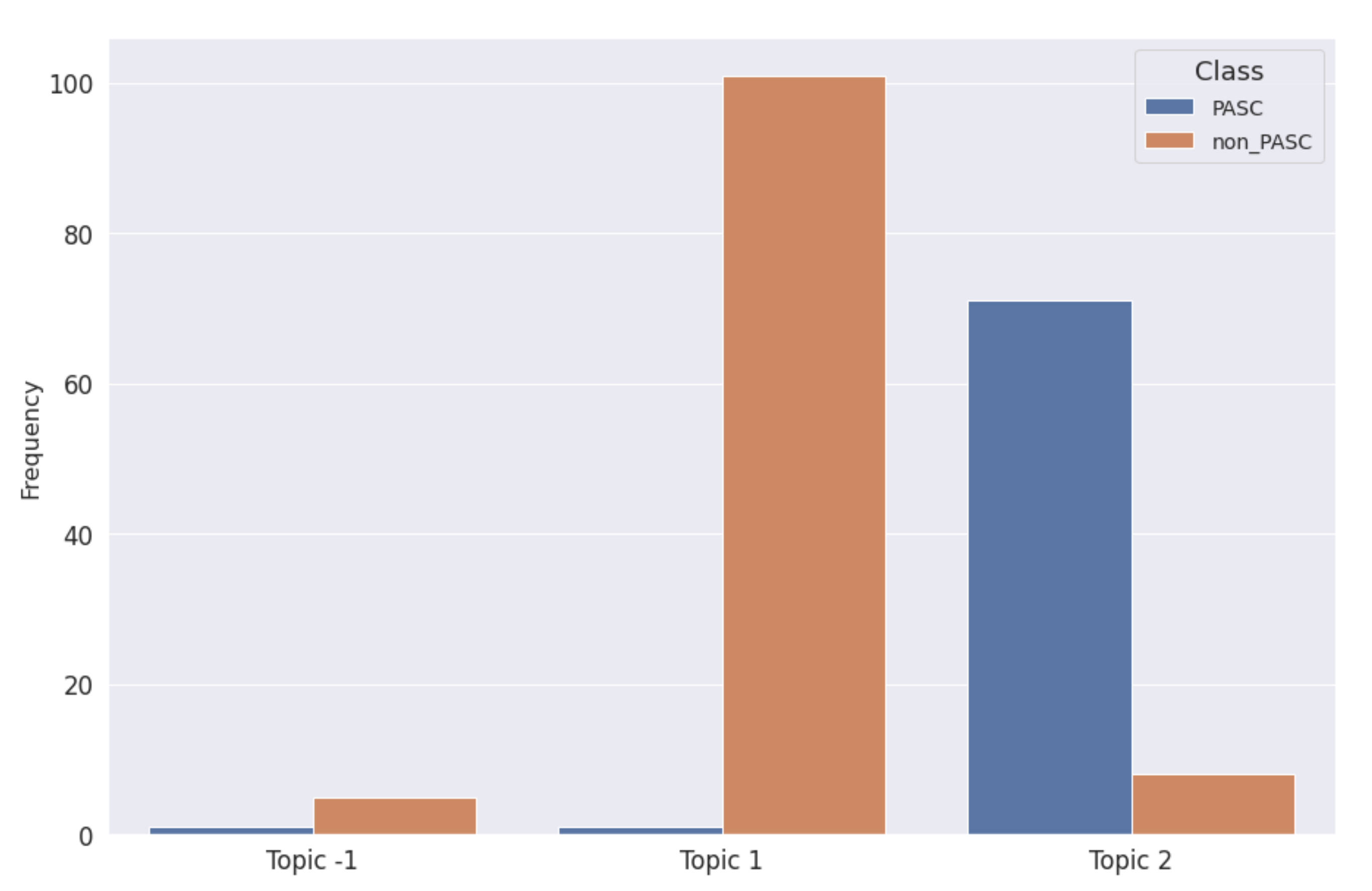
| Assigned BERTopic | Class | Document Count |
|---|---|---|
| −1 | non-PASC | 5 |
| PASC | 1 | |
| 1 | non-PASC | 101 |
| PASC | 1 | |
| 2 | non-PASC | 8 |
| PASC | 71 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Scarpino, I.; Zucco, C.; Vallelunga, R.; Luzza, F.; Cannataro, M. Investigating Topic Modeling Techniques to Extract Meaningful Insights in Italian Long COVID Narration. BioTech 2022, 11, 41. https://doi.org/10.3390/biotech11030041
Scarpino I, Zucco C, Vallelunga R, Luzza F, Cannataro M. Investigating Topic Modeling Techniques to Extract Meaningful Insights in Italian Long COVID Narration. BioTech. 2022; 11(3):41. https://doi.org/10.3390/biotech11030041
Chicago/Turabian StyleScarpino, Ileana, Chiara Zucco, Rosarina Vallelunga, Francesco Luzza, and Mario Cannataro. 2022. "Investigating Topic Modeling Techniques to Extract Meaningful Insights in Italian Long COVID Narration" BioTech 11, no. 3: 41. https://doi.org/10.3390/biotech11030041
APA StyleScarpino, I., Zucco, C., Vallelunga, R., Luzza, F., & Cannataro, M. (2022). Investigating Topic Modeling Techniques to Extract Meaningful Insights in Italian Long COVID Narration. BioTech, 11(3), 41. https://doi.org/10.3390/biotech11030041