
Dermatological Knowledge and Image Analysis Performance of Large Language Models Based on Specialty Certificate Examination in Dermatology


Abstract
1. Introduction
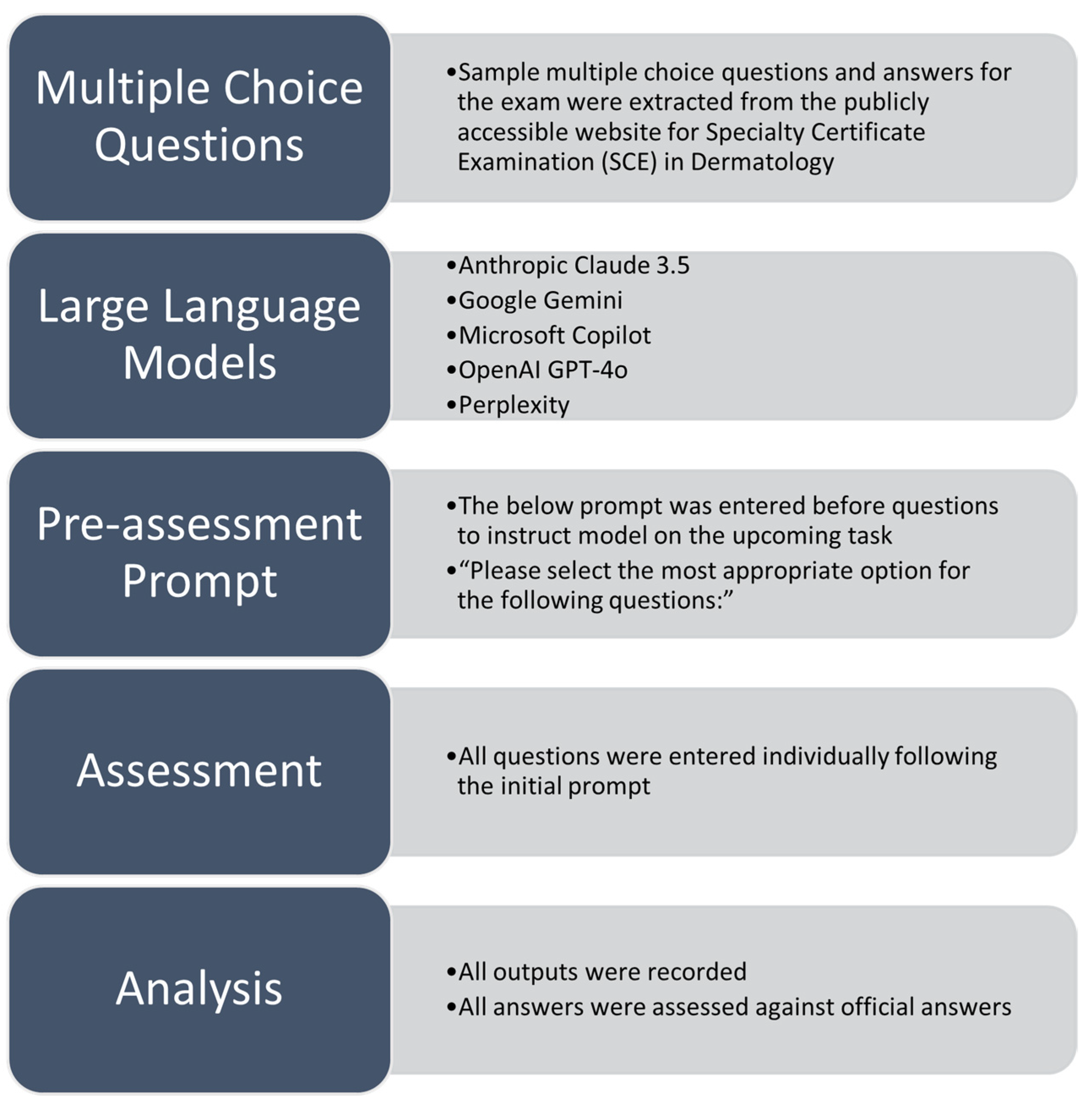
2. Materials and Methods
2.1. Question Bank and LLM
2.2. Data Analysis
2.3. Ethical Statement
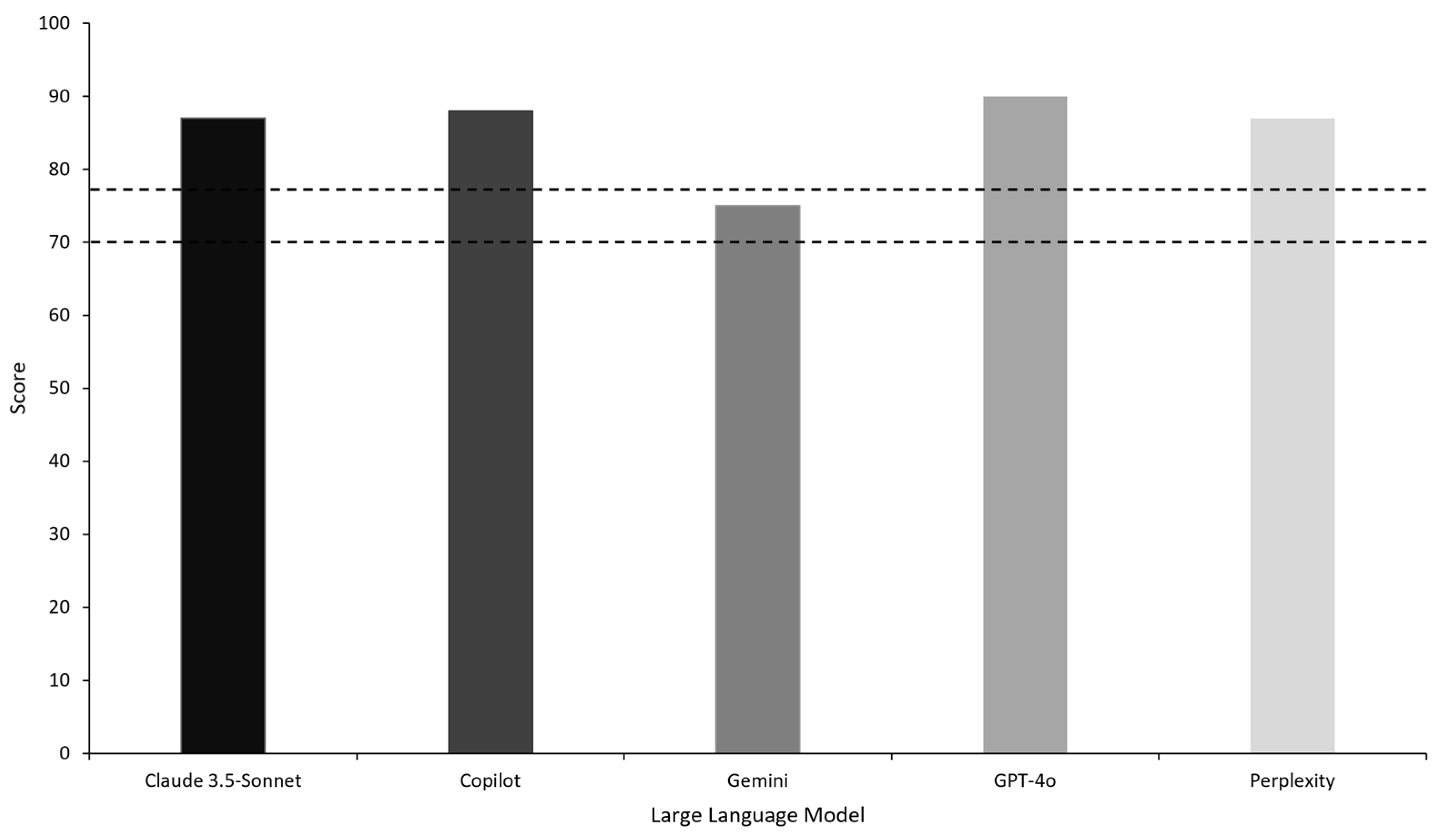
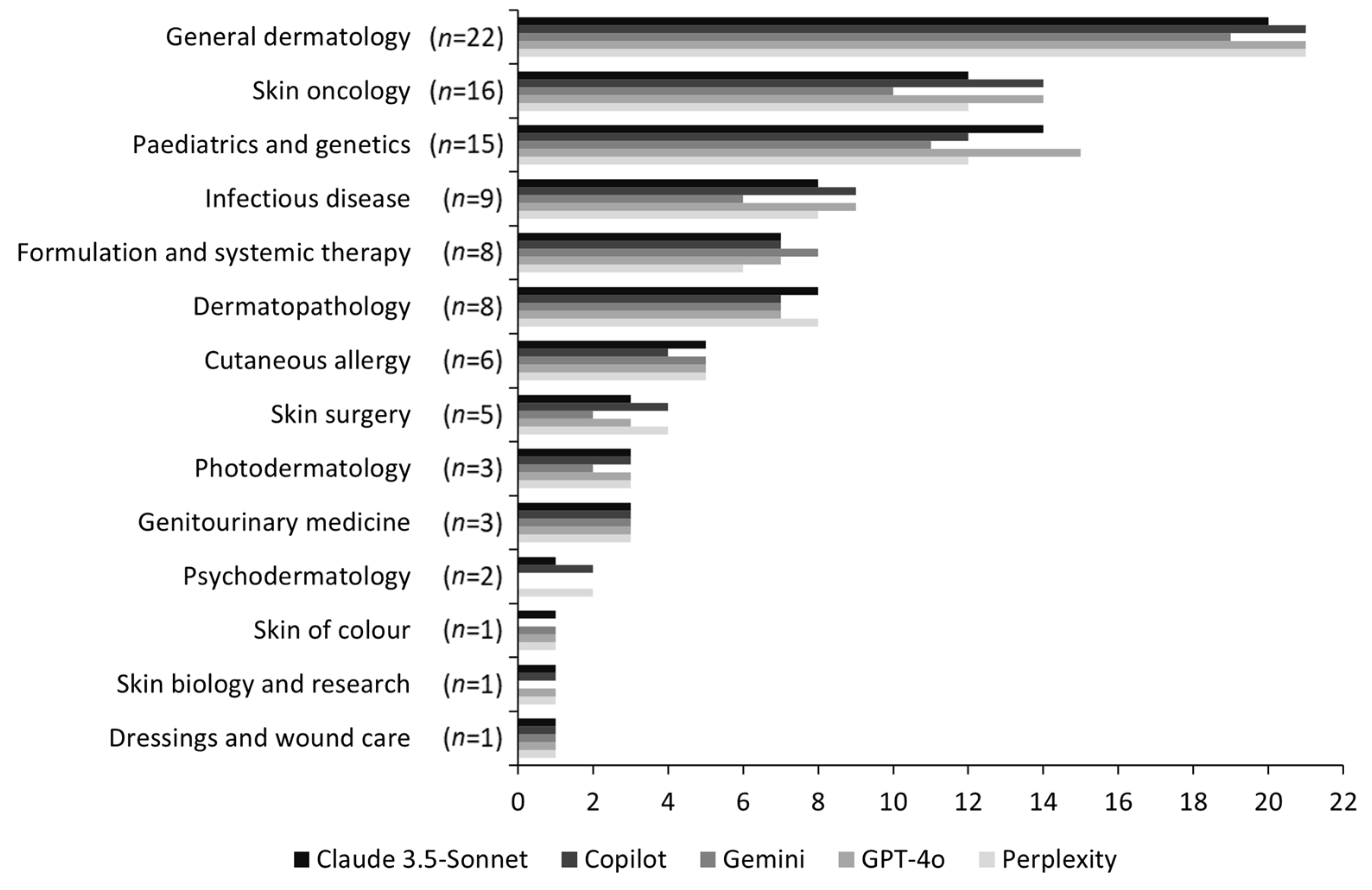
3. Results
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Han, E.R.; Yeo, S.; Kim, M.J.; Lee, Y.H.; Park, K.H.; Roh, H. Medical education trends for future physicians in the era of advanced technology and artificial intelligence: An integrative review. BMC Med. Educ. 2019, 19, 1–15. [Google Scholar] [CrossRef] [PubMed]
- Mogali, S.R. Initial impressions of ChatGPT for anatomy education. Anat. Sci. Educ. 2024, 17, 444–447. [Google Scholar] [CrossRef] [PubMed]
- Abd-alrazaq, A.; AlSaad, R.; Alhuwail, D.; Ahmed, A.; Healy, P.M.; Latifi, S.; Aziz, S.; Damseh, R.; Alrazak, S.A.; Sheikh, J. Large Language Models in Medical Education: Opportunities, Challenges, and Future Directions. JMIR Med. Educ. 2023, 9, e48291. [Google Scholar] [CrossRef] [PubMed]
- Shamil, E.; Jaafar, M.; Fan, K.S.; Ko, T.K.; Schuster-Bruce, J.; Eynon-Lewis, N.; Andrews, P. The use of large language models like ChatGPT on delivering patient information relating to surgery. Facial Plast. Surg. 2024. Available online: https://www.thieme-connect.de/products/ejournals/abstract/10.1055/a-2413-3529 (accessed on 20 September 2024).
- Gerke, S.; Minssen, T.; Cohen, G. Ethical and legal challenges of artificial intelligence-driven healthcare. In Artificial Intelligence in Healthcare; Academic Press: Cambridge, MA, USA, 2020; pp. 295–336. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7332220/ (accessed on 26 September 2024).
- Kobayashi, K. Interactivity: A Potential Determinant of Learning by Preparing to Teach and Teaching. Front. Psychol. 2019, 9, 2755. [Google Scholar] [CrossRef] [PubMed]
- Karampinis, E.; Toli, O.; Georgopoulou, K.-E.; Kampra, E.; Spyridonidou, C.; Schulze, A.-V.R.; Zafiriou, E. Can Artificial Intelligence “Hold” a Dermoscope?—The Evaluation of an Artificial Intelligence Chatbot to Translate the Dermoscopic Language. Diagnostics 2024, 14, 1165. [Google Scholar] [CrossRef] [PubMed]
- Sumbal, A.; Sumbal, R.; Amir, A. Can ChatGPT-3.5 Pass a Medical Exam? A Systematic Review of ChatGPT’s Performance in Academic Testing. J. Med. Educ. Curric. Dev. 2024, 11, 23821205241238641. [Google Scholar] [CrossRef]
- Safranek, C.W.; Sidamon-Eristoff, A.E.; Gilson, A.; Chartash, D. The Role of Large Language Models in Medical Education: Applications and Implications. JMIR Med. Educ. 2023, 9, e50945. [Google Scholar] [CrossRef]
- Chan, J.; Dong, T.; Angelini, G.D. The performance of large language models in intercollegiate Membership of the Royal College of Surgeons examination. Ann. R. Coll. Surg. Engl. 2024. [Google Scholar] [CrossRef]
- Rossettini, G.; Rodeghiero, L.; Corradi, F.; Cook, C.; Pillastrini, P.; Turolla, A.; Castellini, G.; Chiappinotto, S.; Gianola, S.; Palese, A. Comparative accuracy of ChatGPT-4, Microsoft Copilot and Google Gemini in the Italian entrance test for healthcare sciences degrees: A cross-sectional study. BMC Med. Educ. 2024, 24, 694. [Google Scholar] [CrossRef]
- Gilson, A.; Safranek, C.W.; Huang, T.; Socrates, V.; Chi, L.; Taylor, R.A.; Chartash, D. How Does ChatGPT Perform on the United States Medical Licensing Examination (USMLE)? The Implications of Large Language Models for Medical Education and Knowledge Assessment. JMIR Med. Educ. 2023, 9, e45312. [Google Scholar] [CrossRef]
- Bhayana, R.; Krishna, S.; Bleakney, R.R. Performance of ChatGPT on a Radiology Board-style Examination: Insights into Current Strengths and Limitations. Radiology 2023, 307, 230582. [Google Scholar] [CrossRef]
- Antaki, F.; Touma, S.; Milad, D.; El-Khoury, J.; Duval, R. Evaluating the Performance of ChatGPT in Ophthalmology: An Analysis of Its Successes and Shortcomings. Ophthalmol. Sci. 2023, 3, 100324. [Google Scholar] [CrossRef]
- Vij, O.; Calver, H.; Myall, N.; Dey, M.; Kouranloo, K. Evaluating the competency of ChatGPT in MRCP Part 1 and a systematic literature review of its capabilities in postgraduate medical assessments. PLoS ONE 2024, 19, e0307372. [Google Scholar] [CrossRef] [PubMed]
- General Medical Council. Dermatology Curriculum. 2023. Available online: https://www.gmc-uk.org/education/standards-guidance-and-curricula/curricula/dermatology-curriculum (accessed on 1 August 2024).
- Membership of the Royal Colleges of Physicians of the United Kingdom. Specialty Certificate Examination (SCE) in Dermatology 2023 Selected Examination Metrics. 2024. Available online: https://www.thefederation.uk/sites/default/files/2024-02/Dermatology%20results%20report%202023_Liliana%20Chis.pdf (accessed on 1 August 2024).
- Passby, L.; Jenko, N.; Wernham, A. Performance of ChatGPT on Specialty Certificate Examination in Dermatology multiple-choice questions. Clin. Exp. Dermatol. 2024, 49, 722–727. [Google Scholar] [CrossRef] [PubMed]
- Membership of the Royal Colleges of Physicians of the United Kingdom. Dermatology|The Federation. Available online: https://www.thefederation.uk/examinations/specialty-certificate-examinations/specialties/dermatology (accessed on 1 August 2024).
- OpenAI. GPT-4. Available online: https://openai.com/gpt-4 (accessed on 1 August 2024).
- Google. Gemini Models. Available online: https://ai.google.dev/gemini-api/docs/models/gemini (accessed on 1 August 2024).
- Anthropic. Introducing Claude. Available online: https://www.anthropic.com/news/introducing-claude (accessed on 1 August 2024).
- Microsoft. Microsoft Copilot|Microsoft AI. Available online: https://www.microsoft.com/en-us/microsoft-copilot (accessed on 1 August 2024).
- Perplexity Frequently Asked Questions. Available online: https://www.perplexity.ai/hub/faq (accessed on 26 September 2024).
- Hou, W.; Ji, Z. GPT-4V exhibits human-like performance in biomedical image classification. bioRxiv 2024. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10802384/ (accessed on 26 September 2024).
- Joh, H.C.; Kim, M.H.; Ko, J.Y.; Kim, J.S.; Jue, M.S. Evaluating the Performance of ChatGPT in Dermatology Specialty Certificate Examination-style Questions: A Comparative Analysis between English and Korean Language Settings. Indian J. Dermatol. 2024, 69, 338. [Google Scholar] [CrossRef] [PubMed]
- Nicikowski, J.; Szczepański, M.; Miedziaszczyk, M.; Kudliński, B. The potential of ChatGPT in medicine: An example analysis of nephrology specialty exams in Poland. Clin. Kidney J. 2024, 17, 193. [Google Scholar] [CrossRef]
- Meyer, A.; Riese, J.; Streichert, T. Comparison of the Performance of GPT-3.5 and GPT-4 With That of Medical Students on the Written German Medical Licensing Examination: Observational Study. JMIR Med. Educ. 2024, 10, e50965. [Google Scholar] [CrossRef]
- Birkett, L.; Fowler, T.; Pullen, S. Performance of ChatGPT on a primary FRCA multiple choice question bank. Br. J. Anaesth. 2023, 131, e34–e35. [Google Scholar] [CrossRef]
- Singhal, K.; Azizi, S.; Tu, T.; Mahdavi, S.S.; Wei, J.; Chung, H.W.; Tanwani, A.; Cole-Lewis, H.; Pfohl, S.; Payne, P.; et al. Large language models encode clinical knowledge. Nature 2023, 620, 172. [Google Scholar] [CrossRef] [PubMed]
- Sallam, M.; Al-Salahat, K. Below average ChatGPT performance in medical microbiology exam compared to university students. Front. Educ. 2023, 8, 1333415. [Google Scholar] [CrossRef]
- Shamil, E.; Ko, T.K.; Fan, K.S.; Schuster-Bruce, J.; Jaafar, M.; Khwaja, S.; Eynon-Lewis, N.; D’Souza, A.R.; Andrews, P. Assessing the quality and readability of online patient information: ENT UK patient information e-leaflets vs responses by a Generative Artificial Intelligence. Facial Plast. Surg. 2024. Available online: https://www.thieme-connect.de/products/ejournals/abstract/10.1055/a-2413-3675 (accessed on 20 September 2024).
- Humar, P.; Asaad, M.; Bengur, F.B.; Nguyen, V. ChatGPT Is Equivalent to First-Year Plastic Surgery Residents: Evaluation of ChatGPT on the Plastic Surgery In-Service Examination. Aesthetic Surg. J. 2023, 43, NP1085–NP1089. [Google Scholar] [CrossRef] [PubMed]
- Kung, T.H.; Cheatham, M.; Medenilla, A.; Sillos, C.; De Leon, L.; Elepaño, C.; Madriaga, M.; Aggabao, R.; Diaz-Candido, G.; Maningo, J.; et al. Performance of ChatGPT on USMLE: Potential for AI-assisted medical education using large language models. PLoS Digit. Heal. 2023, 2, e0000198. [Google Scholar] [CrossRef]
- Ali, R.; Tang, O.Y.; Connolly, I.D.; Sullivan, P.L.Z.; Shin, J.H.; Fridley, J.S.; Asaad, W.F.; Cielo, D.; Oyelese, A.A.; Doberstein, C.E.; et al. Performance of ChatGPT and GPT-4 on Neurosurgery Written Board Examinations. Neurosurgery 2023, 93, 1353–1365. [Google Scholar] [CrossRef] [PubMed]
- Masalkhi, M.; Ong, J.; Waisberg, E.; Lee, A.G. Google DeepMind’s gemini AI versus ChatGPT: A comparative analysis in ophthalmology. Eye 2024, 38, 1412. [Google Scholar] [CrossRef]
- Bahir, D.; Zur, O.; Attal, L.; Nujeidat, Z.; Knaanie, A.; Pikkel, J.; Mimouni, M.; Plopsky, G. Gemini AI vs. ChatGPT: A comprehensive examination alongside ophthalmology residents in medical knowledge. Graefe’s Arch. Clin. Exp. Ophthalmol. 2024, 1–10. [Google Scholar] [CrossRef]
- Morreel, S.; Verhoeven, V.; Mathysen, D. Microsoft Bing outperforms five other generative artificial intelligence chatbots in the Antwerp University multiple choice medical license exam. PLOS Digit. Heal. 2024, 3, e0000349. [Google Scholar] [CrossRef] [PubMed]
- Uppalapati, V.K.; Nag, D.S. A Comparative Analysis of AI Models in Complex Medical Decision-Making Scenarios: Evaluating ChatGPT, Claude AI, Bard, and Perplexity. Cureus 2024, 16, e52485. [Google Scholar] [CrossRef] [PubMed]
- Torres-Zegarra, B.C.; Rios-Garcia, W.; Ñaña-Cordova, A.M.; Arteaga-Cisneros, K.F.; Chalco, X.C.B.; Ordoñez, M.A.B.; Rios, C.J.G.; Godoy, C.A.R.; Quezada, K.L.T.P.; Gutierrez-Arratia, J.D.; et al. Performance of ChatGPT, Bard, Claude, and Bing on the Peruvian National Licensing Medical Examination: A cross-sectional study. J. Educ. Eval. Health Prof. 2023, 20, 30. [Google Scholar] [CrossRef]
- Yu, P.; Fang, C.; Liu, X.; Fu, W.; Ling, J.; Yan, Z.; Jiang, Y.; Cao, Z.; Wu, M.; Chen, Z.; et al. Performance of ChatGPT on the Chinese Postgraduate Examination for Clinical Medicine: Survey Study. JMIR Med. Educ. 2024, 10, e48514. [Google Scholar] [CrossRef]
- Noda, M.; Ueno, T.; Koshu, R.; Takaso, Y.; Shimada, M.D.; Saito, C.; Sugimoto, H.; Fushiki, H.; Ito, M.; Nomura, A.; et al. Performance of GPT-4V in Answering the Japanese Otolaryngology Board Certification Examination Questions: Evaluation Study. JMIR Med. Educ. 2024, 10, e57054. [Google Scholar] [CrossRef] [PubMed]
- Alhur, A. Redefining Healthcare With Artificial Intelligence (AI): The Contributions of ChatGPT, Gemini, and Co-pilot. Cureus 2024, 16, e57795. [Google Scholar] [CrossRef] [PubMed]
- Kaftan, A.N.; Hussain, M.K.; Naser, F.H. Response accuracy of ChatGPT 3.5 Copilot and Gemini in interpreting biochemical laboratory data a pilot study. Sci. Rep. 2024, 14, 8233. [Google Scholar] [CrossRef] [PubMed]
- Amisha Malik, P.; Pathania, M.; Rathaur, V.K. Overview of artificial intelligence in medicine. J. Fam. Med. Prim. Care 2019, 8, 2328–2331. [Google Scholar] [CrossRef] [PubMed]
- De Angelis, L.; Baglivo, F.; Arzilli, G.; Privitera, G.P.; Ferragina, P.; Tozzi, A.E.; Rizzo, C. ChatGPT and the rise of large language models: The new AI-driven infodemic threat in public health. Front. Public Heal. 2023, 11, 1166120. Available online: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC10166793/ (accessed on 26 September 2024).
- Thomas, L.; Hyde, C.; Mullarkey, D.; Greenhalgh, J.; Kalsi, D.; Ko, J. Real-world post-deployment performance of a novel machine learning-based digital health technology for skin lesion assessment and suggestions for post-market surveillance. Front. Med. 2023, 10, 1264846. [Google Scholar] [CrossRef]
- Fan, K.S. Advances in Large Language Models (LLMs) and Artificial Intelligence (AI); AtCAD: London, UK, 2024; Available online: https://atomicacademia.com/articles/implications-of-large-language-models-in-medical-education.122/ (accessed on 20 September 2024).
- Patel, S.B.; Lam, K. ChatGPT: The future of discharge summaries? Lancet Digit. Heal. 2023, 5, e107–e108. [Google Scholar] [CrossRef]
- Kumar, Y.; Koul, A.; Singla, R.; Ijaz, M.F. Artificial intelligence in disease diagnosis: A systematic literature review, synthesizing framework and future research agenda. J. Ambient. Intell. Humaniz. Comput. 2023, 14, 8459–8486. [Google Scholar] [CrossRef]
- Hosny, A.; Parmar, C.; Quackenbush, J.; Schwartz, L.H.; Aerts, H.J.W.L. Artificial intelligence in radiology. Nat. Rev. Cancer 2018, 18, 500. [Google Scholar] [CrossRef] [PubMed]
- Walker, H.L.; Ghani, S.; Kuemmerli, C.; Nebiker, C.A.; Müller, B.P.; Raptis, D.A.; Staubli, S.M. Reliability of Medical Information Provided by ChatGPT: Assessment Against Clinical Guidelines and Patient Information Quality Instrument. J. Med. Internet Res. 2023, 25, 1–14. [Google Scholar] [CrossRef]
- Howe, P.D.L.; Fay, N.; Saletta, M.; Hovy, E. ChatGPT’s advice is perceived as better than that of professional advice columnists. Front. Psychol. 2023, 14, 1281255. [Google Scholar] [CrossRef] [PubMed]
- Elyoseph, Z.; Hadar-Shoval, D.; Asraf, K.; Lvovsky, M. ChatGPT outperforms humans in emotional awareness evaluations. Front. Psychol. 2023, 14, 1199058. [Google Scholar] [CrossRef] [PubMed]
- Jeffrey, D. Empathy, sympathy and compassion in healthcare: Is there a problem? Is there a difference? Does it matter? J. R. Soc. Med. 2016, 109, 446–452. [Google Scholar] [CrossRef] [PubMed]
- Charilaou, P.; Battat, R. Machine learning models and over-fitting considerations. World J. Gastroenterol. 2022, 28, 605. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Topic | Questions | GPT-4o | Gemini | Claude 3.5-Sonnet | Copilot | Perplexity |
|---|---|---|---|---|---|---|
| General dermatology | 22 | 21 (95%) | 19 (86%) | 20 (91%) | 21 (95%) | 21 (95%) |
| Skin oncology | 16 | 14 (88%) | 10 (63%) | 12 (75%) | 14 (88%) | 12 (75%) |
| Paediatrics and genetics | 15 | 15 (100%) | 11 (73%) | 14 (93%) | 12 (80%) | 12 (80%) |
| Infectious disease | 9 | 9 (100%) | 6 (67%) | 8 (89%) | 9 (100%) | 8 (89%) |
| Formulation and systemic therapy | 8 | 7 (88%) | 8 (100%) | 7 (88%) | 7 (88%) | 6 (75%) |
| Dermatopathology | 8 | 7 (88%) | 7 (88%) | 8 (100%) | 7 (88%) | 8 (100%) |
| Cutaneous allergy | 6 | 5 (83%) | 5 (83%) | 5 (83%) | 4 (67%) | 5 (83%) |
| Skin surgery | 5 | 3 (60%) | 2 (40%) | 3 (60%) | 4 (80%) | 4 (80%) |
| Photodermatology | 3 | 3 (100%) | 2 (67%) | 3 (100%) | 3 (100%) | 3 (100%) |
| Genitourinary medicine | 3 | 3 (100%) | 3 (100%) | 3 (100%) | 3 (100%) | 3 (100%) |
| Psychodermatology | 2 | 0 (0%) | 0 (0%) | 1 (50%) | 2 (100%) | 2 (100%) |
| Skin of colour | 1 | 1 (100%) | 1 (100%) | 1 (100%) | 0 (0%) | 1 (100%) |
| Skin biology and research | 1 | 1 (100%) | 0 (0%) | 1 (100%) | 1 (100%) | 1 (100%) |
| Dressings and wound care | 1 | 1 (100%) | 1 (100%) | 1 (100%) | 1 (100%) | 1 (100%) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fan, K.S.; Fan, K.H. Dermatological Knowledge and Image Analysis Performance of Large Language Models Based on Specialty Certificate Examination in Dermatology. Dermato 2024, 4, 124-135. https://doi.org/10.3390/dermato4040013
Fan KS, Fan KH. Dermatological Knowledge and Image Analysis Performance of Large Language Models Based on Specialty Certificate Examination in Dermatology. Dermato. 2024; 4(4):124-135. https://doi.org/10.3390/dermato4040013
Chicago/Turabian StyleFan, Ka Siu, and Ka Hay Fan. 2024. "Dermatological Knowledge and Image Analysis Performance of Large Language Models Based on Specialty Certificate Examination in Dermatology" Dermato 4, no. 4: 124-135. https://doi.org/10.3390/dermato4040013
APA StyleFan, K. S., & Fan, K. H. (2024). Dermatological Knowledge and Image Analysis Performance of Large Language Models Based on Specialty Certificate Examination in Dermatology. Dermato, 4(4), 124-135. https://doi.org/10.3390/dermato4040013