1. Introduction
Songbirds communicate using various vocalizations that have been classified into two main types: songs and calls. Songs are relatively long and complex vocalizations, which are used for territorial defense and courtship toward females [
1]. Calls are short and simple sounds used to exchange more specific information such as warning of predators and signals for forming social bonds [
2].
A population of songbirds can be regarded as a complex system in that they communicate with each other via vocalization, through which various emergent phenomena have been observed [
3]. Intra-specific interactions in a population of songbirds could produce complex results and various studies have been conducted to understand their interactions. One approach for obtaining such complex vocalization and associated spatial data has been to attach a device to each bird and observe their behaviors[
4,
5,
6]. In particular, Farine et al. investigated the social transmission of information about foraging patches by attaching passive integrated tags (PITs) to songbirds for detecting their presence and absence at bird feeders [
4]. By examining the social network created by the encountering data of each individual, they suggested that the intra-specific network contributed to the transmission of feeder information rather than an inter-specific network. Gill et al. investigated call communication among Zebra Finch (
Taeniopygia guttata, ZF) by using a recording technique that included attaching microphone transmitters to the birds. They found that the vocal interaction and social relationships changed along with breeding stages [
5]. Although such methods enable us to obtain detailed data on contacts between individuals, they are invasive; moreover, it is difficult to obtain the exact spatial information of vocalizations while their vocal communication might depend on their spatial situations (e.g., their territories and vegetation factors) and the relationships among them [
7]. For example, the distance between individuals during their vocal communication may reflect the degree of their social bonding or aggression [
8].
Sound localization techniques based on a microphone array have been recognized as promising, non-invasive approaches that enable us to extract the sound direction and spatial information from the recording [
9,
10]. There have been several empirical studies to spatially localize or estimating the direction of arrival (DOA) bird songs using multiple microphones. Gayk and Mennill successfully estimated the position of the vocalizations of warblers on the wing using three-dimensional triangulation based on 8 microphones [
11]. Mennill et al. conducted playback experiments to examine the accuracy of two-dimensional localization based on an array made up of four stereo recorders [
12]. Hedley et al. conducted three-dimensional estimations of the DOAs of playback sounds using two stereo recorders, showing the ability of the system to discriminate up to four simulated birds singing simultaneously [
13]. Collier et al. conducted playback tests and wild bird observation using an array of microphone arrays [
14]. Also, there have been applications of sound source localization for behavioral or habitat surveys of the songbirds. Araya-Salas et al. used multiple microphones to estimate the distance between two songbirds for investigating the overlap and alternation of the vocal interaction between them [
15]. Ethier and Wilson investigated the microhabitat preference of two songbird species using microphone arrays [
16].
These experiments were conducted mainly in simple situations such as cases in which a sound was replayed from a loudspeaker, or a small number of individuals were vocalizing [
17]. It is worth tackling the challenge of automatically capturing the spatial distribution of many bird vocalizations in a densely populated field environment, and that method could be expanded to a larger field observation if it works.
The objective of this study is to propose a framework for automatic and fine-scale extraction of spatial-spectral-temporal patterns of bird vocalizations in a densely populated environment. For this purpose, we used robot audition techniques to integrate information (i.e., the timing, duration, direction of arrival, and separated sound of localized sources) from multiple microphone arrays (array of arrays) deployed in an environment. Robot audition is a research field aiming at the construction of a robot’s auditory functions, which provides integrated audio signal processing such as sound source localization, separation, and recognition in a real environment. It is currently applied in a wide range of fields such as search and rescue by mounting arrays on unmanned aerial vehicles as well as audio-visual scene reconstruction [
18,
19].
We adopt Honda Research Institute Japan Audition for Robots with Kyoto University (HARK), which is an open-source robot audition software program [
20,
21], among a few software programs for handling sound source localization techniques [
21,
22,
23]. This is because we can extract the spatio-temporal information of sounds (e.g., their DOAs and their timings) and separate the sounds to conduct further processing online, which is essential for robots to grasp the soundscape around them. We used HARKBird, which is a collection of Python scripts used to extend HARK to specialize in monitoring birdsongs [
24,
25]. HARKBird has been applied for observing behavioral patterns of songbirds on playback experiments [
26,
27], and for investigating the temporal dynamics of vocal communication among songbirds [
28].
We devised a spatial division-based 2D localization performed by dividing the entire space in the experimental environment into several areas and selecting an appropriate pair of microphone arrays for each area for triangulation with the directional information of sources with high spectral affinity, which is to reduce the localization error caused by unsuitable positions in such a dense environment.
As a proof of concept of this framework, we examined the ability of the method to extract active vocalizations of a few Zebra Finches in an outdoor mesh tent as a realistic situation in which they could fly and vocalize freely. This species is well known as a model animal for vocal learning [
29,
30] of songs and uses various calls to form social relationships [
5,
31,
32]. In addition, ZF is a colonial species and can be a good example to observe vocalizations of multiple birds in a densely populated field environment by using our approach. It is also recently pointed out that its life history or behavior might be different from many of the well-studied birds in the northern hemisphere [
33].
We first conducted a recording trial of the vocalizations of ZF individuals immediately after introducing them in a tent, expecting their active vocalizations. Then we estimated the spatial distribution of their vocalizations using the proposed method. We also classified their vocalizations as either songs or calls by using a simple method based on the tempo and length of the separated sounds, as an example of the use of the information obtained from the framework.
2. Method
2.1. Experimental Setting and Recording
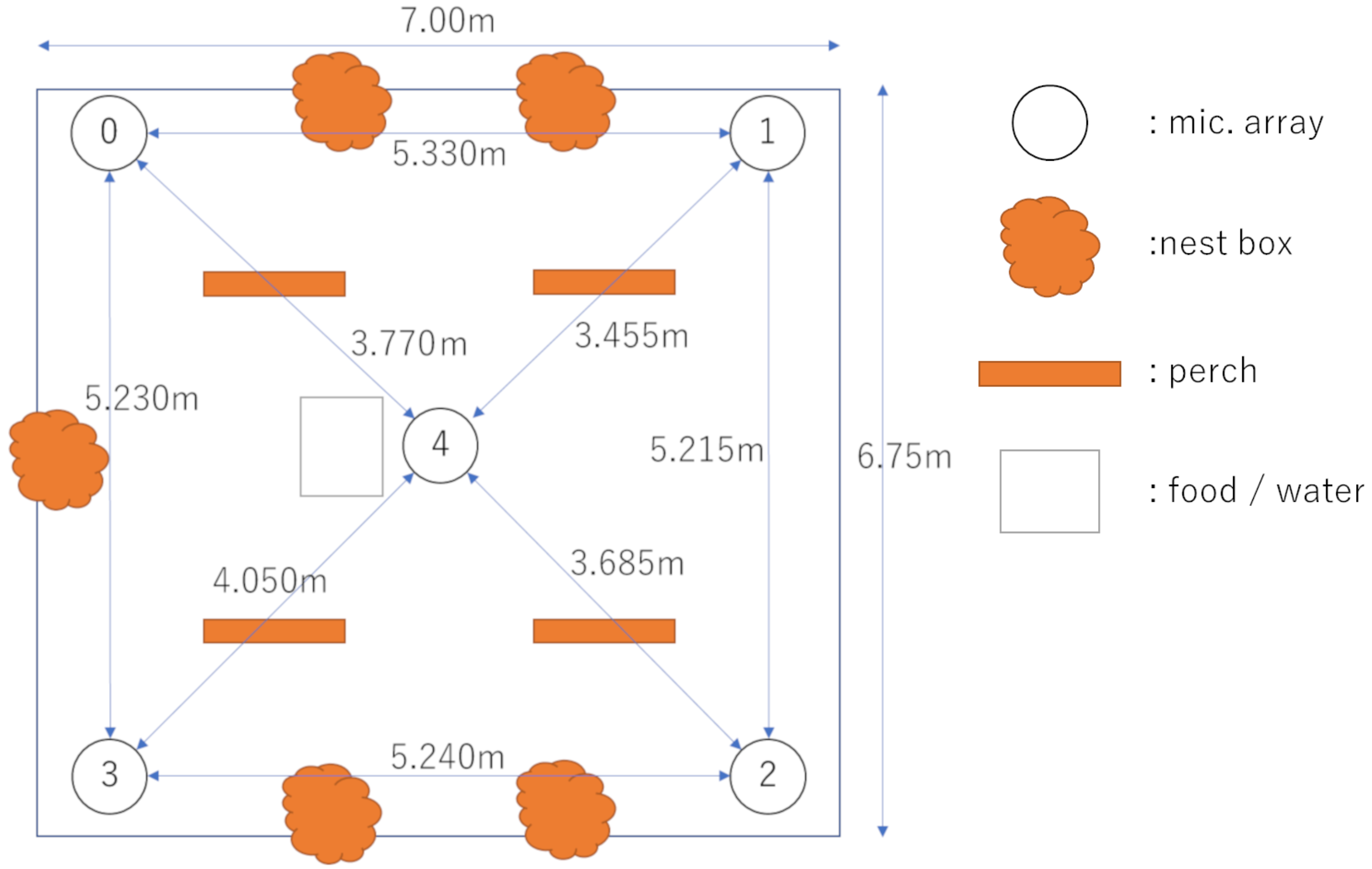
We created a recording environment in a rectangular mesh tent with dimensions of approximately 7 m × 7 m (
Figure 1) set in a field on the campus of Hokkaido University (43
04
18.3
N, 141
20
28.4
E). In this environment, we arranged five straw nests and four perches approximately 1.5 m above the ground, and food and water spaces were provided near the center of the tent, as shown in
Figure 2. This setting enabled the songbirds to fly around freely. We then connected five microphone arrays (TAMAGO-03, System in Frontier Inc., Tokyo, Japan) to a laptop computer (Toughbook CF-C2, Panasonic, Osaka Japan) and arranged them at the four corners and the center of the tent. The TAMAGO-03 has 8 microphones that are horizontally arranged 45 degrees apart around its egg-shaped body, which enables us to conduct 24 bit, 16 kHz recording.
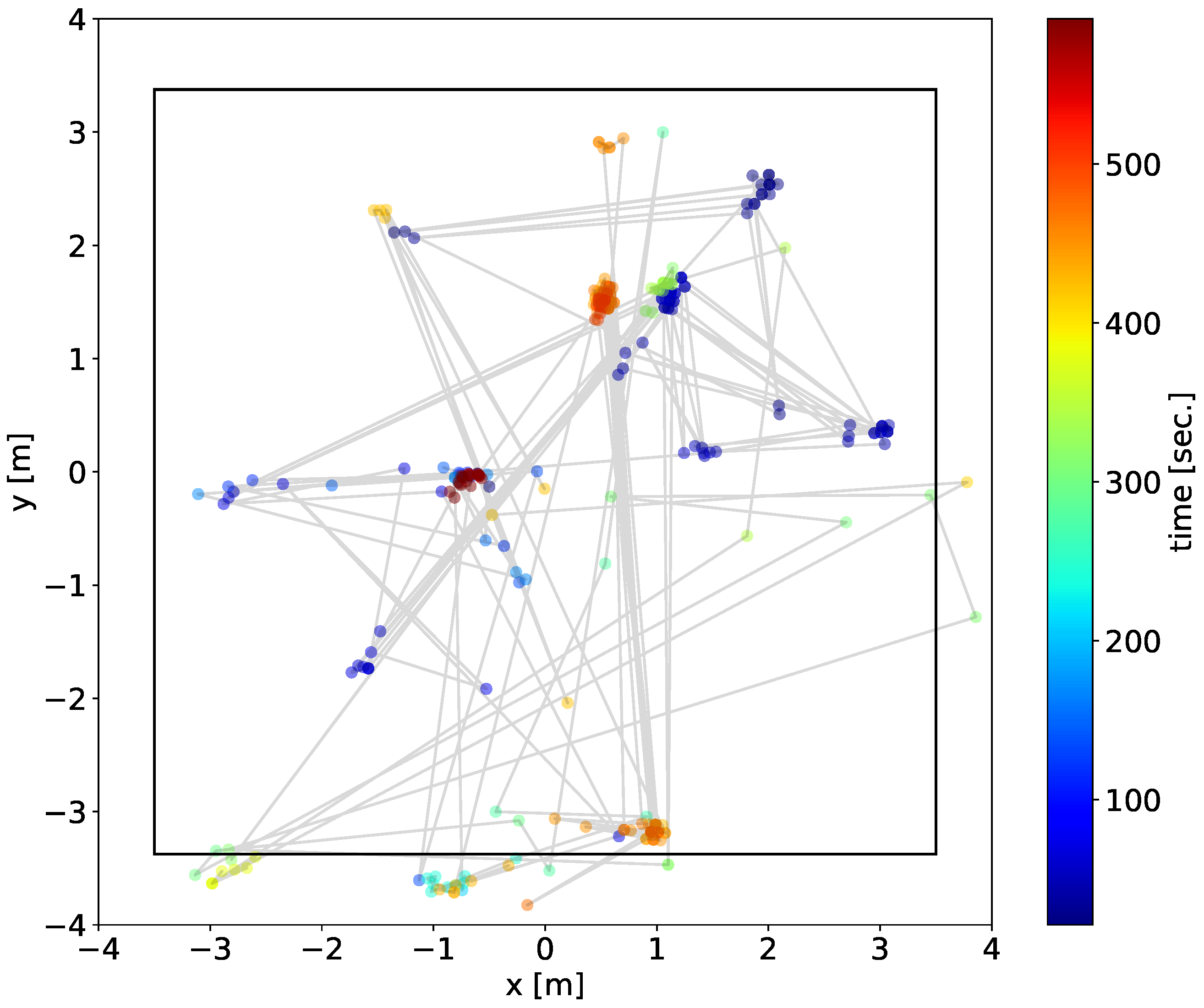
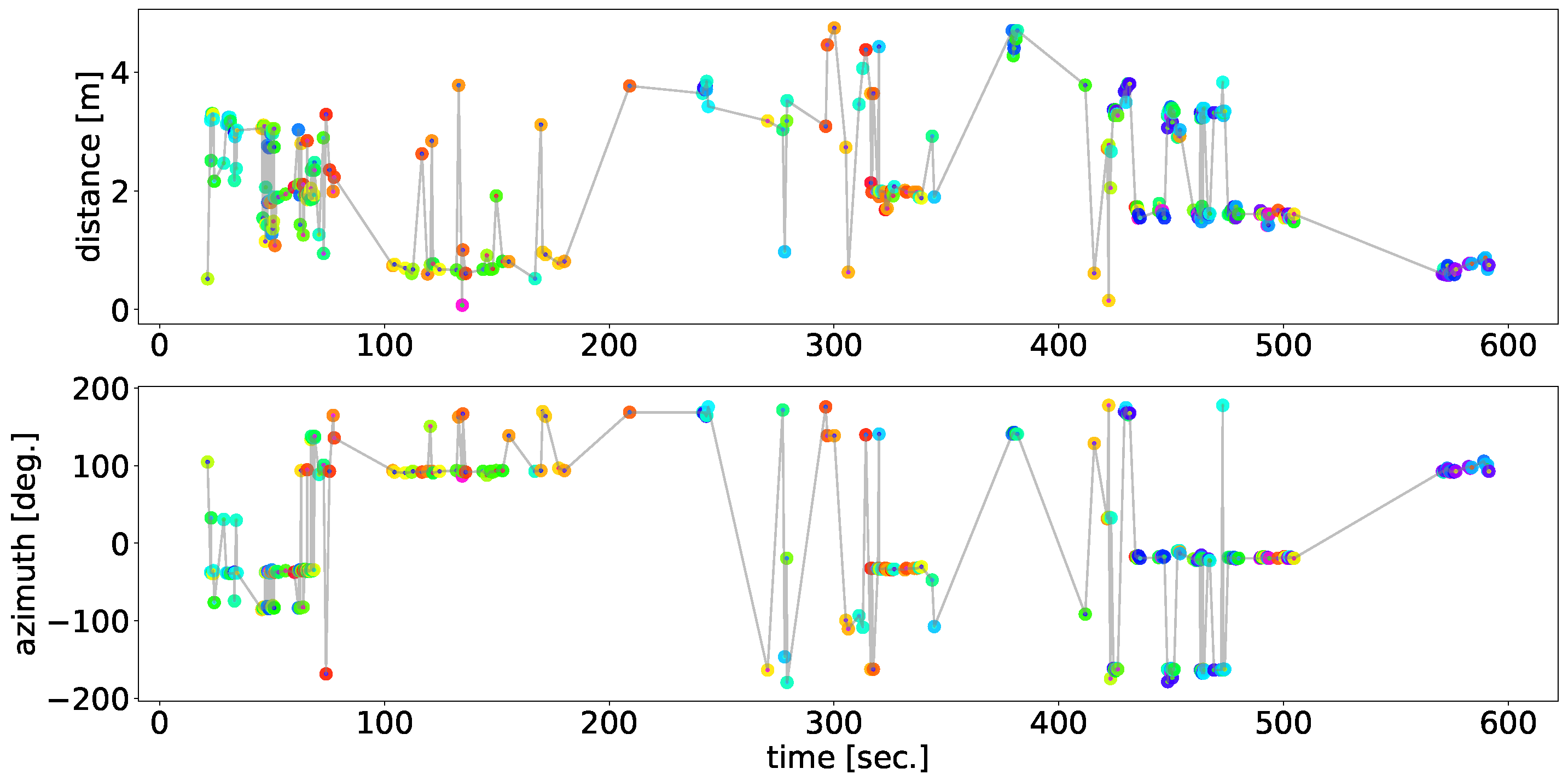
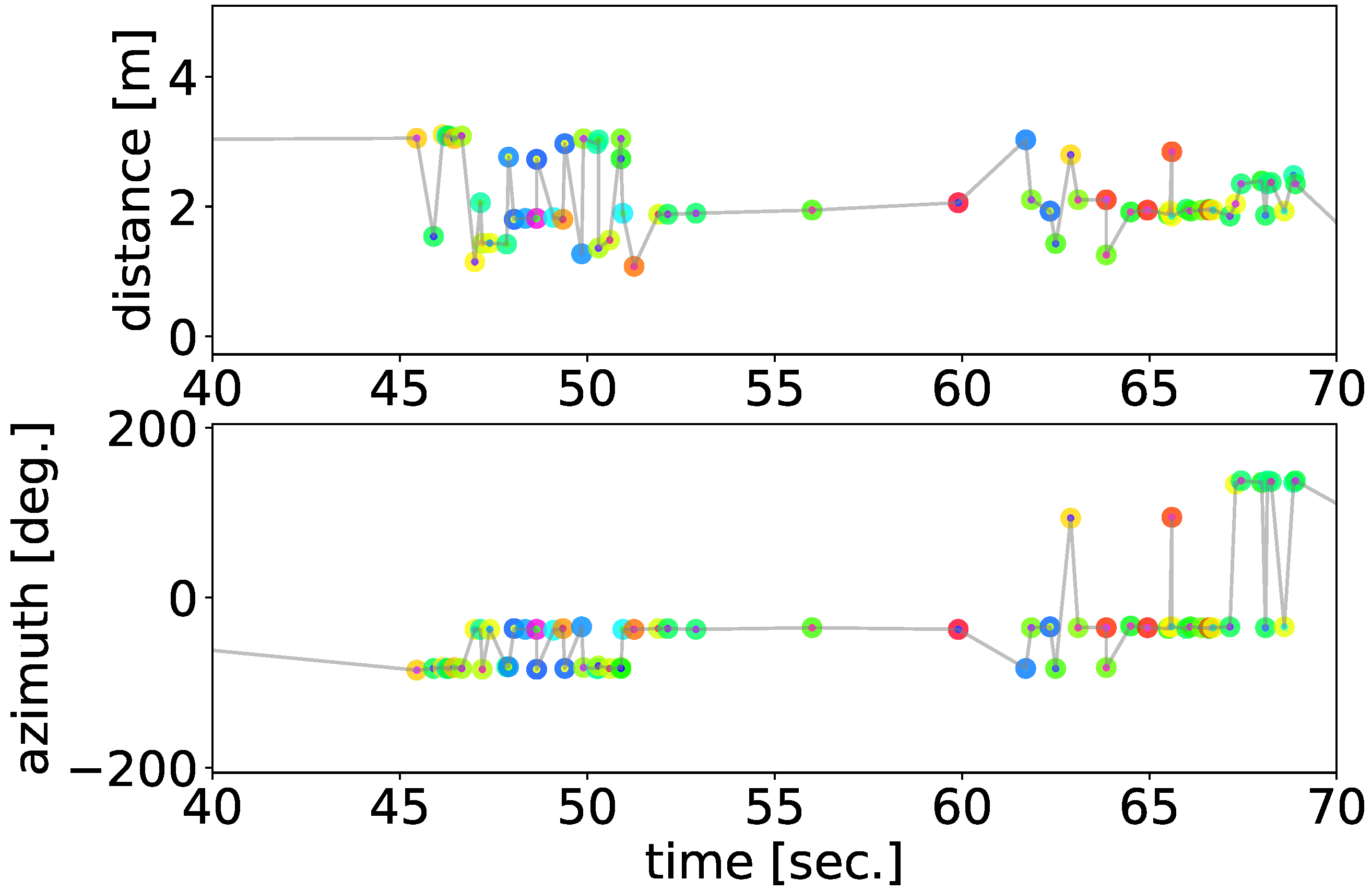
The analysis focused on a 10 min recording captured on 3 June 2019, that included five male individual ZF singing in the experimental environment. All of them were captive-bred individuals chosen from breeding facilities. They had not been familiar with each other and the recording began less than 1 h after the release of the individuals in the tent. Thus, we expected their active vocalizations (e.g., counter-singing between unfamiliar males) within a short time period. The situation in which Zebra Finches are attempting to establish social relationships is a good example for testing the potential of our method to grasp various vocalization patterns. Because these captive-bred birds tend to vocalize close to perches and nests, we expect the observed distribution of vocalizations reflects the spatial structures of perches and nests if the proposed method worked properly.
2.2. HARKBird
HARK is an open-source robot audition software program consisting of multiple modules for sound source localization, sound source separation, and automatic speech recognition of separated sounds that can be applied to any robot with any microphone configuration [
21]. This software platform provides a web-based interface known as HARK designer, which is used for creating real-time signal processing software by composing a network of modules, each corresponding to a signal. We conducted localization and separation of sound sources in the recordings by each microphone array using HARKBird and obtained the DOAs and timings of the localized sound sources. HARKBird runs on Ubuntu Linux in which HARK, HARK-Python, PySide, etc. are installed. The hardware used in our system is commercially available from the developer, including the microphone array we used (TAMAGO, System in Frontier Inc., Tokyo, Japan). The software program is open-source and available online, including both HARKBird (
http://www.alife.cs.i.nagoya-u.ac.jp/~reiji/HARKBird/, accessed on 20 April 2021), and the scripts (
http://www.alife.cs.i.nagoya-u.ac.jp/~sumitani/HARKBird_scripts/, accessed on 20 April 2021) we used in this study.
The employed sound source localization algorithm is based on the multiple signal classification (MUSIC) method [
34] using multiple spectrograms obtained by short-time Fourier transformation (STFT). The MUSIC method is a widely used high-resolution algorithm, and is based on the eigenvalue decomposition of the correlation matrix of multiple signals from a microphone array. All localized sounds are separated the sounds as wave files (16 bit, 16 kHz) using geometric high-order decorrelation-based source separation (GHDSS) [
35].
We briefly reintroduce the basic functions of HARKBird [
25].
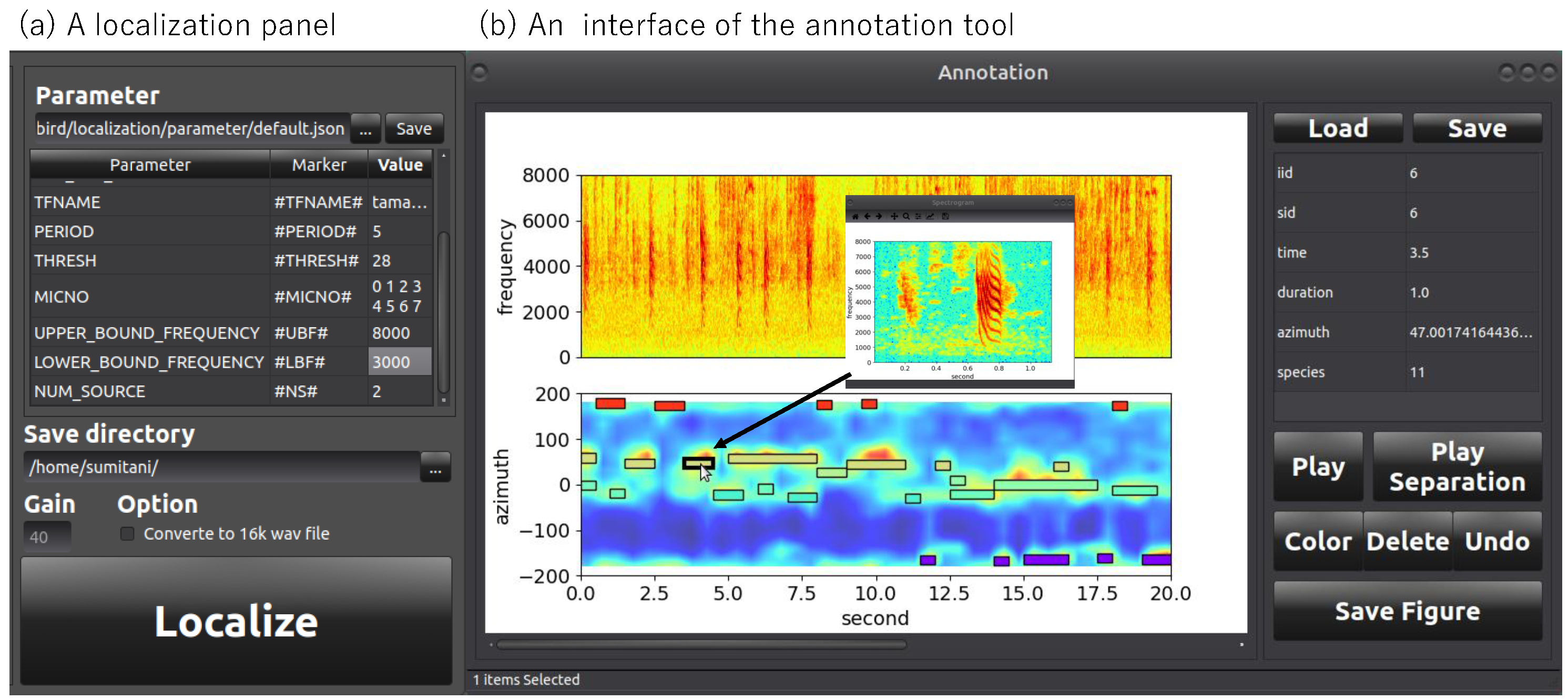
Figure 3 shows the GUI of HARKBird. In the localization panel (a), the user can set specific values of the essential parameters (explained below) related to localization and separation of bird songs using HARK, which are enumerated in a list. Additional parameters can be added to the list by defining the parameter name and the corresponding tag in the network file of HARK. A user can tweak these parameters: this helps to localize the target sound sources (i.e., vocalizations of ZFs) and exclude other noises or unnecessary sounds. This is important because the most appropriate settings depend strongly on the acoustic properties of the environment and the target sounds.This is important because the most appropriate settings depend strongly on the acoustic properties of the environment and the target sounds. The result of the source localization can be checked from the annotation tool interface (b), where both spectrogram and MUSIC spectrum are displayed. The MUSIC spectrum is a vector of values, each represents the power of sound in the corresponding direction. Each colored box represents the time and DOA of a localized sound source. The length of each box indicates the duration of the localization, and the spectrogram of each separated sound pops up and can be replayed by clicking the corresponding box. In addition, the interface also provides editing functions to edit each localization result such as correction of the localization time, duration and direction. Annotations can also be made, and the user can check each localized sound by playing back the separated sound and confirming the spectrogram image.
We used a geometrically computed transfer function, which was needed for sound source localization and separation, generated by a tool for generating and visualizing transfer function, HARKTOOL5. We adopted the values for the parameters: PERIOD (the interval between the frames to perform sound source localization) = 5 (=0.5 s interval), THRESH (the detection threshold of the MUSIC spectrum values for recognizing a sound source) = 28, UPPER(LOWER)_BOUND_FREQUENCY (the upper (lower) bound frequency for the spectrogram to be used in the MUSIC method) = 8000 (3000), and NUM_SOURCE (the number of expected sound sources when calculating the MUSIC spectrum) = 2.
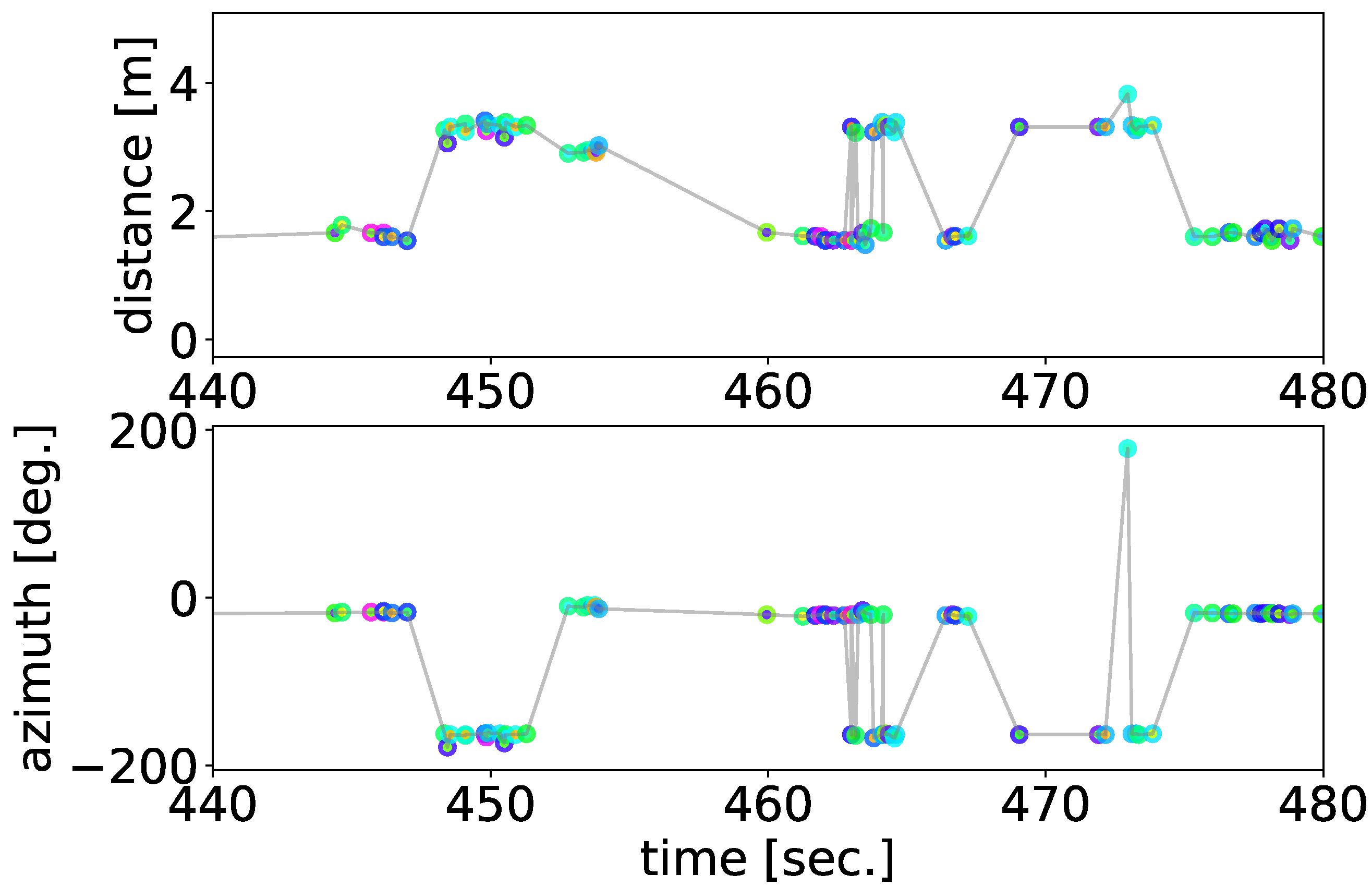
We obtained the localization results of a single recording from each microphone array, as illustrated in
Figure 4. At the period in which the signal of the spectrogram at about 2000–6000 Hz is strong in the top panel of the figure, numerous black bars are displayed in the bottom panel, each indicating a localized sound source. The human inspection confirmed that these localized sounds included almost all vocalizations by the ZF individuals during the recording.
2.3. Spatial Division-Based 2D Localization Using Sound Sources with High Affinity
Algorithm 1 shows the overall procedures of the proposed 2D localization method, and
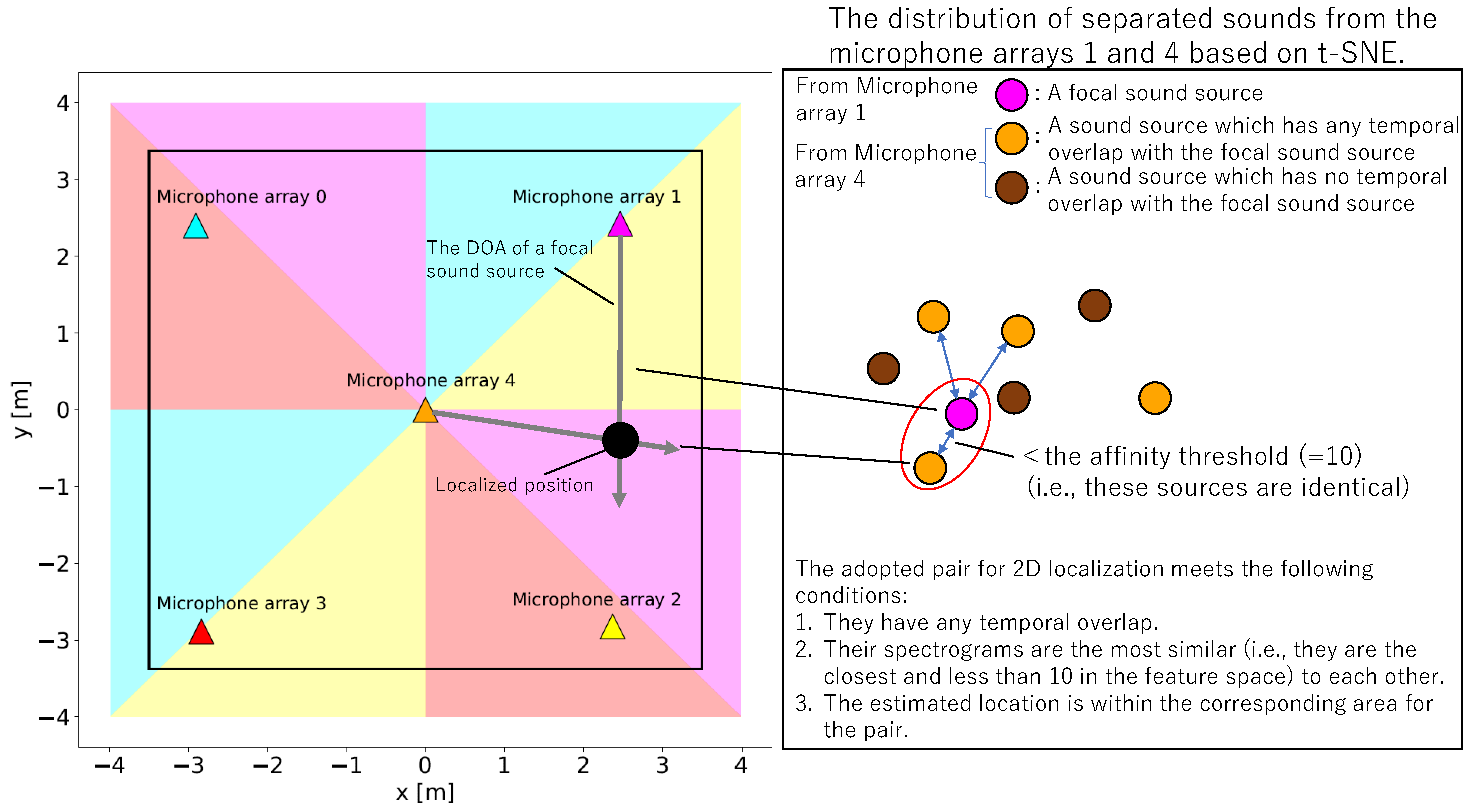
Figure 5 illustrates an example of the 2D localization process. To estimate the spatial positions of the vocalizations, we combined a simple 2D sound localization method based on triangulation of the DOAs of the sound sources using a pair of microphone arrays. Triangulation is a method of determining the location of an object relative to angular measurements made from two other locations. As illustrated in
Figure 5 (left), we extended a half straight line from the position of each microphone array in the direction where the sound source was localized, and created an intersection point as the spatial position of the target source [
36]. A limitation of the standard triangulation described above is that the localization of sources far distant from the two arrays or near the straight line connecting the arrays becomes difficult or unstable due to observation errors in the DOAs [
25].
To address this problem, we divided the entire space in the experimental tent into several areas and selected an appropriate pair of microphone arrays for each area (
Figure 5) to resolve such issues. In each area, we adopted the pair of the microphone array 4 (center) and another corresponding to the color of the area in
Figure 5 (left). This spatial division-based 2D localization enabled us to estimate more accurate positions of the sound sources because each area is close to the corresponding pair of microphone arrays, and, this arrangement avoids the aforementioned localization problem.
| Algorithm 1 Spatial division-based 2D localization. |
Initialize an empty list for keeping localized positions. Initialize an empty list for keeping separated sounds. for each pair of microphone array (the centered and one of the peripheral arrays) do Make a dataset for t-SNE using the separated sounds by two arrays. Conduct t-SNE and obtain the source distribution on the feature space. for each sound source from the peripheral array do Find a separated sound from the centered array which is the closest to on the feature space and has any overlap of localization time to . Calculate the distance between and as . if then Localize the position of the source using their DOAs. if is in the corresponding area of the pair then Append to Append the separated sound of to Create a 2D localization map using . Make a dataset for t-SNE using . Conduct t-SNE using , and obtain the source distribution on the feature space.
|
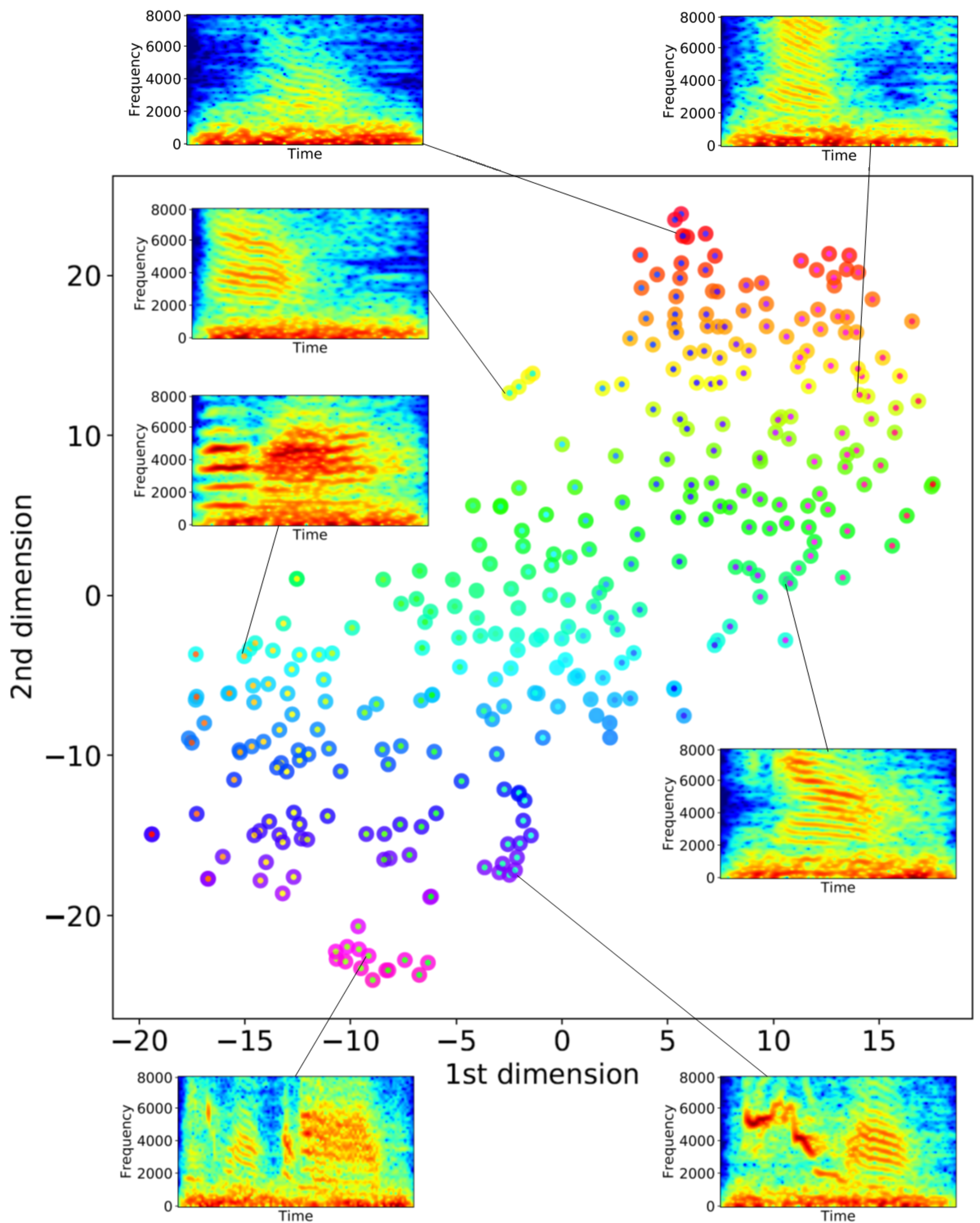
Furthermore, when multiple sources are localized simultaneously, it is necessary to identify a pair of DOA information sets of a unique source from two microphone arrays. Here, we used the t-Distributed Stochastic Neighbor Embedding (t-SNE) dimension reduction algorithm [
37] to select the pair of separated sounds to be localized with similar spectral features (
Figure 5 (right)). t-SNE has a feature to express proximity among data by a probability distribution and it is especially useful for visualizing high dimensional data. We created grey-scale 100 × 64 pixel images of the STFT spectrogram of the separated sounds from the two microphone arrays as a data set for dimension reduction using t-SNE, and we plotted the results on a 2D plane of the resultant feature space. Then, for each spectrogram of the separated sound sources obtained from the peripheral microphone array (0–3), we searched for the separated sound localized by the centered microphone array 4 in the closest proximity to the focal source on the feature space (
Figure 5 (right)). We next conducted 2D localization using the pair of these sources if the distance between them was within 10 on the feature space. From these localization results, we extracted sound sources that were localized in the corresponding area of the pair. For example, in
Figure 5, the DOA of a focal sound source (pink) localized by the microphone array 1 was used for triangulation because there existed a temporally overlapped sound source localized by the microphone array 4 of which the distance from the focal source in the feature space was the smallest and less than 10, and finally the estimated location (black) was within the corresponding area for the pair (pink). This method enabled us to estimate the spatial positions using the information from a unique source without explicit classification. The height of the birds relative to microphone height may affect the accuracy of the localization result. However, we did not take their height into account for sound source localization, assuming that sound sources and the microphone are on the same horizontal plane, for simplicity. This is because the height of the available perches or nests where the ZFs are expected to stay most is set to the same height as the microphone array and thus their movement in the vertical plane is likely much more limited than movement in the horizontal plane.
After estimating the spatial positions of sound sources with each pair, we integrated them and obtained the final result of 2D localization. To eliminate the sound sources outside the tent, we limited the localization range to an area of 4 m at the center of the tent. We regarded the sounds as vocalizations of the ZF individuals and extracted the acoustic features by conducting dimension reduction using t-SNE for the separated sound sources obtained from the recordings of microphone array 4 which was localized in the 2D localization phase. By combining the localization results and the acoustic features, we obtained the integrated spatial, temporal, and spectral dynamics of the vocalizations of the ZF individuals.
2.4. Classification of Vocalization Type
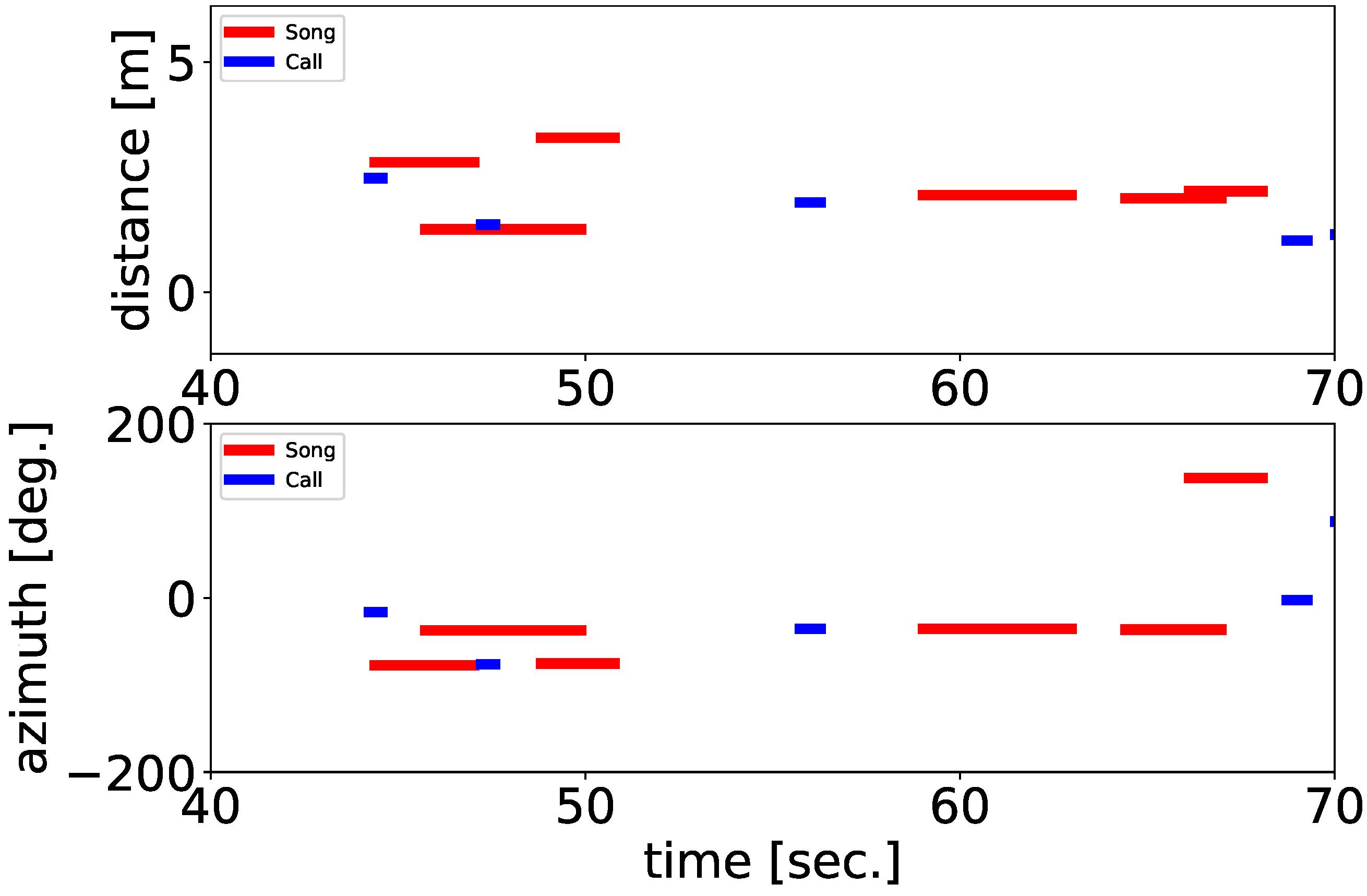
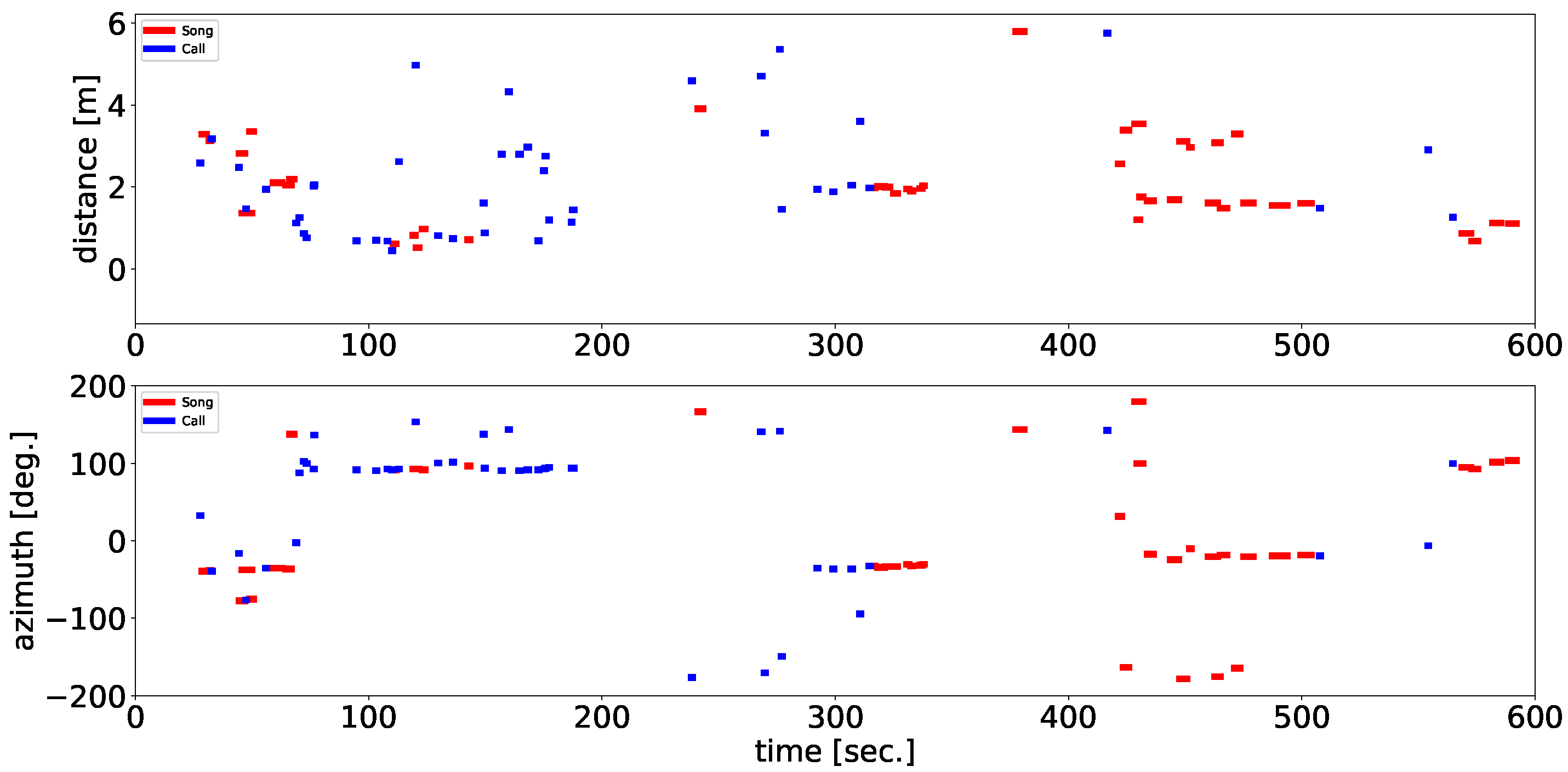
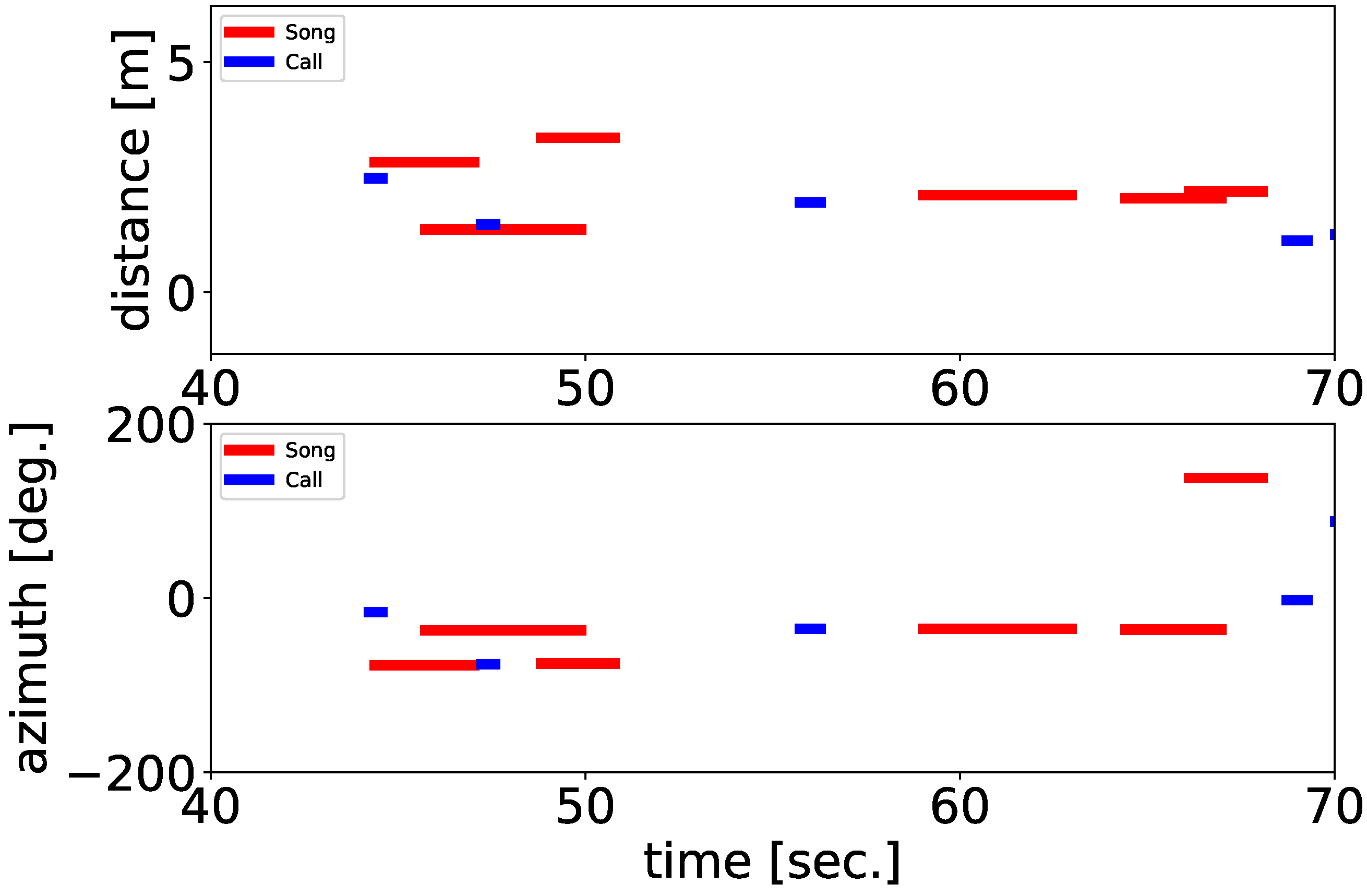
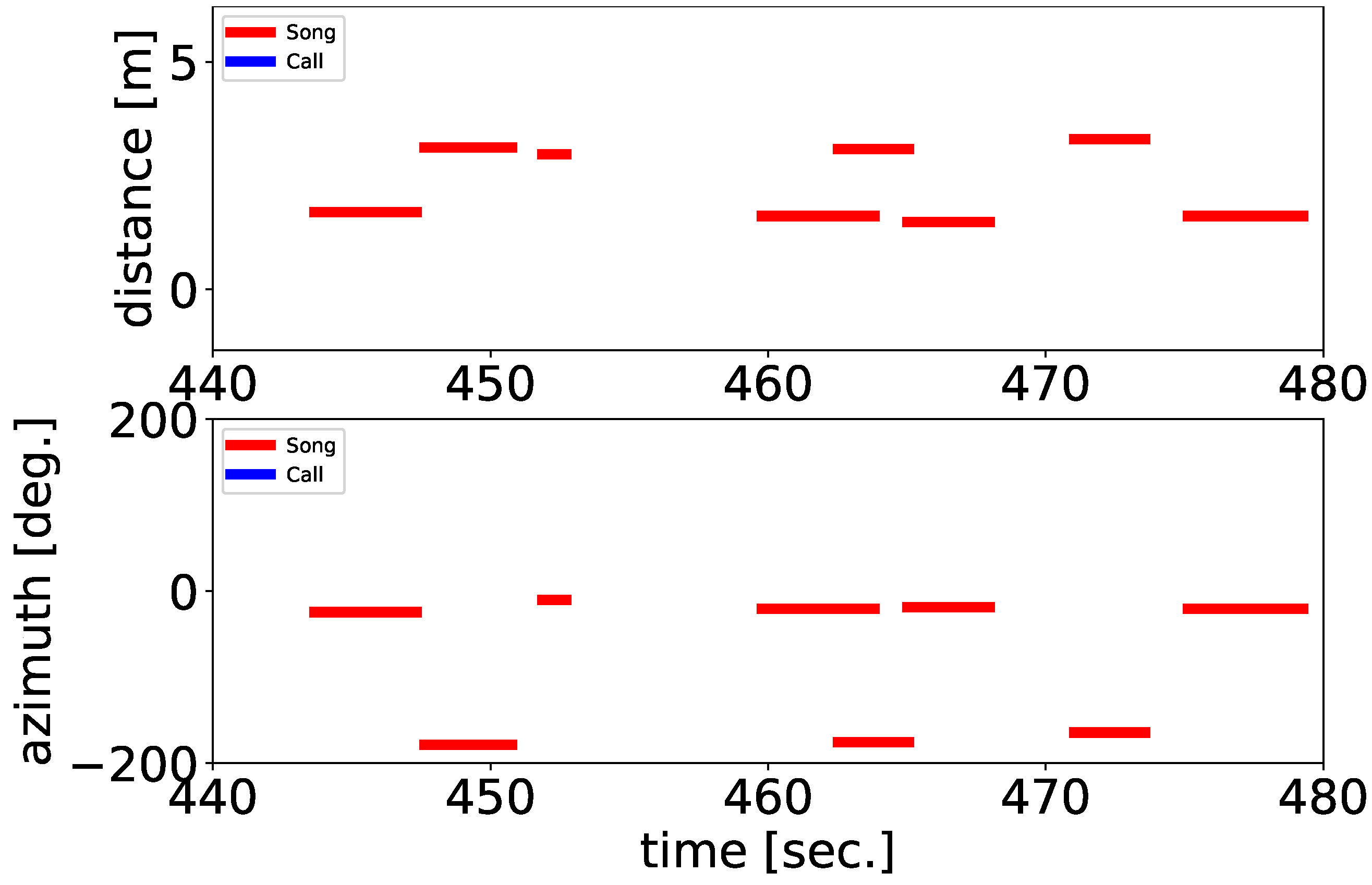
We also classified their vocalizations as either songs or calls by using a simple method based on the tempo and length of the separated sounds, as an example of the use of the information obtained from the framework. As mentioned in the Introduction, songbirds have two vocalization types; are songs and calls. The recordings in our experiments include both songs and calls of the ZFs; classifying them makes it possible to illustrate the details of their interactions. The songs and calls of the ZFs differed significantly in duration and complexity. A song is composed of multiple consecutive syllable structures, whereas a call is a single note. To distinguish between them, we adopted a classification method based on these differences in acoustic properties as follows. First, we conducted sound source localization to better differentiate songs from calls under adjusted parameter settings (PERIOD = 10, THRESH = 28.5) so that a whole song including short breaks between syllables can be localized as a single sound source. Then, we calculated the number of peaks of sound volume and the duration of each separated sound. We regarded them as songs if the duration was longer than 0.8 s and the number of peaks of sound volume was more than four per second; if the separated sounds did not meet both conditions, they were regarded as calls.
4. Conclusions
We proposed a framework based on robot audition techniques for automatic and fine-scale extraction of spatial-spectral-temporal patterns of bird vocalizations in a densely populated environment and examined the ability of the method to extract active vocalizations of multiple ZFs in an outdoor mesh tent as a realistic situation in which they could fly and vocalize freely. In a short 10-minute and proof-of-concept experiment, the proposed localization method enabled us to extract the detailed vocalization positions, which had no spatial limitation within the experimental range. We also automatically classified their vocalizations as either songs or calls, as an example of the use of the information obtained from the framework.
However, there are still several works to be examined to see whether the proposed method can contribute to the understanding of social relationships in a realistic field condition. One is to conduct tests over a longer duration with more subjects and when the birds have had time to settle down. This is because we analyzed the vocalizations occurring so soon after introduction, thus their interactions would hardly be typical of normal, stable sociality.
Another is to compare our results with grand-truth data by direct observations including who is vocalizing, the social context and what the response is. In particular, we need to develop an individual identification method that combines the acoustic properties obtained from microphone arrays and deep learning techniques, by extending the proposed algorithm for the classification of their vocalizations as either songs or calls.
The other is to validate our framework with experiments in a real and wide field situation because this experiment was conducted in a limited space (i.e., a tent). Our framework is itself not limited by the scale (e.g., the number of microphone arrays, and the distance and spatial relationship between them). Thus, conducting more trials in various deployment conditions of microphone arrays will give us knowledge about the broader applicability of this framework.


 ,
, 
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}