
Architectural and Methodological Advancements in Large Language Models †


Abstract
1. Introduction
2. Evolution of Language Models
2.1. Statistical to Neural Transition
2.2. Transformer Era
2.3. Open-Source Initiatives
3. Architectural Innovations and Techniques in Large Language Models
3.1. Mainstream Architectures
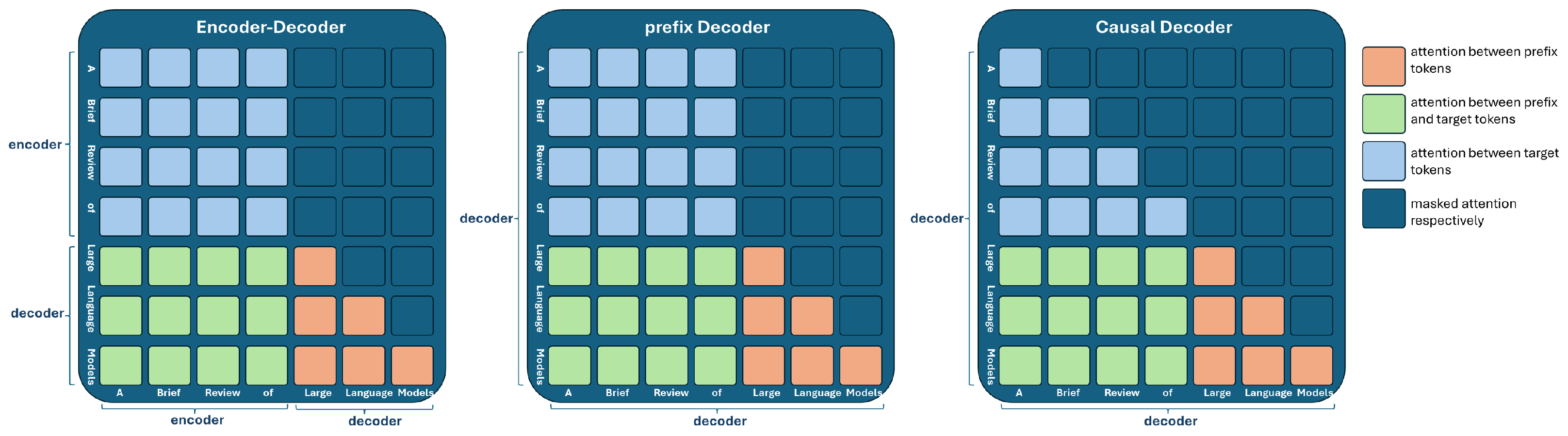
- Encoder–Decoder: Pioneered by Vaswani et al. [8], this architecture is specialized for tasks that necessitate both understanding and generation of sequences. It comprises two main components: an encoder that interprets the input and a decoder that produces the output. Models such as T5 [17] and BART [18] exemplify its effectiveness. (see Figure 1)
- Prefix Decoder: Designed for tasks requiring simultaneous encoding and decoding within a single step [19], prefix decoders blend the capabilities of causal decoders and encoder-decoder models. An example is GLM-130B [20], which combines bidirectional context encoding with autoregressive token prediction. (see Figure 1)
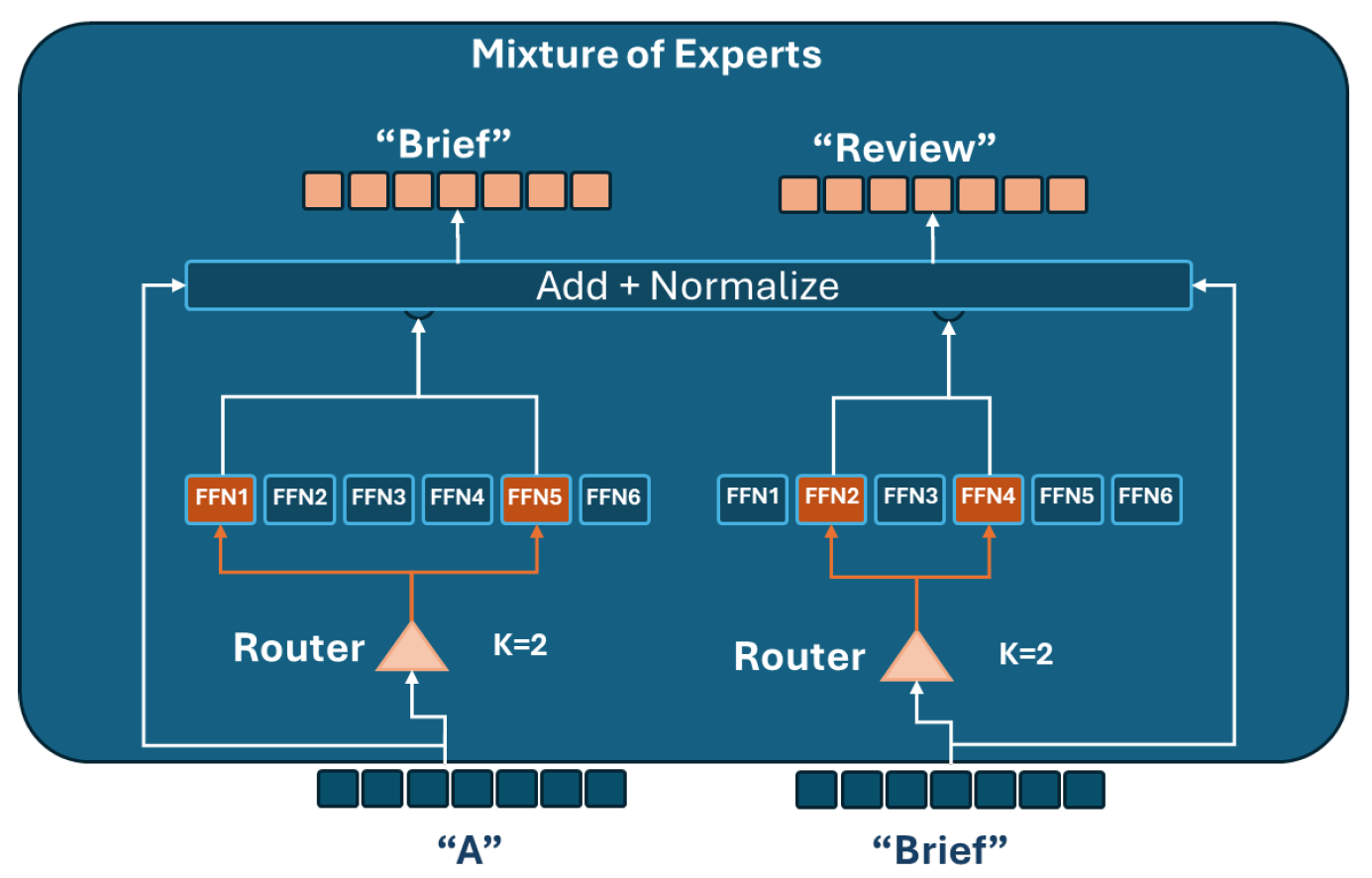
- Mixture-of-Experts (MoE): This approach extends the aforementioned architectures by activating only a subset of expert networks for each input token (see Figure 2). Notable models leveraging MoE include the following:
- –
- Mixtral 8x7B (27 September 2023): A sparse mixture-of-experts model (SMoE) with open weights licensed under Apache 2.0. that outperforms Llama 2 (70 B) on selected benchmarks.
- –
- DeepSeek-V3 (26 December 2024): A large MoE model with 671B parameters, where only 37B parameters are activated for each token, enabling efficient scaling and performance.
3.2. Detailed Configuration
3.2.1. Normalization Methods
3.2.2. Position Embeddings
3.2.3. Activation Functions
3.3. Attention Mechanisms
- Full Attention: The original transformer uses full self-attention, considering all token pairs in a sequence [8].
- Multi-query/Grouped-query Attention: Different heads share parameters for keys and values, aiming to save memory without sacrificing too much in performance [28].
- FlashAttention: Reorganizes the computation to use GPU memory more efficiently, preserving exact attention [29].
- PagedAttention: Splits sequences into non-contiguous blocks to further optimize GPU memory utilization in LLM servers [30].
3.4. Training Strategies for Large Language Models
3.4.1. Optimization Settings
- Batch Training: Stability often depends on batch sizing. GPT-3, for example, scaled from 32 k tokens up to 3.2 M tokens [11].
- Learning-Rate Scheduling: A linear warm-up followed by cosine decay is common.
- Choice of Optimizer: Adam/AdamW with and is standard; Adafactor [31] is also used to reduce memory usage.
3.4.2. Scalable Training Methodologies
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Turing, A.M. Computing Machinery and Intelligence. Mind 1950, 59, 433–460. [Google Scholar] [CrossRef]
- Jelinek, F. Statistical Methods for Speech Recognition; MIT Press: Cambridge, MA, USA, 1998. [Google Scholar]
- Gao, J.; Lin, C. Introduction to the special issue on statistical language modeling. ACM Trans. Asian Lang. Inf. Process. 2004, 3, 87–93. [Google Scholar] [CrossRef]
- Rosenfeld, R. Two decades of statistical language modeling: Where do we go from here? Proc. IEEE 2000, 88, 1270–1288. [Google Scholar] [CrossRef]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the INTERSPEECH, Makuhari, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Kombrink, S.; Mikolov, T.; Karafiát, M.; Burget, L. Recurrent neural network based language modeling in meeting recognition. In Proceedings of the INTERSPEECH, Florence, Italy, 27–31 August 2011; pp. 2877–2880. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the NAACL-HLT, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar]
- Radford, A.; Wu, J.; Child, R.; Luan, D.; Amodei, D.; Sutskever, I. Language models are unsupervised multitask learners. OpenAI Blog 2019, 1, 9. [Google Scholar]
- Brown, T.B.; Mann, B.; Ryder, N.; Subbiah, M.; Kaplan, J.; Dhariwal, P.; Neelakantan, A.; Shyam, P.; Sastry, G.; Askell, A.; et al. Language Models are Few-Shot Learners. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Touvron, H.; Lavril, T.; Izacard, G.; Martinet, X.; Lachaux, M.; Lacroix, T.; Rozière, B.; Goyal, N.; Hambro, E.; Azhar, F.; et al. LLaMA: Open and Efficient Foundation Language Models. arXiv 2023, arXiv:2302.13971. [Google Scholar]
- Chiang, W.-L.; Li, Z.; Lin, Z.; Sheng, Y.; Wu, Z.; Zhang, H.; Hon, H.-W.; Zhang, X. Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90% ChatGPT Quality. Available online: https://lmsys.org/blog/2023-03-30-vicuna/ (accessed on 1 October 2023).
- Hendrycks, D.; Burns, C.; Basart, S.; Zou, A.; Mazeika, M.; Song, D.; Steinhardt, J. Measuring Massive Multitask Language Understanding. In Proceedings of the International Conference on Learning Representations (ICLR), Vienna, Austria, 4–8 May 2021. [Google Scholar]
- Chen, X.; Drori, I.; Pech, H.; Barzilay, R.; Jaakkola, T. Mathematical Language Understanding Evaluation (MATH). arXiv 2021, arXiv:2103.03874. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the ACL, Online, 5–10 July 2020; pp. 7871–7880. [Google Scholar]
- Zhang, A.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.T.; Li, X.; Lin, X.V.; et al. Extending Sequence-to-Sequence Models with Prefix Decoders. arXiv 2022, arXiv:2210.02143. [Google Scholar]
- Zeng, A.; Liu, X.; Du, Z.; Wang, Z.; Lai, H.; Ding, M.; Yang, Z.; Xu, Y.; Zheng, W.; Xia, X.; et al. GLM-130B: An Open Bilingual Pre-trained Model. arXiv 2022, arXiv:2210.02414. [Google Scholar]
- Zhang, B.; Sennrich, R. Root Mean Square Layer Normalization. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Wang, H.; Ma, S.; Dong, L.; Huang, S.; Zhang, D.; Wei, F. DeepNet: Scaling Transformers to 1000 Layers. arXiv 2022, arXiv:2203.00555. [Google Scholar] [CrossRef]
- Anil, R.; Dai, A.M.; Firat, O.; Johnson, M.; Lepikhin, D.; Passos, A.; Shakeri, S.; Taropa, E.; Bailey, P.; Che, Z.; et al. PaLM 2 Technical Report. arXiv 2023, arXiv:2305.10403. [Google Scholar]
- Hendrycks, D.; Gimpel, K. Gaussian Error Linear Units (GELUs). arXiv 2016, arXiv:1606.08415. [Google Scholar]
- Shazeer, N. GLU Variants Improve Transformer. arXiv 2020, arXiv:2002.05202. [Google Scholar]
- Zaheer, M.; Guruganesh, G.; Dubey, K.A.; Ainslie, J.; Alberti, C.; Ontañón, S.; Pham, P.; Ravula, A.; Wang, Q.; Yang, L.; et al. Big Bird: Transformers for Longer Sequences. In Proceedings of the Advances in Neural Information Processing Systems, Online, 6–12 December 2020. [Google Scholar]
- Child, R.; Gray, S.; Radford, A.; Sutskever, I. Generating Long Sequences with Sparse Transformers. arXiv 2019, arXiv:1904.10509. [Google Scholar]
- Shazeer, N. Fast Transformer Decoding: One Write-Head is All You Need. arXiv 2019, arXiv:1911.02150. [Google Scholar]
- Dao, T.; Fu, D.Y.; Ermon, S.; Rudra, A.; Ré, C. FlashAttention: Fast and Memory-Efficient Exact Attention with IO-Awareness. In Proceedings of the Advances in Neural Information Processing Systems, New Orleans, LA, USA, 28 November–9 December 2022. [Google Scholar]
- vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention. Available online: https://vllm.ai/ (accessed on 1 October 2023).
- Shazeer, N.; Stern, M. Adafactor: Adaptive Learning Rates with Sublinear Memory Cost. In Proceedings of the ICML, Stockholm, Sweden, 10–15 July 2018; pp. 4596–4604. [Google Scholar]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the Difficulty of Training Recurrent Neural Networks. In Proceedings of the ICML, Atlanta, GA, USA, 16–21 June 2013; pp. 1310–1318. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled Weight Decay Regularization. arXiv 2017, arXiv:1711.05101. [Google Scholar]
- Shoeybi, M.; Patwary, R.; Puri, R.; LeGresley, P.; Casper, J.; Catanzaro, B. Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism. arXiv 2019, arXiv:1909.08053. [Google Scholar]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, D.; Chen, M.X.; Lee, H.; Ngiam, J.; Le, Q.V.; Wu, Y.; et al. GPipe: Efficient Training of Giant Neural Networks Using Pipeline Parallelism. arXiv 2019, arXiv:1811.06965. [Google Scholar]
- Harlap, A.; Narayanan, D.; Phanishayee, A.; Seshadri, V.; Devanur, N.R.; Ganger, G.R.; Zaharia, M. PipeDream: Fast and Efficient Pipeline Parallel DNN Training. arXiv 2018, arXiv:1806.03377. [Google Scholar]
- Rajbhandari, S.; Rasley, J.; Ruwase, O.; He, Y. ZeRO: Memory Optimizations Toward Training Trillion Parameter Models. In Proceedings of the SC20, Atlanta, GA, USA, 9–19 November 2020; pp. 1–16. [Google Scholar]
- Micikevicius, P.; Narang, S.; Alben, J.; Diamos, G.; Elsen, E.; Garcia, D.; Ginsburg, B.; Houston, M.; Kuchaiev, O.; Venkatesh, G.; et al. Mixed Precision Training. In Proceedings of the ICLR, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]

{kind=link}
{kind=link}
| Benchmark | DeepSeek-V3 | Qwen2.5-72B-Inst | Llama-3.1-405B-Inst | GPT-4 | GPT-3.5 (0-shot CoT) | Claude-3.5 |
|---|---|---|---|---|---|---|
| MMLU [15] (EM) | 75.9 | 71.6 | 73.3 | 72.6 | – | 78.0 |
| GPQA-Diamond (pass@1) | 59.1 | 49.0 | 51.1 | 49.9 | 77.3 | 65.0 |
| MATH 500 [16] (EM) | 90.2 | 80.0 | 73.8 | 74.6 | 94.8 | 78.3 |
| AIME 2024 (pass@1) | 39.2 | 23.3 | 23.3 | 9.3 | 74.4 | 16.0 |
| Codeforces (percentile) | 51.6 | 24.8 | 25.3 | 23.6 | 86.0 | 20.3 |
| SWE-bench (Resolved) | 42.0 | 23.8 | 23.8 | 38.8 | – | 50.8 |
| Model | Size | Category | Normalization | PE | Activation |
|---|---|---|---|---|---|
| DeepSeek-V3 | 671 B | Causal decoder | Pre-LayerNorm | Learned | SwiGLU |
| Qwen2.5-72B-Inst | 72 B | Causal decoder | RMSNorm | RoPE | SwiGLU |
| Llama-3.1-405B-Inst | 405 B | Causal decoder | RMSNorm | RoPE | SwiGLU |
| GPT-4 | 500 B | Causal decoder | Pre-LayerNorm | Learned | GeLU |
| GPT-3.5 | 175 B | Causal decoder | Pre-LayerNorm | Learned | GeLU |
| Claude-3.5 | 100 B | Causal decoder | Pre-LayerNorm | RoPE | SwiGLU |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zaza, Z.; Souissi, O. Architectural and Methodological Advancements in Large Language Models. Eng. Proc. 2025, 97, 8. https://doi.org/10.3390/engproc2025097008
Zaza Z, Souissi O. Architectural and Methodological Advancements in Large Language Models. Engineering Proceedings. 2025; 97(1):8. https://doi.org/10.3390/engproc2025097008
Chicago/Turabian StyleZaza, Zakaria, and Omar Souissi. 2025. "Architectural and Methodological Advancements in Large Language Models" Engineering Proceedings 97, no. 1: 8. https://doi.org/10.3390/engproc2025097008
APA StyleZaza, Z., & Souissi, O. (2025). Architectural and Methodological Advancements in Large Language Models. Engineering Proceedings, 97(1), 8. https://doi.org/10.3390/engproc2025097008