
Federated Learning-Based Framework: A New Paradigm Proposed for Supply Chain Risk Management †

 ,
,  , , , , and
, , , , and
Abstract
:1. Introduction
2. Background and Related Works
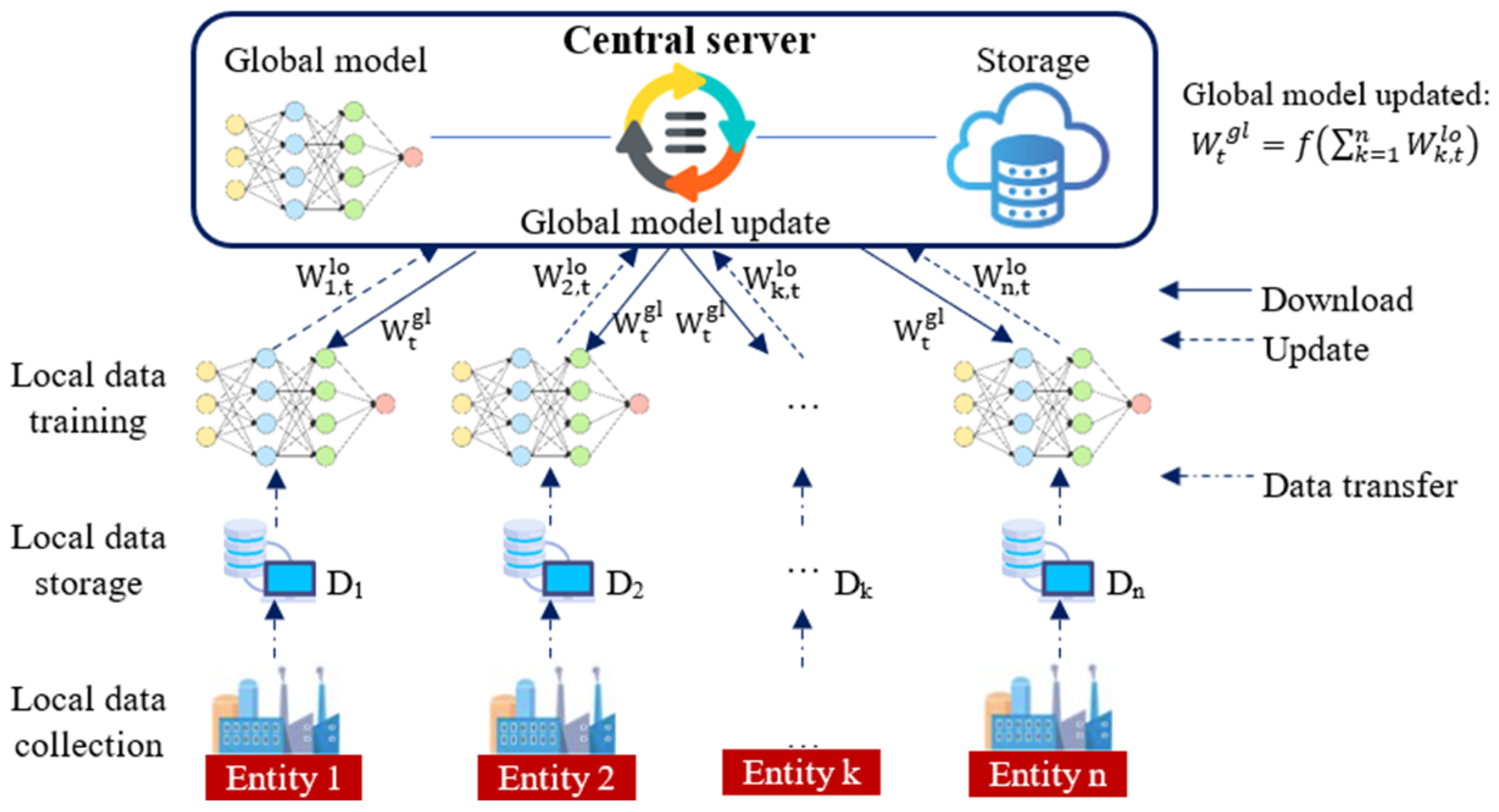
3. Federated Learning and Taxonomy
3.1. Centralized Federated Learning
3.2. Decentralized Federated Learning
3.3. Semi-Centralized Federated Learning
3.4. Semi-Decentralized Federated Learning
3.5. Data in FL
4. An Experiment: Predicting the Delivery Risk in the Textile Supply Chain
4.1. Data Description
4.2. Model Setting and Performance Metrics
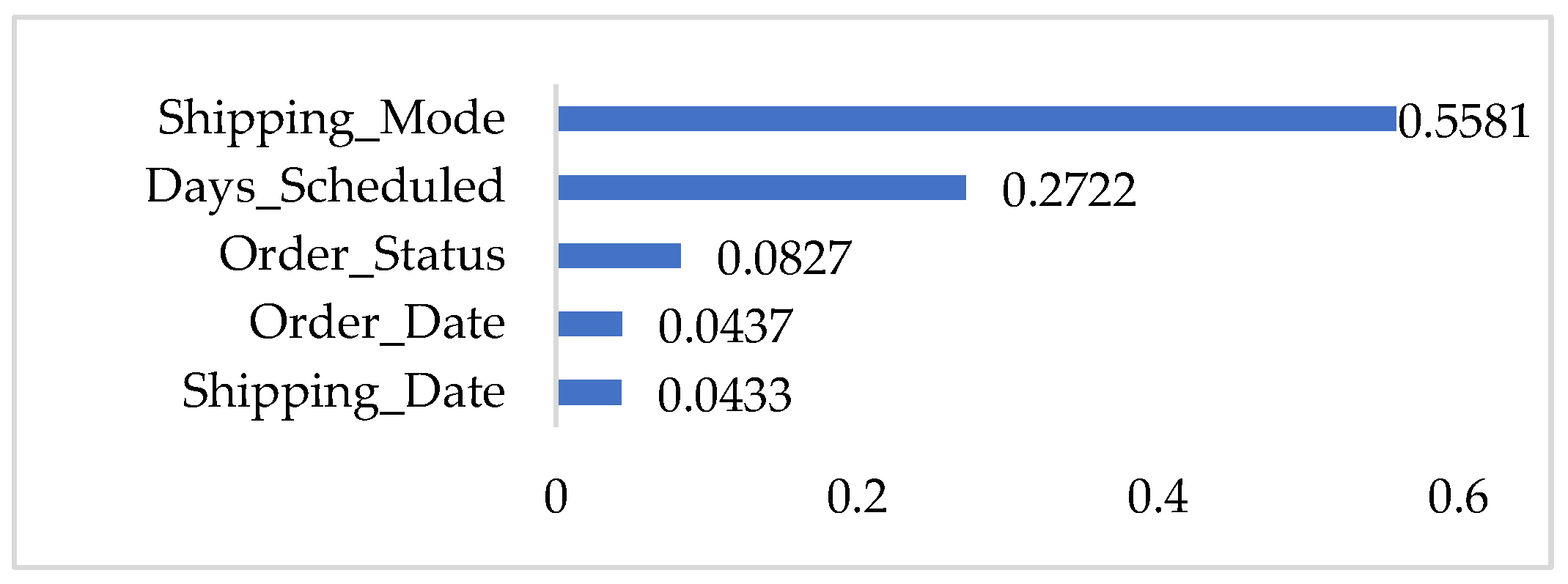
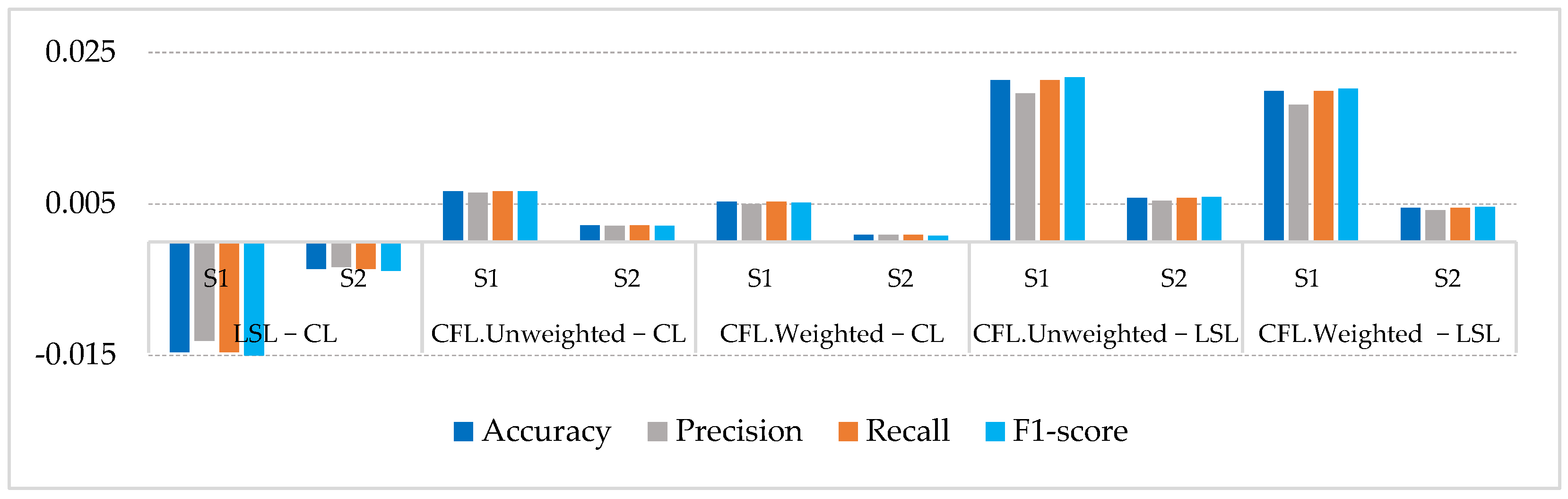
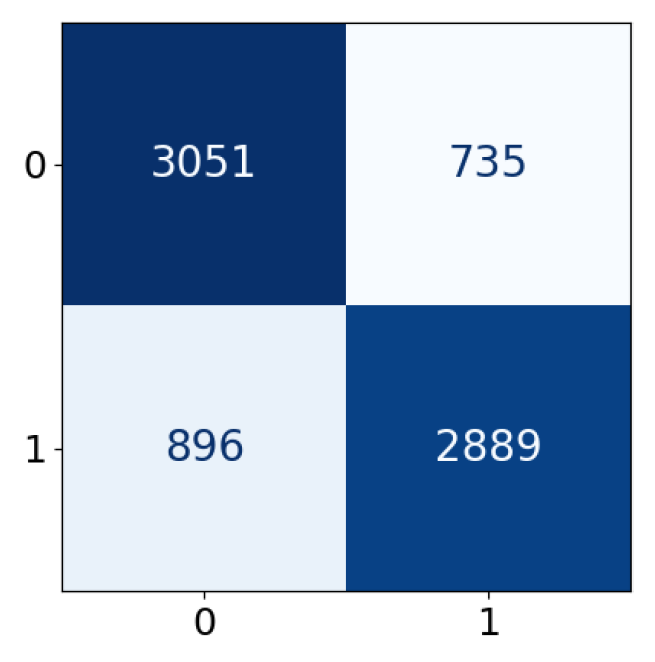
4.3. Results and Discussion
5. Conclusions
Limitations and Further Study
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Xu, Z.; Ni, W.; Liu, S.; Wang, F.; Li, J. Logistics Supply Chain Network Risk Prediction Model Based on Intelligent Random Forest Model. IEEE Trans. Eng. Manag. 2024, 71, 9813–9825. [Google Scholar] [CrossRef]
- Kumar, S.K.; Tiwari, M.K.; Babiceanu, R.F. Minimisation of supply chain cost with embedded risk using computational intelligence approaches. Int. J. Prod. Res. 2010, 48, 3717–3739. [Google Scholar] [CrossRef]
- Niemi, T.; Hameri, A.-P.; Kolesnyk, P.; Appelqvist, P. What is the value of delivering on time? JAMR 2020, 17, 473–503. [Google Scholar] [CrossRef]
- Chen, C.; Gu, T.; Cai, Y.; Yang, Y. Impact of supply chain information sharing on performance of fashion enterprises: An empirical study using SEM. J. Enterp. Inf. Manag. 2019, 32, 913–935. [Google Scholar] [CrossRef]
- Mehrjoo, M.; Pasek, Z.J. Risk assessment for the supply chain of fast fashion apparel industry: A system dynamics framework. Int. J. Prod. Res. 2016, 54, 28–48. [Google Scholar] [CrossRef]
- Nguyen, T.T.; Bekrar, A.; Le, T.M.; Artiba, A.; Chargui, T.; Trinh, T.T.H. Federated Machine Learning in Supply Chain Risk Management: Insights from A Review Using Systematic Method and Future Research Prospects. In Proceedings of the 2024 International Conference of the African Federation of Operational Research Societies (AFROS), Tlemcen, Algeria, 3–5 November 2024. [Google Scholar]
- Zheng, G.; Kong, L.; Brintrup, A. Federated machine learning for privacy preserving, collective supply chain risk prediction. Int. J. Prod. Res. 2023, 61, 8115–8132. [Google Scholar] [CrossRef]
- Arbaoui, M.; Brahmia, M.-A.; Rahmoun, A.; Zghal, M. Federated Learning Survey: A Multi-Level Taxonomy of Aggregation Techniques, Experimental Insights, and Future Frontiers. ACM Trans. Intell. Syst. Technol. 2024, 15, 1–69. [Google Scholar] [CrossRef]
- Kong, L.; Zheng, G.; Brintrup, A. A federated machine learning approach for order-level risk prediction in Supply Chain Financing. Int. J. Prod. Econ. 2024, 268, 109095. [Google Scholar] [CrossRef]
- Zheng, G.; Ivanov, D.; Brintrup, A. An adaptive federated learning system for information sharing in supply chains. Int. J. Prod. Res. 2024, 1–23. [Google Scholar] [CrossRef]
- Ho, W.; Zheng, T.; Yildiz, H.; Talluri, S. Supply chain risk management: A literature review. Int. J. Prod. Res. 2015, 53, 5031–5069. [Google Scholar] [CrossRef]
- Bouchetara, M.; Zerouti, M.; Zouambi, A.R. Leveraging Artificial In℡ligence (ai) in Public Sector Financial Risk Management: Innovations, Challenges, and Future Directions. EDPACS 2024, 69, 124–144. [Google Scholar] [CrossRef]
- Yuan, S.; Pan, X. The effects of digital technology application and supply chain management on corporate circular economy: A dynamic capability view. J. Environ. Manag. 2023, 341, 118082. [Google Scholar] [CrossRef]
- Rezki, N.; Mansouri, M. Machine Learning for Proactive Supply Chain Risk Management: Predicting Delays and Enhancing Operational Efficiency. Manag. Syst. Prod. Eng. 2024, 32, 345–356. [Google Scholar] [CrossRef]
- Du, T.C.; Lai, V.S.; Cheung, W.; Cui, X. Willingness to share information in a supply chain: A partnership-data-process perspective. Inf. Manag. 2012, 49, 89–98. [Google Scholar] [CrossRef]
- Haq, M.Z. How does the General Data Protection Regulation (GDPR) affect financial intelligence exchange with third countries? J. Money Laund. Control 2022, 27, 158–170. [Google Scholar] [CrossRef]
- Li, L.; Fan, Y.; Tse, M.; Lin, K.-Y. A review of applications in federated learning. Comput. Ind. Eng. 2020, 149, 106854. [Google Scholar] [CrossRef]
- Cao, M.; Zhang, Q. Supply chain collaborative advantage: A firm’s perspective. Int. J. Prod. Econ. 2010, 128, 358–367. [Google Scholar] [CrossRef]
- Yang, W.; Zhang, Y.; Ye, K.; Li, L.; Xu, C.-Z. FFD: A Federated Learning Based Method for Credit Card Fraud Detection. In Big Data—BigData 2019; Chen, K., Seshadri, S., Zhang, L.-J., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 18–32. [Google Scholar] [CrossRef]
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A.Y. Communication-Efficient Learning of Deep Networks from Decentralized Data. In Proceedings of the 20th International Conference on Artificial Intelligence and Statistics, PMLR, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. Available online: https://proceedings.mlr.press/v54/mcmahan17a.html (accessed on 6 January 2025).
- Sattler, F.; Müller, K.-R.; Samek, W. Clustered Federated Learning: Model-Agnostic Distributed Multitask Optimization Under Privacy Constraints. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3710–3722. [Google Scholar] [CrossRef]
- Medjadji, C.; Leduc, G.; Kubler, S.; Traon, Y.L. Centralized vs Decentralized Federated Learning: A trade-off performance analysis. In Proceedings of the 2024 11th International Conference on Future Internet of Things and Cloud (FiCloud), Vienna, Austria, 19–21 August 2024; pp. 69–76. [Google Scholar] [CrossRef]
- Li, T.; Sahu, A.K.; Talwalkar, A.; Smith, V. Federated Learning: Challenges, Methods, and Future Directions. IEEE Signal Process. Mag. 2020, 37, 50–60. [Google Scholar] [CrossRef]
- Liu, F.; Zheng, Z.; Shi, Y.; Tong, Y.; Zhang, Y. A survey on federated learning: A perspective from multi-party computation. Front. Comput. Sci. 2023, 18, 181336. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated Machine Learning: Concept and Applications. arXiv 2019, arXiv:1902.04885. [Google Scholar] [CrossRef]
- Constante, F.; Silva, F.; Pereira, A. DataCo Smart Supply Chain for Big Data Analysis. Mendeley Data 2019, 5. [Google Scholar] [CrossRef]
- Tang, Z.; Zhang, Y.; Shi, S.; He, X.; Han, B.; Chu, X. Virtual Homogeneity Learning: Defending against Data Heterogeneity in Federated Learning. arXiv 2022, arXiv:2206.02465. [Google Scholar] [CrossRef]
- Hudnurkar, M.; Renji, K.M.; Ambekar, S.; Sahu, G.; Joseph, K.M. Predicting Delays for Truck Delivery Logistics: An Application of AI and ML. In Proceedings of the 2024 Ninth International Conference on Science Technology Engineering and Mathematics (ICONSTEM), Chennai, India, 4–5 April 2024; pp. 1–10. [Google Scholar] [CrossRef]
- Albahr, A.; Albahar, M.; Thanoon, M.; Binsawad, M. Computational Learning Model for Prediction of Heart Disease Using Machine Learning Based on a New Regularizer. Comput. Intell. Neurosci. 2021, 2021, 8628335. [Google Scholar] [CrossRef]
- Shingi, G. A federated learning based approach for loan defaults prediction. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020; pp. 362–368. [Google Scholar] [CrossRef]
- Divya, M.; Jasmine, K.S. Comparative Study of Federated Learning Vs Centralized Learning. Grenze Int. J. Eng. Technol. 2024, 1004–1012. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Description | Data Type |
|---|---|---|
| Scheduled_Days | Days of scheduled delivery of the purchased product | Numeric |
| Actual_Days | Actual shipping days of the purchased product | Numeric |
| Delivery_Risk | ∆DR represents the difference between “Actual_Days” and “Scheduled_Days” with a value of 1 for “Late” and 0 for “On-time”. | Numeric |
| Order_Date | The date on which the order is made | Date/Time |
| Shipping_Date | The exact date and time of shipment | Date/Time |
| Order_Status | Status of an order delivery includes complete, pending, closed, pending payment, canceled, processing, suspected fraud, on hold, and payment review | Categorical |
| Shipping_Mode | The following shipping modes are presented: Standard class, first class, second class, and same day | Categorical |
| Kolmogorov–Smirnov (K-S) Test : The Distributions of the Two Datasets Are Identical | Chi-Square Test : The Distributions of the Two Datasets Are Identical | |||||
|---|---|---|---|---|---|---|
| Features | Scheduled_Days | Delivery_Risk | Order_Date | Shipping_Date | Order_Status | Shipping_Mode |
| Test Statistic | 0.0031 | 0.0001 | 0.0217 | 0.0216 | 9.5394 | 1.7707 |
| p-value | 0.9999 | 1.0 | 0.0011 | 0.0012 | 0.2988 | 0.6213 |
| Layer | Units | Activation Function | Regularization | Remarks |
|---|---|---|---|---|
| Dense Layer 1 | 32 | ReLU | L2 regularization (0.0001) | First hidden layer |
| Dense Layer 2 | 16 | ReLU | L2 regularization (0.0001) | Second hidden layer |
| Dense Layer 3 | 8 | ReLU | L2 regularization (0.0001) | Third hidden layer |
| Output Layer | 1 | Sigmoid | - | Binary classification (0 or 1) |
| 1: | Initialize the global model weights in the main server |
| 2: | to all entities |
| 3: | For each round |
| 4: | Each entity receives the global model: |
| 5: | Each entity k locally trains ANN model: . |
| 6: | The entity k sends the updated local model to the main server. |
| 7: | Aggregate local weights: . |
| 8: | to all entities for the next round. |
| 9: | Repeat until t = T. |
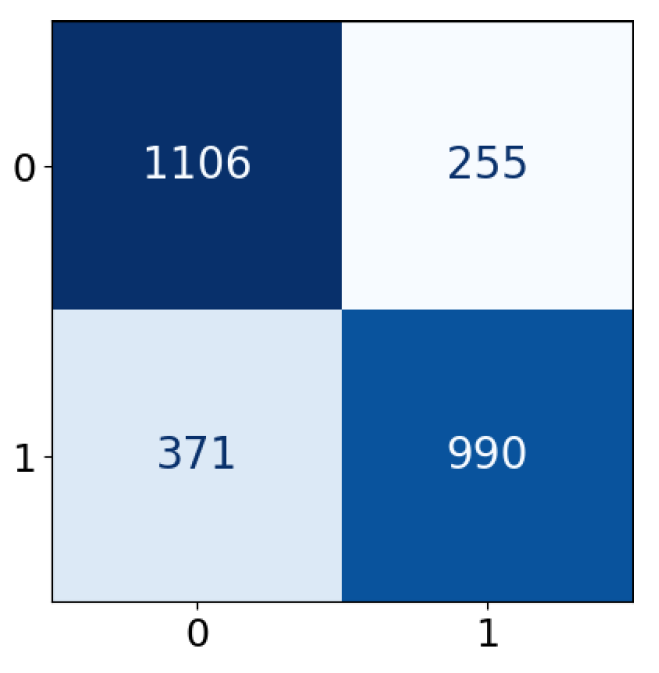
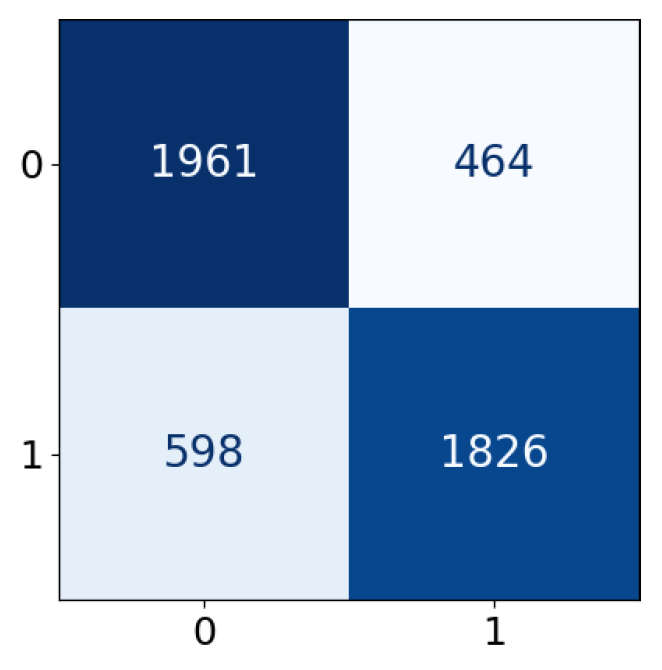
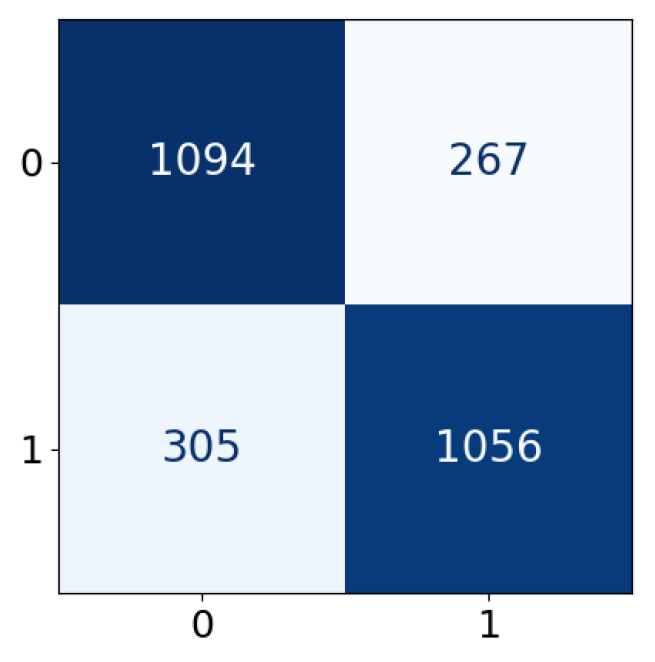
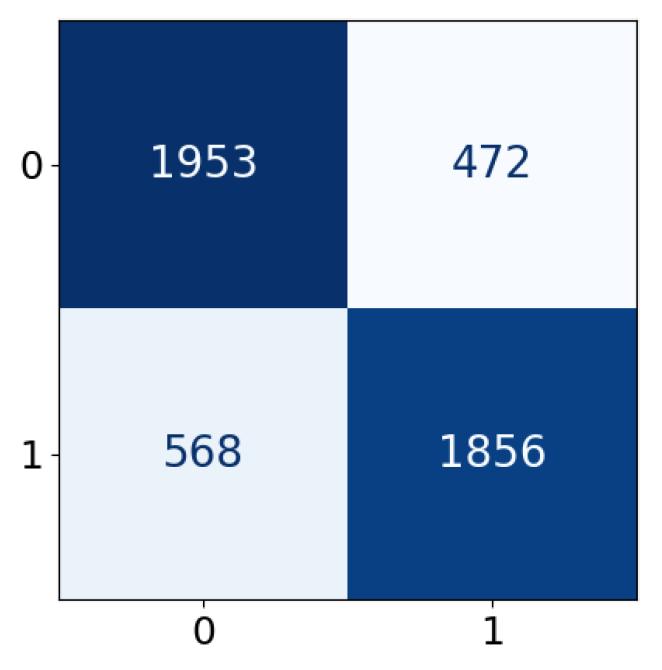
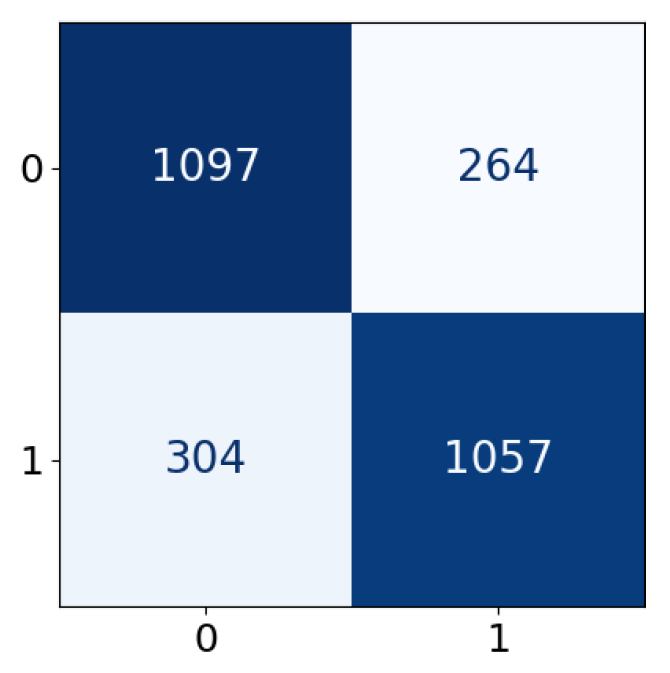
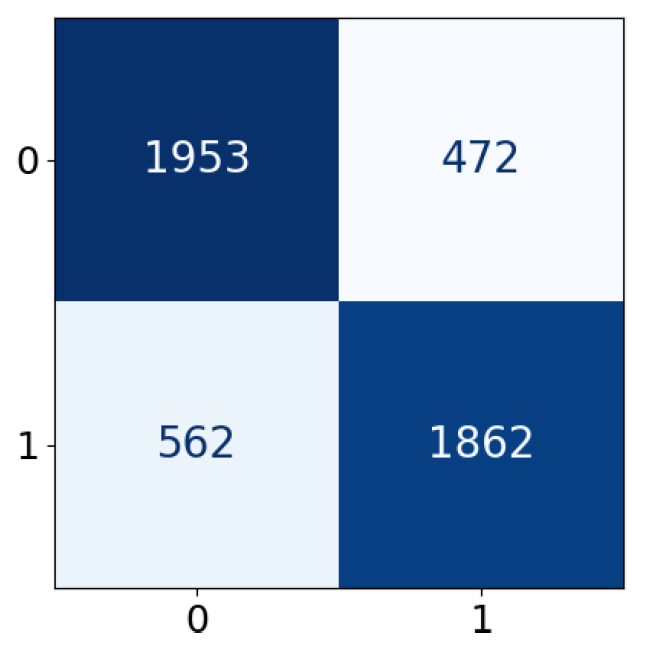
| Predicted label | |||
| Positive | Negative | ||
| True label | Positive | True Positive (TP) | False Negative (FN) |
| Negative | False Positive (FP) | True Negative (TN) | |
| Metrics | CL | LSL | CFL.Weighted | CFL.Unweighted | |||
|---|---|---|---|---|---|---|---|
| S1 | S2 | S1 | S2 | S1 | S2 | ||
| Accuracy | 0.7846 | 0.7700 | 0.7810 | 0.7899 | 0.7855 | 0.7913 | 0.7868 |
| Precision | 0.7851 | 0.7720 | 0.7818 | 0.7901 | 0.7860 | 0.7916 | 0.7872 |
| Recall | 0.7846 | 0.7700 | 0.7810 | 0.7899 | 0.7855 | 0.7913 | 0.7868 |
| F1-score | 0.7846 | 0.7696 | 0.7808 | 0.7898 | 0.7854 | 0.7913 | 0.7867 |
| Metrics | CL | LSL | CFL.Weighted | CFL.Unweighted | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| S1 | S2 | S1 | S2 | S1 | S2 | |||||||||
| On-Time | Late | On-Time | Late | On-Time | Late | On-Time | Late | On-Time | Late | On-Time | Late | On-Time | Late | |
| Precision | 0.7730 | 0.7972 | 0.7488 | 0.7952 | 0.7663 | 0.7974 | 0.7820 | 0.7982 | 0.7747 | 0.7973 | 0.7830 | 0.8002 | 0.7765 | 0.7978 |
| Recall | 0.8059 | 0.7633 | 0.8126 | 0.7274 | 0.8087 | 0.7533 | 0.8038 | 0.7759 | 0.8054 | 0.7657 | 0.8060 | 0.7766 | 0.8054 | 0.7682 |
| F1-score | 0.7891 | 0.7799 | 0.7794 | 0.7598 | 0.7869 | 0.7747 | 0.7928 | 0.7869 | 0.7897 | 0.7811 | 0.7944 | 0.7882 | 0.7907 | 0.7827 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nguyen, T.T.; Bekrar, A.; Le, T.M.; Artiba, A.; Chargui, T.; Trinh, T.T.H.; Snoun, A. Federated Learning-Based Framework: A New Paradigm Proposed for Supply Chain Risk Management. Eng. Proc. 2025, 97, 5. https://doi.org/10.3390/engproc2025097005
Nguyen TT, Bekrar A, Le TM, Artiba A, Chargui T, Trinh TTH, Snoun A. Federated Learning-Based Framework: A New Paradigm Proposed for Supply Chain Risk Management. Engineering Proceedings. 2025; 97(1):5. https://doi.org/10.3390/engproc2025097005
Chicago/Turabian StyleNguyen, Thanh Tuan, Abdelghani Bekrar, Thi Muoi Le, Abdelhakim Artiba, Tarik Chargui, Thi Thu Huong Trinh, and Ahmed Snoun. 2025. "Federated Learning-Based Framework: A New Paradigm Proposed for Supply Chain Risk Management" Engineering Proceedings 97, no. 1: 5. https://doi.org/10.3390/engproc2025097005
APA StyleNguyen, T. T., Bekrar, A., Le, T. M., Artiba, A., Chargui, T., Trinh, T. T. H., & Snoun, A. (2025). Federated Learning-Based Framework: A New Paradigm Proposed for Supply Chain Risk Management. Engineering Proceedings, 97(1), 5. https://doi.org/10.3390/engproc2025097005