
Speech Delay Assistive Device for Speech-to-Text Transcription Based on Machine Learning †

 ,
,
Abstract
1. Introduction
2. Methodology
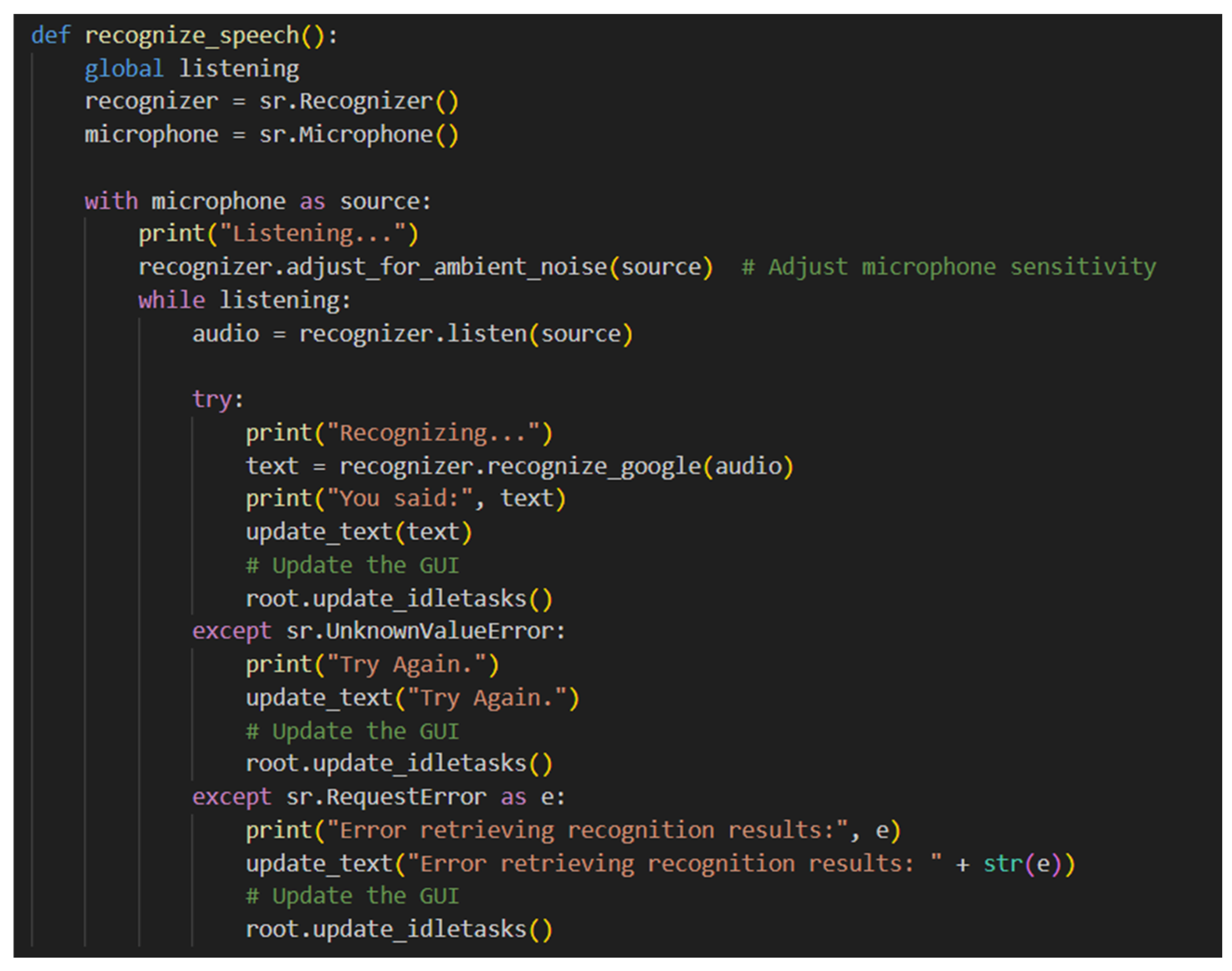
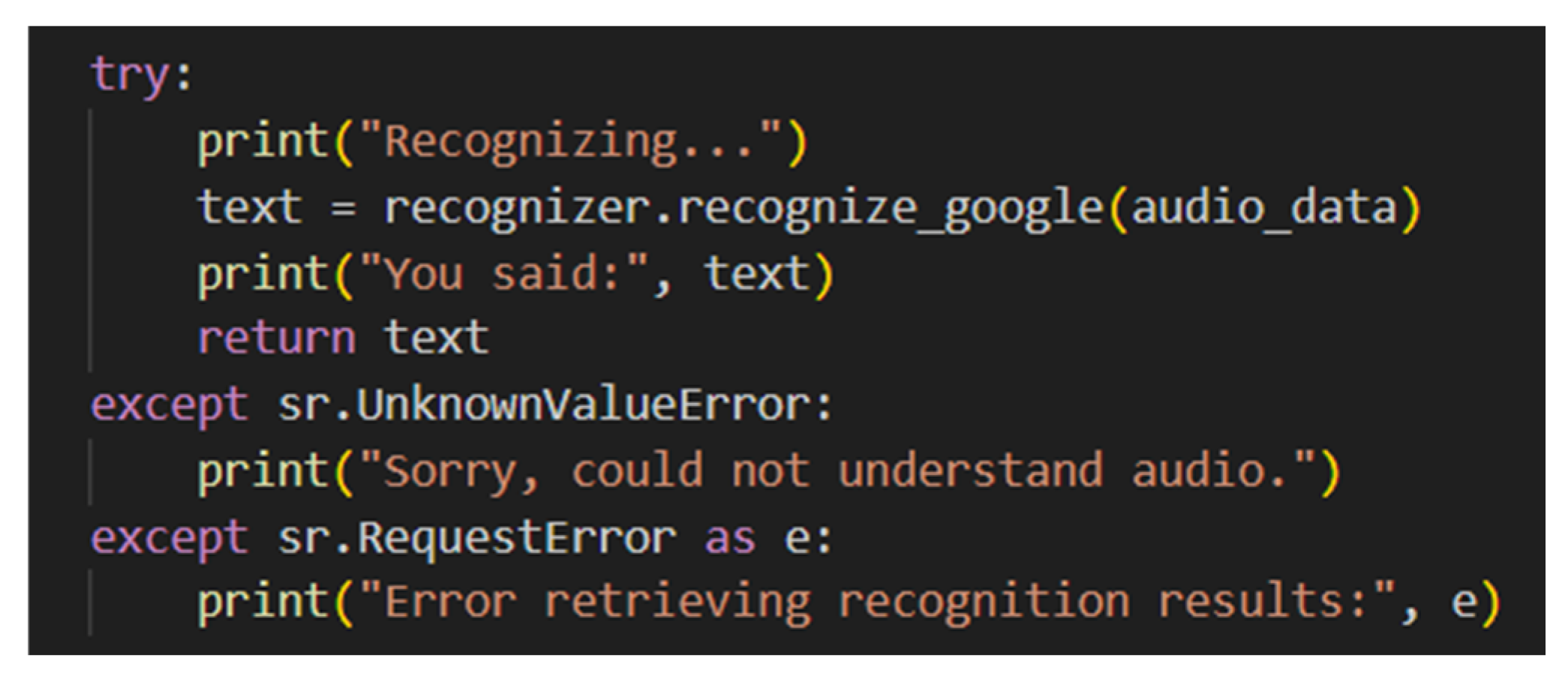
3. Machine Learning
Speech Recognition Algorithm
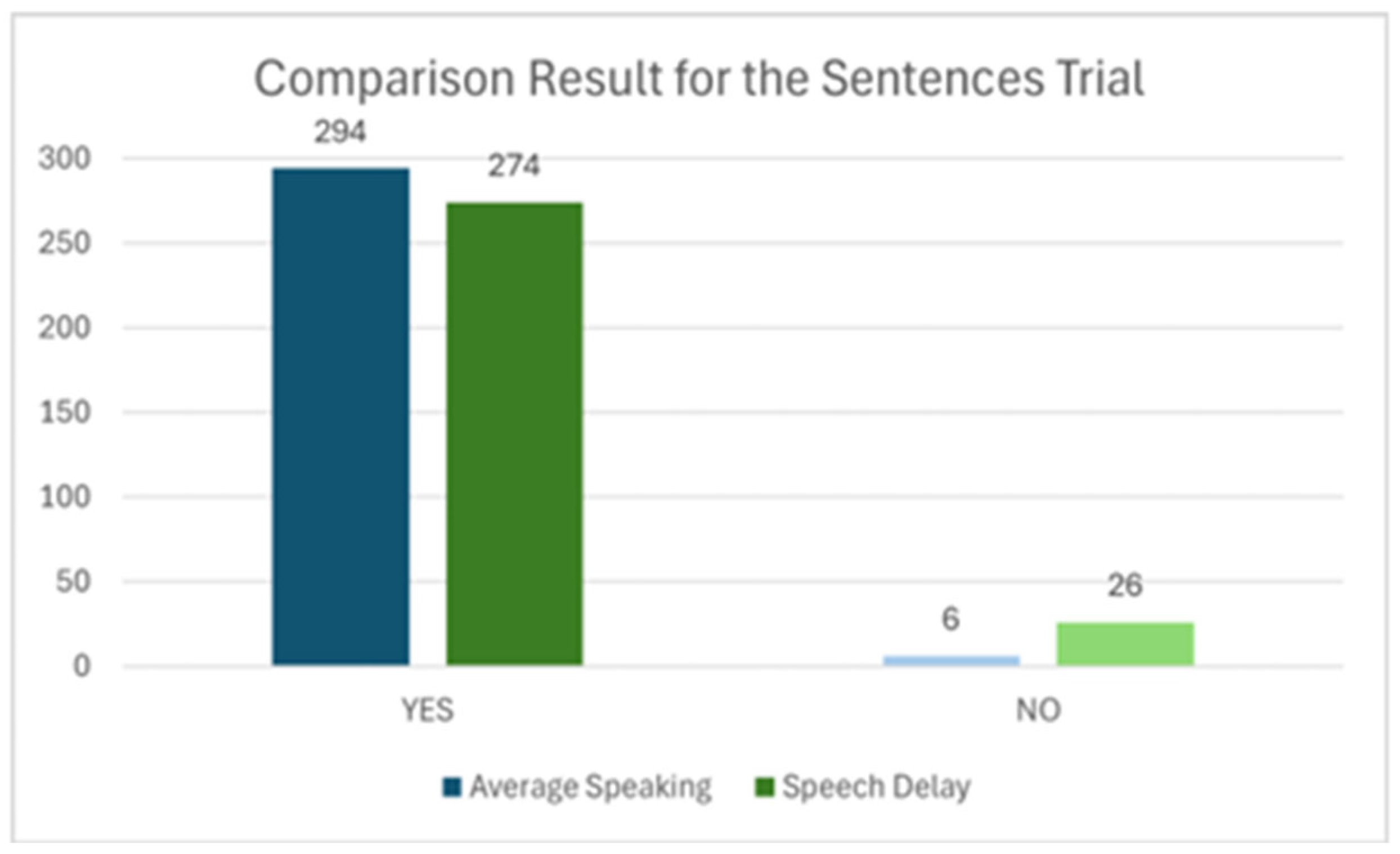
4. Results and Discussion
Trials for Speech Delayed Children
5. Conclusion and Recommendations
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fadchar, N.A.; Dela Cruz, J.C. Design and Development of a Neural Network—Based Coconut Maturity Detector Using Sound Signatures. In Proceedings of the 2020 IEEE 7th International Conference on Industrial Engineering and Applications (ICIEA), Bangkok, Thailand, 16–21 April 2020; pp. 927–931. [Google Scholar] [CrossRef]
- Pauzi, T.M.A.A.T.M.; Samah, A.A.; Dela Cruz, J.C.; Ghaffa, D.; Nordin, R.; Abdullah, N.F. Classification of Stress using ML Based on Physiological and Psychological Data from Wearables. In Proceedings of the 2023 IEEE 15th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment, and Management (HNICEM), Coron, Palawan, Philippines, 19–23 November 2023; pp. 1–6. [Google Scholar] [CrossRef]
- Hammond, N.; Cafasso, J. What Part of the Brain Controls Speech? 2022 Healthline Media. 17 May 2019. Available online: https://www.healthline.com/health/what-part-of-the-brain-controls-speech (accessed on 12 April 2022).
- Mule, P.; Cheeran, A.N.; Palav, T.; Sasi, S. Low cost and easy to use Electronic Learning. Communication System for speech impaired people with Wired and Wireless operability. In Proceedings of the 2016 IEEE International Conference on Engineering and Technology (ICETECH), Coimbatore, India, 17–18 March 2016; pp. 1194–1198. [Google Scholar] [CrossRef]
- Web Docs. Web Speech API. MDN Web Docs. 2021. Available online: https://developer.mozilla.org/en-US/docs/Web/API/Web_Speech_API (accessed on 2 August 2024).
- Bowen, C. Children’s Speech Sound Disorders, 2nd ed.; Wiley Professional, Reference & Trade (Wiley K&L): Hoboken, NJ, USA, 2014; Available online: https://bookshelf.vitalsource.com/books/9781118634011 (accessed on 8 July 2024).
- Hickey, R. Standard English and Standards of English; Cambridge University Press: Cambridge, UK, 2012; Available online: https://www.cambridge.org/core/books/abs/standards-of-english/standard-english-and-standards-of-english/96A3A5BD37C3C294B209BB9B14F141C6#access-block (accessed on 24 June 2024).
- Drongowski, P. Raspberry Pi 4 ARM Cortex-A72 Processor. Sand, Software and Sound—Electronics and Computing for the Fun of It. 2021. Available online: https://sandsoftwaresound.net/raspberry-pi-4-arm-cortex-a72-processor/ (accessed on 2 August 2024).
- Hirsh, I.J. Book Review: Speech Science Primer: Physiology, Acoustics, and Perception of Speech. Ann. Otol. Rhinol. Laryngol. 1981, 90, 412–413. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Patient | Age | Gender | Trial No. | W1 | W2 | W3 | W4 | W5 | W6 | W7 | W8 | W9 | W10 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 6 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | NO | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | NO | NO | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 2 | 6 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | NO | YES | YES | YES | NO | YES | YES | YES | |||
| 3 | YES | YES | NO | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 3 | 6 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | NO | YES | YES | NO | YES | YES | |||
| 3 | YES | NO | YES | YES | YES | YES | YES | NO | YES | YES | |||
| 4 | YES | YES | YES | YES | NO | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | 7 | B | 1 | NO | YES | YES | YES | NO | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | NO | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | 8 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 6 | 10 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 7 | 11 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | NO | NO | YES | YES | YES | NO | YES | YES | YES | |||
| 3 | YES | NO | YES | YES | NO | YES | NO | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | NO | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 8 | 12 | G | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | NO | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | NO | NO | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 9 | 13 | B | 1 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 10 | 13 | G | 1 | YES | YES | YES | NO | YES | YES | NO | YES | YES | YES |
| 2 | YES | YES | NO | NO | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | NO | YES | NO | YES | YES | YES | |||
| 4 | NO | YES | YES | YES | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | YES | YES | YES | YES |
| Patient | Age | Gender | Trial No. | S1 | S4 | S5 | S7 | S8 | S10 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 6 | B | 1 | YES | YES | YES | NO | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 2 | 6 | B | 1 | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | NO | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | NO | |||
| 4 | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 3 | 6 | B | 1 | YES | YES | YES | YES | YES | YES |
| 2 | NO | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | NO | |||
| 4 | NO | NO | YES | YES | YES | NO | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 4 | 7 | B | 1 | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 5 | 8 | B | 1 | YES | YES | YES | YES | YES | NO |
| 2 | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | NO | |||
| 4 | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 6 | 10 | B | 1 | YES | YES | YES | YES | YES | YES |
| 2 | NO | NO | NO | YES | YES | YES | |||
| 3 | NO | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | NO | YES | NO | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 7 | 11 | B | 1 | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | NO | |||
| 3 | YES | YES | NO | YES | YES | NO | |||
| 4 | YES | YES | NO | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 8 | 12 | G | 1 | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 9 | 13 | B | 1 | YES | YES | YES | YES | YES | YES |
| 2 | YES | YES | YES | YES | YES | YES | |||
| 3 | YES | YES | YES | YES | YES | YES | |||
| 4 | YES | YES | YES | YES | YES | YES | |||
| 5 | YES | YES | YES | YES | YES | YES | |||
| 10 | 13 | G | 1 | YES | YES | YES | NO | YES | YES |
| 2 | YES | YES | YES | YES | YES | NO | |||
| 3 | YES | YES | NO | NO | YES | YES | |||
| 4 | YES | YES | YES | NO | YES | NO | |||
| 5 | YES | YES | YES | YES | YES | YES |
| Word | Number of Times the Word Was Recognized | Ranking (1 to 10) |
|---|---|---|
| Caterpillar | 49 | 1st |
| Helicopter | 48 | 2nd |
| Ambulance | 47 | 3rd |
| Butterfly | 46 | 4th |
| Vegetables | 45 | 5th |
| Spaghetti | 43 | 6th |
| Computer | 42 | 7th |
| Hippopotamus | 42 | 8th |
| Animals | 39 | 9th |
| Caravan | 36 | 10th |
| Sentences | Number of Times the Word Was Recognized | Ranking (1 to 6) |
|---|---|---|
| Clap your hands together. | 49 | 1st |
| The boy is taking a bath. | 48 | 2nd |
| I saw a black cat. | 47 | 3rd |
| I want to eat lunch in the kitchen. | 46 | 4th |
| I went to the mall. | 41 | 5th |
| Did you hurt your foot? | 40 | 6th |
| Patient | Age | Gender | Intelligibility Rating | SLP Validation |
|---|---|---|---|---|
| 1 | 6 | Boy | 3 |  |
| 2 | 6 | Boy | 3 | |
| 3 | 6 | Boy | 4 | |
| 4 | 7 | Boy | 2 | |
| 5 | 8 | Boy | 3 | |
| 6 | 10 | Boy | 3 | |
| 7 | 11 | Boy | 4 | |
| 8 | 12 | Girl | 2 | |
| 9 | 13 | Boy | 1 | |
| 10 | 13 | Girl | 5 | |
| Patient | Substitution | Deletion | Insertion | Total Words | WER (%) |
|---|---|---|---|---|---|
| 1 | 0 | 3 | 0 | 50 | 6 |
| 2 | 2 | 1 | 0 | 50 | 6 |
| 3 | 1 | 4 | 0 | 50 | 10 |
| 4 | 2 | 1 | 0 | 50 | 6 |
| 5 | 1 | 0 | 0 | 50 | 2 |
| 6 | 0 | 0 | 0 | 50 | 0 |
| 7 | 2 | 5 | 0 | 50 | 14 |
| 8 | 0 | 3 | 0 | 50 | 6 |
| 9 | 0 | 0 | 0 | 50 | 0 |
| 10 | 1 | 6 | 0 | 50 | 14 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rodriguez, M.K.C.; Santos, G.M.M.; Cruz, J.C.D.; Cruz, J.C.D. Speech Delay Assistive Device for Speech-to-Text Transcription Based on Machine Learning. Eng. Proc. 2025, 92, 60. https://doi.org/10.3390/engproc2025092060
Rodriguez MKC, Santos GMM, Cruz JCD, Cruz JCD. Speech Delay Assistive Device for Speech-to-Text Transcription Based on Machine Learning. Engineering Proceedings. 2025; 92(1):60. https://doi.org/10.3390/engproc2025092060
Chicago/Turabian StyleRodriguez, Maria Kristina C., Gheciel Mayce M. Santos, Jennifer C. Dela Cruz, and Jmi C. Dela Cruz. 2025. "Speech Delay Assistive Device for Speech-to-Text Transcription Based on Machine Learning" Engineering Proceedings 92, no. 1: 60. https://doi.org/10.3390/engproc2025092060
APA StyleRodriguez, M. K. C., Santos, G. M. M., Cruz, J. C. D., & Cruz, J. C. D. (2025). Speech Delay Assistive Device for Speech-to-Text Transcription Based on Machine Learning. Engineering Proceedings, 92(1), 60. https://doi.org/10.3390/engproc2025092060