1. Introduction
Applications of EVT in the analysis of risky events are diverse, such as finance, insurance, material resistance, quality control, telecommunications, sports, environment, hydrology, biology, and seismology, among others.
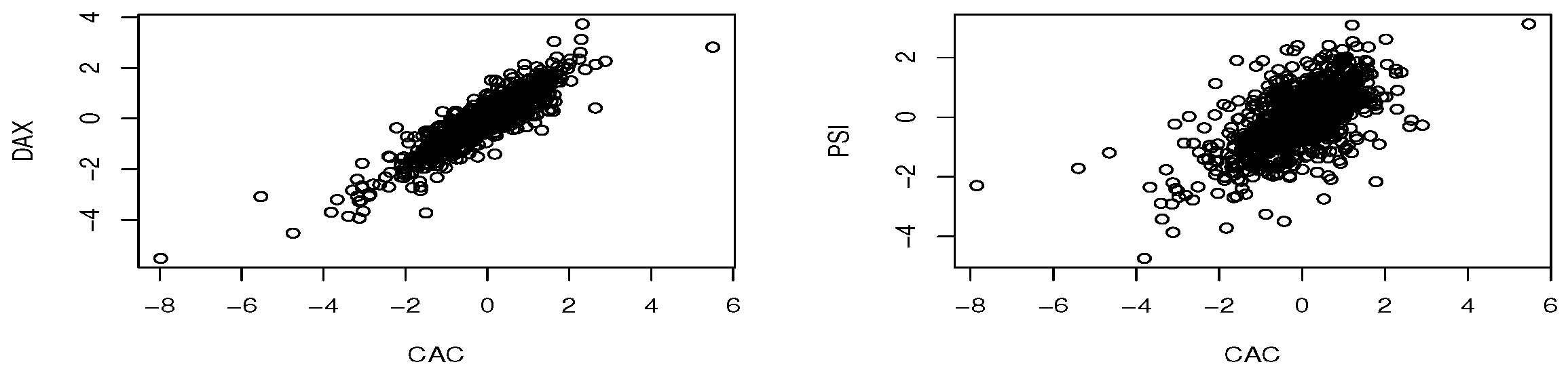
The occurrence of extreme observations can have serious consequences, e.g., high water levels in floods, a vast area burned in wildfires, and losses in stock indexes in financial market crashes, among others. Sometimes, the occurrence of extreme values for one variable can contaminate other variables. Typical examples are the financial markets where the fall of one index leads to falls in others as well. Correlation is a measure of dependence between two variables widely used in applications. Although it works well to measure the association between two variables in the central part of the data, it fails to assess dependence within the tails. For instance, in a bivariate Normal with correlation
, if we are far enough in the tail, extreme values seem to occur independently at each margin, regardless of how high a correlation we choose [
1].
Extremal dependence in a random pair
is typically based on the chance for obtaining large values of both variables. It is helpful to remove the influence of marginal aspects by transforming the marginals to a common distribution function (df), e.g.,
and
, both of which are standard uniform where
and
are the marginal df of
X and
Y, respectively, and considered continuous. Therefore, differences in distributions are solely due to dependence aspects. As
and
are on a common scale, events of the form
and
, for large values of
u, are equally extreme events for each variable, both with their probability approaching zero as
. The tail dependence coefficient (TDC) measures the conditional probability of one variable being extreme, given that the other is extreme too:
Observe that the exact independence corresponds to
, since
, as
, whilst perfect dependence means
. Indeed, we say that
X and
Y are tail independent if
, and tail dependent if
. A positive
means a strong dependence persisting to the limit. A null
comprehends exact independence, but also a weak dependence that gradually vanishes as the limit is approached. Such residual dependency can be captured through the rate of convergence of
towards zero; more precisely, through the asymptotic tail independent coefficient of Ledford and Tawn
[
2], given by
where
is a slowly varying function, i.e.,
, as
,
[
3]. If
= 1 and
,
, the random variables (rvs) are asymptotically dependent. On the other hand, if
or
=1 and
, then
and the rv are asymptotically independent with degree
. The case
means near-independence; in particular, exact independence if
. We can also state that
corresponds to a positive association, in the sense that the probability of both rvs exceeding
u occurs more frequently than under exact independence, whereas in
, the probability of both rvs exceeding
u occur less frequently than under exact independence and, thus, the rvs are negatively associated. Inference on
allows us to distinguish the type of tail (in)dependence:
means tail dependence, whilst
means the presence of a residual tail dependence. According to [
2], assuming independence and ignoring
can lead to misspecified joint extremes estimations, while considering the dependence between rvs, when a residual dependence in fact occurs, may result in an overestimation.
Observe that
where
and
are standard Pareto. Considering rv
and
, by (
1) we can state that
and we say that
T has a regularly varying tail with index
. In EVT, this means that
corresponds to the tail index of
T, the primary measure in EVT inference. There are many estimation methods in the literature for the tail index. For a survey, see, e.g., [
4]. A well-known tail index estimator is the Hill [
5]. Given a sample
, consider
where
,
, are the rvs exceeding the threshold
. In the Hill estimator,
corresponds to the
up order statistics. In EVT, we can also estimate the tail index through a modeling approach. A common technique is to consider the exceedance values above a high threshold of data, and apply a Generalized Pareto Distribution (GPD) according to the Pickands–Balkema–De Haan theorem [
6,
7], known as the
Peaks Over Threshold (POT) approach (see, e.g., [
4] for more details). Here, we apply the POT method on rv
T in order to estimate
, and denote this estimator as
.
Based on (
1), we can rewrite
and, thus, we can estimate
by taking the empirical counterpart of (
3), which we denote as
. More precisely,
Note that, in practice, the margins
and
are usually unknown, and we can estimate by the empirical df. This is the approach followed for estimators
,
and
. Observe also that the standard uniform rvs,
and
,
, have
r-order statistics Beta(
) distributed. Thus, replacing the marginal empirical df in (
4) with Beta(
) df, we have the fourth estimator, which we denote as
. Further details on Beta marginals estimation can be seen in [
8].
In
Section 2, we analyze the referred estimators through simulation and compare their performance. An application to real data illustrates the methods in
Section 3.
2. Estimation of : A Simulation Study
In our study, we consider different models with different values of , as follows, where we use copula notation, :
Bivariate Ali–Mikhail–Haq distribution, where
, with
(
) (see, e.g., [
9]), denoted AMH;
Bivariate Frank distribution, where
, with
(
) (see, e.g., [
9]), denoted Frank;
Bivariate Normal distribution with
(
) (see, e.g., [
10]), denoted BNormal;
Bivariate extreme value distribution with a Logistic dependence function,
,
, with
(
) (see, e.g., [
2]), denoted Logistic.
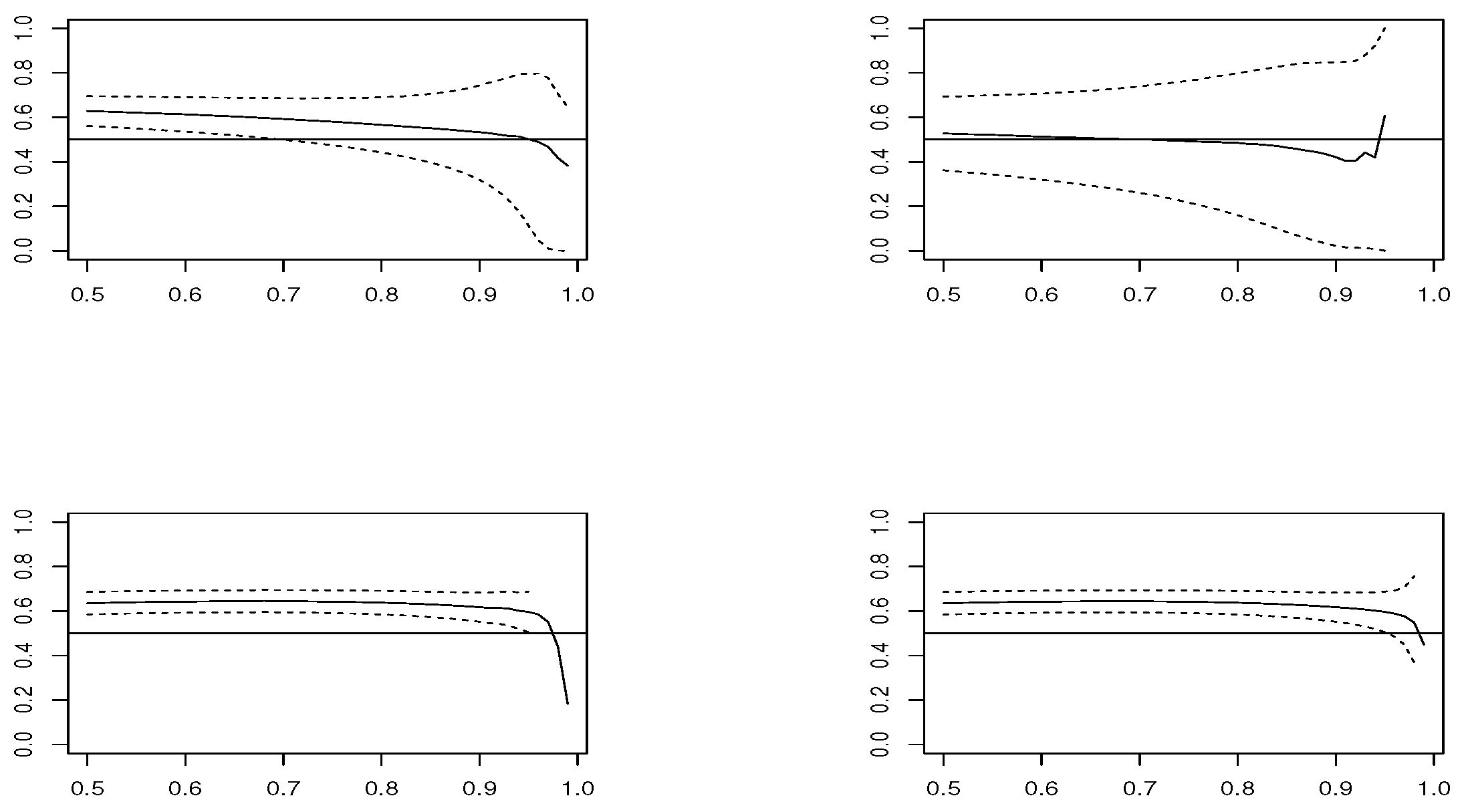
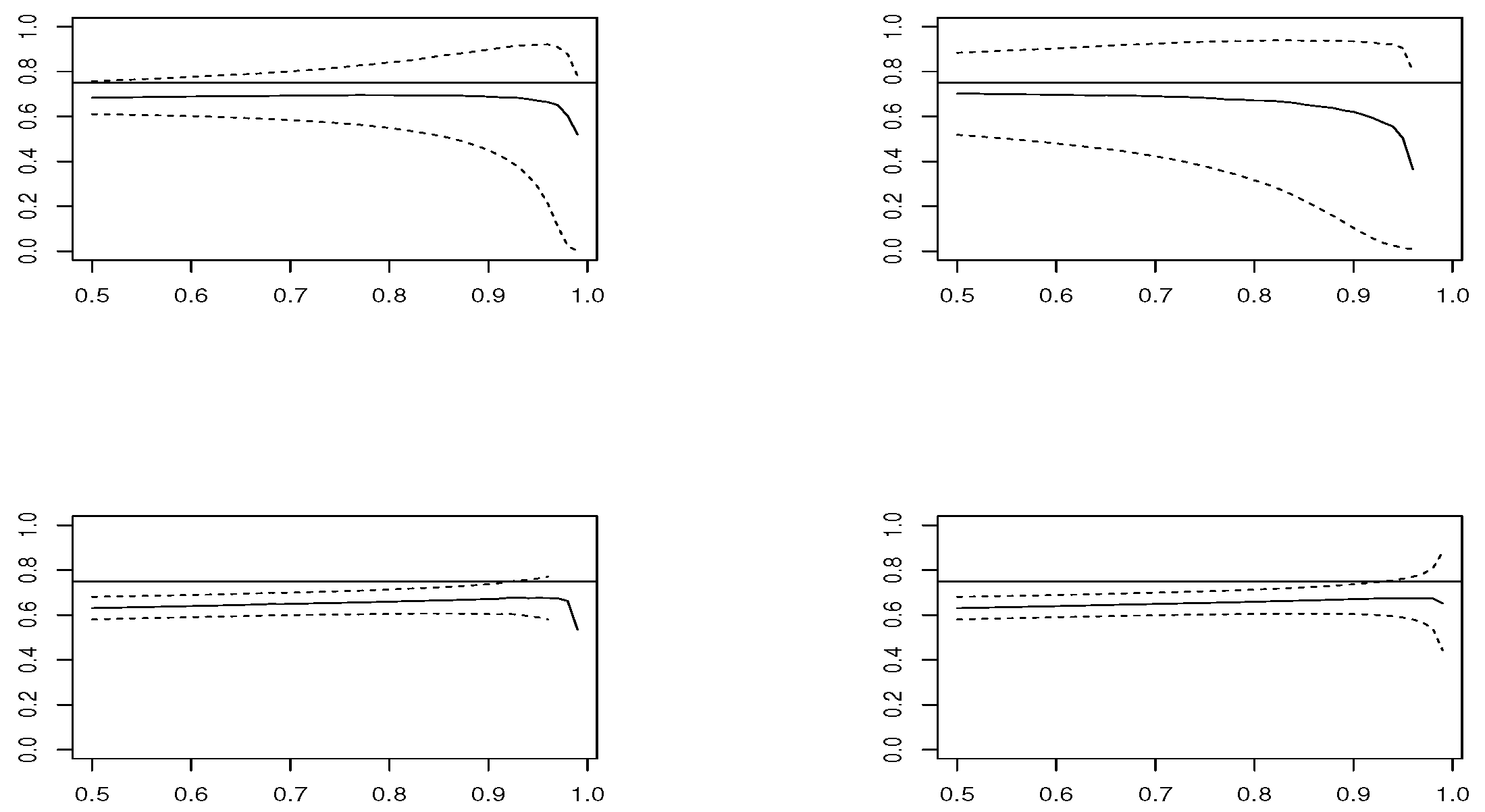
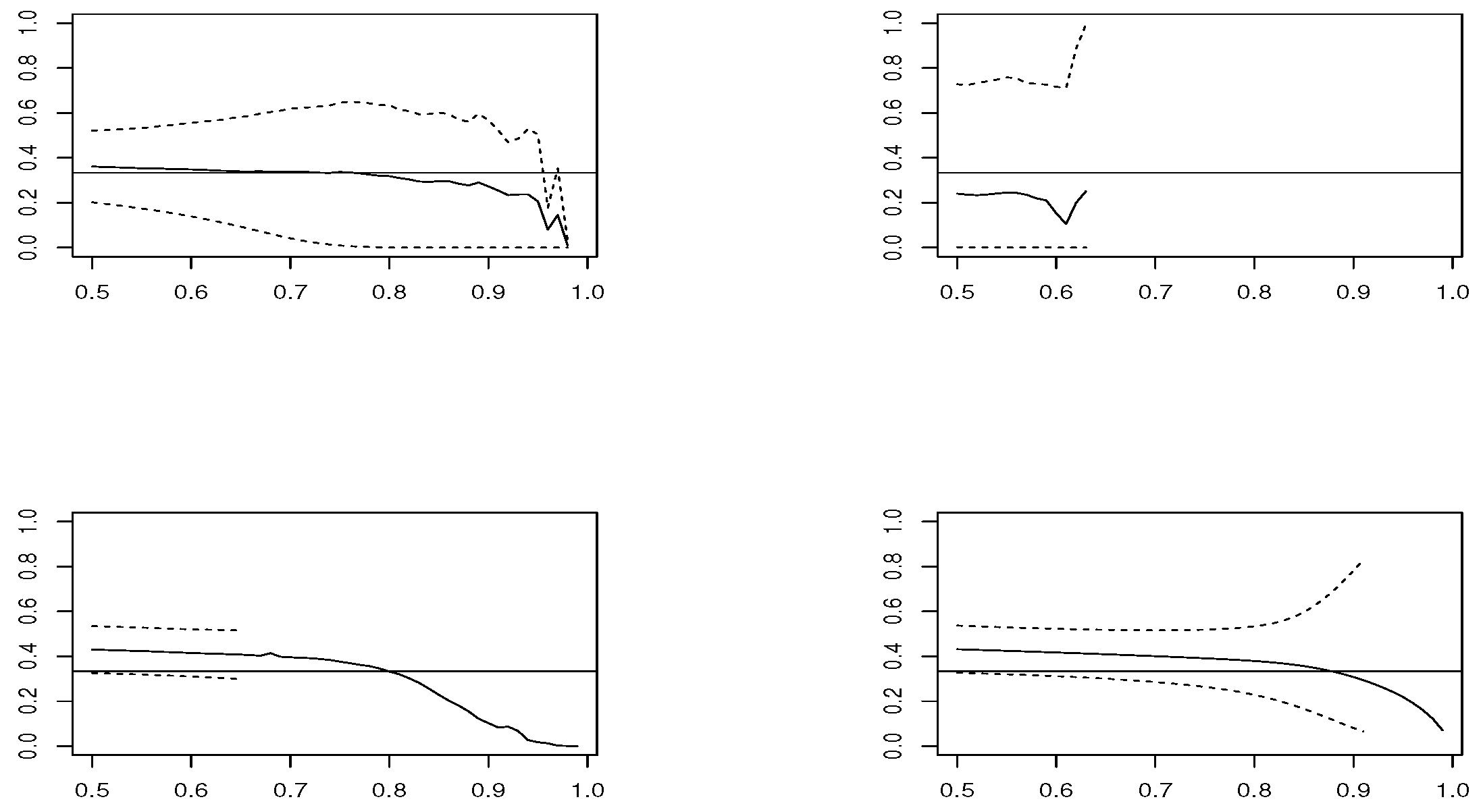
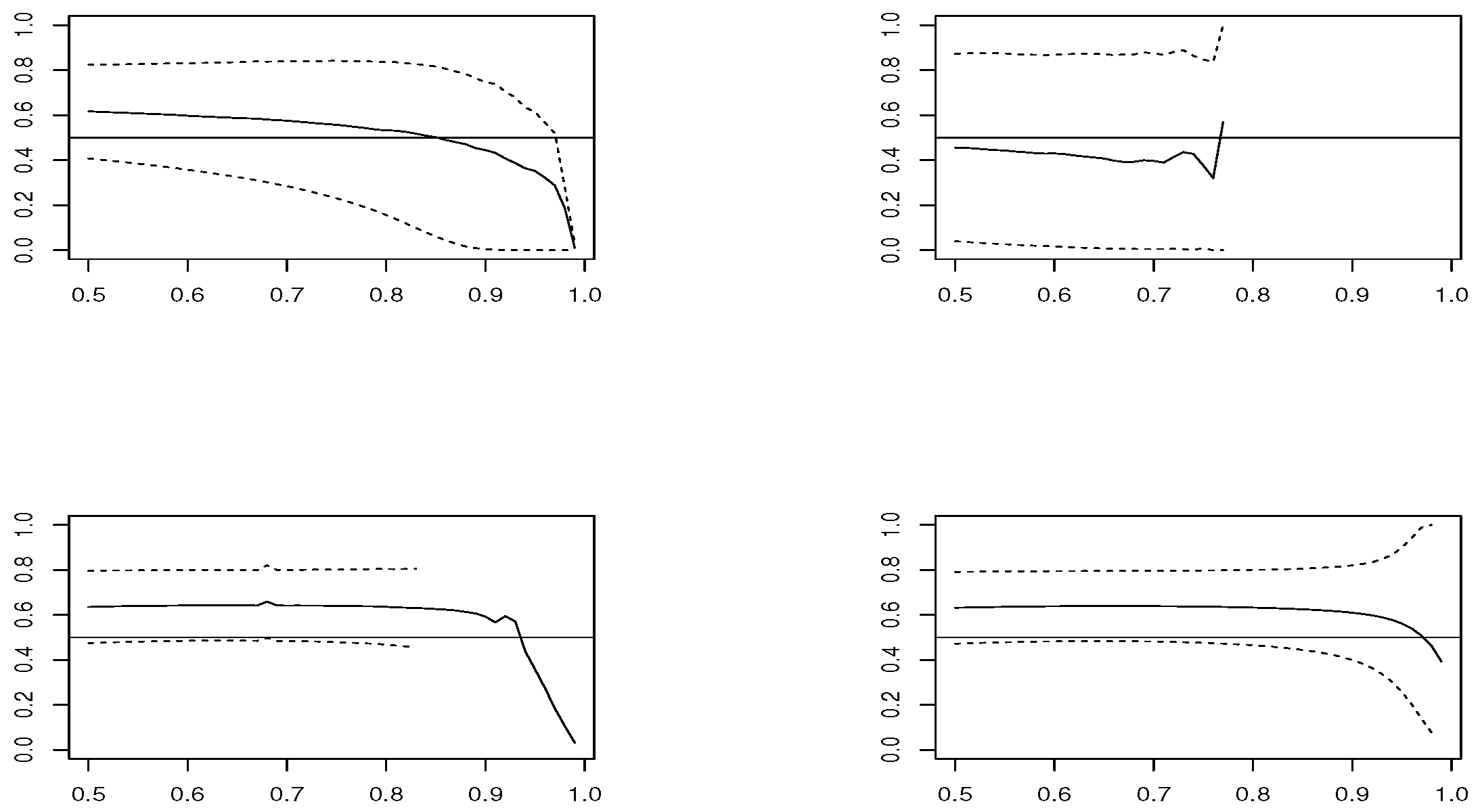
We simulate 1000 replicas of each model, with size
and
. We compute estimators
,
,
and
for thresholds
u corresponding to percentiles
. The estimation is conducted using package mev [
11] within statistical software R 2020 [
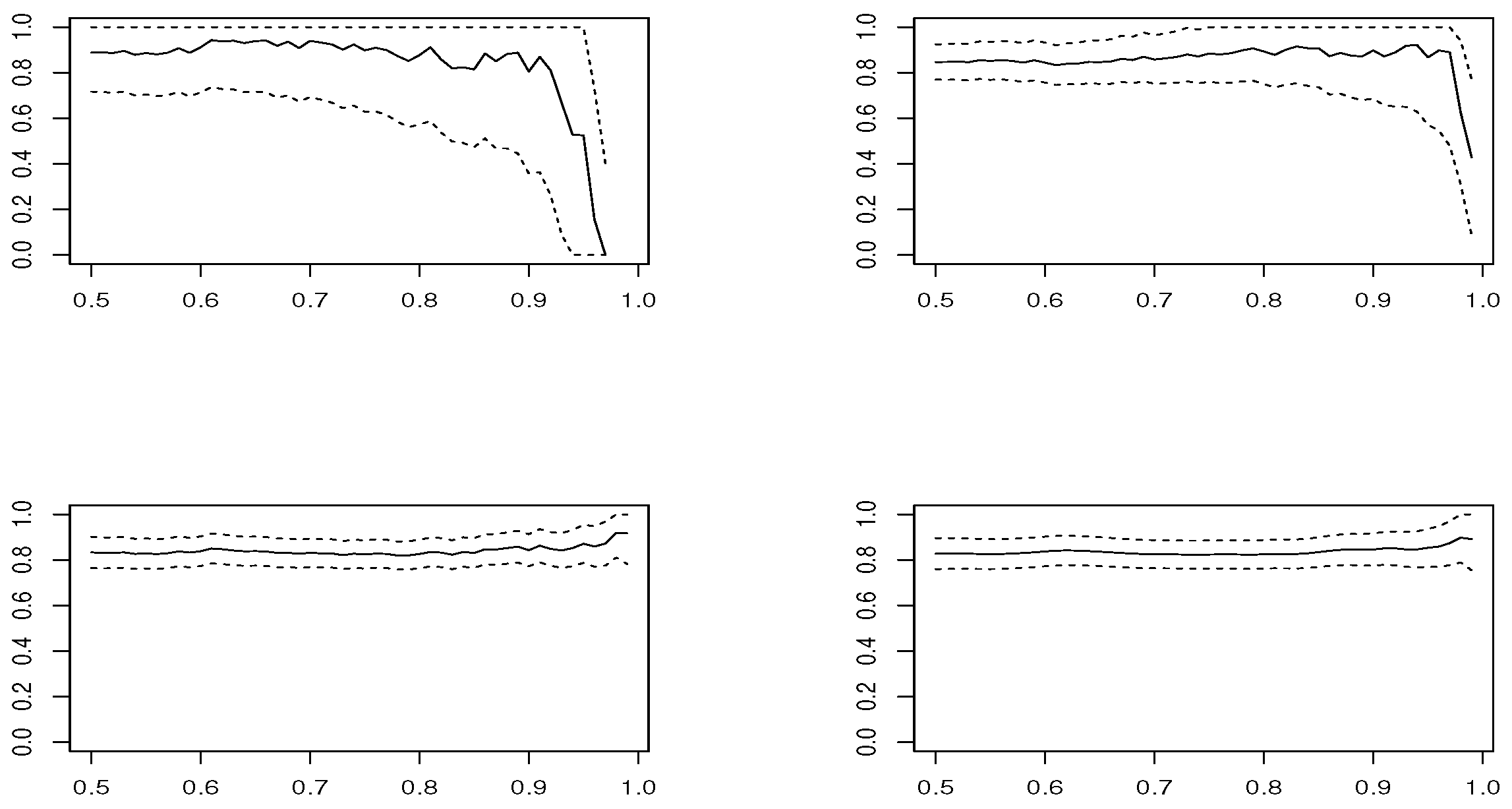
12]. We derive the sample mean of estimates in each threshold
u along with the Wald 95% confidence interval, which are plotted in
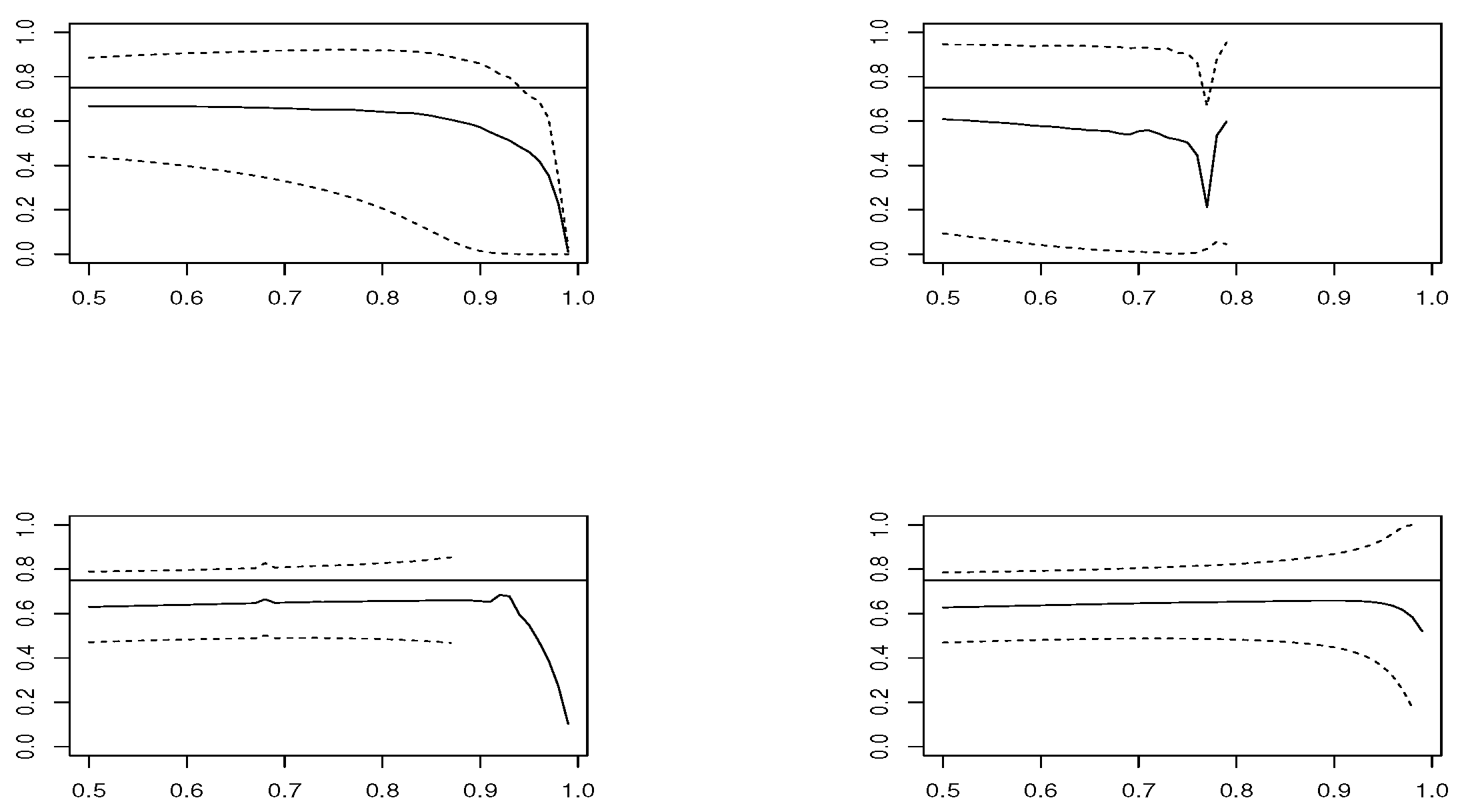
Figure 1,
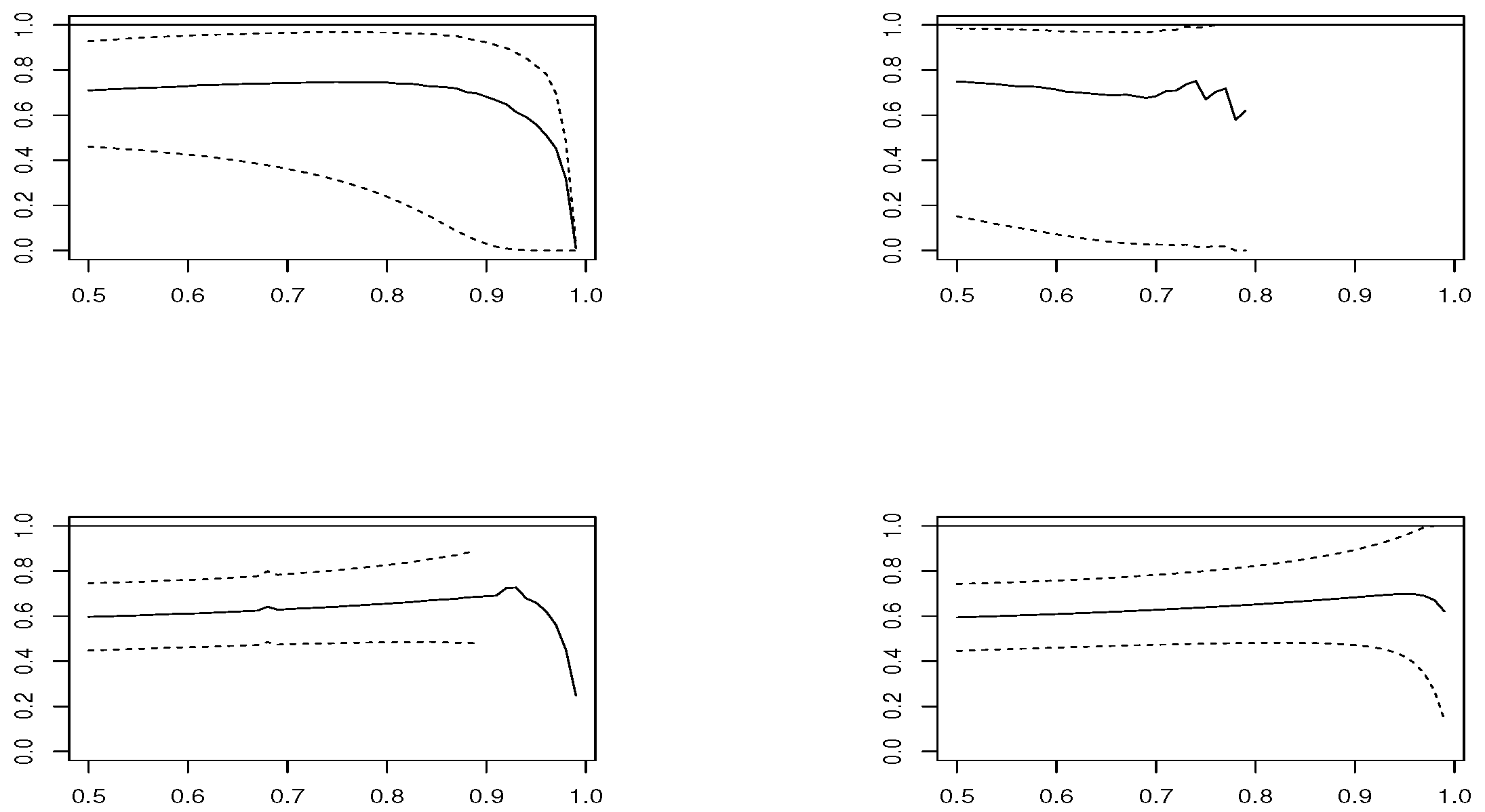
Figure 2,
Figure 3 and
Figure 4, in the case of samples with size
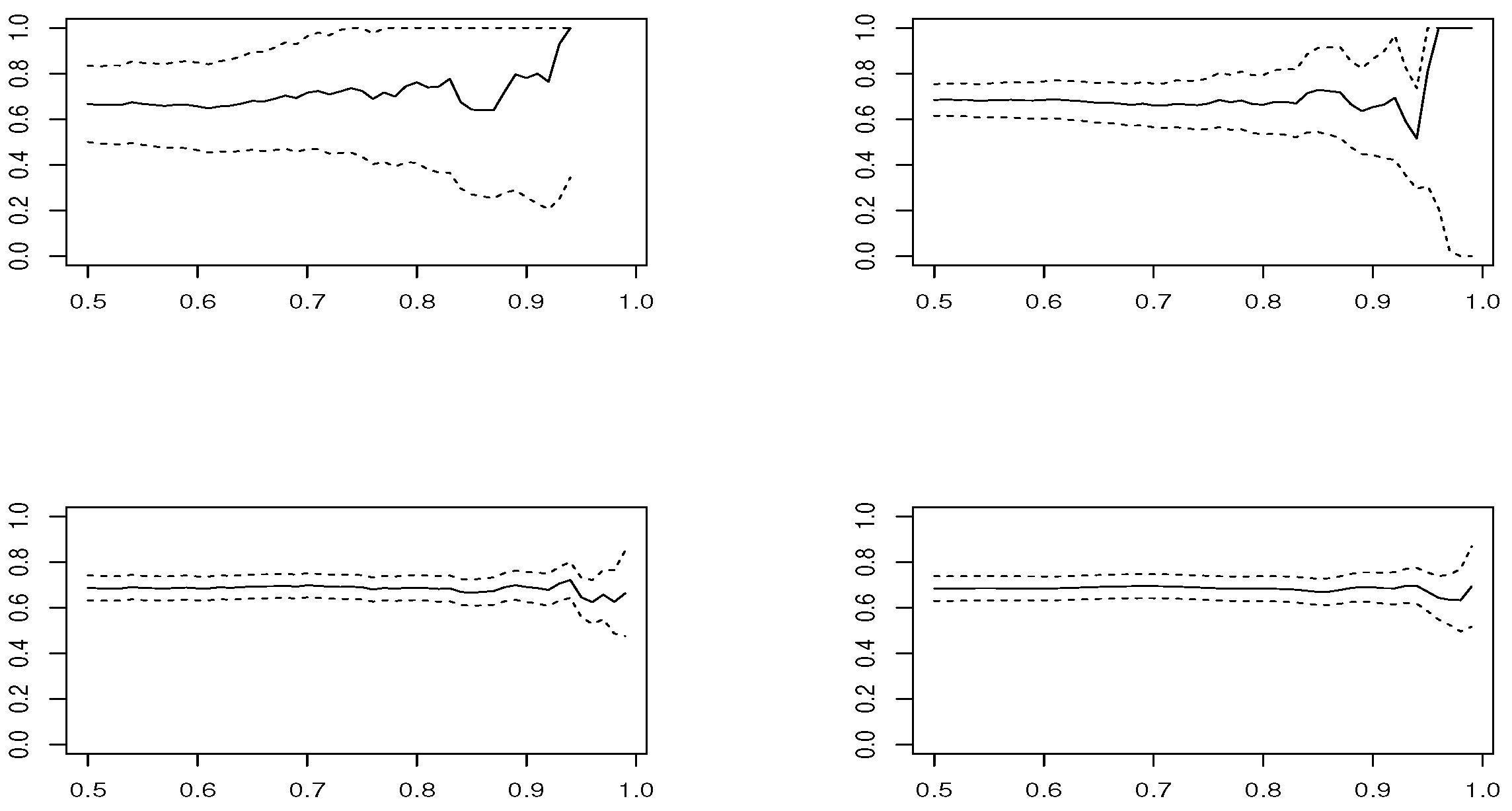
, and
Figure 5,
Figure 6,
Figure 7 and
Figure 8 for
. We also calculate the root mean squared error (RMSE) in each threshold
u, available in
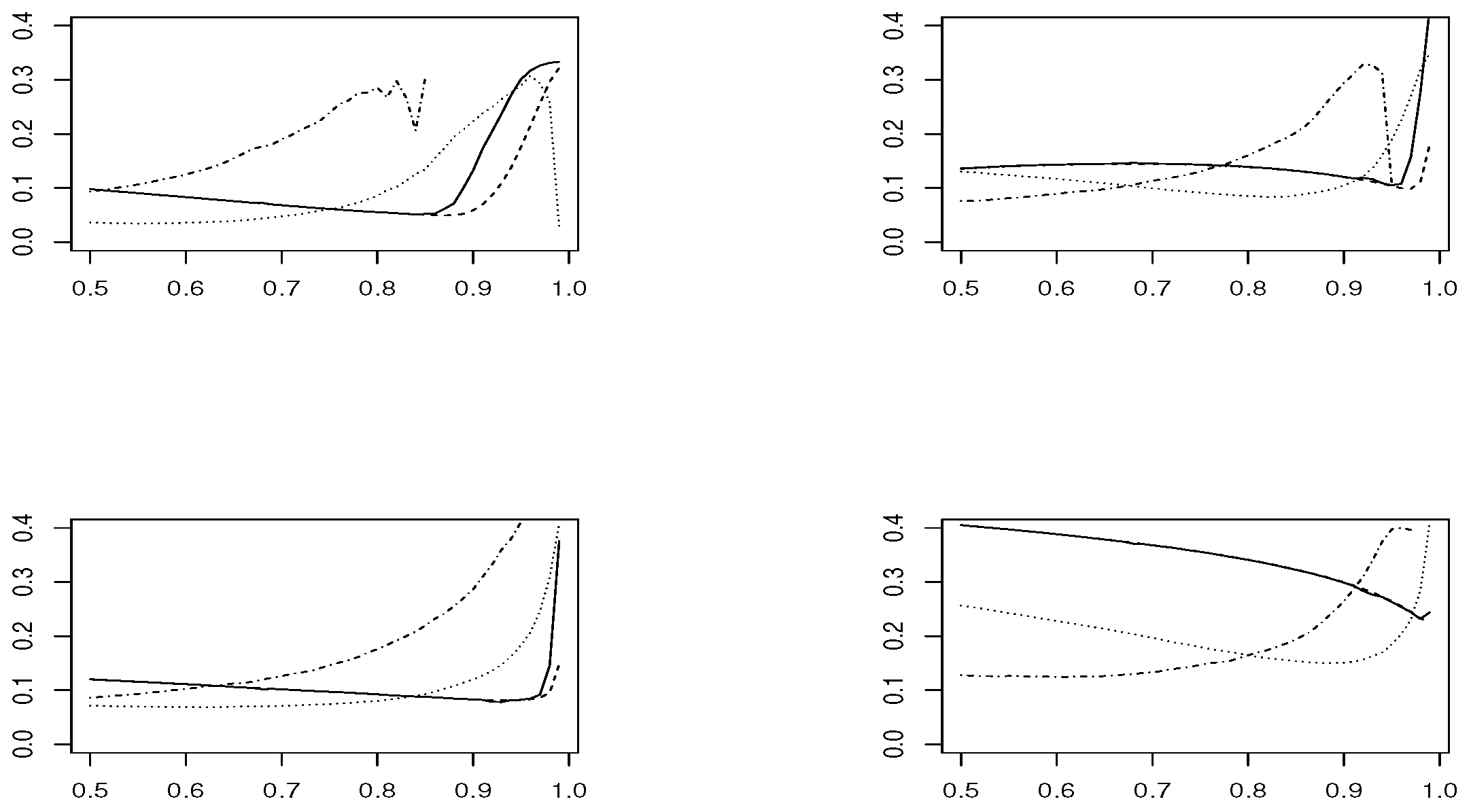
Figure 9 and
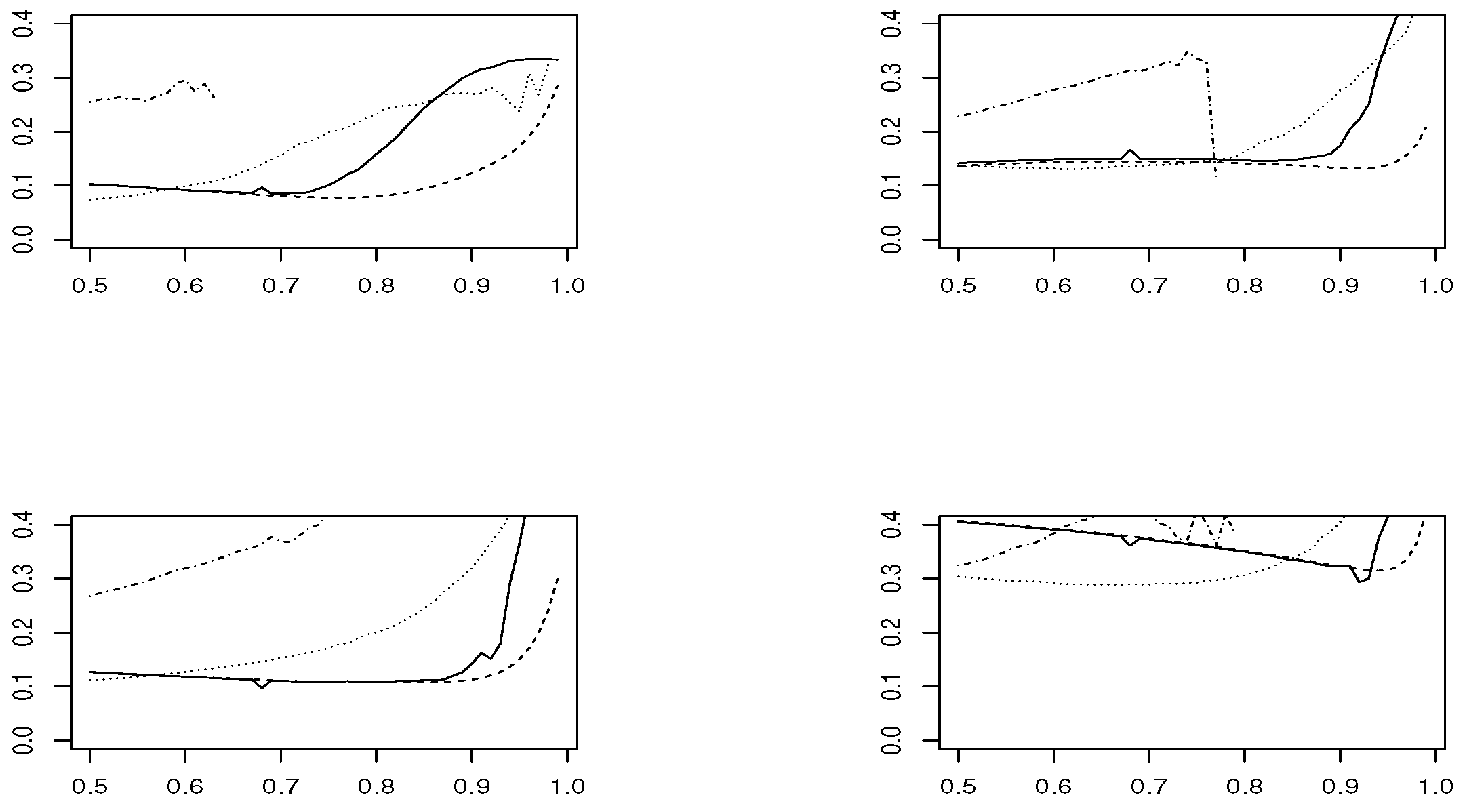
Figure 10, for sample sizes
and
, respectively. The
estimator is based on modeling threshold exceedances through the GPD model and, therefore, fails to be applied at very high thresholds, where the number of observations is small.
In the case , and looking at the estimated means, estimators and have the best performance. However, concerning the RMSE, presents the worst performance, except in the Logistic model, where and are the best choices and and are not recommended. In smaller sample size , the confidence intervals become larger and the results are less precise. The RMSE grows slightly for all estimators, except for , where it clearly increases. The low performance of all estimators is in the Logistic model, where corresponds to a boundary value.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}