1. Introduction
Analyzing sentencing data across multiple districts presents many challenges. The data have many dimensions and change with time. The multidimensional nature of such data makes it difficult to visualize such changes easily and compare sentencing statistics for different offenses and districts [
1,
2,
3].
In this work, we would like to present an approach to address the following questions:
- 1.
How do we visualize sentencing data?
- 2.
How do we use such visualization to quantify sentencing similarities and differences across districts for different offenses?
- 3.
How do we measure variability in sentencing?
- 4.
How do we measure the “most likely” sentencing?
- 5.
How do we measure changes in sentencing over time?
Our approach is to use techniques from machine learning and represent sentencing data in terms of patterns changing over time [
4]. To that end, we choose a small number
k of patterns, or clusters,
, and associate sentencing data for each district with these clusters for each period. We can then construct a trajectory: a sequence of clusters over the entire period. Trajectories can then visualize the time evolution of data in the appropriate (time, cluster) space. We can perform a simple analysis and address the above questions by computing simple statistics on the resulting trajectories. We will use the terms clusters and patterns interchangeably in this paper.
To proceed, we assume that for each offense
, such as narcotics or retail theft, in a period
such as a year and each district
, we have sentencing data
such as a prison term. The sentencing data could be multi-dimensional, with additional information such as parole conditions. For each offense
c, we can split our dataset into a set of objects
of the form
We emphasize that since the sentencing data
could be pretty complex and multi-dimensional (vector), it may be challenging to analyze and visualize the evolution of such multi-dimensional data over time. Moreover, it is difficult to compare changes in data by examining just statistical measures. For example, consider the sentencing data. Different offenses result in a different severity of punishment, so sentencing patterns cannot be directly compared to each other by just statistical measures [
5].
Our approach is to cluster these objects into a small number
k of clusters
and construct the corresponding trajectories [
2]. These clusters represent patterns of sentencing.
How do we choose these clusters? There are several ways to do this. If we have a distance metric for
, we can apply
k-means clustering [
6] and obtain the resulting assignment. Or, if the sentencing data
are simple, such as just the average prison term, then we can choose clusters based on quantiles [
1]. In our approach, patterns can be assigned by any rule(s).
Therefore, the suggested approach is quite general and the methodology presented can be carried out for any user-defined distance between districts. For simplicity of presentation, we choose the quartiles to assign data into clusters. This gives us patterns (clusters).
The critical point is that we choose a small number of
k of patterns and assign our objects to these patterns across all periods. Once our objects are associated with clusters, we can write out a trajectory of clusters over time [
7]. For example, suppose we have
periods. If for period
the pattern is
, for period
the pattern is
, and for period
the pattern is
, then we can construct a trajectory path
in the (time, cluster) space. For convenience, we will write this path by specifying the numbers of the clusters and write
P in a more compact notation as
. Once these trajectories across all periods for offenses of interest are constructed, they can be analyzed and compared for similarities and differences. These trajectories are conceptually similar to the crime trajectories [
8] that are widely used in criminology to analyze crime dynamics data.
We illustrate the proposed approach by analyzing sentencing data for Narcotics and Retail Theft across six district courts over ten years (2012–2021) for Cook County in Chicago, Illinois. We will use superscript to indicate Narcotics and superscript to indicate Retail Theft.
We understand the possible limitations of such an approach. For example, the aggregation of sentencing to the year/district level and then compressing that into clusters (e.g., quartiles) misses the variation within the district. The method also misses the complexity of sentences, which can combine jail, prison, probation, fines, restitution, and community service components. Existing methods of studying trajectories in criminology (though mostly for individual criminal behavior) often use finite mixture models [
7]. Nevertheless, our approach offers simplicity and simple, intuitive explanations, as will be illustrated in subsequent sections.
2. Sentencing Dataset
The data are from Cook County’s open data:
https://datacatalog.cookcountyil.gov/Courts/Sentencing/tg8v-tm6u/data, last accessed on 30 November 2023. For our analysis, we are considering only the primary charges of the cases present in the data, the cases where the defendant was sentenced to prison, and the cases that occurred at a specific time starting from the year 2012 to the year 2021 (10 years). After the initial filtering of the data, the sentence time was standardized into years for the analysis using the standard months-to-years, days-to-years, and hours-to-years conversion. This is illustrated in
Figure 1 and
Figure 2.
Cook County has six districts in total; the primary objective was to assess how each district sentences based on the crime in a particular year. In
Table 1, we present statistics on the district’s annual convictions for both offenses. The annual summary statistics by district are presented in
Table 1 and the summary statistics by district are presented in
Table 2.
We see from
Table 1 that the districts had very uneven numbers of convictions, with some districts having many more convictions than others. For example, district
alone would account for more than 90% of the convictions for narcotics (18,607/20,207) and more than 30% of the convictions for retail theft (2109/6928). By contrast, district
accounts for only 2.5% of the convictions for narcotics (515/20,207) and for less than 8% for retail theft (547/6928). Examining
Table 1, we note that the number of convictions dropped drastically for both offenses as more paroles were offered in later years.
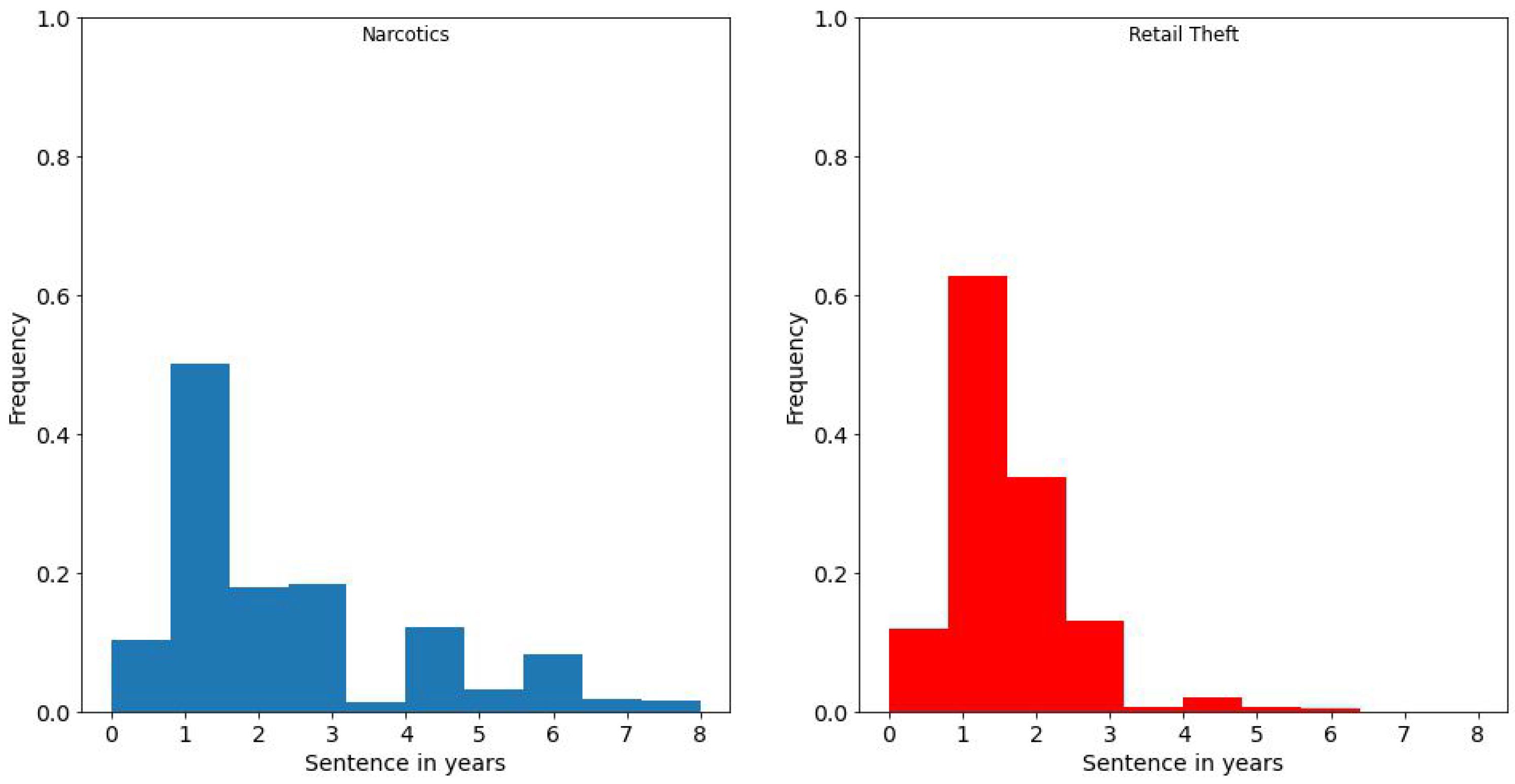
Next, we examine the empirical distribution of sentences shown by (normalized) histograms of sentences for each offense. In
Figure 3, we note that the empirical distribution is more concentrated for Retail Theft than for Narcotics. This means that sentencing for retail theft is more consistent across districts than for narcotics.
3. Reason for Decline in Data Point Values
A significant decline in drug offenses and retail theft cases resulting in jail time and probation has been observed in Cooks County due to the implementation of new state laws [
9]. These laws prioritize diverting non-violent offenders from the criminal justice system and towards community-based programs and services. As a result, the number of drug and theft cases resulting in jail time and probation has decreased. This shift in approach towards rehabilitation and reintegration has been identified as a contributing factor to the decline in data present for drug- and retail theft-related cases.
4. Constructing Trajectories
To illustrate our approach, we will consider two offenses: narcotics and retail theft. To construct trajectories, we need to cluster sentencing data across all years into k clusters.
We can use any of the clustering methods such as
k-means [
4]. For simplicity of presentation, in this paper, we consider a simple assignment of sentencing data to
patterns based on quartiles
,
,
, and
for each offense. These quartiles are computed from the sentence lengths separately for each offense across ten years (2012–2021). The advantage of such an assignment is that we can compare sentencing patterns for different districts and offenses [
3]. Suppose for a particular district
, and for a particular period,
, the patterns for both offenses are the same
. In that case, we can argue that these patterns are similar: both reflect the severity of sentencing according to the quartiles computed for each such offense [
10]. By contrast, the sentences themselves cannot be computed directly to each other since they could carry a different severity of punishment depending on the offense.
Let us show how we construct these trajectories. We start with the offense “Narcotics”. For each district and every year we computed the average sentence. This is summarized in
Table 3:
For Narcotics, the quartiles from the sentencing dataset are , the median , and . If is the average sentence for district for year , then we consider the following assignment of that district to one of four clusters (patterns): , , , and :
- 1.
: sentencing pattern (first quartile);
- 2.
: sentencing pattern (second quartile);
- 3.
: sentencing pattern (third quartile);
- 4.
: sentencing pattern (fourth quartile).
Once we have the above for assigning patterns, we can construct the corresponding trajectories [
11]. For example, take district
for Narcotics. We construct its trajectory as follows. From
Table 3, for year 1 the mean
is in the third quartile, and therefore we have sentencing pattern
. For year 2, the mean
is in the third quartile, and therefore we again assign sentencing pattern
. For year 3, the mean
is in the fourth quartile, and therefore we assign a sentencing pattern
. Continuing in this manner, we compute the trajectory
of sentencing patterns for the remaining years as
. In compact notation, we write this as
. The trajectories for Narcotics are summarized in compact notation in
Table 4.
For retail theft, the quartiles from the sentencing dataset are , the median , and . If is the average sentence for district for the year j, then we consider the following assignment of that district to clusters (patterns), , , , and , like that for Narcotics:
- 1.
: sentencing pattern (first quartile);
- 2.
: sentencing pattern (second quartile);
- 3.
: sentencing pattern (third quartile);
- 4.
: sentencing pattern (fourth quartile).
Once we have the above for assigning patterns, we can construct the corresponding trajectories. For example, consider the computation of the trajectory path
for the same district
. From
Table 3, for year 1, the mean
is in the third quartile and therefore we assign pattern
. For year 2, the mean
is in the third quartile, and we assign sentencing pattern
. For year 3, the mean
is again in the third quartile, and again we assign a sentencing pattern
. Continuing in this manner, we compute the trajectory
of sentencing patterns for the remaining years as
. In compact notation, we write this as
. The trajectories for retail theft for all districts are summarized in compact notation in
Table 4.
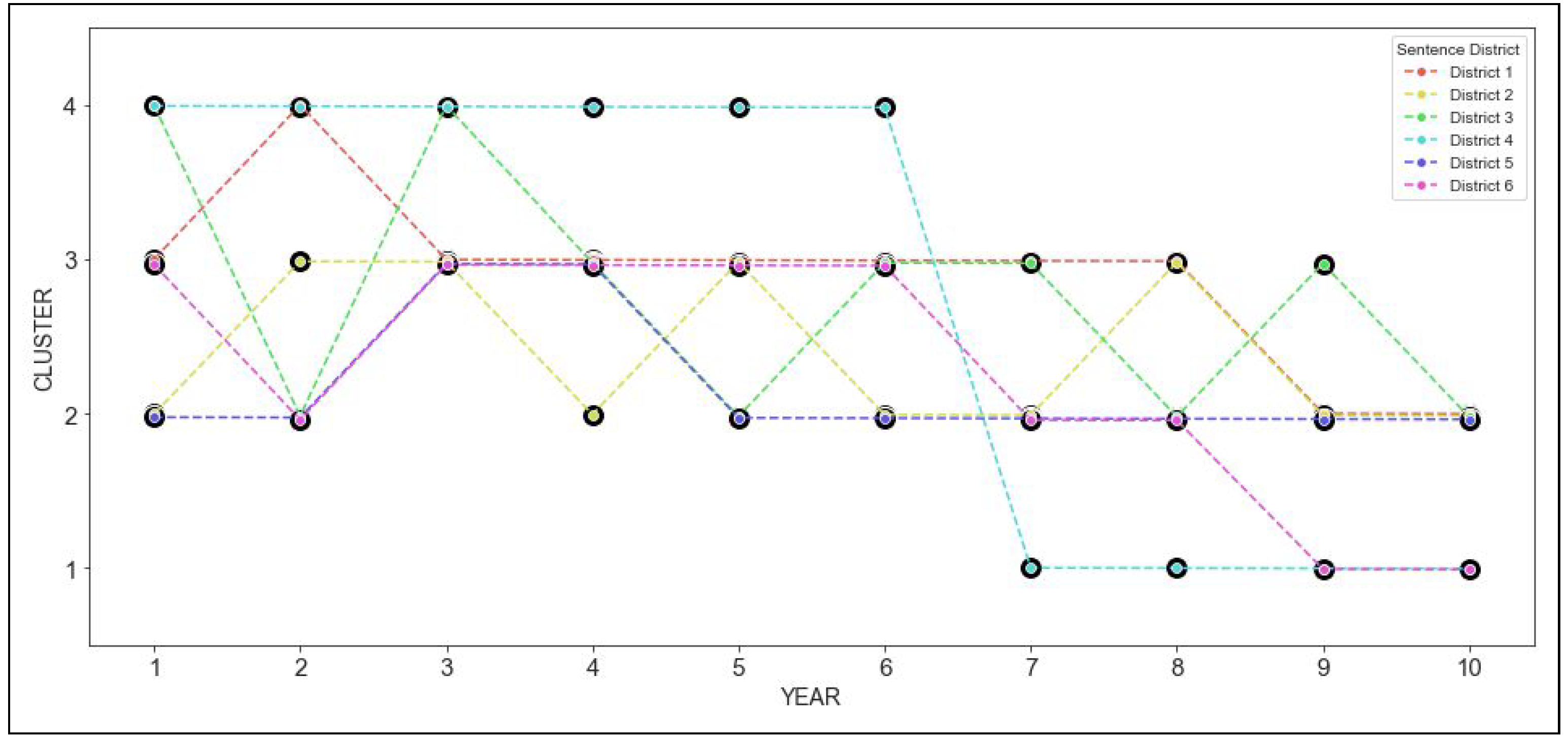
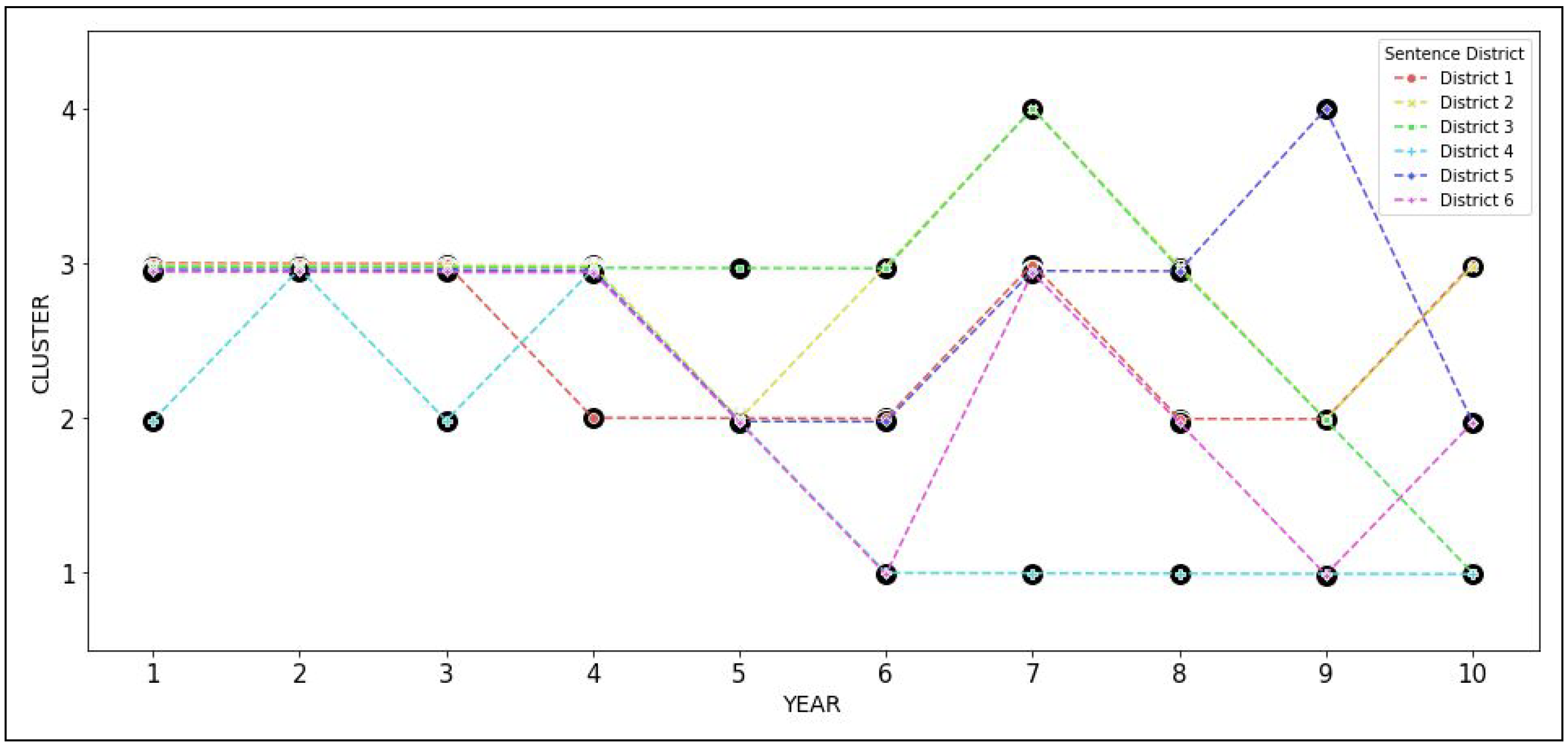
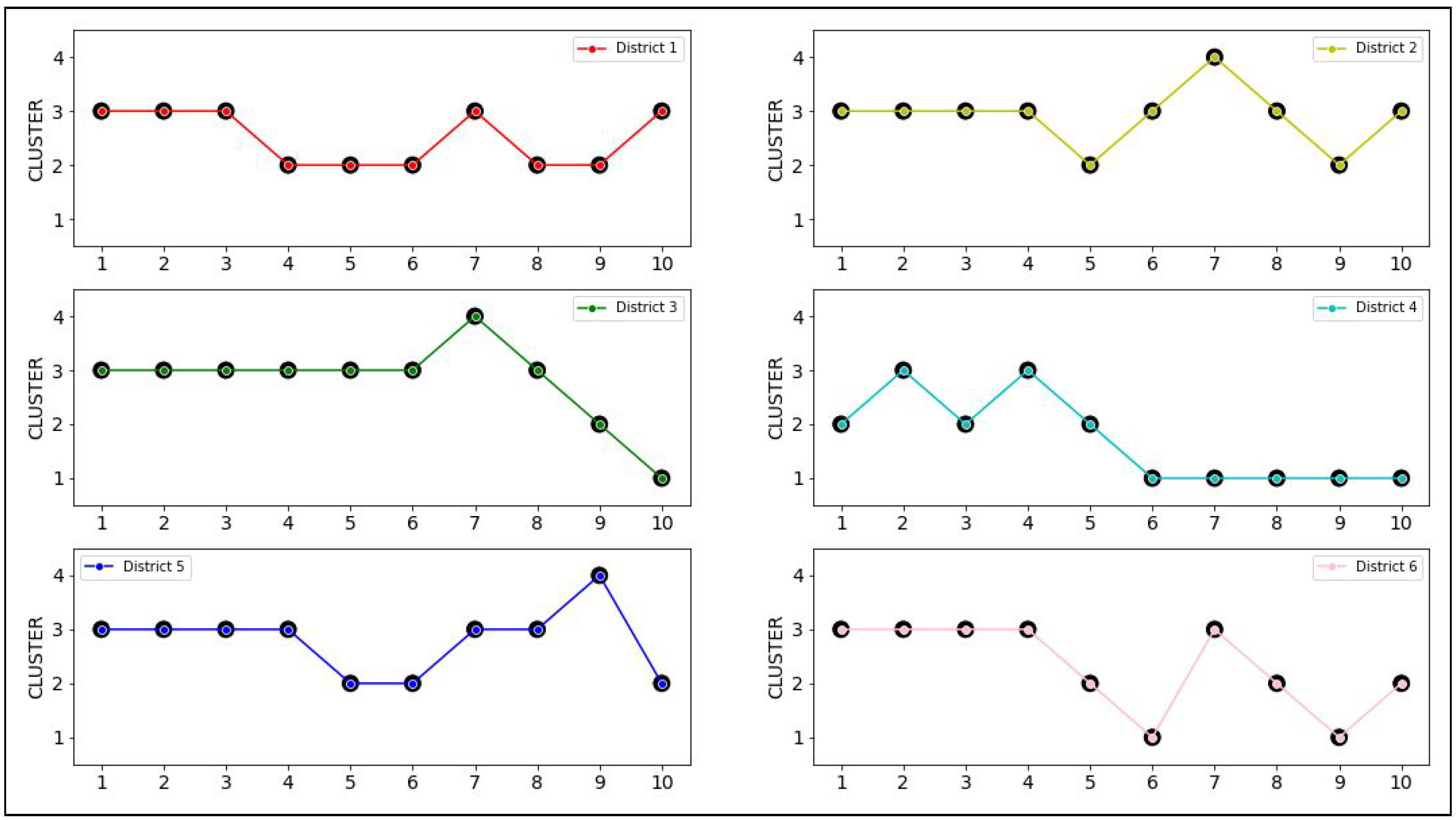
Once we have the assignment of sentencing data to patterns, we can visualize the corresponding trajectories. For Narcotics, the trajectories are shown in
Figure 4, and and for retail theft the corresponding trajectories are shown in
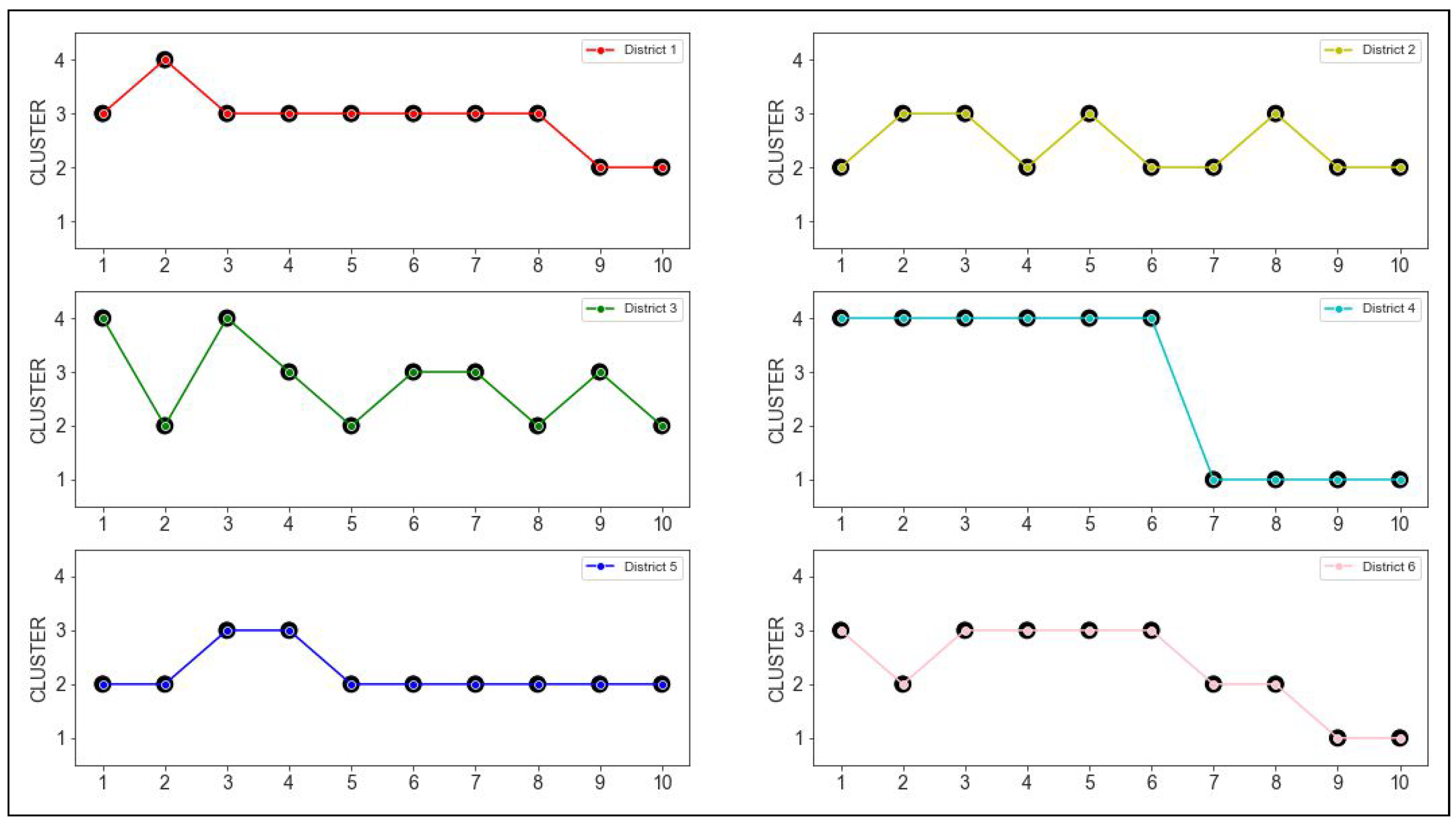
Figure 5. These trajectories are shown separately for each district in
Figure 6 and
Figure 7.
Finally, lets us write down the frequency distribution of patterns for each offense. This is summarized in
Table 5. For both crimes, more than 80% of patterns are
and
, corresponding to the second and third quartiles in sentence length. It is much more concentrated for Retail Theft: more than 50% of all patterns are pattern
, whereas, for Narcotics, the number of patterns
and
are split evenly (38%, 39%). This higher concentration of pattern
for Retail Theft reflects a higher percentage of retail theft offenses receiving a higher sentence than narcotics as measured by pattern counts.
5. Analyzing Similarities and Differences
Once the trajectories are computed, we can look for similarity in patterns over time. To that end, we need to define a “distance” metric to measure this.
We propose to use the so-called Hamming distance. In information theory, the Hamming distance between two strings of equal length is the number of positions at which the corresponding symbols are different [
12]. If
and
denote two trajectories over
n years for some offense
c, then the Hamming distance
is defined as the number of years when the corresponding patterns differ. To analyze similarities and differences in sentencing over time, we can analyze the differences between the corresponding trajectories using this Hamming distance [
13].
For a simple numerical example, consider the Hamming distance between districts
and
for Narcotics. The corresponding trajectories are
and
from
Table 4:
There are five years when the corresponding patterns are different. Therefore, for this example, the Hamming distance between trajectories is . In other words, for Narcotics, the sentencing patterns for districts and are different in 5 out of 10 years.
In a similar manner, we can compute Hamming distances for any pair of trajectories from districts and . We can summarize these pairwise distances as a hlmatrix where an element at row i and column j represents the Hamming distance between trajectory for district and trajectory for district . Similarly, we can compute the corresponding Hamming matrix for trajectories for retail theft.
These corresponding matrices for Narcotics and Retail Theft are given below:
We note that each Hamming matrix is symmetric with 0 on the main diagonal. For
districts, each matrix contains
entries (Hamming distances) above the main diagonal corresponding to distinct pairs of trajectories. Let us write down these 15 entries as sorted sequences for Narcotics and Retail Theft. We will denote these sequences as
and
respectively. We have the following:
We can compute some statistical measures for each of these two sequences and summarize them in
Table 6. This table shows that both median and mean Hamming distances are lower for Retail Theft than for Narcotics. On average, the two trajectories differ in almost seven out of ten years (or 70% of the time) for Narcotics (
) but only in about five years out of ten years (or 50%) for Retail Theft (
). The variability in these distances measured by standard deviations is lower for Retail Theft (
) than for Narcotics (
). In other words, retail theft sentencing was comparatively more consistent across districts than narcotics sentencing.
6. Volatility and Inertia of a Trajectory
In the previous section, we examined the similarities between trajectories using the Hamming distance. We now focus on describing the statistics on individual trajectories. We want to characterize the following performance metrics:
- 1.
The tendency of a trajectory to change patterns over time. We will call this the volatility of trajectory and denote it by V.
- 2.
The tendency of a trajectory to remain in the same pattern in consecutive years. We will call the length of the longest such sub-sequence the inertia of the trajectory. We denote inertia by I.
- 3.
The “average” or “most likely” trajectories for Narcotics and Retail Theft.
We start with volatility. Suppose a pattern in each period was described by a single number. In that case, we could take some measure of deviation, such as standard deviation, and use it as a measure of volatility [
14]. However, in general, we may not have such a single numerical description of a pattern. Therefore, we suggest a simple alternative: measure trajectory volatility by the number of times patterns were switched in the trajectory [
15].
For example, consider district
for Narcotics. Its trajectory is
This trajectory switched patterns after years 2, 3, 4, and 9. We can write it schematically as
where ↗ and ↘ represent changes to a higher-numbered pattern or a lower-numbered pattern, respectively. Therefore, the above trajectory
had three switches between patterns. We use this number as a measure of volatility for trajectories. Therefore,
.
We compute this volatility
and
for the Narcotics and Retail Theft trajectories, respectively, and summarize the results in
Table 7. From this table, we see that for Retail Theft, we have a slightly higher mean volatility (5.3 vs. 4.7) but a lower standard deviation (0.9 vs. 2.1). Examining the pattern of switches, we notice that for Retail Theft, there are many more switches in the last 6 years compared to Narcotics. This suggests that sentencing patterns in the last six years could be quite different than in the first six years. We will present a detailed analysis of such comparison in
Section 7.
Next, we consider inertia—the tendency of a trajectory to stay in the same pattern over consecutive years. We analyze inertia by computing the length of the longest sub-sequence with the same pattern.
For example, consider district
for Narcotics. Its trajectory is
This trajectory spends 6 consecutive years in the same pattern
. It is possible to have a case where we have multiple sub-sequences with the same duration. In such a case, we take the length of a maximum sub-sequence. For example, consider district
In this example, we have three sub-sequences of the same length, 2. In such a case, we will use a sub-sequence containing the most frequent pattern. For this district, pattern is the most frequent and, therefore, we will use as the sub-sequence to measure inertia.
In
Table 7, we present the results for inertia for both offenses. The average inertia is slightly higher for Retail Theft vs. Narcotics (5.3 vs. 4.7) and has a lower standard deviation (0.9 vs. 1.8). This suggests that sentencing patterns for retail theft are more static.
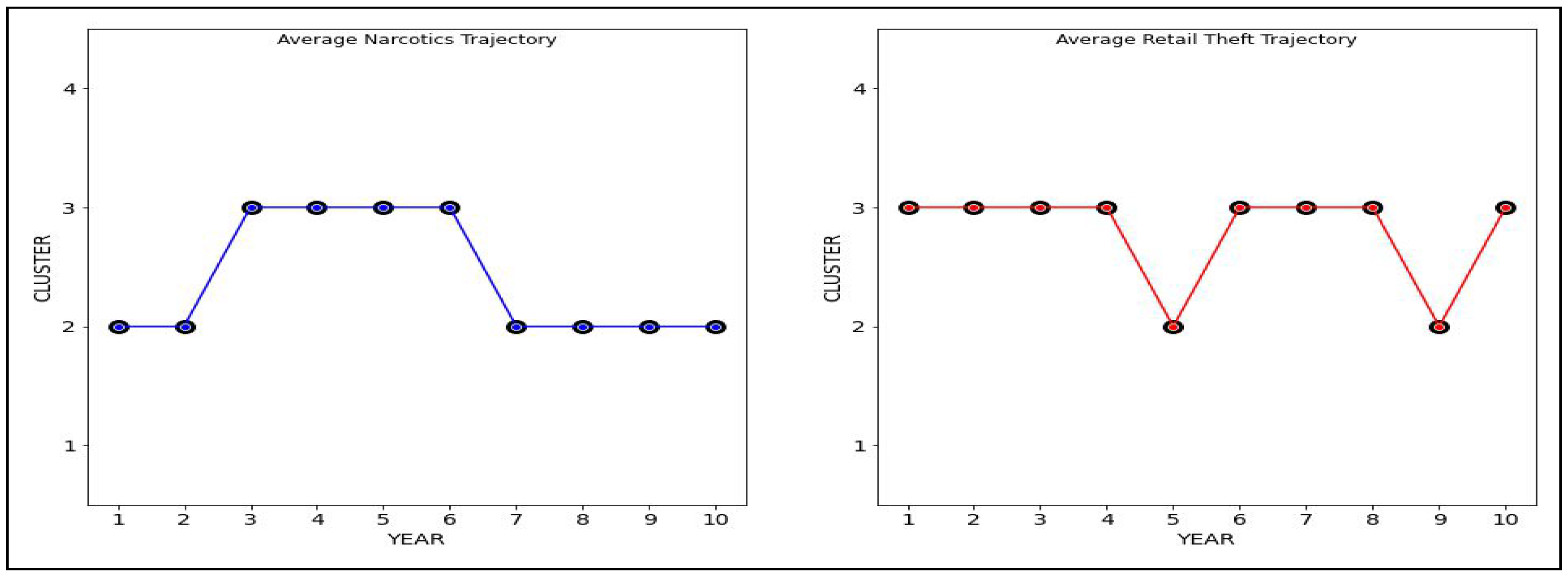
Finally, we can ask the following question: what are the “average” or most likely trajectories for Narcotics and Retail Theft? [
16] We can construct such trajectories as follows. For each offense and year, we write down the most frequent (mode) pattern for that year. This is illustrated in
Table 8.
For some years, we may have multiple choices for the mode. For example, for Narcotics, we have multiple choices for year 1, namely clusters
,
, and
. For Retail Theft, we have multiple choices for year 6 (clusters
,
, and
) and year 10 (clusters
,
, and
). In such cases, we will use the procedure commonly used in machine learning [
1,
4]: use the most frequent pattern across all districts and years for that offense. For example, for year 1 in Narcotics, we must choose between patterns
and
. From
Table 5, we find that for Narcotics, pattern
is (slightly) more frequent than pattern
(23% vs. 22%). Therefore, we assign
for year 2 in Narcotics.
By contrast, for Retail Theft from
Table 5, we find that pattern
is much more frequent than
(54% vs. 28%). Therefore, we assign pattern
in years 6 and 10.
With the above construction, we can compute the “average” trajectories, their volatility
V, and inertia
I for Narcotics and Retail Theft:
Let us rewrite the above paths by indicating pattern switches and sub-trajectories in the same cluster.
These “average” trajectories are illustrated in
Figure 8. Comparing these new “average” trajectories, we note the following:
- 1.
For Narcotics, the trajectory has inertia . It spends the last five years in pattern . During the first 7 years, it switched between patterns and . Its volatility is .
- 2.
For Retail Theft, the trajectory also has inertia , but it spends the first five years in pattern . During the last seven years, it has switched between patterns and . Its volatility is and is higher than that of Narcotics.
7. Changes in Sentencing Patterns over Aggregated Time Periods
In the previous analysis, we constructed the trajectory for patterns and analyzed their similarity and differences by focusing on all 10 years. We now ask the following question: do differences in patterns change over larger (aggregated) periods [
17]?
We illustrate how such analysis is carried out with our trajectories. We will aggregate our ten years into the first five years (years 1–5) and the last five years (years 6–10). Consider the Narcotics offenses first. If we take district
, then its trajectory
from
Table 4,
will be split into sub-trajectories
and
corresponding to the first five and last five years, respectively,
We can split all trajectories into two halves. The resulting partial trajectories are summarized in
Table 9.
Once we have the sub-trajectories, we can compute the Hamming matrices for the first and last five years. We will use the subscripts and to denote the first five years and the last five years. With this notation, we have the following:
- 1.
Hamming distance matrices for Narcotics in the first and last five years:
- 2.
Hamming distance matrices for first and last five years for Retail Theft:
As before, for our
districts, each Hamming distance matrix contains
entries (Hamming distances for sub-trajectories). We can write down these entries in sorted order. As with the Hamming matrices above, we will use subscripts
and
. We have
As before, we can compute some statistical measures for Hamming distances for each sequence. These are summarized in
Table 10. We note that for Narcotics, the statistics on Hamming distances have remained practically unchanged between the two periods. The median Hamming distance for Narcotics remained the same, and the mean changed slightly between the first five years (
) and the last five years (
). The standard deviation remained the same at
.
By contrast, we see a dramatic difference between the first and last periods for Retail Theft. In the first period, the sub-trajectories were very similar, with a median Hamming distance of 1. This median distance increased dramatically to 4 in the second period. The mean distance increased dramatically from 1.3 to 3.8. At the same time, the variability in Hamming distances increased only slightly from to . In other words, the sub-trajectories for Retail Theft became considerably more distinct in the last five years than during the first five years.
Next, we compare both periods separately in terms of volatility
V and inertia
I. We compute these by examining
Table 9. Our results are summarized in
Table 11. Examining this table, we see a dramatic change in sentencing between the two periods. For Narcotics, the average inertia
increased from 2.7 to 3, while the average volatility
decreased from 2.2 to 1.5. The standard deviations for both inertia and volatility decreased as well. By contrast, for Retail Theft, the average inertia
decreased drastically from
to 2, while the average volatility
increased drastically from 1.3 to 3. Standard deviations for these measures increased, especially for volatility from 1.3 to 3. This means that for Retail Theft, the districts became much more different in their sentencing patterns. The most dramatic change for Retail Theft is observed in district
. For the first five years, the trajectory remained in the same cluster
, whereas it changed clusters from one year to the next for the last five years. These results are consistent with the above observation that sub-trajectories became more distinct for Retail Theft than for Narcotics when measured by Hamming distances.
8. Side-by-Side Comparison of Districts
So far, we have compared trajectories to each other separately for Narcotics and Retail Theft and have identified differences and similarities in sentencing patterns. We now ask a different question: how do individual districts compare in terms of their sentencing patterns [
18]?
We can only make such a comparison if we have the same number of patterns and each cluster
for Narcotics is “equivalent” to cluster
for Retail Theft. In our case, we took the same number
of clusters, and districts were assigned to clusters by similar rules based on quartiles of average sentences. Therefore, although the sentences could be radically different, we can compare the individual districts in corresponding patterns. Side-by-side comparisons are shown in
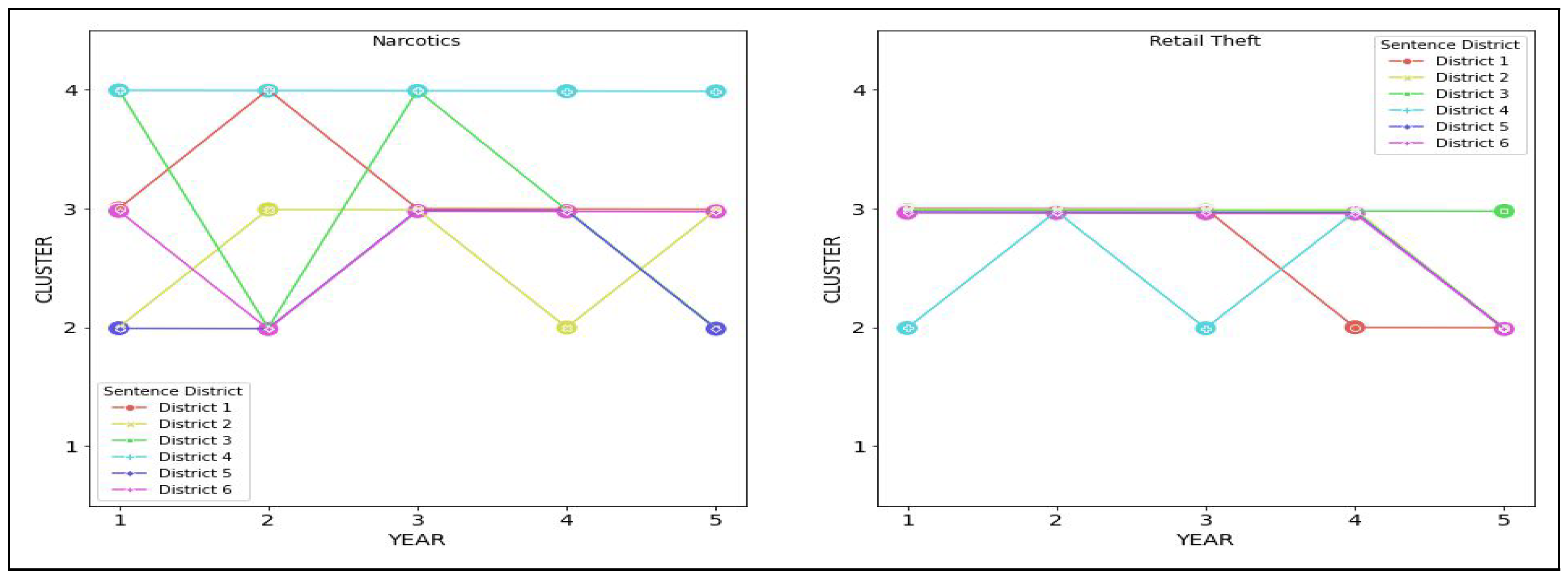
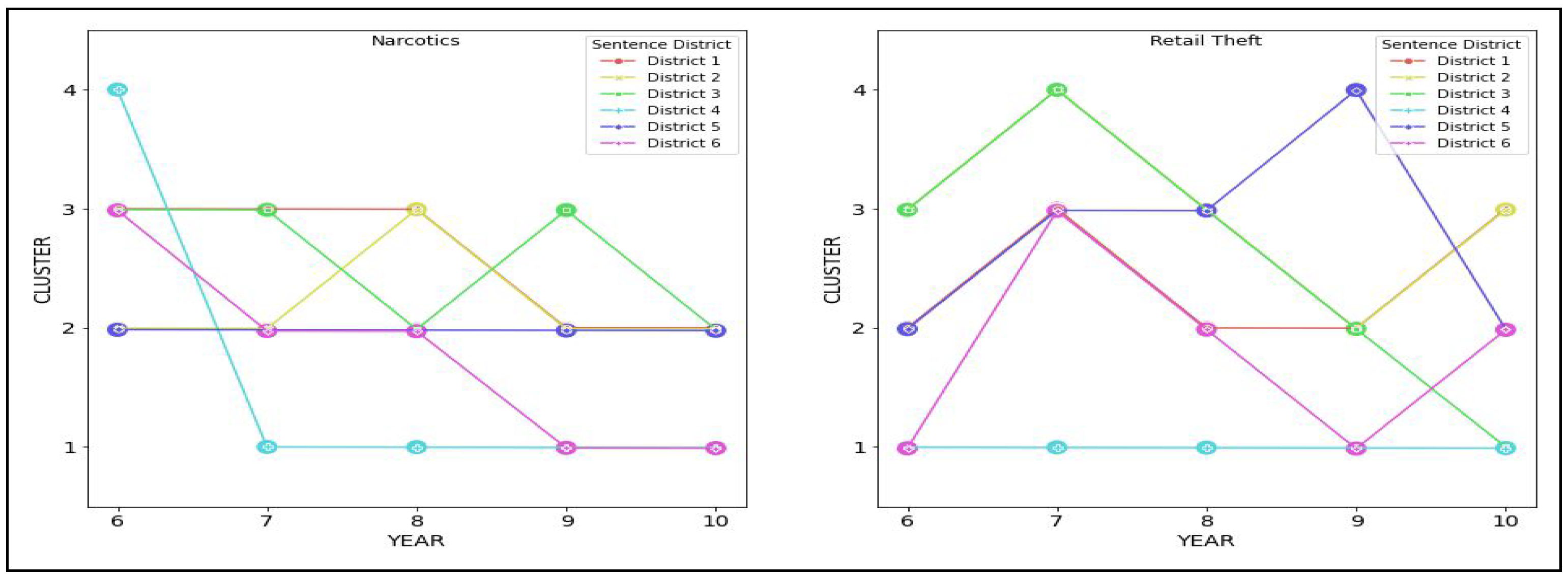
Figure 11 and
Figure 12.
In
Table 12, we consider pairwise trajectories for each district and compute their volatility
V and inertia
I from
Table 7 and their Hamming distances
.
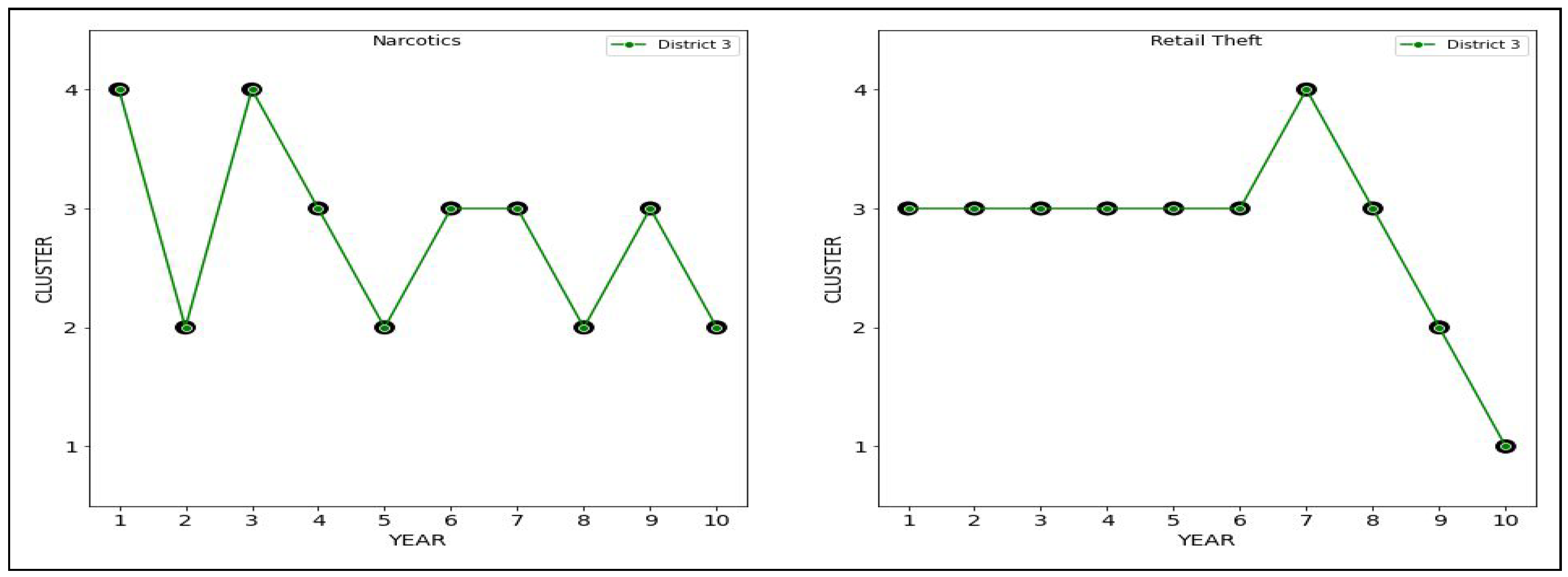
We can see that the most significant difference is in district .
For this district, the Hamming distance is 8. For Narcotics, this district has a maximum value of 8 for volatility and a minimum value of 2 for inertia across all possible trajectories. By contrast, for Retail Theft, this district has a median volatility value of 4 but a maximum value of 6 for inertia across all possible trajectories.
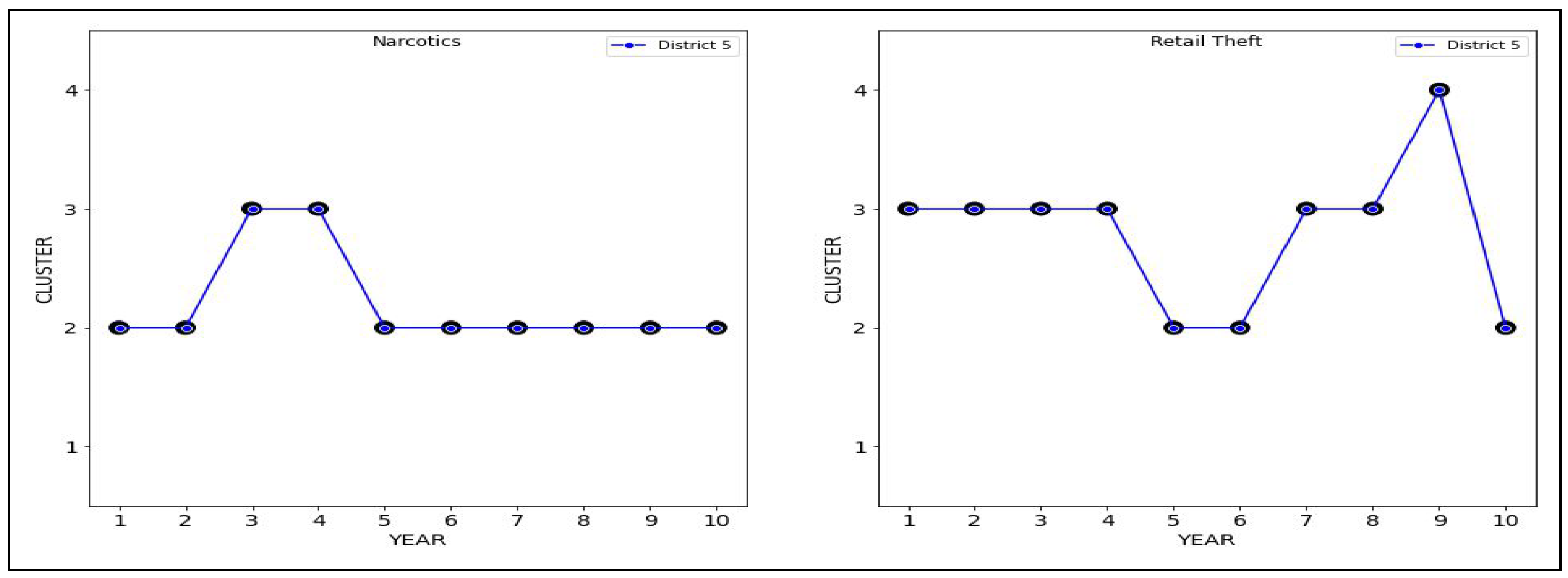
The most minor difference is in district , with a Hamming distance of 6.
For both Narcotics and Retail Theft, we have the same value of 7. For Narcotics, this district has a value of 3. By contrast, for Retail Theft, this district has an inertia value of 4, which is the median value for inertia across all trajectories.
The above comparison suggests that district 3 has the most differences in sentencing patterns for both offenses, whereas district 5 has the most similar patterns in sentencing.
9. Summary of Results and Discussion
Let us start by summarizing our findings for Narcotics and Retail Theft.
The median and mean Hamming distances are lower for Retail Theft than for Narcotics, suggesting that retail theft sentencing was more consistent than Narcotics sentencing
The volatility of trajectories was much higher for Retail Theft than for Narcotics
the inertia is similar for both Narcotics and Retail Theft
For Narcotics, the sentencing patterns did not change much during the last five years as compared to the first five years. For Retail Theft, there was a dramatic change in sentencing patterns as measured by changes in Hamming distances, inertia, and volatility
In a side-by-side comparison of sentencing by district, the most consistent sentencing for both offenses was carried out by district 2, and the most inconsistent sentencing was carried out by district 3
10. Conclusions
In this paper, we presented a general approach to compare sentencing data. The key idea is to associate sentencing data with a small number of patterns (clusters) for each period. This allows a representation of (possibly multi-dimensional) sentencing data in terms of trajectories in the (time, cluster) space. We defined inertia and volatility for these trajectories and used Hamming distance to analyze similarities and differences in sentencing based on visualization. We illustrated our approach by presenting a detailed comparison of sentencing data for Narcotics and Retail Theft. We believe the proposed approach would provide additional tools for quantitative analysis in criminology.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}