
An Analysis of Sentiment: Methods, Applications, and Challenges †


Abstract
:1. Introduction
- The definition of the sentiment analysis procedure in detail, as well as the identification of well-known techniques for performing it in this paper; it was achieved via the reviews of a variety of publications.
- Analyses of the different techniques to select which is best for a certain application.
- To comprehend more easily obtainable techniques like ML, lexicon-based models, and hybrid models, we categorize and describe commonly used SA methodologies.
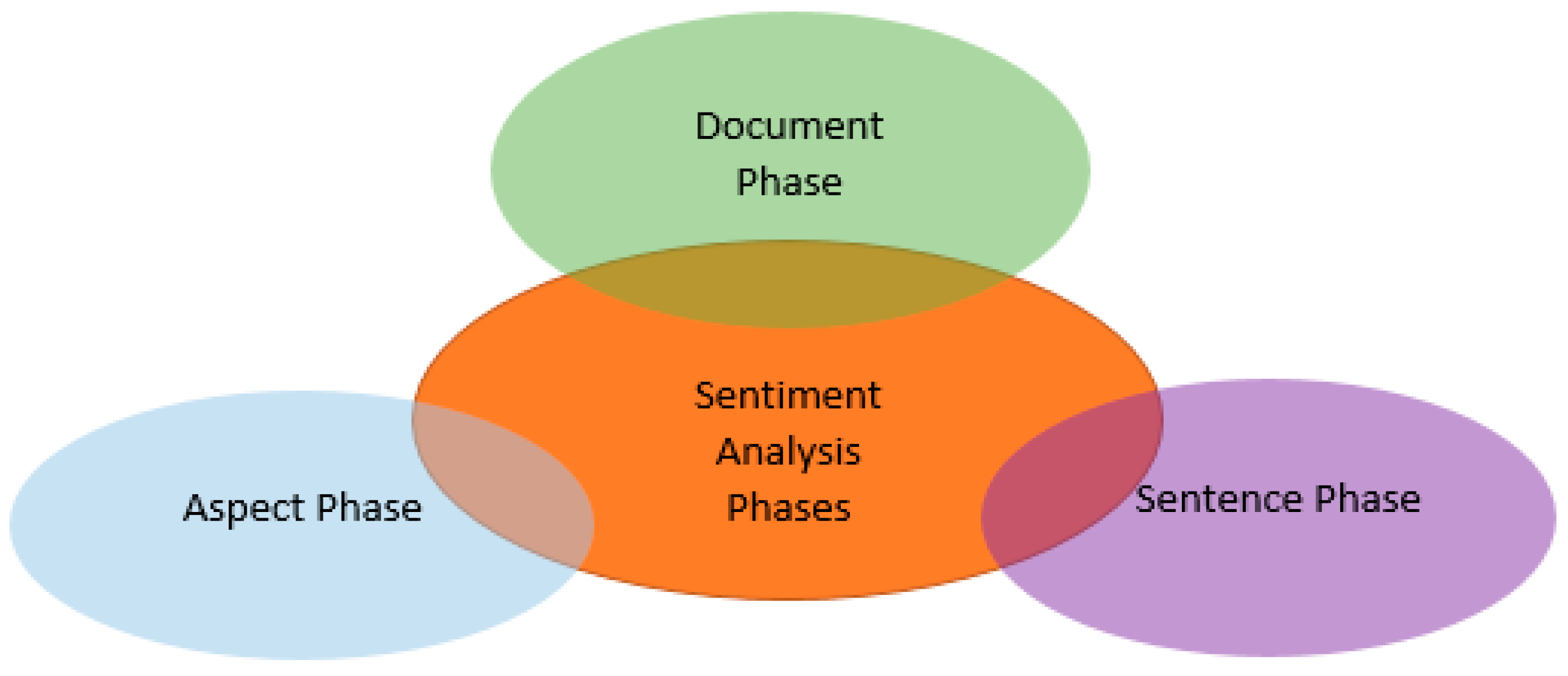
2. Phases of Sentiment Analysis
2.1. Document Phase
2.2. Sentence Phase
2.3. Aspect Phase
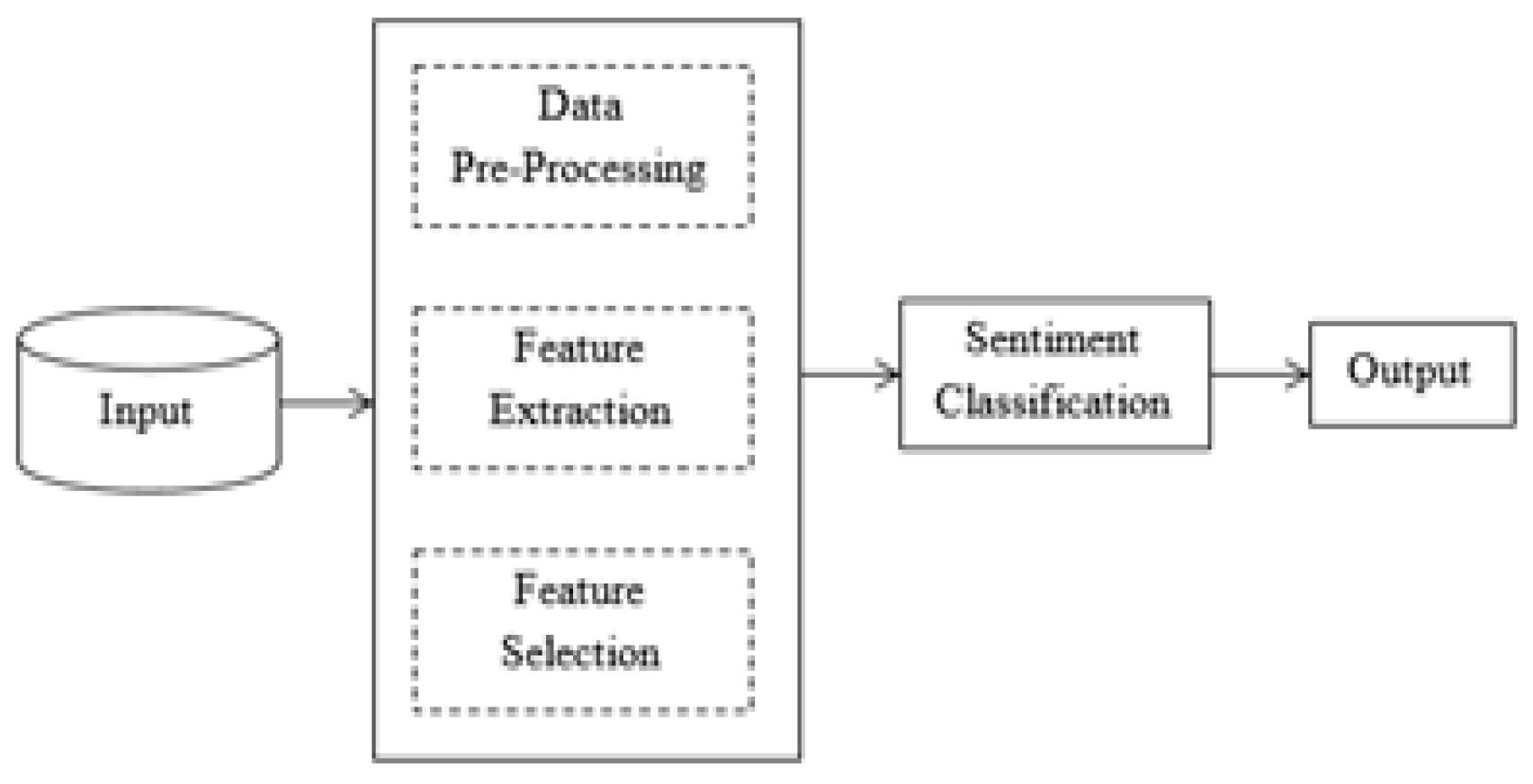
3. Sentiment Analysis Pre-Processing and Feature Extraction
3.1. Data Pre-Processing
- Tokenization;
- Stop-Word Removal;
- Part of Speech Tagging;
- Lemmatization.
3.2. Feature Extraction
3.2.1. Terms Frequency (TF)
3.2.2. Parts of Speech (PoS) Tag
3.2.3. Negations
3.2.4. Bag of Words (BoW)
3.3. Feature Selection (FS)
3.3.1. Filter Method
3.3.2. Wrapper Method
3.3.3. Embedded Method
3.3.4. Hybrid Method
4. Classification of Sentiment Analysis
4.1. Machine Learning Approaches
4.1.1. Naive Bayes (NB)
4.1.2. Support Vector Machine (SVM)
4.1.3. Machine Learning Approaches
4.1.4. K-Nearest Neighbors (KNN)
4.1.5. Decision Tree (DT)
4.2. Lexicon-Based Approach
4.2.1. Corpus-Based Approach
4.2.2. Dictionary-Based Method
4.3. Hybrid Methods
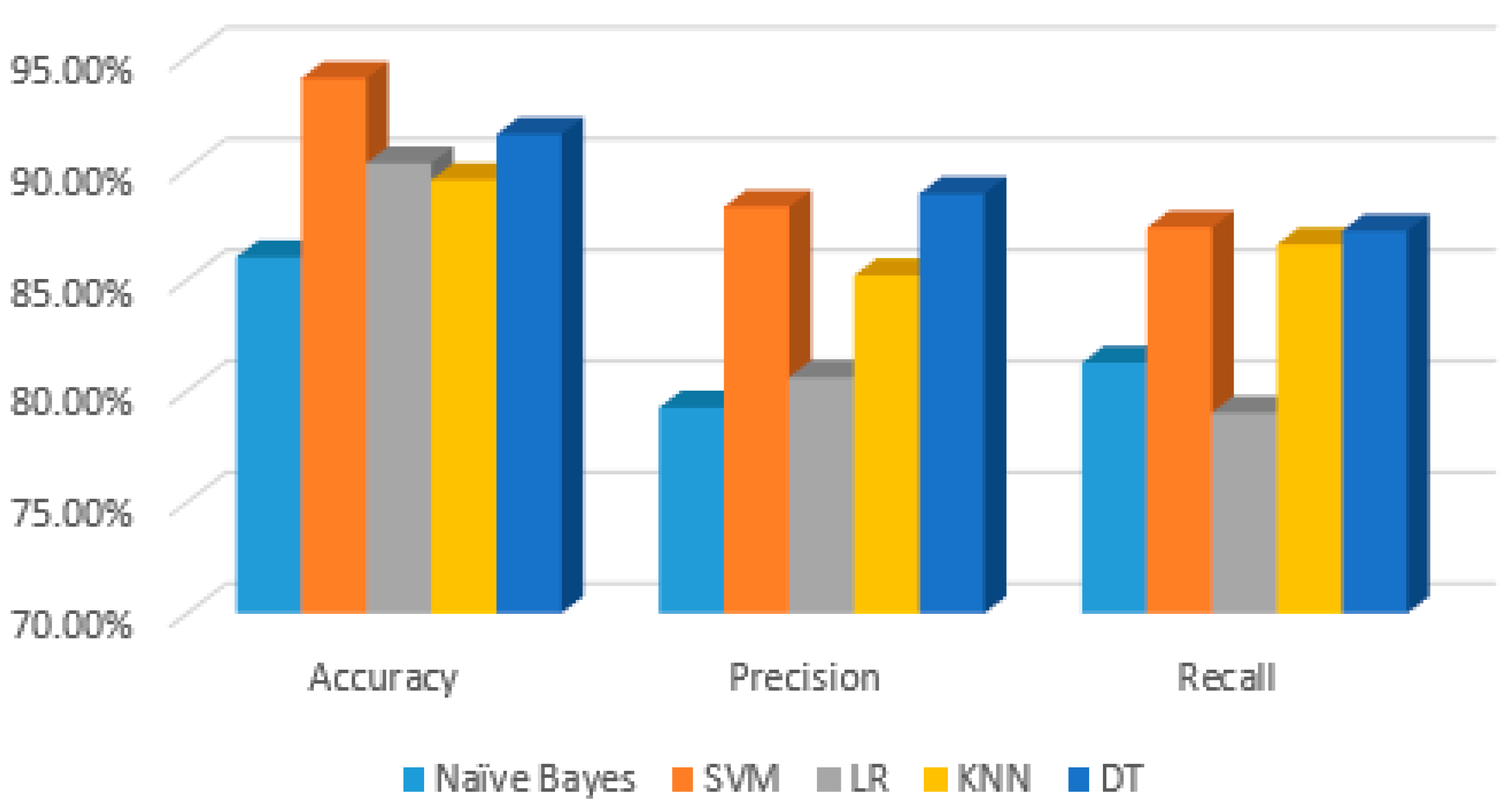
5. Comparison of Different Classification Techniques
6. Applications of Sentiment Analysis
6.1. Business Analysis
6.2. Health Care and Medical Domain
6.3. Review Analysis
6.4. Customer Voice
6.5. Social Media Monitoring
7. Challenges in Sentiment Analysis
7.1. Sarcasm Handling
7.2. Domain Dependency
7.3. Negations
7.4. Spam Detection
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Birjali, M.; Kasri, M.; Beni-Hssane, A. A comprehensive survey on sentiment analysis: Approaches, challenges and trends. Knowl. Based Syst. 2021, 226, 107134. [Google Scholar] [CrossRef]
- Chaturvedi, I.; Cambria, E.; Welsch, R.E.; Herrera, F. Distinguishing between facts and opinions for sentiment analysis: Survey and challenges. Inf. Fusion 2018, 44, 65–77. [Google Scholar] [CrossRef]
- Choi, Y.; Lee, H. Data properties and the performance of sentiment classification for electronic commerce applications. Inf. Syst. Front. 2017, 19, 993–1012. [Google Scholar] [CrossRef]
- Cambria, E.; Das, D.; Bandyopadhyay, S.; Feraco, A. (Eds.) A Practical Guide to Sentiment Analysis; Springer: Cham, Switzerland, 2017. [Google Scholar]
- Valdivia, A.; Luzón, M.V.; Cambria, E.; Herrera, F. Consensus vote models for detecting and filtering neutrality in sentiment analysis. Inf. Fusion 2018, 44, 126–135. [Google Scholar] [CrossRef]
- Sánchez-Rada, J.F.; Iglesias, C.A. Social context in sentiment analysis: Formal definition, overview of current trends and framework for comparison. Inf. Fusion 2019, 52, 344–356. [Google Scholar] [CrossRef]
- Wankhade, M.; Rao, A.C.S.; Kulkarni, C. A survey on sentiment analysis methods, applications, and challenges. Artif. Intell. Rev. 2022, 55, 5731–5780. [Google Scholar] [CrossRef]
- Do, H.H.; Prasad, P.W.C.; Maag, A.; Alsadoon, A. Deep learning for aspect-based sentiment analysis: A comparative review. Expert Syst. Appl. 2019, 118, 272–299. [Google Scholar] [CrossRef]
- Aggarwal, C.C. Machine Learning for Text; Springer: Cham, Switzerland, 2018; Volume 848. [Google Scholar]
- Bhatia, P.; Ji, Y.; Eisenstein, J. Better document-level sentiment analysis from rst discourse parsing. arXiv 2015, arXiv:1509.01599. [Google Scholar]
- Saunders, D. Domain Adaptation for Neural Machine Translation. Doctoral Dissertation, University of Cambridge, Cambridge, UK, 2021. [Google Scholar]
- Yang, B.; Cardie, C. Context-aware learning for sentence-level sentiment analysis with posterior regularization. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MD, USA, 22–27 June 2014; Volume 1, pp. 325–335. [Google Scholar]
- Rao, G.; Huang, W.; Feng, Z.; Cong, Q. LSTM with sentence representations for document-level sentiment classification. Neurocomputing 2018, 308, 49–57. [Google Scholar] [CrossRef]
- Behdenna, S.; Barigou, F.; Belalem, G. Document level sentiment analysis: A survey. EAI Endorsed Trans. Context-Aware Syst. Appl. 2018, 4, e2. [Google Scholar] [CrossRef]
- Ferrari, A.; Esuli, A. An NLP approach for cross-domain ambiguity detection in requirements engineering. Autom. Softw. Eng. 2019, 26, 559–598. [Google Scholar] [CrossRef]
- Indurkhya, N.; Damerau, F.J. Handbook of Natural Language Processing; Chapman and Hall/CRC: Boca Raton, FL, USA, 2010. [Google Scholar]
- Tubishat, M.; Idris, N.; Abushariah, M.A. Implicit aspect extraction in sentiment analysis: Review, taxonomy, oppportunities, and open challenges. Inf. Process. Manag. 2018, 54, 545–563. [Google Scholar] [CrossRef]
- Mowlaei, M.E.; Abadeh, M.S.; Keshavarz, H. Aspect-based sentiment analysis using adaptive aspect-based lexicons. Expert Syst. Appl. 2020, 148, 113234. [Google Scholar] [CrossRef]
- Mai, L.; Le, B. Joint sentence and aspect-level sentiment analysis of product comments. Ann. Oper. Res. 2021, 300, 493–513. [Google Scholar] [CrossRef]
- Liu, B. Sentiment Analysis and Opinion Mining; Synthesis Lectures on Human Language Technologies; Springer: Cham, Switzerland, 2012; Volume 5, pp. 1–167. [Google Scholar]
- Venugopalan, M.; Gupta, D. Exploring sentiment analysis on twitter data. In Proceedings of the 2015 Eighth International Conference on Contemporary Computing (IC3), Noida, India, 20–22 August 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 241–247. [Google Scholar]
- Sharma, A.; Lyons, J.; Dehzangi, A.; Paliwal, K.K. A feature extraction technique using bi-gram probabilities of position specific scoring matrix for protein fold recognition. J. Theor. Biol. 2013, 320, 41–46. [Google Scholar] [CrossRef]
- Weerasooriya, T.; Perera, N.; Liyanage, S.R. A method to extract essential keywords from a tweet using NLP tools. In Proceedings of the 2016 Sixteenth International Conference on Advances in ICT for Emerging Regions (ICTer), Negombo, Sri Lanka, 1–3 September 2016; IEEE: Piscataway, NJ, USA, 2016; pp. 29–34. [Google Scholar]
- George, D.R.; Rovniak, L.S.; Kraschnewski, J.L. Dangers and opportunities for social media in medicine. Clin. Obstet. Gynecol. 2013, 56, 453–462. [Google Scholar] [CrossRef]
- Ahmad, S.R.; Bakar, A.A.; Yaakub, M.R. A review of feature selection techniques in sentiment analysis. Intell. Data Anal. 2019, 23, 159–189. [Google Scholar] [CrossRef]
- Kumar, R.; Kaur, J. Random forest-based sarcastic tweet classification using multiple feature collection. In Multimedia Big Data Computing for IoT Applications; Springer: Singapore, 2020; pp. 131–160. [Google Scholar]
- Hoque, N.; Bhattacharyya, D.K.; Kalita, J.K. MIFS-ND: A mutual information-based feature selection method. Expert Syst. Appl. 2014, 41, 6371–6385. [Google Scholar] [CrossRef]
- Adomavicius, G.; Kwon, Y. Improving aggregate recommendation diversity using ranking-based techniques. IEEE Trans. Knowl. Data Eng. 2011, 24, 896–911. [Google Scholar] [CrossRef]
- Das, H.; Naik, B.; Behera, H.S. A Jaya algorithm based wrapper method for optimal feature selection in supervised classification. J. King Saud Univ.-Comput. Inf. Sci. 2022, 34, 3851–3863. [Google Scholar] [CrossRef]
- Chiew, K.L.; Tan, C.L.; Wong, K.; Yong, K.S.; Tiong, W.K. A new hybrid ensemble feature selection framework for machine learning-based phishing detection system. Inf. Sci. 2019, 484, 153–166. [Google Scholar] [CrossRef]
- Sankar, H.; Subramaniyaswamy, V. Investigating sentiment analysis using machine learning approach. In Proceedings of the 2017 International Conference on Intelligent Sustainable Systems (ICISS), Palladam, India, 7–8 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 87–92. [Google Scholar]
- Jurek, A.; Mulvenna, M.D.; Bi, Y. Improved lexicon-based sentiment analysis for social media analytics. Secur. Inform. 2015, 4, 1–13. [Google Scholar] [CrossRef]
- Yusof, N.N.; Mohamed, A.; Abdul-Rahman, S. Reviewing classification approaches in sentiment analysis. In Proceedings of the International Conference on Soft Computing in Data Science, Putrajaya, Malaysia, 2–3 September 2015; Springer: Singapore, 2015; pp. 43–53. [Google Scholar]
- Yoo, G.; Nam, J. A hybrid approach to sentiment analysis enhanced by sentiment lexicons and polarity shifting devices. In Proceedings of the 13th Workshop on Asian Language Resources, Miyazaki, Japan, 7 May 2018; pp. 21–28. [Google Scholar]
- Borg, A.; Boldt, M. Using VADER sentiment and SVM for predicting customer response sentiment. Expert Syst. Appl. 2020, 162, 113746. [Google Scholar] [CrossRef]
- Li, F.; Wang, W.; Xu, J.; Yi, J.; Wang, Q. Comparative study on vulnerability assessment for urban buried gas pipeline network based on SVM and ANN methods. Process Saf. Environ. Prot. 2019, 122, 23–32. [Google Scholar] [CrossRef]
- Xia, H.; Yang, Y.; Pan, X.; Zhang, Z.; An, W. Sentiment analysis for online reviews using conditional random fields and support vector machines. Electron. Commer. Res. 2020, 20, 343–360. [Google Scholar] [CrossRef]
- Wu, P.; Li, X.; Shen, S.; He, D. Social media opinion summarization using emotion cognition and convolutional neural networks. Int. J. Inf. Manag. 2020, 51, 101978. [Google Scholar] [CrossRef]
- Ali, S.M.; Noorian, Z.; Bagheri, E.; Ding, C.; Al-Obeidat, F. Topic and sentiment aware microblog summarization for twitter. J. Intell. Inf. Syst. 2020, 54, 129–156. [Google Scholar] [CrossRef]
- Hamdan, H.; Bellot, P.; Bechet, F. Lsislif: Crf and logistic regression for opinion target extraction and sentiment polarity analysis. In Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015), Denver, CO, USA, 4–5 June 2015; pp. 753–758. [Google Scholar]
- Zhao, Y.-Y.; Qin, B.; Liu, T. Integrating intra-and inter-document evidences for improving sentence sentiment classification. Acta Autom. Sin. 2010, 36, 1417–1425. [Google Scholar] [CrossRef]
- Jain, P.K.; Pamula, R.; Ansari, S. A supervised machine learning approach for the credibility assessment of user-generated content. Wirel. Pers. Commun. 2021, 118, 2469–2485. [Google Scholar] [CrossRef]
- Gupta, I.; Joshi, N. Enhanced twitter sentiment analysis using hybrid approach and by accounting local contextual semantic. J. Intell. Syst. 2020, 29, 1611–1625. [Google Scholar] [CrossRef]
- Carvalho, J.; Plastino, A. On the evaluation and combination of state-of-the-art features in Twitter sentiment analysis. Artif. Intell. Rev. 2021, 54, 1887–1936. [Google Scholar] [CrossRef]
- Ebadi, A.; Xi, P.; Tremblay, S.; Spencer, B.; Pall, R.; Wong, A. Understanding the temporal evolution of COVID-19 research through machine learning and natural language processing. Scientometrics 2021, 126, 725–739. [Google Scholar] [CrossRef]
- Kumar, S.; Yadava, M.; Roy, P.P. Fusion of EEG response and sentiment analysis of products review to predict customer satisfaction. Inf. Fusion 2019, 52, 41–52. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Classification Techniques | Accuracy | Precision | Recall |
|---|---|---|---|
| Naïve Bayes | 86.01% | 79.25% | 81.26% |
| SVM | 94.05% | 88.27% | 87.34% |
| LR | 90.23% | 80.61% | 79.02% |
| KNN | 89.47% | 85.19% | 86.58% |
| DT | 91.53% | 88.86% | 87.19% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, H.D.; Goyal, P. An Analysis of Sentiment: Methods, Applications, and Challenges. Eng. Proc. 2023, 59, 68. https://doi.org/10.3390/engproc2023059068
Sharma HD, Goyal P. An Analysis of Sentiment: Methods, Applications, and Challenges. Engineering Proceedings. 2023; 59(1):68. https://doi.org/10.3390/engproc2023059068
Chicago/Turabian StyleSharma, Harish Dutt, and Parul Goyal. 2023. "An Analysis of Sentiment: Methods, Applications, and Challenges" Engineering Proceedings 59, no. 1: 68. https://doi.org/10.3390/engproc2023059068
APA StyleSharma, H. D., & Goyal, P. (2023). An Analysis of Sentiment: Methods, Applications, and Challenges. Engineering Proceedings, 59(1), 68. https://doi.org/10.3390/engproc2023059068