Our forecasting experiments are based on the concept of simulation-based forecast model selection. This is a computer-intensive method that has been documented in [
7] and applied by [
8]. In fact, usage of the method may be more widespread and, for example, Ref. [
11] uses an identical concept without explicitly naming it. The first subsection motivates and describes the method, the second subsection reports a small Monte Carlo experiment.
2.1. Simulation-Based Forecast Model Selection
The traditional view on model selection is inspired by statistical hypothesis testing. Researchers may consider nested sequences of models and evaluate restriction tests, such as the simple F- and t-tests of the Wald type. The more complex model is chosen if the tests reject, otherwise the simpler model is maintained. In many situations, this approach is justified by the fact that there is no clear monetary loss that is suffered if the decision turns out to be non-optimal. A decision for a model is regarded as correct when the generating model class is selected, and it is a requirement that incorrect decisions disappear as the sample size increases.
If the aim of the model selection exercise is specified as prediction, it is difficult to maintain this statistical paradigm. A simple model may be preferred to a complex model when it forecasts better, and this decision may depend on the sample size. Larger samples admit precise estimation of more parameters such that even a small advantage for a complex model may be worth the additional sophistication. A decision for a model is regarded as optimal when it minimizes prediction error whether the selected model is correct or not, and the decision may take the sample size into account such that a decision may be good for small samples and bad for larger samples.
An important difference between the tasks of forecasting and of approximating a true structure is that the former decision problem is symmetric, whereas the hypothesis testing framework is asymmetric. Statistical textbooks often explain hypothesis tests using the metaphor of an accused person in a trial. The accused is regarded as innocent until the evidence is so strong that he or she can be regarded as guilty ‘beyond all reasonable doubt’. In practice, this means that a risk of 5% can be accepted for the probability that a convicted person is really innocent. One may take the metaphor further and demand for a risk of 1% if the amount of evidence used before court increases. Some recommend that the null should become harder to reject as the sample size increases.
Forecasting does not need this asymmetry. A small set of potential prediction models is at hand, and the forecaster chooses among less and more sophisticated variants. If the decision is based on an out-of sample forecast evaluation for realized data, concern for simplicity is no longer required. Models are cheap, and the model that comes closest to the realization can be selected even if it is very complex. The winner model, however, is typically not too complex as, otherwise, its performance would be hampered by the sampling variation in parameter estimation.
Thus, the following strategy appears to be informative when the purpose of a model is prediction. All rival models are estimated, i.e., the closest fit to the data at hand within the specified model class is determined, and then all estimated structures are simulated. These simulated pseudo-data are again predicted by all rival models, freshly estimated from the simulated data. For example, the qualitative outcome of this experiment may be as follows:
Model A predicts data generated by model A well;
Model A predicts data generated by model B satisfactorily and only slightly less precisely than model B;
Model B predicts data generated by model B well;
Model B predicts data generated by model A poorly.
Given this general impression, a forecaster may prefer model A as a prediction tool rather than model B, unless support for model B by the data is truly convincing. We note that models do not always perform well in forecasting their own data. For example, models containing parameters that are small and estimable only with large standard errors are often dominated by forecast models that set the critical parameters at zero. Ref. [
12] also suggested quantitative measures for evaluating the four experiments summarily, but within the limits of this article we will stay with qualitative evaluations, particularly processing the reaction to changing sample sizes. For example, model A may forecast B data well up to 300 observations, when model B would clearly dominate. In this case, the preference may depend on the time range for future applications. If the researcher intends to base such forecasts on 500 observations, model B becomes competitive.
It is worthwhile contrasting the method with alternative concepts that have been suggested in the literature. For example, ref. [
13] investigate a related problem, a decision between multivariate and univariate prediction models. They introduce the comparative population-based measure
, which is approximated by sample counterparts
and
. The large-sample measure
depends on the ratio of prediction error variances corresponding to the true best multivariate and the true best univariate prediction model if these are forecasting at a horizon of
h steps. By definition, the multivariate model with known coefficients must always outperform the univariate rival, and
is restricted to the interval
. If the prediction error variances are estimated from data in finite samples, the estimate
will inherit these properties. Ref. [
13] show that, under plausible conditions, the estimate converges to the true value as the sample size grows. Ref. [
13] concede, however, that in empirical applications, the multivariate forecast can be genuinely worse than the univariate rival, so they suggest adjusting the ratio for degrees of freedom, following the role model of information criteria. In particular, they consider the final prediction error (FPE) criterion due to [
14], which multiplies the empirical prediction error variances by the correction factor
, with
k standing for the number of estimated parameters and
N for the sample size. The resulting complexity-adjusted measure can be negative when the multivariate model uses many parameters without delivering better predictive performance.
We see the main differences between this approach and ours in the fact that [
13] do not explicitly forecast the data by the two rival models. They basically use the one sample at hand and fit univariate and multivariate models to it. We proceed one step further and simulate the data under the tentative assumption that the forecast models are data generators. This permits explicitly evaluating the reaction of forecast precision to changing sample sizes. On the other hand, we will focus exclusively on one-step forecasting in the following. There is no impediment in principle, however, to generalizing our simulations to multi-step predictions, and we intend to pursue this track in future work.
2.2. A General Simulation Experiment
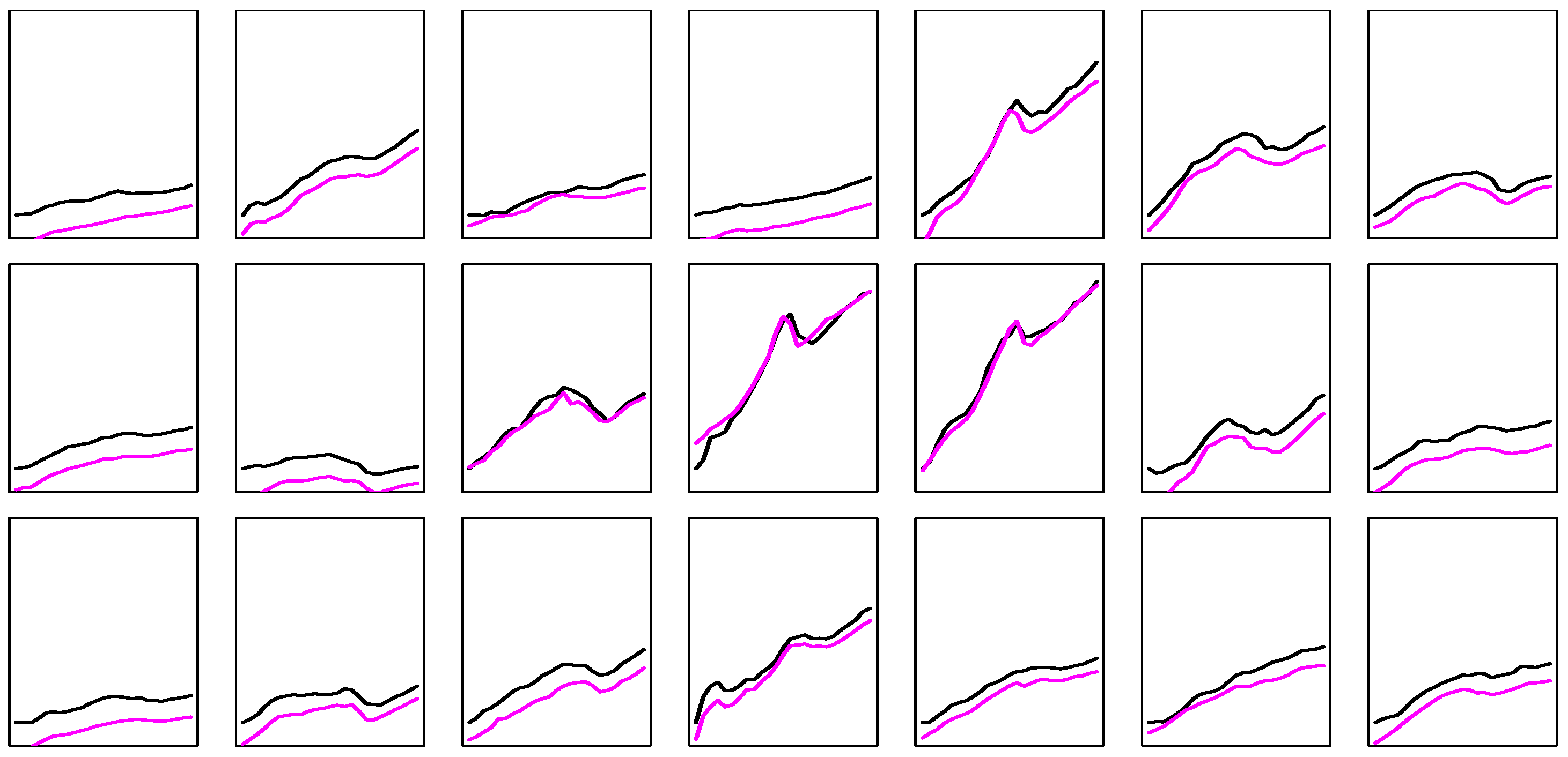
In order to find out a bit more about the strengths and weaknesses of our suggested procedure, we ran some prediction experiments based on simulated data. Because of the hierarchy of steps, such simulation experiments are time-consuming, so the number of replications remains limited. We simulate time-series data from basic time-series models, such as ARMA(1,1), and consider prediction based on ARMA(1,1) with coefficients estimated from the observations and also the simpler AR(1) model. The AR(1) model omits the MA(1) term of the generating model, but it may be competitive for small samples and for small MA coefficients.
We use a grid for the ARMA(1,1) model
over
and
. The intercept
is always kept at zero, but all estimated models include an intercept term. We consider two distributions for the
iid errors
, a standard
and a Cauchy distribution. The simulation-based strategy uses two variants. In the first variant, both the ARMA(1,1) and an AR(1) model are estimated from the data, and both estimated structures are simulated and again predicted based on both models. This delivers four sub-experiments and, finally, the model—either AR(1) or ARMA(1,1)—is selected as a prediction model that
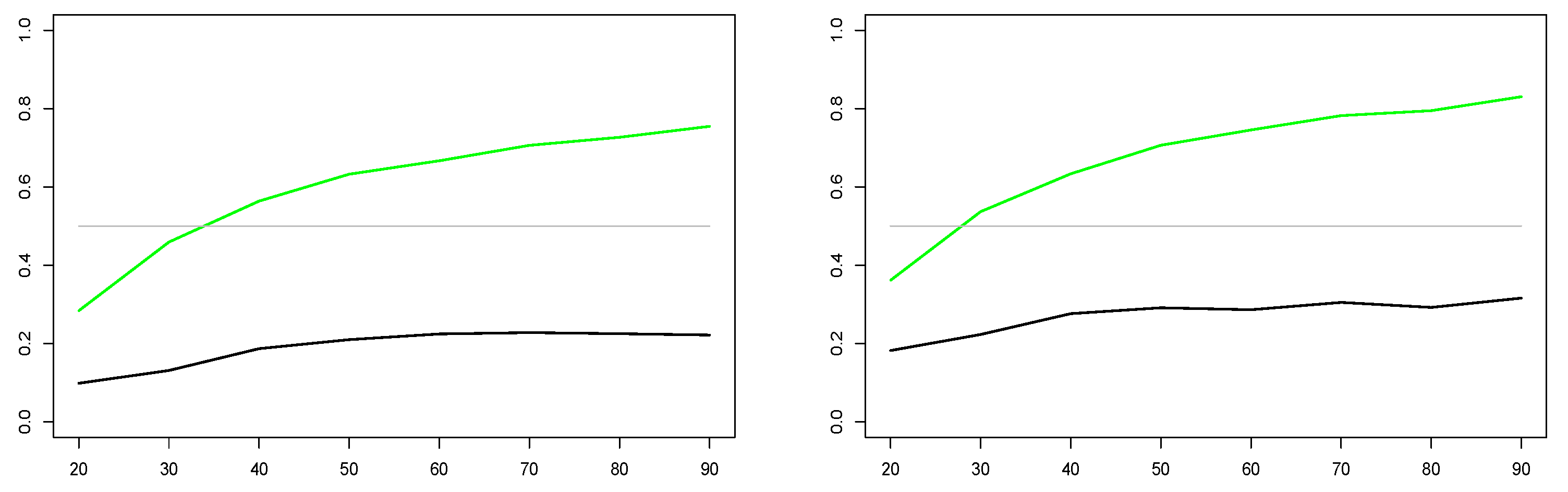
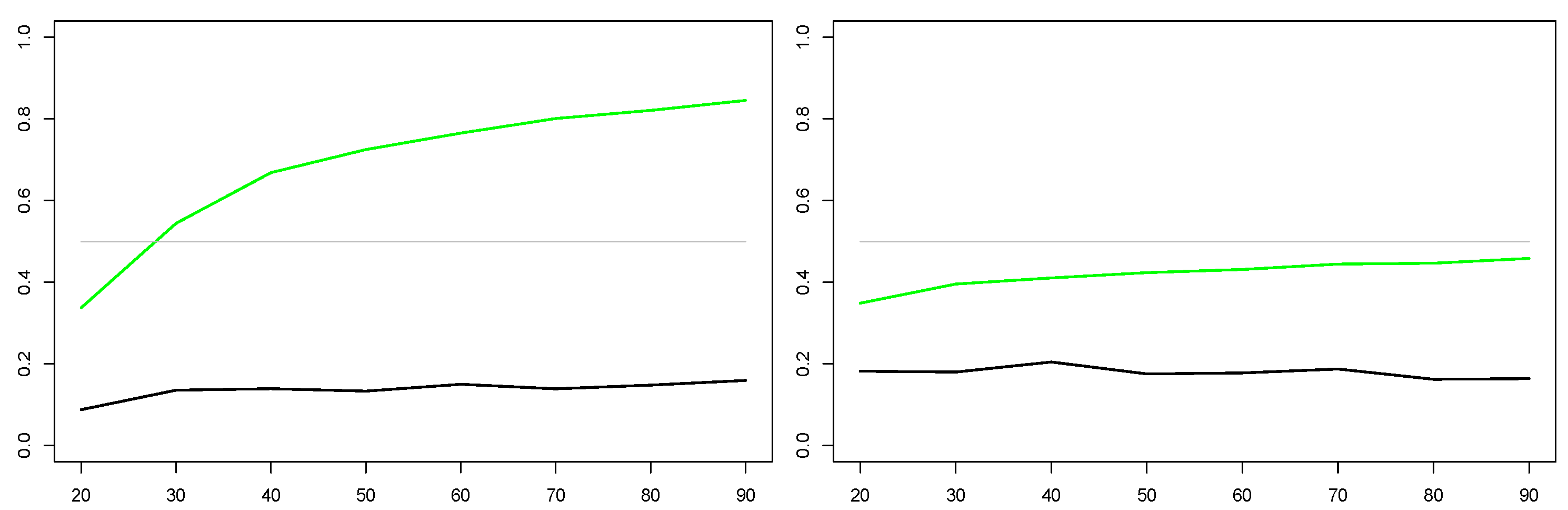
more often defeats its ‘rival’ model. In the other variant, the mean squared forecast errors (MSFE) that evolve from both models are added up, and the model with the smaller average MSFE is selected. Forecasts from the thus selected models are then compared with the choice based on a classical AIC, an extremely competitive benchmark that is hard to beat. The experiments are summarized in
Figure 1, which shows the optimum strategy for each combination of AR and MA coefficients, with an optimum defined as that strategy that ultimately yields the minimum (absolute) forecast error for the out-of-sample observation at position
. By construction, the diagonal connecting the southwest and the northeast corners represents white noise, as AR and MA terms cancel in
. The heterogeneity visible in the graphs reflects sampling variation.
For Gaussian errors,
Figure 1 shows a preponderance of AIC-supporting cases for
and
, whereas the contest is more open for
. Dominance is less explicit for Cauchy errors. From the two different evaluation methods for the simulation method, counting cases is preferable for most cases, so it may be interesting to reduce the rival strategies to two, the AIC and the simulation method with evaluating case counts. This design results in a quite similar figure, with almost all green dots turning blue. In summary, AIC appears invincible for large samples and Gaussian errors, whereas the simulator deserves consideration for small samples. This simulation experiment may be relevant for the empirical example to be studied in the next section, as the macroeconomic time-series sample remains in the lower region of the Monte Carlo evaluated in this section.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}




