
Tourism and Big Data: Forecasting with Hierarchical and Sequential Cluster Analysis †


Abstract
1. Introduction
1.1. Literature Review
2. Methods
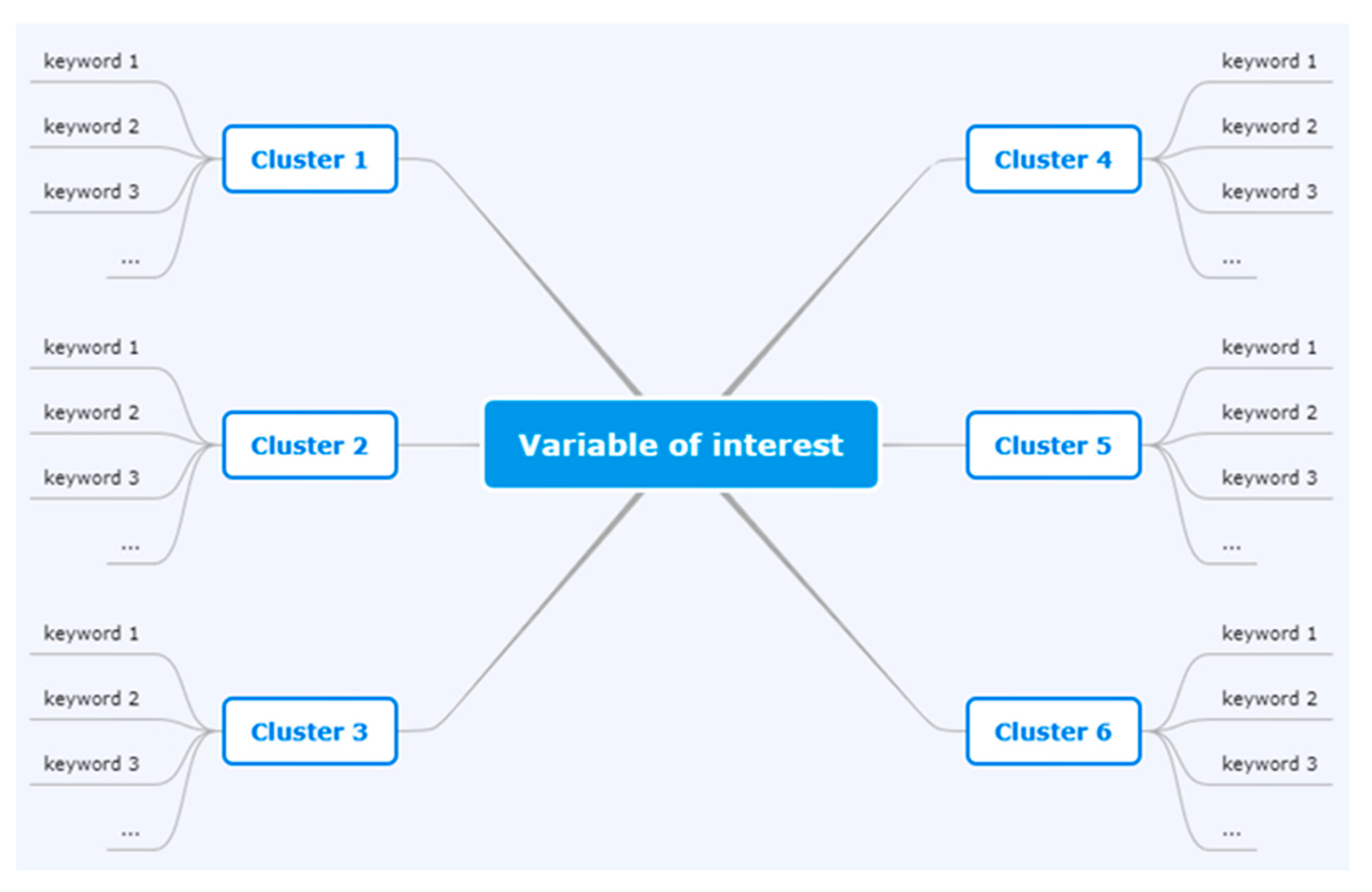
2.1. Hierarchical and Sequential Clustering Analysis (HSCA)
2.2. Comparison of Forecasting and Evaluation
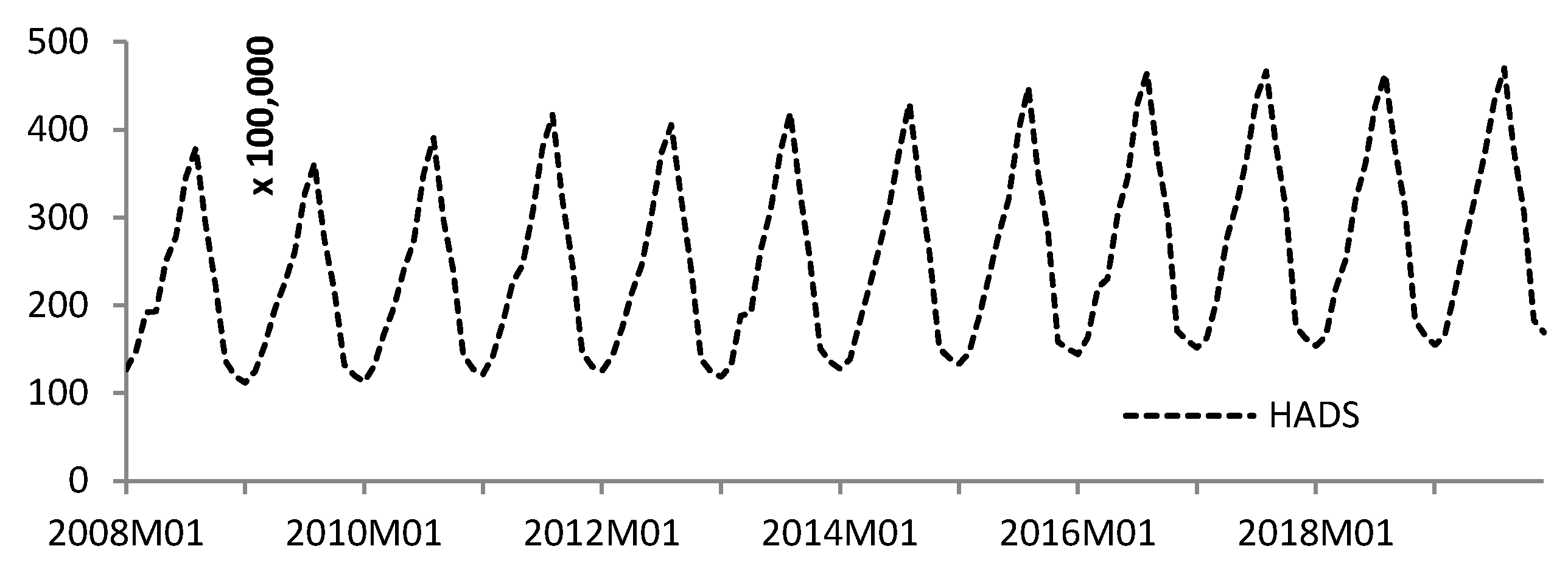
3. Data
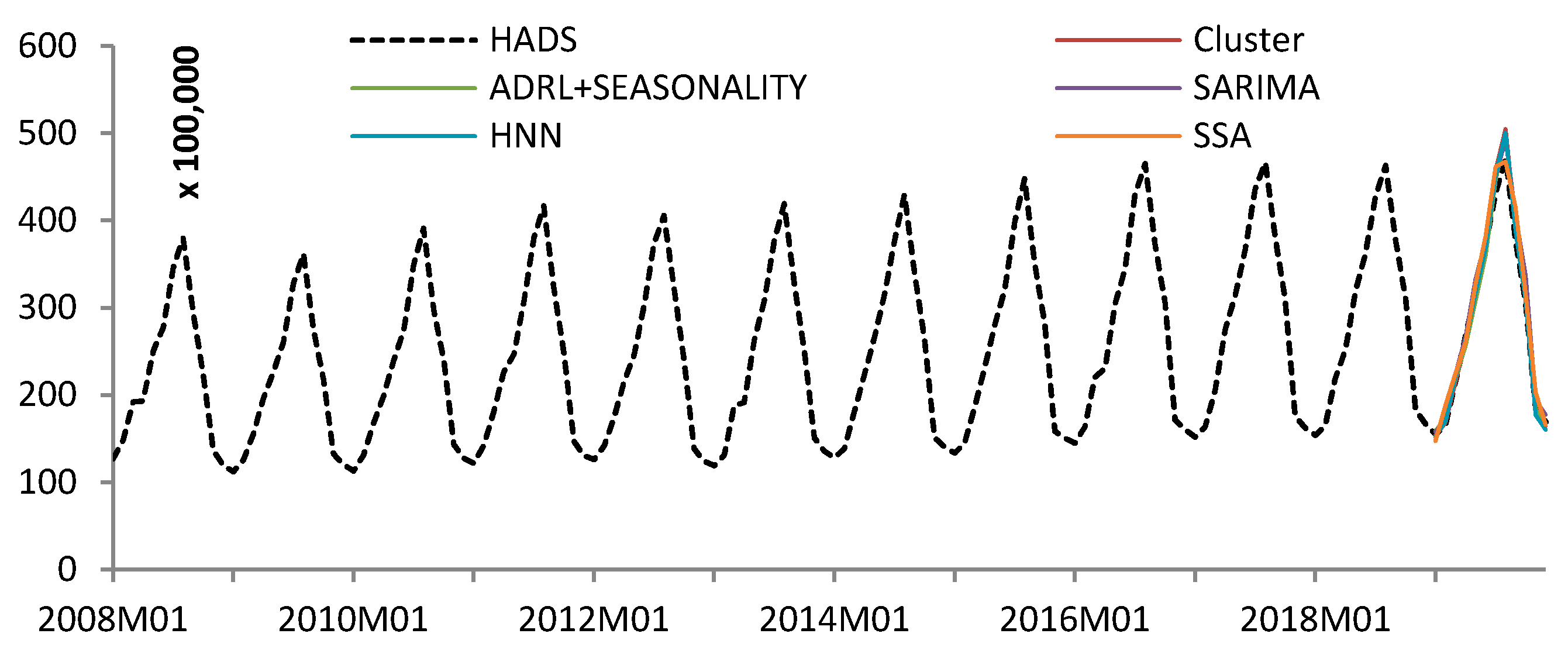
4. Results
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
| Sports | Laws | Transport | Seasonality | Social | Welfare | Searches | Culture | Places |
|---|---|---|---|---|---|---|---|---|
| Sport | Taxes | Transport | Weather | Spanish People | Hospitality | Trip Spain | Monuments | Beach |
| Football | Tax free | Flight | Winter | Mind | Environment | Visit Spain | Musueums | Mountain |
| Basketball | Laws | Train | Summer | vegan Spain | Relax | Spain Tourism | Congress | Island |
| Athletics Spain | Schengen | Roads | Autumn | English | Stress | Hotel Spain | Study | nature |
| Swimming Spain | Spain passport | Cruise ships | Spring | French | Life style | Apartment Spain | Disco | Mediterranean area |
| Volleyball Spain | Visa Spain | Helicopter Spain | Climate Change | Italian | Hospital | Best travel | Concert | Canary Island |
| Tennis Spain | Spain travel insurance | Bus Spain | Easter week Spain | German | Apple Spain | Resort | Food | Zoo Spain |
| Boxing Spain | Medical certificate Spain | Car Spain | Christmas Spain | Android Spain | Ecotourism | Wine | Andalusia Spain | |
| Soccer Spain | Spain driving license | Tolls Spain | - | Samsung Spain | Family Trip | theme parks Spain | Catalonia Spain | |
| Hockey on ice Spain | - | Motorhomes Spain | - | Tripadvisor | Xiaomi Spain | low cost | nightlife Spain | Alcázar de Toledo |
| Baseball Spain | - | - | Hotels.com Spain | Huawei Spain | Rural Spain | Spain architecture | Monasterio del Escorial | |
| - | - | - | - | Booking.com Spain | - | Agriculture Spain | alcohol | Palacio Real |
| - | - | - | - | Wimdu | - | Fishing Spain | City Breaks | Muralla de Ávila |
| - | - | - | - | Kayak Spain | - | Livestock Spain | - | Alcázar de Segovia |
| - | - | - | - | Airbnb | - | Blitz | - | Valencian Community Spain |
| - | - | - | - | - | - | - | Plaza de España | |
| - | - | - | - | Youtube | - | - | - | Teatro Romano de Mérida |
| - | - | - | - | Terrorism | - | - | - | Acueducto de Segovia |
| - | - | - | - | Overtourism | - | - | - | Mezquita de Córdoba |
| - | - | - | - | Tourism Phobia | - | - | - | Sagrada Familia |
| - | - | - | - | Wifi Spain | - | - | - | La Giralda |
| - | - | - | - | 3G, 4G and 5G Spain | - | - | - | La Alhambra and Tours |
References
- Kleinberg, J.; Lakkaraju, H.; Leskovec, J.; Ludwig, J.; Mullainathan, S. Human decisions and machine predictions. Q. J. Econ. 2018, 133, 237–283. [Google Scholar] [CrossRef]
- Carrizosa, E.; Guerrero, V.; Morales, D.R. Visualising data as objects by DC (difference of convex) optimisation. Math. Program. 2018, 169, 119–140. [Google Scholar] [CrossRef]
- Mikalef, P.; Pappas, I.O.; Krogstie, J.; Giannakos, M. Big data analytics capabilities: A systematic literature review and research agenda. Inf. Syst. e-Bus. Manag. 2018. [Google Scholar] [CrossRef]
- Palos-Sanchez, P.R.; Correia, M.B. The collaborative economy based analysis of demand: Study of airbnb case in Spain and Portugal. J. Theor. Appl. Electron. Commer. Res. 2018. [Google Scholar] [CrossRef]
- Ruiz-Reina, M.Á. Big Data: Does it really improve Forecasting techniques for Tourism Demand in Spain? In International Conference on Time Series and Forecasting; Godel Impresiones Digitales S.L.: Granada, Spain, 2019; pp. 694–706. [Google Scholar]
- Song, H.; Li, G. Tourism demand modelling and forecasting—A review of recent research. Tour. Manag. 2008, 29, 203–220. [Google Scholar] [CrossRef]
- Pan, B.; Wu, D.C.; Song, H. Forecasting hotel room demand using search engine data. J. Hosp. Tour. Technol. 2012, 3, 196–210. [Google Scholar] [CrossRef]
- Wu, D.C.; Song, H.; Shen, S. New developments in tourism and hotel demand modeling and forecasting. Int. J. Contemp. Hosp. Manag. 2017, 29, 507–529. [Google Scholar] [CrossRef]
- Mariani, M.; Baggio, R.; Fuchs, M.; Höepken, W. Business intelligence and big data in hospitality and tourism: A systematic literature review. Int. J. Contemp. Hosp. Manag. 2018. [Google Scholar] [CrossRef]
- Li, J.; Xu, L.; Tang, L.; Wang, S.; Li, L. Big data in tourism research: A literature review. Tour. Manag. 2018, 68, 301–323. [Google Scholar] [CrossRef]
- Macedo, P. Freedman’s Paradox: An Info-Metrics Perspective. In International Conference on Time Series and Forecasting; Godel Impresiones Digitales S.L.: Granada, Spain, 2019; pp. 665–676. [Google Scholar]
- Gabrielyan, D.; Masso, J.; Uuskula, L. Powers of Text. In International Conference on Time Series and Forecasting; Godel Impresiones Digitales S.L.: Granada, Spain, 2019; pp. 677–693. [Google Scholar]
- Choi, H.; Varian, H. Predicting the Present with Google Trends. Econ. Rec. 2012, 88, 2–9. [Google Scholar] [CrossRef]
- Bokelmann, B.; Lessmann, S. Spurious patterns in Google Trends data—An analysis of the effects on tourism demand forecasting in Germany. Tour. Manag. 2019, 75, 1–12. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C. Time Series Analysis: Forecasting and Control, 4th ed.; John Wiley & Sons: Hoboken, NJ, USA, 2013. [Google Scholar]
- Athanasopoulos, G.; Hyndman, R.J.; Kourentzes, N.; Petropoulos, F. Forecasting with temporal hierarchies. Eur. J. Oper. Res. 2017, 262, 60–74. [Google Scholar] [CrossRef]
- Liao, T.W. Clustering of time series data—A survey. Pattern Recognit. 2005, 38, 1857–1874. [Google Scholar] [CrossRef]
- Aghabozorgi, S.; Shirkhorshidi, A.S.; Wah, T.Y. Time-series clustering—A decade review. Inf. Syst. 2015, 53, 16–38. [Google Scholar] [CrossRef]
- Caiado, J.; Maharaj, E.A.; D’Urso, P. Time-series clustering. In Handbook of Cluster Analysis; Chapman & Hall/CRC: Boca Raton, FL, USA, 2015; pp. 241–264. [Google Scholar]
- Kakizawa, Y.; Shumway, R.H.; Taniguchi, M. Discrimination and clustering for multivariate time series. J. Am. Stat. Assoc. 1998, 93, 328–340. [Google Scholar] [CrossRef]
- Scotto, M.G.; Alonso, A.M.; Barbosa, S.M. Clustering time series of sea levels: Extreme value approach. J. Waterw. Port Coast. Ocean Eng. 2010, 136, 215–225. [Google Scholar] [CrossRef]
- D’Urso, P.; Maharaj, E.A.; Alonso, A.M. Fuzzy clustering of time series using extremes. Fuzzy Sets Syst. 2017, 318, 56–79. [Google Scholar] [CrossRef]
- Alonso, A.M.; Berrendero, J.R.; Hernández, A.; Justel, A. Time series clustering based on forecast densities. Comput. Stat. Data Anal. 2006, 51, 762–766. [Google Scholar] [CrossRef]
- Scotto, M.G.; Barbosa, S.M.; Alonso, A.M. Model-based clustering of Baltic sea-level. Appl. Ocean Res. 2009, 31, 4–11. [Google Scholar] [CrossRef]
- Vilar, J.A.; Alonso, A.M.; Vilar, J.M. Non-linear time series clustering based on non-parametric forecast densities. Comput. Stat. Data Anal. 2010, 54, 2850–2865. [Google Scholar] [CrossRef]
- Alonso, A.M.; Peña, D. Clustering time series by linear dependency. Stat. Comput. 2019, 29, 655–676. [Google Scholar] [CrossRef]
- Alonso, A.M.; Galeano, P.; Peña, D. A robust procedure to build dynamic factor models with cluster structure. J. Econom. 2020, 216, 3552. [Google Scholar] [CrossRef]
- Chávez, J.C.N.; Torres, A.I.Z.; Torres, M.C. Hierarchical Cluster Analysis of Tourism for Mexico and the Asia-Pacific Economic Cooperation (APEC) Countries. Rev. Tur. Anál. 2016, 27, 235–255. [Google Scholar] [CrossRef]
- Granger, C.W.J. Investigating Causal Relations by Econometric Models and Cross-spectral Methods. Econometrica 1969, 37, 424–438. [Google Scholar] [CrossRef]
- Ruiz-Reina, M.Á. Forecasting using Big Data: The case of Spanish Tourism Demand. In International Conference on Time Series and Forecasting; Godel Impresiones Digitales S.L.: Granada, Spain, 2019; pp. 782–789. [Google Scholar]
- Newey, W.K.; West, K.D. A Simple, Positive Semi-Definite, Heteroskedasticity and Autocorrelation Consistent Covariance Matrix. Econometrica 1987, 55, 703–708. [Google Scholar] [CrossRef]
- Greene, W.W.H. Econometric Analysis, 7th ed.; Prentice Hall: Hoboken, NJ, USA, 2012. [Google Scholar]
- Peng, B.; Song, H.; Crouch, G.I.; Witt, S.F. A Meta-Analysis of International Tourism Demand Elasticities. J. Travel Res. 2015, 54, 611–633. [Google Scholar] [CrossRef]
- Dickey, D.A.; Fuller, W.A. Likelihood Ratio Statistics for Autoregressive Time Series with a Unit Root. Econometrica 1981, 49, 1067–1072. [Google Scholar] [CrossRef]
- Kwiatkowski, D.; Phillips, P.C.B.; Schmidt, P.; Shin, Y. Testing the null hypothesis of stationarity against the alternative of a unit root. How sure are we that economic time series have a unit root? J. Econom. 1992, 54, 159–178. [Google Scholar] [CrossRef]



| Mean | Maximum | Minimum | ADF (p-Value) | KPSS (p-Value) | Observations |
|---|---|---|---|---|---|
| 24,989,874 | 46,998,612 | 11,203,819 | 0.85 | 0.56 | 144 |
| Cluster | Relevant Keywords | R-Squared |
|---|---|---|
| Sports | sport | 0.95 |
| Laws | visa | 0.97 |
| Transport | car, flight | 0.98 |
| Seasonality | summer, winter | 0.95 |
| Social | Airbnb, Youtube, English, Tripadvisor, Twiter | 0.99 |
| Welfare | Android, Xiaomi | 0.98 |
| Searches | low-cost, Spain Tourism, visit Spain | 0.98 |
| Culture | alcohol, city breaks, monuments, architecture | 0.97 |
| Places | Beach, Canary Island, Alhambra, Plaza de España, Sagrada Familia | 0.98 |
| HSCA | ADRL + SEASONALITY | SARIMA | HNN | SSA | |
|---|---|---|---|---|---|
| HSCA (h = 3) | 1.00 | 0.39 | 0.36 | 0.43 | 0.15 |
| HSCA (h = 6) | 1.00 | 0.50 | 0.69 | 0.92 | 0.39 |
| HSCA (h = 12) | 1.00 | 1.14 | 0.86 | 1.13 | 0.79 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ruiz Reina, M.Á. Tourism and Big Data: Forecasting with Hierarchical and Sequential Cluster Analysis. Eng. Proc. 2021, 5, 14. https://doi.org/10.3390/engproc2021005014
Ruiz Reina MÁ. Tourism and Big Data: Forecasting with Hierarchical and Sequential Cluster Analysis. Engineering Proceedings. 2021; 5(1):14. https://doi.org/10.3390/engproc2021005014
Chicago/Turabian StyleRuiz Reina, Miguel Ángel. 2021. "Tourism and Big Data: Forecasting with Hierarchical and Sequential Cluster Analysis" Engineering Proceedings 5, no. 1: 14. https://doi.org/10.3390/engproc2021005014
APA StyleRuiz Reina, M. Á. (2021). Tourism and Big Data: Forecasting with Hierarchical and Sequential Cluster Analysis. Engineering Proceedings, 5(1), 14. https://doi.org/10.3390/engproc2021005014