
Classification of Teas Using Different Feature Extraction Methods from Signals of a Lab-Made Electronic Nose †



Abstract
:1. Introduction
2. Materials and Methods
2.1. Instrumentation and Data Collection
2.2. Data Feature Extraction and Modeling
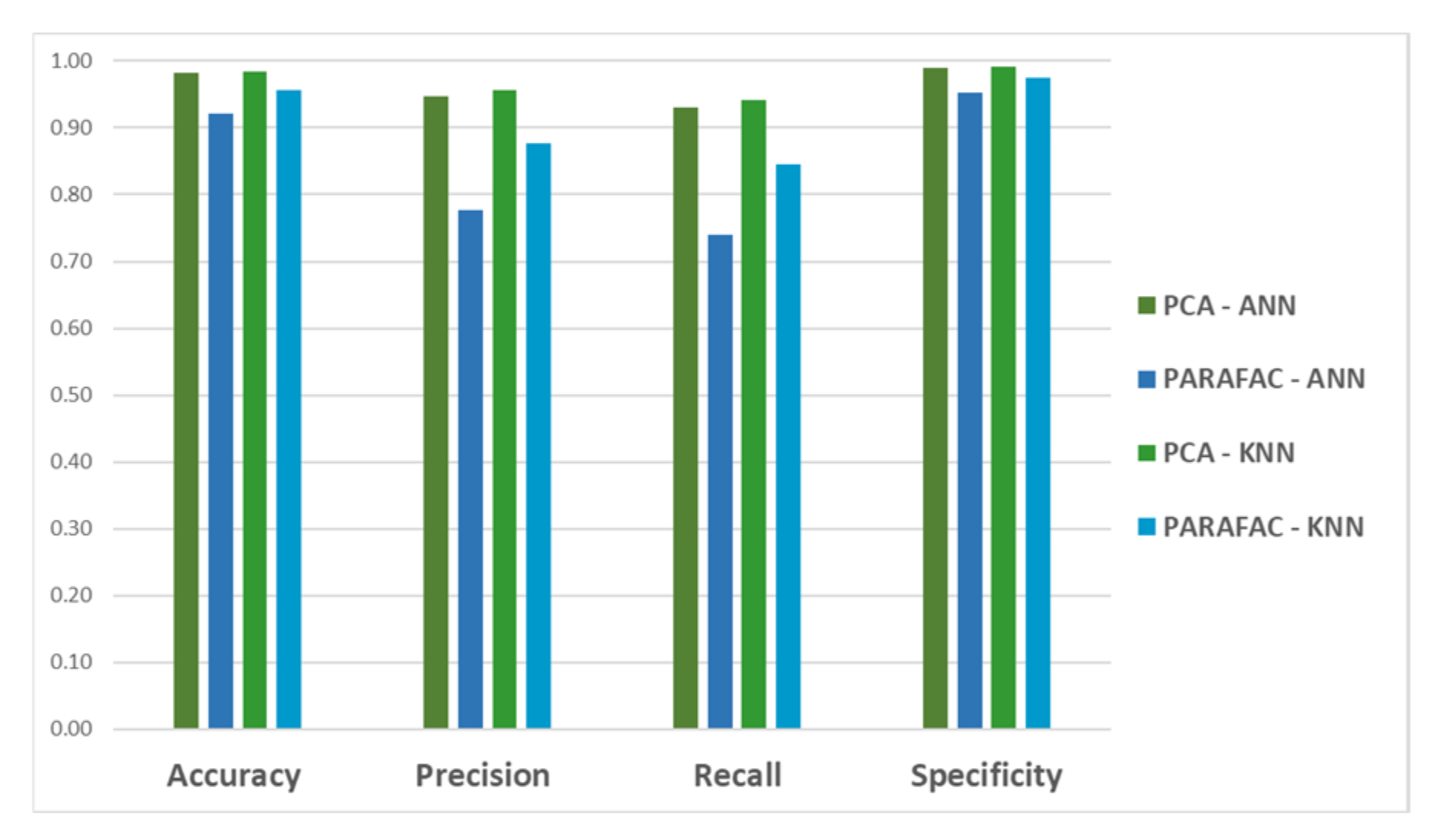
3. Results and Discussion
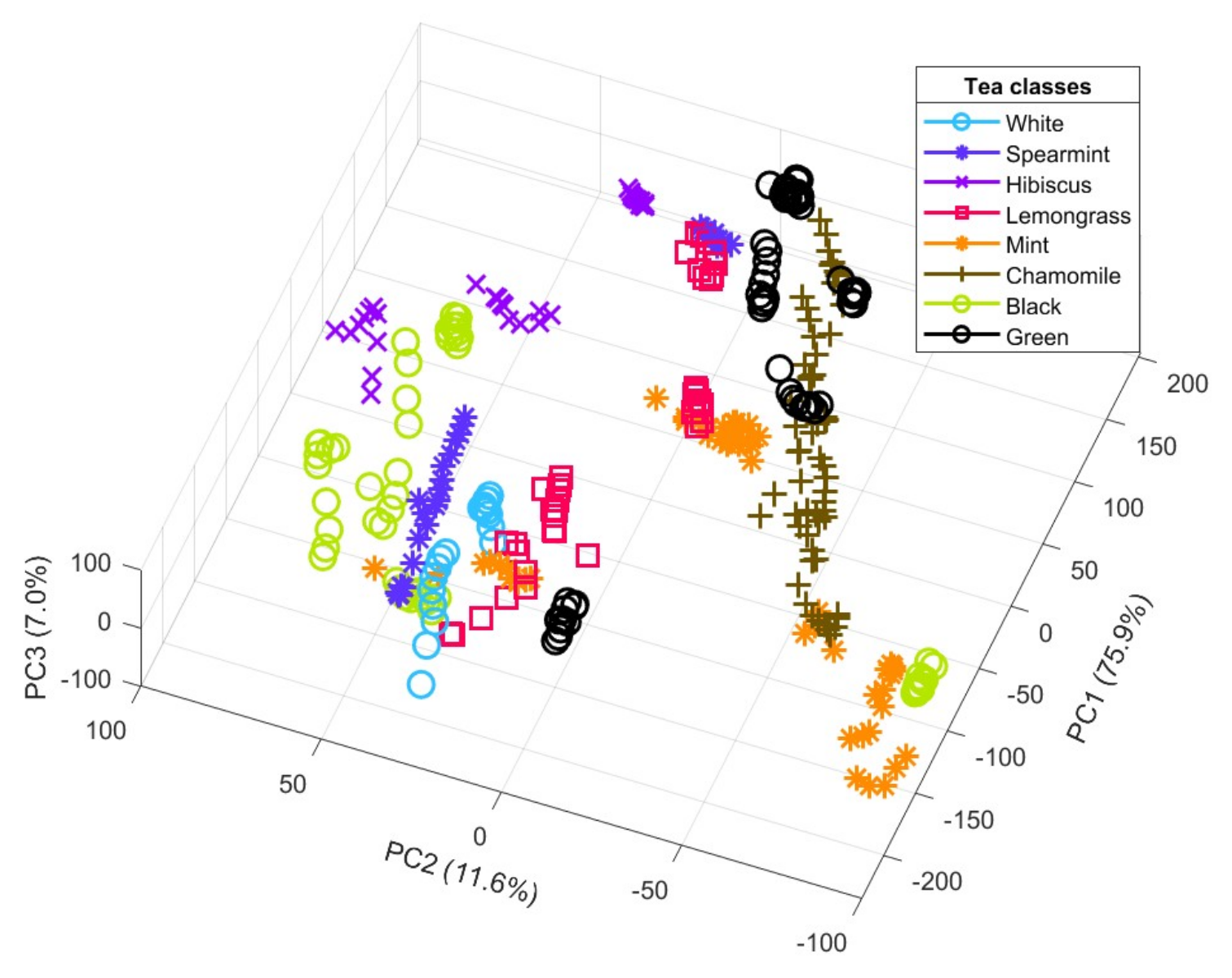
3.1. PCA Results
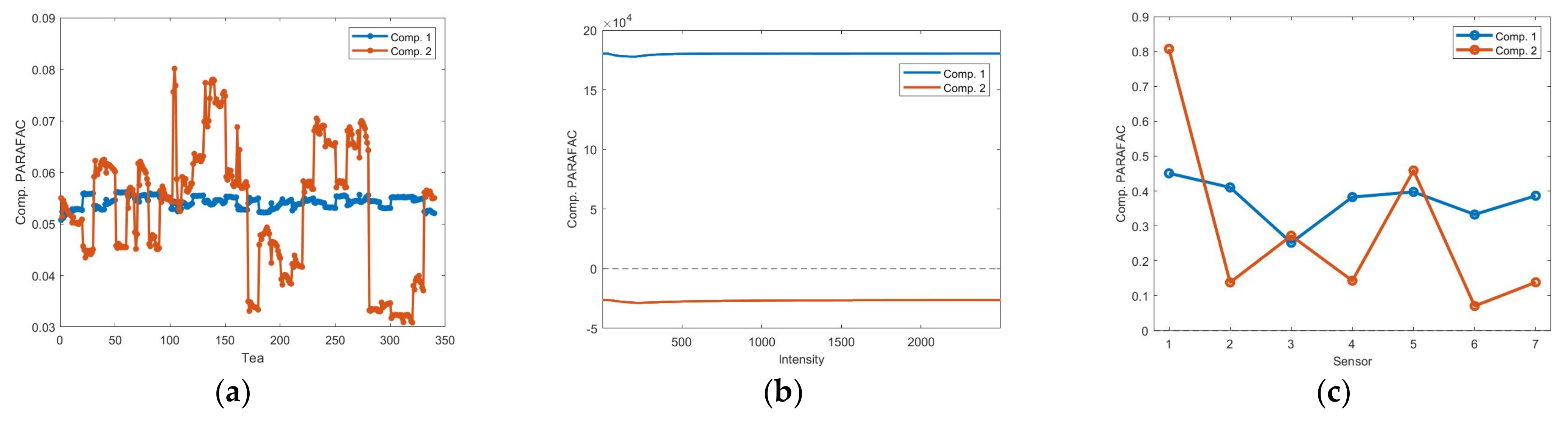
3.2. PARAFAC Results
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ponce, M.d.V.; Cina, M.; López, C.; Cerutti, S. Polyurethane Foam as a Novel Material for Ochratoxin A Removal in Tea and Herbal Infusions–A Quantitative Approach. Foods 2023, 12, 1828. [Google Scholar] [CrossRef]
- Tang, G.Y.; Meng, X.; Gan, R.Y.; Zhao, C.N.; Liu, Q.; Feng, Y.B.; Li, S.; Wei, X.L.; Atanasov, A.G.; Corke, H.; et al. Health Functions and Related Molecular Mechanisms of Tea Components: An Update Review. Int. J. Mol. Sci. 2019, 20, 6196. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Guo, C.; Zang, E.; Shi, R.; Liu, Q.; Zhang, M.; Zhang, K.; Li, M. Review on herbal tea as a functional food: Classification, active compounds, biological activity, and industrial status. J. Future Foods 2023, 3, 206–219. [Google Scholar] [CrossRef]
- Chen, W.; Hu, D.; Miao, A.; Qiu, G.; Qiao, X.; Xia, H.; Ma, C. Understanding the aroma diversity of Dancong tea (Camellia sinensis) from the floral and honey odors: Relationship between volatile compounds and sensory characteristics by chemometrics. Food Control 2022, 140, 109103. [Google Scholar] [CrossRef]
- Yousefbeyk, F.; Ebrahimi-Najafabadi, H.; Dabirian, S.; Salimi, S.; Baniardalani, F.; Azmian Moghadam, F.; Ghasemi, S. Phytochemical Analysis and Antioxidant Activity of Eight Cultivars of Tea (Camellia sinensis) and Rapid Discrimination with FTIR Spectroscopy and Pattern Recognition Techniques. Pharm. Sci. 2023, 29, 100–110. [Google Scholar] [CrossRef]
- Persaud, K.; Dodd, G. Analysis of discrimination mechanisms in the mammalian olfactory system using a model nose. Nature 1982, 299, 352–355. [Google Scholar] [CrossRef] [PubMed]
- Covington, J.A.; Marco, S.; Persaud, K.C.; Schiffman, S.S.; Nagle, H.T. Artificial Olfaction in the 21st Century. IEEE Sens. J. 2021, 21, 12969–12990. [Google Scholar] [CrossRef]
- Padilla, M.; Montoliu, I.; Pardo, A.; Perera, A.; Marco, S. Feature extraction on three way enose signals. Sens. Actuators B Chem. 2006, 116, 145–150. [Google Scholar] [CrossRef]
- Valdez, L.F.; Gutiérrez, J.M. Chocolate Classification by an Electronic Nose with Pressure Controlled Generated Stimulation. Sensors 2016, 16, 1745. [Google Scholar] [CrossRef] [PubMed]
- Jolliffe, I.T. Introduction. In Principal Component Analysis, 2nd ed.; Springer: New York, NY, USA, 2006; pp. 1–6. [Google Scholar]
- Acar, E.; Yener, B. Unsupervised Multiway Data Analysis: A Literature Survey. IEEE Trans. Knowl Data Eng. 2009, 21, 6–20. [Google Scholar] [CrossRef]
- Bro, R.; Kiers, H.A.L. A new efficient method for determining the number of components in PARAFAC models. J. Chemom. 2003, 17, 274–286. [Google Scholar] [CrossRef]
- Mahmood, L.; Ghommem, M.; Bahroun, Z. Smart Gas Sensors: Materials, Technologies, Practical Applications, and Use of Machine Learning—A Review. J. Appl. Comput. Mech. 2023, 9, 775–803. [Google Scholar] [CrossRef]
- Kaushal, S.; Nayi, P.; Rahadian, D.; Chen, H.-H. Applications of Electronic Nose Coupled with Statistical and Intelligent Pattern Recognition Techniques for Monitoring Tea Quality: A Review. Agriculture 2022, 12, 1359. [Google Scholar] [CrossRef]
- Hossin, M.; Sulaiman, M.N. A Review on Evaluation Metrics for Data Classification Evaluations. Int. J. Data Min. Knowl. Manag. Process 2015, 5, 1–11. [Google Scholar] [CrossRef]
- Li, B.; Gu, Y. A Machine Learning Method for the Quality Detection of Base Liquor and Commercial Liquor Using Multidimensional Signals from an Electronic Nose. Foods 2023, 12, 1508. [Google Scholar] [CrossRef] [PubMed]
- Wong, M.; Sirisena, S.; Ng, K. Phytochemical profile of differently processed tea: A review. J. Food Sci. 2022, 87, 1925–1942. [Google Scholar] [CrossRef] [PubMed]
- Jirovetz, L.; Jaeger, W.; Remberg, G.; Espinosa-Gonzalez, J.; Morales, R.; Woidich, A.; Nikiforov, A. Analysis of the volatiles in the seed oil of Hibiscus sabdariffa (Malvaceae) by means of GC-MS and GC-FTIR. J. Agric. Food Chem. 1992, 40, 1186–1187. [Google Scholar] [CrossRef]
- Skaria, B.P.; Joy, P.P.; Mathew, S.; Mathew, G.; Joseph, A.; Joseph, R. Major Sources of Aromatic Oils. In Aromatic Plants, 1st ed.; New India Publishing Agency: New Delhi, India, 2007; pp. 100–109. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
| Classes | White | Spearmi. | Hibiscus | Lemong. | Mint | Chamomi. | Black | Green | CR | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FE1* | FE2** | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | ||
| True class | White | 100 | 90 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.00 | 0.99 |
| Spearmint | 0 | 0 | 90 | 86.6 | 10 | 3.3 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.99 | 0.96 | |
| Hibiscus | 0 | 0 | 3.3 | 6.6 | 86.6 | 60 | 6.6 | 6.6 | 0 | 20 | 0 | 6.6 | 3.3 | 0 | 0 | 0 | 0.97 | 0.93 | |
| Lemongrass | 0 | 0 | 0 | 5 | 7.5 | 12.5 | 85 | 57.5 | 7.5 | 17.5 | 0 | 7.5 | 0 | 0 | 0 | 0 | 0.97 | 0.87 | |
| Mint | 0 | 0 | 0 | 0 | 0 | 2 | 2 | 20 | 94 | 58 | 4 | 16 | 0 | 4 | 0 | 0 | 0.98 | 0.85 | |
| Chamomile | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 8.3 | 93.3 | 75 | 5 | 8.3 | 1.6 | 3.3 | 0.98 | 0.88 | |
| Black | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 8 | 0 | 12 | 100 | 74 | 0 | 4 | 0.98 | 0.91 | |
| Green | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.6 | 5 | 8.3 | 95 | 90 | 0.99 | 0.96 | |
| Total | 0.98 | 0.92 | |||||||||||||||||
| Predicted class | |||||||||||||||||||
| Classes | White | Spearmi. | Hibiscus | Lemong. | Mint | Chamomi. | Black | Green | C.R. | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| FE1* | FE2** | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE1 | FE2 | FE_1 | FE_2 | ||
| True class | White | 100 | 95 | 0 | 0 | 0 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.00 | 0.99 |
| Spearmint | 0 | 0 | 100 | 90 | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.99 | 0.98 | |
| Hibiscus | 0 | 0 | 3.3 | 0 | 90 | 73.3 | 0 | 3.3 | 0 | 13.3 | 0 | 6.6 | 6.6 | 3.3 | 0 | 0 | 0.99 | 0.97 | |
| Lemongrass | 0 | 2.5 | 7.5 | 7.5 | 0 | 0 | 80 | 77.5 | 12.5 | 10 | 0 | 0 | 0 | 0 | 0 | 2.5 | 0.97 | 0.94 | |
| Mint | 0 | 0 | 2 | 0 | 0 | 2 | 2 | 6 | 92 | 78 | 0 | 0 | 4 | 14 | 0 | 0 | 0.97 | 0.91 | |
| Chamomile | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3.3 | 0 | 0 | 91.6 | 86.6 | 0 | 0 | 8.3 | 10 | 0.98 | 0.95 | |
| Black | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 0 | 100 | 84 | 0 | 0 | 0.99 | 0.95 | |
| Green | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 8.3 | 0 | 0 | 100 | 91.6 | 0.98 | 0.96 | |
| Total | 0.98 | 0.96 | |||||||||||||||||
| Predicted class | |||||||||||||||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiménez-López, I.; Molina-Quiroga, J.; Gutiérrez, J.M. Classification of Teas Using Different Feature Extraction Methods from Signals of a Lab-Made Electronic Nose. Eng. Proc. 2023, 48, 20. https://doi.org/10.3390/CSAC2023-14933
Jiménez-López I, Molina-Quiroga J, Gutiérrez JM. Classification of Teas Using Different Feature Extraction Methods from Signals of a Lab-Made Electronic Nose. Engineering Proceedings. 2023; 48(1):20. https://doi.org/10.3390/CSAC2023-14933
Chicago/Turabian StyleJiménez-López, Irari, Jeniffer Molina-Quiroga, and Juan Manuel Gutiérrez. 2023. "Classification of Teas Using Different Feature Extraction Methods from Signals of a Lab-Made Electronic Nose" Engineering Proceedings 48, no. 1: 20. https://doi.org/10.3390/CSAC2023-14933
APA StyleJiménez-López, I., Molina-Quiroga, J., & Gutiérrez, J. M. (2023). Classification of Teas Using Different Feature Extraction Methods from Signals of a Lab-Made Electronic Nose. Engineering Proceedings, 48(1), 20. https://doi.org/10.3390/CSAC2023-14933