
Hourly Load Curves Disaggregated by Type of Consumer Using A Density-Based Spatial Clustering Technique †


Abstract
:1. Introduction
2. Materials and Methods
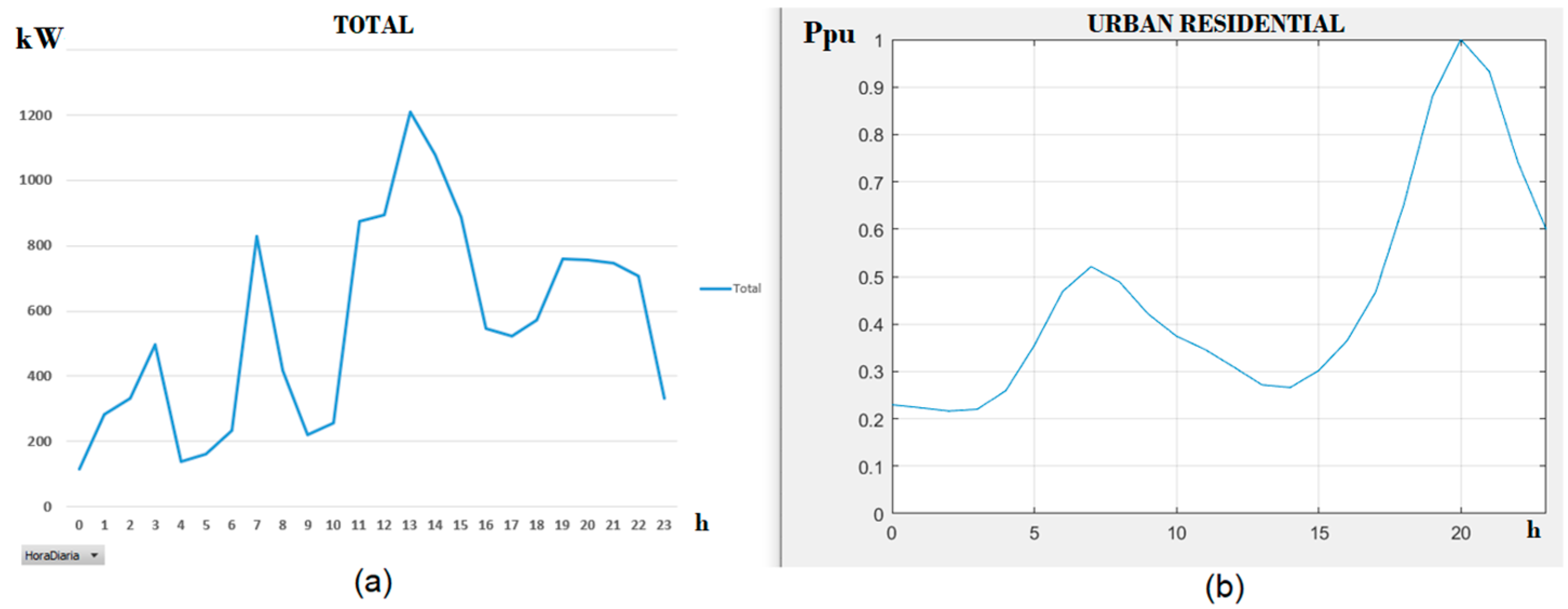
2.1. Meter Measurement Data
2.2. Per unit System of Data
- : Dimensionless value in per unit system.
- : Average value of active power in kW.
- : Maximum value of active power in kW per day.
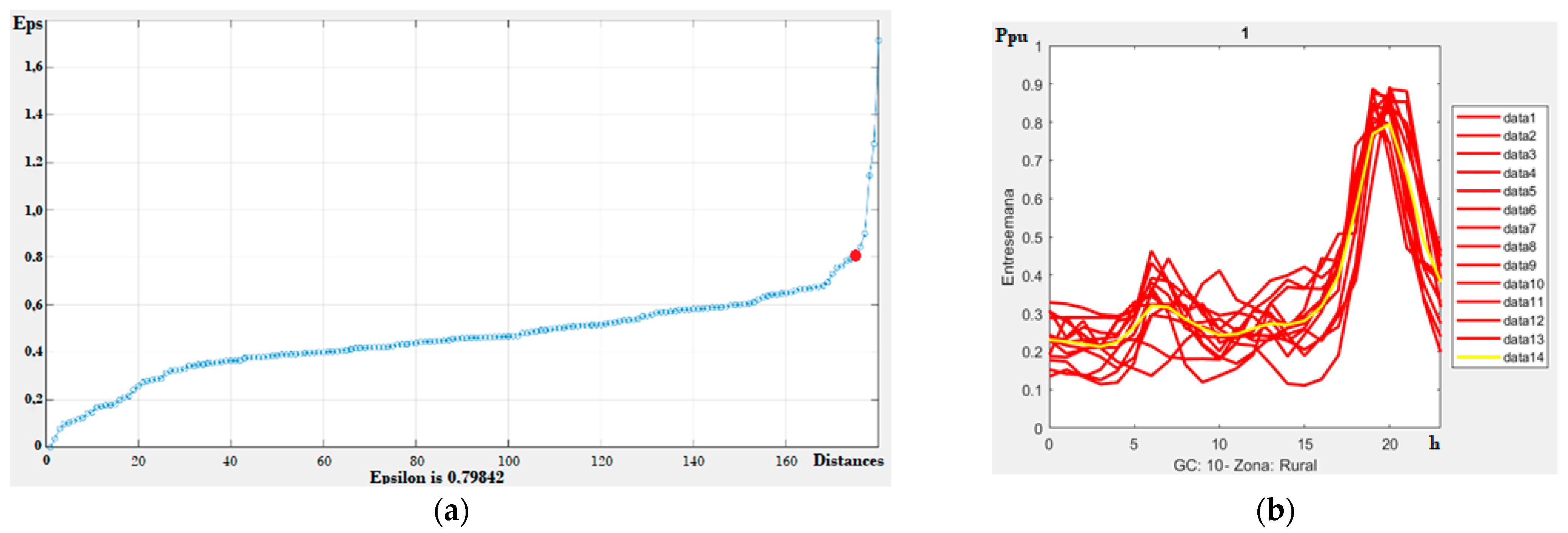
2.3. DBSCAN in MATLAB
- : Size of the neighbor list or data matrix.
- : Radius that delimits the neighborhood area of a point (neighborhood-Eps).
- : Minimum number of data or objects around neighborhood-Eps.
2.4. KNNSearch
- : Values in pu of data 0–23 h for the measurement days.
- : Values in pu 0–23 h.
- : Write “K” and calculate the nearest neighbor distances.
- : Matrix size of how many nearest neighbors in the distance metric.
2.5. Kneepoint
- : Euclidean distances of the K-dist graph.
- : Value in x of the elbow of the K-dist type graph.
2.6. Validation Index Silhouette (IS)
- : Data between objects.
- : is the partition obtained (by applying some grouping or cluster technique).
- : Value between −1 and 1, denoting 1 as belonging to the cluster and −1 not belonging.
3. Discussion
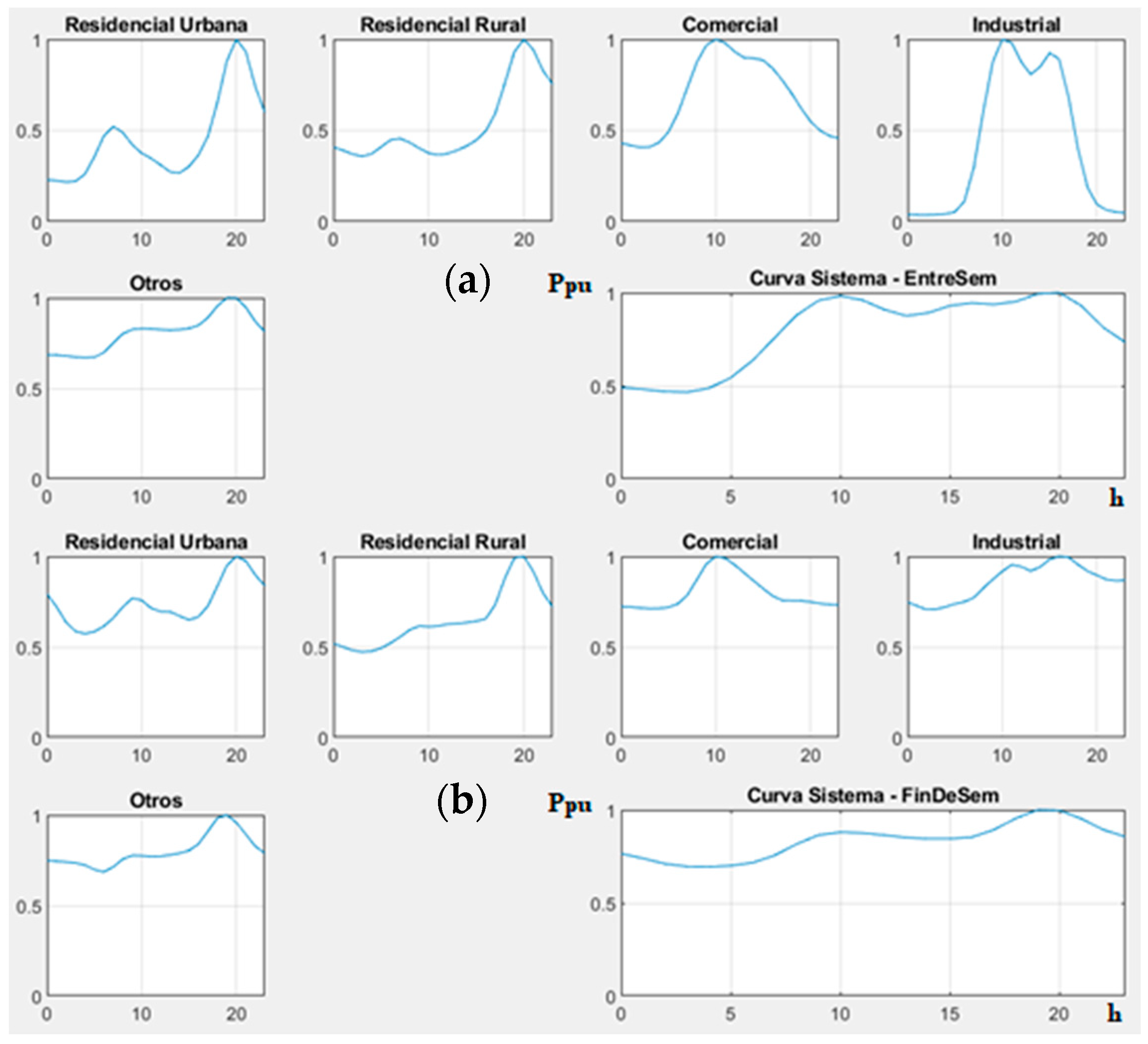
3.1. Clustering on Weekdays and Weekends
3.2. System Results
3.3. Comparison with Previous Method
Weekdays Comparison
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ministerio de Electricidad y Energías Naturales No Renovables, “Plan Maestro de Electricidad 2018–2027”, Chapter 3, Estudio de la Demanda. Available online: https://www.recursosyenergia.gob.ec/plan-maestro-de-electricidad/ (accessed on 13 March 2023).
- ARCONEL. Plan Maestro de Electrificación 2013–2022, Perspectiva y Expansión del Sistema Eléctrico Ecuatoriano. Available online: https://www.regulacionelectrica.gob.ec/plan-maestro-de-electrificacion-2013-2022/ (accessed on 15 April 2023).
- Fong, S.; Rehman, S.U. DBSCAN: Past, Present and future. In Proceedings of the Fifth International Conference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), Chennai, India, 17–19 February 2014. [Google Scholar]
- Irwin, D.; Albrecht, J.; Satopa, V. Finding a “Kneedle” in a Haystack: Detecting Knee Points in System Behavior. In Proceedings of the 31st International Conference on Distributed Computing Systems Workshops, Minneapolis, MN, USA, 20–24 June 2011. [Google Scholar]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1999, 20, 53–65. [Google Scholar] [CrossRef]
- Gönen, T. Electric Power Distribution Engineering; CRC Press: Boca Raton, FL, USA, 2014. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Type of Consumer | Low Voltage 220 V | Medium Voltage 13.8 kV | Total |
|---|---|---|---|
| Commercial | 25 | 20 | 45 |
| Industrial | 18 | 14 | 32 |
| Others | 9 | 9 | 18 |
| Residential | 131 | 0 | 131 |
| No Identified | 5 | 5 | 10 |
| Total | 188 | 48 | 236 |
| (a) weekdays | ||||||
| Daily Hour | Residential U | Residential R | Commercial | Industrial | Others | System Curve-Weekdays |
| 0 | 0.2295 | 0.4077 | 0.4293 | 0.0369 | 0.6848 | 0.4910 |
| 1 | 0.2234 | 0.3907 | 0.4179 | 0.0363 | 0.6836 | 0.4810 |
| 2 | 0.2166 | 0.3690 | 0.4070 | 0.0360 | 0.6790 | 0.4689 |
| 3 | 0.2203 | 0.3577 | 0.4083 | 0.0372 | 0.6730 | 0.4658 |
| 4 | 0.2592 | 0.3706 | 0.4330 | 0.0411 | 0.6695 | 0.4869 |
| 5 | 0.3544 | 0.4089 | 0.4916 | 0.0524 | 0.6723 | 0.5435 |
| 6 | 0.4687 | 0.4478 | 0.5940 | 0.1105 | 0.6973 | 0.6365 |
| 7 | 0.5211 | 0.4553 | 0.7355 | 0.2970 | 0.7510 | 0.7578 |
| 8 | 0.4886 | 0.4338 | 0.8741 | 0.6037 | 0.8016 | 0.8791 |
| 9 | 0.4213 | 0.4020 | 0.9673 | 0.8748 | 0.8257 | 0.9586 |
| 10 | 0.3743 | 0.3749 | 1.0000 | 1.0000 | 0.8305 | 0.9829 |
| 11 | 0.3463 | 0.3649 | 0.9785 | 0.9806 | 0.8287 | 0.9607 |
| 12 | 0.3098 | 0.3726 | 0.9308 | 0.8761 | 0.8245 | 0.9099 |
| 13 | 0.2718 | 0.3909 | 0.8990 | 0.8071 | 0.8219 | 0.8761 |
| 14 | 0.2661 | 0.4143 | 0.8957 | 0.8488 | 0.8245 | 0.8922 |
| 15 | 0.3017 | 0.4465 | 0.8853 | 0.9244 | 0.8312 | 0.9305 |
| 16 | 0.3647 | 0.4969 | 0.8404 | 0.8927 | 0.8480 | 0.9453 |
| 17 | 0.4668 | 0.5931 | 0.7768 | 0.6857 | 0.8909 | 0.9372 |
| 18 | 0.6531 | 0.7578 | 0.7039 | 0.3999 | 0.9550 | 0.9526 |
| 19 | 0.8800 | 0.9303 | 0.6224 | 0.1884 | 1.0000 | 0.9942 |
| 20 | 1.0000 | 1.0000 | 0.5499 | 0.0934 | 0.9988 | 1.0000 |
| 21 | 0.9326 | 0.9422 | 0.4998 | 0.0625 | 0.9487 | 0.9296 |
| 22 | 0.7421 | 0.8288 | 0.4698 | 0.0517 | 0.8692 | 0.8131 |
| 23 | 0.5992 | 0.7542 | 0.4571 | 0.0476 | 0.8148 | 0.7339 |
| (b) weekends | ||||||
| Daily Hour | Residential U | Residential R | Commercial | Industrial | Others | System Curve-Weekends |
| 0 | 0.7927 | 0.5184 | 0.7238 | 0.7468 | 0.7484 | 0.7648 |
| 1 | 0.7219 | 0.5000 | 0.7206 | 0.7263 | 0.7454 | 0.7397 |
| 2 | 0.6370 | 0.4811 | 0.7157 | 0.7064 | 0.7401 | 0.7107 |
| 3 | 0.5861 | 0.4721 | 0.7115 | 0.7083 | 0.7351 | 0.6961 |
| 4 | 0.5732 | 0.4762 | 0.7121 | 0.7213 | 0.7233 | 0.6945 |
| 5 | 0.5842 | 0.4936 | 0.7195 | 0.7379 | 0.6984 | 0.7005 |
| 6 | 0.6141 | 0.5212 | 0.7385 | 0.7494 | 0.6853 | 0.7168 |
| 7 | 0.6598 | 0.5554 | 0.7867 | 0.7726 | 0.7129 | 0.7555 |
| 8 | 0.7203 | 0.5941 | 0.8722 | 0.8246 | 0.7563 | 0.8162 |
| 9 | 0.7689 | 0.6157 | 0.9593 | 0.8731 | 0.7767 | 0.8652 |
| 10 | 0.7579 | 0.6118 | 1.0000 | 0.9177 | 0.7750 | 0.8801 |
| 11 | 0.7140 | 0.6155 | 0.9901 | 0.9538 | 0.7702 | 0.8760 |
| 12 | 0.6959 | 0.6265 | 0.9531 | 0.9438 | 0.7722 | 0.8647 |
| 13 | 0.6944 | 0.6290 | 0.9091 | 0.9199 | 0.7798 | 0.8519 |
| 14 | 0.6704 | 0.6347 | 0.8653 | 0.9420 | 0.7888 | 0.8452 |
| 15 | 0.6497 | 0.6425 | 0.8223 | 0.9834 | 0.8039 | 0.8453 |
| 16 | 0.6661 | 0.6558 | 0.7814 | 1.0000 | 0.8397 | 0.8542 |
| 17 | 0.7262 | 0.7342 | 0.7578 | 0.9952 | 0.9103 | 0.8934 |
| 18 | 0.8355 | 0.8788 | 0.7555 | 0.9549 | 0.9839 | 0.9551 |
| 19 | 0.9500 | 0.9916 | 0.7555 | 0.9188 | 1.0000 | 1.0000 |
| 20 | 1.0000 | 1.0000 | 0.7485 | 0.8959 | 0.9585 | 0.9972 |
| 21 | 0.9745 | 0.9164 | 0.7398 | 0.8728 | 0.8937 | 0.9526 |
| 22 | 0.8981 | 0.7987 | 0.7341 | 0.8659 | 0.8272 | 0.8935 |
| 23 | 0.8380 | 0.7223 | 0.7322 | 0.8689 | 0.7893 | 0.8559 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peñaloza, C.A.; Otero-Valladares, P.E. Hourly Load Curves Disaggregated by Type of Consumer Using A Density-Based Spatial Clustering Technique. Eng. Proc. 2023, 47, 23. https://doi.org/10.3390/engproc2023047023
Peñaloza CA, Otero-Valladares PE. Hourly Load Curves Disaggregated by Type of Consumer Using A Density-Based Spatial Clustering Technique. Engineering Proceedings. 2023; 47(1):23. https://doi.org/10.3390/engproc2023047023
Chicago/Turabian StylePeñaloza, Carlos Andrés, and Patricia Elizabeth Otero-Valladares. 2023. "Hourly Load Curves Disaggregated by Type of Consumer Using A Density-Based Spatial Clustering Technique" Engineering Proceedings 47, no. 1: 23. https://doi.org/10.3390/engproc2023047023
APA StylePeñaloza, C. A., & Otero-Valladares, P. E. (2023). Hourly Load Curves Disaggregated by Type of Consumer Using A Density-Based Spatial Clustering Technique. Engineering Proceedings, 47(1), 23. https://doi.org/10.3390/engproc2023047023