Abstract
We developed a low-cost, high-performance gesture recognition system with a dynamic hand gesture recognition technique based on the Transformer model combined with MediaPipe. The technique accurately extracts hand gesture key points. The system was designed with eight primary gestures: swipe up, swipe down, swipe left, swipe right, thumbs up, OK, click, and enlarge. These gestures serve as alternatives to mouse and keyboard operations, simplifying human–computer interaction interfaces to meet the needs of media system control and presentation switching. The experiment results demonstrated that training deep learning models using the Transformer achieved over 99% accuracy, effectively enhancing recognition performance.
1. Introduction
Technological advancements have introduced assistive tools that enhance daily life, making computers and televisions indispensable. Traditional input methods, such as mice, keyboards, and remote controls, improve efficiency but have limitations. For example, during presentations, speakers need to move freely but are restricted by these devices. Contactless interaction technologies, such as speech recognition and computer vision, are gaining traction nowadays. These technologies use sound, images, or video to interpret user intentions and provide interface control, offering more convenience and mobility.
Table 1 compares traditional input devices with speech recognition-based interaction techniques regarding usage, cost, and system resource requirements. While traditional devices provide low error rates and stable performance, they are expensive and require physical contact. In contrast, speech recognition technologies facilitate touchless control with lower-cost hardware and exhibit greater flexibility and adaptability when combined with deep learning techniques.

Table 1.
Comparison of traditional devices and recognition technologies.
Among computer vision applications, real-time gesture recognition has shown remarkable potential. Hand gesture recognition is classified into static gestures (single-frame images) and dynamic gestures (continuous video sequences). Compared with static gesture recognition, dynamic gesture recognition provides richer feature representations, reducing misclassification risks while supporting natural human body expressions. For instance, static gestures, including “open palm” and “waving hand”, look visually similar, leading to recognition errors. By incorporating temporal motion analysis, dynamic gesture recognition can distinguish between subtle variations.
In this study, we used MediaPipe technology to streamline the extraction of hand gesture key points from images, replacing traditional high-cost image processing and reducing latency issues while minimizing background interference. Meanwhile, the Transformer model is employed for deep learning training to overcome the limitation of static gesture recognition, which fails to handle temporal variations. This approach enhances dynamic gestures’ recognition accuracy and stability in sequential analysis.
2. Literature Review
2.1. Hand Key Point Extraction Tool
2.1.1. MediaPipe
Proposed by Google Research in 2019, MediaPipe [1] enables real-time human structure recognition in resource-limited environments. It first identifies target regions using bounding boxes, then detects face, hand, and body key points for stable performance. MediaPipe consists of multiple modules that are used independently or combined with different architectures. The most commonly used submodule in gesture recognition is MediaPipe Hands, which specializes in extracting hand key points. Each hand consists of 21 key points, and each key point records three coordinate values: horizontal (x), vertical (y), and depth (z).
MediaPipe Hands is widely used in human–computer interaction (HCI), including smart speakers [2], virtual reality (VR), and augmented reality (AR) [3]. It provides real-time, low-latency, high-precision detection, enabling seamless deployment across systems and embedded systems with deep learning integration. Kumar et al. [4] utilized MediaPipe for key point extraction and data normalization in academic settings. Their method involved subtracting the palm center coordinates from each key point and scaling them to match the image size, flattening the data into a one-dimensional array before feeding it into a convolutional neural network (CNN) for classification. This effectively unified the data and stabilized model training. Additionally, Althubiti et al. [5] utilized the MediaPipe Hands submodule to extract 21 key points from the right hand while also incorporating the Pose module to capture skeletal key points 12, 14, 16, 20, 18, 22, and 24. They expanded the feature dimensions for enhanced recognition performance with the corresponding highlighted regions by calculating the angle between the right shoulder and elbow.
2.1.2. OpenPose
Developed by Carnegie Mellon University (CMU) Pittsburgh, PA, USA. in 2017, OpenPose [6] is a real-time human pose estimation system that detects key points in the body, hand, and face, even in complex backgrounds. Its CNN-based architecture uses part affinity fields (PAFs) to link body parts, enabling bottom-up multi-person skeleton analysis with high accuracy. The hand key point module estimates the hand region from wrist positions, applies a CNN for key point detection, and ensures logical connectivity using PAFs and a greedy parsing algorithm. Each hand consists of 21 key points, with coordinate data including horizontal (x) and vertical (y) positions. Mazzia et al. [7] and Gupta [8] also utilized OpenPose for human pose extraction in deep learning training. Their study calculated key points’ relative positions and velocities to increase feature dimensions. Widely applied in gesture recognition, HCI, sports analysis, AR/VR, and surveillance, OpenPose remains a key technology in pose estimation.
OpenPose excels in multi-person detection and single-image accuracy, but its high computational cost and graphics processing unit (GPU) dependency limit real-time use. It also only supports 2D hand key points, restricting 3D applications. MediaPipe, on the other hand, supports both 2D and 3D key points and requires low computational resources, making it ideal for real-time, lightweight applications. Though its multi-person tracking is limited, we prioritized 3D coordinate extraction for MediaPipe. While MediaPipe is integrated with deep learning in previous studies, image-based data are mainly used. The use of transformers in dynamic gesture recognition remains underexplored, which necessitates additional research.
2.2. Deep Learning Models Based on Transformer
The sequence-to-sequence (Seq2Seq) model, introduced in 2014, was first applied to machine translation, enabling neural networks to process and generate multilingual sentences [9]. It consists of an encoder and a decoder, which exchange information via a context vector. The model tokenizes a Chinese sentence, encodes it into a fixed-length vector, and then the decoder generates an English translation.
However, a single vector struggles to capture all semantic details in long sentences, leading to translation degradation. The attention mechanism [10] and self-attention mechanism [11] were introduced to address this problem. The former allows the decoder to focus on different encoder states, while the latter enables learning relationships within the same sequence. The Transformer model, leveraging self-attention, efficiently handles long-range dependencies and has replaced traditional recurrent neural networks (RNNs) and long short-term memory (LSTM) in deep learning. Initially, natural language processing (NLP) included models such as bidirectional encoder representations from transformers (BERT) and generative pre-trained Transformer (GPT). Transformer-based architectures were later extended to image processing. The vision transformer (ViT) showed similar performance to CNNs.
In 2020, D’Eusanio et al. [12] first proposed a dynamic gesture recognition technique based on the Transformer model, emphasizing that extracted gesture features were classified using only the Transformer encoder, eliminating the need for a decoder. Later, in 2024, Besrour et al. [13] utilized data from inertial sensors as input, still relying solely on the Transformer encoder for gesture feature extraction and classification. Althubiti et al. [5] employed skeleton-based image data features as input to the Transformer encoder for gesture classification. Their results demonstrated superior accuracy to traditional recurrent neural network models such as gated recurrent units (GRUs) and LSTMs.
ViT, introduced by Dosovitskiy et al. [14] in 2020, extends the Transformer encoder from language to image processing. When trained on large datasets, ViT outperforms CNNs in feature extraction and classification. In 2023, Tan et al. [15] applied ViT to static gesture recognition, demonstrating significant accuracy gains. ViT embeds images by dividing RGB gestures into fixed-size patches, flattening them into pixel vectors, and mapping them to feature representations via a linear layer. Positional encoding provides spatial structure, enabling gesture classification through the Transformer encoder. Unlike CNNs, ViT captures local and global features without convolution, making it suitable for complex gestures [16]. However, it lacks translation equivariance and locality-based biases, requiring large-scale pretraining. Additionally, its high computational demands challenge real-time recognition and lack temporal modeling for dynamic gestures. We integrated skeleton-based data into ViT to reduce dataset dependency and enable dynamic gesture recognition on low-resource devices.
2.3. HCI Based on Gesture Control
Dynamic hand gesture recognition (HGR) is a key research area in HCI. With technological advancements, contactless interaction has become mainstream, offering intuitive and user-friendly experiences. HGR is widely applied in smart homes, VR/AR, medical assistance, industrial automation, and multimedia control [1,17]. However, traditional image-based methods (e.g., color thresholding, Viola–Jones algorithm) face challenges such as gesture diversity, background interference, and computational complexity. Sen et al. [18] integrated CNNs and ViT for gesture classification using pre-trained models (Visual Geometry Group 16 (VGG16), VGG19, residual network 50 (ResNet50), ResNet101, and Inception-V1) for real-time interaction. Sen et al. also developed a virtual mouse system using Kalman filtering to stabilize cursor movement, addressing hand tremor issues [19].
The advancement of deep learning has significantly enhanced HGR systems, with Transformer-based models increasingly replacing traditional approaches. HGR supports multimedia control, virtual mouse operations, and multimodal applications, including OCR-based handwriting recognition and speech output, improving interaction convenience. Dataset diversity and standardization are necessary to expand HGR’s potential across various fields, establishing it as a fundamental HCI technology.
3. Methodology
Figure 1 illustrates the research process. First, MediaPipe technology extracted key points from dynamic gesture images collected from self-captured and open-source datasets. The extracted data were then categorized into 2D and 3D formats for further study. Subsequently, all data underwent the same preprocessing optimization to ensure a unified input format for model training.
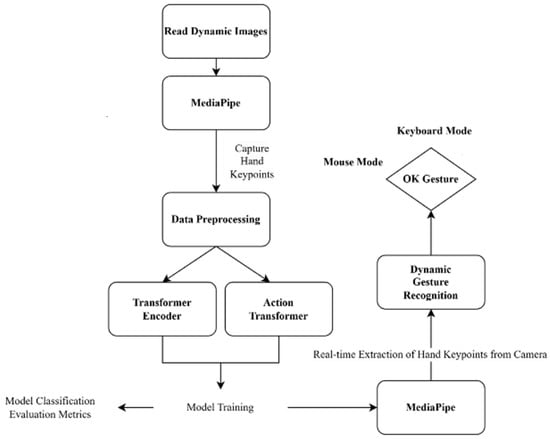
Figure 1.
System flowchart.
We integrated MediaPipe technology with optical character recognition (OCR) to enable air handwriting input, expanding the applications of gesture-based interaction. The “OK” in a mode-switching interface allows users to switch between OCR handwriting, keyboard, and mouse modes. Other gestures are mapped to different keyboard and mouse functionalities, enhancing the flexibility and convenience of human–computer interaction. The dataset consists of Jester Dataset samples combined with self-recorded videos, capturing customized gestures with various resolutions: 1080 × 1920, 2160 × 2160, and 2160 × 3840. Ten participants were invited to perform pre-defined gestures, and key points were extracted for dataset construction. Due to extraction failures and data imbalance, data augmentation techniques, such as horizontal flipping, random translation, rotation, and scaling, were applied to improve dataset quality and efficiency. In the “Big” gesture, 2500 samples were stored in .pt format and split into training and validation datasets in a ratio of 8:2 (Table 2).
Table 2.
Gesture image augmentation by geometric transformation.
MediaPipe Hands extracts 21 key points per hand from images, filtering background noise and standardizing key point data across different resolutions. The extracted key points include (x, y, z) coordinates, where x and y are normalized to [0,1] (Figure 2a), and z represents depth relative to the wrist (key point 0). The standardization ensures consistency across different resolutions, as shown in Figure 2b.
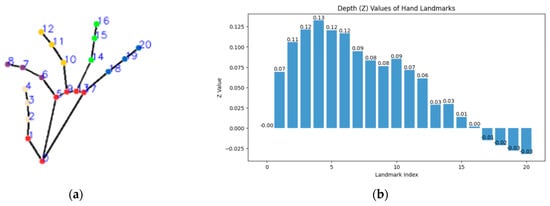
Figure 2.
(a) Key points extracted by MediaPipe Hands, and (b) the visualization of the z-axis corresponds to that point.
All samples were padded to match the maximum frame length using zero padding. A masking mechanism was applied to prevent models from learning irrelevant zero frames. We extract key points from each frame’s left and right hands. The relative positions and frame-to-frame variations are calculated using the wrist (key point 0) as the reference point for each key point’s x and y values.
Based on the computed relative position value and frame-to-frame variation values for the 3D key points, four 2D features and six 3D features are derived, with features represented as “Features.” The feature dimensions () for each frame are 168 for 2D and 252 for 3D (Equation (1)). The terms “key points” and “Hands” refer to the 21 key points per hand, totaling 42 key points per frame. Assuming a gesture action consists of 30 frames (T) of 3D feature dimensions, the tensor shape is () = (30, 252). Finally, the features are combined with positional encoding and fed into the model for training. The 2D feature processing follows the same approach.
d_model = keypoints × Hands × Features,
3.1. Model Parameters and Positional Encoding
A Transformer encoder is used for dynamic gesture recognition, utilizing positional encoding methods and model parameters to process temporal sequences. All samples undergo zero padding to match the maximum frame length to ensure consistent sequence length. A masking mechanism is applied during model input to ignore zero frames, allowing the model to focus on meaningful key point data.
Two-dimensional and three-dimensional feature dimensions (d_model) of 168 and 252 are extracted, respectively, which are then mapped to 64 through a linear layer to match the model’s input requirements. In the Transformer encoder model, fixed sinusoidal (sin) and cosine (cos) positional encoding is applied. This method is based on mathematical functions, eliminating the need for additional learnable parameters. It is computationally efficient and well-suited for processing the sequential nature of dynamic gestures.
The Transformer encoder model in this study consists of 4 encoder layers, a commonly used configuration for small to medium-sized datasets, enabling the learning of deeper features. The multi-head attention mechanism is configured with eight heads (n_heads = 8) to ensure that d_model is evenly divisible. This allows for the effective division of feature representations among different attention heads, facilitating the focus on distinct aspects of gestures. The feedforward network (FFN, d_ff) has a hidden dimension of d_model × 4 = 64 × 4 = 256, which is then transformed back to d_model through an activation function. This design enhances the model’s expressiveness without imposing excessive computational overhead. Furthermore, the cross-entropy loss function (CrossEntropy Loss) measures the discrepancy between ground-truth labels and predicted labels, improving classification performance.
3.2. Training and Regularization Parameter Setting
The Transformer encoder was trained using sinusoidal positional encoding. The model had four encoder layers, eight attention heads, and 256 hidden dimensions. The parameters in training included the following.
- Batch size: 32;
- Epochs: 15 (fine-tuned to 25);
- Learning rate: 0.0005 (adjusted dynamically using ReduceLROnPlateau);
- Optimizer: AdamW;
- Dropout: 0.2.
4. Results and Analysis
4.1. Training and Testing Results
Figure 3a shows the Transformer encoder training process, showing a rapid decline in training and validation loss during the initial epochs. By the third epoch, the training loss dropped from approximately 1.4 to 0.2, with validation loss following a similar trend. The loss curve gradually stabilized and converged to 0, indicating a steady training process without overfitting. From the 10th epoch onward, the loss variation became minimal, confirming that the model has reached a stable state with strong learning capability. Figure 3b presents the training results for 2D feature dimensions, where both training and validation losses decrease steadily as epochs increase. Similar losses indicated that the Transformer encoder did not exhibit significant overfitting, and the final loss value approaching 0 demonstrated the model’s ability to learn gesture features effectively.
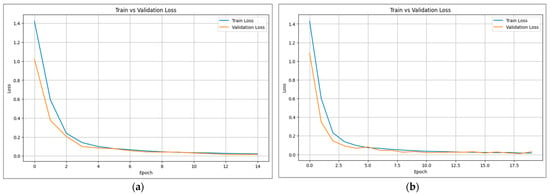
Figure 3.
Loss curves of the Transformer encoder in (a) 2D and (b) 3D.
Figure 4a shows that the Transformer encoder achieved 100% classification accuracy in 3D gesture feature evaluation. However, the other gestures, significant and correct labels, were misclassified. Based on the confusion matrix and recall (Figure 4b), these three gestures showed relatively lower recognition rates. Precision analysis results indicated that six other gesture samples were misclassified as big, and one other gesture, two big, and six right samples were misclassified as left. This suggests that left gestures suffer from the highest misclassification rate. Two fine-tuning training sessions were conducted to improve accuracy. In the Transformer encoder loss rate analysis, 2D and 3D training and validation losses decreased with epochs and remained similar, indicating successful learning and convergence. However, the 2D model took longer to train and showed slight fluctuations after 10 epochs, suggesting that improvements were limited while the model continued learning with longer training times. The more significant fluctuations in the validation set hint at the possibility of slight overfitting due to excessive training time.
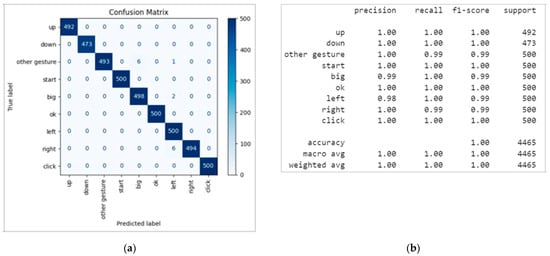
Figure 4.
(a) Confusion matrix and (b) metric of the Transformer encoder in 3D.
4.2. Comparison with Previous Results
We compared the technical aspects of our proposed approach with other related research, as well as the training parameters and accuracy results (Table 3). We adopted the Transformer and compared the results with those of Althubiti et al. [5] and Mazzia et al. [7]. Althubiti et al. recognized five hand gestures (Thumbs Up, Thumbs Down, Left Swipe, Right Swipe, and Stop), with approximately 800 samples per gesture. In contrast, we employed data augmentation to triple the original sample size and expanded the gesture classification task to include eight gesture categories. Mazzia et al. utilized OpenPose and PoseNet to extract skeletal posture data for recognizing 20 human actions. In comparison, we used MediaPipe Hands to extract 3D hand key points to calculate relative positions and frame-to-frame variations to capture richer feature dimensions tailored for eight gesture classifications. Regarding feature dimensions, Mazzia et al. processed 120-dimensional features, while Althubiti et al. utilized 83-dimensional features. In this study, only MediaPipe Hands was used to extract both hands’ key points and compute relative positions and frame differences, resulting in 252 feature dimensions (128 per hand) and enhancing feature representation.
Table 3.
Comparison with previous research.
Through data augmentation, increasing feature dimensions, and focusing on 3D hand key point extraction, we optimized gesture classification and feature representation, demonstrating superior recognition capability to that of existing research. Althubiti et al. reported an average accuracy of 98%. In contrast, while the Transformer encoder model in this study was trained with fewer epochs, fine-tuning was used to achieve a classification accuracy of 100%.
The developed system in this study utilizes a desktop camera and MediaPipe technology for hand detection and key point extraction, enabling gesture recognition and human–computer interaction. Upon system activation, if no hand key points are detected, the interface displays “Searching…” to indicate that the system is awaiting user input. Once the hand key points are successfully detected, the interface changes to a yellow “Ready” indicator and begins a three-second countdown, signaling the user to prepare for data collection. Subsequently, the interface turns green with the “Ready” indicator, indicating that the user can perform the designated gesture. Simultaneously, the system starts collecting dynamic hand gesture key point data. For instance, when performing the “right” gesture, the system captures dynamic hand gesture key point data within five seconds. The collected data is then processed using the proposed method and fed into a pre-trained model for gesture recognition. Finally, the system successfully identifies the gesture as “right.”
5. Conclusions and Prospects
We successfully implemented a dynamic gesture recognition system based on the Transformer model combined with MediaPipe technology for human–computer interaction, with gesture-controlled mouse and keyboard functions. MediaPipe’s lightweight nature enables fast background removal, preserving only hand key points to reduce interference and improve recognition accuracy. The Transformer Encoder leads to 95–100% recognition accuracy, demonstrating the system’s effectiveness. Currently, the developed system focuses on desktop applications, but it needs to include smart TVs, automotive controls, and gesture-based gaming. OCR applications may also be integrated into multimodal recognition, such as speech recognition. Additionally, the reliance on cameras for image capture suggests exploring cost-effective alternatives to improve accessibility.
Author Contributions
Conceptualization, C.-C.H.; methodology, C.-C.H. and H.-H.L.; software, H.-H.L.; validation, C.-C.H.; formal analysis, C.-C.H.; investigation, H.-H.L.; data curation, H.-H.L.; writing—original draft preparation, H.-H.L.; writing—review and editing, C.-C.H.; supervision, C.-C.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lugaresi, C.; Tang, J.; Nash, H.; McClanahan, C.; Uboweja, E.; Hays, M.; Zhang, F.; Chang, C.L.; Yong, M.G.; Lee, J.; et al. MediaPipe: A Framework for Building Perception Pipelines. arXiv 2019, arXiv:1906.08172. [Google Scholar] [CrossRef]
- Xu, S.; Kaul, C.; Ge, X.; Murray-Smith, R. Continuous Interaction with a Smart Speaker via Low-Dimensional Embeddings of Dynamic Hand Pose. arXiv 2023, arXiv:2302.14566. [Google Scholar] [CrossRef]
- Jo, B.J.; Kim, S.K.; Kim, S. Enhancing Virtual and Augmented Reality Interactions with a MediaPipe-Based Hand Gesture Recognition User Interface. Ingén. Syst. Inf. 2023, 28, 633–638. [Google Scholar] [CrossRef]
- Kumar, R.; Singh, S.K.; Bajpai, A.; Sinha, A. Mediapipe and CNNs for Real-Time ASL Gesture Recognition. In Proceedings of the 2023 International Conference on Computer Vision and Pattern Recognition, Greater Noida, India, 28–30 April 2023. [Google Scholar]
- Althubiti, A.H.; Algethami, H. Dynamic Gesture Recognition Using a Transformer and Mediapipe. Int. J. Adv. Comput. Sci. Appl. 2024, 15, 6. [Google Scholar] [CrossRef]
- Cao, Z.; Simon, T.; Wei, S.-E.; Sheikh, Y. Realtime Multi-Person 2D Pose Estimation Using Part Affinity Fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Mazzia, V.; Angarano, S.; Salvetti, F.; Angelini, F.; Chiaberge, M. Action Transformer: A Self-Attention Model for Short-Time Pose-Based Human Action Recognition. arXiv 2022, arXiv:2107.00606v6. [Google Scholar] [CrossRef]
- Gupta, K. Hand Keypoint Detection Using RoboComp. RoboComp Blog. August 2020. Available online: https://robocomp.github.io/web/gsoc/2020/posts/kanav/HandKeypoint (accessed on 11 February 2025).
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. Adv. Neural Inf. Process. Syst. 2014, 27, 3104–3112. [Google Scholar]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. In Proceedings of the International Conference on Learning Representations (ICLR), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention Is All You Need. arXiv 2023, arXiv:1706.03762v7. [Google Scholar] [PubMed]
- D’Eusanio, A.; Simoni, A.; Pini, S.; Borghi, G.; Vezzani, R.; Cucchiara, R. A Transformer-Based Network for Dynamic Hand Gesture Recognition. In Proceedings of the 2020 International Conference on 3D Vision (3DV), Fukuoka, Japan, 25–28 November 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Besrour, S.; Surapaneni, Y.; Mubibya, G.S.; Ashkar, F.; Almhana, J. A Transformer-Based Approach for Better Hand Gesture Recognition. In Proceedings of the 2024 20th International Wireless Communications and Mobile Computing Conference (IWCMC), Limassol, Cyprus, 27–31 May 2024; pp. 1135–1140. [Google Scholar] [CrossRef]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Tan, C.K.; Lim, K.M.; Chang, R.K.Y.; Lee, C.P.; Alqahtani, A. HGR-ViT: Hand Gesture Recognition with Vision Transformer. Sensors 2023, 23, 5555. [Google Scholar] [CrossRef] [PubMed]
- Cordonnier, J.B.; Loukas, A.; Jaggi, M. On the Relationship Between Self-Attention and Convolutional Layers. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Floris, A.; Porcu, S.; Atzori, L. Controlling Media Player with Hands: A Transformer Approach and a Quality of Experience Assessment. ACM Trans. Multimed. Comput. Commun. Appl. 2024, 20, 132. [Google Scholar] [CrossRef]
- Sen, A.; Mishra, T.K.; Dash, R. Deep Learning-Based Hand Gesture Recognition System and Design of a Human-Machine Interface. Multimed. Tools Appl. 2023, 15, 1–20. [Google Scholar] [CrossRef]
- Vaddadi, V.R.; Bharathi, C.; Rout, A.K.; Tirunagari, A.K. A Handwriting Recognition System That Outputs Editable Text and Audio. In Proceedings of the 2024 International Conference on Advances in Modern Age Technologies for Health and Engineering Science (AMATHE), Shivamogga, India, 9–10 May 2024; pp. 1–6. [Google Scholar] [CrossRef]
























Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).