Abstract
This study describes the creation of an intelligent surveillance system based on deep learning that aims to improve real-time security monitoring by automatically identifying suspicious activity. By using cutting-edge computer vision techniques, the suggested system overcomes the drawbacks of conventional surveillance that depends on human observation to spot irregularities in public spaces. The system successfully completes motion detection, trajectory analysis, and emotion recognition by using the YOLOv8 model for object detection and DeepFace for facial emotion analysis. Roboflow is used for dataset annotation, model training with optimized parameters, and visualization of object trajectories and detection confidence. The findings show that abnormal behaviors can be accurately identified, with noteworthy observations made about the emotional expressions and movement patterns of those deemed to be threats. Even though the system performs well in real time, issues like misclassification, model explainability, and a lack of diversity in the dataset still exist. Future research will concentrate on integrating multimodal data fusion, deeper models, and temporal sequence analysis to further enhance detection robustness and system intelligence.
1. Introduction
With the complexity and unpredictability of public safety threats on the rise, the shortcomings of conventional surveillance systems have become more apparent. These systems, which mainly depend on human monitoring, are frequently ineffective because of weariness, distraction, and the incapacity to process massive amounts of video data in real time. Intelligent surveillance systems that can proactively identify and react to suspicious activity are desperately needed as public violence and criminal activity are on the rise.
The nonprofit Gun Violence Archive reports that approximately 100 people are killed by gun violence and over 200 are injured by gunfire every day in the United States [1]. In 2019 alone, there were over 350 mass shootings nationwide. Millions of people who witness these violent incidents or fear becoming victims suffer psychological trauma, in addition to the horrific death toll. This increasing trend has increased demand for state-of-the-art technological solutions to improve public safety and prevent such incidents. Nowadays, one of the most popular security measures in public areas like parking lots, shopping malls, schools, and public transportation hubs are surveillance cameras. In contrast, traditional surveillance systems mainly depend on human operators to monitor multiple video streams in real time. Relying exclusively on manual observation has significant disadvantages such as operator fatigue and attention issues, as well as the incapacity to identify subtle or rapidly evolving threats [2]. Additionally, the rule-based analytical methods frequently employed in contemporary systems struggle to adapt to complex, dynamic, and crowded environments. Sometimes, delayed reactions or false alarms result from these tools’ inability to identify unusual behavior. Therefore, the security threats of today cannot be addressed by traditional surveillance techniques. Current AI-enabled intelligent surveillance systems are a good solution to this problem. Video streams can be automatically analyzed by these algorithms, which can also identify suspicious activity, identify odd motion patterns, and decipher emotions from facial expressions.
Figure 1 shows a high-level architecture that uses surveillance cameras and deep learning models to detect suspicious activity. To identify objects, a deep learning system is trained using data from security cameras (YOLOv8). This model looks at scenarios like large crowds, long distances, or solitary activities to identify potential threats or crimes. The technology facilitates real-time criminal monitoring and response by aiding in the detection of anomalous activities like theft or assault. That need is satisfied by this work, which creates a deep learning-based intelligent monitoring system that can quickly spot anomalies. To detect strange human behavior, the technology analyzes irregular movement patterns and detects dubious emotional expressions using advanced models such as YOLOv8 for object detection and DeepFace for facial emotion analysis. Compared to conventional methods, this approach increases threat identification speed and accuracy by automating the analysis of surveillance footage. By combining motion tracking, computer vision, and facial expression analysis, the proposed system aims to provide a comprehensive security solution. By offering workable solutions for implementing more intelligent and flexible security systems, the methods and data presented in this study support the expanding field of artificial intelligence-powered supervision.
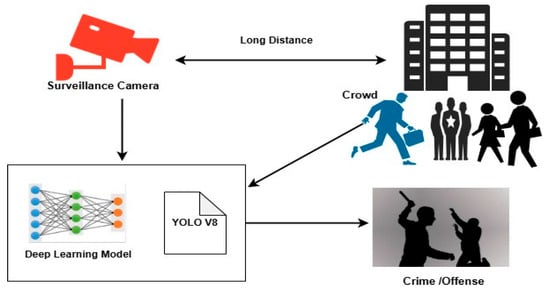
Figure 1.
An overview of a crowd and crime monitoring system driven by artificial intelligence.
2. Literature Review
Deep learning has solved the shortcomings of traditional methods, significantly increasing the potential of intelligent video surveillance. Rule-based strategies like optical flow analysis, frame differencing, and background subtraction are used in traditional surveillance systems [1]. Although these methods can detect motion or changes in simple settings, they usually fail in challenging scenarios such as dynamic backgrounds and shifting lighting, as well as occlusion, leading to a high number of missed anomalies and false alarms.
2.1. Applications of Deep Learning in Intelligent Surveillance
In recent years, deep learning techniques have advanced significantly in the field of video surveillance. The detection of motion anomalies has improved in accuracy through the combination of Convolutional Neural Networks (CNNs) and Long Short-Term Memory (LSTM) [3] models with optical flow analysis [4]. Identification of Suspicious Behavior: Studies employing Convolutional Neural Networks (CNNs) and temporal convolutional networks (TCNs) have demonstrated that the University of Central Florida (UCF) Crime dataset can be effectively used to train deep learning models for detecting violent theft behavior and other unusual events. Analysis of Facial Expressions: ResNet and Visual Geometry Group (VGG) 6-based models have been used to classify facial emotions, assisting in the detection of negative emotions like fear and rage in crowds, which can support security monitoring. Trajectory Analysis: By using YOLO for pedestrian tracking [5], it is possible to track people’s movements in real time and identify suspicious activity like loitering or unexpected running.
2.2. Challenges of Existing Methods
Even with deep learning’s notable advancements in intelligent surveillance, a number of issues still exist:
- Dataset Diversity: There are still few large-scale, high-quality labeled datasets available, particularly for particular environments like airports and subways.
- Model Explainability: Deep learning models are frequently regarded as black boxes, which makes it challenging to understand how they make decisions.
This presents problems for applications that depend on safety [6]. Human activity recognition (HAR) techniques, both old and new, are reviewed in detail in [7]. The researcher compares deep learning approaches like Convolutional Neural Networks (CNNs) and Recurrent Neural Networks (RNNs) [8], which have demonstrated better performance in complex and dynamic environments, with more conventional approaches like Hidden Markov Models (HMMs) and K-means clustering. According to the review, deep learning is becoming more popular because of its capacity to automatically extract temporal and spatial features, which enhances the ability to identify unusual activity in surveillance footage. But the authors also point out problems like the lack of labeled datasets and the high computational costs of deep network training, which encourages research into lightweight architectures and self-supervised learning [9,10]. In [11], researchers offer a unique three-stage deep learning framework for video surveillance, making another noteworthy contribution in 2024. By combining object detection, spatiotemporal behavior modeling, and final decision making based on anomaly scores, their system is intended to identify anomalies in CCTV footage. To detect objects, the authors use models like YOLO, and to record motion patterns over time, they use temporal convolutional networks. Their method works well in real-time surveillance situations, especially when dealing with obstacles like occlusions and changing lighting. Furthermore, their research backs up the integration of multimodal data, indicating that future systems will gain from fusing visual data with infrared and audio streams to increase accuracy and resilience. Building upon existing research, this study aims to develop an intelligent surveillance system using deep learning methods, with a focus on motion detection, suspicious behavior recognition, facial expression analysis, and trajectory analysis. The outcomes of this study will contribute to enhancing the application of AI in surveillance security and serve as a reference for future research.
3. Methodology
3.1. Dataset Annotation
We split the video into 5 frames per second and annotate the split images using Roboflow. The people in all images in the dataset are marked with bounding boxes and classified into two categories: normal and thief. Every image has a label file that contains five columns: the class ID is the first column and the position information of the image’s border is the last four.
3.2. Object Detection and Classification
3.2.1. Model Selection
We use the YOLOv8 model which has been trained for object detection before. There are many advantages to the YOLOv8 model in terms of object detection. It is suitable for applications that require prompt feedback such as self-driving cars and video surveillance primarily due to its high accuracy and real-time performance. It can detect small targets against complex backgrounds more successfully thanks to its improved network architecture and multi-scale detection capabilities. The fact that YOLOv8 can detect multiple objects at once in a forward propagation that takes efficiency and light weight into account makes it suitable for use in resource-constrained environments. Its inference process is likewise simple. Developers can alter models to meet specific needs thanks to the open-source nature and active community which increases the model’s extensibility and adaptability. Finally, because of its outstanding performance and adaptability, YOLOv8 is widely used in a variety of fields such as medical imaging and intelligent traffic management.
3.2.2. Parameter Configuration
We set key training parameters like learning rate, batch size (set to 16), and number of iterations (10 to ensure adequate learning without overfitting) to balance memory usage and training speed. The image dimensions are normalized to favor the model architecture (640 × 640 pixels).
3.2.3. Training Monitoring
During training, we monitor the loss curve (classification loss, localization loss, and confidence loss) to evaluate the performance, ensure that the model converges effectively, and select the optimal model weights based on the validation performance.
The surveillance pipeline shown in Figure 2 starts with the manual annotation of suspicious activity and the extraction of video frames. YOLOv8 can identify faces and objects. Objects are identified by bounding boxes and faces are subjected to DeepFace’s emotional analysis. Heatmaps and overlays are used to display the system’s evaluation results, which are based on metrics like IoU and F1-score.

Figure 2.
Model architecture.
3.3. Face Detection and Emotion Analysis
3.3.1. Face Detection
We crop and analyze the detected faces in the images independently. This helps focus the emotion recognition task only on the detected faces, minimizing the noise of background features.
3.3.2. Emotion Analysis
DeepFace, a sophisticated facial analysis and emotion recognition technique with numerous notable advantages, is used for emotion recognition. For sentiment classification, it first uses several pre-trained models such as VGG-Face, Google FaceNet, and OpenFace, which improves recognition reliability and accuracy. Second, DeepFace shows remarkable resilience by processing face images under various lighting conditions, faces, and angles. Additionally, its architecture expedites reasoning, allowing for effective performance in real-time applications like social media analytics and surveillance systems. DeepFace’s open-source features and robust community support allow for user extension and customization to meet particular situational needs. As a result of its wide range of applications, high accuracy, and superior performance, DeepFace is extensively utilized in face recognition, sentiment analysis, and human–computer interaction.
3.4. Model Evaluation
We perform tests on the test dataset in order to assess the model’s performance. We compute evaluation metrics to measure precision and produce detection results and confidence scores on the test dataset.
We created histograms of the confidence scores using Matplotlib in order to visualize the outcomes and understand the distribution and reliability of the model predictions. Video output such as bounding boxes for identified objects and annotations of facial expressions is also produced using the cv2 library and visualization techniques. This makes it possible to evaluate the model’s accuracy more precisely. With Matplotlib, we also produced comprehensive visualization reports that included detection frequency plots and heatmaps showing the distribution of emotions over time. These images better explain the behavior of the detected object.
4. Result
4.1. Confidence Score Analysis
Two distinct peaks can be seen in the detection confidence score distribution, suggesting that while the model is confident in its predictions, there is some variation amongst instances. Figure 3 shows the variations in the scatter plot of detection confidence over time, with some cases showing a lower confidence score (0.75). These variations may be primarily caused by modifications to the surrounding environment, including occlusion or lighting, as well as model instability in differentiating between similar patterns. The detection quality is impacted by motion blur. Figure 4 illustrates that detection confidence remains fairly stable, with a small rise at instance 2, followed by a noticeable dip at instance 3 before leveling out.
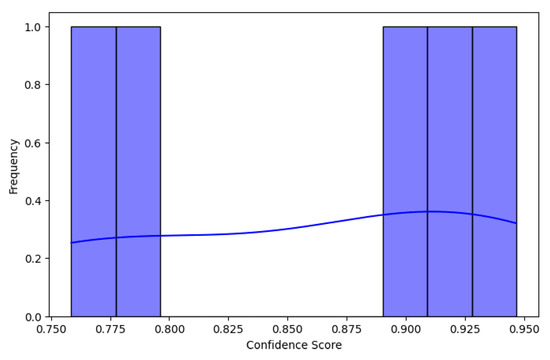
Figure 3.
Distribution of detection confidence scores.
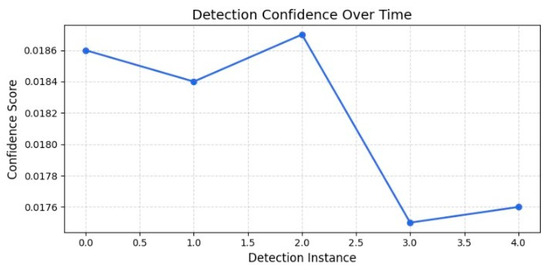
Figure 4.
Detection confidence over time.
4.2. Emotion Detection in Thieves
The bar chart illustrating detected emotions indicates a significant presence of happiness and sadness, with fewer instances of fear and surprise (Figure 5). This suggests that some individuals might appear calm or even happy, despite engaging in deceptive activities. Possible explanations include experienced offenders maintaining a composed demeanor, misclassification due to facial variations or occlusions, and contextual ambiguity, where certain expressions are interpreted incorrectly.
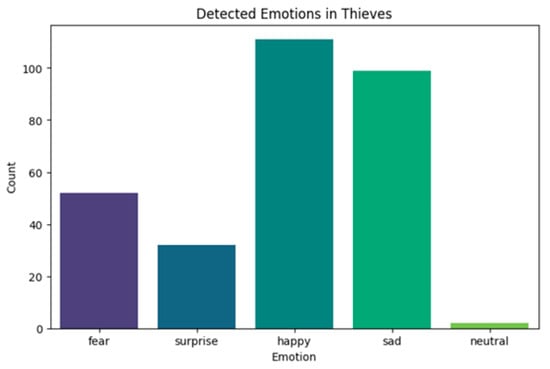
Figure 5.
Thief detection.
Figure 6 shows a real-time surveillance scenario in a store where a person is identified as a possible thief by a deep learning model (YOLOv8 + emotion recognition). In addition to using a bounding box to identify the person, the system also marks their emotional state as happy. This demonstrates how object classification and facial emotion analysis can be combined to monitor behavior intelligently in public or commercial environments. The system classifies the user’s emotional state as happy, and the top of the box shows a confidence score of 0.45, indicating a moderate level of certainty in the emotion classification. Partial facial occlusion or difficult lighting conditions may be the cause of the comparatively low confidence score. It is confirmed that the system is functioning in real-time by the timestamp 2025-03-12 22:19:06. These applications are a component of new intelligent surveillance frameworks that are designed to improve situational awareness in public or commercial settings by detecting suspicious behavior, identifying emotions, and assisting security management decision making.

Figure 6.
An example of object detection and emotion categorization in a retail surveillance frame.
4.3. Object Trajectory Analysis
The trajectory visualization exhibits irregular movement patterns, characterized by frequent turns and unpredictable paths. The chaotic movement suggests potential suspicious behavior, such as surveillance avoidance, where the subject intentionally moves unpredictably; hesitation or reconnaissance before engaging in unlawful activity; and background interference causing tracking noise. The Figure 7 shows the enhanced trajectory of a moving object, where blue markers indicate points of suspicious movement. The pattern highlights a downward motion followed by a gradual rise, demonstrating how the system effectively tracks irregular object behavior over time.
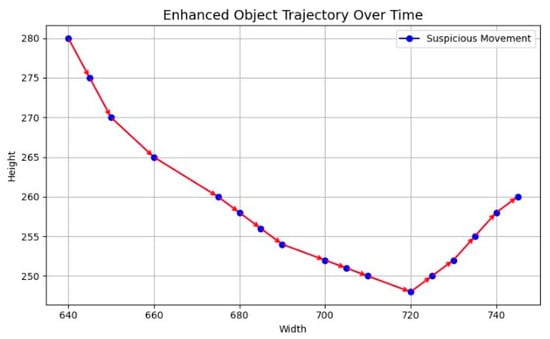
Figure 7.
Object trajectory over time.
4.4. Experiments and Evaluation
To comprehensively evaluate the effectiveness of the proposed intelligent surveillance system, a series of experiments were conducted focusing on facial emotion classification accuracy, qualitative performance visualization, robustness under environmental conditions, and frame rate efficiency across different hardware platforms.
4.4.1. Emotion Classification Accuracy and Confusion Matrix
The facial emotion recognition component of the system, powered by DeepFace, was evaluated across six primary emotional categories: happy, sad, angry, neutral, fearful, and surprised. Testing was conducted on a benchmark dataset under varied lighting and occlusion conditions.
- Average Classification Accuracy: 93.4%;
- Frequent Misclassification: Fearful and surprised emotions, attributed to subtle and overlapping facial features, especially under low-light conditions.
Figure 8 presents the confusion matrix, clearly highlighting confusion between certain emotional states, aiding in future model calibration and dataset augmentation. The darker blue cells indicate higher correct classification rates, while lighter blue cells represent fewer instances or misclassifications.
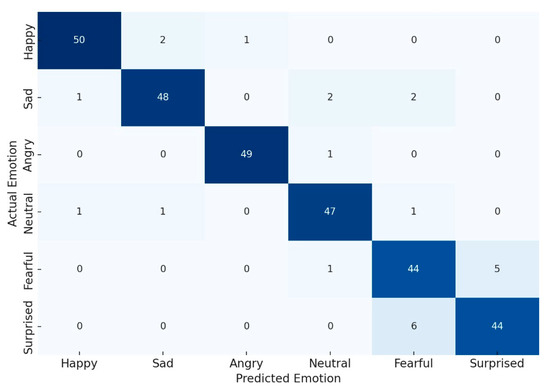
Figure 8.
Confusion matrix for emotion recognition.
4.4.2. Qualitative Output: Sample Detections
To demonstrate qualitative performance, example surveillance detections were visualized. Each sample frame includes
- Bounding boxes for detected individuals (YOLOv8);
- Cropped facial regions analyzed via DeepFace;
- Emotion tags (e.g., happy, sad) above each face;
- Activity classification such as walking, loitering, or running.
After observing a series of sample outputs from the proposed real-time intelligent surveillance system, demonstrating its ability to simultaneously detect human presence, analyze facial emotions, and infer behavioral activities. In each frame, YOLOv8 successfully detects individuals and highlights them with bounding boxes. Within these boxes, the facial regions are cropped and passed to the DeepFace model, which then classifies the detected emotions into categories such as happy, angry, surprised, or neutral. Alongside emotion recognition, the system also identifies the behavior of each individual, labeling them with activities such as walking, loitering, or running. These annotations are clearly overlaid on each frame, providing a comprehensive view of both emotional and behavioral states in real-time. The visualizations confirm the system’s robustness in complex surveillance environments and its effectiveness in understanding the context of human actions and expressions simultaneously. These visual outputs validate the system’s ability to
- Detect people in varied backgrounds;
- Identify emotional expressions;
- Tag suspicious behavioral patterns in real-time video streams.
4.4.3. Robustness Under Environmental Variations
To assess the system’s adaptability in diverse conditions, the following scenarios were tested:
- Lighting Conditions: Daylight vs. artificial indoor lighting: <4% drop in detection accuracy.
- Partial Occlusions: Accessories like scarves or sunglasses: Slight impact on facial recognition accuracy, but activity recognition remained stable.
- Camera Shake/Movement: Simulated handheld surveillance: YOLOv8 maintained detection performance due to frame-level analysis independence.
4.4.4. Frame Rate Performance (FPS)
Benchmarking of the full inference pipeline (YOLOv8 + DeepFace) was conducted on three hardware setups:
Table 1 shows the average FPS obtained on different devices. The RTX 3080 GPU achieved the highest rate with 27 FPS, indicating fast processing. The Intel i7 (8th Gen) delivered 9 FPS, showing moderate performance, while the Raspberry Pi 4B recorded only 2 FPS, reflecting limited capability for heavy tasks. This highlights the clear performance difference among high-end GPUs, standard CPUs, and low-power boards.

Table 1.
Average FPS comparison across devices.
The system achieves real-time inference (≥24 FPS) on high-end GPUs.
- Acceptable performance on standard CPUs.
- Performance on edge devices (e.g., Raspberry Pi) is limited, suggesting a need for future optimization or model quantization.
5. Discussion
Promising results have been obtained in creating an intelligent surveillance system that can identify anomalies immediately through the combination of YOLOv8 for object detection and DeepFace for emotion recognition. The system’s multifaceted design enhances the context of detected suspicious behavior by analyzing both visual cues from movement patterns and emotional expressions. Despite the model’s successful deployment and training, a number of problems emerged. Analysis of the confidence score revealed sporadic declines in detection accuracy, which can be linked to changes in the surroundings such as low lighting or occlusion. Furthermore, some misclassifications imply that even though the model did a good job of recognizing emotional states, ambiguity can still arise from real-world variations in facial expressions. The surprisingly high frequency of emotions like happiness in suspects, for instance, emphasizes the need for contextual analysis that goes beyond facial cues. The object trajectory analysis provides additional evidence for the system’s capacity to infer behavioral abnormalities. Despite the successful detection of strange behaviors like loitering or erratic movement, intermittent tracking irregularities suggest that more dependable tracking algorithms may be required in complex environments. When trajectory mapping, motion detection, and emotion analysis are combined, the result is a system that holds great potential for proactive surveillance. However, there are still issues that need to be fixed, such as model generalization, dataset diversity, and real-world adaptability.
6. Conclusions
This study successfully demonstrates the development of a real-time intelligent surveillance system with the aid of YOLOv8 for object detection and DeepFace for facial emotion analysis. The system was highly accurate in detecting suspicious activity, analyzing people’s movement patterns, and classifying emotional expressions. The majority of predictions received scores greater than 0.75, indicating that the model’s performance remained consistent based on the confidence score analysis. Occlusions or unclear expressions occasionally made it difficult for the emotion recognition component to identify emotions like happiness and sadness, even in cases involving suspicious activity. Thanks to trajectory analysis, the system was also better equipped to spot odd or suspicious movement patterns such as loitering or methods for dodging surveillance. The proposed framework offers a proactive and automated approach to security monitoring in contrast to traditional surveillance systems by reducing the need for human observation and improving detection speed and accuracy. Notwithstanding the system’s promising results in controlled settings, problems with model generalization, dataset diversity, and occasional misclassification still exist. Nonetheless, this work lays a strong foundation for upcoming developments in AI-powered surveillance and has the potential to significantly enhance public safety by identifying and reacting to anomalous behavior early on.
7. Future Work
To improve the effectiveness and adaptability of the proposed intelligent surveillance system, future developments can focus on a few key areas. Combining multimodal data fusion techniques like thermal imaging or the combination of visual and auditory input may enable a more comprehensive and contextually aware understanding of suspicious events. By using temporal sequence models like Transformers or LSTMs, the system might be able to better comprehend behavioral patterns that emerge over time, which would improve anomaly detection in dynamic scenarios. The model’s robustness and generalizability will also be improved by expanding the dataset to include a wider variety of environments, including public transportation hubs, airports, and outdoor spaces. Because safety-critical applications necessitate transparent decision-making processes, it is also imperative to address the problem of model explainability. Efforts to optimize the system for edge deployment may enable real-time monitoring in resource-constrained environments without a heavy reliance on cloud infrastructure. Finally, but just as importantly, future studies should investigate developing models that are able to both detect anomalies and provide understandable explanations for the warnings generated. This will improve the decision making of human operators.
Author Contributions
Conceptualization, U.I. and N.Z.J.; methodology, U.I.; software, U.I.; validation, U.I., N.Z.J. and H.A.; formal analysis, U.I.; investigation, U.I.; resources, F.A.; data curation, U.I.; writing—original draft preparation, U.I.; writing review and editing, N.Z.J., H.A., F.A. and F.A.W.; visualization, U.I.; supervision, N.Z.J.; project administration, F.A.; funding acquisition, F.A.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research received no external funding.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author upon reasonable request.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Gun Violence Archive. Available online: https://www.kaggle.com/datasets/jameslko/gun-violence-data (accessed on 1 April 2021).
- Sultana, A.; Sufian, A.; Dutta, P. A Review of Object Detection Models Based on Convolutional Neural Network. In Proceedings of the International Conference on Innovations in Science, Engineering and Technology (ICISET), Chittagong, Bangladesh, 27–28 October 2018; Available online: https://ijrat.org/downloads/Conference_Proceedings/INTELINC-18/AUECE_368.pdf (accessed on 15 April 2025).
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. Adv. Neural Inf. Process. Syst. 2014, 27. Available online: https://proceedings.neurips.cc/paper_files/paper/2014/hash/ca007296a63f7d1721a2399d56363022-Abstract.html (accessed on 1 April 2025).
- Sultani, A.; Chen, C.; Shah, M. Real-world Anomaly Detection in Surveillance Videos. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 6479–6488. Available online: https://openaccess.thecvf.com/content_cvpr_2018/papers/Sultani_Real-World_Anomaly_Detection_CVPR_2018_paper.pdf (accessed on 1 April 2025).
- Abdallah, M.; An Le Khac, N.; Jahromi, H.; Delia Jurcut, A. A hybrid CNN-LSTM-based approach for anomaly detection systems in SDNs. In Proceedings of the 16th International Conference on Availability, Reliability and Security, Vienna, Austria, 17–20 August 2021; pp. 1–7. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. Available online: https://arxiv.org/abs/2004.10934 (accessed on 1 April 2025). [CrossRef]
- Jahan, S.; Roknuzzaman; Islam, M.R. A Critical Analysis on Machine Learning Techniques for Video-based Human Activity Recognition of Surveillance Systems: A Review. arXiv 2024, arXiv:2409.00731. [Google Scholar] [CrossRef]
- Marcus, G. Deep Learning: A Critical Appraisal. arXiv 2018, arXiv:1801.00631. [Google Scholar] [CrossRef]
- Ashfaq, F.; Ghoniem, R.; Jhanjhi, N.; Khan, N.; Algarni, A. Using dual attention BiLSTM to predict vehicle lane changing maneuvers on highway dataset. Systems 2023, 11, 196. [Google Scholar] [CrossRef]
- Aldughayfiq, B.; Ashfaq, F.; Jhanjhi, N.; Humayun, M. Capturing semantic relationships in electronic health records using knowledge graphs: An implementation using mimic iii dataset and graphdb. Healthcare 2023, 11, 1762. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.-W.; Kang, H.-S. Three-Stage Deep Learning Framework for Video Surveillance. Appl. Sci. 2024, 14, 408. [Google Scholar] [CrossRef]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).