

A Quantitative Approach to Evaluating Multi-Event Resilience in Oil Pipeline Incidents


Abstract
:1. Introduction
2. Literature Review
3. Methodology
3.1. Failure Cause Identification
3.1.1. PHMSA Failure Category
3.1.2. Pipeline Incident
3.2. Multi-Event Incident Sequence Assessment
3.2.1. Multi-Event Probability
3.2.2. Probability of Pipeline Disruption
3.2.3. Probability of Pipeline Shutdown
3.3. Resilience Quantification
3.3.1. Resilience Indicator
3.3.2. Recovery Period
4. Results and Discussion
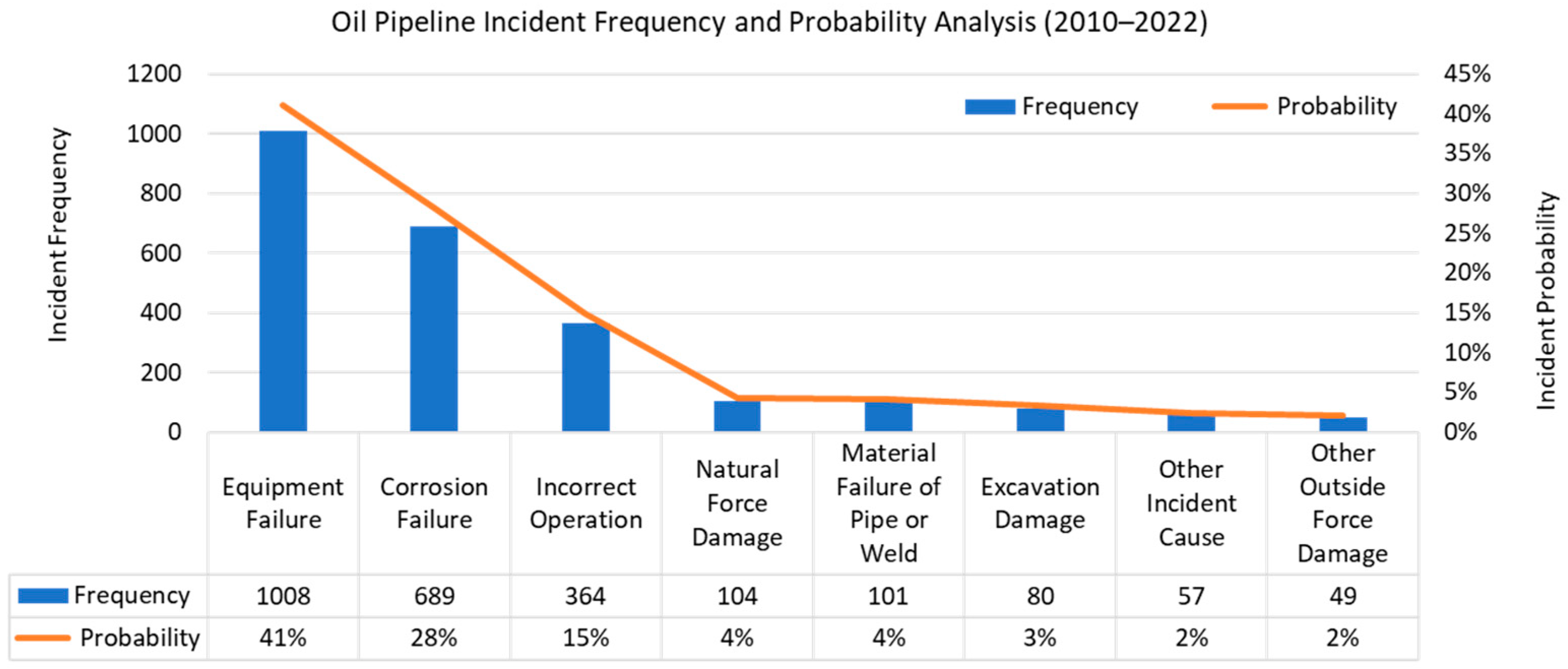
4.1. Multi-Event Analysis
4.2. Recovery Period Analysis
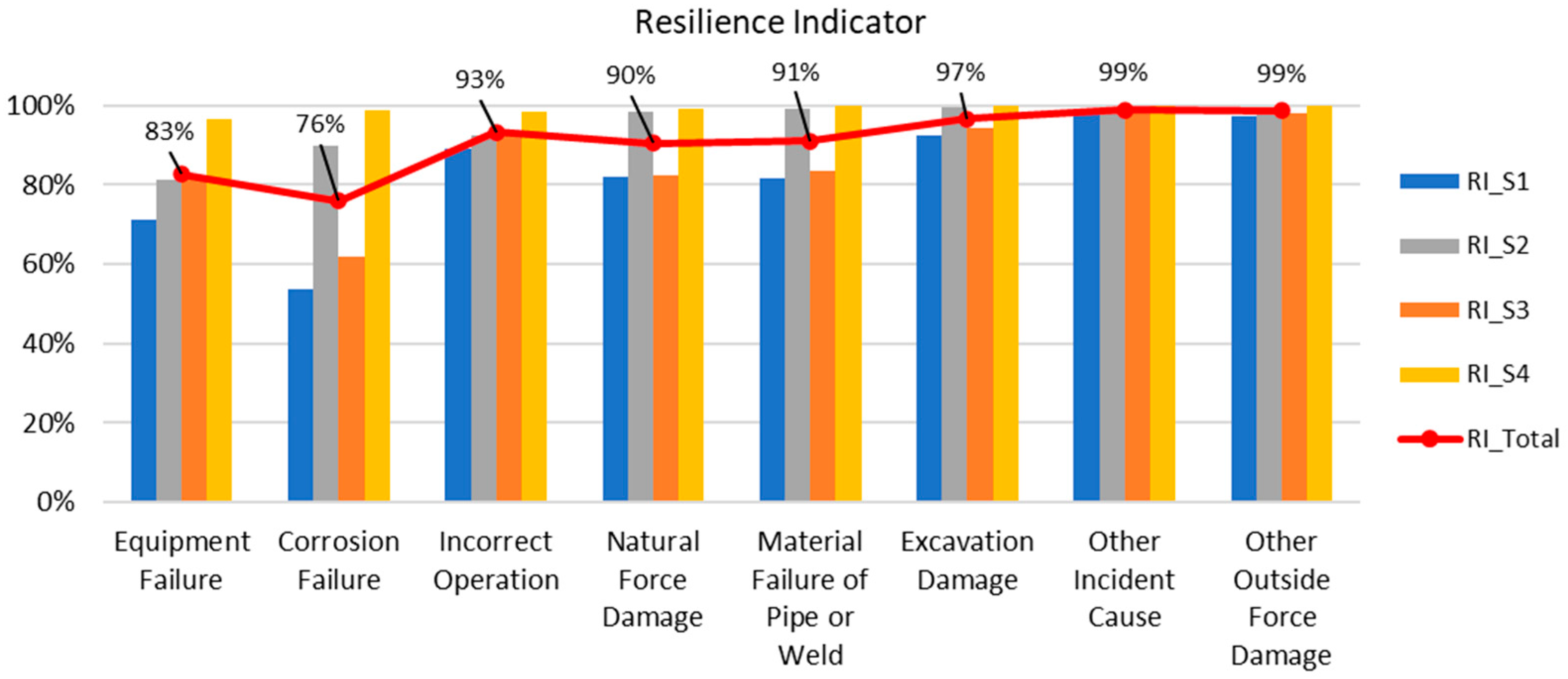
4.3. Resilience Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Mahmood, Y.; Afrin, T.; Huang, Y.; Yodo, N. Sustainable Development for Oil and Gas Infrastructure from Risk, Reliability, and Resilience Perspectives. Sustainability 2023, 15, 4953. [Google Scholar] [CrossRef]
- US Department of Transportation, Pipeline and Hazardous Materials Safety Administration (PHMSA). Pipeline Basics. Available online: https://primis.phmsa.dot.gov/comm/PipelineBasics.htm (accessed on 15 August 2024).
- Biezma, M.V.; Andrés, M.A.; Agudo, D.; Briz, E. Most fatal oil & gas pipeline accidents through history: A lessons learned approach. Eng. Fail. Anal. 2020, 110, 104446. [Google Scholar] [CrossRef]
- Cozzani, V.; Campedel, M.; Renni, E.; Krausmann, E. Industrial accidents triggered by flood events: Analysis of past accidents. J. Hazard. Mater. 2010, 175, 501–509. [Google Scholar] [CrossRef] [PubMed]
- Anifowose, B.; Lawler, D.M.; van der Horst, D.; Chapman, L. Attacks on oil transport pipelines in Nigeria: A quantitative exploration and possible explanation of observed patterns. Appl. Geogr. 2012, 32, 636–651. [Google Scholar] [CrossRef]
- Sovacool, B.K. The costs of failure: A preliminary assessment of major energy accidents, 1907–2007. Energy Policy 2008, 36, 1802–1820. [Google Scholar] [CrossRef]
- Zhu, Y.; Qian, X.-M.; Liu, Z.-Y.; Huang, P.; Yuan, M.-Q. Analysis and assessment of the Qingdao crude oil vapor explosion accident: Lessons learnt. J. Loss Prev. Process Ind. 2015, 33, 289–303. [Google Scholar] [CrossRef]
- Girgin, S.; Krausmann, E. Historical analysis of U.S. onshore hazardous liquid pipeline accidents triggered by natural hazards. J. Loss Prev. Process Ind. 2016, 40, 578–590. [Google Scholar] [CrossRef]
- Ramírez-Camacho, J.G.; Carbone, F.; Pastor, E.; Bubbico, R.; Casal, J. Assessing the consequences of pipeline accidents to support land-use planning. Saf. Sci. 2017, 97, 34–42. [Google Scholar] [CrossRef]
- Restrepo, C.E.; Simonoff, J.S.; Zimmerman, R. Causes, cost consequences, and risk implications of accidents in US hazardous liquid pipeline infrastructure. Int. J. Crit. Infrastruct. Prot. 2009, 2, 38–50. [Google Scholar] [CrossRef]
- Siler-Evans, K.; Hanson, A.; Sunday, C.; Leonard, N.; Tumminello, M. Analysis of pipeline accidents in the United States from 1968 to 2009. Int. J. Crit. Infrastruct. Prot. 2014, 7, 257–269. [Google Scholar] [CrossRef]
- Yang, Z.; Xiang, Q.; He, Y.; Peng, S.; Faber, M.H.; Zio, E.; Zuo, L.; Su, H.; Zhang, J. Resilience of Natural Gas Pipeline System: A Review and Outlook. Energies 2023, 16, 6237. [Google Scholar] [CrossRef]
- Yodo, N.; Wang, P. Engineering resilience quantification and system design implications: A literature survey. J. Mech. Des. 2016, 138, 111408. [Google Scholar] [CrossRef]
- Zobel, C.W.; Khansa, L. Characterizing multi-event disaster resilience. Comput. Oper. Res. 2014, 42, 83–94. [Google Scholar] [CrossRef]
- Nguyen, S.; Chen, P.S.-L.; Du, Y. Risk assessment of maritime container shipping blockchain-integrated systems: An analysis of multi-event scenarios. Transp. Res. Part E Logist. Transp. Rev. 2022, 163, 102764. [Google Scholar] [CrossRef]
- Han, Z.Y.; Weng, W.G. An integrated quantitative risk analysis method for natural gas pipeline network. J. Loss Prev. Process Ind. 2010, 23, 428–436. [Google Scholar] [CrossRef]
- Lawson, K. Pipeline corrosion risk analysis—An assessment of deterministic and probabilistic methods. Anti-Corros. Methods Mater. 2005, 52, 3–10. [Google Scholar] [CrossRef]
- Li, X.; Chen, G.; Zhu, H. Quantitative risk analysis on leakage failure of submarine oil and gas pipelines using Bayesian network. Process Saf. Environ. Prot. 2016, 103, 163–173. [Google Scholar] [CrossRef]
- Farahani, S.; Tahershamsi, A.; Behnam, B. Earthquake and post-earthquake vulnerability assessment of urban gas pipelines network. Nat. Hazards 2020, 101, 327–347. [Google Scholar] [CrossRef]
- Toprak, S.; Taskin, F. Estimation of Earthquake Damage to Buried Pipelines Caused by Ground Shaking. Nat. Hazards 2007, 40, 1–24. [Google Scholar] [CrossRef]
- Eskandari, M.; Omidvar, B.; Modiri, M.; Nekooie, M.A.; Alesheikh, A.A. Geospatial Analysis of Earthquake Damage Probability of Water Pipelines Due to Multi-Hazard Failure. ISPRS Int. J. Geo-Inf. 2017, 6, 169. [Google Scholar] [CrossRef]
- Asha, L.N.; Huang, Y.; Yodo, N.; Liao, H. A Quantitative Approach of Measuring Sustainability Risk in Pipeline Infrastructure Systems. Sustainability 2023, 15, 14229. [Google Scholar] [CrossRef]
- Ceravolo, R.; Civera, M.; Lenticchia, E.; Miraglia, G.; Surace, C. Damage detection and localisation in buried pipelines using entropy in information theory. In Proceedings of the 1st International Electronic Conference on Applied Sciences, Online, 27 October–10 November 2023; pp. 30–36. [Google Scholar]
- Lee, S.-H.; Park, C.-S.; Yoon, D.-J. Source location and anomaly detection for damage identification of buried pipelines using kurtosis-based transfer function. Struct. Health Monit. 2024, 23, 1742–1765. [Google Scholar] [CrossRef]
- Arun Sundaram, B.; Kesavan, K.; Parivallal, S. Recent Advances in Health Monitoring and Assessment of In-service Oil and Gas Buried Pipelines. J. Inst. Eng. (India) Ser. A 2018, 99, 729–740. [Google Scholar] [CrossRef]
- Ma, J.; Chen, G.; Zeng, T.; Zhou, L.; Zhao, J.; Zhao, Y. Methodology for resilience assessment of oil pipeline network system exposed to earthquake. Sustainability 2023, 15, 972. [Google Scholar] [CrossRef]
- Ahmadian, N.; Lim, G.J.; Cho, J.; Bora, S. A quantitative approach for assessment and improvement of network resilience. Reliab. Eng. Syst. Saf. 2020, 200, 106977. [Google Scholar] [CrossRef]
- Argyroudis, S.A.; Mitoulis, S.A.; Hofer, L.; Zanini, M.A.; Tubaldi, E.; Frangopol, D.M. Resilience assessment framework for critical infrastructure in a multi-hazard environment: Case study on transport assets. Sci. Total Environ. 2020, 714, 136854. [Google Scholar] [CrossRef]
- Rehak, D.; Senovsky, P.; Hromada, M.; Lovecek, T. Complex approach to assessing resilience of critical infrastructure elements. Int. J. Crit. Infrastruct. Prot. 2019, 25, 125–138. [Google Scholar] [CrossRef]
- Sathurshan, M.; Saja, A.; Thamboo, J.; Haraguchi, M.; Navaratnam, S. Resilience of Critical Infrastructure Systems: A Systematic Literature Review of Measurement Frameworks. Infrastructures 2022, 7, 67. [Google Scholar] [CrossRef]
- Yazdi, M.; Khan, F.; Abbassi, R.; Quddus, N. Resilience assessment of a subsea pipeline using dynamic Bayesian network. J. Pipeline Sci. Eng. 2022, 2, 100053. [Google Scholar] [CrossRef]
- Golara, A.; Esmaeily, A. Quantification and Enhancement of the Resilience of Infrastructure Networks. J. Pipeline Syst. Eng. Pract. 2017, 8, 04016013. [Google Scholar] [CrossRef]
- Okoro, A.; Khan, F.; Ahmed, S. A methodology for time-varying resilience quantification of an offshore natural gas pipeline. J. Pipeline Sci. Eng. 2022, 2, 100054. [Google Scholar] [CrossRef]
- Ahmed, T.; Mahmood, Y.; Yodo, N.; Huang, Y. Weather-Related Combined Effect on Failure Propagation and Maintenance Procedures towards Sustainable Gas Pipeline Infrastructure. Sustainability 2024, 16, 5789. [Google Scholar] [CrossRef]
- Huang, Y.; Liang, X.; Azarmi, F. Innovative Fiber optic sensors for pipeline corrosion monitoring. In Pipelines 2014: From Underground to the Forefront of Innovation and Sustainability; ASCE: Reston, VA, USA, 2014; pp. 1502–1511. [Google Scholar] [CrossRef]
- Sresakoolchai, J.; Kaewunruen, S. Detection and severity evaluation of combined rail defects using deep learning. Vibration 2021, 4, 341–356. [Google Scholar] [CrossRef]
- Shang, L.; Zhang, Z.; Tang, F.; Cao, Q.; Yodo, N.; Pan, H.; Lin, Z. Deep learning enriched automation in damage detection for sustainable operation in pipelines with welding defects under varying embedment conditions. Computation 2023, 11, 218. [Google Scholar] [CrossRef]
- Afrin, T.; Yodo, N. A Hybrid Recovery Strategy toward Sustainable Infrastructure Systems. J. Infrastruct. Syst. 2022, 28, 04021054. [Google Scholar] [CrossRef]
- Yodo, N.; Afrin, T.; Yadav, O.P.; Wu, D.; Huang, Y. Condition-based monitoring as a robust strategy towards sustainable and resilient multi-energy infrastructure systems. Sustain. Resilient Infrastruct. 2022, 8, 170–189. [Google Scholar] [CrossRef]
- Miano, A.; Civera, M.; Aloschi, F.; De Biagi, V.; Chiaia, B.; Parisi, F.; Prota, A. Efficiency Assessment of Urban Road Networks Connecting Critical Node Pairs under Seismic Hazard. Sustainability 2024, 16, 7465. [Google Scholar] [CrossRef]
- Afrin, T.; Aragon, L.G.; Lin, Z.; Yodo, N. An Integrated Data-Driven Predictive Resilience Framework for Disaster Evacuation Traffic Management. Appl. Sci. 2023, 13, 6850. [Google Scholar] [CrossRef]
- PHMSA ALL REPORTED INCIDENT 20 YEAR TREND, P.a.H.M.S. Administration, Editor. 2023. Available online: https://www.phmsa.dot.gov/data-and-statistics/pipeline/pipeline-incident-20-year-trends (accessed on 15 August 2023).
- Yodo, N.R. Melvin, Statistics. Math. Cyber Res. 2022, 303. [Google Scholar] [CrossRef]
- Nagel, E. A frequency theory of probability. J. Philos. 1933, 30, 533–554. [Google Scholar] [CrossRef]
- Garthwaite, P.H.; Kadane, J.B.; O’Hagan, A. Statistical methods for eliciting probability distributions. J. Am. Stat. Assoc. 2005, 100, 680–701. [Google Scholar] [CrossRef]
- Muhlbauer, W.K.; Murray, J. Pipeline Risk Management. In Handbook of Pipeline Engineering; Springer: Berlin/Heidelberg, Germany, 2024; pp. 939–957. [Google Scholar] [CrossRef]
- Murray, A. Pipeline emergency response protocols and incident investigation. In Handbook of Pipeline Engineering; Springer: Berlin/Heidelberg, Germany, 2024; pp. 1005–1036. [Google Scholar] [CrossRef]
- Yodo, N.; Wang, P.; Rafi, M. Enabling resilience of complex engineered systems using control theory. IEEE Trans. Reliab. 2017, 67, 53–65. [Google Scholar] [CrossRef]
- Hainen, A.M.; Harbin, K.B.; Dye, D.; Lindly, J.K. Duration analysis of emergency shutdown incidents regarding hazardous liquid pipelines. J. Perform. Constr. Facil. 2020, 34, 04020040. [Google Scholar] [CrossRef]
- Valinejad, J. Measuring and Enhancing the Resilience of Interdependent Power Systems, Emergency Services, and Social Communities. 2022. Available online: https://vtechworks.lib.vt.edu/items/3bae12e5-5f6e-4636-9d02-973bf538b376 (accessed on 15 October 2024).
- Bonvicini, S.; Antonioni, G.; Cozzani, V. Assessment of the risk related to environmental damage following major accidents in onshore pipelines. J. Loss Prev. Process Ind. 2018, 56, 505–516. [Google Scholar] [CrossRef]
- Asha, L.N.; Aragon, L.G.; Dey, A.; Yodo, N. Location Optimization Strategies for Corn Production and Distribution towards Sustainable Green Supply Chain. Logistics 2024, 8, 78. [Google Scholar] [CrossRef]
- Tan, X.; Fan, L.; Huang, Y.; Bao, Y. Detection, visualization, quantification, and warning of pipe corrosion using distributed fiber optic sensors. Autom. Constr. 2021, 132, 103953. [Google Scholar] [CrossRef]
- Lustenberger, P.; Schumacher, F.; Spada, M.; Burgherr, P.; Stojadinovic, B. Assessing the performance of the European natural gas network for selected supply disruption scenarios using open-source information. Energies 2019, 12, 4685. [Google Scholar] [CrossRef]
- Iqbal, H.; Tesfamariam, S.; Haider, H.; Sadiq, R. Inspection and maintenance of oil & gas pipelines: A review of policies. Struct. Infrastruct. Eng. 2017, 13, 794–815. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Failure Causes | Description | Examples |
|---|---|---|
| Corrosion failure | Time-dependent threats occur as metals deteriorate through a natural electrochemical process called oxidation, often leading to leakage from affected metal body. |
|
| Equipment failure | Failure involving pipeline components or devices other than the pipe itself: either a specific part of the equipment fails, or the whole equipment fails to operate correctly, sometimes resulting in leakage. |
|
| Excavation damage | Damage from various excavation activities such as digging, grading, trenching, boring, and other related operations around the pipeline area, potentially causing punctures, leaks, or fractures. |
|
| Incorrect operation | Indirect failure occurs when human or operating errors by personnel lead to pipeline or equipment failures which may result in unintended leakage, fatigue, or other malfunctions. |
|
| Material failure of pipe or weld | Failure occurs when defects or weaknesses in the materials or welds lead to leaks, fractures, or fatigue cracking under repeated stresses, affecting pipeline integrity. |
|
| Natural hazard damage | Disruptions of unpredictable force toward pipeline operations and their associated facilities because of naturally occurring events. |
|
| Other outside force damage | Damage includes activities caused by outside parties or forces other than through excavation or naturally occurring events. |
|
| Other incident cause | Incidents caused by unspecified internal or external factors lead to pipeline disruptions that do not fall into any of the previously discussed categories. | |
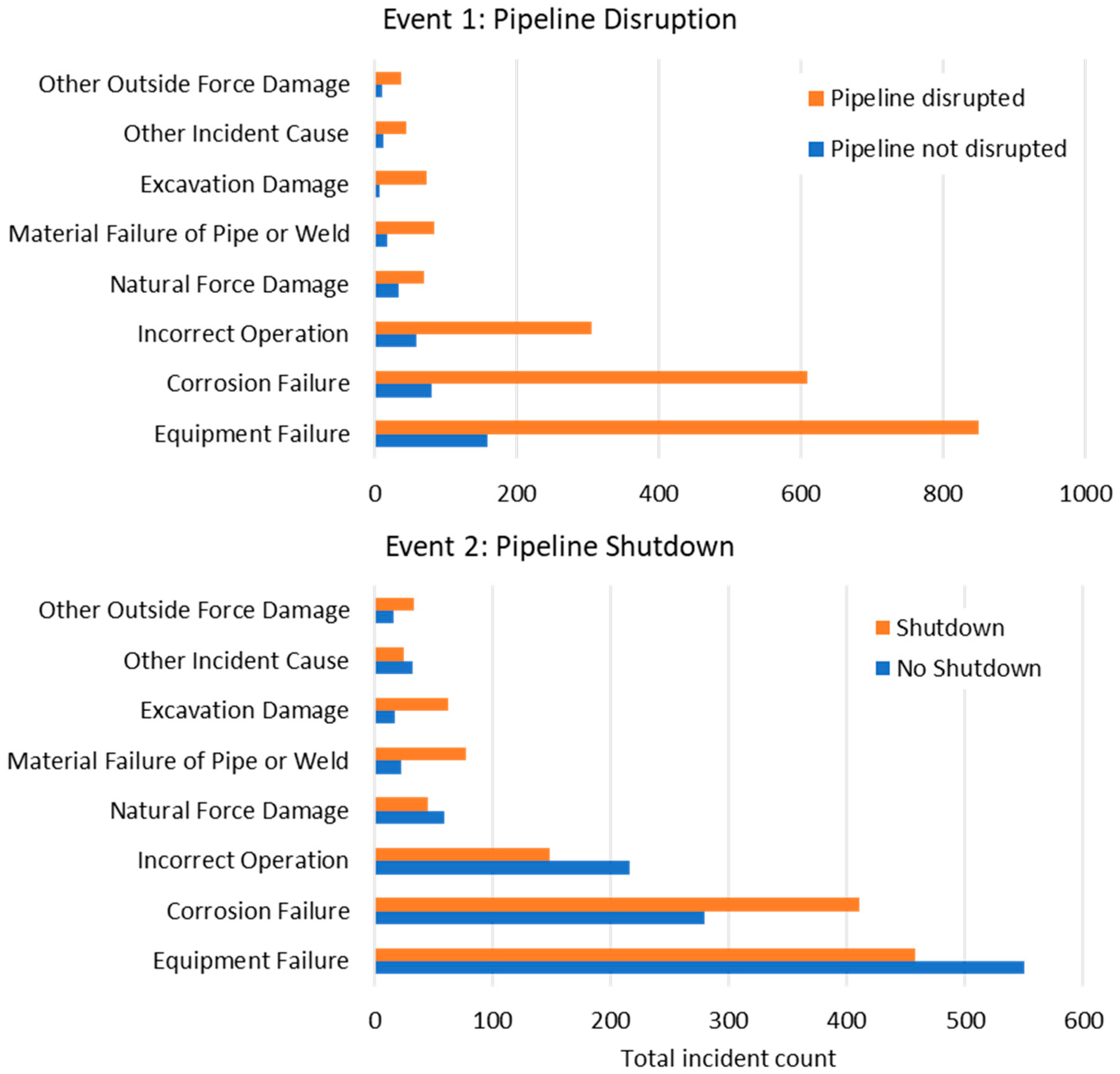
| Failure Cause, i | Pipeline Disrupted P(Event 1) | Pipeline Shutdown P(Event 2) |
|---|---|---|
| Equipment Failure | 0.84 | 0.45 |
| Corrosion Failure | 0.88 | 0.60 |
| Incorrect Operation | 0.84 | 0.41 |
| Natural Hazard Damage | 0.67 | 0.43 |
| Material Failure of Pipe or Weld | 0.82 | 0.77 |
| Excavation Damage | 0.91 | 0.79 |
| Other Incident Cause | 0.79 | 0.44 |
| Other Outside Force Damage | 0.78 | 0.67 |
| Failure Cause, i | Recovery Duration (hours) | Relative Recovery Period (RPi) |
|---|---|---|
| Equipment Failure | 35,757 | 0.84 |
| Corrosion Failure | 84,670 | 0.63 |
| Incorrect Operation | 14,091 | 0.94 |
| Natural Hazard Damage | 39,081 | 0.83 |
| Material Failure of Pipe or Weld | 36,752 | 0.84 |
| Excavation Damage | 12,156 | 0.95 |
| Other Incident Cause | 2384 | 0.99 |
| Other Outside Force Damage | 3521 | 0.98 |
| Failure Cause, i | Resilience Indicator | |||
|---|---|---|---|---|
| Scenario 1 (RI_S1) | Scenario 2 (RI_S2) | Scenario 3 (RI_S3) | Scenario 4 (RI_S4) | |
| Equipment Failure | 71.1% | 81.1% | 81.9% | 96.5% |
| Corrosion Failure | 53.6% | 89.9% | 61.7% | 98.7% |
| Incorrect Operation | 89.1% | 92.6% | 92.9% | 98.6% |
| Natural Hazard Damage | 81.9% | 98.4% | 82.4% | 99.2% |
| Material Failure of Pipe or Weld | 81.7% | 99.2% | 83.4% | 99.8% |
| Excavation Damage | 92.5% | 99.4% | 94.5% | 99.9% |
| Other Incident Cause | 98.2% | 99.0% | 98.7% | 99.7% |
| Other Outside Force Damage | 97.4% | 99.5% | 98.2% | 99.9% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Asha, L.N.; Yodo, N.; Huang, Y. A Quantitative Approach to Evaluating Multi-Event Resilience in Oil Pipeline Incidents. CivilEng 2025, 6, 1. https://doi.org/10.3390/civileng6010001
Asha LN, Yodo N, Huang Y. A Quantitative Approach to Evaluating Multi-Event Resilience in Oil Pipeline Incidents. CivilEng. 2025; 6(1):1. https://doi.org/10.3390/civileng6010001
Chicago/Turabian StyleAsha, Labiba N., Nita Yodo, and Ying Huang. 2025. "A Quantitative Approach to Evaluating Multi-Event Resilience in Oil Pipeline Incidents" CivilEng 6, no. 1: 1. https://doi.org/10.3390/civileng6010001
APA StyleAsha, L. N., Yodo, N., & Huang, Y. (2025). A Quantitative Approach to Evaluating Multi-Event Resilience in Oil Pipeline Incidents. CivilEng, 6(1), 1. https://doi.org/10.3390/civileng6010001