
Predicting Fluid Intelligence via Naturalistic Functional Connectivity Using Weighted Ensemble Model and Network Analysis

Abstract
:1. Introduction
2. Materials and Methods
2.1. Data Acquisition
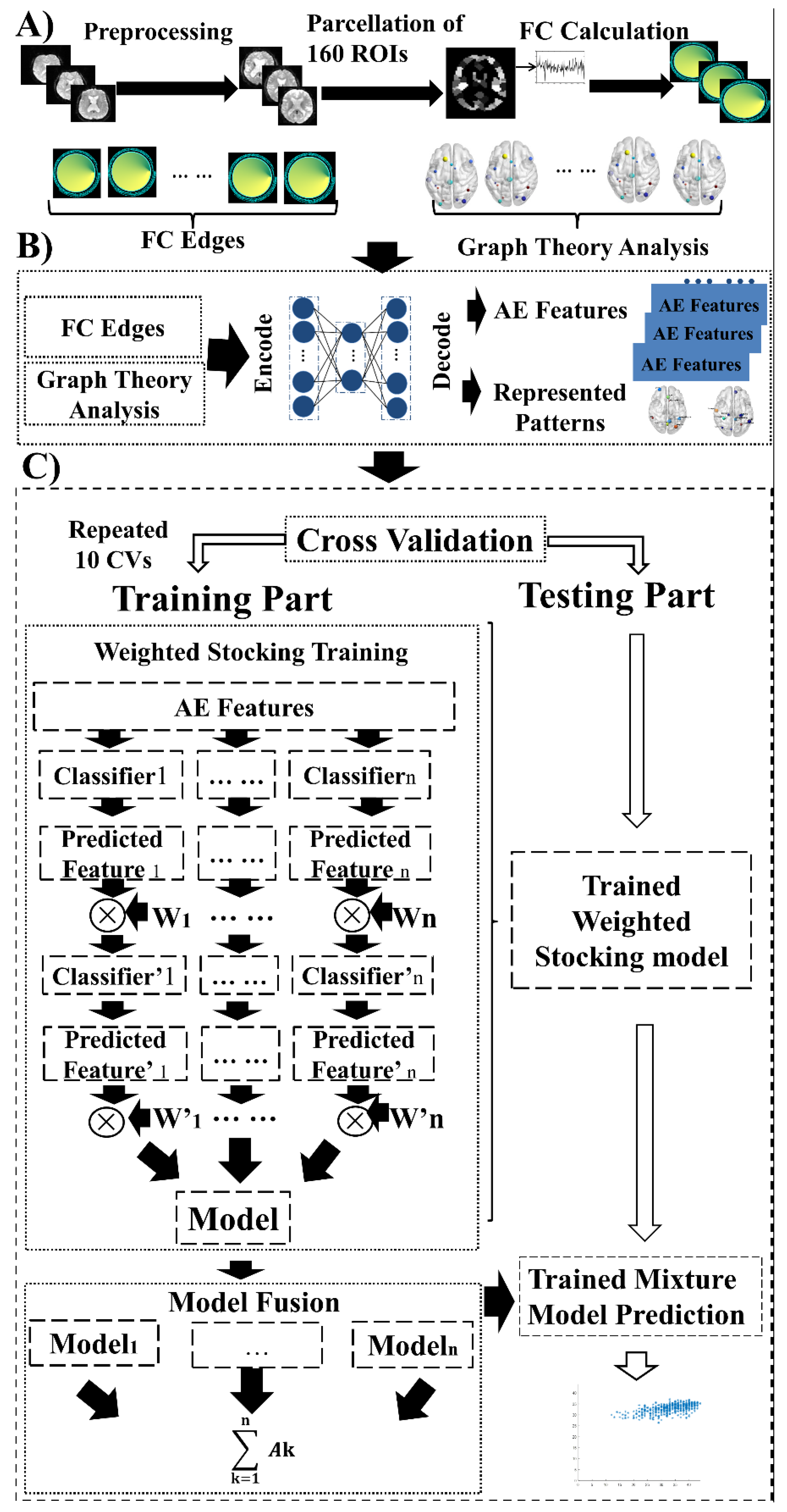
2.2. Experimental Pipeline
2.3. Data Preprocessing
2.4. Functional Connectivity and Network Property
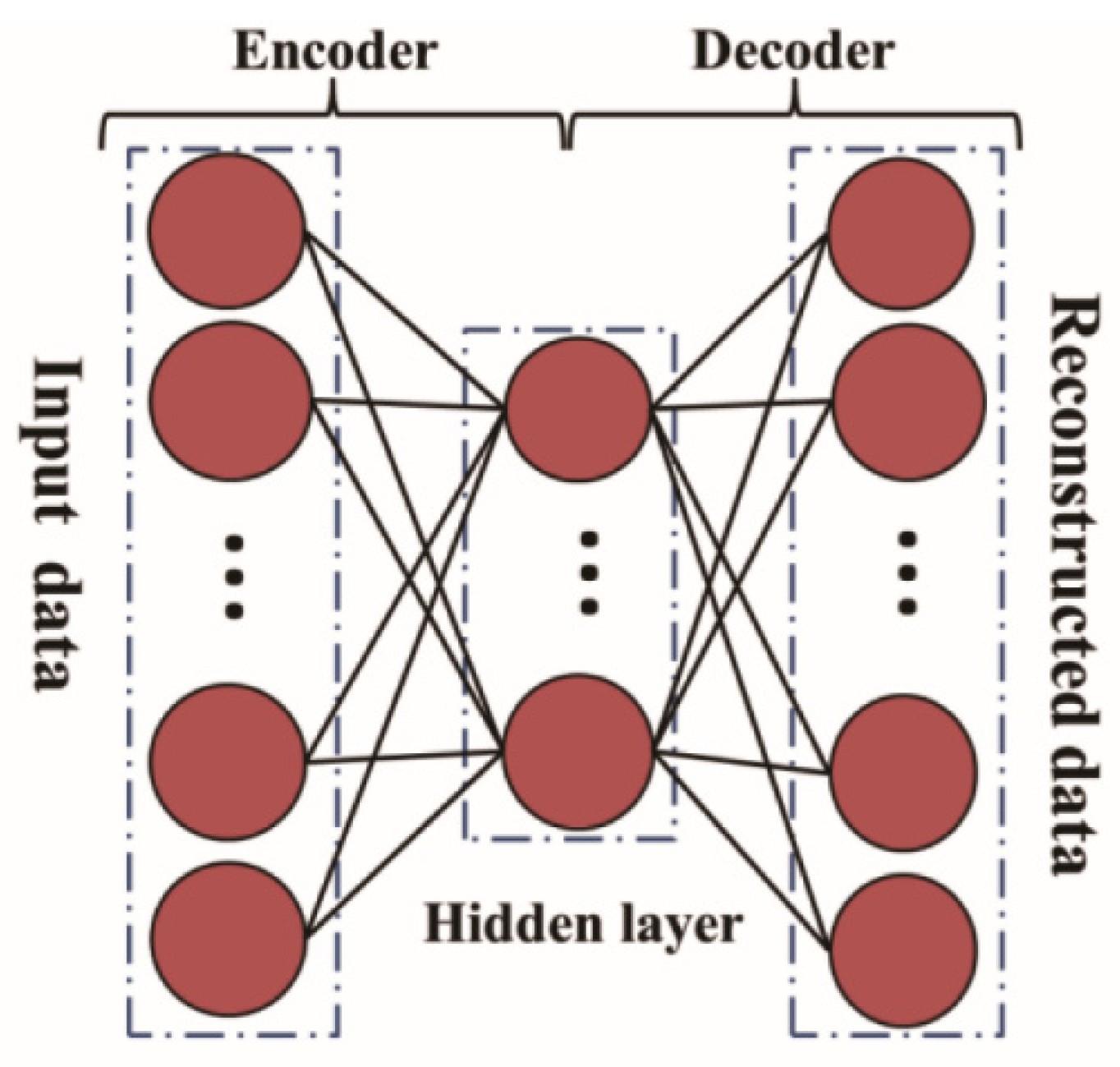
2.5. Feature Encoder and Network Pattern Construction
2.6. Weighted Ensemble Models and Network Analysis Framework
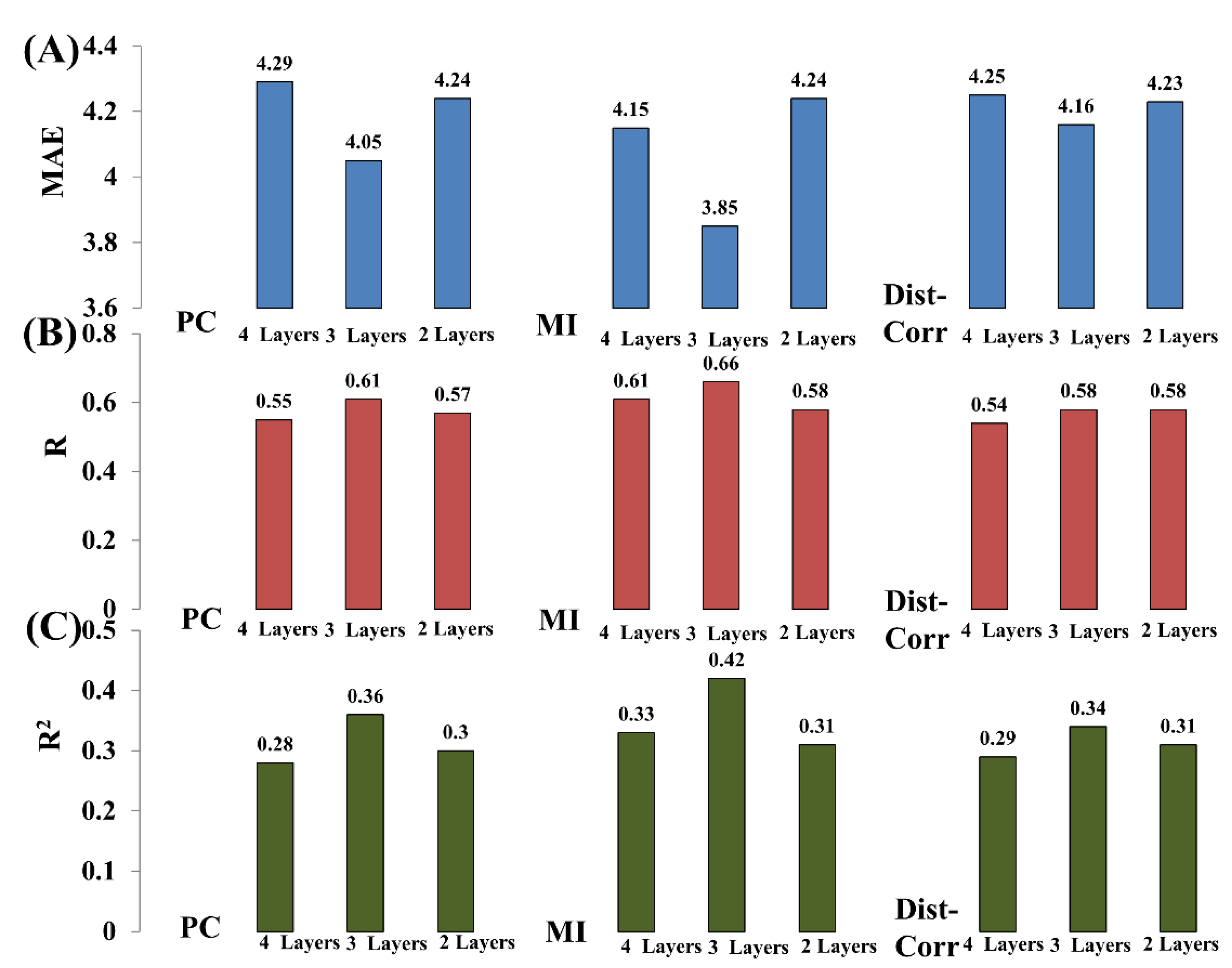
2.7. Parameter Test of Proposed WENA
2.8. Methods Comparison
3. Evaluation Metrics
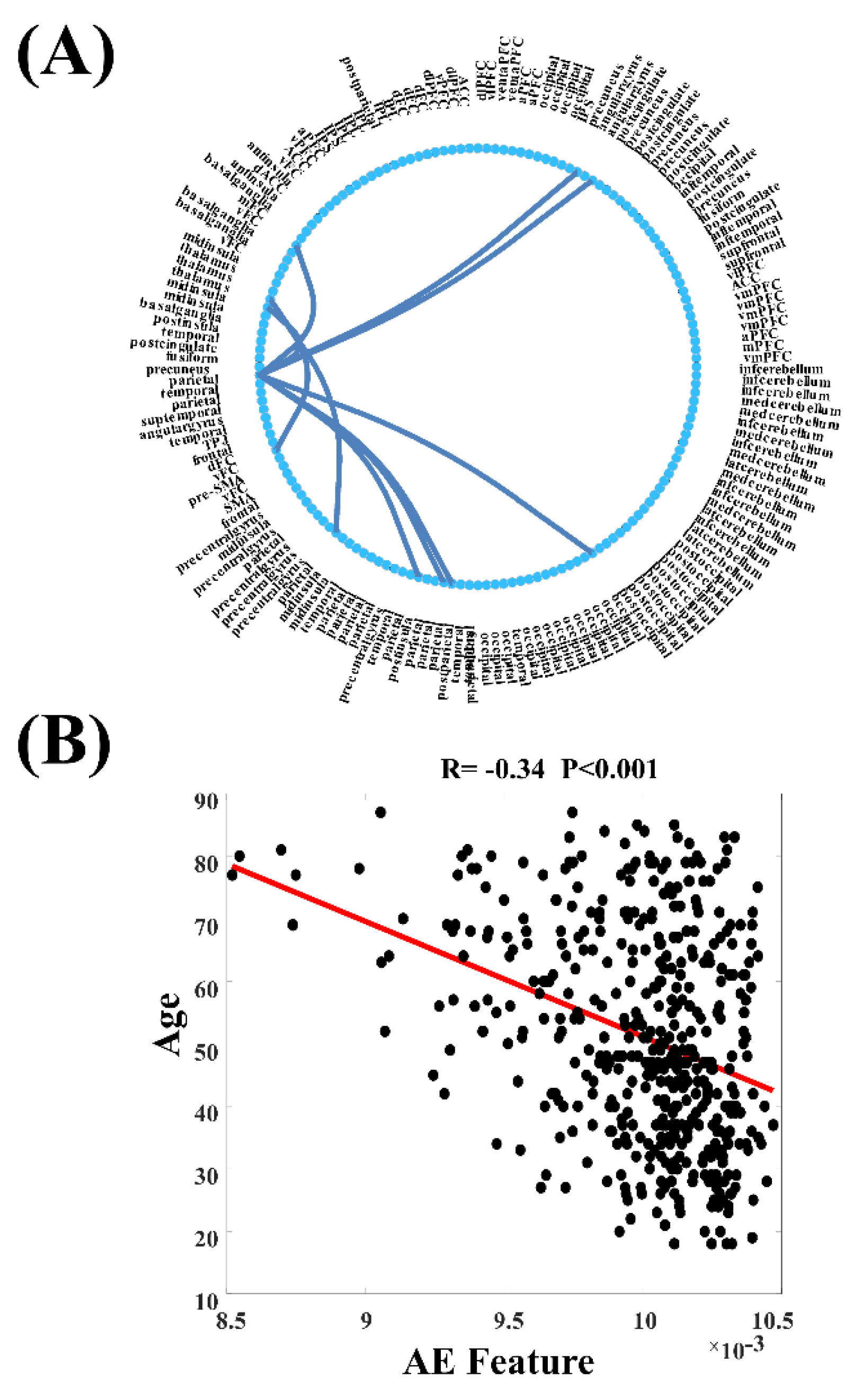
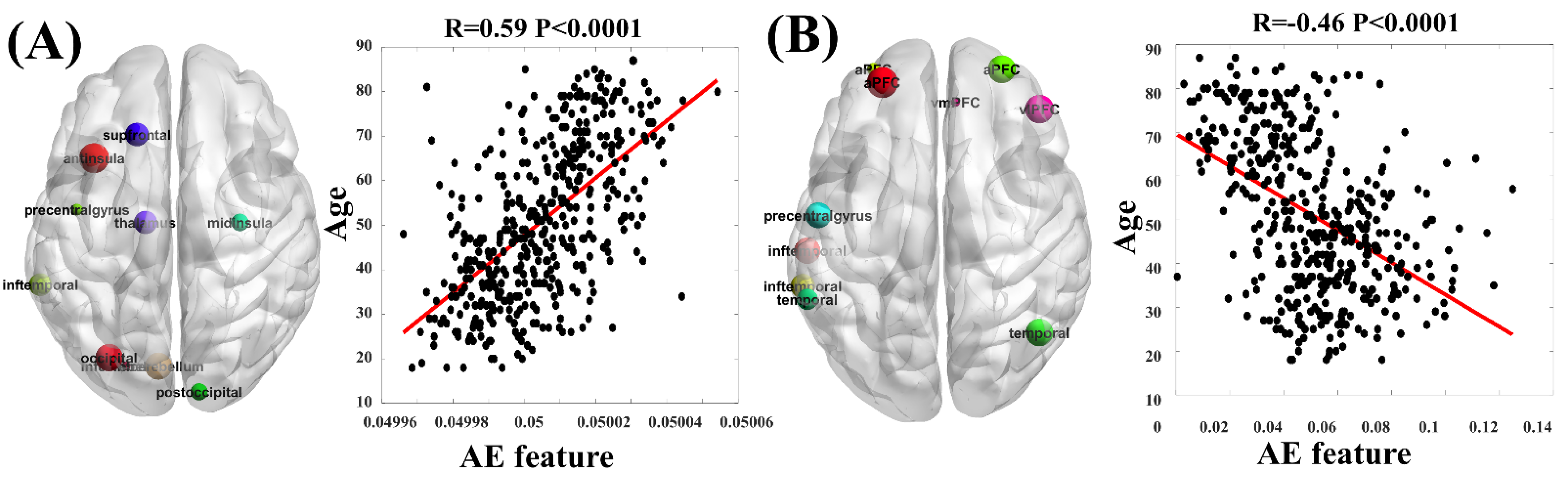
Biological Pattern Visualization
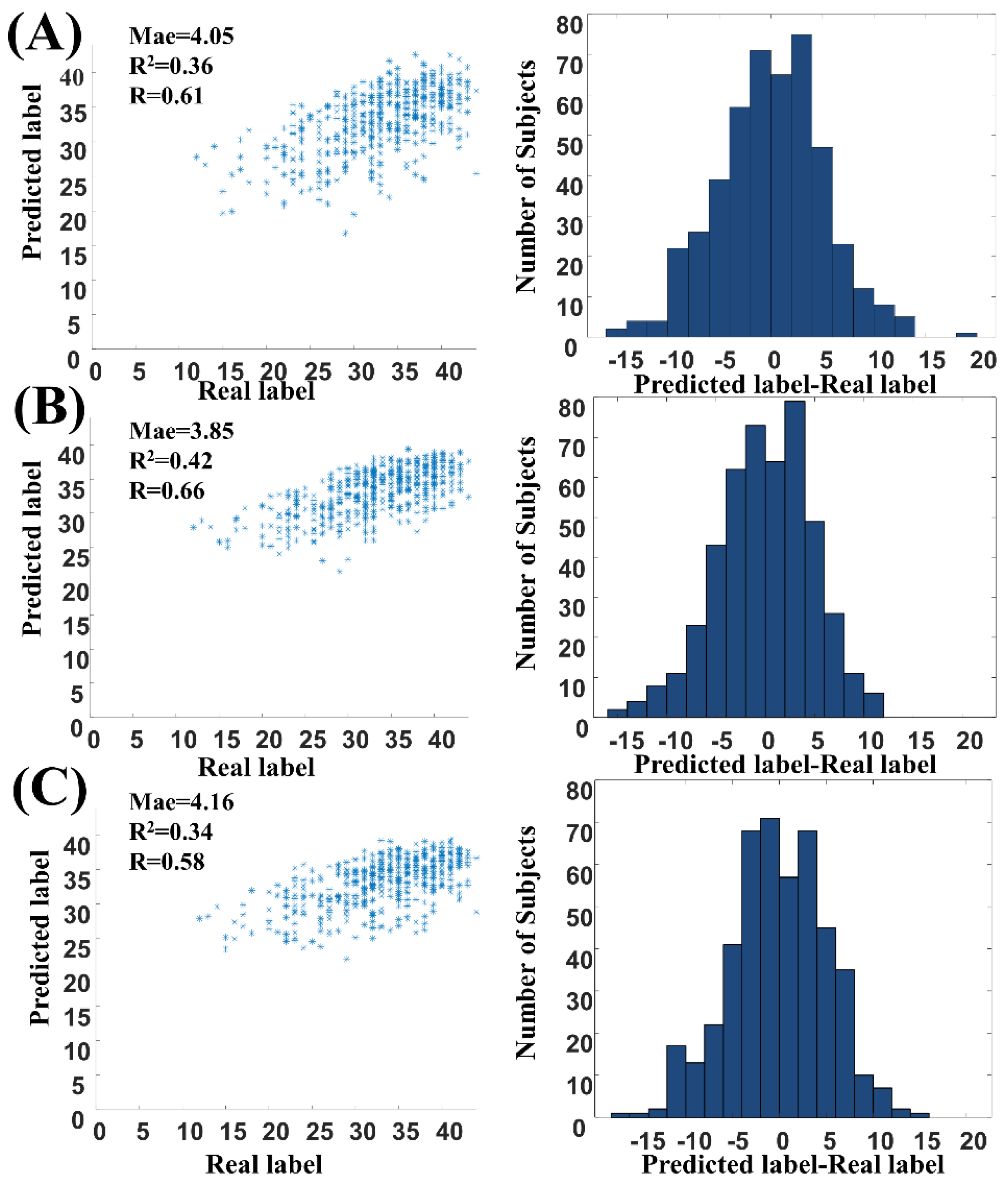
4. Experiment Results
5. Discussion
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Logothetis, N.K.; Wandell, B.A. Interpreting the BOLD signal. Annu. Rev. Physiol. 2004, 66, 735–769. [Google Scholar] [CrossRef] [PubMed]
- Van Den Heuvel, M.P.; Pol, H.E.H. Exploring the brain network: A review on resting-state fMRI functional connectivity. Eur. Neuropsychopharmacol. 2010, 20, 519–534. [Google Scholar] [CrossRef] [PubMed]
- Centeno, M.; Tierney, T.M.; Perani, S.; Shamshiri, E.A.; StPier, K.; Wilkinson, C.; Konn, D.; Banks, T.; Vulliemoz, S.; Lemieux, L. Optimising EEG-fMRI for localisation of focal epilepsy in children. PLoS ONE 2016, 11, e0149048. [Google Scholar]
- Sonkusare, S.; Breakspear, M.; Guo, C. Naturalistic Stimuli in Neuroscience: Critically Acclaimed. Trends Cogn. Sci. 2019, 23, 699–714. [Google Scholar] [CrossRef] [PubMed]
- Wang, J.; Ren, Y.; Hu, X.; Nguyen, V.T.; Guo, L.; Han, J.; Guo, C.C. Test–retest reliability of functional connectivity networks during naturalistic fMRI paradigms. Hum. Brain Mapp. 2017, 38, 2226–2241. [Google Scholar] [CrossRef] [Green Version]
- Lynn, C.W.; Papadopoulos, L.; Kahn, A.E.; Bassett, D.S. Human information processing in complex networks. Nat. Phys. 2020, 16, 965–973. [Google Scholar] [CrossRef]
- Bzdok, D.; Altman, N.; Krzywinski, M. Points of significance: Statistics versus machine learning. Nat. Methods 2018, 2018, 1–7. [Google Scholar]
- Bzdok, D.; Meyer-Lindenberg, A. Machine learning for precision psychiatry: Opportunities and challenges. Biol. Psychiatr. Cogn. Neurosci. 2018, 3, 223–230. [Google Scholar] [CrossRef] [Green Version]
- Shen, X.; Finn, E.S.; Scheinost, D.; Rosenberg, M.D.; Chun, M.M.; Papademetris, X.; Constable, R.T. Using connectome-based predictive modeling to predict individual behavior from brain connectivity. Nat. Protoc. 2017, 12, 506. [Google Scholar] [CrossRef] [Green Version]
- Rosenberg, M.D.; Hsu, W.-T.; Scheinost, D.; Todd Constable, R.; Chun, M.M. Connectome-based models predict separable components of attention in novel individuals. J. Cogn. Neurosci. 2018, 30, 160–173. [Google Scholar] [CrossRef]
- Greene, A.S.; Gao, S.; Scheinost, D.; Constable, R.T. Task-induced brain state manipulation improves prediction of individual traits. Nat. Commun. 2018, 9, 2807. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Huang, H.; Hu, X.; Zhao, Y.; Makkie, M.; Dong, Q.; Zhao, S.; Guo, L.; Liu, T. Modeling task fMRI data via deep convolutional autoencoder. IEEE Trans. Med. Imaging 2017, 37, 1551–1561. [Google Scholar] [CrossRef] [PubMed]
- Plis, S.M.; Hjelm, D.R.; Salakhutdinov, R.; Allen, E.A.; Bockholt, H.J.; Long, J.D.; Johnson, H.J.; Paulsen, J.S.; Turner, J.A.; Calhoun, V.D. Deep learning for neuroimaging: A validation study. Front. Neurosci. 2014, 8, 229. [Google Scholar] [CrossRef] [Green Version]
- Finn, E.S.; Shen, X.; Scheinost, D.; Rosenberg, M.D.; Huang, J.; Chun, M.M.; Papademetris, X.; Constable, R.T. Functional connectome fingerprinting: Identifying individuals using patterns of brain connectivity. Nat. Neurosci. 2015, 18, 1664. [Google Scholar] [CrossRef]
- Breiman, L.; Last, M.; Rice, J. Random Forests: Finding Quasars. In Statistical Challenges in Astronomy; Springer: New York, NY, USA, 2003. [Google Scholar]
- Kesler, S.R.; Rao, A.; Blayney, D.W.; Oakleygirvan, I.A.; Karuturi, M.; Palesh, O. Predicting Long-Term Cognitive Outcome Following Breast Cancer with Pre-Treatment Resting State fMRI and Random Forest Machine Learning. Front. Hum. Neurosci. 2017, 11, 555. [Google Scholar] [CrossRef] [Green Version]
- Taylor, J.R.; Williams, N.; Cusack, R.; Auer, T.; Shafto, M.A.; Dixon, M.; Tyler, L.K.; Henson, R.N. The Cambridge Centre for Ageing and Neuroscience (Cam-CAN) data repository: Structural and functional MRI, MEG, and cognitive data from a cross-sectional adult lifespan sample. Neuroimage 2017, 144, 262–269. [Google Scholar] [CrossRef]
- Dosenbach, N.U.; Nardos, B.; Cohen, A.L.; Fair, D.A.; Power, J.D.; Church, J.A.; Nelson, S.M.; Wig, G.S.; Vogel, A.C.; Lessov-Schlaggar, C.N.; et al. Prediction of individual brain maturity using fMRI. Science 2010, 329, 1358–1361. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Alahmadi, A.; Zhu, D.; Li, T. Brain functional connectivity analysis using mutual information. In Proceedings of the 2015 IEEE Global Conference on Signal and Information Processing (GlobalSIP), Orlando, FL, USA, 14–16 December 2015; pp. 542–546. [Google Scholar]
- Geerligs, L.; Henson, R.N. Functional connectivity and structural covariance between regions of interest can be measured more accurately using multivariate distance correlation. NeuroImage 2016, 135, 16–31. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- He, Y.; Evans, A. Graph theoretical modeling of brain connectivity. Curr. Opin. Neurol. 2010, 23, 341–350. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kim, J.; Calhoun, V.D.; Shim, E.; Lee, J.-H.J.N. Deep neural network with weight sparsity control and pre-training extracts hierarchical features and enhances classification performance: Evidence from whole-brain resting-state functional connectivity patterns of schizophrenia. Neuroimage 2016, 124, 127–146. [Google Scholar] [CrossRef] [Green Version]
- Hinton, G.E. Learning multiple layers of representation. Trends Cogn. Sci. 2007, 11, 428–434. [Google Scholar] [CrossRef]
- Ng, A. Sparse Autoencoder. CS294A Lecture Notes. 2011. Available online: https://web.stanford.edu/class/cs294a/sparseAutoencoder_2011new (accessed on 1 December 2021).
- Robnik-Šikonja, M.; Kononenko, I. An adaptation of Relief for attribute estimation in regression. In Proceedings of the Machine Learning: The Fourteenth International Conference (ICML’97), San Francisco, CA, USA, 8–12 July 1997; pp. 296–304. [Google Scholar]
- Suk, H.-I.; Wee, C.-Y.; Lee, S.-W.; Shen, D. State-space model with deep learning for functional dynamics estimation in resting-state fMRI. NeuroImage 2016, 129, 292–307. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Vakli, P.; Deák-Meszlényi, R.J.; Hermann, P.; Vidnyánszky, Z. Transfer learning improves resting-state functional connectivity pattern analysis using convolutional neural networks. GigaScience 2018, 7, giy130. [Google Scholar] [CrossRef]
- He, T.; Kong, R.; Holmes, A.J.; Sabuncu, M.R.; Eickhoff, S.B.; Bzdok, D.; Feng, J.; Yeo, B.T. Is deep learning better than kernel regression for functional connectivity prediction of fluid intelligence? In Proceedings of the 2018 International Workshop on Pattern Recognition in Neuroimaging (PRNI), Singapore, 12–14 June 2018; pp. 1–4. [Google Scholar]
- Zhu, M.; Liu, B.; Li, J. Prediction of general fluid intelligence using cortical measurements and underlying genetic mechanisms. In Proceedings of the IOP Conference Series: Materials Science and Engineering, Xi’an, China, 18–20 May 2018; Available online: https://iopscience.iop.org/article/10.1088/1757-899X/381/1/012186/meta (accessed on 1 December 2021).
- Hosseini, M.-P.; Pompili, D.; Elisevich, K.; Soltanian-Zadeh, H. Random ensemble learning for EEG classification. Artif. Intell. Med. 2018, 84, 146–158. [Google Scholar] [CrossRef]
- Deng, L.; Yu, D.; Platt, J. Scalable stacking and learning for building deep architectures. In Proceedings of the 2012 IEEE International conference on Acoustics, speech and signal processing (ICASSP), Kyoto, Japan, 25–30 March 2012; pp. 2133–2136. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the dimensionality of data with neural networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Dietterich, T.G. Ensemble learning. The handbook of brain theory neural networks. Arbib MA 2002, 2, 110–125. [Google Scholar]
- Khosla, M.; Jamison, K.; Ngo, G.H.; Kuceyeski, A.; Sabuncu, M.R. Machine learning in resting-state fMRI analysis. Magn. Reson. Imaging 2019, 64, 101–121. [Google Scholar] [CrossRef] [Green Version]
- Qiao, J.; Lv, Y.; Cao, C.; Wang, Z.; Li, A. Multivariate Deep Learning Classification of Alzheimer’s Disease Based on Hierarchical Partner Matching Independent Component Analysis. Front. Aging Neurosci. 2018, 10, 417. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Suk, H.-I.; Lee, S.-W.; Shen, D.; Initiative, A.s.D.N. Latent feature representation with stacked auto-encoder for AD/MCI diagnosis. Brain Struct. Funct. 2015, 220, 841–859. [Google Scholar] [CrossRef]
- Carpenter, P.A.; Just, M.A.; Shell, P. What one intelligence test measures: A theoretical account of the processing in the Raven Progressive Matrices Test. Psychol. Rev. 1990, 97, 404. [Google Scholar] [CrossRef]
- Kievit, R.A.; Davis, S.W.; Mitchell, D.J.; Taylor, J.R.; Duncan, J.; Tyler, L.K.; Brayne, C.; Bullmore, E.; Calder, A.; Cusack, R. Distinct aspects of frontal lobe structure mediate age-related differences in fluid intelligence and multitasking. Nat. Commun. 2014, 5, 5658. [Google Scholar] [CrossRef] [PubMed]
- Ward, N.S. Compensatory mechanisms in the aging motor system. Ageing Res. Rev. 2006, 5, 239–254. [Google Scholar] [CrossRef] [PubMed]
- Seidler, R.; Erdeniz, B.; Koppelmans, V.; Hirsiger, S.; Mérillat, S.; Jäncke, L. Associations between age, motor function, and resting state sensorimotor network connectivity in healthy older adults. Neuroimage 2015, 108, 47–59. [Google Scholar] [CrossRef] [PubMed]
- Buckner, R.L.; Sepulcre, J.; Talukdar, T.; Krienen, F.M.; Liu, H.; Hedden, T.; Andrews-Hanna, J.R.; Sperling, R.A.; Johnson, K.A. Cortical hubs revealed by intrinsic functional connectivity: Mapping, assessment of stability, and relation to Alzheimer’s disease. J. Neurosci. 2009, 29, 1860–1873. [Google Scholar] [CrossRef] [Green Version]
- Ruiz-Rizzo, A.L.; Sorg, C.; Napiórkowski, N.; Neitzel, J.; Menegaux, A.; Müller, H.J.; Vangkilde, S.; Finke, K. Decreased cingulo-opercular network functional connectivity mediates the impact of aging on visual processing speed. Neurobiol. Aging 2019, 73, 50–60. [Google Scholar] [CrossRef] [PubMed]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Total Number | Age | FIS | Gender (Female/Male) |
|---|---|---|---|
| 461 | 54.64 ± 18.63 | 32.97 ± 6.30 | 231/230 |
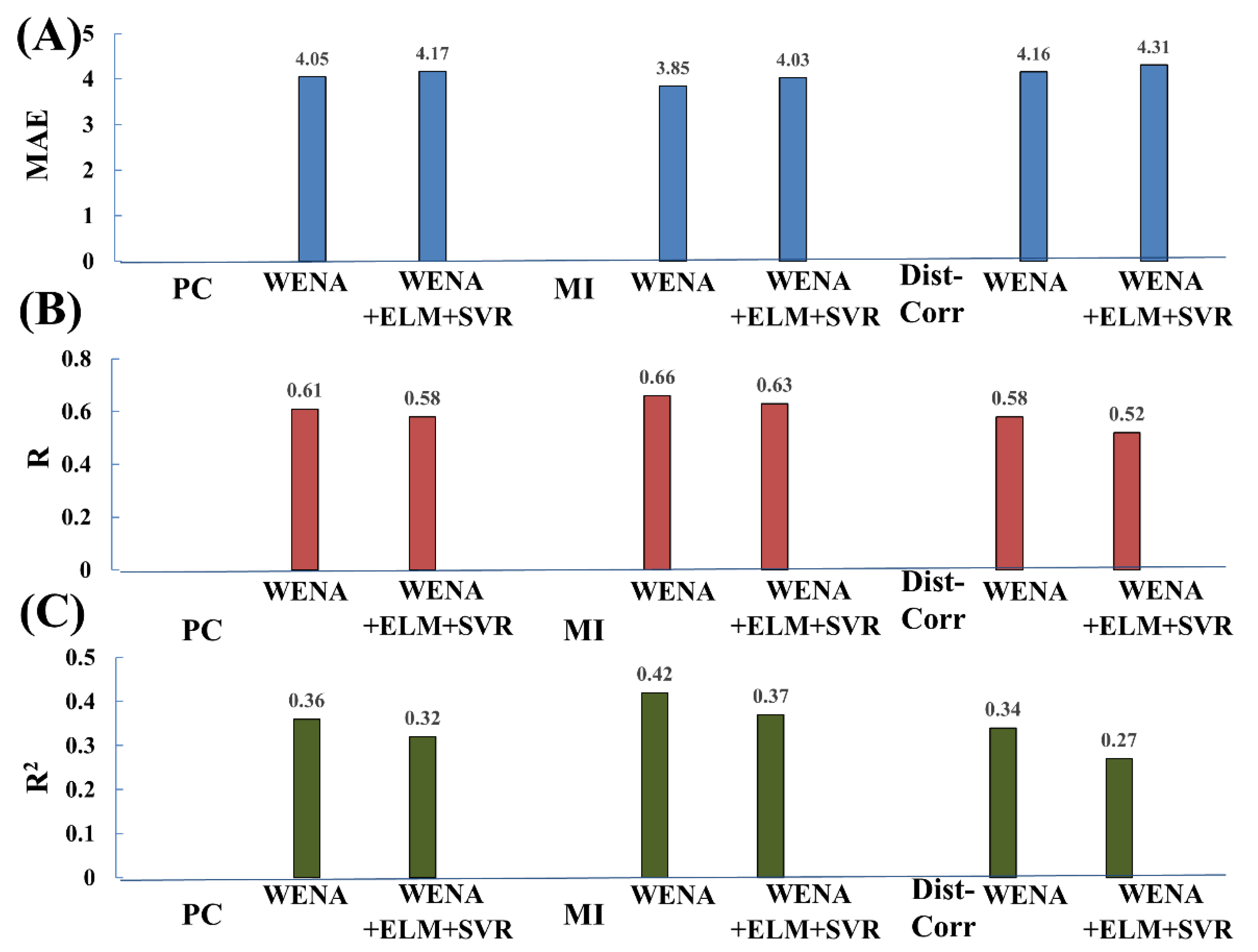
| Network | Feature Reduction | Classification Strategy | MAE | R | R2 |
|---|---|---|---|---|---|
| PC | AE | WS- ETR | 4.21 | 0.57 | 0.31 |
| WS–RR | 4.07 | 0.59 | 0.33 | ||
| WS-SVR | 4.21 | 0.55 | 0.28 | ||
| WS-ELMR | 4.47 | 0.54 | 0.21 | ||
| WENA | 4.05 | 0.61 | 0.36 | ||
| MI | WS-ETR | 4.06 | 0.63 | 0.36 | |
| WS- RR | 3.90 | 0.64 | 0.39 | ||
| WS-SVR | 4.11 | 0.60 | 0.35 | ||
| WS-ELMR | 4.43 | 0.57 | 0.24 | ||
| WENA | 3.85 | 0.66 | 0.42 | ||
| DistCorr | WS-ETR | 4.20 | 0.56 | 0.31 | |
| WS- RR | 4.32 | 0.56 | 0.28 | ||
| WS-SVR | 4.38 | 0.52 | 0.25 | ||
| WS-ELMR | 4.55 | 0.52 | 0.19 | ||
| WENA | 4.16 | 0.58 | 0.34 |
| Network | Feature Reduction | Classification Strategy | MAE | R | R2 |
|---|---|---|---|---|---|
| PC | AE | Stacking—ETR | 4.26 | 0.53 | 0.28 |
| Stacking—RR | 5.05 | 0.054 | 0.0041 | ||
| Stacking—SVR | 4.25 | 0.53 | 0.26 | ||
| Stacking—ELMR | 12.16 | 0.27 | 0.0039 | ||
| MI | Stacking—ETR | 4.20 | 0.54 | 0.29 | |
| Stacking—RR | 5.05 | 0.038 | 0.0042 | ||
| Stacking—SVR | 4.42 | 0.50 | 0.21 | ||
| Stacking—ELMR | 11.62 | 0.23 | 0.0010 | ||
| DistCorr | Stacking—ETR | 4.25 | 0.54 | 0.29 | |
| Stacking—RR | 5.04 | 0.25 | 0.055 | ||
| Stacking—SVR | 4.33 | 0.25 | 0.061 | ||
| Stacking—ELMR | 11.98 | 0.23 | 0.0038 | ||
| MI (Basic regression models) | ETR | 4.22 | 0.54 | 0.29 | |
| RR | 4.23 | 0.52 | 0.23 | ||
| SVR | 4.20 | 0.53 | 0.28 | ||
| ELMR | 4.41 | 0.49 | 0.18 |
| Feature Reduction Method | Classification Strategy | Method | MAE | R | R2 |
|---|---|---|---|---|---|
| PCA | WS | WS—ETR | 4.25 | 0.54 | 0.29 |
| WS—RR | 4.37 | 0.55 | 0.23 | ||
| WS—SVR | 4.24 | 0.54 | 0.27 | ||
| WS—ELMR | 4.58 | 0.52 | 0.19 | ||
| WENA | 4.12 | 0.58 | 0.33 | ||
| ICA | WS | WS—ETR | 4.86 | 0.27 | 0.0065 |
| WS—RR | 4.92 | 0.30 | 0.0097 | ||
| WS—SVR | 4.77 | 0.33 | 0.092 | ||
| WS—ELMR | 5.24 | 0.25 | 0.0013 | ||
| WENA | 4.77 | 0.32 | 0.10 |
| Feature | MAE | R | ||
|---|---|---|---|---|
| [27] | fMRI | -- | 0.2~0.5 | -- |
| [28] | fMRI | -- | 0.25~0.3 | -- |
| [29] | fMRI | -- | 0.26 | -- |
| Full Name | Abbreviations |
|---|---|
| Auto-encoder | AE |
| Functional connectivity | FC |
| Functional magnetic resonance imaging | fMRI |
| Blood oxygen level-dependent | BOLD |
| Connectome-based predictive modeling | CPM |
| Weighted ensemble model and network analysis | WENA |
| Weighted stacking | WS |
| Fluid intelligence score | FIS |
| Pearson’s correlation | PC |
| Mutual information | MI |
| Distance correlation | DistCorr |
| Degree centrality | DC |
| ROI’s strength | RS |
| Local efficiency | LE |
| Betweenness centrality | BC |
| Principal components analysis | PCA |
| Tree regression | ETR |
| Ridge regression | RR |
| Support vector regression | SVR |
| Extreme learning machine regression | ELMR |
| Independent component analysis | ICA |
| Mean absolute deviation | MAE |
| Pearson correlation coefficient | R value |
| R-squared coefficient | R2 value |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, X.; Yang, S.; Liu, Z. Predicting Fluid Intelligence via Naturalistic Functional Connectivity Using Weighted Ensemble Model and Network Analysis. NeuroSci 2021, 2, 427-442. https://doi.org/10.3390/neurosci2040032
Liu X, Yang S, Liu Z. Predicting Fluid Intelligence via Naturalistic Functional Connectivity Using Weighted Ensemble Model and Network Analysis. NeuroSci. 2021; 2(4):427-442. https://doi.org/10.3390/neurosci2040032
Chicago/Turabian StyleLiu, Xiaobo, Su Yang, and Zhengxian Liu. 2021. "Predicting Fluid Intelligence via Naturalistic Functional Connectivity Using Weighted Ensemble Model and Network Analysis" NeuroSci 2, no. 4: 427-442. https://doi.org/10.3390/neurosci2040032
APA StyleLiu, X., Yang, S., & Liu, Z. (2021). Predicting Fluid Intelligence via Naturalistic Functional Connectivity Using Weighted Ensemble Model and Network Analysis. NeuroSci, 2(4), 427-442. https://doi.org/10.3390/neurosci2040032