Abstract
Poultry waste composting is a necessary technique for agricultural farm sustainability. Composting is a dynamic process influenced by multiple variables. Humidity and temperature play fundamental roles in analyzing its different phases according to the environment and composting technique. Current developments for monitoring these variables include automation via intelligent Internet of Things (IoT)-based sensor networks for variable tracking. These advancements serve as efficient tools for modeling that facilitate the simulation and prediction of composting process variables to improve system efficiency. Therefore, this paper presents the dynamic modeling of composting via forced aeration processes in high-mountain climates, with the intent of estimating biomass temperature dynamics in different phases using system identification techniques. To this end, four dynamic model estimation structures are employed: transfer function (TF), state space (SS), process (P), and Hammerstein–Wiener (HW). The and model quality, fitting results, and standard error metrics of the different models found in each phase are assessed through residual analysis from each structure by validation with real system data. Our results show that the second-order underdamped multiple-input–single-output (MISO) process model with added noise demonstrates the best fit and validation performance.
1. Introduction
Global poultry production generates substantial nutrient-rich waste if mismanaged, with environmental risks involving soil, groundwater, and greenhouse gas emissions [1]. Composting transforms poultry litter into organic fertilizer, mitigating these impacts while enhancing soil fertility for sustainable agriculture [2]. In high-mountain climates such as Cundinamarca, Colombia (2835 m above sea level), low temperatures (7–19 °C) and fluctuating moisture levels hinder the achievement of optimal composting conditions such as the thermophilic temperatures (≥50 °C) necessary for effective pathogen elimination [3]. This study employs system identification techniques with IoT-based monitoring to model and optimize poultry litter composting dynamics under these challenging conditions.
The surge in global meat demand has intensified poultry production, resulting in substantial waste from egg production that requires sustainable management [4]. Aerobic composting using forced-aeration static piles effectively transforms poultry litter into fertilizer, mitigating emissions, soil erosion, and dependence on synthetic fertilizers [5,6]. The key parameters of temperature, moisture, and aeration govern microbial activity and process efficiency; however, their complex interactions challenge traditional modeling [7,8,9]. In high-mountain environments, these challenges are amplified by environmental variability, necessitating advanced adaptable modeling approaches [1].
High-mountain composting faces unique constraints, as low ambient temperatures and variable moisture impede the thermophilic phases that are critical for organic matter stabilization [3,7]. Insufficient aeration risks anaerobic conditions, whereas excessive aeration may reduce efficiency by preventing thermophilic temperatures [9]. In addition, variations in moisture levels tied to the makeup of the substrate make microbial activity more difficult to manage [8]. Traditional models focusing on heat and mass transfer are computationally intensive and typically tailored to specific materials, which limits their usefulness in varied settings [10,11].
In Colombia, an experimental study was conducted at high altitude to evaluate composting strategies under mountain climate conditions [12]. The research showed that low temperatures and small-scale operations hinder the development of thermophiles and effective sanitization. The application of bioactivators and bokashi has improved compost quality and reduced pathogen levels. While this study offers a comprehensive experimental evaluation, it does not incorporate modeling approaches or system identification techniques.
Recent advancements in composting modeling include statistical methods such as response surface optimization [13] and artificial neural networks (ANN) [14,15,16], which have been extended by hybrid mechanistic data-driven models and advanced machine learning approaches to enhance process optimization. For instance, a hybrid modeling approach integrating mechanistic and data-driven methods for fermentation process optimization was reviewed in [17], with an emphasis on system identification for bioreactor control. Similarly, a deep hybrid model for bioreactor systems combining first principles with neural networks was developed in [18], resulting in enhanced control accuracy Advanced ML approaches such as random forest [19], deep learning (e.g., transformers), and reinforcement learning offer improved predictive accuracy for complex biological processes [11,20]. Concurrently, system identification methods have become relevant in modeling biological and environmental processes. Hybrid differential equations have shown good predictive capabilities when employed for simulating water systems, as demonstrated in [21]. Similarly, a system identification approach for real-time control of anaerobic digestion was described in [22], emphasizing its flexibility. Industry 4.0 technologies such as IoT and AI can enable real-time monitoring and control to provide enhanced agricultural efficiency [23,24,25,26]. These advancements highlight the potential of such data-driven approaches, including the one proposed in this study to address the complexities of composting in high-mountain climates.
Compared to traditional models, ML techniques exhibit higher predictive accuracy when simulating compost dynamics. In addition to this enhanced accuracy, ML approaches offer advantages such as faster computation, lower processing costs, and reduced demand for experimental resources and human labor, making them highly suitable in organic waste composting systems [27]. For example, [28] reported that the use of AI and ML tools has enabled the optimization of composting parameters, prediction of compost maturity, monitoring of moisture content in industrial-scale systems, estimation of compost enzymatic activity, and classification of compost maturity using theoretical, analytical and statistical methods [29].
In [30], the authors forecast humic acid content using a backpropagation ANN, while [31] found that ANN models provided the best performance for modeling the composting process. In [32], the authors compared the performance of an ANN and a response surface methodology (RSM) model in optimizing compost maturity parameters. Their study demonstrated that while both models were efficient, ANN presented an advantage compared to RSM. In another study [33], the authors employed six ML methods to develop models for predicting the germination index (GI) during manure composting, finding that the random forest (RF) and extra trees (ET) models presented the best predictive performances for GI. Similarly, [34] tested seven ML models to predict the humification index (HI) during composting, finding that the gradient boosting regression tree technique provided the best performance for modeling HI. The authors also identified that the C/N ratio and aeration rate were the most influential variables in HI modeling. Finally, [35] presented a sensor-based ML system to predict compost maturity and monitor gas emissions in real time. Using environmental data and ten composting datasets, models such as XGBoost and CatBoost achieved high predictive accuracy. The tested approach was found to enhance waste management efficiency, transparency, and sustainability. While the above studies demonstrate the relevance of ML in composting modeling, there are still challenges related to data requirements and model complexity, highlighting the need for alternative approaches [10,11].
System identification offers a practical and data-driven approach for the modeling of composting in high-mountain climates, yet its application in such contexts remains underexplored [19,36]. The integration of system identification with IoT data provides a resource-efficient alternative that can model composting dynamics without the need for extensive biochemical characterization [37,38].
Despite these advances, a gap remains in modeling composting processes for high-mountain conditions using adaptable methods. Several methods require extensive knowledge of biochemical processes, which consider large datasets or do not respond well to environmental variability. In contrast, this study uses IoT data to develop and test dynamic models for controlling temperature in a forced-aeration poultry litter composting system in Cundinamarca, Colombia. The resulting models help to improve process efficiency and provide a scalable, environmentally friendly solution for waste management in challenging environmental conditions.
2. Materials and Methods
This section describes the experimental setup and methods used to develop dynamic models for temperature control in poultry litter composting systems under high-mountain climate conditions. The study was conducted at an automated composting pilot plant in La Vega, Cundinamarca, Colombia which is equipped with IoT-based monitoring and control systems. The facility enables forced aeration and temperature regulation through a heat exchanger, supported by real-time data acquisition from calibrated environmental sensors. Two composting experiments were carried out using poultry manure and sawdust mixtures, with sensor data collected at regular intervals to capture process dynamics. The collected data were used to develop and compare several system identification models aiming to represent the biopile’s thermal behavior efficiently under variable environmental and operational conditions.
2.1. Automated Composting Plant
This study was conducted at a research and training center located in La Vega (4°52′18.932″ N, 74°25′6.54″ W), Cundinamarca, Colombia, at the Alto del Vino (2835 m above sea level) on the eastern mountain range to the west of Bogotá. The poultry production farm experiences average daytime temperatures of approximately 19 °C, which decrease to around 7 °C during the night [1]. The composting plant, housed in a greenhouse with brick and cement flooring, comprises four cubicles (i, j, k, l), each with a 4.3 m3 capacity, as shown in Figure 1. Each cubicle uses 4.0-inch perforated PVC pipes for aeration, supplied by an industrial fan (c) controlled by manual valves (n, o, p, q). The fan assembly includes a damper valve (d) and a gas burner (b) with a heat exchanger equipped with a solenoid valve and an ignition pilot. A variable speed drive adjusts airflow. Three sensors monitor the process: a temperature sensor (e) at the heat exchanger outlet, a combined temperature and oxygen sensor (g) inside the biopile, and a humidity sensor (h), also in the biopile. All sensors are connected to an IoT-based control system (f) for both manual and remote operation. The thermophilic phase was maintained at approximately 40 °C for 7 days, constrained by the high-mountain climate’s low ambient temperatures (7–19 °C) and the heat exchanger’s capacity, preventing the system from reaching the ≥55 °C threshold recommended for pathogen elimination [3]. This phase is aligned with cold-climate composting studies, where lower temperatures suffice to stabilize organic matter.
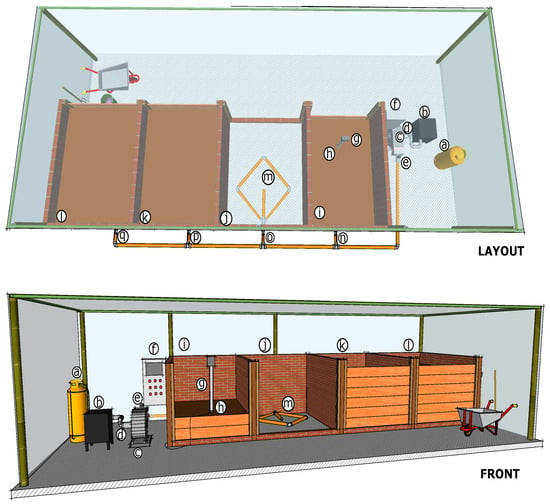
Figure 1.
Process and instrumentation diagram: (a) gas pipe, (b) heat exchanger, (c) blower, (d) damper, (e) temperature sensor, (f) system control, (g) temperature and oxygen sensors, (h) moisture sensor, (i–l) modules, (m) floor aeration pipe, hand valves (n–q).
2.2. Control and Communications Architecture
Figure 2 shows the control and communications architecture, which is composed of an industrial Arduino that acquires all analog signals of the system (biopile temperature, air temperature, moisture, and damper position). The acquired signals are sent by serial communication to an industrial Raspberry Pi that includes an integrated human–machine interface where the plant commissioning operations are performed (ignition of the gas heat exchanger, output control, control of the frequency inverter cfw 300b, and control of the damper valve). The Raspberry Pi is connected to a modem to allow internet access via GSM/GPRS.
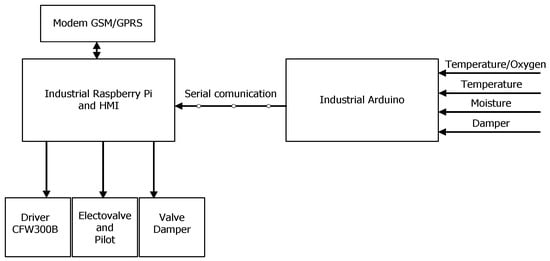
Figure 2.
Technology architecture for control and communications.
The experimental procedure at the pilot plant began with manual collection of poultry manure from the barn, which was subsequently placed in each cubicle. Manure–pine sawdust mixtures were prepared to control excess moisture and enhance biomass porosity [3]. Figure 3a shows the four cubicles loaded and ready for operation. Before starting, two pipeline valves were opened to aerate two cubicles simultaneously and a temperature and oxygen sensor (LSI Lastem) and moisture sensor were inserted into the biomass, as shown in Figure 3c. The operator verified the process variables (Figure 3d) and activated the heat exchanger and industrial fan via the inverter. Aeration was conducted separately for cubicles i and j (Experiment 2) and cubicles k and l (Experiment 1) over 15 days each, with a 5-min sampling interval used to capture rapid temperature changes during the thermophilic phase while balancing computational efficiency [7].

Figure 3.
Commissioning of the automated composting plant with forced aeration: (a) cubicles loaded with chicken manure, (b) forced aeration techniques, (c) sensor implementation in the biopile, (d) plant verification and commissioning.
The plant operated 12 h nightly due to low temperatures (7–19 °C). Table 1 lists the initial conditions. This decision was based on local environmental conditions, where daytime temperatures in the region rise to around 19 °C and with peaks of up to 23 °C. The plant is located inside a greenhouse that retains heat and minimizes sharp daytime temperature drops; these conditions reduced the need for additional heating during daylight hours, allowing for efficient thermal management with nighttime operation only.

Table 1.
Characteristics of the experiments.
Experiment 1 collected 4302 data points related to biomass temperature, substrate moisture, and hot air temperature, while Experiment 2 collected 3077 data points at the same sampling rate, which were used for model validation. All sensor data were preprocessed using a moving average filter (window size = 5 samples) to reduce high-frequency noise, and outliers exceeding ±3 standard deviations were removed. Data acquisition was implemented using Node-RED with parallel storage in MariaDB and Firebase databases.
Substrate moisture was measured using an FDS-100 resistive soil moisture sensor (probe diameter: 3 mm, output signal: 4–20 mA, operating voltage: 7–24 V, current consumption: 3–5 mA, cable length: 1.5 m). Biomass temperature and oxygen concentration were monitored with an EXP421 LSI Lastem sensor (thermistor-based for temperature and electrochemical for oxygen; temperature range: from −40 to −70 °C, accuracy: ±0.5 °C; oxygen range: 0–25 %, accuracy: ±0.3 %). The hot air temperature inside the combustion chamber was measured using a Type-K thermocouple connected to a gas burner unit. All sensors were calibrated weekly to minimize measurement drift. Measurements were taken every 5 min (sampling frequency: 0.0033 Hz) throughout the experimental periods.
Selection of the Estimation Model
After collecting the data of the measured variables [39], the input (humidity, heater temperature, and air flow) and output (biomass temperature) data were preprocessed and the system was classified as MISO [40]. Within the theory of system identification, it is recommended to start with a mathematical relationship of inputs and outputs and then move on to more complex structures [41]. Therefore, three structures were initially selected: transfer function (TF), state space (SS), and process (P); then, a nonlinear Hammerstein–Wiener (HW) structure was selected. Another important characteristic to consider in system identification is the model order; accordingly, the study began with a review of classical energy and mass balance equations found in the literature describing the composting process. It was observed that most of these models are first-order; for this reason, the modeling work was started with first- and second-order models. Model estimation was performed using 50% of the measured data from Experiment 1. The dataset used for this purpose started at data point 1235, as the humidity from that point onward remained within the range of 50% to 60%, ensuring that the composting process had properly commenced.
2.3. Model Estimation by Transfer Function
Model estimation using a discrete transfer function was applied to the composting process, as it enables straightforward implementation of a simulation model or future predictions of plant behavior [42]. For this purpose, the model was implemented in Matlab using the tfest function, which applies the output-error (OE) polynomial algorithm [43]. The values of the three inputs and one output were parameterized using a sampling time of 300 s. Among the evaluated models, the second-order model provided the best response in terms of system representation. The identified transfer functions are presented in Equations (1)–(3):
Respectively corresponding to the inputs of (heater temperature), (humidity), and (flow) used in the estimation. The system’s sole output is (biopile temperature).
2.4. State-Space Model Estimation
The state-space model is a mathematical representation of a system in which the inputs and outputs are related through a set of first-order differential equations. To estimate the discrete-time model of the composting process, a sampling time was defined and the model order was determined using the ssest function in Matlab, which employs the canonical variate algorithm. The discrete-time state-space representation of the system is provided by Equations (4) and (5) [44]:
where , and K are matrices in the state space of the appropriate dimensions, is the input vector, is the output, is the perturbation, and is the state vector. The estimated matrices of this type of representation are presented below in Equations (6)–(10):
An observable canonical form was realized, representing the state-space system in a reduced-parameter structure where specific elements of the matrices are fixed to zero or one. The canonical indices are identifiable in matrices A and B. This model enables the estimation of two perturbation coefficients, denoted by K; the D matrix is a zero vector, indicating that there is no direct feed-through from the input to the output.
2.5. Model Estimation by Process Structure
The process model represents poultry litter composting dynamics using a continuous-time transfer function, capturing heat transfer and microbial degradation in the biopile [45]. Key parameters include (static gain, reflecting the steady-state temperature response to inputs such as aeration), (inverse of the natural frequency, indicating the speed of temperature changes), and (the damping coefficient, representing microbial activity stabilization) [46]. These parameters simplify modeling for high-mountain climates, where temperature control is critical. The model’s simplicity allows for estimation of delay and for coefficients that are interpretable as poles and zeros, supporting first- to third-order models with real or complex poles [47]. Noise (white or colored) is included in the output, as shown in the discrete-domain input–output relationship in Equation (11):
where is the output corresponding to , is the discrete transfer function, represents the input or inputs, is the error (white Gaussian noise), and is the noise sensitivity function. Model estimation was performed taking into account two dominant complex poles and a second-order underdamped system, leading to the structure presented in Equation (12), which is expressed in the frequency domain with :
The resulting model structure for a multiple-input–single-output (MISO) system with three inputs and one output is presented in Equation (13):
where , , and are shown in Equations (14), (15), and (16), respectively:
For estimation of the noise sensitivity function, an autoregressive moving average (ARMA) structure is used for the perturbation model, as shown in Equation (17):
where and are provided by Equations (18) and (19), respectively:
ARMA models are autoregressive models that do not incorporate exogenous inputs, making them well suited for modeling processes based solely on time series data. They include a polynomial component that accounts for the moving average of the noise [48]. In this particular case, a second-order ARMA model was estimated, resulting in a total of twelve model coefficients.
2.6. Hammerstein–Wiener (HW) Model Estimation
The HW model implemented for system identification combines nonlinear input/output blocks with a linear transfer function, which can model interactions between aeration, moisture, and temperature in high-mountain biopiles [49]. As shown in Figure 4, the structure includes a nonlinear input block , a linear transfer function , and a nonlinear output block .
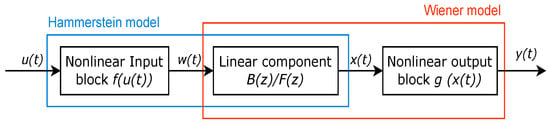
Figure 4.
Hammerstein–Wiener (HW) structure.
This enables accurate representation of the nonlinear dynamics involved in poultry litter composting, where:
- is a smooth nonlinear function that transforms the input signal into as the output of the nonlinear block.
- The linear state space composed of matrices of appropriate sizes can be taken to a transfer function realization provided by that transforms into .
- is an internal variable that represents the output of the linear block and has the same dimension as .
- is a smooth nonlinear function that maps the output of the linear block to the output of the system as .
For outputs and inputs, the linear block is a transfer function matrix containing inputs, as shown in Equation (20):
where and . In order to use this structure, it is necessary to specify (number of zeros), (number of poles), and (delay from input to output in terms of samples) [50]. Finally, the method was implemented in the software by excluding input and output nonlinearities, resulting in a linear transfer function. All corresponding parameters are presented in Equations (21)–(29):
where the terms InputNonlinearity and OutputNonlinearity, specified as idUnitGain in the software implementation, correspond to identity mappings in the mathematical model; that is, the nonlinear functions and are defined as in Equation (30):
which implies that the input and output signals are passed through the system without any nonlinear transformation. In this case, both blocks act as identity functions, meaning that the overall system behaves as a purely linear transfer function model. This simplification is often used to validate the linear dynamics of the system before introducing nonlinear components in more complex identification procedures.
The biggest strength of this approach is how flexible it is and how well it fine-tunes its settings. It starts with a basic model such as a linear state-space or transfer function, then uses a nonlinear unknown set of building blocks to tweak the model’s parameters. This method helps to capture real-world input–output behaviors such as actuator saturation and hysteresis. The data are fitted much better by modeling each unique behavior separately. This adaptability represents a key breakthrough in this research, resulting in plans to continue improving the model in order to make it more accurate and reduce errors in the future.
3. Results and Discussion
Four dynamic system identification models were studied in the context of an automated chicken manure composting plant using forced aeration under extreme high-mountain humidity and temperature conditions. The composting process progressed satisfactorily, as shown in Figure 5. The mesophilic phase, dominated by mesophilic microorganisms breaking down soluble and degradable molecules, lasted 7 days (25–40 °C), with rapid temperature increases from spontaneous heat release. The thermophilic phase followed, where thermophilic microorganisms facilitates rapid decomposition of proteins, fats, and complex carbohydrates, lasting 5 days at approximately 45 °C. The maturation phase began on day 13, reaching 30 °C by day 16 and cooling toward ambient temperature [1]. Physicochemical properties (e.g., C/N ratio, pH) were not measured due to experimental constraints. According to the literature, a carbon-to-nitrogen (C/N) ratio below 20 and pH range of 6.5–8.0 are indicative of mature compost [5]. The experiment was conducted in a research facility located in a high-mountain climate; this environmental condition influenced the thermophilic phase, which exhibited a moderate temperature peak below the typical range of (50–65 °C). The temperature dynamics highlight the influence of lower temperatures on heat retention. In real-world composting systems, this may require supplemental strategies such as structural insulation, longer aeration cycles, and robust heat-exchanging processes; however, as reported in composting studies, a range of (40–65 °C) is adequate for a thermophilic phase [51,52].
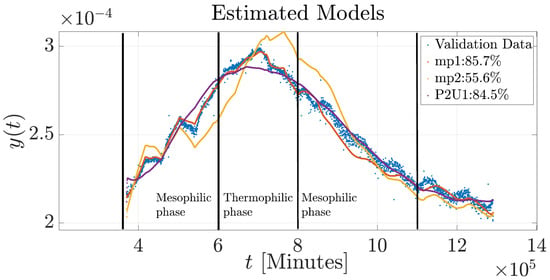
Figure 5.
Validation of the mp1, mp2, and P2U1 models for simulating the composting process in Experiment 1.
The dynamic responses of the BT obtained from the three modeling techniques in comparison with the experimental data are shown in Figure 5. In addition, Figure 6 hows how the temperature profile follows the expected biological behavior from the initial mesophilic stage, through the thermophilic peak, then into mesophilic cooling and maturation stage. The three models describe the basic temperature pattern of the composting process. The state-space model (mp1) demonstrated superior fitting performance (85.71%) during the mesophilic and thermophilic phases, mirroring the peaks of biological activity commonly found during proliferation of microorganisms. State-space models can represent higher-order physical systems and analyze any nonlinear systems with multiple inputs and outputs [53], making them better suited for modeling transient dynamics that occur in the early stages of composting. However, mp1 showed limitations in describing the mesophilic cooling phase, reflecting its reduced sensitivity to the decrease in metabolic activity and system stabilization. On the other hand, the process model (P2U1) showed better fitting (84.48%) during the cooling phase, although it showed lower accuracy during the biologically active phases. This suggests that this model more effectively depicts the slower dynamics associated with microbial decline and humification processes. The transfer function model (mp2) presented the lowest overall performance (55.59%), failing to model transitional behaviors or the thermophilic peak. This finding suggests that a simplified model may be insufficient to accurately represent the thermal dynamics of the composting process.
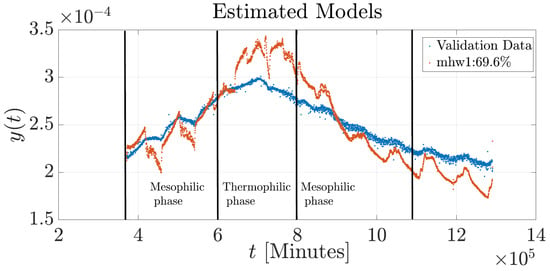
Figure 6.
Validation of the nonlinear simulation model of the composting process in Experiment 1.
In contrast, Figure 6 shows the BT of the biopile using the nonlinear structure, which exhibits a good model fit. However, the HW model (mhw1) exhibits oscillations throughout all phases of the composting process when compared to the validation data, and a mismatch is observed in the initial conditions. This mismatch may be attributed to the high variability in the initial composting conditions, such as moisture content, material density, and microbial diversity. Nevertheless, the model provided a more accurate representation during the mesophilic cooling phase. Similarly, Figure 7 displays the validation results for all models using 50% of the real data that were not used in the estimation process. All models reproduce the general composting behavior to some extent.
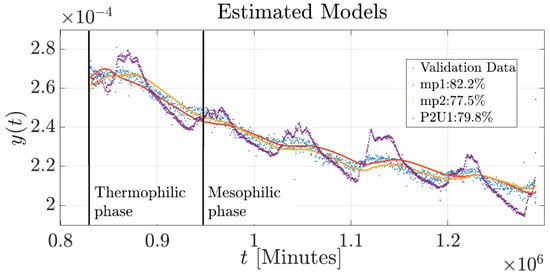
Figure 7.
Validation of all simulation models of the composting process.
Subsequently, the results of the four model structures were compared using data from Experiment 2, which were different from those used in the identification process. Figure 8 illustrates the behavior of three models compared against the data from Experiment 2. The mp1 and P2U1 models were able to reproduce the basic dynamics of the composting process. In contrast, the mp2 model failed to reflect the fundamental temperature profile, exhibiting a significant mismatch. The mp1 model also showed deviations in the initial conditions as well as during the mesophilic and thermophilic phases. The P2U1 model demonstrated improved performance in capturing the initial conditions and the mesophilic phase compared to the mp1 model; however, it was not able to accurately reproduce the behavior during the thermophilic phase.
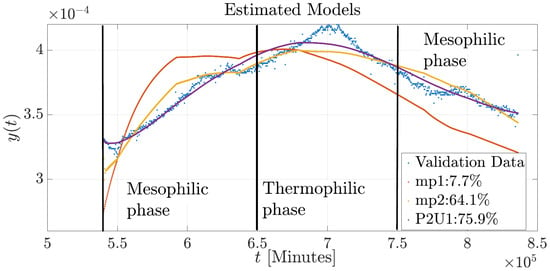
Figure 8.
Validation of the mp1, mp2, and P2U1 simulation models of the composting process in Experiment 2.
Figure 9 presents the results of the model with a nonlinear structure using data from Experiment 2. A noticeable discrepancy is observed in the initial conditions and across all phases of the composting process. To determine the fitness and error of the models, we considered several well-known metrics: the normalized root mean square error (NRMSE), expressed as ; the root mean square error (RMSE), ; and the mean absolute error (MAE), , which indicates the overall quality of the adjustment. The performance metrics computed for the different estimated models are summarized in Table 2.
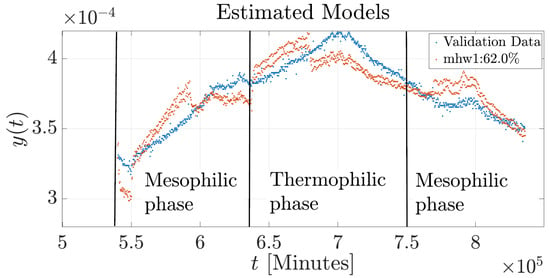
Figure 9.
Validation of the nonlinear simulation model of the composting process in Experiment 2.
Table 2.
Model fit and error metrics.
The system identification approach effectively modeled poultry litter composting under high-mountain climate conditions, with the P2U1 process model achieving the highest fit (75.89% in Experiment 2). The inaccuracies observed during the thermophilic phase may be attributed to the biological complexity of the process, as microbial activity is highly sensitive to variations in composting parameters such as aeration and moisture content. These variations exhibit the need for adaptive modeling strategies that can effectively address environmental variability and emphasize the importance of integrating real-time environmental sensing. Overall, our study demonstrates the potential of using system identification as a data-driven tool for optimizing composting processes in Cundinamarca, Colombia without relying on complex biochemical models [7].
The use of system identification to effectively model poultry litter composting in the high-mountain climate of Cundinamarca, Colombia offers a data-driven alternative to complex biochemical models. Table 2 presents the comparative results of the dynamic models evaluated under three experimental conditions. In Experiment 1, using 100% of the data, the mp1 model achieved the highest fit (85.71%) and the lowest error values (RMSE: 0.581 °C, MAE: 0.432 °C), accurately capturing temperature dynamics under ideal data conditions. The P2U1 model also performed well (fit: 84.4%), with slightly higher errors but consistent accuracy. In contrast, the mp2 and mhw1 models demonstrated lower performance, with reduced fits (55.59% and 69.63%, respectively) and higher error magnitudes.
When evaluated using only 50% of the data in Experiment 1, simulating sensor failure or data scarcity, the P2U1 model outperformed all others (fit: 84.45%, RMSE: 0.432 °C, MAE: 0.336 °C), demonstrating greater robustness and adaptability. Although the mp1 and mhw1 models maintained acceptable performance, with fits of 82.20% and 79.78%, respectively, their error metrics increased slightly, indicating reduced reliability under limited data conditions. Interestingly, the mp2 model showed improved performance in this case, but still did not surpass P2U1, particularly in overall accuracy and consistency.
In Experiment 2, where process variability was significantly higher, model performance declined across the board. The mp1 model’s fit dropped sharply to 7.70% (RMSE: 3.340 °C MAE: 2.995 °C), highlighting its limited adaptability. In contrast, the P2U1 model again led the results with a strong fit of 75.89% and relatively low errors (RMSE: 0.873 °C, MAE: 0.648 °C), confirming its ability to handle dynamic and uncertain composting conditions. The mhw1 and mp2 models showed intermediate performance but did not match the robustness of P2U1. These findings suggest that simpler models such as mp1 perform well under stable and complete data conditions but struggle under variable or incomplete scenarios; conversely, P2U1 remains accurate and reliable across a range of operating conditions. Although it exhibited some limitations during the thermophilic phase, the adaptability of a model to process variability is more critical for composting systems located in high-mountain climates than achieving extreme accuracy in a specific phase. Overall, these results demonstrate the potential of P2U1 for practical composting applications, and reinforce system identification as a promising tool for optimizing processes in unpredictable environments.
Model performance was evaluated not only through fit and error metrics but also through statistical residual analysis, specifically:
- The whiteness test; a good model has its residuals within the confidence interval of the data obtained from the simulation model, with the exception of lag 0, which ensures that the residuals are uncorrelated.
- The test of independence; a good model has residuals that are uncorrelated with the data, i.e., the residuals should not show a systematic pattern.
Figure 10 presents the autocorrelation of the residuals and the cross-correlation between the residuals and the inputs based on the validation using 50% of the data from Experiment 1. It is evident that the autocorrelation for the mp2 (red) and mhw1 (light blue) models is the highest among all cases. A similar trend is observed in the cross-correlation results, indicating that the residuals of these two models are significantly correlated with the input data, which is an indication of poor model quality. The shaded band along the x-axis represents the 99% confidence interval; correlations falling within this region are considered statistically insignificant, provided that the lag values remain close to zero. The figure illustrates that the residuals of the mp2 and mhw1 models exceed the confidence bounds more frequently, suggesting the presence of structure in the residuals that these models fail to capture. In contrast, the state-space model (mp1) (green) and process model (P2U1) (purple) exhibit residual behaviors that fall mostly within the confidence region, further supporting the better performance and adequacy of these models seen in the previous evaluations.
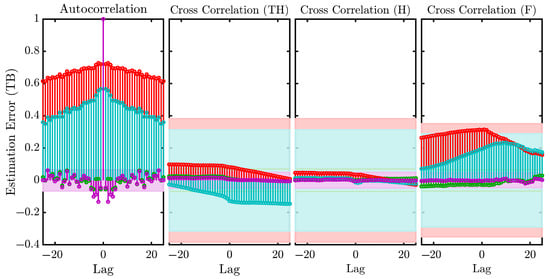
Figure 10.
Residuals analysis, showing autocorrelation of the models with data from Experiment 1.
Finally, Figure 11 shows the autocorrelation of the residuals and cross-correlation between the residuals and inputs for model validation using 100% of the data from Experiment 2. The P2U1 process model and HW model exhibit the highest autocorrelation (red and light blue, respectively); in contrast, the Hammerstein–Wiener and state-space models show higher cross-correlation than the mp1 and P2U1 models. The P2U1 model shows the best fit to the experimental data. Composting processes involving microbial activity, heat transfer, and organic matter degradation are complex due to variable feedstock, making precise modeling challenging. Mechanistic models are often inflexible and data-intensive, making them less suitable for decision-making than the data-driven approach provided by system identification, which enhances accessibility and optimization [54]. The P2U1 model’s robust fit (75.89%) supports its integration into the IoT system (Figure 2) by embedding its transfer function in a Raspberry Pi controller to adjust fan speed or heat exchanger settings for thermophilic conditions. Based on simulations, the model predicts potential aeration energy savings of 10–15%; however, these are simulation-based estimates and require real-world validation through operational testing in the pilot plant [23].
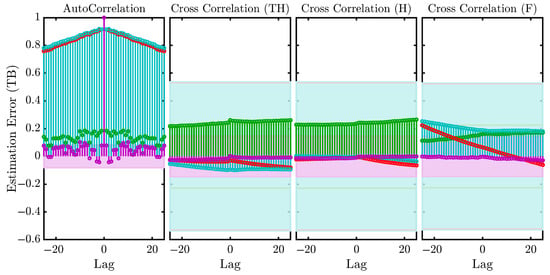
Figure 11.
Residuals analysis, showing autocorrelation of the models with data from Experiment 2.
4. Conclusions
This study employed system identification to model the composting process in forced-aeration piles under high mountain climates utilizing four techniques: three linear models (state-space, process, and transfer function) and one nonlinear model (Hammerstein–Wiener). The process model best captured the mesophilic phases, while the state space model excelled in describing both mesophilic and thermophilic stages. Despite capturing mesophilic behavior, the HW model showed limitations due to oscillations, while the transfer function model underperformed overall. Validation with independent datasets revealed the process model’s superior predictive accuracy, although none of the models adequately described the thermophilic phase, likely due to environmental variability. This study’s key contribution lies in demonstrating system identification as a robust data-driven alternative to traditional energy and mass balance approaches, enabling accurate modeling of composting dynamics without extensive biochemical characterization. However, limitations include the tested models’ focus on temperature, excluding moisture and ventilation, and the use of identical substrates, which restricts generalizability. Future work should integrate these factors and explore adaptive or hybrid models in order to enhance robustness and scalability.
This study provides practical ideas for sustainably handling waste in poultry farming. Using the tested IoT setup, farmers can monitor key factors such as airflow and temperature in real time, which helps to save energy and produce better compost. What stands out is how flexible this method is; for instance, it can be adjusted to work with various materials and climates, meaning that it is not limited to high-mountain areas. Finally, these models can be easily integrated into existing composting processes, taking into account automated tools that fit into modern agricultural systems. This approach enables informed decisions, can predict when compost is ready with greater accuracy, and considers environmental regulations, helping to make farming more sustainable.
Author Contributions
Conceptualization, A.A.P.-F. and H.R.-M.; methodology, F.S.-C. and F.F.F.; software, A.A.P.-F. and F.S.-C.; validation, R.R. and G.S.-R.; formal analysis, F.S.-C. and H.R.-M.; investigation, R.R. and F.F.F.; data curation, H.R.-M. and R.R.; writing—original draft preparation, F.S.-C. and H.R.-M.; writing—review and editing, R.R. and G.S.-R.; funding acquisition, A.A.P.-F. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Vicerrectoría de Investigación y Transferencia (VRIT) at Universidad de La Salle, Bogotá, Colombia under institutional code IAU202-146. The APC was funded by Universidad de La Salle, Bogotá, Colombia.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Datasets related to this article can be found at https://data.mendeley.com/datasets/dgxxj2pk8s/2 (accessed on 25 June 2025), hosted at Mendeley [39].
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| AI | Artificial Intelligence |
| ANN | Artificial Neural Networks |
| ARMA | Autoregresive Moving Average |
| BT | Biopile Temperature |
| CatBoost | Categorical Boosting |
| C/N | Carbon-to-Nitrogen ratio |
| ET | Extra Trees |
| GI | Germination Index |
| GPRS | General Packet Radio Service |
| GSM | Global System for Mobile Communications |
| H | Humidity |
| HI | Humification Index |
| HT | Heater Temperature |
| HW | Hammerstein–Wiener |
| IoT | Internet of Things |
| LSI | Latent Semantic Indexing |
| MAE | Mean Absolute Error |
| mhw1 | Hammerstein–Wiener Model |
| MISO | Multiple-Input–Single-Output |
| ML | Machine Learning |
| mp1 | State-Space Model |
| mp2 | Transfer Function Model |
| NRMSE | Normalized Root Mean Square Error |
| OE | Output-Error Polynomial Algorithm |
| P | Process |
| P2U1 | Process Model |
| RF | Random Forest |
| RMSE | Root Mean Square Error |
| RSM | Response Surface Methodology |
| SS | State Space |
| TF | Transfer Function |
| XGBoost | eXtreme Gradient Boosting |
References
- Sayara, T.; Basheer-Salimia, R.; Hawamde, F.; Sánchez, A. Recycling of Organic Wastes through Composting: Process Performance and Compost Application in Agriculture. Agronomy 2020, 10, 1838. [Google Scholar] [CrossRef]
- Gao, M.; Li, B.; Yu, A.; Liang, F.; Yang, L.; Sun, Y. The effect of aeration rate on forced-aeration composting of chicken manure and sawdust. Bioresour. Technol. 2010, 101, 1899–1903. [Google Scholar] [CrossRef]
- Kang, J.; Yin, Z.; Pei, F.; Ye, Z.; Song, G.; Ling, H.; Gao, D.; Jiang, X.; Zhang, C.; Ge, J. Aerobic composting of chicken manure with penicillin G: Community classification and quorum sensing mediating its contribution to humification. Bioresour. Technol. 2022, 352, 127097. [Google Scholar] [CrossRef]
- Mottet, A.; Tempio, G. Global poultry production: Current state and future outlook and challenges. World’s Poult. Sci. J. 2017, 73, 245–256. [Google Scholar] [CrossRef]
- Gao, M.; Liang, F.; Yu, A.; Li, B.; Yang, L. Evaluation of stability and maturity during forced-aeration composting of chicken manure and sawdust at different C/N ratios. Chemosphere 2010, 78, 614–619. [Google Scholar] [CrossRef]
- Michel, F.; O’Neill, T.; Rynk, R.; Gilbert, J.; Wisbaum, S.; Halbach, T. Passively aerated composting methods, including turned windrows. In The Composting Handbook; Rynk, R., Ed.; Academic Press: Cambridge, MA, USA, 2022; pp. 159–196. [Google Scholar] [CrossRef]
- Wang, N.; Yang, W.; Wang, B.; Bai, X.; Wang, X.; Xu, Q. Predicting maturity and identifying key factors in organic waste composting using machine learning models. Bioresour. Technol. 2024, 400, 130663. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Ai, P.; Cao, H.; Liu, Z. Prediction of moisture variation during composting process: A comparison of mathematical models. Bioresour. Technol. 2015, 193, 200–205. [Google Scholar] [CrossRef] [PubMed]
- López, M.; Martinez-Farre, X.; Casas, O.; Quilez, M.; Polo, J.; Lopez, O.; Hornero, G.; Pinilla, M.R.; Rovira, C.; Ramos, P.M.; et al. Intelligent composting assisted by a wireless sensing network. Waste Manag. 2014, 34, 738–746. [Google Scholar] [CrossRef] [PubMed]
- Walling, E.; Trémier, A.; Vaneeckhaute, C. A review of mathematical models for composting. Waste Manag. 2020, 113, 379–394. [Google Scholar] [CrossRef]
- Aydın Temel, F.; Cagcag Yolcu, O.; Turan, N.G. Artificial intelligence and machine learning approaches in composting process: A review. Bioresour. Technol. 2023, 370, 128539. [Google Scholar] [CrossRef]
- Martinez-Nieto, P.; Abaunza, C.; Garcia, G. Swine manure management by bokashi fermentation and composting with biological activators in a Colombian High Mountain Region. Int. J. Recycl. Org. Waste Agric. 2024, 13, 1–12. [Google Scholar] [CrossRef]
- Sokač, T.; Valinger, D.; Benković, M.; Jurina, T.; Gajdoš Kljusurić, J.; Radojčić Redovniković, I.; Jurinjak Tušek, A. Application of Optimization and Modeling for the Composting Process Enhancement. Processes 2022, 10, 229. [Google Scholar] [CrossRef]
- Yılmaz, E.C.; Aydın Temel, F.; Cagcag Yolcu, O.; Turan, N.G. Modeling and optimization of process parameters in co-composting of tea waste and food waste: Radial basis function neural networks and genetic algorithm. Bioresour. Technol. 2022, 363, 127910. [Google Scholar] [CrossRef]
- Shi, C.-F.; Yang, H.-T.; Chen, T.-T.; Guo, L.-P.; Leng, X.-Y.; Deng, P.-B.; Bi, J.; Pan, J.-G.; Wang, Y.-M. Artificial neural network-genetic algorithm-based optimization of aerobic composting process parameters of Ganoderma lucidum residue. Bioresour. Technol. 2022, 357, 127248. [Google Scholar] [CrossRef]
- Aycan Dümenci, N.; Cagcag Yolcu, O.; Aydin Temel, F.; Turan, N.G. Identifying the maturity of co-compost of olive mill waste and natural mineral materials: Modelling via ANN and multi-objective optimization. Bioresour. Technol. 2021, 338, 125516. [Google Scholar] [CrossRef] [PubMed]
- Du, Y.H.; Wang, M.Y.; Yang, L.H.; Tong, L.L.; Guo, D.S.; Ji, X.J. Optimization and scale-up of fermentation processes driven by models. Bioengineering 2022, 9, 473. [Google Scholar] [CrossRef] [PubMed]
- Pinto, J.; Mestre, M.; Ramos, J.; Costa, R.S.; Striedner, G.; Oliveira, R. A general deep hybrid model for bioreactor systems: Combining first principles with deep neural networks. Comput. Chem. Eng. 2022, 165, 107952. [Google Scholar] [CrossRef]
- Wan, X.; Li, J.; Xie, L.; Wei, Z.; Wu, J.; Tong, Y.W.; Wang, X.; He, Y.; Zhang, J. Machine learning framework for intelligent prediction of compost maturity towards automation of food waste composting system. Bioresour. Technol. 2022, 365, 128107. [Google Scholar] [CrossRef]
- Bwambale, E.; Abagale, F.K.; Anornu, G.K. Data-Driven Modelling of Soil Moisture Dynamics for Smart Irrigation Scheduling. Smart Agric. Technol. 2023, 5, 100251. [Google Scholar] [CrossRef]
- Quaghebeur, W.; Torfs, E.; De Baets, B.; Nopens, I. Hybrid differential equations: Integrating mechanistic and data-driven techniques for modelling of water systems. Water Res. 2022, 213, 118166. [Google Scholar] [CrossRef]
- Awhangbo, L.; Schmitt, V.; Marcilhac, C.; Charnier, C.; Latrille, E.; Steyer, J.P. Determination of the optimal feed recipe of anaerobic digesters using a mathematical model and a genetic algorithm. Bioresour. Technol. 2024, 393, 130091. [Google Scholar] [CrossRef]
- Gillani, S.A.; Abbasi, R.; Martinez, P.; Ahmad, R. Review on Energy Efficient Artificial Illumination in Aquaponics. Clean. Circ. Bioeconomy 2022, 2, 100015. [Google Scholar] [CrossRef]
- Mandal, S.; Yadav, A.; Panme, F.A.; Devi, K.M.; Kumar, S.M.S. Adaption of smart applications in agriculture to enhance production. Smart Agric. Technol. 2024, 7, 100431. [Google Scholar] [CrossRef]
- Mishra, A.; Alzoubi, Y.I.; Gavrilovic, N. Quality attributes of software architecture in IoT-based agricultural systems. Smart Agric. Technol. 2024, 8, 100523. [Google Scholar] [CrossRef]
- Kumar, V.; Sharma, K.V.; Kedam, N.; Patel, A.; Kate, T.R.; Rathnayake, U. A comprehensive review on smart and sustainable agriculture using IoT technologies. Smart Agric. Technol. 2024, 8, 100487. [Google Scholar] [CrossRef]
- Huang, L.-T.; Hou, J.-Y.; Liu, H.-T. Machine-learning intervention progress in the field of organic waste composting: Simulation, prediction, optimization, and challenges. Waste Manag. 2022, 178, 155–167. [Google Scholar] [CrossRef]
- Makisha, N. Preliminary Design Analysis of Membrane Bioreactors Application in Treatment Sequences for Modernization of Wastewater Treatment Plants. Membranes 2022, 12, 819. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Gamal, A.; Moustafa, N.; Askar, S.S.; Abouhawwash, M. A risk assessment model for cyber-physical water and wastewater systems: Towards sustainable development. Sustainability 2022, 14, 4480. [Google Scholar] [CrossRef]
- Zhang, Y.; Wu, H.; Xu, R.; Wang, Y.; Chen, L.; Wei, C. Machine learning modeling for the prediction of phosphorus and nitrogen removal efficiency and screening of crucial microorganisms in wastewater treatment plants. Sci. Total Environ. 2024, 907, 167730. [Google Scholar] [CrossRef]
- Wang, D.; Thunéll, S.; Lindberg, U.; Jiang, L.; Trygg, J.; Tysklind, M.; Souihi, N. A machine learning framework to improve effluent quality control in wastewater treatment plants. Sci. Total Environ. 2021, 784, 147138. [Google Scholar] [CrossRef]
- Xu, B.; Pooi, C.K.; Tan, K.M.; Huang, S.; Shi, X.; Ng, H.Y. A novel long short-term memory artificial neural network (LSTM)-based soft-sensor to monitor and forecast wastewater treatment performance. J. Water Process Eng. 2023, 54, 104041. [Google Scholar] [CrossRef]
- Shi, S.; Guo, Z.; Bao, J.; Jia, X.; Fang, X.; Tang, H.; Zhang, H.; Sun, Y.; Xu, X. Machine learning-based prediction of compost maturity and identification of key parameters during manure composting. Bioresour. Technol. 2025, 419, 132024. [Google Scholar] [CrossRef]
- Jia, P.; Huang, Y.; Guo, W.; Zhu, Z.; Dou, Y. Condition optimizing, process predicting, and key physicochemical factor identifying for yak dung compost humification: Integrating response surface methodology with interpretable machine learning. Chem. Eng. J. 2025, 517, 164537. [Google Scholar] [CrossRef]
- Khandakar, A.; Ashraf, A.; Ayari, M.A.; Esmaeili, A.; Aljarrah, M.; Michael, P.; Nahiduzzaman, M.; Kibria, H.B.; Gerokosta, V.M.; Shehbaz, A.A.; et al. Compost maturity prediction and gas emissions monitoring: A sensor-based and interpretable machine learning approach. Comput. Electr. Eng. 2025, 123, 110115. [Google Scholar] [CrossRef]
- Makarov, V. Fundamental Scientific Discipline “Identification of Systems” and Fundamental Education. In Proceedings of the 2023 16th International Conference Management of Large-Scale System Development (MLSD), Moscow, Russia, 26–28 September 2023; pp. 1–4. [Google Scholar] [CrossRef]
- Islam, N.; Rashid, M.M.; Pasandideh, F.; Ray, B.; Moore, S.; Kadel, R. A Review of Applications and Communication Technologies for Internet of Things (IoT) and Unmanned Aerial Vehicle (UAV) Based Sustainable Smart Farming. Sustainability 2021, 13, 1821. [Google Scholar] [CrossRef]
- Mahore, V.; Soni, P.; Patidar, P.; Nagar, H.; Chouriya, A.; Machavaram, R. Development and implementation of a raspberry Pi-based IoT system for real-time performance monitoring of an instrumented tractor. Smart Agric. Technol. 2024, 9, 100530. [Google Scholar] [CrossRef]
- Patiño-Forero, A. Dynamic Modeling of Poultry Litter Composting in High Mountain Climates using System Identification Techniques. 2024. [Dataset]. Available online: https://data.mendeley.com/datasets/dgxxj2pk8s/1 (accessed on 30 June 2025.).
- Esfandiari, R.S.; Lu, B. Modeling and Analysis of Dynamic Systems; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ljung, L. System Identification: Theory for the User; Prentice Hall PTR: Upper Saddle River, NJ, USA, 1999. [Google Scholar]
- Gonzalez-Villagomez, J.; Gonzalez-Villagomez, E.; Rodriguez-Donate, C.; Cabal-Yepez, E.; Ledesma-Carrillo, L.M.; Hernández-Gómez, G. An Experimental Study of the Empirical Identification Method to Infer an Unknown System Transfer Function. Robotics 2023, 12, 140. [Google Scholar] [CrossRef]
- Chen, T.; Ohlsson, H.; Ljung, L. On the estimation of transfer functions, regularizations and Gaussian processes—Revisited. Automatica 2012, 48, 1525–1535. [Google Scholar] [CrossRef]
- Favoreel, W.; De Moor, B.; Van Overschee, P. Subspace State Space System Identification for Industrial Processes. IFAC Proc. Vol. 1998, 31, 319–327. [Google Scholar] [CrossRef]
- MathWorks. What Is a Process Model? 2024. [Online]. Available online: https://la.mathworks.com/help/ident/ug/what-is-a-process-model.html (accessed on 20 June 2025).
- Tangirala, A.K. Principles of System Identification: Theory and Practice; CRC Press: Boca Raton, FL, USA, 2018. [Google Scholar]
- Ljung, L. Some Classical and Some New Ideas for Identification of Linear Systems. J. Control Autom. Electr. Syst. 2013, 24, 3–10. [Google Scholar] [CrossRef]
- Box, G.E.P.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control, 5th ed.; Wiley: Hoboken, NJ, USA, 2015. [Google Scholar]
- Ljung, L. System Identification Toolbox: User’s Guide; Citeseer: Natick, MA, USA, 1995. [Google Scholar]
- Sun, L.; Hou, J.; Xing, C.; Fang, Z. A Robust Hammerstein-Wiener Model Identification Method for Highly Nonlinear Systems. Processes 2022, 10, 2664. [Google Scholar] [CrossRef]
- Lai, J.C.; Then, Y.L.; Hwang, S.S.; Yu, C.T.; Cheryl, C.N.C. Modelling Temperature Profiles in Food Waste Composting: Monod Kinetics Under Varied Aeration Conditions. Process Integr. Optim. Sustain. 2025. [Google Scholar] [CrossRef]
- Awasthi, M.K.; Wang, Q.; Wang, M.; Chen, H.; Ren, X.; Zhao, J.; Zhang, Z. In-Vessel Co-Composting of Food Waste Employing Enriched Bacterial Consortium. Food Technol. Biotechnol. 2018, 56, 83–89. [Google Scholar] [CrossRef] [PubMed]
- Mumtaz, F.; Zaihar Yahaya, N.; Tanzim Meraj, S.; Singh, B.; Kannan, R.; Ibrahim, O. Review on non-isolated DC-DC converters and their control techniques for renewable energy applications. Ain Shams Eng. J. 2021, 12, 3747–3763. [Google Scholar] [CrossRef]
- Yan, J.; Deller, J.R. Biologically-motivated system identification: Application to microbial growth modeling. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 322–325. [Google Scholar] [CrossRef]











Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).