
Training from Zero: Forecasting of Radio Frequency Machine Learning Data Quantity



Abstract
1. Introduction
- What data should be or are available to be used in order to train the system;
- How many data are needed for the current approach to achieve the desired performance level?
1.1. Machine Learning Concepts
1.1.1. Deep Learning
1.1.2. Transfer Learning
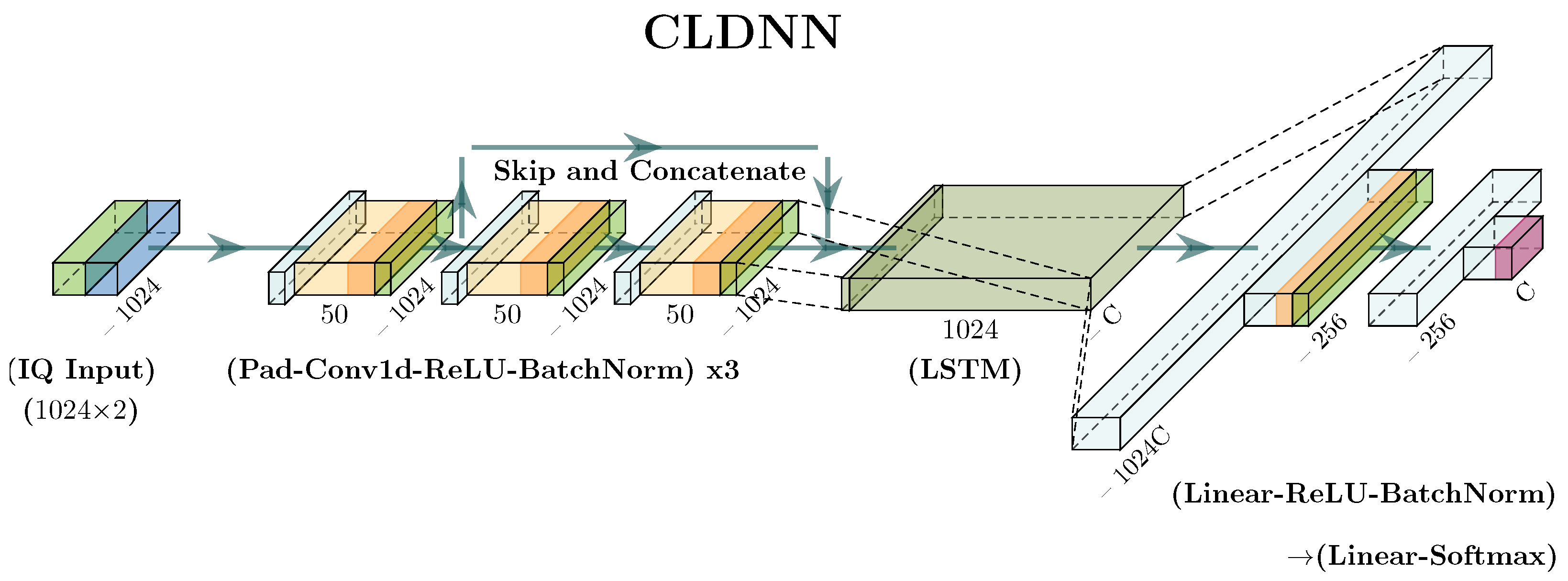
1.1.3. Automatic Modulation Classification
1.2. RF Characteristics
1.2.1. Real-World Degradation
1.2.2. Understanding RF Data Origin
2. Materials and Methods
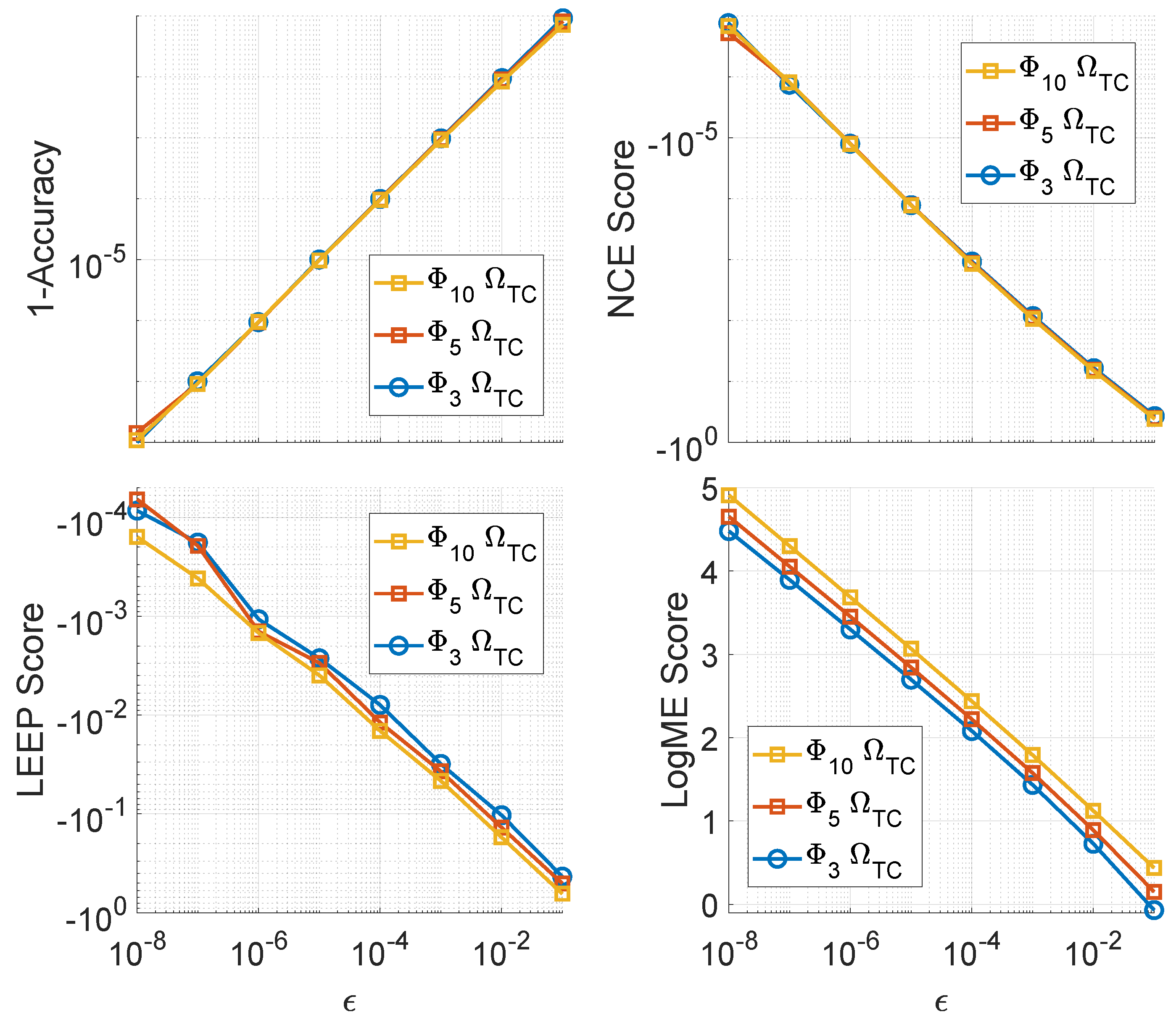
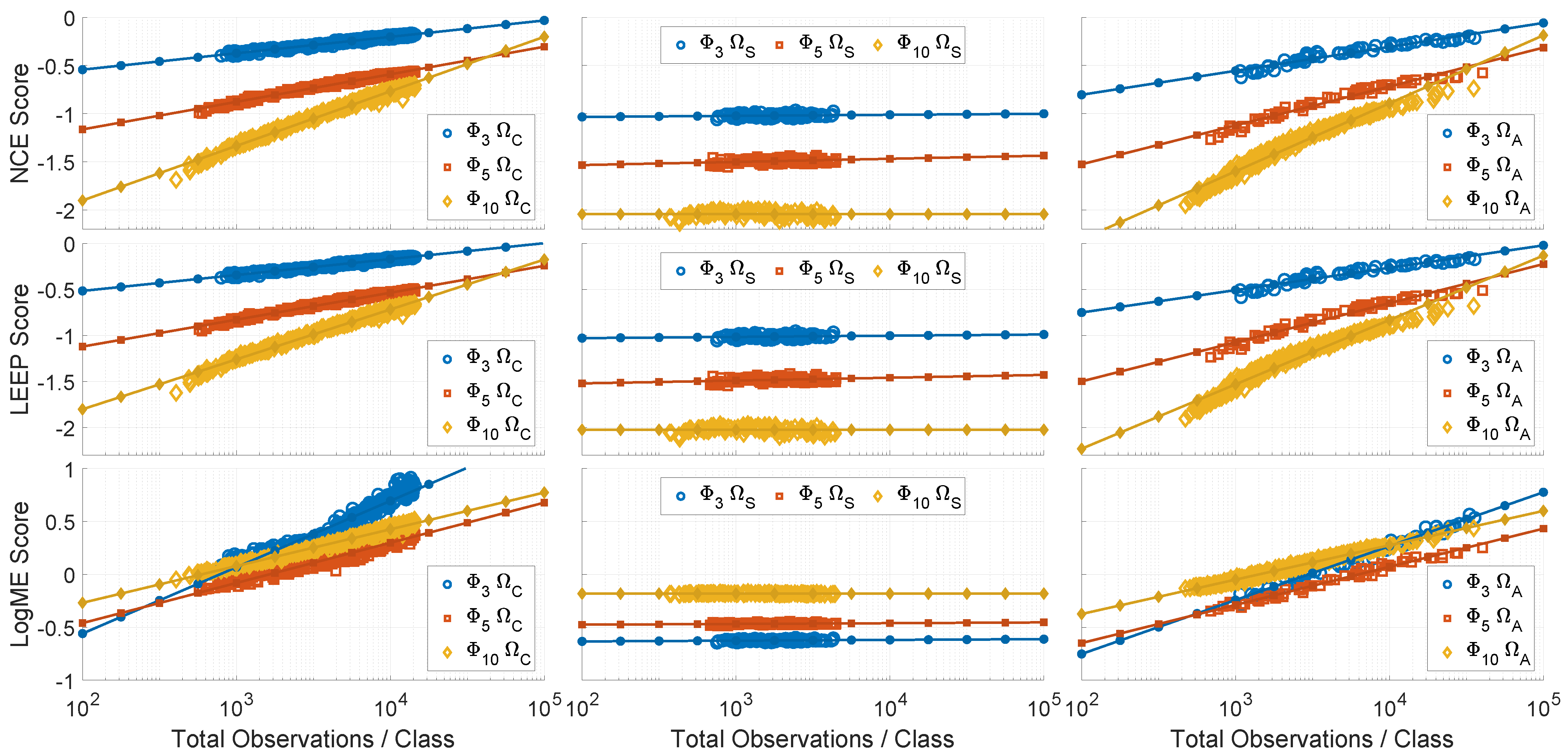
2.1. Examining the Correlation between Performance and Metrics
2.2. Regression of Quantity and Metrics
- accuracy M OPC
- accuracy M OPC
- accuracy M OPC,
- M OPC accuracy
- OPC accuracy
- M OPC accuracy.
2.3. Predicting the Data Quantity Needed
3. Results and Discussion
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Oxford University Press. Machine Learning. In Oxford English Dictionary, 3rd ed.; Oxford University Press: Oxford, UK, 2012. [Google Scholar]
- Sanders, H.; Saxe, J. Garbage In, Garbage Out: How Purportedly Great ML Models can be Screwed up by Bad Data; Technical Report; Black Hat: Las Vegas, NV, USA, 2017. [Google Scholar]
- O’Shea, T.; West, N. Radio Machine Learning Dataset Generation with GNU Radio. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 6 September 2016; Volume 1. [Google Scholar]
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://tensorflow.org (accessed on 7 January 2020).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Glasgow, UK, 2019; pp. 8024–8035. [Google Scholar]
- Blossom, E. GNU Radio: Tools for Exploring the Radio Frequency Spectrum. Linux J. 2004, 2004, 122. [Google Scholar]
- Gaeddart, J. Liquid DSP. Available online: https://liquidsdr.org/ (accessed on 7 January 2020).
- Wong, L.J.; Clark, W.H., IV; Flowers, B.; Buehrer, R.M.; Headley, W.C.; Michaels, A.J. An RFML Ecosystem: Considerations for the Application of Deep Learning to Spectrum Situational Awareness. IEEE Open J. Commun. Soc. 2021, 2, 2243–2264. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 7 January 2020).
- Cengiz, A.B.; McGough, A.S. How much data do I need? A case study on medical data. In Proceedings of the IEEE International Conference on Big Data (BigData), Sorrento, Italy, 15–18 December 2023; pp. 3688–3697. [Google Scholar] [CrossRef]
- Wang, Z.; Li, Z.; Zhao, X. How Much Data is Sufficient for Neural Transliteration? In Proceedings of the 2022 International Conference on Asian Language Processing (IALP), Singapore, 27–28 October 2022; pp. 470–475. [Google Scholar] [CrossRef]
- Meyer, B.M.; Depetrillo, P.; Franco, J.; Donahue, N.; Fox, S.R.; O’Leary, A.; Loftness, B.C.; Gurchiek, R.D.; Buckley, M.; Solomon, A.J.; et al. How Much Data Is Enough? A Reliable Methodology to Examine Long-Term Wearable Data Acquisition in Gait and Postural Sway. Sensors 2022, 22, 6982. [Google Scholar] [CrossRef] [PubMed]
- Ng, L.H.X.; Robertson, D.C.; Carley, K.M. Stabilizing a supervised bot detection algorithm: How much data is needed for consistent predictions? Online Soc. Netw. Media 2022, 28, 100198. [Google Scholar] [CrossRef]
- Balcan, M.F.; DeBlasio, D.; Dick, T.; Kingsford, C.; Sandholm, T.; Vitercik, E. How much data is sufficient to learn high-performing algorithms? Generalization guarantees for data-driven algorithm design. In Proceedings of the 53rd Annual ACM SIGACT Symposium on Theory of Computing, STOC 2021, New York, NY, USA, 21–25 June 2021; pp. 919–932. [Google Scholar] [CrossRef]
- Estepa, R.; Díaz-Verdejo, J.E.; Estepa, A.; Madinabeitia, G. How Much Training Data is Enough? A Case Study for HTTP Anomaly-Based Intrusion Detection. IEEE Access 2020, 8, 44410–44425. [Google Scholar] [CrossRef]
- Besser, K.L.; Matthiesen, B.; Zappone, A.; Jorswieck, E.A. Deep Learning Based Resource Allocation: How Much Training Data is Needed? In Proceedings of the 2020 IEEE 21st International Workshop on Signal Processing Advances in Wireless Communications (SPAWC), Atlanta, GA, USA, 26–29 May 2020; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, D.; Liu, P.; Wang, H.; Beadnall, H.; Kyle, K.; Ly, L.; Cabezas, M.; Zhan, G.; Sullivan, R.; Cai, W.; et al. How Much Data are Enough? Investigating Dataset Requirements for Patch-Based Brain MRI Segmentation Tasks. arXiv 2024, arXiv:2404.03451. [Google Scholar] [CrossRef]
- Mühlenstädt, T.; Frtunikj, J. How much data do you need? Part 2: Predicting DL class specific training dataset sizes. arXiv 2024, arXiv:2403.06311. [Google Scholar] [CrossRef]
- Mahmood, R.; Lucas, J.; Acuna, D.; Li, D.; Philion, J.; Alvarez, J.M.; Yu, Z.; Fidler, S.; Law, M.T. How Much More Data Do I Need? Estimating Requirements for Downstream Tasks. In Proceedings of the 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 18–24 June 2022; pp. 275–284. [Google Scholar] [CrossRef]
- Cortes, C.; Jackel, L.D.; Solla, S.; Vapnik, V.; Denker, J. Learning Curves: Asymptotic Values and Rate of Convergence. In Proceedings of the Advances in Neural Information Processing Systems; Cowan, J., Tesauro, G., Alspector, J., Eds.; Morgan-Kaufmann: Denver, CO, USA, 1993; Volume 6. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Caballero, E.; Gupta, K.; Rish, I.; Krueger, D. Broken Neural Scaling Laws. arXiv 2023, arXiv:2210.14891. [Google Scholar]
- Bahri, Y.; Dyer, E.; Kaplan, J.; Lee, J.; Sharma, U. Explaining neural scaling laws. Proc. Natl. Acad. Sci. USA 2024, 121, e2311878121. [Google Scholar] [CrossRef]
- Bordelon, B.; Atanasov, A.; Pehlevan, C. A Dynamical Model of Neural Scaling Laws. arXiv 2024, arXiv:2402.01092. [Google Scholar]
- Chen, H.; Chen, J.; Ding, J. Data Evaluation and Enhancement for Quality Improvement of Machine Learning. IEEE Trans. Reliab. 2021, 70, 831–847. [Google Scholar] [CrossRef]
- West, N.E.; O’Shea, T. Deep architectures for modulation recognition. In Proceedings of the 2017 IEEE International Symposium on Dynamic Spectrum Access Networks (DySPAN), Baltimore, MD, USA, 6–9 March 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Flowers, B.; Headley, W.C. Adversarial Radio Frequency Machine Learning (RFML) with PyTorch. In Proceedings of the 2019 IEEE Military Communications Conference (MILCOM 2019), Norfolk, VA, USA, 12–14 November 2019. [Google Scholar]
- Pan, S.J.; Yang, Q. A Survey on Transfer Learning. IEEE Trans. Knowl. Data Eng. 2010, 22, 1345–1359. [Google Scholar] [CrossRef]
- Zhuang, F.; Qi, Z.; Duan, K.; Xi, D.; Zhu, Y.; Zhu, H.; Xiong, H.; He, Q. A Comprehensive Survey on Transfer Learning. Proc. IEEE 2021, 109, 43–76. [Google Scholar] [CrossRef]
- Wong, L.J.; Michaels, A.J. Transfer Learning for Radio Frequency Machine Learning: A Taxonomy and Survey. Sensors 2022, 22, 1416. [Google Scholar] [CrossRef] [PubMed]
- Nguyen, C.V.; Hassner, T.; Archambeau, C.; Seeger, M.W. LEEP: A New Measure to Evaluate Transferability of Learned Representations. arXiv 2020, arXiv:2002.12462. [Google Scholar]
- Tran, A.; Nguyen, C.; Hassner, T. Transferability and Hardness of Supervised Classification Tasks. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Republic of Korea, 27 October–2 November 2019; pp. 1395–1405. [Google Scholar] [CrossRef]
- You, K.; Liu, Y.; Wang, J.; Long, M. LogME: Practical Assessment of Pre-trained Models for Transfer Learning. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; Volume 139, pp. 12133–12143. [Google Scholar]
- Kendall, M.G. A New Measure of Rank Correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Dandawate, A.V.; Giannakis, G.B. Detection and classification of cyclostationary signals via cyclic-HOS: A unified approach. SPIE 1992, 1770, 315–326. [Google Scholar] [CrossRef]
- Swami, A.; Sadler, B. Hierarchical digital modulation classification using cumulants. Commun. IEEE Trans. 2000, 48, 416–429. [Google Scholar] [CrossRef]
- Headley, W.; da Silva, C. Asynchronous Classification of Digital Amplitude-Phase Modulated Signals in Flat-Fading Channels. Commun. IEEE Trans. 2011, 59, 7–12. [Google Scholar] [CrossRef]
- Dobre, O.; Abdi, A.; Bar-Ness, Y.; Su, W. Survey of automatic modulation classification techniques: Classical approaches and new trends. Commun. IET 2007, 1, 137–156. [Google Scholar] [CrossRef]
- Nandi, A.; Azzouz, E. Modulation recognition using artificial neural networks. Signal Process. 1997, 56, 165–175. [Google Scholar] [CrossRef]
- O’Shea, T.J.; Corgan, J.; Clancy, T.C. Convolutional Radio Modulation Recognition Networks. In Proceedings of the Engineering Applications of Neural Networks; Jayne, C., Iliadis, L., Eds.; Springer: Cham, Switzerland, 2016; pp. 213–226. [Google Scholar]
- Clark, W.H., IV; Hauser, S.; Headley, W.C.; Michaels, A.J. Training data augmentation for deep learning radio frequency systems. J. Def. Model. Simul. 2021, 18, 217–237. [Google Scholar] [CrossRef]
- Clark, W.H., IV. Efficient waveform spectrum aggregation for algorithm verification and validation. In Proceedings of the GNU Radio Conference, Boulder, CO, USA, 6 September 2016. [Google Scholar]
- Fettweis, G.; Lohning, M.; Petrovic, D.; Windisch, M.; Zillmann, P.; Rave, W. Dirty RF: A new paradigm. In Proceedings of the 2005 IEEE 16th International Symposium on Personal, Indoor and Mobile Radio Communications, Berlin, Germany, 11–14 September 2005; Volume 4, pp. 2347–2355. [Google Scholar] [CrossRef]
- Clark, W.H., IV; Michaels, A.J. Quantifying Dataset Quality in Radio Frequency Machine Learning. In Proceedings of the MILCOM 2021 Track 1-Waveforms and Signal Processing (MILCOM 2021 Track 1), San Diego, CA, USA, 29 Novembar–2 December 2021. [Google Scholar]
- Virtanen, P.; Gommers, R.; Oliphant, T.E.; Haberland, M.; Reddy, T.; Cournapeau, D.; Burovski, E.; Peterson, P.; Weckesser, W.; Bright, J.; et al. SciPy 1.0: Fundamental Algorithms for Scientific Computing in Python. Nat. Methods 2020, 17, 261–272. [Google Scholar] [CrossRef] [PubMed]
- Müller, R.; Kornblith, S.; Hinton, G. When does label smoothing help? In Proceedings of the 33rd International Conference on Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2024; Curran Associates Inc.: Red Hook, NY, USA, 2019. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training | ||
|---|---|---|
| Symbol | Source | Description |
| Capture | Consists of only capture examples | |
| Synthetic generation using KDE | Consists of simulated examples using the KDE of the capture dataset | |
| Augmentation using KDE | Consists of augmented examples from the capture dataset using the KDE | |
| Evaluation | ||
| Capture | Consists of only capture examples | |
| Set | Waveforms |
|---|---|
| BPSK, QPSK, Noise | |
| , QAM16, QAM64 | |
| , AM-DSB, BFSK, FM-NB, BGFSK, GMSK |
| Set | NCE | LEEP | LogME | |
|---|---|---|---|---|
| 0.9774 | 0.9533 | 0.8033 | ||
| 0.8249 | 0.8144 | 0.7382 | ||
| 0.9666 | 0.9639 | 0.9377 | ||
| 0.9438 | 0.9443 | 0.8788 | ||
| 0.6554 | 0.6553 | 0.6334 | ||
| 0.9794 | 0.9791 | 0.9582 | ||
| 0.9794 | 0.9688 | 0.9609 | ||
| 0.5165 | 0.4262 | 0.5298 | ||
| 0.9836 | 0.9808 | 0.9764 |
| NCE | LEEP | LogME | |||
|---|---|---|---|---|---|
| 0.2478 | 0.2054 | 0.1885 | 0.2662 | ||
| 1.0196 | 0.9515 | 0.9521 | 0.9531 | ||
| 0.3120 | 0.2674 | 0.2636 | 0.1672 | ||
| 0.2499 | 0.1552 | 0.1458 | 0.1987 | ||
| 0.9491 | 0.9367 | 0.9451 | 0.9652 | ||
| 0.3016 | 0.2163 | 0.2208 | 0.1433 | ||
| 0.1514 | 0.1138 | 0.1173 | 0.1179 | ||
| 0.9853 | 0.9783 | 0.9731 | 0.9697 | ||
| 0.2706 | 0.2652 | 0.2797 | 0.1102 |
| NCE | LEEP | LogME | NCE | LEEP | LogME | ||||
|---|---|---|---|---|---|---|---|---|---|
| Metric | Metric | Metric | Metric | Quantity | Quantity | Quantity | Quantity | ||
| 0.999990 | 2.696 | ||||||||
| ∞ | |||||||||
| 0.999990 | 2.842 | ||||||||
| ∞ | ∞ | ||||||||
| 0.999990 | 3.066 | ||||||||
| ∞ | ∞ | ∞ | ∞ | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Clark, W.H., IV; Michaels, A.J. Training from Zero: Forecasting of Radio Frequency Machine Learning Data Quantity. Telecom 2024, 5, 632-651. https://doi.org/10.3390/telecom5030032
Clark WH IV, Michaels AJ. Training from Zero: Forecasting of Radio Frequency Machine Learning Data Quantity. Telecom. 2024; 5(3):632-651. https://doi.org/10.3390/telecom5030032
Chicago/Turabian StyleClark, William H., IV, and Alan J. Michaels. 2024. "Training from Zero: Forecasting of Radio Frequency Machine Learning Data Quantity" Telecom 5, no. 3: 632-651. https://doi.org/10.3390/telecom5030032
APA StyleClark, W. H., IV, & Michaels, A. J. (2024). Training from Zero: Forecasting of Radio Frequency Machine Learning Data Quantity. Telecom, 5(3), 632-651. https://doi.org/10.3390/telecom5030032